Python:自动化处理PDF文档集合,提取文献标题、合并文献PDF并生成目录和页码
Python:自动化处理PDF文档集合,提取文献标题、合并文献PDF并生成目录和页码
- 引言:
- 功能概述
- 步骤一:提取PDF标题
- 步骤二:生成目录和页码,合并PDF
- 技术亮点
- 代码
- 步骤一:提取PDF标题(Step_two.ipynb)
- 步骤二:生成目录和页码,合并PDF(Step_two.ipynb)
引言:
在学术研究、文档管理等领域,经常需要处理大量的PDF文档。手动整理这些文档既耗时又低效。本文介绍一个使用Python自动化这一过程的方法,包括提取PDF文件的标题,生成目录,添加页码,并最终合并为一个PDF文件。这不仅提高了工作效率,也增加了文档的可用性和可读性。
功能概述
本项目通过两个主要步骤实现PDF文档的自动化处理:
- 提取PDF文档的标题:从每个PDF文件中提取标题,并保存到一个CSV文件中。这一步允许用户手动校对和修正自动提取的标题。
- 生成目录和页码,然后合并PDF文件:根据校对后的标题,自动生成目录页,为每个PDF文件的每一页添加页码,最后将所有文件合并成一个PDF。
步骤一:提取PDF标题
首先,将所有待处理的PDF文件放入指定的目录中。运行第一步脚本(Step_one.ipynb),该脚本自动遍历目录中的每个PDF文件,提取其标题,并将文件名及对应的标题保存到一个CSV文件中。
这一步骤涉及PDF元数据的读取和文本提取技术。对于难以直接从元数据中获取标题的情况,脚本尝试从PDF的内容中分析出可能的标题。处理完所有文件后,用户可以检查CSV文件,并手动修正错误的标题。
步骤二:生成目录和页码,合并PDF
在校对完CSV文件中的标题后,运行第二步脚本(Step_two.ipynb)。该脚本首先根据CSV文件中的信息生成一个目录页,然后为每个PDF页面添加页码,并将所有PDF文件合并为一个。
目录页的生成考虑了标题的长度,对过长的标题进行适当的分行处理,确保目录的整洁性。页码的添加在页面底部中央,通过绘制白色矩形覆盖原有页码区域后添加新的页码信息,以避免页码重叠。最终,所有页面(包括目录页和带有新页码的原始页面)被合并成一个PDF文件。
技术亮点
- 文本提取与处理:通过
PyMuPDF和PyPDF2库提取PDF文件的文本和元数据,使用正则表达式和文本处理技术清洗和格式化标题。 - 动态内容生成:使用
reportlab库动态生成包含自定义文本(如页码和目录项)的PDF页面。 - 文档合并与修改:利用
PyPDF2库合并PDF页面,并在合并过程中添加自定义内容。
通过这个Python项目,我们可以自动化处理一系列复杂的PDF文档管理任务,包括提取标题、生成目录、添加页码和合并文件。这大大减轻了手动处理的负担,使得管理大量PDF文档变得既简单又高效。无论是学术研究者、图书管理员还是文档管理专业人士,都可以从这个项目中受益。
代码
步骤一:提取PDF标题(Step_two.ipynb)
### 第一步:读取pdf_dir路径下所有.pdf为后缀的文件,打开CSV文件以写入文件名和标题
### 第二步:手动对CSV文件内错误标题进行修改# 读取路径下所有.pdf为后缀的文件
pdf_dir = '老师的论文集/'# 合并后的PDF名字
output_pdf_path = "合并后/老师的论文集.pdf"# 用于中间 存放文件名与标题的CSV文件
TitlesCSV = '合并后/老师的论文集.csv'```import csv
import html
import os
import re # 导入正则表达式模块import fitz # PyMuPDF
from PyPDF2 import PdfReaderdef find_non_text_chars(sentence):# 用于检测提取的文本中是否出现非文本类型的,若有则通过类似title = title.replace("fi", "fi")替换import regex as re# 定义正则表达式,匹配非文本字符(除了字母、数字、空格和标点符号之外的字符)non_text_pattern = re.compile(r'[^a-zA-Z0-9\s\p{P}]', re.UNICODE)# 使用正则表达式搜索句子中的非文本字符non_text_chars = non_text_pattern.findall(sentence)# 打印出非文本字符及其类型for char in non_text_chars:print(title)print(f"非文本字符 '{char}' 的类型是 '{type(char)}\n\n'")return Nonedef get_pdf_title_1(pdf_path):"""读取PDF文件的标题,并进行处理。"""with open(pdf_path, 'rb') as pdf_file:pdf_reader = PdfReader(pdf_file)doc_info = pdf_reader.metadata# 尝试从文档信息中获取标题paper_title = doc_info.get('/Title', 'untitled') if doc_info else 'untitled'# 如果标题有效,则进行进一步处理if paper_title != 'untitled' and paper_title != 'Untitled' and not paper_title.endswith('.pdf'):# 解码HTML实体paper_title = html.unescape(paper_title)# 替换不适合作为文件名的字符paper_title = re.sub(r'[:/\\*?"\'<>|]', ' ', paper_title)else:# 无效的标题,返回默认值paper_title = 'untitled'return paper_titledef get_pdf_title_2(pdf_path):# 检查文件名是否符合特定模式filename = os.path.basename(pdf_path)if filename == "[SCI 】ions for nonlinear dynamical systems.pdf":return "Estynamical systems"doc = fitz.open(pdf_path)first_page = doc[0] # 只查看第一页# 获取页面上所有文本块,每个块包含文字、字体大小和位置blocks = first_page.get_text("dict")["blocks"]# 只考虑页面上半部分的文本块mid_y = first_page.rect.height / 2top_blocks = [b for b in blocks if b['type'] == 0 and b['bbox'][3] < mid_y]# 提取每个文本块的字体大小和文本内容text_blocks_with_size = []for block in top_blocks:if 'lines' in block: # 确保文本块包含行for line in block['lines']:if 'spans' in line: # 确保行包含spanfor span in line['spans']:if 'size' in span and len(span['text'].strip()) >= 2: # 检查span中是否有size信息且文本长度符合要求text_blocks_with_size.append((span['text'], span['size'], span['bbox']))# 排除特定关键词excluded_keywords = ["Research Article", "Physica A", "Neurocomputing","Sustainable Energy Technologies and Assessments"]filtered_blocks = [block for