浏览器缓存 四种缓存分类 两种缓存类型
浏览器缓存
本文主要包含以下内容:
- 什么是浏览器缓存
- 按照缓存位置分类
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
- 按照缓存类型分类
- 强制缓存
- 协商缓存
- 缓存读取规则
- 浏览器行为
什么是浏览器缓存
在正式开始讲解浏览器缓存之前,我们先来回顾一下整个 Web 应用的流程。
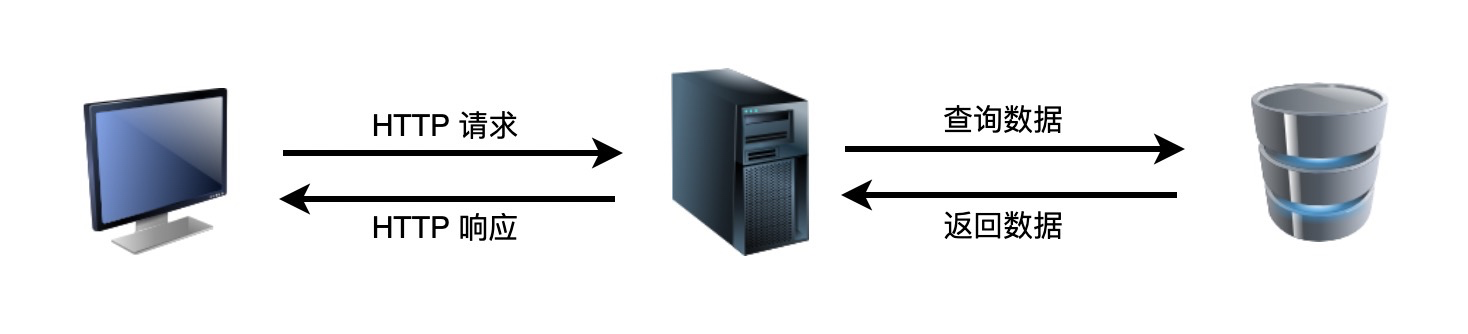
上图展示了一个 Web 应用最最简单的结构。客户端向服务器端发送 HTTP 请求,服务器端从数据库获取数据,然后进行计算处理,之后向客户端返回 HTTP 响应。
那么上面整个流程中,哪些地方比较耗费时间呢?总结起来有如下两个方面:
-
发送请求的时候
-
涉及到大量计算的时候
一般来讲,上面两个阶段比较耗费时间。
首先是发送请求的时候。这里所说的请求,不仅仅是 HTTP 请求,也包括服务器向数据库发起查询数据的请求。
其次是大量计算的时候。一般涉及到大量计算,主要是在服务器端和数据库端,服务器端要进行计算这个很好理解,数据库要根据服务器发送过来的查询命令查询到对应的数据,这也是比较耗时的一项工作。
因此,单论缓存的话,我们其实在很多地方都可以做缓存。例如:
- 数据库缓存
- CDN 缓存
- 代理服务器缓存
- 浏览器缓存
- 应用层缓存
针对各个地方做出适当的缓存,都能够很大程度的优化整个 Web 应用的性能。但是要逐一讨论的话,是一个非常大的工程量,所以本文我们主要来看一下浏览器缓存,这也是和我们前端开发息息相关的。
整个浏览器的缓存过程如下:
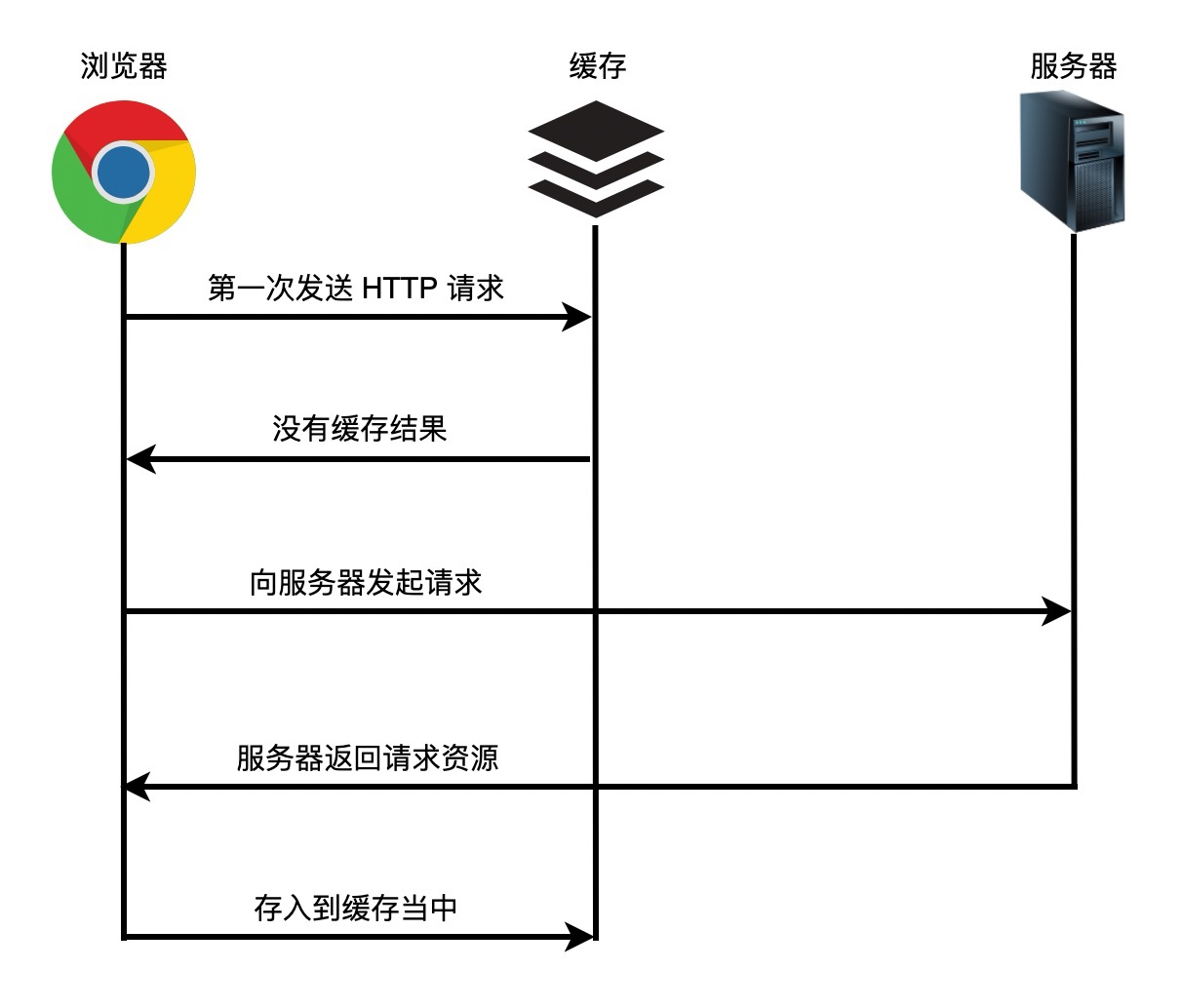
从上图我们可以看到,整个浏览器端的缓存其实没有想象的那么复杂。其最基本的原理就是:
-
浏览器每次发起请求,都会先在浏览器缓存中查找该请求的结果以及缓存标识
-
浏览器每次拿到返回的请求结果都会将该结果和缓存标识存入浏览器缓存中
以上两点结论就是浏览器缓存机制的关键,它确保了每个请求的缓存存入与读取,只要我们再理解浏览器缓存的使用规则,那么所有的问题就迎刃而解了。
接下来,我将从两个维度来介绍浏览器缓存:
-
缓存的存储位置
-
缓存的类型
按照缓存位置分类
从缓存位置上来说分为四种,并且各自有优先级,当依次查找缓存且都没有命中的时候,才会去请求网络。这四种依次为:
-
Service Worker
-
Memory Cache
-
Disk Cache
-
Push Cache
Service Worker
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。
使用 Service Worker 的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。
Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。.
当 Service Worker 没有命中缓存的时候,我们需要去调用 fetch 函数获取数据。也就是说,如果我们没有在 Service Worker 命中缓存的话,会根据缓存查找优先级去查找数据。

