【2024-完整版】python爬虫 批量查询自己所有CSDN文章的质量分:附整个实现流程
【2024】批量查询CSDN文章质量分
- 写在最前面
- 一、分析获取步骤
- 二、获取文章列表
- 1. 前期准备
- 2. 获取文章的接口
- 3. 接口测试(更新重点)
- 三、查询质量分
- 1. 前期准备
- 2. 获取文章的接口
- 3. 接口测试
- 四、python代码实现
- 1. 分步实现
- 2. 批量获取文章信息
- 3. 从excel中读取文章url,查询质量分,再将质量分添加到excel
- 4. 全部代码

前些天发现了一个人工智能学习网站,内容深入浅出、易于理解。如果对人工智能感兴趣,不妨点击查看。
写在最前面
之前的代码一直报错521,不清楚什么原因
因此重新分析整个过程,并对代码进行更新
结果如图
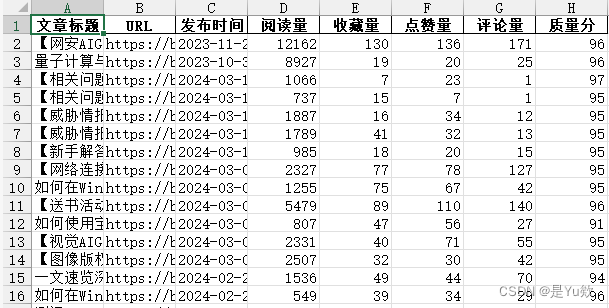
参考:
批量获取CSDN文章对文章质量分进行检测,有助于优化文章质量
【python】我用python写了一个可以批量查询文章质量分的小项目(纯python、flask+html、打包成exe文件)
一、分析获取步骤
- 获取博主的所有文章,并且拿到对应的url地址。(需要分析接口)
- 获取到url地址,我们需要使用官方查询质量分网页的接口进行请求。(需要分析接口)
- 接口分析完成后,我们就可以按照我们的需求进行代码编写了。
二、获取文章列表
1. 前期准备
浏览器访问需要获取文章的博主首页地址,并且打开开发者工具快捷键F12
然后点击网络选项,我们在刷新页面可以看到发送的请求地址。
然后我们选择XHR过滤掉我们不需要看到请求,但是这里面也没有我们需要的请求,但是没关系,我们只要想一下什么情况下会发送请求获取文章呢?答案就是下滑底部后,会重新发送请求获取新的文章并且渲染到页面。
点击删除请求这样我们下拉就可以清晰看到请求的接口数据
发现就是该接口发送的请求获取文章数据
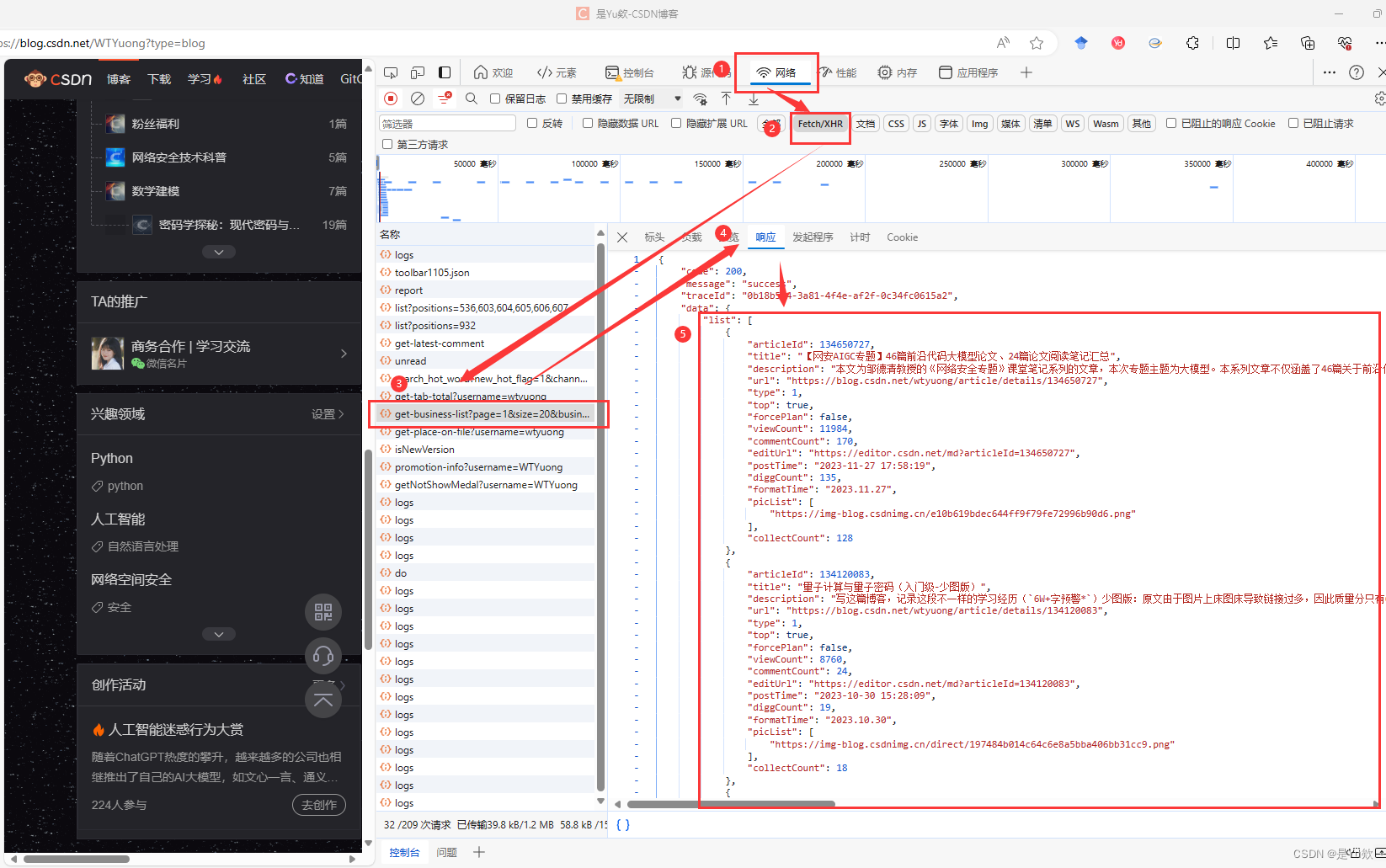
2. 获取文章的接口
我们主要还是研究获取文章的接口
看请求的 url,是一个 GET 请求。
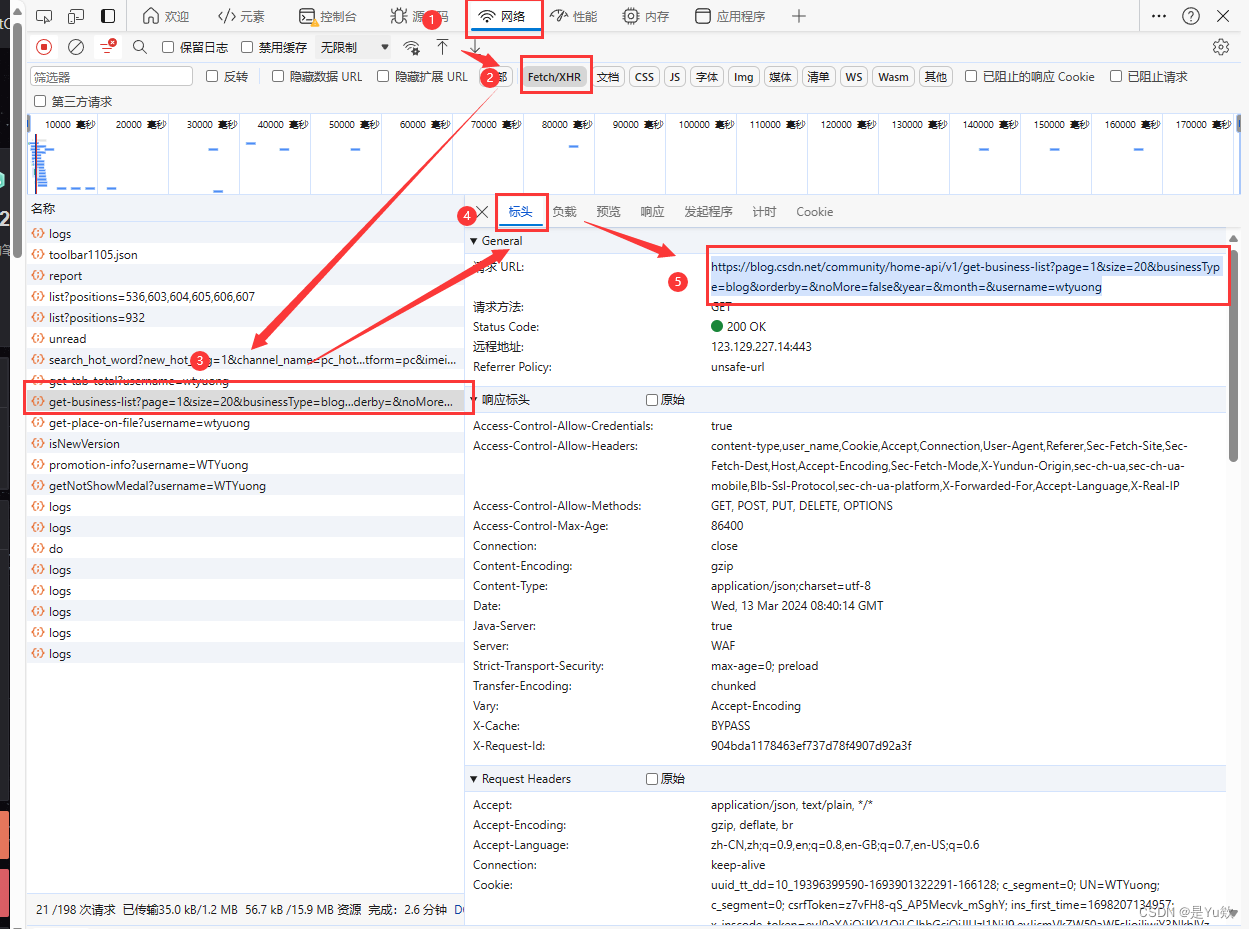
请求URL:
https://blog.csdn.net/community/home-api/v1/get-business-list
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=wtyuong
这个接口也比较简单只需要携带4个参数:
- 页码:page 第几页
- 页数:size 页码展示的条数
- 用户名称:username 需要查询的博主名(csdn id)
- 业务类型:businessType 默认使用 blog 这个类型对应
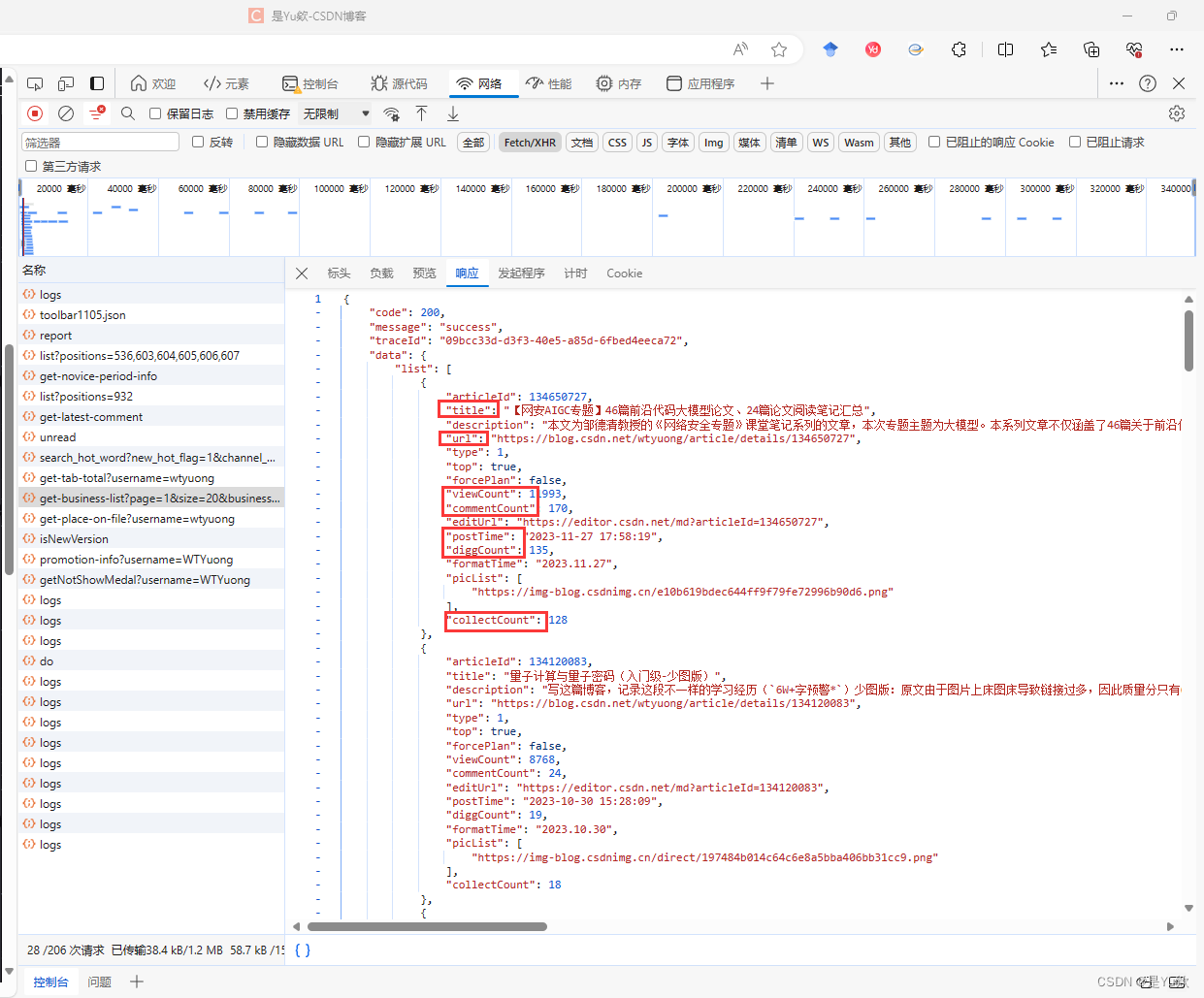
分析响应体:可以返回每篇文章的地址、阅读量、评论量等数据。
['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']
['文章标题', 'URL', '发布时间', '阅读量', '收藏量', '点赞量', '评论量']
3. 接口测试(更新重点)
用ApiPost这个软件来进行接口测试
发现实际上,如果只发送url是会报错的,提示:请进行安全验证
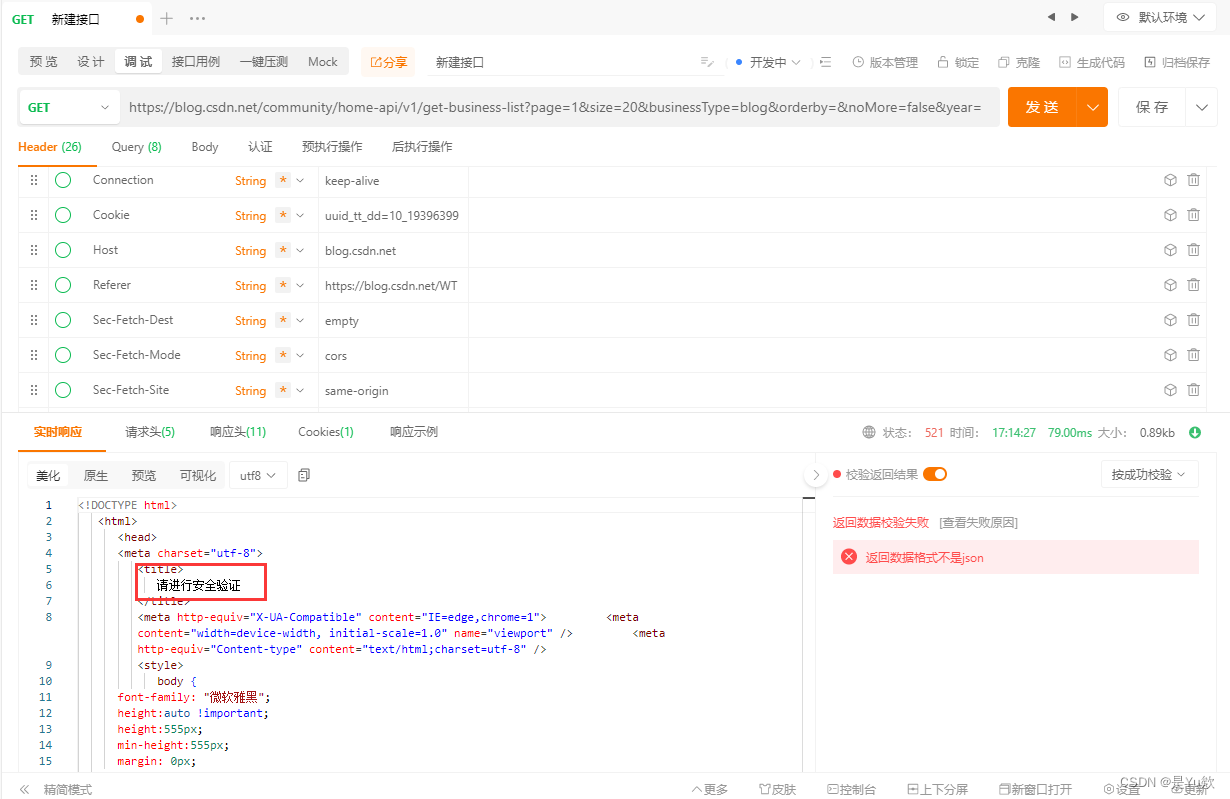
服务器要求进行“安全验证”以继续访问。这通常是网站的防爬机制之一,用于识别和阻止自动化的访问尝试。面对这种情况,有几个可能的解决方案:
用户代理(User-Agent):确保你的请求头中包含了一个合理的用户代理(User-Agent)字符串。有些网站会检查这个字段来判断请求是否来自真实的浏览器用户。尝试使用常见浏览器的用户代理字符串。
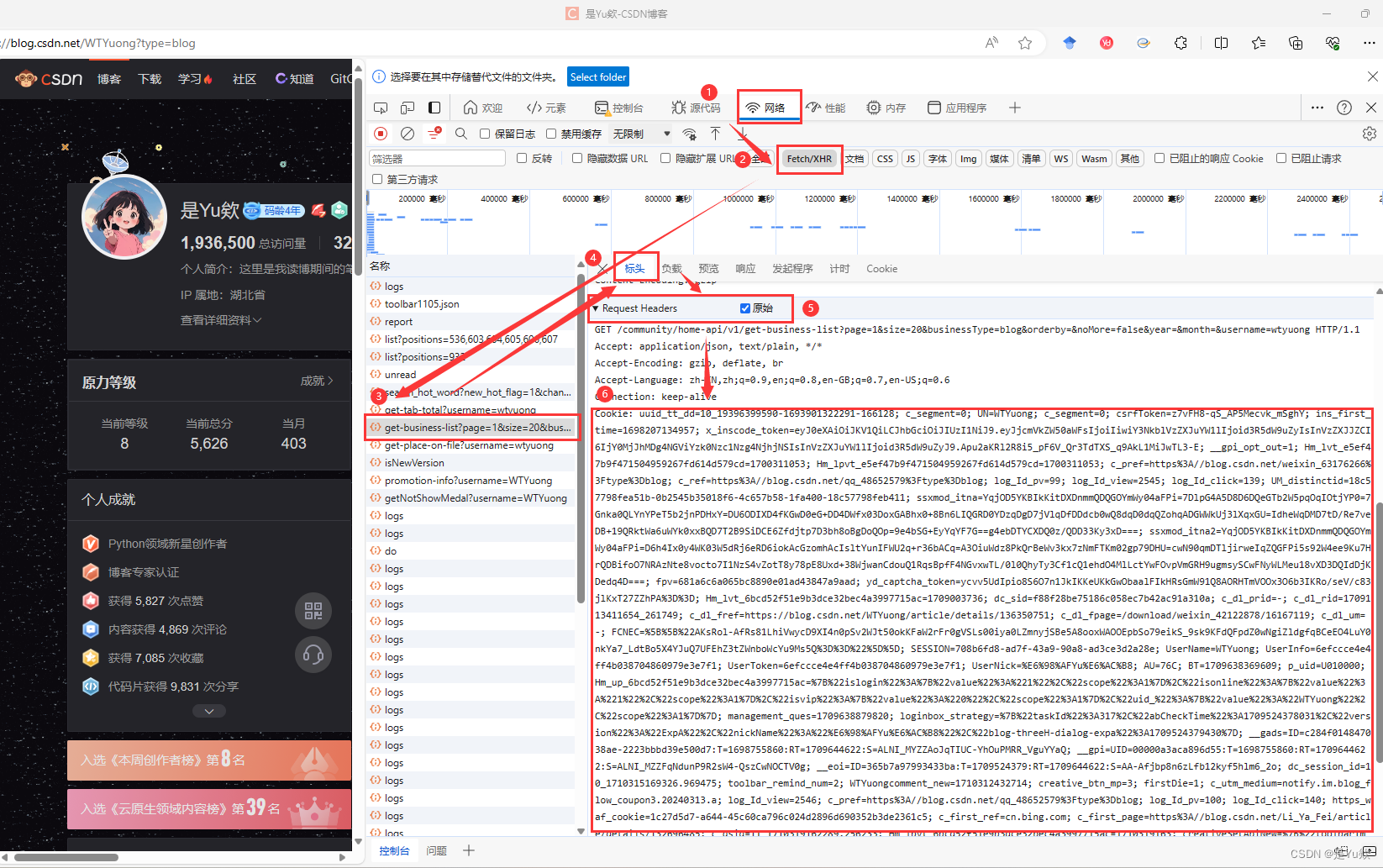
Cookies:某些网站要求请求携带有效的cookies来通过安全验证。你可以先手动访问该网站,通过浏览器获取到有效的cookies,并在你的爬虫请求中携带这些cookies。
处理JavaScript挑战:如果网站使用JavaScript生成动态内容或执行安全验证,你可能需要使用Selenium或Puppeteer这类工具,它们可以模拟真实的浏览器环境,执行JavaScript代码,并处理复杂的交互。
验证码识别:如果需要验证码验证,你可能需要集成验证码识别服务(如Google reCAPTCHA解决方案)或使用OCR(光学字符识别)技术尝试自动识别和填写验证码,虽然这可能面临法律和道德问题。
频率限制:确保你的请求频率不要太高,高频率的请求更容易触发网站的安全防护机制。尝试降低请求频率,或者在连续的请求之间增加延时。
经过测试,请求头只需要包括Cookies、Referer参数即可。
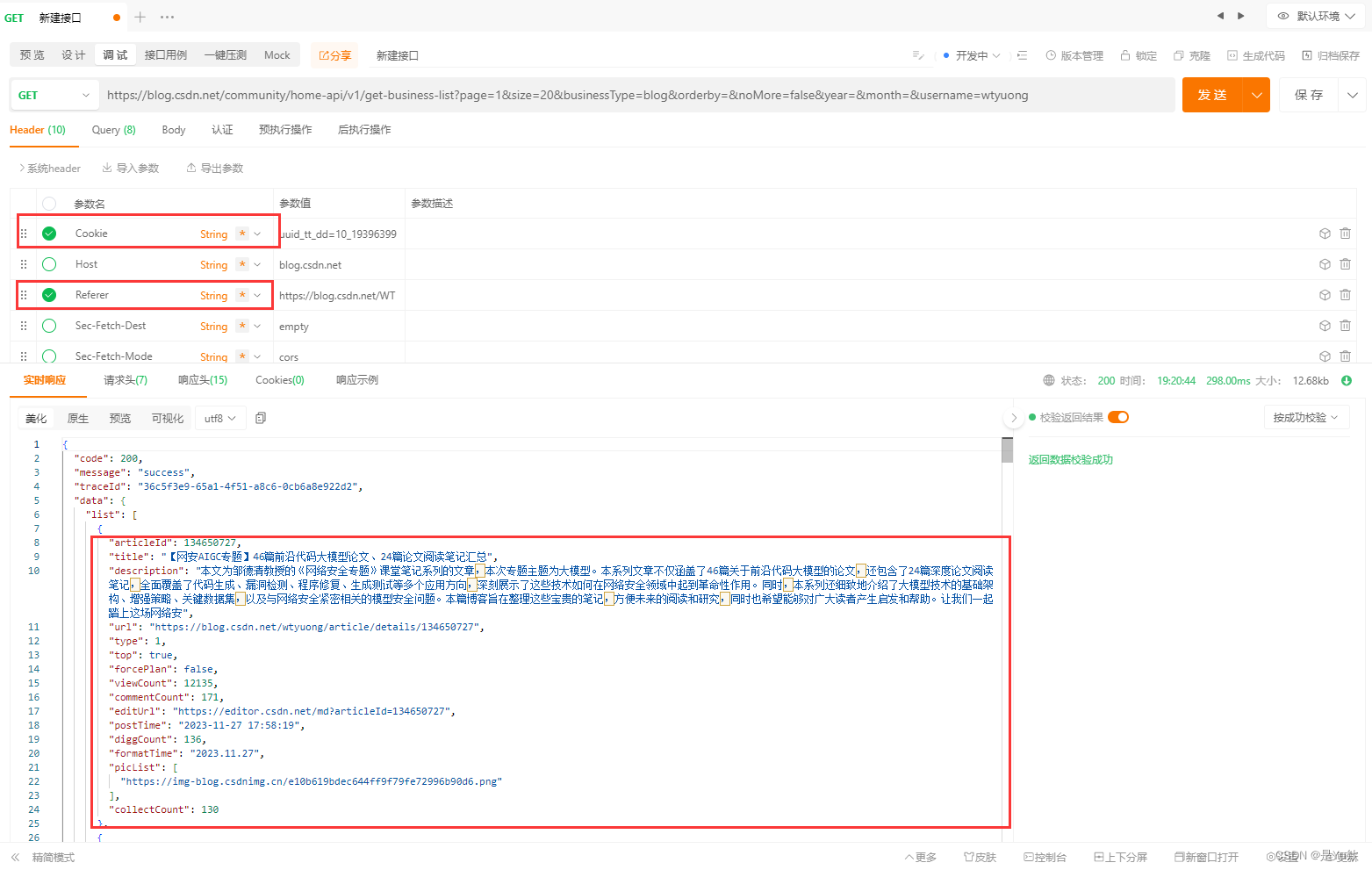
nice!
关于如何获取cookie:
三、查询质量分
流程和上述一样
1. 前期准备
先去质量查询地址:https://www.csdn.net/qc
2. 获取文章的接口
输入任意一篇文章地址进行查询,同时检查页面,在Network选项下即可看到调用的API的请求地址、请求方法、请求头、请求体等内容:
看请求的 url,是一个 POST 请求。
https://bizapi.csdn.net/trends/api/v1/get-article-score
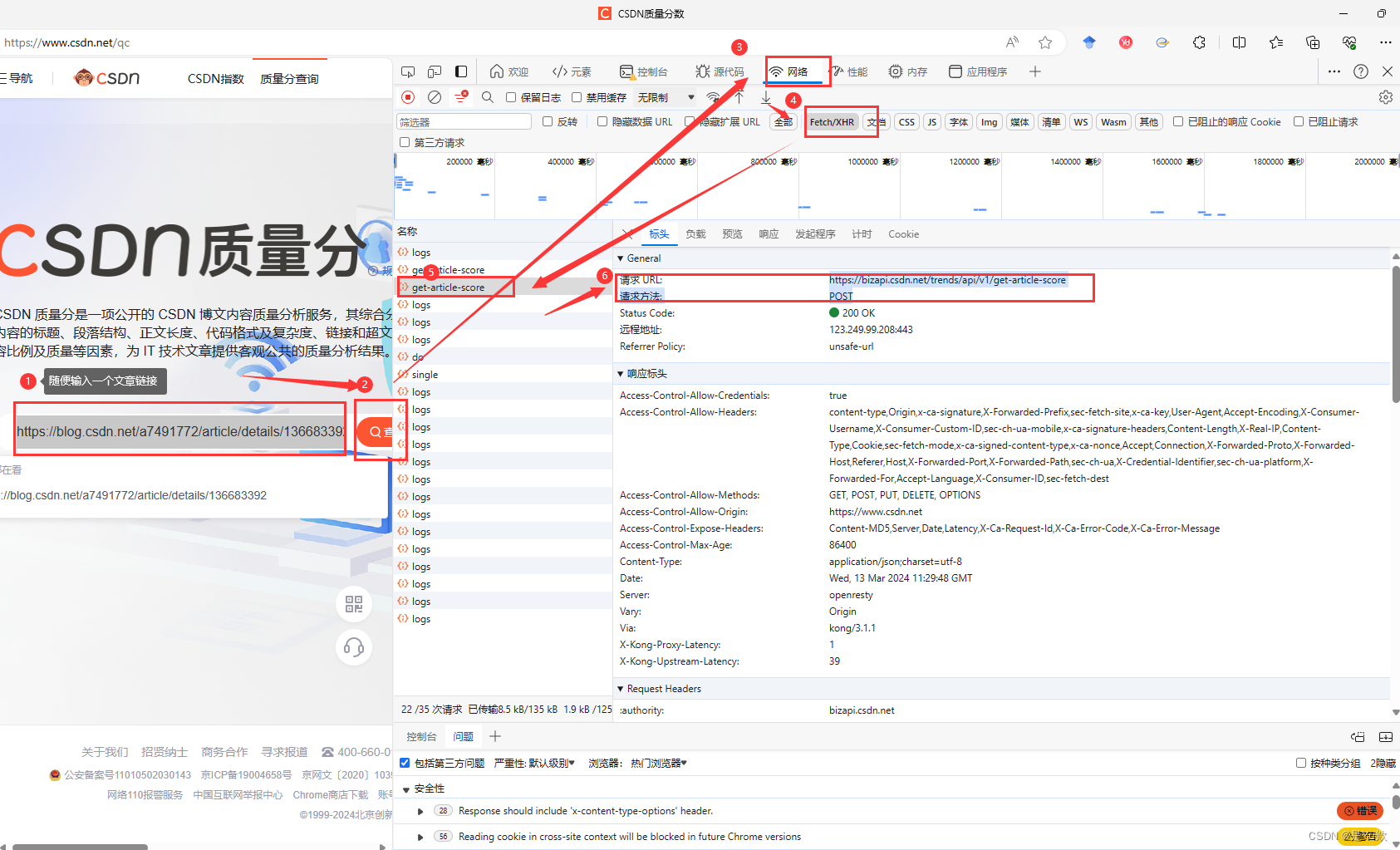
POST 请求携带参数是 url。
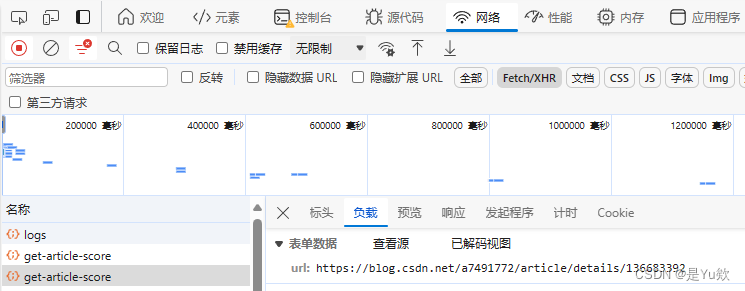
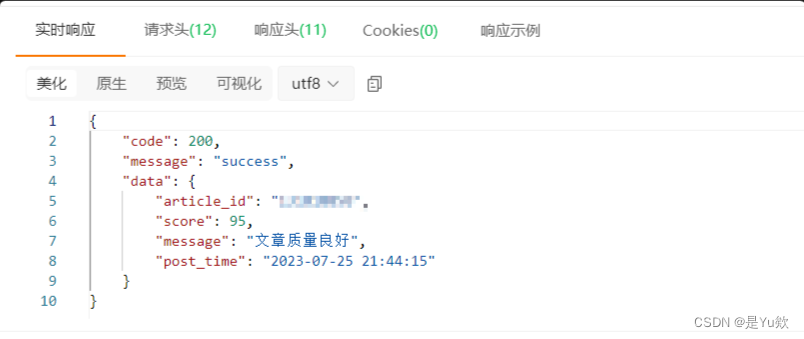