block in text_blocks_with_size ifnot any(keyword in block[0] for keyword in excluded_keywords)]# 在过滤后的文本块中基于字体大小和垂直位置来识别可能的标题if filtered_blocks:max_font_size = max([size for _, size, _ in filtered_blocks], default=0)possible_title_blocks = [block for block in filtered_blocks if block[1] == max_font_size]# 合并具有相同最大字体大小的连续文本块title_texts = [block[0] for block in possible_title_blocks]title = " ".join(title_texts) if title_texts else "untitled"else:title = "untitled"doc.close()title = title.replace("fi", "fi")title = title.replace("ff", "ff")# 查找句子中的非文本字符find_non_text_chars(title)return titledef get_pdf_title(pdf_path):# 先使用get_pdf_title_1获取标题,若获取失败则使用get_pdf_title_2获取paper_title = get_pdf_title_1(pdf_path) # 假设这是从PDF提取标题的函数# 编写一个正则表达式来匹配以连续4个数字和.pdf为后缀的字符串# 匹配以连续三个数字和.pdf结尾的字符串,或者包含空格和点的字符串,以及不包含空格但包含点的字符串regex_pattern = r'\d{3}\.pdf$|^[A-Z]+-\w+\s\d+\.\.\d+$|\w+\.\d+\s\d+\.\.\d+$|^[a-zA-Z]+_\d+\w*$'# 判断条件:标题不是'untitled'且不匹配正则表达式(即不是以连续4个数字和.pdf结尾)if paper_title != 'untitled' and not re.search(regex_pattern, paper_title):return paper_titleelse:paper_title = get_pdf_title_2(pdf_path)return paper_titledef get_titles_from_directory(directory_path, specific_file):titles = []specific_pdf_path = None # 用于存储特定文件的路径for root, dirs, files in os.walk(directory_path):for file in files:if file.lower().endswith('.pdf'):pdf_path = os.path.join(root, file)if file == specific_file: # 如果当前文件是特定文件specific_pdf_path = pdf_pathelse:try:title = get_pdf_title(pdf_path)titles.append((file, title))except Exception as e:print(f"Error processing {file}: {e}")# 处理特定文件if specific_pdf_path:try:title = get_pdf_title(specific_pdf_path)titles.insert(0, (specific_file, title)) # 将特定文件的标题插入到列表的最前面except Exception as e:print(f"Error processing {specific_file}: {e}")return titlesspecific_file = "lic health.pdf"# 替换为你的PDF文件所在的目录路径
directory_path = pdf_dir
titles = get_titles_from_directory(directory_path, specific_file)with open(TitlesCSV, 'w', newline='', encoding='utf-8') as csv_file:csv_writer = csv.writer(csv_file, delimiter=',')csv_writer.writerow(['Files', 'Title']) # 写入头部信息for file, title in titles:# 写入文件名和标题csv_writer.writerow([file, title])步骤二:生成目录和页码,合并PDF(Step_two.ipynb)
### 第三步:读取 Step_one.ipynb获取的标题的CSV文件
### 第四步:根据文件名字 标题 合并PDF 并生成目录与页码# 读取路径下所有.pdf为后缀的文件
pdf_dir = '老师的论文集/'
# 合并后的PDF名字
output_pdf_path = "合并后/老师的论文集.pdf"
# 用于中间 存放文件名与标题的CSV文件
TitlesCSV = '合并后/老师的论文集.csv'import csv
import io
import osfrom PyPDF2 import PdfReader, PdfWriter
from reportlab.lib.pagesizes import letter
from reportlab.pdfbase.pdfmetrics import stringWidth
from reportlab.pdfgen import canvasdef create_footer_page(footer_text):packet = io.BytesIO()c = canvas.Canvas(packet, pagesize=letter)width, height = letter # letter页面的宽度和高度font_name = "Helvetica" # 使用的字体font_size = 12 # 字体大小cover_height = font_size + 4 # 覆盖区域的高度稍大于字体大小,以确保完全覆盖原有页码cover_y_position = 28 # 覆盖区域的Y位置,根据需要进行调整以确保覆盖原有页码# 计算文本宽度和起始X位置以居中文本text_width = c.stringWidth(footer_text, font_name, font_size)text_start_position = (width - text_width) / 2# 绘制一个足够大的白色矩形以覆盖原有页码c.setFillColorRGB(1, 1, 1) # 设置填充颜色为白色c.rect(0, cover_y_position, width, cover_height, stroke=False, fill=True)# 在页脚区域居中添加文本,高度可以根据需要调整c.setFont(font_name, font_size) # 设置字体和大小c.setFillColorRGB(0, 0, 0) # 设置文本颜色为黑色c.drawString(text_start_position, 32, footer_text) # 绘制居中的页脚文本c.save()packet.seek(0)return PdfReader(packet)# 定义用于分割过长标题的函数,以适应页面宽度
