CTR之行为序列建模用户兴趣:DIEN
前言
在上一篇文章中 CTR之行为序列建模用户兴趣:DIN,开启了用户行为序列建模用户兴趣的篇章。DIN引入了Attention机制,对于不同的候选item,可以根据用户的历史行为序列,动态地学习用户的兴趣表征向量。但是,DIN没有考虑用户历史行为序列之间的相关性,也没考虑序列的先后顺序,难以捕获用户兴趣的变化。
概要
论文:Deep Interest Evolution Network for Click-Through Rate Prediction
链接:https://arxiv.org/pdf/1809.03672.pdf
在CTR模型中,通过用户的行为数据捕获用户的潜在兴趣是非常重要的。另外,考虑到外在环境和内在认知的变化,用户的兴趣是随着时间在动态演变的。
而许多CTR预估模型直接把用户行为(item)的表征当做兴趣,而缺少具体的行为下潜在兴趣的特定建模;少部分研究也会考虑到兴趣的变化趋势。
因此,在这篇论文中,阿里提出了一种新的模型 Deep Interest Evolution Network (DIEN):
- 设计了一种兴趣提取网络(interest extractor layer),从历史行为序列来捕获用户的时间性兴趣(temporal interests),并且针对GRU的隐状态(hidden state)在兴趣表征上能力不足的问题,加入了一种辅助loss,它使用连续的行为来激励每一步隐状态的学习,提升隐状态表征潜在的兴趣的能力;
- 另外,还设计了兴趣演变网络(interest evolving layer),使用引入注意力机制的更新门控网络(AUGRU),增强相关的兴趣对目标item的影响,并克服了推理时的兴趣漂移问题。
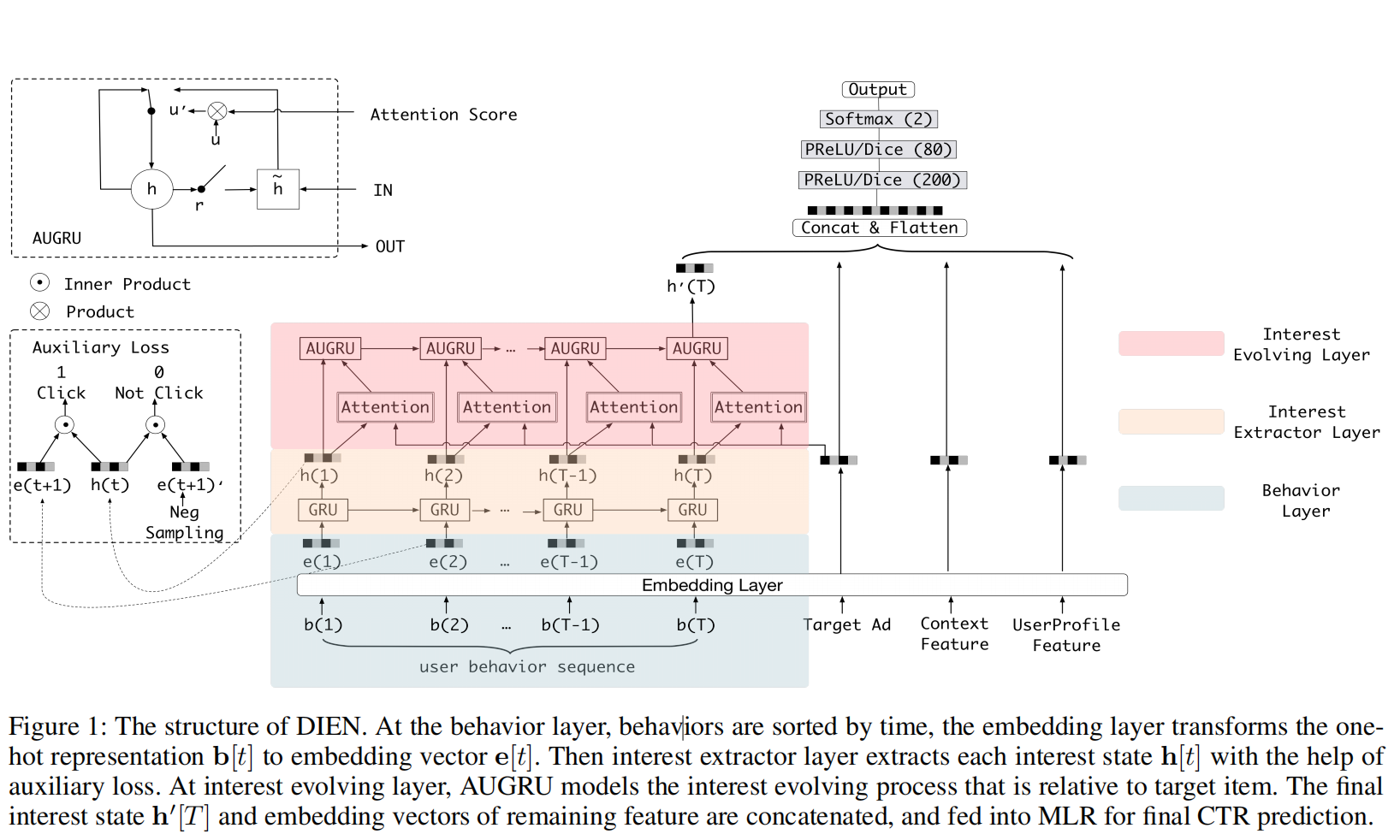
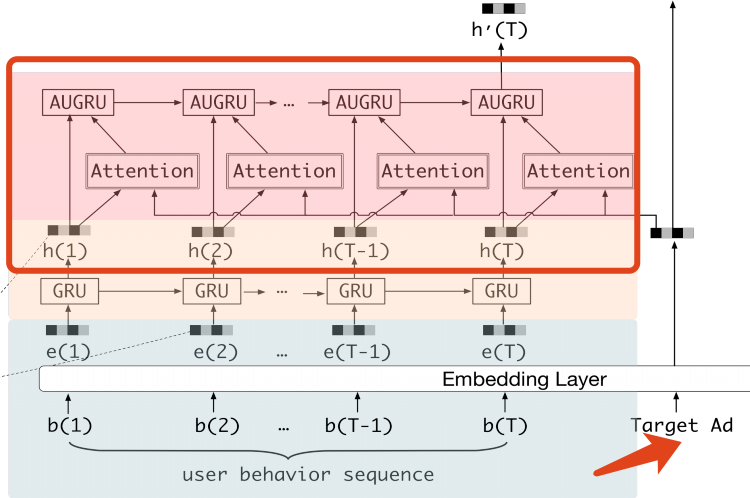
DIEN的整体网络结构如下图:
对比DIN的优势
用户的行为序列信息是非常有价值的,即能够捕获用户的兴趣演变过程在许多推荐场景下是十分有用的,比如电商推荐场景,用户前段时间在挑选手机,那么这段时间的行为序列会集中在手机这个品类的商品,但在他完成手机的购买之后,近期的兴趣可能就会变成篮球。
