Python爬虫入门
什么是爬虫
爬虫就是程序,一个能获取互联网上的资源(文字、图片、音视频)数据的程序。
不用爬⾍, 打开浏览器, 输⼊百度的⽹址,就能在浏览器上看到百度的内容了。那换成爬⾍呢? 道理是⼀样的。只不过,是⽤代码来模拟⼀个浏览器, 然后同样的输⼊百度的⽹址。那么程序也能拿到百度的内容
爬虫合法吗
爬虫在法律上暂时是不被禁止的。但服务器上的数据有产权归属,如果网络爬虫获取数据后牟利将带来法律风险。小规模,数据量小,频率不高, 不窃取用户隐私的爬取是可以的,合法的
反爬与反反爬
反爬机制:网站可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取
反反爬策略:爬虫程序可以通过制定相关的策略或者技术手段,破解网站中具备的反爬机制,从而可以获取网站中相关的数据。
robots.txt协议:君子协议。规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取
requests请求库
- 安装
pip install requests
- 请求百度首页源代码
import requests# 这样运行的话就把百度首页的html提取出来了
url = "https://www.baidu.com/"
response = requests.get(url)
response.encoding = "utf-8"
print(response.text)
XPath解析库
- ⼤多数情况下, 我们并不需要整个⽹⻚的内容, 只是需要那么⼀⼩部分。所以我们要做数据解析和提取。常见的有:xpath解析、BeautifulSoup解析、正则表达式re解析
- XPath是⼀⻔在 XML ⽂档中查找信息的语⾔, XPath可⽤来在 XML⽂档中对元素和属性进⾏遍历,⽽我们熟知的HTML恰巧属于XML的⼀个⼦集,所以完全可以⽤xpath去查找html中的内容
- 在python中想要使⽤xpath,需要安装lxml模块:pip install lxml
- 基础用法:①将要解析的html内容构造出etree对象②使⽤etree对象的xpath()⽅法配合xpath表达式来完成对数据的提取
html = """
<!DOCTYPE html>
<html><head><meta charset="UTF-8" /><title>Title</title></head><body><ul><li><a href="http://www.baidu.com">百度</a></li><li><a href="http://www.google.com">⾕歌</a></li><li><a href="http://www.sogou.com">搜狗</a></li></ul><ol><li><a href="feiji">⻜机</a></li><li><a href="dapao">⼤炮</a></li><li><a href="huoche">⽕⻋</a></li></ol><div>李嘉诚</div><div>胡辣汤</div></body>
</html>
"""
from lxml import etreetree = etree.XML(html)
result = tree.xpath("/html/body/ul/li/a/@href")
print(result)result = tree.xpath("/html/body/ul/li")
for li in result:print(li.xpath("./a/@href"))result = tree.xpath("/html/body/ol/li/a/@href")
print(result)
BeautifulSoup解析库
- 安装库:pip intall bs4
<html lang="en">
<head><meta charset="UTF-8" /><title>测试bs4</title>
</head>
<body><div><p>百里守约</p></div><div class="song"><p>李清照</p><p>王安石</p><p>苏轼</p><p>柳宗元</p><a href="http://www.song.com/" title="赵匡胤" target="_self"><span>this is span</span>宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a><a href="" class="du">总为浮云能蔽日,长安不见使人愁</a><img src="http://www.baidu.com/meinv.jpg" alt="" /></div><div class="tang"><ul><li><a href="百度一下,你就知道" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li><li><a href="网易" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li><li><a href="126网易免费邮--你的专业电子邮" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li><li><a href="home.sina.com" class="du">杜甫</a></li><li><a href="Awesome Coming Soon Widget Responsive Widget" class="du">杜牧</a></li><li><b>杜小月</b></li><li><i>度蜜月</i></li><li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li></ul></div>
</body>
</html>from bs4 import BeautifulSoup#本地的html
fp = open(r"test.html","r",encoding="utf-8")
soup = BeautifulSoup(fp,"lxml")
print(soup) #返回这个网页的源代码
print(soup.a) #返回第一个a标签的内容
print(soup.div) #返回第一个div 的内容
print(soup.find("div")) #返回第一个div 的内容
print(soup.find("div",class_="song")) #返回class = "song" 的div的内容
print(soup.find_all("a")) #返回所有a标签的内容
print(soup.find("div",class_="song").a.get("href"))# 返回http://www.song.com/
print(soup.find("div",class_="song").img.get("src"))#返回http://www.baidu.com/meinv.jpg
print(soup.find("div",class_="song").a.text) # 返回文本
print(soup.select('.tang')) 返回class = "tang" 的div的内容
print(soup.select(".tang > ul > li > a")[0].text) # 返回tang下的第一个标签的内容
print(soup.select(".tang > ul > li > a")[0]['href']) # 返回tang下的第一个标签的链接
正则表达式
- 正则表达式是用来简洁表达一组字符串的表达式

