数据集踩的坑及解决方案汇总
数据集踩的坑及解决方案汇总
- 数据集各种格式
- 构建并训练自己的数据集汇总
- Yolo系列
- SSD
- Mask R-CNN
- 报错 NotADirectoryError: [Errno 20] Not a directory: '/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed2/labelme_json/.DS_Store'
- Faster R-CNN
- 数据的格式转换
- 划分数据集
- 设定内容居中、居左、居右
- SmartyPants
- 关于连接远程服务器的坑
- 如何创建一个注脚
- 注释也是必不可少的
- KaTeX数学公式
- 新的甘特图功能,丰富你的文章
- UML 图表
- FLowchart流程图
- 导出与导入
- 导出
- 导入
数据集各种格式
ssd支持的训练格式为VOC和Coco
Yolo支持的训练格式:VOC或COCO
Faster R-CNN支持的训练格式:VOC或COCO
Mask R-CNN支持的训练格式:Coco
Transformer支持的训练格式:BPE。
Voc格式长这样

- JPEGImages:存放的是训练与测试的所有图片。
- Annotations(注释):数据集标签的存储路径,通过XML文件格式,为图像数据存储各类任务的标签。其中部分标签为目标检测的标签。里面存放的是每张图片打完标签所对应的XML文件。
- ImageSets:ImageSets文件夹下本次讨论的只有Main文件夹,此文件夹中存放的主要又有四个文本文件test.txt、train.txt、trainval.txt、val.txt,
其中分别存放的是测试集图片的文件名、训练集图片的文件名、训练验证集图片的文件名、验证集图片的文件名。- SegmentationClass与SegmentationObject:存放的都是图片,且都是图像分割结果图,对目标检测任务来说没有用。class
- segmentation 标注出每一个像素的类别 object segmentation 标注出每一个像素属于哪一个物体。目录如下所示
voc数据集的标签主要以xml文件形式进行存放
Coco格式长这样

