python爬虫实战——小红书
目录
1、博主页面分析
2、在控制台预先获取所有作品页的URL
3、在 Python 中读入该文件并做准备工作
4、处理图文类型作品
5、处理视频类型作品
6、异常访问而被中断的现象
7、完整参考代码
任务:在 win 环境下,利用 Python、webdriver、JavaScript等,获取 xiaohongshu 某个博主的全部作品。
本文仅做学习和交流使用。
1、博主页面分析
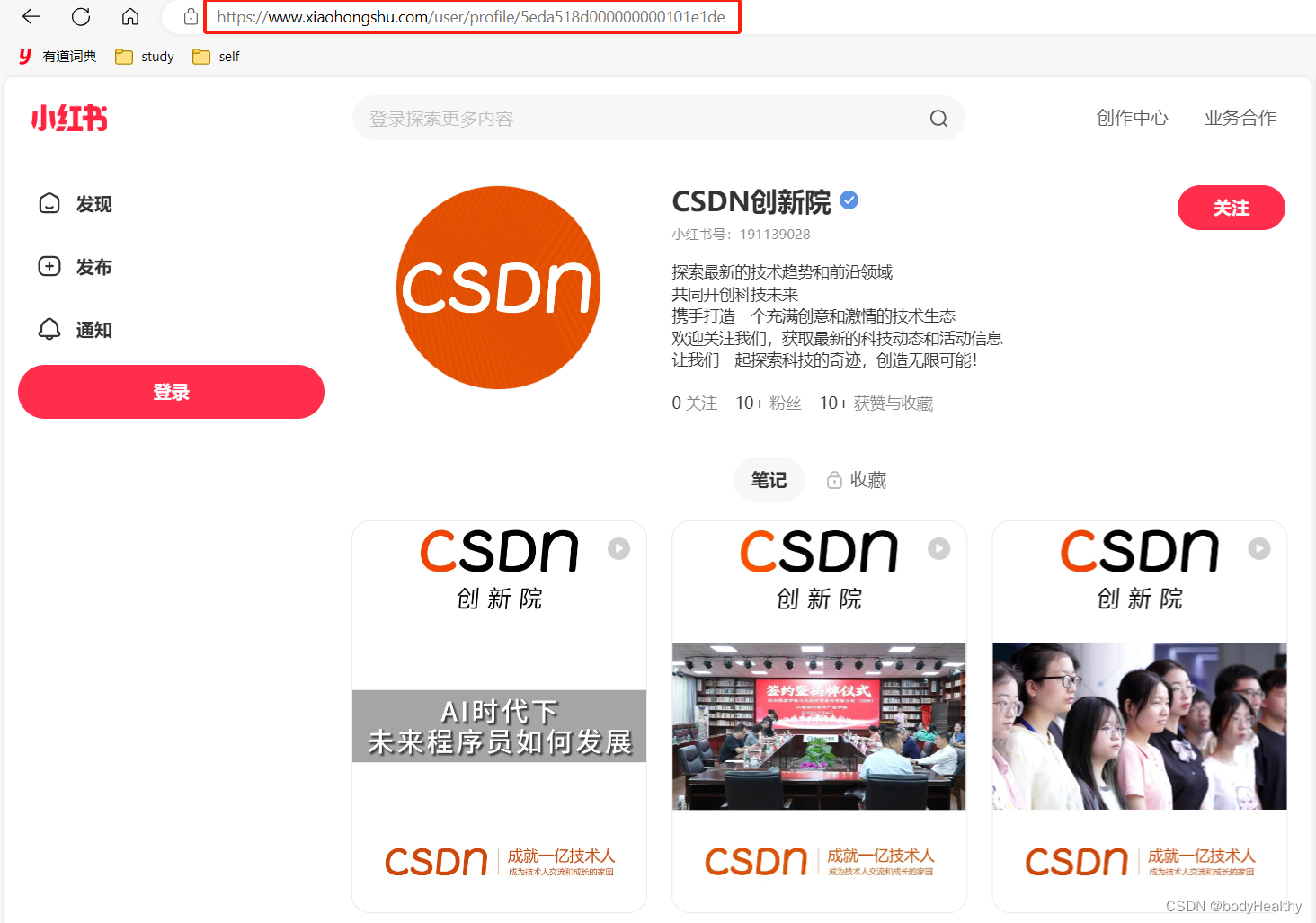
section 代表每一项作品,但即使博主作品有很多,在未登录状态下,只会显示 20 项左右。向下滚动页面,section 发生改变(个数不变),标签中的 index 会递增。
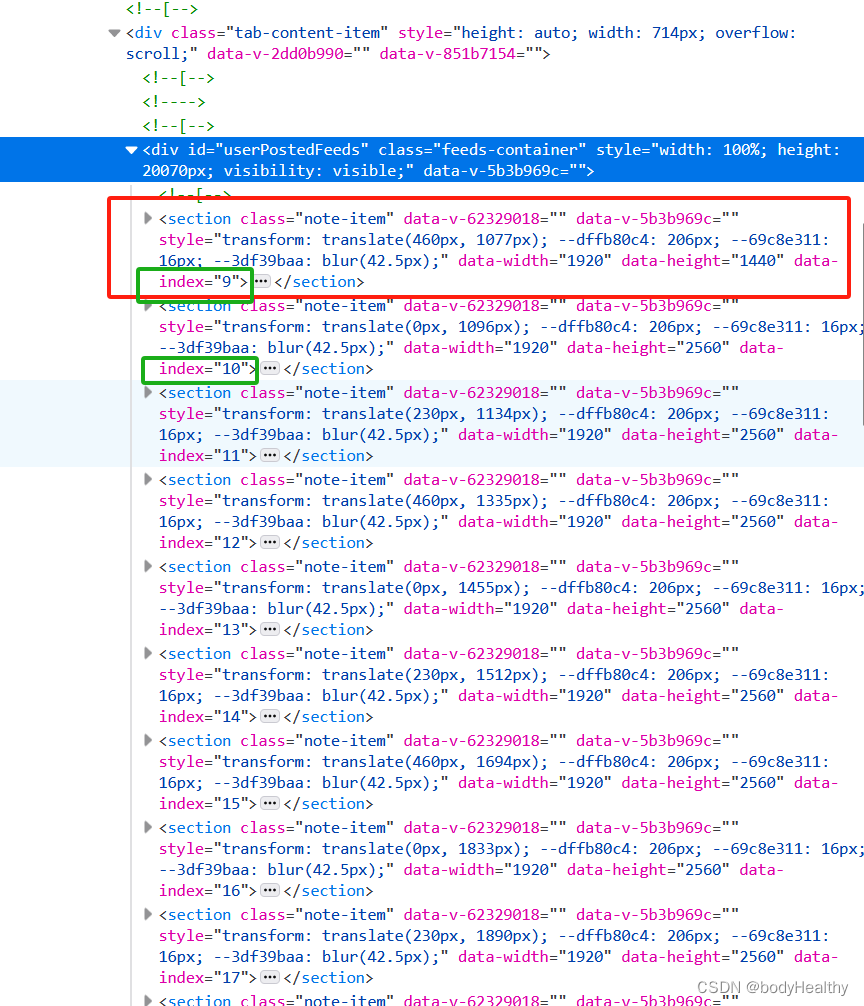
向下滚动页面时,到一定的范围时,会发送一个获取作品数据的请求,该请求每次只请求 30 项作品数据。该请求携带了 cookies 以及其他不确定值的参数。
2、在控制台预先获取所有作品页的URL
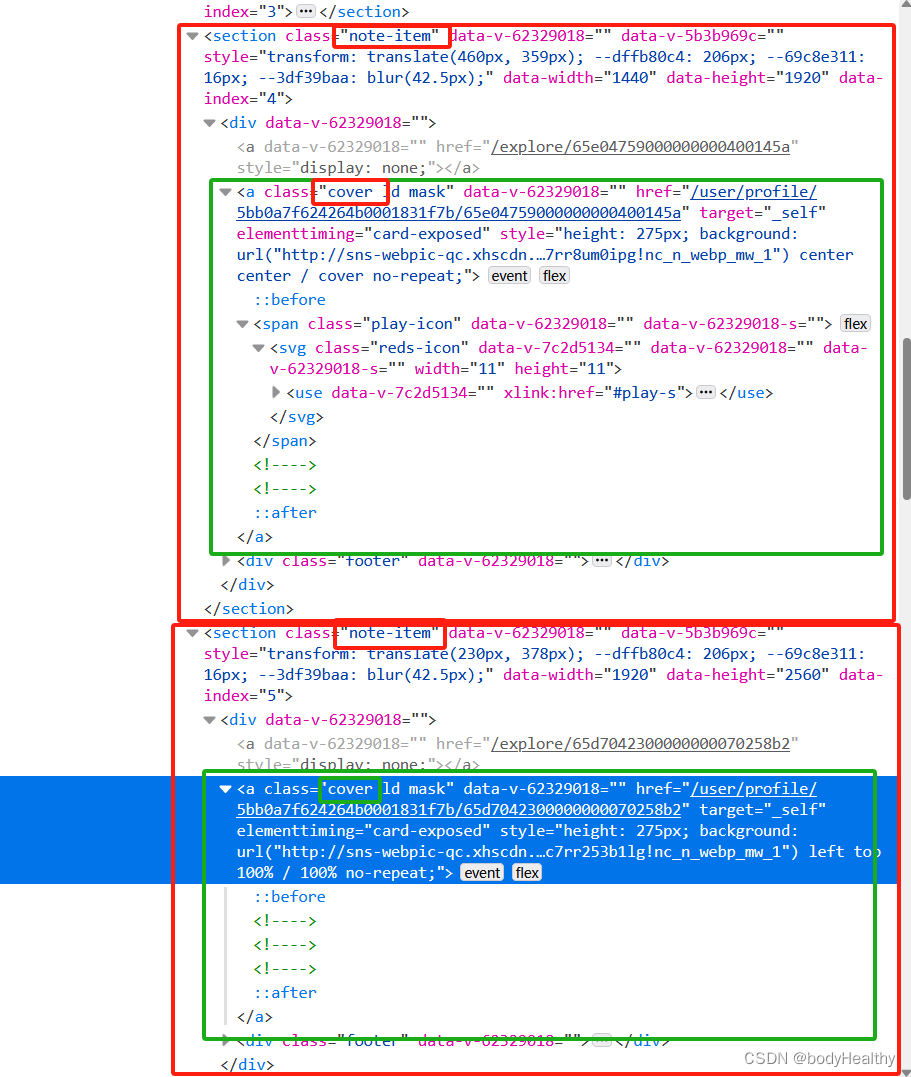
为了获取博主的全部作品数据,在登录的状态下访问目标博主页面,在控制台中注入JavaScript 脚本(在没有滚动过页面的情况下)。该脚本不断滚动页面到最底部,每次滚动一段距离后,都获取每一个作品的信息(通过a标签的 href 获取到作品页URL;通过判断a标签是否有一个 class='play-icon' 的后代元素来判断是图文还是视频类型的作品,如果有该标签就是视频作品,反之则是图文作品)。
将作品页 URL 作为键,作品是视频作品还是图文作品作为值,添加到 js 对象中。
显示完所有的作品,即滚动到最底部时,将所有获取到的作品信息导出为 txt 文件。
在控制台中执行:
// 页面高度
const vh = window.innerHeight
let work_obj = {}// 延迟
function delay(ms){ return new Promise(resolve => setTimeout(resolve, ms));
}async function action() { let last_height = document.body.offsetHeight;window.scrollTo(0, window.scrollY + vh * 1.5)ul = document.querySelector('#userPostedFeeds').querySelectorAll('.cover')ul.forEach((e,index)=>{// length 为 0 时是图片,为 1 时为视频work_obj[e.href] = ul[index].querySelector('.play-icon') ? 1 : 0})// 延迟500msawait delay(500);// console.log(last_height, document.body.offsetHeight)// 判断是否滚动到底部if(document.body.offsetHeight > last_height){action()}else{console.log('end')// 作品的数量console.log(Object.keys(work_obj).length)// 转换格式,并下载为txt文件var content = JSON.stringify(work_obj); var blob = new Blob([content], {type: "text/plain;charset=utf-8"}); var link = document.createElement("a"); link.href = URL.createObjectURL(blob); link.download = "xhs_works.txt"; link.click();}
}action()写出的 txt 文件内容如下:

3、在 Python 中读入该文件并做准备工作
# 获取当前时间
def get_current_time():now = datetime.now()format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")return format_time# 下载的作品保存的路径,以作者主页的 id 号命名
ABS_BASE_URL = f'G:\\639476c10000000026006023'# 检查作品是否已经下载过
def check_download_or_not(work_id, is_pictures):end_str = 'pictures' if is_pictures else 'video'# work_id 是每一个作品的目录,检查目录是否存在并且是否有内容,则能判断对应的作品是否被下载过path = f'{ABS_BASE_URL}/{work_id}-{end_str}'if os.path.exists(path) and os.path.isdir(path):if os.listdir(path):return Truereturn False# 下载资源
def download_resource(url, save_path):response = requests.get(url, stream=True)if response.status_code == 200:with open(save_path, 'wb') as file:for chunk in response.iter_content(1024):file.write(chunk)读入文件,判断作品数量然后进行任务分配:
# 读入文件
content = ''
with open('./xhs_works.txt', mode='r', encoding='utf-8') as f:content = json.load(f)# 转换成 [[href, is_pictures],[href, is_pictures],...] 类型
# 每一维中分别是作品页的URL、作品类型
url_list = [list(pair) for pair in content.items()]# 有多少个作品
length = len(url_list)if length > 3:ul = [url_list[0: int(length / 3) + 1], url_list[int(length / 3) + 1: int(length / 3) * 2 + 1],url_list[int(length / 3) * 2 + 1: length]]# 开启三个线程并分配任务for child_ul in ul:thread = threading.Thread(target=thread_task, args=(child_ul,))thread.start()
else:thread_task(url_list)若使用多线程,每一个线程处理自己被分配到的作品列表:
# 每一个线程遍历自己分配到的作品列表,进行逐项处理
def thread_task(ul):for item in ul:href = item[0]is_pictures = (True if item[1] == 0 else False)res = work_task(href, is_pictures)if res == 0: # 被阻止正常访问break处理每一项作品:
# 处理每一项作品
def work_task(href, is_pictures):# href 中最后的一个路径参数就是博主的idwork_id = href.split('/')[-1]# 判断是否已经下载过该作品has_downloaded = check_download_or_not(work_id, is_pictures)# 没有下载,则去下载if not has_downloaded:if not is_pictures:res = deal_video(work_id)else:res = deal_pictures(work_id)if res == 0:return 0 # 无法正常访问else:print('当前作品已被下载')return 2return 14、处理图文类型作品
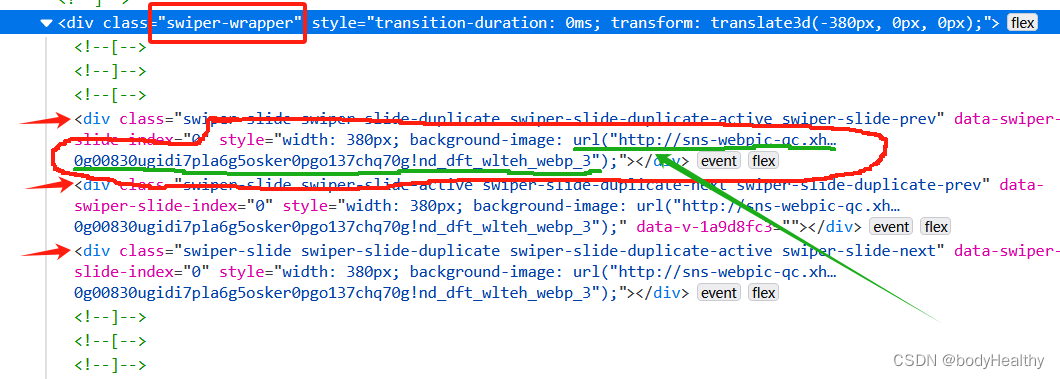
对于图文类型,每一张图片都作为 div 元素的背景图片进行展示,图片对应的 URL 在 div 元素的 style 中。 可以先获取到 style 的内容,然后根据圆括号进行分隔,最后得到图片的地址。
这里拿到的图片是没有水印的。
# 处理图片类型作品的一系列操作
def download_pictures_prepare(res_links, path, date):# 下载作品到目录index = 0for src in res_links:download_resource(src, f'{path}/{date}-{index}.webp')index += 1# 处理图片类型的作品
def deal_pictures(work_id):# 直接 requests 请求回来,style 是空的,使用 webdriver 获取当前界面的源代码temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(5)temp_driver.get(f'https://www.xiaohongshu.com/explore/{work_id}')sleep(1)try:# 如果页面中有 class='feedback-btn' 这个元素,则表示不能正常访问temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException: # 没有该元素,则说明能正常访问到作品页面WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'swiper-wrapper')))# 获取页面的源代码source_code = temp_driver.page_sourcetemp_driver.quit()html = BeautifulSoup(source_code, 'lxml')swiper_sliders = html.find_all(class_='swiper-slide')# 当前作品的发表日期date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()# 图片路径res_links = []for item in swiper_sliders:# 在 style 中提取出图片的 urlurl = item['style'].split('url(')[1].split(')')[0].replace('"', '').replace('"', '')if url not in res_links:res_links.append(url)#为图片集创建目录path = f'{ABS_BASE_URL}/{work_id}-pictures'try:os.makedirs(path)except FileExistsError:# 目录已经存在,则直接下载到该目录下download_pictures_prepare(res_links, path, date)except Exception as err:print(f'deal_pictures 捕获到其他错误:{err}')else:download_pictures_prepare(res_links, path, date)finally:return 1except Exception as err:print(f'下载图片类型作品 捕获到错误:{err}')return 1else:print(f'访问作品页面被阻断,下次再试')return 05、处理视频类型作品
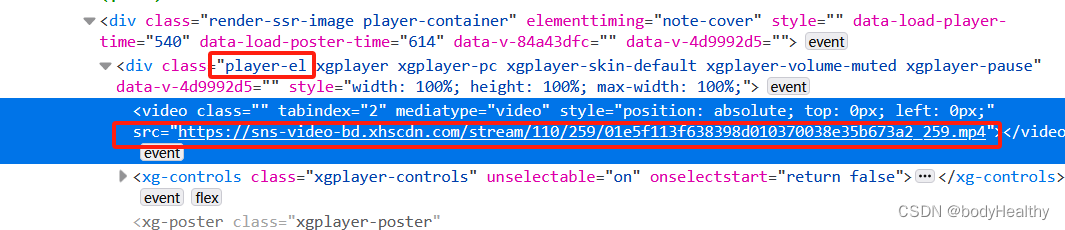
获取到的视频有水印。
# 处理视频类型的作品
def deal_video(work_id):temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(5)temp_driver.get(f'https://www.xiaohongshu.com/explore/{work_id}')sleep(1)try:temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException:WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'player-container')))source_code = temp_driver.page_sourcetemp_driver.quit()html = BeautifulSoup(source_code, 'lxml')video_src = html.find(class_='player-el').video['src']# 作品发布日期date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()# 为视频作品创建目录,以 作品的id号 + video 命名目录path = f'{ABS_BASE_URL}/{work_id}-video'try:os.makedirs(path)except FileExistsError:download_resource(video_src, f'{path}/{date}.mp4')except Exception as err:print(f'deal_video 捕获到其他错误:{err}')else:download_resource(video_src, f'{path}/{date}.mp4')finally:return 1except Exception as err:print(f'下载视频类型作品 捕获到错误:{err}')return 1else:print(f'访问视频作品界面被阻断,下次再试')return 06、异常访问而被中断的现象
频繁的访问和下载资源会被重定向到如下的页面,可以通过获取到该页面的特殊标签来判断是否被重定向连接,如果是,则及时中断访问,稍后再继续。
使用 webdriver 访问页面,页面打开后,在 try 中查找是否有 class='feedback-btn' 元素(即下方的 我要反馈 的按钮)。如果有该元素,则在 else 中进行提示并返回错误码退出任务。如果找不到元素,则会触发 NoSuchElementException 的错误,在 except 中继续任务即可。

try:temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException:# 正常访问到作品页面passexcept Exception as err:# 其他的异常return 1else:# 不能访问到作品页面return 07、完整参考代码
import json
import threading
import requests,os
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from datetime import datetime
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup# 获取当前时间
def get_current_time():now = datetime.now()format_time = now.strftime("_%Y-%m-%d__%H-%M-%S-%f__")return format_time# 下载的作品保存的路径,以作者主页的 id 号命名
ABS_BASE_URL = f'G:\\639476c10000000026006023'# 检查作品是否已经下载过
def check_download_or_not(work_id, is_pictures):end_str = 'pictures' if is_pictures else 'video'# work_id 是每一个作品的目录,检查目录是否存在并且是否有内容,则能判断对应的作品是否被下载过path = f'{ABS_BASE_URL}/{work_id}-{end_str}'if os.path.exists(path) and os.path.isdir(path):if os.listdir(path):return Truereturn False# 下载资源
def download_resource(url, save_path):response = requests.get(url, stream=True)if response.status_code == 200:with open(save_path, 'wb') as file:for chunk in response.iter_content(1024):file.write(chunk)# 处理图片类型作品的一系列操作
def download_pictures_prepare(res_links, path, date):# 下载作品到目录index = 0for src in res_links:download_resource(src, f'{path}/{date}-{index}.webp')index += 1# 处理图片类型的作品
def deal_pictures(work_id):# 直接 requests 请求回来,style 是空的,使用 webdriver 获取当前界面的源代码temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(5)temp_driver.get(f'https://www.xiaohongshu.com/explore/{work_id}')sleep(1)try:temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException:WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'swiper-wrapper')))source_code = temp_driver.page_sourcetemp_driver.quit()html = BeautifulSoup(source_code, 'lxml')swiper_sliders = html.find_all(class_='swiper-slide')# 当前作品的发表日期date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()# 图片路径res_links = []for item in swiper_sliders:url = item['style'].split('url(')[1].split(')')[0].replace('"', '').replace('"', '')if url not in res_links:res_links.append(url)#为图片集创建目录path = f'{ABS_BASE_URL}/{work_id}-pictures'try:os.makedirs(path)except FileExistsError:# 目录已经存在,则直接下载到该目录下download_pictures_prepare(res_links, path, date)except Exception as err:print(f'deal_pictures 捕获到其他错误:{err}')else:download_pictures_prepare(res_links, path, date)finally:return 1except Exception as err:print(f'下载图片类型作品 捕获到错误:{err}')return 1else:print(f'访问作品页面被阻断,下次再试')return 0# 处理视频类型的作品
def deal_video(work_id):temp_driver = webdriver.Chrome()temp_driver.set_page_load_timeout(5)temp_driver.get(f'https://www.xiaohongshu.com/explore/{work_id}')sleep(1)try:# 访问不到正常内容的标准元素temp_driver.find_element(By.CLASS_NAME, 'feedback-btn')except NoSuchElementException:WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, 'player-container')))source_code = temp_driver.page_sourcetemp_driver.quit()html = BeautifulSoup(source_code, 'lxml')video_src = html.find(class_='player-el').video['src']# 作品发布日期date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()# 为视频作品创建目录path = f'{ABS_BASE_URL}/{work_id}-video'try:os.makedirs(path)except FileExistsError:download_resource(video_src, f'{path}/{date}.mp4')except Exception as err:print(f'deal_video 捕获到其他错误:{err}')else:download_resource(video_src, f'{path}/{date}.mp4')finally:return 1except Exception as err:print(f'下载视频类型作品 捕获到错误:{err}')return 1else:print(f'访问视频作品界面被阻断,下次再试')return 0# 检查作品是否已经下载,如果没有下载则去下载
def work_task(href, is_pictures):work_id = href.split('/')[-1]has_downloaded = check_download_or_not(work_id, is_pictures)# 没有下载,则去下载if not has_downloaded:if not is_pictures:res = deal_video(work_id)else:res = deal_pictures(work_id)if res == 0:return 0 # 受到阻断else:print('当前作品已被下载')return 2return 1def thread_task(ul):for item in ul:href = item[0]is_pictures = (True if item[1] == 0 else False)res = work_task(href, is_pictures)if res == 0: # 被阻止正常访问breakif __name__ == '__main__':content = ''with open('xhs_works.txt', mode='r', encoding='utf-8') as f:content = json.load(f)url_list = [list(pair) for pair in content.items()]length = len(url_list)if length > 3:ul = [url_list[0: int(length / 3) + 1], url_list[int(length / 3) + 1: int(length / 3) * 2 + 1],url_list[int(length / 3) * 2 + 1: length]]for child_ul in ul:thread = threading.Thread(target=thread_task, args=(child_ul,))thread.start()else:thread_task(url_list)
相关文章:
python爬虫实战——小红书
目录 1、博主页面分析 2、在控制台预先获取所有作品页的URL 3、在 Python 中读入该文件并做准备工作 4、处理图文类型作品 5、处理视频类型作品 6、异常访问而被中断的现象 7、完整参考代码 任务:在 win 环境下,利用 Python、webdriver、JavaS…...
Linux信号机制
目录 一、信号的概念 二、定时器 1. alarm函数 2. setitimer函数 3.signal和sigaction函数 三、使用SIGCHLD信号实现回收子进程 一、信号的概念 概念:信号是在软件层次上对中断机制的一种模拟,是一种异步通信方式 。所有信号的产生及处理全部都是由内…...
区块链技术中的共识机制算法:以权益证明(PoS)为例
引言: 在区块链技术的演进过程中,共识机制算法扮演着至关重要的角色。除了广为人知的工作量证明(PoW)外,权益证明(Proof of Stake,PoS)也是近年来备受关注的一种共识算法。 …...

