软件杯 垃圾邮件(短信)分类算法实现 机器学习 深度学习
文章目录
- 0 前言
- 2 垃圾短信/邮件 分类算法 原理
- 2.1 常用的分类器 - 贝叶斯分类器
- 3 数据集介绍
- 4 数据预处理
- 5 特征提取
- 6 训练分类器
- 7 综合测试结果
- 8 其他模型方法
- 9 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 垃圾邮件(短信)分类算法实现 机器学习 深度学习
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 垃圾短信/邮件 分类算法 原理
垃圾邮件内容往往是广告或者虚假信息,甚至是电脑病毒、情色、反动等不良信息,大量垃圾邮件的存在不仅会给人们带来困扰,还会造成网络资源的浪费;
网络舆情是社会舆情的一种表现形式,网络舆情具有形成迅速、影响力大和组织发动优势强等特点,网络舆情的好坏极大地影响着社会的稳定,通过提高舆情分析能力有效获取发布舆论的性质,避免负面舆论的不良影响是互联网面临的严肃课题。
将邮件分为垃圾邮件(有害信息)和正常邮件,网络舆论分为负面舆论(有害信息)和正面舆论,那么,无论是垃圾邮件过滤还是网络舆情分析,都可看作是短文本的二分类问题。
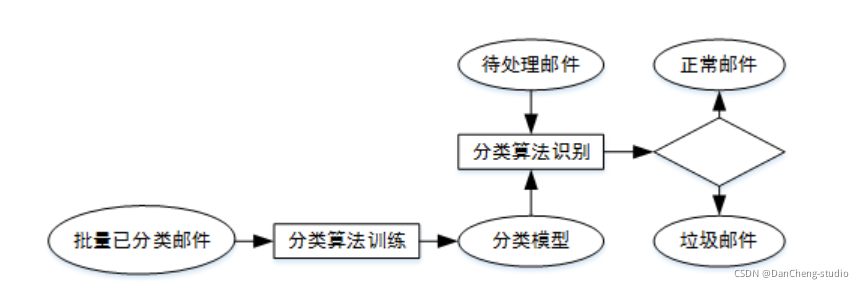
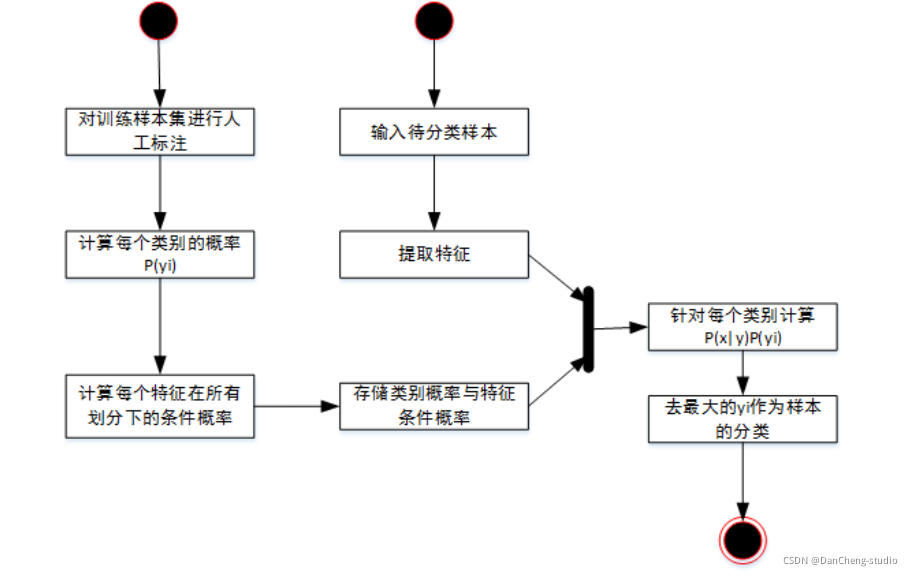
2.1 常用的分类器 - 贝叶斯分类器
贝叶斯算法解决概率论中的一个典型问题:一号箱子放有红色球和白色球各 20 个,二号箱子放油白色球 10 个,红色球 30
个。现在随机挑选一个箱子,取出来一个球的颜色是红色的,请问这个球来自一号箱子的概率是多少?
利用贝叶斯算法识别垃圾邮件基于同样道理,根据已经分类的基本信息获得一组特征值的概率(如:“茶叶”这个词出现在垃圾邮件中的概率和非垃圾邮件中的概率),就得到分类模型,然后对待处理信息提取特征值,结合分类模型,判断其分类。
贝叶斯公式:
P(B|A)=P(A|B)*P(B)/P(A)
P(B|A)=当条件 A 发生时,B 的概率是多少。代入:当球是红色时,来自一号箱的概率是多少?
P(A|B)=当选择一号箱时,取出红色球的概率。
P(B)=一号箱的概率。
P(A)=取出红球的概率。
代入垃圾邮件识别:
P(B|A)=当包含"茶叶"这个单词时,是垃圾邮件的概率是多少?
P(A|B)=当邮件是垃圾邮件时,包含“茶叶”这个单词的概率是多少?
P(B)=垃圾邮件总概率。
P(A)=“茶叶”在所有特征值中出现的概率。
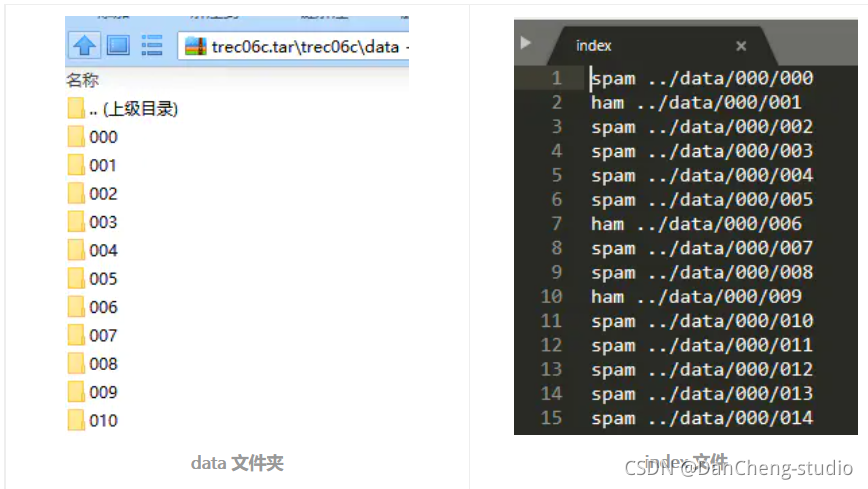
3 数据集介绍
使用中文邮件数据集:丹成学长自己采集,通过爬虫以及人工筛选。
数据集“data” 文件夹中,包含,“full” 文件夹和 “delay” 文件夹。
“data” 文件夹里面包含多个二级文件夹,二级文件夹里面才是垃圾邮件文本,一个文本代表一份邮件。“full” 文件夹里有一个 index
文件,该文件记录的是各邮件文本的标签。
数据集可视化:
4 数据预处理
这一步将分别提取邮件样本和样本标签到一个单独文件中,顺便去掉邮件的非中文字符,将邮件分好词。
邮件大致内容如下图:
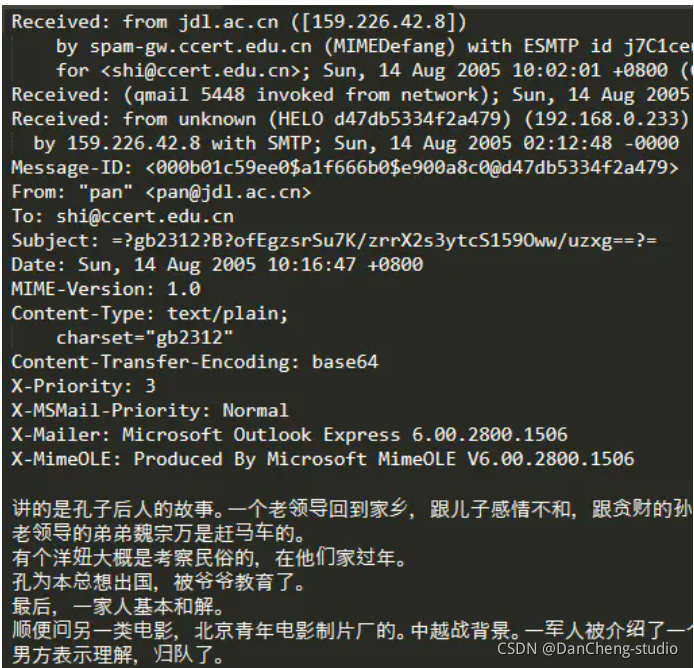
每一个邮件样本,除了邮件文本外,还包含其他信息,如发件人邮箱、收件人邮箱等。因为我是想把垃圾邮件分类简单地作为一个文本分类任务来解决,所以这里就忽略了这些信息。