- 与VOC一个文件一个xml标准不同的是,COCO所有的目标框标注都是在同一个json里。json解析出来是字典格式。
- COCO格式数据集的目录结构的train2017和val2017成为set_name,annotations文件夹中的json格式的标准文件名要与之对应并以instances_开头。
Yolo格式长这样
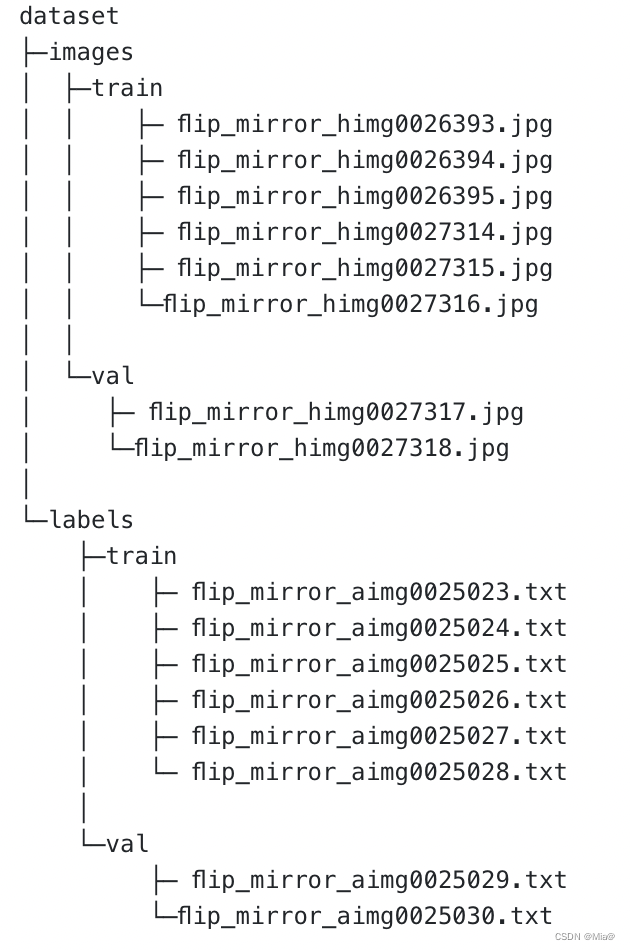
标签用txt存
更多详细介绍http://www.bryh.cn/a/330849.html
OK,接下来总结各种数据格式直接的转换方法
数据集的各种操作
构建并训练自己的数据集汇总
将近期实验中数据集制作及训练的经验做如下汇总:
- Yolo系列 主要是5和7,大差不差
- Mask R-CNN 踩坑最多,最头疼
- Faster R-CNN 功;
- SSD 语法;
- ;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
Yolo系列
1、数据集标注:LabelImg
在线LabelImg参考
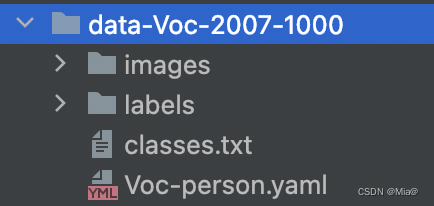
注意最终的数据集文件长这样:
2、训练
在训练过程中遇到的坑及解决方案
1>出现AssertionError:Label class 1 exceeds nc=1 in yolo/dataset.ymal Possible class labels are 0-0
注释掉train.py中下面的代码
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
批量将label中txt中的标签转为0的代码
mport ostxt_folder = "/Volumes/开着UU撞彗星/Git/yolov5-7.0/data-Voc-2007-1000/labels/val" # txt文件所在的文件夹路径# 遍历txt文件列表
for txt_file in os.listdir(txt_folder):if txt_file.endswith(".txt"):txt_path = os.path.join(txt_folder, txt_file)with open(txt_path, "r") as f:lines = f.readlines()# 修改类别索引为0modified_lines = []for line in lines:line = line.strip().split()line[0] = "0" # 将类别索引修改为0modified_lines.append(" ".join(line))# 将修改后的内容写回txt文件with open(txt_path, "w") as f:f.write("\n".join(modified_lines))
查找:Ctrl/Command + F
替换:Ctrl/Command + G
SSD
1、生成自己的数据集
参考
2、训练预测
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
Mask R-CNN
Mask R-CNN 需要的数据集格式长这样

