spark 总结
1.spark 配置文件
spark-default.conf
spark.yarn.historyServer.address = xiemeng-01:18080
spark.history.port=18080
hive-site.xml
<configuration><property><name>javax.jdo.option.ConnectionURL</name>
</property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value>
</property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value>
</property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value>
</property><property><name>hive.metastore.warehouse.dir</name><value>hdfs://mycluster/hive/warehouse</value>
</property><property><name>hive.metastore.schema.verification</name><value>false</value>
</property><property><name>datanucleus.schema.autoCreateAll</name><value>true</value>
</property>
<property><!-- hiveserver2用户名 --><name>beeline.hs2.connection.user</name><value>hive2</value></property><property><!-- hiveserver2密码 --><name>beeline.hs2.connection.password</name><value>hive2</value></property><property><!-- hiveserver2端口 --><name>beeline.hs2.connection.hosts</name><value>xiemeng-01:10000</value></property>
</configuration>2.spark 命令
export JAVA_HOME=/home/xiemeng/software/jdk1.8.0_251
export SPARK_HOME=/home/xiemeng/software/spark
export SPARK_WORKER_CORES=2export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=xiemeng-01,xiemeng-02,xiemeng-03
-Dspark.deploy.zookeeper.dir=/spark"export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://xiemeng-01:8020
-Dspark.history.retainedApplications=30"spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
spark-examples_2.12-3.0.1.jarspark-submit --class WordCountTest \
--master yarn \
--deploy-mode cluster \
spark-review-demo-1.0-SNAPSHOT.jar \
101.spark rdd dataframe
/*** spark sql'测试类** @author xiemeng* @since 2020-11-30*/
object DFTest {case class People(name:String,age:Int,address:String);def main(args: Array[String]): Unit = {var sc = new SparkContext(new SparkConf().setAppName("test").setMaster("local[*]"));val res = sc.makeRDD(List(People("zhangsan",20,"陕西省"),People("wangwu",10,"北京市")));val spark = SparkSession.builder().appName("test").getOrCreate();//第一种创建dfval df2 = spark.read.json("data/student.json");//df2.show();//第二种创建dfval df = spark.createDataFrame(res);//df.show();df.createTempView("student")//println("sql查询如下");//df.select("name").show();//spark.sql("select name,age from student").show();import spark.implicits._val numRDD = sc.makeRDD(List(("zhangsan",20,"男"),("wangwu",10,"男")))var numDF = numRDD.toDF("name","age","sex");//numDF.show();val peopleRDD:RDD[People] = numRDD.map{p => People(p._1,p._2,null)}var peopleDF = peopleRDD.toDF()//peopleDF.show();var peopleRow:RDD[Row] = peopleDF.rdd;peopleRow.foreach(r=>println(r.getString(0)+"\t"+r.getInt(1)+"\t"+r.getString(2)));//从df创建dsval ds = df.as[People];//ds.show();//从数据直接创建ds//spark.createDataset(res).show();var peopleDS = numRDD.map {case (name, age, address) =>People(name,age,address)}.toDS();peopleDS.show();//spark.stop();spark.udf.register("addName",(name:String) => "Name:"+name );spark.sql("select addName(name),age from student").show();}
}object HotWordSearch {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local").appName("test").getOrCreate()val filePath = "file:///D:\\code\\spark-start-demo\\src\\main\\resources\\input\\txt\\hotwordsearch.txt";val hotDateTuple = spark.sparkContext.textFile(filePath).map(_.split(",")).map(line => {val date = line(0);val user = line(1);val hot = line(2);((date, hot), user)})val groupRDD = hotDateTuple.groupByKey()val uvRDD = groupRDD.map(line => {val distinctUser = new ListBuffer[String];val dataAndKeyWord = line._1;val users = line._2.iterator;while (users.hasNext) {val user = users.next();if (!distinctUser.contains(user)) {distinctUser.add(user);}}val size = distinctUser.size();(dataAndKeyWord, size);})val rowDatas = uvRDD.map(line => {Row(line._1._1, line._1._2, line._2);})rowDatasvar structType = types.StructType(List(StructField("date",StringType),StructField("keyword",StringType),StructField("uv",IntegerType)))val dataFrame = spark.createDataFrame(rowDatas, structType);dataFrame.createTempView("date_keyword_uv");spark.sql("""|select date,keyword,uv|from (| select date,| keyword,| uv,| row_number() over ( partition by date order by uv desc) as rank| from date_keyword_uv|) t|where t.rank <=3""".stripMargin).show();}
}
package com.example.demoimport org.apache.spark.sql.{Encoder, Encoders}
