勾八头歌之数据科学导论—数据采集实战
一、数据科学导论——数据采集基本概念
第1关:巧妇难为无米之炊
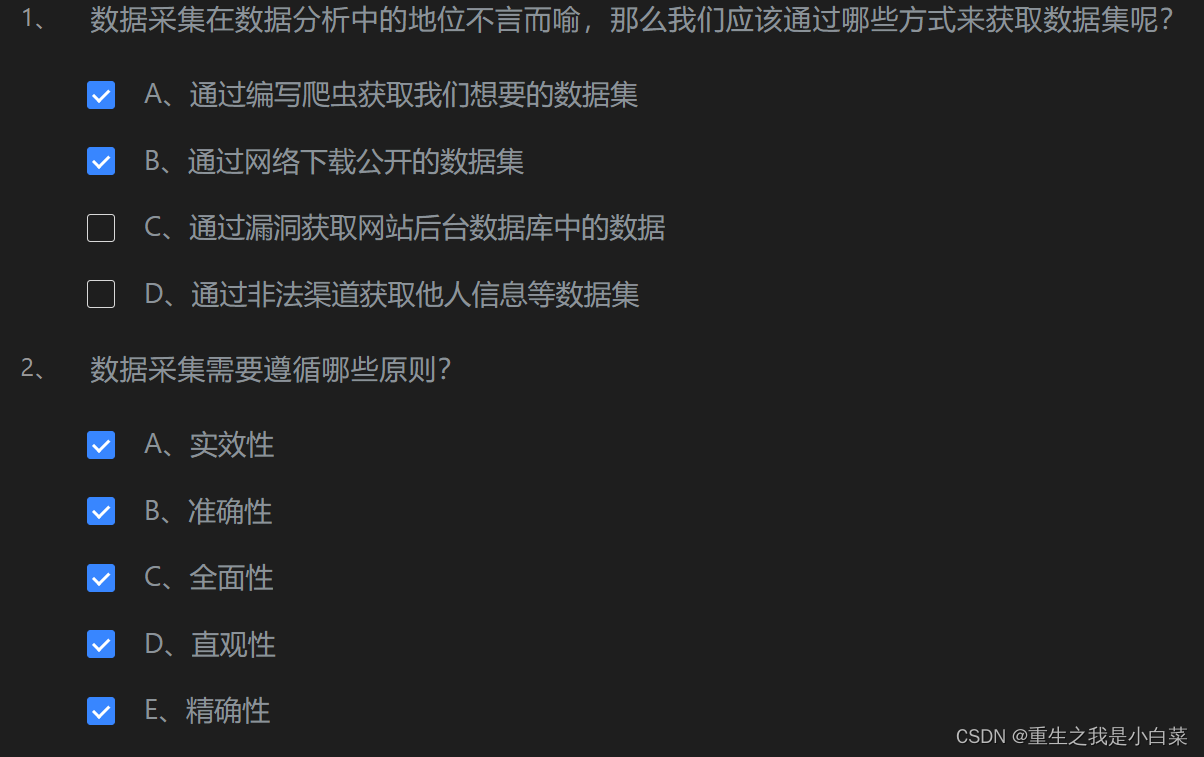
第2关:数据采集概念与内涵
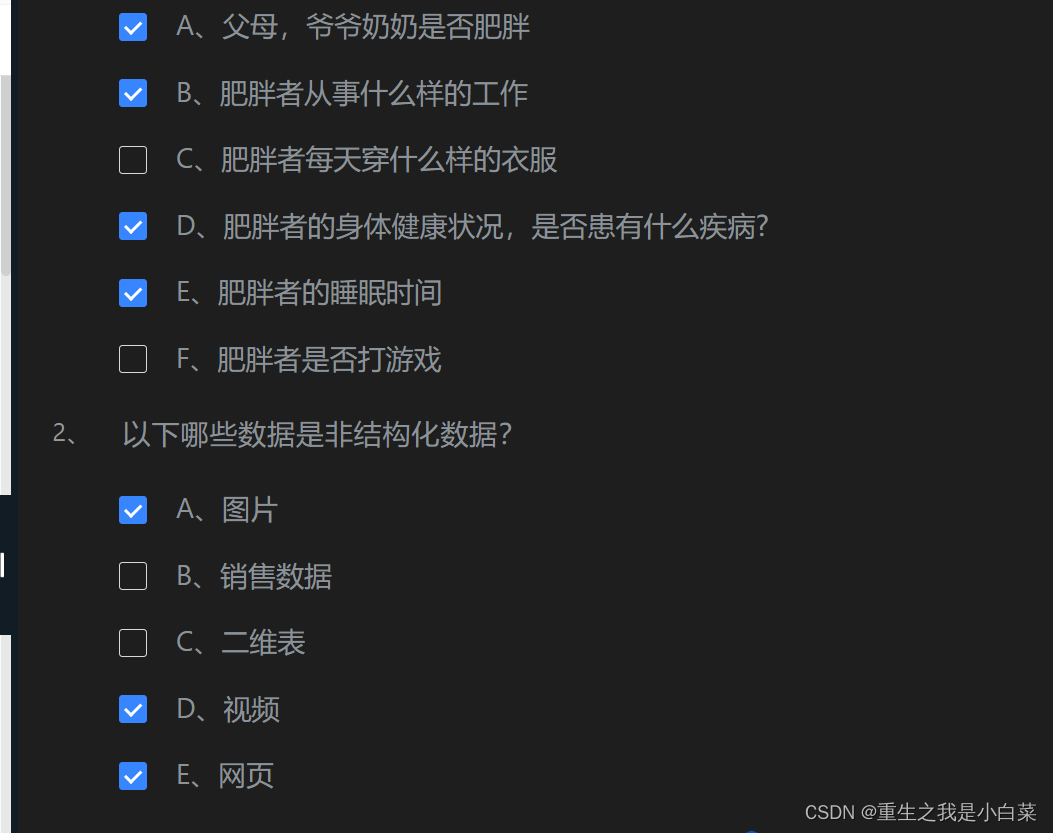
二、数据科学导论——数据采集实战
第1关:单网页爬取
import urllib.request
import csv
import re# ********** Begin ********** #
data=urllib.request.urlopen("http://www.jd.com").read().decode("utf-8","ignore")
#打开京东,读取并爬到内存中,解码, 并赋值给data
urllib.request.urlretrieve("http://www.jd.com",filename="./step1/京东.html")
#打开京东,读取保存到本地
# ********** End ********** #
# ********** Begin ********** #
#正则表达式(Regular Expression)
pattern="<title>(.*?)</title>"
#re.compile()指编译正则表达式
#re.S是模式修正符,网页信息往往包含多行内容,re.S可以消除多行影响
title=set(re.compile(pattern,re.S).findall(data))
#保存数据到csv文件中
with open("./step1/csv_file.csv", 'w') as f:f_csv = csv.writer(f)f_csv.writerow(title)
# ********** End ********** #第2关:网站爬取策略
from bs4 import BeautifulSoup
import requests
import reclass linkQuence:def __init__(self):# 已访问的url集合self.visted = []# 待访问的url集合self.unVisited = []# 获取访问过的url队列def getVisitedUrl(self):return self.visted# 获取未访问的url队列def getUnvisitedUrl(self):return self.unVisited# 添加到访问过得url队列中def addVisitedUrl(self, url):self.visted.append(url)# 移除访问过得urldef removeVisitedUrl(self, url):self.visted.remove(url)# 未访问过得url出队列def unVisitedUrlDeQuence(self):try:return self.unVisited.pop()except:return None# 保证每个url只被访问一次def addUnvisitedUrl(self, url):if url != "" and url not in self.visted and url not in self.unVisited:self.unVisited.insert(0, url)# 获得已访问的url数目def getVisitedUrlCount(self):return len(self.visted)# 获得未访问的url数目def getUnvistedUrlCount(self):return len(self.unVisited)# 判断未访问的url队列是否为空def unVisitedUrlsEnmpy(self):return len(self.unVisited) == 0class MyCrawler:def __init__(self, seeds):# 初始化当前抓取的深度self.current_deepth = 1# 使用种子初始化url队列self.linkQuence = linkQuence()if isinstance(seeds, str):self.linkQuence.addUnvisitedUrl(seeds)if isinstance(seeds, list):for i in seeds:self.linkQuence.addUnvisitedUrl(i)print("Add the seeds url %s to the unvisited url list" %str(self.linkQuence.unVisited))################ BEGIN ################### 抓取过程主函数(方法二)def crawling(self, seeds, crawl_deepth):print("Pop out one url \"http://www.cyberpolice.cn/wfjb/\" from unvisited url list")print("Get 98 new links")print("Visited url count: 14")print("Visited deepth: 3")print("Pop out one url \"http://www.cyberpolice.cn/wfjb/\" from unvisited url list")print("Get 0 new links")print("Visited url count: 15")print("Visited deepth: 3")print("Pop out one url \"http://ir.baidu.com/phoenix.zhtml?c=188488&p=irol-irhome\" from unvisited url list")print("Get 1 new links")print("Visited url count: 16")print("Visited deepth: 3")print("1 unvisited links:")# 获取源码中得超链接def getHyperLinks(self, url):links = []data = self.getPageSource(url) # 获取url网页源码soup = BeautifulSoup(data, 'html.parser')a = soup.findAll("a", {"href": re.compile('^http|^/')})for i in a:if i["href"].find("http://") != -1:links.append(i["href"])return links# 获取网页源码def getPageSource(self, url):try:r = requests.get(url)r.raise_for_status()r.encoding = 'utf-8'return r.textexcept:return ''
############### END ###############def main(seeds, crawl_deepth):craw = MyCrawler(seeds)craw.crawling(seeds, crawl_deepth)# 爬取百度超链接,深度为3
if __name__ == '__main__':main("http://www.baidu.com", 3)第3关:爬取与反爬取