用递归的方法读取所有目录里的邮件样本,用 jieba 分好词后写入到一个文本中,一行文本代表一个邮件样本:
import re
import jieba
import codecs
import os
# 去掉非中文字符
def clean_str(string):string = re.sub(r"[^\u4e00-\u9fff]", " ", string)string = re.sub(r"\s{2,}", " ", string)return string.strip()def get_data_in_a_file(original_path, save_path='all_email.txt'):files = os.listdir(original_path)for file in files:if os.path.isdir(original_path + '/' + file):get_data_in_a_file(original_path + '/' + file, save_path=save_path)else:email = ''# 注意要用 'ignore',不然会报错f = codecs.open(original_path + '/' + file, 'r', 'gbk', errors='ignore')# lines = f.readlines()for line in f:line = clean_str(line)email += linef.close()"""发现在递归过程中使用 'a' 模式一个个写入文件比 在递归完后一次性用 'w' 模式写入文件快很多"""f = open(save_path, 'a', encoding='utf8')email = [word for word in jieba.cut(email) if word.strip() != '']f.write(' '.join(email) + '\n')print('Storing emails in a file ...')
get_data_in_a_file('data', save_path='all_email.txt')
print('Store emails finished !')
然后将样本标签写入单独的文件中,0 代表垃圾邮件,1 代表非垃圾邮件。代码如下:
def get_label_in_a_file(original_path, save_path='all_email.txt'):f = open(original_path, 'r')label_list = []for line in f:# spamif line[0] == 's':label_list.append('0')# hamelif line[0] == 'h':label_list.append('1')f = open(save_path, 'w', encoding='utf8')f.write('\n'.join(label_list))f.close()print('Storing labels in a file ...')
get_label_in_a_file('index', save_path='label.txt')
print('Store labels finished !')
5 特征提取
将文本型数据转化为数值型数据,本文使用的是 TF-IDF 方法。
TF-IDF 是词频-逆向文档频率(Term-Frequency,Inverse Document Frequency)。公式如下:

在所有文档中,一个词的 IDF 是一样的,TF 是不一样的。在一个文档中,一个词的 TF 和 IDF
越高,说明该词在该文档中出现得多,在其他文档中出现得少。因此,该词对这个文档的重要性较高,可以用来区分这个文档。

import jieba
from sklearn.feature_extraction.text import TfidfVectorizerdef tokenizer_jieba(line):# 结巴分词return [li for li in jieba.cut(line) if li.strip() != '']def tokenizer_space(line):# 按空格分词return [li for li in line.split() if li.strip() != '']def get_data_tf_idf(email_file_name):# 邮件样本已经分好了词,词之间用空格隔开,所以 tokenizer=tokenizer_spacevectoring = TfidfVectorizer(input='content', tokenizer=tokenizer_space, analyzer='word')content = open(email_file_name, 'r', encoding='utf8').readlines()x = vectoring.fit_transform(content)return x, vectoring
6 训练分类器
这里学长简单的给一个逻辑回归分类器的例子
from sklearn.linear_model import LogisticRegression
from sklearn import svm, ensemble, naive_bayes
from sklearn.model_selection import train_test_split
from sklearn import metrics
import numpy as npif __name__ == "__main__":np.random.seed(1)email_file_name = 'all_email.txt'label_file_name = 'label.txt'x, vectoring = get_data_tf_idf(email_file_name)y = get_label_list(label_file_name)# print('x.shape : ', x.shape)# print('y.shape : ', y.shape)# 随机打乱所有样本index = np.arange(len(y)) np.random.shuffle(index)x = x[index]y = y[index]# 划分训练集和测试集x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)clf = svm.LinearSVC()# clf = LogisticRegression()# clf = ensemble.RandomForestClassifier()clf.fit(x_train, y_train)y_pred = clf.predict(x_test)print('classification_report\n', metrics.classification_report(y_test, y_pred, digits=4))print('Accuracy:', metrics.accuracy_score(y_test, y_pred))
7 综合测试结果
测试了2000条数据,使用如下方法:
-
支持向量机 SVM
-
随机数深林
-
逻辑回归
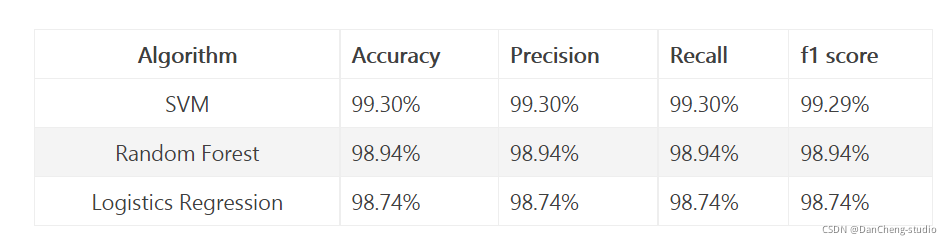
可以看到,2000条数据训练结果,200条测试结果,精度还算高,不过数据较少很难说明问题。
8 其他模型方法
还可以构建深度学习模型
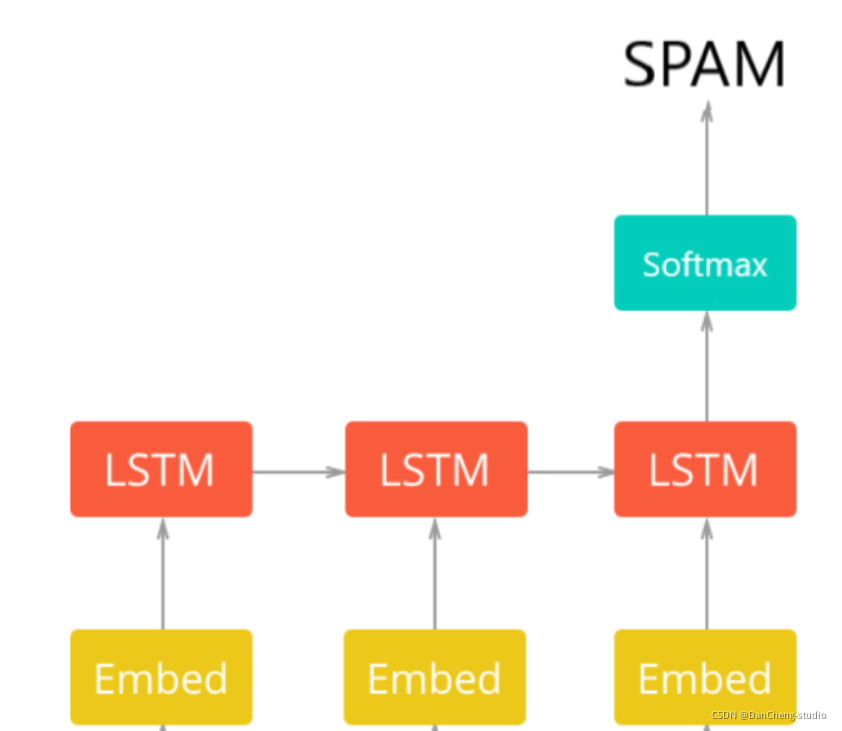
网络架构第一层是预训练的嵌入层,它将每个单词映射到实数的N维向量(EMBEDDING_SIZE对应于该向量的大小,在这种情况下为100)。具有相似含义的两个单词往往具有非常接近的向量。
第二层是带有LSTM单元的递归神经网络。最后,输出层是2个神经元,每个神经元对应于具有softmax激活功能的“垃圾邮件”或“正常邮件”。
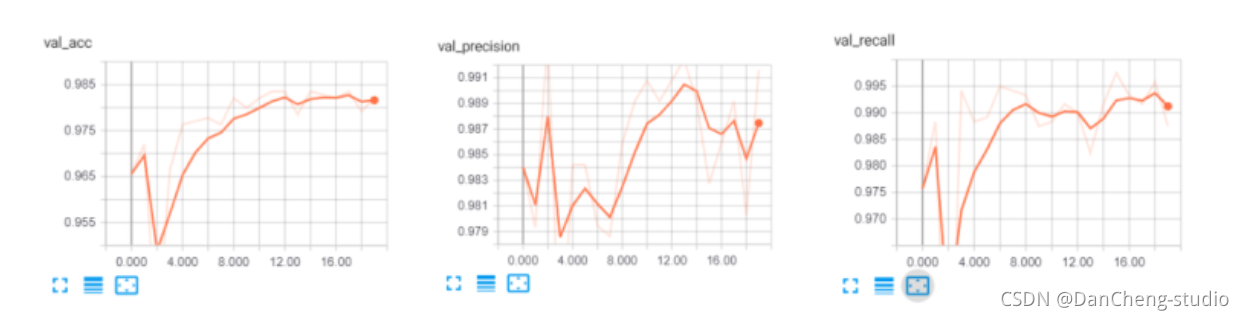
