2. gin中间件注意事项、路由拆分与注册技巧
文章目录
- 一、中间件
- 二、Gin路由简介
- 1、普通路由
- 2、路由组
- 三、路由拆分与注册
- 1、基本的路由注册
- 2、路由拆分成单独文件或包
- 3、路由拆分成多个文件
- 4、路由拆分到不同的APP
一、中间件
在日常工作中,经常会有一些计算接口耗时和限流的操作,如果每写一个接口都需要手动的去加上计算耗时和限流的代码,显然是很冗余且不好维护的,还很容易遗漏。这个时候我们一般会想到使用中间件的方式,将这些与业务无关的代码写到中间件去,然后安到每个接口中去就行了。
package mainimport ("fmt""net/http""time""github.com/gin-gonic/gin"
)func timeMiddleware() gin.HandlerFunc {return func(ctx *gin.Context) {begin := time.Now()defer func() {fmt.Printf("use time %d ms\n", time.Since(begin).Milliseconds())}()ctx.Next()}
}func limitMiddleware() gin.HandlerFunc {// 限流最高并发为10,这里return的func会必闭包使用这个limitChan,从而达到限流效果limitChan := make(chan struct{}, 10) return func(ctx *gin.Context) {defer func() {<-limitChan}()limitChan <- struct{}{}ctx.Next()}
}func bizHandler(ctx *gin.Context) {time.Sleep(100 * time.Millisecond)ctx.String(http.StatusOK, "gin 中间件")}func main() {engine := gin.Default()// Use方法就是将中间件放到了链条的首部,注意Use接收的是可变参数,可接收多个中间件// engine.Use(timeMiddleware(),limitMiddleware())// 如果是分别使用use,则要注意一下顺序,如这里将timeMiddleware后写,//是因为想把timeMiddleware放到链条首部,从而将限流中间件的耗时也统计到engine.Use(limitMiddleware())engine.Use(timeMiddleware())engine.GET("/v1", bizHandler)// engine.GET("/v2",timeMiddleware(), bizHandler)engine.Run("127.0.0.1:8080")
}注意事项:
- 中间件是
gin.HandlerFunc类型,在使用limitMiddleware和timeMiddleware时,我们加了小括号,因为它们的返回值才是gin.HandlerFunc类型 engine.Get,engine.Post,engine.Use方法,接收的都是可变长参数,如示例中的v2路径,可以直接将中间件对指定的路径使用,或者用Use一次全局使用多个中间件- 使用多个
Use时,注意使用顺序,后使用的Use,里面的中间件会放到链表首部 - 如果中间件中没有使用
ctx.Next,则是将当前中间件执行完后再去执行链表上的下一个handler,如果使用了ctx.Next则表示从此处开始,先将链表后面的handler都执行完,然后再回溯到这里的ctx.Next位置来,继续执行当前中间件函数中的后续代码。
二、Gin路由简介
1、普通路由
r.GET("/index", func(c *gin.Context) {...})
r.GET("/login", func(c *gin.Context) {...})
r.POST("/login", func(c *gin.Context) {...})
此外,还有一个可以匹配所有请求方法的Any方法如下:
r.Any("/test", func(c *gin.Context) {...})
为没有配置处理函数的路由添加处理程序,默认情况下它返回404代码,下面的代码为没有匹配到路由的请求都返回views/404.html页面。
r.NoRoute(func(c *gin.Context) {c.HTML(http.StatusNotFound, "views/404.html", nil)})
2、路由组
我们可以将拥有共同URL前缀的路由划分为一个路由组。习惯性一对{}包裹同组的路由,这只是为了看着清晰,用不用{}包裹功能上没什么区别。
func main() {r := gin.Default()userGroup := r.Group("/user"){userGroup.GET("/index", func(c *gin.Context) {...})userGroup.GET("/login", func(c *gin.Context) {...})userGroup.POST("/login", func(c *gin.Context) {...})}shopGroup := r.Group("/shop"){shopGroup.GET("/index", func(c *gin.Context) {...})shopGroup.GET("/cart", func(c *gin.Context) {...})shopGroup.POST("/checkout", func(c *gin.Context) {...})}r.Run()
}
通常我们将路由分组用在划分业务逻辑或划分API版本时。
三、路由拆分与注册
1、基本的路由注册
下面是最基础的gin路由注册方式,适用于路由比较少的简单项目或者项目demo。
package mainimport ("net/http""github.com/gin-gonic/gin"
)func helloHandler(c *gin.Context) {c.JSON(http.StatusOK, gin.H{"message": "Hello q1mi!",})
}func main() {r := gin.Default()r.GET("/hello", helloHandler)if err := r.Run(); err != nil {fmt.Println("startup service failed, err:%v\n", err)}
}
2、路由拆分成单独文件或包
当项目的规模增大后就不太适合继续在项目的main.go文件中去实现路由注册相关逻辑了,我们会倾向于把路由部分的代码都拆分出来,形成一个单独的文件或包:
我们在routers.go文件中定义并注册路由信息:
package mainimport ("net/http""github.com/gin-gonic/gin"
)func helloHandler(c *gin.Context) {c.JSON(http.StatusOK, gin.H{"message": "Hello q1mi!",})
