MySQL·SQL优化
目录
一 . 前言
二 . 优化方法
1 . 索引
(1)数据构造
(2)单索引
(3)explain
(4)组合索引
(5)索引总结
2 . 避免使用select *
3 . 用union all代替union
4 . 批量操作
5 . 多用limit
6 . in中值太多
7 . 增量查询
8 . 高效的分页
9 . 用连接查询代替子查询
10 . join的表不宜过多
11 . join时要注意
12 . 控制索引的数量
13 . 选择合理的字段类型
14 . 提升group by的效率
三 . 参考资料
一 . 前言
SQL优化是为了提高数据库查询的性能和效率。在应用程序响应以及数据处理方面,数据库操作通常是性能瓶颈之一,尤其是在处理大量数据或者并发请求的情况下。进行SQL优化可以带来以下几个好处:
-
提高查询速度: 减少查询执行的时间,从而加快响应速度。这对于用户体验至关重要,尤其是在在线交易系统和网站应用中。
-
减少资源消耗: 减少数据库服务器的负载和资源消耗,包括CPU、内存和磁盘IO等,从而提高整个系统的性能和可伸缩性。
-
降低数据库锁定和阻塞: 减少数据库锁定和阻塞的可能性,提高系统的并发处理能力,从而避免因为等待资源而导致的性能下降。
-
节省成本: 通过减少服务器资源的使用和提高系统的吞吐量
二 . 优化方法
1 . 索引
(1)数据构造
我们先创建库以及表,并且在表中插入300万数据量,下列是表语句SQL
-- mtc_base.t_mine definitionCREATE TABLE `t_mine` (`ID` int(11) NOT NULL AUTO_INCREMENT,`SN` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`DELWHOSN` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`SNINGOVS` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`MINECODE_S` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`MINECODE_C` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`MINECODE_P` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`FULLNAME` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`XVALUE` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`YVALUE` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`ZVALUE` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`NICKNAME` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`PRODUCTIONSTATE` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT '' COMMENT '煤矿生产状态',`MINECODE_V` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`OUTLINE` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`DATETIME` datetime DEFAULT NULL,`MINECODE` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`NICKNAME_OLD` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,PRIMARY KEY (`ID`),
) ENGINE=InnoDB AUTO_INCREMENT=3000001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;插入SQL代码,我需要的数据不同,所以每次我插入100万条之后修改插入数据继续执行
import datetime
from dbutils.pooled_db import PooledDB
import pymysql
import threading# 创建数据库连接池
pool = PooledDB(pymysql, maxconnections=10, host='192.168.14.93', user='root', password='abc123', database='mtc_base',charset='utf8')# 定义插入数据的函数
def insert_data_batch(data_batch):# 从连接池获取连接connection = pool.connection()cursor = connection.cursor()# 批量插入数据try:sql = "INSERT INTO t_mine (SN, DELWHOSN, SNINGOVS, MINECODE, MINECODE_S, MINECODE_C, MINECODE_P, NICKNAME_OLD, FULLNAME, XVALUE, YVALUE, ZVALUE, NICKNAME, PRODUCTIONSTATE, MINECODE_V, OUTLINE, DATETIME) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"cursor.executemany(sql, data_batch)connection.commit()except Exception as e:print("Error:", e)connection.rollback()# 关闭游标和连接cursor.close()connection.close()# 定义多线程插入数据的函数
def insert_data_multithread(data, batch_size, num_threads):data_batches = [data[i:i+batch_size] for i in range(0, len(data), batch_size)]threads = []for i in range(num_threads):thread = threading.Thread(target=insert_data_batch, args=(data_batches[i],))threads.append(thread)thread.start()for thread in threads:thread.join()if __name__ == "__main__":# 准备300万条数据,这里使用示例数据代替data = [('SN003', 'DELWHOSN00-第三次', 'SNINGOVS001-第三次', 'MINECODE001-第三次', 'MINECODE_S001-第三次', 'MINECODE_C001','MINECODE_P001', 'NICKNAME_OLD001', 'FULLNAME001', 'XVALUE001', 'YVALUE001', 'ZVALUE001', 'NICKNAME001','PRODUCTIONSTATE001', 'MINECODE_V001', 'OUTLINE001', datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))for _ in range(2000000)]# 指定每个批次的大小和线程数量batch_size = 100000 # 每个批次的大小num_threads = 10 # 线程数量# 执行多线程插入数据操作insert_data_multithread(data, batch_size, num_threads)
(2)单索引
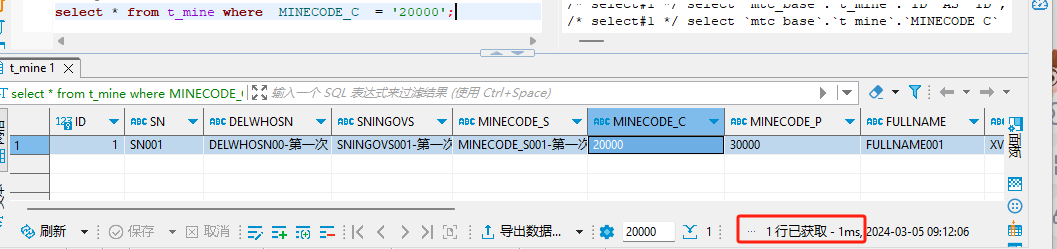
当我们要查询一条数据 (我手动将MINECODE_C一条数据修改为20000)
-
没有索引的时候
使用的全表检索的方式,直接访问文件中的数据,对该列的每一个值进行访问,此时访问文件中数据使用了大量的IO操作,而IO操作是要耗费大量性能
当没有索引的时候300万数据查询时间为 :18秒
这个效率是每个人都接受不来的,因为我们没法等他这么长时间

