微博热搜榜单采集,微博热搜榜单爬虫,微博热搜榜单解析,完整代码(话题榜+热搜榜+文娱榜和要闻榜)
文章目录
- 代码
- 1. 话题榜
- 2. 热搜榜
- 3. 文娱榜和要闻榜
- 过程
- 1. 话题榜
- 2. 热搜榜
- 3. 文娱榜和要闻榜
代码
1. 话题榜
import requests
import pandas as pd
import urllib
from urllib import parse headers = { 'authority': 'weibo.com', 'accept': 'application/json, text/plain, */*', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'client-version': 'v2.44.64', 'referer': 'https://weibo.com/newlogin?tabtype=topic&gid=&openLoginLayer=0&url=', 'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'server-version': 'v2024.02.19.1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69', 'x-requested-with': 'XMLHttpRequest', 'x-xsrf-token': 'HOU1s1Hak41bvvQjYsR86Oar',
} def get_page_resp(num): params = { 'sid': 'v_weibopro', 'category': 'all', 'page': f'{num}', 'count': '10', } response = requests.get('https://weibo.com/ajax/statuses/topic_band', params=params, headers=headers) return response def process_resp(response): statuses = response.json()['data']['statuses'] if statuses: _df = pd.DataFrame([[statuse['topic'], statuse['summary'], statuse['read'], statuse['mention'], f"https://s.weibo.com/weibo?q=%23{urllib.parse.quote(statuse['topic'])}%23"] for statuse in statuses], columns=['topic', 'summary', 'read', 'mention', 'href']) return _df else: return if __name__ == '__main__': df_list = [] num = 1 while num: resp = get_page_resp(num) _df = process_resp(resp) if isinstance(_df, pd.DataFrame): df_list.append(_df) num += 1 else: num = 0 df = pd.concat(df_list).reset_index(drop=True) print(df) df.to_csv('话题榜.csv')
2. 热搜榜
import requests
import urllib
import pandas as pd
