Redis开发规范与性能优化(二)
开发规范与性能优化
3.客户端使用
1.【推荐】避免多个应用使用一个Redis示例
正例:不相干的业务拆分,公共数据库做服务化
2.【推荐】使用带有连接池的数据库,可以有效控制链接,同时提高效率,标准使用方式如代码所示
public class Main {public static void main(String[] args){JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();jedisPoolConfig.setMaxTotal(5);jedisPoolConfig.setMaxIdle(2);jedisPoolConfig.setTestOnBorrow(true);JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.0.60", 6379, 3000, null);Jedis jedis = null;try {jedis = jedisPool.getResource();// 具体的指令jedis.executeCommand();} catch (Exception e) {log.error("op key {} error:{}", key, e);} finally {//注意这里不是关闭链接,在JedisPool模式下,Jedis会被归还给资源池if (jedis != null) {jedis.close()}}}
}
连接池参数含义:
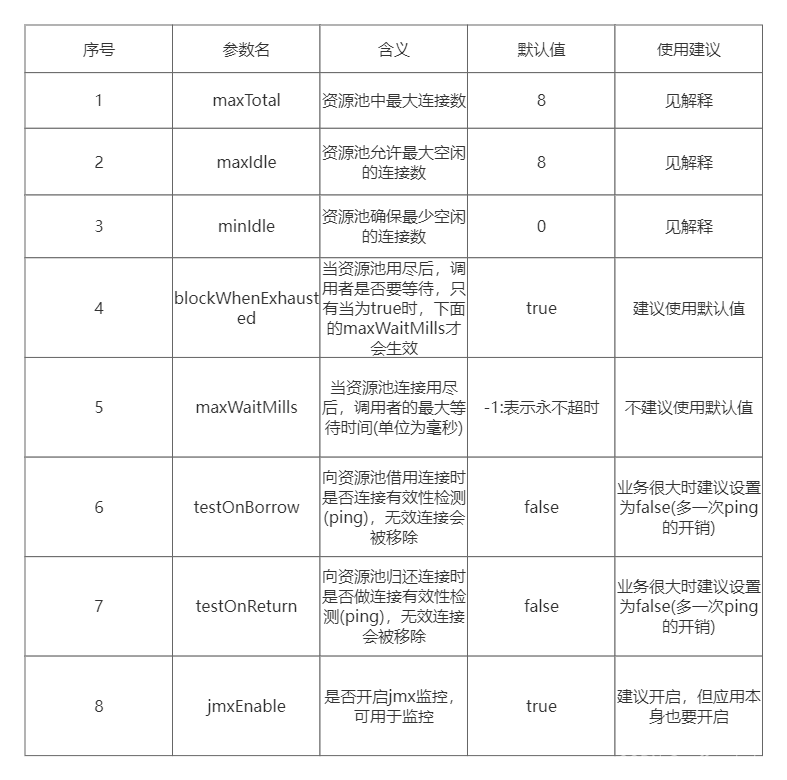
优化建议:
- 1.maxTotal:最大连接数,早期的版本叫maxActive实际上这个是一个很难回答的问题,
考虑的因素比较多:
1.1 业务希望Redis并发量
1.2 客户端执行命令时间
1.3 Redis资源:例如nodes(例如应用个数) * maxTotal是不能超过redis的最大连接数maxclients
1.4 资源开销:例如虽然希望控制空闲连接(连接池此可可马上使用的连接),但是不希望因为连接池
的频繁释放创建连接造成不必要开销
举个例子:假设
- 1.一次命令时间(borrow|return resource + Jedis执行命令(含网络))的平均耗时约为1ms,一个链接的QPS大约是1000
- 2.业务期望的QPS是50000那么理论上需要的资源池大小是50000 / 1000 = 50 个。但事实上这是个理论值,还要考虑到要比理论值预留一些资源,通常来讲maxTotal可以比理论值大一些。但这个值不是越大越好,一方面连接太多占用客户端和服务端资源,另一方面对于Redis这种高QPS的服务器,一个大命令的阻塞即时设置再大资源池仍然会无济于事。
优化建议:
- 2.maxIdle和minIdle
maxIdle实际上才是业务需要的最大连接数,maxTotal是为了给出雨量,所以maxIdle不要设置过小,否则会有new Jedis(新连接)开销
连接池的最佳性能是maxTotal = maxIdle,这样就避免连接池伸缩带来的性能干扰,到那时如果并发量不大或者maxTotal设置过高,会导致不必要的连接资源浪费。一般推荐maxIdle可以设置为上面的业务期望QPS计算出来的理论连接数,maxTotal可以再放大一倍。minIdle()最小空闲连接数,与其说是最小空闲连接数,不如说是"至少需要保持的空闲连接数",在使用连接的过程中如果连接数超过了minIdle那么继续建立连接,如果超过了maxIdle,当超过的连接执行完业务后会慢慢被移除连接池释放掉,如果系统启动完马上就会有很多的请求过来,那么可以给redis连接池
做预热,比如快速的创建一些redis连接,执行简单命令,类似ping(),快速地将连接池里地空闲连接提升到minIdle地数量
