数据分析Pandas专栏---第十三章<Pandas训练题(初)>
前言:
写这篇是为了弄一个富有挑战性的Pandas练习题库,涵盖了许多常见和实用的数据处理问题。通过解决这些练习,能够深入了解Pandas提供的关键功能,掌握有效处理数据的技巧和方法。
练习题库涵盖了选择特定列并创建新DataFrame、对DataFrame进行随机抽样、将字符串列转换为日期时间类型等常见任务。讨论如何根据给定条件进行行的筛选、对字符串列进行大小写转换以及重命名DataFrame的列。此外,还会探索处理缺失数据、重复数据和进行分组计算的方法,以及如何进行数据透视、排序和滑动窗口计算。
实践这些练习,培养自己解决实际数据处理问题的能力,并在日常工作中更加熟练地使用Pandas库。
正文:
---------------------------------------------------难度从低到高------------------------------------------------
题1:
根据给定的DataFrame,选择特定的列,并将其转换为一个新的DataFrame。
案例:
假设我们有一个DataFrame,其中包含了用户的姓名、年龄、性别以及邮箱地址等信息。我们需要选择其中的姓名和邮箱地址这两列,并将其转换为一个新的DataFrame。
解题思路:
要解决这个问题,我们可以使用Pandas中的索引操作来选择特定的列。首先,我们需要创建一个新的DataFrame对象,并从原始DataFrame中选择所需的列进行复制。
解决方案代码如下:
import pandas as pd# 创建原始DataFrame
data = {'姓名': ['张三', '李四', '王五', '赵六'],'年龄': [25, 30, 35, 40],'性别': ['男', '女', '男', '女'],'邮箱地址': ['zhangsan@gmail.com', 'lisi@gmail.com', 'wangwu@gmail.com', 'zhaoliu@gmail.com']}
df = pd.DataFrame(data)# 选择特定列并创建新的DataFrame
new_df = pd.DataFrame()
new_df['姓名'] = df['姓名']
new_df['邮箱地址'] = df['邮箱地址']# 打印新的DataFrame
print(new_df)
输出结果:
姓名 邮箱地址
0 张三 zhangsan@gmail.com
1 李四 lisi@gmail.com
2 王五 wangwu@gmail.com
3 赵六 zhaoliu@gmail.com
在这个案例中,我们创建了一个原始的DataFrame,并使用选择特定列的方法将姓名和邮箱地址这两列提取出来,赋值给新的DataFrame对象new_df。最后,我们打印出新的DataFrame,以确认我们成功地选择了所需的列并创建了新的DataFrame。
掌握知识点:
理解如何根据给定的DataFrame选择特定的列,并将其转换为一个新的DataFrame。这是Pandas中一个常用的基础操作,为处理和分析数据提供了基础。深入思考如何将这个方法应用到实际的数据处理任务中,如特征选择、数据提取等,以更好地利用Pandas的强大功能。
题2:
如何对DataFrame的行进行随机抽样?
案例:
假设我们有一个包含学生姓名和测试成绩的DataFrame,我们需要对这个DataFrame的行进行随机抽样,选择其中一部分学生进行分析。
解题思路:
要解决这个问题,我们可以使用Pandas中的sample()函数来对DataFrame的行进行随机抽样。我们可以指定抽样的比例或具体的抽样数量,并设置随机种子以保证结果的可重复性。
解决方案代码如下:
import pandas as pd# 创建原始DataFrame
data = {'学生姓名': ['张三', '李四', '王五', '赵六', '小明', '小红'],'测试成绩': [85, 78, 90, 92, 88, 91]}
df = pd.DataFrame(data)# 对DataFrame行进行随机抽样
sample_df = df.sample(frac=0.5, random_state=42) # 抽取50%的行,设置随机种子为42# 打印抽样结果
print(sample_df)
输出结果:
学生姓名 测试成绩
1 李四 78
4 小明 88
3 赵六 92
在这个案例中,我们创建了一个原始的DataFrame,并使用sample()函数对DataFrame的行进行随机抽样。通过设置frac参数为0.5,我们抽取了原始DataFrame中50%的行作为抽样结果,并设置了随机种子为42,以保证结果的可重复性。
掌握知识点:
了解如何对DataFrame的行进行随机抽样。这是一个常见的数据处理任务,可以帮助我们在大规模数据集上进行快速的初步分析和检验。可以尝试修改案例中的参数,如抽样比例或抽样数量,进一步了解抽样对结果的影响,并将这个方法应用到实际的数据分析中。
题3:
如何将DataFrame中的字符串列转换为日期时间类型?
案例:
假设我们有一个包含日期和销售额的DataFrame,日期列是以字符串格式表示的。我们需要将这个日期列转换为日期时间类型,以便更方便地进行日期操作和分析。
解题思路:
要解决这个问题,我们可以使用Pandas的to_datetime()函数将字符串列转换为日期时间类型。我们可以指定日期列的格式,并将转换后的结果赋值给原始的日期列。
解决方案代码如下:
import pandas as pd# 创建原始DataFrame
data = {'日期': ['2022-01-01', '2022-02-01', '2022-03-01', '2022-04-01'],'销售额': [1000, 1500, 2000, 1800]}
df = pd.DataFrame(data)# 将字符串列转换为日期时间类型
df['日期'] = pd.to_datetime(df['日期'])# 打印转换后的DataFrame
print(df)
输出结果:
日期 销售额
0 2022-01-01 1000
1 2022-02-01 1500
2 2022-03-01 2000
3 2022-04-01 1800
在这个案例中,我们创建了一个包含日期和销售额的DataFrame,并使用to_datetime()函数将日期列从字符串格式转换为日期时间类型。我们直接在原始DataFrame上进行操作,将转换后的结果赋值给原始日期列。
掌握知识点:
可以了解如何将DataFrame中的字符串列转换为日期时间类型。这对于处理和分析时间序列数据非常重要,可以进行更精准的日期运算和可视化分析。可以尝试修改案例中的日期格式,并观察结果的变化,以更深入理解日期时间类型的转换。
题4:
给定一个DataFrame和一个条件,如何筛选出满足条件的行?
案例:
假设我们有一个包含学生姓名、年龄和成绩的DataFrame,我们需要根据条件筛选出年龄大于等于18岁的学生。
解题思路:
要解决这个问题,我们可以使用布尔索引(Boolean indexing)来筛选出满足条件的行。首先,我们需要定义条件,然后使用该条件对DataFrame进行布尔索引操作,得到满足条件的行。
解决方案代码如下:
import pandas as pd# 创建原始DataFrame
data = {'姓名': ['张三', '李四', '王五', '赵六'],'年龄': [20, 17, 19, 22],'成绩': [85, 78, 90, 92]}
df = pd.DataFrame(data)# 定义条件并筛选出满足条件的行
condition = df['年龄'] >= 18
filtered_df = df[condition]# 打印筛选结果
print(filtered_df)
输出结果:
姓名 年龄 成绩
0 张三 20 85
2 王五 19 90
3 赵六 22 92
在这个案例中,我们创建了一个包含学生姓名、年龄和成绩的DataFrame,并定义了筛选的条件,即年龄大于等于18岁。通过使用布尔索引df[condition],我们对DataFrame进行筛选操作,将满足条件的行提取出来并赋值给新的DataFrame对象filtered_df。
掌握知识点:
可以了解如何根据给定的条件筛选DataFrame中的行。这是一个常见的数据处理任务,对于数据的筛选和过滤非常有用。可以尝试修改案例中的筛选条件,并观察结果的变化,以更进一步理解布尔索引的使用。
题5:
如何对DataFrame中的字符串列进行大小写转换?
案例:
假设我们有一个包含学生姓名和性别的DataFrame,我们需要将学生姓名的字符串列转换为大写或小写形式,以统一姓名的格式。
解题思路:
要解决这个问题,我们可以使用Pandas的字符串方法对字符串列进行大小写转换。Pandas提供了str.upper()方法将字符串转换为大写形式,以及str.lower()方法将字符串转换为小写形式。我们可以对字符串列应用这些方法,并将转换后的结果赋值给原始的字符串列。
解决方案代码如下:
import pandas as pd# 创建原始DataFrame
data = {'姓名': ['张三', '李四', '王五', '赵六'],'性别': ['male', 'Female', 'female', 'MALE']}
df = pd.DataFrame(data)# 将字符串列转换为大写形式
df['姓名'] = df['姓名'].str.upper()# 将字符串列转换为小写形式
df['性别'] = df['性别'].str.lower()# 打印转换后的DataFrame
print(df)
输出结果:
姓名 性别
0 张三 male
1 李四 female
2 王五 female
3 赵六 male
在这个案例中,我们创建了一个包含学生姓名和性别的DataFrame,并使用str.upper()方法将姓名列转换为大写形式,使用str.lower()方法将性别列转换为小写形式。
掌握知识点:
可以了解如何对DataFrame中的字符串列进行大小写转换。这对于数据的清洗和统一非常有用,可以消除大小写带来的差异,并提高数据的一致性。可以尝试应用相反的转换方法,如str.lower()和str.upper(),并观察结果的变化,以进一步了解字符串转换的效果。
题6:
如何对DataFrame中的列进行重命名?
案例:
假设我们有一个包含学生姓名和年龄的DataFrame,我们需要对这两列进行重命名,将列名从英文改为中文。
解题思路:
要解决这个问题,我们可以使用Pandas的rename()函数对DataFrame的列进行重命名。我们可以通过指定columns参数,传入一个字典,其中键是原始列名,值是新的列名,来对列进行重命名操作。
解决方案代码如下:
import pandas as pd# 创建原始DataFrame
data = {'Name': ['张三', '李四', '王五', '赵六'],'Age': [20, 21, 19, 22]}
df = pd.DataFrame(data)# 对列进行重命名
df = df.rename(columns={'Name': '姓名', 'Age': '年龄'})# 打印重命名后的DataFrame
print(df)
输出结果:
姓名 年龄
0 张三 20
1 李四 21
2 王五 19
3 赵六 22
在这个案例中,我们创建了一个包含学生姓名和年龄的DataFrame,并使用rename()函数对两列进行重命名。我们通过传入一个字典{'Name': '姓名', 'Age': '年龄'}来指定原始列名和新的列名。
掌握知识点:
可以了解如何对DataFrame中的列进行重命名。这对于数据的清洗和整理非常有用,可以使列名更加有意义和可读性。可以尝试修改案例中的重命名字典,并观察结果的变化,以进一步理解对列进行重命名的操作。
题7:
给定一个DataFrame和一个字符串,如何判断该字符串是否在DataFrame的某一列中存在?
案例:
假设我们有一个包含学生姓名和年龄的DataFrame,我们需要判断某个给定的学生姓名是否存在于DataFrame的姓名列中。
解题思路:
要解决这个问题,我们可以使用Pandas的isin()函数来判断字符串是否存在于某一列中。我们可以将给定的学生姓名转换为一个列表,然后使用isin()函数将这个列表与姓名列进行比较,返回一个布尔序列,表示每个值是否存在于姓名列中。
解决方案代码如下:
import pandas as pd# 创建原始DataFrame
data = {'姓名': ['张三', '李四', '王五', '赵六'],'年龄': [20, 21, 19, 22]}
df = pd.DataFrame(data)# 给定的学生姓名
given_name = '李四'# 判断学生姓名是否存在于姓名列中
name_exists = given_name in df['姓名'].values# 打印判断结果
print(f'学生姓名"{given_name}"存在于姓名列中: {name_exists}')
输出结果:
学生姓名"李四"存在于姓名列中: True
在这个案例中,我们创建了一个包含学生姓名和年龄的DataFrame,并给定了一个学生姓名为'李四'。我们使用in关键字和df['姓名'].values将学生姓名与姓名列进行比较,得到一个布尔值,表示学生姓名是否存在于姓名列中。
掌握知识点:
可以了解如何判断给定的字符串是否存在于DataFrame的某一列中。这在数据查找和匹配方面非常有用,可以帮助我们快速地找到数据中是否存在某个特定的值。可以尝试修改给定的学生姓名,然后观察结果的变化,以进一步了解判断字符串存在性的操作。
相关文章:
>)
数据分析Pandas专栏---第十三章<Pandas训练题(初)>
前言: 写这篇是为了弄一个富有挑战性的Pandas练习题库,涵盖了许多常见和实用的数据处理问题。通过解决这些练习,能够深入了解Pandas提供的关键功能,掌握有效处理数据的技巧和方法。 练习题库涵盖了选择特定列并创建新DataFrame、对DataFrame进…...
 错误的解决方案)
Delete `␍`eslint(prettier/prettier) 错误的解决方案
最近开始一个新的项目,由他人构建,clone下来后,发现页面每行都有黄色的波浪线的提示:Delete ␍eslint(prettier/prettier) ,尝试了很多方法不能解决,最后选择关闭Prettier: 在.eslintrc.js文件…...

