谷歌开源的LLM大模型 Gemma 简介

相关链接:
- Hugging face模型下载地址:https://huggingface.co/google/gemma-7b
- Github地址:https://github.com/google/gemma_pytorch
- 论文地址:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
- 官方博客:Gemma: Google introduces new state-of-the-art open models
Gemma简介
谷歌推出了 Gemma,一个开放大型语言模型 (LLM) 的尖端系列,标志着其致力于开源人工智能的重要一步。同时Gemma 与 Hugging Face 平台的无缝集成,可以让AIGC爱好者更好的去使用。
Gemma 是基于 Gemini 技术推出的四款新型大型语言模型(LLM),提供了 2B 和 7B 两种不同规模的版本,每种都包含了预训练基础版本和经过指令优化的版本。所有版本均可在各类消费级硬件上运行,无需数据量化处理,拥有高达 8K tokens 的处理能力:
- gemma-7b:7B 参数的基础模型。
- gemma-7b-it:7B 参数的指令优化版本。
- gemma-2b:2B 参数的基础模型。
- gemma-2b-it:2B 参数的指令优化版本。
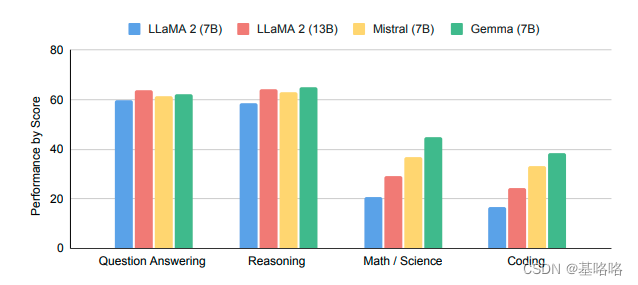
Gemma 模型的性能如何?以下是其基础版本与其他开放模型在 LLM 排行榜 上的比较(得分越高越好):
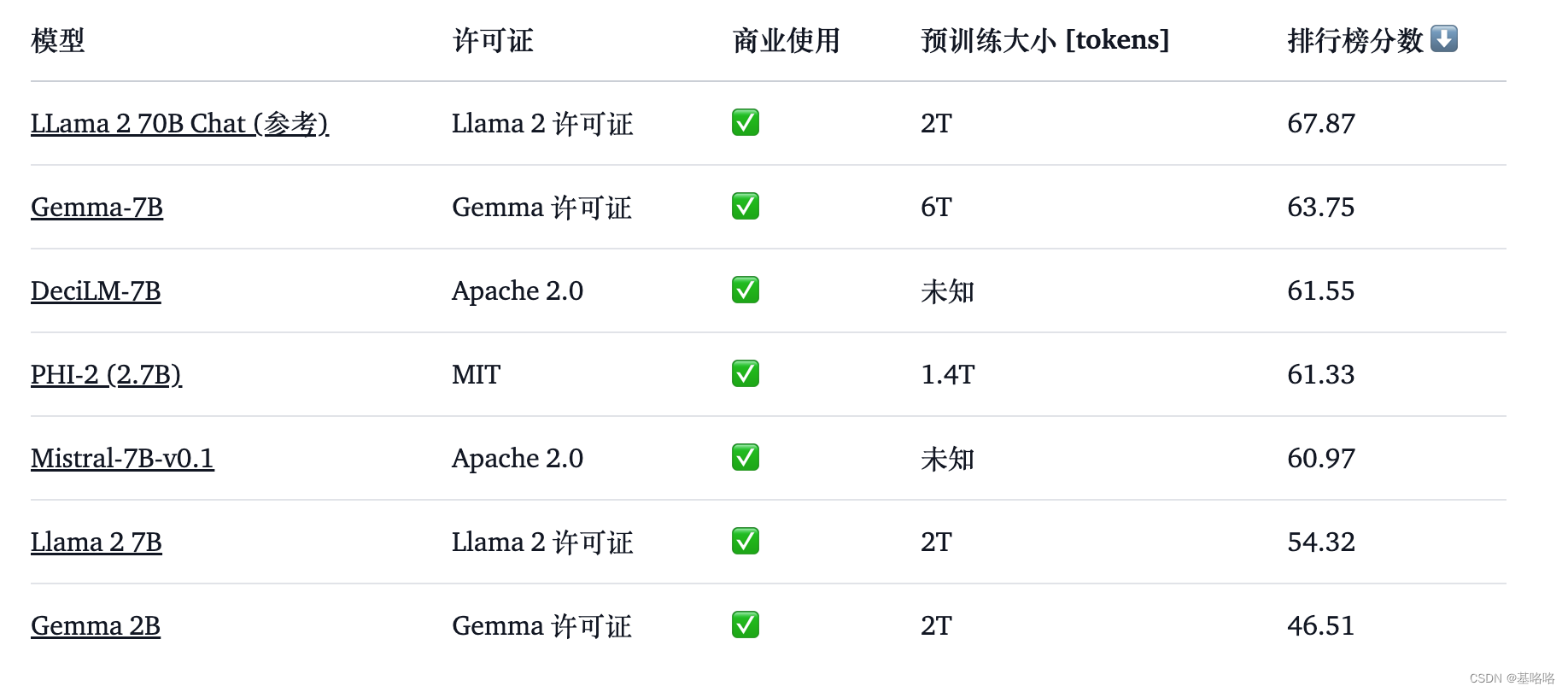
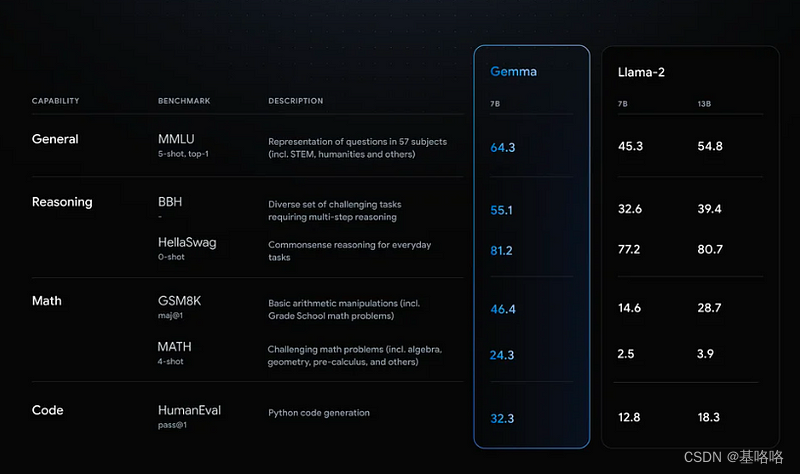
Gemma 7B 型号脱颖而出,是一款特别强大的选择,其性能可与 7B 重量级顶级竞争者的性能相媲美,包括 Mistral 7B 等。另一方面,Gemma 2B 型号的尺寸提供了一个有趣的选择。然而,与类似尺寸的最熟练模型(例如 Phi 2)相比,它在排行榜上的排名并不高。
数据集
这些模型在包含各种来源、总计 6 万亿个Token的文本数据集上进行训练。以下是关键信息:
- 网络文档:多样化的网络文本集合确保模型能够接触到广泛的语言风格、主题和词汇。主要是英语内容。
- 代码:将模型暴露给代码有助于它学习编程语言的语法和模式,从而提高其生成代码或理解与代码相关的问题的能力。
- 数学:数学文本训练有助于模型学习逻辑推理、符号表示以及解决数学查询。

