Elasticsearch:dense vector 数据类型及标量量化

密集向量(dense_vector)字段类型存储数值的密集向量。 密集向量场主要用于 k 最近邻 (kNN) 搜索。
dense_vector 类型不支持聚合或排序。
默认情况下,你可以基于 element_type 添加一个 dend_vector 字段作为 float 数值数组:
PUT my-index
{"mappings": {"properties": {"my_vector": {"type": "dense_vector","dims": 3},"my_text" : {"type" : "keyword"}}}
}PUT my-index/_doc/1
{"my_text" : "text1","my_vector" : [0.5, 10, 6]
}PUT my-index/_doc/2
{"my_text" : "text2","my_vector" : [-0.5, 10, 10]
}注意:与大多数其他数据类型不同,密集向量始终是单值。 不可能在一个密集向量字段中存储多个值。
kNN 搜索的索引向量
k 最近邻 (kNN) 搜索可找到与查询向量最接近的 k 个向量(通过相似性度量来衡量)。
密集向量字段可用于对 script_score 查询中的文档进行排名。 这使你可以通过扫描所有文档并按相似度对它们进行排名来执行强力(brute-force) kNN 搜索。
在许多情况下,强力 kNN 搜索效率不够高。 因此,dense_vector 类型支持将向量索引到专门的数据结构中,以支持通过 search API 中的 knn 选项进行快速 kNN 检索。
大小在 128 到 4096 之间的浮点元素的未映射数组字段动态映射为具有默认余弦相似度的密集向量。 你可以通过将字段显式映射为具有所需 similarity 的 dend_vector 来覆盖默认 similarity。
默认情况下为密集向量场启用索引。 启用索引后,你可以定义在 kNN 搜索中使用的向量 similarity:
PUT my-index-2
{"mappings": {"properties": {"my_vector": {"type": "dense_vector","dims": 3,"similarity": "dot_product"}}}
}注意:用于近似 kNN 搜索的索引向量是一个昂贵的过程。 提取包含启用了 index 的向量字段的文档可能需要花费大量时间。 请参阅 k 最近邻 (kNN) 搜索以了解有关内存要求的更多信息。
你可以通过将 index 参数设置为 false 来禁用索引:
PUT my-index-2
{"mappings": {"properties": {"my_vector": {"type": "dense_vector","dims": 3,"index": false}}}
}Elasticsearch 使用 HNSW 算法来支持高效的 kNN 搜索。 与大多数 kNN 算法一样,HNSW 是一种近似方法,会牺牲结果精度以提高速度。
自动量化向量以进行 kNN 搜索
密集向量类型支持量化以减少搜索浮点向量时所需的内存占用。 目前唯一支持的量化方法是 int8,并且提供的向量 element_type 必须是 float。 要使用量化索引,你可以将索引类型设置为 int8_hnsw。
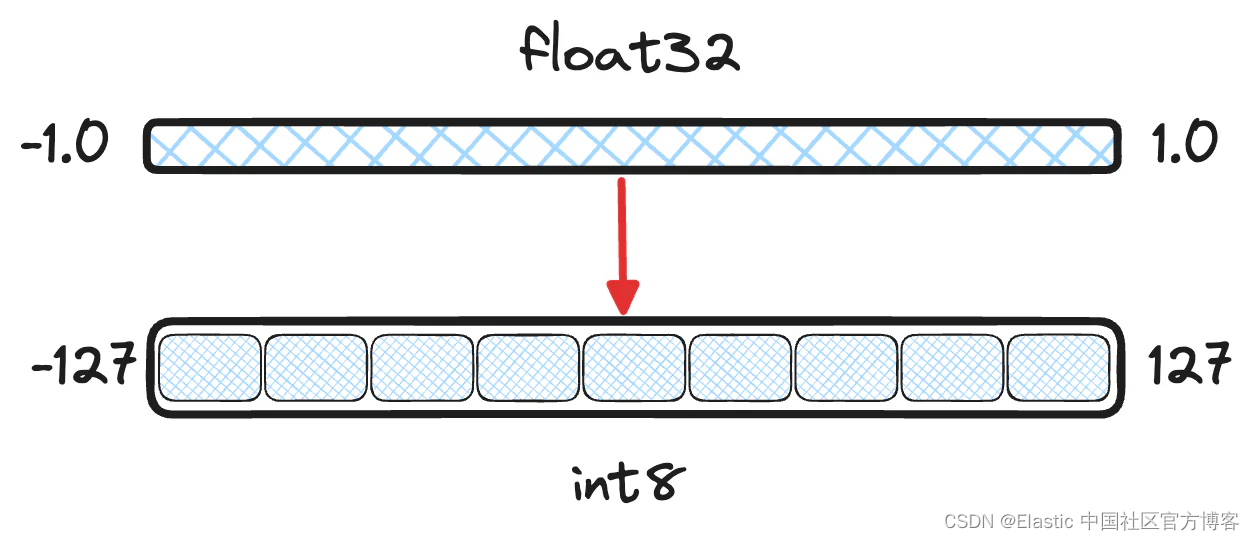
使用 int8_hnsw 索引时,每个浮点向量的维度都会量化为 1 字节整数。 这可以减少多达 75% 的内存占用,但会牺牲一定的准确性。 然而,由于存储量化向量和原始向量的开销,磁盘使用量可能会增加 25%。
PUT my-byte-quantized-index
{"mappings": {"properties": {"my_vector": {"type": "dense_vector","dims": 3,"index": true,"index_options": {"type": "int8_hnsw"}}}}
}密集向量场的参数
接受以下映射参数:
element_type
(可选,字符串)用于对向量进行编码的数据类型。 支持的数据类型为 float(默认)和 byte。 float 对每个维度的 4 字节浮点值进行索引。 byte 索引每个维度的 1-byte 整数值。 使用 byte 可以显着减小索引大小,但代价是精度较低。 使用字节的向量需要具有 -128 到 127 之间整数值的维度,包括索引和搜索。
dims
(可选,整数)向量维数。 不能超过 4096。如果未指定 dims,它将设置为添加到该字段的第一个向量的长度。
index
(可选,布尔值)如果为 true,你可以使用 kNN 搜索 API 搜索此字段。 默认为 true。
similarity
(可选*,字符串)kNN 搜索中使用的向量相似度度量。 文档根据向量场与查询向量的相似度进行排名。 每个文档的 _score 将从相似度中得出,以确保分数为正并且分数越高对应于越高的排名。 默认为余弦。
* 该参数只有当 index 为 true 时才能指定。
| 值 | 描述 |
|---|---|
