Python中Pandas常用函数及案例详解
Pandas是一个强大的Python数据分析工具库,它为Python提供了快速、灵活且表达能力强的数据结构,旨在使“关系”或“标签”数据的操作既简单又直观。Pandas的核心数据结构是DataFrame,它是一个二维标签化数据结构,可以看作是一个表格,其中可以存储不同类型的数据。
下面是Pandas中一些关于导入、导出、查看、检查、选取、清理、合并、统计等常用函数的详解以及案例说明:
第一、导入函数
Pandas 提供了多种方式来导入不同格式的数据。以下是一个详细的案例,展示如何使用 Pandas 从 CSV、JSON、Excel、SQL、URL 和剪贴板导入数据:
案例:从不同来源导入数据
步骤1:导入 Pandas 库
import pandas as pd
步骤2:从 CSV 文件导入数据
# 从 CSV 文件读取数据
csv_df = pd.read_csv('data.csv')# 查看 CSV 数据
print(csv_df)
步骤3:从 JSON 文件导入数据
# 从 JSON 文件读取数据
json_df = pd.read_json('data.json')# 查看 JSON 数据
print(json_df)
步骤 4:从 Excel 文件导入数据
# 从 Excel 文件读取数据
excel_df = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 查看 Excel 数据
print(excel_df)
步骤 5:从 SQL 数据库导入数据
# 连接 SQL 数据库
conn = sqlite3.connect('example.db')
sql_df = pd.read_sql_query('SELECT * FROM table_name', conn)# 查看 SQL 数据
print(sql_df)
步骤 6:从 URL 导入数据
# 从 URL 读取数据
url_df = pd.read_csv('https://example.com/data.csv')# 查看 URL 数据
print(url_df)
步骤 7:从剪贴板导入数据
# 从剪贴板读取数据
clipboard_df = pd.read_clipboard()# 查看剪贴板数据
print(clipboard_df)
通过以上步骤,我们展示了如何使用 Pandas 从不同来源导入数据。Pandas 的 read_csv、read_json、read_excel、read_sql、read_csv 和 read_clipboard 函数分别用于从 CSV、JSON、Excel、SQL、URL 和剪贴板读取数据。这些函数具有多个参数,可以用来指定读取数据的详细选项,例如分隔符、表单名称、列类型等。导入数据后,我们可以使用 Pandas 的丰富功能对数据进行进一步的处理和分析。
第二、导出函数
在使用Pandas处理数据时,我们经常需要将处理后的数据导出到不同的格式,以便于其他数据分析工具使用或者进行数据的备份。Pandas支持多种数据格式导出,如CSV、Excel、HTML、JSON、HDF5等。
以下是一些常见格式的导出案例:
1. 导出到CSV文件
import pandas as pd# 创建一个DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 导出到CSV文件,如果文件不存在,将会被创建
df.to_csv('data.csv', index=False) # index=False表示不将行索引作为单独的一列导出
2. 导出到Excel文件
# 同样先创建一个DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 导出到Excel文件,如果文件不存在,将会被创建
df.to_excel('data.xlsx', index=False) # index=False表示不将行索引作为单独的一列导出
3. 导出到HTML文件
# 创建DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 导出到HTML文件,如果文件不存在,将会被创建
df.to_html('data.html', index=False) # index=False表示不将行索引作为单独的一列导出
4. 导出到JSON文件
# 创建DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 将DataFrame转换为JSON格式,如果文件不存在,将会被创建
df.to_json('data.json', orient='split') # orient='split'会使得导出的JSON格式更适合于DataFrame
5. 导出到HDF5文件
import pandas as pd# 创建一个DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6],'C': [7, 8, 9]
})# 导出到HDF5文件,如果文件不存在,将会被创建
df.to_hdf('data.h5', key='df', mode='w') # mode='w'表示写模式
第三、查看、检查数据
在Pandas中,查看和检查数据是数据处理的重要部分。以下是一些常用的方法来查看和检查DataFrame中的数据:
1. 使用head()和tail()查看数据的前几行和后几行
import pandas as pd# 创建一个DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [6, 7, 8, 9, 10],'C': [11, 12, 13, 14, 15]
})# 查看前5行数据
print(df.head())# 查看后5行数据
print(df.tail())
2. 使用info()查看基本信息
# 查看DataFrame的基本信息,如列数、行数、数据类型等
print(df.info())
3. 使用describe()查看统计信息
# 查看DataFrame的统计信息,包括计数、均值、标准差等
print(df.describe())
4. 使用memory_usage()查看内存使用情况
# 查看DataFrame的内存使用情况
print(df.memory_usage())
5. 使用shape属性查看形状
# 查看DataFrame的形状,即行数和列数
print(df.shape)
6. 使用isnull()和notnull()检查缺失值
# 检查DataFrame中的缺失值
print(df.isnull())# 检查DataFrame中没有缺失值
print(df.notnull())
7. 使用value_counts()查看值的分布
# 查看某一列中不同值的计数
print(df['A'].value_counts())
8. 使用unique()查看唯一值
# 查看某一列中唯一的出现的值
print(df['A'].unique())
9. 使用duplicated()检查重复值
# 检查DataFrame中的重复行
print(df.duplicated())# 检查DataFrame中没有重复行
print(~df.duplicated())
10. 使用sort_values()对数据进行排序
# 对某一列进行升序排序
print(df.sort_values(by='A'))# 对某一列进行降序排序