-
有索引的时候
给 MINECODE_C 字段 创建索引
CREATE INDEX t_mine_MINECODE_C_IDX USING BTREE ON mtc_base.t_mine (MINECODE_C);
索引,其实就相当于书中的目录,它是帮助MySQL系统快速检索数据的一种存储结构。我们可以在索引中按照查询条件,检索索引字段的值,然后快速定位数据记录的位置,这样就不需要遍历整个数据表了。
当有索引的时候300万数据查询时间为 :1 ms
与没有索引查询时间可谓是天差地别
(3)explain
要想知道MySQL中索引是怎么起作用的,我们需要借助explain关键字。
explain关键字能够查看SQL语句的执行细节,包括表的加载顺序,表示如何建立连接的,以及索引的使用情况等。
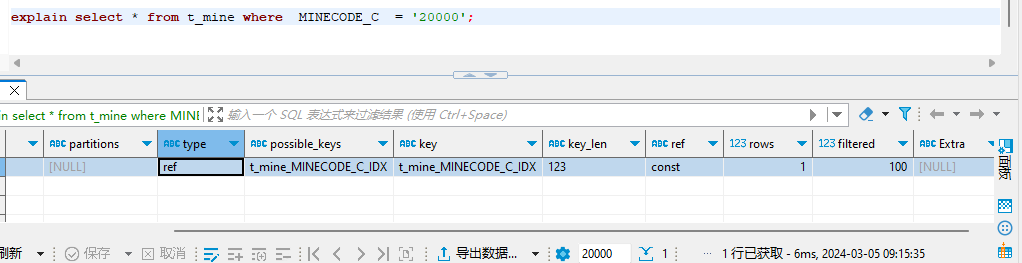
解释一下代码里的关键内容:
- rows=1:表示需要读取的记录数
- possible_keys=index_trans:表示可以选择的索引是 index_trans
- key=index_trans:表示实际选择的索引是 index_trans
我们发现,有了索引之后,MySQL在执行SQL语句的时候多了一种优化的手段。也就是说,在查询的时候,可以先通过查询索引快速定位,然后再找到对应的数据进行读取,这样就大大提高了查询的速度。
组合索引类似同理
(4)组合索引
CREATE INDEX t_mine_MINECODE USING BTREE ON mtc_base.t_mine (MINECODE_C,MINECODE_S,MINECODE_P);
如果有多个索引,而这些索引的字段同时作为筛选字段出现在查询中的时候,MySQL 会选择使用最优的索引来执行查询操作。
组合索引的多个字段是有序的,遵循左对齐的原则。比如我们创建的组合索引,排序的方式是 MINECODE_C、MINECODE_S 和 MINECODE_P。因此,筛选的条件也要遵循从左向右的原则,如果中断,那么,断点后面的条件就没有办法利用索引了。
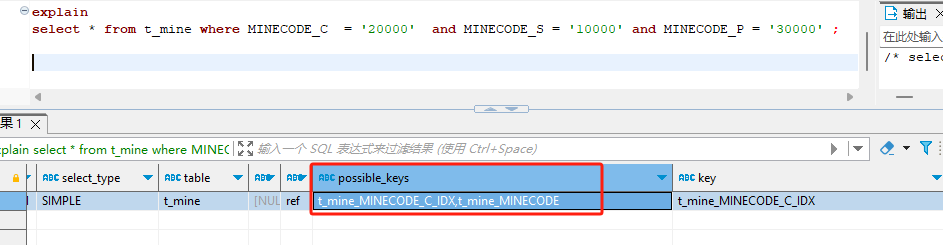
MySQL没有选择组合索引,选择了创建的普通索引。因为如果只使用组合索引的一部分,效果没有单字段索引那么好。
(5)索引总结
索引能够提升查询的效率,但是创建索引是有成本的,主要有2个方面,一个存储空间的开销,还有一个是数据操作上的开销。
- 存储空间的开销,是指索引需要单独占用存储空间;
- 数据操作上的开销,是指一旦数据表有变动,无论是插入一条新数据,还是删除一条旧数据,甚至是修改数据,如果涉及索引字段,都需要对索引本身进行修改,以确保索引能够指向正确的记录。
(6)索引失效场景
联合索引不满足最左匹配原则。模糊查询最前面的为不确定匹配字符。索引列参与了运算。索引列使用了函数。索引列存在类型转换。索引列使用 is not null 查询。
索引失效情况1:非最左匹配
最左匹配原则指的是,以最左边的为起点字段查询可以使用联合索引,否则将不能使用联合索引。 我们本文的联合索引的字段顺序是 sn + name + age,我们假设它们的顺序是 A + B + C,以下联合索引的使用情况如下:
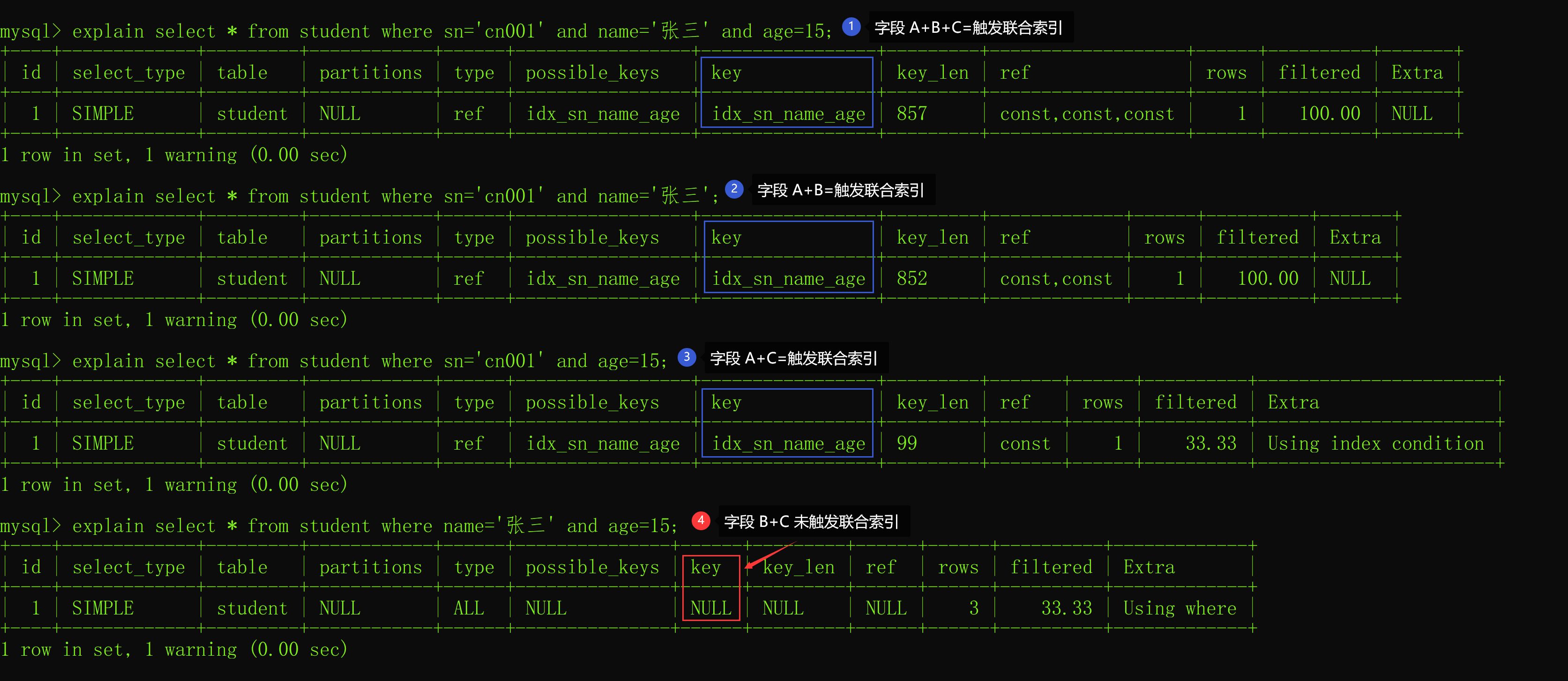
从上述结果可以看出,如果是以最左边开始匹配的字段都可以使用上联合索引,比如:
A+B+C
A+B
A+C 其中:A 等于字段 sn,B 等于字段 name,C 等于字段 age。
而 B+C 却不能使用到联合索引,这就是最左匹配原则。
索引失效情况2:错误模糊查询
模糊查询 like 的常见用法有 3 种:
模糊匹配后面任意字符:like ‘张%’
模糊匹配前面任意字符:like ‘%张’
模糊匹配前后任意字符:like ‘%张%’而这 3 种模糊查询中只有第 1 种查询方式可以使用到索引,具体执行结果如下:

索引失效情况3:列运算
如果索引列使用了运算,那么索引也会失效,如下图所示:

索引失效情况4:使用函数
查询列如果使用任意 MySQL 提供的函数就会导致索引失效,比如以下列使用了 ifnull 函数之后的执行计划如下:

索引失效情况5:类型转换
如果索引列存在类型转换,那么也不会走索引,比如 address 为字符串类型,而查询的时候设置了 int 类型的值就会导致索引失效,如下图所示:

索引失效情况6:使用 is not null
当在查询中使用了 is not null 也会导致索引失效,而 is null 则会正常触发索引的,如下图所示: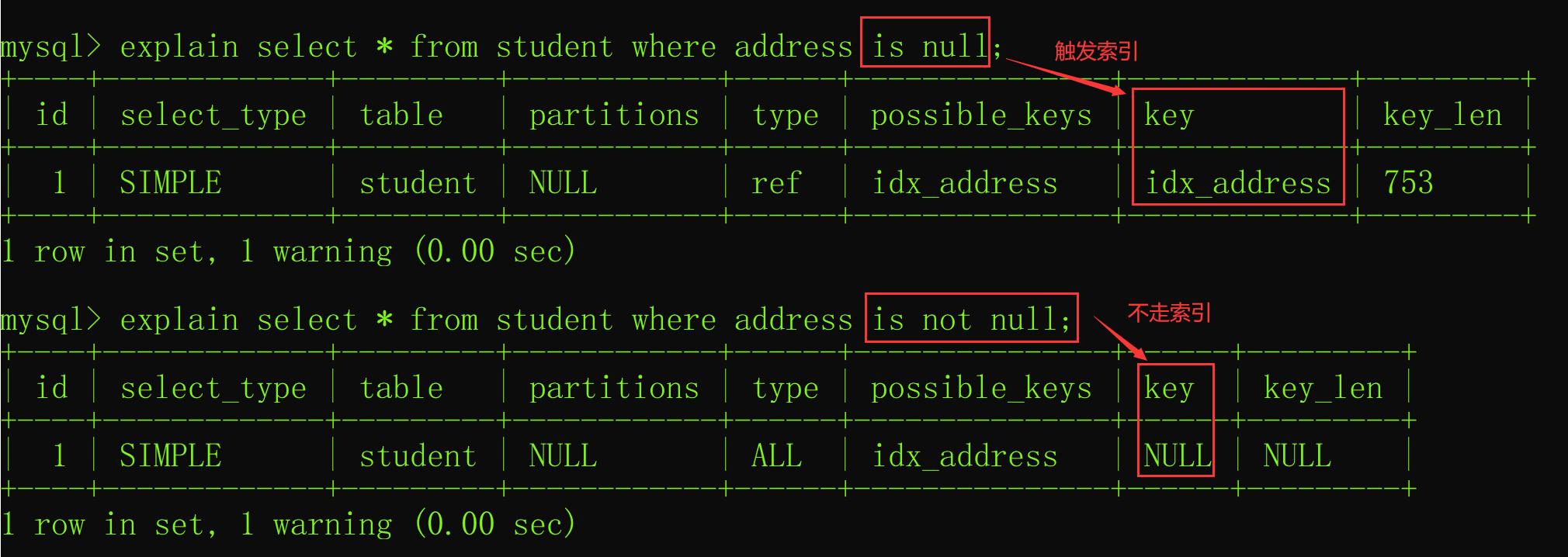
2 . 避免使用select *
反例:
select * from user where id=1;
在实际业务场景中,可能我们真正需要使用的只有其中一两列。查了很多数据,但是不用,白白浪费了数据库资源,比如:内存或者cpu。
此外,多查出来的数据,通过网络IO传输的过程中,也会增加数据传输的时间。
还有一个最重要的问题是:select *不会走覆盖索引,会出现大量的回表操作,而从导致查询sql的性能很低。
正例:
select name,age from user where id=1;
sql语句查询时,只查需要用到的列,多余的列根本无需查出来。
3 . 用union all代替union
我们都知道sql语句使用union关键字后,可以获取排重后的数据。
而如果使用union all关键字,可以获取所有数据,包含重复的数据。
反例:
(select * from user where id=1) union (select * from user where id=2);排重的过程需要遍历、排序和比较,它更耗时,更消耗cpu资源。
所以如果能用union all的时候,尽量不用union。
正例:
(select * from user where id=1) union (select * from user where id=2);除非是有些特殊的场景,比如union all之后,结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这时可以使用union。
4 . 批量操作
如果你有一批数据经过业务处理之后,需要插入数据,该怎么办?
反例:
在循环中逐条插入数据。
insert into order(id,code,user_id) values(123,'001',100);该操作需要多次请求数据库,才能完成这批数据的插入。
但众所周知,我们在代码中,每次远程请求数据库,是会消耗一定性能的。而如果我们的代码需要请求多次数据库,才能完成本次业务功能,势必会消耗更多的性能。
那么如何优化呢?
正例:
提供一个批量插入数据的方法。
insert into order(id,code,user_id) values (123,'001',100),(124,'002',100),(125,'003',101);这样只需要远程请求一次数据库,sql性能会得到提升,数据量越多,提升越大。
但需要注意的是,不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在500以内。如果数据多于500,则分多批次处理。
5 . 多用limit
select id, create_date from order where user_id=123 order by create_date asc limit 1;使用limit 1,只返回该用户下单时间最小的那一条数据即可。增加数据响应效率
6 . in中值太多
对于批量查询接口,我们通常会使用in关键字过滤出数据。比如:想通过指定的一些id,批量查询出用户信息。
sql语句如下:
select id,name from category where id in (1,2,3...100000000);如果我们不做任何限制,该查询语句一次性可能会查询出非常多的数据
7 . 增量查询
有时候,我们需要通过远程接口查询数据,然后同步到另外一个数据库。
反例:
select * from user;
如果直接获取所有的数据,然后同步过去。这样虽说非常方便,但是带来了一个非常大的问题,就是如果数据很多的话,查询性能会非常差。
这时该怎么办呢?
正例:
select * from user where id>#{lastId} and create_time >= #{lastCreateTime} limit 100;按id和时间升序,每次只同步一批数据,这一批数据只有100条记录。每次同步完成之后,保存这100条数据中最大的id和时间,给同步下一批数据的时候用。
通过这种增量查询的方式,能够提升单次查询的效率。
8 . 高效的分页
有时候,列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。
在mysql中分页一般用的limit关键字:
select id,name,age from user limit 10,20;9 . 用连接查询代替子查询
mysql中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。
子查询的例子如下:
select * from order where user_id in (select id from user where status=1)子查询语句可以通过in关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。
子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。
但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。
这时可以改成连接查询。具体例子如下:
select * from order o inner join user u on o.user_id = u.id where u.status=110 . join的表不宜过多
根据阿里巴巴开发者手册的规定,join表的数量不应该超过3个。
如果join太多,mysql在选择索引的时候会非常复杂,很容易选错索引。
所以我们应该尽量控制join表的数量。
11 . join时要注意
我们在涉及到多张表联合查询的时候,一般会使用join关键字。
而join使用最多的是left join和inner join。
-
left join:求两个表的交集外加左表剩下的数据。 -
inner join:求两个表交集的数据。
使用inner join的示例如下:
如果两张表使用inner join关联,mysql会自动选择两张表中的小表,去驱动大表,所以性能上不会有太大的问题。
如果两张表使用left join关联,mysql会默认用left join关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。
要特别注意的是在用left join关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。
12 . 控制索引的数量
众所周知,索引能够显著的提升查询sql的性能,但索引数量并非越多越好。
因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。
阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。
mysql使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。
13 . 选择合理的字段类型
14 . 提升group by的效率
我们有很多业务场景需要使用group by关键字,它主要的功能是去重和分组。
通常它会跟having一起配合使用,表示分组后再根据一定的条件过滤数据。
反例:
select user_id,user_name from order group by user_id having user_id <= 200;这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。
分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?
正例:
select user_id,user_name from order where user_id <= 200 group by user_id使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。
其实这是一种思路,不仅限于group by的优化。我们的sql语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升sql整体的性能。
三 . 参考资料
MySQL第九讲·索引怎么提高查询的速度?_mysql range索引速度-CSDN博客
sql优化的15个小技巧(必知五颗星),面试说出七八个就有了_sql优化常用的15种方法-CSDN博客
相关文章:
MySQL·SQL优化
目录 一 . 前言 二 . 优化方法 1 . 索引 (1)数据构造 (2)单索引 (3)explain (4)组合索引 (5)索引总结 2 . 避免使用select * 3 . 用union all代替u…...