import org.apache.spark.sql.expressions.Aggregatorcase class StudentBuffer(var sum: BigInt, var count: Int);case class Stu(name: String, age: BigInt);class UserAvg extends Aggregator[Stu, StudentBuffer, Double] {override def zero: StudentBuffer = {var sb = new StudentBuffer(0L, 0);sb}/*** 聚合** @param b* @param a* @return*/override def reduce(b: StudentBuffer, a: Stu): StudentBuffer = {b.sum = b.sum + a.age;b.count = b.count + 1;b}/*** 合并** @param b1* @param b2* @return*/override def merge(b1: StudentBuffer, b2: StudentBuffer): StudentBuffer = {b1.sum = b1.sum + b2.sum;b1.count = b1.count + b2.count;b1}/*** 业务处理** @param reduction* @return*/override def finish(reduction: StudentBuffer): Double = {reduction.sum.toDouble / reduction.count;}override def bufferEncoder: Encoder[StudentBuffer] = Encoders.product;override def outputEncoder: Encoder[Double] = Encoders.scalaDouble;
}读数据库
读csv
object ReadCsv {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local").appName("csv").config("spark.sql.crossJoin.enabled", "true").getOrCreate();val schema: StructType = new StructType().add(new StructField("a0", StringType, true)).add(new StructField("a1", DoubleType, true));print(schema);val df = spark.read.format("csv").option("header", true).option("inferSchema", true).option("sep", ",").schema(schema).load("file:///D:\\code\\spark-start-demo\\src\\main\\resources\\input\\csv")df.show();df.registerTempTable("t1");spark.sql("select a0, percentile_approx(a1,0.95,200) from t1 group by a0").show();///1,3 ,5//2*0 =0.9 i = 1 j = 9//(1-0.9)*5+ 0.9*5 = 4.5 +0.t//94.05 = (1 -0.05) *95 + 0.05*96 = 95.05//93.1 = (1-0.1)* 194 + 0.1*195 = 195.05}}读数据库
object JdbcSink {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("jdbc").master("local").getOrCreate();val url = "jdbc:mysql://192.168.64.1:3306/student?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT";val driver = "com.mysql.cj.jdbc.Driver";val user = "root";writeData(spark,driver,url,user);val rowDatas = readData(spark, url, driver);val jdbcDF = readData2(spark, url, driver);jdbcDF.show();//val jdbcDF2 = readData3(spark, url, driver);//jdbcDF2.show();}def readData(spark: SparkSession, url: String, driver: String): DataFrame = {val rowDatas = spark.read.format("jdbc").option("url", url).option("driver", driver).option("dbtable", "student").option("user", "root").option("password", "123456").load();return rowDatas;}def readData2(spark: SparkSession, url: String, driver: String): DataFrame = {val map = Map(("url", url),("driver", driver),("user", "root"),("password", "123456"),("dbtable", "student"));val jdbcDF = spark.read.format("jdbc").options(map).load()jdbcDF;}def readData3(spark: SparkSession, url: String, driver: String): DataFrame = {val properies = new Properties();properies.put("driver", driver);properies.put("user", "root");properies.put("password", "123456");val frame = spark.read.jdbc(url, "student", properies)frame;}def writeData(spark: SparkSession, driver: String, url: String, user: String) = {val list = Array("周瑜,20,1", "诸葛亮,30,0");val structType = StructType(List(StructField("name", StringType),StructField("age", IntegerType),StructField("sex",StringType)));val rowDatas = spark.sparkContext.parallelize(list).map(_.split(","))val studentRDD: RDD[Row] = rowDatas.map(line => Row(line(0).toString, line(1).toInt,line(2).toString))val dataFrame = spark.createDataFrame(studentRDD, structType)dataFrame.write.mode("append").format("jdbc").option("url", url).option("user", user).option("password", "123456").option("driver", driver).option("dbtable", "student").save();}
}读kafaka
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}object StreamKafka {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("test");val ssc = new StreamingContext(conf, Seconds(1))ssc.checkpoint("file:///D:\\code\\spark-start-demo\\spark-warehouse")val kafkaTopics = Array("test");val kafkaParams = Map[String, Object]("bootstrap.servers" -> "192.168.64.128:9092,192.168.64.130:9092,192.168.64.131:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "test","enable.auto.commit" -> (false: java.lang.Boolean))val inputStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](kafkaTopics, kafkaParams));val lineDstream = inputStream.map(record => (record.key(), record.value()))val word = lineDstream.map(_._2).flatMap(_.split(" "))val pair = word.map(word => (word, 1))val result: DStream[(String, Int)] = pair.updateStateByKey(updateFunc);result.print();ssc.start();ssc.awaitTermination();}def updateFunc = (values: Seq[Int], state: Option[Int]) => {val currentCount = values.fold(0)(_ + _);val previousCount = state.getOrElse(0);Some(currentCount + previousCount);}}
读hbase
ackage com.example.demoimport org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.hadoop.hbase._
import org.apache.hadoop.hbase.client.{ConnectionFactory, Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.{HFileOutputFormat2, TableInputFormat}
import org.apache.hadoop.hbase.tool.LoadIncrementalHFiles
