【深度学习笔记】计算机视觉——FCN(全卷积网络
全卷积网络
sec_fcn
如 :numref:sec_semantic_segmentation中所介绍的那样,语义分割是对图像中的每个像素分类。
全卷积网络(fully convolutional network,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换 :cite:Long.Shelhamer.Darrell.2015。
与我们之前在图像分类或目标检测部分介绍的卷积神经网络不同,全卷积网络将中间层特征图的高和宽变换回输入图像的尺寸:这是通过在 :numref:sec_transposed_conv中引入的转置卷积(transposed convolution)实现的。
因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
构造模型
下面我们了解一下全卷积网络模型最基本的设计。
如 :numref:fig_fcn所示,全卷积网络先使用卷积神经网络抽取图像特征,然后通过 1 × 1 1\times 1 1×1卷积层将通道数变换为类别个数,最后在 :numref:sec_transposed_conv中通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。
因此,模型输出与输入图像的高和宽相同,且最终输出通道包含了该空间位置像素的类别预测。

🏷fig_fcn
下面,我们[使用在ImageNet数据集上预训练的ResNet-18模型来提取图像特征],并将该网络记为pretrained_net。
ResNet-18模型的最后几层包括全局平均汇聚层和全连接层,然而全卷积网络中不需要它们。
pretrained_net = torchvision.models.resnet18(pretrained=True)
list(pretrained_net.children())[-3:]
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /home/ci/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth0%| | 0.00/44.7M [00:00<?, ?B/s][Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))),AdaptiveAvgPool2d(output_size=(1, 1)),Linear(in_features=512, out_features=1000, bias=True)]
接下来,我们[创建一个全卷积网络net]。
它复制了ResNet-18中大部分的预训练层,除了最后的全局平均汇聚层和最接近输出的全连接层。
net = nn.Sequential(*list(pretrained_net.children())[:-2])
给定高度为320和宽度为480的输入,net的前向传播将输入的高和宽减小至原来的 1 / 32 1/32 1/32,即10和15。
X = torch.rand(size=(1, 3, 320, 480))
net(X).shape
torch.Size([1, 512, 10, 15])
接下来[使用 1 × 1 1\times1 1×1卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。]
最后需要(将特征图的高度和宽度增加32倍),从而将其变回输入图像的高和宽。
回想一下 :numref:sec_padding中卷积层输出形状的计算方法:
由于 ( 320 − 64 + 16 × 2 + 32 ) / 32 = 10 (320-64+16\times2+32)/32=10 (320−64+16×2+32)/32=10且 ( 480 − 64 + 16 × 2 + 32 ) / 32 = 15 (480-64+16\times2+32)/32=15 (480−64+16×2+32)/32=15,我们构造一个步幅为 32 32 32的转置卷积层,并将卷积核的高和宽设为 64 64 64,填充为 16 16 16。
我们可以看到如果步幅为 s s s,填充为 s / 2 s/2 s/2(假设 s / 2 s/2 s/2是整数)且卷积核的高和宽为 2 s 2s 2s,转置卷积核会将输入的高和宽分别放大 s s s倍。
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes, num_classes,kernel_size=64, padding=16, stride=32))
[初始化转置卷积层]
在图像处理中,我们有时需要将图像放大,即上采样(upsampling)。
双线性插值(bilinear interpolation)
是常用的上采样方法之一,它也经常用于初始化转置卷积层。
为了解释双线性插值,假设给定输入图像,我们想要计算上采样输出图像上的每个像素。
- 将输出图像的坐标 ( x , y ) (x,y) (x,y)映射到输入图像的坐标 ( x ′ , y ′ ) (x',y') (x′,y′)上。
例如,根据输入与输出的尺寸之比来映射。
请注意,映射后的 x ′ x′ x′和 y ′ y′ y′是实数。 - 在输入图像上找到离坐标 ( x ′ , y ′ ) (x',y') (x′,y′)最近的4个像素。
- 输出图像在坐标 ( x , y ) (x,y) (x,y)上的像素依据输入图像上这4个像素及其与 ( x ′ , y ′ ) (x',y') (x′,y′)的相对距离来计算。
双线性插值的上采样可以通过转置卷积层实现,内核由以下bilinear_kernel函数构造。
限于篇幅,我们只给出bilinear_kernel函数的实现,不讨论算法的原理。
def bilinear_kernel(in_channels, out_channels, kernel_size):factor = (kernel_size + 1) // 2if kernel_size % 2 == 1:center = factor - 1else:center = factor - 0.5og = (torch.arange(kernel_size).reshape(-1, 1),torch.arange(kernel_size).reshape(1, -1))filt = (1 - torch.abs(og[0] - center) / factor) * \(1 - torch.abs(og[1] - center) / factor)weight = torch.zeros((in_channels, out_channels,kernel_size, kernel_size))weight[range(in_channels), range(out_channels), :, :] = filtreturn weight
让我们用[双线性插值的上采样实验]它由转置卷积层实现。
我们构造一个将输入的高和宽放大2倍的转置卷积层,并将其卷积核用bilinear_kernel函数初始化。
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2,bias=False)
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4));
读取图像X,将上采样的结果记作Y。为了打印图像,我们需要调整通道维的位置。
img = torchvision.transforms.ToTensor()(d2l.Image.open('../img/catdog.jpg'))
X = img.unsqueeze(0)
Y = conv_trans(X)
out_img = Y[0].permute(1, 2, 0).detach()
可以看到,转置卷积层将图像的高和宽分别放大了2倍。
除了坐标刻度不同,双线性插值放大的图像和在 :numref:sec_bbox中打印出的原图看上去没什么两样。
d2l.set_figsize()
print('input image shape:', img.permute(1, 2, 0).shape)
d2l.plt.imshow(img.permute(1, 2, 0));
print('output image shape:', out_img.shape)
d2l.plt.imshow(out_img);
input image shape: torch.Size([561, 728, 3])
output image shape: torch.Size([1122, 1456, 3])

