【STL】模拟实现list
目录
1、list介绍
所要实现类及其成员函数接口总览
2、结点类的模拟实现
基本框架
构造函数
3、迭代器类的模拟实现
迭代器类存在的意义
3.1、正向迭代器
基本框架
默认成员函数
构造函数
++运算符重载
--运算符重载
!=运算符重载
==运算符重载
*运算符重载
->运算符重载
3.2、反向迭代器
4、list类的模拟实现
基本框架
4.1、默认成员函数
构造函数
拷贝构造函数
赋值运算符重载函数
析构函数
4.2、迭代器相关函数
begin和end
rbegin和rend
4.3、访问容器相关函数
front和back
4.4、增加的相关函数
insert
push_back尾插
push_front头插
4.5、删除的相关函数
erase
pop_back尾删
pop_front头删
4.6、其他函数
size
resize
clear
empty
empty_init空初始化
swap交换
1、list介绍
在STL的底层实现当中,list其实就是一个带头双向循环链表:
我们现在要模拟实现list,要实现以下三个类:
- 模拟实现结点类
- 模拟实现迭代器的类
- 模拟list主要功能的类
第三个类的实现是基于前两个类。我们依次递进进行讲解。

所要实现类及其成员函数接口总览
namespace Fan {//模拟实现list当中的结点类template<class T>struct _list_node{//成员函数_list_node(const T& val = T()); //构造函数//成员变量T _data; //数据域_list_node<T>* _next; //后驱指针_list_node<T>* _prev; //前驱指针}; //模拟实现list迭代器template<class T,class Ref,class Ptr>struct _list_iterator{typedef _list_node<T> Node;typedef _list_iterator<T, Ref, Ptr> self;_list_iterator(Node*node); //构造函数//各种运算符重载函数self operator++();self operator--();self operator++(int);self operator--(int);bool operator==(const self& s)const;bool operator!=(const self& s)const;Ref operator*();Ptr operator->();//成员变量Node* _node; //一个指向结点的指针};//模拟实现listtemplate<class T>class list{public:typedef _list_node<T> Node;typedef _list_iterator<T, T&, T*> iterator;typedef _list_iterator<T, const T&, const T*> const_iterator;//默认成员函数list();list(const list<T>& lt);list<T>& operator=(const list<T>& lt);~list();//迭代器相关函数iterator begin();iterator end();const_iterator begin()const;const_iterator end()const;//访问容器相关函数T& front();T& back();const T& front()const;const T& back() const;//插入、删除函数void insert(iterator pos, const T& x);iterator erase(iterator pos);void push_back(const T& x);void pop_back();void push_front(const T& x);void pop_front();//其它函数size_t size()const;void resize(size_t n, const T& val = T());void clear();bool empty()const;void swap(list<T>& lt);private:Node* _head; //指向链表头结点的指针}; }
2、结点类的模拟实现
基本框架
因为list的本质为带头双向循环链表,所以我们要确保其每个结点有以下成员:
- 前驱指针
- 后继指针
- data值存放数据
//模拟实现list当中的结点类template<class T>struct _list_node{//成员变量T _data; //数据域_list_node<T>* _next; //后驱指针_list_node<T>* _prev; //前驱指针};
构造函数
对于结点类的成员函数,我们只需要实现一个构造函数即可。结点的释放则由list默认生成的析构函数来完成。
//构造函数 _list_node(const T& val=T()):_data(val),_next(nullptr),_prev(nullptr) {}
3、迭代器类的模拟实现
迭代器类存在的意义
我们知道list是带头双向循环链表,对于链表,我们知道其内存空间并不是连续的,是通过结点的指针顺次链接。而string和vector都是将数据存储在一块连续的内存空间,我们可以通过指针进行自增、自减以及解引用等操作,就可以对相应位置的数据进行一系列操作,因此string和vector的迭代器都是原生指针。而对于list,其各个结点在内存中的位置是随机的,并不是连续的,我们不能通过结点指针的自增、自减以及解引用等操作来修改对应结点数据。为了使得结点指针的各种行为和普通指针一样,我们对结点指针进行封装,对其各种运算符进行重载,使得我们可以用和string和vector当中的迭代器一样的方式使用list当中的迭代器。
3.1、正向迭代器
基本框架
//模拟实现list迭代器 template<class T,class Ref,class Ptr> struct _list_iterator {typedef _list_node<T> Node;typedef _list_iterator<T, Ref, Ptr> self;//成员变量Node* _node; //一个指向结点的指针 };
- 注意:
我们这里迭代器类的模板参数里面包含了3个参数:
template<class T,class Ref,class Ptr>在后文list类的模拟实现中,我对迭代器进行了两种typedef:
typedef _list_iterator<T, T&, T*> iterator;//普通迭代器 typedef _list_iterator<T, const T&, const T*> const_iterator;//const迭代器根据这里的对应关系:Ref对应的是&引用类型,Ptr对应的是*指针类型。当我们使用普通迭代器时,编译器就会实例化出一个普通迭代器对象;当我们使用const迭代器时,编译器就会实例化出一个const迭代器对象。提高代码复用性。
默认成员函数
这里的默认成员函数我们只需要写构造函数。
- 析构函数—结点并不属于迭代器,不需要迭代器释放
- 拷贝构造—编译器默认生成的浅拷贝即可
- 赋值重载—编译器默认生成的浅拷贝即可
构造函数
我们这里通过结点的指针即可完成构造。
//构造函数 _list_iterator(Node* node):_node(node) {}
++运算符重载
++运算符非为前置++和后置++
- 前置++
迭代器++的返回值还是迭代器。对于结点指针的前置++,我们就应该先让结点指针指向后一个结点,然后返回“自增”后的结点指针。
//前置++ self& operator++() {_node = _node->_next; //直接让自己指向下一个结点即可实现++return *this; //返回自增后的结点指针 }
- 后置++
为了和前置++进行区分,后置++通常需要加上一个参数。此外,后置++是返回自增前的结点指针。
//后置++ self operator++(int) //加参数以便于区分前置++ {self tmp(*this); //拷贝构造tmp_node = _node->_next; //直接让自己指向下一个结点即可实现++return tmp; }
--运算符重载
--运算符分为前置--和后置--
- 前置--
前置--是让结点指针指向上一个结点,然后再返回“自减”后的结点指针即可。
//前置-- self operator--() {_node = _node->_prev; //让结点指针指向前一个结点return *this; //返回自减后的结点指针 }
- 后置--
先记录当前结点指针的指向,然后让结点指针指向前一个结点,最后返回“自减”前的结点指针即可。
//后置-- self operator--(int) //加参数以便于区分前置-- {self tmp(*this); //拷贝构造tmp_node = _node->_prev;return tmp; }
!=运算符重载
这里的比较是两个迭代器的比较,我们直接返回两个结点的位置是否不同即可。
//!=运算符重载 bool operator!=(const self& it) {return _node != it._node; //返回两个结点指针的位置是否不同即可 }
==运算符重载
我们直接返回两个结点指针是否相同即可。
//==运算符重载 bool operator==(const self& it) {return _node == it._node; //返回两个结点指针是否相同 }
*运算符重载
当我们使用解引用操作符时,是想要得到该位置的数据内容。因此我们直接返回结点指针指向的_data即可。
//*运算符重载 Ref operator*() //结点出了作用域还在,我们用引用返回 {return _node->_data; //返回结点指向的数据 }
->运算符重载
假设出现此类情形,我们链表中存储的不是内置类型,而是自定义类型,如下:
struct AA {AA(int a1 = 0, int a2 = 0):_a1(a1),_a2(a2){}int _a1;int _a2; }; void test() {Fan::list<AA> lt;lt.push_back(AA(1, 1));lt.push_back(AA(2, 2));lt.push_back(AA(3, 3));lt.push_back(AA(4, 4)); }对于内置类型和自定义类型成员的指针,其访问方式是不同的:
int* *it AA* (*it). 或者 it->这里我们应该重载一个->运算符。以便于访问自定义类型成员的指针的数据。
//->运算符重载 Ptr operator->() {return &(operator*()); //返回结点指针所指向的数据的地址//或者return &_node->_data; }实现了->运算符重载后,我们执行it->_a1,编译器就将其转换成it.operator->(),此时获得的是结点位置的地址即AA*,这里应该还有一个箭头->才能获取数据,也就是这样:it.operator->()->_a1
- 编译器为了可读性将其进行优化处理,如果不进行优化应该是it->->a1,优化以后省略了一个箭头->。
3.2、反向迭代器
反向迭代器是一种适配器模式(后面我们会讲到适配器)。相比于正向迭代器,反向迭代器主要有以下三种变化。
- 反向迭代器里面的++执行的操作是正向迭代器里面的--。
- 反向迭代器里面的--执行的操作是正向迭代器里面的++。
- 反向迭代器里面的*解引用和->操作指向的是前一个数据。
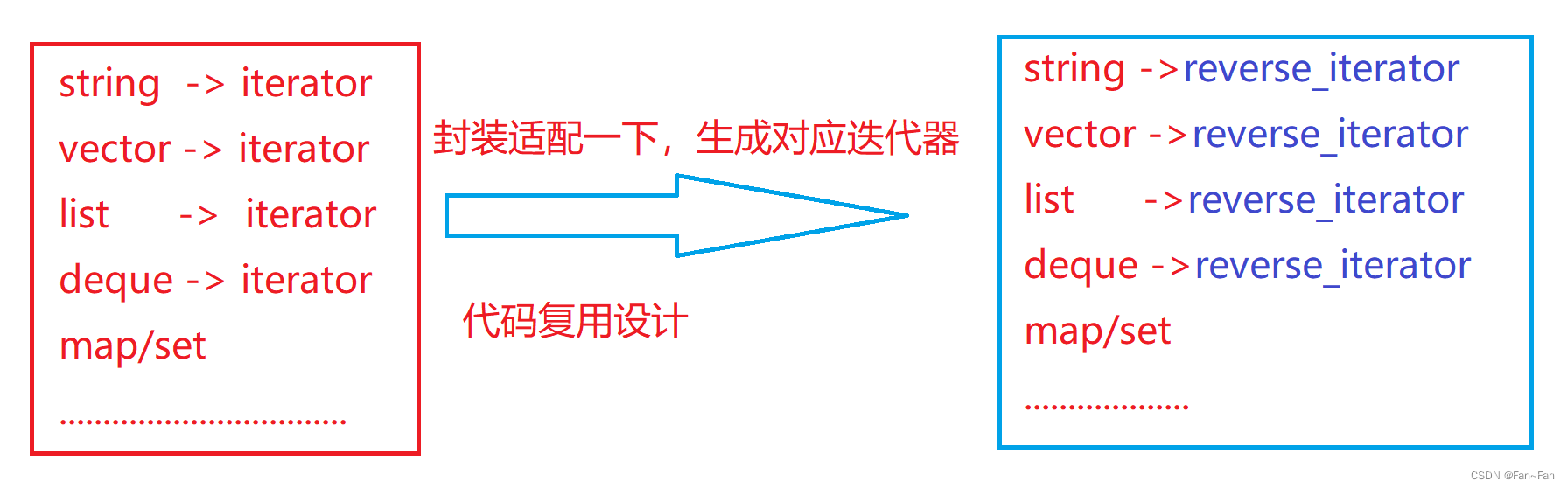
⭐反向迭代器是一种适配器模式。任何容器的迭代器封装适配一下都能够生成对应的反向迭代器。
⭐反向迭代器里面的*解引用和->操作指向的是前一个数据。其目的主要是为了对称设计。在代码实现当中,rbegin函数对应的是end函数,rend函数对应的是begin函数。
代码如下:
namespace Fan {template<class Iterator,class Ref,class Ptr>struct Reverse_iterator{Iterator _it;typedef Reverse_iterator<Iterator, Ref, Ptr> Self;//构造函数Reverse_iterator(Iterator it):_it(it){}//*运算符重载Ref operator*(){Iterator tmp = _it;//返回上一个数据return *(--tmp);}//->运算符重载Ptr operator->(){//复用operator*,返回上一个数据return &(operator*());}//++运算符重载Self& operator++(){--_it;return *this;}Self operator++(int){Iterator tmp = _it;--_it;return tmp;}//--运算符重载Self& operator--(){++_it;return *this;}Self operator--(int){Iterator tmp = _it;++_it;return tmp;}//!=运算符重载bool operator!=(const Self& s){return _it != s._it;}//==运算符重载bool operator==(const Self& s){return _it == s._it;}}; }