加粗文本 加粗文本
1、实现labelme批量json_to_dataset方法
参考1
参考2
调试好的代码如下:
Note:需要将图片与json文件全部放在同一个文件夹My-data下
# 增加yaml文件
import argparse
import base64
import json
import os
import os.path as ospimport imgviz
import PIL.Imagefrom labelme.logger import logger
from labelme import utilsimport glob# 最前面加入导包
import yamldef main():logger.warning("This script is aimed to demonstrate how to convert the ""JSON file to a single image dataset.")logger.warning("It won't handle multiple JSON files to generate a ""real-use dataset.")parser = argparse.ArgumentParser()###############################################增加的语句############################### parser.add_argument("json_file")parser.add_argument("--json_dir",default="/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed/My-data")###############################################end###################################parser.add_argument("-o", "--out", default=None)args = parser.parse_args()###############################################增加的语句##############################assert args.json_dir is not None and len(args.json_dir) > 0# json_file = args.json_filejson_dir = args.json_dirif osp.isfile(json_dir):json_list = [json_dir] if json_dir.endswith('.json') else []else:json_list = glob.glob(os.path.join(json_dir, '*.json'))###############################################end###################################for json_file in json_list:json_name = osp.basename(json_file).split('.')[0]out_dir = args.out if (args.out is not None) else osp.join(osp.dirname(json_file), json_name)###############################################end###################################if not osp.exists(out_dir):os.makedirs(out_dir)data = json.load(open(json_file))imageData = data.get("imageData")if not imageData:imagePath = os.path.join(os.path.dirname(json_file), data["imagePath"])with open(imagePath, "rb") as f:imageData = f.read()imageData = base64.b64encode(imageData).decode("utf-8")img = utils.img_b64_to_arr(imageData)label_name_to_value = {"_background_": 0}for shape in sorted(data["shapes"], key=lambda x: x["label"]):label_name = shape["label"]if label_name in label_name_to_value:label_value = label_name_to_value[label_name]else:label_value = len(label_name_to_value)label_name_to_value[label_name] = label_valuelbl, _ = utils.shapes_to_label(img.shape, data["shapes"], label_name_to_value)label_names = [None] * (max(label_name_to_value.values()) + 1)for name, value in label_name_to_value.items():label_names[value] = namelbl_viz = imgviz.label2rgb(lbl, imgviz.asgray(img), label_names=label_names, loc="rb")PIL.Image.fromarray(img).save(osp.join(out_dir, "img.png"))utils.lblsave(osp.join(out_dir, "label.png"), lbl)PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))with open(osp.join(out_dir, "label_names.txt"), "w") as f:for lbl_name in label_names:f.write(lbl_name + "\n")logger.info("Saved to: {}".format(out_dir))########增加了yaml生成部分logger.warning('info.yaml is being replaced by label_names.txt')info = dict(label_names=label_names)with open(osp.join(out_dir, 'info.yaml'), 'w') as f:yaml.safe_dump(info, f, default_flow_style=False)logger.info('Saved to: {}'.format(out_dir))if __name__ == "__main__":main()最后得到了这样的文件
现在需要将里面的文件夹分离出来,放入名为labelme_json的文件夹下,可以将My Data文件中以.json和.png结尾的文件删除,删除代码如下:
# Python程序删除具有特定扩展名的所有文件
import os
from os import listdir
my_path = '/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed/labelme_json/'for file_name in listdir(my_path):if file_name.endswith('.json'):os.remove(my_path + file_name)2、生成cv2_mask内的黑图(掩码数据)
首先,将label_json文件夹中的label.png(黑图)改为原图名.png
import os
for root, dirs, names in os.walk("/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed/labelme_json"): # 改成你自己的labelme_json文件夹所在的目录for dr in dirs:file_dir = os.path.join(root, dr)# print(dr)file = os.path.join(file_dir, 'label.png')# print(file)new_name = dr.split('_')[0] + '.png'new_file_name = os.path.join(file_dir, new_name)os.rename(file, new_file_name)然后,
import os
path='labelme_json'
files=os.listdir(path)
for file in files:jpath=os.listdir(os.path.join(path,file))
# print(file[:-5])new=file[:-5]
# print(jpath[0])
# newname=os.path.join(path,file,new)newnames=os.path.join('cv2_mask的文件位置',new)filename=os.path.join(path,file,jpath[0])print(filename)print(newnames)os.rename(filename,newnames+'.png')报错 NotADirectoryError: [Errno 20] Not a directory: ‘/Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed2/labelme_json/.DS_Store’
原因:M1芯片系统设置
解决参考
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
Faster R-CNN
链接: link.
图片:
带尺寸的图片:
居中的图片:
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
数据的格式转换
- txt转xml(Voc)
- 项目2
- 项目3
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的代码片.
// An highlighted block
var foo = 'bar';
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
划分数据集
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' | ‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" | “Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash | – is en-dash, — is em-dash |
关于连接远程服务器的坑
参考1
Authors
: John
: Luke
如何创建一个注脚
一个具有注脚的文本。1
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎
相关文章:
数据集踩的坑及解决方案汇总
数据集踩的坑及解决方案汇总 数据集各种格式构建并训练自己的数据集汇总Yolo系列SSDMask R-CNN报错 NotADirectoryError: [Errno 20] Not a directory: /Users/mia/Desktop/P-Clean/mask-RCNN/PennFudanPed2/labelme_json/.DS_StoreFaster R-CNN数据的格式转换划分数据集设定内…...