def split_title(title, available_width, font_name="Helvetica", font_size=12):split_titles = [] # 存储分割后的标题部分# 循环直到标题宽度小于可用宽度while stringWidth(title, font_name, font_size) > available_width:split_point = len(title) # 初始分割点设置为标题长度# 寻找适合分割的位置,使分割后的宽度小于可用宽度while split_point > 0 and stringWidth(title[:split_point] + "-", font_name, font_size) > available_width:split_point -= 1 # 逐字符减少分割点if split_point == 0: # 如果找不到分割点,添加整个标题并结束循环split_titles.append(title)breaksplit_titles.append(title[:split_point] + "-") # 添加分割后的标题部分title = title[split_point:] # 准备处理剩余的标题部分if title: # 确保添加剩余的未分割部分split_titles.append(title)return split_titles# 添加目录页的函数,包含书签的标题和页码
def add_catalog_page(bookmarks):packet = io.BytesIO() # 创建内存流以存储PDF数据c = canvas.Canvas(packet, pagesize=letter) # 创建PDF画布width, height = letter # 获取页面尺寸top_margin = 60 # 顶部边距bottom_margin = 60 # 底部边距y_position = height - top_margin # 初始Y坐标位置c.setFont("Helvetica-Bold", 16) # 设置目录标题字体和大小c.drawString(280, y_position, "Directory") # 绘制目录标题y_position -= 30 # 更新Y坐标为目录项c.setFont("Helvetica", 12) # 设置目录项字体和大小left_margin = 72 # 左边距right_margin = width - 72 # 右边距dot_space = 5 # 点线间隔different_title_spacing = 25 # 不同标题间隔same_title_line_spacing = 15 # 同一标题行间隔title_number = 1 # 标题编号初始值for title, page_number in bookmarks:split_titles = split_title(title, right_margin - left_margin - 25, "Helvetica", 12) # 分割长标题for index, part_title in enumerate(split_titles):if index == 0:# 对新标题的第一部分添加编号formatted_number = str(title_number).zfill(2)full_title = f"{formatted_number}. {part_title}"title_number += 1else:# 分割的部分不添加编号# 分割的行需要空出编号和第一行相同的空间full_title_blank = " " * len(str(title_number).zfill(2) + ". ")full_title = f"{full_title_blank}{part_title}"c.drawString(left_margin, y_position, full_title) # 绘制标题if index == len(split_titles) - 1: # 在最后一部分标题处添加页码c.drawRightString(right_margin, y_position, str(page_number)) # 绘制页码# 绘制连接标题和页码的点线dot_line_start = left_margin + stringWidth(full_title, "Helvetica", 12) + 10dot_line_end = right_margin - stringWidth(str(page_number), "Helvetica", 12) - 10current_position = dot_line_startwhile current_position < dot_line_end:c.drawString(current_position, y_position, ".")current_position += dot_spacey_position -= same_title_line_spacing # 更新Y坐标为同一标题的下一行y_position -= different_title_spacing - same_title_line_spacing # 为下一个标题更新Y坐标,减去已应用的间隔if y_position < bottom_margin: # 如果超出页面底部,创建新页面c.showPage()y_position = height - top_marginc.setFont("Helvetica", 12) # 确保新页面使用相同的字体设置c.save() # 保存PDF数据到内存流packet.seek(0) # 将内存流指针重置到起始位置return PdfReader(packet) # 创建PDF阅读器对象,返回包含目录页数据的对象# 读取CSV文件
pdf_titles_info = []
with open(TitlesCSV, 'r', encoding='utf-8') as csvfile:reader = csv.reader(csvfile)next(reader) # 跳过标题行for row in reader:# 假设第一列是文件名,第二列是标题pdf_titles_info.append(row)# 准备工作区
all_pages = []
bookmarks = []
total_pages = 0# 更新:根据pdf_titles_info直接处理文件
for filename, title in pdf_titles_info:pdf_path = os.path.join(pdf_dir, filename)bookmarks.append((title, total_pages + 1)) # 使用提供的标题而不是重新获取reader = PdfReader(pdf_path)for page in reader.pages:all_pages.append(page)total_pages += 1# 创建目录页
writer = PdfWriter()
catalog_pdf = add_catalog_page(bookmarks) # 这里假设add_catalog_page可以处理bookmarks列表
for page in catalog_pdf.pages:writer.add_page(page)# 为每页添加页脚
current_page_number = 1
for page in all_pages:footer_pdf = create_footer_page(f"Page number:{current_page_number}")page.merge_page(footer_pdf.pages[0])writer.add_page(page)current_page_number += 1# 保存最终的PDF文件
output_pdf_path = output_pdf_path
with open(output_pdf_path, "wb") as f_out:writer.write(f_out)相关文章:

Python:自动化处理PDF文档集合,提取文献标题、合并文献PDF并生成目录和页码
Python:自动化处理PDF文档集合,提取文献标题、合并文献PDF并生成目录和页码 引言:功能概述步骤一:提取PDF标题步骤二:生成目录和页码,合并PDF技术亮点 代码步骤一:提取PDF标题(Step_…...

vue 基于elementUI/antd-vue, h函数实现message中嵌套链接跳转到指定路由 (h函数点击事件的写法)
效果如图: 点击message 组件中的 工单管理, 跳转到工单管理页面。 以下是基于vue3 antd-vue 代码如下: import { message } from ant-design-vue; import { h, reactive, ref, watch } from vue; import { useRouter } from vue-router; c…...

数字排列 - 华为OD统一考试(C卷)
OD统一考试(C卷) 分值: 200分 题解: Java / Python / C 题目描述 小明负责公司年会,想出一个趣味游戏: 屏幕给出 1−9 中任意 4 个不重复的数字,大家以最快时间给出这几个数字可拼成的数字从小到大排列位于第 n 位置…...
yocto 编译raspberrypi 4B并启动
yocto 编译raspberrypi 4B并启动 环境准备 最近到手一个树莓派4B,准备拿来玩一玩,下面记录下使用yocto构建RaspberryPi的镜像并刷写启动的过程。 首先准备主机编译环境,必要组件安装: sudo apt install gawk wget git diffstat…...

Nginx、LVS、HAProxy工作原理和负载均衡架构
当前大多数的互联网系统都使用了服务器集群技术,集群是将相同服务部署在多台服务器上构成一个集群整体对外提供服务,这些集群可以是 Web 应用服务器集群,也可以是数据库服务器集群,还可以是分布式缓存服务器集群等等。 在实际应用…...

C语言标准库函数qsort( )——数据排序
大家好!我是保护小周ღ,本期为大家带来的是深度解剖C语言标准库函数 qsort(),qsort()函数他可以对任意类型的数据排序,博主会详细解释函数使用方法,以及使用快速排序的左右指针法模拟实现函数功能,这样的排…...