| l2_norm | 根据向量之间的 L2 距离(也称为欧氏距离)计算相似度。 文档 _score 的计算公式为 1 / (1 + l2_norm(query, vector)^2)。 |
| dot_product | 计算两个单位向量的点积。 此选项提供了执行余弦相似度的优化方法。 约定和计算得分由 element_type 定义。 当 element_type 为 float 时,所有向量都必须是 unit 长度,包括文档向量和查询向量。 文档 _score 的计算方式为 (1 + dot_product(query, vector)) / 2。 当 element_type 为 byte 时,所有向量必须具有相同的长度,包括文档向量和查询向量,否则结果将不准确。 文档 _score 的计算公式为 0.5 + (dot_product(query, vector) / (32768 * dims)),其中 dims 是每个向量的维度数。 |
| cosine | 计算余弦相似度。 请注意,执行余弦相似度的最有效方法是将所有向量标准化为单位长度,并改为使用 dot_product。 仅当需要保留原始向量且无法提前对其进行标准化时,才应使用余弦。 文档 _score 的计算方式为 (1 + cosine(query, vector)) / 2。余弦相似度不允许向量的幅值为零,因为在这种情况下未定义余弦。 |
| max_inner_product | 计算两个向量的最大内积。 这与 dot_product 类似,但不需要向量标准化。 这意味着每个向量的大小都会显着影响分数。 调整文档 _score 以防止出现负值。 对于 max_inner_product 值 < 0,_score 为 1 / (1 + -1 * max_inner_product(query, vector))。 对于非负 max_inner_product 结果,_score 计算为 max_inner_product(query, vector) + 1。 |
注意:尽管它们在概念上相关,但相似性参数与文本字段相似性不同,并且接受一组不同的选项。
index_options
(可选*,对象)配置 kNN 索引算法的可选部分。 HNSW 算法有两个影响数据结构构建方式的内部参数。 可以调整这些以提高结果的准确性,但代价是索引速度较慢。
* 该参数只有当 index 为 true 时才能指定。
| 属性 | 描述 |
|---|---|
| type | (必需,字符串)要使用的 kNN 算法的类型。 可以是 hnsw 或 int8_hnsw。 |
| m | (可选,整数)HNSW 图中每个节点将连接到的邻居数量。 默认为 16。 |
| ef_construction | (可选,整数)在组装每个新节点的最近邻居列表时要跟踪的候选者数量。 默认为 100。 |
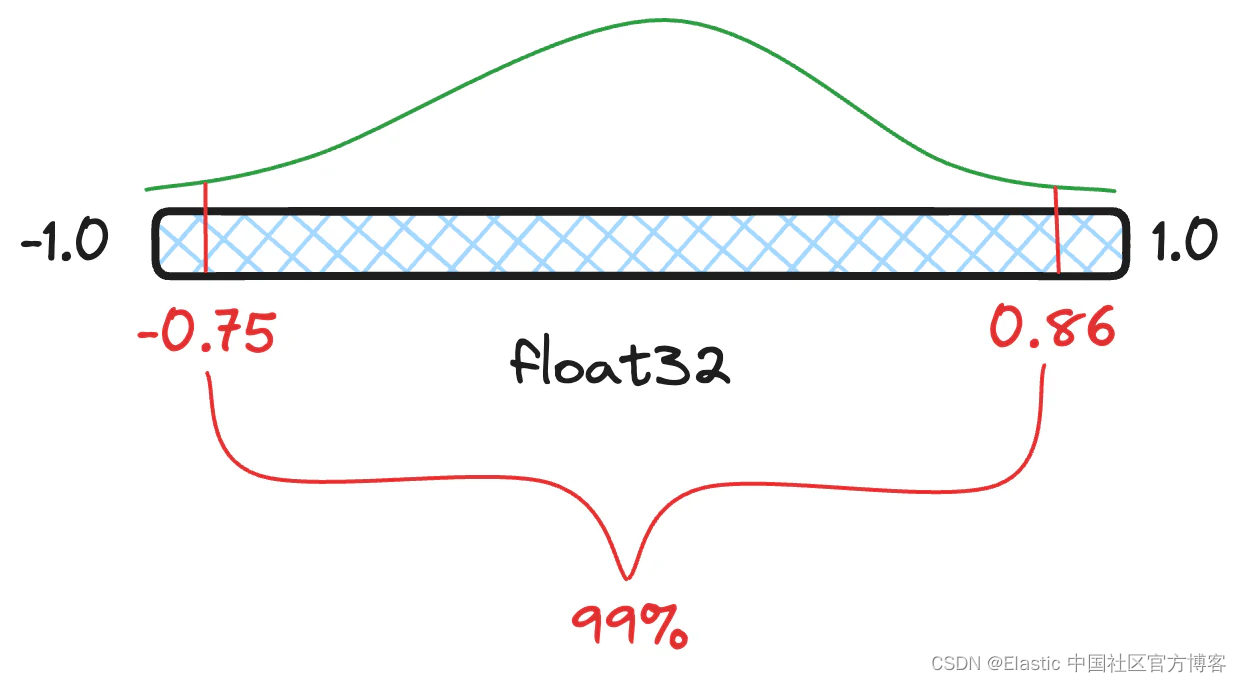
| confidence_interval | (可选,float)仅适用于 int8_hnsw 索引类型。 量化向量时使用的置信区间可以是 0.90 和 1.0 之间(包括 0.90 和 1.0)之间的任何值。 该值限制计算量化阈值时使用的值。 例如,值 0.95 在计算量化阈值时将仅使用中间 95% 的值(例如,最高和最低 2.5% 的值将被忽略)。 默认为 1/(dims + 1)。 |
Synthetic _source
重要:Synthetic _source 通常仅适用于 TSDB 索引(index.mode 设置为 time_series 的索引)。 对于其他索引,synthetic _source 处于技术预览阶段。 技术预览版中的功能可能会在未来版本中更改或删除。 Elastic 将努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束。
dense_vector 字段支持 synthetic _source。
更多阅读:
-
Elasticsearch:标量量化 101 - scalar quantization 101
-
Elasticsearch:Lucene 中引入标量量化
相关文章:
Elasticsearch:dense vector 数据类型及标量量化
密集向量(dense_vector)字段类型存储数值的密集向量。 密集向量场主要用于 k 最近邻 (kNN) 搜索。 dense_vector 类型不支持聚合或排序。 默认情况下,你可以基于 element_type 添加一个 dend_vector 字段作为 float 数值数组: …...
Linux C/C++下使用Lex/Yacc构建实现DBMS(Minisql)
DBMS(数据库管理系统)是一种用于管理和组织数据库的软件系统。它的重要性在于提供了一种有效地存储、管理和访问大量数据的方式。本文将深入探讨如何使用C语言、Lex(词法分析器生成器)和Yacc(语法分析器生成器…...
c语言指针小白基础教学
指针 1. 什么是指针?2. 如何编址(即如何给地址分配空间呢)3. 概念和基本术语3.1指针的值指针所指向的地址/内存区3.2 指针的类型(指针本身的类型)思考: 3.3 指针所指向的类型3.4 指针本身所占据的内存区3.5…...