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object HbaseReadTest {def main(args: Array[String]): Unit = {var conf = new SparkConf().setMaster("local[8]").setAppName("Test").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");val sc = new SparkContext(conf)val hbaseConf: Configuration = getHbaseConf()val hbaseRDD = sc.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result])//putData(sc);//addHadoopJobConf(sc);doBulkLoad(sc);hbaseRDD.foreach {case (_, result) =>val key = Bytes.toString(result.getRow);val name = Bytes.toString(result.getValue("info".getBytes, "name".getBytes()));val address = Bytes.toString(result.getValue("info".getBytes(), "address".getBytes()));var age = Bytes.toString(result.getValue("info".getBytes(), "age".getBytes()));println(s"行键:\t $key,姓名:\t $name,地址:\t $address,年龄:\t $age");}}def mkData(sc: SparkContext, arr: Array[String]): RDD[String] = {val rowDataRDD = sc.makeRDD(arr)rowDataRDD}/*** 不能序列化的对象加@transient** @param sc* @param hbaseConf*/def putData(@transient sc: SparkContext): Unit = {val arr = Array[String]("003,王五,山东,20","004,赵六,陕西,23");var rowDataRDD: RDD[String] = mkData(sc, arr);rowDataRDD.foreach(rowData => {val hbaseConf: Configuration = getHbaseConf()val connection = ConnectionFactory.createConnection(hbaseConf)val table = connection.getTable(TableName.valueOf("student"))val rows = rowData.split(",")val put = new Put(Bytes.toBytes(rows(0)))put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(rows(1)))put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("address"),Bytes.toBytes(rows(2)))put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(rows(3)));table.put(put);})}def fetchHbaseData(sc: SparkContext): Unit = {val hbaseConf = getHbaseConf()val hbaseRDD = sc.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result])hbaseRDD.foreach {case (_, result) =>val key = Bytes.toString(result.getRow);val name = Bytes.toString(result.getValue("info".getBytes, "name".getBytes()));val address = Bytes.toString(result.getValue("info".getBytes(), "address".getBytes()));var age = Bytes.toString(result.getValue("info".getBytes(), "age".getBytes()));println(s"行键:\t $key,姓名:\t $name,地址:\t $address,年龄:\t $age");}}def getHbaseConf() = {val hbaseConf = HBaseConfiguration.create()hbaseConf.set("hbase.zookeeper.quorum", "192.168.64.128");hbaseConf.set("hbase.zookeeper.property.clientPort", "2181");hbaseConf.set(TableInputFormat.INPUT_TABLE, "student");hbaseConf;}def addHadoopJobConf(@transient sc: SparkContext): Unit = {val rowDataRDD = mkData(sc, Array[String]("005,ab,西安,20","006,ac,西安,20"))var jobConf = new JobConf();jobConf.set("hbase.zookeeper.quorum", "192.168.64.128");jobConf.set("hbase.zookeeper.property.clientPort", "2181");jobConf.setOutputFormat(classOf[TableOutputFormat]);jobConf.set(TableOutputFormat.OUTPUT_TABLE, "student");val resultRDD = rowDataRDD.map(line => line.split(",")).map(rows => {val put = new Put(Bytes.toBytes(rows(0)));put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(rows(1)))put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("address"),Bytes.toBytes(rows(2)))put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(rows(3)));(new ImmutableBytesWritable, put)})resultRDD.saveAsHadoopDataset(jobConf);}def doBulkLoad(sc: SparkContext): Unit = {val hadoopConf = new Configuration();hadoopConf.set("fs.defaultFS", "hdfs://192.168.64.128:9870");val fileSystem = FileSystem.get(hadoopConf);val hbaseConf = HBaseConfiguration.create(hadoopConf);hbaseConf.set("hbase.zookeeper.quorum", "192.168.64.128");hbaseConf.set("hbase.zookeeper.property.clientPort", "2181");val connection = ConnectionFactory.createConnection(hbaseConf);val tableName = TableName.valueOf("student")val table = connection.getTable(tableName)val admin = connection.getAdminif (!admin.tableExists(tableName)) {val tableDescriptor = new HTableDescriptor(tableName)val columnDescriptor = new HColumnDescriptor("info");tableDescriptor.addFamily(columnDescriptor);admin.createTable(tableDescriptor);}val path = "hdfs://192.168.64.128:9876/hbase";if (fileSystem.exists(new Path(path))) {fileSystem.delete(new Path(path));}val rowDataRDD = sc.makeRDD(Array[String]("rowKey:001,name:wangwu","rowKey:008,address:陕西","rowKey:001,age:20"))val keyValues = rowDataRDD.map(_.split(",")).map(arr => {val rowKey = arr(0).split(":")(1);val qualify = arr(1).split(":")(0);var value = arr(1).split(":")(1);val kv = new KeyValue(Bytes.toBytes(rowKey), Bytes.toBytes("info"), Bytes.toBytes(qualify), Bytes.toBytes(value))(new ImmutableBytesWritable(), kv)})keyValues.saveAsNewAPIHadoopFile(path,classOf[ImmutableBytesWritable],classOf[KeyValue],classOf[HFileOutputFormat2],hbaseConf)val bulkLoader = new LoadIncrementalHFiles(hbaseConf);val regionLocator = connection.getRegionLocator(tableName);bulkLoader.doBulkLoad(new Path(path), admin, table, regionLocator);}
