第三篇【传奇开心果系列】Python的自动化办公库技术点案例示例:深度解读Pandas股票市场数据分析
传奇开心果博文系列
- 系列博文目录
- Python的自动化办公库技术点案例示例系列
- 博文目录
- 前言
- 一、Pandas进行股票市场数据分析常见步骤和示例代码
- 1. 加载数据
- 2. 数据清洗和准备
- 3. 分析股票价格和交易量
- 4. 财务数据分析
- 二、扩展思路介绍
- 1. 技术指标分析
- 2. 波动性分析
- 3. 相关性分析
- 4. 时间序列分析
- 5. 事件驱动分析
- 6. 情绪分析
- 7. 机器学习预测
- 8. 可视化分析
- 三、技术指标分析示例代码
- 1. 移动平均线(Moving Average)
- 2. 相对强弱指标(Relative Strength Index, RSI)
- 3. 布林带(Bollinger Bands)
- 四、波动性分析示例代码
- 1. 历史波动率(Historical Volatility)
- 2. 标准差(Standard Deviation)
- 五、相关性分析示例代码
- 1. 计算相关系数
- 2. 绘制热力图
- 六、时间序列分析示例代码
- 七、事件驱动分析示例代码
- 八、情绪分析示例代码
- 九、机器学习预测示例代码
- 十、可视化分析示例代码
- 十一、知识点归纳总结
系列博文目录
Python的自动化办公库技术点案例示例系列
博文目录
前言

 Pandas是一个流行的Python库,用于数据操作和分析。在金融领域,特别是股票市场数据分析中,Pandas非常有用。通常分析股票价格、交易量和财务数据时,你可以使用Pandas来加载、处理和分析这些数据。
Pandas是一个流行的Python库,用于数据操作和分析。在金融领域,特别是股票市场数据分析中,Pandas非常有用。通常分析股票价格、交易量和财务数据时,你可以使用Pandas来加载、处理和分析这些数据。
一、Pandas进行股票市场数据分析常见步骤和示例代码
 下面是一些常见的步骤,可以帮助你使用Pandas进行股票价格、交易量和财务数据的分析:
下面是一些常见的步骤,可以帮助你使用Pandas进行股票价格、交易量和财务数据的分析:
1. 加载数据
首先,你需要加载股票数据到Pandas DataFrame中。你可以从各种来源获取数据,比如CSV文件、API接口等。
import pandas as pd# 从CSV文件加载数据
df = pd.read_csv('stock_data.csv')# 显示数据的前几行
print(df.head())
2. 数据清洗和准备
在加载数据后,通常需要进行数据清洗和准备,包括处理缺失值、处理异常值等。
# 处理缺失值
df.dropna(inplace=True)# 转换日期列为日期时间格式
df['Date'] = pd.to_datetime(df['Date'])
3. 分析股票价格和交易量
股票价格分析
# 计算股票价格的统计信息
print(df['Close'].describe())# 绘制股票价格走势图
import matplotlib.pyplot as plt
df['Close'].plot()
plt.show()
交易量分析
# 计算交易量的统计信息
print(df['Volume'].describe())# 绘制交易量走势图
df['Volume'].plot()
plt.show()
4. 财务数据分析
如果你有财务数据,比如财务报表数据,你可以使用Pandas进行财务数据分析,比如计算财务指标、绘制财务报表图表等。
# 计算财务指标,比如收入、利润等
revenue = df['Revenue'].sum()
profit = df['Profit'].sum()# 绘制财务报表图表
df[['Revenue', 'Profit']].plot()
plt.show()
以上是使用Pandas进行股票价格、交易量和财务数据分析的基本步骤。根据具体的需求,你可以进一步扩展分析内容,比如计算技术指标、进行时间序列分析等。
二、扩展思路介绍
 当涉及股票价格、交易量和财务数据分析时,除了基本的数据加载、清洗和统计分析之外,还有许多扩展思路可以帮助你深入挖掘数据并得出更深入的见解。以下是一些扩展思路:
当涉及股票价格、交易量和财务数据分析时,除了基本的数据加载、清洗和统计分析之外,还有许多扩展思路可以帮助你深入挖掘数据并得出更深入的见解。以下是一些扩展思路:
1. 技术指标分析
使用股票价格数据计算和绘制各种技术指标,如移动平均线、相对强弱指标(RSI)、布林带等,以帮助你更好地了解股票价格走势和交易信号。
2. 波动性分析
计算股票价格的波动性,比如历史波动率、标准差等,以帮助你评估风险和预测未来价格波动。
3. 相关性分析
分析股票价格、交易量和财务数据之间的相关性,可以使用相关系数或绘制热力图来查看不同变量之间的关联程度。
4. 时间序列分析
使用时间序列分析技术,如自回归模型(ARIMA)、指数平滑等,来预测股票价格走势和交易量的未来走向。
5. 事件驱动分析
考虑外部事件对股票价格和交易量的影响,比如公司公告、行业新闻等,以帮助你理解市场的反应和预测未来走势。
6. 情绪分析
结合社交媒体数据或新闻数据,进行情绪分析,以了解投资者情绪对股票价格和交易量的影响。
7. 机器学习预测
使用机器学习算法,如回归、分类或聚类算法,来预测股票价格走势或交易量的未来变化。
8. 可视化分析
使用数据可视化工具,如Matplotlib、Seaborn或Plotly,创建交互式图表和仪表板,以更直观地展示股票数据分析的结果。
这些扩展思路可以帮助你深入挖掘股票数据的潜力,提供更全面的分析和见解,从而更好地指导投资决策或财务分析。根据具体的需求和研究目的,你可以选择适合的方法来分析股票价格、交易量和财务数据。
三、技术指标分析示例代码
 当涉及使用Pandas进行技术指标分析时,你可以使用一些常见的技术指标计算方法来衡量股票价格的走势和交易信号。下面是一些示例代码,演示如何使用Pandas计算和绘制移动平均线、相对强弱指标(RSI)和布林带:
当涉及使用Pandas进行技术指标分析时,你可以使用一些常见的技术指标计算方法来衡量股票价格的走势和交易信号。下面是一些示例代码,演示如何使用Pandas计算和绘制移动平均线、相对强弱指标(RSI)和布林带:
1. 移动平均线(Moving Average)
移动平均线是一种平滑股价波动的方法,常用的有简单移动平均线(SMA)和指数移动平均线(EMA)。
# 计算简单移动平均线(SMA)
df['SMA_20'] = df['Close'].rolling(window=20).mean()# 计算指数移动平均线(EMA)
df['EMA_20'] = df['Close'].ewm(span=20, adjust=False).mean()
2. 相对强弱指标(Relative Strength Index, RSI)
RSI是一种用于衡量股票价格波动强度的指标,通常在0到100之间变化。
# 计算RSI指标
def calculate_rsi(data, window=14):delta = data['Close'].diff()gain = (delta.where(delta > 0, 0)).rolling(window=window).mean()loss = (-delta.where(delta < 0, 0)).rolling(window=window).mean()rs = gain / lossrsi = 100 - (100 / (1 + rs))return rsidf['RSI'] = calculate_rsi(df)
3. 布林带(Bollinger Bands)
布林带是一种利用股价波动率来确定股价相对高低水平的技术指标。
# 计算布林带指标
def calculate_bollinger_bands(data, window=20, num_std=2):data['MA'] = data['Close'].rolling(window=window).mean()data['std'] = data['Close'].rolling(window=window).std()data['Upper_band'] = data['MA'] + (data['std'] * num_std)data['Lower_band'] = data['MA'] - (data['std'] * num_std)return datadf = calculate_bollinger_bands(df)
以上代码演示了如何使用Pandas计算和绘制移动平均线、相对强弱指标(RSI)和布林带。这些技术指标可以帮助你更好地了解股票价格走势和交易信号,从而指导你的投资决策。
请注意,以上代码仅提供了基本的计算方法,实际应用中可能需要根据具体需求进行调整和优化。你可以根据自己的数据和分析目的来进一步扩展和定制这些技术指标分析方法。
四、波动性分析示例代码
 要进行股票价格的波动性分析,可以使用Pandas计算历史波动率、标准差等指标。下面是一些示例代码,演示如何使用Pandas计算这些指标:
要进行股票价格的波动性分析,可以使用Pandas计算历史波动率、标准差等指标。下面是一些示例代码,演示如何使用Pandas计算这些指标:
1. 历史波动率(Historical Volatility)
历史波动率衡量资产价格的变动程度,是评估风险和预测未来价格波动的重要指标。
# 计算历史波动率
def calculate_historical_volatility(data, window=252):data['log_return'] = np.log(data['Close'] / data['Close'].shift(1))data['historical_volatility'] = data['log_return'].rolling(window=window).std() * np.sqrt(252)return datadf = calculate_historical_volatility(df)
2. 标准差(Standard Deviation)
标准差是另一种衡量价格波动性的指标,可以帮助评估资产价格的波动程度。
# 计算标准差
df['Price_Std'] = df['Close'].rolling(window=20).std()
以上代码演示了如何使用Pandas计算股票价格的历史波动率和标准差。这些指标可以帮助你评估风险并预测未来价格波动。你可以根据需要调整窗口大小和其他参数来适应不同的分析需求。
请注意,这些指标提供了一种量化股票价格波动性的方式,但在实际应用中,还需要结合其他因素进行综合分析。
五、相关性分析示例代码
 要进行股票价格、交易量和财务数据之间的相关性分析,可以使用Pandas计算相关系数或绘制热力图来查看不同变量之间的关联程度。下面是一些示例代码,演示如何使用Pandas进行相关性分析:
要进行股票价格、交易量和财务数据之间的相关性分析,可以使用Pandas计算相关系数或绘制热力图来查看不同变量之间的关联程度。下面是一些示例代码,演示如何使用Pandas进行相关性分析:
1. 计算相关系数
可以使用Pandas的corr()函数计算不同变量之间的相关系数,从而了解它们之间的线性关系程度。
# 计算相关系数
correlation_matrix = df[['Close', 'Volume', 'Revenue']].corr()
print(correlation_matrix)
2. 绘制热力图
热力图可以直观地显示不同变量之间的相关性,颜色越深表示相关性越强。
import seaborn as sns
import matplotlib.pyplot as plt# 绘制热力图
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Matrix')
plt.show()
以上代码演示了如何使用Pandas计算不同变量之间的相关系数,并通过绘制热力图来可视化相关性。这些分析可以帮助你了解股票价格、交易量和财务数据之间的关联程度,从而指导你的投资决策。
请根据实际数据和分析需求来调整代码,并深入研究相关性分析的结果。
六、时间序列分析示例代码
 当涉及时间序列分析时,可以使用Pandas和其他库来进行股票价格和交易量的预测。以下是一个示例代码,展示如何使用ARIMA模型来预测股票价格的走势:
当涉及时间序列分析时,可以使用Pandas和其他库来进行股票价格和交易量的预测。以下是一个示例代码,展示如何使用ARIMA模型来预测股票价格的走势:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA# 读取数据
data = pd.read_csv('stock_data.csv', parse_dates=['Date'], index_col='Date')# 只选择股票价格列
price_data = data['Close']# 拟合ARIMA模型
model = ARIMA(price_data, order=(5,1,0)) # 这里选择ARIMA模型的参数,可以根据实际情况调整
model_fit = model.fit()# 进行未来走向预测
forecast = model_fit.forecast(steps=30) # 预测未来30天的股票价格# 绘制预测结果
plt.figure(figsize=(12, 6))
plt.plot(price_data, label='Actual Price')
plt.plot(np.append(price_data.iloc[-1], forecast), label='Forecasted Price', linestyle='--')
plt.title('Stock Price Forecast using ARIMA')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
这段代码演示了如何使用ARIMA模型来预测股票价格的走势。请确保将stock_data.csv替换为你的实际股票数据文件,并根据需要调整ARIMA模型的参数以获得更好的预测结果。
对于交易量的预测,你可以类似地处理交易量数据列。你还可以尝试其他时间序列分析技术,如指数平滑(Exponential Smoothing)、Prophet等,以探索更多预测股票价格和交易量走势的可能性。
以下是一个简单的示例代码,演示如何使用指数平滑(Exponential Smoothing)来预测股票交易量的走势:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.holtwinters import ExponentialSmoothing# 读取数据
data = pd.read_csv('stock_data.csv', parse_dates=['Date'], index_col='Date')# 只选择交易量列
volume_data = data['Volume']# 拟合指数平滑模型
model = ExponentialSmoothing(volume_data, trend='add', seasonal='add', seasonal_periods=7)
model_fit = model.fit()# 进行未来走向预测
forecast = model_fit.forecast(steps=30) # 预测未来30天的交易量# 绘制预测结果
plt.figure(figsize=(12, 6))
plt.plot(volume_data, label='Actual Volume')
plt.plot(forecast, label='Forecasted Volume', linestyle='--')
plt.title('Stock Volume Forecast using Exponential Smoothing')
plt.xlabel('Date')
plt.ylabel('Volume')
plt.legend()
plt.show()
在这段代码中,我们使用了ExponentialSmoothing模型来拟合股票交易量数据,并预测未来的交易量走势。请确保将stock_data.csv替换为你的实际股票数据文件,并根据需要调整指数平滑模型的参数以获得更好的预测结果。
这只是一个简单的示例,实际情况可能更复杂。你可以尝试不同的模型、参数和技术来提高预测准确性。
七、事件驱动分析示例代码