Dockerfile指令大全
Dockerfile文件由一系列指令和参数组成。指令的一般格式为INSTRUCTION arguments。具体来说,包括"配置指令"(配置镜像信息)和"操作指令"(具体执行操作)。每条指令,如FROM,都是大小写不敏感的。但是为了区分指令和参数&am…...
第八个实验:(A+B)-C的结果判断奇偶特性
实验内容:(A+B)-C的结果判断奇偶特性,最后显示结果 实验步骤: 第一步:建立项目 第二步:实验步骤,编写程序 第三步:实验结果...
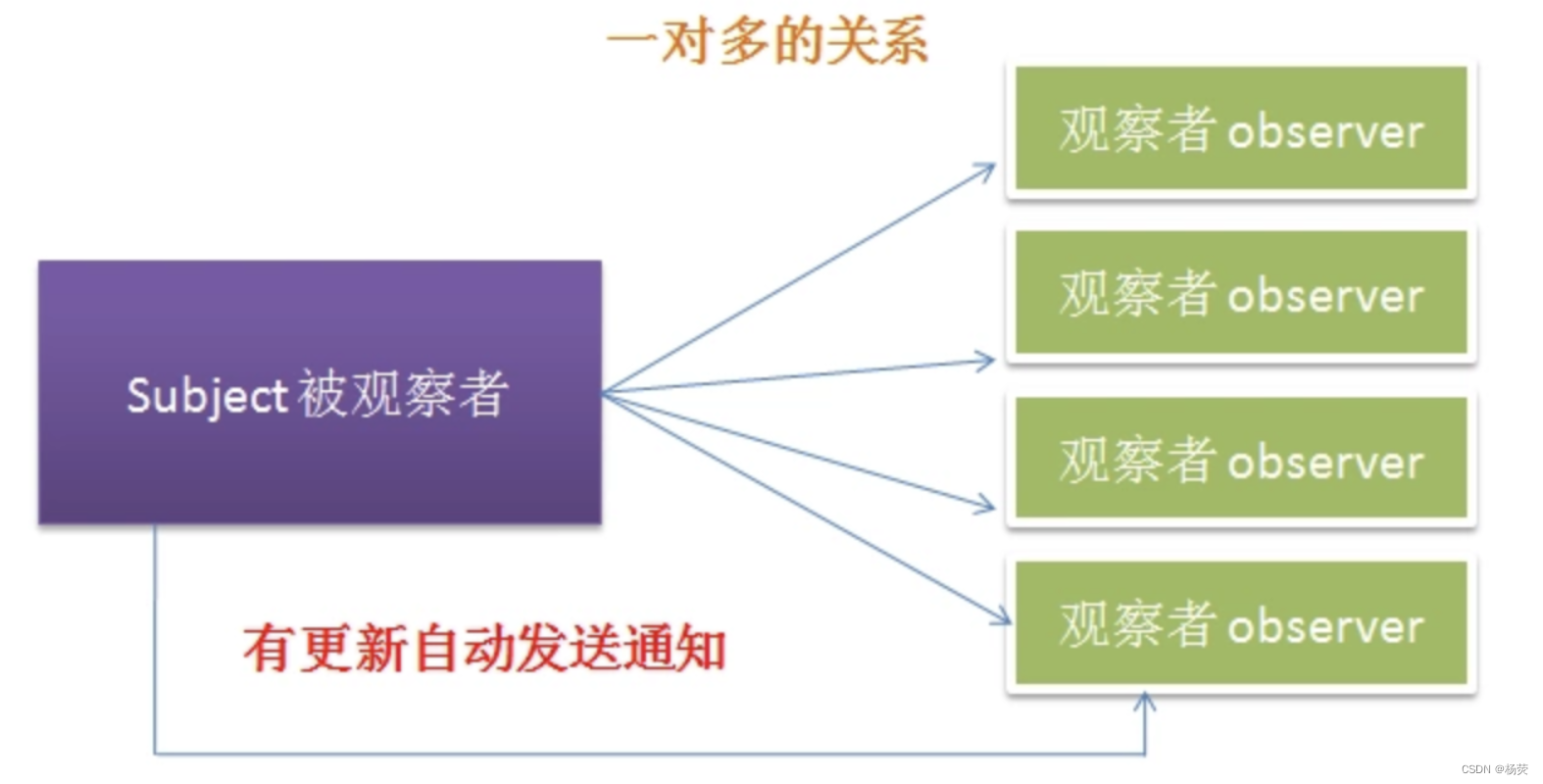
设计模式:观察者模式 ⑧
一、思想 观察者模式是一种常见的设计模式,也称作发布-订阅模式。它主要解决了对象之间的通知依赖关系问题。在这种模式中,一个对象(称作Subject)维护着一个对象列表,这些对象(称作Observers)都…...

