ELK 日志分析系统
ELK (Elasticsearch、Logstash、Kibana)日志分析系统的好处是可以集中查看所有服务器日志,减轻了工作量,从安全性的角度来看,这种集中日志管理可以有效查询以及跟踪服务器被攻击的行为。
Elasticsearch 是个开源分布式实时分析搜索引擎,建立在全文搜索引擎库Apache Lucene基 础上,同时隐藏了Apache Lucene的复杂性。Elasticsearch 将所有的功能打包成一个独立的服务,并提供了一个简单的RESTful API接口。它具有分布式、零配置、自动发现、索引自动分片、索引副本机制、RESTful 风格接口、多数据源,自动搜索负载等特点。
> Logstash 是一个完全开源的工具,主要用于日志收集,同时可以对数据处理,并输出给 Elasticsearch。
> Kibana 也是一个开源和免费的工具,Kibana可以为Logstash 和 ElasticSearch提供图形化的日志分析 Web 界面,可以汇总、分析和搜索重要数据日志。
进行日志处理分析,一般需要经过以下几个步骤。
(1) 将日志进行集中化管理。
(2) 将日志格式化(Logstash)并输出到 Elasticsearch。
(3) 对格式化后的数据进行索引和存储(Elasticsearch)。
(4) 前端数据的展示(Kibana)。
1. Elasticscarch介绍
Elasticsearch是一个基于Lucene 的搜索服务器。它稳定、可靠、快速,而且具有比较好的水平扩展能力,为分布式环境设计,在云计算中被广泛应用。Elasticsearch提供了一个分布式多用户能力的全文搜索引擎,基于RESTful Web接口。通过该接口,用户可以通过浏览器和 Elasticsearch 通信, Elasticsearch 是用 Java 开发的,并作为Apache许可条款下的开放源码发布,Wikipedia、 Stack、Overflow、GitHub等都基于Elasticsearch 来构建搜索引擎,具有实时搜索、稳定,可靠、快速,安装使用方便等特点,
Elasticsearch的基础核心概念。
> 接近实时(NRT): Elasticsearch 是一个搜索速度接近实时的搜索平台,响应速度非常快,从 索引一个文档直到这个文档能够被搜索到只有一个轻微的延迟(通常是1s)。
> 群集(cluster):群集就是由一个或多个节点组织在一起,在所有的节点上存放用户数据并一起提供索引和搜索功能。通过选举产生主节点,并提供跨节点的联合索引和搜索的功能。每个群集都有一个唯一标示的名称,默认是Elasticsearch,每个节点是基于群集名字加 入到其群集中的。一个群集可以只有一个节点,为了具备更好的容错性,通常配置多个节 点,在配置群集时,建议配置成群集模式。
> 节点(node):是指一台单一的服务器,多个节点组织为一个群集,每个节点都存储数据并 参与群集的索引和搜索功能。和群集一样,节点也是通过名字来标识的,默认情况下,在节点启动时会随机分配字符名。也可以自定义。通过指定群集名字,节点可以加入到群集 中。默认情况,每个节点都已经加入 Elasticsearch群集。如果群集中有多个节点,它们将会 自动组建一个名为Elasticsearch 的群集。
> 索引 (index):类似于关系型数据库中的“库”。当索引一个文档后.就可以使用 Elasticsearch 搜索到该文档,也可以简单地将索引理解为存储数据的地方,可以方便地进行全文索引。 在 index下面包含存储数据的类型(Type),Type类似于关系型数据库中的“表”,用来存放具体数据,而Type 下面包含文档(Document),文档相当于关系型数据库的“记录”,一个 文档是一个可被索引的基础信息单元。
> 分片和副本(shards & replicas):Elasticsearch 将索引分成若干个部分,每个部分称为一个分片,每个分片就是一个全功能的独立的索引。分片的数量一般在索引创建前指定,且创建索引后不能更改。
分片的两个最主要原因如下。
* 水平分割扩展,增大存储量。
* 分布式并行跨分片操作,提高性能和吞吐量。
2. Logstash 介绍
Logstash 的理念很简单,它只做三件事情:数据输入、数据加工(如过滤,改写等)以及数据输出。通过组合输入和输出,可以实现多种需求。Logstash 处理日志时,典型的部署架构围。
LogStash的主要组件如下。
> Shipper:日志收集者。负责监控本地日志文件的变化,及时收集最新的日志文件内容。通常,远程代理端(agent)只需要运行这个组件即可。
> Indexer:日志存储者。负责接收日志并写入到本地文件。
> Broker:日志Hub。负责连接多个Shipper和多个Indexer.