而DIN没有考虑序列信息,无法学习到这种时间性的兴趣趋势演变,那么DIN就会变成基于所有历史行为进行综合推荐,而不是像DIEN这种“针对下一次购买动机的推荐”。
基础模型
CTR的深度学习基础模型结构基本都是一致的,包括特征表征(feature representation)、模型结构(model structure)、损失函数(loss function),而模型结构由Embedding和MLP组成。
特征表征
通常的在线推荐系统,主要包括四类特征:用户属性(User Profile)、用户行为(User Behavior)、广告Ad(target item)和上下文(Context),每一类都有多个特征域fields:
- 用户属性的fields一般有性别、年龄等
- 用户行为的fields则是用户点击过的goods id列表,当然也可以有其他的field,比如用户点击过的的shop_id、cat_id等
- 广告的fields一般有ad_id,shop_id等
- 上下文的fields则有时间等
每一个field的特征值可以编码为one-hot向量,如性别=男编码为[1,0],而性别=女则编码为[0,1]。四类特征对应的不同fields的编码向量拼接起来分别用 x p , x b , x a , x c x_p,x_b,x_a,x_c xp,xb,xa,xc 来表示。
在序列CTR模型中,用户行为的每一种field是多个行为组成的列表,而每一个行为对应一个one-hot向量:
x b = [ b 1 ; b 2 ; b T ] ∈ R K × T , b t ∈ { 0 , 1 } K x_b=[b_1;b_2;b_T] \in \mathbb{R}^{K \times T},b_t \in \{0,1\}^K xb=[b1;b2;bT]∈RK×T,bt∈{0,1}K
b t b_t bt是第t个行为的one-hot向量,T是用户历史行为的个数,K则是用户可能点击到的商品的总量。
Embedding&MLP
Embedding.
