计算机毕业设计-基于大数据技术下的高校舆情监测与分析
收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、研究背景与意义
- 1.1背景与意义
- 1.2 研究内容
- 二、舆情监测与分析的关键技术
- 2.1 robot协议对本设计的影响
- 2.2 爬虫
- 2.2.1 工作原理
- 2.2.2 工作流程
- 2.2.3 抓取策略
- 2.3 scrapy架构
- 2.3.1 scrapy:开源爬虫架构
- 2.3.2 scrapy框架结构
- 2.3.3 两种继承,两种爬虫模式
- 三、需求分析和系统总体架构
- 3.2 系统需求分析
- 3.2.1 业务需求分析
- 3.2.2 功能性需求分析
- 3.3 系统总体架构
- 3.3.1 爬取对象分析
- 3.3.2 模块设计
- 四、系统实现
- 4.1爬虫模块
- 4.1.1 环境搭建与前期分析
- 4.1.2 系统爬取
- 4.2数据分析模块
- 4.3数据可视化模块
- 4.3.1词云展示
- 4.3.2热点话题词频
- 4.3.3贴吧评论数量区间
- 五、 总结
概要
随着科技的飞跃式发展,通讯手段与交流方式不断更新,网络作为信息通讯的重要媒介,成为了高校学生沟通交流、发表观点的重要平台。高校学生通过利用网络公民自发形成的舆论圈,交流更为便捷,传播更为多元,使得高校舆情具有了随意性、直接性、偏差性、突发性四大特征,对社会中的舆情传播产生的影响不可小觑,所以高校需要及时掌握学生舆情的发展动态,可以及时做出有效的监管和正确的引导。
通过对高校网络舆情监测的实际需求分析和概要分析,本文在现有国内外舆情监测的基础上,构建了以python爬虫技术为基础的高校舆情监测与分析系统,并且根据高校管理人员的实际需求对系统做了详细的分析与设计,通过网络讨论平台获取大量舆情数据进行整合分析,从而实现多态势舆情的实时监控和舆情数据分析的可视化,其中包含媒体分析、热度分析、受众分析等。舆情监测与分析系统包括了四个模块:舆情关键字管理模块、舆情分析模块、舆情结果可视化模块、舆情报告模块。从舆情关键词建立到舆情报告的展示,高校舆情监测与分析系统将为高校管理人员提供准确高效的舆情发展态势,辅助高校了解学生内心动态,及时发展舆情的产生,调整高校的管理政策,促进学生的健康成长和高校的稳健发展。
关键词:高校舆情;网络爬虫;舆情监测;舆情分析
一、研究背景与意义
当互联网技术逐渐渗透进入社会的各种领域,已然成为社会中不可或缺的一部分。人们获取信息的途径以及日常交流也逐渐由线下转为线上,使得信息的传播速度呈指数式增长,同时随着生活条件的提升和互联网工具的普及,网民数量急剧增长,年龄趋于年轻化。其中作为生活得到初步自由的高校学生,他们是在网络上发表意见和关注社会热点的重要群体,因而高校学生对于网络舆情的爆发和推动起到关键性作用。由于高校学生涉世未深,长期处于校园生活,对社会热点的看法容易受到蛊惑和欺骗,从而在网络上肆意表达自己的情绪,对社会和学校造成严重的后果。随着大数据时代的到来,应用大数据技术分析网络舆情发展走向,遏制舆情的产生,是高校管理部门对舆情监测与分析的研究方向。
1.1背景与意义
随着信息时代的崛起,网络对人们的作用越来越大。几年之间,信息的传播还依靠传统的报纸、广播等方式传播,现如今网络时代的快速发展使得互联网成为信息最主流的传播途径。截止2019年6月,我国的网民规模高达8.54亿。人们可以通过网络平台及时获取信息,并且快速对信息做出反馈 舆情在网络中产生的方式,就是人们通过网络平台针对社会热点问题发表自己的看法和宣泄情绪的过程。网络舆情的要素包括:互联网、网民、热点事件、互动传播、情感。互联网舆情信息以公共媒体、自媒体为载体,围绕某个社会热点事件,通过网络传播的迅速性大量聚集情感信息,对相关管理部门产生一定的影响。