19113133262(微信同号)【征稿进行时|见刊、检索快速稳定】2024年区块链、物联网与复合材料与国际学术会议 (ICBITC 2024)
【征稿进行时|见刊、检索快速稳定】2024年区块链、物联网与复合材料与国际学术会议 (ICBITC 2024) 大会主题: (主题包括但不限于, 更多主题请咨询会务组苏老师) 区块链: 区块链技术和系统 分布式一致性算法和协议 块链性能 信息储存系统 区块链可扩展性 区块…...

Doris:使用表函数explode实现array字段列转行
文章目录 使用场景相关知识点介绍explodesplit_by_stringlateral view 具体实现和SQLlateral view explode列转行SPLIT_BY_STRING拆分字符串为数组element_at获取数据创建视图 使用场景 我们的大数据数据库,由clickhouse换成了doris我们有一张路口指标表࿰…...
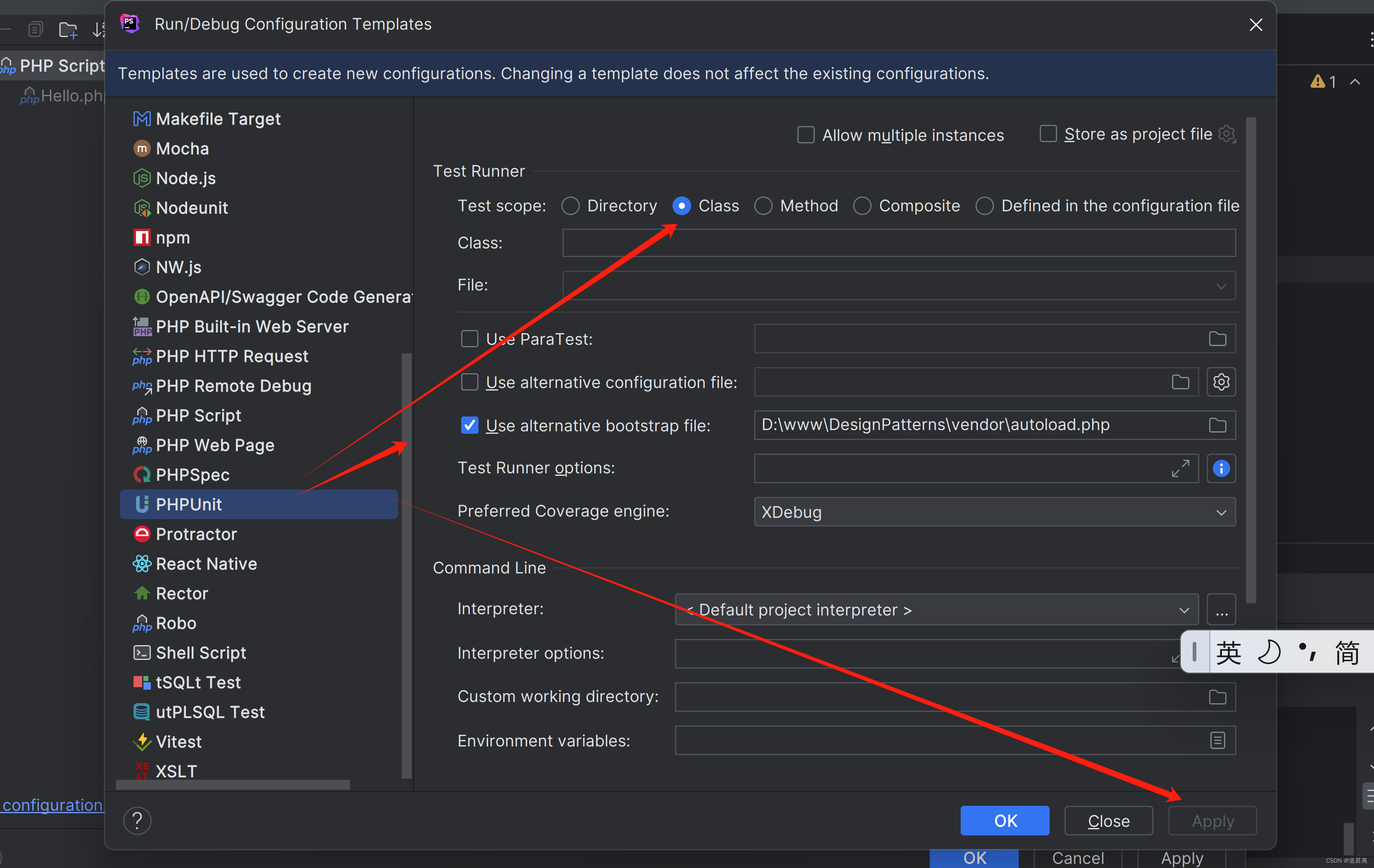
原生php单元测试示例
下载phpunit.phar https://phpunit.de/getting-started/phpunit-9.html 官网 然后win点击这里下载 新建目录 这里目录可以作为参考,然后放在根目录下 新建一个示例类 <?phpdeclare(strict_types1);namespace Hjj\DesignPatterns\Creational\Hello;class He…...
计算机毕业设计-springboot+vue前后端分离电竞社交平台管理系统部分成果分享
4.5系统结构设计 本系统使用的角色主要有系统管理员、顾客、接单员,本系统为后台管理系统,游客用户可以经过账号注册,管理员审核通过后,用账号密码登录系统,查看后台首页,模块管理(顾客信息&am…...