import requestsdef spider():url = "https://www.zhihu.com/"try:# 使用 requests 库发送请求response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})# 检查响应状态码if response.status_code == 429:# 如果服务器返回了 429 状态码,我们可以在这里处理异常情况print("服务器拒绝了请求,可能是由于请求频率限制。")return None# 读取内容data = response.text# 将获取的数据写入文件with open('step3/result.txt', 'w', encoding='utf-8') as fp:fp.write(data)return dataexcept requests.exceptions.RequestException as e:# 打印错误信息print(f"请求出错: {e}")return None# 在主程序中调用 spider 函数
if __name__ == "__main__":result = spider()if result and len(result) >= 30000:print("数据量已达到30000个字符。")第4关:爬取与反爬取进阶

import urllib.request
import re
import random# 请求头
uapools = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]def UA():# 使用随机请求头opener = urllib.request.build_opener()thisua = random.choice(uapools)ua = ("User-Agent", thisua)opener.addheaders = [ua]urllib.request.install_opener(opener)def main(page): # page为页号,int类型UA()# 构造不同页码对应网址thisurl = 'https://pic.netbian.com/4kyingshi/index_{}.html'.format(page + 1)data = urllib.request.urlopen(thisurl).read().decode("utf-8", "ignore")# 利用<img src="(.*?)"提取图片内容pat = '<img src="(.*?)"'rst = re.compile(pat, re.S).findall(data)with open("./step4/content.txt", "a", encoding="utf-8") as f:f.write("\n".join(rst))# 爬取第1页到第N页的内容
main(1) # 假设只爬取第1页相关文章:
勾八头歌之数据科学导论—数据采集实战
一、数据科学导论——数据采集基本概念 第1关:巧妇难为无米之炊 第2关:数据采集概念与内涵 二、数据科学导论——数据采集实战 第1关:单网页爬取 import urllib.request import csv import re# ********** Begin ********** # dataurllib.r…...
微信小程序云开发教程——墨刀原型工具入门(素材面板)
引言 作为一个小白,小北要怎么在短时间内快速学会微信小程序原型设计? “时间紧,任务重”,这意味着学习时必须把握微信小程序原型设计中的重点、难点,而非面面俱到。 要在短时间内理解、掌握一个工具的使用…...

C#与WPF通用类库
个人集成封装,仓库已公开 NetHelper 集成了一些常用的方法; 如通用的缓存静态操作类、常用的Wpf的ValueConverters、内置的委托类型、通用的反射加载dll操作类、Wpf的ViewModel、Command、Navigation、Messenger、部分常用UserControls(可绑定的Passwo…...
