docker学习入门篇
1、docker简介
docker官网: www.docker.com
dockerhub官网: hub.docker.com
docker文档官网:docs.docker.com
Docker是基于Go语言实现的云开源项目。
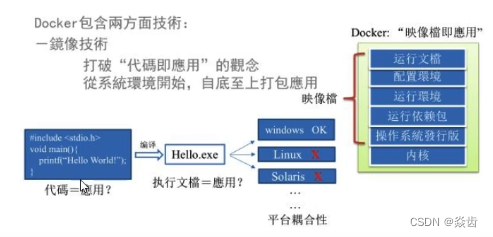
Docker的主要目标是:Build, Ship and Run Any App, Anywhere(构建,装载任何应用在任何地方),也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的APP及其运行环境能做到一次镜像,处处运行。
1.1、docker解决了什么问题?
试想如下场景,是不是经常遇到?
运维/测试: 你的程序不能跑呀!
开发:这里能跑啊!!!
(1)环境不一致导致诸多困扰。换一台机器就要重来一次费时费力。
(2)扩缩容同样也是个棘手问题(因为需要同样的环境),移植非常麻烦。
于是有人在想能不能从根本上解决问题。软件带环境安装,也就是说安装的时候把原始环境一模一样地复制过来。
有个docker后,我们就可以把跑通的程序的源码+配置+环境+版本等统一打包成一个镜像问题。也就是说以前开发提交的只是一份源代码,但是现在变成了源码+配置+环境+依赖包等等。可以以搬家进行比喻。以前搬家要收拾自己的东西,打包、运输、解包,期间肯定会丢失很多东西。有了docker之后搬家就相当于是搬楼,整栋楼移植过去。
注:其实就类似于vmware虚拟机那样,既然虚拟机能把整个系统都打包,那这里把程序依赖打包自然不是什么大问题。
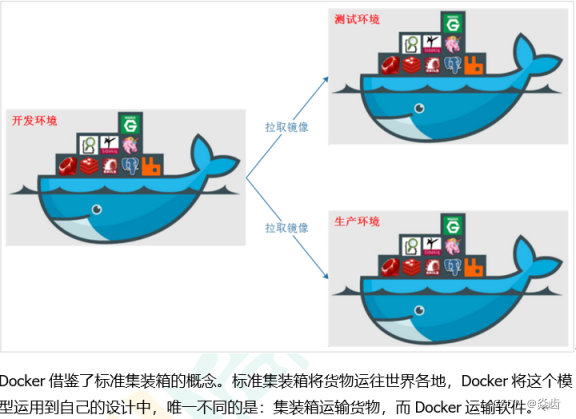
上图中。鲸鱼就是docker,集装箱可以是任何东西,例如redis、mysql、mongodb等。
所以docker的理念也就非常清晰了:
一次镜像,处处运行!!
从搬家到搬楼!!
1.2、传统虚拟机→容器虚拟化技术
传统虚拟机(virtual machine):
传统虚拟机技术基于安装在主操作系统上的虚拟机管理系统(如VirtualBox、VMware等),创建虚拟机(虚拟出各种硬件),在虚拟机上安装从操作系统,在从操作系统中安装部署各种应用。
缺点:资源占用多、冗余步骤多、启动慢
Linux容器(Linux Container,简称LXC):
Linux容器是与系统其他部分分隔开的一系列进程,从另一个镜像运行,并由该镜像提供支持进程所需的全部文件。容器提供的镜像包含了应用的所有依赖项,因而在从开发到测试再到生产的整个过程中,它都具有可移植性和一致性。
Linux容器不是模拟一个完整的操作系统,而是对进程进行隔离。有了容器,就可以将软件运行所需的所有资源打包到一个隔离的容器中。容器与虚拟机不同,不需要捆绑一整套操作系统,只需要软件工作所需的库资源和设置。系统因此而变得高效轻量并保证部署在任何环境中的软件都能始终如一的运行。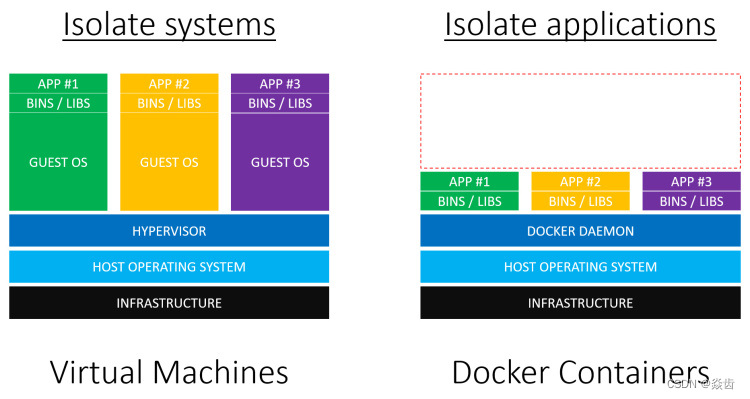
特性对比如下:
| 特性 | 容器 | 虚拟机 |
| 启动 | 秒级 | 分钟级 |
| 大小 | 一般为Mb | 一般为Gb |
| 速度 | 接近原生 | 比较慢 |
| 系统支持数量 | 单机支持上千个容器 | 一般几十个 |
1.3、docker运行速度快的原因
docker有比虚拟机更少的抽象层:
由于docker不需要hypervisor(虚拟机)实现硬件资源虚拟化,运行在Docker容器上的程序直接使用实际物理机的硬件资源,因此在CPU、内存利用率上docker有明显优势。
docker利用的是宿主机的内核,不需要加载操作系统os内核。当新建一个容器时,Docker不需要和虚拟机一样重新加载一个操作系统内核。进而避免引寻、加载操作系统内核返回等比较耗时耗资源的过程。当新建一个虚拟机时,虚拟机软件需要加载OS,返回新建过程是分钟级别的。而Docker由于直接利用宿主机的操作系统,则省略了返回过程,因此新建一个docker容器只需要几秒钟。
Docker容器的本质是一个进程。
1.4、docker带来的影响
DevOps(开发兼运维): 借助docker就可以实现开发运维一体化。
1.5、docker的基本组成
docker。docker本身是一个容器运行载体、管理引擎。其组成包括如下三要素:
①镜像(image)。是一个只读的模板。镜像可以用来创建Docker容器,一个镜像可以创建很多容器。相当于容器的模板,类比到C++中镜像就是类模板。
②容器(container)。通过镜像创建出来的运行实例。容器为镜像提供了一个标准且隔离的运行环境,他可以被创建、开始、停止、删除,每个容器都是相互隔离的,就像鲸鱼身上的一个个集装箱那样。类比到C++中容器就相当于类模板new出来的一个个实例。
可以把容器看做是一个简易版的Linux环境(进程空间、用户空间、网络空间)和运行在其上的应用程序。
③仓库(repository)。集中存放镜像文件的场所。类似于存放各种git项目的github、类似于存放各种jar包的Maven。Docker公司提供的官方的registry被称为Docker Hub。仓库分为公开(Public)仓库和私有(Private)仓库两种形式。目前最大的公开仓库就是 hub.docker.com ,国内的公开仓库包括阿里云、网易云等 都存放了大量的镜像供用户下载;私有仓库则是个人或者企业自己搭建的仓库。
如下为docker入门版架构:
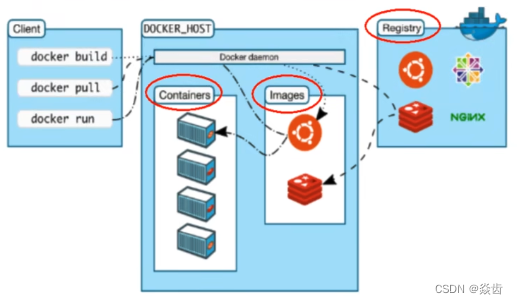
Docker也是典型的Client-Server架构,后端是一个搜耦合架构,众多模块各司其职。docker运行的基本流程如下:
(1)用户使用docker client与dockerdaemon建立通信,并发请求给后者。
(2)docker daemon作为docker架构中的主体部分,首先提供docker server的功能时期可以接受client的请求。
(3)docker engine执行docker内部的一系列工作,每一项工作都是以job的形式存在。
(4)job在运行过程中当需要镜像的时候就会从docker registry中下载镜像,并通过镜像管理驱动Graph driver将下载的镜像以Graph的形式存储。
(5)当需要为docker创建网络环境时,通过网络管理驱动Network driver创建并配置docker容器网络环境。
(6)当需要限制docker容器资源或执行用户命令等操作时,通过Exec driver来完成。
(7)libcontainer是一项独立的容器管理包,Newwork driver以及Exec driver都是通过libcontainer实现容器的具体操作。

2、Linux环境安装docker
官网上可以看到安装教程。
Develops → Getting Starts → Learn how to install Docker,我们这里要安装的应该是docker engine。
centos安装教程如下:
Install Docker Engine on CentOS | Docker Docs
2.1、确认安装环境符合要求
Docker并非是一个通用的容器工具,它依赖存在并运行中的Linux内核环境。此外,对Linux也有一定要求,要求64位、Linux系统内核版本为3.8以上。注意:是强依赖Linux环境,即便在windows上部署Docker其本质也都是先安装一个虚拟机,然后在虚拟出来的Linux上再安装并运行Docker。
此处在Centos7进行安装,在 CentOS 7安装docker要求系统为64位、系统内核版本为 3.8 以上,可以使用以下命令查看。