import numpy as np def get_hot(): headers = { 'authority': 'weibo.com', 'accept': 'application/json, text/plain, */*', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'client-version': 'v2.44.64', 'referer': 'https://weibo.com/newlogin?tabtype=search&gid=&openLoginLayer=0&url=', 'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'server-version': 'v2024.02.19.1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69', 'x-requested-with': 'XMLHttpRequest', 'x-xsrf-token': 'HOU1s1Hak41bvvQjYsR86Oar', } response = requests.get('https://weibo.com/ajax/side/hotSearch', headers=headers) df = pd.DataFrame(response.json()['data']['realtime']) df['url'] = df['word'].map(lambda x: 'https://s.weibo.com/weibo?q=' + urllib.parse.quote(x)) df['onboard_time'] = pd.to_datetime(df['onboard_time'], unit='s') gov_name = response.json()['data']['hotgov']['name'] gov_url = response.json()['data']['hotgov']['url'] df = df[['word_scheme', 'word', 'star_name', 'realpos', 'label_name', 'onboard_time', 'url', 'raw_hot']] gov_info = [gov_name, gov_name[1:-1], {}, 0, '顶', np.nan, gov_url, np.nan] df = pd.DataFrame(np.insert(df.values, 0, gov_info, axis=0), columns=df.columns) return df if __name__ == '__main__': df = get_hot() df.to_csv('热搜榜.csv')
3. 文娱榜和要闻榜
这里需要更换cookies
import requests
import pandas as pd
import urllib # 跟换为自己的cookies
def get_entertainment_and_news(): headers = { 'authority': 'weibo.com', 'accept': 'application/json, text/plain, */*', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'client-version': 'v2.44.75', # 跟换为自己的cookies 'cookie': 