def get_embedding_vectors(tokenizer, dim=100):embedding_index = {}with open(f"data/glove.6B.{dim}d.txt", encoding='utf8') as f:for line in tqdm.tqdm(f, "Reading GloVe"):values = line.split()word = values[0]vectors = np.asarray(values[1:], dtype='float32')embedding_index[word] = vectorsword_index = tokenizer.word_indexembedding_matrix = np.zeros((len(word_index)+1, dim))for word, i in word_index.items():embedding_vector = embedding_index.get(word)if embedding_vector is not None:# words not found will be 0sembedding_matrix[i] = embedding_vectorreturn embedding_matrixdef get_model(tokenizer, lstm_units):"""Constructs the model,Embedding vectors => LSTM => 2 output Fully-Connected neurons with softmax activation"""# get the GloVe embedding vectorsembedding_matrix = get_embedding_vectors(tokenizer)model = Sequential()model.add(Embedding(len(tokenizer.word_index)+1,EMBEDDING_SIZE,weights=[embedding_matrix],trainable=False,input_length=SEQUENCE_LENGTH))model.add(LSTM(lstm_units, recurrent_dropout=0.2))model.add(Dropout(0.3))model.add(Dense(2, activation="softmax"))# compile as rmsprop optimizer# aswell as with recall metricmodel.compile(optimizer="rmsprop", loss="categorical_crossentropy",metrics=["accuracy", keras_metrics.precision(), keras_metrics.recall()])model.summary()return model训练结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 100) 901300
_________________________________________________________________
lstm_1 (LSTM) (None, 128) 117248
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 1,018,806
Trainable params: 117,506
Non-trainable params: 901,300
_________________________________________________________________
X_train.shape: (4180, 100)
X_test.shape: (1394, 100)
y_train.shape: (4180, 2)
y_test.shape: (1394, 2)
Train on 4180 samples, validate on 1394 samples
Epoch 1/20
4180/4180 [==============================] - 9s 2ms/step - loss: 0.1712 - acc: 0.9325 - precision: 0.9524 - recall: 0.9708 - val_loss: 0.1023 - val_acc: 0.9656 - val_precision: 0.9840 - val_recall: 0.9758Epoch 00001: val_loss improved from inf to 0.10233, saving model to results/spam_classifier_0.10
Epoch 2/20
4180/4180 [==============================] - 8s 2ms/step - loss: 0.0976 - acc: 0.9675 - precision: 0.9765 - recall: 0.9862 - val_loss: 0.0809 - val_acc: 0.9720 - val_precision: 0.9793 - val_recall: 0.9883
9 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
软件杯 垃圾邮件(短信)分类算法实现 机器学习 深度学习
文章目录 0 前言2 垃圾短信/邮件 分类算法 原理2.1 常用的分类器 - 贝叶斯分类器 3 数据集介绍4 数据预处理5 特征提取6 训练分类器7 综合测试结果8 其他模型方法9 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 垃圾邮件(短信)分类算…...