4、list类的模拟实现
基本框架
在list类中的唯一一个成员变量即为先前的结点类构成的头结点指针:
//模拟实现list template<class T> class list { public:typedef _list_node<T> Node;//正向迭代器typedef _list_iterator<T, T&, T*> iterator; //普通迭代器typedef _list_iterator<T, const T&, const T*> const_iterator; //const迭代器//反向迭代器typedef Reverse_iterator<iterator, T&, T*> reverse_iterator;typedef Reverse_iterator<const_iterator, const T&, const T*> const_reverse_iterator;private:Node* _head; //指向链表头结点的指针 };
4.1、默认成员函数
构造函数
- 无参构造:
list是一个带头双向循环链表,在构造一个list对象时,我们直接申请一个头结点,并让其前驱指针和后继指针都指向自己即可。
//构造函数 list() {_head = new Node();//申请一个头结点_head->_next = _head;//头结点的下一个结点指向自己构成循环_head->_prev = _head;//头结点的上一个结点指向自己构成循环 }
- 传迭代器区间构造:
先进行初始化,然后利用循环对迭代器区间的元素挨个尾插。
//传迭代器区间构造 template <class InputIterator> list(InputIterator first, InputIterator last) {empty_init();while (first != last){push_back(*first);first++;} }
拷贝构造函数
假设我们要用lt1去拷贝构造lt2。
- 传统写法:
我们首先复用empty_init对头结点进行初始化,接着遍历lt1的元素,在遍历的过程中将lt1的元素尾插到lt2上即可。接着使用push_back自动开辟空间完成深拷贝。
//传统写法 list(const list<T>& lt) {//先初始化lt2empty_init();//遍历lt1,把lt1的元素push_back到lt2里面for (auto e : lt){push_back(e); //自动开辟新空间,完成深拷贝} }
- 现代写法:
这里我们先初始化lt2,然后把lt1引用传参传给lt,传lt的迭代器区间构造tmp,复用swap交换头结点指针即可完成深拷贝的现代写法。
//现代写法 list(const list<T>& lt) {//先进行初始化empty_init();list<T>tmp(lt.begin(), lt.end()); //用迭代器区间去构造tmpswap(tmp); }
赋值运算符重载函数
对于赋值运算符的重载,我们仍然提供两种写法:
- 传统写法
先调用clear函数将原容器清空,然后再将lt当中的数据通过遍历的方式一个个尾插到清空后的容器当中即可。
//传统写法 list<T>& operator=(const list<T>& lt) {if (this != <) //避免自己给自己赋值{clear(); //清空容器for (const auto& e : lt){push_back(e); //将容器lt当中的数据一个个尾插到链表后面}}return *this; //支持连续赋值 }
- 现代写法
利用编译器机制,故意不使用引用传参,通过编译器自动调用list的拷贝构造函数构造出一个list对象lt,然后调用swap函数将原容器与该list对象进行交换即可。
//现代写法 list<T>& operator=(list<T> lt) //编译器接收右值的时候自动调用其拷贝构造函数 {swap(lt); //交换这两个对象return *this; //支持连续赋值 }
析构函数
我们可以先复用clear函数把除了头结点的所有结点给删除掉,最后delete头结点即可。
//析构函数 ~list() {clear();delete _head; //删去哨兵位头结点_head = nullptr; }
4.2、迭代器相关函数
begin和end
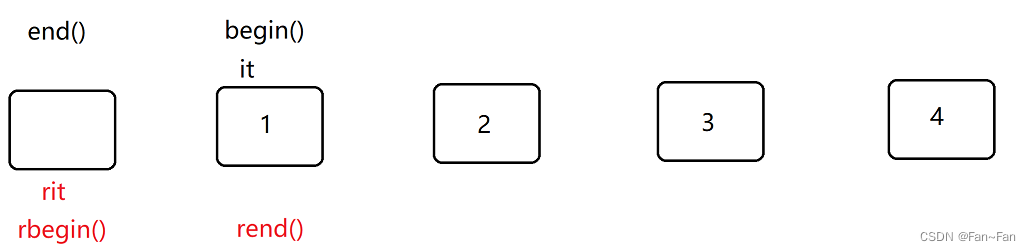
- begin的作用是返回第一个位置的结点的迭代器,而第一个结点就是哨兵位头结点的下一个结点。因此我们直接返回_head的_next即可。
- end的作用是返回最后一个有效数据的下一个位置的迭代器,对于list指的就是哨兵位头结点_head的位置。
begin和end均分为普通对象调用和const对象调用,因此我们要写两个版本。
- 普通对象调用
//begin iterator begin() //begin返回的就是第一个有效数据,即头结点的下一个结点 {return iterator(_head->_next);//return _head->_next; }//end iterator end() {return iterator(_head);//return _head; }
- const对象调用
//begin const_iterator begin() const {return const_iterator(_head->_next);//return _head->_next; } //end const_iterator end() const {return const_iterator(_head);//return _head; 也可以这样写 }
rbegin和rend
rbegin就是正向迭代器里的end()位置,rend就是正向迭代器里的begin()位置。
rbegin和rend同样分为普通对象调用和const对象调用:
- 普通对象调用
//rbegin() reverse_iterator rbegin() {return reverse_iterator(end()); } //rend reverse_iterator rend() {return reverse_iterator(begin()); }
- const对象调用
//const反向迭代器 const_reverse_iterator rbegin() const {return const_reverse_iterator(end()); } const_reverse_iterator rend() const {return const_reverse_iterator(begin()); }
4.3、访问容器相关函数
front和back
front和back函数分别用于获取第一个有效数据和最后一个有效数据,因此在实现front和back函数时,直接返回第一个有效数据和最后一个有效数据的引用即可。
- 普通对象调用
//front T& front() {return *begin(); //直接返回第一个有效数据的引用 } T& back() {return *(--end()); //返回最后一个有效数据的引用 }
- const对象调用
const T& front() const {return *begin(); //直接返回第一个有效数据的引用 } const T& back() const {return *(--end()); //返回最后一个有效数据的引用 }
4.4、增加的相关函数
insert