机器学习流程—数据预处理 Encoding
机器学习流程—数据预处理 Encoding 在机器学习中,我们经常会遇到分类变量,这些分量变量往往机器学习模型没有办法从中学习,往往有两种,一种是字符型,一种是数值型。通常需要对分类型变量做一些处理,常用的方法有两种:label encoding和one hot encoding。 例如,假设数…...

04-微服务 面试题
目录 1.Spring Cloud 常见的组件有哪些? 2.服务注册和发现是什么意思?(Spring Cloud 如何实现服务注册发现) 3.你们项目负载均衡如何实现的 ? 4.什么是服务雪崩,怎么解决这个问题? 5.你们服务是怎么监控的? 6.微服务限流(漏桶算法、令牌桶算法) 7.解释一下CAP…...

Qt连接所有同类部件到同一个槽函数
void MainWindow::AutoConnectSignals() {// 查找所有 QSpinBoxconst auto spinBoxes findChildren<QSpinBox*>();for (auto *spinBox : spinBoxes){connect(spinBox, static_cast<void(QSpinBox::*)(int)>(&QSpinBox::valueChanged), this, &ParameterW…...

spring boot 使用 webservice
spring boot 使用 webservice 使用 java 自带的 jax-ws 依赖 如果是jdk1.8,不需要引入任何依赖,如果大于1.8 <dependency><groupId>javax.jws</groupId><artifactId>javax.jws-api</artifactId><version>1.1</version&g…...

【嵌入式】嵌入式系统稳定性建设:最后的防线
🧑 作者简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟。提供嵌入式方向的学习指导、简历面…...
【算法】一类支持向量机OC-SVM
【算法】一类支持向量机OC-SVM 前言一类支持向量机OC-SVM 概念介绍示例编写数据集创建实现一类支持向量机OC-SVM完整的示例输出 前言 由于之前毕设期间主要的工具就是支持向量机,从基础的回归和分类到后来的优化,在接触到支持向量机还有一类支持向量机的…...
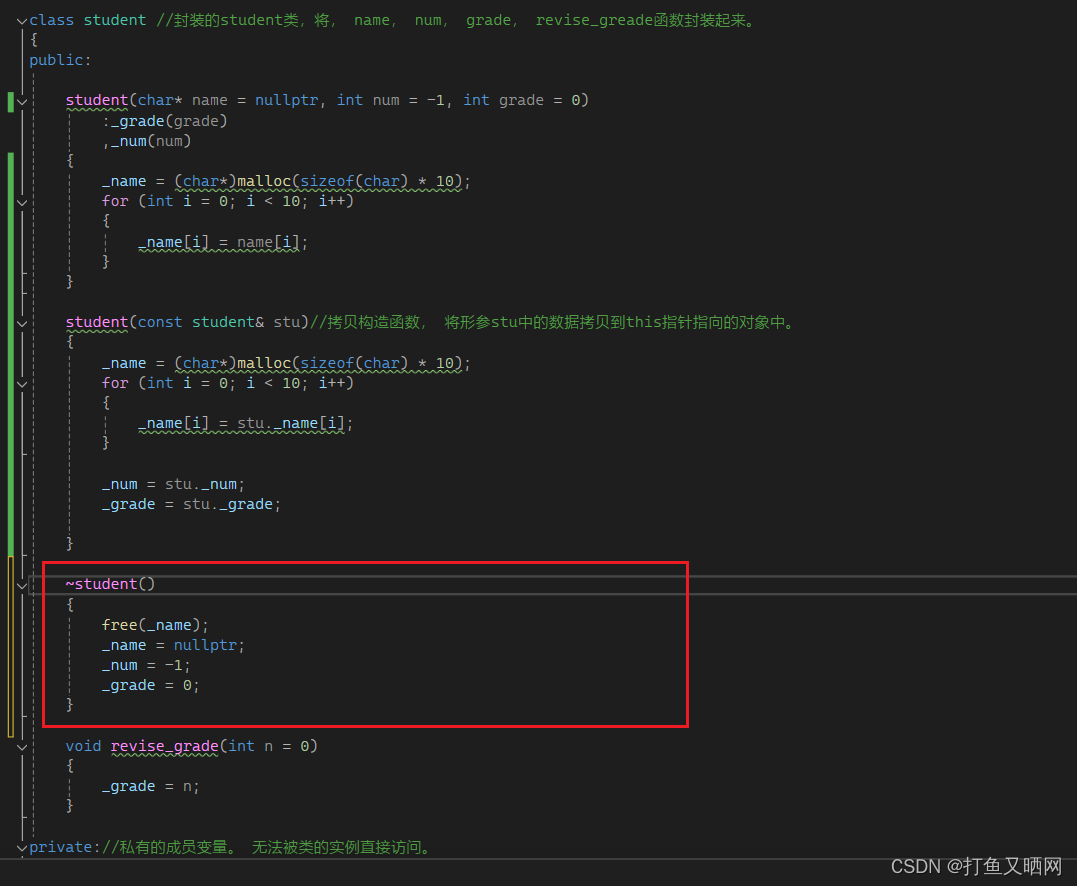
深入学习默认成员函数——c++指南
前言:类和对象是面向对象语言的重要概念。 c身为一门既面向过程,又面向对象的语言。 想要学习c, 首先同样要先了解类和对象。 本节就类和对象的几种构造函数相关内容进行深入的解析。 目录 类和对象的基本概念 封装 类域和类体 访问限定符…...