public class Main {public static void main(String[] args){List<Jedis> minIdleJedisList = new ArrayList<Jedis>(jedisPoolConfig.getMinIdle());for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {Jedis jedis = null;try {jedis = pool.getResource();minIdleJedisList.add(jedis);jedis.ping();} catch(Exception e) {log.error(e.getMessage(), e);} finally {// 注意,这里不能马上close将连接还回连接池,// 否则最后连接池里只会建立1个连接// jedis.close();}}// 同一将预热的连接还回连接池for (int i = 0; i < jedisPoolConfig.getMinDile(); i++) {Jedis jedis = null;try {jedis = minIdleJedisList.get(i);// 将连接该归还回连接池jedis.close();} catch (Exception e) {log.error(e.getMessage(), e);} finally {}}}
}
3.【建议】高并发下建议客户端添加熔断功能(例如sentinel、hystrix)
4.【推荐】设置合理的密码,如有必要可以使用SSL加密访问
5.【建议】Redis对于过期键有三种清除策略:
- 5.1 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
- 5.2 主动删除:由于惰性删除策略无法保证冷数据被即时删除,所以Redis会定期主动淘汰一批已过期的key
- 5.3 当前医用内存超过maxmemory限定时,触发主动清理策略
主动清理策略在Redis4.0之前以供实现了6中内存淘汰策略,在4.0之后又加了2种策略,总共8种:
- a.针对设置了过期时间的key做处理
a.1 volatile-ttl 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早
过期的越先被删除
a.2 volatile-random 就像它的名称一样,在设置了过期时间的键值对种,进行随机删除
a.3 volatile-lru 会使用LRU算法筛选设置了过期时间的键值对删除
a.4 volatile-lfu 会使用LFU算法筛选设置了过期时间的键值对删除 - b.针对所有的key做处理
b.1 allkeys-random:从所有键值对中随机选择并删除数据
b.2 allkeys-lru 使用LRU算法在所有数据中进行筛选删除
b.3 allkeys-lfu 使用LFU算法在所有数据中进行筛选删除 - c.不处理
c.1 noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息error OOM command not allowed when used memory,此时Redis只相应读操作
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。这时使用LFU可能更好点.
根据自身业务类型,配置好maxmemory-policy(默认时noeviction)推荐使用volatile-lru.如果不设置最大内存,当Redis内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换(swap)会让redis的性能急剧下降。当Redis运行在主从模式时,只有主节点才会执行过期删除策略,然后把删除操作"del key"同步到从节点删除数据
LRU算法(least Recently Used,最近最少使用)
淘汰很久没有被访问过的数据,以最近一次访问时间作为参考
LFU算法(Least Frequently Used,最不经常使用)
淘汰最近一段时间被访问次数最少的数据,以次数作为参考
4.系统内核参数优化
vm.swapiness