Embedding是一种很广泛使用的将大规模离散特征转化为低维的稠密特征。在embedding layer中,每一个field会有一个对应的embedding矩阵。例如用户点击过的商品的embedding矩阵可以表示为:
E g o o d s = [ m 1 ; m 2 ; m K ] ∈ R n E × K E_{goods}=[m_1;m_2;m_K] \in \mathbb{R}^{n_E \times K} Egoods=[m1;m2;mK]∈RnE×K, m j ∈ R n E m_j \in \mathbb{R}^{n_E} mj∈RnE代表一个维度为 n E n_E nE的embedding向量。
再具体一点,对于用户行为特征 b t b_t bt,当 b t [ j t ] = 1 b_t[j_t]=1 bt[jt]=1时,它对应的embedding向量便是 m j t m_{j_t} mjt,因此一个用户的行为的有序的embedding向量列表可以表示为:
e b = [ m j 1 ; m j 2 ; . . . ; m j T ] e_b=[m_{j_1};m_{j_2};...;m_{j_T}] eb=[mj1;mj2;...;mjT]
同理, e a e_a ea代表上述四类中的广告这类特征中所有fields的拼接embedding向量。
Multilayer Perceptron(MLP).
首先,这四类特征的embedding向量会分别进行pooling操作(concat、mean pooling或sum pooling等),然后再拼接起来。最后,拼接后的向量再进入MLP,得到最后的预测值。
损失函数
深度学习CTR模型最常用的损失函数是负negative log-likelihood(负对数似然)函数,使用target item的标签来监督整体的预测:

x = [ x p , x b , x a , x b ] ∈ D , D x=[x_p,x_b,x_a,x_b] \in \mathcal{D},\mathcal{D} x=[xp,xb,xa,xb]∈D,D是数量为N的训练样本集合。 y ∈ { 0 , 1 } y \in \{0,1\} y∈{0,1}表示用户是否点击了target item。 p ( x ) p(x) p(x)是整个网络的输出,表示用户点击target item的预估概率。
DIEN结构
如下图所示,DIEN由以下几部分组成:
- 所有类别特征通过Embedding Layer转换为embedding向量;
- DIEN通过两个步骤来捕获兴趣演变:interest extractor layer(兴趣提取层)会通过历史行为序列来提取兴趣序列;interest evolving layer(兴趣演变层)来建模与target item相关的兴趣演变过程;
- 最后的兴趣表征(final interest)和广告、用户属性、上下文的embedding向量进行拼接;
- 拼接的向量输入到MLP,得到最后的预测值。
DIEN-兴趣提取层
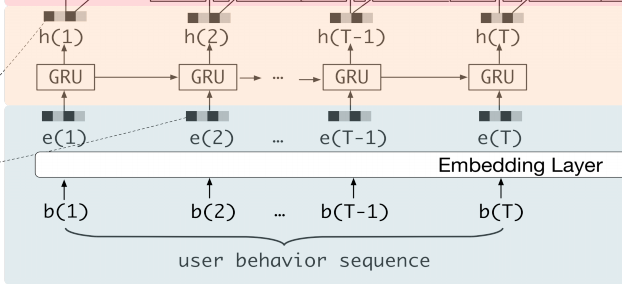
在电商系统中,用户的行为是潜在兴趣的载体,用户的兴趣会在产生一个行为之后发生改变。在这个兴趣提取层中,将会从用户行为序列中提取一系列兴趣状态(interest states)。
GRU建模
用户的点击行为包含丰富的信息,即使在短期内,行为序列长度也可能是很长的,比如两周内。综合了效率和效果,论文使用GRU来建模不同行为之间的关系,输入是根据发生时间排序的行为。GRU解决了RNN的梯度消失问题,并且比LSTM更快。GRU的数学表达式如下:
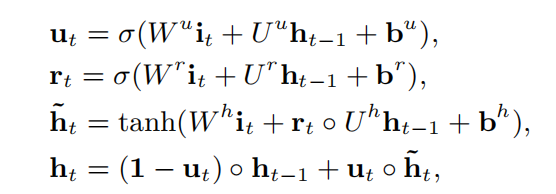
- σ \sigma σ是sigmoid函数, ∘ \circ ∘ 是element-wise product, W u , W r , W h ∈ R n H × n I W^u,W^r,W^h \in \mathbb{R}^{n_H \times n_I} Wu,Wr,Wh∈RnH×nI, U z , U r , U h ∈ n H × n H U^z,U^r,U^h \in n_H \times n_H Uz,Ur,Uh∈nH×nH
- n H n_H nH是隐藏层维度, n I n_I nI是输入的维度, i t i_t it是GRU的输入, i t = e b [ t ] i_t=e_b[t] it=eb[t] 是第t个行为的表征, h t h_t ht是第t个隐状态(hidden states)。
辅助损失
然而,捕获行为之间的关系的隐状态 h t h_t ht并不能高效地表征兴趣。因为target item的点击行为的驱动是final interest,即标签 L t a r g e t L_{target} Ltarget,仅仅是对final interest的预测的监督的ground truth,然而历史状态 h t ( t < T ) h_t(t<T) ht(t<T)并不能得到正确的监督。
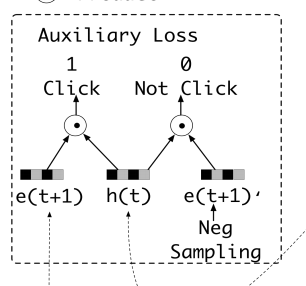
众所周知,每一步的兴趣状态会直接引导连续的行为。所以,论文提出一种辅助loss:
- 使用下一个行为 b t + 1 b_{t+1} bt+1来监督兴趣状态当前 h t h_t ht的学习
- 除了使用真实的下一个行为来作为正样例,还进行负采样,从所有item中采样一个未被点击过的item来作为负样例
因此,存在N对行为序列,其对应的embedding如下:
{ e b i , e ^ b i } ∈ D B , i ∈ 1 , 2 , . . . , N \{e_b^i,\hat{e}_b^i\} \in \mathcal{D}_{\mathcal{B}},i \in 1,2,...,N {ebi,e^bi}∈DB,i∈1,2,...,N
- e b i ∈ R T × n E e_b^i \in \mathbb{R}^{T \times n_E} ebi∈RT×nE 对应用户点击过的序列,而 e ^ b i ∈ R T × n E \hat{e}_b^i \in \mathbb{R}^{T \times n_E} e^bi∈RT×nE 则对应负采样的序列。
- n E n_E nE是embedding的维度大小,T是历史行为item的数量。
- e b i [ t ] ∈ G e_b^i[t] \in \mathcal{G} ebi[t]∈G 代表用户i点击的第t个item的embedding。
辅助loss的表达式如下:
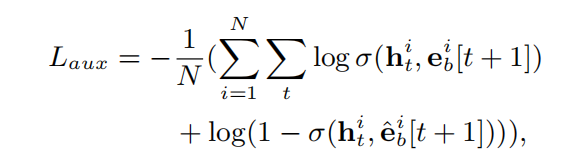
其中,论文提到 σ ( x 1 , x 2 ) = 1 1 + e x p ( − [ x 1 , x 2 ] ) \sigma(x_1,x_2)=\frac{1}{1+exp(-[x_1,x_2])} σ(x1,x2)=1+exp(−[x1,x2])1 是一个sigmoid激活函数,但看源码实现其实是一个激活函数为sigmoid的MLP。 h t i h_t^i hti 是用户i的第t个GRU隐状态。
加入辅助loss之后,全局的loss则变成了:
L = L t a r g e t + α ∗ L a u x L=L_{target}+\alpha\ *\ L_{aux} L=Ltarget+α ∗ Laux
α \alpha α是一个平衡兴趣表征和CTR预估的超参数。
辅助loss带来的好处有以下几点:
- 在兴趣学习方面,提升GRU的隐状态对兴趣的表征能力
- 在GRU学习迭代方面,降低反向传播的难度,当对较长的历史行为序列进行建模时
- 为embedding层的学习提供更多的语义信息,能够得到一个更好的embedding矩阵
在辅助loss的作用下,每一个隐状态 h i h_i hi应有能够充分表征兴趣状态,在用户进行了行为 i t i_t it 之后。
T个兴趣状态 [ h 1 , h 2 , . . . , h T ] [h_1,h_2,...,h_T] [h1,h2,...,hT] 拼接之后,组成了用户的兴趣序列,会作为下一个网络层-兴趣演变层的输入,来建模兴趣演变趋势。
DIEN-兴趣演变层
兴趣演变
上述提到,在外在环境和内在认知的联合影响下,用户的不同兴趣类型是一直在变化的。拿服装来说,随着流行趋势和用户品类的变化,用户的服装偏好也在演变。这个兴趣的演变过程直接决定了CTR模型的服装候选集。
建模这个演变过程的好处有以下几点:
- 兴趣演变模块能够用更多的相关历史信息来补充final interest的表征
- 它更好地随着兴趣变化趋势来进行target item的预估
在演变过程中,兴趣尤其表现了两个特性:
- 由于兴趣的多样性,兴趣是会漂移的。比如用户可能在前一段时间比较关注书籍,但在下一段时间却更需要衣服。
- 即使兴趣会彼此影响,但每个兴趣都有着自己的演变过程。比如书籍和服装的演变过程是几乎完全独立,我们只需要关注与target item相关的演变。
注意力机制的GRU
通过分析兴趣演变的特征,论文结合注意力机制的局部激活能力和GRU的序列化学习能力,来建模这个兴趣演变。GRU的每一步局部激活可以加强相关兴趣的相互作用,弱化兴趣漂移的困扰,这对建模与target item相关的演变过程是非常有帮助的。
与原始GRU的表达式一样,使用 i t ′ , h t ′ i'_t,h'_t it′,ht′ 表示兴趣演变模块的输入和隐状态,第二个GRU的输入则对应兴趣提取层的兴趣状态: i t ′ = h t i'_t=h_t it′=ht,最后一个隐状态 h T ′ h'_T hT′ 代表final interest state,具体的注意力函数如下式:

e a e_a ea 是上述四类特征中的广告Ad(target item)的不同fields的embedding向量拼接。
W ∈ R n H × n A W \in \mathbb{R}^{n_H \times n_A} W∈RnH×nA, n H n_H nH 是隐状态的维度, n A n_A nA 是广告embedding向量的维度。
注意力得分会影响广告 e a e_a ea 和输入 h t h_t ht 的相关关系,更高的得分则代表着更强的相关性。
下面是论文提出的GRU结合注意力机制的几种方式:
GRU with attentional input (AIGRU).