2.2、安装方法一:使用rpm库安装(Install using the rpm repository)
注:这种是最大众的安装方式,用这种就好了。
(1)卸载旧版本(如果之前安装过)
sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine#yum安装gcc相关
yum -y install gcc
yum -y install gcc-c++
注:我的1核机器有点弱,没反应就重启下在试试。
(2)设置存储库
安装yum-utils包(它提供了yum-config-manager实用程序)并设置存储库。
sudo yum install -y yum-utilssudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
#注:链接外网可能不行此时切换成国内的仓库
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
(3)yum makecache fast
执行以下如下指令会更快。
yum makecache fastyum makecache fast命令是将软件包信息提前在本地索引缓存,用来提高搜索安装软件的速度,建议执行这个命令可以提升yum安装的速度。
(4)安装docker engine
1)安装docker engine,containerd 和 docker compose
sudo yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin如果提示是否接受GPG密钥,请验证指纹是否与060A 61C5 1B55 8A7F 742B 77AA C52F EB6B 621E 9F35匹配,如果匹配请接受。
此命令安装Docker,但不会启动Docker。它还创建了一个docker组,但默认情况下不会向该组添加任何用户。
(5)启动docker
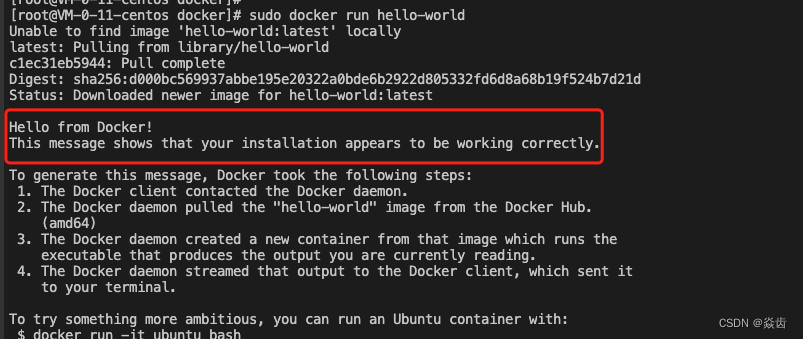
sudo systemctl start docker(6)验证docker engine被成功安装
sudo docker run hello-world此命令下载测试映像并在容器中运行。当容器运行时,它会打印一条确认消息并退出。
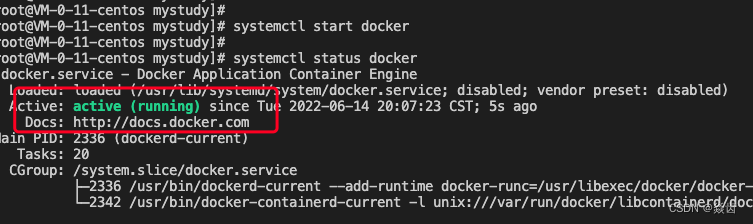
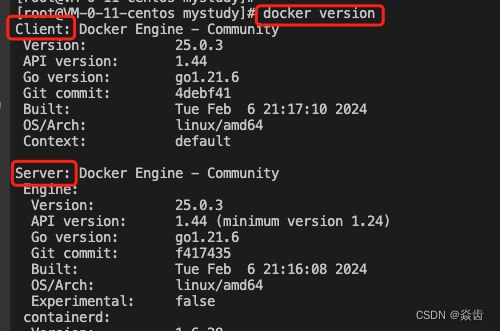
(6) 查看docker服务状态/版本
systemctl status docker
docker version以下说明安装成功
符合预期的话就安装好了。
2.3、卸载docker
systemctl stop docker
sudo yum remove docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin docker-ce-rootless-extras
sudo rm -rf /var/lib/docker
sudo rm -rf /var/lib/containerd2.4、配置镜像加速(利用腾讯云等的镜像更快)
安装docker软件后,可以通过docker pull命令拉取镜像。如果没有配置镜像加速源,就默认直接拉取dockerhub中的镜像,通常这个会比较慢。
为了解决这个问题我们可以配置镜像加速器。例如此处可以配置腾讯云docker镜像源来加速进项下载。步骤如下:
vim /etc/docker/daemon.json #初次进来可能没有此文件,创建即可。
{"registry-mirrors": ["https://mirror.ccs.tencentyun.com","https://hub-mirror.c.163.com","https://mirror.baidubce.com"]
}#重新启动docker
systemctl daemon-reload
systemctl restart docker2.5、使用腾讯云镜像服务
简介: 腾讯云提供的容器镜像云端托管服务。一方面上面有很多腾讯云认证的镜像源;另一方面还可以搞一个自己私有的镜像仓库(推送自己的镜像上去)。
参照腾讯云的指引:
https://cloud.tencent.com/document/product/1141/63910
步骤1:登陆腾讯云账号
步骤2:开通容器镜像服务
步骤3:初始化个人版服务
初始化个人版镜像仓库密码。
用户名:100011009150
密码: Zs+qq
步骤4:创建命名空间,此处为 shuozhuo
步骤5:创建镜像(注此处不创建) 注:命名空间下面就是一个个镜像列表了。
步骤6:然后就可以推送或拉取镜像了。
#首先查看本地已经存在的镜像 注:其中存在镜像 hello-world 是我们上面run的时候拉下来的
docker images#也可以直接指定名字相当于加了where条件
docker images hello-world#推送hello-world这个镜像到私有镜像仓库
sudo docker tag hello-world:latest ccr.ccs.tencentyun.com/shuozhuo/hello-world:latest
sudo docker push ccr.ccs.tencentyun.com/shuozhuo/hello-world:latest注: docker tag的作用就是将本地的hello-world:latest这个镜像重新创建了一个名为ccr.ccs.tencentyun.com/shuozhuo/hello-world:latest的tag。执行前后通过docker images就可以看到其效果仅此而已。然后在我们的镜像仓库里面就可以看到对应记录(hello-world镜像)了,如下:
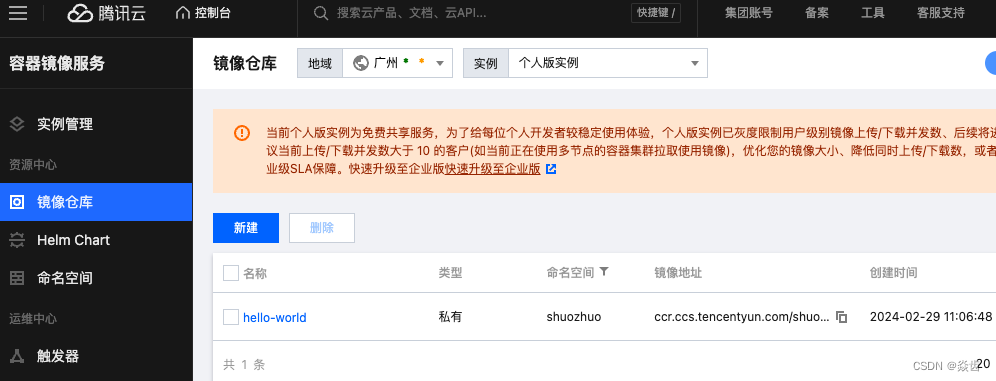
#删除一个docker repository(复制images中的名称)
docker rm -f ccr.ccs.tencentyun.com/shuozhuo/shuozhuohub/hello-world3、docker相关指令
官方指令文档:docker | Docker Docs
3.1、帮助启动类命令
#启动docker
systemctl start docker
#停止docker
systemctl stop docker
#重启docker
systemctl restart docker
#查看docker状态
systemctl status docker
#开启自启动(配置后Linux服务器启动的时候就启动docker,不配linux重启后需要手动启动docker)
systemctl enable docker
#查看概要信息
docker info
#查看docker整体帮助文档
docker --help
#查看docker命令帮助文档
docker run/pull/…… --help3.2、镜像命令
(1)docker images
列出本地主机上已有的镜像
docker images#各项含义如下
repository:镜像仓库源
tag: 镜像的版本(默认就是最新版本)。
image id:镜像id
created:镜像创建时间
size:镜像大小
(2)docker search xxx_imagename
搜索某个镜像是否在镜像仓库
①一般都会搜到很多记录例如redis;这种通常是不同的组织/个人自己只做的镜像。
②我们就选择官方认证过的就好(OFFICAL是ok的那个),通常是第一个。
③加上 --limit 5,我们就查看点赞数最多个前5个就可以了。
docker search hello-world
docker search redis
docker search --limit 5 redi

(3)docker pull
下载镜像。没有TAG就是最新版本即latest。
docker pull imagename[:TAG]
docker pull imagenamedocker pull hello-world
docker pull ubuntu
docker pull redis:6.0.8
(4)docker system df
查看镜像/容器/数据卷所占的空间;盘点下鲸鱼装了多少东西了。
(5)docker stats
查看每个镜像占用了多cpu、内存、网络。