基础---nginx 启动不了,跟 Apache2 服务冲突
文章目录 查看 nginx 服务状态nginx 启动后 访问页面 127.0.0.1停止 nginx 服务,访问不了页面停止/启动 Apache2 服务,启动 Apache2 页面访问显示正确nginx 莫名启动不了卸载 Apache2 服务器 启动 nginx ,但是总是不能实现反向代理࿰…...

如何利用百度SEO优化技巧将排到首页
拥有一个成功的网站对于企业和个人来说是至关重要的,在当今数字化的时代。在互联网上获得高流量和优质的访问者可能并不是一件容易的事情,然而。一个成功的SEO战略可以帮助你实现这一目标。需要一些特定的技巧和策略、但要在百度搜索引擎中获得较高排名。…...

CSS隐藏元素的方法 ( 5 种)
还是大剑师兰特:曾是美国某知名大学计算机专业研究生,现为航空航海领域高级前端工程师;CSDN知名博主,GIS领域优质创作者,深耕openlayers、leaflet、mapbox、cesium,canvas,webgl,ech…...
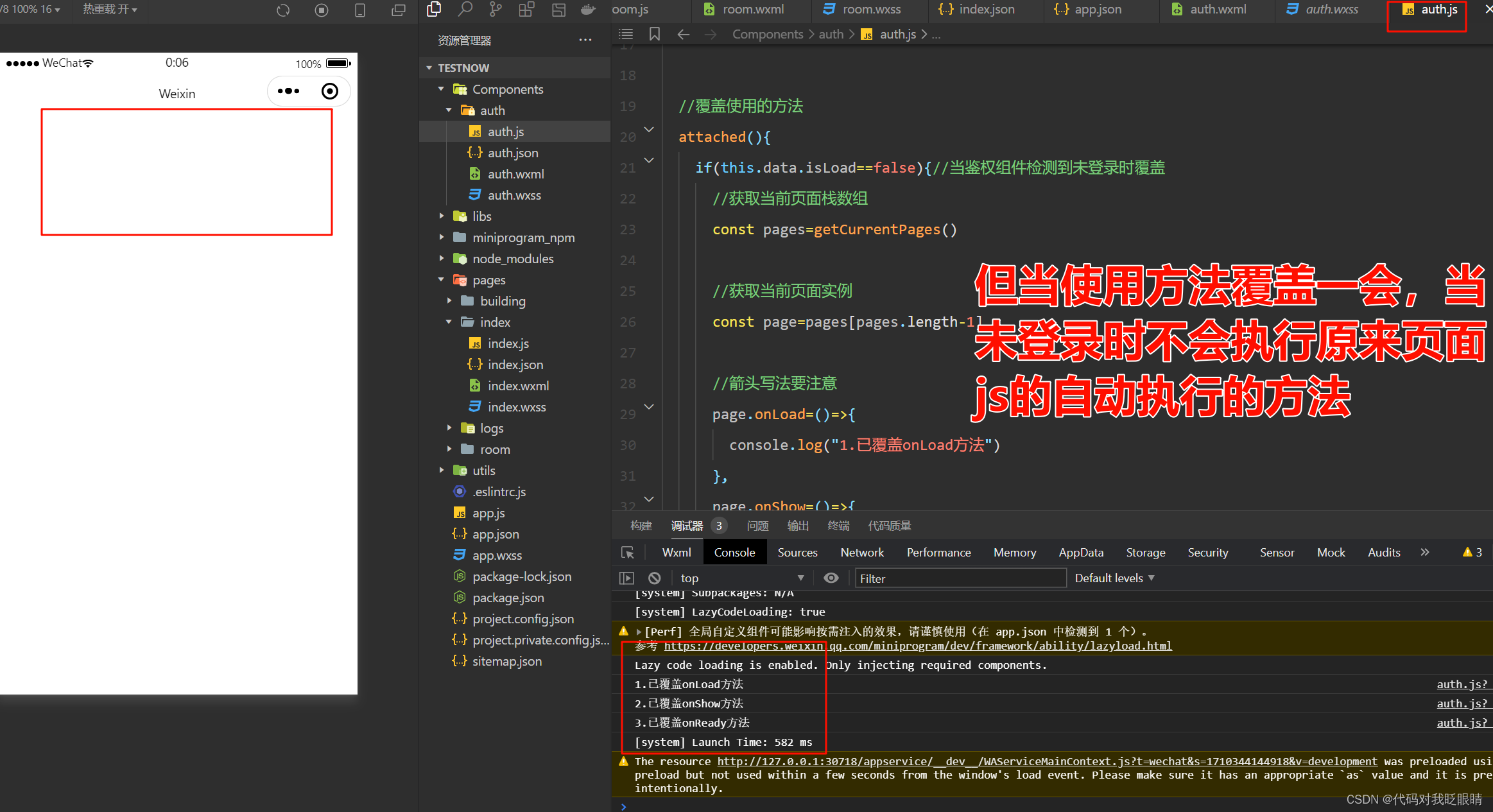
微信小程序(五十九)使用鉴权组件时原页面js自动加载解决方法(24/3/14)
注释很详细,直接上代码 上一篇 新增内容: 1.使用覆盖函数的方法阻止原页面的自动执行方法 2.使用判断实现只有当未登录时才进行方法覆盖 源码: app.json {"pages": ["pages/index/index","pages/logs/logs"],…...
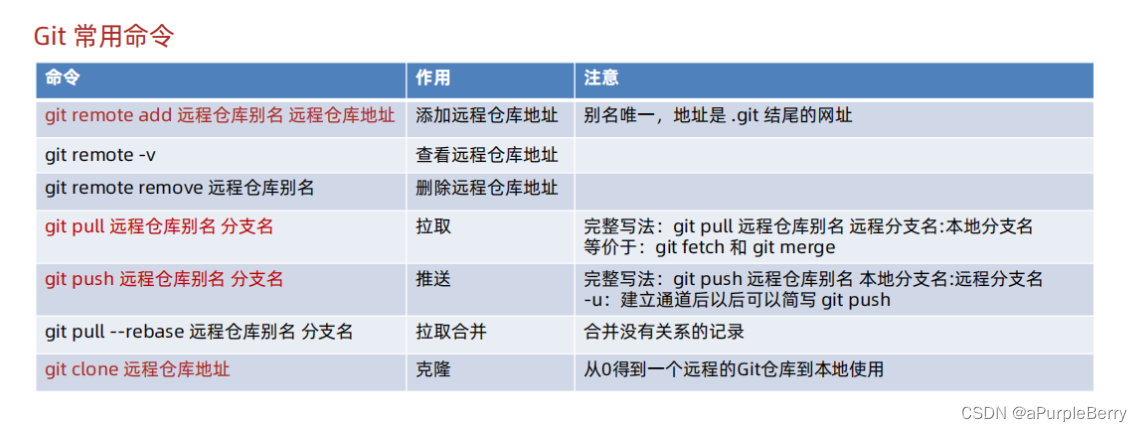
Git 学习笔记 三个区域、文件状态、分支、常用命令
Git 学习 GitGit概念VS Code中使用仓库(repository)示例 Git 使用时的三个区域示例 Git 文件状态示例 Git 暂存区示例 Git 回退版本删除文件忽略文件示例 分支分支的使用分支的合并与删除分支的合并冲突 Git常用命令Git远程仓库 (HTTP)步骤远程仓库 克隆…...