为了激活相关的兴趣,AIGRU是一种最直接的方法,使用注意力得分来影响输入兴趣状态,如下式:
i t ′ = h t ∗ α t i'_t=h_t\ *\ \alpha_t it′=ht ∗ αt
h t h_t ht是兴趣提取层的第t个隐状态,而 i t ′ i'_t it′ 是第二个GRU的的输入,即上图[兴趣演变模块]中的AUGRU的输入, ∗ * ∗ 表示是向量点积。
对于AIGRU,不怎么相关的兴趣会降低注意力得分。理论上,得分可以降低直为0。然而AIGRU并不能很好起效,因为即使接近0的输入也可以改变GRU的隐状态,所以不怎么相关的兴趣会影响到兴趣演变的学习。
Attention based GRU(AGRU).
AGRU在QA问答领域中第一次被提出,通过来自注意力机制的embedding信息优化了GRU的结构之后,AGRU可以在复杂的查询中有效提取关键信息。
基于此,论文也使用AGRU这种有效机制,在兴趣演变过程中来捕获相关的兴趣。具体的,AGRU使用注意力得分来替代GRU中的更新门控,直接地改变隐状态:
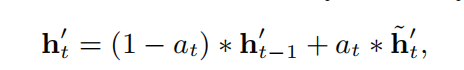
h t ′ , h t − 1 ′ , h ~ t ′ h'_t,h'_{t-1}, \tilde{h}'_t ht′,ht−1′,h~t′ 都是隐状态。
**AGRU利用注意力得分来直接控制隐状态的更新,减弱在演变过程中不相关的兴趣。**进入的注意力embedding提升了注意力机制的影响,并且克服了AIGRU的缺点。
GRU with attentional update gate (AUGRU).
AGRU使用一个标量形式的注意力得分 α t \alpha_t αt 来代替向量形式的更新门控 u t u_t ut,但这忽略了不同维度是有着不同重要性的。因此提出了注意力的更新门控(AUGRU):

u t ′ u'_t ut′ 是原来的更新门控, u ~ t ′ \tilde{u}'_t u~t′ 是注意力的更新门控, h t ′ , h t − 1 ′ , h ~ t ′ h'_t,h'_{t-1}, \tilde{h}'_t ht′,ht−1′,h~t′ 都是隐状态。