全卷积网络[用双线性插值的上采样初始化转置卷积层。对于 1 × 1 1\times 1 1×1卷积层,我们使用Xavier初始化参数。]
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W);
[读取数据集]
我们用 :numref:sec_semantic_segmentation中介绍的语义分割读取数据集。
指定随机裁剪的输出图像的形状为 320 × 480 320\times 480 320×480:高和宽都可以被 32 32 32整除。
batch_size, crop_size = 32, (320, 480)
train_iter, test_iter = d2l.load_data_voc(batch_size, crop_size)
read 1114 examples
read 1078 examples
[训练]
现在我们可以训练全卷积网络了。
这里的损失函数和准确率计算与图像分类中的并没有本质上的不同,因为我们使用转置卷积层的通道来预测像素的类别,所以需要在损失计算中指定通道维。
此外,模型基于每个像素的预测类别是否正确来计算准确率。
def loss(inputs, targets):return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
loss 0.443, train acc 0.863, test acc 0.848
254.0 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]

[预测]
在预测时,我们需要将输入图像在各个通道做标准化,并转成卷积神经网络所需要的四维输入格式。
def predict(img):X = test_iter.dataset.normalize_image(img).unsqueeze(0)pred = net(X.to(devices[0])).argmax(dim=1)return pred.reshape(pred.shape[1], pred.shape[2])
为了[可视化预测的类别]给每个像素,我们将预测类别映射回它们在数据集中的标注颜色。
def label2image(pred):colormap = torch.tensor(d2l.VOC_COLORMAP, device=devices[0])X = pred.long()return colormap[X, :]
测试数据集中的图像大小和形状各异。
由于模型使用了步幅为32的转置卷积层,因此当输入图像的高或宽无法被32整除时,转置卷积层输出的高或宽会与输入图像的尺寸有偏差。
为了解决这个问题,我们可以在图像中截取多块高和宽为32的整数倍的矩形区域,并分别对这些区域中的像素做前向传播。
请注意,这些区域的并集需要完整覆盖输入图像。
当一个像素被多个区域所覆盖时,它在不同区域前向传播中转置卷积层输出的平均值可以作为softmax运算的输入,从而预测类别。
为简单起见,我们只读取几张较大的测试图像,并从图像的左上角开始截取形状为 320 × 480 320\times480 320×480的区域用于预测。
对于这些测试图像,我们逐一打印它们截取的区域,再打印预测结果,最后打印标注的类别。
voc_dir = d2l.download_extract('voc2012', 'VOCdevkit/VOC2012')