面向对象设计之里氏替换原则
设计模式专栏:http://t.csdnimg.cn/4Mt4u 思考:什么样的代码才算违反里氏替换原则? 目录 1.里氏替换原则的定义 2.里氏替换原则与多态的区别 3.违反里氏替换原则的反模式 4.总结 1.里氏替换原则的定义 里氏替换原则(Liskov S…...
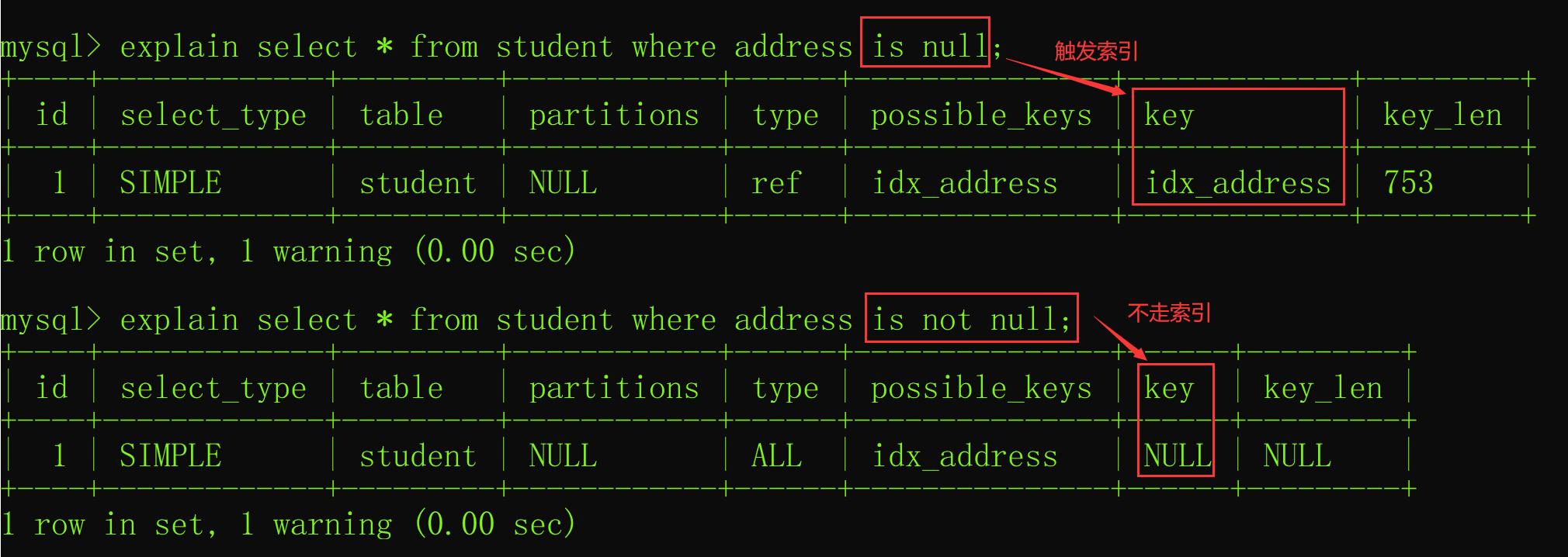
MySQL·SQL优化
目录 一 . 前言 二 . 优化方法 1 . 索引 (1)数据构造 (2)单索引 (3)explain (4)组合索引 (5)索引总结 2 . 避免使用select * 3 . 用union all代替u…...