}func setupRouter() *gin.Engine {r := gin.Default()r.GET("/hello", helloHandler)return r
}
此时main.go中调用上面定义好的setupRouter函数:
func main() {r := setupRouter()if err := r.Run(); err != nil {fmt.Println("startup service failed, err:%v\n", err)}
}
此时的目录结构:
gin_demo
├── go.mod
├── go.sum
├── main.go
└── routers.go
一般会把路由部分的代码单独拆分成包的,拆分后的目录结构如下:
gin_demo
├── go.mod
├── go.sum
├── main.go
└── routers└── routers.go
routers/routers.go
需要注意此时setupRouter需要改成首字母大写,因为和main.go已经不在一个包中了,要在main.go中调用SetupRouter,所以他必须是可导出的:
package routersimport ("net/http""github.com/gin-gonic/gin"
)func helloHandler(c *gin.Context) {c.JSON(http.StatusOK, gin.H{"message": "Hello q1mi!",})
}// SetupRouter 配置路由信息
func SetupRouter() *gin.Engine {r := gin.Default()r.GET("/hello", helloHandler)return r
}
main.go文件内容如下:
package mainimport ("fmt""gin_demo/routers"
)func main() {r := routers.SetupRouter()if err := r.Run(); err != nil {fmt.Println("startup service failed, err:%v\n", err)}
}
3、路由拆分成多个文件
当我们的业务规模继续膨胀,单独的一个routers文件或包已经满足不了我们的需求了,
func SetupRouter() *gin.Engine {r := gin.Default()r.GET("/hello", helloHandler)r.GET("/xx1", xxHandler1)...r.GET("/xx30", xxHandler30)return r
}
因为我们把所有的路由注册都写在一个SetupRouter函数中的话就会太复杂了。
我们可以分开定义多个路由文件,例如:
gin_demo
├── go.mod
├── go.sum
├── main.go
└── routers├── blog.go└── shop.go
routers/shop.go中添加一个LoadShop的函数,将shop相关的路由注册到指定的路由器:
func LoadShop(e *gin.Engine) {e.GET("/hello", helloHandler)e.GET("/goods", goodsHandler)e.GET("/checkout", checkoutHandler)...
}
routers/blog.go中添加一个LoadBlog的函数,将blog相关的路由注册到指定的路由器:
func LoadBlog(e *gin.Engine) {e.GET("/post", postHandler)e.GET("/comment", commentHandler)...
}
在main函数中实现最终的注册逻辑如下:
func main() {r := gin.Default()routers.LoadBlog(r)routers.LoadShop(r)if err := r.Run(); err != nil {fmt.Println("startup service failed, err:%v\n", err)}
}
4、路由拆分到不同的APP
有时候项目规模实在太大,那么我们就更倾向于把业务拆分的更详细一些,例如把不同的业务代码拆分成不同的APP。
因此我们在项目目录下单独定义一个app目录,用来存放我们不同业务线的代码文件,这样就很容易进行横向扩展。大致目录结构如下:
gin_demo
├── app
│ ├── blog
│ │ ├── handler.go
│ │ └── router.go
│ └── shop
│ ├── handler.go
│ └── router.go
├── go.mod
├── go.sum
├── main.go
└── routers└── routers.go
其中app/blog/router.go用来定义post相关路由信息,具体内容如下:
func Routers(e *gin.Engine) {e.GET("/post", postHandler)e.GET("/comment", commentHandler)
}
app/shop/router.go用来定义shop相关路由信息,具体内容如下:
func Routers(e *gin.Engine) {e.GET("/goods", goodsHandler)e.GET("/checkout", checkoutHandler)
}
在第三步迭代中(3、路由拆分成多个文件),我们在main.go中使用了两次routers.LoadXXX(r),事实上他们是同种类型的函数,当这种调用比较多时也是累赘,故可以定义option,使用函数数选项模式使得代码更优雅。
func main() {r := gin.Default()// 使用了两次routers.LoadXXX(r)routers.LoadBlog(r)routers.LoadShop(r)if err := r.Run(); err != nil {fmt.Println("startup service failed, err:%v\n", err)}
}
routers/routers.go中根据需要定义Include函数用来注册子app中定义的路由,Init函数用来进行路由的初始化操作:
type Option func(*gin.Engine)var options = []Option{}// 注册app的路由配置
func Include(opts ...Option) {options = append(options, opts...)
}// 初始化
func Init() *gin.Engine {r := gin.New()for _, opt := range options {opt(r)}return r
}
main.go中按如下方式先注册子app中的路由,然后再进行路由的初始化:
func main() {// 加载多个APP的路由配置routers.Include(shop.Routers, blog.Routers)// 初始化路由r := routers.Init()if err := r.Run(); err != nil {fmt.Println("startup service failed, err:%v\n", err)}
}
相关文章:

2. gin中间件注意事项、路由拆分与注册技巧
文章目录 一、中间件二、Gin路由简介1、普通路由2、路由组 三、路由拆分与注册1、基本的路由注册2、路由拆分成单独文件或包3、路由拆分成多个文件4、路由拆分到不同的APP 一、中间件 在日常工作中,经常会有一些计算接口耗时和限流的操作,如果每写一个接…...

R语言复现:如何利用logistic逐步回归进行影响因素分析?
Logistic回归在医学科研、特别是观察性研究领域,无论是现况调查、病例对照研究、还是队列研究中都是大家经常用到的统计方法,而在影响因素研究筛选自变量时,大家习惯性用的比较多的还是先单后多,P<0.05纳入多因素研究&…...
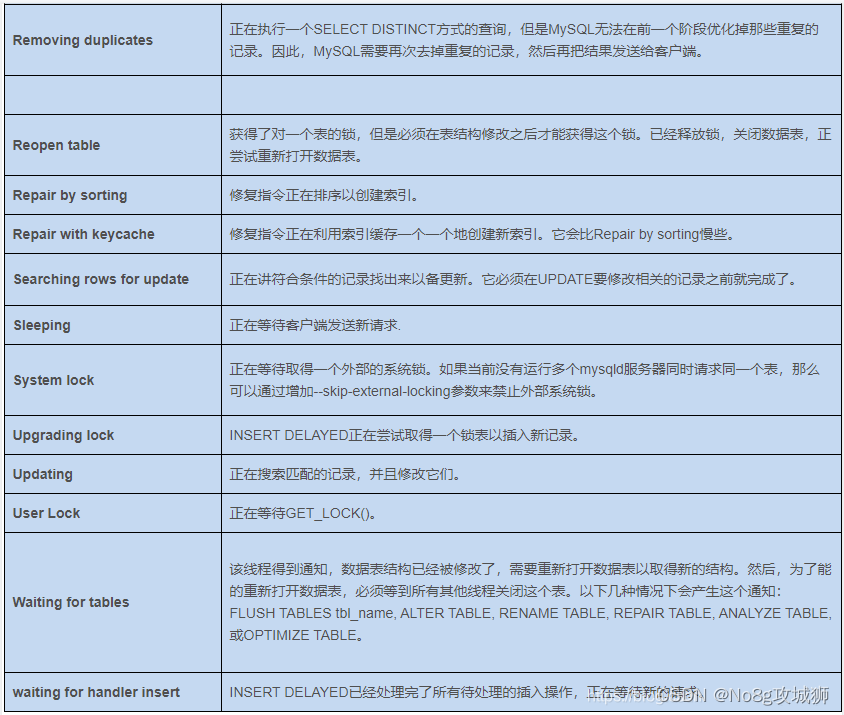
【MySQL使用】show processlist 命令详解
show processlist 命令详解 一、命令含义二、命令返回参数三、Command值解释四、State值解释五、参考资料 一、命令含义 对于一个MySQL连接,或者说一个线程,任何时刻都有一个状态,该状态表示了MySQL当前正在做什么。SHOW PROCESSLIST 命令的…...
分类算法(Classification algorithms)
逻辑回归(logical regression): 逻辑回归这个名字听上去好像应该是回归算法的,但其实这个名字只是在历史上取名有点区别,但实际上它是一个完全属于是分类算法的。 我们为什么要学习它呢?在用我们的线性回归时会遇到一…...