import re
# 将正则表达式编译成为⼀个正则表达式对象, 规则要匹配的是3个数字
obj = re.compile(r'\d{3}')
# 正则表达式对象调⽤search, 参数为待匹配的字符串
ret = obj.search('abc123eeee')
print(ret.group()) # 结果: 123
元字符:具有固定含义的特殊符号 常⽤元字符:
. 匹配除换⾏符以外的任意字符
\w 匹配字⺟或数字或下划线
\s 匹配任意的空⽩符 \d 匹配数字
\n 匹配⼀个换⾏符
\t 匹配⼀个制表符
^ 匹配字符串的开始 $ 匹配字符串的结尾
\W 匹配⾮字⺟或数字或下划线
\D 匹配⾮数字
\S 匹配⾮空⽩符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示⼀个组
[…] 匹配字符组中的字符
[^…] 匹配除了字符组中字符的所有字符
量词: 控制前⾯的元字符出现的次数
*重复零次或更多次
+重复⼀次或更多次
? 重复零次或⼀次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
贪婪匹配和惰性匹配
str: 玩⼉吃鸡游戏, 晚上⼀起上游戏, ⼲嘛呢? 打游戏啊
reg: 玩⼉.*?游戏
此时匹配的是: 玩⼉吃鸡游戏
reg: 玩⼉.*游戏
此时匹配的是: 玩⼉吃鸡游戏, 晚上⼀起上游戏, ⼲嘛呢? 打游戏str: <div>胡辣汤</div>
reg: <.*>
结果: <div>胡辣汤</div>str: <div>胡辣汤</div>
reg: <.*?>
结果:
<div>
</div>str: <div>胡辣汤</div><span>饭团</span>
reg: <div>.*?</div>
结果:
<div>胡辣汤</div>
- 案例:练习用正则表达式提取豆瓣电影top250的数据并保存
# 拿到页面源代码. requests
# 通过re来提取想要的有效信息 re
import requests
import re
import csvurl = "https://movie.douban.com/top250"
headers = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36"
}
resp = requests.get(url, headers=headers)
page_content = resp.text# 解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?<span 'r'class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'r'<span>(?P<num>.*?)人评价</span>', re.S)
# 开始匹配
result = obj.finditer(page_content)
f = open("data.csv", mode="w")
csvwriter = csv.writer(f)
for it in result:print(it.group("name"))print(it.group("score"))print(it.group("num"))print(it.group("year").strip())dic = it.groupdict()dic['year'] = dic['year'].strip()csvwriter.writerow(dic.values())f.close()
print("over!")
cookies:处理需要登陆的网站
headers为HTTP协议中的请求头。⼀般存放⼀些和请求内容⽆关的数据。有时也会存放⼀些安全验证信息,比如常⻅的User-Agent,cookies等。通过requests发送的请求, 我们可以把请求头信息放在headers中。也可以单独进⾏存放, 最终由requests⾃动帮我们拼接成完整的http请求头
selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接调用浏览器,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏等
- 在下载好chromedriver以及安装好selenium模块后,可以执行下列代码并观察运行的过程
from selenium import webdriver
# 如果driver没有添加到了环境变量,则需要将driver的绝对路径赋值给executable_path参数
# driver = webdriver.Chrome(executable_path='driver的绝对路径')# 如果driver添加了环境变量则不需要设置executable_path
driver = webdriver.Chrome()
# 向一个url发起请求
driver.get("https://www.baidu.com/")
# 把网页保存为图片
driver.save_screenshot("baidu.png")
# 打印页面的标题
print(driver.title)
# 在百度搜索框中搜索'python'
driver.find_element_by_id('kw').send_keys('python')
# 点击'百度搜索'
driver.find_element_by_id('su').click()
# 退出模拟浏览器
driver.quit()
- selenium工作原理:利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)
- 在selenium中可以通过多种方式来定位标签,返回标签元素对象
find_element_by_id (返回一个元素)
find_element(s)_by_class_name (根据类名获取元素列表)
find_element(s)_by_name (根据标签的name属性值返回包含标签对象元素的列表)
find_element(s)_by_xpath (返回一个包含元素的列表)
find_element(s)_by_link_text (根据连接文本获取元素列表)
find_element(s)_by_partial_link_text (根据链接包含的文本获取元素列表)
find_element(s)_by_tag_name (根据标签名获取元素列表)
find_element(s)_by_css_selector (根据css选择器来获取元素列表)
- selenium获取cookie:driver.get_cookies()返回列表,其中包含的是完整的cookie信息!不光有name、value,还有domain等cookie其他维度的信息。所以如果想要把获取的cookie信息和requests模块配合使用的话,需要转换为name、value作为键值对的cookie字典
# 获取当前标签页的全部cookie信息
print(driver.get_cookies())
# 把cookie转化为字典
cookies_dict = {cookie[‘name’]: cookie[‘value’] for cookie in driver.get_cookies()}
- selenium控制浏览器执行js代码
import time
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("http://www.itcast.cn/")
time.sleep(1)js = 'window.scrollTo(0,document.body.scrollHeight)' # js语句
driver.execute_script(js) # 执行js的方法 跳转到最底部time.sleep(5)
driver.quit()
scrapy框架
- Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架
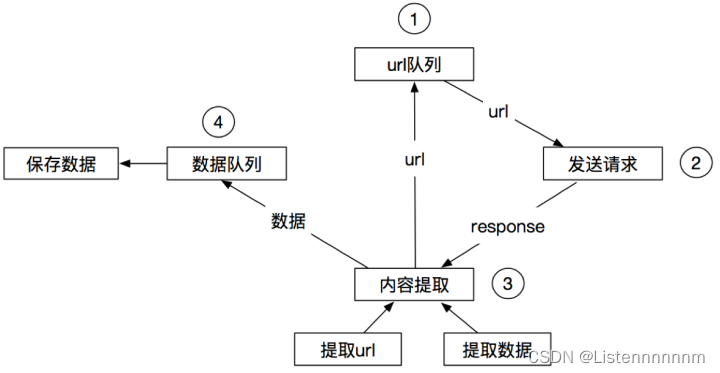
- scrapy的架构如下图,图中中文是为了方便理解后加上去的。图中绿色线条的表示数据的传递。注意图中中间件的位置,决定了其作用。注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互