但是不管我们是从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示我们是从 Service Worker 中获取的内容。
Memory Cache
Memory Cache 也就是内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。
读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。
那么既然内存缓存这么高效,我们是不是能让数据都存放在内存中呢?
这是不可能的。计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存必然不多。
当我们访问过页面以后,再次刷新页面,可以发现很多数据都来自于内存缓存。

Memory Cache 机制保证了一个页面中如果有两个相同的请求。
例如两个 src 相同的 <img>,两个 href 相同的 <link>,都实际只会被请求最多一次,避免浪费。
Disk Cache
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。
在所有浏览器缓存中,Disk Cache 覆盖面基本是最大的。它会根据 HTTP Herder 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。
并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。绝大部分的缓存都来自 Disk Cache。
凡是持久性存储都会面临容量增长的问题,Disk Cache 也不例外。
在浏览器自动清理时,会有特殊的算法去把“最老的”或者“最可能过时的”资源删除,因此是一个一个删除的。不过每个浏览器识别“最老的”和“最可能过时的”资源的算法不尽相同,这也可以看作是各个浏览器差异性的体现。
Push Cache
Push Cache 翻译成中文叫做“推送缓存”,是属于 HTTP/2 中新增的内容。
当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在 Chrome 浏览器中只有 5 分钟左右,同时它也并非严格执行 HTTP/2 头中的缓存指令。
Push Cache 在国内能够查到的资料很少,也是因为 HTTP2 在国内还不够普及。
这里推荐阅读 Jake Archibald 的 HTTP/2 push is tougher than I thought 这篇文章。
文章中的几个结论:
-
所有的资源都能被推送,并且能够被缓存,但是 Edge 和 Safari 浏览器支持相对比较差
-
可以推送 no-cache 和 no-store 的资源
-
一旦连接被关闭,Push Cache 就被释放
-
多个页面可以使用同一个 HTTP/2 的连接,也就可以使用同一个 Push Cache。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的 tab 标签使用同一个 HTTP 连接。
-
Push Cache 中的缓存只能被使用一次
-
浏览器可以拒绝接受已经存在的资源推送
-
你可以给其他域名推送资源
如果一个请求在上述几个位置都没有找到缓存,那么浏览器会正式发送网络请求去获取内容。之后为了提升之后请求的缓存命中率,自然要把这个资源添加到缓存中去。具体来说:
-
根据 Service Worker 中的 handler 决定是否存入 Cache Storage (额外的缓存位置)。Service Worker 是由开发者编写的额外的脚本,且缓存位置独立,出现也较晚,使用还不算太广泛。
-
Memory Cache 保存一份资源的引用,以备下次使用。Memory Cache 是浏览器为了加快读取缓存速度而进行的自身的优化行为,不受开发者控制,也不受 HTTP 协议头的约束,算是一个黑盒。
-
根据 HTTP 头部的相关字段( Cache-control、Pragma 等 )决定是否存入 Disk Cache。Disk Cache 也是平时我们最熟悉的一种缓存机制,也叫 HTTP Cache (因为不像 Memory Cache,它遵守 HTTP 协议头中的字段)。平时所说的强制缓存,协商缓存,以及 Cache-Control 等,也都归于此类。
按照缓存类型分类
按照缓存类型来进行分类,可以分为强制缓存和协商缓存。需要注意的是,无论是强制缓存还是协商缓存,都是属于 Disk Cache 或者叫做 HTTP Cache 里面的一种。
强制缓存
强制缓存的含义是,当客户端请求后,会先访问缓存数据库看缓存是否存在。如果存在则直接返回;不存在则请求真的服务器,响应后再写入缓存数据库。
强制缓存直接减少请求数,是提升最大的缓存策略。如果考虑使用缓存来优化网页性能的话,强制缓存应该是首先被考虑的。
可以造成强制缓存的字段是 Cache-control 和 Expires。
Expires
这是 HTTP 1.0 的字段,表示缓存到期时间,是一个绝对的时间 (当前时间+缓存时间),如:
Expires: Thu, 10 Nov 2017 08:45:11 GMT
在响应消息头中,设置这个字段之后,就可以告诉浏览器,在未过期之前不需要再次请求。
但是,这个字段设置时有两个缺点:
-
由于是绝对时间,用户可能会将客户端本地的时间进行修改,而导致浏览器判断缓存失效,重新请求该资源。此外,即使不考虑自行修改的因素,时差或者误差等因素也可能造成客户端与服务端的时间不一致,致使缓存失效。
-
写法太复杂了。表示时间的字符串多个空格,少个字母,都会导致变为非法属性从而设置失效。
Cache-control
已知 Expires 的缺点之后,在 HTTP/1.1 中,增加了一个字段 Cache-control,该字段表示资源缓存的最大有效时间,在该时间内,客户端不需要向服务器发送请求
这两者的区别就是前者是绝对时间,而后者是相对时间。如下:
Cache-control: max-age=2592000
下面列举一些 Cache-control 字段常用的值:(完整的列表可以查看 MDN)
-
max-age:即最大有效时间,在上面的例子中我们可以看到
-
must-revalidate:如果超过了 max-age 的时间,浏览器必须向服务器发送请求,验证资源是否还有效。
-
no-cache:虽然字面意思是“不要缓存”,但实际上还是要求客户端缓存内容的,只是是否使用这个内容由后续的协商缓存来决定。
-
no-store:真正意义上的“不要缓存”。所有内容都不走缓存,包括强制缓存和协商缓存。
-
public:所有的内容都可以被缓存(包括客户端和代理服务器, 如 CDN )
-
private:所有的内容只有客户端才可以缓存,代理服务器不能缓存。默认值。
这些值可以混合使用,例如 Cache-control:public, max-age=2592000。在混合使用时,它们的优先级如下图:

max-age=0 和 no-cache 等价吗?
从规范的字面意思来说,max-age 到期是 应该( SHOULD )重新验证,而 no-cache 是 必须( MUST )重新验证。但实际情况以浏览器实现为准,大部分情况他们俩的行为还是一致的。(如果是 max-age=0, must-revalidate 就和 no-cache 等价了)
在 HTTP/1.1 之前,如果想使用 no-cache,通常是使用 Pragma 字段,如 Pragma: no-cache(这也是 Pragma 字段唯一的取值)。
但是这个字段只是浏览器约定俗成的实现,并没有确切规范,因此缺乏可靠性。它应该只作为一个兼容字段出现,在当前的网络环境下其实用处已经很小。
总结一下,自从 HTTP/1.1 开始,Expires 逐渐被 Cache-control 取代。
Cache-control 是一个相对时间,即使客户端时间发生改变,相对时间也不会随之改变,这样可以保持服务器和客户端的时间一致性。而且 Cache-control 的可配置性比较强大。Cache-control 的优先级高于 Expires。
为了兼容 HTTP/1.0 和 HTTP/1.1,实际项目中两个字段我们都会设置。
协商缓存
当强制缓存失效(超过规定时间)时,就需要使用协商缓存,由服务器决定缓存内容是否失效。
流程上说,浏览器先请求缓存数据库,返回一个缓存标识。之后浏览器拿这个标识和服务器通讯。如果缓存未失效,则返回 HTTP 状态码 304 表示继续使用,于是客户端继续使用缓存;

如果失效,则返回新的数据和缓存规则,浏览器响应数据后,再把规则写入到缓存数据库。

协商缓存在请求数上和没有缓存是一致的,但如果是 304 的话,返回的仅仅是一个状态码而已,并没有实际的文件内容,因此 在响应体体积上的节省是它的优化点。
它的优化主要体现在“响应”上面通过减少响应体体积,来缩短网络传输时间。所以和强制缓存相比提升幅度较小,但总比没有缓存好。
协商缓存是可以和强制缓存一起使用的,作为在强制缓存失效后的一种后备方案。实际项目中他们也的确经常一同出现。
对比缓存有 2 组字段(不是两个):
-
Last-Modified & If-Modified-Since
-
Etag & If-None-Match
Last-Modified & If-Modified-Since
-
服务器通过 Last-Modified 字段告知客户端,资源最后一次被修改的时间,例如:
Last-Modified: Mon, 10 Nov 2018 09:10:11 GMT -
浏览器将这个值和内容一起记录在缓存数据库中。
-
下一次请求相同资源时时,浏览器从自己的缓存中找出“不确定是否过期的”缓存。因此在请求头中将上次的 Last-Modified 的值写入到请求头的 If-Modified-Since 字段
-
服务器会将 If-Modified-Since 的值与 Last-Modified 字段进行对比。如果相等,则表示未修改,响应 304;反之,则表示修改了,响应 200 状态码,并返回数据。
但是他还是有一定缺陷的:
-
如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
-
如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,尽管文件可能没有变化,所以起不到缓存的作用。
因此在 HTTP/1.1 出现了 ETag 和 If-None-Match
Etag & If-None-Match
为了解决上述问题,出现了一组新的字段 Etag 和 If-None-Match。
Etag 存储的是文件的特殊标识(一般都是一个 Hash 值),服务器存储着文件的 Etag 字段。
之后的流程和 Last-Modified 一致,只是 Last-Modified 字段和它所表示的更新时间改变成了 Etag 字段和它所表示的文件 hash,把 If-Modified-Since 变成了 If-None-Match。
浏览器在下一次加载资源向服务器发送请求时,会将上一次返回的 Etag 值放到请求头里的 If-None-Match 里,服务器只需要比较客户端传来的 If-None-Match 跟自己服务器上该资源的 ETag 是否一致,就能很好地判断资源相对客户端而言是否被修改过了。
如果服务器发现 ETag 匹配不上,那么直接以常规 GET 200 回包形式将新的资源(当然也包括了新的 ETag)发给客户端;如果 ETag 是一致的,则直接返回 304 告诉客户端直接使用本地缓存即可。