}自定义分区器
class MyPartitioner(partitions: Int) extends Partitioner {override def numPartitions: Int = partitionsoverride def getPartition(key: Any): Int = {val project = key.toString;if (project.equals("chinese")) 0else if (project.equals("math")) 1else 2}
}object CustomPartitionerTest {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("test").setMaster("local");val sc = new SparkContext(conf)val arr = Array("chinese,333","math,22","english,23")val data = sc.makeRDD(arr).map(line => {(line.split(",")(0), line.split(",")(1))})data.partitionBy(new MyPartitioner(3)).saveAsTextFile("/output/partitioner");}
}2.spark sql udf
package com.example.demo.udfimport org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, LongType, StructType}private [udf] class AVGFunc extends UserDefinedAggregateFunction {/*** 输入* @return*/override def inputSchema: StructType = {new StructType().add("age",LongType)}/*** 缓冲区类型* @return*/override def bufferSchema: StructType = {new StructType().add("sum",LongType).add("count",LongType);}/*** 输出类型* @return*/override def dataType: DataType = DoubleType;/*** 是否稳定* @return*/override def deterministic: Boolean = true/*** 初始化缓冲区* @param buffer*/override def initialize(buffer: MutableAggregationBuffer): Unit = {buffer(0) = 0L;buffer(1) = 0L;}/*** 更新缓冲区* @param buffer* @param input*/override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {buffer(0) = buffer.getLong(0) + input.getLong(0);buffer(1) = buffer.getLong(1) + 1;}/*** 合并缓冲区* @param buffer1* @param buffer2*/override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0);buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1);}override def evaluate(buffer: Row): Any = {return buffer.getLong(0).toDouble / buffer.getLong(1);}}package com.example.demo.udfimport org.apache.hadoop.hive.ql.exec.UDFArgumentException
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactoryclass LenFunction extends GenericUDF {override def initialize(args: Array[ObjectInspector]): ObjectInspector = {if (args.length == 0) {throw new UDFArgumentException("参数个数为0");}return PrimitiveObjectInspectorFactory.writableIntObjectInspector;}override def evaluate(args: Array[GenericUDF.DeferredObject]): AnyRef = {val str = args(0).get().toString();val inspector = PrimitiveObjectInspectorFactory.writableIntObjectInspectorif (str == null) {return inspector.create(0);}return inspector.create(str.length);}override def getDisplayString(strings: Array[String]): String = "";}object HiveFunctionTest {def main(args: Array[String]): Unit = {val session = SparkSession.builder().appName("test").master("yarn").enableHiveSupport().getOrCreate()session.sql("""|CREATE TEMPORARY FUNCTION c_test AS 'com.example.demo.udf.DIVFunction'""".stripMargin)session.sql("select c_test(3,4)").show();}
}3.spark stream
object StreamingBlackListFilter {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("test") setMaster ("local[8]");val ssc = new StreamingContext(conf, Seconds(1))val blackList = Array(("tom", true), ("leo", true));val blackRDD = ssc.sparkContext.makeRDD(blackList);val logDStream = ssc.socketTextStream("192.168.64.128", 9000);val logTupleStream = logDStream.map(line => {(line.split(" ")(1), line)})val resultDStream = logTupleStream.transform(rdd => {val leftOuterRDD = rdd.leftOuterJoin(blackRDD)val filteRDD = leftOuterRDD.filter(line => {if (line._2._2.getOrElse(false)) {false} else {true}});val resultRDD = filteRDD.map(line => line._2._1);resultRDD})resultDStream.print();ssc.start();ssc.awaitTermination();}
}4.spark 调优
5.maven 依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example.demo</groupId><artifactId>spark-start-demo</artifactId><version>1.0-SNAPSHOT</version><properties><hadoop.version>3.2.0</hadoop.version><hbase.version>2.2.6</hbase.version><spark.version>3.0.1</spark.version></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-yarn_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.8</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.20</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-mapreduce</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-auth</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.0.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-yarn_2.12</artifactId><version>3.0.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.12.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.2.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.2.0</version></dependency></dependencies><build><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.1.3</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build>
</project>相关文章:

spark 总结
1.spark 配置文件 spark-default.conf spark.yarn.historyServer.address xiemeng-01:18080 spark.history.port18080 hive-site.xml <configuration><property><name>javax.jdo.option.ConnectionURL</name> </property><property>&…...
Gitlab修改仓库权限为public、Internal、Private
Public(公开):所有人都可以访问该仓库; Internal(内部):同一个GitLab群组或实例内的所有用户都可以访问该仓库; Private(私人):仅包括指定成员的用…...
)
Python语言例题集(008)
#!/usr/bin/python3 #建立链表类和遍历此链表 class Node(): def init(self,dataNone): self.datadata self.nextNone class LinkedList(): def init(self): self.headNone def printList(self):ptrself.headwhile ptr:print(ptr.data)ptrptr.nextlinkLinkedList() link.he…...
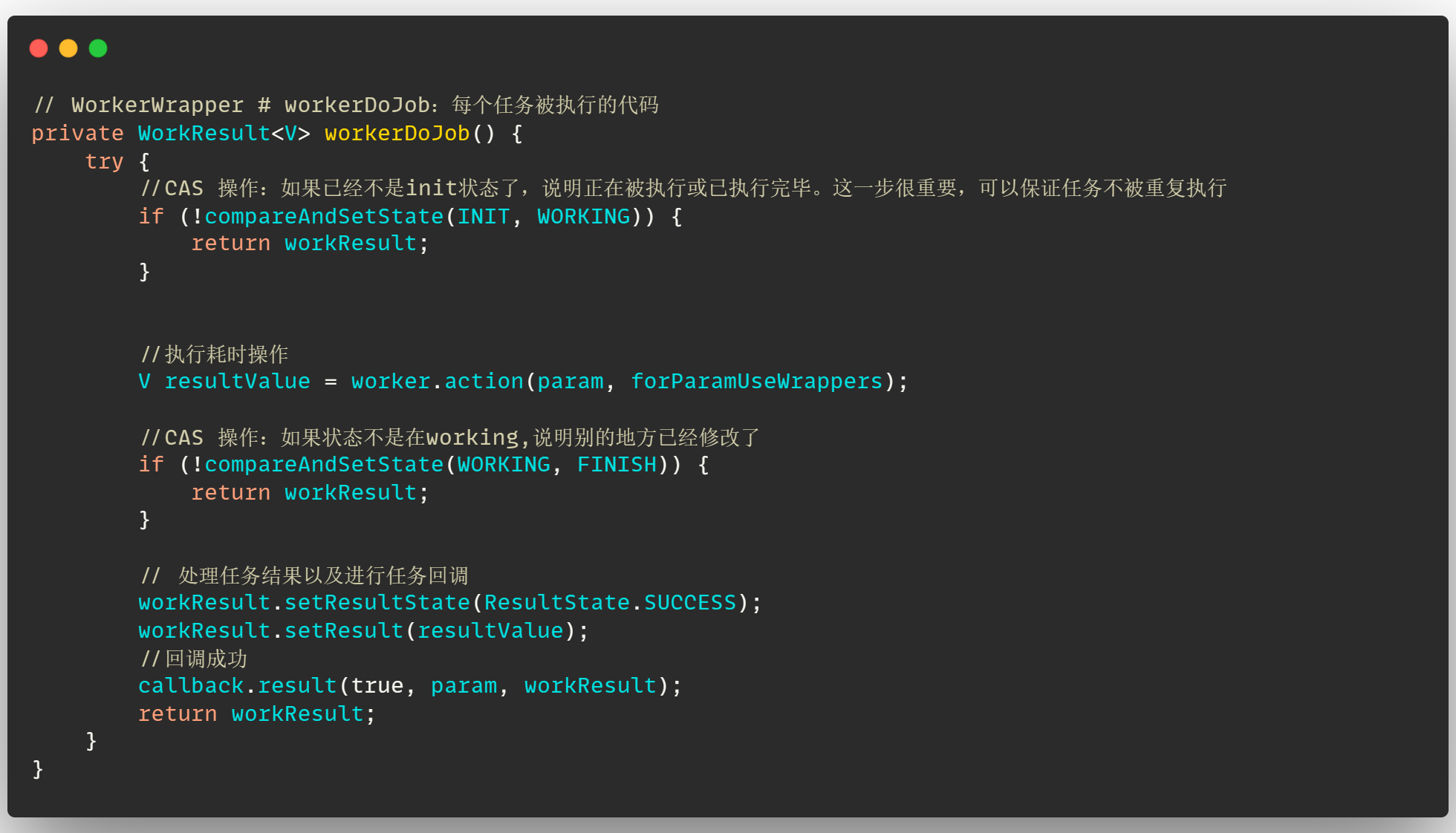
【Java核心能力】京东并行框架asyncTool如何针对高并发场景进行优化?
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送! 在我后台回复 「资料」 可领取编程高频电子书! 在我后台回复「面试」可领取硬核面试笔记! 文章导读地址…...
如何在Mapbox GL中处理大的GEOJSON文件
Mapbox GL可以将 GeoJSON 数据由客户端(Web 浏览器或移动设备)即时转换为 Mapbox 矢量切片进行显示和处理。本文的目的是教大家如何有效加载和渲染大型 GeoJSON 源,并优化渲染显示速度,增强用户体验,减少客户端卡顿问题。本文以Mapbox 为例,至于其它框架原理大致相同,可…...