(一)基本的事件驱动分析示例代码
要进行基于事件驱动的股票价格和交易量分析,你可以结合Pandas和外部事件数据,比如公司公告、行业新闻等,来探索事件与股票市场之间的关联。以下是一个简单的示例代码,演示如何结合股票数据和事件数据进行分析:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 读取股票数据
stock_data = pd.read_csv('stock_data.csv', parse_dates=['Date'])# 读取事件数据,这里假设事件数据包含日期和事件描述
event_data = pd.read_csv('event_data.csv', parse_dates=['Date'])# 合并股票数据和事件数据
merged_data = pd.merge(stock_data, event_data, how='left', on='Date')# 分析事件对股票价格的影响
# 这里可以根据事件类型进行分组,计算事件发生后股票价格的平均变化
price_change_by_event = merged_data.groupby('Event Description')['Close'].mean()# 分析事件对交易量的影响
# 类似地,可以计算事件发生后交易量的平均变化
volume_change_by_event = merged_data.groupby('Event Description')['Volume'].mean()# 可视化结果
plt.figure(figsize=(12, 6))
price_change_by_event.plot.bar(title='Average Price Change by Event')
plt.ylabel('Price Change')plt.figure(figsize=(12, 6))
volume_change_by_event.plot.bar(title='Average Volume Change by Event')
plt.ylabel('Volume Change')plt.show()
在这段代码中,我们首先读取股票数据和事件数据,然后将它们合并在一起。接着,我们根据事件描述分组数据,计算事件发生后股票价格和交易量的平均变化,并通过条形图可视化结果。
请确保将stock_data.csv和event_data.csv替换为你的实际股票数据和事件数据文件。这个示例代码提供了一个基本框架,你可以根据实际情况和需求对其进行扩展和优化。