- 爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件—>下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据
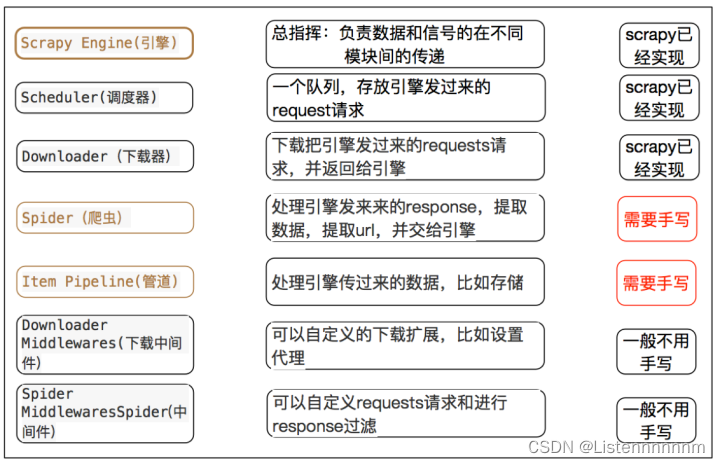
scrapy的三个内置对象
- request请求对象:由url method post_data headers等构成
- response响应对象:由url body status headers等构成
- item数据对象:本质是个字典
scrapy中每个模块的具体作用
相关文章:
Python爬虫入门
什么是爬虫 爬虫就是程序,一个能获取互联网上的资源(文字、图片、音视频)数据的程序。 不用爬⾍, 打开浏览器, 输⼊百度的⽹址,就能在浏览器上看到百度的内容了。那换成爬⾍呢? 道理是⼀样的。只不过,是⽤…...