Vue.js过滤器:让数据展示更灵活
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

【深度学习笔记】计算机视觉——FCN(全卷积网络
全卷积网络 sec_fcn 如 :numref:sec_semantic_segmentation中所介绍的那样,语义分割是对图像中的每个像素分类。 全卷积网络(fully convolutional network,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换 :cite:Long.Sh…...

物联网行业如何发展新质生产力
物联网行业作为当今科技发展的前沿领域,其在新质生产力的提升中扮演着举足轻重的角色。为了推动物联网行业的快速发展,我们需要从技术创新、产业融合、人才培养和政策支持等多个方面入手,共同构建一个有利于物联网行业发展的生态环境。 首先…...

manjaro 安装 wps 教程
内核: Linux 6.6.16.2 wps-office版本: 11.10.11719-1 本文仅作为参考使用, 如果以上版本差别较大不建议参考 安装wps主体 yay -S wps-office 安装wps字体 (如果下载未成功看下面的方法) yay -S ttf-waps-fonts 安装wps中文语言 yay …...

Spring AOP基于注解方式实现
1. 场景介绍 目前假设我们有一个计算器类,并要为其中的方法添加日志功能。 计算器类如代码所示: public interface Calculator {int add(int i, int j);int sub(int i, int j);int mul(int i, int j);int div(int i, int j);}public class Calculator…...
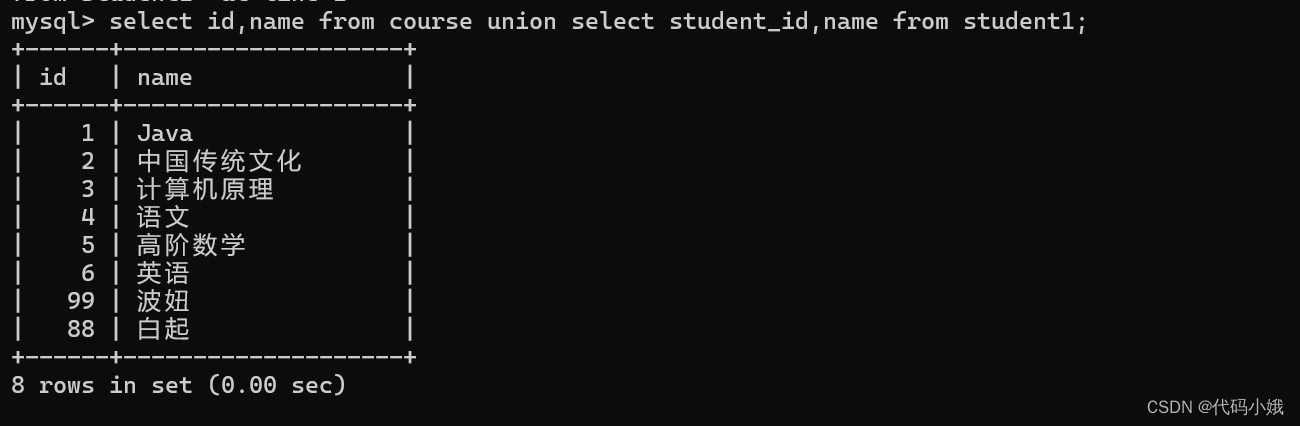
MySQL中常用的操作语句已汇总
目录 一、库语句 1.查询现有数据库 2.创建数据库 3.选中数据库 编辑 4.删除数据库 二、初阶表操作 1.查看数据库现有表 2.查看表结构 3.创建表 4.删除表 5.全列查询 6.删除表2 7.修改操作 三、插入操作 1.全列插入 2.指定列插入 3.一次插入多组数据 4.插入…...

