【机器学习】【决策树】分类树|回归树学习笔记总结
决策树算法概述
基本概念
决策树:从根节点开始一步步走到叶子节点,每一步都是决策过程 对于判断的先后顺序把控特别严格 一旦将判断顺序进行变化则最终的结果将可能发生改变
往往将分类效果较佳的判断条件放在前面,即先初略分在进行细节分
所有的数据最终都将会落到叶子节点,树模型既可以做分类也可以做回归
树的组成:
根节点:第一个选择点
非叶子节点与分支:中间过程
叶子节点:最终的决策结果
决策树的训练与测试:
训练阶段:从给定的训练集构造出一棵树(从根节点开始选择特征,即判断条件等;如何进行特征切分)
测试阶段:根据构造出来的树模型从上至下运行一遍即可
熵
熵:是表示随机变量不确定性的度量,即物体内部的混乱程度
在实际运用过程中,熵值越低越好 在树模型构建时也是使得熵值降低的的好
信息增益
表示特征X使得类别Y的不确定性减少的程度。(分类后的专一性,希望分类后的结果是同类在一起)
即如何经过一个节点后左右子树的熵值之和比原来的要小,则信息增益为正
计算各个特征的信息增益,再选择最大的那个作为根节点 对于下一个节点其操作过程与选择根节点一致,每次都需要对剩下的特征进行遍历,选择出信息增益max的特征
信息增益存在的问题
当特征中存在非常稀疏,并且种类非常多的特征时,如id值 这时熵值经过该特征判断后值接近于0
信息增益率
公式为:信息增益/该节点的熵值
该方式很好的解决了信息增益所存在的问题
gini系数
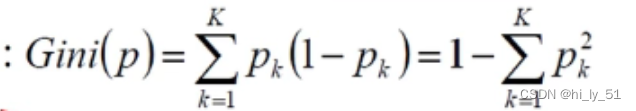
如何处理连续值
选取连续值的哪个分界点:——对连续值的各个分界点进行尝试,判断每个分界点的信息增益率等,以选择最佳的分界点
剪枝策略
决策树过拟合风险很大,理论上可以将数据完全分开,即每个叶子节点只有一个数据
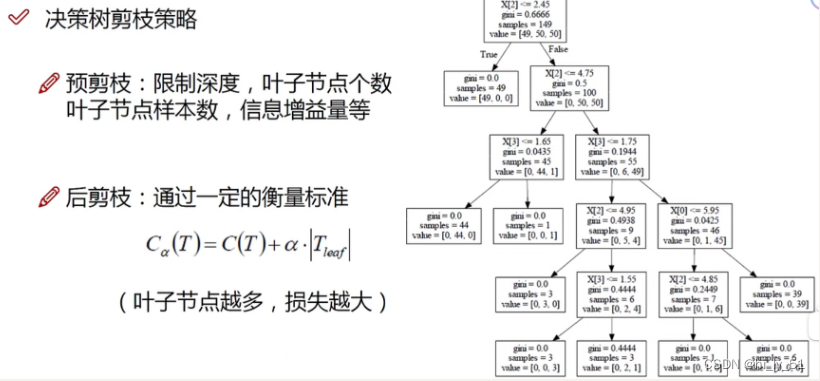
预剪枝
边建立决策树边进行剪枝操作
可以通过限制树的深度、叶子节点个数、叶子节点样本数、信息增益量等
预剪枝的参数都是需要通过实验不断的进行尝试来选择最佳参数的
后剪枝
建立完成决策树之后进行剪枝操作
在计算公式中ɑ的值需要自己设定,值越大说明希望自己的树模型越不过拟合,但是得到的结果可能不是很好;值越小说明希望结果好为主,对于过拟合程度不是很关注
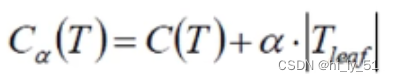
C(T):gini系数或熵值
Tleaf:叶子节点个数
回归/分类问题解决
分类问题:
由于原始数据有自己的标签,对于最终的叶子节点,其类别所属类型使用众数方式,即何种类别数据多则该叶子节点属于该类型;
回归问题
回归由于没有具体的类别,因而无熵值。
判断标准:方差
在进行预测时该节点的节点值等于其平均数
树模型的可视化展示
下载安装包:Download | Graphviz
环境变量配置:GraphViz如何配置环境变量并保存图片-百度经验 (baidu.com)
import numpy as np
import os
# %matplotlib inline
import matplotlib
import matplotlib.pyplot as pltplt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warningswarnings.filterwarnings('ignore')'''导入鸢尾花数据集'''
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifieriris = load_iris()
X = iris.data[:, 2:]
y = iris.target'''创建决策树模型'''
tree_clf = DecisionTreeClassifier(max_depth=2) ##max_depth限制决策树模型最大深度
tree_clf.fit(X,y) ##模型训练'''画图展示决策树模型'''
from sklearn.tree import export_graphvizexport_graphviz(tree_clf, ##当前树模型 之前训练好的树模型out_file="iris_tree.dot", ##输出文件 .dot文件 后续会将其转为图片文件feature_names=iris.feature_names[2:], ##绘图时展示的特征名字class_names=iris.target_names,rounded=True,filled=True
)
将在文件夹中生成一个.dot文件,
再利用之前下载好的软件将该文件转为png图片文件
dot -Tpng iris_tree.dot -o iris_tree.png
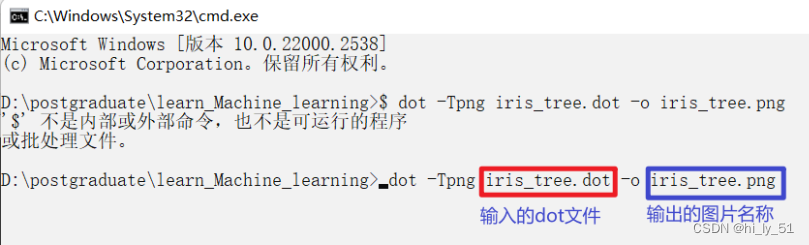
将会得到对应的png图片