swap对于操作系统来说比较重要,当物理内存不足时可以将一部分内存页进行swap到硬盘上,以解燃眉之急。但世界上没有免费午餐,swap空间由硬盘提供,对于需要高并发、高吞吐的应用来说,磁盘IO通常会称为系统瓶颈。在Linux中,并不是等到所有物理内存都使用完才会使用到swap,
系统参数swappniess会决定操作系统使用swap的倾向程度。swappiness的取只范围是0~100,swappiness的值越大,说明操作系统可能使用swap的概率越高,swappiness值越低,表示操作系统更加倾向于使用物理内存。swappiness的取值越大,说明操作系统可能使用swap的概率越高,越低则越倾向于使用物理内存。如果linux内核版本小于3.5 那么wappiness设置为0,这样系统宁愿swap不会oom killer(杀掉进程)
如果linux内核版本>=3.5,那么swappiness设置为1,这样系统宁愿swap也不会oom killer一般需要保证redis不会被kill掉
cat /proc/version # 查看linux内核版本
echo 1> /proc/sys/vm/swappiness
echo vm.swappiness = 1 >> /etc/sysctl.cnf
PS:OOM killer机制是指Linux操作系统发现可用内存不足时,强制杀死一些用户进程(非内核进程),来保证系统有足够的可用内存进行分配
vm.overcommit_memory(默认0)
- 0:表示内核将检查是否有足够的可用物理内存(实际不一定用满)供应用进程使用;如果有足够的可用物理内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程
- 1:表示内核允许分配所有的物理内存,而不管当前的内存状态如何,如果是0的化,可能导致类似fork等操作执行失败,申请不倒足够的内存空间
Redis建议把这个值设置为1,就是为了让fork操作能够在低内存下也能执行成功
cat /proc/sys/vm/overcommit_memory
echo "vm.overcoimmit_memory=1" >> /etc/sysctl.conf
sysctl vm.overcommit_memory =1
合理设置文件句柄数。
操作系统进程试图打开一个文件(或者叫句柄),但是现在进程打开的句柄数已经达到了上限,继续打开会报错"Too many open files"
ulimit -a # 查看系统文件句柄数,看open files选项
ulimt -n 65535 # 设置系统文件句柄数
慢查询日志:slowlog
Redis满日志命令说明
-
config get slow* #查看有关满日志的配置信息
-
config set slowlog-log-slower-than 20000 #设置满日志使用时间阈值,此处为20毫秒,即超过20毫秒的操作都会记录下来,生产环境建议设置1000,也就是1ms,这样理论上redis并发至少达到1000,如果要求
单机并发达到1万以上,这个值可能设置为100 -
config set slowlog-max-len 1024 # 设置慢日志记录保存数量,如果保存数量已满,会删除最早的记录,最新的日志追加进来,记录慢查询日志时Redis会对长命令做截断操作,并不会占用大量内存,建议设置稍大些,防止丢失日志
-
config rewrite #将服务器当前所使用的配置保存到redis.conf
-
slowlog len #获取慢查询日志列表的当前长度
-
slowlog get 5 # 获取最新的5条慢查询日志,慢查询日志由四个属性组成:标识ID,发生时间戳,命令耗时,执行命令和参数
-
slowlog reset #重置慢查询
相关文章:
Redis开发规范与性能优化(二)
开发规范与性能优化 3.客户端使用 1.【推荐】避免多个应用使用一个Redis示例 正例:不相干的业务拆分,公共数据库做服务化 2.【推荐】使用带有连接池的数据库,可以有效控制链接,同时提高效率,标准使用方式如代码所示 public c…...