(6)docker rmi xxx_imagename/image_id
删除某个镜像,"rmi"即remove image。
docker rmi hello-world
docker rmi -f hello-world #-f强制删除
docker rmi -f image1:TAG image2:TAG #一次删除多个镜像
docker rmi -f $(docker images -qa) #组合命令,效果是删除全部
(7)谈谈docker的虚悬镜像是什么?
答:仓库名、标签都是<none>的镜像,俗称虚悬镜像(dangling image)。
3.3、容器命令
接下来演示在docker下运行一个ubuntu系统,从中学习各容器命令。
注: centos太大了有200多M,ubuntu就比较小才70多M(Linux内核之外好多东西都瘦身没了例如vim指令之类的)。
(1)新建+启动容器
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]#指定多个端口映射
docker run -p 80:80/tcp -p 80:80/udp ...
注意:docker run之后一定要docker ps看下是否真的启动了。
OPTIONS说明(常用):有些是"-",有些是"--"。
-name="容器新名字" 为容器指定一个名称(不指定的话会随机分配一个名字)。
-d: 后台运行容器并返回容器ID,也就启动守护式容器(后台运行)
-i: 以交互模式运行容器,通常与-t同时使用
-t: 为容器重新分配一个伪输入终端,通常与-i同时使用。
也即启动交互式容器(前台有伪终端,等待交互)-P: 随机端口映射,大写P
-p: 指定端口映射,小写p 注:一般用这个比较多--restart=always: 指明docker整体重启后改容器也随之重启
-p指定端口映射的几种不同形式:
● -p hostPort:containerPort:端口映射,例如-p 8080:80 #注:用这个就行了
● -p ip:hostPort:containerPort:配置监听地址,例如 -p 10.0.0.1:8080:80
● -p ip::containerPort:随机分配端口,例如 -p 10.0.0.1::80
● -p hostPort1:containerPort1 -p hostPort2:containerPort2:指定多个端口映射,例如-p 8080:80 -p 8888:3306
关于端口映射这里稍微解释下。以前我们访问机器直接安装的redis直接访问这台机器的6349端口就好了。用户想访问容器的80端口但又没法直接访问容器只能先访问宿主机;"-p 8080:80"的含义就是用户访问宿主机的8080端口docker会自动的将其映射到容器的80端口。
1)直接启动
docker run ubuntu你会发现执行后啥都没有,起码的交互没有;显然我们是需要交互的。
2)启动交互式容器(需要有终端进行交互)
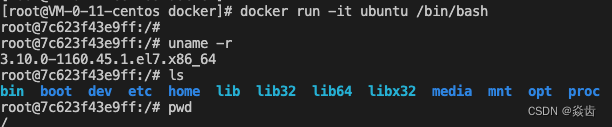
docker run -it ubuntu /bin/bash #没有自定义名字
docker run -it --name myubuntu1 ubuntu bash #自定义名字-i: 交互式操作
-t: 终端
ubuntu: ubuntu镜像
/bin/bash: 放在镜像后面是命令,这里希望有个交互式shell,因此使用/bin/bash显然,此时就在ubuntu系统里面了(通过docker去操作另外一个系统即ubuntu)。
3)启动守护式容器
大部分场景下我们希望docker服务后台运行,此时可以通过 -d 指令指定容器的后台运行模式。此处以redis演示。
#redis前台交互式启动: ctrl+c一下容器就没了,显然没法接受。
docker run -it redis#redis后台守护式启动: 就是可以的
docker run -d redis带来的好处显而易见,以后安装redis等软件就这么简单!!!!!!!
注意:千万注意有些镜像是不可以通过-d运行,必须要-it。
docker run -d ubuntu例如对于ubuntu,执行上述指令后好像是启动成功了,但是执行 docker ps 的时候发现啥也没有(已经退出了)。
注意:这种是docker的机制问题;"docker容器后台运行,就必须有一个前台进程"。如果没有前台进程执行,容器会认为没事可做然后自动退出
那么如何启动一个一直停留在后台运行的ubuntu呢?
docker run -dit ubuntu /bin/bash
(2)列出正在运行的容器
docker ps #另起一个终端在linux机器下执行,而不是在ubuntu中执行()。
docker ps -n 2 #查看最近两次启动的docker(查看启动不成功的容器非常有用)更多参数见 docker ps --helpdocker ps -n 3 #查看启动不成功的容器 非常有用

此时可以看到正在运行的两个容器,都是基于ubuntu镜像创建的两个容器id不同的容器。
(3)退出容器
1)exit
run进去容器,exit退出容器也随之停止
2)ctrl+p+q
run进去容器,ctrl+p+q退出,容器不停止(我的mac目前是: windows+p+q)
#可以通过如下指令重新进入该容器
docker exec -it 容器id /bin/bash
(4)启动已停止运行的容器
docker start 容器id或容器名
docker ps -n 2 #赋值一个容器id
docker start 5930c3d1a376 #重新启动这个容器(5)重启容器
docker restart 容器id或容器名(6)停止容器
docker stop 容器id或容器名(7)强制停止容器
docker kill 容器id或容器名(8)删除已停止的容器
docker rm 容器id
docker rm -f 容器id #强制删除(直接掀桌子)注: rmi删的是镜像;rm删的是容器。然后 docker ps -n 2 就看不到这个容器了。
(9)查看容器日志
docker logs 容器id注:docker run之后容器没有成功启动可通过“docker logs 容器id”查看失败日志。
(10)查看容器内运行的进程
top是查看宿主机centos运行的进程;docker top查看鲸鱼集装箱内部(或者叫容器内部)运行的进程(切记:每个集装箱都可以视为一个小的操作系统)。
docker top 容器id(11)查看容器内部细节
#更细致地查看容器的情况,后续会用到
docker inspect 容器id
(12)进入正在运行的容器并以命令行交互
1)docker exec进入容器
docker exec -it 容器id /bin/bash2)docker attache进入容器
docker attache 容器id问:docker exec和docker attache有什么区别?
答:attache直接进入容器启动命令的终端,不会启动新的进程。显然此时用exit退出的话会导致容器停止。exec是在容器中打开一个新的终端,启动了新的进程。用exit退出不会导致容器的停止。
推荐大家使用 docker exec命令,因为退出终端不会导致容器停止。
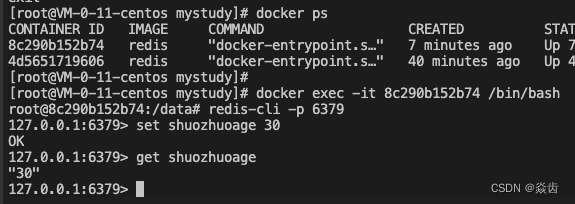
如下图所示。①通过docker exec进入redis的容器 ②通过客户端连接上redis服务器 ③设置数据并读取。
(13)从容器内拷贝文件到主机
把容器内的重要的数据拷贝到主机上
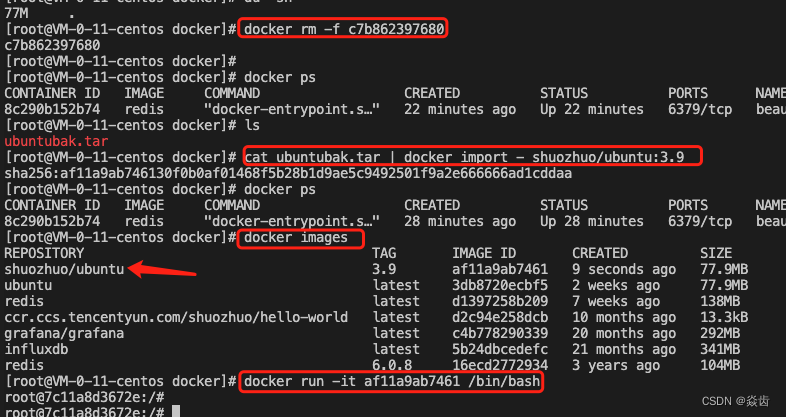
docker cp 容器id:容器内路径 目的主机路径docker cp c7b862397680:/tmp/aa.txt /root/mystudy(14)导入和导出容器
整个容器维度进行备份。
docker export 容器id > 文件名.tar
cat 文件名.tar | docker import 镜像用户/镜像名:镜像版本号#具体操作流程如下:
docker export c7b862397680 > ubuntubak.tar #对容器 c7b862397680 进行备份
docker rm -f c7b862397680 #强制删除这个容器
cat ubuntubak.tar | docker import - shuozhuo/ubuntu:3.9
docker images #会发现多了 shuozhuo/ubuntu 这个镜像
docker run -it 镜像id /bin/bash #即完成恢复
注:后续还会介绍数据卷功能用于容器→宿主机的数据传输/备份!!!
3.4、小结
4、docker镜像
4.1、UnionFS文件系统
UnionFS(联合文件系统):Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,
同时可以将不同目录挂在到同一个虚拟文件系统下。Union文件系统是Docker镜像的记录。镜像可以通过封层来进行继承,基于基础镜像可以制作出各种具体的应用镜像。
特性:一次同时加载多个文件系统。但是从外面看起来只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录。
4.2、bootfs和rootfs
bootfs(boot file system)主要包含 bootloader 和 kernel,bootloader主要是引导加载 kernel,Linux刚启动时会加载bootfs文件系统。
在Docker镜像的最底层是引导文件系统bootfs。这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已经由 bootfs 转交给内核,此时系统也会卸载 bootfs。
rootfs(root file system)。在bootfs之上,包含的就是典型Linux系统中的 /dev、/proc、/bin、/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu、CentOS等。

docker镜像底层层次:
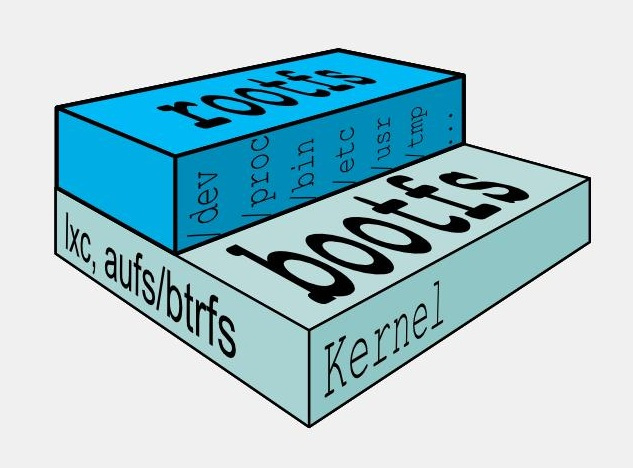
对于一个精简的OS,rootfs可以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接使用Host的Kernel,自己只需要提供rootfs就可以。所以,对于不同的Linux发行版,bootfs基本是一致的,rootfs会有差别,不同的发行版可以共用bootfs。
4.3、镜像的分层
Docker支持扩展现有镜像,创建新的镜像。新镜像是从base镜像一层一层叠加生成的。
例如我们可以在一个基础的debian上安装emacs、然后再安装apache。过程如下:

镜像分层优势:镜像分层的一个最大好处就是共享资源,方便复制迁移,方便复用。
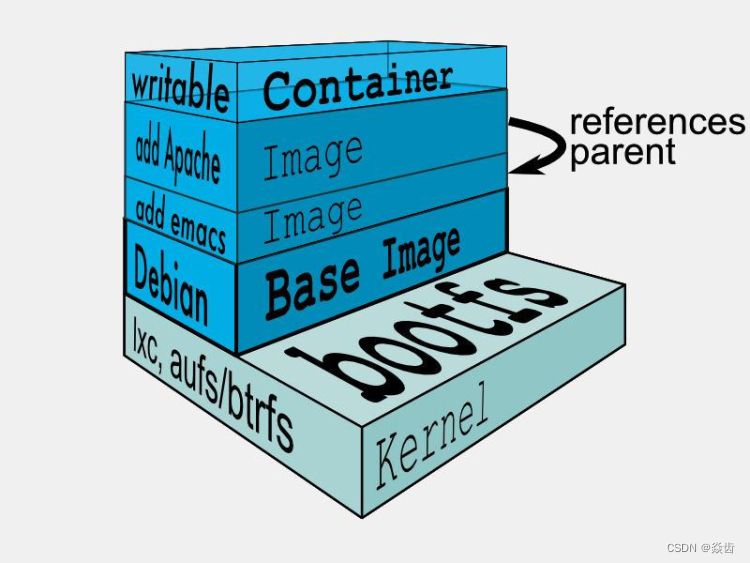
4.4、镜像层与容器层
Docker镜像层都是只读的,容器层是可写的。
当容器启动时,一个新的可写层被加载到镜像顶部。
这一层通常被称作“容器层”,“容器层”之下都叫“镜像层”。
所有对容器的改动,包括添加、删除、修改文件都只发生在容器层。
4.5、基于容器制作镜像(docker commit)
镜像的生成主要有两种方式。
①基于容器制作镜像 —— docker commit。
②编写dockerfile制作镜像 —— 后续介绍
通过docker commit可以提交容器副本使其称为一个新的镜像;就是说对一个具体的容器采用类似“反射”的方式生成模板镜像。
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
docker commit -m="描述信息" -a="作者" 容器id 要创建的目标镜像名:[TAG]#语句如下
docker commit -m="add vim cmd" -a="shuozhuo" 7274ef1a61a9 shuozhuo/ubuntuvim:1.0
我们知道官网默认的ubuntu是个极简的版本,简略到vim都是没有的。接下来我们要做的事情是基于官网ubuntu安装vim后打包成一个全新的具有vim的镜像版本。
#先更新管理工具
apt-get update
#安装vim
apt-get -y install vim安装后就可以使用vim了,我们此处通过vim在绝对路径/tmp下创建aa.txt文件,并编辑若干字符。
接下来提交新镜像。
docker commit -m="add vim cmd" -a="shuozhuo" 7274ef1a61a9 shuozhuo/ubuntuvim:1.0然后执行docker images 查看本地镜像如下。显然符合预期。

接下来,我们把容器 7274ef1a61a9 停掉;并通过新commit的镜像重新创建一个容器,验证这个容器是不是具备vim功能。
显然根据新版本镜像创建的这个全新的容器(f3c63bd3753d)就是具备vim功能的。
思考:显然我们可以在新的镜像run出来的容器的基础上继续增强并创建新的镜像;这就是分层涉及带来的好处—— 不断叠加。
4.6、将本地镜像推送腾讯云
注:我这里地域选的广州!!!
制作出好用的镜像后接下来发布出去(此处发布到腾讯云)供其他人使用,服务广大人民群众。
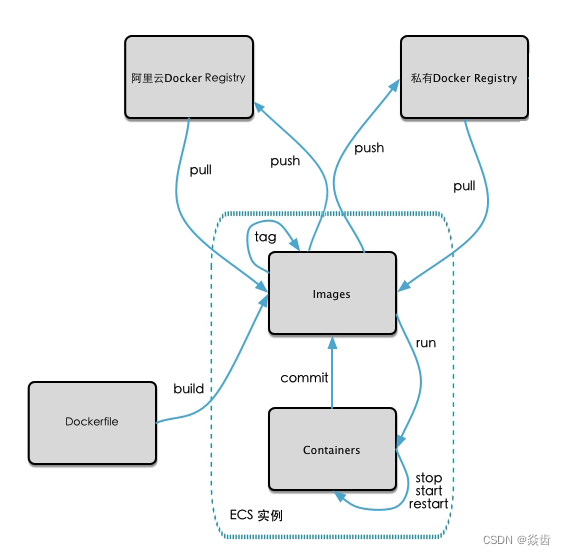
仓库、镜像、容器流转关系如下:
进入腾讯云 → 容器镜像服务。按照之前的方式配置好命令空间之类的。
然后在镜像仓库中创建一项用于盛放我们增强后的ubuntu系统。
点击气候的快捷指令,执行提示的指令即可。

#登陆腾讯云容器镜像服务(Docker Registry)
docker login ccr.ccs.tencentyun.com --username=100011009150
#向 Registry 中推送镜像
docker tag d27d7fcb0280 ccr.ccs.tencentyun.com/shuozhuo/myubuntu:1.0
docker push ccr.ccs.tencentyun.com/shuozhuo/myubuntu:1.0
观察腾讯云目标仓库,发现确实有了对应数据。

接下来验证发布到腾讯云私有仓库的这个可以正常使用。
首先,将本地的原有镜像(shuozhuo/ubuntuvim d27d7fcb0280) 删除
docker rmi -f d27d7fcb0280验证删除无误后按照提示指令拉取腾讯云私有仓库的镜像
docker pull ccr.ccs.tencentyun.com/shuozhuo/myubuntu:1.0#docker images发现果然拉取到本地了
docker images#利用此镜像启动一个容器
docker run -it d27d7fcb0280 /bin/bash#经验证确实是安装vim的增强后的ubuntu4.7、私人建立Docker Registry
有些数据可能比较重要且敏感,直接放到腾讯云、阿里云上不放心;此时就可以建立私有的docker registry用于存放镜像(例如专门为自己的公司搭建一个)。
Docker Registry就是docker官方提供的用于构建私有仓库的工具。
#下载镜像docker registry至本地
docker pull registry#运行私有库registry
docker run -d -p 5000:5000 -v /app/myregistry/:/tmp/registry --privileged=true registry
默认情况下,仓库会被创建到/var/lib/registry目录下;建议自行用容器卷映射方便宿主机联调。
左侧是宿主机的路径,右侧是容器内的路径。
其含义就是降容器内的数据在宿主机进行持久化(重要资料映射),将容器内的数据备份+持久化到当前宿主机的目录。
#查询我们这个库看看有什么镜像(最初一般都啥也没有)
curl http://192.168.xxx.xxx:5000/v2/_catalog#使用docker tag将本地的shuozhuo/myubuntu:1.1这个镜像修改为192.168.xxx:5000:myubuntu:1.1
docker tag shuozhuo/myubuntu:1.1 192.168.xxx.xxx:5000/shuozhuo/myubuntu:1.1#使docker运行http方式推送镜像(默认不允许),通过配置 /etc/docker/daemon.json 来取消这个限制。不生效的话就重启下docker服务。
添加了 insecure-registries这一项。注意逗号!!!
{"registry-mirros": ["https://xxxx.mirror.aliyuncs.com"],"insecure-registries": ["192.168.xxx.xxx:5000"]
}#推送到本地
docker push 192.168.xxx.xxx:5000/shuozhuo/myubuntu:1.1#查看镜像仓库的目录验证已经存在
curl http://192.168.xxx.xxx:5000/v2/_catalog5、docker容器数据卷
5.1、是什么?能干什么?
一句话:将容器内的数据保存进宿主机磁盘,以实现容器内数据持久化存储或共享。类似于redis的RDB、AOF文件。
卷就是目录或文件,可以存在一个或多个容器中,是由docker挂在到容器,但它不属于联合文件系统。卷的数据目的就是数据持久化,它完全独立于容器的生存周期,因此docker不会在容器删除时影响其挂在的数据卷。
另外数据卷有如下几个特点:
(1)数据卷可在容器之间共享或重用数据
(2)卷中的更改实时生效
(3)数据卷中的更改不会包含在进项的更新中
(4)数据卷的声名周期一直持续到没有容器使用它为止
5.2、运行一个带有容器卷存储功能的容器
docker run -it --privileged=true -v /宿主机绝对路径:/容器内目录 镜像名
注:该指令会默认创建宿主机、容器中不存在的路径
1)宿主机与容器之间添加容器卷映射
#通过如下指令创建容器(其含义是将容器内的路径/tmp/docker_data 映射到宿主机的路径 /tmp/host_data)
docker run -it --privileged=true -v /tmp/host_data:/tmp/docker_data --name=ubuntu1 3db8720ecbf5#一次指令可以同时绑定多个目录,此时多个几个-v选项就可以了。
2)验证效果
在容器中touch aa.txt bb.txt; 观察宿主机路径发现也有这两个文件。反之亦然。
3)查看绑定情况(docker inspect)
docker inspect 容器iddocker inspect bcf4f5f29419在其中的 Mounts 中可以看到绑定信息情况。