Prompt 提示词格式
Gemma 的基础模型不限定特定的提示格式。如同其他基础模型,它们能够根据输入序列生成一个合理的续接内容,适用于零样本或少样本的推理任务。这些模型也为针对特定应用场景的微调提供了坚实的基础。指令优化版本则采用了一种极其简洁的对话结构:
<start_of_turn>用户_ _
敲击<end_of_turn>
<start_of_turn>模型
谁在那里< end_of_turn >
< start_of_turn >用户
Gemma <end_of_turn>
<start_of_turn>模型_ _ _ _
杰玛是谁?<转弯结束>要有效利用这一格式,必须严格按照上述结构进行对话。
探索未知领域
尽管技术报告提供了关于基础模型训练和评估过程的信息,但关于数据集构成和预处理的具体细节则较为欠缺。据悉,这些模型是基于来自互联网文档、编程代码和数学文本等多种数据源训练而成,经过严格筛选,以排除含有敏感信息和不适内容的数据。
对于 Gemma 的指令优化模型,关于微调数据集以及与顺序微调技术(SFT)和 基于人类反馈的强化学习(RLHF)相关的超参数设置,细节同样未公开。
演示
可以在 Hugging Chat 上体验与 Gemma 指令模型的互动对话!点击此处访问:https://huggingface.co/chat?model=google/gemma-7b-it
或者也可以在其他开源社区体验Gemma。
使用 Transformers
借助 Transformers 的 4.38 版本,你可以轻松地使用 Gemma 模型,并充分利用 Hugging Face 生态系统内的工具,包括:
- 训练和推理脚本及示例
- 安全文件格式(
safetensors) - 集成了诸如 bitsandbytes(4位量化)、PEFT(参数效率微调)和 Flash Attention 2 等工具
- 辅助工具和帮助器,以便使用模型进行生成
- 导出模型以便部署的机制
另外,Gemma 模型支持 torch.compile() 与 CUDA 图的结合使用,在推理时可实现约 4 倍的速度提升!
确保你使用的是最新版本的 transformers:
pip install -U "transformers==4.38.1" --upgrade
以下代码片段展示了如何结合 transformers 使用 gemma-7b-it。运行此代码需大约 18 GB 的 RAM,适用于包括 3090 或 4090 在内的消费级 GPU。
from transformers import AutoTokenizer, pipeline
import torchmodel = "google/gemma-7b-it"tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = pipeline("text-generation",model=model,model_kwargs={"torch_dtype": torch.bfloat16},device="cuda",
)messages = [{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt,max_new_tokens=256,do_sample=True,temperature=0.7,top_k=50,top_p=0.95
)
print(outputs[0]["generated_text"][len(prompt):])
Avast me, me hearty. I am a pirate of the high seas, ready to pillage and plunder. Prepare for a tale of adventure and booty!
- 我们使用了
bfloat16数据类型进行模型推理,该数据类型是所有评估中使用的参考精度。如果你的硬件支持,使用float16可能会更快。 - 你还可以将模型自动量化,以 8 位或 4 位模式加载。以 4 位模式加载模型大约需要 9 GB 的内存,使其适用于多种消费级显卡,包括 Google Colab 上的所有 GPU。以下是以 4 位加载生成 pipeline 的方法:
pipeline = pipeline("text-generation",model=model,model_kwargs={"torch_dtype": torch.float16,"quantization_config": {"load_in_4bit": True}},
)
更多关于如何使用 transformers 和模型的详情,请参阅 模型卡片。
JAX 权重
所有 Gemma 模型变种都可以用 PyTorch 或 JAX / Flax 使用。若要加载 Flax 权重,你需要按照以下方式使用仓库中的 flax 修订版本:
import jax.numpy as jnp
from transformers import AutoTokenizer, FlaxGemmaForCausalLMmodel_id = "google/gemma-2b"tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.padding_side = "left"model, params = FlaxGemmaForCausalLM.from_pretrained(model_id,dtype=jnp.bfloat16,revision="flax",_do_init=False,
)inputs = tokenizer("Valencia and Málaga are", return_tensors="np", padding=True)
output = model.generate(inputs, params=params, max_new_tokens=20, do_sample=False)
output_text = tokenizer.batch_decode(output.sequences, skip_special_tokens=True)
['Valencia and Málaga are two of the most popular tourist destinations in Spain. Both cities boast a rich history, vibrant culture,']