> Search and Storage:允许对事件进行搜索和存储。
> Web Interface:基于Web的展示界面。
3. Kibana介绍
Kibana是一个针对Elasticsearch 的开源分析及可视化平台,主要设计用来和 Elasticsearch 一起工作,可以搜索,查看存储在Elasticsearch 索引中的数据,并通过各种图表进行高级数据分析及展示。 Kibana可以让数据看起来一目了然。它操作简单,基于浏览器的用户界面可以让用户在任何位置都可以实时浏览。Kibena可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。Kibana使 用非常简单,只需要添加索引就可以监测Elasticsearch 索引数据。
Kibana的主要功能如下。
> Elasticsearch无缝之集成。Kibana架构是为Elasticsearch 定制的,可以将任何(结构化和非结 构化)数据加入Elasticsearch索引。Kibana还充分利用了 Elasticsearch 强大的搜索和分析功能。
> 整合数据。Kibana可以让海是数据变得更容易理解,根据数据内容可以创建形象的柱形图, 折线图、散点图、直方图、饼图和地图,以方便用户查看。
> 复杂数据分析。Kibana 提升了 Elasticsearch 的分析能力,能够更加智能地分析数据,执行数 学转换并且根据要求对数据切割分块,
> 让更多团队成员受益。强大的数据库可视化接口让各业务岗位都能够从数据集合受益。 接口灵活,分享更容易。使用Kibana可以更加方便地创建、保存、分享数据,并将可视化数据快速交流。
> 配置简单。Kibana的配置和启用非常简单,用户体验非常友好。Kibana自带Web服务器。 可以快速启动运行,
> 可视化多数据源。Kibana可以非常方便地把来自Logstash、ES-Hadoop、Beats 或第三方技术 的数据整合到 Elasticsearch,支持的第三方技术包括Apache Flume、Fluentd等,
> 简单数据导出。Kibana可以方便地导出感兴趣的数据,与其他数据集合并融合后快速建模分析,发现新结果。
实验环境
虚拟机 3台 centos7.9
网卡NAT模式 数量 1
组件包
elasticsearch-5.5.0.rpm elasticsearch-head.tar.gz node-v8.2.1.tar.gz
phantomjs-2.1.1-linux-x86_64.tar.bz2 logstash-5.5.1.rpm
kibana-5.5.1-x86_64.rpm
| 设备 | IP | 备注 |
| Centos01 | 192.168.8.34 | Node1 elasticsearch |
| Centos02 | 192.168.8.35 | Node2 kibana |
| Centos03 | 192.168.8.36 | Node3 logstash+httpd |
初始化配置
都需安装 java运行环境jdk 192.168.8.34 192.168.8.35
yum -y install java jcc jcc-j++安装elasticsearch
Node1 Node2 都配置 192.168.8.34 192.168.8.35
cat << EOF >> /etc/hosts
192.168.8.34 node1
192.168.8.35 node2
EOF上传安装包 elasticsearch-5.5.0.rpm 192.168.8.34 192.168.8.35
rpm -ivh elasticsearch-5.5.0.rpm编辑elasticsearch 配置文件 192.168.8.34 192.168.8.35
vim /etc/elasticsearch/elasticsearch.ymlcluster.name: my-elk-cluster #群集名称
node.name: node1 #节点名称,不同节点修改编号
path.data: /data/elk_data #日志收集目录
path.logs: /data/elk_log #日志存放路径
bootstrap.memory_lock: false #不锁定内存
network.host: 0.0.0.0 #监听IP
http.port: 9200 #监听端口
discovery.zen.ping.unicast.hosts: ["node1", "node2"] #单播实现群集[root@node1 ~]# mkdir -p /data/elk_data && mkdir -p /data/elk_log
[root@node1 ~]# chown -R elasticsearch:elasticsearch /data[root@node1 ~]# systemctl start elasticsearch