print(df.sort_values(by='A', ascending=False))
通过这些方法,可以快速地了解和检查DataFrame中的数据,帮助我们在进行数据处理之前对数据有一个基本的认识。
第四、数据选取
在Pandas中,数据选取是通过索引来实现对DataFrame或Series中数据的选择。索引可以是标签(label-based)或整数(integer-based)。以下是一些常用的数据选取方法:
1. 使用标签索引(Label-based Indexing)
import pandas as pd# 创建一个DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [6, 7, 8, 9, 10],'C': [11, 12, 13, 14, 15]
})# 使用列标签名称选取整列数据
print(df['A'])# 使用列标签名称和行标签选取单个值
print(df.loc[0, 'A'])# 使用行标签列表和列标签名称选取多个值
print(df.loc[[0, 2], ['A', 'C']])# 使用布尔索引选取满足条件的数据
print(df[df['A'] > 2])
2. 使用整数索引(Integer-based Indexing)
# 使用整数索引选取单个值
print(df.iloc[0])# 使用整数索引选取单个列
print(df.iloc[:, 0])# 使用整数索引和布尔索引选取满足条件的数据
print(df.iloc[df['A'] > 2, :])# 使用整数索引和切片选取数据
print(df.iloc[0:3, 1:3])
3. 使用行和列的混合格式索引
# 使用行列混合格式索引选取数据
print(df.loc[0:2, 'A':'C'])# 使用行列混合格式索引和布尔索引选取数据
print(df.loc[df['A'] > 2, 'A':'C'])
4. 使用at()和iat()选取单个值
# 使用`at()`根据行标签和列标签选取单个值
print(df.at[0, 'A'])# 使用`iat()`根据整数索引选取单个值
print(df.iat[0, 0])
5. 使用query()方法查询数据
# 使用`query()`方法查询满足条件的数据
print(df.query('A > 2'))
6. 使用xs()方法跨越多级索引选取数据
# 使用`xs()`方法选取某列或某行
print(df.xs(2, level='A')) # 选取列标签为2的行
print(df.xs('B', axis=1)) # 选取列名称为B的列
7. 使用filter()方法根据条件选取数据
# 使用`filter()`方法根据条件选取数据
def is_even(x):return x % 2 == 0print(df.filter(items=['A', 'B'], like='e')) # 选取列名包含'e'的列
print(df.filter(func=is_even, axis=0)) # 选取列中值为偶数的列
第五、数据清理
在Pandas中,数据清理是数据处理的重要步骤,它包括处理缺失值、异常值、重复值等。以下是一些常用的数据清理方法:
1. 处理缺失值
import pandas as pd# 创建一个包含缺失值的DataFrame
df = pd.DataFrame({'A': [1, 2, None, 4, 5],'B': [6, 7, 8, 9, None],'C': [11, None, 13, 14, 15]
})# 删除包含缺失值的行
df.dropna(inplace=True)# 填充缺失值,可以使用均值、中位数、众数等
df.fillna(df.mean(), inplace=True)# 向前填充缺失值
df.fillna(method='ffill', inplace=True)# 向后填充缺失值
df.fillna(method='bfill', inplace=True)
2. 处理异常值
# 使用Z-分数方法识别异常值(大于3或小于-3)
z_scores = df.apply(zscore)
abs_z_scores = np.abs(z_scores)
filtered_entries = (abs_z_scores < 3)
df = df[filtered_entries]# 使用IQR(四分位距)方法识别异常值
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
df = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]
3. 处理重复值
# 检查重复值
print(df.duplicated())# 删除重复值
df.drop_duplicates(inplace=True)# 根据特定列删除重复值
df.drop_duplicates(subset='A', inplace=True)# 删除重复值,保留第一次出现的值
df.drop_duplicates(keep='first', inplace=True)# 删除重复值,保留最后一次出现的值
df.drop_duplicates(keep='last', inplace=True)
4. 数据类型转换
# 转换数据类型
df['A'] = df['A'].astype('int')
df['B'] = df['B'].astype('float')
df['C'] = df['C'].astype('str')
5. 重置索引
# 重置索引
df.reset_index(drop=True, inplace=True)
6. 缺失值分析
# 缺失值分析
missing_values = df.isnull().sum()
missing_percentage = df.isnull().mean() * 100
print(missing_values)
print(missing_percentage)
通过这些方法,可以有效地清理DataFrame中的数据,为后续的数据分析和工作准备干净、可靠的数据集。
第六、数据处理(Filter、Sort和GroupBy)
在Pandas中,Filter、Sort和GroupBy是处理数据的基本操作,它们可以帮助我们筛选数据、排序数据和分组数据。以下是一个详细的案例,展示如何使用这些操作:
案例:员工绩效数据分析
假设我们有一个DataFrame,其中包含了员工的姓名、部门、工资和绩效评分。我们想要根据绩效评分对员工进行排序,并筛选出绩效优秀的员工。
步骤1:加载数据
import pandas as pd# 创建一个DataFrame
df = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Department': ['HR', 'Engineering', 'HR', 'Sales', 'Engineering'],'Salary': [70000, 90000, 60000, 80000, 100000],'Performance': [4.5, 3.5, 4.0, 2.5, 5.0]
})# 查看数据前几行
print(df.head())
步骤2:排序数据
# 根据绩效评分对数据进行降序排序
sorted_df = df.sort_values(by='Performance', ascending=False)# 查看排序后的数据
print(sorted_df)
步骤3:筛选数据
