ELK介绍使用
文章目录
- 一、ELK介绍
- 二、Elasticsearch
- 1. ElasticSearch简介:
- 2. Elasticsearch核心概念
- 3. Elasticsearch安装
- 4. Elasticsearch基本操作
- 1. 字段类型介绍
- 2. 索引
- 3. 映射
- 4. 文档
- 5. Elasticsearch 复杂查询
- 三、LogStash
- 1. LogStash简介
- 2. LogStash安装
- 四、kibana
- 1. kibana简介
- 2. Kibana安装
- 五、ELK监控项目,收集项目日志
- 1. springboot集成LogStash
- 2. 启动项目,监控项目运行
- 六、搭建ELK日志系统demo(提供搭建思路)
一、ELK介绍
ELK就是由Elasticsearch + LogStash + Kibana来组成的,这三个技术就是我们常说的ELK技术栈,这是一种很典型的MVC思想,模型持久层,视图层和控制层。
Logstash担任控制层的角色,负责搜集和过滤数据。
Elasticsearch担任数据持久层的角色,负责储存数据。
Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
二、Elasticsearch
1. ElasticSearch简介:
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2. Elasticsearch核心概念
集群cluster
- 一个集群由一个唯一的名字标识在定义,这个名字默认就是“elasticsearch”
- 定义的这个名字非常重要,因为一个节点只能通过指定某个集群的名字,来加入这个集群
- 一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
索引index
- 一个索引由一个名字来标识 (必须全部是小写字母的),并且当我们要对对应于这个索引中的文档 进行索引、搜索、更新和删除的时候,都要使用到这个名字。
- 一个索引就是一个拥有几分相似特征的文档的集合,在一个集群中,可以定义任意多的索引。
映射 mapping
- 映射是定义一个文档和它所包含的字段如何被存储和索引的过程,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的
- ES可以根据插入的数据自动地创建mapping,也可以手动创建mapping。 mapping中主要包括字段名、字段类型等
文档 document
- 一个文档是一个可被索引的基础信息单元。
- 文档是索引中存储的一条条数据。一条文档是一个可被索引的最小单元
- 在一个index里面,你可以存储任意多的文档。
字段 Field
- 相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
主分片 shards
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间,那么可以将索引划分成多份存储在不同的节点,这就叫做分片
- 当创建一个索引的时候,可以指定分片数量
- 分片允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
- 每个分片本身也是一个功能完善并且独立的“索引”
- 至于一个分片怎样分布,它的文档怎样聚合搜索请求,是完全由Elasticsearch管理的
副本分片 replicas
- 副本分片主要是用来备份主分片的,达到高可用,Elasticsearch允许创建的分片有一份或多份拷贝,这些拷贝叫做副本分片
- 一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引创建的时候指定
- 在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
3. Elasticsearch安装
docker安装ES、LogStash、Kibana
4. Elasticsearch基本操作
1. 字段类型介绍
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 字符串类型 | text / keyword | 需要进行全文检索的字段,通常使用 text 类型来对应,text 主要对应 非结构化的数据,可分词 keyword来对应结构化的数据,不可分词 |
| 日期类型 | date | 保存格式化的日期数据,可以指定格式:”format”: “yyyy-MM-dd HH:mm:ss” |
| 数值类型 | long / integer / short / byte | 64位整数/32位整数/16位整数/8位整数 |
| 浮点类型 | double / float / half_float | 64位双精度浮点/32位单精度浮点/16位半进度浮点 |
| 布尔类型 | boolean | “true” / ”false” |
| 简单类型 | ip | IPV4(192.168.1.110)/IPV6(192.168.0.0/16) |
| JSON分层嵌套类型 | object | 用于保存JSON对象 |
| JSON分层嵌套类型 | nested | 用于保存JSON数组 |
| 经纬度类型 | geo_point | 用于保存经纬度坐标 |
| 特殊类型 | geo_shape | 用于保存地图上的多边形坐标 |
2. 索引
# 1.创建索引-->phone_index
PUT /phone_index# 2.创建索引 进行索引分片配置
PUT /phone_index
{"settings": {"number_of_shards": 1, // 指定主分片的数量"number_of_replicas": 0 // 指定副本分片的数量}
}# 3.查看全部索引
GET /_cat/indices?v# 4.删除索引-->phone_index
DELETE /phone_index# 5.删除全部索引 *代表通配符,代表所有索引
DELETE /*
3. 映射
创建映射
# 1.创建索引phone_index,指定映射
PUT /phone_index
{ "settings": {"number_of_shards": 1, // 指定主分片"number_of_replicas": 0 // 指定副本分片}, "mappings": { // 创建映射"properties": { // 设置属性"title":{ // 指定字段为title"type": "keyword" // 指定字段类型为字符串keyword,不可分词},"price":{ // 指定字段为price"type": "double" // 指定字段类型为浮点型double},"created_at":{ // 指定字段为created_at"type": "date" // 指定字段类型为日期类型date},"desc":{ // 指定字段为desc"type": "text" // 指定字段类型为字符串text,可分词}}}