我们是否生活在一个超大型生物的大脑之中?——对多元宇宙观与生命存在形式的哲学探讨
随着科技和哲学思辨的深入,关于人类所处宇宙的本质及我们自身存在的真实性的讨论越发引人入胜。其中一种颇具科幻色彩的观点认为,我们可能生活在某个巨大生物的大脑之中,所有的物理规律、自然现象以及我们的感知体验,都可能是这个…...

【Python数据结构与判断7/7】数据结构小结
目录 序言 整体回忆 定义方式 访问元素 访问单个元素 访问多个与元素 修改元素 添加元素 列表里添加元素 字典里添加元素 删除元素 in运算符 实战案例 总结 序言 今天将对前面学过的三种数据结构:元组(tuple)、列表(…...

探讨:MySQL和PostgreSQL谁更火
一、有人说PostgreSQL比MySQL火🔥 PostgreSQL相比于MySQL越来越受欢迎的原因可以从以下几个方面来阐述: 许可协议灵活性: PostgreSQL采用的是较为宽松的BSD许可证,允许企业在开源的基础上自由使用、修改和分发,而无需…...

hbase和es的选取 hbase与es结合
hbase和es的选取 hbase与es结合 背景介绍 HBase与ElasticSearch是现代应用在处理海量数据的技术架构会经常被使用的两款产品,其中HBase是一个分布式KV系统,具有灵活Schema、水平扩展、低成本、高并发的优势,但在复杂查询、分析能力方面相对…...

GoLang:云原生时代致力于构建高性能服务器的后端语言
Go语言的介绍 概念 Golang(也被称为Go)是一种编程语言,由Google于2007年开始设计和开发,并于2009年首次公开发布。Golang是一种静态类型、编译型的语言,旨在提供高效和可靠的软件开发体验。它具有简洁的语法、高效的编…...

高频面试必备(Java研发岗),一线互联网架构师设计思想解读开源框架
BeanFactory 和 ApplicationContext 有什么区别? 如何用基于 XML 配置的方式配置 Spring? 如何用基于 Java 配置的方式配置 Spring? 请解释 Spring Bean 的生命周期? Tomcat Tomcat 的缺省端口是多少,怎么修改&…...
React——react 的基本使用
前提:安装全局的脚手架,通过create-creat-app 项目名,我们创建好一个新项目,cd进去,通过npm start去运行该项目 注意:简单看下demo的配置,在根目录我们可以看到,没有任何webpack的…...
Unity资源热更新----AssetBundle
13.1 资源热更新——AssetBundle1-1_哔哩哔哩_bilibili Resources 性能消耗较大 Resources文件夹大小不能超过2个G 获取AssetBundle中的资源 打包流程 选择图片后点击 创建文件夹,Editor优先编译 打包文件夹位置 using UnityEditor; using UnityEngine; public cla…...
bootstrap企业网站前端模板
介绍 企业网站前端模板 软件架构 前端所用技术html/css/js/jquery 前端框架bootstrap 安装教程 浏览器本地路径访问发布到服务器比如(tomcat/nginx等)云服务器/虚拟机 网站效果图 网站预览 点击预览 源码地址 https://gitee.com/taisan/company…...
分类预测 | Matlab实现GSWOA-KELM混合策略改进的鲸鱼优化算法优化核极限学习机的数据分类预测
分类预测 | Matlab实现GSWOA-KELM混合策略改进的鲸鱼优化算法优化核极限学习机的数据分类预测 目录 分类预测 | Matlab实现GSWOA-KELM混合策略改进的鲸鱼优化算法优化核极限学习机的数据分类预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 GSWOA-KELM分类࿰…...