Dockerfile指令大全
Dockerfile文件由一系列指令和参数组成。指令的一般格式为INSTRUCTION arguments。具体来说,包括"配置指令"(配置镜像信息)和"操作指令"(具体执行操作)。每条指令,如FROM,都是大小写不敏感的。但是为了区分指令和参数&am…...
第八个实验:(A+B)-C的结果判断奇偶特性
实验内容:(A+B)-C的结果判断奇偶特性,最后显示结果 实验步骤: 第一步:建立项目 第二步:实验步骤,编写程序 第三步:实验结果...
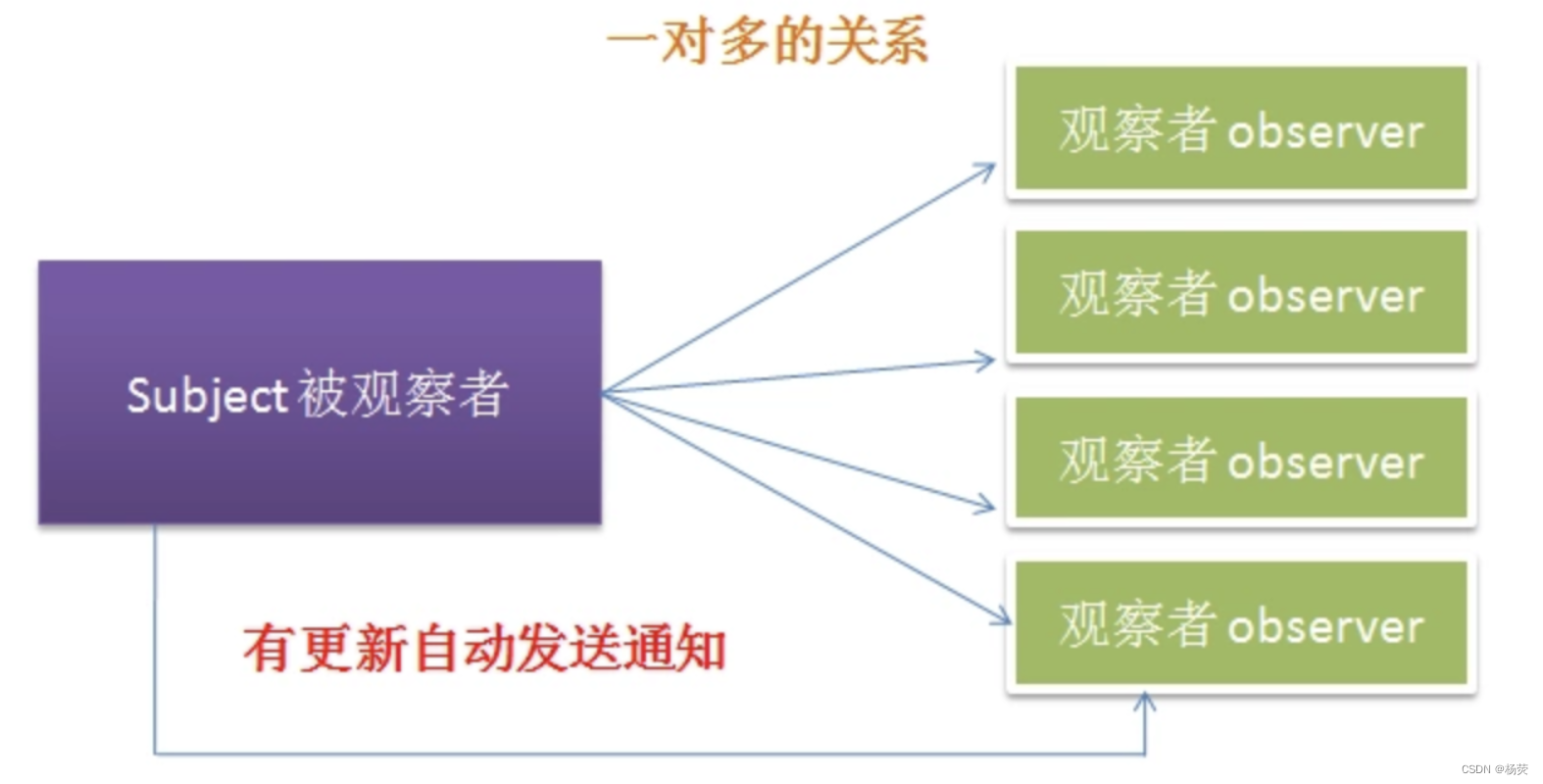
设计模式:观察者模式 ⑧
一、思想 观察者模式是一种常见的设计模式,也称作发布-订阅模式。它主要解决了对象之间的通知依赖关系问题。在这种模式中,一个对象(称作Subject)维护着一个对象列表,这些对象(称作Observers)都…...