Node1 部署elasticearch-head插件 192.168.8.34
上传安装包
node-v8.2.1.tar.gz
elasticsearch-head.tar.gz
phantomjs-2.1.1-linux-x86_64.tar.bz2
tar zxf node-v8.2.1.tar.gz
cd node-v8.2.1
./configure && make && make install安装phantomjs 组件 192.168.8.34
yum -y install bzip2[root@node1 ~]# tar jxf phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node1 ~]# mv phantomjs-2.1.1-linux-x86_64 /usr/src/phantomjs2.1
[root@node1 ~]# ln -s /usr/src/phantomjs2.1/bin/* /usr/local/bin/安装elasticsearch-head 组件 192.168.8.34
[root@node1 ~]# tar zxf elasticsearch-head.tar.gz [root@node1 ~]# cd elasticsearch-head
[root@node1 elasticsearch-head]# npm install
cat << EOF >> /etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,Content-Type
EOFsystemctl restart elasticsearch
npm run start &Node3上部署 httpd+ logstash 192.168.8.36
上传安装包 logstash-5.5.1.rpm
yum -y install httpdrpm -ivh logstash-5.5.1.rpmln -s /usr/share/logstash/bin/logstash /usr/local/sbin/编辑自定义提交日志配置 192.168.8.36
vim /etc/logstash/conf.d/httpd_log.confinput {file {path => "/var/log/httpd/access_log"type => "access"start_position => "beginning"}file {path => "/var/log/httpd/error_log"type => "error"start_position => "beginning"}
}
output {if [type] == "access" {elasticsearch {hosts => ["192.168.8.34:9200"]index => "httpd_access-%{+YYYY.MM.dd}"}}if [type] == "error" {elasticsearch {hosts => ["192.168.8.34:9200"]index => "httpd_error-%{+YYYY.MM.dd}"}}
}启动httpd 192.168.8.36
systemctl start httpd启动日志传递 192.168.8.36
nohup logstash -f /etc/logstash/conf.d/httpd_log.conf &访问http://192.168.8.34:9200/
验证

Node2安装 kibana 图形化查看工具 192.168.8.35
上传安装包 kibana-5.5.1-x86_64.rpm
rpm -ivh kibana-5.5.1-x86_64.rpmvim /etc/kibana/kibana.ymlcat << EOF >> /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.8.34:9200"
kibana.index: ".kibana"
EOFsystemctl enable kibana --now验证
http://192.168.8.35:5601
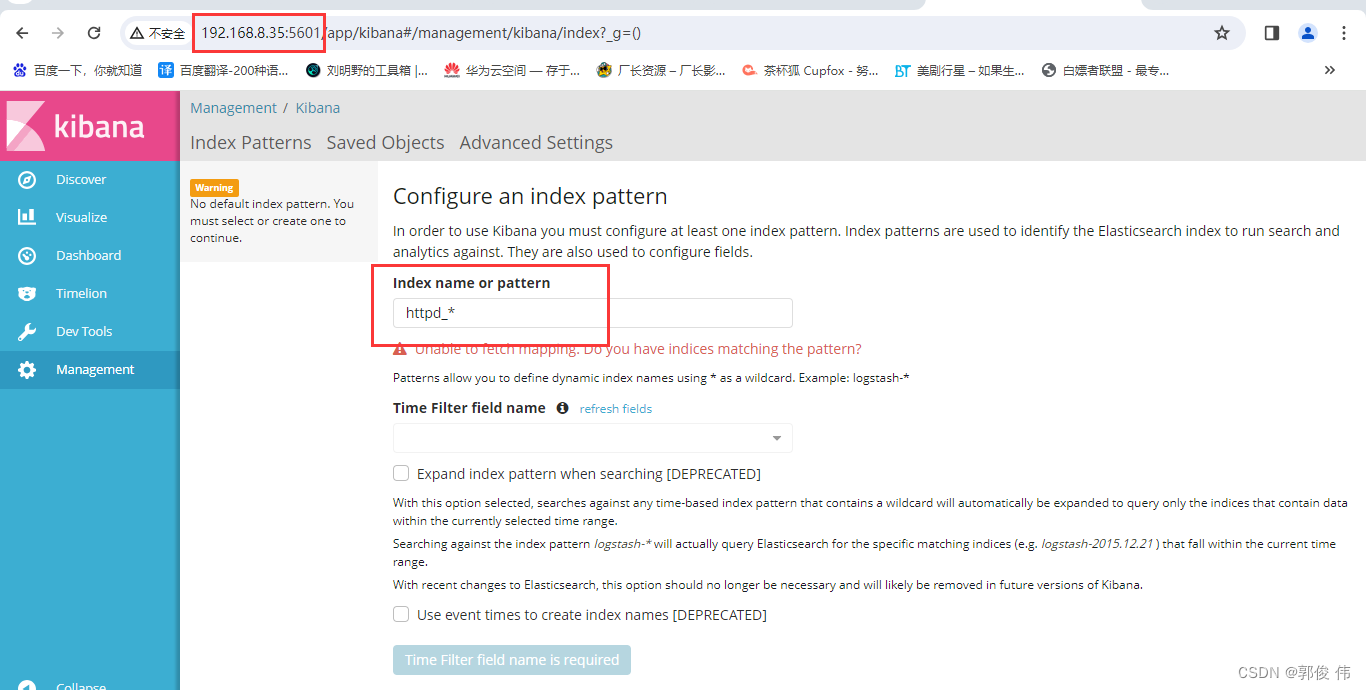
相关文章:
ELK 日志分析系统
ELK (Elasticsearch、Logstash、Kibana)日志分析系统的好处是可以集中查看所有服务器日志,减轻了工作量,从安全性的角度来看,这种集中日志管理可以有效查询以及跟踪服务器被攻击的行为。 Elasticsearch 是个开源分布式…...