}
查看映射
# 1.语法:GET /索引名/_mapping
GET /item_index/_mapping
4. 文档
添加文档
# 1. 指定文档id 语法:POST /索引名/_doc/指定文档id
POST /phone_index/_doc/1 // 指定文档id
{"title":"华为手机","desc":"华为,遥遥领先","price":1900
}# 2. 自动生成id 语法:POST /索引名/_doc/
POST /phone_index/_doc/
{"title":"苹果手机","desc":"苹果4,肾机","price":2900
}
查询文档
# 1.语法:GET /索引名/_doc/文档id
GET /phone_index/_doc/1
删除文档
# 1.语法:GET /索引名/_doc/文档id
DELETE /phone_index/_doc/1
更新文档
# 1.更新文档 语法:PUT /索引名/_doc/文档id
PUT /phone_index/_doc/1
{"title":"iphon16"
}
# 2. 先删除,在将更新文档以新的内容插入。
POST /phone_index/_doc/1/_update
{"doc" : {"title" : "华为旗舰版"}
}
批量更新文档
批量时不会因为一个失败而全部失败,而是继续执行后续操作,在返回时按照执行的状态返回!
# 1. 批量更新两条文档
POST /phone_index/_doc/_bulk{"index":{"_id":"1"}}{"title":"华为","desc":"遥遥领先,遥遥领先"}{"index":{"_id":"2"}}{"title":"iphone4","desc":"iPhone 4屏幕采用LED屏幕"}# 2. 更新,删除,新增
POST /phone_index/_doc/_bulk {"update":{"_id":"1"}}{"doc":{"title":"小米"}}{"delete":{"_id":2}}{"index":{"_id":3}}{"title":"荣耀手机","desc":"LED屏幕。。。。", "price":900}
5. Elasticsearch 复杂查询
| 命令 | 含义 |
|---|---|
| match_all | 查询所有,返回索引中的全部文档 |
| term | 关键字,用来使用关键词查询 |
| range | 范围查询,用来指定查询指定范围内的文档 |
| prefix | 前缀查询,用来检索含有指定前缀的关键词的相关文档 |
| wildcard | 通配符查询, ? 用来匹配一个任意字符 * 用来匹配多个任意字符 |
| ids | 多id查询, 值为数组类型,用来根据一组id获取多个对应的文档 |
| fuzzy | 模糊查询含有指定关键字的文档 |
| multi_match | 多字段查询 |
| highlight | 高亮查询,符合条件的文档中的关键词高亮 |
| size | 定查询结果中返回指定条数。 默认返回值10条 |
| from | 指定起始返回位置,和size关键字连用可实现分页效果 |
| sort | 指定字段排序 |
| _source | 返回指定字段,在数组中用来指定展示那些字段 |
- match_all 查询所有
GET /phone_index/_search
{"query": {"match_all": {}}
}
- range 范围查询
GET /phone_index/_search
{"query": {"range": {"price": {"gte": 1400, // 大于等于"lte": 9999 // 小于等于}}}
}
- wildcard 通配符查询
Wildcard 查询是一种基于通配符的查询,它使用单个字符(?)代表一个字符,使用星号(*)代表零个或多个字符。Wildcard 查询可用于对单个词执行模糊匹配,也可以用于对短语进行模糊匹配。它可以在搜索中用于查找某些词汇的变体或拼写错误的单词。
GET /phone_index/_search
{"query": {"wildcard": {"desc": "hua*"}}
}
- fuzzy 模糊查询
注意:
- fuzzy 模糊查询 最大模糊错误 必须在0-2之间
- 搜索关键词长度为 2 不允许存在模糊
- 搜索关键词长度为3-5 允许一次模糊
- 搜索关键词长度大于5 允许最大2模糊
GET /phone_index/_search
{"query": {"fuzzy": {"desc": {"value": "hua"}}}
}
- highlight 高亮查询
POST /phone_index/_search
{"query": {"match": {"title": "huawei"}},"highlight": {"fields": {"*": {}},"pre_tags": "<font color='red'>","post_tags": "</font>","fragment_size": 10}
}
三、LogStash
LogStash参考,想要深度了解LogStash的可以看一看
1. LogStash简介
gstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地进行存储。任何事件类型都可以加入分析,通过输入、过滤器和输出插件进行转换。与此同时,还提供了很多原生编解码工具简化消息处理。Logstash通过海量数据处理和多种多样的数据格式支持延伸了我们对数据的洞察力。
LogStash工作原理:
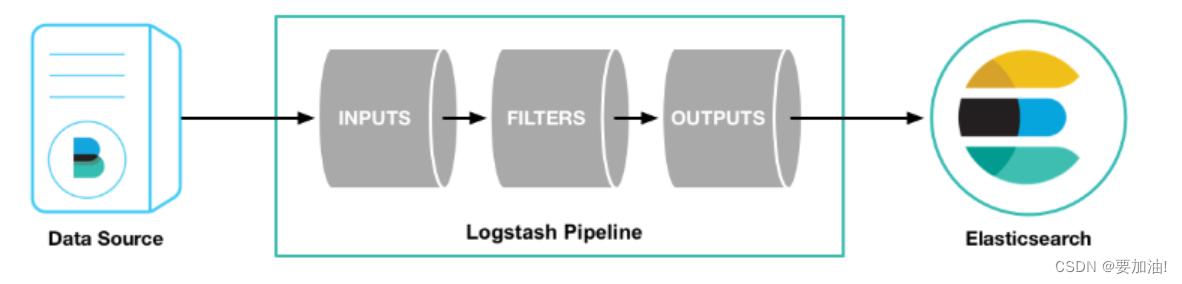
- 输入,以下是常见得输入内容
- file:从文件系统上的文件读取,与UNIX命令非常相似 tail -0F
- syslog:在已知端口上侦听syslog消息进行解析
- redis:使用redis通道和redis列表从redis服务器读取。Redis通常用作集中式Logstash安装中的“代理”,该安装将Logstash事件从远程Logstash“托运人”排队。
- beats:处理 Beats发送的事件,beats包括filebeat、packetbeat、winlogbeat。
- 过滤,以下是常见得过滤器
- grok:解析并构造任意文本。Grok是目前Logstash中将非结构化日志数据解析为结构化和可查询内容的最佳方式。Logstash内置了120种模式,您很可能会找到满足您需求的模式!