【重温设计模式】迭代器模式及其Java示例
迭代器模式的介绍 在编程领域,迭代器模式是一种常见的设计模式,它提供了一种方法,使得我们可以顺序访问一个集合对象中的各个元素,而又无需暴露该对象的内部表示。你可以把它想象成一本书,你不需要知道这本书是怎么印…...
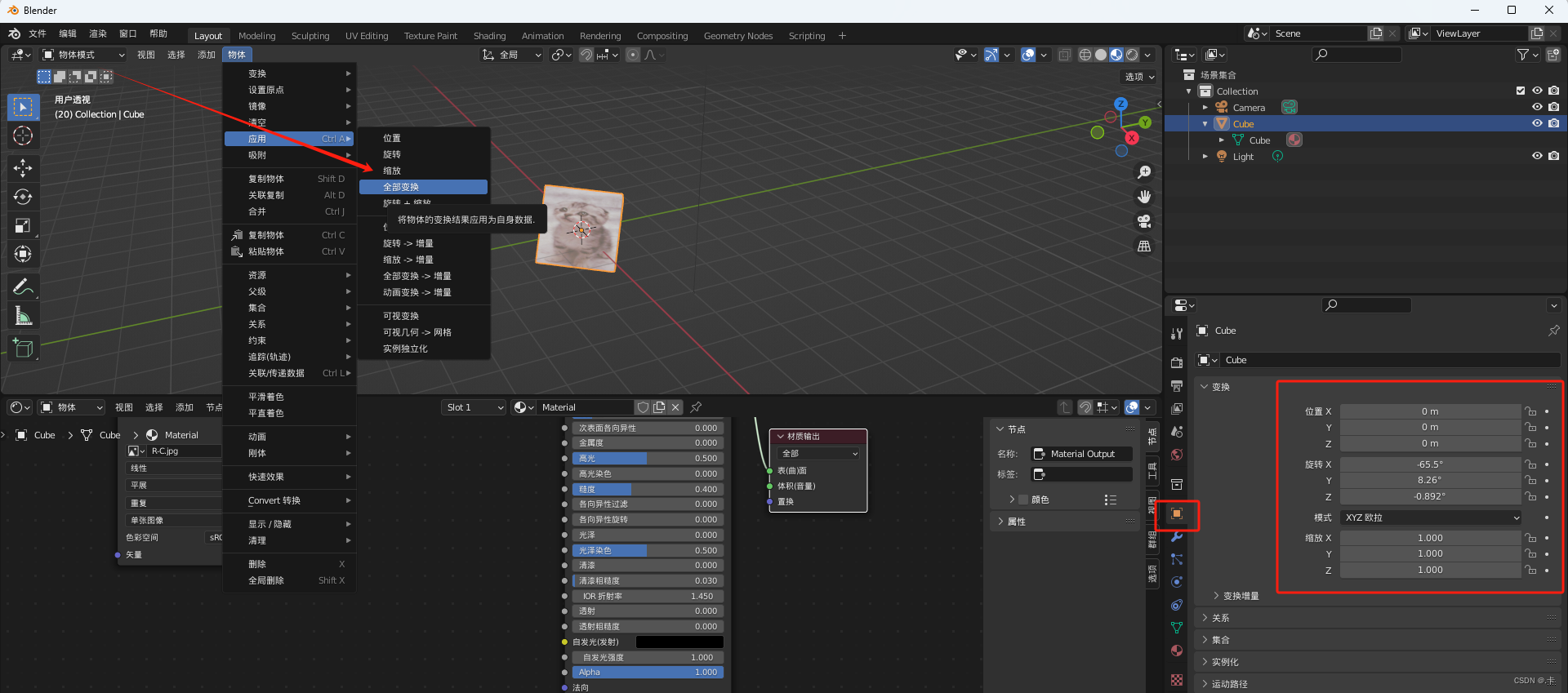
(001)UV 的使用以及导出
文章目录 UV窗口导出模型的主要事项导出时材质的兼容问题unity贴图导出导出FBX附录 UV窗口 1.uv主要的工作区域: 2.在做 uv 和贴图之前,最好先应用下物体的缩放、旋转。 导出模型的主要事项 1.将原点设置到物体模型的底部: 2.应用修改器的…...