我们得到的响应数据:文章id、分数、消息、发布时间。
3. 接口测试
请求头里面很多参数是不需要的,我们用ApiPost这个软件来测试哪些是必要参数。
需要注意的是请求体的类型是form-data类型
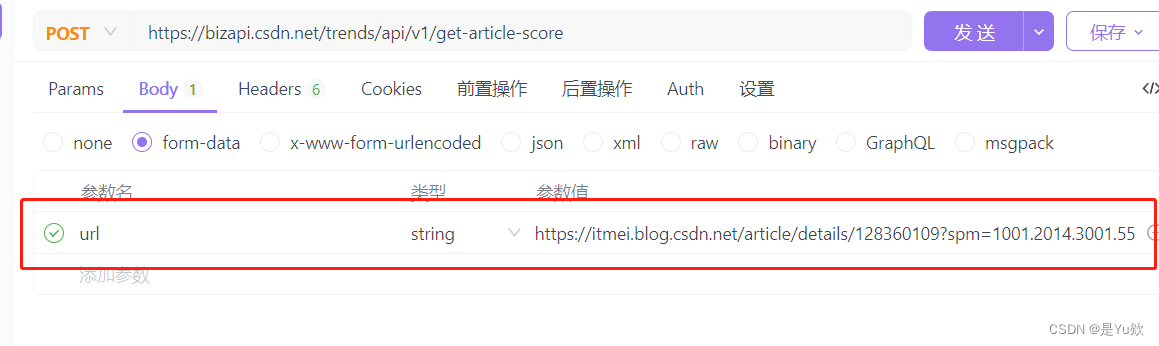
经过测试,请求头只需要下面这几个参数即可。
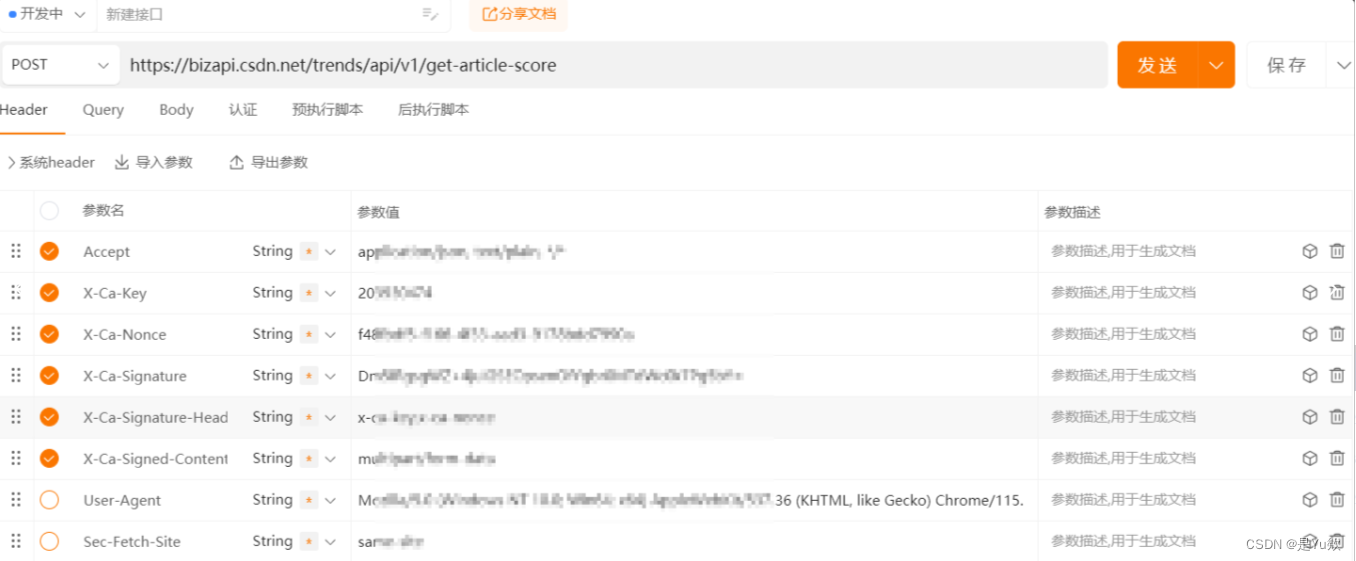
请求头分析
X-Ca-Key:使用自己浏览器的
X-Ca-Nonce:使用自己浏览器的
X-Ca-Signature:使用自己浏览器的
X-Ca-Signature-Headers:x-ca-key,x-ca-nonce
X-Ca-Signed-Content-Type:multipart/form-data
Accept :application/json, text/plain, /
响应体分析:
- score:文章的分数
- message:给出的建议
四、python代码实现
1. 分步实现
为了便于理解,把程序分为2个部分:
- 批量获取文章信息,保存为excel文件;
- 从excel中读取文章url,查询质量分,再将质量分添加到excel。
2. 批量获取文章信息
# 批量获取文章信息并保存到excel
class CSDNArticleExporter:def __init__(self, username, cookies, Referer, page, size, filename):self.username = usernameself.cookies = cookiesself.Referer = Refererself.size = sizeself.filename = filenameself.page = pagedef get_articles(self):url = "https://blog.csdn.net/community/home-api/v1/get-business-list"params = {"page": {self.page},"size": {self.size},"businessType": "blog","username": {self.username}}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3','Cookie': self.cookies, # Setting the cookies string directly in headers'Referer': self.Referer}try:response = requests.get(url, params=params, headers=headers)response.raise_for_status() # Raises an HTTPError if the response status code is 4XX or 5XXdata = response.json()return data.get('data', {}).get('list', [])except requests.exceptions.HTTPError as e:print(f"HTTP错误: {e.response.status_code} {e.response.reason}")except requests.exceptions.RequestException as e:print(f"请求异常: {e}")except json.JSONDecodeError:print("解析JSON失败")return []def export_to_excel(self):df = pd.DataFrame(self.get_articles())df = df[['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']]df.columns = ['文章标题', 'URL', '发布时间', '阅读量', '收藏量', '点赞量', '评论量']# df.to_excel(self.filename)# 下面的代码会让excel每列都是合适的列宽,如达到最佳阅读效果# 你只用上面的保存也是可以的# Create a new workbook and select the active sheetwb = Workbook()sheet = wb.active# Write DataFrame to sheetfor r in dataframe_to_rows(df, index=False, header=True):sheet.append(r)# Iterate over the columns and set column width to the max length in each columnfor column in sheet.columns:max_length = 0column = [cell for cell in column]for cell in column:try:if len(str(cell.value)) > max_length:max_length = len(cell.value)except:passadjusted_width = (max_length + 5)sheet.column_dimensions[column[0].column_letter].width = adjusted_width# Save the workbookwb.save(self.filename)
3. 从excel中读取文章url,查询质量分,再将质量分添加到excel