psutil, 一个超级有用的Python库
Python的psutil是一个跨平台的库,可以用于获取系统运行时的各种信息,包括CPU使用率、内存使用情况、磁盘和网络信息等。它主要用来做系统监控,性能分析,进程管理。它实现了同等命令行工具提供的功能,如ps、top、lsof、…...

[Python]`threading.local`创建线程本地数据
在Python中,threading.local是一个用于创建线程本地数据的工具。它允许每个线程拥有自己独立的变量副本,这样可以在多线程程序中避免共享变量带来的问题。 通过使用threading.local,你可以为每个线程创建一个独立的变量空间,这样…...

删除数据表
oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 删除数据表属于数据库对象的操作 drop table 表名称; 删除 emp30 表 SQL> drop table emp30;表已删除。 上面这个语句运行后,就会把数据表 emp30 删除 在…...

前端自带的base64转化方法
前端html的base64使用方法window.btoa()和window.atob()_html用window.btoa();-CSDN博客...

图论(二)之最短路问题
最短路 Dijkstra求最短路 文章目录 最短路Dijkstra求最短路栗题思想题目代码代码如下bellman-ford算法分析只能用bellman-ford来解决的题型题目完整代码 spfa求最短路spfa 算法思路明确一下松弛的概念。spfa算法文字说明:spfa 图解: 题目完整代码总结ti…...

.NET Core 日志记录功能详解
在软件开发和运维过程中,日志记录是一个非常重要的功能。它可以帮助开发者跟踪应用程序的运行状况、诊断和监控问题。.NET Core 提供了一个灵活且易于使用的日志系统,本文将详细介绍.NET Core日志的相关概念、配置和使用方法。 1. 什么是日志记录以及它…...