实现insert首先创建一个新的结点存储插入的值,接着取出插入位置pos处的结点指针保存在cur里面,记录cur的上一个结点位置prev,先衔接prev和newnode,再链接newnode和cur即可,最后返回新插入元素的迭代器位置。
- list的insert不存在野指针失效的迭代器失效问题。
//头插 void push_front(const T& x) {insert(begin(), x); } //insert,插入pos位置之前 iterator insert(iterator pos, const T& x) {Node* newnode = new Node(x);//创建新的结点Node* cur = pos._node; //迭代器pos处的结点指针Node* prev = cur->_prev;//prev newnode cur//链接prev和newnodeprev->_next = newnode;newnode->_prev = prev;//链接newnode和curnewnode->_next = cur;cur->_prev = newnode;//返回新插入元素的迭代器位置return iterator(newnode); }
push_back尾插
- 法一
首先要创建一个新结点用来存储尾插的值,接着找到尾结点。将尾结点和新结点前后链接并将头结点和新结点前后链接构成循环即可。
//尾插 void push_back(const T& x) {Node* tail = _head->_prev; //找尾Node* newnode = new Node(x); //创建一个新的结点//_head tail newnode//链接tail和newnodetail->_next = newnode;newnode->_prev = tail;//链接newnode和头结点_headnewnode->_next = _head;_head->_prev = newnode; }
- 法二
这里也可以直接复用insert函数,当insert中的pos位置为哨兵位头结点的位置时,实现的就是尾插。
//尾插 void push_back(const T& x) {//法二:复用insertinsert(end(), x); }
push_front头插
直接复用insert函数,当pos位置为begin()时,获得的pos就是第一个有效结点数据,即可满足头插。
//头插 void push_front(const T& x) {insert(begin(), x); }
4.5、删除的相关函数
erase
erase删除的是pos位置的结点。我们首先取出pos位置的结点指针cur,记录cur上一个结点位置为prev,再记录cur下一个结点位置为next,链接prev和next,最后delete释放掉cur的结点指针即可。返回删除元素后一个元素的迭代器位置。
//erase iterator erase(iterator pos) {assert(pos != end());Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;//prev cur next//链接prev和nextprev->_next = next;next->_prev = prev;//delete要删除的结点delete cur;//返回删除元素后一个元素的迭代器位置//return next;return iterator(next); }
pop_back尾删
直接复用erase即可,当pos位置为--end()时,pos就是最后一个结点的位置,实现的就是尾删。
//尾删 void pop_back() {erase(--end()); }
pop_front头删
直接复用erase即可,当pos位置为begin()时,pos就是第一个有效数据,实现的就是头删。
//头删 void pop_front() {erase(begin()); }
4.6、其他函数
size
size函数用于获取当前容器当中的有效数据个数,因为list是链表,所以我们只能通过遍历的方式逐个统计有效数据的个数。
//size size_t size()const {size_t sz = 0; //统计有效数据个数const_iterator it = begin(); //获取第一个有效数据的迭代器while (it != end()) //通过遍历统计有效数据个数{sz++;it++;}return sz; //返回有效数据个数 }
resize
resize函数的规则:
- 若当前容器的size小于所给n,则尾插结点,直到size等于n为止。
- 若当前容器的size大于所给n,则只保留前n个有效数据。
当我们实现resize函数时,我们不要直接调用size函数获取当前容器的有效数据个数,因为当我们调用resize函数后就已经遍历了一次容器。如果结果是size大于n,那么还需要遍历容器,找到第n个有效结点并释放之后的结点。
这里实现resize的方法是:设置一个变量len,用于记录当前所遍历的数据个数,然后开始遍历容器,在遍历的过程中:
- 当len大于或者是等于n时遍历结束,此时说明该结点后的结点都应该被释放,将之后的结点释放即可。
- 遍历完容器,此时说明容器当中的有效数据个数小于n,则需要尾插结点,直到容器当中的有效数据个数为n时停止尾插即可。
void resize(size_t n, const T& val = T()) {iterator i = begin(); //获取第一个有效数据的迭代器size_t len = 0; //记录当前所遍历的数据个数while (len < n && i != end()){len++;i++;}if (len == n) //说明容器当中的有效数据个数大于或者是等于n{while (i != end()) //只保留前n个有效数据{i = erase(i); //接收下一个数据的迭代器}}else //说明容器当中的有效数据个数小于n{while (len < n){push_back(val);len++;}} }
clear
clear函数用于清空容器,我们通过遍历的方式,逐个删除结点,只保留头结点即可。
void clear() {iterator it = begin();while (it != end()){it = erase(it); //用it接收删除后的下一个结点的位置} }
empty
empty函数用于判断容器是否为空,我们直接判断该容器的begin函数和end函数所返回的迭代器是否是同一个位置的迭代器即可。(此时说明容器当中只有一个头结点)
bool empty()const {return begin() == end(); //判断是否只有头结点 }
empty_init空初始化
该函数的作用是哨兵位的头结点开出来,再对其进行初始化。该函数是库里面的。
//空初始化 对头结点进行初始化 void empty_init() {_head = new Node();_head->_next = _head;_head->_prev = _head; }
swap交换
对于链表的swap,我们直接交换头结点指针的指向即可完成。直接复用库函数的swap即可。
//swap交换函数 void swap(list<T>& lt) {std::swap(_head, lt._head);//交换头指针 }
相关文章:
【STL】模拟实现list
目录 1、list介绍 所要实现类及其成员函数接口总览 2、结点类的模拟实现 基本框架 构造函数 3、迭代器类的模拟实现 迭代器类存在的意义 3.1、正向迭代器 基本框架 默认成员函数 构造函数 运算符重载 --运算符重载 !运算符重载 运算符重载 *运算符重载 …...