第3周 Python字典、集合刷题
第3周 Python字典、集合刷题 单击题目,直接跳转到页面刷题,一周后公布答案。 B2125:最高分数的学生姓名28:返回字典的键值75:字符串转字典77:映射字符串中的字母87:按条件过滤字典B3632&#…...
文字校对的首选——爱校对:用户真实反馈汇编
在今日快节奏、高标准的工作环境下,准确与效率成为了每位专业人士追求的双重目标。不论是在政府机构、学术领域、企业界,还是在自由职业者的行列中,我们都面临着同一个挑战:如何在保持工作速度的同时,确保每一份文档的…...

Llama-3即将发布:Meta公布其庞大的AI算力集群
Meta,这家全球科技巨头,再次以其在人工智能(AI)领域的雄心壮志震惊了世界。3月13日,公司在其官方网站上宣布了两个全新的24K H100 GPU集群,这些集群专为训练其大型模型Llama-3而设计,总计拥有高…...

【JAVA】Date、LocalDate、LocalDateTime 详解,实践应用
Date、LocalDate、LocalDateTime 详解,实践应用 一、Date、LocalDate 简介1、 java.util.Date:2、 java.time.LocalDateTime:3、 java.time.LocalDate: 二、输出格式1、使用 java.util.Date 的示例代码如下:2、使用 ja…...

分布式链路追踪(一)SkyWalking(1)介绍与安装
一、介绍 1、简介: 2、组成 以6.5.0为例,该版本下Skywalking主要分为oap、webapp和agent三部分,oap和webapp分别用于汇总数据和展示,这两块共同组成了Skywalking的平台;agent是探针,部署在需要收集数据的…...

蓝桥杯历年真题省赛之 2016年 第七届 生日蜡烛
一、题目 生日蜡烛 某君从某年开始每年都举办一次生日party,并且每次都要吹熄与年龄相同根数的蜡烛。 现在算起来,他一共吹熄了236根蜡烛。 请问,他从多少岁开始过生日party的? 请填写他开始过生日party的年龄数。 注意&…...

SCAU 8580 合并链表
8580 合并链表 时间限制:1000MS 代码长度限制:10KB 提交次数:3724 通过次数:2077 题型: 编程题 语言: G;GCC Description 线性链表的基本操作如下: #include<stdio.h> #include<malloc.h> #define ERROR 0 #define OK 1 #define ElemType inttyped…...
Docker安装Gitlab
下载镜像 直接下载最新版,比较大有2.36G docker pull gitlab/gitlab-ce创建数据存放的目录位置 按自己习惯位置创建目录 mkdir -p /usr/local/docker/docker_gitlab编写docker-compose.yml 在上面创建的挂载目录里面(/usr/local/docker/docker_gitl…...