class ArticleScores:def __init__(self, filepath):self.filepath = filepath@staticmethoddef get_article_score(article_url):url = "https://bizapi.csdn.net/trends/api/v1/get-article-score"# TODO: Replace with your actual headersheaders = {"Accept": "application/json, text/plain, */*","X-Ca-Key": "203930474","X-Ca-Nonce": "b35e1821-05c2-458d-adae-3b720bb15fdf","X-Ca-Signature": "gjeSiKTRCh8aDv0UwThIVRITc/JtGJkgkZoLVeA6sWo=","X-Ca-Signature-Headers": "x-ca-key,x-ca-nonce","X-Ca-Signed-Content-Type": "multipart/form-data",}data = {"url": article_url}try:response = requests.post(url, headers=headers, data=data)response.raise_for_status() # This will raise an error for bad responsesreturn response.json().get('data', {}).get('score', 'Score not found')except requests.RequestException as e:print(f"Request failed: {e}")return "Error fetching score"def get_scores_from_excel(self):df = pd.read_excel(self.filepath)urls = df['URL'].tolist()scores = [self.get_article_score(url) for url in urls]return scoresdef write_scores_to_excel(self):df = pd.read_excel(self.filepath)df['质量分'] = self.get_scores_from_excel()df.to_excel(self.filepath, index=False)
4. 全部代码
import json
import pandas as pd
from openpyxl import Workbook, load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
import math
import requests# 批量获取文章信息并保存到excel
class CSDNArticleExporter:def __init__(self, username, cookies, Referer, page, size, filename):self.username = usernameself.cookies = cookiesself.Referer = Refererself.size = sizeself.filename = filenameself.page = pagedef get_articles(self):url = "https://blog.csdn.net/community/home-api/v1/get-business-list"params = {"page": {self.page},"size": {self.size},"businessType": "blog","username": {self.username}}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3','Cookie': self.cookies, # Setting the cookies string directly in headers'Referer': self.Referer}try:response = requests.get(url, params=params, headers=headers)response.raise_for_status() # Raises an HTTPError if the response status code is 4XX or 5XXdata = response.json()return data.get('data', {}).get('list', [])except requests.exceptions.HTTPError as e:print(f"HTTP错误: {e.response.status_code} {e.response.reason}")except requests.exceptions.RequestException as e:print(f"请求异常: {e}")except json.JSONDecodeError:print("解析JSON失败")return []def export_to_excel(self):df = pd.DataFrame(self.get_articles())df = df[['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']]df.columns = ['文章标题', 'URL', '发布时间', '阅读量', '收藏量', '点赞量', '评论量']# df.to_excel(self.filename)# 下面的代码会让excel每列都是合适的列宽,如达到最佳阅读效果# 你只用上面的保存也是可以的# Create a new workbook and select the active sheetwb = Workbook()sheet = wb.active# Write DataFrame to sheetfor r in dataframe_to_rows(df, index=False, header=True):sheet.append(r)# Iterate over the columns and set column width to the max length in each columnfor column in sheet.columns:max_length = 0column = [cell for cell in column]for cell in column:try:if len(str(cell.value)) > max_length:max_length = len(cell.value)except:passadjusted_width = (max_length + 5)sheet.column_dimensions[column[0].column_letter].width = adjusted_width# Save the workbookwb.save(self.filename)class ArticleScores:def __init__(self, filepath):self.filepath = filepath@staticmethoddef get_article_score(article_url):url = "https://bizapi.csdn.net/trends/api/v1/get-article-score"# TODO: Replace with your actual headersheaders = {"Accept": "application/json, text/plain, */*","X-Ca-Key": "203930474","X-Ca-Nonce": "b35e1821-05c2-458d-adae-3b720bb15fdf","X-Ca-Signature": "gjeSiKTRCh8aDv0UwThIVRITc/JtGJkgkZoLVeA6sWo=","X-Ca-Signature-Headers": "x-ca-key,x-ca-nonce","X-Ca-Signed-Content-Type": "multipart/form-data",}data = {"url": article_url}try:response = requests.post(url, headers=headers, data=data)response.raise_for_status() # This will raise an error for bad responsesreturn response.json().get('data', {}).get('score', 'Score not found')except requests.RequestException as e:print(f"Request failed: {e}")return "Error fetching score"def get_scores_from_excel(self):df = pd.read_excel(self.filepath)urls = df['URL'].tolist()scores = [self.get_article_score(url) for url in urls]return scoresdef write_scores_to_excel(self):df = pd.read_excel(self.filepath)df['质量分'] = self.get_scores_from_excel()df.to_excel(self.filepath, index=False)if __name__ == '__main__':total = 10 #已发文章总数量# TODO:调整为你自己的cookies,Referer,CSDNid, headerscookies = 'uuid_tt_dd=10' # Simplified for brevityReferer = 'https://blog.csdn.net/WTYuong?type=blog'CSDNid = 'WTYuong't_index = math.ceil(total/100)+1 #向上取整,半闭半开区间,开区间+1。# 获取文章信息# CSDNArticleExporter("待查询用户名", 2(分页数量,按总文章数量/100所得的分页数),总文章数量仅为设置为全部可见的文章总数。# 100(最大单次查询文章数量不大于100), 'score1.xlsx'(待保存数据的文件,需要和下面的一致))for index in range(1,t_index): #文章总数filename = "score"+str(index)+".xlsx"exporter = CSDNArticleExporter(CSDNid, cookies, Referer, index, 100, filename) # Replace with your usernameexporter.export_to_excel()# 批量获取质量分score = ArticleScores(filename)score.write_scores_to_excel()
相关文章:
【2024-完整版】python爬虫 批量查询自己所有CSDN文章的质量分:附整个实现流程
【2024】批量查询CSDN文章质量分 写在最前面一、分析获取步骤二、获取文章列表1. 前期准备2. 获取文章的接口3. 接口测试(更新重点) 三、查询质量分1. 前期准备2. 获取文章的接口3. 接口测试 四、python代码实现1. 分步实现2. 批量获取文章信息3. 从exce…...