如果你在 TPU 或多个 GPU 设备上运行,可以利用 jit 和 pmap 来编译和并行执行推理任务。
与 Google Cloud 集成
你可以通过 Vertex AI 或 Google Kubernetes Engine (GKE) 在 Google Cloud 上部署和训练 Gemma,利用 文本生成推理 和 Transformers 实现。
要从 Hugging Face 部署 Gemma 模型,请访问模型页面并点击部署 -> Google Cloud。这将引导你进入 Google Cloud Console,在那里你可以通过 Vertex AI 或 GKE 一键部署 Gemma。文本生成推理为 Gemma 在 Google Cloud 上的部署提供支持,这是我们与 Google Cloud 合作伙伴关系的初步成果。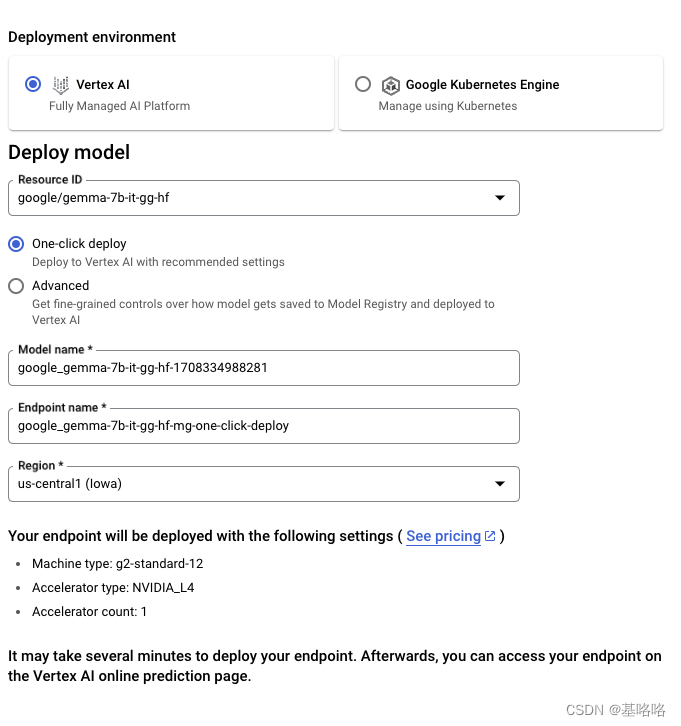
你也可以通过 Vertex AI Model Garden 直接访问 Gemma。
要在 Hugging Face 上微调 Gemma 模型,请访问 模型页面 并点击 训练 -> Google Cloud。这将引导你进入 Google Cloud Console,在那里你可以在 Vertex AI 或 GKE 上访问笔记本,以在这些平台上微调 Gemma。
这些集成是我们 与 Google 合作伙伴关系成果的一部分,未来还会有更多精彩内容发布,敬请期待!
与推理端点集成
你可以在 Hugging Face 的 推理端点 上部署 Gemma,该端点使用文本生成推理作为后端。文本生成推理 是由 Hugging Face 开发的可用于生产环境的推理容器,旨在简化大型语言模型的部署。它支持连续批处理、令牌流式传输、多 GPU 张量并行加速推理,并提供生产就绪的日志记录和跟踪功能。
要部署 Gemma 模型,请访问 HF Hub 模型页面 并点击 部署 -> 推理端点。有关 使用 Hugging Face 推理端点部署 LLM的更多信息,请参阅我们之前的博客文章。推理端点通过文本生成推理支持 消息 API,使你可以通过简单地更换 URL 从其他封闭模型切换到开放模型。
from openai import OpenAI# initialize the client but point it to TGI
client = OpenAI(base_url="<ENDPOINT_URL>" + "/v1/", # replace with your endpoint urlapi_key="<HF_API_TOKEN>", # replace with your token
)
chat_completion = client.chat.completions.create(model="tgi",messages=[{"role": "user", "content": "Why is open-source software important?"},],stream=True,max_tokens=500
)# iterate and print stream
for message in chat_completion:print(message.choices[0].delta.content, end="")
使用 🤗 TRL 进行微调
在消费级 GPU 上训练大型语言模型既是技术上的挑战,也是计算上的挑战。本节将介绍 Hugging Face 生态系统中可用的工具,这些工具可以帮助你高效地在消费级 GPU 上训练 Gemma。
一个微调 Gemma 的示例命令如下。我们利用 4 位量化和 QLoRA(一种参数效率微调技术)来减少内存使用,目标是所有注意力块的线性层。值得注意的是,与密集型 Transformer 不同,MLP 层(多层感知器层)因其稀疏性不适合与 PEFT(参数效率微调)技术结合使用。
首先,安装 🤗 TRL 的最新版本并克隆仓库以获取 训练脚本:
pip install -U transformers trl peft bitsandbytes
git clone https://github.com/huggingface/trl
cd trl
然后运行脚本:
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \examples/scripts/sft.py \--model_name google/gemma-7b \--dataset_name OpenAssistant/oasst_top1_2023-08-25 \--per_device_train_batch_size 2 \--gradient_accumulation_steps 1 \--learning_rate 2e-4 \--save_steps 20_000 \--use_peft \--lora_r 16 --lora_alpha 32 \--lora_target_modules q_proj k_proj v_proj o_proj \--load_in_4bit \--output_dir gemma-finetuned-openassistant
在单个 A10G GPU 上,这个训练过程大约需要 9 小时。通过调整 --num_processes 参数为你可用的 GPU 数量,可以实现并行化训练,从而缩短训练时间。
其他资源
- Hub 上的模型
- 开放 LLM 排行榜
- Hugging Chat 上的聊天演示
- Gemma 官方博客
- Gemma 产品页面
- Vertex AI 模型花园链接
- Google Notebook 教程
相关文章:
谷歌开源的LLM大模型 Gemma 简介
相关链接: Hugging face模型下载地址:https://huggingface.co/google/gemma-7bGithub地址:https://github.com/google/gemma_pytorch论文地址:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf官方博客&…...