两者之间的简单对比:
-
首先在精确度上,Etag 要优于 Last-Modified。
Last-Modified 的时间单位是秒,如果某个文件在 1 秒内改变了多次,那么 Last-Modified 其实并没有体现出来修改,但是 Etag 是一个 Hash 值,每次都会改变从而确保了精度。
-
第二在性能上,Etag 要逊于 Last-Modified,毕竟 Last-Modified 只需要记录时间,而 Etag 需要服务器通过算法来计算出一个 Hash 值。
-
第三在优先级上,服务器校验优先考虑 Etag,也就是说 Etag 的优先级高于 Last-Modified。
缓存读取规则
接下来我们来对上面所讲的缓存做一个总结。
当浏览器要请求资源时:
-
从 Service Worker 中获取内容( 如果设置了 Service Worker )
-
查看 Memory Cache
-
查看 Disk Cache。这里又细分:
-
如果有强制缓存且未失效,则使用强制缓存,不请求服务器。这时的状态码全部是 200
-
如果有强制缓存但已失效,使用协商缓存,比较后确定 304 还是 200
-
-
发送网络请求,等待网络响应
-
把响应内容存入 Disk Cache (如果 HTTP 响应头信息有相应配置的话)
-
把响应内容的引用存入 Memory Cache (无视 HTTP 头信息的配置)
-
把响应内容存入 Service Worker 的 Cache Storage( 如果设置了 Service Worker )
其中针对第 3 步,具体的流程图如下:

浏览器行为
在了解了整个缓存策略或者说缓存读取流程后,我们还需要了解一个东西,那就是用户对浏览器的不同操作,会触发不同的缓存读取策略。
对应主要有 3 种不同的浏览器行为:
-
打开网页,地址栏输入地址:查找 Disk Cache 中是否有匹配。如有则使用;如没有则发送网络请求。
-
普通刷新 (F5):因为 TAB 并没有关闭,因此 Memory Cache 是可用的,会被优先使用(如果匹配的话)。其次才是 Disk Cache。
-
强制刷新 ( Ctrl + F5 ):浏览器不使用缓存,因此发送的请求头部均带有 Cache-control: no-cache(为了兼容,还带了 Pragma: no-cache )。服务器直接返回 200 和最新内容。
实操案例
实践才是检验真理的唯一标准。上面已经将理论部分讲解完毕了,接下来我们就来用实际代码验证一下上面所讲的验证规则。
下面是使用 Node.js 搭建的服务器:
const http = require('http');
const path = require('path');
const fs = require('fs');var hashStr = "A hash string.";
var hash = require("crypto").createHash('sha1').update(hashStr).digest('base64');http.createServer(function (req, res) {const url = req.url; // 获取到请求的路径let fullPath; // 用于拼接完整的路径if (req.headers['if-none-match'] == hash) {res.writeHead(304);res.end();return;}if (url === '/') {// 代表请求的是主页fullPath = path.join(__dirname, 'static/html') + '/index.html';} else {fullPath = path.join(__dirname, "static", url);res.writeHead(200, {'Cache-Control': 'max-age=5',"Etag": hash});}// 根据完整的路径 使用fs模块来进行文件内容的读取 读取内容后将内容返回fs.readFile(fullPath, function (err, data) {if (err) {res.end(err.message);} else {// 读取文件成功,返回读取的内容,让浏览器进行解析res.end(data);}});