AUGRU保留原来更新门控的维度信息,这可以来学习每个维度的重要性。在此基础上,使用注意力得分来缩放更新门控的所有维度,这可以减少不相关的兴趣对隐状态的影响。AUGRU有效避免了兴趣漂移的困扰,并且让相关的兴趣更顺滑地演变。
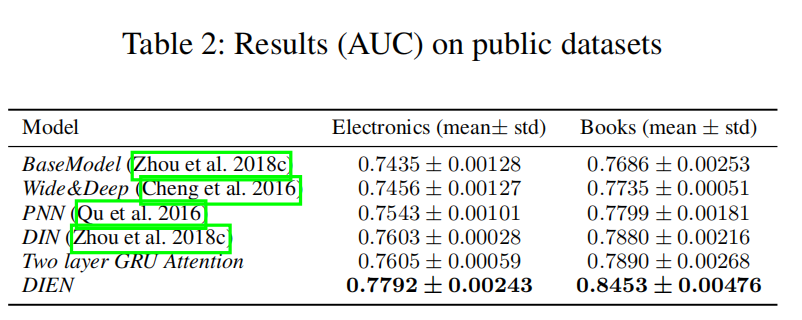
实验结果

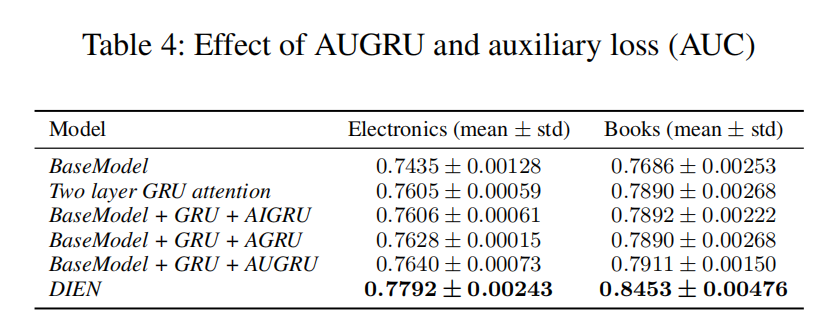
总结
- DIEN相比DIN,引入用户历史行为序列的时间性信息,使用GRU来建模兴趣状态,并且引入辅助loss来提升对兴趣的表征能力;
- 接着第二个GRU再利用上一步的兴趣状态序列来建模用户兴趣演变过程,得到最终的兴趣状态,并且加入注意力机制,来减弱不相关的兴趣的影响,避免了兴趣漂移的问题;
- 其实整个DIEN结构还是比较好理解的,但是一些对行为序列和用户兴趣的分析还是值得仔细阅读的。
代码实现
git
推荐系统CTR建模系列文章:
CTR之行为序列建模用户兴趣:DIN
CTR特征重要性建模:FiBiNet&FiBiNet++模型
CTR预估之FMs系列模型:FM/FFM/FwFM/FEFM
CTR预估之DNN系列模型:FNN/PNN/DeepCrossing
CTR预估之Wide&Deep系列模型:DeepFM/DCN
CTR预估之Wide&Deep系列(下):NFM/xDeepFM
CTR特征建模:ContextNet & MaskNet(Twitter在用的排序模型)
相关文章:
CTR之行为序列建模用户兴趣:DIEN
前言 在上一篇文章中 CTR之行为序列建模用户兴趣:DIN,开启了用户行为序列建模用户兴趣的篇章。DIN引入了Attention机制,对于不同的候选item,可以根据用户的历史行为序列,动态地学习用户的兴趣表征向量。但是ÿ…...
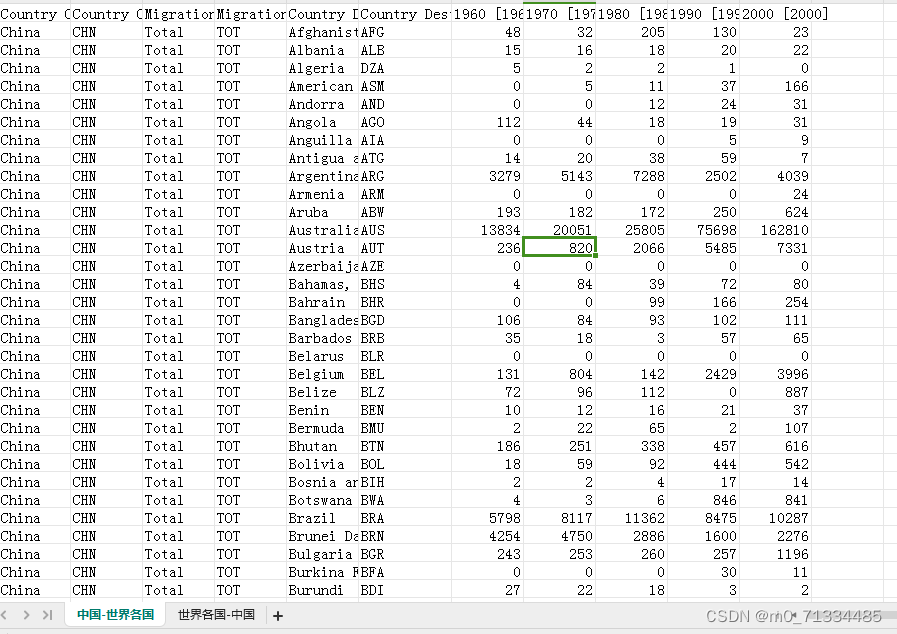
1960-2020年全球双边迁移数据库(Global Bilateral MigrationDatabase)
1960-2020年全球双边迁移数据库(Global Bilateral MigrationDatabase) 1、时间:1960-2000年,每10年一次具体为:1960年、1970年、1980年、1990年、2000年 2、来源:世界银行 3、指标:Country O…...