Stable Diffusion 详解
整体目标 文本生成图片;文本图片生成图片 网络结构 CLIP的文本编码器和图片生成器组成图像生成器,输入是噪声经过UNet得到图像特征,最后解码得到图像 前向扩散 模型直接预测图片难度比较大,所有让模型预测噪音然后输入-噪音…...

Go函数全景:从基础到高阶的深度探索
目录 一、Go函数基础1.1 函数定义和声明基础函数结构返回值类型和命名返回值 1.2 参数传递方式值传递引用传递 二、Go特殊函数类型2.1 变参函数定义和使用变参变参的限制 2.2 匿名函数与Lambda表达式何为匿名函数Lambda表达式的使用场景 2.3 延迟调用函数(defer&…...
)
探秘Nutch:揭秘开源搜索引擎的工作原理与无限应用可能(一)
本系列文章简介: 本系列文章将带领大家深入探索Nutch的世界,从其基本概念和架构开始,逐步深入到爬虫、索引和查询等关键环节。通过了解Nutch的工作原理,大家将能够更好地理解搜索引擎背后的原理,并有能力利用Nutch构建…...
MySQL 数据库 下载地址 国内阿里云站点
mysql安装包下载_开源镜像站-阿里云 以 MySQL 5.7 为例 mysql-MySQL-5.7安装包下载_开源镜像站-阿里云...
)
【25届秋招备战C++】算法篇-贪心算法(Greedy)
【25届秋招备战C】算法篇-贪心算法 一、简介二、解题思路三、应用场景四、模板函数五、参考 一、简介 一种在每次决策时,总是采取在当前状态下的最好选择,从而希望导致结果是最好或最优的算法。通常用于解决一些最优化问题,如找零问题、霍夫…...
scrcpy远程投屏控制Android
下载 下载后解压压缩包scrcpy-win64-v2.4.zip scrcpy连接手机 1. 有线连接 - 手机开启开发者选项,并开启USB调试,连接电脑,华为手机示例解压scrcpy,在scrcpy目录下打开终端,(或添加scrcpy路径为环境变…...