cnpm install报错:报错Error: certificate has expired ,淘宝镜像证书过期了解决办法
方案1: 不校验证书 cnpm install --insecure; 方案2: 替换镜像源,比如换成华为的 cnpm confg set registry https://mirrors.huaweicloud.com/repository/npm/ 方案3: 使用http作为镜像源 cnpm confg set registry http://re…...
生成式 AI:使用 Pytorch 通过 GAN 生成合成数据
导 读 生成对抗网络(GAN)因其生成图像的能力而变得非常受欢迎,而语言模型(例如 ChatGPT)在各个领域的使用也越来越多。这些 GAN 模型可以说是人工智能/机器学习目前主流的原因; 因为它向每个人࿰…...
C#/WPF 清理任务栏托盘图标缓存
在我们开发Windows客户端程序时,往往会出现程序退出后,任务还保留之前程序的缓存图标。每打开关闭一次程序,图标会一直增加,导致托盘存放大量缓存图标。为了解决这个问题,我们可以通过下面的程序清理任务栏托盘图标缓存…...
java SSM科研管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
一、源码特点 java SSM科研管理系统是一套完善的web设计系统(系统采用SSM框架进行设计开发,springspringMVCmybatis),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S…...
C# OpenCvSharp 图片批量改名
目录 效果 项目 代码 下载 C# OpenCvSharp 图片批量改名 效果 项目 代码 using NLog; using OpenCvSharp; using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Windows.Forms; namespace OpenCvSharp_Demo { publi…...
大数据开发-Hive介绍以及安装配置
文章目录 数据库和数据仓库的区别Hive安装配置Hive使用方式Hive日志配置 数据库和数据仓库的区别 数据库:传统的关系型数据库主要应用在基本的事务处理,比如交易,支持增删改查数据仓库:主要做一些复杂的分析操作,侧重…...
指针篇章-(4)+qsort函数的模拟
学习目录 ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————…...