【数据结构学习笔记】选择排序
【数据结构学习笔记】选择排序 参考电子书:排序算法精讲 算法原理 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元…...

小资金适合做伦敦金的投资吗?
在回答这个问题之前,我们首先需要了解伦敦金是什么。伦敦金,也称为伦敦金市场交易的黄金,是一种国际性的金融交易产品,其价格受全球政治、经济、货币政策、供求关系等多种因素影响,波动性较大。因此,投资伦…...
自动化运维工具 ---------------Ansible
一、Ansible 发展史及功能 作者:Michael DeHaan( Cobbler pxe kikstar 与 Func 作者)ansible 的名称来自科幻小说《安德的游戏》中跨越时空的即时通信工具,使用它可以在相距数光年的距离,远程实时控制前线的舰队战斗2…...

富格林:有效做单安全盈利方法
富格林悉知,在伦敦金的投资中,是否安全盈利很大一部分因素取决于是否有效做单,投资者在进入市场之后,需要学习了解伦敦金相关规则,学习一定的做单的技巧,这样有利于我们后续做单顺畅盈利。以下总结几点安全…...
二分查找的理解及应用场景。
一、是什么 在计算机科学中,二分查找算法,也称折半搜索算法,是一种在有序数组中查找某一特定元素的搜索算法 想要应用二分查找法,则这一堆数应有如下特性: 存储在数组中有序排序 搜索过程从数组的中间元素开始&…...
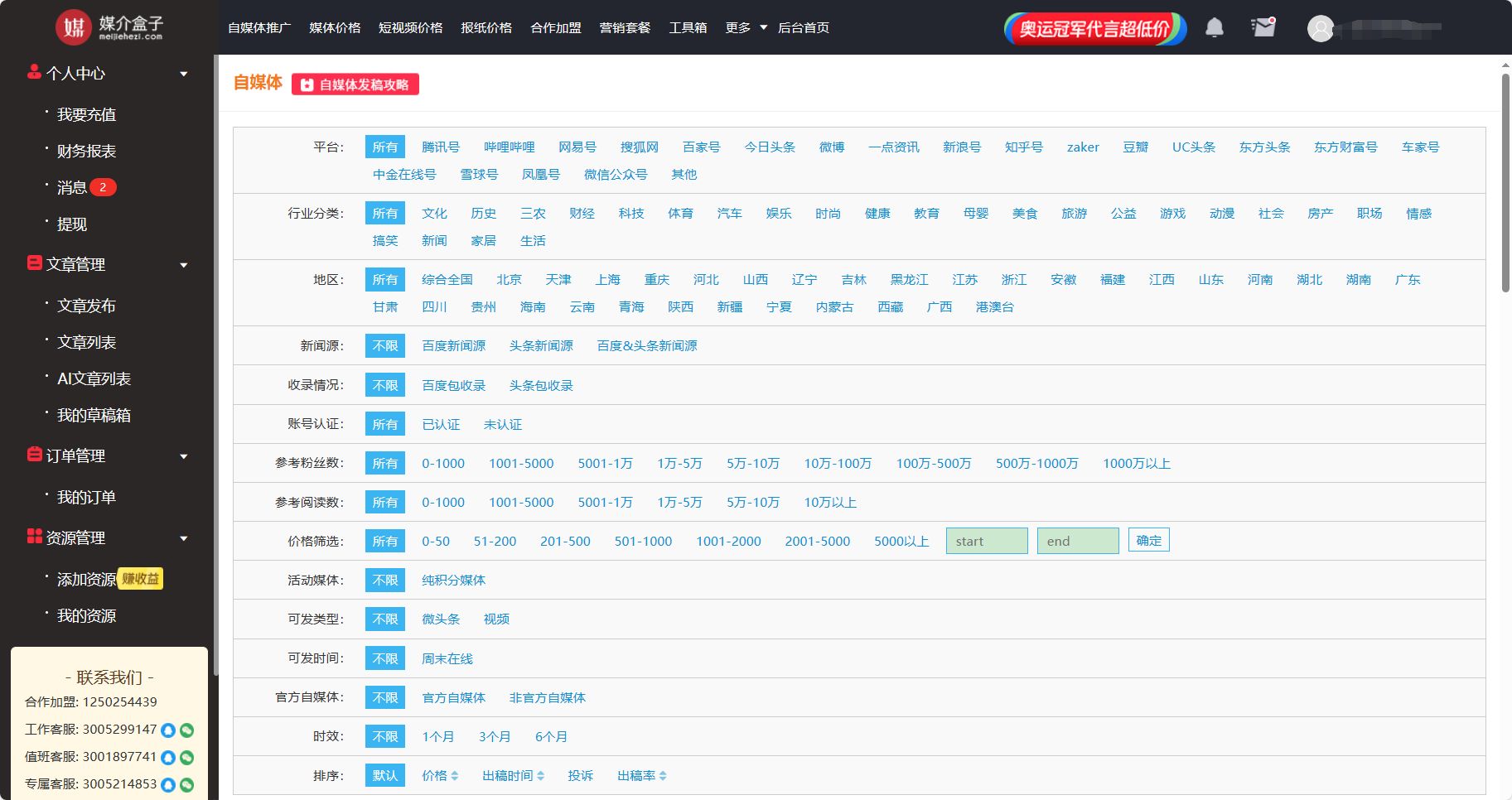
共创时代,品牌如何做好UGC营销?