【重温设计模式】迭代器模式及其Java示例
迭代器模式的介绍 在编程领域,迭代器模式是一种常见的设计模式,它提供了一种方法,使得我们可以顺序访问一个集合对象中的各个元素,而又无需暴露该对象的内部表示。你可以把它想象成一本书,你不需要知道这本书是怎么印…...
(001)UV 的使用以及导出
文章目录 UV窗口导出模型的主要事项导出时材质的兼容问题unity贴图导出导出FBX附录 UV窗口 1.uv主要的工作区域: 2.在做 uv 和贴图之前,最好先应用下物体的缩放、旋转。 导出模型的主要事项 1.将原点设置到物体模型的底部: 2.应用修改器的…...

一文理解CAS和自旋的区别(荣耀典藏版)
目录 一、自旋 二、CAS 三、什么是 ABA 问题 大家好,我是月夜枫,通常在面试的时候,或者在学习的时候,经常性的会遇到一些关于锁的问题,尤其是面试官会提出提问,你对锁了解的多么?你知道锁的原…...
【吊打面试官系列】Java虚拟机JVM篇 - 关于内存溢出
大家好,我是锋哥。今天分享关于内存溢出的JVM面试题,希望对大家有帮助; 什么是内存溢出? 内存溢出(OOM)是指可用内存不足。程序运行需要使用的内存超出最大可用值,如果不进行处理就会影响到其他…...
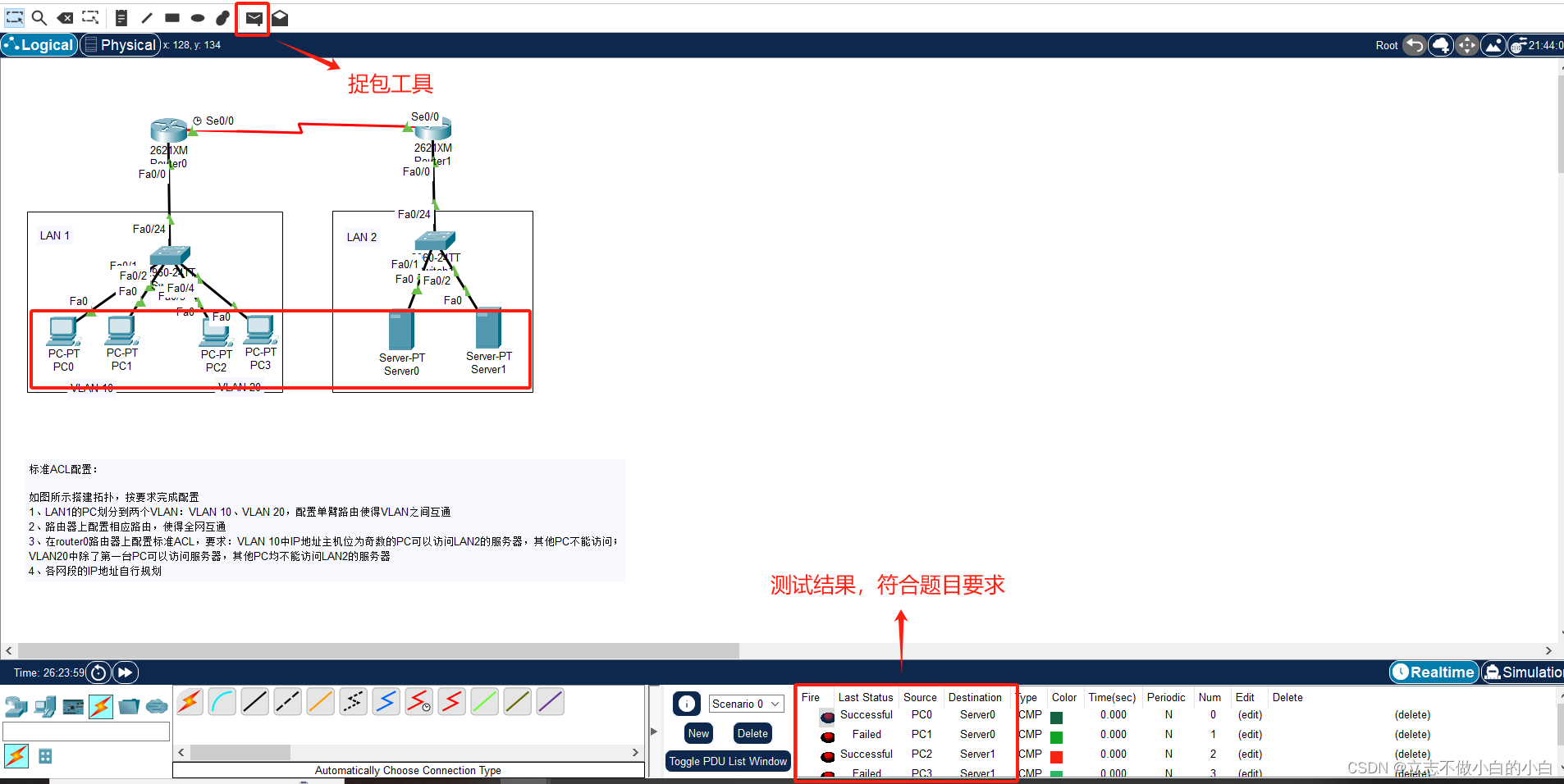
思科网络中如何配置标准ACL协议
一、什么是标准ACL协议?有什么作用及配置方法? (1)标准ACL(Access Control List)协议是一种用于控制网络设备上数据流进出的协议。标准ACL基于源IP地址来过滤数据流,可以允许或拒绝特定IP地址范…...