机器学习模型—逻辑回归
机器学习模型—逻辑回归 逻辑回归是一种用于分类任务的监督机器学习算法,其目标是预测实例属于给定类别的概率。逻辑回归是一种分析两个数据因素之间关系的统计算法。本文探讨了逻辑回归的基础知识、类型和实现。 什么是逻辑回归 逻辑回归用于二元分类,其中我们使用sigmoi…...

Ubuntu20.04 创建新的用户
1、了解Linux目录结构 推荐看一下:https://www.runoob.com/linux/linux-system-contents.html Linux支持多个用户进行操作的,这样提高了系统的安全性,也可以多人共用一个系统,不过要注意的是系统中安装的软件相关路径࿰…...

大数据入门之hadoop学习
大数据 1. 学习hadoop之前,我们先了解一下什么是大数据? 大数据通常指的是数据集规模非常庞大且难以在常规数据库和数据处理工具中有效处理的数据。 大数据的特点: 容量:大数据具有庞大的规模,远远超出了传统数据库和…...
MySQL安装使用(mac、windows)
目录 macOS环境 一、下载MySQL 二、环境变量 三、启动 MySql 四、初始化密码设置 windows环境 一、下载 二、 环境配置 三、安装mysql 1.初始化mysql 2.安装Mysql服务 3.更改密码 四、检验 1.查看默认安装的数据库 2.其他操作 macOS环境 一、下载MySQL 打开 MyS…...
Day27:安全开发-PHP应用TP框架路由访问对象操作内置过滤绕过核心漏洞
目录 TP框架-开发-配置架构&路由&MVC模型 TP框架-安全-不安全写法&版本过滤绕过 思维导图 PHP知识点 功能:新闻列表,会员中心,资源下载,留言版,后台模块,模版引用,框架开发等 技…...
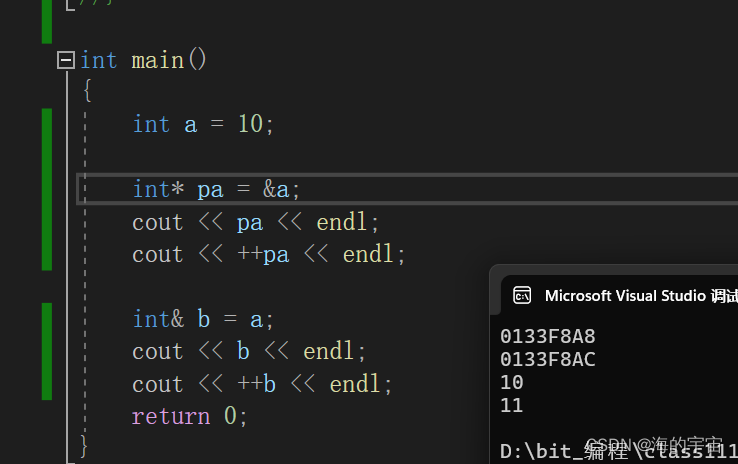
c++: 引用能否替代指针? 详解引用与指针的区别.
文章目录 前言1. 引用和指针的最大区别:引用不能改变指向2. 引用和指针在底层上面是一样的3. 引用和指针在sizeof面前大小不同4. 有多级指针,没有多级引用5.引用是引用的实体,指针会向后偏移同一个类型的大小 总结 前言 新来的小伙伴如果不知道引用是什么?可以看我的上一篇文…...

Java项目源码基于springboot的家政服务平台的设计与实现
大家好我是程序员阿存,在java圈的辛苦码农。辛辛苦苦板砖,今天要和大家聊的是一款Java项目源码基于springboot的家政服务平台的设计与实现,项目源码以及部署相关请联系存哥,文末附上联系信息 。 项目源码:Java基于spr…...