软考77-上午题-【面向对象技术3-设计模式】-创建型设计模式02
一、生成器模式 1-1、意图 将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。 1-2、结构图 Builder 为创建一个 Product 对象的各个部件指定抽象接口。ConcreteBuilder 实现 Builder 的接口以构造和装配该产品的各个部件,定…...
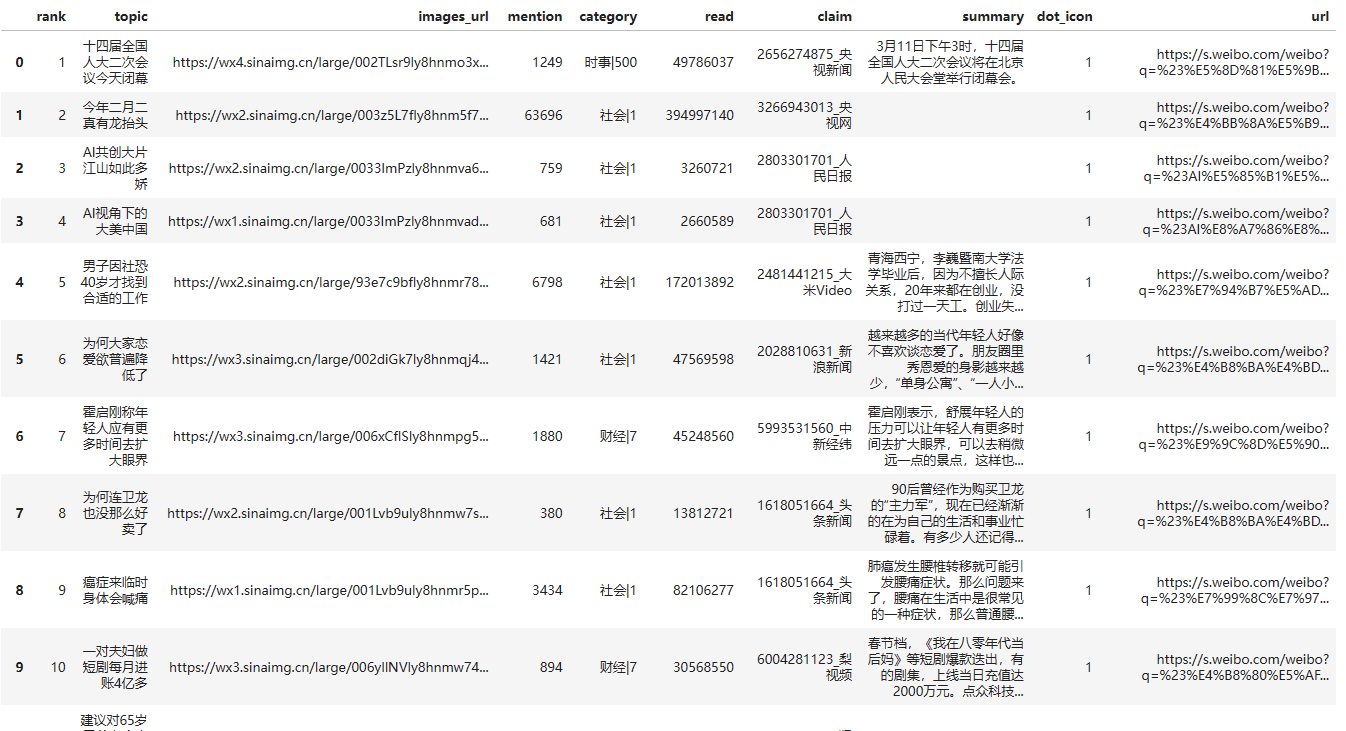
微博热搜榜单采集,微博热搜榜单爬虫,微博热搜榜单解析,完整代码(话题榜+热搜榜+文娱榜和要闻榜)
文章目录 代码1. 话题榜2. 热搜榜3. 文娱榜和要闻榜 过程1. 话题榜2. 热搜榜3. 文娱榜和要闻榜 代码 1. 话题榜 import requests import pandas as pd import urllib from urllib import parse headers { authority: weibo.com, accept: application/json, text/pl…...

有趣的前端知识(三)
推荐阅读 有趣的前端知识(一) 有趣的前端知识(二) 文章目录 推荐阅读JS内置对象JS外部对象BOM模型history对象screen对象navigator对象 DOM(文档对象模型)DOM的方法(对于节点的操作)…...