找机厅 洛谷 BFS
P10234 [yLCPC2024] B. 找机厅 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) #include<bits/stdc.h> #define pii pair<int,int> #define fr first #define sc second using namespace std; string maze[2000]; int vis[2000][2000]; char dirs[2005][2005]; st…...
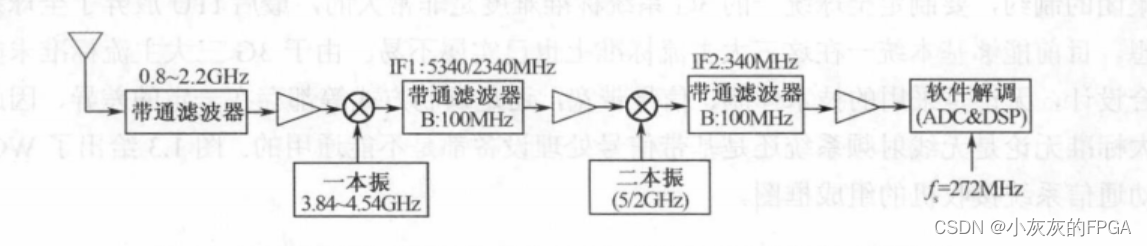
软件无线电系列——模拟无线电、数字无线电、软件无线电
本节目录 一、模拟无线电 二、数字无线电 1、窄带数字无线电 2、宽带数字无线电 三、软件无线电本节内容 一、模拟无线电 20世纪80年代的模拟体制(美国的AMPS/欧洲的TACS)被称为第一代移动通信,简称1G,主要目标是为在大范围内有限的用户提供移动电话服务。最主要的…...
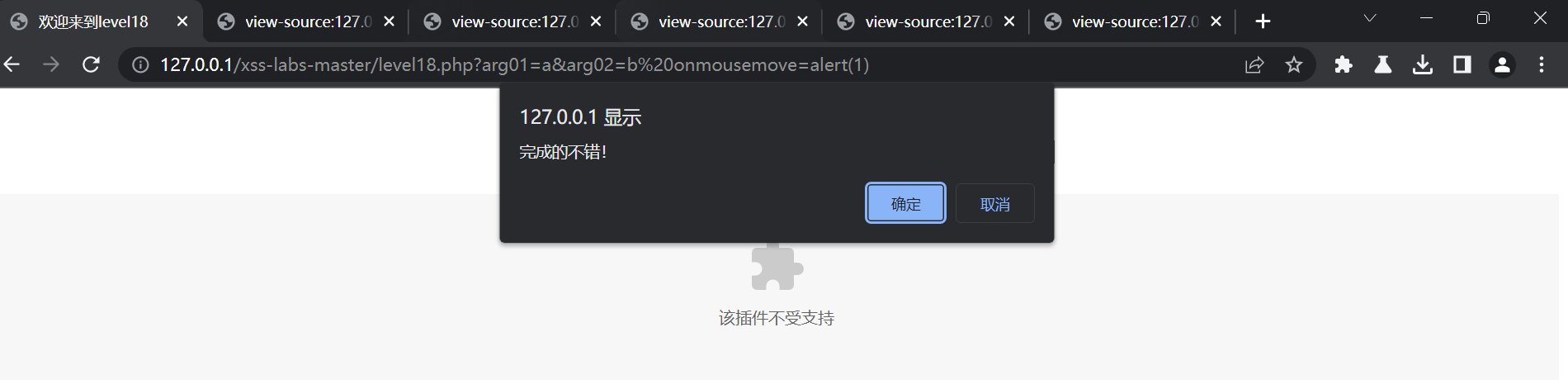
XSS_lab(level11-level18)
level11: 还是url这里,输入:<script>alert(1)</script> 与上一题相似 构建:?t_link1&t_history2&t_sort3&t_ref4 我们发现t_sort是可用的 构建:?t_sort1" type"button" οnclickalert(1) // 把双引号过滤了 这里无法使用实体编码…...

【git】常用操作
基础操作 git init 初始化仓库 要使用 Git 进行版本管理,必须先初始化仓库, 执行了 git init命令的目录下就会生成 .git 目录。这个 .git 目录里存储着管理当前目录内容所需的仓库数据 git status 查看仓库状态 工作树和仓库在被操作的过程中࿰…...

蓝桥杯第十一届电子类单片机组程序设计
目录 前言 单片机资源数据包_2023(点击下载) 一、第十一届比赛原题 1.比赛题目 2.赛题解读 1)计数功能 2)连续按下无效按键 二、部分功能实现 1.计数功能的实现 2.连续按下无效按键的处理 3.其他处理 1)对于…...