在当下的互联网时代,众多品牌已经逐渐意识到“产品为重”的影响方式已经很难提升转化率,内容才是吸引用户的必胜法宝,然而当代人被海量信息裹挟,人们的注意力成为稀缺资源,在这个环境下,UGC成为品牌的营销方…...
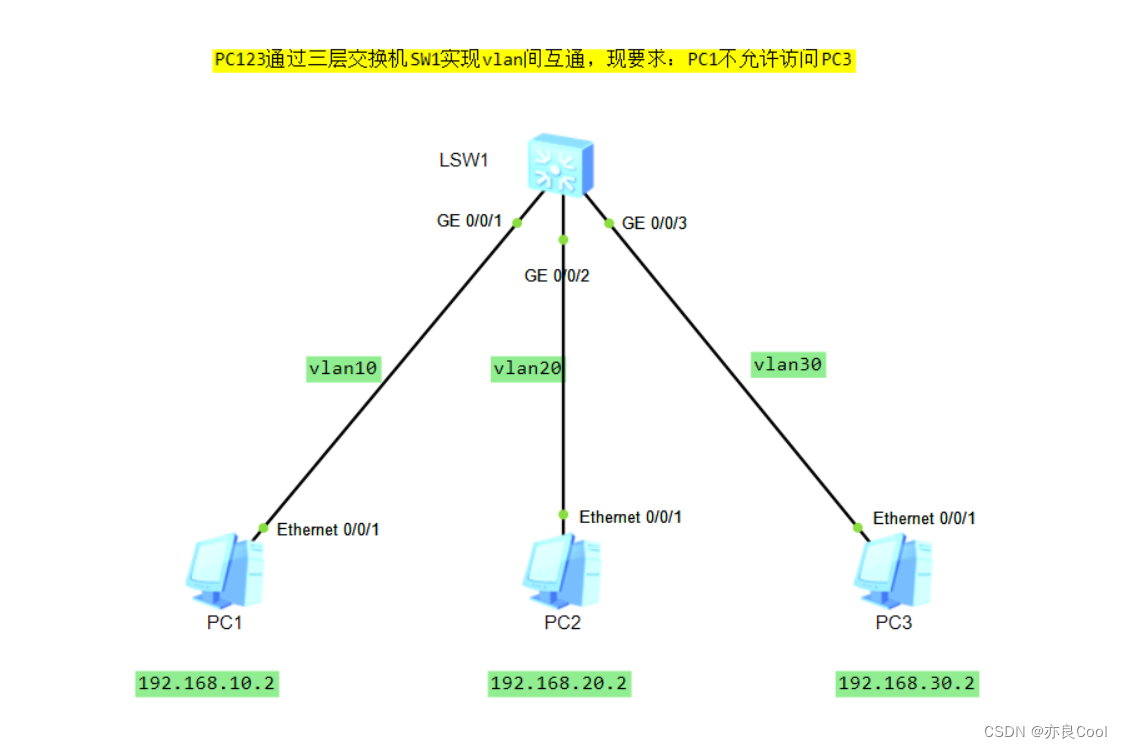
华为三层交换机:ACL的基本实验
实验要求: PC1不允许访问PC3,PC3可以访问PC1 分析问题: PC1不允许访问PC3,问题中含有“目标地址”则我们需要设置目标地址,这样基本ACL是不行的,必须使用高级ACL [sw1]acl ? INTEGER<2000-2999>…...
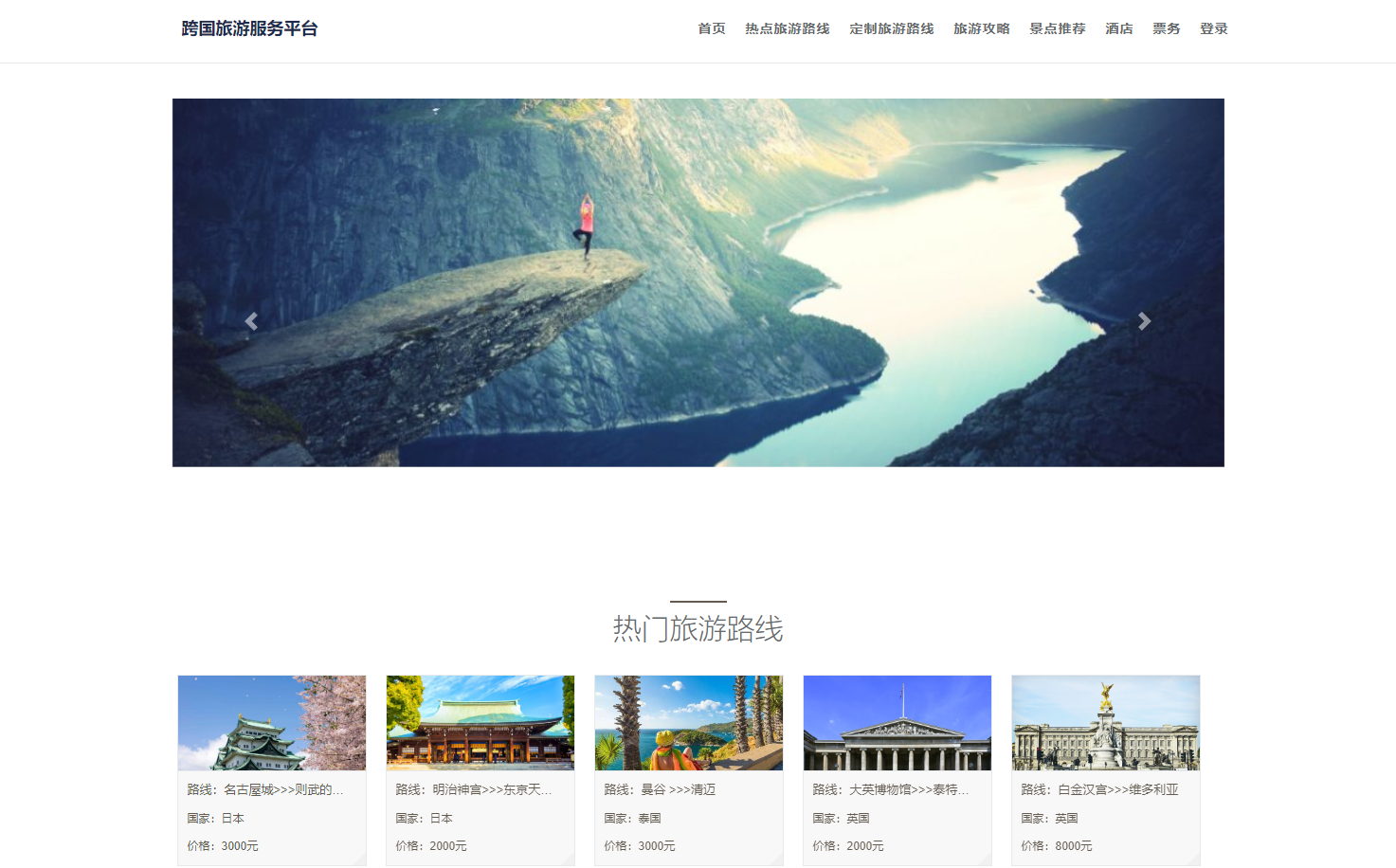
基于springboot+vue的旅游管理系统
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