- mutate:对事件字段执行常规转换。您可以重命名,删除,替换和修改事件中的字段。
- drop:完全删除事件,例如调试事件。
- clone:制作事件的副本,可能添加或删除字段。
- geoip:添加有关IP地址的地理位置的信息(也在Kibana中显示惊人的图表!)
- 输出,以下是常见得输出内容
- elasticsearch:将事件数据发送给Elasticsearch。如果您计划以高效,方便且易于查询的格式保存数据… Elasticsearch是您的最佳选择
- file:将事件数据写入磁盘上的文件。
- graphite:将事件数据发送到graphite,这是一种用于存储和绘制指标的流行开源工具。http://graphite.readthedocs.io/en/latest/
- statsd:将事件数据发送到statsd,这是一种“侦听统计信息,如计数器和定时器,通过UDP发送并将聚合发送到一个或多个可插入后端服务”的服务。如果您已经在使用statsd,这可能对您有用!
- 编解码器
编解码器基本上是流过滤器,可以作为输入或输出的一部分运行。使用编解码器可以轻松地将消息传输与序列化过程分开。流行的编解码器包括json, multiline等。
json:以JSON格式编码或解码数据。
multiline:将多行文本事件(例如java异常和堆栈跟踪消息)合并到一个事件中
2. LogStash安装
docker安装ES、LogStash、Kibana
四、kibana
1. kibana简介
- Kibana提供了一系列交互式的可视化组件,包括图表、表格、地图、仪表盘等,用户可以通过简单的拖拽和点击操作,将Elasticsearch中数据转化为易于理解和分析的图形化展示。
- Kibana还支持自定义查询和过滤器,用户可以根据自己的需求对Elasticsearch中数据进行深入挖掘和分析。Kibana还提供了一些其他的功能,例如实时监控、警报、报告等;
2. Kibana安装
docker安装ES、LogStash、Kibana
五、ELK监控项目,收集项目日志
1. springboot集成LogStash
- maven坐标
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>6.3</version>
- application.yml
server:port: 80 #tomcat端口servlet:context-path: /
- logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--该日志将日志级别不同的log信息保存到不同的文件中 -->
<configuration><include resource="org/springframework/boot/logging/logback/defaults.xml"/><springProperty scope="context" name="springAppName" source="spring.application.name"/><!-- 日志在工程中的输出位置 --><property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/><!-- 控制台的日志输出样式 --><property name="CONSOLE_LOG_PATTERN"value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/><!-- 控制台输出 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>INFO</level></filter><!-- 日志输出编码 --><encoder><pattern>${CONSOLE_LOG_PATTERN}</pattern><charset>utf8</charset></encoder></appender><!-- logstash远程日志配置--><appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><destination>192.168.128.23:4560</destination><encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/></appender><!-- 日志输出级别 --><root level="DEBUG"><appender-ref ref="console"/><appender-ref ref="logstash"/></root>
</configuration>
2. 启动项目,监控项目运行
提示:按照以下步骤进行设置
- 访问kibana,点击 Stack Management
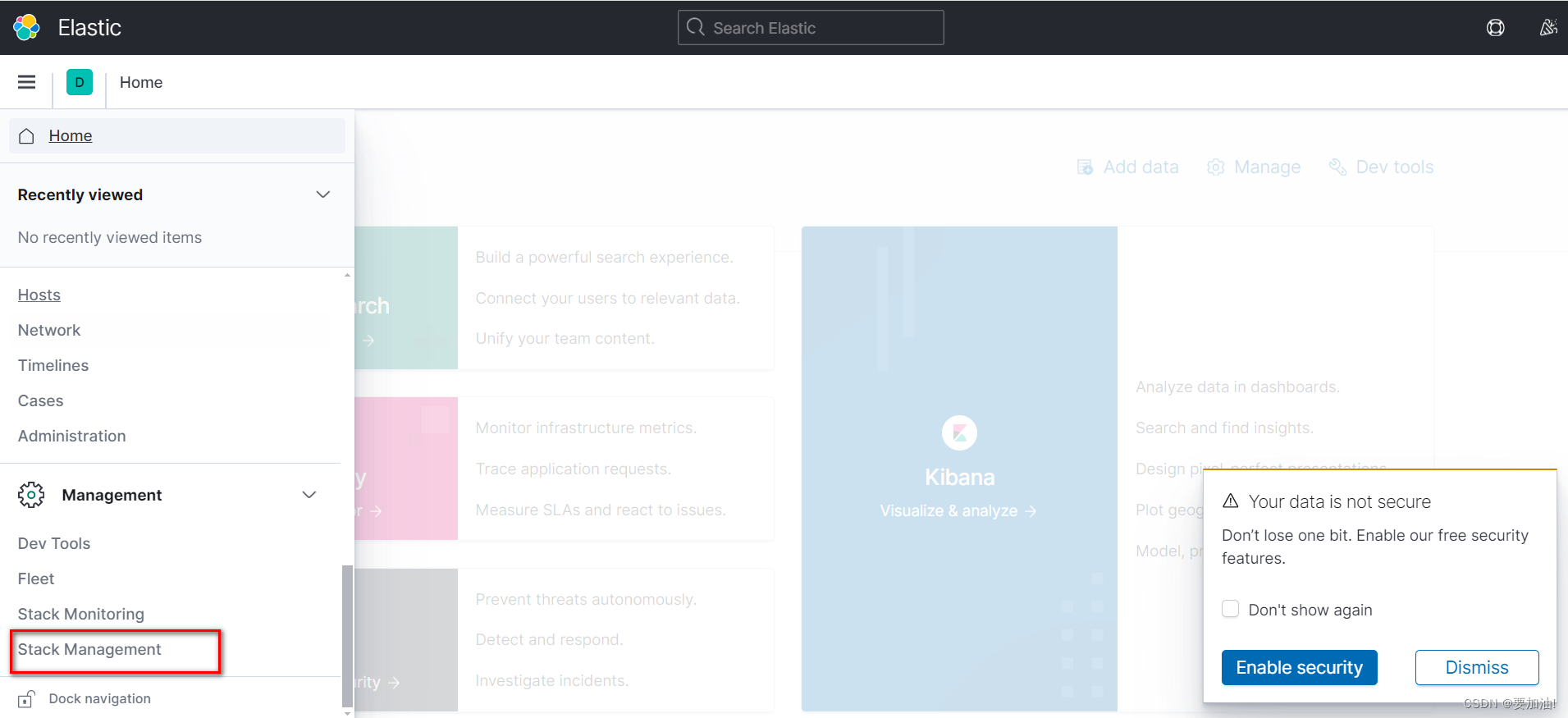
- 点击 Index Patterns
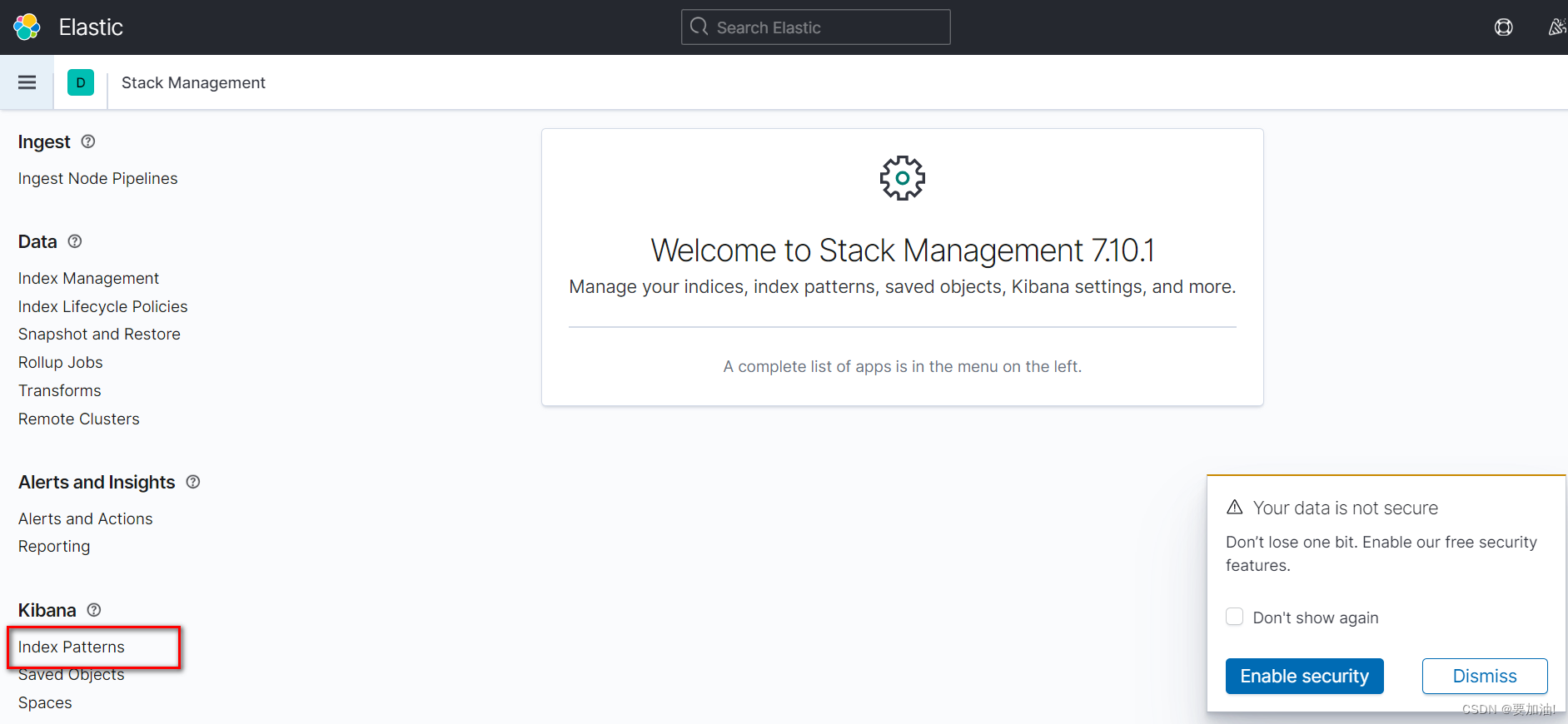
- 点击 Create Index Patterns
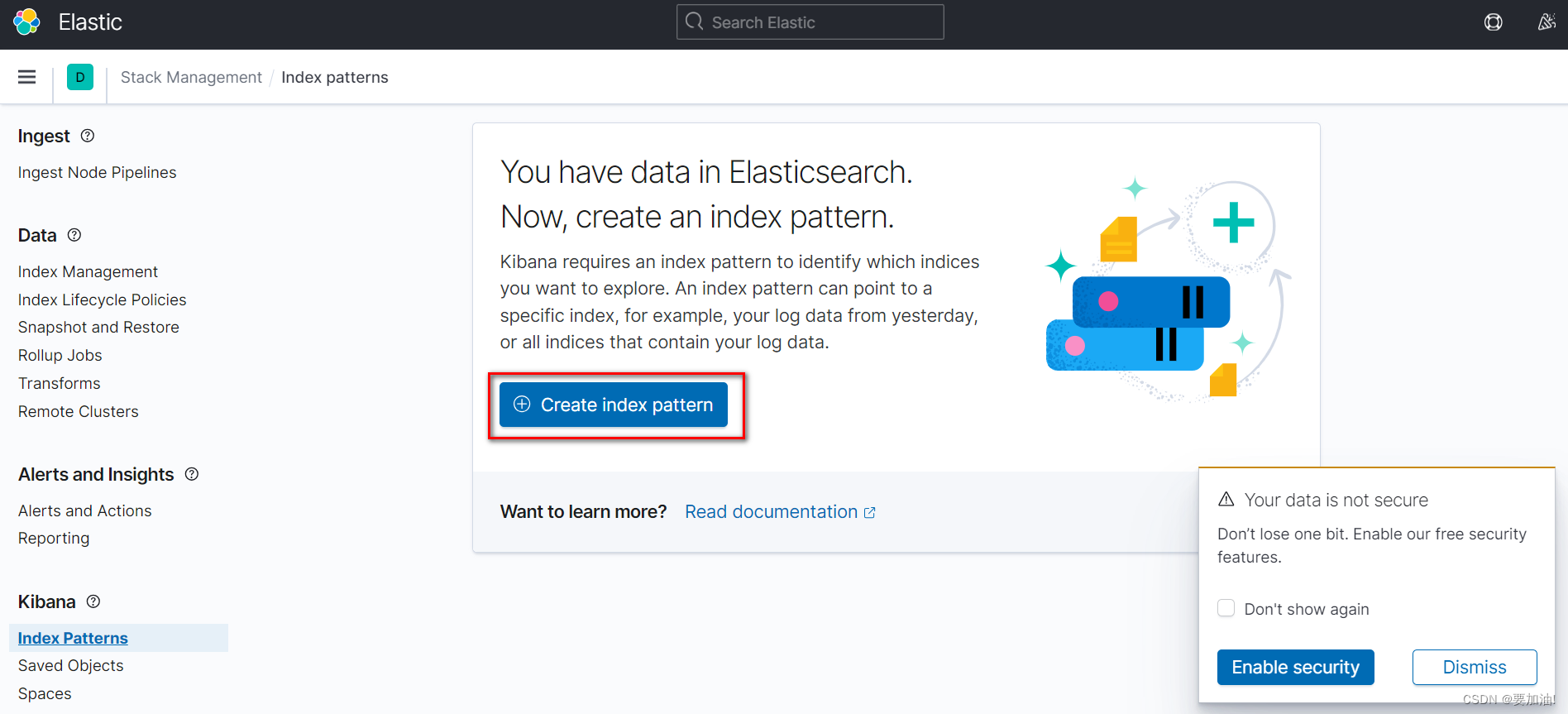
- 设置索引模式名,关联索引,点击 Next step
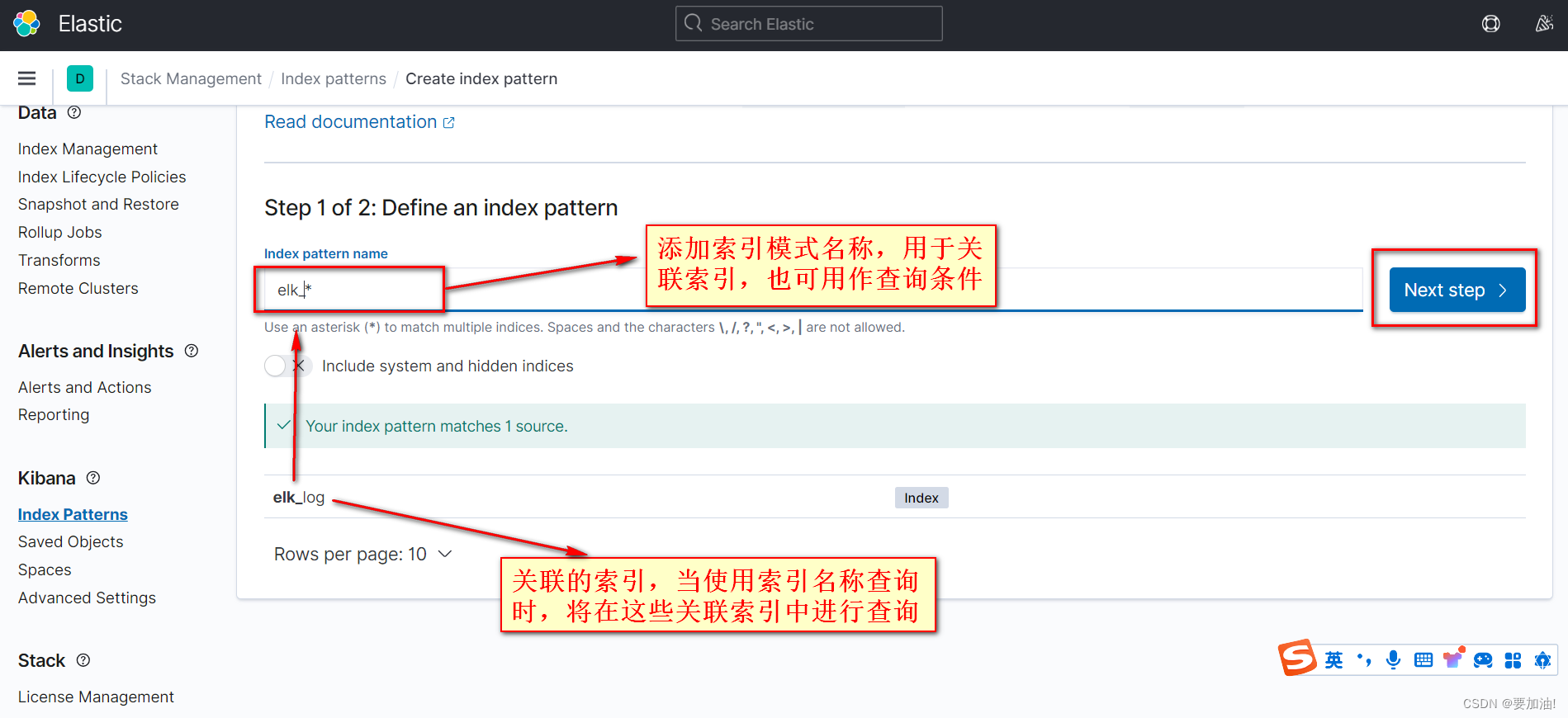
- 选择时间字段, 点击 Create Index Patterns
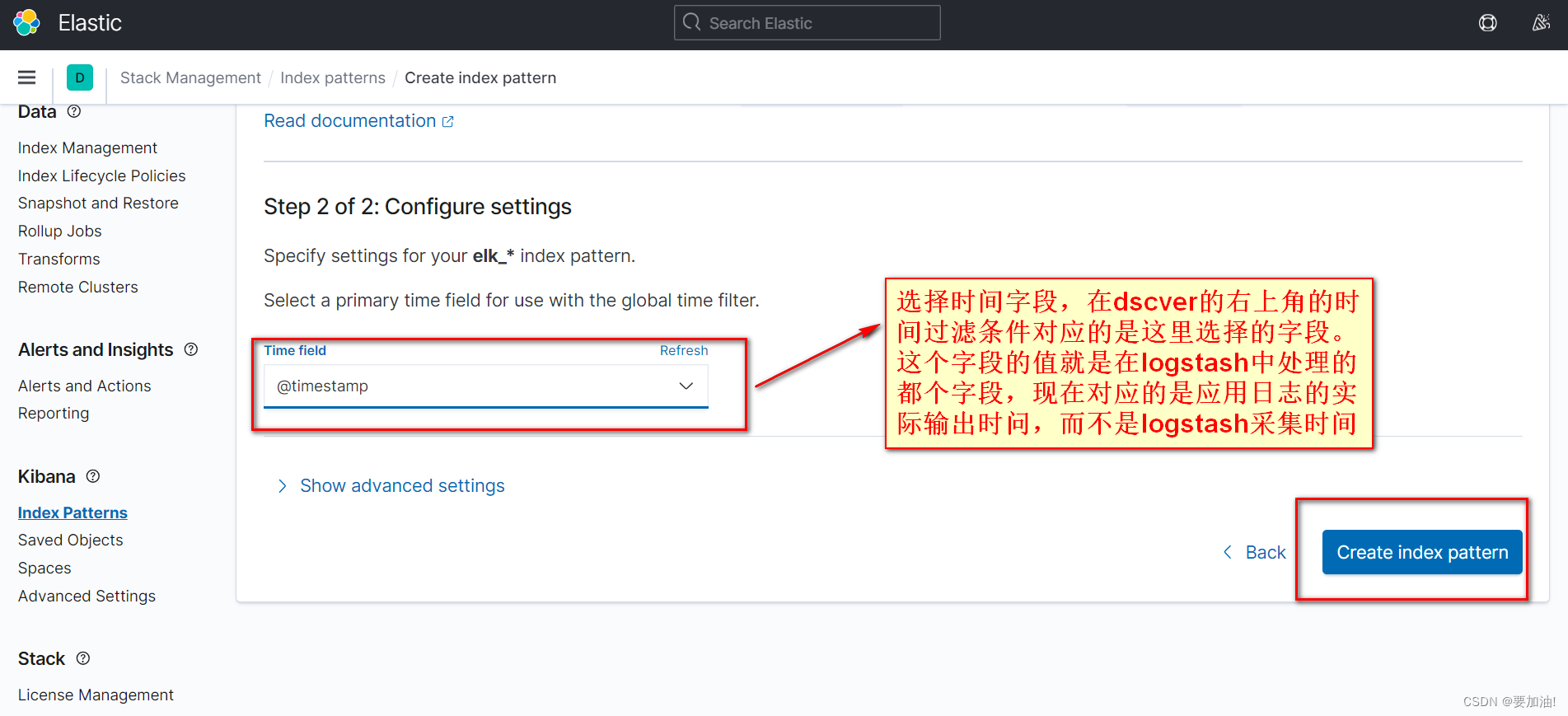
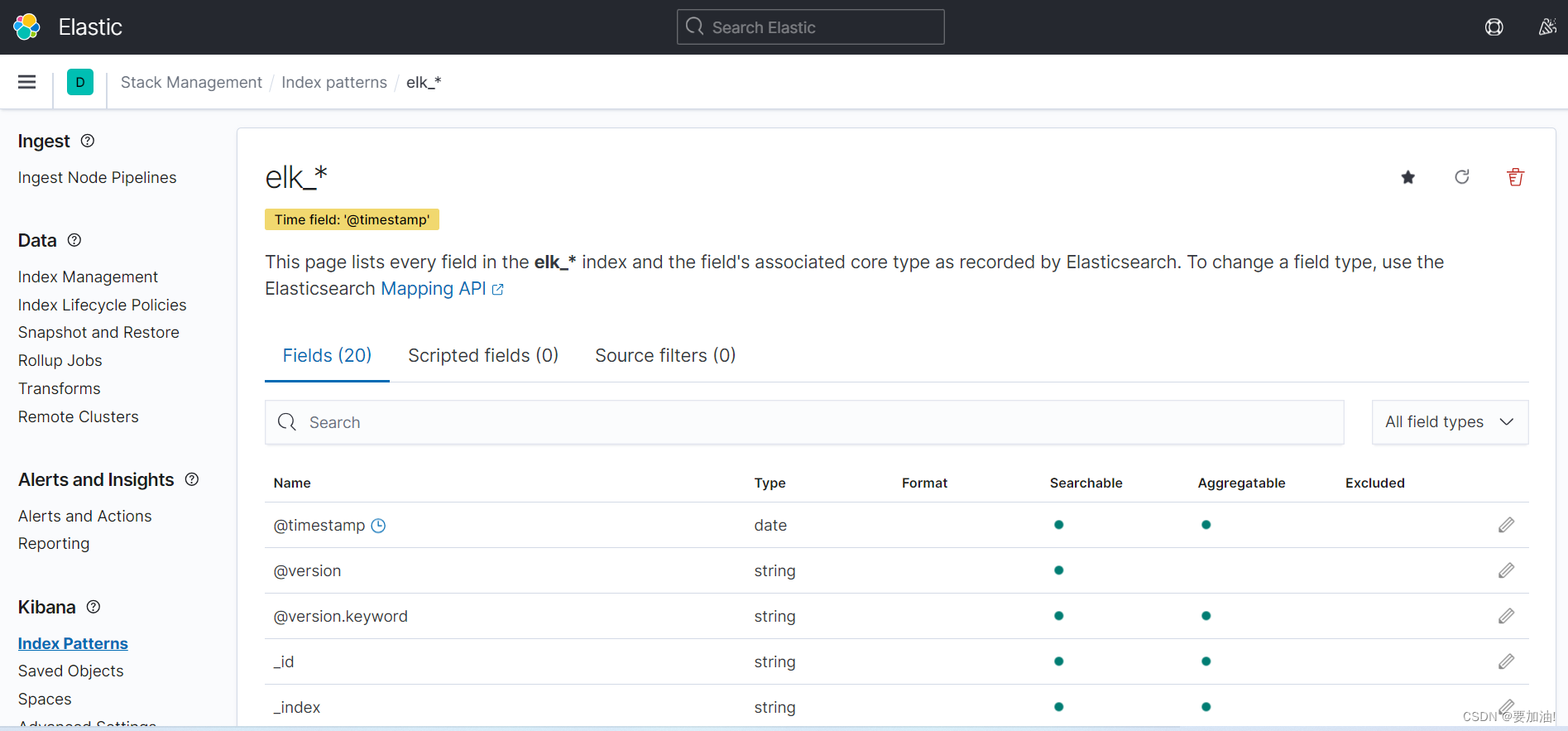
- 设置好的索引模式如下
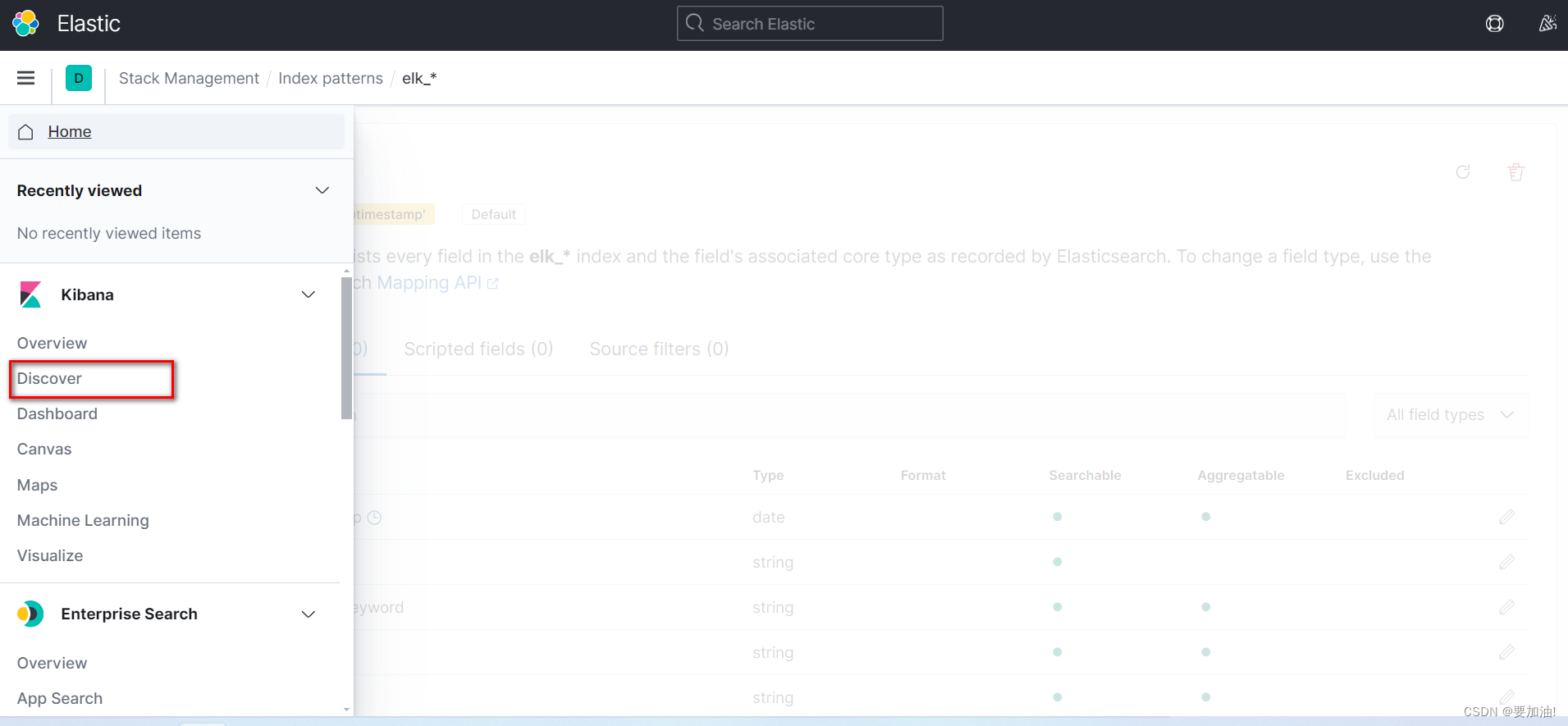
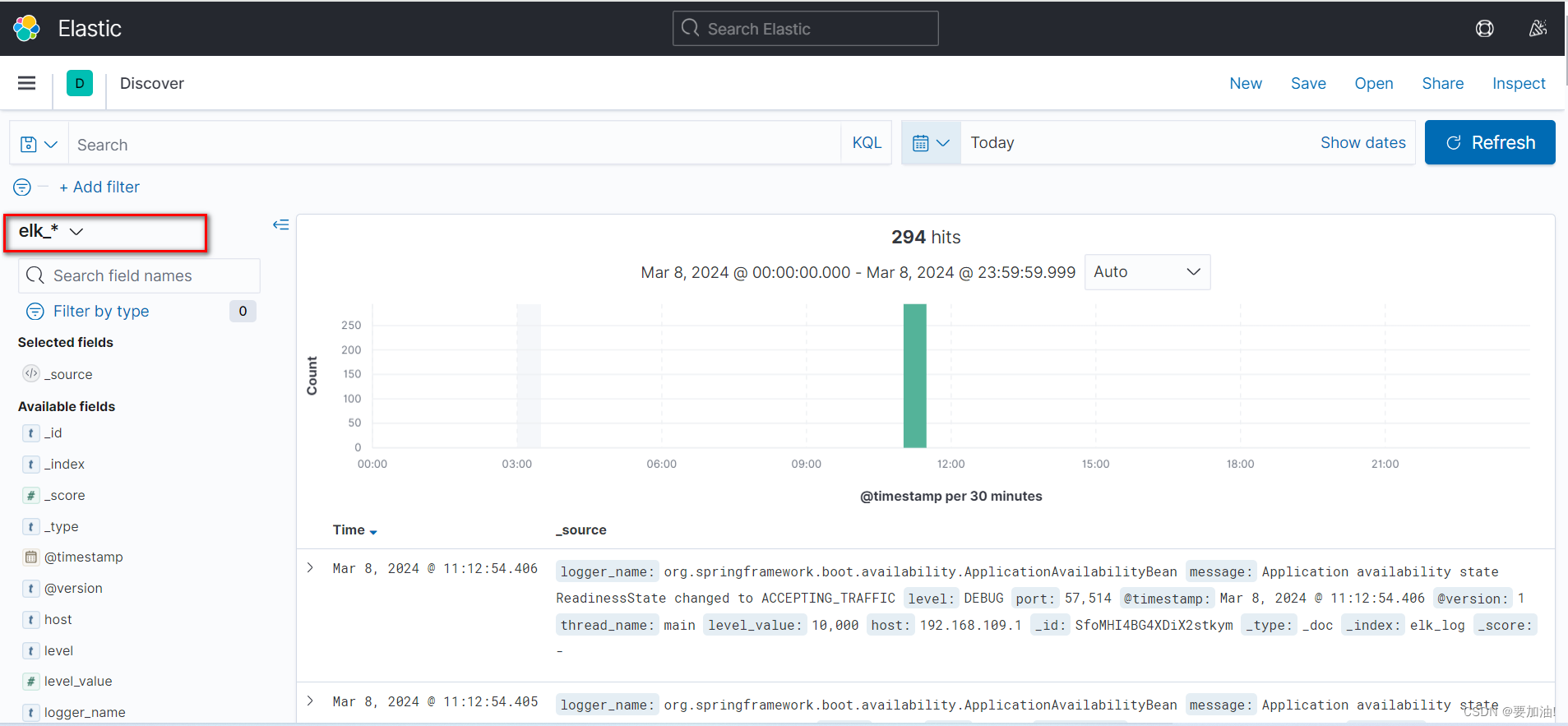
- 点击 Discover ,进行项目监控
- 监控项目运行情况
六、搭建ELK日志系统demo(提供搭建思路)
- maven
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>6.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.16</version><scope>compile</scope></dependency></dependencies>
- application.yml
server:port: 8081 #tomcat端口servlet:context-path: /
spring:elasticsearch:rest:uris: XXX.XXX.XXX.XXX:9200- pojo(这个很重要)