蓝桥杯刷题(二)
参考大佬代码:(区间合并二分) import os import sysn, L map(int, input().split()) # 输入n,len arr [list(map(int, input().split())) for _ in range(n)] # 输入Li,Si def check(Ti, arr, L)->bool:sec [] # 存入已打开的阀门在…...

【Python】牛客网—软件开发-Python专项练习(day1)
1.(单选)下面哪个是Python中不可变的数据结构? A.set B.list C.tuple D.dict 可变数据类型:列表list[ ]、字典dict{ }、集合set{ }(能查询,也可更改)数据发生改变,但内存地址不变 不…...

P3405 [USACO16DEC] Cities and States S题解
题目 Farmer John有若干头奶牛。为了训练奶牛们的智力,Farmer John在谷仓的墙上放了一张美国地图。地图上表明了每个城市及其所在州的代码(前两位大写字母)。 由于奶牛在谷仓里花了很多时间看这张地图,他们开始注意到一些奇怪的…...
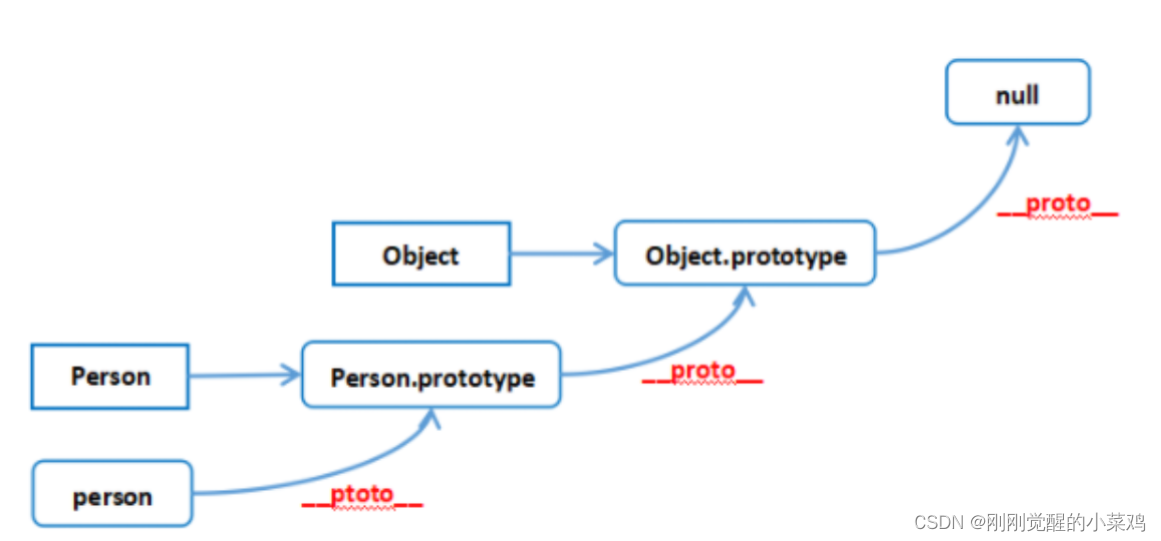
JavaScript原型和原型链
JavaScript每个对象拥有一个原型对象 需要注意的是,只有函数对象才有 prototype 属性 当试图访问一个对象的属性时,它不仅仅在该对象上搜寻,还会搜寻该对象的原型,以及该对象的原型的原型,依次层层向上搜索ÿ…...
PyTorch之完整的神经网络模型训练
简单的示例: 在PyTorch中,可以使用nn.Module类来定义神经网络模型。以下是一个示例的神经网络模型定义的代码: import torch import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()# 定义神经…...
基于神经网络的偏微分方程求解器再度取得突破,北大字节的研究成果入选Nature子刊
目录 一.引言:神经网络与偏微分方程 二.如何基于神经网络求解偏微分方程 1.简要概述 2.基于神经网络求解偏微分方程的三大方向 2.1数据驱动 基于CNN 基于其他网络 2.2物理约束 PINN 基于 PINN 可测量标签数据 2.3物理驱动(纯物理约束) 全连接神经网路(FC-NN) CN…...