(二)事件驱动分析扩展建议
当涉及到事件驱动分析时,你可以进一步扩展分析,以更深入地探索事件与股票市场之间的关系。以下是一些扩展建议:
-
事件影响分析:
-事件窗口分析: 考虑事件发生前后的时间窗口,分析事件对股票价格和交易量的影响持续时间。
-事件类型分析: 将事件按照类型分类,比如公司业绩公告、行业新闻、政策变化等,分析不同类型事件对市场的影响。 -
情感分析:
-新闻情感分析: 利用自然语言处理技术对事件描述进行情感分析,了解事件对市场情绪的影响。
-情感指数计算: 根据事件描述中的情感内容,计算事件的情感指数,并与股票价格和交易量变化进行关联分析。 -
事件相关性分析:
-事件相关性计算: 分析不同事件之间的相关性,了解多个事件同时发生时对市场的综合影响。
-事件热度分析: 根据事件的频率和影响力,计算事件的热度指数,探索事件热度与市场表现之间的关系。 -
事件预测:
-事件预测模型: 基于历史数据和事件特征,建立事件发生的预测模型,帮助提前预测可能影响市场的事件。
-事件驱动交易策略: 结合事件预测结果,开发事件驱动的交易策略,以此指导投资决策。 -
机器学习应用:
-事件-价格预测模型: 利用机器学习算法,构建事件与股票价格之间的预测模型,探索事件对价格的影响程度。
-事件分类器: 使用机器学习方法对事件进行分类和重要性评分,以更精细地分析事件对市场的影响。
通过这些扩展,你可以更全面地理解事件对股票市场的影响,提高预测准确性,并为投资决策提供更多有益信息。

(三)事件窗口分析示例代码
在Pandas中进行事件窗口分析可以帮助你研究事件对股票价格和交易量的影响持续时间。下面是一个示例代码,演示了如何使用事件窗口分析来研究事件对股票价格和交易量的影响:
import pandas as pd# 创建一个示例数据集
data = {'Date': pd.date_range(start='2024-01-01', periods=30),'Close': [100, 105, 110, 108, 112, 115, 120, 118, 122, 125, 124, 126, 130, 128, 132, 135, 138, 140, 142, 145, 143, 140, 138, 135, 132, 130, 128, 132, 135, 138],'Volume': [100000, 120000, 110000, 105000, 125000, 130000, 140000, 135000, 145000, 150000, 148000, 152000, 160000, 155000, 165000, 170000, 175000, 180000, 185000, 190000, 188000, 185000, 180000, 175000, 170000, 168000, 165000, 170000, 175000, 180000],'Event': [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
}df = pd.DataFrame(data)# 定义事件窗口大小
event_window = 5# 创建一个新列来标识事件窗口
df['Event_Window'] = df['Event'].rolling(window=event_window).sum()# 打印数据集
print(df)
在这个示例中,我们创建了一个包含日期、收盘价格、交易量和事件的示例数据集。然后,我们定义了事件窗口的大小为5,创建了一个新列’Event_Window’,该列是对事件发生前后5天内事件发生次数的累积计数。通过这种方式,你可以分析事件对股票价格和交易量的影响持续时间。你可以根据需要进一步扩展分析,比如计算事件窗口内的平均价格或交易量变化,以更深入地了解事件对股票市场的影响。

(四)事件类型分析示例代码
要进行事件类型分析,你可以按照事件类型对市场的影响进行分类和比较。下面是一个示例代码,演示了如何使用Pandas对不同类型事件进行分类,并分析它们对市场的影响:
import pandas as pd# 创建一个示例数据集
data = {'Date': pd.date_range(start='2024-01-01', periods=30),'Close': [100, 105, 110, 108, 112, 115, 120, 118, 122, 125, 124, 126, 130, 128, 132, 135, 138, 140, 142, 145, 143, 140, 138, 135, 132, 130, 128, 132, 135, 138],'Volume': [100000, 120000, 110000, 105000, 125000, 130000, 140000, 135000, 145000, 150000, 148000, 152000, 160000, 155000, 165000, 170000, 175000, 180000, 185000, 190000, 188000, 185000, 180000, 175000, 170000, 168000, 165000, 170000, 175000, 180000],'Event_Type': ['Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News', 'Policy Change', 'Company Announcement', 'Industry News']
}df = pd.DataFrame(data)# 按照事件类型分组并计算平均收盘价格和平均交易量
grouped = df.groupby('Event_Type').agg({'Close': 'mean', 'Volume': 'mean'})# 打印分组结果
print(grouped)
在这个示例中,我们创建了一个包含日期、收盘价格、交易量和事件类型的示例数据集。然后,我们按照事件类型对数据进行分组,并计算每个事件类型的平均收盘价格和平均交易量。通过这种方式,你可以比较不同类型事件对市场的影响,了解它们对股票价格和交易量的影响情况。你可以根据需要进一步扩展分析,比如计算不同事件类型的价格波动性或交易量变化情况,以更深入地了解不同类型事件对市场的影响。

(五)新闻情感分析示例代码
要进行新闻情感分析,你可以使用自然语言处理技术来对事件描述进行情感分析,从而了解事件对市场情绪的影响。下面是一个示例代码,演示了如何使用Pandas和NLTK库对事件描述进行情感分析:
首先,确保已安装NLTK库,如果没有安装,可以使用以下命令进行安装:
pip install nltk
接下来是示例代码:
import pandas as pd
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer# 下载VADER情感分析器的模型和词汇表
nltk.download('vader_lexicon')# 创建一个示例数据集
data = {'Event_Description': ['Good news for the company, stock prices soar.', 'Market reacts positively to industry developments.', 'Policy changes lead to uncertainty in the market.', 'Company faces challenges with new regulations.']
}df = pd.DataFrame(data)# 初始化情感分析器
sia = SentimentIntensityAnalyzer()# 对事件描述进行情感分析并添加情感得分列
df['Sentiment_Score'] = df['Event_Description'].apply(lambda x: sia.polarity_scores(x)['compound'])# 打印带有情感得分的数据集
print(df)
在这个示例中,我们创建了一个包含事件描述的示例数据集。然后,我们使用NLTK中的VADER情感分析器对事件描述进行情感分析,并计算出每个事件描述的情感得分(compound score)。通过这种方式,你可以了解每个事件描述所传达的情感,从而推断事件对市场情绪的影响。你可以进一步分析情感得分的分布情况,比较不同事件描述的情感影响,以及探索情感得分与股票价格或交易量之间的关系。

(六)情感指数计算示例代码
要计算事件的情感指数,并与股票价格和交易量变化进行关联分析,你可以结合情感分析结果和股票数据,进一步探索它们之间的关系。下面是一个示例代码,演示了如何计算事件的情感指数,并与股票价格和交易量变化进行关联分析:
import pandas as pd
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer# 创建一个示例数据集
data = {'Date': pd.date_range(start='2024-01-01', periods=30),'Close': [100, 105, 110, 108, 112, 115, 120, 118, 122, 125, 124, 126, 130, 128, 132, 135, 138, 140, 142, 145, 143, 140, 138, 135, 132, 130, 128, 132, 135, 138],'Volume': [100000, 120000, 110000, 105000, 125000, 130000, 140000, 135000, 145000, 150000, 148000, 152000, 160000, 155000, 165000, 170000, 175000, 180000, 185000, 190000, 188000, 185000, 180000, 175000, 170000, 168000, 165000, 170000, 175000, 180000],'Event_Description': ['Good news for the company, stock prices soar.', 'Market reacts positively to industry developments.', 'Policy changes lead to uncertainty in the market.', 'Company faces challenges with new regulations.']
}df = pd.DataFrame(data)# 初始化情感分析器
sia = SentimentIntensityAnalyzer()
# 对事件描述进行情感分析并添加情感得分列
df['Sentiment_Score'] = df['Event_Description'].apply(lambda x: sia.polarity_scores(x)['compound'])# 计算情感指数(情感得分的平均值)
sentiment_index = df['Sentiment_Score'].mean()# 打印情感指数
print("情感指数:", sentiment_index)# 计算股票价格和交易量的变化
df['Price_Change'] = df['Close'].pct_change()
df['Volume_Change'] = df['Volume'].pct_change()# 关联分析:计算情感指数与股票价格变化和交易量变化的相关性
price_correlation = df['Sentiment_Score'].corr(df['Price_Change'])
volume_correlation = df['Sentiment_Score'].corr(df['Volume_Change'])# 打印相关性
print("情感指数与股票价格变化的相关性:", price_correlation)
print("情感指数与交易量变化的相关性:", volume_correlation)
在这个示例中,我们计算了事件描述的情感指数,即事件描述中情感得分的平均值。然后,我们计算了股票价格和交易量的变化,并计算了情感指数与股票价格变化和交易量变化之间的相关性。这样可以帮助你了解事件描述中的情感对股票价格和交易量的影响程度,以及它们之间可能存在的关联关系。
你可以根据实际数据和更复杂的情感分析模型进一步扩展这个示例,以深入探索事件描述的情感对股票市场的影响,并进行更细致的分析和预测。