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;import java.util.Date;/*** ELK日志实体类*/
@Data
//指定索引和主分片/副分片的数量
@Document(indexName = "elk_log", shards = 1, replicas = 1)
public class ElkLog {@Idprivate String id;@Field(type = FieldType.Integer)private Integer port;@Field(type = FieldType.Keyword)private String host;@Field(type = FieldType.Text)private String message;@Field(name = "@version", type = FieldType.Keyword)private String version;//时间转换@Field(name = "@timestamp", type = FieldType.Date, format = DateFormat.date_time)private Date timestamp;
}
- controller
import com.elk.pojo.ElkLog;
import com.elk.service.ElkLogService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
@RequestMapping("/elkLog")
public class ElkLogController {@Autowiredprivate ElkLogService elkLogService;/*** 分页查询日志** @return*/@RequestMapping("/selectListByPage")public List<ElkLog> selectListByPage() {return elkLogService.selectListByPage(1, 1000, 10);}
}
- service
import com.elk.pojo.ElkLog;
import java.util.List;public interface ElkLogService {//分页查询日志List<ElkLog> selectListByPage(Integer page, Integer pagSize, Integer time);}
- serviceimpl
import com.elk.pojo.ElkLog;
import com.elk.service.ElkLogService;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.Query;
import org.springframework.stereotype.Service;import java.util.ArrayList;
import java.util.Calendar;
import java.util.List;@Service
public class ElkLogServiceImpl implements ElkLogService {@Autowiredprivate ElasticsearchRestTemplate elasticsearchTemplate;/*** 分页查询日志** @param page* @param pagSize* @param time* @return*/@Overridepublic List<ElkLog> selectListByPage(Integer page, Integer pagSize, Integer time) {Calendar calendar = Calendar.getInstance();//当前时间往前推time分钟calendar.add(Calendar.MINUTE, -time);//设置查询条件 查询当前时间往前推time分钟的数据Query query = new NativeSearchQuery(QueryBuilders.rangeQuery("@timestamp").gte(calendar.getTime()));//设置分页query.setPageable(PageRequest.of(page - 1, pagSize));//将进行查询SearchHits<ElkLog> elkLogHits = elasticsearchTemplate.search(query, ElkLog.class);List<ElkLog> elkLogList = new ArrayList<>();for (SearchHit<ElkLog> elkLogHit : elkLogHits) {ElkLog elkLog = elkLogHit.getContent();elkLogList.add(elkLog);}return elkLogList;}
}
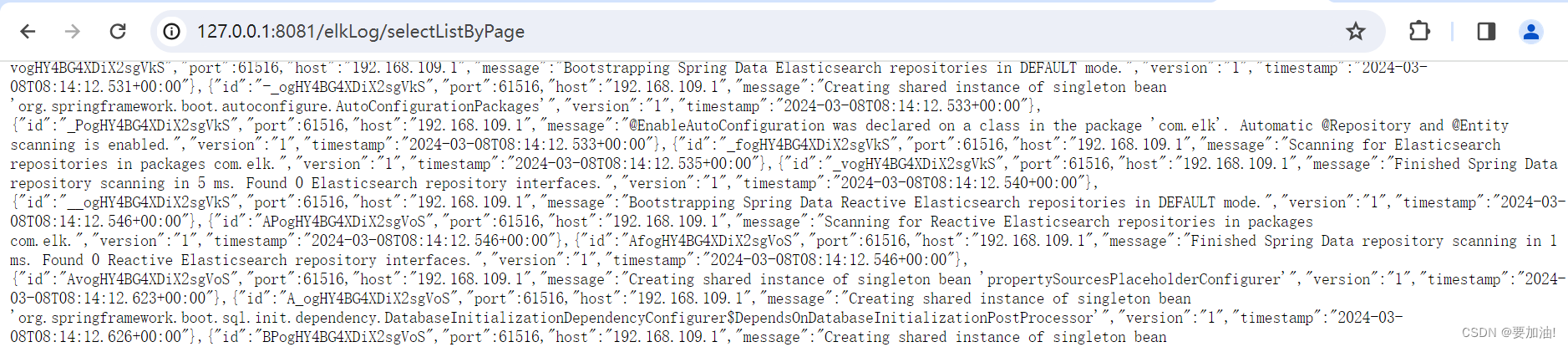
- 验证
相关文章:
ELK介绍使用
文章目录 一、ELK介绍二、Elasticsearch1. ElasticSearch简介:2. Elasticsearch核心概念3. Elasticsearch安装4. Elasticsearch基本操作1. 字段类型介绍2. 索引3. 映射4. 文档 5. Elasticsearch 复杂查询 三、LogStash1. LogStash简介2. LogStash安装 四、kibana1. …...
【UE5】非持枪状态蹲姿移动的动画混合空间
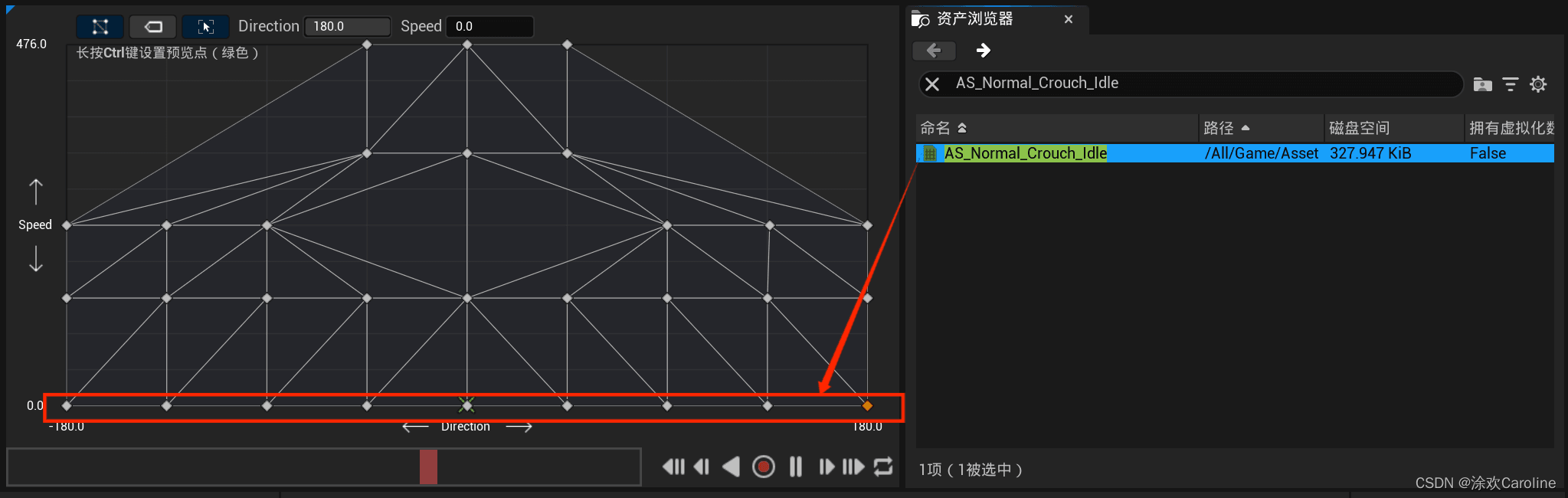
项目资源文末百度网盘自取 在BlendSpace文件夹中单击右键选择动画(Animation)中的混合空间(Blend Space) ,选择SK_Female_Skeleton,命名为BS_NormalCrouch 打开BS_NormalCrouch 水平轴表示角色的方向,命名为Direction,方向的最…...
)
Windows C++ TCP开发(使用select函数以及设置非阻塞/Reuse属性)
1、select官方函数说明: 语法 C int WSAAPI select([in] int nfds,[in, out] fd_set *readfds,[in, out] fd_set *writefds,[in, out] fd_set *exceptfds,[in] const timeval *timeout );参数 [in] nfds 已忽略。 包含 nf…...