How to install teams in ubuntu
Download deb file download link: https://mirrors.sdu.edu.cn/spark-store-repository/store/office/teams/ install deb sudo apt install ./teams_1.5.00.23861_amd64.deb open and login teams....
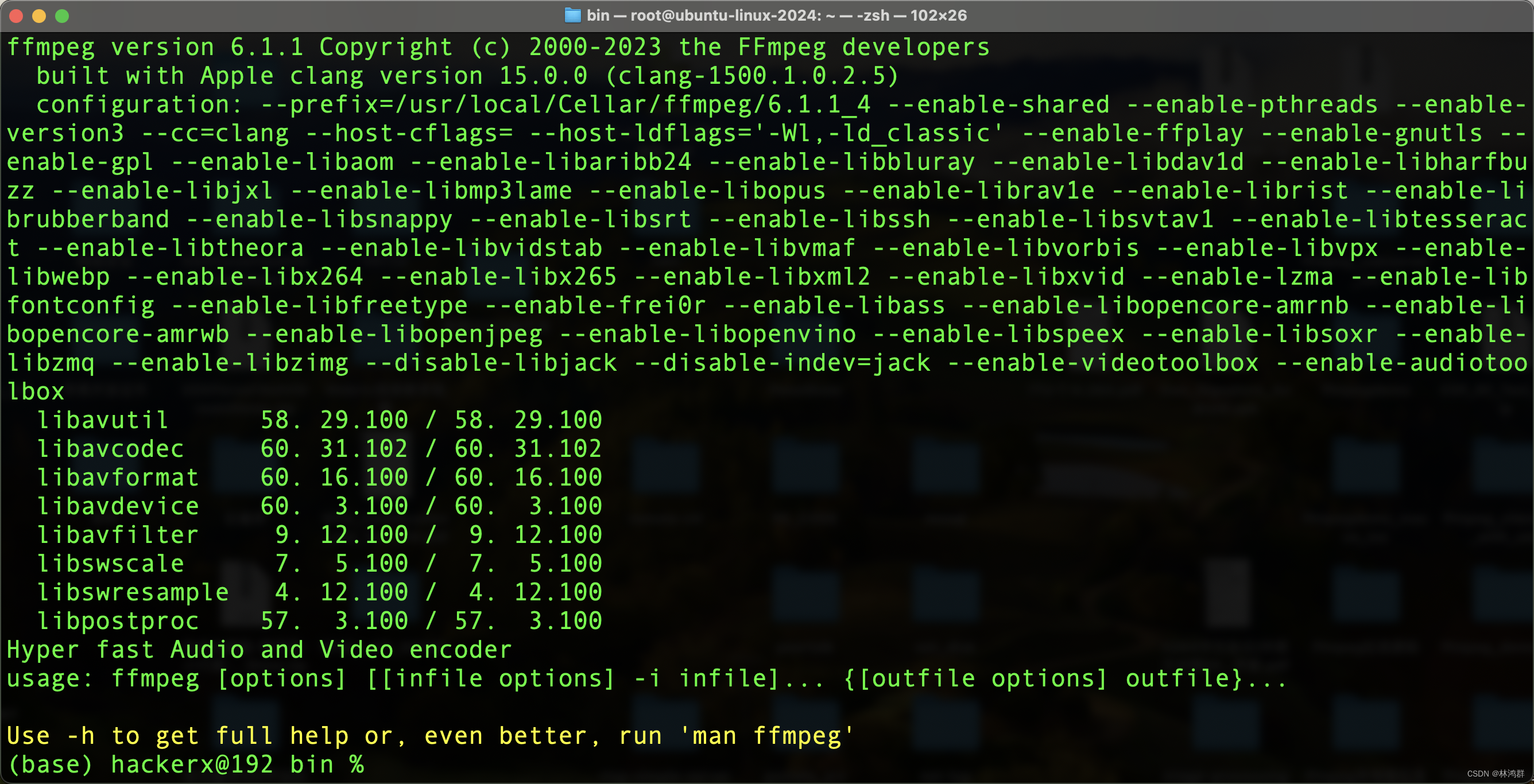
macOS14.4安装FFmpeg及编译FFmpeg源码
下载二进制及源码包 二进制 使用brew安装ffmpeg : brew install ffmpeg 成功更新到ffmpeg6.1 下载FFmpeg源码...
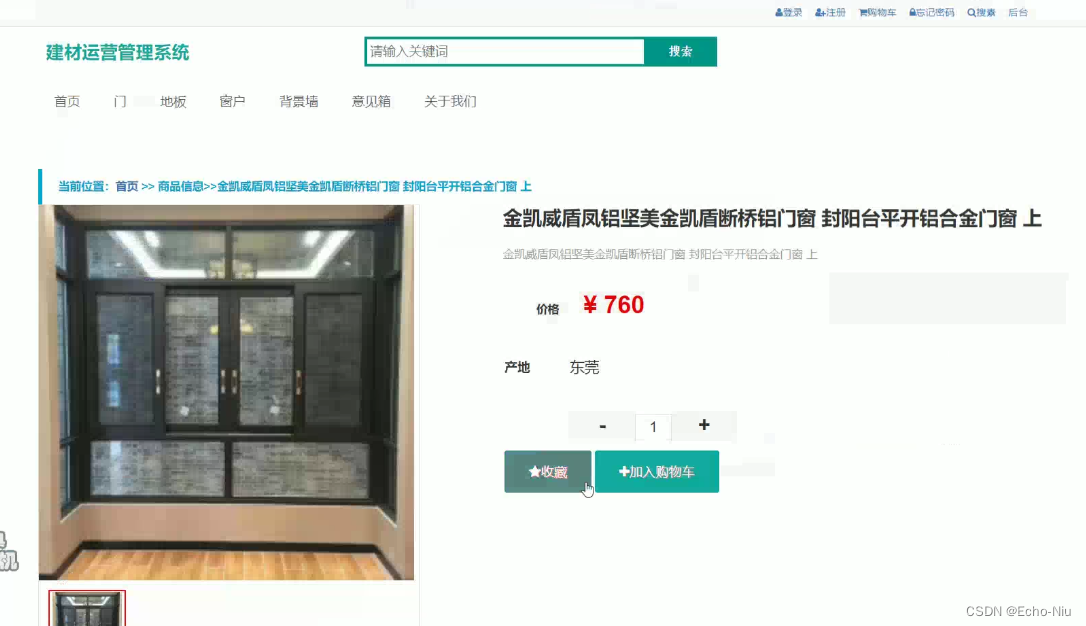
基于Springboot+vue+mybatis框架的建材运营管理系统的设计与实现【附项目源码】分享
基于Springbootvuemybatis框架的建材运营管理系统的设计与实现: 源码地址:https://download.csdn.net/download/weixin_43894652/88842715 一、引言 随着信息技术的快速发展,各行各业都在积极地进行数字化转型。建材行业作为传统行业之一&a…...