一文理解CAS和自旋的区别(荣耀典藏版)
目录 一、自旋 二、CAS 三、什么是 ABA 问题 大家好,我是月夜枫,通常在面试的时候,或者在学习的时候,经常性的会遇到一些关于锁的问题,尤其是面试官会提出提问,你对锁了解的多么?你知道锁的原…...
【吊打面试官系列】Java虚拟机JVM篇 - 关于内存溢出
大家好,我是锋哥。今天分享关于内存溢出的JVM面试题,希望对大家有帮助; 什么是内存溢出? 内存溢出(OOM)是指可用内存不足。程序运行需要使用的内存超出最大可用值,如果不进行处理就会影响到其他…...
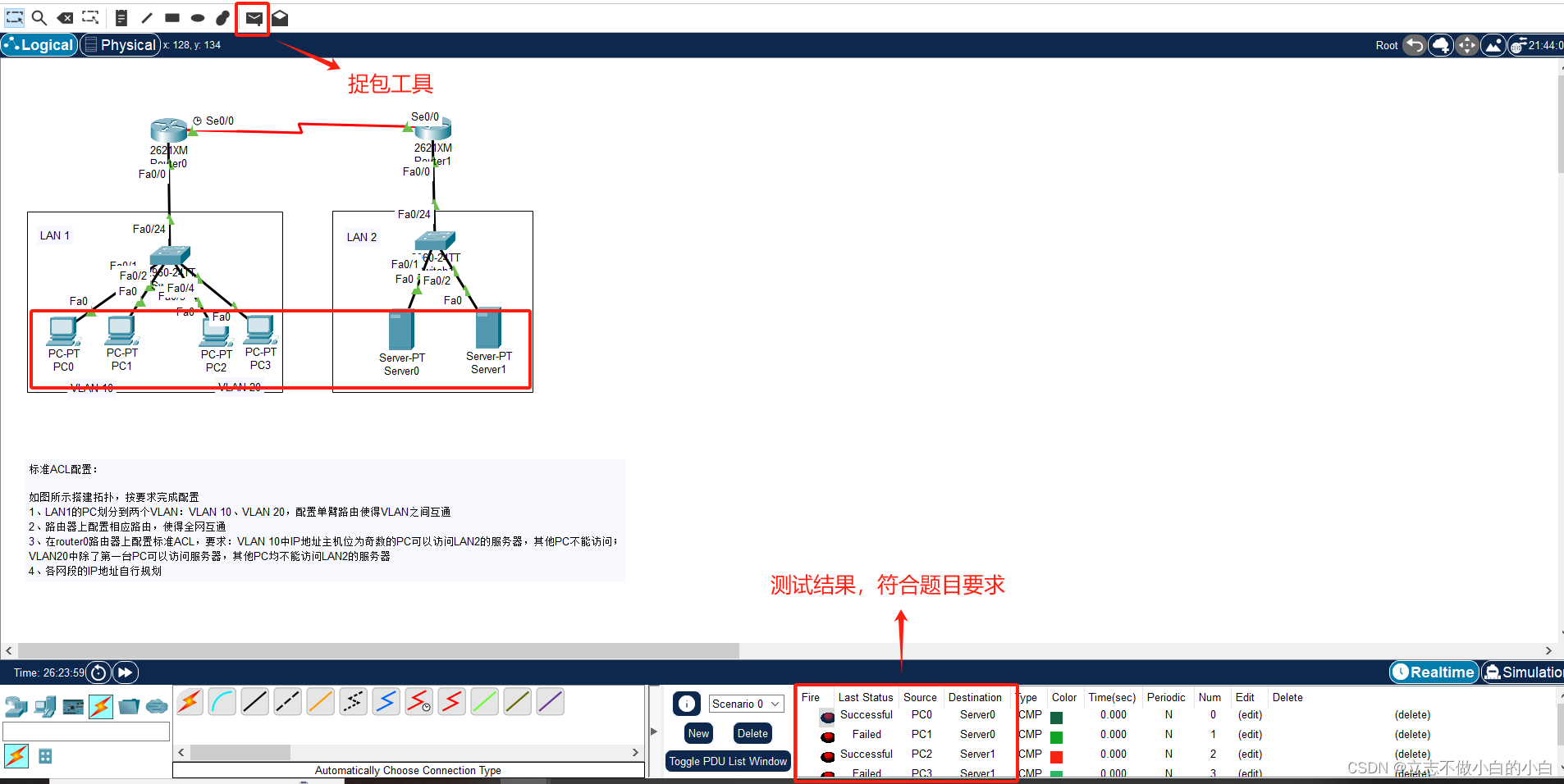
思科网络中如何配置标准ACL协议
一、什么是标准ACL协议?有什么作用及配置方法? (1)标准ACL(Access Control List)协议是一种用于控制网络设备上数据流进出的协议。标准ACL基于源IP地址来过滤数据流,可以允许或拒绝特定IP地址范…...

蓝桥杯刷题(二)
参考大佬代码:(区间合并二分) import os import sysn, L map(int, input().split()) # 输入n,len arr [list(map(int, input().split())) for _ in range(n)] # 输入Li,Si def check(Ti, arr, L)->bool:sec [] # 存入已打开的阀门在…...

【Python】牛客网—软件开发-Python专项练习(day1)
1.(单选)下面哪个是Python中不可变的数据结构? A.set B.list C.tuple D.dict 可变数据类型:列表list[ ]、字典dict{ }、集合set{ }(能查询,也可更改)数据发生改变,但内存地址不变 不…...