ARM TrustZone技术解析:构建嵌入式系统的安全扩展基石
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法|MySQL| 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-LOdvohfCEnd8eKyd {font-family:"trebuchet ms",verdana,arial,sans-serif;f…...

初识Python语言-课堂练习【pyhton123题库】
初识Python语言-课堂练习【pyhton123题库】 一、单项选择题 1、Guido van Rossum正式对外发布Python版本的年份是: A 2008B 1998C 1991D 2002 【答案】C 【解析】暂无解析2、下面不是Python语言特点的是:…...

chrome高内存占用问题
chrome号称内存杀手不是盖的,不设设置的话,经常被它内存耗尽死机是常事。以下自用方法 1 自带的memory saver chrome://settings/performance PerformanceMemory Saver When on, Chromium frees up memory from inactive tabs. This gives active tab…...
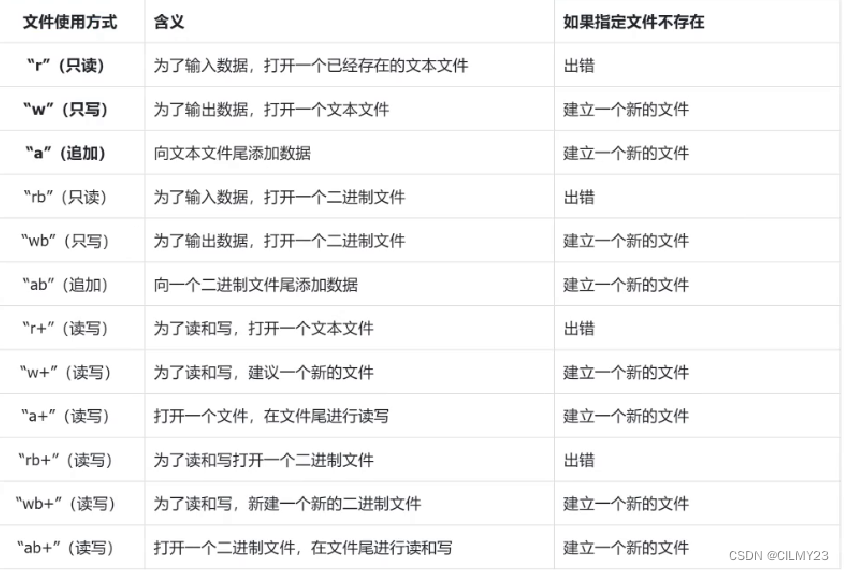
【C语言】文件操作篇-----程序文件和数据文件,文件的打开和关闭,二进制文件和文本文件,fopen,fclose【图文详解】
欢迎来CILMY23的博客喔,本篇为【C语言】文件操作篇-----程序文件和数据文件,文件的打开和关闭,二进制文件和文本文件【图文详解】,感谢观看,支持的可以给个一键三连,点赞关注收藏。 前言 在了解完动态内存管…...