OrangePiLinux连接小米手机使用adb显示“List of devices attached”的问题解决
参考文章adb连接不上手机,提示“List of devices attached” - 简书 (jianshu.com) adb解决报错error: no devices/emulators found error: cannot connect to daemon_adb.exe: no devices/emulators found-CSDN博客 error: no devices/emulators found解决办法-C…...
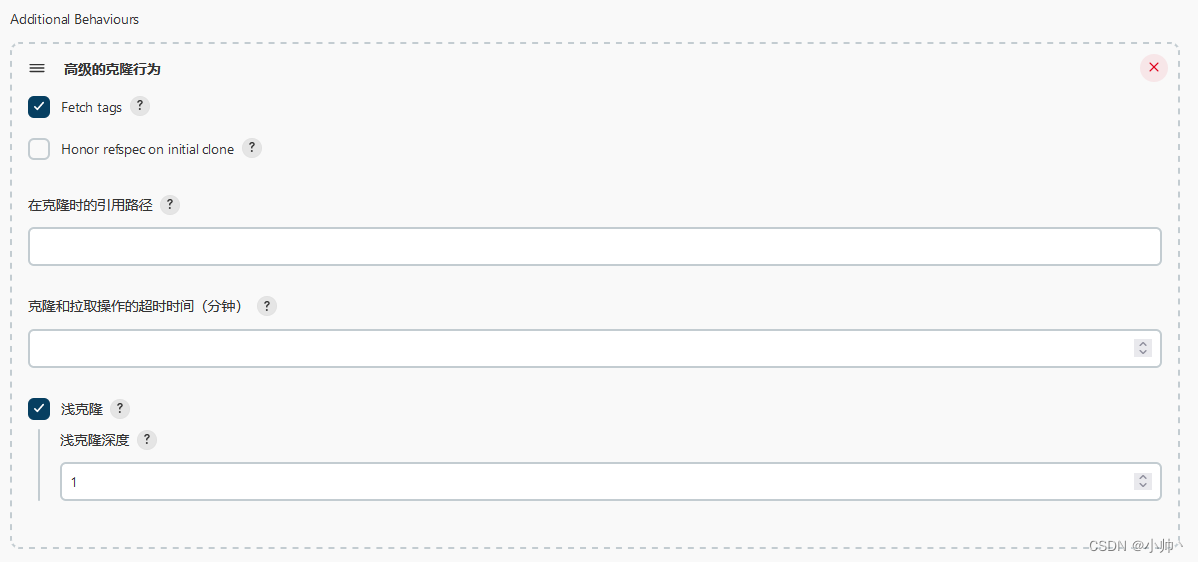
【Jenkins】data stream error|Error cloning remote repo ‘origin‘ 错误解决【亲测有效】
错误构建日志 17:39:09 ERROR: Error cloning remote repo origin 17:39:09 hudson.plugins.git.GitException: Command "git fetch --tags --progress http://domain/xxx.git refs/heads/*:refs/remotes/origin/*" returned status code 128: 17:39:09 stdout: 17…...