linux设置nginx systemctl启动
生成nginx.pid文件 #验证nginx的配置,并生成nginx.pid文件 /usr/local/nginx/sbin/nginx -t #pid文件目录在 /usr/local/nginx/run/nginx.pid 设置systemctl启动nginx #添加之前需要先关闭启动状态的nginx,让nginx是未启动状态 #关闭nginx /usr/local…...

stable diffusion faceswaplab换脸插件报错解决
错误提示: ERROR - Failed to swap face in postprocess method : apply_overlay() takes 3 positional arguments but 4 were given 打开插件对应目录: \sd-webui-aki-v4.6.1\extensions\sd-webui-faceswaplab\scripts\faceswaplab_utils中 imgutil…...
Kap - macOS 开源录屏工具
文章目录 关于 Kap 关于 Kap Kap 是一个使用web技术的开源的屏幕录制工具 官网:https://getkap.cogithub : https://github.com/wulkano/Kap 目前只支持 macOS 12 以上,支持 Intel 和 Apple silicon 你可以前往官网,右上方下载 你也可以使…...

Linux/Ubuntu/Debian基本命令:光标移动命令
Linux系统真的超级好用,免费,有很多开源且功能强大的软件。尤其是Ubuntu,真的可以拯救十年前的老电脑。从今天开始我将做一个Linux的推广者,推广普及Linux基础。 光标移动命令对于在终端(Terminal)内有效导…...

nvm下载,nodejs下载
进入nvm中文网,按照它的教程来,很简单!!! 往下翻...
)
大数据开发(Hadoop面试真题-卷七)
大数据开发(Hadoop面试真题) 1、Map的分片有多大?2、MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?3、MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中吗&a…...

计算机网络(基础篇)复习笔记——体系结构/协议基础(持续更新中......)
目录 1 计算机网络基础相关技术Rip 路由更新操作 2 体系结构(OSI 7层, TCP/IP4层)应用层运输层网络层IPv4无分类域间路由选择 CIDRIPV6 数据链路层循环冗余校验CRC协议设备 物理层传输媒体信道复用技术宽带接入技术数据通信 3 网络局域网(以太网Ethernet) 4 通信过程编码:信道极…...
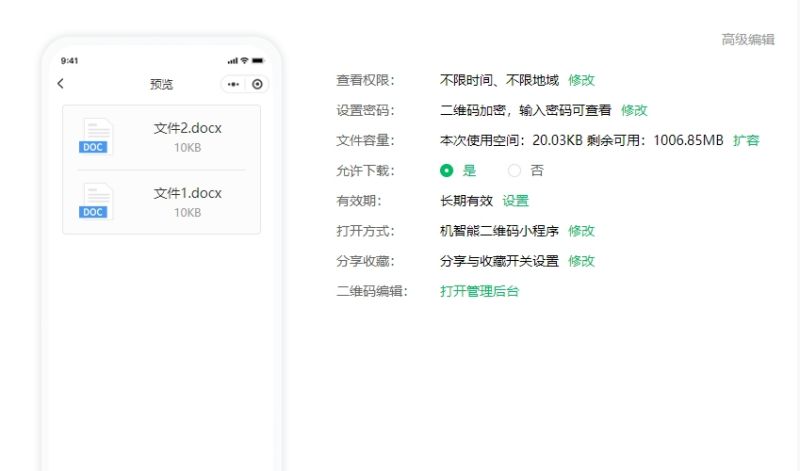
怎么做加密文件二维码?分享文件更安全
怎么做一个加密文件二维码?在日常的工作和生活中,通过扫描二维码来查看或者下载文件的方式,被越来越多的人所使用,一方面是二维码的成本低,另一方面有利于提升便捷性和用户体验。 为了保证内容的隐私性和安全性&#…...