(七)事件相关性计算示例代码
要分析不同事件之间的相关性,并了解多个事件同时发生时对市场的综合影响,你可以使用相关性分析方法来探索事件之间的关系。下面是一个示例代码,演示了如何计算不同事件之间的相关性:
import pandas as pd# 创建一个示例数据集
data = {'Date': pd.date_range(start='2024-01-01', periods=30),'Event1': [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0],'Event2': [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1]'Event3': [1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0]
}df = pd.DataFrame(data)# 计算事件之间的相关性
event_correlation = df[['Event1', 'Event2', 'Event3']].corr()# 打印事件之间的相关性矩阵
print("事件之间的相关性矩阵:")
print(event_correlation)
在这个示例中,我们创建了一个包含三个事件的示例数据集,并使用corr()方法计算了这三个事件之间的相关性矩阵。相关性矩阵展示了每对事件之间的相关性系数,帮助你了解不同事件之间的关联程度。
你可以根据实际数据集和更多事件的情况扩展这个示例,进一步探索不同事件之间的相关性,从而更好地理解多个事件同时发生时对市场的综合影响。

(八)事件热度分析示例代码
要进行事件热度分析,可以结合事件数据和市场表现数据,计算事件的热度指数,并探索事件热度与市场表现之间的关系。下面是一个简单的示例代码,演示了如何计算事件热度指数并分析其与市场表现的关系:
import pandas as pd# 创建一个示例数据集,包括事件数据和市场表现数据
event_data = {'Date': pd.date_range(start='2024-01-01', periods=30),'Event_Frequency': [3, 2, 4, 1, 5, 2, 3, 1, 4, 2, 3, 1, 5, 3, 2, 4, 1, 4, 2, 3, 1, 5, 3, 2, 4, 1, 5, 2, 3, 1],'Event_Impact': [0.1, 0.2, 0.3, 0.1, 0.4, 0.2, 0.1, 0.2, 0.3, 0.1, 0.4, 0.2, 0.1, 0.3, 0.2, 0.3, 0.1, 0.3, 0.2, 0.1, 0.4, 0.5, 0.2, 0.1, 0.3, 0.1]
}market_data = {'Date': pd.date_range(start='2024-01-01', periods=30),'Market_Return': [0.02, -0.01, 0.03, -0.02, 0.01, 0.02, -0.03, 0.01, 0.02, -0.01, 0.03, -0.02, 0.01, 0.02, -0.03, 0.01, 0.02, -0.01, 0.03, -0.02, 0.01, 0.02, -0.03, 0.01, 0.02, -0.01, 0.03, -0.02, 0.01, 0.02]
}# 将数据转换为DataFrame
event_df = pd.DataFrame(event_data)
market_df = pd.DataFrame(market_data)# 计算事件热度指数
event_df['Event_Score'] = event_df['Event_Frequency'] * event_df['Event_Impact']# 合并事件数据和市场表现数据
merged_df = pd.merge(event_df, market_df, on='Date')# 计算事件热度与市场表现之间的相关性
correlation = merged_df['Event_Score'].corr(merged_df['Market_Return'])print("事件热度与市场表现之间的相关性:", correlation)
在这个示例中,我们首先创建了示例的事件数据和市场表现数据,并将它们转换为DataFrame。然后,我们计算了事件的热度指数,即事件频率乘以事件影响力。接下来,我们合并了事件数据和市场表现数据,并计算了事件热度与市场表现之间的相关性,以探索它们之间的关系。
你可以根据实际情况扩展和优化这个示例,进一步探索事件热度与市场表现之间的关系,或者进行更深入的分析和可视化。
(九)事件预测模型示例代码
要建立事件发生的预测模型,可以使用历史数据和事件特征来训练机器学习模型,以预测未来事件的发生。下面是一个简单的示例代码,演示如何基于历史数据和事件特征建立事件预测模型:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 创建一个示例数据集,包括历史事件特征和事件发生标签
data = {'Date': pd.date_range(start='2023-01-01', periods=100),'Event_Feature_1': [0.1, 0.2, 0.3, 0.1, 0.4] * 20,'Event_Feature_2': [0.2, 0.3, 0.1, 0.4, 0.2] * 20,'Event_Label': [0, 1, 0, 1, 0] * 20 # 0表示事件未发生,1表示事件发生
}# 将数据转换为DataFrame
df = pd.DataFrame(data)# 划分特征和标签
X = df[['Event_Feature_1', 'Event_Feature_2']]
y = df['Event_Label']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 建立随机森林分类器模型
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = rf_model.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型在测试集上的准确率:", accuracy)
在这个示例中,我们首先创建了示例的历史数据集,包括事件特征和事件发生标签。然后,我们将数据划分为特征(X)和标签(y),并将其进一步划分为训练集和测试集。接下来,我们建立了一个随机森林分类器模型,并在训练集上训练该模型。最后,我们在测试集上进行预测,并计算了模型的准确率。
你可以根据实际情况扩展和优化这个示例,例如尝试不同的特征工程方法、调整模型参数、尝试其他机器学习模型等,以提高事件预测的准确性。

(十)事件驱动交易策略示例代码
要开发事件驱动的交易策略,你可以结合事件预测结果和市场数据来制定交易决策。下面是一个简单的示例代码,演示了如何根据事件预测结果生成交易信号,并模拟交易策略:
import pandas as pd# 创建一个示例数据集,包括事件预测结果和市场数据
data = {'Date': pd.date_range(start='2024-01-01', periods=30),'Event_Prediction': [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0],'Price': [100, 102, 98, 105, 99, 101, 97, 104, 96, 103, 95, 107, 93, 106, 94, 108, 92, 109, 91, 110, 90, 111, 89, 112, 88, 113, 87, 114, 86, 115]
}df = pd.DataFrame(data)# 根据事件预测结果生成交易信号
df['Signal'] = df['Event_Prediction'].shift(1)
# 使用前一天的事件预测结果生成交易信号,这里简单地使用前一天的事件预测结果作为交易信号# 模拟交易策略
df['Position'] = df['Signal'].diff() # 计算每天的头寸变化,即信号变化
df['Profit'] = df['Position'] * df['Price'].shift(-1) # 计算每天的收益,即头寸变化乘以下一天的价格变化# 打印交易信号和收益
print(df[['Date', 'Price', 'Signal', 'Position', 'Profit']])
在这个示例中,我们根据事件预测结果生成交易信号,并基于这些信号模拟了一个简单的交易策略。我们使用前一天的事件预测结果作为当天的交易信号,计算了每天的头寸变化和收益情况。
这只是一个简单的示例,实际的事件驱动交易策略可能会更加复杂,涉及更多因素和数据。你可以根据实际情况扩展和优化这个示例,以开发更加有效的事件驱动交易策略。