4)容器停止后在宿主机路径下的修改在容器重新启动后也会存在。
5.3、带有读写规则的映射添加
默认情况下双方都是可读可写(如下),但是我们也可以配置其读写规则。
docker run -it --privileged=true -v /宿主机绝对路径:/容器内目录:rw 镜像名
如果要求容器的目录只读即容器内部不能写,那么配置如下ro(read only)即可。
docker run -it --privileged=true -v /宿主机绝对路径:/容器内目录:ro 镜像名
5.4、卷的继承和共享
我们先创建一个和宿主机有映射的容器ubuntu1;接下来在创建ubuntu1的时候指定继承ubuntu1的容器数据卷。此时就可以实现容器ubuntu1、容器ubuntu2、宿主机三者之间的数据共享。
(1)先搞一个和宿主机有映射的容器ubuntu1
docker run -it --privileged=true -v /tmp/host_data:/tmp/docker_data --name=ubuntu1 3db8720ecbf5(2)验证宿主机和容器ubuntu1间的数据共享没有任何问题(3)然后创建容器ubuntu2,创建的时候继承ubuntu1的容器卷
docker run -it --privileged=true --volumes-from ubuntu1 --name=ubuntu2 3db8720ecbf5(4)经过验证三者的数据确实是共享的注意:ubuntu2继承的是ubuntu1的卷规则,u1挂了丝毫不影响u2因为他们是两个完全不同的容器。
6、docker安装常用组件
注意:生产环境中容器卷是一定要挂的,确保容器没了但是数据依然在。
6.1、安装步骤
①搜索镜像
②拉取镜像
③查看镜像
④启动镜像(注意服务端口映射)
⑤停止容器
⑥移除容器
其实我们就在官网 https://hub.docker.com 上搜就可以了。
例如对于tomcat选择官方认证的那个,点击进去。
指令、介绍、如何使用镜像等信息都有。
6.2、安装tomcat
#安装tomcat
docker run -itd -p 8080:8080 tomcat
#进入tomcat
docker exec -it ab4ec80ae7b9 /bin/bash
注: tomcat新版本的webapps为空非常奇怪,启动都放在了webapps.dist中了。
rm -rf webapps
mv webapps.dist webapp#验证是否好用(然后在验证就可以了)
浏览器直接访问 118.195.1xx.xx:80806.3、安装mysql —— 简易安装
#拉取mysql
docker pull mysql:5.7
#运行容器
docker run -p 3306:3306 --name=testmysql -e MYSQL_ROOT_PASSWORD=123456 -itd mysql
#进入容器
docker exec -it 04e70f2be7d9 /bin/bash#连接mysql
mysql -uroot -p 注意事项1:默认插入中文插入不了。
解决:在mysql中使用以下命令查看数据库字符集,发现都是latin1字符集所以报错。
show variables like 'character%';
注意事项2:删除容器后mysql的数据不就没了? —— 挂在数据卷
6.4、安装mysql —— 生产环境安装
docker run -d -p 3306:3306 \--privileged=true \-v /app/mysql/log:/var/log/mysql \-v /app/mysql/data:/var/lib/mysql \-v /app/mysql/conf:/etc/mysql/conf.d \-e MYSQL_ROOT_PASSWORD=123456 \--name mysql \mysql在/app/mysql/conf下新建 my.cnf,通过容器卷将一下配置同步给mysql实例,解决中文乱码问题。
(复制如下配置至配置文件 my.cnf 中)[client]
default_character_set=utf8
[mysqld]
collation_server = utf8_general_ci
character_set_server = utf8重启mysql容器,使得容器重新加载配置文件:docker restart mysql
6.5、安装mysql —— 主从复制集安装
1、安装主服务器
(1)启动容器实例
docker run -p 3307:3306 \--name mysql-master \--privileged=true \-v /app/mysql-master/log:/var/log/mysql \-v /app/mysql-master/data:/var/lib/mysql \-v /app/mysql-master/conf:/etc/mysql \-e MYSQL_ROOT_PASSWORD=123456 \-d mysql:5.7注意事项:docker run之后通过docker ps发现并没有真正运行起来,docker logs发现如下日志。

原因:大概意思就是说没找到
/etc/mysql/conf.d这个文件夹。#先创建一个简单的容器实例,看看路径下究竟是啥。
docker run -p 3306:3306 --name sample-mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7#进入看看 /etc/mysql 文件夹,发现只有两个空文件夹 conf.d、 mysql.conf.d
docker exec -it 065cb34b4b0b /bin/bash#复制容器 /etc/mysql 文件夹内容至 /app/mysql-master/conf
docker cp sample-mysql:/etc/mysql/. /app/mysql-master/conf注:其实也可以在 /app/mysql-master/conf 中分别建立 conf.d 、 mysql.conf.d 两个文件夹(因为cp过来的也是两个空文件夹)。
然后就可以成功启动了!!
(2)进入 /app/mysql-master/conf ,新建 my.cnf配置文件
[mysqld]
## 设置server_id, 同一个局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062(3)重启容器实例
docker restart mysql-master(4)进入容器实例
docker exec -it mysql-master /bin/bash(5)登陆mysql,创建数据同步用户
注:有这个用户密码的从机才能从我这儿同步数据,不能说随便来什么人都能赋值!!
-- 首先登录mysql
mysql -uroot -p
-- 创建数据同步用户
create user 'slave'@'%' identified by '123456';
-- 授权 授权可以做哪些操作
grant replication slave, replication client on *.* to 'slave'@'%';
flush privileges;2、安装从服务器
(0)启动之前同样在宿主机的 /app/mysql-slave/conf 路径下建立 conf.d 、 mysql.conf.d 两个文件夹。
1)启动服务器
docker run -p 3308:3306 \--name mysql-slave \--privileged=true \-v /app/mysql-slave/log:/var/log/mysql \-v /app/mysql-slave/data:/var/lib/mysql \-v /app/mysql-slave/conf:/etc/mysql \-e MYSQL_ROOT_PASSWORD=123456 \-d mysql:5.7(2)进入 /app/mysql-slave/conf 目录,创建my.cnf配置文件
[mysqld]
## 设置server_id, 同一个局域网内需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置只读(具有super权限的用户除外)
read_only=1
(3)修改完配置重启slave容器实例
docker restart mysql-slave
3、在主数据库中查看主从同步状态
(1)进入主数据库
docker exec -it mysql-master /bin/bash(2)连接mysql
mysql -uroot -p(3)查看主从同步状态
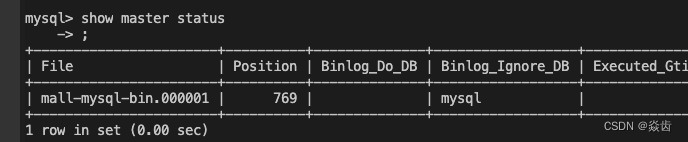
show master status;主要查看返回结果的文件名File、当前位置Position
4、从数据库容器配置主从复制
1)进入从数据库容器
docker exec -it mysql-slave /bin/bash(2)连接数据库
mysql -uroot -p(3)配置从数据库所属的主数据库
#格式 change master to master_host='宿主机ip(内网不是外网)',master_user='主数据库配置的主从复制用户名',master_password='主数据库配置的主从复制用户密码',master_port=宿主机主数据库端口,master_log_file='主数据库主从同步状态的文件名File',master_log_pos=主数据库主从同步状态的Position,master_connect_retry=连接失败重试时间间隔(秒);change master to master_host='10.206.0.11',master_user='slave',master_password='123456',master_port=3307,master_log_file='mall-mysql-bin.000001',master_log_pos=769,master_connect_retry=30;(4)查看主从同步状态
show slave status \G;除了展示刚刚配置的主数据库信息外,主要关注 Slave_IO_Running、Slave_SQL_Running。目前两个值应该都为 No,表示还没有开始。
(5)开启主从同步
start slave;(6)再次查看主从同步状态
再次查看主从同步状态,Slave_IO_Running、Slave_SQL_Running都变为Yes。 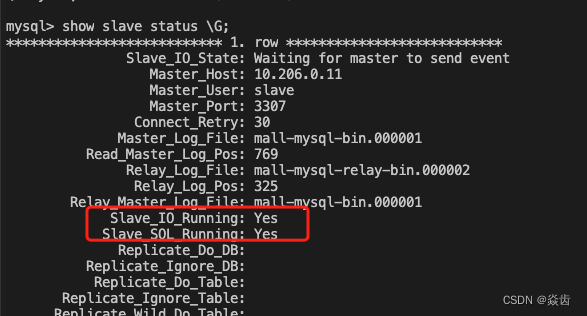
5、测试主从复制效果
(1) 在主数据库上新建库、使用库、新建表、插入数据
create database db01;
use db01;
create table t1 (id int, name varchar(20));
insert into t1 values (1, 'abc');(2)在从数据库上使用库、查看记录
show databases;
use db01;
select * from t1;(3)效果如下,显然数据都同步过来了。