'''使用代码的方式展示照片'''
from IPython.display import Image
Image(filename="iris_tree.png",width=400,height=400)
##前提是已经将dot文件转为相关的照片格式决策树的决策边界展示
import numpy as np
import os
# %matplotlib inline
import matplotlib
import matplotlib.pyplot as pltplt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warningswarnings.filterwarnings('ignore')'''导入鸢尾花数据集'''
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifieriris = load_iris()
X = iris.data[:, 2:]
y = iris.target'''创建决策树模型'''
tree_clf = DecisionTreeClassifier(max_depth=2) ##max_depth限制决策树模型最大深度
tree_clf.fit(X, y) ##模型训练print(tree_clf.predict_proba([[5, 1.5]])) ##预测概率值
'''绘制决策边界'''
from matplotlib.colors import ListedColormapdef plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True):##找特征x1s = np.linspace(axes[0], axes[1], 100)x2s = np.linspace(axes[2], axes[3], 100)# 构建棋盘x1, x2 = np.meshgrid(x1s, x2s)##在棋盘中构建待测试数据X_new = np.c_[x1.ravel(), x2.ravel()]##预测最终结果值y_pred = clf.predict(X_new).reshape(x1.shape)##确定绘制的颜色 与等高线样式custom_cmap = ListedColormap(['#fafab0', '#9898ff', '#a0faa0'])plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)if not iris:custom_cmap2 = ListedColormap(['#7d7d58', '#4c4c7f', '#507d50'])plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)if plot_training:plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], "yo", label="Iris-Setosa")plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], "bs", label="Iris-Versicolor")plt.plot(X[:, 0][y == 2], X[:, 1][y == 2], "g^", label="Iris-Virginica")plt.axis(axes)if iris:plt.xlabel("Petal length", fontsize=14)plt.ylabel("Petal width", fontsize=14)else:plt.xlabel(r"$x_1$", fontsize=18)plt.ylabel(r"Sx_2$", fontsize=18, rotation=0)if legend:plt.legend(loc="lower right", fontsize=14)plt.figure(figsize=(8, 4))
plot_decision_boundary(tree_clf, X, y)
###传入实际的位置值 即切割位置
plt.plot([2.45, 2.45], [0, 3], "k-", linewidth=2)
plt.plot([2.45, 7.5], [1.75, 1.75], "k--", linewidth=2)
plt.plot([4.95, 4.95], [0, 1.75], "k:", linewidth=2)
plt.plot([4.85, 4.85], [1.75, 3], "k:", linewidth=2)
plt.text(1.40, 1.0, "Depth=0", fontsize=15)
plt.text(3.2, 1.80, "Depth=1", fontsize=13)
plt.text(4.05, 0.5, "(Depth=2)", fontsize=11)
plt.title('Decision Tree decision boundaries')
plt.show()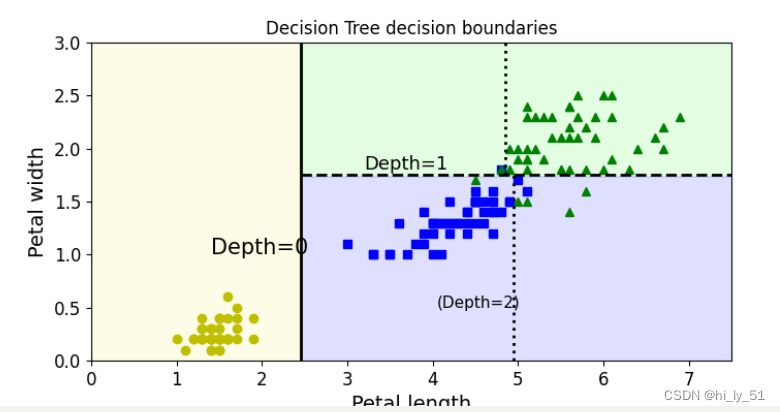
树模型预剪枝参数作用