浅淡 C++ 与 C++ 入门
我们知道,C语言是结构化和模块化的语言,适用于较小规模的程序。而当解决复杂问题,需要高度抽象和建模时,C语言则不合适,而C正是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库…...
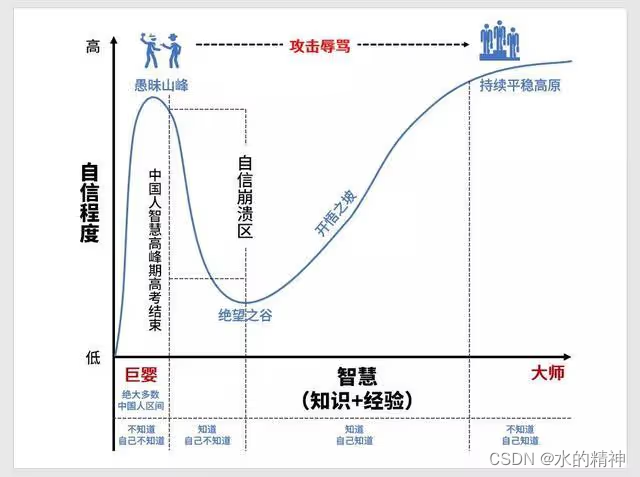
学习和认知的四个阶段,以及学习方法分享
本文分享学习的四个不同的阶段,以及分享个人的一些学习方法。 一、学习认知的四个阶段 我们在学习的过程中,总会经历这几个阶段: 第一阶段:不知道自己不知道; 第二阶段:知道自己不知道; 第三…...
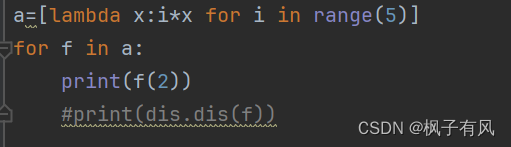
Python编程从入门到实践中的一些误区
1.num 使用num时python报错,后来查过后才知道是因为python不支持自增或自减,可以用1。 2.字符串和非字符串连接 要先将非字符串转换为字符串类型之后才能连接 print(2int(‘2’))#4 3.关键字参数必须在未…...

Kanebo HITECLOTH 高科技擦镜布介绍
Kanebo HITECLOTH,这款由日本KBSeiren公司制造的高科技擦镜布,以其卓越的清洁能力和超柔软的布质,成为了市场上备受瞩目的产品。 材质与特性 HITECLOTH采用0.1旦尼尔特级高级微纤维制造,质地细致、坚韧、不起颗粒。这种纤维的特…...
政务云安全风险分析与解决思路探讨
1.1概述 为了掌握某市政务网站的网络安全整体情况,在相关监管机构授权后,我们组织人员抽取了某市78个政务网站进行安全扫描,通过安全扫描,对该市政务网站的整体安全情况进行预估。 1.2工具扫描结果 本次利用漏洞扫描服务VSS共扫…...
Linux tcpdump抓包转Wireshark 分析
简介 tcpdump 是Linux系统下的一个强大的命令,可以将网络中传送的数据包完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,本文将展示如何使用 tcpdump 抓包,以及如何用 tcpdump 和 wireshark 分析网络流量 tcpdump指…...

【Spring高级】Aware与InitializingBean接口
目录 Aware接口概述为什么需要Aware接口 InitializingBean接口Autoware失效分析 Aware接口 概述 在Spring框架中,Aware 接口是一种常用的设计模式,用于允许bean在初始化时感知(或获取)Spring容器中的某些资源或环境信息。这些接…...

打造你的HTML5打地鼠游戏:零基础入门教程
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...

C++默认构造函数/拷贝构造函数/赋值构造函数
概述 本文主要讲解C默认构造函数,拷贝构造函数和赋值构造函数在哪些场景下会被调用到 代码 类定义 class A{public:A() { cout<<"construct function"<<endl; }A(const A& other) { cout<<"copy construct function"…...

前端框架的发展历史介绍
前端框架的发展历史是Web技术进步的一个重要方面。从最初的简单HTML页面到现在的复杂单页应用程序(SPA),前端框架和库的发展极大地推动了Web应用程序的构建方式。以下是一些关键的前端框架和库,以及它们的发布年份、创建者和主要特…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...

Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹
Cesium动态数据可视化实战:CallbackProperty结合setInterval打造实时运动轨迹 在三维地理信息系统中,实时数据可视化一直是开发者面临的挑战之一。想象一下,当我们需要在地球表面追踪一架正在飞行的无人机,或者监控城市中数百辆出…...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元
HiveWE地图编辑器:告别卡顿,开启魔兽争霸III地图制作新纪元 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器的缓慢加载和频繁卡顿而烦恼吗?你…...

Windows HEIC缩略图解决方案:让iPhone照片在资源管理器中重获新生
Windows HEIC缩略图解决方案:让iPhone照片在资源管理器中重获新生 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 想…...

Unity背包拖拽实战:三坐标系映射与跨Panel交互原理
1. 这不是“拖一拖就完事”的UI小功能,而是Unity UI系统能力的实战压力测试 在Unity项目里,“背包装备拖拽”这六个字,新手常以为只是给Image加个DragHandler接口、写几行OnBeginDrag/OnDrag/OnEndDrag回调——结果上线前一周,策划…...