6.4、3主3从redis集群搭建
6.4.0、架构如下
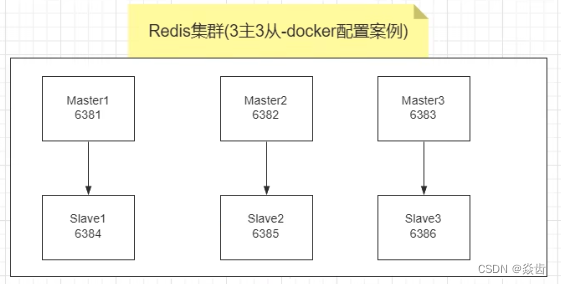
6.4.1、搭建
(1)启动6台redis容器
# 启动第1台节点
# --net host 使用宿主机的IP和端口,默认
# --cluster-enabled yes 开启redis集群
# --appendonly yes 开启redis持久化
# --port 6381 配置redis端口号#注:上述 "cluster-enabled" 等参数都是 redis.conf 中存在的配置参数。
wget http://download.redis.io/redis-stable/redis.conf //下载redis配置文件
vim redis.conf //可以看看有哪些参数docker run -d --name redis-node-1 --net host --privileged=true -v /app/redis-cluster/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381# 启动第2台节点
docker run -d --name redis-node-2 --net host --privileged=true -v /app/redis-cluster/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382# 启动第3台节点
docker run -d --name redis-node-3 --net host --privileged=true -v /app/redis-cluster/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383# 启动第4台节点
docker run -d --name redis-node-4 --net host --privileged=true -v /app/redis-cluster/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384# 启动第5台节点
docker run -d --name redis-node-5 --net host --privileged=true -v /app/redis-cluster/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385# 启动第6台节点
docker run -d --name redis-node-6 --net host --privileged=true -v /app/redis-cluster/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386(2)随便进入一个容器(此处进入容器1)
docker exec -it redis-node-1 /bin/bash(3)构建主从关系
# 宿主机IP(内网ip):端口
# --cluster-replicas 1 :表示每个主节点需要1个从节点
注:参见如下redis集群维护命令
https://blog.csdn.net/cj_eryue/article/details/132811758redis-cli --cluster create 10.206.0.11:6381 10.206.0.11:6382 10.206.0.11:6383 10.206.0.11:6384 10.206.0.11:6385 10.206.0.11:6386 --cluster-replicas 1执行效果如下.
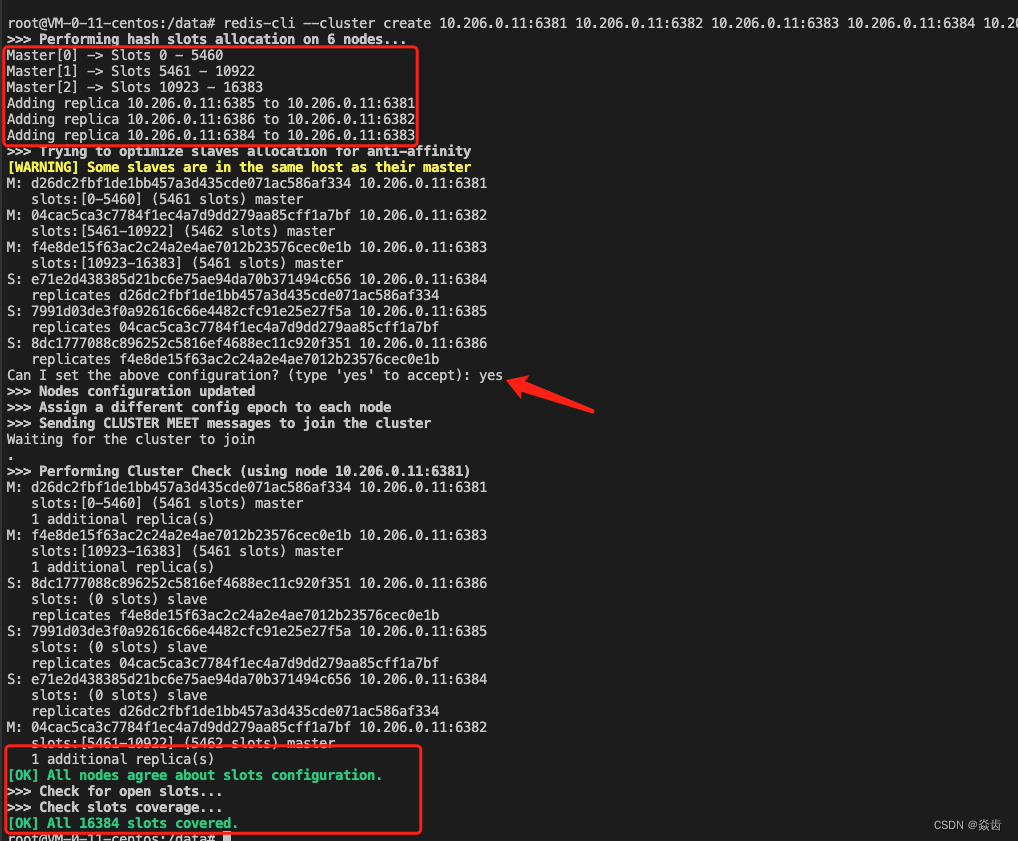
(4)按提示输入 yes 确认配置信息
显然从上面我们可以看到16384个数据槽的分配情况。
(5)查看集群状态
#进入node1
docker exec -it redis-node-1 /bin/bash#连接redis-node-1
redis-cli -p 6381#cluster info查看集群状态
cluster info其中,分配的哈希槽数量 cluster_slots_assigned为16384,集群节点数量cluster_known_nodes为6 #查看集群节点信息
cluster nodes6.4.2、读写出错(应该用集群的方式读写)
当使用 redis-cli连接redis集群时,需要添加 -c参数,否则可能会出现读写出错。
(1)进入node1所在容器
docker exec -it redis-node-1 /bin/bash(2)使用redis-cli连接(不带-c参数)
redis-cli -p 6381(3)向redis添加如下键值对
set k1 v1报错:k1经过计算得到的哈希槽为12706,但是当前连接的redis-server为6381(即节点1),它的哈希槽为:[0,5460](在创建构建主从关系时redis有提示,也可以通过 cluster nodes查看),所以会因为存不进去而报错。
执行 set k2 v2可以成功,因为k2计算出的哈希槽在[0-5460]区间中。 (4)使用-c参数连接
redis-cli -p 6381 -c(5)此时可以正常插入所有数据
set k1 v1会有提示信息,哈希槽为12706,重定向到6383(即节点3,哈希槽[10923, 16383]): 6.4.3、集群信息检查
(1)进入node1
docker exec -it redis-node-1 /bin/bash(2)输入任意一台主节点地址都可以进行集群检查
redis-cli --cluster check 10.206.0.11:6381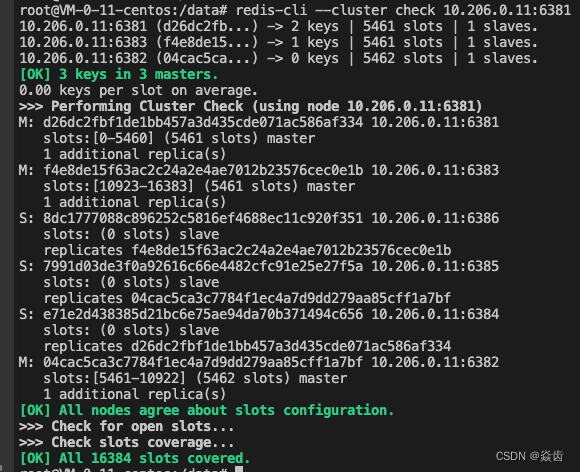
6.4.4、集群扩容
(1)启动两台新的redis容器节点
# 启动第7台节点
docker run -d --name redis-node-7 --net host --privileged=true -v /app/redis-cluster/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387# 启动第8台节点
docker run -d --name redis-node-8 --net host --privileged=true -v /app/redis-cluster/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388(2)进入node7内部
docker exec -it redis-node-7 /bin/bash(3)将6387作为master加入集群
# redis-cli --cluster add-node 本节点地址 要加入的集群中的其中一个节点地址
redis-cli --cluster add-node 10.206.0.11:6387 10.206.0.11:6381(4)检查当前集群状态
redis-cli --cluster check 10.206.0.11:6381发现,6387节点已经作为master加入了集群,但是并没有被分配槽位。
(5)reshard重新分配槽位
redis-cli --cluster reshard 10.206.0.11:6381例如,我们现在是4台master,我们想要给node7分配4096(16384/4)个槽位,这样每个节点都是4096个槽位。
输入 4096 后,会让输入要接收这些哈希槽的节点ID,填入node7的节点ID即可。(就是节点信息中很长的一串十六进制串)。
然后会提示,询问要从哪些节点中拨出一部分槽位凑足4096个分给Node7。一般选择 all,即将之前的3个主节点的槽位都均一些给Node7,这样可以使得每个节点的槽位数相等均衡。
输入all之后,redis会列出一个计划,内容是自动从前面的3台master中拨出一部分槽位分给Node7的槽位,需要确认一下分配的计划。
输入yes确认后,redis便会自动重新洗牌,给Node7分配槽位。
(6)重新分配完成后,可以进行集群信息检查,查看分配结果:
redis-cli --cluster check 10.206.0.11:6381可以发现重新洗牌后的槽位分配为:
节点1:[1365-5460](供4096个槽位),,,分配前为[0-5460](共5461个槽位)
节点2:[6827-10922](共4096个槽位),,,分配前为[5461-10922](共5461个槽位)
节点3:[12288-16383](共4096个槽位),,,分配前为[10923-16383](共5462个槽位)节点7:[0-1364],[5461-6826],[10923-12287](共4096个槽位),从每个节点中匀出来了一部分给了节点7因为可能有些槽位中已经存储了key,完全的重新洗牌重新分配的成本过高,所以redis选择从前3个节点中匀出来一部分给节点7。这种方式是非常合理的。
(7)为主节点6387分配从节点6388
redis-cli --cluster add-node 10.206.0.11:6388 10.206.0.11:6381 --cluster-slave --cluster-master-id 341fe8f923673ba24de54c78e5b55db084afae5aredis便会向6388发送消息,使其加入集群并成为6387的从节点。
(8)执行check验证效果
显然可以看到6388已经作为6387的副节点了。
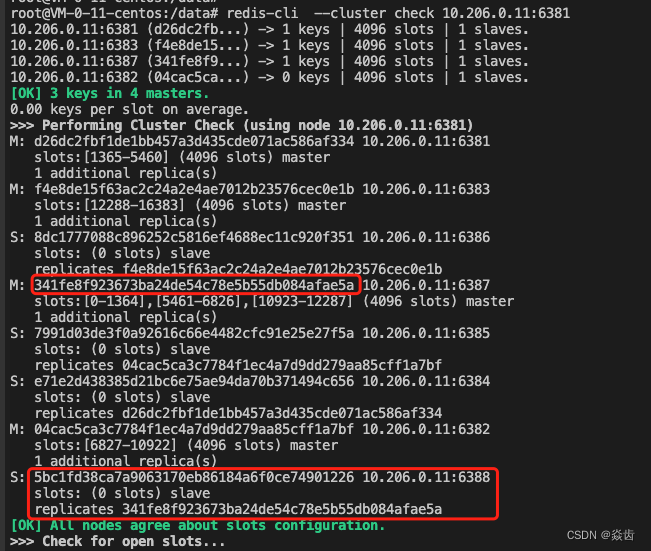
6.4.5、redis集群故障自动转移(选主)
(0)初始状态node7作为master,node8作为slave。
redis-cli --cluster check 10.206.0.11:6381(1)人为制造node7宕机
docker stop redis-node-7(2)查看状态,发现node8成功上位master
redis-cli --cluster check 10.206.0.11:6381#检查挂了并重新选主会有个过程,稍等几秒
(3)重新启动node7,发现node7会作为node8的slave加入
docker start redis-node-7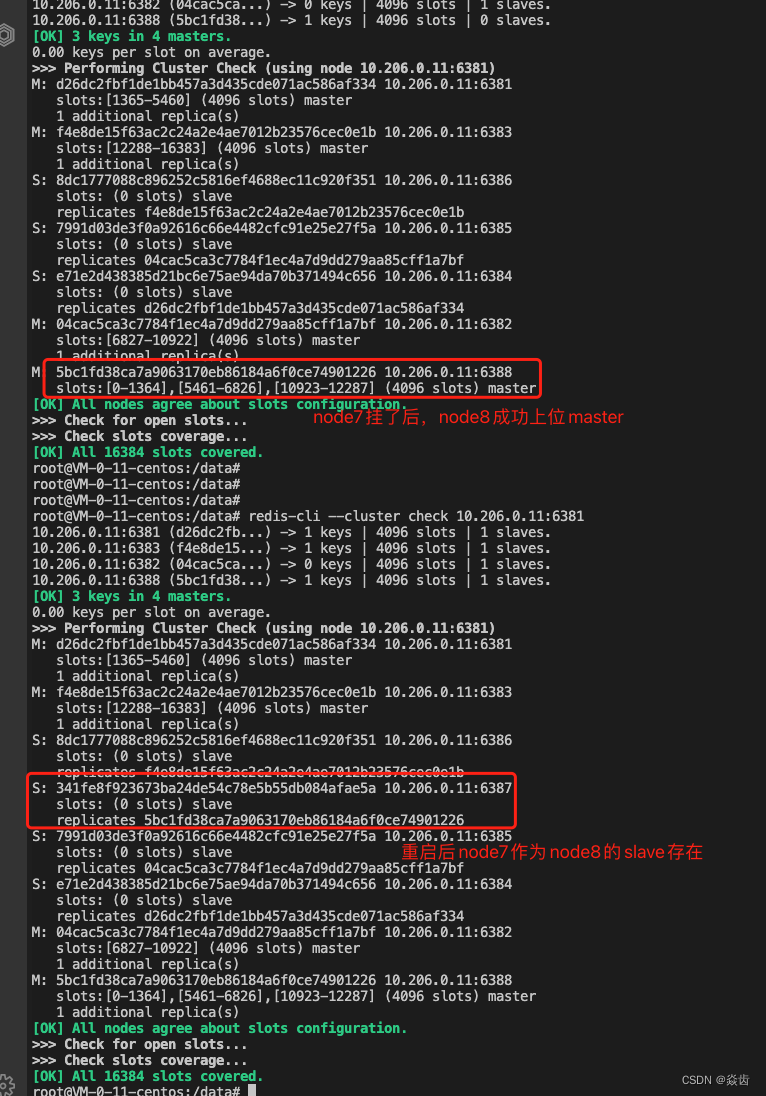
以此类推。
6.4.6、集群缩容
将4主4从重新缩容到3主3从,即从集群移除node7和node8.
(1)进入容器节点1
docker exec -it redis-node-1 /bin/bash(2)检查容器状态,获取6388的节点编号
redis-cli --cluster check 10.206.0.11:6381(3)将6388(这个副本)从集群中移除
redis-cli --cluster del-node 10.206.0.11:6388 5bc1fd38ca7a9063170eb86184a6f0ce74901226(4)对node7重新分配哈希槽
1)对集群重新分配哈希槽
redis-cli --cluster reshard 10.206.0.11:63812)redis经过槽位检查后会提示需要分配的槽位数量。
如果我们想直接把node7的4096个哈希槽全部分给某个节点,可以直接输入4096。
输入4096后,会让输入要接收这些哈希槽的节点ID。假如我们想把这4096个槽都分给Node1,直接输入node1节点的编号即可。
然后会提示,询问要从哪些节点中拨出一部分槽位凑足4096个分给Node1。这里我们输入node7的节点编号,回车后输入done。
3)确认node7没有哈希槽后就可以将node7从集群中删除了
redis-cli --cluster del-node 10.206.0.11:6387 341fe8f923673ba24de54c78e5b55db084afae5a6.5、安装nginx
后续补充
6.6、安装MongoDB
(1)简易版安装
#拉取mongodb4.0版本
docker pull mongo:4.0#运行容器
docker run -d -p 27017:27017 --name=zsmognodb \-e MONGO_INITDB_ROOT_USERNAME=root \-e MONGO_INITDB_ROOT_PASSWORD=123456 \mongo:4.0#进入容器
docker exec -it 4e48c5135ed7 /bin/bash#首先尝试容器内连接数据库(是可以的)
mongo --host localhost -u root#在尝试远端连接数据库
./mongo --host 118.195.193.69 --port 27017 -u "root" -p "123456"
注:记得安全组规则中放开对27017端口的限制,否则连接不上。(2)实用级安装
其实主要就是数据卷、复制集的部署。
对于数据卷在hub.docker.com中mongo相关说明都有相关实例(搜 "-v"),按提示知道mongdb数据库容器的数据默认在 /data/db路径下。
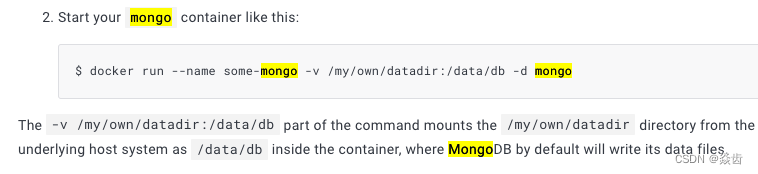
#如下即为带数据卷的启动
docker run -d -p 27017:27017 --name=zsmognodb \-e MONGO_INITDB_ROOT_USERNAME=root \-e MONGO_INITDB_ROOT_PASSWORD=123456 \-v /data/app/mongodb/data:/data/db \mongo:4.06.7、安装Influxdb
先不启用密码验证, 创建用户和密码,启动后进入创建好用户和密码后,修改auth-enabled = true 重启容器生效,就必须要用户和密码
docker run -d --name shuozhuo-influxdb \
-p 8086:8086 \
-p 8083:8083 \
-p 2003:2003 \
-e INFLUXDB_GRAPHITE_ENABLED=true \
-v /data/influxdb/conf/influxdb.conf:/etc/influxdb/influxdb.conf \
-v /data/influxdb:/var/lib/influxdb \
-v /etc/localtime:/etc/localtime \
influxdb#进入容器
docker exec -it shuozhuo1-influxdb /bin/bash#删除一个镜像
docker rm -f shuozhuo-influxdb#新建并启动容器,参数:-i 以交互模式运行容器;-t 为容器重新分配一个伪输入终端;--name 为容器指定一个名称
docker run -i -t --name mycentos 镜像名称/镜像ID#后台启动容器,参数:-d 已守护方式启动容器
docker run -d mycentos#启动止容器
docker start 容器id
# 重启容器
docker restart 容器id
# 关闭容器
docker kill 容器id
docker stop 容器id-t 参数让Docker分配一个伪终端并绑定到容器的标准输入上
-i 参数则让容器的标准输入保持打开。
-c 参数用于给运行的容器分配cpu的shares值
-m 参数用于限制为容器的内存信息,以 B、K、M、G 为单位
-v 参数用于挂载一个volume,可以用多个-v参数同时挂载多个volume
-p 参数用于将容器的端口暴露给宿主机端口 格式:host_port:container_port 或者 host_ip:host_port:container_port
--name 容器名称
--net 容器使用的网络
-d 创建一个后台运行容器
#接下来就是influxdb的操作了!!
#创建用户和密码
create user "admin" with password 'admin' with all privileges
create user "admin" with password 'beyond_2021' with all privilegesauth admin admin 登录show databases; 展示数据库create database demo 创建表
参考:
容器常用命令:
docker 常用命令大全_保护我方胖虎的博客-CSDN博客_docker常用命令
docker 常用命令_docker常用命令-CSDN博客
学习笔记:
https://www.yuque.com/tmfl/cloud/rifotq #yuque
https://www.yuque.com/li.xx/open/elw9tu #yuque
相关文章:
docker学习入门篇
1、docker简介 docker官网: www.docker.com dockerhub官网: hub.docker.com docker文档官网:docs.docker.com Docker是基于Go语言实现的云开源项目。 Docker的主要目标是:Build, Ship and Run Any App, Anywhere(构建&…...