深入理解 Vuex:从基础到应用场景
前言 在之前的文章中,我们已经对 Vue.js 有了一定的了解。今天我们要对Vue官方的状态共享管理器Vuex进行详细讲解,将其基本吃透,目标是面对大多数业务需求; 一、介绍 Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用…...

自定义 classNames hooks
什么是自定义 hooks 自定义hooks是react提供的编写公共函数的方法 自定hooks 和 通用函数的区别 一定有人会说 hooks 可以使用react 的方法,但是公共函数也可以,因为 jsx 语法的原因 函数必须开头进行大写 其实这些都是 react 的语法规范ÿ…...

玩转centos 下的core 文件
玩转centos 下的core 文件 ------------------------------------------------------------ author: hjjdebug date: 2024年 03月 06日 星期三 12:38:35 CST description: 玩转centos 下的core 文件 ------------------------------------------------------------ 一: 准备一…...
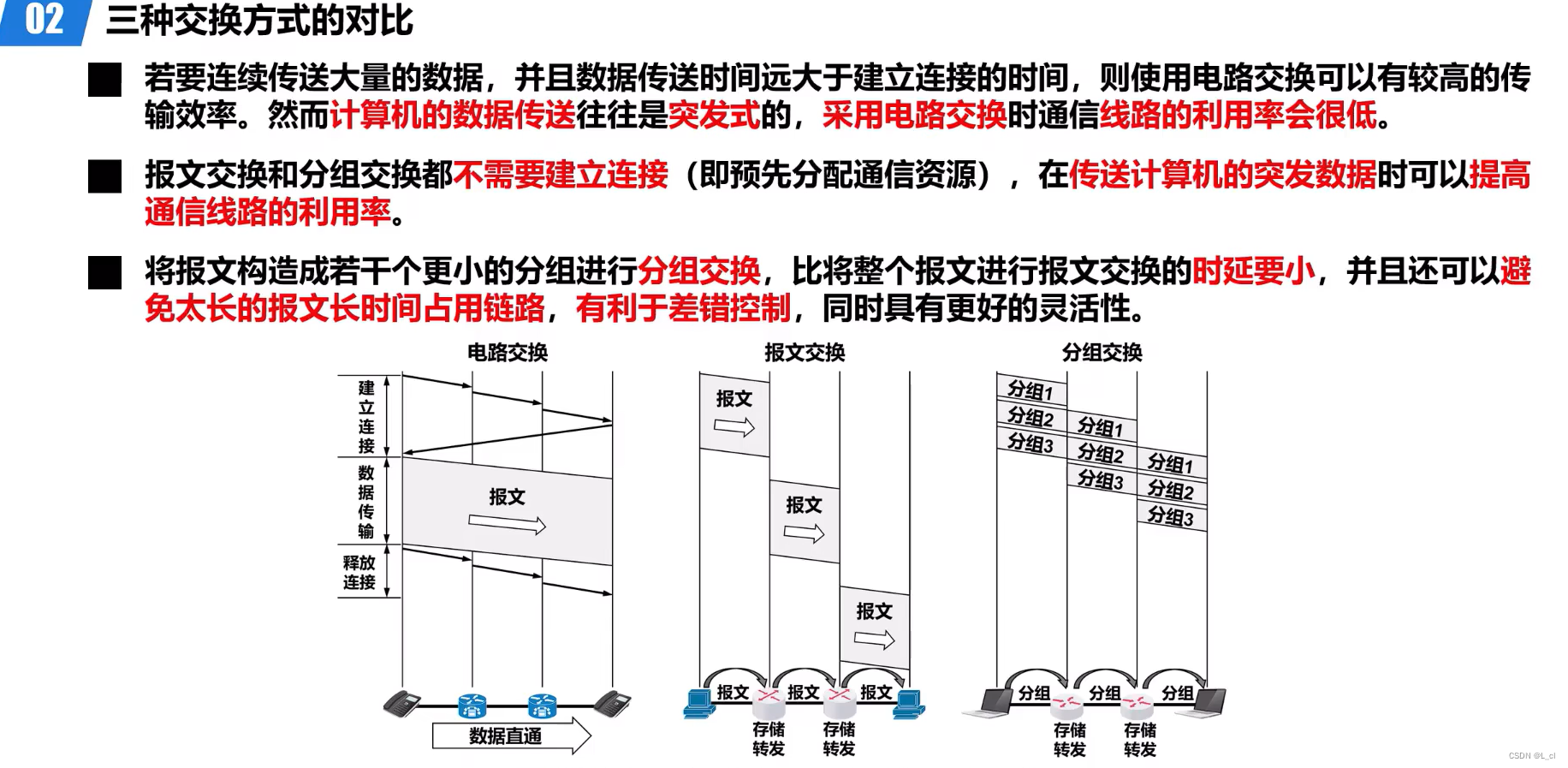
深入浅出计算机网络 day.1 概论③ 电路交换、分组交换和报文交换
人无法同时拥有青春和对青春的感受 —— 04.3.9 内容概述 01.电路交换、分组交换和报文交换 02.三种交换方式的对比 一、电路交换、分组交换和报文交换 1.电路交换 计算机之间的数据传送是突发式的,当使用电路交换来传送计算机数据时,其线路的传输效率一…...