网络媒体具有极强的自由性,目前网络监管机制尚不完善,网民利用网络自由和可匿名的特点,肆意的在网络平台发表观点、宣泄情绪,使得网民的表达增加真实、顺畅。对于传统的信件报纸而言,网络可以直观的、迅速的看到社会问题,表达人们的心声,分享他人的意见。同时,网络又具有极强的交互性,网民通过参与社会热点问题的讨论或者向有关部门的反映,网民在交流互动的过程中,难免有时无法控制住自己的情绪,导致网络暴力事件频发,成为网络安全的一大隐患。由于消息是由网民自发性传播扩散,其中掺杂着浓厚的感情色彩,在传播的过程中背离信息原有的真实性,甚至有些为了达到目的故意歪曲事实,随着传播过程的积累,往往会形成强大的舆论,对社会甚至国家产生重大的影响,从而如何利用好网络弘扬社会正气,完善舆情监测分析系统,对舆情的产生提早发现,管理人员及时制定相应的解决方案,是新时代下国家的重点任务。对于高校来说,第一时
间监测到舆情发展动向,是高校掌握学生动态的重要因素,也是对学生的心理需求进行相应的疏导的首要前提。
1.2 研究内容
高校学生作为信息爆炸时代舆情产生和传播的主力军,对舆情的走向起到关键性作用,所以建立高校舆情监测与分析系统成为当下首要的任务,尤其是在当下信息多元化的时代。因此本文针对以上问题,设计一个高校的舆情监测与分析系统的模型和框架,并对模块和组件之间的关系完善了其主要功能。本文完成的工作包含以下内容:
1.通过对多所高校的管理人员的询问调查,在图书馆翻阅相关书籍,对高校舆情监测与分析系统的需求做出了分析,建立了一套高校舆情监测的系统框架,并且使用信息系统中常见的模块化思想对系统做出设计。
2.根据需求分析,对高校舆情监测与分析系统作了详细设计,对数据采集模块和数据分析模块做了详细的设计。
3.通过对高校学生的了解,贴吧是学生讨论、发表观点最集中的平台,对高校贴吧论坛进行帖子的规模爬取,得到数据分析所需要的数据。
4.对所得的数据进行敏感词分析,得到关键词在贴吧中的出现频率,进而反应某些舆情的出现。
本文的整体结构安排由五章构成,各章节安排如下。
第一章:绪论,阐述高校舆情监测与分析研究的背景,网络舆情中高校学生所占据的重要性,并阐述了舆情监测与分析国内外的研究现状。
第二章:高校舆情监测与分析的相关介绍,并对相关技术以及算法进行了介绍。如爬虫架构scrapy等。
第三章:系统需求分析与系统架构,通过对需求的分析和架构的设计,明确了系统的模块构成。然后对各个模块进行了介绍。
第四章:根据高校舆情监测与分析系统,对高校舆情检测结果的分析,展示了高校舆情监测与分析系统的部分界面。
第五章:总结与展望。总结了系统设计过程中的一些所思所想。然后对本系统的进一步研究方向进行了展望。
二、舆情监测与分析的关键技术
2.1 robot协议对本设计的影响
robot协议的全称为“网络爬虫排除标准”,网络站点通过Robot协议告知爬虫此站的网页哪些能进行爬取,哪些不能爬取。
robots.txt文件为robot协议最根本的表现。将网站视作交通信号的话,robots.txt则是某些路口的红绿灯“红灯禁行”或“绿灯可行”的信号,爬虫就是通过路口的汽车,根据信号灯的指示通行。
robot协议在法律中也没有强制的规定,更没有正式的协议表明,他只是爬虫技术中约定好的一种内部协议,更像是一种行业规范,爬取与被爬取者需要自觉遵守的协议[13]。当今社会大多数互联网企业都在遵循robot协议,很好的体现出互联网行业的一种契约精神。