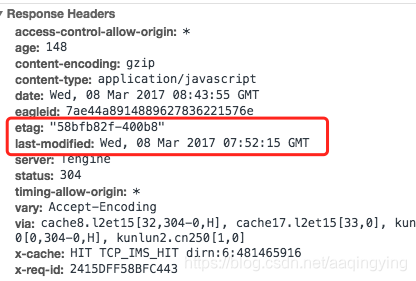
http协议中的强缓存与协商缓存,带图详解
此篇抽自本人之前的文章:http面试题整理 。 别急着跳转,先把缓存知识学会了~ http中的缓存分为两种:强缓存、协商缓存。 强缓存 响应头中的 status 是 200,相关字段有expires(http1.0),cache-control&…...

蓝桥杯2019年第十届省赛真题-修改数组
查重类题目,想到用标记数组记录是否出现过 但是最坏情况下可能会从头找到小尾巴,时间复杂度O(n2),数据范围106显然超时 再细看下题目,我们重复进行了寻找是否出现过,干脆把每个元素出现过的次数k记录下来,直…...
【Python使用】python高级进阶知识md总结第3篇:静态Web服务器-返回指定页面数据,静态Web服务器-多任务版【附代码文档】
python高级进阶全知识知识笔记总结完整教程(附代码资料)主要内容讲述:操作系统,虚拟机软件,Ubuntu操作系统,Linux内核及发行版,查看目录命令,切换目录命令,绝对路径和相对…...
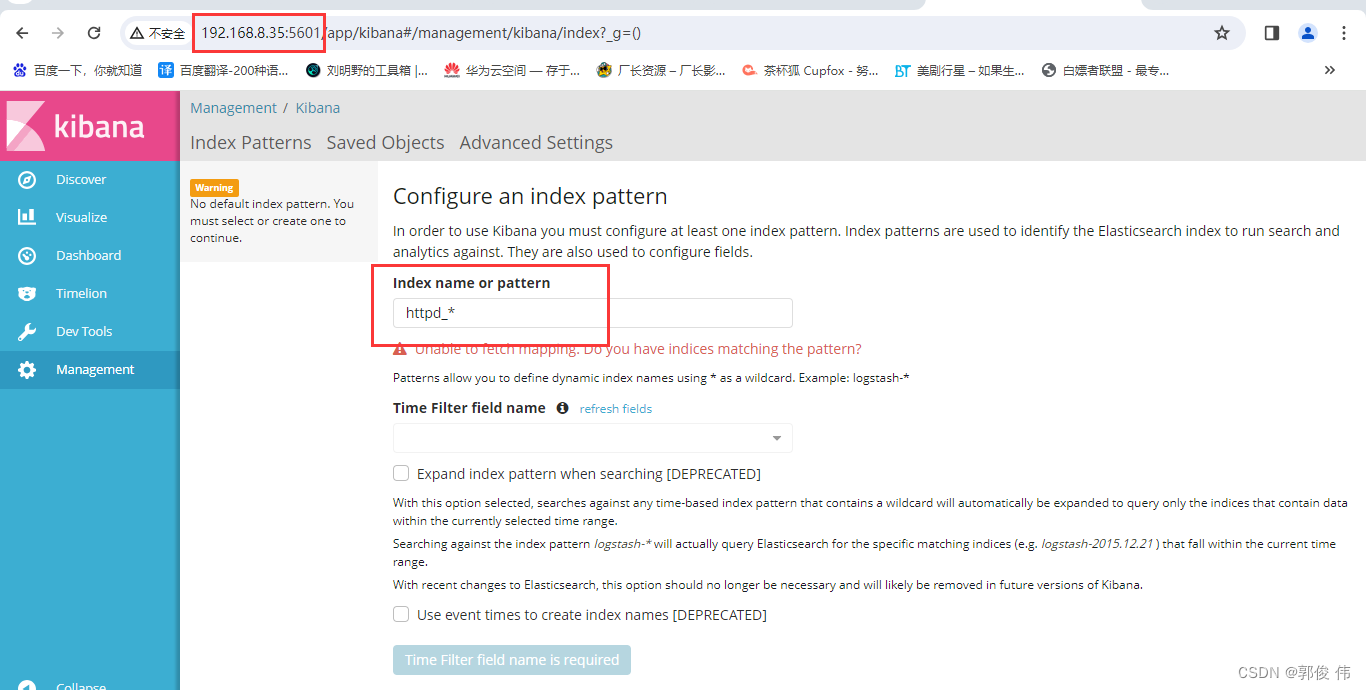
ELK 日志分析系统
ELK (Elasticsearch、Logstash、Kibana)日志分析系统的好处是可以集中查看所有服务器日志,减轻了工作量,从安全性的角度来看,这种集中日志管理可以有效查询以及跟踪服务器被攻击的行为。 Elasticsearch 是个开源分布式…...