4. git 添加版本标签
要给某一分支的某一提交版本添加标签(tag),你首先需要确定该提交版本在分支上的具体哈希值(commit hash)。 一旦你有了这个哈希值,你就可以像之前描述的那样使用 git tag 命令来创建标签。 以下是如何操作的…...
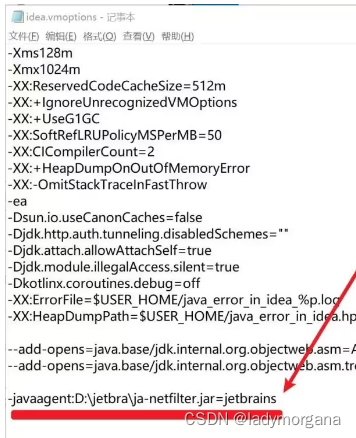
2024 PhpStorm激活,分享几个PhpStorm激活的方案
文章目录 PhpStorm 公司简介我这边使用PhpStorm的理由PhpStorm 2023.3 最新变化AI Assistant 预览阶段结束 正式版基于 LLM 的代码补全测试代码生成编辑器内代码生成控制台中基于 AI 的错误解释 Pest 更新PHP 8.3 支持#[\Override] 特性新的 json_validate() 函数类型化类常量弃…...
)
2419. prufer序列(prufer编码,模板题)
活动 - AcWing 本题需要你实现prufer序列与无根树之间的相互转化。 假设本题涉及的无根树共有 n 个节点,编号 1∼n。 为了更加简单明了的描述无根树的结构,我们不妨在输入和输出时将该无根树描述为一个以 n 号节点为根的有根树。 这样就可以设这棵无…...

鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Text)
显示一段文本的组件。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 可以包含Span和ImageSpan子组件。 接口 Text(content?: string | Resource, value?: TextOptions) 从API versi…...

开源大数据集群部署(十五)Zookeeper集群部署
作者:櫰木 1、集群规划 主机版本角色系统用户hd1.dtstack.com3.7.1followerzookeeperhd2.dtstack.com3.7.1leaderzookeeperhd3.dtstack.com3.7.1followerzookeeper 2、zookeeper kerberos主体创建 在生产中zk服务端和客户端票据可以设置成不通名称或相同名称&am…...

服务器镜像是什么
镜像即镜像服务器。镜像服务器与主服务器的服务内容都是一样的,只是放在一个不同的地方,分担主服务器的负载量。 可以使用,但不是原版的。在网上内容完全相同而且同步更新的两个或多个服务器,除主服务器外,其余的都被称…...
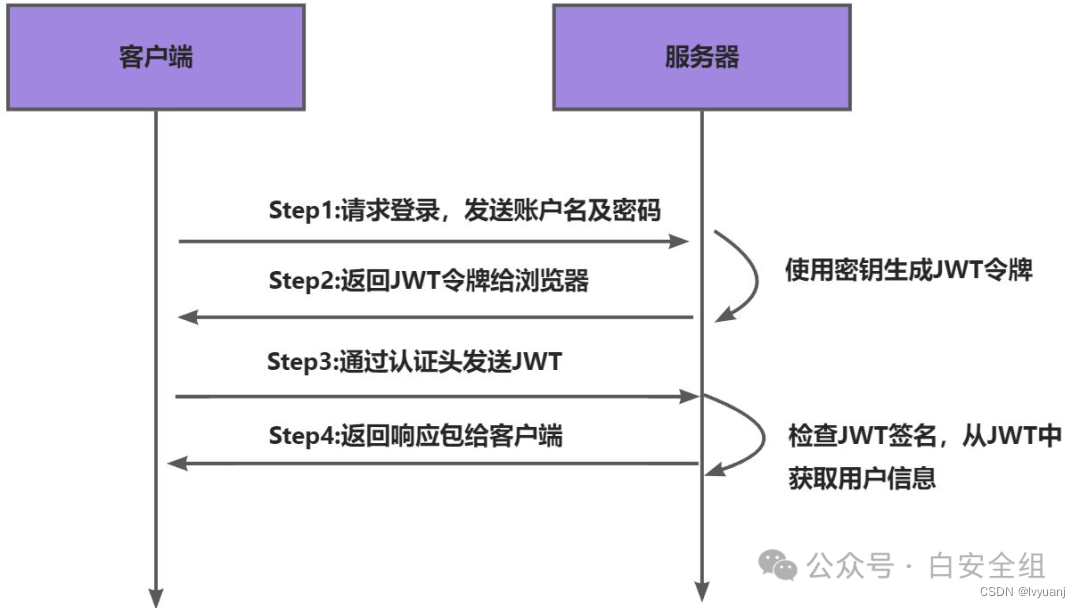
JWT原理
JWT 介绍 JWT(JSON Web Token)是一个开放标准(RFC 7519),它定义了一种简洁的、自包含的方法用于通信双方之间以 JSON 对象的形式安全地传输信息。这种信息可以被验证和信任,因为它是数字签名的。JWT通常用于…...

操作系统:一款纯正的“管理”软件
目录 前言: 1.操作系统的概念 2.操作系统的结构示意图: 3.什么是接口? 4.什么是驱动程序? 4.什么是系统调用(system call)? 5.操作系统和操作系统内核的区别 6.设计OS的核心目的 前言&…...

Mac笔记本聚焦SpotLight占用内存太高的 解法
分享一个自创的绝对有效的解决苹果电脑Mac笔记本SpotLight聚焦占用内存过高的方法! 一、背景 / 问题原因 1、Mac的聚焦功能,可以快速打开应用程序,非常方便! But,随着电脑的使用文件等越来越多,就会导致SpotLight聚焦需要更多更多甚至巨多的内存来建立索引,就会导致电脑…...

C++中.h和.hpp文件有什么区别?
在C中,.h和.hpp文件都是用于包含函数声明、类定义、宏定义等内容的头文件,它们的主要区别在于约定和习惯。 历史与来源:.h后缀是C语言头文件的标准后缀,随着C的演变,一些开发者开始使用.hpp后缀来表示C头文件ÿ…...

MongoDB聚合运算符:$derivative
$derivative聚合运算符返回返回指定窗口内的平均变化率(即求导),变化率使用以下公式计算: $setWindowFields阶段窗口中的第一个和最后一个文件。分子,等于最后一个文档的表达式的值减去第一个文档表达式的值。分母&am…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

3步搞定B站缓存视频转换:m4s转MP4的终极解决方案
3步搞定B站缓存视频转换:m4s转MP4的终极解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的视频&a…...

通过Taotoken用量看板清晰追踪各模型的Token消耗情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰追踪各模型的Token消耗情况 对于依赖大模型API进行开发的个人或团队而言,成本控制与预算规划…...

Windows HEIC缩略图解决方案:让iPhone照片在资源管理器中重获新生
Windows HEIC缩略图解决方案:让iPhone照片在资源管理器中重获新生 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 想…...

LeetCode 每日一题笔记 日期:2026.05.24 题目:1340. 跳跃游戏 V
LeetCode 每日一题笔记 0. 前言 日期:2026.05.24题目:1340. 跳跃游戏 V难度:困难标签:数组、动态规划、记忆化搜索、单调栈 1. 题目理解 问题描述: 给定一个整数数组 arr 和整数 d,从下标 i 出发࿰…...

3D CNN与ITK-SNAP融合:实现肺结节三维体积自动量化的工程实践
1. 项目概述:从一维测量到三维量化的跨越在肺部CT影像的临床判读中,肺结节的评估一直是核心且充满挑战的环节。作为一名长期关注医学影像分析技术落地的从业者,我深刻体会到传统方法的局限性。过去,医生们主要依赖一维的实性成分最…...