3.1_9 基本分段存储管理
文章目录 3.1_9 基本分段存储管理(一)分段(二)段表(三)地址变换(四)分段、分页管理的对比 总结 3.1_9 基本分段存储管理 (一)分段 进程的地址空间:…...

基于SpringBoot+Druid实现多数据源:baomidou多数据源
前言 本博客姊妹篇 基于SpringBootDruid实现多数据源:原生注解式基于SpringBootDruid实现多数据源:注解编程式基于SpringBootDruid实现多数据源:baomidou多数据源 一、功能描述 支持 数据源分组 ,适用于多种场景 纯粹多库 读写…...
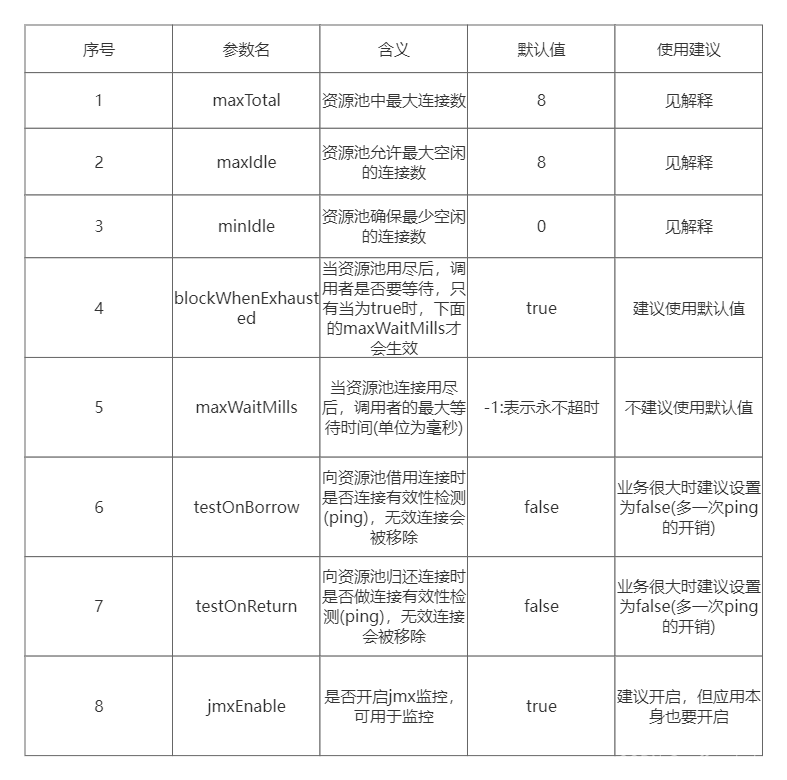
Redis开发规范与性能优化(二)
开发规范与性能优化 3.客户端使用 1.【推荐】避免多个应用使用一个Redis示例 正例:不相干的业务拆分,公共数据库做服务化 2.【推荐】使用带有连接池的数据库,可以有效控制链接,同时提高效率,标准使用方式如代码所示 public c…...