Java中文乱码问题解析与解决方案
在日常工作中,我们经常会遇到中文乱码的问题。乱码问题不仅影响用户体验,还可能导致数据丢失或解析错误。因此,了解和掌握中文乱码问题的原因和解决方案,对于Java开发者来说至关重要。本文将分析常见的Java中文乱码场景࿰…...
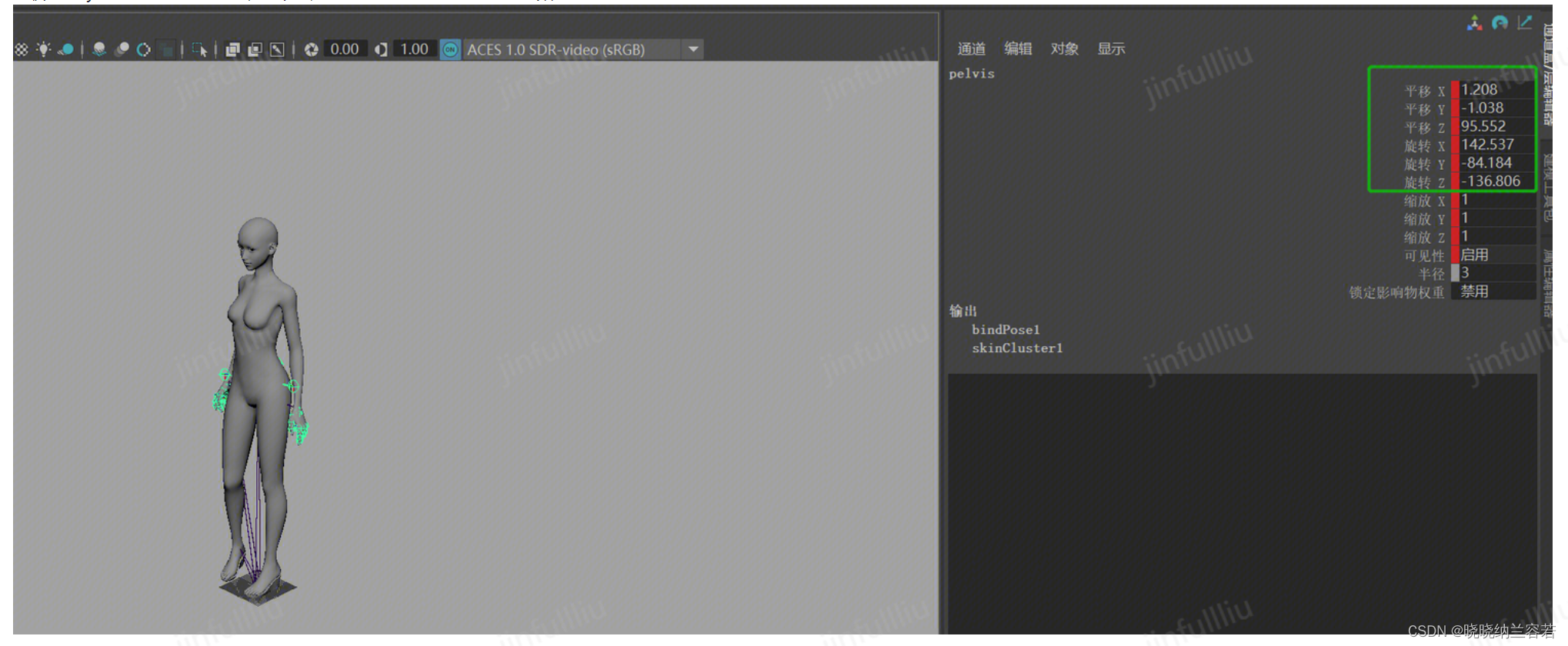
AIGC笔记--Maya提取和修改FBX动作文件
目录 1--Maya数据解析 2--FBX SDK导出6D数据 3--6D数据映射和Maya可视化 完整项目代码:Data-Processing/FBX_SDK_Maya 1--Maya数据解析 在软件Maya中直接拖入FBX文件,可以播放和查看人体各个骨骼关节点的数据: 对于上图来说,…...

Java 求职面试:微服务架构与安全框架的探索
Java 求职面试:微服务架构与安全框架的探索 Java 求职面试:微服务架构与安全框架的探索在一次互联网大厂的面试中,燕双非,一个搞笑的程序员,迎来了他的挑战。他坐在面试官面前,心里忐忑不安,…...
)
Codex CLI 接 Gemini 3.5 Flash 实测:代码生成、推理速度、价格三维度横评(2026)
上周 Google 发了 Gemini 3.5 Flash,我当天晚上就拿 Codex CLI 接上跑了几个项目里的真实任务。原因很简单——我们团队最近 token 开销涨得太快,老板让我找个"又快又便宜还不太拉胯"的模型顶日常编码场景。Claude Sonnet 4.6 质量没话说但贵&…...

三星固件下载神器Bifrost:跨平台一站式解决方案深度解析
三星固件下载神器Bifrost:跨平台一站式解决方案深度解析 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost Bifrost是一款基于Kotlin Multiplatform构建…...

AI调用BurpSuite实现可审计漏洞检测闭环
1. 这不是“AI安全工具”的营销话术,而是一套可落地的漏洞发现流水线最近帮一家做金融SaaS的客户做渗透测试流程优化,他们原来的方案是:每周安排2名中级渗透工程师,用BurpSuite手动跑一遍核心业务流,再人工翻看Proxy历…...

Rshell框架实战:红队内网渗透的信道管理与双平台协同
1. 这不是“教你怎么黑”,而是还原一次真实红队作业的完整切片Rshell框架——这个名字在渗透测试圈子里不算陌生,但真正把它用透、用稳、用出生产级效果的人,远比想象中少。我见过太多人把Rshell当成一个“带图形界面的msfvenomnc组合包”&am…...

从零开始掌握ShiroAttack2:5步搞定Shiro反序列化漏洞利用
从零开始掌握ShiroAttack2:5步搞定Shiro反序列化漏洞利用 【免费下载链接】ShiroAttack2 shiro反序列化漏洞综合利用,包含(回显执行命令/注入内存马)修复原版中NoCC的问题 https://github.com/j1anFen/shiro_attack 项目地址: https://gitc…...

矿道遮挡重度干扰,无感定位碾压UWB穿透弱、断链频繁痛点
矿道遮挡重度干扰,无感定位碾压UWB穿透弱、断链频繁痛点矿山井下矿道蜿蜒曲折、岩壁岩体层层阻隔,支护钢架、采掘设备密集排布,叠加粉尘雾气、巷道拐角、纵深盲区等复杂条件,形成重度遮挡强干扰作业环境。数字孪生与视频孪生技术深…...

对比按Token计费与传统套餐在项目中的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按Token计费与传统套餐在项目中的成本体感差异 在开发项目中引入大模型能力时,成本控制是团队必须面对的现实问题。…...

大麦抢票终极指南:告别手速焦虑,轻松锁定心仪演出门票
大麦抢票终极指南:告别手速焦虑,轻松锁定心仪演出门票 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 面对热门演唱会门票&q…...

ADAS系统设计全解析:从传感器融合到域控制器实战
1. 项目概述与行业背景最近几年,但凡和汽车沾点边的行业,都绕不开“智能化”这三个字。作为一名在汽车电子和嵌入式系统领域摸爬滚打了十多年的工程师,我亲眼见证了从简单的倒车雷达,到如今能自动跟车、紧急刹车的ADAS系统&#x…...