Linux的基本权限
一、对shell的浅显认识 shell是操作系统下的一个外壳程序,无论是Linux操作系统,还是Windows操作系统,用户都不会直接对操作系统本身直接进行操作,需要通过一个外壳程序去间接的进行各种操作 在Linux的shell外壳就是命令行&#…...
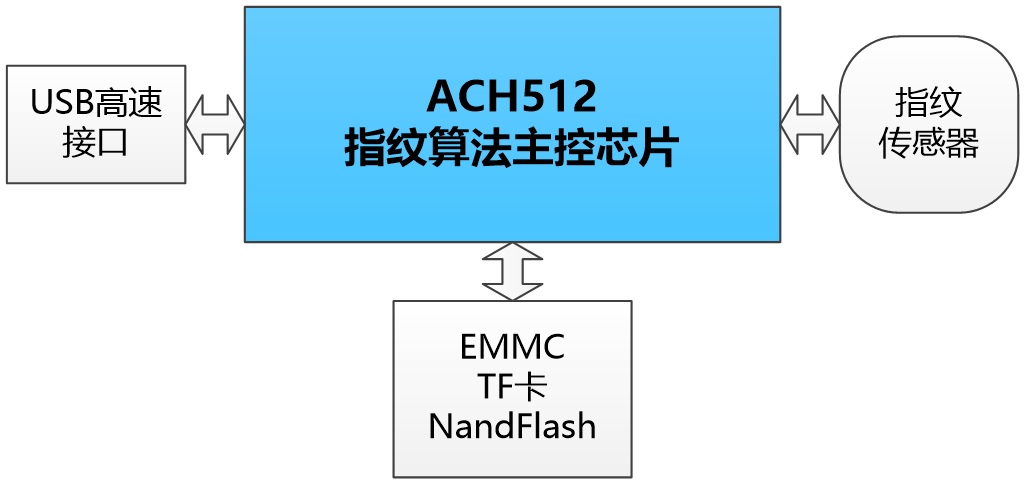
指纹加密U盘/指纹KEY方案——采用金融级安全芯片 ACH512
方案概述 指纹加密U盘解决方案可实现指纹算法处理、数据安全加密、数据高速存取(EMMC/TF卡/NandFlash),可有效保护用户数据安全。 方案特点 • 采用金融级安全芯片 ACH512 • 存储介质:EMMC、TF卡、NandFlash • 支持全系列国密…...
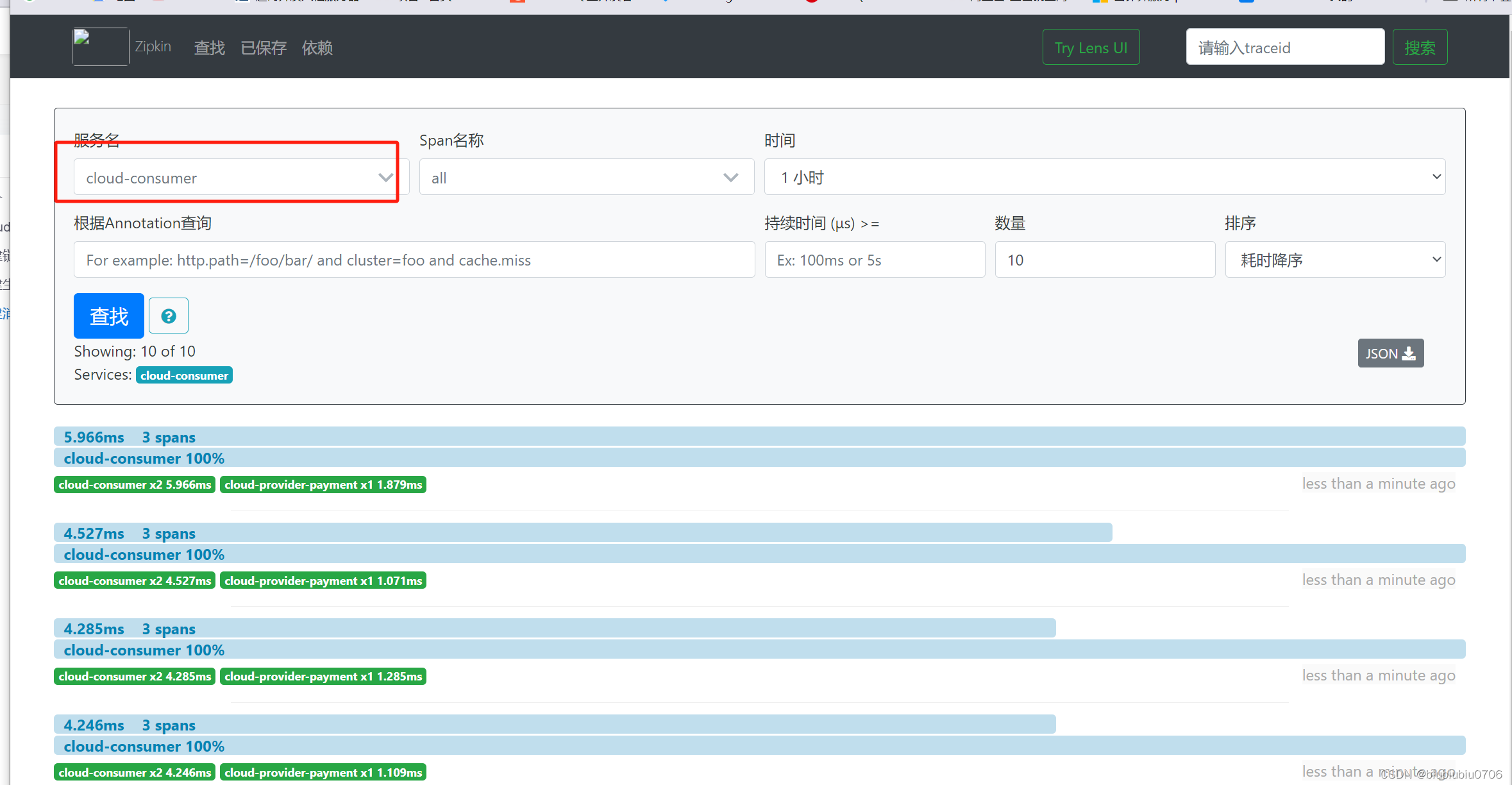
Cloud-Sleuth分布式链路追踪(服务跟踪)
简介 在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的服务节点调用来协同产生最后的请求结果,每一个前端请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败 GitHub - spring-cloud/spring-cloud-sl…...
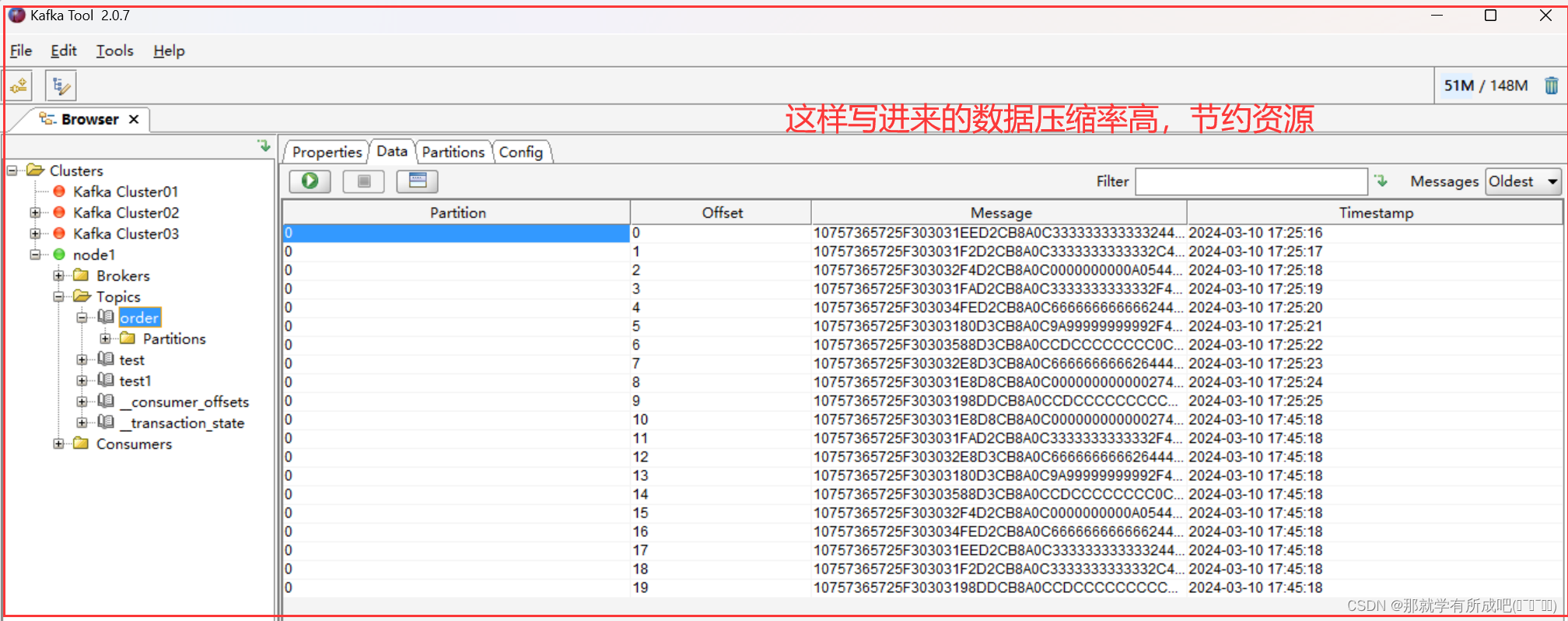
flink重温笔记(十四): flink 高级特性和新特性(3)——数据类型及 Avro 序列化
Flink学习笔记 前言:今天是学习 flink 的第 14 天啦!学习了 flink 高级特性和新特性之数据类型及 avro 序列化,主要是解决大数据领域数据规范化写入和规范化读取的问题,avro 数据结构可以节约存储空间,本文中结合企业真…...
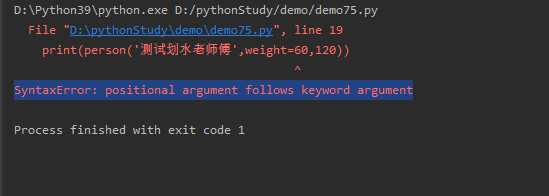
python75-Python的函数参数,关键字(keyword)参数
在定义Python函数时可定义形参(形式参数的意思)这些形参的值要等到调用时才能确定下来,由函数的调用者负责为形参传入参数值。简单来说,就是谁调用函数,谁负责传入参数值。 关键字(keyword)参数 Python函数的参数名不是无意义的,…...