机器学习模型—逻辑回归
机器学习模型—逻辑回归 逻辑回归是一种用于分类任务的监督机器学习算法,其目标是预测实例属于给定类别的概率。逻辑回归是一种分析两个数据因素之间关系的统计算法。本文探讨了逻辑回归的基础知识、类型和实现。 什么是逻辑回归 逻辑回归用于二元分类,其中我们使用sigmoi…...

Ubuntu20.04 创建新的用户
1、了解Linux目录结构 推荐看一下:https://www.runoob.com/linux/linux-system-contents.html Linux支持多个用户进行操作的,这样提高了系统的安全性,也可以多人共用一个系统,不过要注意的是系统中安装的软件相关路径࿰…...

大数据入门之hadoop学习
大数据 1. 学习hadoop之前,我们先了解一下什么是大数据? 大数据通常指的是数据集规模非常庞大且难以在常规数据库和数据处理工具中有效处理的数据。 大数据的特点: 容量:大数据具有庞大的规模,远远超出了传统数据库和…...
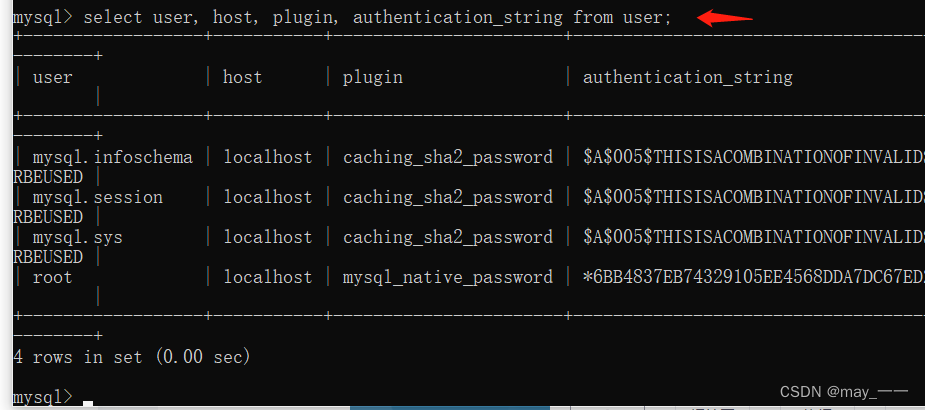
MySQL安装使用(mac、windows)
目录 macOS环境 一、下载MySQL 二、环境变量 三、启动 MySql 四、初始化密码设置 windows环境 一、下载 二、 环境配置 三、安装mysql 1.初始化mysql 2.安装Mysql服务 3.更改密码 四、检验 1.查看默认安装的数据库 2.其他操作 macOS环境 一、下载MySQL 打开 MyS…...
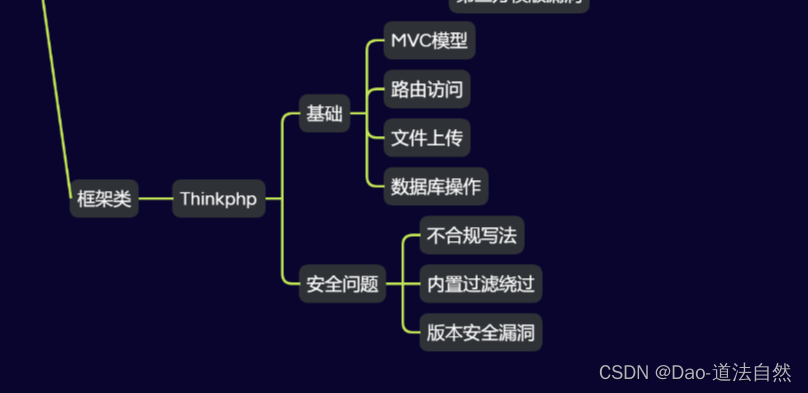
Day27:安全开发-PHP应用TP框架路由访问对象操作内置过滤绕过核心漏洞
目录 TP框架-开发-配置架构&路由&MVC模型 TP框架-安全-不安全写法&版本过滤绕过 思维导图 PHP知识点 功能:新闻列表,会员中心,资源下载,留言版,后台模块,模版引用,框架开发等 技…...