Nuxt3: useFetch使用过程常见一种报错
一、问题描述 先看一段代码: <script setup> const fetchData async () > {const { data, error } await useFetch(https://api.publicapis.org/entries);const { data: data2, error: error2 } await useFetch(https://api.publicapis.org/entries);…...

当代计算机语言占比分析
在当今快速发展的科技领域,计算机语言作为程序员的工具之一,扮演着至关重要的角色。随着技术的不断演进,各种编程语言层出不穷,但在实际开发中,哪些计算机语言占据主导地位?本文将对当代计算机语言的占比进…...
基于大模型和向量数据库的 RAG 示例
1 RAG 介绍 RAG是一种先进的自然语言处理方法,它结合了信息检索和文本生成技术,用于提高问答系统、聊天机器人等应用的性能。 2 RAG 的工作流程 文档加载(Document Loading) 从各种来源加载大量文档数据。这些文档…...
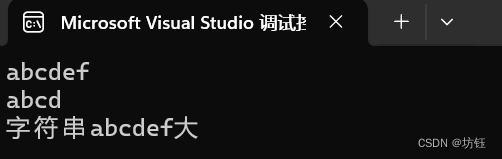
【C语言】比较两个字符串大小,strcmp函数
目录 一,strcmp函数 1,strcmp函数 2,函数头文件: 3,函数原型: 4,返回取值: 二,代码实现 三,小结 一,strcmp函数 1,strcmp函数 …...