linux:线程的控制
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》《Linux》 文章目录 前言一、线程的总结1. 线程的优点2. 线程的缺点3. 线程异常4.线程和进程 二、线程的控制创建线程线程终止线程等待获取返回值 线程分离 总结 前言 本文作为我对于线程的…...
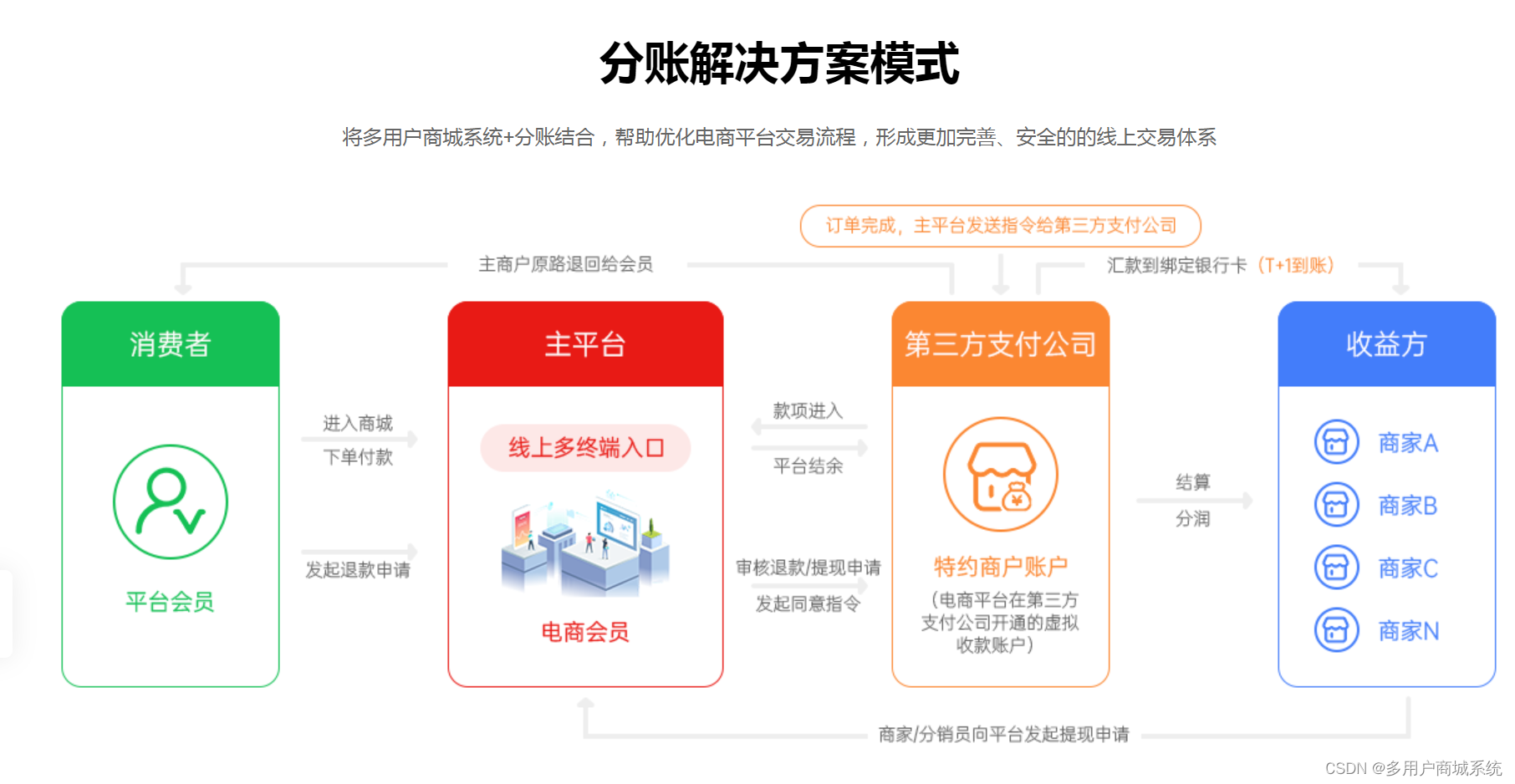
小程序分账方案:实现商户分账的简便与灵活
随着移动支付的普及和小程序的快速发展,越来越多的商家选择在微信小程序上开展业务。然而,对于一些有多个分账方的商户而言,如何实现快速、准确和灵活的资金分账成为了一个挑战。本文将介绍一种高效的小程序分账方案,帮助商户轻松…...