知识碎片收集
目录 1. 如何计算两点经纬度之间的距离2. 加权随机采样3.什么时LLDB和GDB 1. 如何计算两点经纬度之间的距离 1.知乎-如何计算两点经纬度间距离 2.根据两点经纬度坐标计算距离 3.根据经纬度计算两点之间的距离的公式推导过程以及google.maps的测距函数 4.根据经纬度点计算经…...
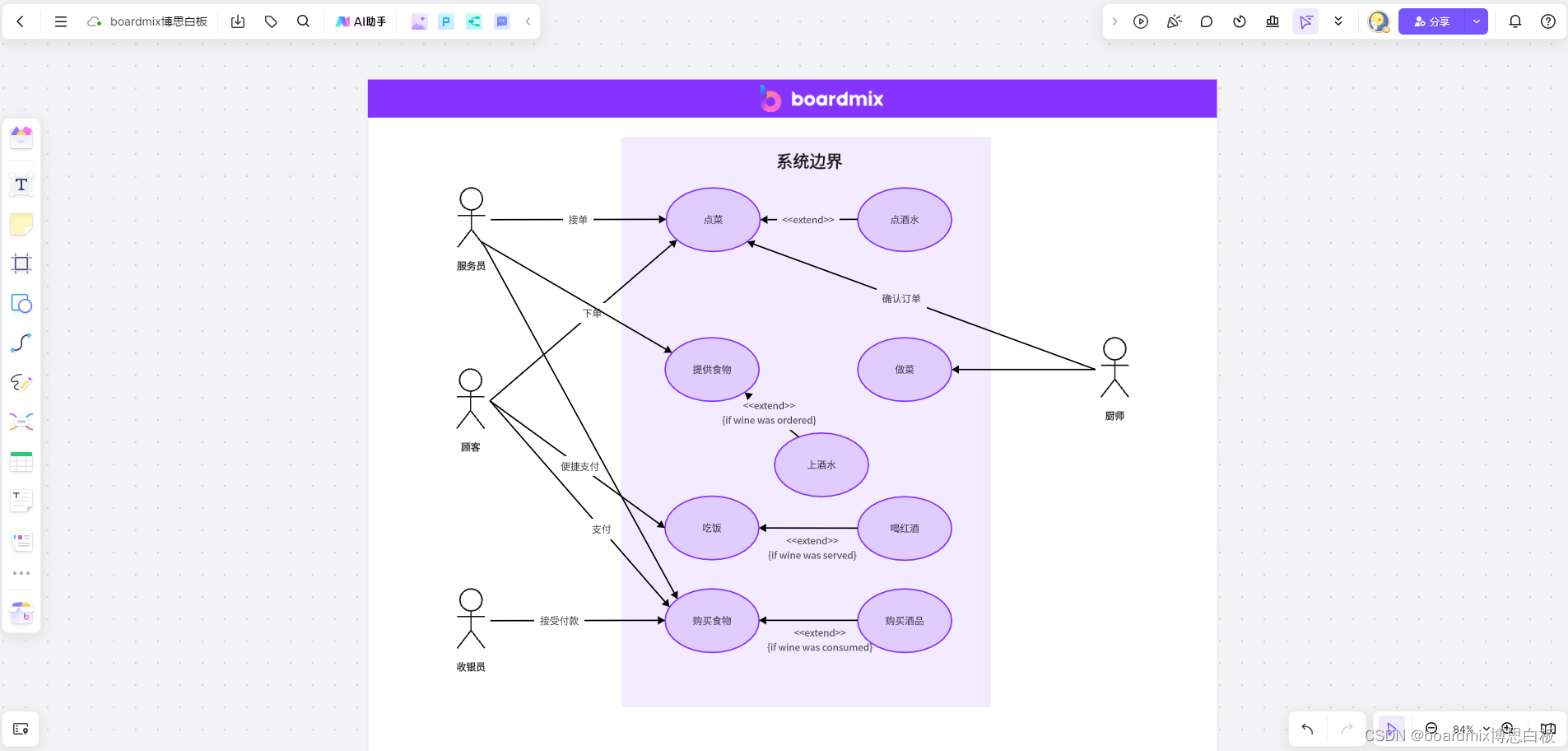
不可不知!用例图的绘制与应用全指南深度解析
在软件开发领域中,用例图是一种强大的工具,用于描述系统的功能需求以及系统与外部实体之间的交互。无论是在需求分析阶段还是在系统设计过程中,用例图都扮演着至关重要的角色。本文将全面介绍用例图的绘制方法和其在软件开发中的应用…...
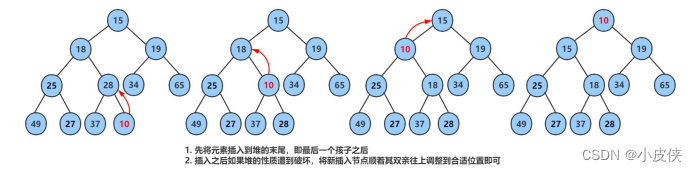
【数据结构七】堆与PriorityQueue详解
堆 在Java中有一种数据结构基于队列,并保证操作的数据带有优先级,该数据结构应该提供了两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。它的底层使用了堆这种数据结…...