docker——启动各种服务
1.Mysql 2.Redis 3.nginx 4.ES 注意:ES7之后环境为 -e ELASTICSEARCH_HOSTS http://ip地址:9200...
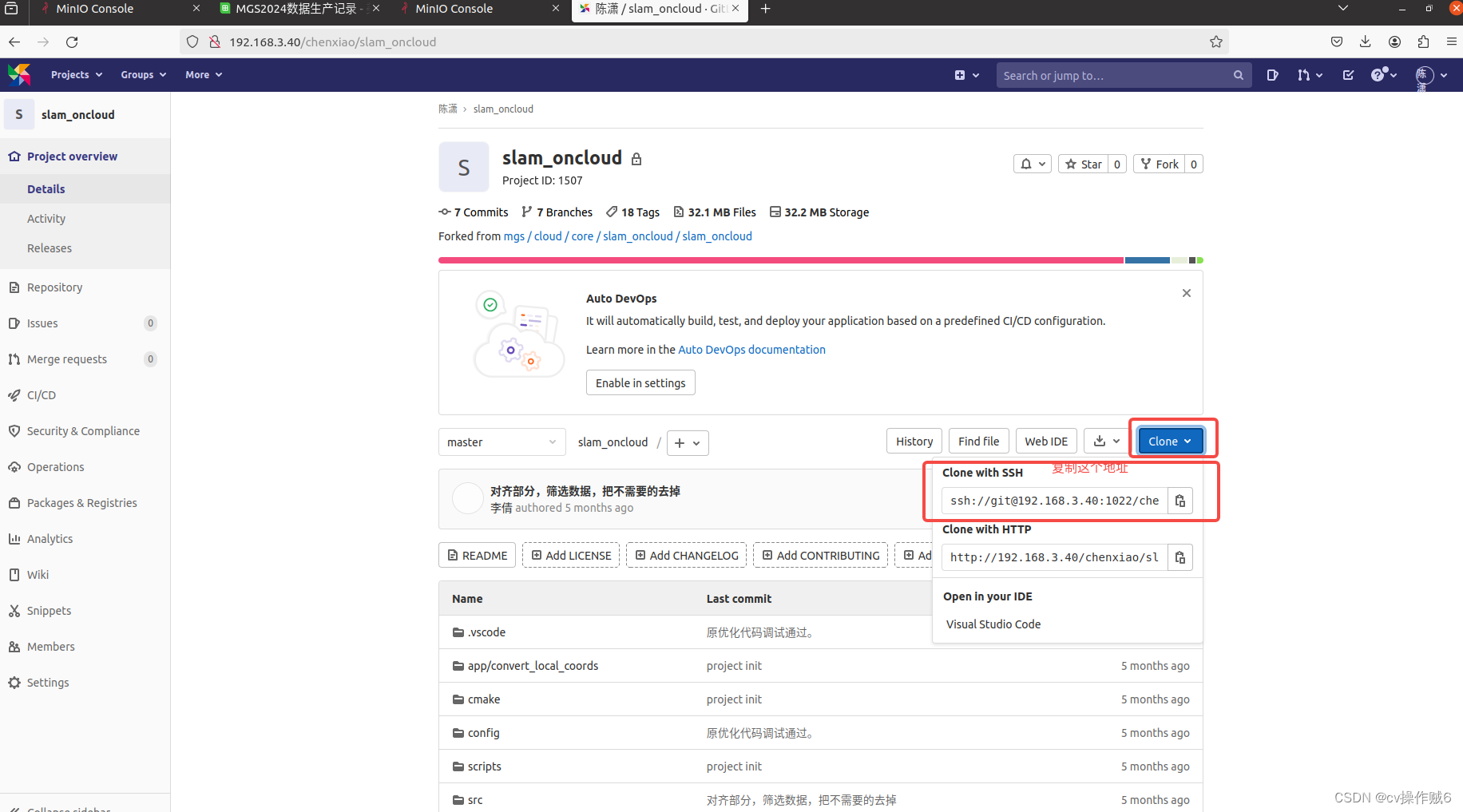
git远程仓库使用
赋值这个地址clone 克隆之后 cd slam_oncloud/ git remote add chenxnew ssh://git192.168.3.40:1022/chenxiao/slam_oncloud.git 查看一下 linuxchenxiao:/media/linux/mydisk/cloud_slam/slam_oncloud$ git remote add chenxnew ssh://git192.168.3.40:1022/chenxiao/sla…...
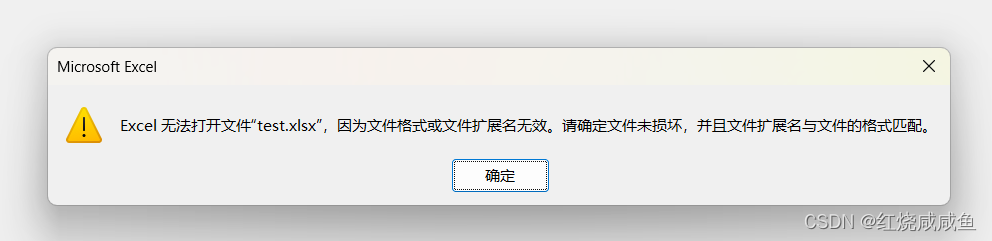
js导出的excel文件无法打开/打开乱码,excel无法打开xxx.xlsx因为文件格式或文件扩展无效
excel无法打开xxx.xlsx因为文件格式或文件扩展无效 使用 a 标签导出这里就不细说了,直接说上述问题解决方案 在调用导出接口的时候加上两个参数 responseType: “blob” responseEncoding: “utf8” export function test(data) {return util({url: /test,method: …...
)
透明多级分流系统(用户端缓存和负载均衡)
部件考虑 有些设备位于客户端或者网络边缘,能够迅速响应用户请求,避免给cpu和数据库带来压力,比如,本地缓存,内容分发网络,反向代理等。 有些设备处理能力能够线性扩展,易于伸缩,应…...