通常max_features不做限制,默认情况下全部使用,除非特征数非常多;max_depth(树最大的深度)
import numpy as np
import os
# %matplotlib inline
import matplotlib
import matplotlib.pyplot as pltplt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warningswarnings.filterwarnings('ignore')'''绘制决策边界'''
from matplotlib.colors import ListedColormapdef plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True):##找特征x1s = np.linspace(axes[0], axes[1], 100)x2s = np.linspace(axes[2], axes[3], 100)# 构建棋盘x1, x2 = np.meshgrid(x1s, x2s)##在棋盘中构建待测试数据X_new = np.c_[x1.ravel(), x2.ravel()]##预测最终结果值y_pred = clf.predict(X_new).reshape(x1.shape)##确定绘制的颜色 与等高线样式custom_cmap = ListedColormap(['#fafab0', '#9898ff', '#a0faa0'])plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)if not iris:custom_cmap2 = ListedColormap(['#7d7d58', '#4c4c7f', '#507d50'])plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)if plot_training:plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], "yo", label="Iris-Setosa")plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], "bs", label="Iris-Versicolor")plt.plot(X[:, 0][y == 2], X[:, 1][y == 2], "g^", label="Iris-Virginica")plt.axis(axes)if iris:plt.xlabel("Petal length", fontsize=14)plt.ylabel("Petal width", fontsize=14)else:plt.xlabel(r"$x_1$", fontsize=18)plt.ylabel(r"Sx_2$", fontsize=18, rotation=0)if legend:plt.legend(loc="lower right", fontsize=14)from sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import make_moonsX, y = make_moons(n_samples=100, noise=0.25, random_state=53) ##构造数据
tree_clf1 = DecisionTreeClassifier(random_state=42)
tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4, random_state=42) # 设置min_samples_leaf参数
tree_clf1.fit(X, y)
tree_clf2.fit(X, y)
##绘图展示对比
plt.figure(figsize=(12, 4))
plt.subplot(121)
plot_decision_boundary(tree_clf1, X, y, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("min_samples_leaf=4")
plt.subplot(122)
plot_decision_boundary(tree_clf2, X, y, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("No restrictions")
plt.show()