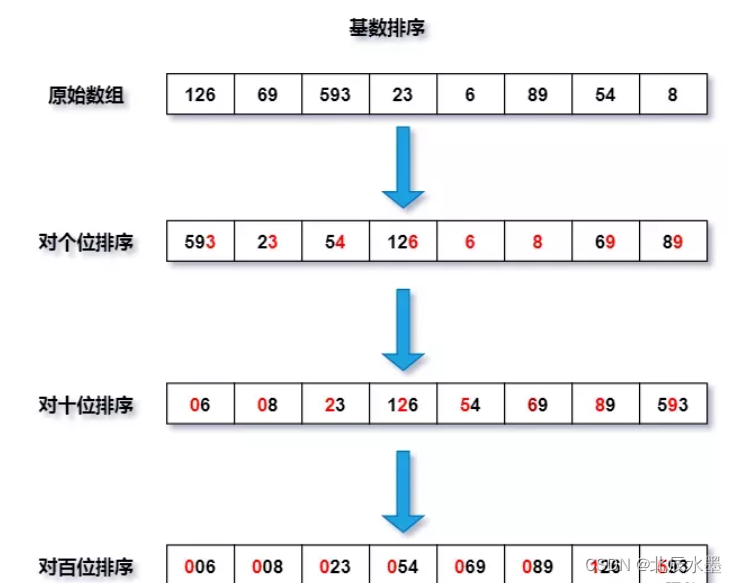
十大排序算法(冒泡排序、插入排序、选择排序、希尔排序、堆排序、快排、归并排序、桶排序、计数排序、基数排序)
目录 一、冒泡排序: 二、插入排序: 三、选择排序: 四、希尔排序: 五、堆排序: 六、快速排序: 6.1挖坑法: 6.2左右指针法 6.3前后指针法: 七、归并排序: 八、桶…...
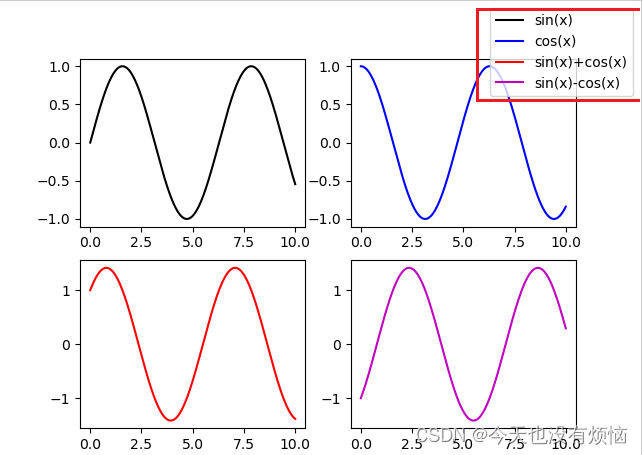
matplotlib 画多子图的时候添加图例/legend
一开始搞不懂图例是什么意思,以为是整个图,最后发现原来图例就是代码中的legend: 子图的图例(legend)用于解释图表中各条线、点或其他元素所代表的含义。图例通常位于图表的一角,以帮助观众理解图表中展示的…...

手写一个线程池
自己手动写一个线程池的必要条件需要先了解我们使用的线程池的功能。为什么会有线程池?这是为了减少线程创建和销毁的开销。复用线程的目的。为了达到这个目的。预计方案是:需要一个存放任务的队列,主线程相当于生产者,在这个队列…...
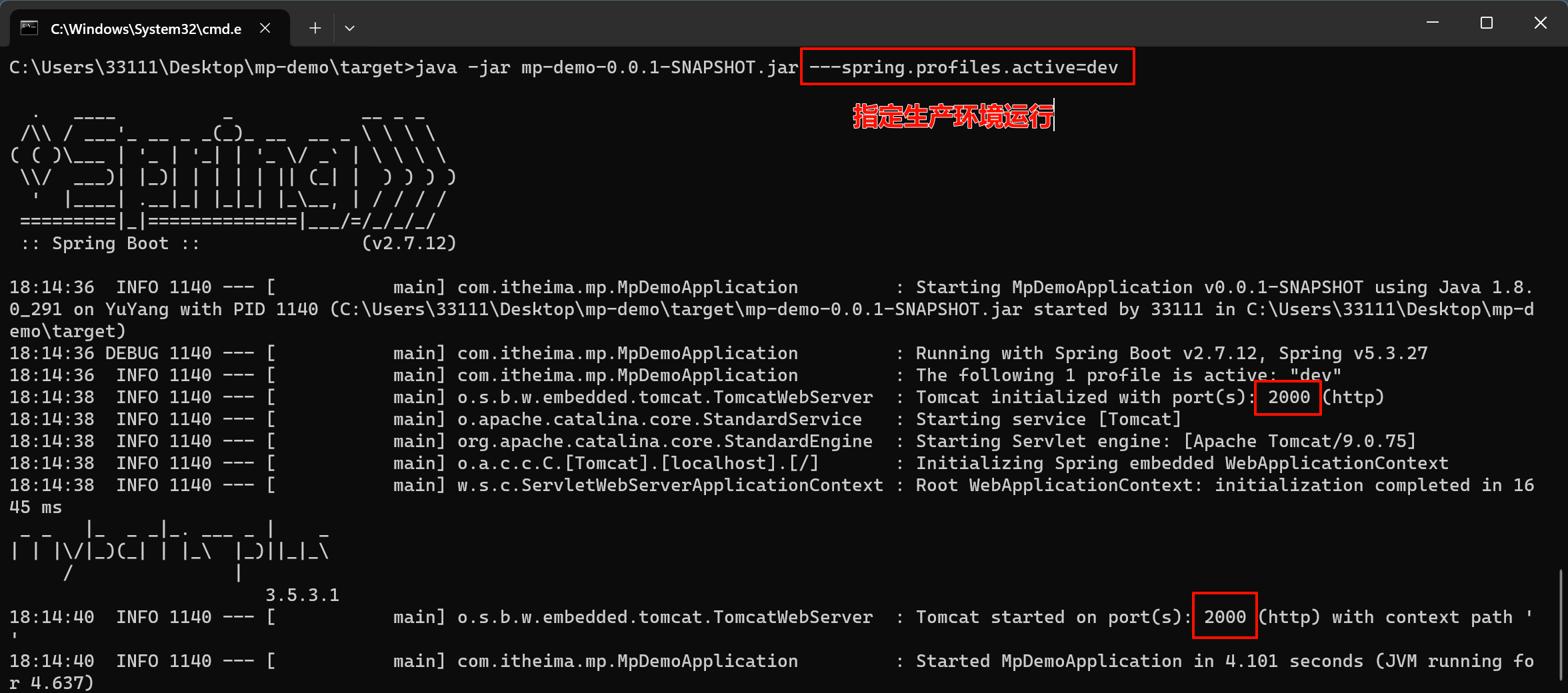
Spring Boot 多环境配置