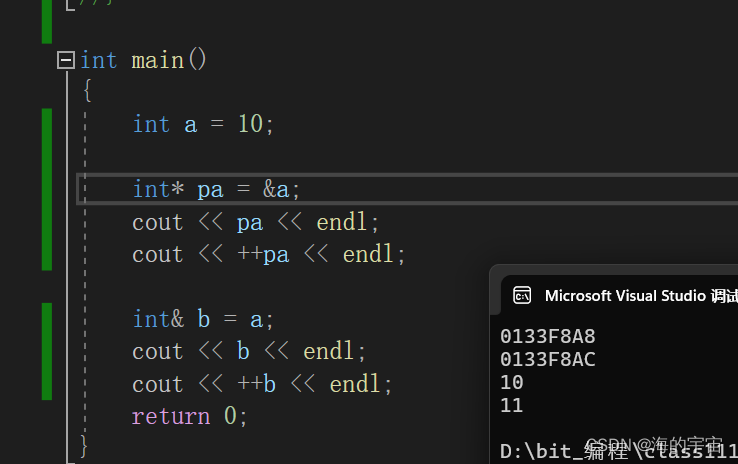
c++: 引用能否替代指针? 详解引用与指针的区别.
文章目录 前言1. 引用和指针的最大区别:引用不能改变指向2. 引用和指针在底层上面是一样的3. 引用和指针在sizeof面前大小不同4. 有多级指针,没有多级引用5.引用是引用的实体,指针会向后偏移同一个类型的大小 总结 前言 新来的小伙伴如果不知道引用是什么?可以看我的上一篇文…...

Java项目源码基于springboot的家政服务平台的设计与实现
大家好我是程序员阿存,在java圈的辛苦码农。辛辛苦苦板砖,今天要和大家聊的是一款Java项目源码基于springboot的家政服务平台的设计与实现,项目源码以及部署相关请联系存哥,文末附上联系信息 。 项目源码:Java基于spr…...
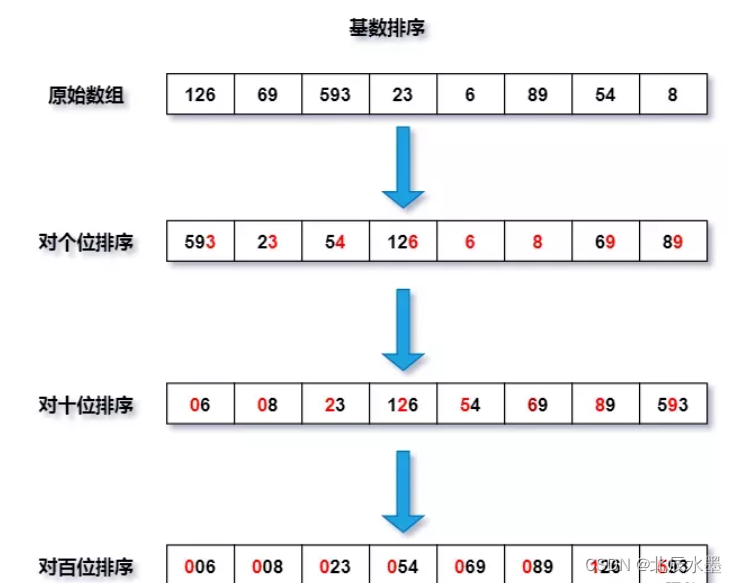
十大排序算法(冒泡排序、插入排序、选择排序、希尔排序、堆排序、快排、归并排序、桶排序、计数排序、基数排序)
目录 一、冒泡排序: 二、插入排序: 三、选择排序: 四、希尔排序: 五、堆排序: 六、快速排序: 6.1挖坑法: 6.2左右指针法 6.3前后指针法: 七、归并排序: 八、桶…...