【Spring Boot 3】动态注入和移除Bean
【Spring Boot 3】动态注入和移除Bean 背景介绍开发环境开发步骤及源码工程目录结构总结动态注入Bean的方法动态移除Bean的方法注意事项背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个…...
555经典电路
1、555介绍: 555 定时器是一种模拟和数字功能相结合的中规模集成器件。一般用双极性工艺制作的称为 555,用 CMOS 工艺制作的称为 7555,除单定时器外,还有对应的双定时器 556/7556。555 定时器的电源电压范围宽,可在 4…...
vue 下载的插件从哪里上传?npm发布插件详细记录
文章参考: 参考文章一: 封装vue插件并发布到npm详细步骤_vue-cli 封装插件-CSDN博客 参考文章二: npm发布vue插件步骤、组件、package、adduser、publish、getElementsByClassName、important、export、default、target、dest_export default…...
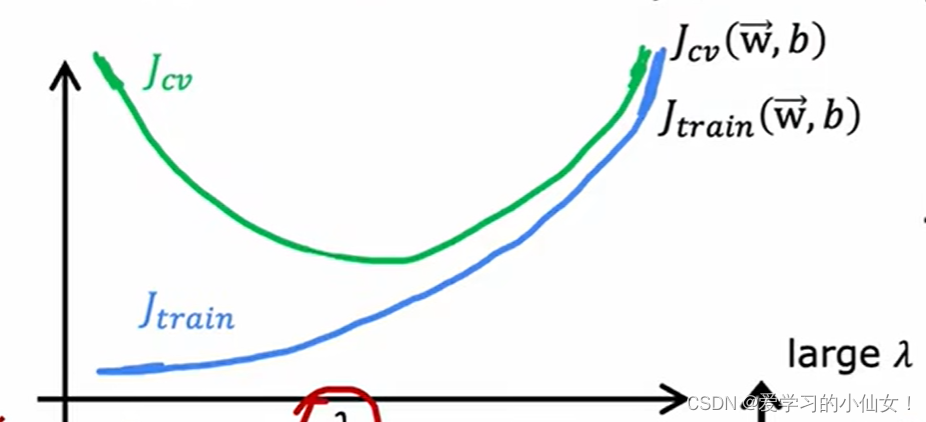
吴恩达机器学习笔记 十七 通过偏差与方差诊断性能 正则化 偏差 方差
高偏差(欠拟合):在训练集上表现得也不好 高方差(过拟合):J_cv要远大于J_train 刚刚好:J_cv和J_train都小 J_cv和J_train与拟合多项式阶数的关系 从一阶到四阶,训练集的误差越来越小…...