test_images, test_labels = d2l.read_voc_images(voc_dir, False)
n, imgs = 4, []
for i in range(n):crop_rect = (0, 0, 320, 480)X = torchvision.transforms.functional.crop(test_images[i], *crop_rect)pred = label2image(predict(X))imgs += [X.permute(1,2,0), pred.cpu(),torchvision.transforms.functional.crop(test_labels[i], *crop_rect).permute(1,2,0)]
d2l.show_images(imgs[::3] + imgs[1::3] + imgs[2::3], 3, n, scale=2);

小结
- 全卷积网络先使用卷积神经网络抽取图像特征,然后通过 1 × 1 1\times 1 1×1卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。
- 在全卷积网络中,我们可以将转置卷积层初始化为双线性插值的上采样。
相关文章:
【深度学习笔记】计算机视觉——FCN(全卷积网络
全卷积网络 sec_fcn 如 :numref:sec_semantic_segmentation中所介绍的那样,语义分割是对图像中的每个像素分类。 全卷积网络(fully convolutional network,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换 :cite:Long.Sh…...

物联网行业如何发展新质生产力
物联网行业作为当今科技发展的前沿领域,其在新质生产力的提升中扮演着举足轻重的角色。为了推动物联网行业的快速发展,我们需要从技术创新、产业融合、人才培养和政策支持等多个方面入手,共同构建一个有利于物联网行业发展的生态环境。 首先…...

manjaro 安装 wps 教程
内核: Linux 6.6.16.2 wps-office版本: 11.10.11719-1 本文仅作为参考使用, 如果以上版本差别较大不建议参考 安装wps主体 yay -S wps-office 安装wps字体 (如果下载未成功看下面的方法) yay -S ttf-waps-fonts 安装wps中文语言 yay …...

Spring AOP基于注解方式实现
1. 场景介绍 目前假设我们有一个计算器类,并要为其中的方法添加日志功能。 计算器类如代码所示: public interface Calculator {int add(int i, int j);int sub(int i, int j);int mul(int i, int j);int div(int i, int j);}public class Calculator…...
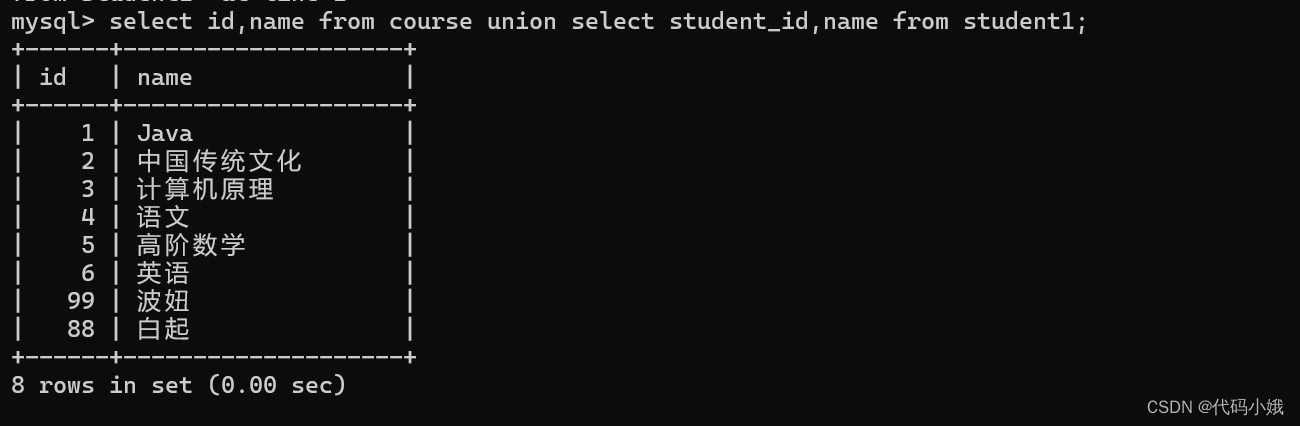
MySQL中常用的操作语句已汇总
目录 一、库语句 1.查询现有数据库 2.创建数据库 3.选中数据库 编辑 4.删除数据库 二、初阶表操作 1.查看数据库现有表 2.查看表结构 3.创建表 4.删除表 5.全列查询 6.删除表2 7.修改操作 三、插入操作 1.全列插入 2.指定列插入 3.一次插入多组数据 4.插入…...