'SINAGLOBAL=1278126679099.0298.1694199077980; UOR=,,localhost:8888; _s_tentry=localhost:8888; Apache=6414703468275.693.1710132397752; XSRF-TOKEN=4A9SIIBq9XqCDDTlkpxBLz76; ULV=1710132397782:20:1:1:6414703468275.693.1710132397752:1708482016120; login_sid_t=b637e1846742b4dd85dfe4d86c2c9413; cross_origin_proto=SSL; wb_view_log=1920*10801; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFARU4r6-VQ2BMDorVsYLdC5JpX5o275NHD95Qce0eX1KefehMXWs4DqcjMi--NiK.Xi-2Ri--ciKnRi-zNSoe0Sh.0SK5NS5tt; ALF=1712724726; SSOLoginState=1710132727; SCF=ApDYB6ZQHU_wHU8ItPHSso29Xu0ZRSkOOiFTBeXETNm74LTwE3TL5gaw4A4raSthpN-_7ynDOKXDUkiKc1jk720.; SUB=_2A25I6v2nDeRhGeBN6FYY8yvMzDiIHXVrhn9vrDV8PUNbktAGLXb1kW9NRGsSAV5UnWQYNJKU-WfqLNcAf0YTSxtn; WBPSESS=LZz_sqga1OZFrPjFnk-WNlnL5lU4G2v_-YZmcP-p0RFdJenqKjvGkmGWkRfJEjOjxH0yfYfrC4xwEi4ExzfXLO84Lg-HDSQgWx5p8cnO_TnE_Gna1RnTgtIpZu7xWJpq8fJ35LrwI2KAkj4nnVzB_A==', 'referer': 'https://weibo.com/hot/entertainment', 'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'server-version': 'v2024.03.06.1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69', 'x-requested-with': 'XMLHttpRequest', 'x-xsrf-token': '4A9SIIBq9XqCDDTlkpxBLz76', } response_entertainment = requests.get('https://weibo.com/ajax/statuses/entertainment', headers=headers) response_news = requests.get('https://weibo.com/ajax/statuses/news', headers=headers) df_entertainment = pd.DataFrame(response_entertainment.json()['data']['band_list']) df_entertainment['url'] = df_entertainment['word'].map( lambda x: 'https://s.weibo.com/weibo?q=' + '%23' + urllib.parse.quote(x) + '%23') df_news = pd.DataFrame(response_news.json()['data']['band_list']) df_news['url'] = df_news['topic'].map( lambda