# 筛选绩效评分大于4的员工
filtered_df = df[df['Performance'] > 4]# 查看筛选后的数据
print(filtered_df)
步骤4:分组和聚合
# 根据部门对数据进行分组
grouped_df = df.groupby('Department')# 查看每个部门的平均工资和平均绩效评分
print(grouped_df.agg({'Salary': 'mean', 'Performance': 'mean'}))
步骤5:进一步筛选和排序
# 筛选绩效评分大于4且工资在60000到100000之间的员工
double_filtered_df = filtered_df[(filtered_df['Performance'] > 4) & (filtered_df['Salary'].between(60000, 100000))]# 根据绩效评分对筛选后的数据进行升序排序
double_sorted_df = double_filtered_df.sort_values(by='Performance', ascending=True)# 查看最终筛选和排序后的数据
print(double_sorted_df)
第七、数据合并
Pandas提供了多种方法来合并DataFrame,包括merge、concat、join等。以下是一个详细的案例,展示如何使用这些方法来合并不同的DataFrame:
案例:合并销售和库存数据
假设我们有两个DataFrame,一个包含销售数据,另一个包含库存数据。我们想要将这两个DataFrame合并为一个,以便进行综合分析。
步骤1:创建DataFrame
import pandas as pd# 创建销售DataFrame
sales_df = pd.DataFrame({'Product': ['Product A', 'Product B', 'Product C', 'Product D'],'Quantity': [100, 150, 200, 50],'Sale_Date': ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04']
})# 创建库存DataFrame
inventory_df = pd.DataFrame({'Product': ['Product A', 'Product B', 'Product C', 'Product D'],'Stock_Level': [100, 200, 300, 0],'Last_Update': ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04']
})
步骤2:使用merge合并数据
# 使用外连接合并销售和库存数据
merged_df = pd.merge(sales_df, inventory_df, on='Product', how='outer')# 查看合并后的数据
print(merged_df)
步骤3:使用concat合并数据
# 使用垂直堆叠合并销售和库存数据
combined_df = pd.concat([sales_df, inventory_df], axis=1)# 查看合并后的数据
print(combined_df)
步骤4:使用join合并数据
# 使用内连接合并销售和库存数据,只保留共有的键
joined_df = sales_df.join(inventory_df.set_index('Product'), how='inner')# 查看合并后的数据
print(joined_df)
步骤5:处理重复数据
# 删除重复的行
merged_df.drop_duplicates(inplace=True)# 查看删除重复数据后的数据
print(merged_df)
通过这个案例,我们展示了如何使用Pandas的merge、concat和join方法来合并不同的DataFrame。这些方法可以根据需要选择,以实现不同的合并效果。例如,merge适用于需要保留所有相关行的场景,concat适用于需要将数据垂直或水平堆叠的场景,而join适用于需要根据共有的键来合并数据的场景。此外,我们还展示了如何处理重复数据,以确保合并后的数据集是干净的。
第八、数据统计
Pandas提供了丰富的函数来对DataFrame进行统计分析。以下是一个详细的案例,展示如何使用这些函数来获取数据的基本统计信息:
案例:学生成绩数据分析
假设我们有一个DataFrame,其中包含了学生的姓名、课程分数和考试分数。我们想要对学生们的总分数和平均分数进行统计。
步骤1:创建DataFrame
import pandas as pd# 创建学生成绩DataFrame
scores_df = pd.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],'Course_Score': [85, 90, 78, 88, 92],'Exam_Score': [90, 85, 88, 92, 80]
})# 查看数据前几行
print(scores_df.head())
步骤2:计算总分数和平均分数
# 计算每个学生的总分数
total_scores = scores_df[['Course_Score', 'Exam_Score']].sum(axis=1)# 计算每个学生的平均分数
average_scores = scores_df[['Course_Score', 'Exam_Score']].mean(axis=1)# 查看统计结果
print(total_scores)
print(average_scores)
步骤3:获取基本统计信息
# 获取所有列的基本统计信息
statistics = scores_df.describe()# 查看统计信息
print(statistics)
步骤4:计算标准差
# 计算每个学生分数的标准差
std_deviation = scores_df[['Course_Score', 'Exam_Score']].std(axis=1)# 查看标准差
print(std_deviation)
步骤5:计算中位数和四分位数
# 计算每个学生分数的中位数
median_scores = scores_df[['Course_Score', 'Exam_Score']].median(axis=1)# 计算每个学生分数的第一和第三四分位数
first_quartile = scores_df[['Course_Score', 'Exam_Score']].quantile(0.25, axis=1)
third_quartile = scores_df[['Course_Score', 'Exam_Score']].quantile(0.75, axis=1)# 查看中位数和四分位数
print(median_scores)
print(first_quartile)
print(third_quartile)
通过这个案例,我们展示了如何使用Pandas来获取学生成绩的基本统计信息,包括总分数、平均分数、标准差、中位数和四分位数。这些统计信息对于了解数据集的分布和特征非常重要,可以帮助我们做出更准确的数据分析和决策。
这些函数只是Pandas库中众多功能的一部分。Pandas强大的数据处理能力使其成为数据分析和机器学习领域中不可或缺的工具。在使用Pandas时,我们应当遵循良好的编程实践,确保代码的可读性和可维护性,同时注意数据处理过程中的隐私和安全性问题。
相关文章:

Python中Pandas常用函数及案例详解
Pandas是一个强大的Python数据分析工具库,它为Python提供了快速、灵活且表达能力强的数据结构,旨在使“关系”或“标签”数据的操作既简单又直观。Pandas的核心数据结构是DataFrame,它是一个二维标签化数据结构,可以看作是一个表格…...
VR全景看房:超越传统的看房方式
近年来,新兴技术不断涌出,例如大数据、VR全景、人工智能、元宇宙等。随着科技不断发展,VR全景技术在房地产行业中的应用也是越发广泛,逐渐超越了传统的看房方式。今天,就让我们一起来深入探讨一下VR全景技术在VR看房中…...

pip 配置镜像加速安装
在使用pip安装Python第三方库时,默认是使用pip官网的非常慢,可通过配置国内镜像源加速下载速度,以下是如何使用国内镜像源安装Python库的两种常见方式: 临时使用镜像源安装 如果你只是想临时使用某个镜像源安装单个或几个库&…...

LUA语法复习总结
文章目录 简记变量数据类型运算符算术运算符关系运算符逻辑运算符杂项运算符 列表(表)表格操作表连接插入和删除排序表 模块元表__index 元方法实例 总结__newindex 元方法实例实例 为表添加操作符实例 __call 元方法实例 __tostring 元方法实例 简记 lua下标从1开始迭代器pai…...