如果此系统遵循robot协议,则此舆情监测系统将不能爬取到完整的数据。由于此爬虫系统不是用于商业利益而开发设计,仅仅作为研究学习使用,此系统为了数据的完整性获取,此爬虫系统需要不遵守robot协议。在scrapy架构中的setting.py文件中设置即可。
2.2 爬虫
2.2.1 工作原理
爬虫的含义是指一段自动的向互联网上某些网页发出请求并接收响应,根据一定规则继续爬取信息或从响应中提取出有用的信息的一段程序。爬虫的运行中会涉及到:网络请求、网络解析,其可以主要运行依托于以下几种技术。
URL(Universal Resource Identifier):通用资源标识符,网络中每个资源都是由一个唯一的URL确定,根据URL也可以定位到网络中的唯一一个资源。
HTTP协议:超文本传输协议,此协议是网络中应用最为常见的一种协议,HTTP协议提供了发布与接收HTML页面的方法,由HTML语言编写的网页代码可由浏览器渲染成结构清晰的页面。
2.2.2 工作流程
一个传统的爬虫往往是从一批URL开始的,爬虫先请求这批URL的网页内容,得到正确的应答后,对页面内容进行解析,然后根据预先设计好的规则从网页中找到某些URL加入到请求队列中,或者从网页中定位到所需要的信息,并将信息进行封装保存。循环往复,不断从请求队列中提取URL进行请求,直至请求队列为空或某些其他情况导致爬虫程序终止为止
2.2.3 抓取策略
爬虫抓取大致可分为两种:横向、纵向,也可以称为深度优先算法与广度优先算法。
横向爬虫抓取是图算法中最常见的也是最重要的,更是许多其他图算法策略的原型。横向爬虫抓取的设计与实现较简单,从原始URL出发,寻找距离原始URL最近的URL,加入请求队列进行搜索。在本系统中,以百度贴吧为例,横向爬虫抓取是从列表第一页开始,根据输入的爬取页数不断地的向后翻页,把下一页的URL加入到等待爬取的队列当中。
纵向爬虫抓取的策略与横向爬虫抓取相反,其从起始页开始,层层深入,一直寻找到没有更深的节点,再通过层层递归返回起始页,搜索完毕所有的节点。在本系统中,纵向爬虫抓取即指从列表的第一页开始,获取所设定的页数详情页的URL,加入到待爬取队列中等待抓取。由于百度贴吧的网页特性,从一个详情页无法直接到达另外一个详情页,故此纵向深度为2。
本系统需要完成的是双向爬取,即从列表页第一页开始,一次性爬取到下一页的URL和每一页中详情页的URL,直至爬取完所设定的爬取页数。
2.3 scrapy架构
2.3.1 scrapy:开源爬虫架构
scrapy爬虫框架,是python开发的开源爬虫框架,具有抓取效率高、易于使用、和开发迅速的特点,用于爬取互联网中的web站点并从网页中提取结构化的数据。scrapy是一个爬虫框架,而且开源,任何人都可以根据需求对其进行修改。本系统采用scrapy框架的原因如下:
1.scrapy是基于Twisted的一种框架。Twisted框架是一个异步IO框架。由于Twisted具有特性,scrapy框架内置实现了单机多线程,十分有效的提升了性能。应用此框架,程序的执行流将被外部事件所影响。由于他的此种特性,scrapy不支持分布式爬虫,如要实现分布式,需要使用其他的库。
2.scrapy的扩展功能非常多。在他的框架中包含了众多的模块,几乎包含爬虫技术需要处理的问题,多数扩展的功能都可以在下载第三方库中实现,开发效率极高。
3.scrapy包含了两种定位方式css和XPath,可以使爬取到的页面进行元素的定位,可以对网页的解析效率提升很多。
4.scrapy框架开发容易。使用Scrapy框架完成一个爬虫系统的工作量可以小很多,他其中包含了众多的第三方库,每个库的相互协作使得该框架的性能十分突出。