Spring Cloud Alibaba全家桶(五)——微服务组件Nacos配置中心
前言 本文小新为大家带来 微服务组件Nacos配置中心 相关知识,具体内容包括Nacos Config快速开始指引,搭建nacos-config服务,Config相关配置,配置的优先级,RefreshScope注解等进行详尽介绍~ 不积跬步,无以至…...

【微信小程序】-- 页面事件 - 下拉刷新(二十五)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...
springboot启动过程加载数据笔记(springboot3)
SpringApplication AbstractApplicationContext PostProcessorRegistrationDelegate ConfigurationClassPostProcessor ConfigurationClassParser 一堆循环和调用 ComponentScanAnnotationParser扫描 processConfigurationClass.doProcessConfigurationClass(configClass, so…...

中文代码86
PK 嘚釦 docProps/PK 嘚釦諿A眎 { docProps/app.xml漅薾?糤?D?v拢W4揣狤"攃e9 睔貣m*:PAz韒g?项弇}R珁湧4嶱 ]I禑菦?櫮戵\U佳 珩 ]铒e礎??X(7弅锿?jl筀儸偛佣??z窊梈ZT炰攷 ?\ 銒沆?状尧绥>蕮 ?斬殕{do]?o乗YX?:??罢秗,泿)怟 …...
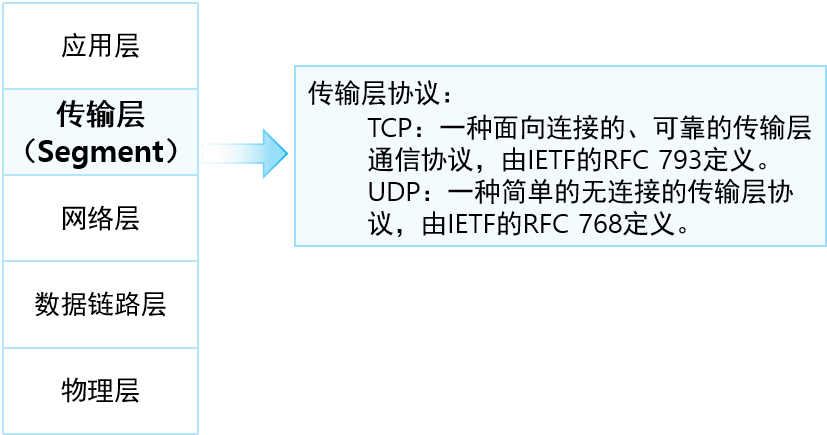
网络参考模型
OSI参考模型 应用层 不服务于任何其他层,就是位APP提供相应的服务,不如HTTP、域名解析DNS提供服务表示层 1.使得应用数据能够被不同的系统(Windows\Linux)进行识别和理解 2.数据的解码和编码、数据的加密与解密、数据的压缩和解…...

Spark Tungsten
Spark Tungsten数据结构Unsafe Row内存页管理全阶段代码生成火山迭代模型WSCG运行时动态生成Tungsten (钨丝计划) : 围绕内核引擎的改进: 数据结构设计全阶段代码生成(WSCG,Whole Stage Code Generation) 数据结构 Tungsten 在…...