深度学习-Softmax 回归 + 损失函数 + 图片分类数据集
Softmax 回归 损失函数 图片分类数据集 1 softmax2 损失函数1均方L1LossHuber Loss 3 图像分类数据集4 softmax回归的从零开始实现 1 softmax Softmax是一个常用于机器学习和深度学习中的激活函数。它通常用于多分类问题,将一个实数向量转换为概率分布。Softmax函…...
)
分布式锁从0到1落地实现01(mysql/redis/zk)
1 准备数据库表 CREATE TABLE user ( id bigint(20) NOT NULL COMMENT 主键ID, name varchar(30) DEFAULT NULL COMMENT 姓名, age int(11) DEFAULT NULL COMMENT 年龄, email varchar(50) DEFAULT NULL COMMENT 邮箱, PRIMARY KEY (id) ) ENGINEInnoDB DEFAULT CHARSETutf8;I…...

安全运营方案的基本框架和关键要素
一、前言 阐述安全运营方案的目的和重要性。强调安全运营与组织整体战略目标的关联。 二、安全运营原则 确立安全运营的基本原则,如保密性、完整性和可用性。明确安全责任划分,确保各部门和人员履行安全职责。 三、安全风险评估与管理 进行全面的安…...
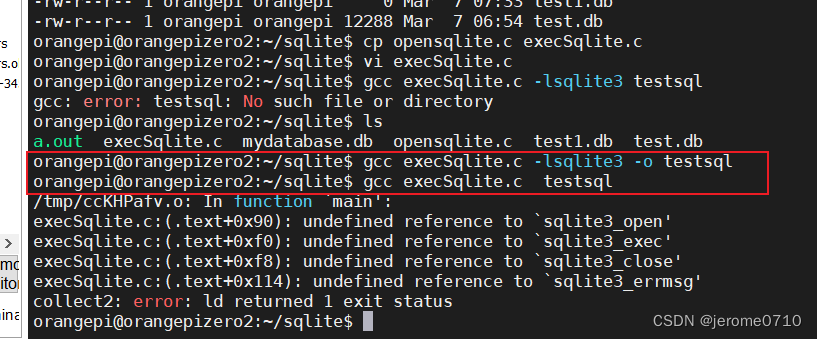
用C语言执行SQLite3的gcc编译细节
错误信息: /tmp/cc3joSwp.o: In function main: execSqlite.c:(.text0x100): undefined reference to sqlite3_open execSqlite.c:(.text0x16c): undefined reference to sqlite3_exec execSqlite.c:(.text0x174): undefined reference to sqlite3_close execSqlit…...
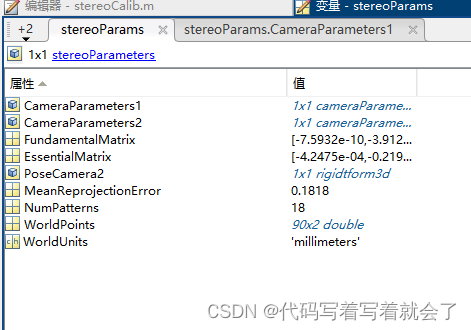
matlab双目相机标定-需要什么参数、怎么获得
相机标定目的:获得相机内参、外参、畸变系数,摄像头的内参(f,1/dx,1/dy,cx,cy)、畸变参数(k1,k2,k3,p1,p1)和外参(R,t),用于接下来的双目校正和深度图生成从而实现二维到三维的转换。 相机标定方法:opencv 双目相机标定以及立体…...
)
大型语言模型的智能助手:检索增强生成(RAG)
背景 在人工智能的浪潮中,大型语言模型(LLMs)如GPT系列和LLama系列在自然语言处理(NLP)领域取得了显著成就。它们能够完成复杂的语言任务,如文本摘要、机器翻译、甚至创作诗歌。然而,这些模型在…...
Ubuntu 安装谷歌拼音输入法
一、Fcitx 安装 在Ubuntu 下,谷歌拼音输入法是基于Fcitx输入法的。所以,首先需要安装Fcitx。一般来说,Ubuntu最新版中都默认安装了Fcitx,但是为了确保一下,我们可以在系统终端中运行如下命令: sudo apt ins…...
修改MonkeyDev默认配置适配Xcode15
上一篇文章介绍了升级Xcode15后,适配MonkeyDev的一些操作,具体操作可以查看:Xcode 15 适配 MonkeyDev。 但是每次新建项目都要去修改那些配置,浪费时间和精力,这篇文章主要介绍如何修改MonkeyDev的默认配置࿰…...

deepinlinux打包deb文件完善
最近学习了一篇qt入门文章,做了一个小应用,要给另一台电脑用时发现还需考虑另一台没有qt,要把相关库带过去,后来就学了打包成deb安装包,看起来更专业。 win下搜索qt依赖库的程序是windeployqt,先将应用输出…...