某赛通电子文档安全管理系统 DecryptApplication 任意文件读取漏洞(2024年3月发布)
漏洞简介 某赛通电子文档安全管理系统 DecryptApplication 接口处任意文件读取漏洞,未经身份验证的攻击者利用此漏洞获取系统内部敏感文件信息,导致系统处于极不安全的状态。 漏洞等级高危影响版本*漏洞类型任意文件读取影响范围>1W 产品简介 …...

Mac-自动操作 实现双击即可执行shell脚本
背景 在Mac上运行shell脚本,总是需要开启终端窗口执行,比较麻烦 方案 使用Mac上自带的“自动操作”程序,将shell脚本打包成可运行程序(.app后缀),实现双击打开即可执行shell脚本 实现细节 找到Mac上 应用程序中的 自动操作&am…...
)
人工智能入门之旅:从基础知识到实战应用(六)
一、人工智能学习之路总结 人工智能学习的关键点与挑战可以总结如下: 关键点: 理论基础: 理解机器学习、深度学习等人工智能的基本原理和算法是学习的基础,包括线性代数、概率统计、微积分等数学知识,以及神经网络、…...

Debezium日常分享系列之:Debezium2.5稳定版本之Mysql连接器的工作原理
Debezium日常分享系列之:Debezium2.5稳定版本之Mysql连接器的工作原理 一、Mysql连接器的工作原理1.支持的 MySQL 拓扑2.MariaDB 支持3.Schema history topic4.Schema change topic5.Snapshots1)使用全局读锁的初始快照2)Debezium MySQL 连接…...

Linux服务器,使用ssh登录时越来越慢,有时甚至出现超时的现象,解决方案
一台Linux服务器,使用ssh登录时越来越慢,有时甚至出现超时的现象。一直以为这不算问题,但是有时候登录时间长的让人无法接受,查了一下,这“ssh登录慢”还真的是个问题,解决方案如下: 客户端进行…...

GPT-SoVITS开源音色克隆框架的训练与调试
GPT-SoVITS开源框架的报错与调试 遇到的问题解决办法 GPT-SoVITS是一款创新的跨语言音色克隆工具,同时也是一个非常棒的少样本中文声音克隆项目。 它是是一个开源的TTS项目,只需要1分钟的音频文件就可以克隆声音,支持将汉语、英语、日语三种…...

C#十大排序总结
一、冒泡排序 传送门 一、C#冒泡排序算法-CSDN博客 未完待续。。。...
Vue首屏优化方案
在Vue项目中,引入到工程中的所有js、css文件,编译时都会被打包进vendor.js,浏览器在加载该文件之后才能开始显示首屏。若是引入的库众多,那么vendor.js文件体积将会相当的大,影响首屏的体验。可以看个例子:…...