深入理解与应用Keepalive机制
目录 引言 一、VRRP协议 (一)VRRP概述 1.诞生背景 2.基本理论 (二)VRRP工作原理 (三)VRRP相关术语 二、keepalive基本理论 (一)基本性能 (二)实现原…...

嵌入(embedding)概念
嵌入(embedding)在数学和相关领域中的确是指将一个数学对象在保持其某些关键性质不变的前提下,注入到一个更大或更高维的空间中。这个过程不仅仅是简单的映射,而是要求注入的对象在新空间中的表现形式能够完整反映原有对象的内在结…...
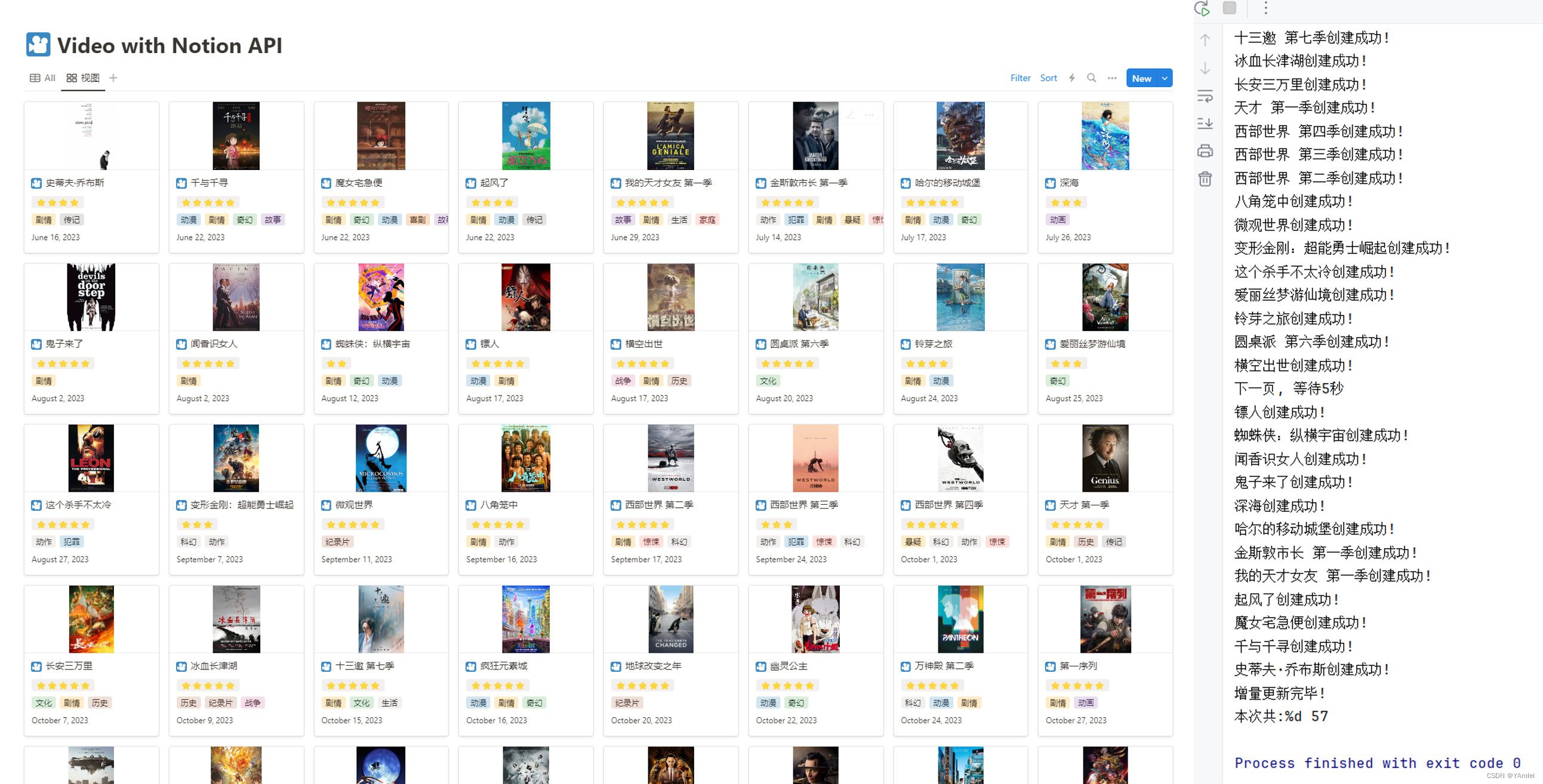
豆瓣书影音存入Notion
使用Python将图书和影视数据存放入Notion中。 🖼️介绍 环境 Python 3.10 (建议 3.11 及以上)Pycharm / Vs Code / Vs Code Studio 项目结构 │ .env │ main.py - 主函数、执行程序 │ new_book.txt - 上一次更新书籍 │ new_video.…...