x: 'https://s.weibo.com/weibo?q=' + '%23' + urllib.parse.quote(x) + '%23') return df_entertainment, df_news if __name__ == '__main__': df_entertainment, df_news = get_entertainment_and_news() df_entertainment.to_csv('文娱榜.csv') df_news.to_csv('要闻榜.csv')
过程
1. 话题榜
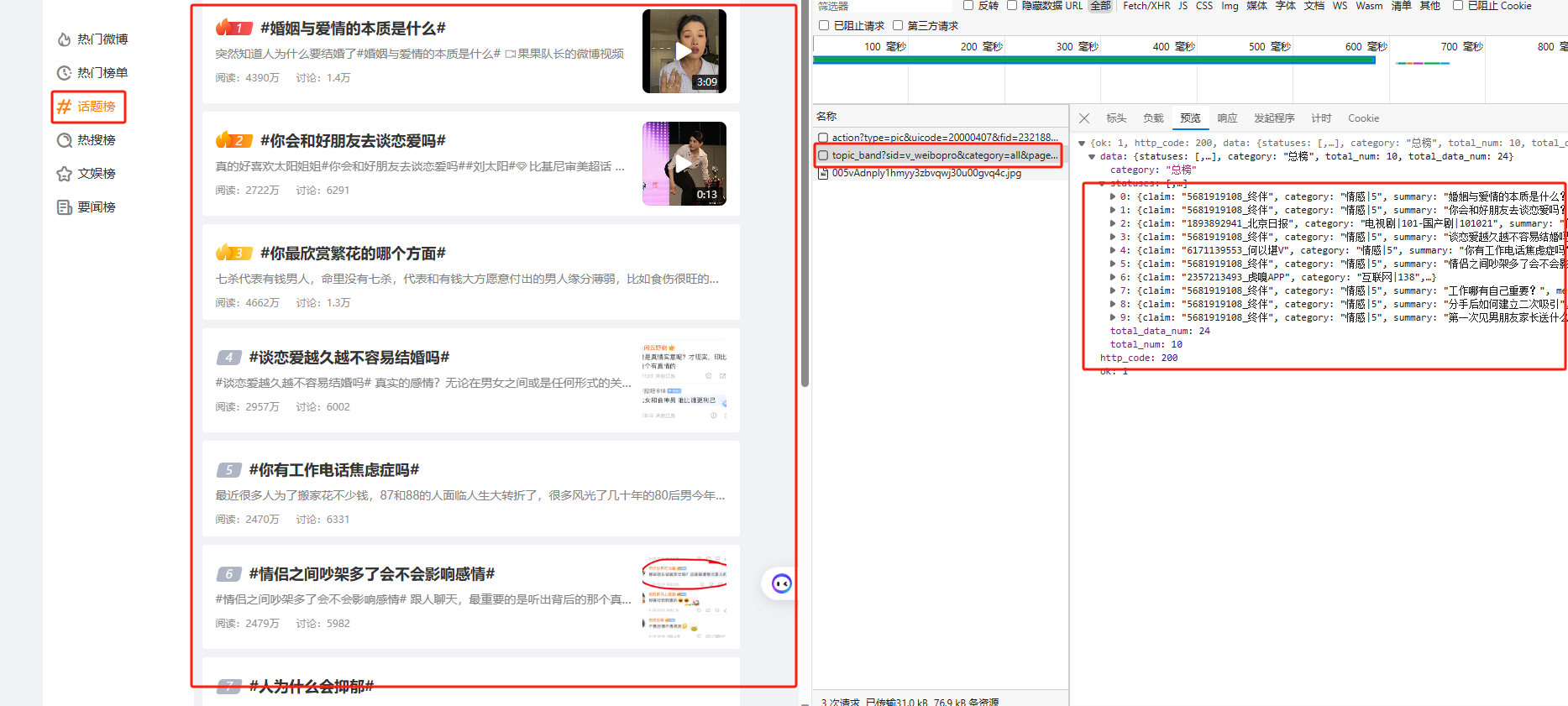
从F12中可以得到所有数据在右侧请求中,解析可以得到参数如下:
- sid: 这个值为 v_weibopro 是固定的
- category: 这个值为 all 是固定的
- page: 这个值为页码,每一页10个,从第一页开始计算
- count: 这个值为 10 是固定的,修改无效
所有的数据存储在['data']['statuses']下,进行解析,代码如下:
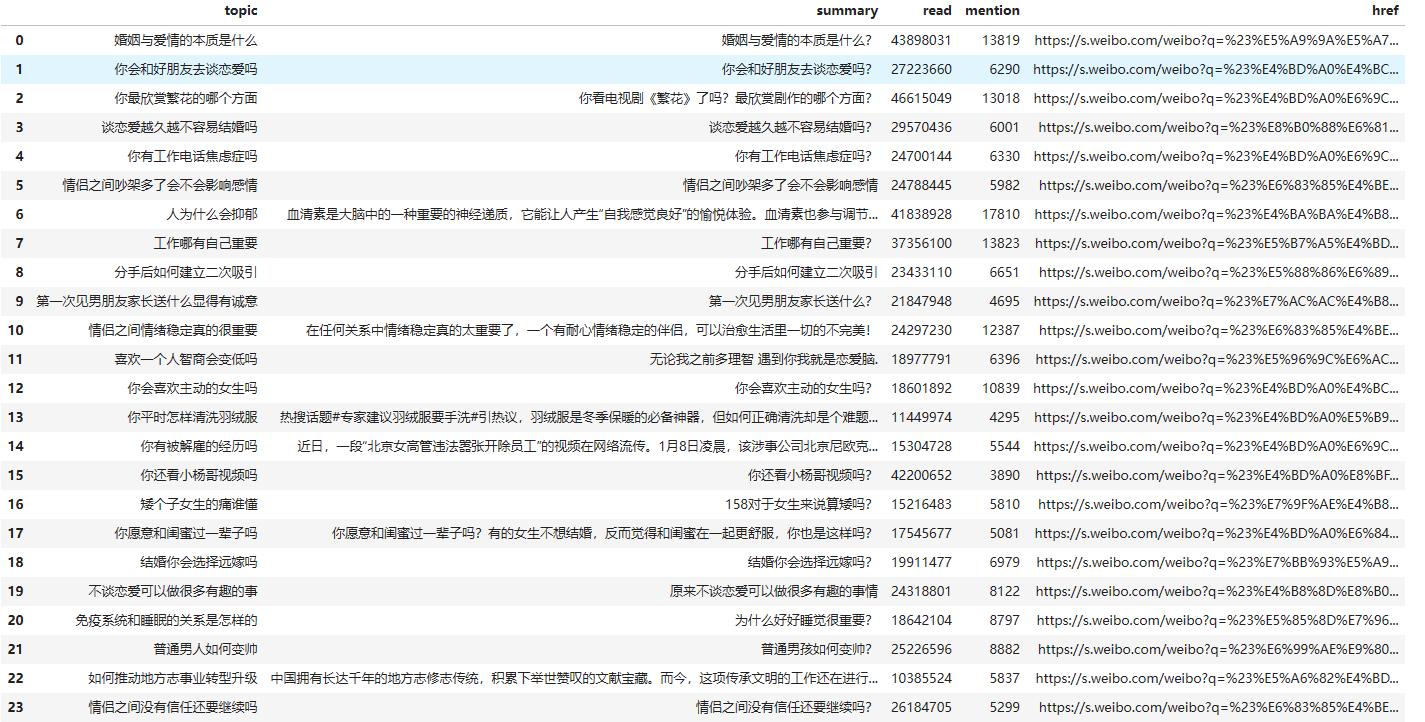
statuses = response.json()['data']['statuses']if statuses:_df = pd.DataFrame([[statuse['topic'], statuse['summary'], statuse['read'], statuse['mention'], f"https://s.weibo.com/weibo?q=%23{urllib.parse.quote(statuse['topic'])}%23"] for statuse in statuses], columns=['topic', 'summary', 'read', 'mention', 'href'])return _dfelse:return 0
可以获得所有结果:
2. 热搜榜
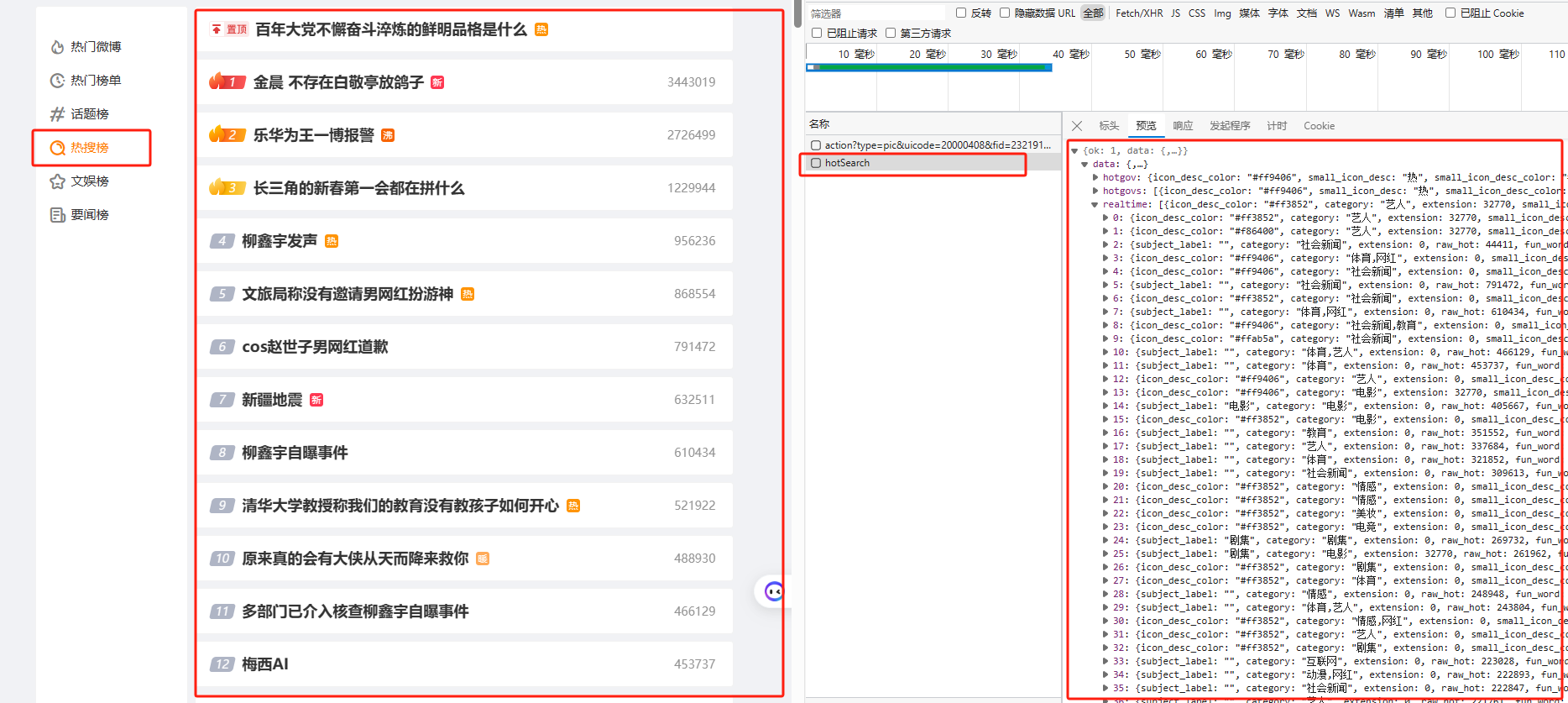
从F12中发现,这个请求是Get型的请求,什么参数都不需要,估计微博是直接放弃了
直接将得到的数据进行处理,
df = pd.DataFrame(response.json()['data']['realtime'])
df['url'] = df['word'].map(lambda x: 'https://s.weibo.com/weibo?q=' + urllib.parse.quote(x))
df['onboard_time'] = pd.to_datetime(df['onboard_time'], unit='s')
gov_name = response.json()['data']['hotgov']['name']
gov_url = response.json()['data']['hotgov']['url']
df = df[['word_scheme', 'word', 'star_name', 'realpos', 'label_name', 'onboard_time', 'url', 'raw_hot']]
gov_info = [gov_name, gov_name[1:-1], {}, 0, '顶', np.nan, gov_url, np.nan]
df = pd.DataFrame(np.insert(df.values, 0, gov_info, axis=0), columns=df.columns)
得到:

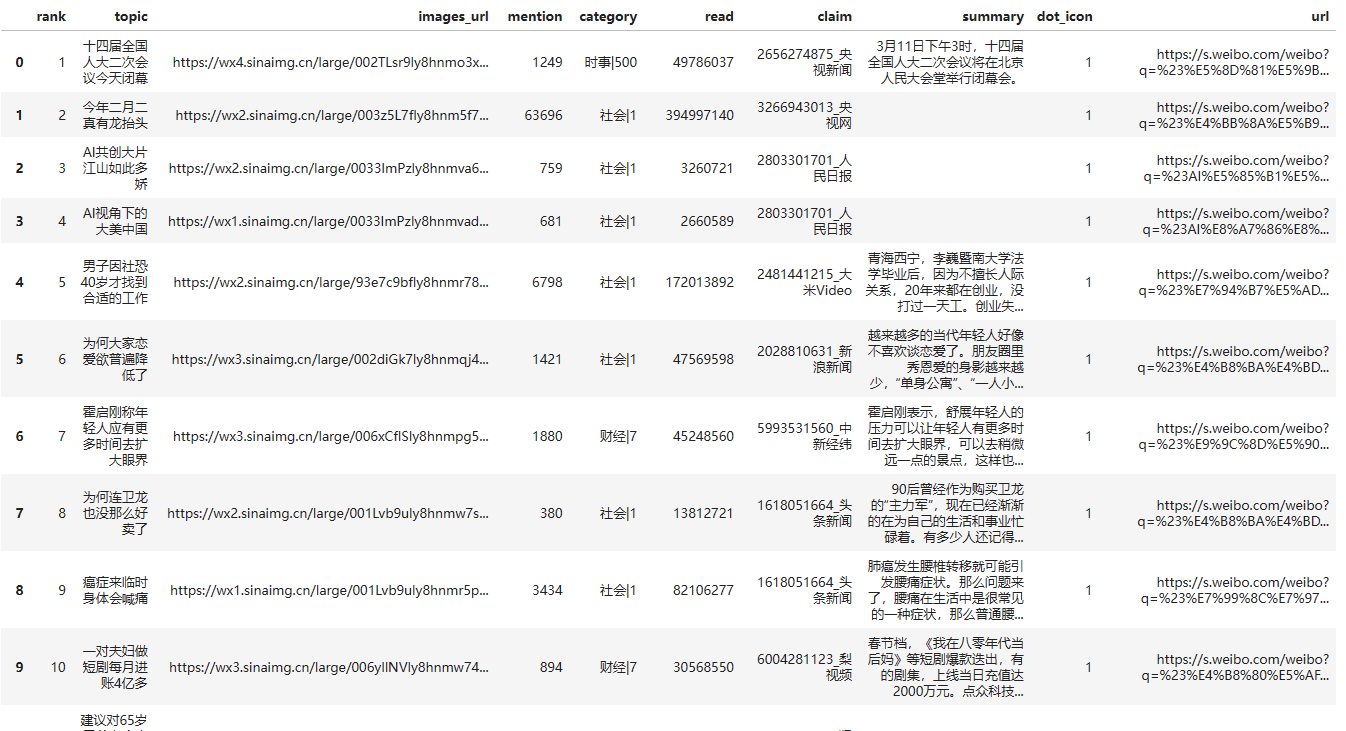
3. 文娱榜和要闻榜

这里从F12中可以发现,文娱榜和要闻榜 直接一个请求就可以获取,但是在解析的过程中,发现还是需要cookie的,所以这里需要自己获取cookies;
在response中发现数据无需要清理,直接在表格中获取一下自己需要的参数即可,在这里还是把url添加一下,有的人根本不看前文怎么获取的;
response_entertainment = requests.get('https://weibo.com/ajax/statuses/entertainment', headers=headers)response_news = requests.get('https://weibo.com/ajax/statuses/news', headers=headers)df_entertainment = pd.DataFrame(response_entertainment.json()['data']['band_list'])df_entertainment['url'] = df_entertainment['word'].map(lambda x: 'https://s.weibo.com/weibo?q=' + '%23' + urllib.parse.quote(x) + '%23')df_news = pd.DataFrame(response_news.json()['data']['band_list'])df_news['url'] = df_news['topic'].map(lambda x: 'https://s.weibo.com/weibo?q=' + '%23' + urllib.parse.quote(x) + '%23')
得到文娱榜如下:

得到要闻榜如下:
相关文章:
微博热搜榜单采集,微博热搜榜单爬虫,微博热搜榜单解析,完整代码(话题榜+热搜榜+文娱榜和要闻榜)