2023年总结的web前端学习路线分享(学习导读)
如果你打开了这篇文章,说明你是有兴趣想了解前端的这个行业的,以下是博主2023年总结的一些web前端的学习分享路线,如果你也想从事前端或者有这方面的想法的,请接着往下看! 前端发展前景 前端入门 巩固基础 前端工程…...
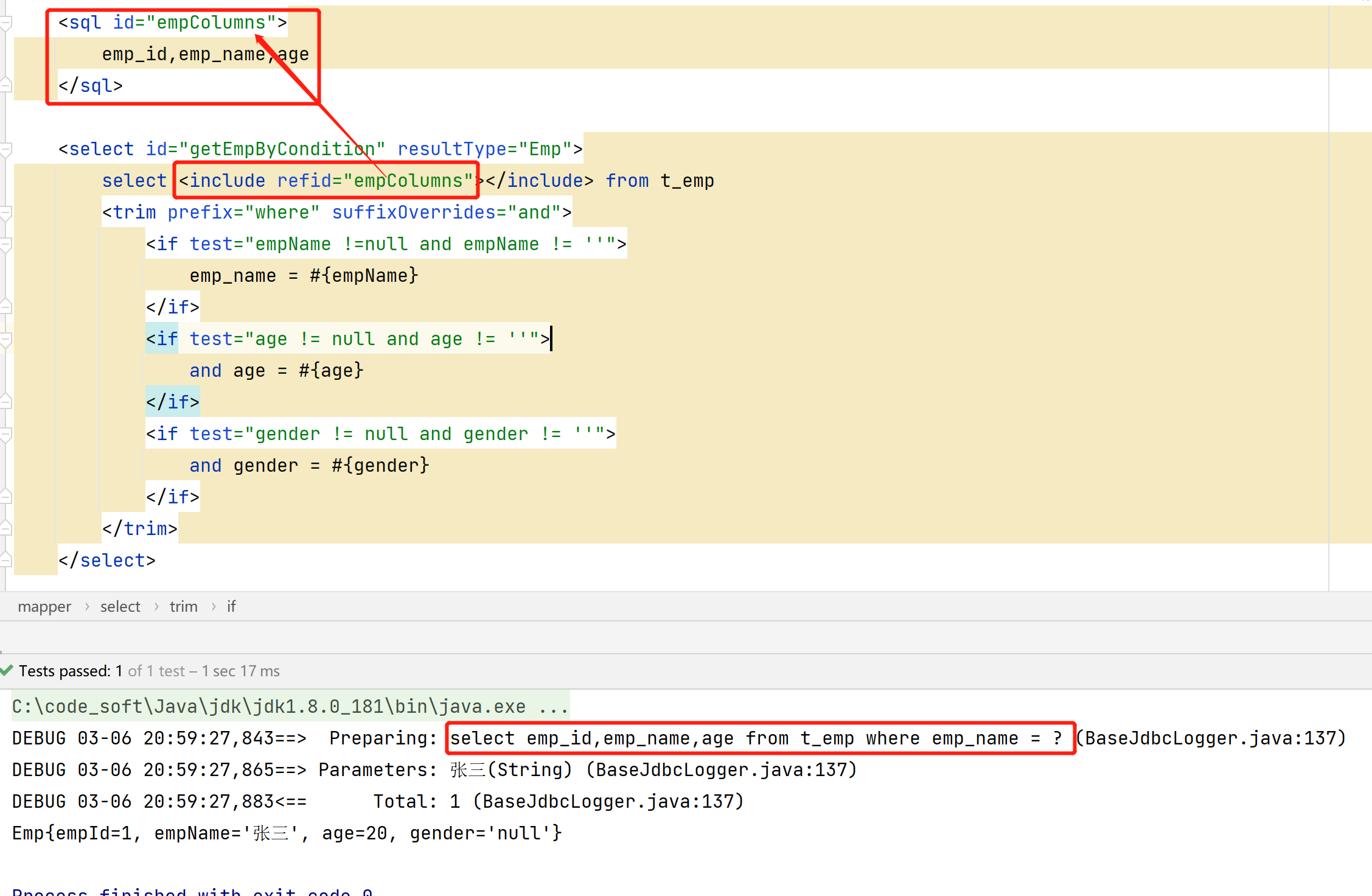
MyBatis学习笔记(十) —— 动态SQL
10、动态SQL MyBatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串的痛点问题。 动态SQL: 1、if 标签:通过test属性中的表达式判断标签中的内容是否有效(是否会拼接到sql中…...