Lucene 分词 示例代码
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.TokenStream; import org...

2.18 校招 实习 内推 面经
绿*泡*泡VX: neituijunsir 交流*裙 ,内推/实习/校招汇总表格 1、自动驾驶一周资讯 - 李想回应“年终奖有点大”;智界升级为奇瑞独立事业部;小鹏汽车春节累计智驾总里程公布 自动驾驶一周资讯 - 李想回应“年终奖有点大”&…...

spring中事务失效的场景有哪些?
异常捕获处理 在方法中已经将异常捕获处理掉并没有抛出。 事务只有捕捉到了抛出的异常才可以进行处理,如果有异常业务中直接捕获处理掉没有抛出,事务是无法感知到的。 解决:在catch块throw抛出异常。 抛出检查异常 spring默认只会回滚非检…...
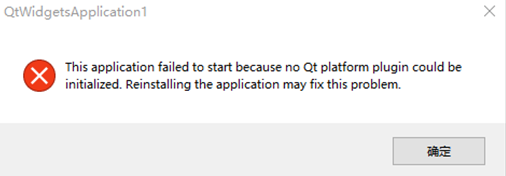
Visual Studio 2022之Release版本程序发送到其它计算机运行
目录 1、缺少dll 2、应用程序无法正常启动 3、This application failed to start because no Qt platform plugin could be initialized. 代码在Debug模式下正常运行,然后切换到Release模式下,也正常运行,把第三方平台的dll拷贝到exe所在…...
.)
Xcode下载模拟器报错Could not download iOS 17.4 Simulator (21E213).
xcode14以后最小化安装包,从而将模拟器不集中在安装包中 因此xcode14至以后的版本安装后第一次启动会加载提示安装模拟器的提示框 或者根据需要到xcode中进行所需版本|平台的模拟器进行安装 Xcode > Settings > Platforms 问题来了尝试多次都安装失败例如…...

mac在终端设置代理
前言 本篇文章介绍如何在mac终端设置代理服务器,有时候,我们需要在终端进行外网的资源访问,比如我构建v8引擎项目的时候,需要使用gclient更新组件和下载构建工具。如果单单设置了计算机的代理,依然是无法下载资源的&a…...