文章目录 代码1. 话题榜2. 热搜榜3. 文娱榜和要闻榜 过程1. 话题榜2. 热搜榜3. 文娱榜和要闻榜 代码 1. 话题榜 import requests import pandas as pd import urllib from urllib import parse headers { authority: weibo.com, accept: application/json, text/pl…...

有趣的前端知识(三)
推荐阅读 有趣的前端知识(一) 有趣的前端知识(二) 文章目录 推荐阅读JS内置对象JS外部对象BOM模型history对象screen对象navigator对象 DOM(文档对象模型)DOM的方法(对于节点的操作)…...

How to install teams in ubuntu
Download deb file download link: https://mirrors.sdu.edu.cn/spark-store-repository/store/office/teams/ install deb sudo apt install ./teams_1.5.00.23861_amd64.deb open and login teams....
macOS14.4安装FFmpeg及编译FFmpeg源码
下载二进制及源码包 二进制 使用brew安装ffmpeg : brew install ffmpeg 成功更新到ffmpeg6.1 下载FFmpeg源码...
基于Springboot+vue+mybatis框架的建材运营管理系统的设计与实现【附项目源码】分享
基于Springbootvuemybatis框架的建材运营管理系统的设计与实现: 源码地址:https://download.csdn.net/download/weixin_43894652/88842715 一、引言 随着信息技术的快速发展,各行各业都在积极地进行数字化转型。建材行业作为传统行业之一&a…...