uniapp写支付的操作
支付的时候一般需要几个参数: ‘timeStamp’: 时间戳,‘nonceStr’: 随机字符串,不超过32位‘package’: 下单后接口返回的prepauid‘signType’: 签名的算法‘paySign’: 后端会给前端一个签名sign: data.sign // 根据签名算法生成签名 <template&…...

微信小程序开发系列(二十四)·wxml语法·列表渲染·wx:for-item 和 wx:for-index
目录 1. 如果需要对默认的变量名和下标进行修改,可以使用wx:for-item 和 wx:for-index 2. 将 wx:for 用在 标签上,以渲染一个包含多个节点的结构块 方法一 方法二 3. 总结 3.1 wx:for-item 和 wx:for-index总结 3.2 总结 1. 如果需要对默…...
下载无水印抖音视频
在抖音看到某些视频想下载,却出现无法保存在本地【显示"作品暂时无法保存,链接已复制"】。或者下载的视频有水印。 而某些微信小程序下载可能需要付费或者有水印。其实我们可以直接使用电脑浏览器直接下载。 举个例子: 这是来自王道官方账号的一条视频链…...
)
L1-039 古风排版(C++)
中国的古人写文字,是从右向左竖向排版的。本题就请你编写程序,把一段文字按古风排版。 输入格式: 输入在第一行给出一个正整数N(<100),是每一列的字符数。第二行给出一个长度不超过1000的非空字符串&a…...