傅立叶之美:深入研究傅里叶分析背后的原理和数学
一、说明 T傅里叶级数及其伴随的推导是数学在现实世界中最迷人的应用之一。我一直主张通过理解数学来理解我们周围的世界。从使用线性代数设计神经网络,从混沌理论理解太阳系,到弦理论理解宇宙的基本组成部分,数学无处不在。 当然,…...
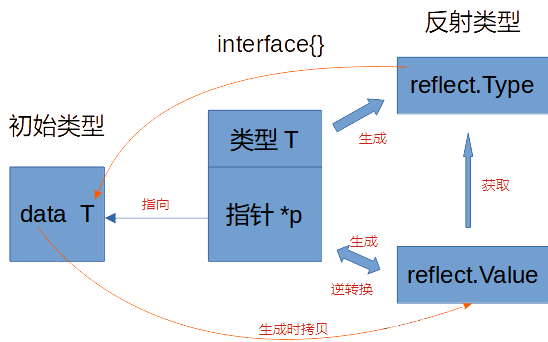
golang学习随便记16-反射
为什么需要反射 下面的例子中编写一个 Sprint 函数,只有1个参数(类型不定),返回和 fmt.Fprintf 类似的格式化后的字符串。实现方法大致为:如果参数类型本身实现了 String() 方法,那调用 String() 方法即可…...

识别恶意IP地址的有效方法
在互联网的环境中,恶意IP地址可能会对网络安全造成严重威胁,例如发起网络攻击、传播恶意软件等。因此,识别恶意IP地址是保护网络安全的重要一环。IP数据云将探讨一些有效的方法来识别恶意IP地址。 IP地址查询:https://www.ipdata…...

探索信号处理:低通滤波器的原理与应用
在信号处理领域,滤波器的应用至关重要,它能够帮助我们从复杂的信号中提取需要的信息,而低通滤波器则是其中一种被广泛应用的滤波器类型。本文旨在深入探讨低通滤波器的基本原理、主要类型以及在实际应用中的作用和实现方式。 ### 1. 低通滤波…...
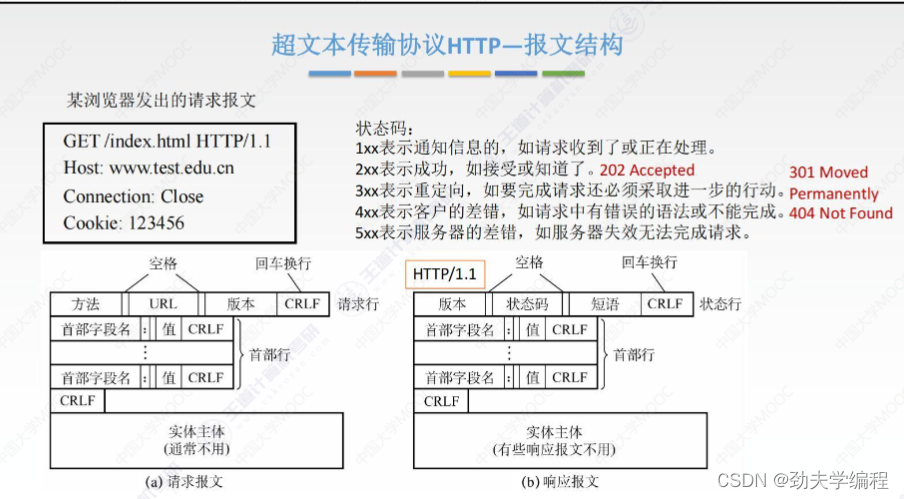
计算机网络:应用层知识点汇总
文章目录 一、网络应用模型二、域名系统(DNS)三、文本传输协议(FTP)四、电子邮件五、万维网和HTTP协议 一、网络应用模型 p2p也就是对等模型 二、域名系统(DNS) 我们知道,随着人们建立一个网站…...
金三银四!一个年薪160W+的就业方向!
前言 随着越来越多的科技大厂加入鸿蒙生态建设,鸿蒙开发人才正在市场上被争抢。资深工程师开出的年薪高达近百万,架构师更是高至160万,真可谓“鸿蒙猿年薪超百万”。如何抓住新技术红利,尽早上车?你会成为下一个鸿蒙开…...

Taotoken用量看板与成本分析功能,如何帮助团队控制大模型支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本分析功能,如何帮助团队控制大模型支出 对于任何将大模型能力集成到产品开发流程中的团队而言&a…...

保姆级教程:用UE4/UE5的WebUI插件,把Web页面嵌入数字孪生项目
虚幻引擎WebUI插件实战:数字孪生项目中无缝嵌入Web页面的完整指南在数字孪生项目的开发过程中,将实时数据可视化的Web页面嵌入到虚幻引擎场景中已成为提升用户体验的关键技术。本文将以UE4/UE5的WebUI插件为核心工具,手把手演示如何将Web前端…...

Propius:面向协同机器学习的异构边缘资源管理平台架构解析
1. 项目概述:当协同机器学习遇上异构边缘资源在分布式机器学习领域,尤其是联邦学习(Federated Learning)这类强调数据隐私的范式,我们常常面临一个核心矛盾:一方面,我们希望利用海量、异构的边缘…...

2026年降AI工具处理速度横评:五款主流工具一万字论文处理时长完整数据报告
2026年降AI工具处理速度横评:五款主流工具一万字论文处理时长完整数据报告 拿同一篇论文,用三款工具分别处理,记录了完整检测数据。 结论先说:嘎嘎降AI(www.aigcleaner.com)效果最稳,价格也最…...

Obsidian Calendar Plugin:时间维度驱动的笔记工作流架构革新
Obsidian Calendar Plugin:时间维度驱动的笔记工作流架构革新 【免费下载链接】obsidian-calendar-plugin Simple calendar widget for Obsidian. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-calendar-plugin Obsidian Calendar Plugin 作为 Obs…...
)
生物医药合成生物学解决方案(2026版)
生物医药合成生物学解决方案(2026版) 目录 第1章项目概述 7 1.1项目背景 7 1.2项目目标 8 1.2.1技术目标 8 1.2.2业务目标 8 1.2.3经济目标 9 1.2.4社会目标 9 1.3项目范围 10 1.4项目意义 11 1.4.1产业意义 11 1.4.2技术意义 11 1.4.3经济意义 11 1.4.4社会意义 12 1.5项目…...

Unity WebGL项目内存爆了别慌!用Profiler揪出2048大贴图,5分钟搞定优化
Unity WebGL内存优化实战:用Profiler精准定位2048大贴图当Unity WebGL项目在浏览器中运行时突然弹出"Out Of Memory"错误,不少开发者会感到手足无措。这种内存溢出问题往往源于未被注意到的资源"巨无霸"——比如一张20482048的高清贴…...

告别卡顿!用IL2CPP优化你的Unity游戏:性能提升与包体瘦身实测
告别卡顿!用IL2CPP优化你的Unity游戏:性能提升与包体瘦身实测最近在优化一款Unity游戏时,我发现了一个令人头疼的问题:游戏在低端设备上频繁卡顿,包体大小也超出了预期。经过一番探索,我决定尝试将脚本后端…...

安全稀疏矩阵乘法:基于二叉树递归传播的MPC算法优化详解
1. 项目概述:当稀疏矩阵乘法遇上安全多方计算 在分布式机器学习、联合数据分析以及隐私保护推荐系统的构建中,我们常常面临一个核心矛盾:数据的所有权分散在多个互不信任的参与方手中,大家希望共同训练一个模型或进行一次计算&…...

Kali NetHunter移动渗透实战:Magisk模块化部署与外设适配
1. 这不是“手机装Kali”,而是重构移动安全测试的工作流很多人第一次看到“手机跑Kali NetHunter”时,下意识反应是:这不就是把Linux桌面系统硬塞进安卓里?界面卡、命令少、工具打不开,最后变成一个炫技失败的摆设。我…...