SpringBoot使用log4j2将日志记录到文件及自定义数据库
目录 一、环境说明 二、进行配置 1、pom.xml 2、log4j2.xml 3、CustomDataSourceProperties 4、ConfigReader 5、ConnectionFactory 连接工厂类,用于管理数据库连接 三、进行简单测试配置 1、LogUtils 2、LoginUserInfoHelper 3、LoginLogUtils 4、…...
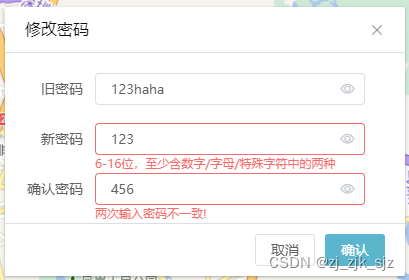
vue+elementUI用户修改密码的前端验证
用户登录后修改密码,密码需要一定的验证规则。旧密码后端验证是否正确;前端验证新密码的规范性,新密码规范为:6-16位,至少含数字/字母/特殊字符中的两种;确认密码只需要验证与新密码是否一致; 弹…...
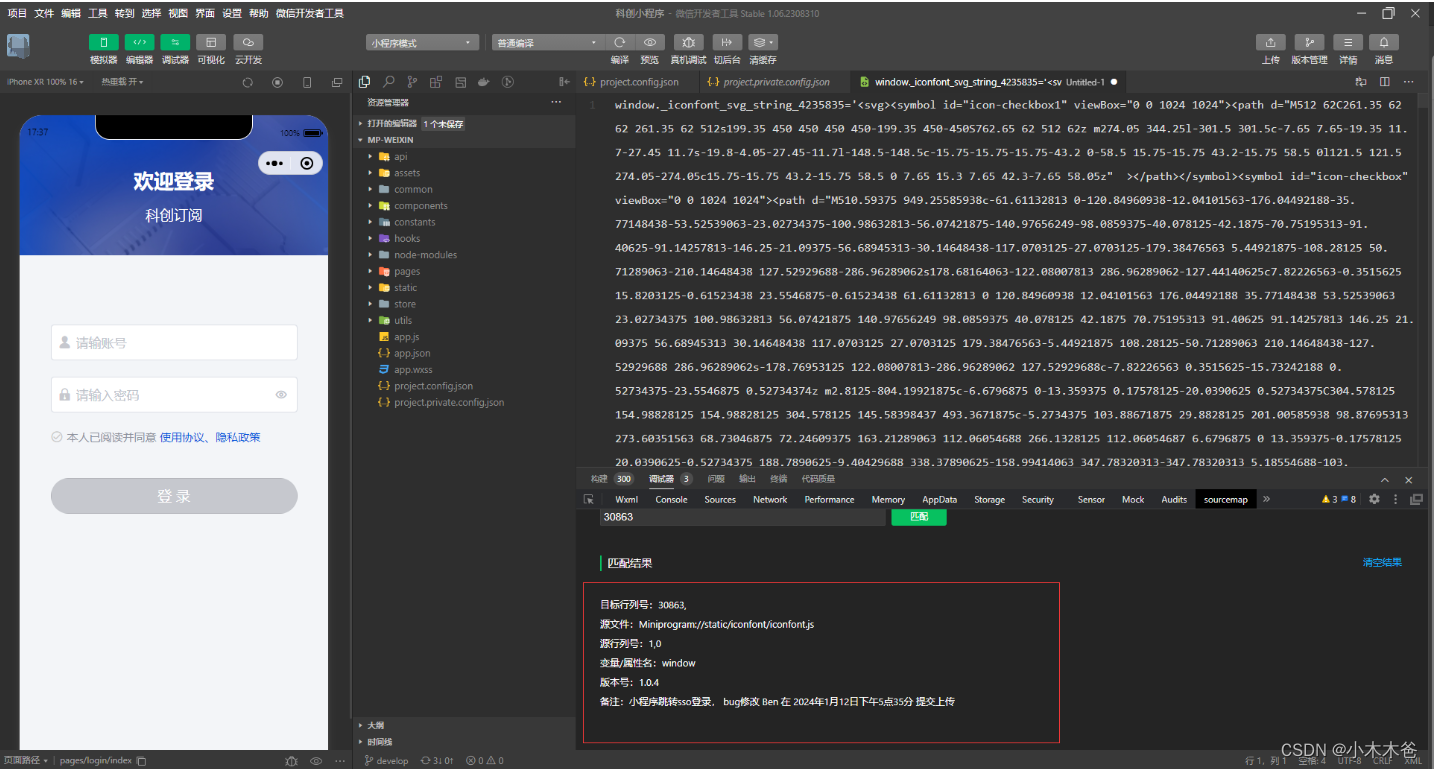
微信小程序问题定位——sourcemap文件
使用sourceMap在微信小程序中进行线上问题定位,主要可以通过以下步骤实现: 下载微信开发者工具首先,确保已经安装了微信开发者工具,这是进行小程序开发和调试的基础。登录微信公众平台并下载sourceMap文件:登录微信小…...