Android studioSDK集成:com.yechaoa.yutilskt
文章目录 1、工具介绍2、集成 1、工具介绍 com.yechaoa.yutilskt是一个Android开发工具库,提供了一些常用的工具类和方法,方便开发者进行Android应用程序的开发。该库包含了以下功能: 网络请求工具类:提供了简化的网络请求方法&…...

openssl3.2 - exp - PEM <==> DER
文章目录 openssl3.2 - exp - PEM <> DER概述笔记加密用的私钥(带口令保护) - PEM > DER加密用的私钥(不带口令保护) - DER > PEM将不带口令的PEM转成带口令的PEM支持口令的算法备注END openssl3.2 - exp - PEM <> DER 概述 想将客户端私钥 服务端公钥 数…...

云计算的部署方式(公有云、私有云、混合云、社区云)
云计算的部署方式(公有云、私有云、混合云、社区云) 目录 零、00时光宝盒 一、云计算的部署方式 1.1、公有云(Public Cloud) 1.2、私有云(Private Cloud) 1.3、混合云(Hybrid Cloud) 1.4、社区云&am…...
umi4 项目使用 keepalive 缓存页面(umi-plugin-keep-alive、react-activation)
umi4使用keepalive 配置文件config\config.ts export default defineConfig({plugins: [umi-plugin-keep-alive], });安装add umi-plugin-keep-alive yarn add umi-plugin-keep-alive页面 A import { KeepAlive, history, useAliveController } from umijs/max; const Page…...
new;getline();重载<<和>>
面向对象程序设计的优点: 易维护易扩展模块化:通过设置访问级别,限制别人对自己的访问,保护了数据安全 int main(){ return 0;} 返回值0在windows下编程一般没用,但是在linux中编程,返回值有时有用 汇编与…...

python报错
Missing optional dependency ‘xlrd’. Install xlrd > 1.0.0 for Excel support Use pip or conda to install xlrd 安装xlrd库...
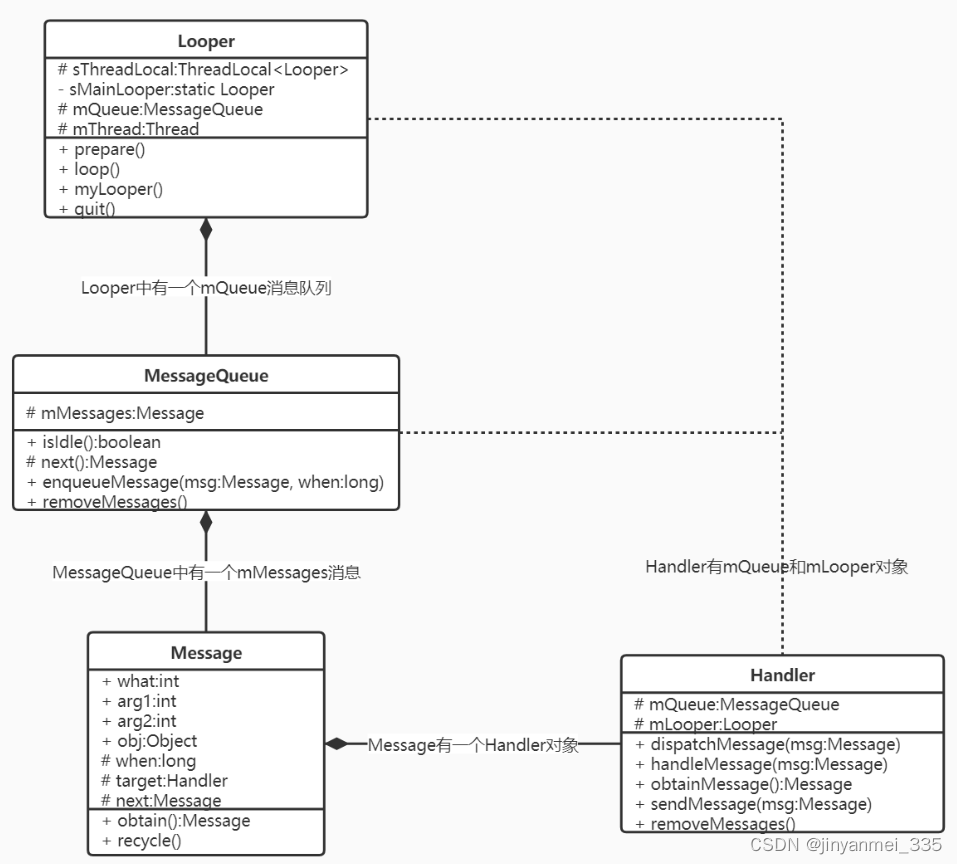
Android14 Handle机制
Handle是进程内部, 线程之间的通信机制. handle主要接受子线程发送的数据, 并用此数据配合主线程更新UI handle可以分发Message对象和Runnable对象到主线程中, 每个handle实例, 都会绑定到创建他的线程中, 它有两个作用,: (1) 安排消息在某个主线程中某个地方执行 (2) 安排…...