(十一)事件-价格预测模型示例代码
要构建事件与股票价格之间的预测模型,可以结合事件特征和股票价格数据,利用机器学习算法进行建模。下面是一个简单的示例代码,演示如何构建事件-价格预测模型:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error# 创建一个示例数据集,包括事件特征、股票价格和事件影响标签
data = {'Date': pd.date_range(start='2023-01-01', periods=100),'Event_Feature_1': [0.1, 0.2, 0.3, 0.1, 0.4] * 20,'Event_Feature_2': [0.2, 0.3, 0.1, 0.4, 0.2] * 20,'Stock_Price': [100, 105, 102, 98, 110] * 20,'Event_Impact': [0.1, 0.2, -0.1, 0.3, 0.2] * 20 # 事件对股票价格的影响程度
}# 将数据转换为DataFrame
df = pd.DataFrame(data)# 划分特征和标签
X = df[['Event_Feature_1', 'Event_Feature_2', 'Event_Impact']]
y = df['Stock_Price']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 建立随机森林回归模型
rf_model = RandomForestRegressor(random_state=42)
rf_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = rf_model.predict(X_test)# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("模型在测试集上的均方误差:", mse)
在这个示例中,我们创建了一个示例的数据集,包括事件特征、股票价格和事件对股票价格的影响程度。然后,我们将数据划分为特征(X)和标签(y),并将其进一步划分为训练集和测试集。接着,我们建立了一个随机森林回归模型,并在训练集上训练该模型。最后,我们在测试集上进行股票价格的预测,并计算了模型的均方误差。
你可以根据实际情况扩展和优化这个示例,例如尝试不同的特征工程方法、调整模型参数、尝试其他回归模型等,以提高事件对股票价格的影响程度的预测准确性。
(十二)事件分类器
要构建一个事件分类器,并对事件进行重要性评分,以更精细地分析事件对市场的影响,可以使用机器学习方法。下面是一个示例代码,演示如何构建事件分类器并评估事件的重要性:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score# 创建一个示例数据集,包括事件文本和事件重要性标签
data = {'Event_Text': ['公司发布财报', '政府发布经济数据', '新产品发布', 'CEO辞职', '并购消息'],'Event_Importance': [1, 2, 1, 3, 2] # 事件重要性评分,1为低,3为高
}# 将数据转换为DataFrame
df = pd.DataFrame(data)# 特征工程:使用TF-IDF向量化文本特征
tfidf = TfidfVectorizer()
X = tfidf.fit_transform(df['Event_Text'])y = df['Event_Importance']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 建立随机森林分类器模型
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = rf_model.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型在测试集上的准确率:", accuracy)
在这个示例中,我们创建了一个示例的数据集,包括事件文本和事件重要性标签。然后,我们使用TF-IDF向量化文本特征,并将事件重要性作为标签。接着,我们建立了一个随机森林分类器模型,并在训练集上训练该模型。最后,我们在测试集上进行事件重要性的预测,并计算了模型的准确率。
你可以根据实际情况扩展和优化这个示例,例如尝试不同的文本特征提取方法、调整模型参数、尝试其他分类器模型等,以更精细地分析事件对市场的影响。
八、情绪分析示例代码
 要进行情绪分析并了解投资者情绪对股票价格和交易量的影响,可以结合社交媒体数据或新闻数据,利用情感分析技术来分析文本数据中的情绪。下面是一个示例代码,演示如何使用情感分析对文本数据进行情绪分析:
要进行情绪分析并了解投资者情绪对股票价格和交易量的影响,可以结合社交媒体数据或新闻数据,利用情感分析技术来分析文本数据中的情绪。下面是一个示例代码,演示如何使用情感分析对文本数据进行情绪分析:
import pandas as pd
from textblob import TextBlob# 创建一个示例数据集,包括文本数据
data = {'Text': ['股市今天表现不错,投资者信心高涨。','市场波动较大,投资者情绪开始恶化。','新闻报道称公司业绩不佳,投资者情绪受挫。']
}# 将数据转换为DataFrame
df = pd.DataFrame(data)# 对文本数据进行情感分析
def analyze_sentiment(text):analysis = TextBlob(text)sentiment = analysis.sentiment.polarityif sentiment > 0:return'积极情绪'elif sentiment < 0:return '负面情绪'else:return '中性情绪'# 添加情绪分析结果到数据集
df['Sentiment'] = df['Text'].apply(analyze_sentiment)# 输出情绪分析结果
print(df)
在这个示例中,我们使用TextBlob库对文本数据进行情感分析。定义了一个analyze_sentiment函数,该函数计算文本的情感极性,并根据情感极性返回情绪分类。然后,我们将情绪分析结果添加到数据集中,并输出结果。
通过这种方式,你可以对社交媒体数据或新闻数据进行情感分析,以了解投资者情绪对股票价格和交易量的影响。你可以进一步分析情绪与股票价格、交易量之间的关联,以帮助预测市场走势和指导投资决策。
九、机器学习预测示例代码
 要使用机器学习算法来预测股票价格走势或交易量的未来变化,你可以使用Pandas来处理数据,并结合机器学习库(如scikit-learn)来构建预测模型。下面是一个简单的示例代码,演示如何使用线性回归算法来预测股票价格的未来变化:
要使用机器学习算法来预测股票价格走势或交易量的未来变化,你可以使用Pandas来处理数据,并结合机器学习库(如scikit-learn)来构建预测模型。下面是一个简单的示例代码,演示如何使用线性回归算法来预测股票价格的未来变化:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 创建一个示例数据集,包括股票价格和特征数据
data = {'Date': pd.date_range(start='1/1/2022', periods=100),'Price': np.random.randint(100, 200, 100),'Feature1': np.random.rand(100),'Feature2': np.random.rand(100)
}# 将数据转换为DataFrame
df = pd.DataFrame(data)# 创建特征集和目标变量
X = df[['Feature1', 'Feature2']]
y = df['Price']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)# 进行预测
y_pred = model.predict(X_test)# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print('均方误差:', mse)
在这个示例中,我们生成了一个包含股票价格和两个特征数据的示例数据集。然后,我们将数据分为特征集(X)和目标变量(y),划分训练集和测试集,创建并训练了一个线性回归模型。最后,我们用模型进行预测,并计算了预测结果的均方误差。
你可以根据实际情况选择不同的特征、算法和参数来构建更复杂的预测模型,以预测股票价格走势或交易量的未来变化。这种方法可帮助你利用历史数据进行预测,指导投资决策。
十、可视化分析示例代码
 要使用数据可视化工具(如Matplotlib、Seaborn或Plotly)来创建交互式图表和仪表板,以展示股票数据分析的结果,你可以结合Pandas和这些库来实现。下面是一个示例代码,演示如何使用Matplotlib和Pandas创建股票价格走势图:
要使用数据可视化工具(如Matplotlib、Seaborn或Plotly)来创建交互式图表和仪表板,以展示股票数据分析的结果,你可以结合Pandas和这些库来实现。下面是一个示例代码,演示如何使用Matplotlib和Pandas创建股票价格走势图:
import pandas as pd
import matplotlib.pyplot as plt# 创建一个示例数据集,包括日期和股票价格
data = {'Date': pd.date_range(start='1/1/2022', periods=100),'Price': np.random.randint(100, 200, 100)
}# 将数据转换为DataFrame
df = pd.DataFrame(data)# 设置日期为索引
df.set_index('Date', inplace=True)# 创建股票价格走势图
plt.figure(figsize=(12, 6))
plt.plot(df.index, df['Price'], label='股票价格')
plt.title('股票价格走势图')
plt.xlabel('日期')
plt.ylabel('价格')
plt.legend()
plt.show()
这段代码将生成一个简单的股票价格走势图,展示了股票价格随时间变化的情况。你也可以使用Seaborn或Plotly来创建更丰富的交互式图表和仪表板,以展示更多股票数据分析的结果。
当使用Seaborn进行股票市场数据分析可视化时,你可以创建各种类型的图表来展示数据。以下是一些示例代码,展示如何使用Seaborn库创建不同类型的股票市场数据可视化图表:
- 股票价格走势图:
import matplotlib.pyplot as plt
import seaborn as sns# 假设df是包含股票价格数据的DataFrame,日期作为索引
sns.set(style="whitegrid")
plt.figure(figsize=(12, 6))
sns.lineplot(data=df['Close'])
plt.title('Stock Price Trend')
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()
- 技术指标分析图:
plt.figure(figsize=(12, 6))
sns.lineplot(data=df[['Close', 'MA_50', 'MA_200']])
plt.title('Moving Averages Analysis')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend(['Close', 'MA 50', 'MA 200'])
plt.show()
- 波动性分析图:
plt.figure(figsize=(12, 6))
sns.histplot(df['Volatility'], bins=30, kde=True)
plt.title('Volatility Distribution')
plt.xlabel('Volatility')
plt.ylabel('Frequency')
plt.show()
- 相关性热力图:
correlation = df.corr()
plt.figure(figsize=(10, 8))
sns.heatmap(correlation, annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap')
plt.show()
这些示例代码演示了如何使用Seaborn库创建股票市场数据的不同可视化图表,包括股价走势图、技术指标分析图、波动性分析图和相关性热力图。通过这些可视化图表,可以更直观地理解股票市场数据,并帮助做出更准确的分析和决策。
当使用Plotly时,你可以创建更丰富的交互式图表和仪表板,以展示更多股票数据分析的结果。下面是一个示例代码,演示如何使用Plotly创建一个交互式股票价格走势图:
import pandas as pd
import plotly.express as px# 创建一个示例数据集,包括日期和股票价格
data = {'Date': pd.date_range(start='1/1/2022', periods=100),'Price': np.random.randint(100, 200, 100)
}# 将数据转换为DataFrame
df = pd.DataFrame(data)# 使用Plotly创建交互式股票价格走势图
fig = px.line(df, x='Date', y='Price', title='股票价格走势图')
fig.update_xaxes(title_text='日期')
fig.update_yaxes(title_text='价格')
fig.show()
这段代码将生成一个交互式股票价格走势图,你可以通过鼠标悬停查看具体数据点的数值,放大或缩小图表等。Plotly提供了丰富的交互功能,能够更直观地展示股票数据分析的结果。
除了股票价格走势图,你还可以使用Plotly创建更多类型的图表,如热力图、散点图、直方图等,以更全面地展示股票数据的特征和趋势。
十一、知识点归纳总结
 在使用Pandas进行股票市场数据分析时,以下是一些重要的知识点归纳总结:
在使用Pandas进行股票市场数据分析时,以下是一些重要的知识点归纳总结:
-
数据导入与处理:
-使用Pandas的read_csv()函数导入股票市场数据文件,创建DataFrame。
-使用head()、info()、describe()等方法查看数据的前几行、信息和统计摘要。
-处理缺失值:使用dropna()删除缺失值或fillna()填充缺失值。 -
时间序列处理:
-将日期列转换为Datetime类型,设置为索引。
-使用resample()方法对时间序列数据进行重采样,如按月、季度或年。
-使用shift()方法计算收盘价的涨跌幅。 -
技术指标分析:
-计算移动平均线(MA)和指数移动平均线(EMA)。
-计算相对强弱指数(RSI)、布林带(Bollinger Bands)等技术指标。
-可以使用Pandas的rolling()函数进行滚动计算。 -
波动性分析:
-计算股价的波动性,如历史波动率。
-使用波动率指标(如ATR)评估股票的波动情况。
-可以使用Pandas的pct_change()计算价格的变化率。 -
基于事件驱动的分析:
-进行情感分析:利用自然语言处理技术对新闻或社交媒体情绪进行分析,了解市场情绪对股价的影响。
-事件相关性分析:研究特定事件对股票价格和交易量的影响,如公司发布财报、政治事件等。
-事件预测:结合历史数据和事件数据,尝试预测未来股票价格的走势。 -
交易策略分析:
-开发和测试交易策略:利用历史数据回测不同的交易策略,评估其盈利能力和风险。
-量化分析:使用数据驱动的方法制定交易策略,如均值回归策略、趋势跟踪策略等。 -
数据可视化:
-使用Matplotlib、Seaborn和Plotly等库创建股票数据可视化图表,如线图、柱状图、热力图等。
-可视化技术指标和波动性分析结果,帮助更直观地理解股票市场数据。
 以上知识点涵盖了使用Pandas进行股票市场数据分析的关键内容,包括数据处理、技术指标分析、波动性分析、基于事件驱动的分析、交易策略分析和数据可视化。这些技能可以帮助投资者更好地理解市场走势、制定有效的交易策略,并提高投资决策的准确性和效率。如果你有任何进一步的问题或需要帮助,请随时告诉我。
以上知识点涵盖了使用Pandas进行股票市场数据分析的关键内容,包括数据处理、技术指标分析、波动性分析、基于事件驱动的分析、交易策略分析和数据可视化。这些技能可以帮助投资者更好地理解市场走势、制定有效的交易策略,并提高投资决策的准确性和效率。如果你有任何进一步的问题或需要帮助,请随时告诉我。
相关文章:
第三篇【传奇开心果系列】Python的自动化办公库技术点案例示例:深度解读Pandas股票市场数据分析
传奇开心果博文系列 系列博文目录Python的自动化办公库技术点案例示例系列 博文目录前言一、Pandas进行股票市场数据分析常见步骤和示例代码1. 加载数据2. 数据清洗和准备3. 分析股票价格和交易量4. 财务数据分析 二、扩展思路介绍1. 技术指标分析2. 波动性分析3. 相关性分析4.…...