linux设置nginx systemctl启动
生成nginx.pid文件 #验证nginx的配置,并生成nginx.pid文件 /usr/local/nginx/sbin/nginx -t #pid文件目录在 /usr/local/nginx/run/nginx.pid 设置systemctl启动nginx #添加之前需要先关闭启动状态的nginx,让nginx是未启动状态 #关闭nginx /usr/local…...

stable diffusion faceswaplab换脸插件报错解决
错误提示: ERROR - Failed to swap face in postprocess method : apply_overlay() takes 3 positional arguments but 4 were given 打开插件对应目录: \sd-webui-aki-v4.6.1\extensions\sd-webui-faceswaplab\scripts\faceswaplab_utils中 imgutil…...
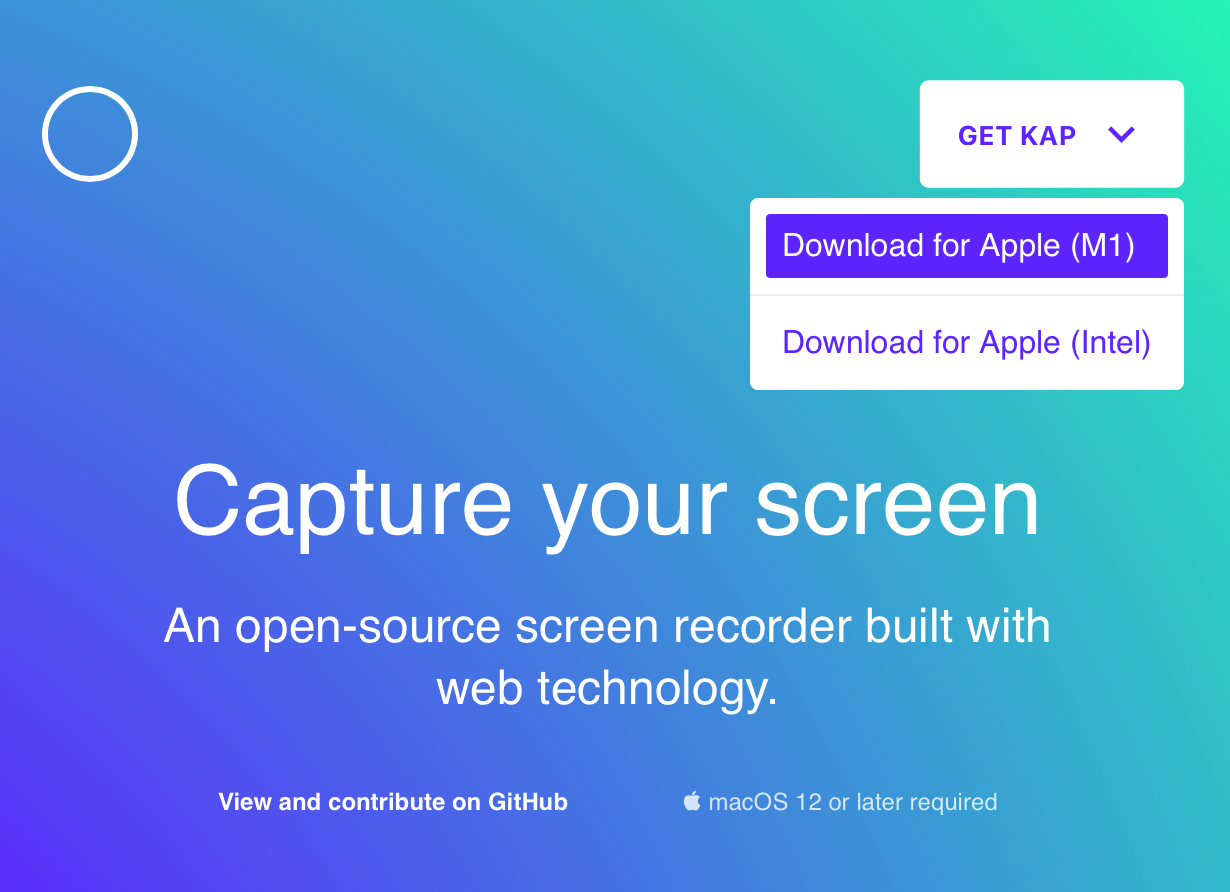
Kap - macOS 开源录屏工具
文章目录 关于 Kap 关于 Kap Kap 是一个使用web技术的开源的屏幕录制工具 官网:https://getkap.cogithub : https://github.com/wulkano/Kap 目前只支持 macOS 12 以上,支持 Intel 和 Apple silicon 你可以前往官网,右上方下载 你也可以使…...