P3405 [USACO16DEC] Cities and States S题解
题目 Farmer John有若干头奶牛。为了训练奶牛们的智力,Farmer John在谷仓的墙上放了一张美国地图。地图上表明了每个城市及其所在州的代码(前两位大写字母)。 由于奶牛在谷仓里花了很多时间看这张地图,他们开始注意到一些奇怪的…...
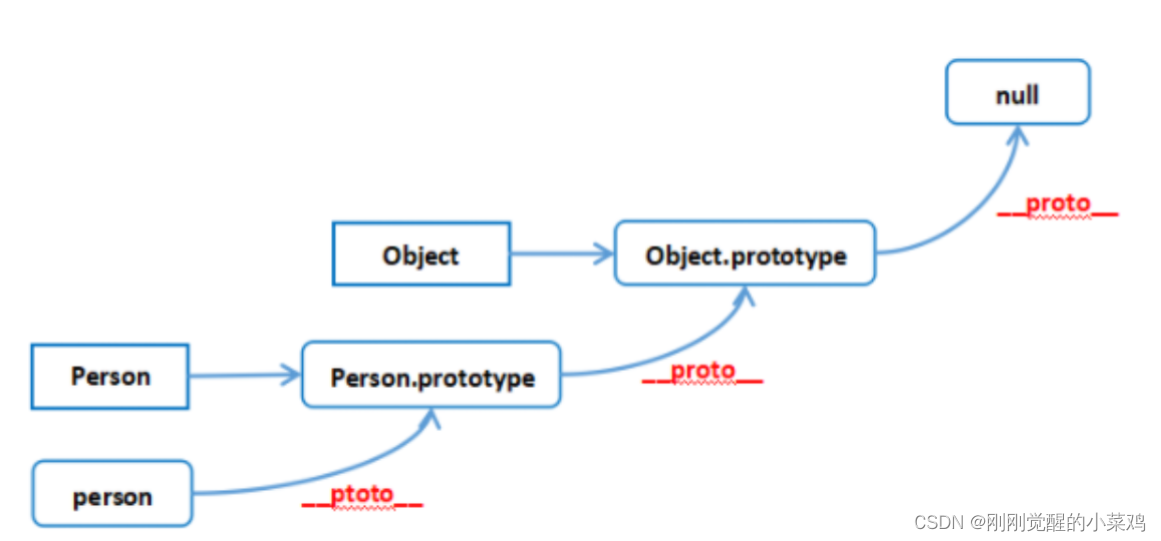
JavaScript原型和原型链
JavaScript每个对象拥有一个原型对象 需要注意的是,只有函数对象才有 prototype 属性 当试图访问一个对象的属性时,它不仅仅在该对象上搜寻,还会搜寻该对象的原型,以及该对象的原型的原型,依次层层向上搜索ÿ…...
PyTorch之完整的神经网络模型训练
简单的示例: 在PyTorch中,可以使用nn.Module类来定义神经网络模型。以下是一个示例的神经网络模型定义的代码: import torch import torch.nn as nnclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()# 定义神经…...
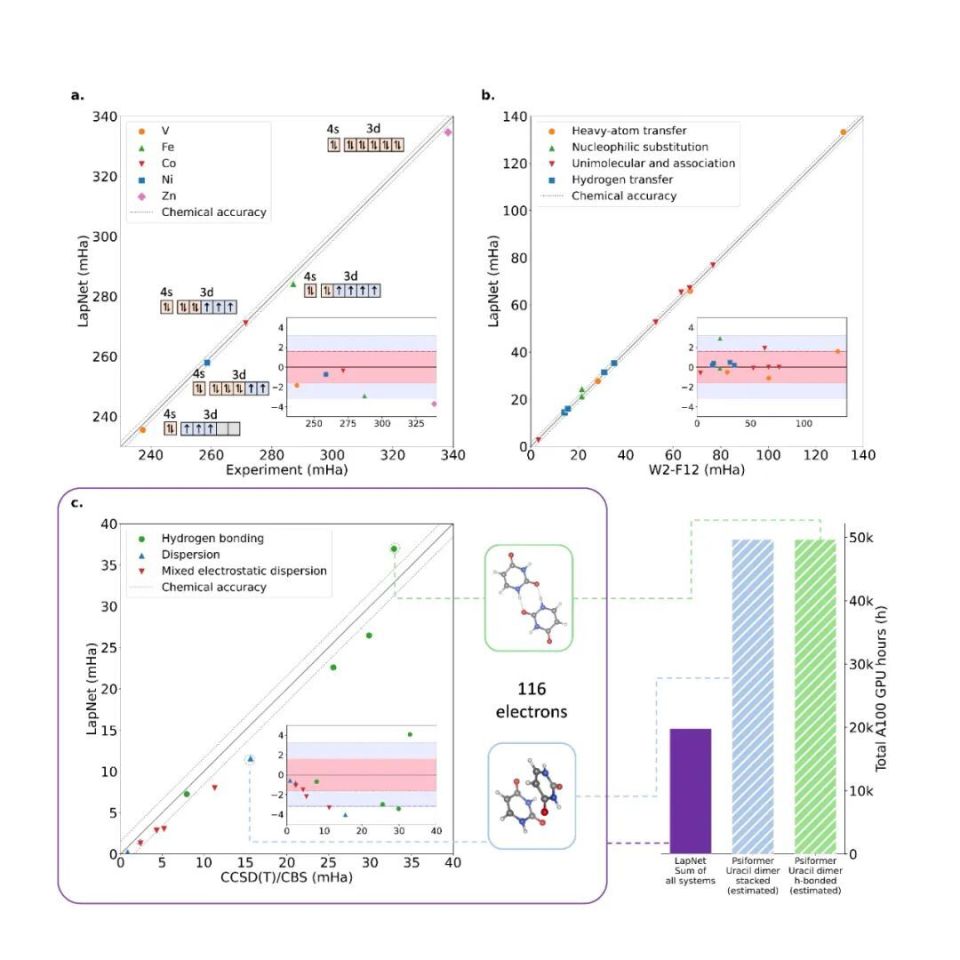
基于神经网络的偏微分方程求解器再度取得突破,北大字节的研究成果入选Nature子刊
目录 一.引言:神经网络与偏微分方程 二.如何基于神经网络求解偏微分方程 1.简要概述 2.基于神经网络求解偏微分方程的三大方向 2.1数据驱动 基于CNN 基于其他网络 2.2物理约束 PINN 基于 PINN 可测量标签数据 2.3物理驱动(纯物理约束) 全连接神经网路(FC-NN) CN…...