前端路由跳转bug
路由后面拼接了id的千万不能取相近的名字,浏览器分辩不出,只会匹配前面的路径 浏览器自动跳转到上面的路径页面,即使在菜单管理里面配置了正确的路由 跳转了无数次,页面始终不对,检查了路由配置,没有任何问…...
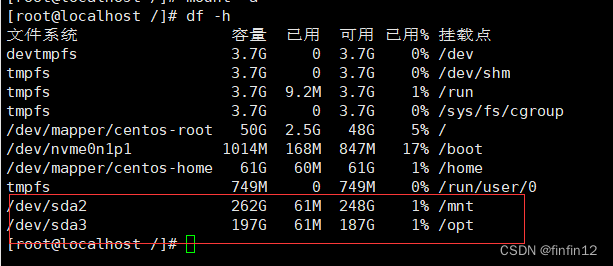
二 centos 7.9 磁盘挂载
上一步 一 windso10 笔记本刷linux cent os7.9系统-CSDN博客 笔记本有两个盘,系统装在128G的系统盘上,现在把另外一个盘挂载出来使用 lsblk 发现磁盘已经分好了,直接挂载就好了,参考文章:Centos7.9 挂载硬盘_centos7.9挂载硬盘-CSDN博客 永久挂载 lsblk -f分区格式化 mkfs…...
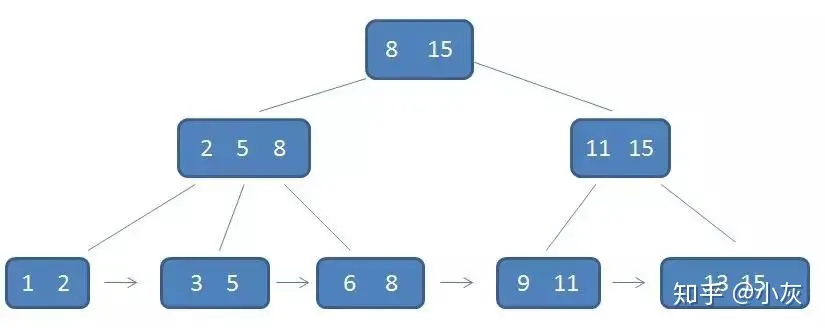
二叉搜索树、B-树、B+树
二叉搜索树 二叉查找树,也称为二叉搜索树、有序二叉树或排序二叉树,是指一棵空树或者具有下列性质的二叉树: 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;若任意节点的右子树不空࿰…...