回归树模型
树模型对数据的形状较为敏感,当对数据进行旋转等变换后其得到的结果也是不同的
回归树与其他的不同的于 其使用的不是gini系数而是均方误差mse
import numpy as np
import os
# %matplotlib inline
import matplotlib
import matplotlib.pyplot as pltplt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warningswarnings.filterwarnings('ignore')
'''构造数据'''
np.random.seed(42)
m = 200
X = np.random.rand(m, 1)
y = 4 * (X - 0.5) ** 2
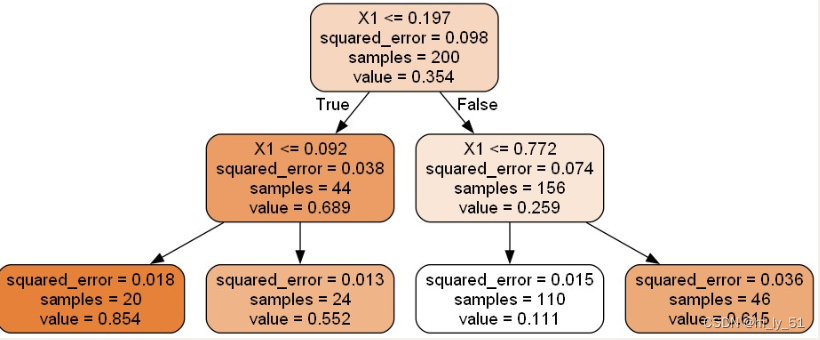
y = y + np.random.randn(m, 1) / 10'''导入包 但是不同于分类决策树的包'''from sklearn.tree import DecisionTreeRegressortree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
from sklearn.tree import export_graphvizexport_graphviz(tree_reg, ##当前树模型 之前训练好的树模型out_file="regression_tree.dot", ##输出文件 .dot文件 后续会将其转为图片文件feature_names=["X1"], ##绘图时展示的特征名字rounded=True,filled=True
)
sklearn工具包中都是使用CRT算法,即得到的都是二叉树
相关文章:
【机器学习】【决策树】分类树|回归树学习笔记总结
决策树算法概述 基本概念 决策树:从根节点开始一步步走到叶子节点,每一步都是决策过程 对于判断的先后顺序把控特别严格 一旦将判断顺序进行变化则最终的结果将可能发生改变 往往将分类效果较佳的判断条件放在前面,即先初略分在进行细节分…...
之docker搭建mysql主从集群(Replication)))
运维随录实战(14)之docker搭建mysql主从集群(Replication))
1, 从官方景镜像中拉取mysql镜像: docker pull mysql:8.0.24 --platform linux/x86_64 2, 创建master和slave容器: 在创建之前先设置网段 docker network create --subnet=172.20.0.0/24 soil_network master: docker run -d -p 3306:3306 --name mysql-master --net soi…...
CI/CD笔记.Gitlab系列:2024更新后-设置GitLab导入源
CI/CD笔记.Gitlab系列 设置GitLab导入源 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/qq_…...
一款Mac系统NTFS磁盘读写软件Tuxera NTFS 2023 for Mac
当您获得一台新 Mac 时,它只能读取 Windows NTFS 格式的 USB 驱动器。要将文件添加、保存或写入您的 Mac,您需要一个附加的 NTFS 驱动程序。Tuxera 的 Microsoft NTFS for Mac 2023是一款易于使用的软件,可以在 Mac 上打开、编辑、复制、移动…...
Error while Deploying HAP
第一个程序就遇到这么恶心的bug,也查了很多类似的问题是什么情况,后来无意中菜解决了这个bug,确实也是devicps下面加一个参数,但是找了半天 这是我遇到这个问题的解决办法。其他解决办法如下: https://blog.51cto.com…...

多线程扩展:乐观锁、多线程练习
悲观锁、乐观锁 悲观锁:一上来就加锁,没有安全感,每次只能一个线程进入访问完毕后,再解锁。线程安全,性能较差。 乐观锁:一开始不上锁,认为是没有问题的,等要出现线程安全问题的时…...

代码随想录day31 Java版
今天开始刷动态规划,先拿简单题练手 509. 斐波那契数 class Solution {public int fib(int n) {if (n < 1) return n; int[] dp new int[n 1];dp[0] 0;dp[1] 1;for (int index 2; index < n; index){dp[index] dp[index - 1] dp[index -…...
linux系统adb调试工具
adb的全称为Android Debug Bridge,就是起到调试桥的作用。通过adb可以在Eclipse中通过DDMS来调试Android程序,说白了就是调试工具。 adb的工作方式比较特殊,采用监听Socket TCP 5554等端口的方式让IDE和Qemu通讯,默认情况下adb会…...

【Golang星辰图】全面解析:Go语言在Web开发中的顶尖库和框架
创造无限可能:探索Go语言在Web开发中的强大库和框架 前言 Go语言作为一门简洁、高效的编程语言,在Web开发领域也展现出了强大的潜力。本文将会带您深入了解Go语言在Web开发中的相关库和框架,以及它们的优势和使用方法。通过学习这些内容&am…...