}).listen(3000, function () {console.log("服务器已启动,监听 3000 端口...");
})
在上面的代码中,我们使用 Node.js 创建了一个服务器,根据请求头的 if-none-match 字段接收从客户端传递过来的 Etag 值,如果和当前的 Hash 值相同,则返回 304 的状态码。
在资源方面,我们除了主页没有设置缓存,其他静态资源我们设置了 5 秒的缓存,并且设置了 Etag 值。
注:上面的代码只是服务器部分代码,完整代码请参阅本章节所对应的代码。
效果如下:
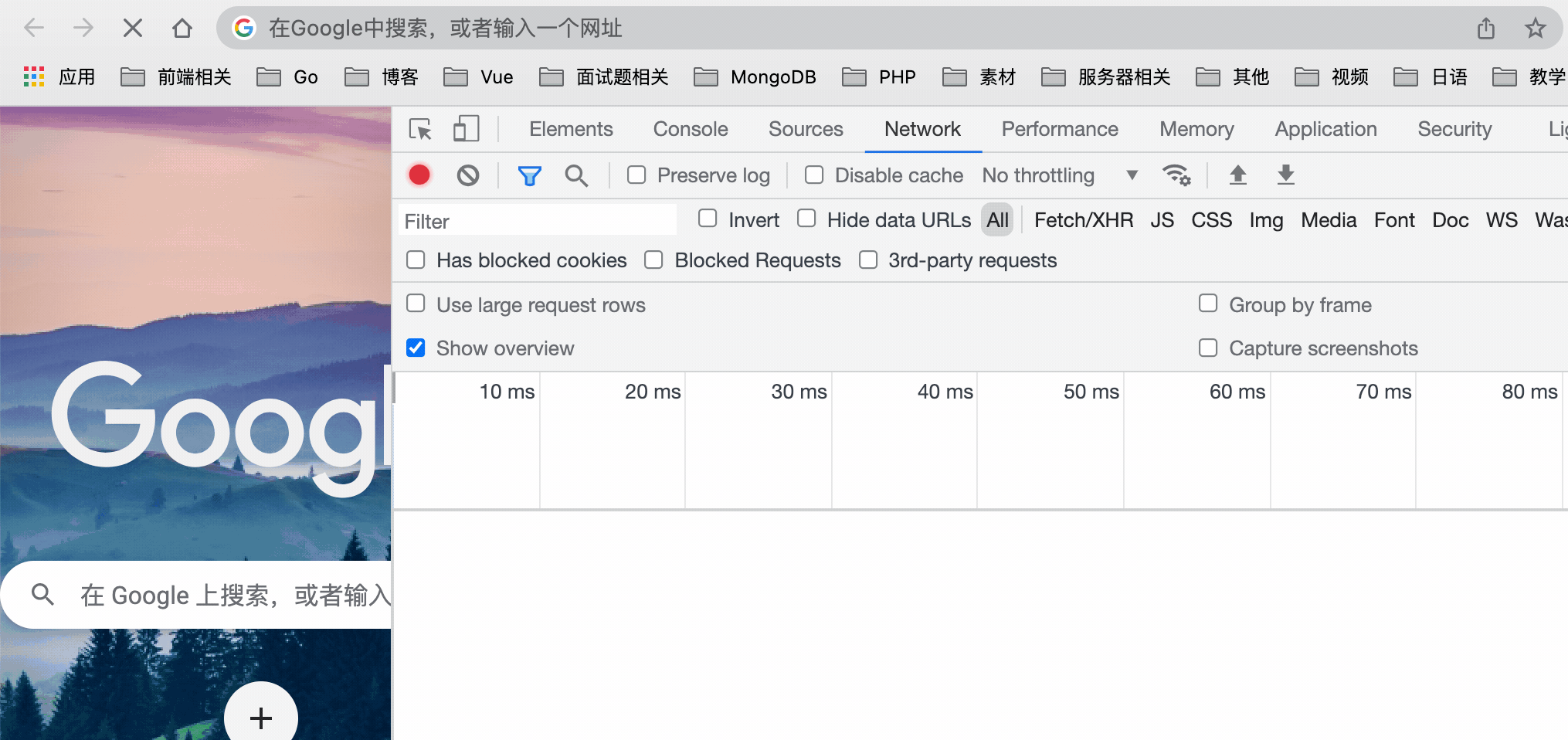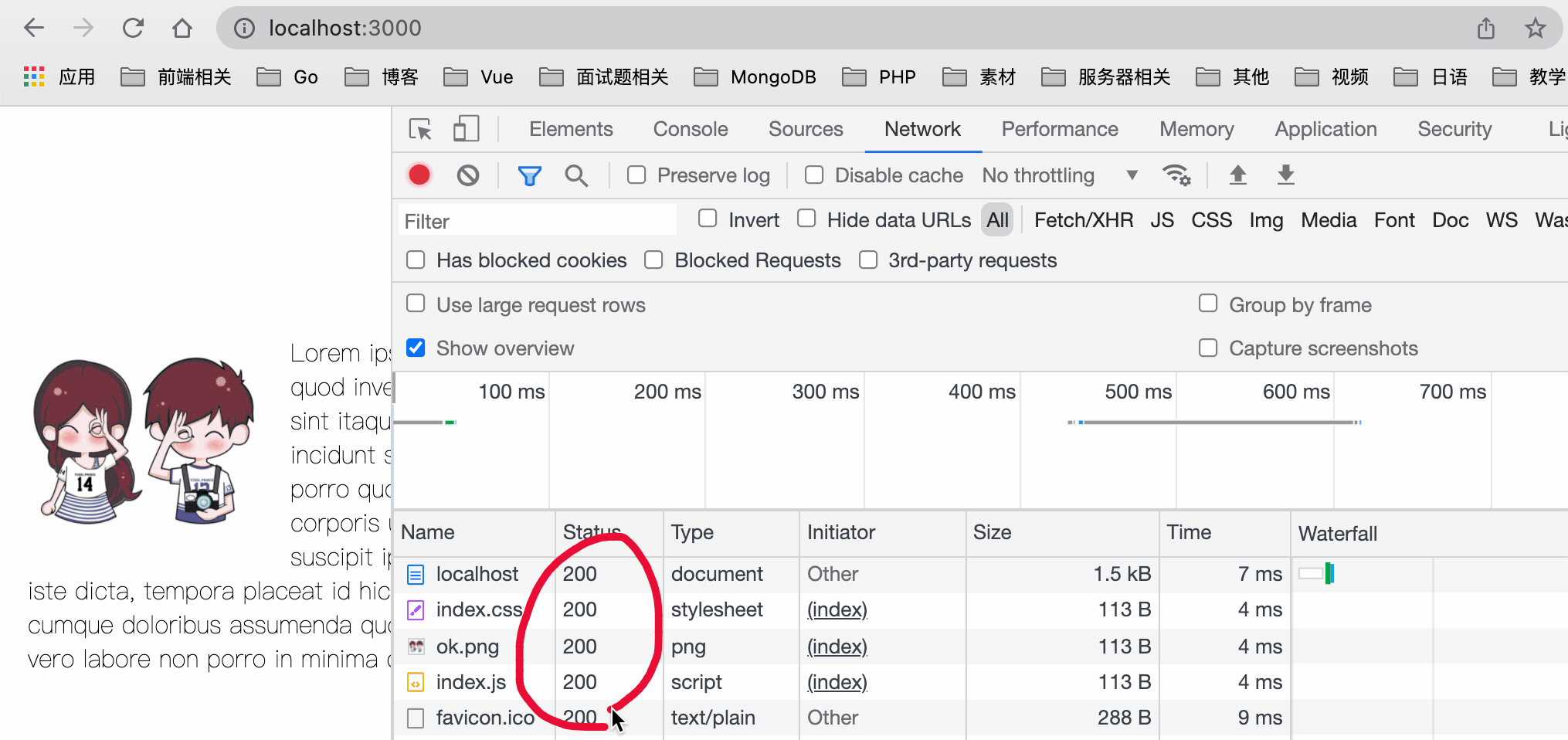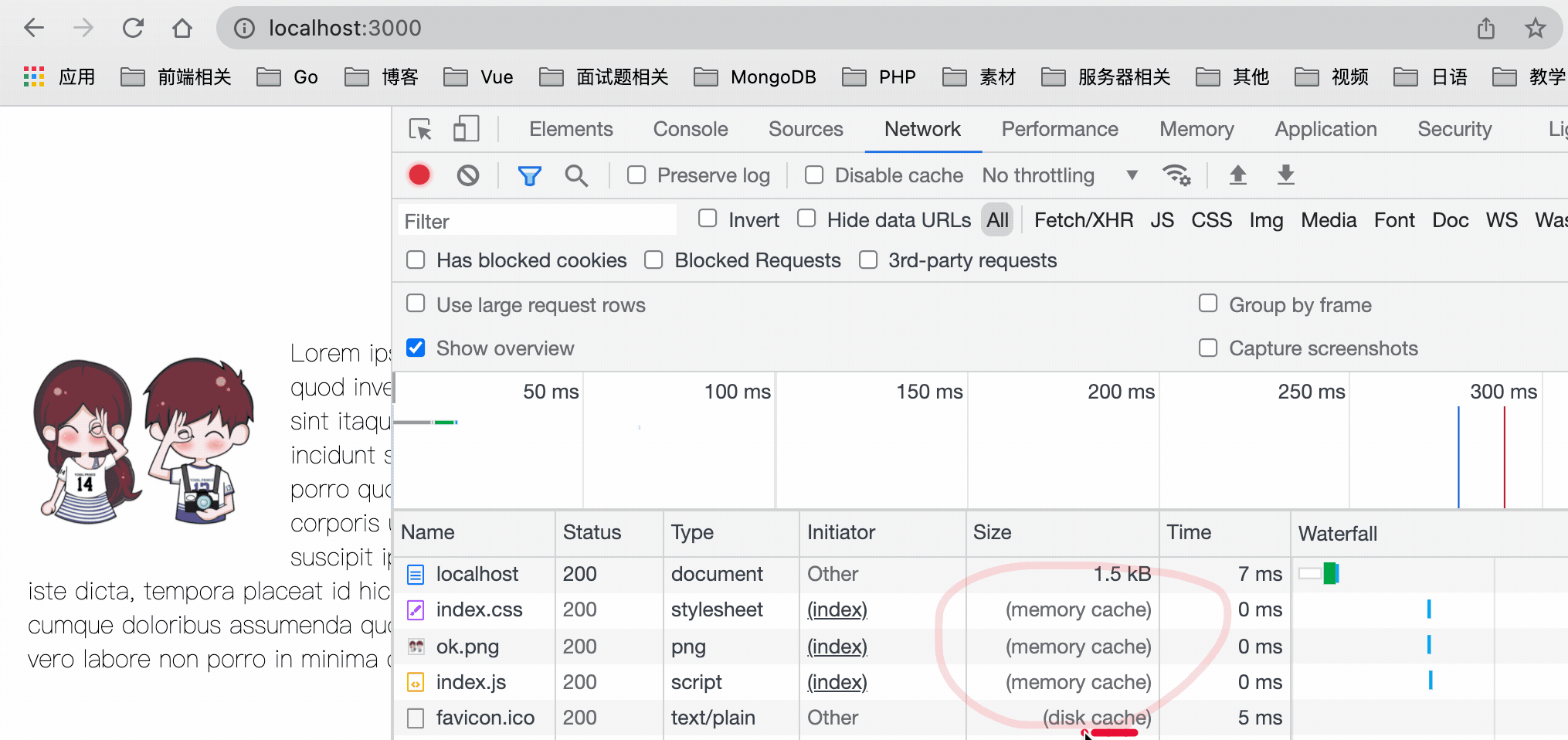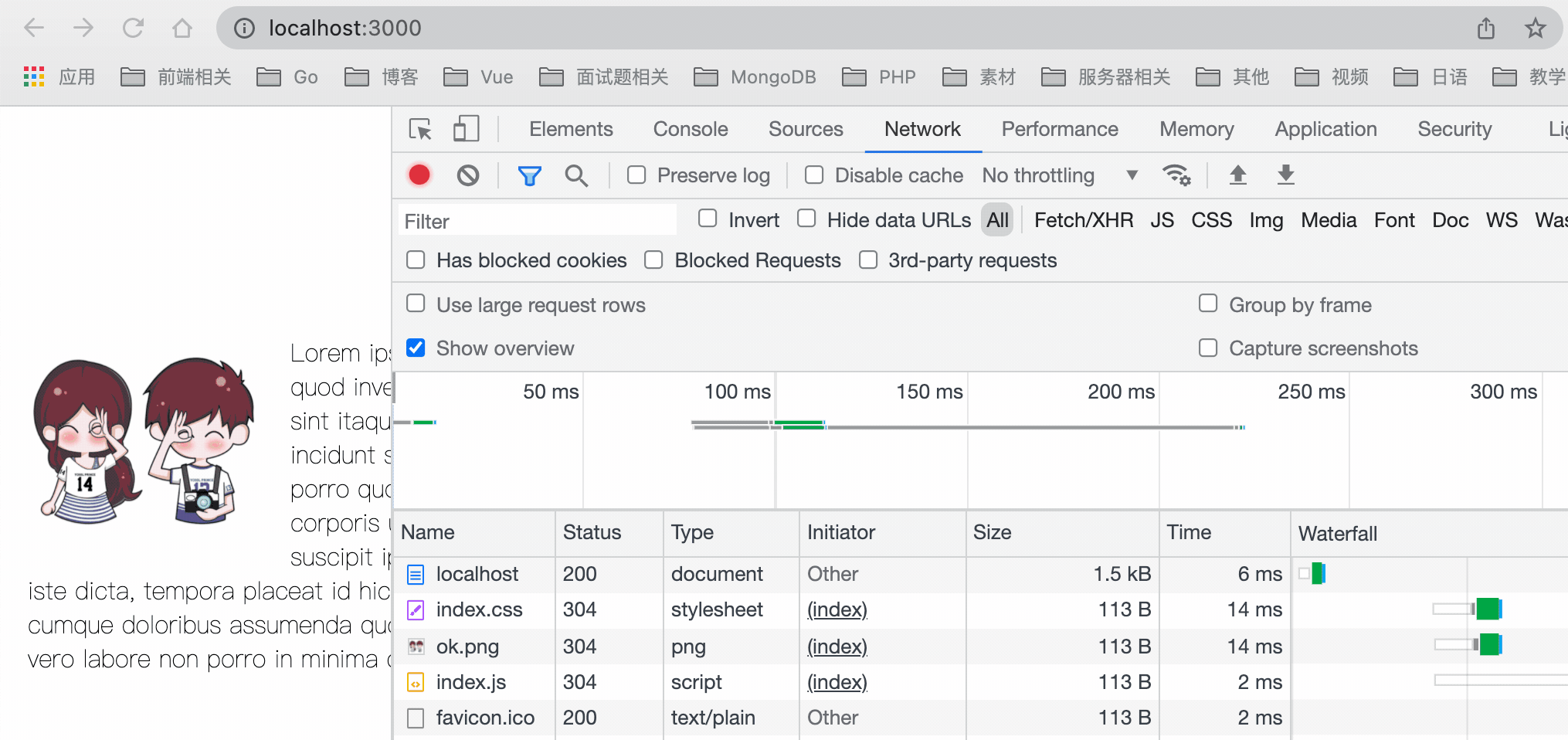
可以看到,第一次请求时因为没有缓存,所以全部都是从服务器上面获取资源,之后我们刷新页面,是从 memory cache 中获取的资源,但是由于我们的强缓存只设置了 5 秒,所以之后再次刷新页面,走的就是协商缓存,返回 304 状态码。
但是在这个示例中,如果我们修改了服务器的静态资源,客户端是没办法实时的更新的,因为静态资源是直接返回的文件,只要静态资源的文件名没变,即使该资源的内容已经发生了变化,服务器也会认为资源没有变化。
那怎么解决呢?
解决办法也就是我们在做静态资源构建时,在打包完成的静态资源文件名上根据它内容 Hash 值添加上一串 Hash 码,这样在 CSS 或者 JS 文件内容没有变化时,生成的文件名也就没有变化,反映到页面上的话就是 url 没有变化。
如果你的文件内容有变化,那么对应生成的文件名后面的 Hash 值也会发生变化,那么嵌入到页面的文件 url 也就会发生变化,从而可以达到一个更新缓存的目的。这也是为什么在使用 webpack 等一些打包工具时,打包后的文件名后面会添加上一串 Hash 码的原因。
目前来讲,这在前端开发中比较常见的一个静态资源缓存方案。
相关文章:
浏览器缓存 四种缓存分类 两种缓存类型
浏览器缓存 本文主要包含以下内容: 什么是浏览器缓存按照缓存位置分类 Service WorkerMemory CacheDisk CachePush Cache 按照缓存类型分类 强制缓存协商缓存 缓存读取规则浏览器行为 什么是浏览器缓存 在正式开始讲解浏览器缓存之前,我们先来回顾一…...