2.3.2 scrapy框架结构
scrapy框架结构如图2.1所示。
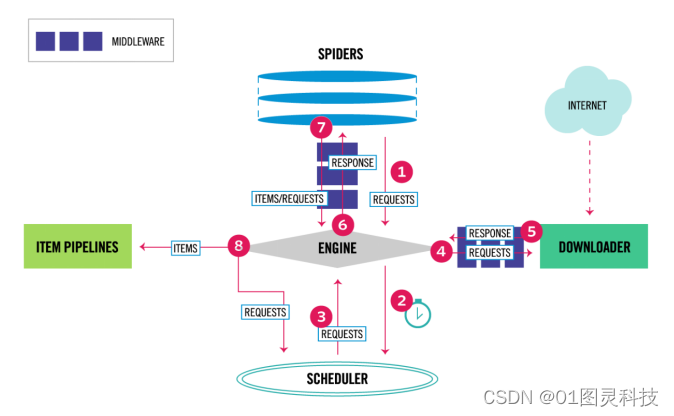
图2.1 scrapy框架结构
整个scrapy框架由中心引擎所控制。中心引擎是管理每个子功能协同工作的核心所在,他管理着在爬取中数据的流动,在不定事件发生的时侯控制整个框架。数据爬取时,首先中心引擎向调度器索要需要爬取数据的链接,调度器将请求等待队列中的URL交给中心引擎,中心引擎将URL分给下载器,下载器则向这些网页发起请求。下载器取得这些网页的返回以后,则交给中心引擎,中心引擎将其交给Spiders。根据网页的不同返回值,找到适合爬取该网页的爬虫代码,对网页的返回数据进行提取与解析。提取的网页数据被送到pipeline进行下一步处理,pipeline对网页数据进行打包,完成对数据的持久化操作,可以存入数据库或着存入指定文件下。完整的爬取过程依次进行,直至调度器下的请求队列中没有需要请求的页面,爬虫系统将会停止运行。
2.3.3 两种继承,两种爬虫模式
Scrapy爬虫框架下,每个scrapy爬虫框架提供的爬虫类都需要被相应的Spider所继承,不同的爬虫类都是不同的爬取方式,下面两个是最常用的爬虫类。本系统将主要采用第一种Spider,只有少数地方使用到了第二种爬虫类。
第一种类称为scrapy.Spider。Spider是相对最简单的爬虫类。下面编写的spider类必须每个都要继承自该类。Spider类是一个普通的爬虫类,一般用来请求特定的start_urls或调用start_requests方法,并根据返回的结果选择不同的parse方法解析数据。
该类中有以下几个关键的参数:
name,字符串类型,确定一个爬虫的唯一标识,在使用爬虫系统时必须使用该名字,所以在爬虫中,名字必须保证唯一,name是整个爬虫框架中确定后就不能修改的一个字段。
allowed_domains,列表类型,当OffsiteMiddleware是开启状态时,要是URL不在该列表内,该URL也不会被跟进。
start_urls:列表类型,如果没有特定的起始URL,此列表中的URL作为起始URL,提供给中心引擎。爬取系统的URL将从此处开始爬取。
start_request():此方法须返回一个可迭代的对象,使用yield返回最为常见。该返回的对象包括了spider用于爬取的第一个request请求,当爬虫系统启动且未指定起始URL时,系统将自动使用此方法,开始请求URL。
parse():此函数是爬虫类中最为关键的方法,同时也是爬虫系统逻辑实现的关键地方。response没有指定回调函数时,parse是scrapy处理获取到的网页数据的默认方法。网页将在其中被处理,被解析,并通过定位到的数据以生成器的形式返回给管道处理。
第二种为CrawlSpider。若爬取网页为一般网页时,使用Spider最为便捷,如果需要完成对URL的进一步解析,则需继承该类。CrawlSpider类是爬取全站的关键工具,可以从起始页面开始不断爬取本站点的数据,如不加限制,将可以爬取整个站点的所有网页。
该类最关键的字段为:
rules:包括了一个或多个的Rule集合,每个Rule对爬取网站的动作进行了特定表现。 Rule中的多个参数共同筛选,筛选出匹配的URL进一步解析。其中重要的参数有:link_extractor,负责从页面中提取a标签下的href链接;follow,布尔类型,定义了对爬取到的URL是否需要进一步解析。