Python数值微积分,摆脱被高数支配的恐惧
文章目录 差分和累加积分多重积分 Python科学计算:数组💯数据生成 差分和累加 微积分是现代科学最基础的数学工具,但其应用对象往往是连续函数,而其在非连续函数的类比,便是差分与累加。在【numpy】中,可…...
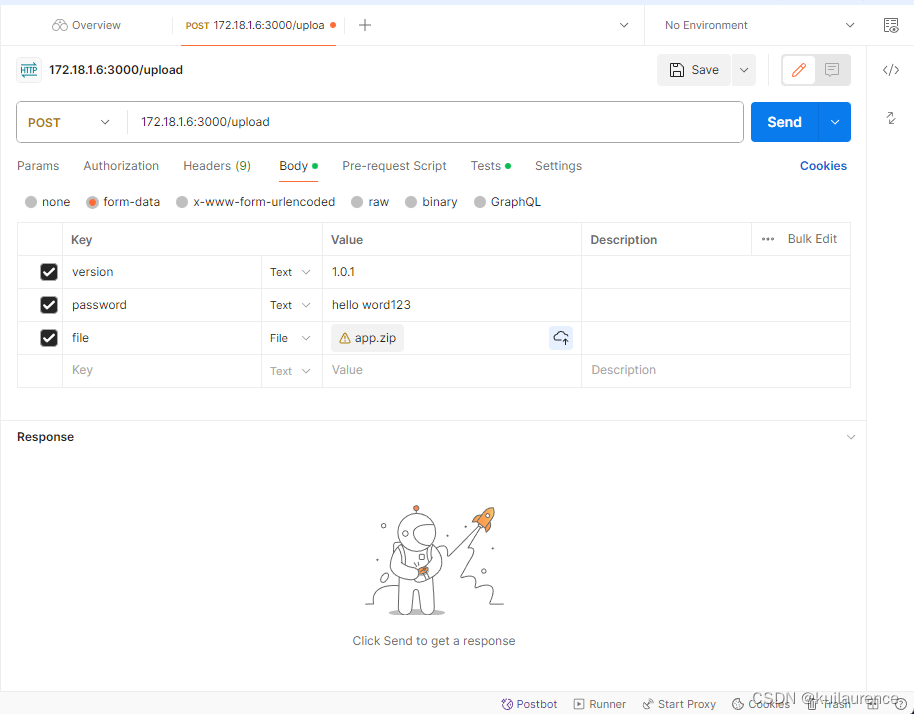
使用express+nginx+pm2+postman实现推送zip包自动更新前端网页
1.nginx配置将80端口代理到项目的3000端口 server {listen 80; #监听的端口server_name localhost; #监听的域名#charset koi8-r;#access_log logs/host.access.log main;location / {#root html;#index index.html index.html;proxy_pass http://127.0.0.1:3000; #转…...