Java高频面试之SSM篇
有需要互关的小伙伴,关注一下,有关必回关,争取今年认证早日拿到博客专家 Java高频面试之总纲篇 Java高频面试之集合篇 Java高频面试之异常篇 Java高频面试之并发篇 Java高频面试之SSM篇 Java高频面试之Mysql篇 Java高频面试之Redis篇 Java高频面试之消息队列与分布式篇…...

【软件工程】介绍
软件工程 软件工程是一门应用计算机科学、数学和工程原则来设计、开发、维护和测试软件的学科。软件工程着重于创建质量高效、可靠、可使用、可维护和快速开发的系统。这个领域从20世纪60年代初开始蓬勃发展,主要是为了解决软件危机,即随着计算机和软件…...

考研复习C语言初阶(4)+标记和BFS展开的扫雷游戏
目录 1. 一维数组的创建和初始化。 1.1 数组的创建 1.2 数组的初始化 1.3 一维数组的使用 1.4 一维数组在内存中的存储 2. 二维数组的创建和初始化 2.1 二维数组的创建 2.2 二维数组的初始化 2.3 二维数组的使用 2.4 二维数组在内存中的存储 3. 数组越界 4. 冒泡…...

在 Python 中从键盘读取用户输入
文章目录 如何在 Python 中从键盘读取用户输入input 函数使用input读取键盘输入使用input读取特定类型的数据处理错误从用户输入中读取多个值 getpass 模块使用 PyInputPlus 自动执行用户输入评估总结 如何在 Python 中从键盘读取用户输入 原文《How to Read User Input From t…...
linux设置systemctl启动
linux设置nginx systemctl启动 生成nginx.pid文件 #验证nginx的配置,并生成nginx.pid文件 /usr/local/nginx/sbin/nginx -t #pid文件目录在 /usr/local/nginx/run/nginx.pid 设置systemctl启动nginx #添加之前需要先关闭启动状态的nginx,让nginx是未…...

蓝桥杯历年真题省赛 Java b组 2016年 第七届 煤球数目
一、题目 煤球数目. 有一堆煤球,堆成三角棱锥形。具体: 第一层放1个, 第二层3个(排列成三角形), 第三层6个(排列成三角形), 第四层10个(排列成三角形&#x…...

NTFS安全权限
NTFS是新技术文件系统(New Technology File System)的缩写,是一种用于Windows操作系统的文件系统。NTFS提供了高级的功能和性能,包括文件和目录的权限控制、加密、压缩以及日志等。它被广泛应用于Windows NT、Windows 2000、Windo…...
rt-thread组件之audio组件(结合mp3player包使用)
前言 继上一篇RT-Thread组件之Audio框架i2s驱动的编写的编写,应用层使用rt-thread软件包里面的wavplayer组件以及 rt-thread组件之audio组件(结合wavplayer包使用)的文章本篇使用的是 mp3player软件包,与wavplayer设计框架基本上是一样的,只…...
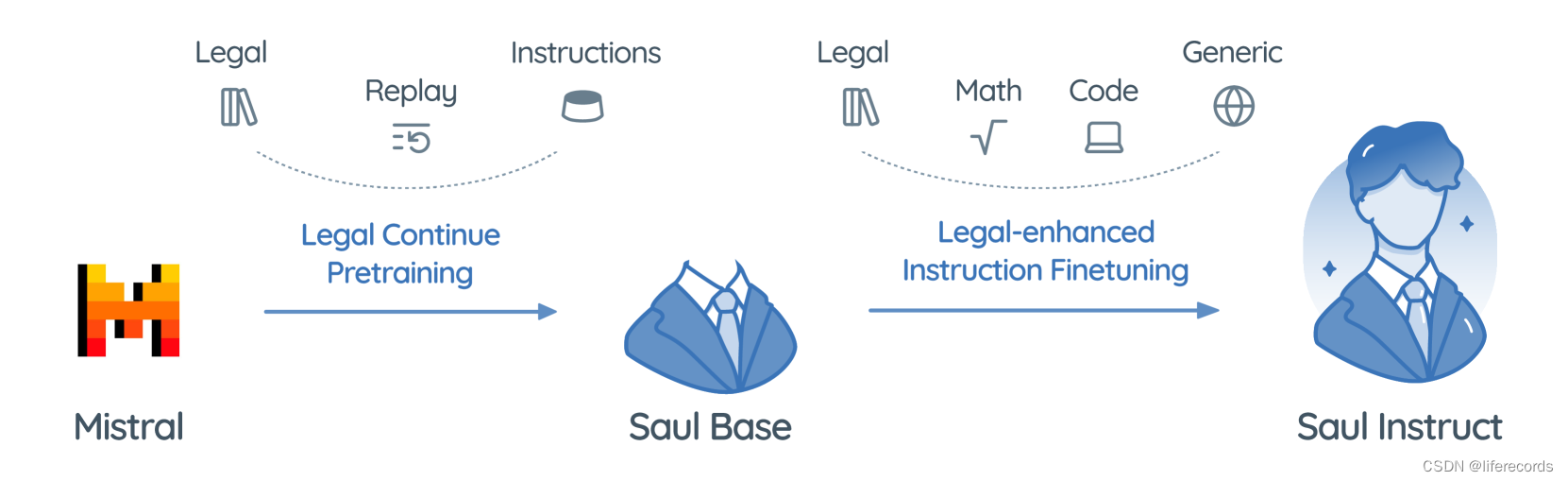
SaulLM-7B: A pioneering Large Language Model for Law
SaulLM-7B: A pioneering Large Language Model for Law 相关链接:arxiv 关键字:Large Language Model、Legal Domain、SaulLM-7B、Instructional Fine-tuning、Legal Corpora 摘要 本文中,我们介绍了SaulLM-7B,这是为法律领域量…...
概要了解postman、jmeter 、loadRunner
postman还蛮好理解的,后续复习的话着重学习关联接口测试即可,感觉只要用几次就会记住: 1 从接口的响应结果当中提取需要的数据 2 设置成环境变量/全局变量(json value check 、set environment para 3写入到下一个接口的请求数据中…...

3642. 最大公约数和最小公倍数 考研上机真题
输入两个正整数 m和 n,求其最大公约数和最小公倍数。 输入格式 一行,两个整数 m和 n。 输出格式 一行,输出两个数的最大公约数和最小公倍数。 数据范围 1≤n,m≤10000 输入样例: 5 7输出样例: 1 35 #include…...

Java客户端调用elasticsearch进行深度分页查询 (search_after)
Java客户端调用elasticsearch进行深度分页查询 (search_after) 一. 代码二. 测试结果 前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者:神的孩子都在歌唱 具体的Search_after解…...

C#使用自定义的泛型节点类 Node<T>实现二叉树类BinaryTree<T>及其方法
目录 一、涉及到的知识点 1.Comparer.Default 属性 2.实现二叉树类BinaryTree步骤 (1)先设计一个泛型节点类 (2)再设计一个泛型的二叉树类 (3)最后设计Main方法 二、 使用泛型节点类 Node实现二叉树…...

美团2025春招第一次笔试题
第四题 题目描述 塔子哥拿到了一个大小为的数组,她希望删除一个区间后,使得剩余所有元素的乘积未尾至少有k个0。塔子哥想知道,一共有多少种不同的删除方案? 输入描述 第一行输入两个正整数 n,k 第二行输入n个正整数 a_i,代表…...

用游戏面试应聘者的方法
用游戏面试应聘者的方法 例如使用俄罗斯方块来面试,如果对方对这个游戏没有兴趣,或者是游戏结果不够好, 那么可以肯定的是,这个人做不好文物修复的工作。 象棋或者是围棋之类的棋类下得好的人,一般来说,做…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...
 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例)
招行+工行:ReAct(Reasoning + Acting) 讲清楚,并结合 金融场景(含自进化智能体) 给出可直接用的案例
下面我把 ReAct(Reasoning Acting) 讲清楚,并结合 ** 金融场景(含自进化智能体)** 给出可直接用的案例与话术,适合分享 / 汇报。一、ReAct 是什么(一句话)ReAct 推理(T…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

AB包相关知识
Lua与AB包/Addressables以及YooAsset 摘自千问: Lua 是菜谱(逻辑):决定了菜怎么做,味道如何。因为你需要随时换菜谱(热更新),所以菜谱不能死板地印在墙上(编译进主包&a…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

国产大模型新王登基?Qwen3.7-Max全球第五、编程Agent登顶,千问APP免费体验全攻略
AI前线观察 | 2026.05.25 就在刚刚过去的阿里云峰会上,通义千问甩出了一张“王炸”。万亿参数MoE架构的旗舰模型Qwen3.7-Max正式接入千问APP、PC端及网页端。这不仅仅是一次版本更新,更是国产大模型在权威第三方榜单中首次稳居全球前五、国产第一的里程碑…...