html5cssjs代码 003 50以内的乘法算式
html5&css&js代码 003 50以内的乘法算式 一、代码二、解释 综合应用代码示例。50以内的乘法算式。 一、代码 <!DOCTYPE html> <html lang"en"> <head><title>20以内的乘法</title><meta charset"UTF-8"><…...

安全先行,合规的内外网文件摆渡要重点关注什么?
内外网隔离在政府、军工部门、科研单位等已成为很常见的网络安全建设措施,内外网隔离是一种网络安全措施,用于保护内部网络免受外部网络的攻击和威胁。 内外网隔离的目的在于限制内外网之间的通信和数据交换,但网络隔离后,仍有数据…...

python:牛客NP9---16进制数字大小
文章目录 一、题意描述输入描述:输出描述: 二、代码1.代码的实现2.读入数据 总结 一、题意 描述 计算的世界,除了二进制与十进制,使用最多的就是十六进制了,现在使用input读入一个十六进制的数字,输出它的…...

【惠友小课堂】你玉米几几呀?关爱青少年骨骼健康,助力“神兽”成长
玉 米 几 几 “你玉米几几呀”这是什么梗?怎么突然火了? 起因是一位来自云南的网友有金记录真实生活,在社交媒体平台上发布了一则视频,视频中字幕“玉米六六”实际上是对“一米六六”身高的一种谐音替换,这种创意表…...
【办公类-21-09】三级育婴师 视频转文字docx(等线小五单倍行距),批量改成“宋体小四、1.5倍行距、蓝色字体”
作品展示: 背景需求: 一、视频处理 1、育婴师培训的现场视频 2、下载视频,将视频换成考题名称 二、音频 视频用格式工厂转成MP3音频 3、转文字doc 把音频放入“网易云见外工作台”转换为“文字" 等待5分钟,音频文字会被写…...
Unity DropDown 组件 详解
Unity版本 2022.3.13f1 Dropdown下拉菜单可以快速创建大量选项 一、 Dropwon属性详解 属性:功能:Interactable此组件是否接受输入?请参阅 Interactable。Transition确定控件以何种方式对用户操作进行可视化响应的属性。请参阅过渡选项。Nav…...
Spring AOP常见面试题
目录 一、对于AOP的理解 二、Spring是如何实现AOP的 1、execution表达式 2、annotation 3、基于Spring API,通过xml配置的方式。 4、基于代理实现 三、Spring AOP的实现原理 四、Spring是如何选择使用哪种动态代理 1、Spring Framework 2、Spring Boot 五…...

Java学习笔记14——常量与变量
曾和儿子分享过所谓计算机程序,都是编写代码进行“数据处理和处理数据”而已。任何编程语言编写何种应用,数据都必须以某种方式表示。掌握变量和常量的用法,可以使代码的可维护性、可读性大大提高。 一、常量 常量就是在程序中固定不变的量…...

代码随想录算法训练营第四十四天 | 卡码网52. 携带研究材料 ,LeetCode 518. 零钱兑换 II , 377. 组合总和 Ⅳ
题目链接:52. 携带研究材料(第七期模拟笔试) (kamacoder.com) #include<bits/stdc.h> using namespace std;int main(){ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);int n,v;cin>>n>>v;vector<int> dp(v1,…...

Android Kotlin知识汇总(四)Kotlin 协程实践
Kotlin的重要优势及特点之——结构化并发 Kotlin 协程是一种并发设计模式,可以在 Android 平台上让异步代码像阻塞代码一样易于使用。协程可大幅简化后台任务管理,例如网络调用、本地数据访问等任务的管理。 简单来说,协程就是一种轻量级的非…...