剑指 Offer 55 - II. 平衡二叉树
剑指 Offer 55 - II. 平衡二叉树 难度:easy\color{Green}{easy}easy 题目描述 输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。 示例 1: 给定二叉树 […...
一文吃透前端低代码的 “神仙生活”
今天来说说前端低代码有多幸福? 低代码是啥?顾名思义少写代码…… 这种情况下带来的幸福有:代码写得少,bug也就越少(所谓“少做少错”),因此开发环节的两大支柱性工作“赶需求”和“修bug”就…...
【深度学习】预训练语言模型-BERT
1.BERT简介 BERT是一种预训练语言模型(pre-trained language model, PLM),其全称是Bidirectional Encoder Representations from Transformers。下面从语言模型和预训练开始展开对预训练语言模型BERT的介绍。 1-1 语言模型 语言模型 …...
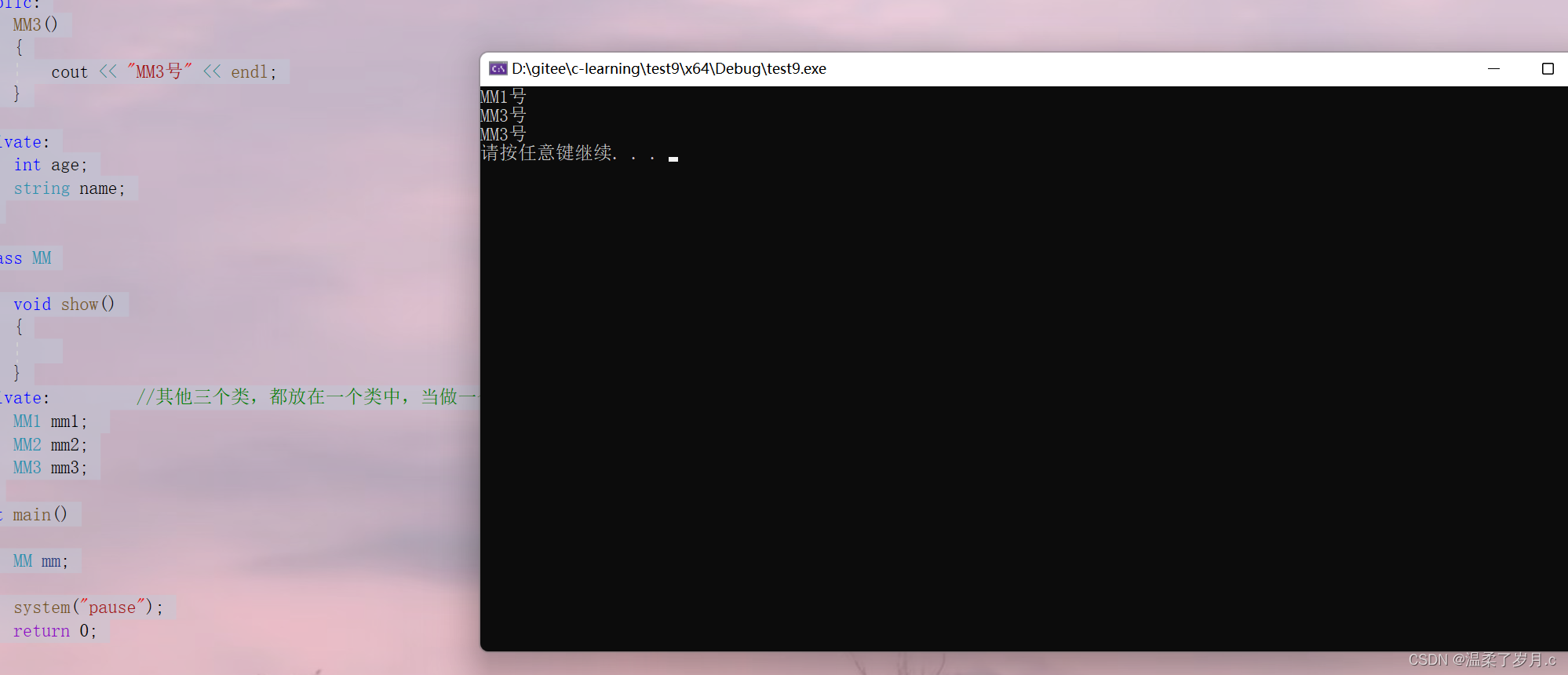
C++类的组合
C类的组合什么是类的组合初始化参数列表使用类的组合案例分析组合构造和析构顺序问题this指针基本用法和作用什么是类的组合 类的组合就是以另一个对象为数据成员,这种情况称为类的组合 1.优先使用类的组合,而不是继承 2.组合表达式的含义 一部分关系 初…...
的配置与使用)
2.伪随机数生成器(ctr_drbg)的配置与使用
零、随机数应用 生成盐,用于基于口令的密码 生成密钥,用于加密和认证 生成一次性整数Nonce,防止重放攻击 生成初始化向量IV 构成 种子,真随机数生成器的种子来源于物理现象 内部状态,种子用来初始化内部状态 一、真随机数和伪随机数 1.区别 随机数在安全技术中通常被用于…...

CentOS7 切换图形模式和多用户命令行模式
备注: 主机名 hw 含义:hardware 缩写,意思是硬件(物理机) 文章目录1、查看源头2、查看当前系统运行模式3、设置系统运行模式为多用户命令行模式4、查看当前系统运行模式5、重启系统6、确认当前系统运行模式7、设置系统…...

在linux上用SDKMan对Java进行多版本管理
在linux上用SDKMan对Java进行多版本管理 有一个工具叫SDKMan,它允许我们这样做。官方网站这样描述: TIP: "SDKMan 是一个工具,用于在大多数基于Unix的系统上管理多个软件开发工具包的并行版本。它提供了一个方便的命令行接口(CLI)和API,…...
、Gson(JsonObject)区别)
JSONObject、fastJson(JsonObject)、Gson(JsonObject)区别
概述 Java中并没有内置的 JSON 解析,需要使用第三方类库 fastJson :阿里巴巴的JSON 库,优势在于解析速度快,解析效率高,可以轻松处理大量的 JSON 数据JackSon : 社区十分活跃,spring框架默认使…...