OpenGL-贴纸方案
OpenGL-贴纸方案 普通贴纸(缩放、Z轴旋转、平移) OpenGL环境说明 OpenGL渲染区域使用正交投影换算,正常OpenGL坐标是vertexData,这样的 Matrix.orthoM 进行换算 //顶点坐标(原点为显示区域中心店)private final float[] vertex…...
【性能测试】移动测试md知识总结第1篇:移动端测试课程介绍【附代码文档】
移动测试完整教程(附代码资料)主要内容讲述:移动端测试课程介绍,移动端测试知识概览,移动端测试环境搭建,ADB常用命令学习主要内容,学习目标,学习目标,1. window安装andorid模拟器,学习目标。主流移动端自动…...
)
Vue2和vue3的区别(前端面试常见问题)
1.Api的变化:vue3使用组合式Api(compostion Api)和Vue2是选项式Api(options Api)。选项式Api具有data ,watch,methods,computed,一个个的模块。如果代码过多可读性会很差…...

openGauss学习笔记-241 openGauss性能调优-SQL调优-审视和修改表定义
文章目录 openGauss学习笔记-241 openGauss性能调优-SQL调优-审视和修改表定义241.1 审视和修改表定义概述241.2 选择存储模型241.3 使用局部聚簇241.4 使用分区表241.5 选择数据类型 openGauss学习笔记-241 openGauss性能调优-SQL调优-审视和修改表定义 241.1 审视和修改表定…...
)
PDFPlumber解析PDF文本报错:AssertionError: (‘Unhandled’, 6)
文章目录 1、问题描述2、问题原因3、问题解决 1、问题描述 今天在使用PDFPlumber模块提取PDF文本时extract_text()方法报错,报错内容如下: Traceback (most recent call last):......File "F:\Python\...\site-packages\pdfminer\pdffont.py"…...

51WORLD正式落地中东,助力沙特伙伴与客户数字化升级!
近日,在被誉为中东“数字达沃斯”的LEAP科技展上,51WORLD首次震撼亮相Digital Twin Riyadh2924k㎡ 全要素城市底座、数字地球平台51Earth,向中东及全球科技从业者展现中国企业技术实力与创新能力。此外,以LEAP为起点,5…...
嵌入式学习38-数据库
数据库软件: 关系型数据库: Mysql (开源) Oracle SqlServer Sqlite (小型数据) 非关系型数据库:(快速查找数据) Redis NoSQ…...

去除PDF论文行号的完美解决方案
去除PDF论文行号的完美解决方案 1. 遇到的问题 我想去除论文的行号,但是使用网上的Adobe Acrobat裁剪保存后 如何去掉pdf的行编号? - 知乎 (zhihu.com) 翻译时依然会出现行号,或者是转成word,这样就大大损失了格式,…...
《ElementPlus 与 ElementUI 差异集合》icon 图标使用(包含:el-button,el-input和el-dropdown 差异对比)
安装 注意 ElementPlus 的 Icon 图标 要额外安装插件 element-plus/icons-vue. npm install element-plus/icons-vue注册 全局注册 定义一个文件 element-icon.js ,注意代码第 6 行。加上了前缀 ElIcon ,避免组件命名重复,且易于理解为 e…...

力扣题库第8题:去重后的最长子串
题目: 给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 示例 2: 输入: s "bbbbb" …...

CSS样式中长度单位含义解析:rpx、px、vw、vh、em、rem、pt
在 CSS 样式中,有几种常见的长度单位,包括 rpx 、 px 、 vw 和 vh 等,含义解析如下: 1 . rpx (响应像素): 是微信小程序中的一种相对长度单位,可以根据屏幕宽度进行自适应缩放。 1rp…...
全国车辆识别代码信息API查询接口-VIN深度解析
我们先来介绍下什么是vin码,以及vin码的构成结构解析,汽车VIN码,也叫车辆识别号码,通俗可以理解为汽车的身份证号码。 VIN码一共分四大部分: 1~3位,是世界制造厂识别代号(WMI)&…...
python django 模型中字段设置blank, null属性值用法说明
问题1: ShareUser models.CharField(max_length128, blankTrue) blank设置True和false分别代表什么含义, 有什么区别?chatgpt回答的答案如下: 在 Django 模型字段中,blank 参数用于指定在创建对象时该字段是否可以为空值。它的含义如下: blankTrue:…...