3.11笔记2
目前使用的格里高利历闰年的规则如下: 公元年分非4的倍数,为平年。公元年分为4的倍数但非100的倍数,为闰年。公元年分为100的倍数但非400的倍数,为平年。公元年分为400的倍数为闰年。 请用一个表达式 (不能添加括号) 判断某一年…...
web服务器基础
目录 web服务器简介 (1)什么是www (2)网址及HTTP简介 (3)http协议请求的工作流程 主配置文件内的参数 目录标签 缺点 虚拟主机vhosts 示例的格式如下 实例 多IP实现多网页 修改监听端口号 hosts文件及域名解析 修改hosts文件内缓存格式 实现效果 实现多域名解析IP地址 在linux…...
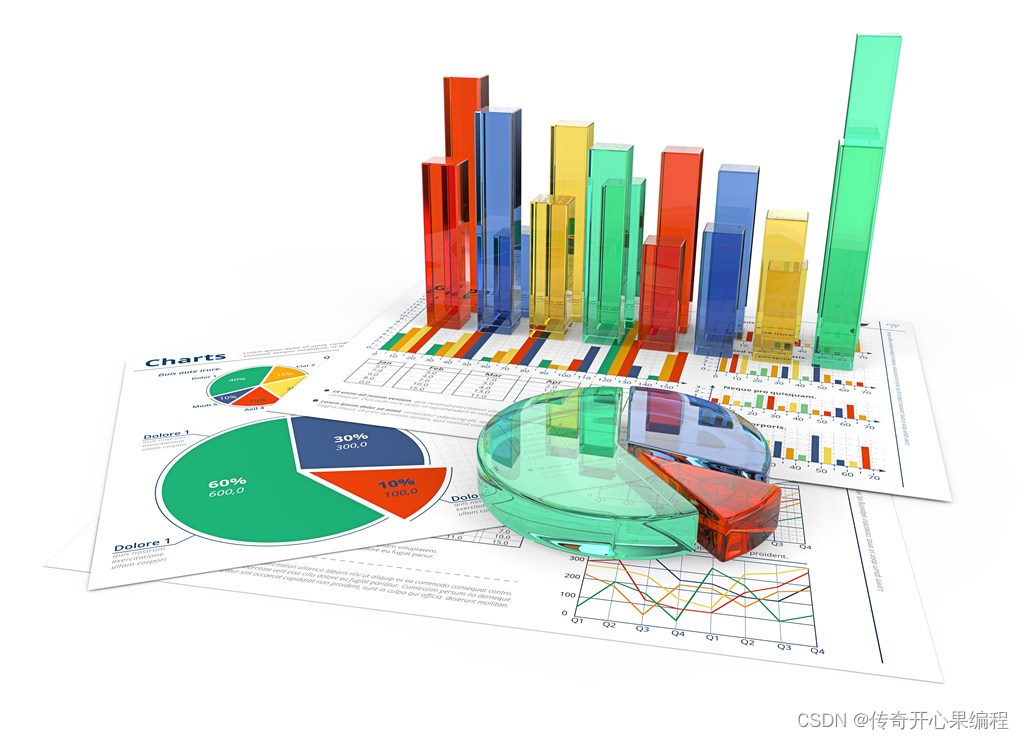
矢量图片转换软件Vector Magic mac中文版功能特色
Vector Magic mac中文版是一款非常流行的矢量图片转换软件,它的功能特色主要体现在以下几个方面: 首先,Vector Magic mac中文版拥有出色的矢量转换能力。它采用世界上最好的全彩色自动描摹器,能够将JPG、PNG、BMP和GIF等位图图像…...
Window部署Oracle并实现公网环境远程访问本地数据库
文章目录 前言1. 数据库搭建2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射 3. 公网远程访问4. 配置固定TCP端口地址4.1 保留一个固定的公网TCP端口地址4.2 配置固定公网TCP端口地址4.3 测试使用固定TCP端口地址远程Oracle 前言 Oracle,是甲骨文公司的一款关系…...
灵魂指针,教给(三)
欢迎来到白刘的领域 Miracle_86.-CSDN博客 系列专栏 C语言知识 先赞后看,已成习惯 创作不易,多多支持! 目录 一、 字符指针变量 二、数组指针变量 2.1 数组指针变量是什么 2.2 数组指针变量如何初始化 三、二维数组传参本质 四、函数…...
纯手工搭建一个springboot maven项目
前言:idea社区版无法自动搭建项目,手动搭建的经验分享如下: 1 包结构 参考下图: 2 项目结构 3 maven依赖 具体的项目包结构如下图: 依据这个项目包结构配置一个springboot 的 pom依赖: <?xml ve…...