如何在小程序中绑定身份证
在小程序中绑定身份证信息是一项常见的需求,特别是在需要进行实名认证或者身份验证的场景下。通过绑定身份证信息,可以提高用户身份的真实性和安全性,同时也为小程序提供了更多的个性化服务和功能。下面就介绍一下怎么在小程序中绑定居民身份…...
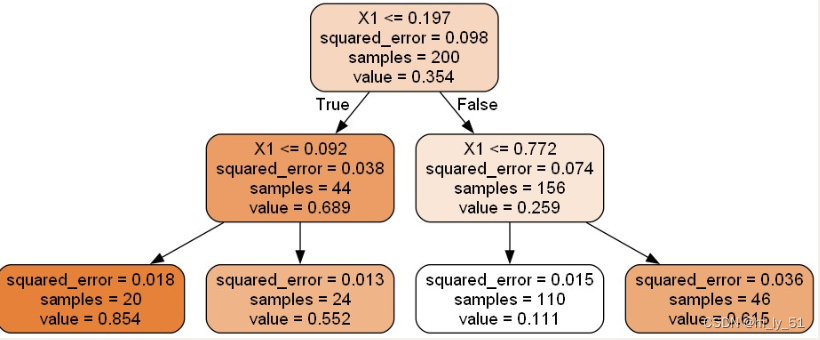
【机器学习】【决策树】分类树|回归树学习笔记总结
决策树算法概述 基本概念 决策树:从根节点开始一步步走到叶子节点,每一步都是决策过程 对于判断的先后顺序把控特别严格 一旦将判断顺序进行变化则最终的结果将可能发生改变 往往将分类效果较佳的判断条件放在前面,即先初略分在进行细节分…...
之docker搭建mysql主从集群(Replication)))
运维随录实战(14)之docker搭建mysql主从集群(Replication))
1, 从官方景镜像中拉取mysql镜像: docker pull mysql:8.0.24 --platform linux/x86_64 2, 创建master和slave容器: 在创建之前先设置网段 docker network create --subnet=172.20.0.0/24 soil_network master: docker run -d -p 3306:3306 --name mysql-master --net soi…...
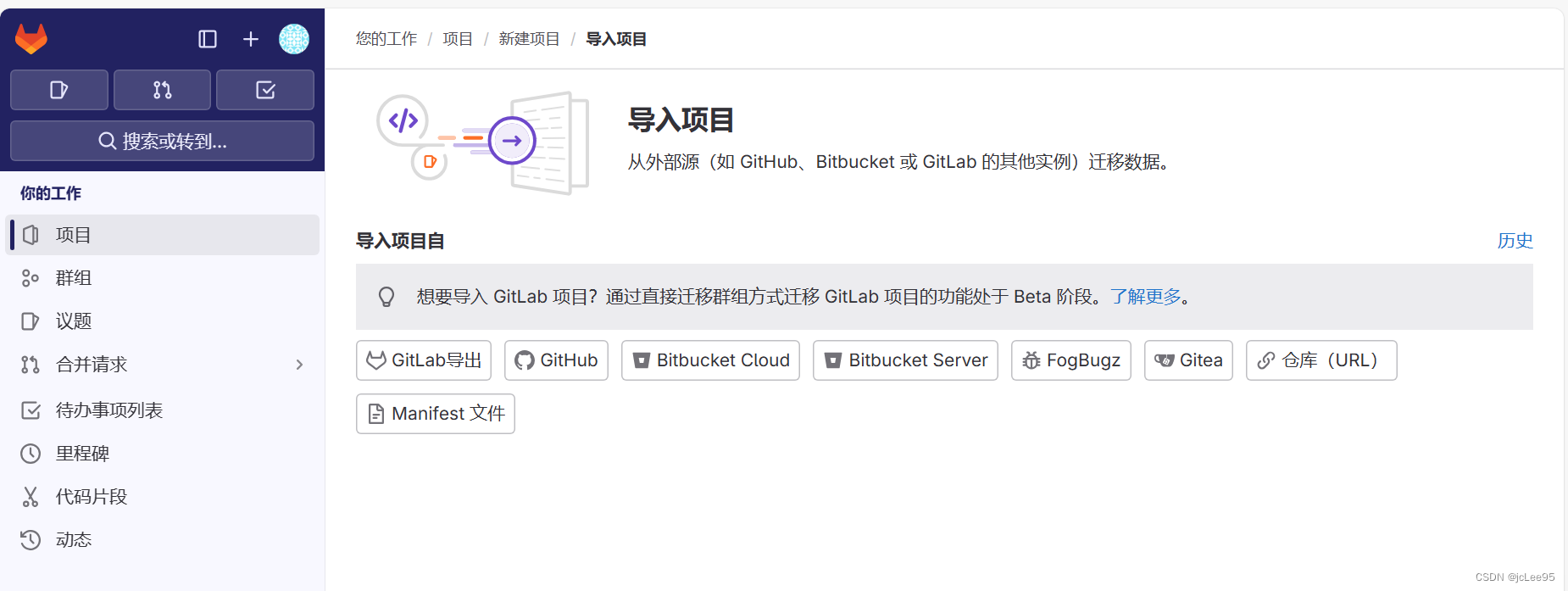
CI/CD笔记.Gitlab系列:2024更新后-设置GitLab导入源
CI/CD笔记.Gitlab系列 设置GitLab导入源 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/qq_…...
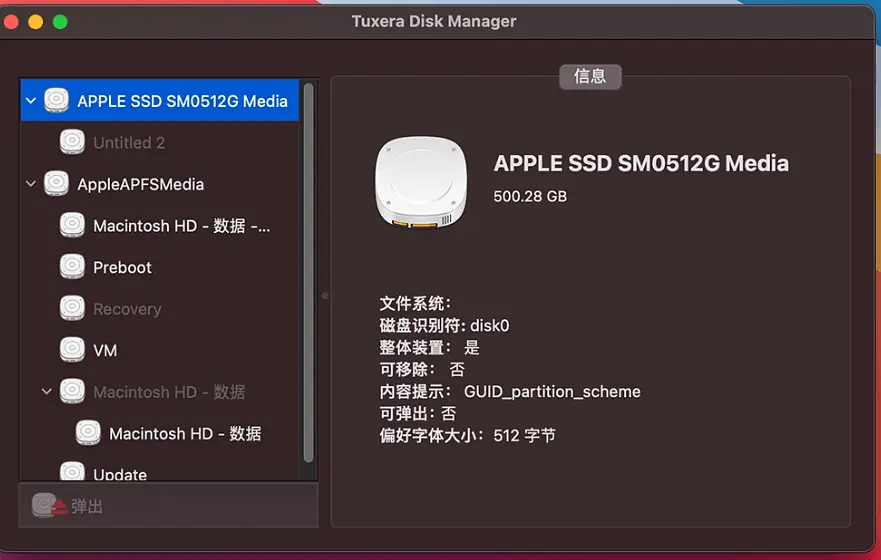
一款Mac系统NTFS磁盘读写软件Tuxera NTFS 2023 for Mac
当您获得一台新 Mac 时,它只能读取 Windows NTFS 格式的 USB 驱动器。要将文件添加、保存或写入您的 Mac,您需要一个附加的 NTFS 驱动程序。Tuxera 的 Microsoft NTFS for Mac 2023是一款易于使用的软件,可以在 Mac 上打开、编辑、复制、移动…...
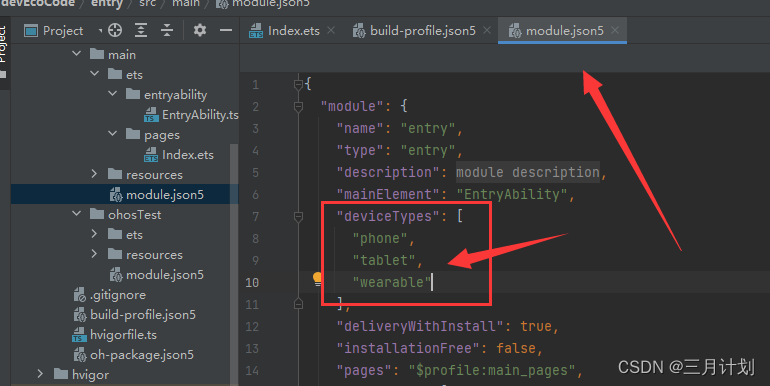
Error while Deploying HAP
第一个程序就遇到这么恶心的bug,也查了很多类似的问题是什么情况,后来无意中菜解决了这个bug,确实也是devicps下面加一个参数,但是找了半天 这是我遇到这个问题的解决办法。其他解决办法如下: https://blog.51cto.com…...