springboot项目docker分层构建
一、需求场景 在使用dockerfile构建springboot项目时,速度较慢,用时比较长,为了加快构建docker镜像的速度,采用分层构建的方式 二、构建配置 1、pom.xml配置 <properties><project.build.sourceEncoding>UTF-8<…...

深入理解SPA、CSR与SSR的区别及应用
随着Web技术的快速发展,前端开发架构也在不断演进。在现代Web应用中,单页面应用(SPA)、客户端渲染(CSR)和服务器端渲染(SSR)是三种常见的实现方式,它们各自拥有独特的特性…...
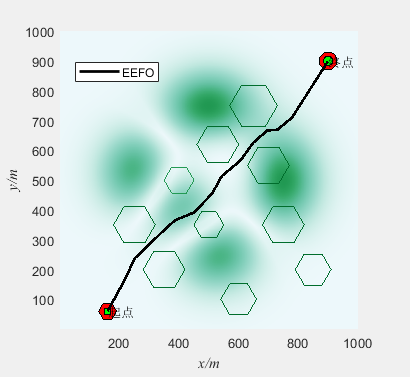
基于电鳗觅食优化算法(Electric eel foraging optimization,EEFO)的无人机三维路径规划(提供MATLAB代码)
一、无人机路径规划模型介绍 无人机三维路径规划是指在三维空间中为无人机规划一条合理的飞行路径,使其能够安全、高效地完成任务。路径规划是无人机自主飞行的关键技术之一,它可以通过算法和模型来确定无人机的航迹,以避开障碍物、优化飞行…...

将SQL数据库转换为Mysql数据库
一、准备工作 1、SQL server安装包与已经有数据的mdf、ldf数据库文件; 2、.net Framework安装包;(用于支持SQL Server安装的组件) 3、MySql安装包;(用于目标数据库的环境安装) 4、navicat安装包…...

Java集合进阶
双列集合 单列集合的特点:一次添加一个。 双列集合的特点:一次添加一对/键值对/键值对对象/Entry。 左键(不可重复)右值(可重复),一一对应。 Map是双列集合的顶层接口,他的功能是…...

一.算法基础
目录 1.算法基础 2.算法概念 3.时间复杂度--用来评估算法运行效率的一个式子 如何简单快速的判断算法复杂度? 4.空间复杂度 1.算法基础 2.算法概念 --静态动态 3.时间复杂度--用来评估算法运行效率的一个式子 ----一个单位!!! 1-在什么配置下运行(机器) 2-问题的规模…...

2026年免费照片去水印软件App推荐,一看就会的保姆级详细教程
你是不是也遇到过这样的场景:好不容易在网上看到一张心水的壁纸、一张有趣的表情包,或者自己拍的视频截图里有碍眼的日期戳、平台logo,想拿来发朋友圈,结果那个水印就像一块顽固的“牛皮癣”,怎么都去不掉?…...

XLASSO:高维稀疏建模在极端事件尾部预测中的原理与实践
1. 项目概述:当极端事件遇见高维稀疏性在金融风险管理、气候极端事件预测或是网络流量异常检测中,我们常常面临一个共同的挑战:如何基于有限的历史极端观测数据,对未来可能发生的、更为罕见的“黑天鹅”事件做出可靠预测ÿ…...

棋牌类网站渗透测试五大高危漏洞实战解析
1. 为什么棋牌类网站总在渗透测试中“反复栽跟头”做渗透测试这十多年,我经手过上百个在线游戏类系统,其中棋牌类网站的漏洞复现率之高、利用链之典型、业务逻辑之“反直觉”,在所有垂直领域里排得上前三。不是它们代码写得最差,而…...

【深度解析】从 Mythos 到 DeepSeek 降价:大模型工程化选型、成本控制与 API 实战
摘要 近期 AI 大模型市场持续加速迭代:Anthropic Mythos 进入部署测试信号增强,OpenAI、Gemini 系列持续升级,DeepSeek 则通过永久降价重塑开发成本结构。本文从工程视角解析模型发布信号、Agentic 系统成本模型,并给出 OpenAI 兼…...

专业级AI音频处理实战指南:OpenVINO插件让Audacity变身智能音频工作站 [特殊字符]
专业级AI音频处理实战指南:OpenVINO插件让Audacity变身智能音频工作站 🎵 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openv…...

Claude Code用户如何通过Taotoken解决API不稳定与Token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code用户如何通过Taotoken解决API不稳定与Token不足问题 对于依赖Claude Code进行编程辅助的开发者来说,稳定的…...

别再乱改sshd_config主文件了!Ubuntu 22.04下用sshd_config.d目录的正确姿势
Ubuntu 22.04下SSH配置管理的现代实践:告别直接修改sshd_config的时代 在Linux系统管理中,SSH服务的配置一直是个看似简单实则暗藏玄机的领域。许多管理员至今仍保持着直接修改 /etc/ssh/sshd_config 文件的习惯,却不知道Ubuntu等现代Linux…...

本地大语言模型推理新选择:为什么llama-cpp-python成为开发者首选?
本地大语言模型推理新选择:为什么llama-cpp-python成为开发者首选? 【免费下载链接】llama-cpp-python Python bindings for llama.cpp 项目地址: https://gitcode.com/gh_mirrors/ll/llama-cpp-python 在人工智能快速发展的今天,能够…...

机器学习势函数在暗物质探测中的应用:计算晶体缺陷存储能
1. 项目概述:当机器学习势函数遇上暗物质探测在粒子物理与凝聚态物理的交叉前沿,有一个看似微小却至关重要的物理细节,正困扰着新一代的暗物质与中微子探测实验:当一个来自宇宙的弱相互作用粒子(WIMP)或一个…...

TV Bro电视浏览器:让智能电视变身全能上网终端的终极指南
TV Bro电视浏览器:让智能电视变身全能上网终端的终极指南 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 你是否曾经尝试在智能电视上浏览网页,却…...