暴雨信息:可持续转型更需要“以人为本”
数字化正在开启新的商业模式和价值流,为企业与组织带来巨大收益。其中,“人 (People)”这一因素至关重要。 提供更好的工作与生活体验,应对人口老龄化、劳动力短缺等挑战。对于企业而言,解决这些问题既是社会责任,也是…...
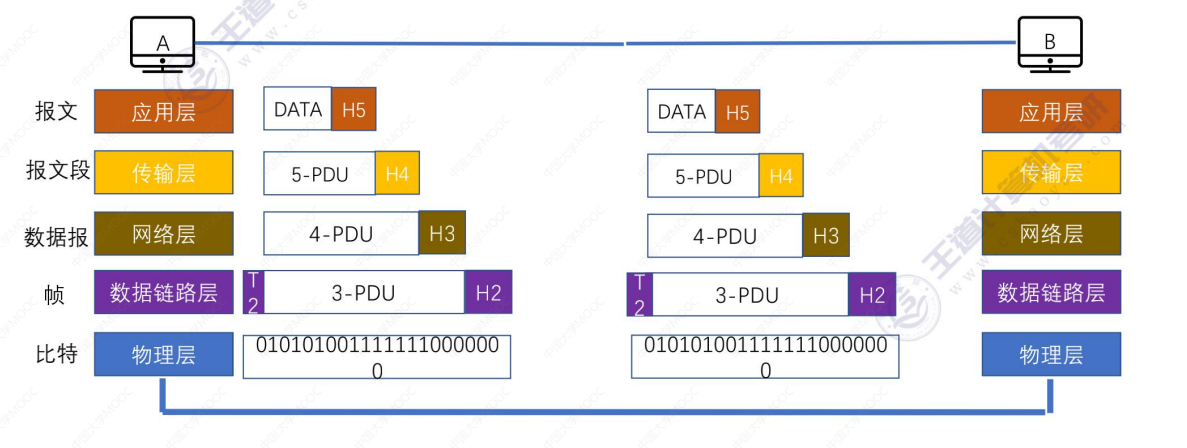
1.2_3 TCP/IP参考模型
文章目录 1.2_3 TCP/IP参考模型(一)OSI参考模型与TCP/IP参考模型(二)5层参考模型(三)5层参考模型的数据封装与解封装 1.2_3 TCP/IP参考模型 (一)OSI参考模型与TCP/IP参考模型 TCP/I…...
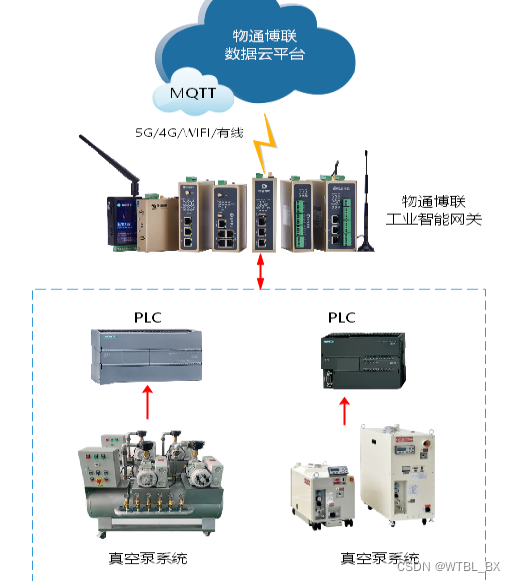
真空泵系统数据采集远程监控解决方案
行业背景 半导体制造业可以说是现代电子工业的核心产业,广泛应用于计算机、通信、汽车、医疗等领域。而在半导体生产加工过程中,如刻蚀、 镀膜、 扩散、沉积、退火等环节,真空泵都是必不可少的关键设备,它可以构建稳定受控的真空…...
Python语言在编程业界的地位——《跟老吕学Python编程》附录资料
Python语言在编程业界的地位——《跟老吕学Python编程》附录资料 ⭐️Python语言在编程业界的地位2024年3月编程语言排行榜(TIOBE前十) ⭐️Python开发语言开发环境介绍1.**IDLE**2.⭐️PyCharm3.**Anaconda**4.**Jupyter Notebook**5.**Sublime Text** …...

基于Redis自增实现全局ID生成器(详解)
本博客为个人学习笔记,学习网站与详细见:黑马程序员Redis入门到实战 P48 - P49 目录 全局ID生成器介绍 基于Redis自增实现全局ID 实现代码 全局ID生成器介绍 背景介绍 当用户在抢购商品时,就会生成订单并保存到数据库的某一张表中&#…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...