CSS 居中对齐 (水平居中 )
水平居中 1.文本居中对齐 内联元素(给容器添加样式) 限制条件:仅用于内联元素 display:inline 和 display: inline-block; <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><…...

数据结构:图及相关算法讲解
图 1.图的基本概念2. 图的存储结构2.1邻接矩阵2.2邻接表2.3两种实现的比较 3.图的遍历3.1 图的广度优先遍历3.2 图的深度优先遍历 4.最小生成树4.1 Kruskal算法4.2 Prim算法4.3 两个算法比较 5.最短路径5.1两个抽象存储5.2单源最短路径--Dijkstra算法5.3单源最短路径--Bellman-…...
)
【c++设计模式06】创建型4:单例模式(Singleton Pattern)
【c++设计模式06】创建型4:单例模式(Singleton Pattern) 一、定义二、适用场景三、确保,一个类可以实例化一个对象四、分类1、懒汉式——首次访问时才创建实例2、饿汉式——类加载时就创建实例五、线程安全性深入讨论(懒汉式单例模式)1、懒汉式单例真的线程不安全吗?——…...

Python-OpenCV-边缘检测
摘要: 本文介绍了使用Python和OpenCV进行边缘检测的方法,涵盖了基本概念、核心组件、工作流程,以及详细的实现步骤和代码示例。同时,文章也探讨了相关的技巧与实践,并给出了常见问题与解答。通过阅读本文,…...

C#中使用 Prism 框架
C#中使用 Prism 框架 前言一、安装 Prism 框架二、模块化开发三、依赖注入四、导航五、事件聚合六、状态管理七、测试 前言 Prism 框架是一个用于构建可维护、灵活和可扩展的 XAML 应用程序的框架。它提供了一套工具和库,帮助开发者实现诸如依赖注入、模块化、导航…...
什么是线程池,线程池的概念、优点、缺点,如何使用线程池,最大线程池怎么定义?
线程池(Thread Pool)是一种并发编程中常用的技术,用于管理和重用线程。它由线程池管理器、工作队列和线程池线程组成。 线程池的基本概念是,在应用程序启动时创建一定数量的线程,并将它们保存在线程池中。当需要执行任…...
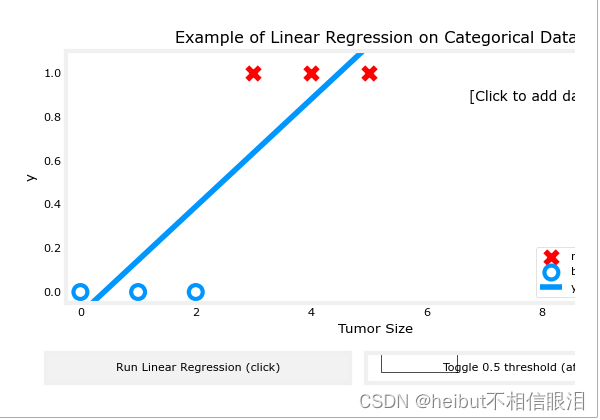
吴恩达机器学习-可选实验室:可选实验:使用逻辑回归进行分类(Classification using Logistic Regression)
在本实验中,您将对比回归和分类。 import numpy as np %matplotlib widget import matplotlib.pyplot as plt from lab_utils_common import dlc, plot_data from plt_one_addpt_onclick import plt_one_addpt_onclick plt.style.use(./deeplearning.mplstyle)jupy…...
)
序列的第 k 个数(c++题解)
题目描述 BSNY 在学等差数列和等比数列,当已知前三项时,就可以知道是等差数列还是等比数列。现在给你序列的前三项,这个序列要么是等差序列,要么是等比序列,你能求出第 m项的值吗。 如果第 项的值太大,对…...
Nexus - Maven私服构建和使用
文章目录 1. Maven 私服简介2. Nexus下载安装3. 如何使用Nexus私服3.1 通过Nexus下载Jar包3.2 将Jar包部署到Nexus3.3 引用别人部署的jar包 1. Maven 私服简介 Maven 私服是一种特殊的Maven远程仓库,它是架设在局域网内的仓库服务,用来代理位于外部的远…...

SpringMVC09、Ajax
9、Ajax 9.1、简介 AJAX Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。 AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。 Ajax 不是一种新的编程语言,而是一种用于创建更好更快以及交互…...