接口测试实战--使用docker方案去部署jenkins并搭建接口自动化项目
一、搭建环境 1.几个概念 CI:持续集成 CD:持续交付 DevOps(development and operations):是一个框架,是一种方法论,并不是一套工具,包括一系列基本原则和实践,核心价值在于更快速的交付和响应市场变化。 jenkins:一个开源框架,需要操作什么流程,就下载什么插件 2…...

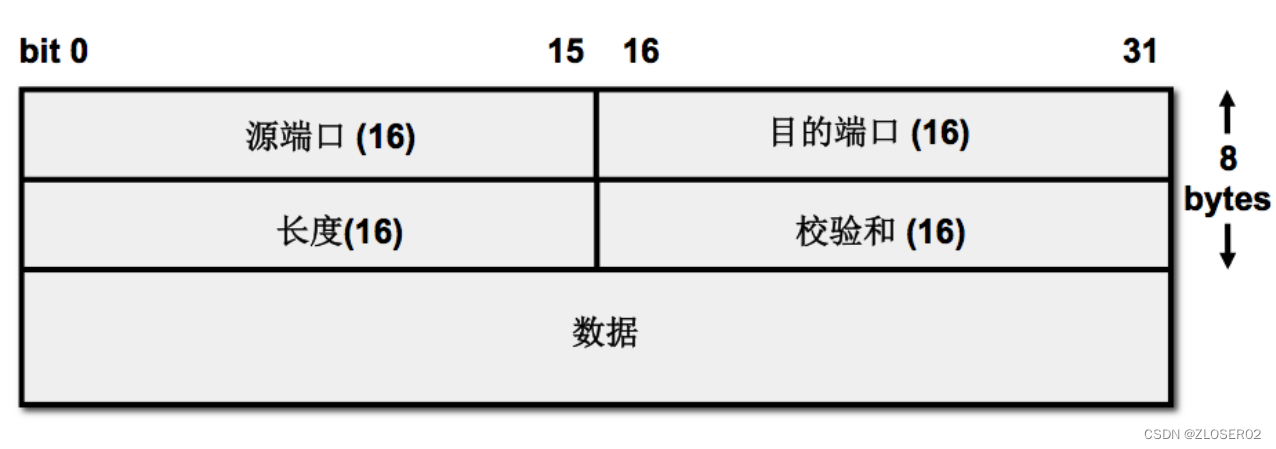
Day 8.TCP包头和HTTP
TCP包头 1.序号:发送端发送数据包的编号 2.确认号:已经确认接收到的数据的编号(只有当ACK为1时、确认号才有用); TCP为什么安全可靠 1.在通信前建立三次握手 SYP SYPACK ACK 2.在通信过程中通过序列号和确认号和…...