python基础篇--学习记录2
1.深浅拷贝 l1 ["张大仙","徐凤年",["李淳刚","邓太阿"]] # 变量名对应的就是内存地址,这里就是将l1的内存地址给了l2 # 现在两个变量指向同一个内存地址,l1变化l2也会变化 l2 l1 现在的需求是l2是l1的拷贝版本,但是两者是完全分割…...
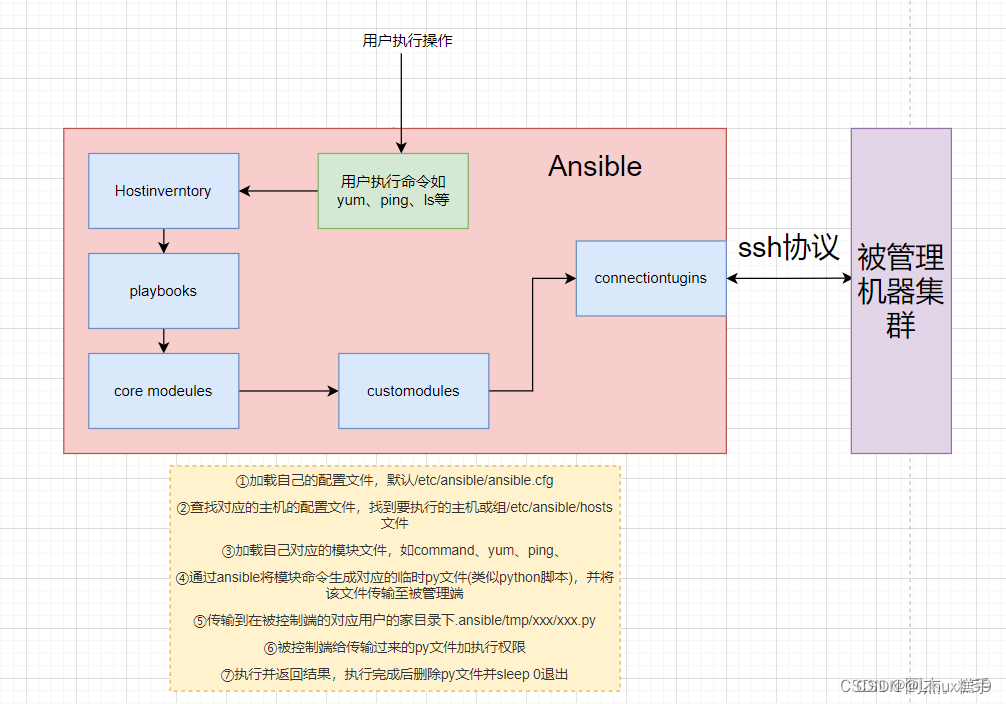
自动化运维工具Ansible
一.Ansible基本内容 1.定义 Ansible是基于模块工作的,只是提供了一种运行框架,本身没有完成任务的能力,真正操作的是Anisble的模块。每个模块都是独立的、实现了批量系统配置、批量程序部署、批量运行命令等功能。 2.特点与优势 优势&…...
VR全景在智慧园区中的应用
VR全景如今以及广泛的应用于生产制造业、零售、展厅、房产等领域,如今720云VR全景更是在智慧园区的建设中,以其独特的优势,发挥着越来越重要的作用。VR全景作为打造智慧园区的重要角色和呈现方式已经受到了越来越多智慧园区企业的选择和应用。…...
用信号的方式回收僵尸进程
当子进程退出后,会给父进程发送一个17号SIGCHLD信号,父进程接收到17号信号后,进入信号处理函数调用waitpid函数回收僵尸进程若多个子进程同时退出后,这是切回到父进程,此时父进程只会处理一个17号信号,其他…...

计算机服务器中了locked勒索病毒怎么解密,locked勒索病毒解密流程
科技的发展带动了企业生产,越来越多的企业开始利用计算机服务器办公,为企业的生产运营提供了极大便利,但随之而来的网络安全威胁也引起了众多企业的关注。近日,云天数据恢复中心接到许多企业的求助,企业的计算机服务器…...

【C语言刷题】——初识位操作符
【C语言刷题】——初识位操作符 位操作符介绍题一、 不创建临时变量(第三个变量),实现两个数的交换(1)法一(2)法二 题二、 求一个数存储在内存中的二进制中“一”的个数(1࿰…...
Python 对Excel工作表中的数据进行排序
在Excel中,排序是整理数据的一种重要方式,它可以让你更好地理解数据,并为进一步的分析和报告做好准备。本文将介绍如何使用第三方库Spire.XLS for Python通过Python来对Excel中的数据进行排序。包含以下三种排序方法示例: 按数值…...
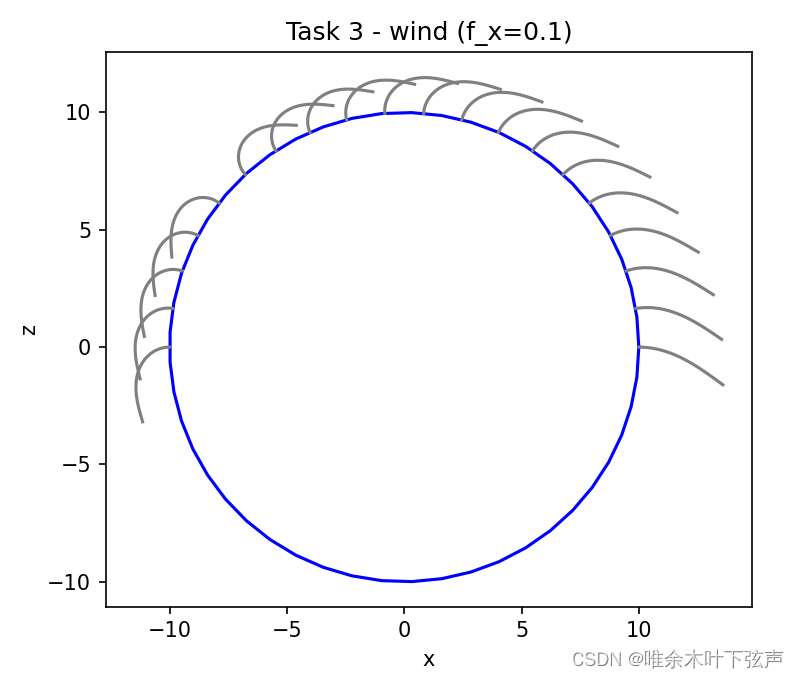
Python对头发二维建模(考虑风力、重力)
目录 一、背景 二、代码 一、背景 数值方法被用于创建电影、游戏或其他媒体中的计算机图形。例如,生成“逼真”的烟雾、水或爆炸等动画。本文内容是对头发的模拟,要求考虑重力、风力的影响。 假设: 1、人的头部是一个半径为10厘米的球体。…...

Python基础快速入门
Python基础快速入门 前置知识 Python Python是一种广泛使用的高级编程语言,以其易于学习和使用的语法而闻名。以下是Python的一些主要特点: 高级语言:Python是一种高级语言,这意味着它提供了较高层次的抽象,使编程更…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

基于SMD与贝壳的微型音频装置:从电路设计到嵌入式开发的完整实践
1. 项目概述:一个藏在贝壳里的声音世界你小时候有没有捡起一个海螺壳,把它贴在耳边,然后听到里面传来“呜呜”的海风声?那个瞬间,仿佛整个海洋都被装进了小小的贝壳里。今天这个项目,就是把那个童年的魔法&…...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南
Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: http…...