Photoshop_00000
简介 Adobe官网:https://www.adobe.com Adobe中文官网:https://www.adobe.com/cn Adobe中国服务商:http://adobe.sxbyu.cn/adobe/adobe_index?flag800&bd_vid5593893117402635109# Photoshop安装 基础操作 文件的打开和新建 打开文…...
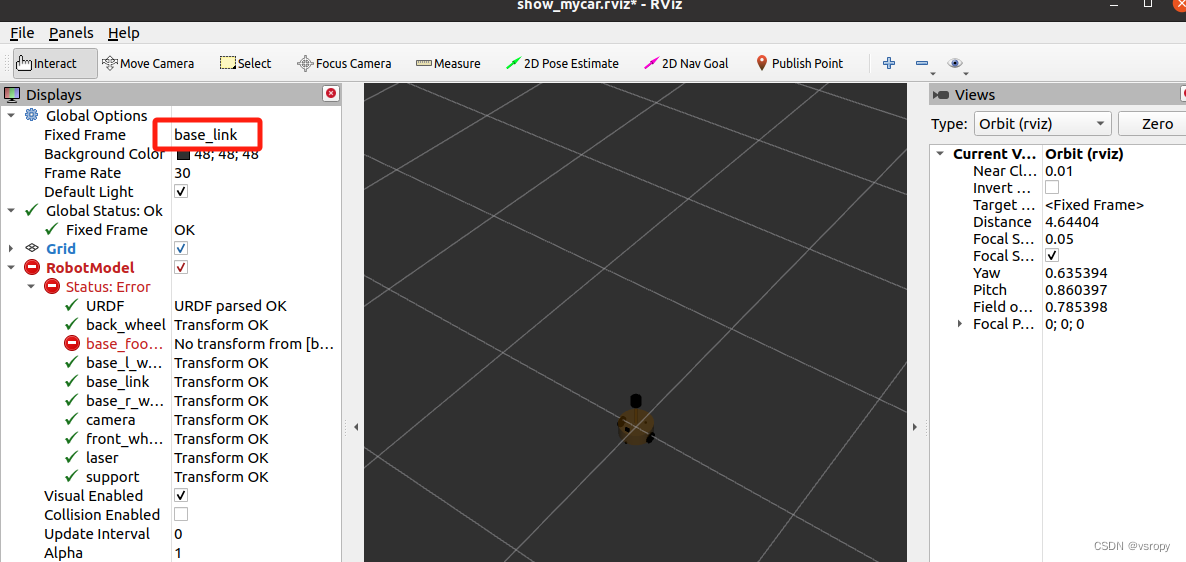
rviz上不显示机器人模型(模型只有白色)
文档中的是base_footprint,需要根据自己所设的坐标系更改,我的改为base_link 如何查看自己设的坐标系: 这些parent父坐标系就是 同时打开rviz后需要更改成base_link...

Android 录屏操作
Android 录屏操作 本文主要介绍android中如何通过MediaRecorder实现录屏操作的. 1: 申请权限 <uses-permission android:name"android.permission.RECORD_AUDIO" /> <uses-permission android:name"android.permission.WRITE_EXTERNAL_STORAGE"…...

基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的血细胞智能检测与计数(深度学习模型+UI界面代码+训练数据集)
摘要:开发血细胞智能检测与计数系统对于疾病的预防、诊断和治疗具有关键作用。本篇博客详细介绍了如何运用深度学习构建一个血细胞智能检测与计数系统,并提供了完整的实现代码。该系统基于强大的YOLOv8算法,并对比了YOLOv7、YOLOv6、YOLOv5&a…...
Selenium 学习(0.20)——软件测试之单元测试
我又(浪完)回来了…… 很久没有学习了,今天忙完终于想起来学习了。没有学习的这段时间,主要是请了两个事假(5工作日和10工作日)放了个年假(13天),然后就到现在了。 看了下…...