Spring Boot 多环境配置 在现代的软件开发中,通常需要将应用程序部署到不同的环境中,如开发环境、生产环境和测试环境等。每个环境可能需要不同的配置参数,例如数据库连接信息、日志级别等。在 Spring Boot 中,我们可以通过简单的…...

【Python】一文带你详解sys.executable函数的作用
【Python】一文带你详解sys.executable函数的作用 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支…...
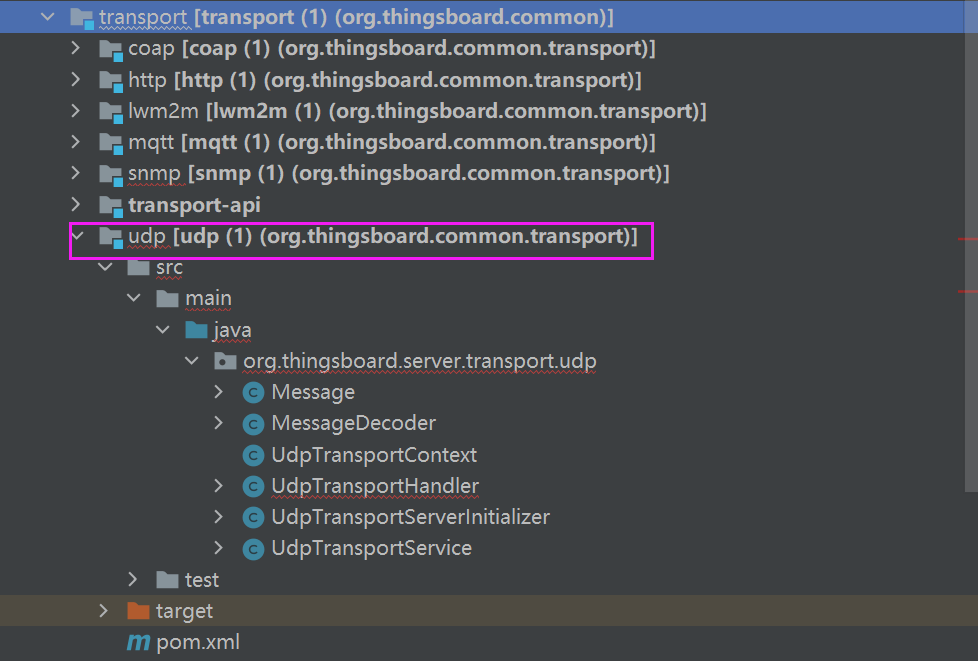
thingsboard如何自定义udp-transport
0、参考netty实现udp的文章 https://github.com/narkhedesam/Netty-Simple-UDP-TCP-server-client/blob/master/netty-udp/src/com/sam/netty_udp/server/MessageDecoder.java 调试工具使用的是:卓岚TCP&UDP调试工具 1、在common\transport下面创建udp模块,仿照mqtt的创…...