我们是否生活在一个超大型生物的大脑之中?——对多元宇宙观与生命存在形式的哲学探讨
随着科技和哲学思辨的深入,关于人类所处宇宙的本质及我们自身存在的真实性的讨论越发引人入胜。其中一种颇具科幻色彩的观点认为,我们可能生活在某个巨大生物的大脑之中,所有的物理规律、自然现象以及我们的感知体验,都可能是这个…...

【Python数据结构与判断7/7】数据结构小结
目录 序言 整体回忆 定义方式 访问元素 访问单个元素 访问多个与元素 修改元素 添加元素 列表里添加元素 字典里添加元素 删除元素 in运算符 实战案例 总结 序言 今天将对前面学过的三种数据结构:元组(tuple)、列表(…...

探讨:MySQL和PostgreSQL谁更火
一、有人说PostgreSQL比MySQL火🔥 PostgreSQL相比于MySQL越来越受欢迎的原因可以从以下几个方面来阐述: 许可协议灵活性: PostgreSQL采用的是较为宽松的BSD许可证,允许企业在开源的基础上自由使用、修改和分发,而无需…...

hbase和es的选取 hbase与es结合
hbase和es的选取 hbase与es结合 背景介绍 HBase与ElasticSearch是现代应用在处理海量数据的技术架构会经常被使用的两款产品,其中HBase是一个分布式KV系统,具有灵活Schema、水平扩展、低成本、高并发的优势,但在复杂查询、分析能力方面相对…...

3步解决方案:用BG3 Mod Manager彻底解决博德之门3模组管理难题
3步解决方案:用BG3 Mod Manager彻底解决博德之门3模组管理难题 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 博德之门3模组管理器&…...
)
客制化键盘党必看:在Ubuntu 22.04上让F1-F12键失灵的HS75T/珂芝K75恢复正常(附一键脚本)
客制化键盘在Ubuntu下的F键修复指南:从原理到一键解决方案作为一名长期使用客制化机械键盘的Linux开发者,我深知那种当F5调试键突然失灵时的崩溃感。特别是当你刚入手一款颜值与手感俱佳的HS75T或珂芝K75,却发现在Ubuntu下连接蓝牙或2.4G接收…...

VisualGGPK2:流放之路游戏资源编辑器的完整使用指南
VisualGGPK2:流放之路游戏资源编辑器的完整使用指南 【免费下载链接】VisualGGPK2 Library for Content.ggpk of PathOfExile (Rewrite of libggpk) 项目地址: https://gitcode.com/gh_mirrors/vi/VisualGGPK2 VisualGGPK2是一款专为《流放之路》(Path of Ex…...

英雄联盟玩家必备的本地化效率神器:League Akari 全面解析与使用指南
英雄联盟玩家必备的本地化效率神器:League Akari 全面解析与使用指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联…...

JHenTai:5大核心功能打造你的全平台漫画阅读体验
JHenTai:5大核心功能打造你的全平台漫画阅读体验 【免费下载链接】JHenTai A cross-platform manga app made for e-hentai & exhentai by Flutter 项目地址: https://gitcode.com/gh_mirrors/jh/JHenTai 在数字阅读时代,寻找一款既能在手机上…...

VisualGGPK2终极指南:如何轻松编辑《流放之路》游戏资源文件
VisualGGPK2终极指南:如何轻松编辑《流放之路》游戏资源文件 【免费下载链接】VisualGGPK2 Library for Content.ggpk of PathOfExile (Rewrite of libggpk) 项目地址: https://gitcode.com/gh_mirrors/vi/VisualGGPK2 VisualGGPK2是一款专为《流放之路》玩家…...

WarcraftHelper魔兽争霸3兼容性解决方案:让经典游戏在现代电脑上重获新生
WarcraftHelper魔兽争霸3兼容性解决方案:让经典游戏在现代电脑上重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为心爱的魔兽…...

3个关键步骤:用Universal x86 Tuning Utility彻底释放你的电脑性能潜力
3个关键步骤:用Universal x86 Tuning Utility彻底释放你的电脑性能潜力 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility …...

如何用Python双引擎架构实现90%成功率的自动抢票系统?
如何用Python双引擎架构实现90%成功率的自动抢票系统? 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 当热门演唱会门票在几秒内售罄,当体育赛事门票成…...

量子纠缠分发技术在城域网络中的实践与优化
1. 量子纠缠分发技术概述量子纠缠是量子力学中最奇特的现象之一,两个或多个量子系统之间可以形成一种强关联,这种关联无法用经典物理理论解释。在量子通信领域,纠缠光子对的分发是实现量子密钥分发、量子隐形传态等应用的基础。传统实验室环境…...