Linux/Ubuntu/Debian基本命令:光标移动命令
Linux系统真的超级好用,免费,有很多开源且功能强大的软件。尤其是Ubuntu,真的可以拯救十年前的老电脑。从今天开始我将做一个Linux的推广者,推广普及Linux基础。 光标移动命令对于在终端(Terminal)内有效导…...

nvm下载,nodejs下载
进入nvm中文网,按照它的教程来,很简单!!! 往下翻...
)
大数据开发(Hadoop面试真题-卷七)
大数据开发(Hadoop面试真题) 1、Map的分片有多大?2、MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?3、MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中吗&a…...

计算机网络(基础篇)复习笔记——体系结构/协议基础(持续更新中......)
目录 1 计算机网络基础相关技术Rip 路由更新操作 2 体系结构(OSI 7层, TCP/IP4层)应用层运输层网络层IPv4无分类域间路由选择 CIDRIPV6 数据链路层循环冗余校验CRC协议设备 物理层传输媒体信道复用技术宽带接入技术数据通信 3 网络局域网(以太网Ethernet) 4 通信过程编码:信道极…...
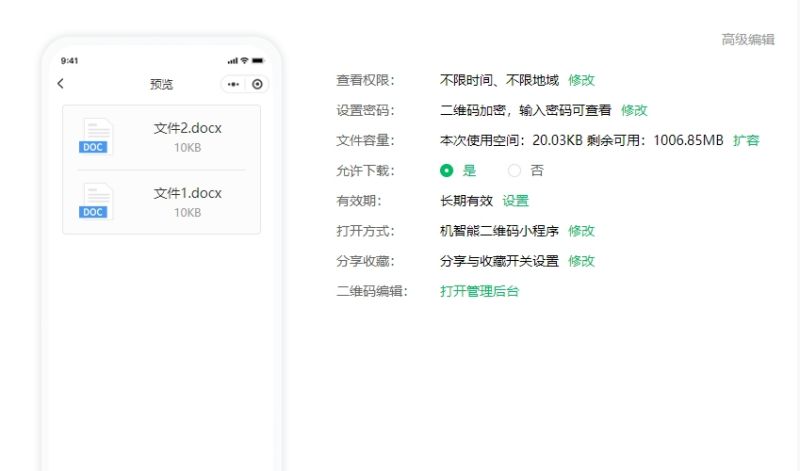
怎么做加密文件二维码?分享文件更安全
怎么做一个加密文件二维码?在日常的工作和生活中,通过扫描二维码来查看或者下载文件的方式,被越来越多的人所使用,一方面是二维码的成本低,另一方面有利于提升便捷性和用户体验。 为了保证内容的隐私性和安全性&#…...