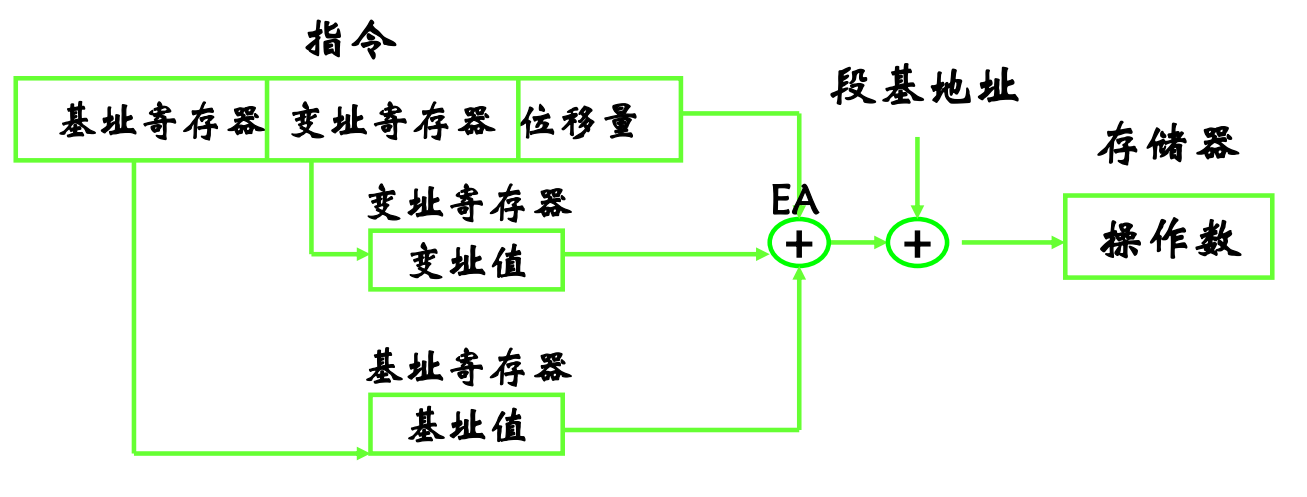
【汇编】#3 8086与数据有关的寻址方式
文章目录 操作码与操作数1. 8086处理器的与数据有关的寻址方式1.1 立即数寻址方式1.2 寄存器寻址方式 2. 有效(偏移)地址(effective address,EA)与缺省段寄存器选择tips:段跨越前缀2.1 直接寻址tips:直接寻址与立即寻址…...
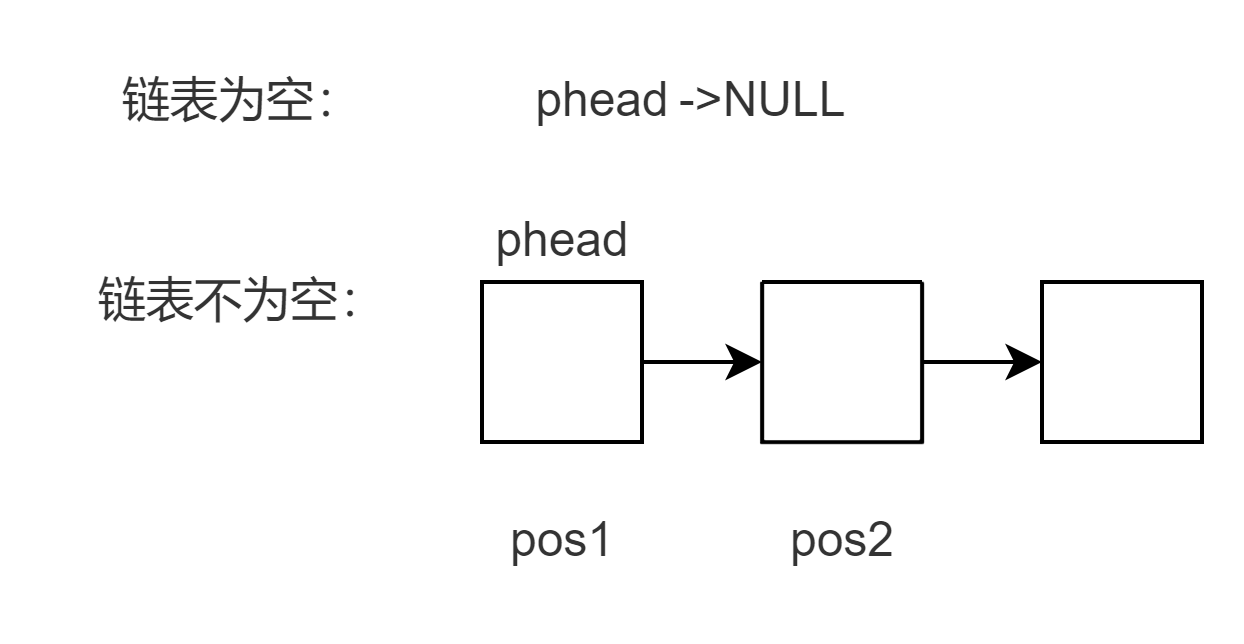
【数据结构】单链表的层层实现!! !