前端路由跳转bug
路由后面拼接了id的千万不能取相近的名字,浏览器分辩不出,只会匹配前面的路径 浏览器自动跳转到上面的路径页面,即使在菜单管理里面配置了正确的路由 跳转了无数次,页面始终不对,检查了路由配置,没有任何问…...
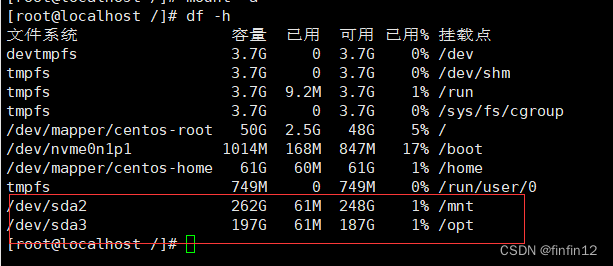
二 centos 7.9 磁盘挂载
上一步 一 windso10 笔记本刷linux cent os7.9系统-CSDN博客 笔记本有两个盘,系统装在128G的系统盘上,现在把另外一个盘挂载出来使用 lsblk 发现磁盘已经分好了,直接挂载就好了,参考文章:Centos7.9 挂载硬盘_centos7.9挂载硬盘-CSDN博客 永久挂载 lsblk -f分区格式化 mkfs…...
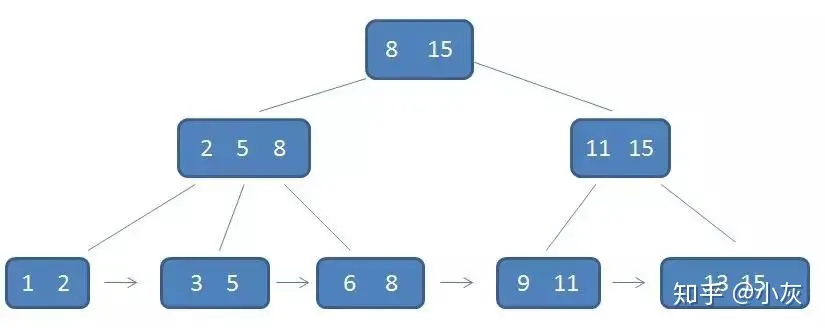
二叉搜索树、B-树、B+树
二叉搜索树 二叉查找树,也称为二叉搜索树、有序二叉树或排序二叉树,是指一棵空树或者具有下列性质的二叉树: 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;若任意节点的右子树不空࿰…...
Docker简介与安装
简介 用来快速构建、运行、管理应用的工具简单说,帮助我们部署项目以及项目所依赖的各种组件典型的运维工具 安装 1.卸载旧版 首先如果系统中已经存在旧的Docker,则先卸载: yum remove docker \docker-client \docker-client-latest \dock…...

Swift 单元测试
Swift 单元测试是用于检查代码的正确性和稳定性的一种测试方法。它可以帮助开发者在编写代码时及时发现和解决错误,提高代码质量。 在 Swift 中,可以使用 XCTest 框架来编写和运行单元测试。以下是一个简单的示例: import XCTestclass MyMa…...

有来团队后台项目-解析10
axios 安装 pnpm i axios创建文件 src 目录下创建 utils 文件夹,utils 文件夹下创建request.ts src 目录下创建store 文件夹,文件夹下创建index.ts ,创建modules 文件夹 编写request.ts // 引入axios,引入请求拦截器类型约束…...

【自动化】在C#中创建和配置串口对象SerialPort
串口通信在各种应用场景中都有广泛的应用,如工业控制、数据采集等。在.NET框架中,SerialPort类是用于串口通信的一个非常实用的类。本文将介绍如何在C#中使用SerialPort类进行串口通信,包括SerialPort的创建方法、基本属性设置和数据发送的基…...
)
突破编程_C++_设计模式(访问者模式)
1 访问者模式的基本概念 C中的访问者模式是一种行为设计模式,它允许你在不修改类层次结构的情况下增加新的操作。这种模式将数据结构与数据操作解耦,使得操作可以独立于对象的类来定义。 访问者模式的主要组成部分包括: (1&…...
)
C语言入门到精通之练习53:矩阵交换行问题(附带源码)
描述 给定一个 5*5 的矩阵(数学上,一个 rc 的矩阵是一个由 r 行 c 列元素排列成的矩形阵列),将第 n 行和第 m 行交换,输出交换后的结果。 输入输入共 6 行,前 5 行为矩阵的每一行元素, 元素与元素之间以一…...

Python白练-2统计下列5行字符串中字符出现的频数
问题:统计下列5行字符串中字符a、c、g、t出现的频数 数据:data2_2: 1.aggcacggaaaaacgggaataacggaggaggacttggcacggcattacacggagg 2.cggaggacaaacgggatggcggtattggaggtggcggactgttcgggga 3.gggacggatacggattctggccacggacggaaaggaggacacggcg…...

深入理解DHCP服务:网络地址的自动化分配
深入理解DHCP服务:网络地址的自动化分配 在现代网络环境中,动态主机配置协议(DHCP) 是一个至关重要的服务,它允许自动分配IP地址和其他相关配置信息给网络中的设备。本文将深入探讨DHCP服务的工作原理、配置方法以及如…...