SillyTavern角色系统深度解析:构建沉浸式AI交互体验的技术架构与实践
SillyTavern角色系统深度解析:构建沉浸式AI交互体验的技术架构与实践 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern SillyTavern作为面向高级用户的LLM前端工具,其…...

数组arr
一.概念[必须是常量值] 1.概念2.一维数组的创及其初始化(怎么定义数组) 2.1数组创建2.2数组初始化2.2数组类型(去掉数组名)3.一维数组的使用 3.1数组下标(从0开始)3.2如何打印目标数组元素3.3如何打印数组所…...

org.openpnp.vision.pipeline.stages.DetectLinesHough
文章目录org.openpnp.vision.pipeline.stages.DetectLinesHough功能参数例子测试图像generate_line_test_image.pycv-pipeline效果ENDorg.openpnp.vision.pipeline.stages.DetectLinesHough 功能 在图像中检测直线段 在DetectLinesHough之前,需要执行DetectEdgesC…...

智慧医疗中的诊断辅助与健康管理
智慧医疗中的诊断辅助与健康管理:科技重塑健康未来 在人工智能与大数据技术的推动下,智慧医疗正逐步改变传统医疗模式,其中诊断辅助与健康管理成为核心应用场景。通过智能算法分析海量医疗数据,医生可以更精准地判断疾病…...

CentOS 7.9 搭建 PXE 服务器,批量网络安装 CentOS 7.9和9双系统【20260414】004篇
文章目录 一、CentOS 7.9 最终版 KS:ks7.cfg 二、CentOS Stream 9 最终版 KS:ks9.cfg 三、配套 PXE 菜单最终版(pxelinux.cfg/default) 四、UEFI 引导 grub.cfg 最终版 五、关键说明(一次讲清) 环境约定(你之前的 PXE 服务器): PXE 服务器 IP:192.168.1.100 安装源:…...

从理论到实践:深入剖析LightGaussian如何实现3DGS的极致压缩与加速
1. LightGaussian为何能成为3DGS压缩的颠覆者 去年还在为3D高斯泼溅(3DGS)的存储问题头疼的我,第一次看到LightGaussian论文时差点从椅子上跳起来。这个来自德克萨斯大学奥斯汀分校和厦门大学团队的工作,直接把3DGS模型从782MB压缩…...

intv_ai_mk11 AI对话机器人快速上手:5分钟开启你的智能助手
intv_ai_mk11 AI对话机器人快速上手:5分钟开启你的智能助手 1. 认识你的AI助手 intv_ai_mk11是一款基于7B参数Llama架构的AI对话机器人,运行在GPU服务器上。它就像一位随时待命的智能助手,能帮你处理各种文字工作、解答问题、激发创意。 这…...

PHP怎么处理Eloquent Attribute Inference属性推断_Laravel从数据自动推导类型【操作】
PHPStorm 识别 Eloquent 属性类型依赖 property 注解,$casts 等运行时配置不参与静态分析;需配合 Laravel Idea 插件生成注解,并用 Larastan/ Psalm 插件增强类型检查。PHP 本身不支持 Eloquent 属性类型推断,Laravel 也不提供运行…...

佳能打印机报错5b00,1700,p07,e08这些错误解决方法,只需用清零软件清零即可修好了。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

WSL2-ubuntu18.04进阶指南:通过xrdp与xfce4打造高效远程开发环境
1. 为什么选择xrdpxfce4组合? 如果你正在使用WSL2进行开发,可能会遇到图形界面需求。传统的VNC方案虽然能用,但实际体验中经常出现卡顿、延迟高的问题。我在多个项目实测中发现,xrdp协议配合轻量级的xfce4桌面环境,能够…...