Python sort从大到小排序面试题
在Python中,你可以使用内置的sorted()函数或者列表的sort()方法来对列表中的元素进行从大到小的排序。 使用sorted()函数: numbers [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5] sorted_numbers sorted(numbers, reverseTrue) # 设置reverseTrue实现从大到小排…...

【Stable Diffusion】入门:AI绘画提示词+参数设置攻略
目录 1 提示词1.1 分类和书写方式1.1.1 内容型提示词1.1.2 标准化提示词1.1.3 通用模板 1.2 权重1.2.1 套括号1.2.2 数字权重1.2.3 进阶语法 1.3 负面提示词 2 参数详解2.1 Sampling steps2.2 Sampling method2.3 Width, Height2.4 CFG Scale2.5 Seed2.6 Batch count, Batch si…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

应对Claude Code访问不稳定,快速切换至Taotoken的应急方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对Claude Code访问不稳定,快速切换至Taotoken的应急方案 对于依赖Claude Code进行日常开发或自动化任务的用户来说&a…...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...
)
为什么你的DeepSeek总漏检重构后代码?4步反混淆预处理法(附LLM辅助去装饰器Python脚本)
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

视频转PPT终极指南:3分钟自动化提取教学视频中的幻灯片内容
视频转PPT终极指南:3分钟自动化提取教学视频中的幻灯片内容 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 还在为从海量教学视频中手动截取PPT页面而苦恼吗?…...

数据预处理实战:缺失值、噪声与归一化处理的核心技术与Python实现
1. 项目概述:为什么数据预处理是模型成败的“胜负手” 在数据科学和机器学习的实战中,我见过太多团队将80%的精力投入到模型调参和算法选型上,却对数据预处理草草了事。结果往往是,一个理论上精妙的模型,因为“喂”进去…...

如何3步实现视频字幕精准提取:video-subtitle-extractor终极指南
如何3步实现视频字幕精准提取:video-subtitle-extractor终极指南 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测…...

机器学习在金融风控中的应用:随机森林与SVM银行破产预测对比
1. 项目概述与核心价值在金融这个精密运转的系统中,银行就像心脏,它的每一次搏动都关乎整个经济体的健康。从业十几年,我见过太多因为风险预警失灵而引发的系统性震荡。传统的银行风险评估,比如大家熟知的Altman‘s Z-Score模型&a…...

融合gws-PINNs与马尔可夫切换模型:反演跳跃系数PDE的混合框架
1. 项目概述与核心挑战在科学计算和工程建模领域,我们经常遇到一个“反着来”的难题:已知一个物理系统的观测数据(比如某个区域随时间变化的温度场、流速场),也知道描述这个系统的大致物理规律(比如热传导方…...