关注小庄 顿顿解馋(●’◡’●) 上篇回顾 我们上篇学习了本质为数组的数据结构—顺序表,顺序表支持下标随机访问而且高速缓存命中率高,然而可能造成空间的浪费,同时增加数据时多次移动会造成效率低下,那有什么解决之法呢ÿ…...
丰田研究所(TRI)最新成果——可实现全身操控的软体机器人Punyo
文 | BFT机器人 人形机器人在近年的科技浪潮中迅速崛起,成为了各界瞩目的焦点,众多企业纷纷推出自家的机器人模型,但仔细观察,不难发现它们中的许多在操作方式上仍显得颇为相似。这些典型的人形机器人,以其机械臂和抓…...
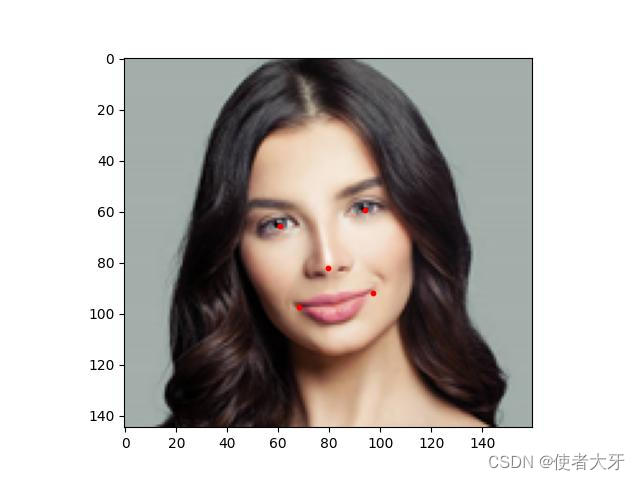
【PyTorch实战演练】深入剖析MTCNN(多任务级联卷积神经网络)并使用30行代码实现人脸识别
文章目录 0. 前言1. 级联神经网络介绍2. MTCNN介绍2.1 MTCNN提出背景2.2 MTCNN结构 3. MTCNN PyTorch实战3.1 facenet_pytorch库中的MTCNN3.2 识别图像数据3.3 人脸识别3.4 关键点定位 0. 前言 按照国际惯例,首先声明:本文只是我自己学习的理解ÿ…...

MFC中字符串string类型和CString类型互转方法
在Microsoft Foundation Classes (MFC)中,CString是一个非常方便的类,用于处理C风格的字符串。有时,你可能需要在MFC的CString和C标准库中的std::string之间进行转换。下面是如何在两者之间进行转换的方法: CString转std::string…...

Jmeter-使用http proxy代理录制脚本
Jmeter-使用http proxy代理录制脚本 第1步:打卡jmeter工具新增1个线程组 第2步:给线程组添加1个HTTP请求默认值 第3步:设置下HTTP请求默认值第4步:在工作台中新增1个----HTTP代理服务器 第5步:设置HTTP代理服务器 …...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

遭遇薪酬倒挂后的反向谈判与资产重估策略「蒸汽求职分享」
在 2026 年全球科技大厂与跨国泛金融巨头追求极致人效、频繁进行组织架构重组(Reorg)的买方市场中,一个让无数海外名校留学生在入职两年后心态瞬间崩塌的现象,正在高频发生——“薪酬倒挂(Salary Inversion)…...

SHAP原理与特征贡献解析
SHAP(SHapley Additive exPlanations)是一种基于博弈论中Shapley值的模型解释方法,它为机器学习模型的预测提供了一种统一、理论完备的特征归因框架。其核心思想是将模型的预测值视为所有特征协同合作的“总收益”,然后公平地分配…...

还在古法编程?OpenAI Codex 全自动编程!稳定中转 Token 保姆级教程
OpenAI Codex 从安装到进阶实战|终端 AI 编程完全指南(2026 最新) 摘要:OpenAI Codex 是目前最强大的终端 AI 编程工具,支持代码生成、项目重构、Bug 修复、脚本自动化、批量代码优化等全场景能力。本文从零起步&…...