【数据结构初阶 9】内排序
文章目录 🌈 1. 直接插入排序🌈 2. 希尔排序🌈 3. 简单选择排序🌈 4. 堆排序🌈 5. 冒泡排序🌈 6. 快速排序6.1 霍尔版快排6.2 挖坑版快排6.3 双指针快排6.4 非递归快排 🌈 7. 归并排序7.1 递归版…...
Pixel Dimension Fissioner 创意编程:结合Node.js构建实时图像生成服务
Pixel Dimension Fissioner 创意编程:结合Node.js构建实时图像生成服务 1. 为什么需要实时图像生成服务 电商平台需要每天生成上千张商品展示图,社交媒体运营要快速产出吸引眼球的视觉内容,广告公司面临紧急修改需求...这些场景都在呼唤一个…...
)
Win11与Ubuntu22.04 LTS双系统安装避坑指南(附分区优化建议)
1. 双系统安装前的准备工作 第一次尝试在Win11上安装Ubuntu22.04 LTS时,我犯了个低级错误——只给根目录分配了30G空间。结果安装CUDA时直接爆满,不得不重装整个系统。这个惨痛教训让我意识到,分区规划是双系统安装中最容易被忽视却最关键的一…...

GLM-TTS效果实测:方言克隆、情感控制,音色还原度惊人
GLM-TTS效果实测:方言克隆、情感控制,音色还原度惊人 1. 开篇:重新定义语音合成的可能性 想象一下这样的场景:你只需要录制3秒钟的语音,就能让AI完美复刻你的声音,甚至可以用你的声音说出你从未说过的话。…...

SiameseAOE模型在STM32嵌入式产品用户手册反馈分析中的潜在应用
SiameseAOE模型在STM32嵌入式产品用户手册反馈分析中的潜在应用 1. 引言 你有没有遇到过这样的情况?作为一名嵌入式工程师,拿到一块新的STM32开发板,兴致勃勃地翻开数据手册,准备大干一场,结果发现某个关键外设的配置…...

ELi_MdM_4_00电机驱动库:工业嵌入式多模式PWM控制框架
1. ELi_MdM_4_00 电机驱动库深度解析:面向工业级嵌入式控制的多模式驱动框架ELi_MdM_4_00 是 E-LAGORi 公司推出的第四代电机驱动模块专用固件库,专为嵌入式系统对多类型执行机构的精确、可靠、低开销控制而设计。该库并非通用型电机控制抽象层ÿ…...

MOOTDX终极指南:免费构建你的股票量化分析系统
MOOTDX终极指南:免费构建你的股票量化分析系统 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 你是否曾因股票数据获取困难而放弃量化分析的想法?是否被高昂的数据费用吓退…...

Qwen3-14B部署教程:JupyterLab集成环境与交互式推理演示
Qwen3-14B部署教程:JupyterLab集成环境与交互式推理演示 1. 开箱即用的私有部署方案 Qwen3-14B作为通义千问系列的最新大语言模型,在14B参数规模下展现出惊人的多轮对话和复杂推理能力。今天我们要介绍的是一个专为RTX 4090D 24GB显存优化的私有部署镜…...
AgentCPM-Report深度应用:Pixel Epic智识终端多源数据整合研报生成
AgentCPM-Report深度应用:Pixel Epic智识终端多源数据整合研报生成 1. 产品概览:像素史诗智识终端 Pixel Epic智识终端是一款基于AgentCPM-Report大模型构建的创新研究报告生成系统。它将传统枯燥的科研分析过程转化为一场充满像素美学的数字冒险&…...

LangGraph 实战指南:拒绝 AI 应用面条代码,像搭地铁一样构建企业级 Agent
LangGraph 实战指南:拒绝 AI 应用面条代码,像搭地铁一样构建企业级 Agent 文章目录LangGraph 实战指南:拒绝 AI 应用面条代码,像搭地铁一样构建企业级 Agent前言:那个让程序员崩溃的周五晚上一、LangGraph 是什么&…...

React 组件渲染流程剖析
React组件渲染流程剖析:深入理解UI构建机制 在现代前端开发中,React凭借其高效的组件化开发模式成为主流框架之一。理解React组件的渲染流程,不仅能帮助开发者优化性能,还能避免常见的渲染陷阱。本文将从核心流程出发,…...