用while循环语句求和
在“用for循环语句求和”中,学习了for循环语句,这篇博文继续学习另一种形式的循环程序结构while循环语句。while循环语句一般用于事先不能确定循环次数的情况,格式为while 表达式循环体end如果表达式为真,就执行循环体的内容&…...

【芯片测试】:6. 向量、Sequencer 指令与高速串行 IO
Pattern 详解:向量、Sequencer 指令与高速串行 IO系列: Advantest V93000 SmarTest 8 核心概念解析|第 6 篇(共 8 篇) 适合读者: 需要理解数字测试激励数据结构的工程师前言 Pattern(模式&#…...

范畴论与拓扑斯理论:为深度神经网络构建形式化语义分析框架
1. 项目概述:当范畴论遇见深度神经网络如果你和我一样,既对深度神经网络(DNN)内部那看似“黑箱”的运作机制感到好奇,又对背后那套精妙的数学语言心向往之,那么“范畴论”和“拓扑斯理论”这两个词…...

Arm嵌入式工具链全解析:从获取到优化
1. Arm嵌入式工具链概述Arm Toolchain for Embedded是Arm公司为嵌入式系统开发提供的一套完整工具链集合,包含编译器、调试器、链接器等核心组件。作为嵌入式开发领域的标准工具链,它支持从Cortex-M系列微控制器到Cortex-A系列应用处理器的全系列Arm架构…...

准最优最小二乘框架:破解PDE非齐次边界数值求解难题
1. 项目概述:当最小二乘遇上非齐次边界——一个准最优框架的构建在偏微分方程(PDE)的数值求解领域,最小二乘法一直以其数学上的优雅和稳定性吸引着研究者。其核心思想直白而有力:将微分方程问题转化为一个最小化残差范…...

Necesse 多人沙盒生存 RPG 服务器搭建教程
Necesse 多人沙盒生存 RPG 服务器搭建教程 Necesse 是一款融合了《泰拉瑞亚》式俯视角探索与《边缘世界》式基地管理的沙盒生存 RPG 游戏。当你和朋友想一起挖矿、打地牢、建造基地时,自建专用服务器能带来更稳定的连接、更低的延迟,以及完全由你掌控的…...

【AI Agent法律应用实战指南】:20年律所技术总监亲授3大落地场景与5个避坑红线
更多请点击: https://kaifayun.com 第一章:AI Agent法律应用的认知重构与行业定位 传统法律服务长期依赖人工经验、线性流程与静态知识体系,而AI Agent的出现正推动法律行业从“工具辅助”迈向“自主协同”的范式跃迁。它不再仅是检索法条或…...

旅游客服响应时效提升至8.3秒?揭秘某出境游龙头AI Agent上线72小时后的5项关键调优动作
更多请点击: https://codechina.net 第一章:旅游客服响应时效提升至8.3秒?揭秘某出境游龙头AI Agent上线72小时后的5项关键调优动作 在AI Agent正式上线首周,该出境游平台客服系统平均首次响应时间从原42.6秒骤降至8.3秒…...

8051单片机PDATA与XDATA存储访问优化解析
1. PDATA与XDATA变量生成的指令解析在8051单片机开发中,外部数据存储器的访问方式直接影响程序效率和硬件设计。作为从业十余年的嵌入式工程师,我经常需要针对不同存储区域优化代码。PDATA和XDATA作为两种常见的外部数据存储模式,其指令生成机…...

如何用Nvidia Geforce RTX 5060 Ti显卡进行本地Whisper语音转文字任务?
在Windows平台上,用你的RTX 5060 Ti 16GB显卡搭建本地Whisper语音转文字服务,主要有几种方式:从开箱即用的图形界面,到追求极致速度的命令行,再到能集成其他AI应用的API服务。我整理了详细的步骤,你可以根据…...