如何在CSDN中使用ChatGPT
本篇文章致力于帮助大家理解和使用ChatGPT(现在CSDN改成”C知道“了)。简介ChatGPT是OpenAI公司开发的一种大型语言模型。它是一种基于Transformer架构的深度学习模型,可以对语言进行建模和生成。它可以处理问答、对话生成、文本生成等多种任…...
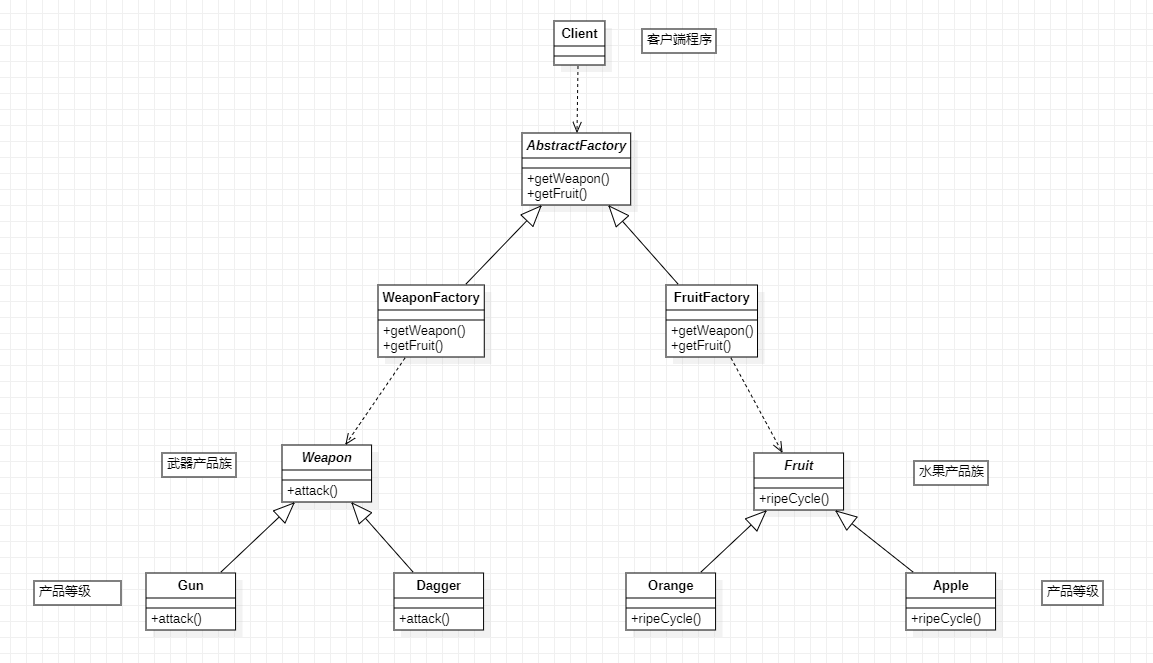
【Spring6】| GoF之工厂模式
目录 一:GoF之工厂模式 1. 工厂模式的三种形态 2. 简单工厂模式 3. 工厂方法模式 4. 抽象工厂模式(了解) 一:GoF之工厂模式 (1)GoF(Gang of Four),中文名——四人组…...

初识Node.js
文章目录初识Node.jsNode.js简介fs模块演示路径问题path路径模块http模块创建web服务器得基本步骤req请求对象res响应对象解决中文乱码问题模块化的基本慨念1、模块化2、Node.js中模块的分类3、Node.js中的模块作用域3.1什么是模块作用域4、向外共享模块作用域中的成员4.1modul…...

AI智能体在加密货币领域的架构设计与实战指南
1. 项目概述:当AI智能体闯入加密世界最近在GitHub上闲逛,发现一个挺有意思的项目,叫cutupdev/Crypto-AI-Agent。光看名字,两个最火的概念——“Crypto”(加密货币)和“AI Agent”(人工智能体&am…...

Beyond Compare 5 开源密钥生成器:逆向工程与授权机制的深度解析
Beyond Compare 5 开源密钥生成器:逆向工程与授权机制的深度解析 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 在软件安全与逆向工程领域,授权验证机制始终是开发者与安…...

跟着 MDN 学 HTML day_55:HTML 音频与视频嵌入实战指南
在现代网页设计中,多媒体内容已经成为提升用户体验的核心元素。无论是背景音乐、播客节目,还是产品演示视频,都离不开 HTML 中的音频和视频嵌入技术。HTML5 为我们提供了原生的 audio 和 video 元素,使得在网页中嵌入媒体内容变得…...

Web无障碍性自动化检查:CLI工具集成与工程实践指南
1. 项目概述:一个为开发者赋能的Web无障碍性CLI工具 如果你是一名前端开发者、测试工程师,或者正在构建一个需要服务广泛用户群体的Web应用,那么“无障碍性”(Accessibility, 常缩写为 a11y)这个词对你来说…...

基于BLE与CircuitPython的远程服务器重启开关设计与实现
1. 项目概述与核心思路手头有几台电脑分散在家里各个角落,有时候它们死机了需要重启,但偏偏其中一台作为监控录像存储的服务器,被我塞进了一个带锁的柜子里。每次都得找钥匙、开门、按按钮,实在麻烦。这个需求催生了我动手做一个无…...

Neovim原生GitHub Copilot客户端gp.nvim:从安装配置到高级实战
1. 项目概述:一个为Neovim量身打造的GitHub Copilot客户端如果你和我一样,是个重度Neovim用户,同时又对GitHub Copilot这类AI编程助手爱不释手,那你肯定也经历过那种“鱼与熊掌”的纠结时刻。在VSCode里,Copilot的集成…...

树莓派AI智能体进化框架:轻量级边缘持续学习实践
1. 项目概述:一个面向树莓派的AI智能体进化框架最近在折腾树莓派上的AI应用时,发现了一个挺有意思的项目,叫pk-pi-hermes-evolve。光看这个名字,就能拆出不少信息量:“pk”可能指代项目作者或一个特定系列,…...

性能巨兽:基于AMD EPYC 9755与RTX 5090D的UltraLAB GA660M仿真工作站深度解析
在高端制造、能源勘探和前沿科学计算领域,算力永远是稀缺资源。每一次CPU与GPU的代际更迭,都意味着仿真效率的指数级提升。今天,我们解析的这款UltraLAB GA660M241256-MBD工作站,正是集成了2026年顶级硬件技术的算力平台。它不仅是…...

全网首份DeepSeek-MMLU交叉验证报告:在真实业务场景中,高分≠高可用——5类典型失败案例与鲁棒性加固方案
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-MMLU基准测试成绩全景概览 MMLU(Massive Multitask Language Understanding)是评估大语言模型跨学科知识广度与推理能力的关键基准,涵盖57个学科领域&#…...

这个内核 bug 潜伏了 9 年。
TL;DR — Linux 内核加密子系统的一行 sg_chain() 调用,让 page cache 页被放进了可写的 scatterlist。任何普通用户通过 splice() AF_ALG 就能精准覆盖 setuid 二进制的内存映像,5 秒 root。潜伏 9 年,影响 2017 年以来几乎所有主流发行版。…...