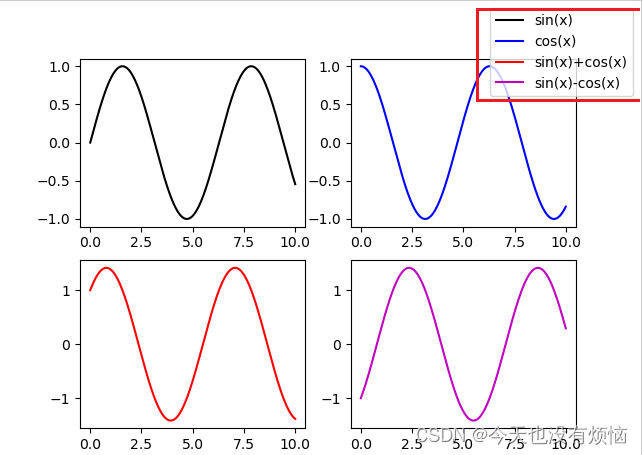
matplotlib 画多子图的时候添加图例/legend
一开始搞不懂图例是什么意思,以为是整个图,最后发现原来图例就是代码中的legend: 子图的图例(legend)用于解释图表中各条线、点或其他元素所代表的含义。图例通常位于图表的一角,以帮助观众理解图表中展示的…...

手写一个线程池
自己手动写一个线程池的必要条件需要先了解我们使用的线程池的功能。为什么会有线程池?这是为了减少线程创建和销毁的开销。复用线程的目的。为了达到这个目的。预计方案是:需要一个存放任务的队列,主线程相当于生产者,在这个队列…...
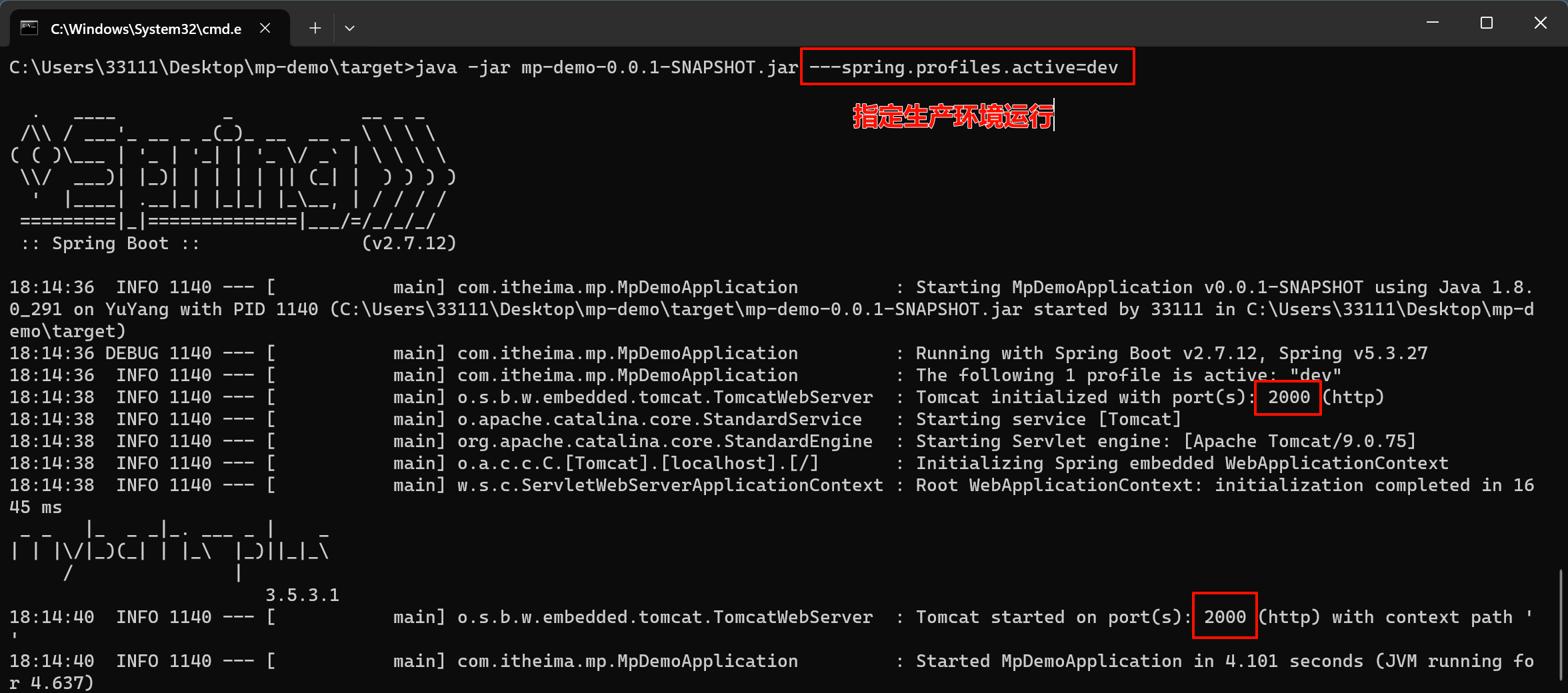
Spring Boot 多环境配置
Spring Boot 多环境配置 在现代的软件开发中,通常需要将应用程序部署到不同的环境中,如开发环境、生产环境和测试环境等。每个环境可能需要不同的配置参数,例如数据库连接信息、日志级别等。在 Spring Boot 中,我们可以通过简单的…...