手机中常用的传感器
文章目录 重力传感器 Gravity sensor三维坐标 加速度传感器 Accelerometer三维坐标 陀螺仪 Gyroscope三维坐标 磁力传感器 Magnetometer三维坐标 光线传感器 Light Sensor接近传感器 Proximity Sensor其他传感器协同工作相机自动调整 传感器有唤醒和非唤醒属性 关于重力传感器和…...

电脑工作电压是多少你要看看光驱电源上面标的输入电压范围
要确定电脑的工作电压,必须查看电源上标注的输入电压范围。 国内法规规定民用220V电压范围为10%-15%,也就是说通信220V电压正常范围为187--242V,供电设备一般为180V。 --250V电压范围,即正常情况下电脑电源电压不低于187V即可工作…...

自动驾驶---Motion Planning之Speed Boundary
1 背景 在上篇博客《自动驾驶---Motion Planning之Path Boundary》中,笔者主要介绍了path boundary的一些内容,通过将道路中感兴趣区域的动静态障碍物投影到车道坐标系中,用于确定L或者S的边界,并利用道路信息再确定Speed的边界,最后结合粗糙的速度曲线和路径曲线,即可使…...

php文件操作
一、文件读取的5种方法 1,file_get_contents: 将整个文件读入一个字符串 file_get_contents( string $filename, bool $use_include_path false, ?resource $context null, int $offset 0, ?int $length null ): string|false 可以读取本地的文件也可以用来打…...
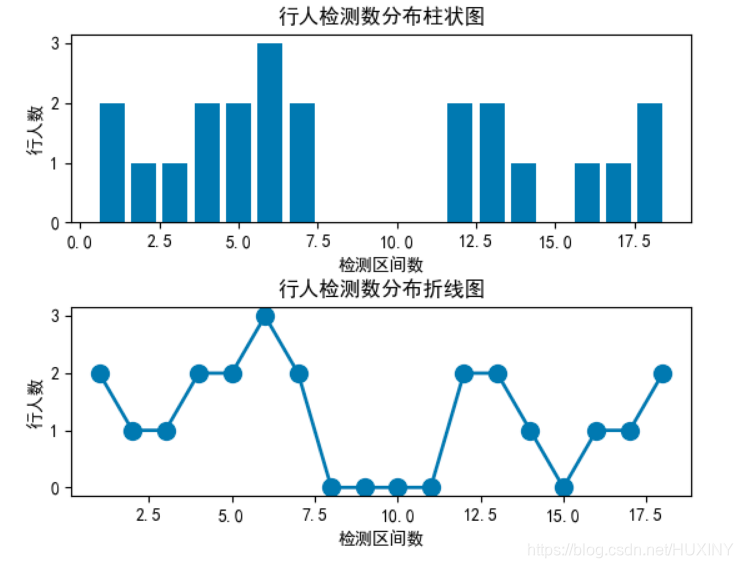
计算机设计大赛 目标检测-行人车辆检测流量计数
文章目录 前言1\. 目标检测概况1.1 什么是目标检测?1.2 发展阶段 2\. 行人检测2.1 行人检测简介2.2 行人检测技术难点2.3 行人检测实现效果2.4 关键代码-训练过程 最后 前言 🔥 优质竞赛项目系列,今天要分享的是 行人车辆目标检测计数系统 …...
Java二叉树 (2)
🐵本篇文章将对二叉树的一些基础操作进行梳理和讲解 一、操作简述 int size(Node root); // 获取树中节点的个数int getLeafNodeCount(Node root); // 获取叶子节点的个数int getKLevelNodeCount(Node root,int k); // 获取第K层节点的个数int getHeight(Node r…...
—— 模型工作流)
R语言数学建模(三)—— 模型工作流
R语言数学建模(三)—— 模型工作流 文章目录 R语言数学建模(三)—— 模型工作流前言一、模型工作流1.1 模型的起点和终点在哪里?1.2 Workflow基础1.3 将原始变量添加到workflow()1.4 workflow()如何使用formula基于树的…...