手机中常用的传感器
文章目录 重力传感器 Gravity sensor三维坐标 加速度传感器 Accelerometer三维坐标 陀螺仪 Gyroscope三维坐标 磁力传感器 Magnetometer三维坐标 光线传感器 Light Sensor接近传感器 Proximity Sensor其他传感器协同工作相机自动调整 传感器有唤醒和非唤醒属性 关于重力传感器和…...

为什么92%的多模态情感模型在跨域测试中崩溃?SITS2026首次披露3类隐性模态失配陷阱
第一章:SITS2026多模态情感分析核心洞察 2026奇点智能技术大会(https://ml-summit.org) SITS2026框架重新定义了多模态情感分析的技术边界,其核心在于跨模态对齐粒度的动态可调性与语义冲突消解机制。该系统不再依赖静态模态权重融合,而是通…...

VeraCrypt加密U盘实战:从创建加密卷到日常使用的完整指南
VeraCrypt加密U盘实战:从零开始打造移动数据保险箱 在这个数据泄露事件频发的时代,我们随身携带的U盘和SD卡就像一个个行走的数据炸弹。想象一下,当你遗失了存有客户资料、财务报告或个人隐私的移动存储设备时,那种头皮发麻的感觉…...

【Bootloader实战解析】基于UDS与CAN实现单片机固件无感升级
1. 为什么需要无感固件升级? 想象一下你的手机系统更新:点击"立即安装"后,系统自动下载更新包,重启时完成安装,整个过程无需连接电脑或使用特殊工具。这种"无感升级"体验在汽车电子和工业控制领域…...

澜起科技年营收55亿:净利22亿 上海融迎及一致行动人套现超10亿
雷递网 雷建平 4月14日澜起科技股份有限公司(简称:“澜起科技”,公司代码:688008)日前发布2025年的财报。财报显示,澜起科技2025年营收为54.56亿元,较上年同期的36.39亿元增长49.94%。澜起科技称…...
AAAI认证! Transformer+多模态融合2026仍是王炸,持续狂揽顶会
最近回顾了多模态相关的研究,这领域实在太火了,如果还想快速上手、快速出成果,那我推荐做Transformer多模态融合,这是目前对新手最友好的热点方向之一。至于具体方向和创新点?根据发展趋势和最近的成果来看,…...

MCP协议如何重塑前端开发工作流
前言 2026年,AI与前端开发的融合进入新阶段。MCP(Model Context Protocol)协议作为Anthropic推出的开放标准,正在彻底改变我们构建AI驱动应用的方式。本文将深入探讨MCP在前端工程中的实战应用。 正文 一、MCP协议核心概念 MCP协议…...

客服机器人支持快捷键操作吗?Agent 系统后台可自定义热键,客服效率能提升多少?
在数字化客服时代,企业每天面对海量咨询,如何让客服团队从重复劳动中解放出来,同时实现秒级响应和精准转化,成为竞争关键。许多企业主和客服负责人都在问:客服机器人支持快捷键操作吗?Agent 系统后台可自定…...

基于LLM的高校招生智能问答系统
一、 研究目的 本研究旨在利用大语言模型(LLM)强大的自然语言理解与生成能力,解决当前高校招生咨询工作中存在的痛点与瓶颈。随着高等教育普及化程度的加深,每年招生季高校需面对海量、重复且时效性极强的咨询需求。传统的人工客服模式受限于人力成本、工作时间及答复一致…...

嵌入式驱动分层设计与模块化实践:以RT-Thread为例
1. 嵌入式驱动分层设计基础 在嵌入式系统开发中,驱动分层设计是提高代码复用性和可维护性的关键策略。想象一下,如果把整个系统比作一家餐厅,硬件设备就是厨房里的各种厨具,而驱动分层就像是把厨师(应用层)…...

对抗样本攻防博弈全解析,深度拆解AIAgent在金融风控场景中被投毒的3大隐蔽入口与实时拦截策略
第一章:AIAgent架构中的对抗样本防御 2026奇点智能技术大会(https://ml-summit.org) 在多层协同的AIAgent系统中,对抗样本不再仅威胁单个模型组件,而是可能通过意图解析、工具调用、记忆检索等模块链式传播,导致任务失败或行为偏…...