【Python】一文带你详解sys.executable函数的作用
【Python】一文带你详解sys.executable函数的作用 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支…...
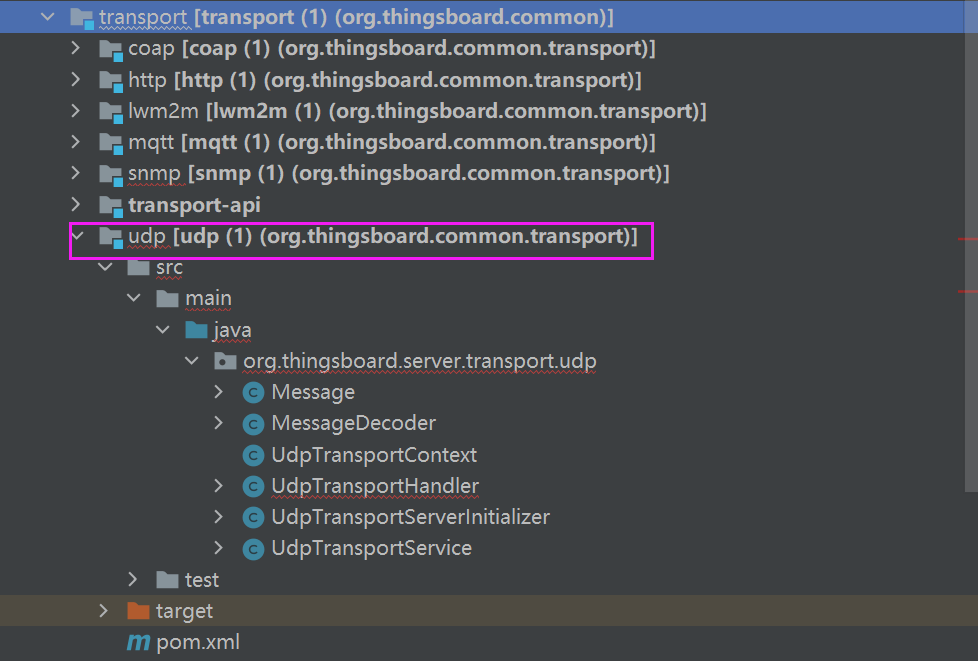
thingsboard如何自定义udp-transport
0、参考netty实现udp的文章 https://github.com/narkhedesam/Netty-Simple-UDP-TCP-server-client/blob/master/netty-udp/src/com/sam/netty_udp/server/MessageDecoder.java 调试工具使用的是:卓岚TCP&UDP调试工具 1、在common\transport下面创建udp模块,仿照mqtt的创…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

AB包相关知识
Lua与AB包/Addressables以及YooAsset 摘自千问: Lua 是菜谱(逻辑):决定了菜怎么做,味道如何。因为你需要随时换菜谱(热更新),所以菜谱不能死板地印在墙上(编译进主包&a…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...

基于Arduino Uno与MQ-2传感器的智能气体检测报警系统DIY全攻略
1. 项目概述与核心思路最近在捣鼓家里的智能安防,琢磨着能不能自己做一个成本可控、反应灵敏的气体检测报警装置。市面上成品烟雾报警器虽然成熟,但要么功能单一,要么价格不菲,而且很难根据自己的需求进行定制化调整,比…...