【Java】使用`LinkedList`类来实现一个队列,并通过继承`AbstractQueue`或者实现`Queue`接口来实现自定义队列
使用LinkedList类来实现一个队列,并通过继承AbstractQueue或者实现Queue接口来实现自定义队列。 以下是一个简单的示例,其中队列的大小与另一个List的容量保持一致: import java.util.LinkedList; import java.util.List; import java.util…...

ChatGPT消息发不出去了?我找到解决方案了
现象 今天忽然发现 ChatGPT无法发送消息,能查看历史对话,但是无法发送消息。 猜测原因 出现这个问题的各位,应该都是点击登录后顶部弹窗邀请[加入多语言 alapha 测试]了,并且语言选择了中文,抓包看到ab.chatgpt.com…...

《量子计算:下一个大风口,还是一个热炒概念?》
引言 量子计算,作为一项颠覆性的技术,一直以来备受关注。它被认为是未来计算领域的一次革命,可能改变我们对计算能力和数据处理的理解。然而,随着技术的不断进步和商业应用的探索,人们开始思考,量子计算到底是一个即将到来的大风口,还是一个被过度炒作的概念? 量子计…...

在Ubuntu中如何基于conda安装jupyterlab
在Ubuntu中如何创建ipykernel 可以用下面命令完成 conda create -n newenv python3.8conda activate enwenvconda install ipykernel5.1.4conda install ipython_genutilsipython -m ipykernel install --user --namepython3 --display-name Python3conda install -c conda-fo…...

Unity 中的 PlayFab 入门
要开始在 Unity 中使用 PlayFab,你只需执行以下两个简单步骤即可。第一步是设置 PlayFab 帐户。第二步是通过安装 Unity 编辑器扩展将其连接到 Unity。或者,你也可以下载 PlayFab SDK 并在没有扩展的情况下进行配置。 设置你的 PlayFab 帐户 访问 PlayFab 的网站并创建你的…...
)
常见排序算法(C++)
评判一个排序算法时除了时间复杂度和空间复杂度之外还要考虑对cache的捕获效果如何,cache友好的排序算法应该对数据的访问相对集中,快速排序相较于堆排序优点就是在于对cache的捕获效果好。 堆排序 时间复杂度:O(n log n …...

多线程编程互斥锁mutex的创建
在Linux下的多线程编程中,互斥锁(mutex)的创建主要有两种方式:静态分配和动态分配。这两种方式的主要区别在于互斥锁的生命周期和初始化方式。 静态分配(静态方式) 静态分配方式是在程序编译时就已经确定互…...