Java高级编程—泛型
文章目录 1.为什么要有泛型 (Generic)1.1 泛型的概念1.2 使用泛型后的好处 2.在集合中使用泛型3.自定义泛型结构3.1 自定义泛型类、泛型接口3.2 自定义泛型方法 4.泛型在继承上的体现5.通配符的使用5.1 基本使用5.2 有限制的通配符的使用 1.为什么要有泛型 (Generic) Java中的…...

Exam in MAC [容斥]
题意 思路 正难则反 反过来需要考虑的是: (1) 所有满条件一的(x,y)有多少对: x 0 时,有c1对 x 1 时,有c对 ...... x c 时,有1对 以此类推 一共有 (c2)(c1)/2 对 (2) 符合 x y ∈ S的有多少对:…...

Java 学习和实践笔记(36):接口(interface)
面向对象的精髓,最能体现这一点的就是接口! 为什么我们讨论设计模式都只针对具备了抽象能力的语言(比如C、Java、C#等),就是因为设计模式所研究的,实际上就是如何合理的去抽象。 接口就是一组规范,所有实…...

Elastic Stack--10--QueryBuilders UpdateQuery
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 QueryBuildersESUtil QueryBuilders package com.elasticsearch; import org.elasticsearch.action.ActionListener; import org.elasticsearch.action.search.Sea…...

AI教材生成新突破!低查重AI写教材工具,快速打造专业教材书稿!
写教材的过程,总能遇到“慢节奏”带来的各种困扰。虽然框架和材料已经准备好,但内容撰写却常常陷入瓶颈——一句话反复推敲半小时,总觉得不够完美;章节之间的衔接过渡,总是费尽脑筋也找不到合适的表述,创作…...

如何快速掌握tsMuxer:视频无损封装的终极指南
如何快速掌握tsMuxer:视频无损封装的终极指南 【免费下载链接】tsMuxer tsMuxer is a transport stream muxer for remuxing/muxing elementary streams, EVO/VOB/MPG, MKV/MKA, MP4/MOV, TS, M2TS to TS to M2TS. Supported video codecs H.264/AVC, H.265/HEVC, V…...
)
CANoe安装总失败?别慌,这7个排查步骤帮你搞定(附Win10临时文件夹清理指南)
CANoe安装疑难全解析:从报错根源到系统级解决方案当你在实验室或办公室急切地需要启动CANoe进行总线仿真时,却遭遇安装程序反复报错,这种挫败感恐怕只有经历过的人才能体会。不同于普通应用软件,CANoe作为汽车电子开发的核心工具链…...

如何用Xournal++实现跨平台手写笔记:免费开源PDF批注工具完全指南 [特殊字符]
如何用Xournal实现跨平台手写笔记:免费开源PDF批注工具完全指南 🚀 【免费下载链接】xournalpp Xournal is a handwriting notetaking software with PDF annotation support. Written in C with GTK3, supporting Linux (e.g. Ubuntu, Debian, Arch, SU…...

可解释AI与随机森林在工人绩效分析中的工业实践
1. 项目概述:当AI不只是“黑箱”,如何用它看清工人的真实能力?在智能制造的浪潮里,我们谈论了太多关于机器、数据和算法的故事。传感器在轰鸣,数据在流淌,预测性维护和自动化流程优化成了标准配置。然而&am…...

Taotoken 用量看板如何帮助个人开发者清晰掌握月度 AI 支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 用量看板如何帮助个人开发者清晰掌握月度 AI 支出 对于独立开发者和小型项目团队而言,将大模型能力集成到产品…...

英雄联盟玩家必备的本地化效率神器:League Akari 全面解析与使用指南
英雄联盟玩家必备的本地化效率神器:League Akari 全面解析与使用指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联…...

qmcdump:3分钟学会的QQ音乐加密文件免费解码终极指南
qmcdump:3分钟学会的QQ音乐加密文件免费解码终极指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...

【Claude文档分析高阶战法】:3个被90%用户忽略的PDF/OCR/多语言混合解析技巧
更多请点击: https://intelliparadigm.com 第一章:Claude文档分析高阶战法总览 Claude在处理长文本、结构化文档与跨段落语义推理方面展现出独特优势,但要释放其全部潜力,需超越基础提问,构建系统化的分析范式。本章聚…...

DamaiHelper:基于Python+Selenium的大麦网自动化抢票解决方案
DamaiHelper:基于PythonSelenium的大麦网自动化抢票解决方案 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 你是否曾经在演唱会门票开售的瞬间,面对"秒光"的票…...