Linux的基本权限
一、对shell的浅显认识 shell是操作系统下的一个外壳程序,无论是Linux操作系统,还是Windows操作系统,用户都不会直接对操作系统本身直接进行操作,需要通过一个外壳程序去间接的进行各种操作 在Linux的shell外壳就是命令行&#…...

3步解锁LOL全皮肤体验:R3nzSkin国服特供版完全指南
3步解锁LOL全皮肤体验:R3nzSkin国服特供版完全指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在《英雄联盟》中免费体验所有限定皮…...

社区生活服务升级,Java 家政系统源码提升服务效率
在社区生活服务数字化转型的浪潮中,Java家政系统源码凭借其技术成熟度、功能完整性和可扩展性,成为提升家政服务效率、优化用户体验的核心工具。以下从技术架构、效率提升机制、功能模块设计三个维度,解析如何通过Java源码实现社区家政服务的…...

2026年AI风口已来!小白程序员必备:收藏这份大模型学习路线,轻松解锁职业新可能!
本文详细介绍了从后端学习到转AI开发的学习路线,包括大模型基础认知、核心技术模块、开发基础能力、应用场景开发、项目落地流程以及面试求职冲刺等六大模块。文章旨在帮助有意向进入AI领域或寻求职业发展的程序员,提供一份全面且实用的学习清单和资料&a…...

FUTURE POLICE语音模型Ubuntu 20.04部署全流程详解
FUTURE POLICE语音模型Ubuntu 20.04部署全流程详解 想试试那个能生成未来感、赛博朋克风格语音的FUTURE POLICE模型吗?自己动手在服务器上部署,听起来好像挺复杂,又是系统环境,又是GPU驱动,还有各种依赖包。别担心&am…...

【完整源码+数据集+部署教程】交通锥检测检测系统源码 [一条龙教学YOLOV8标注好的数据集一键训练_70+全套改进创新点发刊_Web前端展示]
背景意义 随着城市化进程的加快,交通管理面临着日益严峻的挑战。交通锥作为一种重要的交通管理工具,广泛应用于道路施工、交通引导及安全防护等场景。其有效的使用不仅能够提高道路安全性,还能减少交通事故的发生。因此,开发一个高…...
)
AutoRunner365自动化测试工具保姆级安装指南(附注册流程详解)
AutoRunner365自动化测试工具从安装到实战的全流程解析 对于现代软件开发团队来说,自动化测试已经成为提升交付效率的关键环节。作为国内知名的测试工具之一,AutoRunner365凭借其友好的操作界面和稳定的测试性能,赢得了众多测试工程师的青睐。…...

【Gin】参数处理练习题
学生编号动态获取接口 题目描述 使用 Gin 框架编写 Web 服务,定义 GET 路由 /student/:id,通过 c.Param("id") 获取学生编号,返回字符串:学生编号:xxx,立志成才,报效祖国࿰…...

Endnote样式深度定制:从GBT-7142005基础版到完美适配你学校论文格式的完整指南
Endnote样式深度定制:从GBT-7142005基础版到完美适配学校论文格式的完整指南 当你熬夜赶完论文最后一章,满心欢喜地用Endnote插入参考文献,却发现生成的格式与学校要求相差甚远——中文文献的标点仍是半角,作者列表的"et al&…...

Qwen3-VL-8B教育应用:为视障学生实时解说教材插图,打开视觉之窗
Qwen3-VL-8B教育应用:为视障学生实时解说教材插图,打开视觉之窗 想象一下,当一位视障学生翻开一本物理教材,面对描绘“光的折射”原理的复杂插图时,他只能依靠文字描述去想象那个看不见的世界。传统的辅助方式&#x…...

告别姿态依赖:基于DUSt3R与规范空间的高斯重建新范式
1. 为什么我们需要告别姿态依赖? 在传统3D重建领域,相机姿态(pose)一直是个让人又爱又恨的存在。就像盖房子需要先打好地基一样,大多数3D重建方法都需要准确的相机位置和角度信息作为基础。但现实情况是,获…...