【机器学习】支持向量机 | 支持向量机理论全梳理 对偶问题转换,核方法,软间隔与过拟合
支持向量机走的路和之前介绍的模型不同 之前介绍的模型更趋向于进行函数的拟合,而支持向量机属于直接分割得到我们最后要求的内容 1 支持向量机SVM基本原理 当我们要用一条线(或平面、超平面)将不同类别的点分开时,我们希望这条…...

【JS】APIs:事件流、事件委托、其他事件、页面尺寸、日期对象与节点操作
1 事件流 捕获阶段:从父到子 冒泡阶段:从子到父 1.1 事件捕获 <body> <div class"fa"><div class"son"></div> </div> <script>const fadocument.querySelector(.fa);const sondocument.qu…...

定制红酒:如何根据客户需求调整红酒口感与风格
在云仓酒庄洒派,云仓酒庄洒派深知不同消费者对于红酒的口感与风格有着不同的喜好和需求。因此,云仓酒庄洒派根据消费者的具体要求,灵活调整红酒的口感与风格,以满足他们的期望。 首先,云仓酒庄洒派会与消费者进行深入的…...

利用excel批量修改图片文件名
今天同事提出需求要实现利用excel批量修改某文件夹下的图片重命名,衡量到各种条件,最后还是选择了vbs来实现。代码如下 代码 创建Excel对象 Set objExcel CreateObject("Excel.Application") objExcel.Visible False 隐藏Excel窗口 打开Ex…...
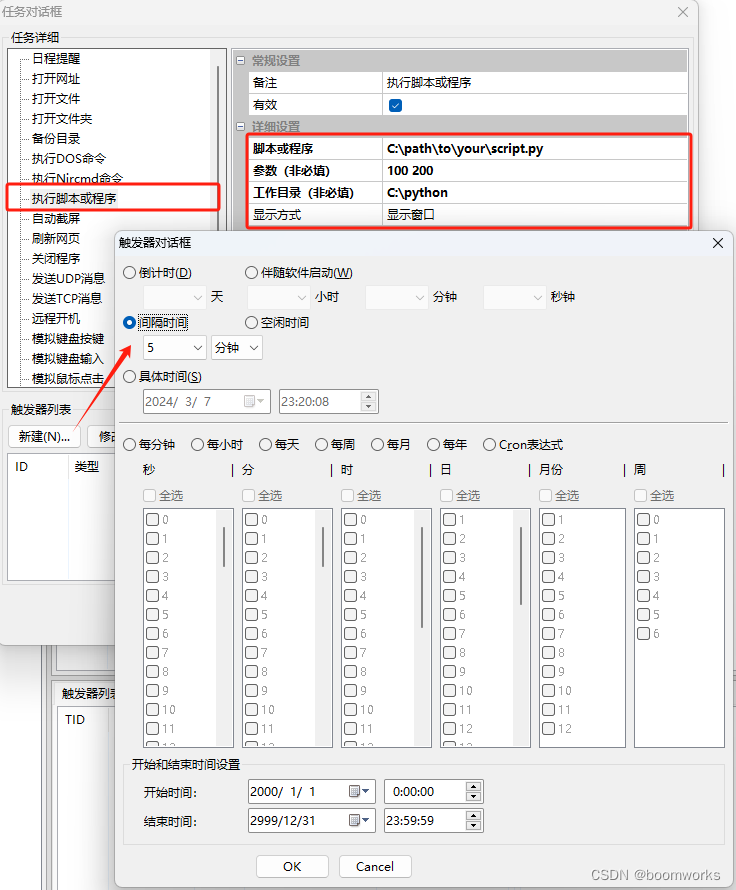
间隔5分钟执行1次Python脚本设置步骤 —— 定时执行专家
《定时执行专家》是一款制作精良、功能强大、毫秒精度、专业级的定时任务执行软件,用于在 Windows 系统上定时执行各种任务,包括执行脚本或程序。 下面是使用 "定时执行专家" 软件设置定时执行 Python 脚本的步骤: 步骤 1: 设置 P…...
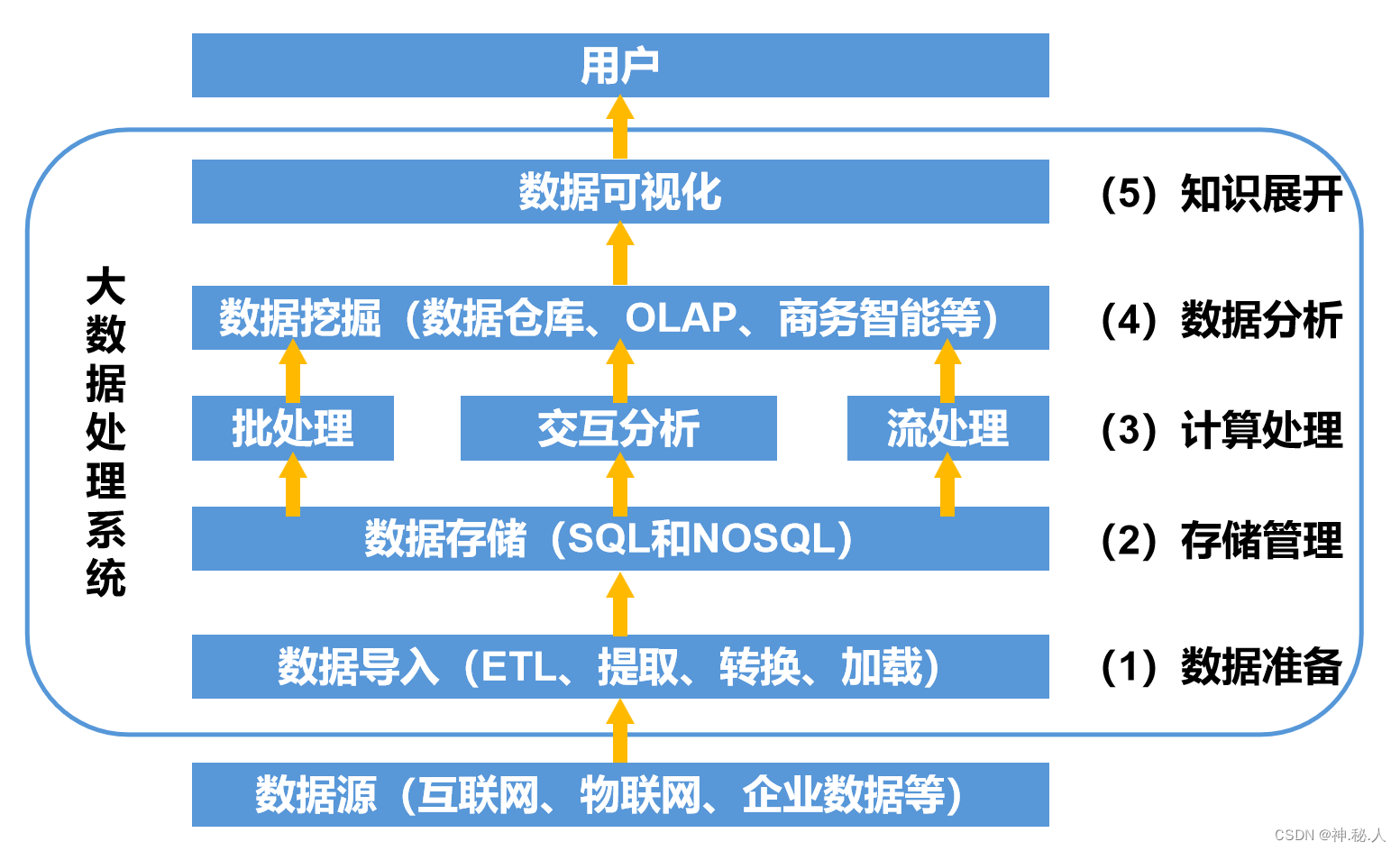
计算机网络基础【信息系统监理师】
计算机网络基础【信息系统监理师】 1、OSI七层参考模型2、TCP/IP协议3、网络拓扑结构分类4、网络传输介质分类5、网络交换技术6、网络存储技术7、网络规划技术8、综合布线系统8.1、综合布线工程内容8.1、隐蔽工程-金属线槽安装8.2、隐蔽工程-管道安装槽道与各种管线间的最小净距…...