多线程扩展:乐观锁、多线程练习
悲观锁、乐观锁 悲观锁:一上来就加锁,没有安全感,每次只能一个线程进入访问完毕后,再解锁。线程安全,性能较差。 乐观锁:一开始不上锁,认为是没有问题的,等要出现线程安全问题的时…...

代码随想录day31 Java版
今天开始刷动态规划,先拿简单题练手 509. 斐波那契数 class Solution {public int fib(int n) {if (n < 1) return n; int[] dp new int[n 1];dp[0] 0;dp[1] 1;for (int index 2; index < n; index){dp[index] dp[index - 1] dp[index -…...
linux系统adb调试工具
adb的全称为Android Debug Bridge,就是起到调试桥的作用。通过adb可以在Eclipse中通过DDMS来调试Android程序,说白了就是调试工具。 adb的工作方式比较特殊,采用监听Socket TCP 5554等端口的方式让IDE和Qemu通讯,默认情况下adb会…...

【Golang星辰图】全面解析:Go语言在Web开发中的顶尖库和框架
创造无限可能:探索Go语言在Web开发中的强大库和框架 前言 Go语言作为一门简洁、高效的编程语言,在Web开发领域也展现出了强大的潜力。本文将会带您深入了解Go语言在Web开发中的相关库和框架,以及它们的优势和使用方法。通过学习这些内容&am…...

CSS 居中对齐 (水平居中 )
水平居中 1.文本居中对齐 内联元素(给容器添加样式) 限制条件:仅用于内联元素 display:inline 和 display: inline-block; <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><…...

【chrony】从原理到实战:构建高精度企业级时间同步服务
1. 为什么企业需要高精度时间同步 想象一下这样的场景:证券交易所里,一笔价值上亿的交易因为两台服务器的时间差0.1秒而被系统判定为无效;医院的手术室里,来自不同设备的生命体征监测数据因为时间不同步而无法准确关联࿱…...

ccmusic-database/music_genre在音乐治疗中的应用:基于流派的疗法推荐系统
ccmusic-database/music_genre在音乐治疗中的应用:基于流派的疗法推荐系统 1. 音乐治疗的新机遇 音乐治疗作为一种非药物干预手段,正逐渐成为心理健康领域的重要辅助方式。传统的音乐治疗往往依赖治疗师的经验选择音乐,但这种方式存在一定的…...

为什么92%的大模型项目卡在L3?SITS2026圆桌解密工程化跃迁的3个断层与1套验证框架
第一章:SITS2026圆桌:大模型工程化的未来趋势 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026圆桌讨论中,来自Meta、阿里云、Hugging Face与CNCF模型工作组的七位工程实践者共同指出:大模型工程化正从“能跑通”迈向“…...

如何高效使用TrollInstallerX:从安装到精通的完整指南
如何高效使用TrollInstallerX:从安装到精通的完整指南 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 你是否曾经希望在未越狱的iOS设备上自由安装第三方应用…...

MySQL Explain 输出结果与执行逻辑分析
MySQL Explain 输出结果与执行逻辑分析是数据库性能优化的核心工具之一。通过Explain命令,开发者可以深入理解SQL语句的执行计划,从而发现潜在的性能瓶颈并优化查询效率。无论是初学者还是资深DBA,掌握Explain的输出解读技巧都至关重要。本文…...

终极Walkway.js进阶教程:掌握复杂交互动画与响应式设计的完整指南
终极Walkway.js进阶教程:掌握复杂交互动画与响应式设计的完整指南 【免费下载链接】walkway An easy way to animate SVG elements. 项目地址: https://gitcode.com/gh_mirrors/wa/walkway Walkway.js是一款轻量级的SVG动画库,让开发者能够轻松为…...

EcomGPT-7B在Unity引擎中的应用:打造沉浸式虚拟电商购物助手
EcomGPT-7B在Unity引擎中的应用:打造沉浸式虚拟电商购物助手 想象一下,你走进一个由Unity引擎构建的、光影绚丽的3D虚拟商场。货架上琳琅满目,商品细节纤毫毕现。这时,一位虚拟导购员微笑着向你走来,你随口问了一句&a…...

Phi-3-mini-4k-instruct-gguf赋能课程设计:自动生成Multisim电路仿真报告
Phi-3-mini-4k-instruct-gguf赋能课程设计:自动生成Multisim电路仿真报告 1. 电子工程学生的文档困境 每次课程设计最头疼的是什么?不是画电路图,不是调参数,而是写那份永远写不完的实验报告。电子工程专业的学生都深有体会&…...

Qwen2.5-VL-7B-Instruct部署优化:显存占用从16GB降至13.2GB的实测技巧
Qwen2.5-VL-7B-Instruct部署优化:显存占用从16GB降至13.2GB的实测技巧 1. 模型概述与部署挑战 Qwen2.5-VL-7B-Instruct是一款强大的多模态视觉-语言模型,能够同时处理图像和文本输入,生成高质量的响应。该模型在BF16精度下的标准显存占用约…...
)
Llama2跑不起来?别急,可能是flash-attn的ABI版本搞的鬼(CUDA 12.2 + PyTorch 2.1.2 实测避坑)
Llama2部署遇阻?深入解析flash-attn的ABI兼容陷阱 当你在本地部署Llama2等大语言模型时,是否遇到过这样的场景:按照官方文档一步步操作,flash-attn显示安装成功,却在import时遭遇莫名其妙的报错?这种"…...