在 SpringBoot3 中使用 Mybatis-Plus 报错
在 SpringBoot3 中使用 Mybatis-Plus 报错 Property ‘sqlSessionFactory’ or ‘sqlSessionTemplate’ are required Caused by: java.lang.IllegalArgumentException: Property sqlSessionFactory or sqlSessionTemplate are requiredat org.springframework.util.Assert.no…...
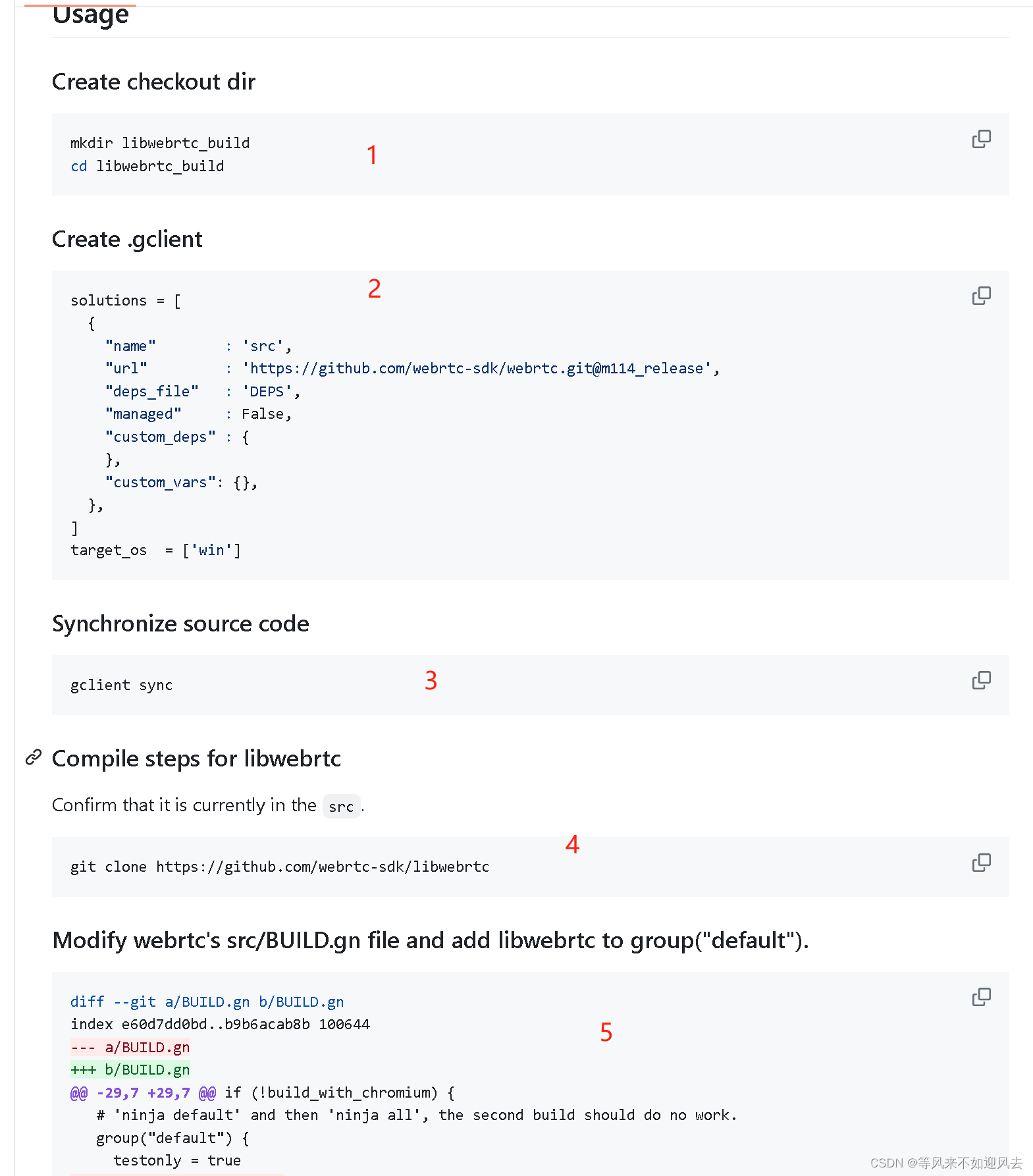
【libwebrtc】基于m114的构建
libwebrtc A C++ wrapper for binary release, mainly used for flutter-webrtc desktop (windows, linux, embedded).是 基于m114版本的webrtc 最新(20240309 ) 的是m122了。官方给出的构建过程 .gclient 文件 solutions = [{"name" : src,"url...
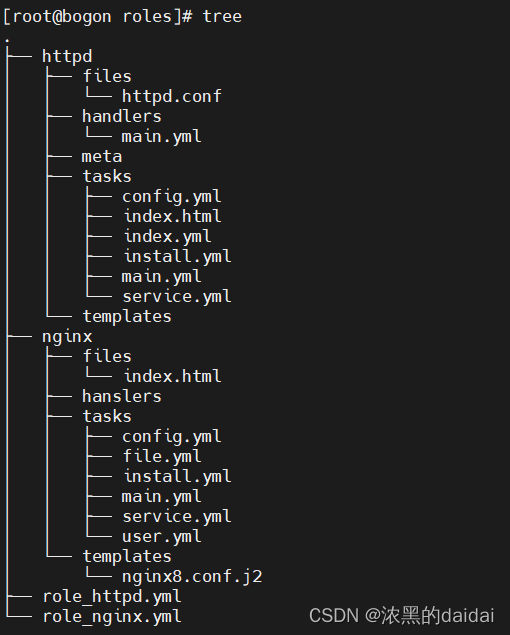
ansible-playbook的角色(role)
1前言 角色目录如下(分别为httpd角色和nginx角色) handlers/ :至少应该包含一个名为 main.yml 的文件; 其它的文件需要在此文件中通过include 进行包含 vars/ :定义变量,至少应该包含一个名为 main.yml 的…...
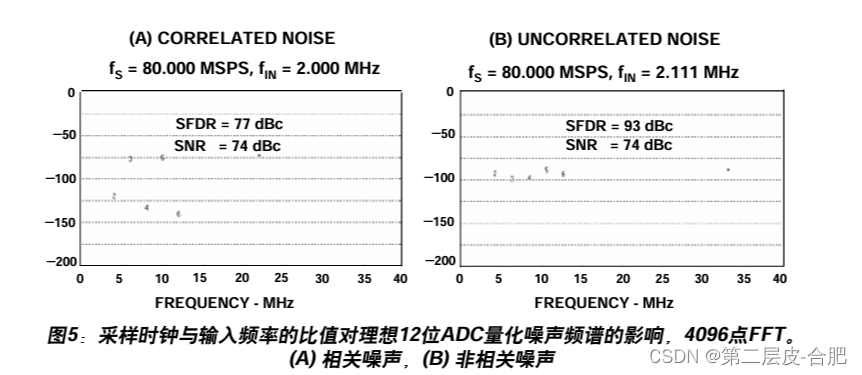
SNR = 6.02N + 1.76dB 公式推导
简介 接触ADC或DAC时您一定会碰到这个经常被引用的公式,用于计算转换器理论信噪比 (SNR)。与其盲目地相信表象,不如从根本上了解其来源,因为该公式蕴含着一些微妙之 处,如果不深入探究,可能导致对数据手册技术规格和转…...

归并排序 刷题笔记
归并排序的写法 归并排序 分治双指针 1.定义一个mid if(l>r)return ; 2.分治 sort(q,l,mid); sort(q,mid1,r); 3. 双指针 int il,jmid,k0; 将双序列扫入 缓存数组 条件 while(i<mid&&j<r) 两个数列比较大小 小的一方 进入缓存数组 4. 扫尾 while(…...

字节一面:TCP 和 UDP 可以使用同一个端口吗?
数据包是计算机网络通信的核心,包含头部和数据负载。TCP和UDP协议在传输层使用端口号区分服务和应用。操作系统通过IP头部中的协议字段和端口号来管理网络流量,确保TCP和UDP流量即使共用端口号也不会相互干扰。 在现代计算机网络中,数据传输…...

Claude Code 之父:2026 年我一行代码都没写,编程已被 AI 解决
2026 年,你还在一行一行敲代码吗?Claude Code 的创造者、Anthropic 核心人物 Boris Cherny,在公开访谈里抛出一句让整个行业震动的话:2026 年到现在,我没有写过一行代码。所有开发工作,100% 交给 AI 代理完…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...

告别RaiDrive广告!用开源rclone+Alist,免费把阿里云盘/百度网盘变成电脑本地硬盘
开源方案实战:用rcloneAlist打造无广告的云盘本地化体验 每次打开RaiDrive时弹出的广告窗口是否让您感到困扰?商业软件的收费模式是否让您犹豫不决?今天,我们将彻底解决这些问题。通过开源工具Alist和rclone的组合,您不…...

从‘找不到dll’到流畅运行:一份给VS2022新手的Zbar+OpenCV3.6.0环境配置避坑指南
从“找不到dll”到流畅运行:VS2022下ZbarOpenCV3.6.0环境配置全解析 当你第一次在Visual Studio 2022中尝试整合Zbar和OpenCV 3.6.0时,可能会遇到各种令人沮丧的错误提示。最常见的就是那个让人头疼的“找不到libzbar64-0.dll”问题。本文将带你一步步解…...

[特殊字符] 高效统计排序数组中目标元素的出现次数
给定一个已排序的数组和一个目标值,如何快速统计该目标值在数组中出现的次数?这是面试中非常经典的一道题,今天就来聊聊两种解法:线性搜索和二分搜索。 问题描述 假设有一个已排序的数组 arr[] 和一个整数 target,需…...

机器学习赋能分子模拟:从数据驱动CV到自适应采样破解采样瓶颈
1. 项目概述与核心价值在分子模拟的世界里,我们常常面临一个根本性的困境:我们想理解一个复杂系统(比如一个蛋白质如何折叠,或者一个催化剂表面如何发生反应)的微观机理,但系统的相空间维度高得吓人——动辄…...

终极跨平台空洞骑士模组管理器:Lumafly如何让模组管理变得简单高效
终极跨平台空洞骑士模组管理器:Lumafly如何让模组管理变得简单高效 【免费下载链接】Lumafly A cross platform mod manager for Hollow Knight written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/lu/Lumafly 你是否曾经因为空洞骑士模组安装…...

如何精准识别高校院所与企业之间的潜在合作机会?
核心要点 传统“相亲角”式校企对接效率低下,根源在于科研供给与市场需求间的信息断层,必须转向以数据驱动、模型研判为核心的精准识别机制,才能将模糊的产学研线索转化为可落地的合作机会。精准识别合作机会的关键在于分拆为“供给侧”与“需…...