深度学习驱动的遥感影像变化检测:技术演进与前沿应用
1. 遥感影像变化检测的深度学习革命 十年前我第一次接触遥感影像分析时,传统方法需要手工设计特征提取算法,光是处理一幅卫星图像就要花上大半天。现在用深度学习模型,一杯咖啡还没喝完就能完成整个区域的变化检测。这种技术飞跃的核心在于**…...

保姆级教程:ROS Melodic下用usb_cam驱动UVC摄像头,解决花屏和像素格式警告
ROS Melodic下UVC摄像头驱动配置全指南:从花屏排查到像素格式优化 第一次在ROS中连接USB摄像头时,看到屏幕上闪烁的彩色噪点和扭曲图像,那种挫败感我至今记忆犹新。这不是简单的设备故障,而是ROS视觉开发中典型的"入门仪式&q…...

WaveTools:解锁《鸣潮》120帧流畅体验的终极工具箱
WaveTools:解锁《鸣潮》120帧流畅体验的终极工具箱 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 你是否曾经在《鸣潮》的开放世界中驰骋时,感觉画面流畅度总差那么一点࿱…...

Unlock Music终极指南:如何免费解锁加密音乐文件,获得真正的音乐自由
Unlock Music终极指南:如何免费解锁加密音乐文件,获得真正的音乐自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev…...

ArcGIS数据入库避坑指南:为什么你的BSM标识码总出错?3个常见问题解析
ArcGIS数据入库避坑指南:BSM标识码生成的3个致命陷阱与实战解决方案 自然资源数据入库就像给城市绘制数字身份证,而BSM标识码就是每块土地的"身份证号"。去年某省级国土调查项目中,37%的入库驳回案例都源于标识码错误——要么行政代…...

终极Cursor Pro破解指南:三步实现AI编程助手无限制访问
终极Cursor Pro破解指南:三步实现AI编程助手无限制访问 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

Univer 预设模式 vs 插件模式:新手到底该选哪个?一次讲清区别、坑点和最佳实践
Univer 预设模式 vs 插件模式:从设计哲学到实战选择的深度解析 第一次接触 Univer 的开发者,往往会在官方文档的"预设模式"和"插件模式"两种集成方式前陷入选择困难。这就像站在自助餐厅的入口,一边是搭配好的套餐&#…...

tao-8k Embedding效果实测:对比BGE、text2vec,8K上下文优势凸显
tao-8k Embedding效果实测:对比BGE、text2vec,8K上下文优势凸显 1. 引言:为什么需要长文本嵌入模型? 在日常的文本处理任务中,我们经常需要将文本转换为向量表示,这就是嵌入模型的作用。传统的嵌入模型如…...

Lingyuxiu MXJ LoRA开发技巧:VSCode调试配置详解
Lingyuxiu MXJ LoRA开发技巧:VSCode调试配置详解 1. 为什么需要在VSCode里调试LoRA项目 你可能已经用过Lingyuxiu MXJ LoRA镜像生成出不少惊艳的人像作品,但当想修改模型行为、排查生成异常,或者给引擎加新功能时,光靠重启服务和…...

ACSL-6310-06TE,多通道双向15MBd高速数字逻辑门光耦合器
简介今天我要向大家介绍的是 Broadcom 的光耦合器——ACSL-6310-06TE。它是一款三通道、双向(2/1配置)高速数字逻辑门光耦合器。该器件采用专有的GaAsP LED背发射设计,内部集成具有高增益和高带宽的两级放大器,输出端为肖特基钳位…...