Postman便携版:基于Portapps架构的无痕API测试环境构建方案
Postman便携版:基于Portapps架构的无痕API测试环境构建方案 【免费下载链接】postman-portable 🚀 Postman portable for Windows 项目地址: https://gitcode.com/gh_mirrors/po/postman-portable 在API开发与测试领域,Postman已成为开…...

行人动力学新视角:用速度、密度、避免数与侵入数量化交叉人流行为
1. 项目概述:当行人流交汇时,我们如何“看懂”人群?想象一下早高峰的地铁换乘通道,或是大型演唱会散场时的十字路口。两股、甚至多股人流以不同的角度交汇、穿插、最终分离。作为城市管理者或空间设计师,你可能会问&am…...

海洋潮汐预测真的那么难吗?揭秘Python潮汐计算工具pyTMD的强大功能
海洋潮汐预测真的那么难吗?揭秘Python潮汐计算工具pyTMD的强大功能 【免费下载链接】pyTMD Python-based tidal prediction software 项目地址: https://gitcode.com/gh_mirrors/py/pyTMD 你是否曾好奇,海洋潮汐预测背后的科学原理是什么…...

3分钟搞定插画分层?LayerDivider用AI技术重新定义数字艺术工作流
3分钟搞定插画分层?LayerDivider用AI技术重新定义数字艺术工作流 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾面对一张精美的插画…...

如何快速掌握游戏逆向工程:FromSoftware资源解析终极指南
如何快速掌握游戏逆向工程:FromSoftware资源解析终极指南 【免费下载链接】BinderTool Dark Souls II / Dark Souls III / Bloodborne / Elden Ring bdt, bhd, bnd, dcx, tpf, fmg and param unpacking tool 项目地址: https://gitcode.com/gh_mirrors/bi/BinderT…...

如何高效安装Adobe插件:ZXPInstaller终极指南
如何高效安装Adobe插件:ZXPInstaller终极指南 【免费下载链接】ZXPInstaller Open Source ZXP Installer for Adobe Extensions 项目地址: https://gitcode.com/gh_mirrors/zx/ZXPInstaller 还在为Adobe插件安装而烦恼吗?每次遇到.zxp文件时&…...

终极指南:如何让老款Mac免费升级到最新macOS系统
终极指南:如何让老款Mac免费升级到最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老款Mac无法升级最新系统而烦恼吗&…...

ThinkPHP 5.x远程代码执行漏洞原理与实战防御
1. 这个漏洞不是“理论存在”,而是真实打穿过生产环境的链路ThinkPHP 5.x远程代码执行漏洞(CVE-2018-1002015)——这个名字在2018年中后期的Web安全圈里,几乎等同于“默认可打穿”。它不像某些需要苛刻前置条件的逻辑漏洞…...

DOTT-Carbon:一种新型二维金属性多孔碳负极材料的理论设计与性能预测
1. 项目概述:从石墨烯到DOTT-Carbon的探索之路在能源存储领域,尤其是锂离子电池技术中,负极材料的性能瓶颈一直是制约电池能量密度和快充能力的关键。石墨作为商业主流,其理论容量(372 mAh/g)已接近天花板&…...

3分钟彻底清理Windows右键菜单!ContextMenuManager让你的效率提升200%
3分钟彻底清理Windows右键菜单!ContextMenuManager让你的效率提升200% 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是也遇到过这种情况&…...