3分钟搞定!免费解锁AMD/Intel处理器性能的终极指南
3分钟搞定!免费解锁AMD/Intel处理器性能的终极指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 还在为电脑性能…...
)
LLM系列:1.python入门:5.列表型对象 (List)
列表型对象 (List) 一. 列表基础 1. 列表创建 list可以存储任意类型对象 (1).直接创建 lst [1, 2, 3, 4](2).列表推导式 ①.表推导式的语法结构基本形式: [表达式 for 变量 in 可迭代对象]带条件: [表达式 for 变量 in 可迭代对象 if 条件]例子…...

如何修改图片的exif信息?6款工具,新手也能秒会
一、什么是EXIF信息?为什么要修改?EXIF信息就像图片的"身份证",记录着拍摄时的详细数据,比如相机型号、拍摄时间、GPS位置、光圈快门等参数。平时发朋友圈、传文件时,如果不注意这些信息,可能会不…...

如何快速构建电商库存扫描系统:QuaggaJS条形码识别终极指南
如何快速构建电商库存扫描系统:QuaggaJS条形码识别终极指南 【免费下载链接】quaggaJS An advanced barcode-scanner written in JavaScript 项目地址: https://gitcode.com/gh_mirrors/qu/quaggaJS 在电商运营中,高效的库存管理是提升效率和降低…...
)
别再乱改XML了!手把手教你用RimWorld Mod制作第一把自定义远程武器(从栓动步枪到电荷步枪)
从零构建RimWorld自定义武器:避开XML陷阱的实战指南 当你第一次打开RimWorld的Mod文件夹,看到密密麻麻的XML标签时,是否感到无从下手?作为一款深度沙盒游戏,RimWorld的武器系统看似简单,实则暗藏玄机。本文…...

如何在AMD RX590上高效运行DeepSeek R1 32B大模型?
1. AMD RX590运行DeepSeek R1 32B的可行性分析 用一张2018年发布的千元级显卡跑动320亿参数的大模型?这听起来像是天方夜谭,但实测证明完全可行。我的迪兰恒进RX590恶魔版(8GB显存)在降频至1170MHz的状态下,成功跑起了…...

Windows Defender终极移除指南:windows-defender-remover工具完整使用教程
Windows Defender终极移除指南:windows-defender-remover工具完整使用教程 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode…...
)
基于单片机的智能太阳能热水器设计(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T0852310M设计简介:本设计是基于单片机的智能太阳能热水器设计,主要实现以下功能:通过温度传感器检测水温 通过超声波模…...

《深度解析QClaw同步架构:为什么它比所有云盘都快10倍》
绝大多数人对跨设备同步的理解还停留在文件传输的层面,认为只要能把一个文件从A电脑传到B电脑就叫同步。但真正的工作同步远不止于此,它应该包括你未完成的任务队列、上下文记忆、技能配置、甚至是你和AI助手之间形成的独特工作默契。QClaw 2.0带来的本地P2P状态快照机制,第…...

应届生面试:3分钟搞定自我介绍
文章目录前言一、为什么应届生面试,自我介绍这么重要?1.1 面试官的真实目的:3秒筛选,3分钟定印象1.2 3分钟不是上限,是“黄金区间”1.3 2026年校招趋势:更看重“务实”,不看“空喊口号”二、90%…...