网络安全风险评估:详尽百项清单要点
网络安全风险评估是识别、分析和评估组织信息系统、网络和资产中潜在风险和漏洞的系统过程。主要目标是评估各种网络威胁和漏洞的可能性和潜在影响,使组织能够确定优先顺序并实施有效的安全措施来减轻这些风险。该过程包括识别资产、评估威胁和漏洞、分析潜在影响以…...
不会用虚拟机装win10?超详细教程解决你安装中的所有问题!
前言:安装中有任何疑问,可以在评论区提问,博主身经百战会快速解答小伙伴们的疑问 BT、迅雷下载win10镜像(首先要下载win10的镜像):ed2k://|file|cn_windows_10_business_editions_version_1903_updated_sep…...

洛谷 素数环 Prime Ring Problem
题目描述 PDF 输入格式 输出格式 题意翻译 输入正整数 nn,把整数 1,2,\dots ,n1,2,…,n 组成一个环,使得相邻两个整数之和均为素数。输出时,从整数 11 开始逆时针排列。同一个环恰好输出一次。n\leq 16n≤16,保证一定有解。 多…...
【DPDK】基于dpdk实现用户态UDP网络协议栈
文章目录 一.背景及导言二.协议栈架构设计1. 数据包接收和发送引擎2. 协议解析3. 数据包处理逻辑 三.网络函数编写1.socket2.bind3.recvfrom4.sendto5.close 四.总结 一.背景及导言 在当今数字化的世界中,网络通信的高性能和低延迟对于许多应用至关重要。而用户态网…...

Vue3生命周期钩子详解:从创建到销毁的全过程
Vue3 生命周期 Vue3 的生命周期钩子函数与 Vue2 有所不同,主要通过 Composition API 的方式使用。以下是 Vue3 的主要生命周期钩子及其用途: beforeCreate 在实例初始化之后、数据观测和事件配置之前被调用。此时组件的选项还未被处理,data 和…...

Windows系统下Mamba-SSM避坑指南:从WSL配置到编译成功
1. 为什么选择WSL安装Mamba-SSM Mamba-SSM作为新一代深度学习架构,在处理长序列任务时展现出显著优势。但官方仅支持Linux系统,这让Windows用户面临两难选择:要么重装系统,要么放弃体验新技术。WSL(Windows Subsystem …...
)
华为服务器SP380网卡固件升级保姆级教程(附避坑指南)
华为SP380网卡固件升级全流程实战手册 当数据中心运维团队遇到网络性能瓶颈或安全漏洞时,网卡固件升级往往是最经济高效的解决方案。作为华为服务器搭载的高性能网卡,SP380在企业级环境中承担着关键的网络流量处理任务。本文将深入解析通过Smart Provisi…...

祝贺电影《日掛中天》荣获2026亚洲艺术电影节两项提名
祝贺电影《日掛中天》荣获2026亚洲艺术电影节两项提名 。 祝贺演员辛芷蕾 提名最佳女主角; 祝贺演员冯绍峰 提名最佳男配角。#亚洲艺术电影节#AAFF2026#电影节#辛芷蕾#冯绍峰#电影日掛中天...

简报:2026年3月具身智能机器人融资情况
2026年3月,国内具身智能机器人赛道迎来融资热潮,在政策东风产业加速的双重驱动下,融资数量、金额、单笔规模均创历史新高,呈现出“大额融资密集、头部效应凸显、全产业链覆盖” 的爆发态势。具身人工智能(E-AI…...

NTC温度采样
该电路实现了一个带缓冲、滤波和电压钳位的NTC温度采样通道。其目的是安全、准确地将反映IGBT温度的NTC电阻值,转换为MCU可安全读取的模拟电压。前端是一个NTC和电阻组成的分压,将热信号变为阻值变化,阻值变化通过电压反应。这部分是RC低通滤…...

晶晨A311D开发板:从零构建Ubuntu/Debian固件的完整指南
1. 环境准备:搭建Ubuntu编译环境 第一次接触晶晨A311D开发板时,我也被复杂的编译环境吓到过。但实际搭建起来,只要跟着步骤走,半小时就能搞定。建议使用Ubuntu 20.04 LTS系统,这是经过验证最稳定的选择。我试过在Ubunt…...

C#联合halcon开发框架源码。 拖拽式编程,无halcon基础也能上手,匹配,测量,条码识...
C#联合halcon开发框架源码。 拖拽式编程,无halcon基础也能上手,匹配,测量,条码识别,ocr,定位引导,对位等,支持plc通讯,集成主流相机sdk,系统集成. 最近在工业视觉项目里折腾Halcon的时候&#x…...

将OpenSSH集成到OpenHarmony系统镜像:从编译到system分区的完整配置流程
OpenHarmony系统集成OpenSSH全流程:从编译到安全部署实战 在物联网和嵌入式设备快速发展的今天,远程设备管理已成为开发者不可或缺的能力。作为开源远程管理协议的黄金标准,OpenSSH在OpenHarmony系统中的集成能够为开发者提供安全可靠的远程访…...

3步彻底解决ComfyUI-Manager中SVD模型加载失败的NoneType错误
3步彻底解决ComfyUI-Manager中SVD模型加载失败的NoneType错误 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custom no…...