当使用Spider类时,通过parse与start_request两种方法的相配合,可实现对网页的纵向爬取,通过start_urls列表,可依据URL的直接指定横向爬取方法。使用CrawlSpider时,可直接由列表页的首页开始爬取,依据制定的爬取规则进行横向与纵向同时爬取。使用第一种方式进行代码编写,便于维护,逻辑较为简单,可实现多种功能,所以本系统大部分采用第一种爬取逻辑进行爬虫模块的编写。
三、需求分析和系统总体架构
3.2 系统需求分析
3.2.1 业务需求分析
本文以高校贴吧作为信息源进行分析研究,以爬取到贴吧内容作为系统的初步目标,由于贴吧内容繁杂,反爬虫机制健全,无法通过短时间内获取到一定规模的有效信息,故本系统可以根据需求任意选择爬取的贴吧名字和爬取的页数,根据舆情发展时间和热度的高低设定贴吧爬取范围。主要工作放在信息分析方面,通过数据展示出高校学生最为关心的问题,从而提前预知高校舆情的走向。
由于本系统的主要实现功能是围绕高校舆情监测与分析展开,所以本系统应该完成的关键功能包括以下方面的内容:
1.高校贴吧的帖子信息
该系统本身不会生成数据信息,系统所需的数据信息来源于高校贴吧中学生的发帖与评论。但是由于贴吧的数据库并不向用户开放,所以要想得到所需要的数据需要利用爬虫技术对高校贴吧中的原始数据进行爬取,为系统进行数据分析创造条件。根据舆情监测者的需求选择爬取的贴吧名字与爬取帖子的页数。
2.数据进行分析并且将数据可视化
3.2.2 功能性需求分析
系统通过对于贴吧数据的水平广度爬取。其中水平爬取是将贴吧网页进行广度优先爬取操作,可以实现在网页的第一层就可获得所需要的数据,很大程度上提升了数据爬取的效率。由于百度贴吧对反爬虫机制做得相对完善,反爬虫机制对于一个主机IP频繁访问和流量访问进行监控,从而达到对爬虫的限制,一旦对本机IP进行封锁后,此IP将不能继续进行数据的爬取,所以此系统必须要克服反爬虫机制的限制,具备在反爬虫机制下爬取数据的能力。
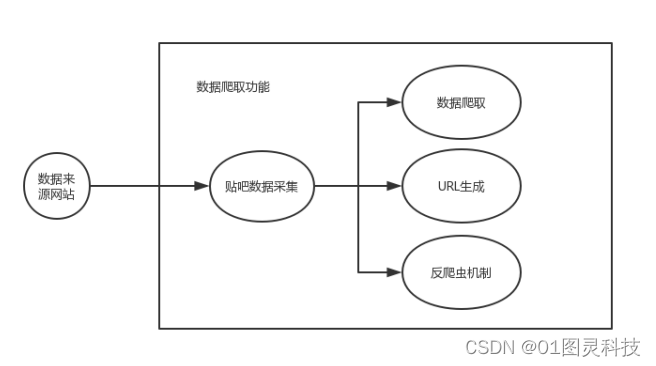
图3.1 数据爬取功能
系统分析数据功能是指将爬取数据得到的帖子以及评论信息进行处理,实现数据的可视化功能。数据处理首先除去数据中无效的数据,将有效的数据按照类别特征转化为相应的特征数值,筛选掉冗余的数据。其次处理干净的数据通过图表的形式,将贴吧中有效的信息进行挖掘,从而达到用户可读的可视化效果,给予用户提供参考依据。
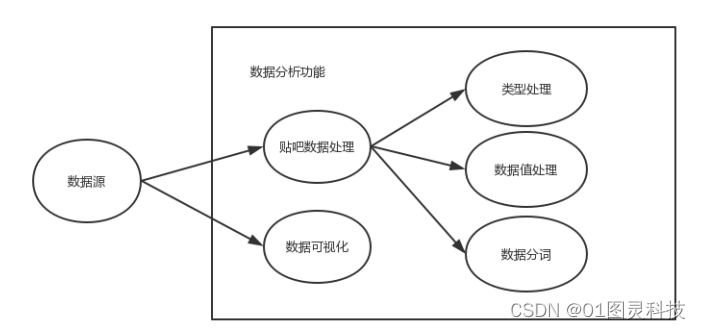
图3.2 数据分析功能
3.3 系统总体架构
本系统的主要功能如下:
1.搭建scrapy爬虫框架运行环境、搭建MongoDB运行环境,为系统的开发做出前期环境支持。
2.通过网页的不同特征,编写相应的爬虫代码,从而实现对贴吧贴子以及评论的爬取,再通过数据的封装、清洗,在数据中提取到有价值的信息,并将信息存入到数据库中。
3.有效利用反爬虫技术,避开贴吧对爬虫的限制。
4.通过对提取出的信息进行分析处理,实现数据的可视化操作。
3.3.1 爬取对象分析
该系统以爬取高校贴吧帖子和评论为目标,其贴吧帖子和评论格式较为固定,因此数据库的设定相对简单。本次将爬取贴吧中的标题、帖子内容、评论等内容。表3.1为爬取的目标网站以及网站的分析。
表3.1 爬取对象分析

“百度贴吧”作为高校学生发表评论、分享观点最密集的地方,其中含有大量的学生生活动态和内心活动。选取其为爬取对象,其中的内容足以支撑本系统的分析需求。其次,动过对贴吧网页的分析,了解到了贴吧网站的网站协议,使我对爬虫的原理有了更加深入的了解。
3.3.2 模块设计
该系统整体分作三个部分,爬虫模块、数据可视化模块、数据分析模块。
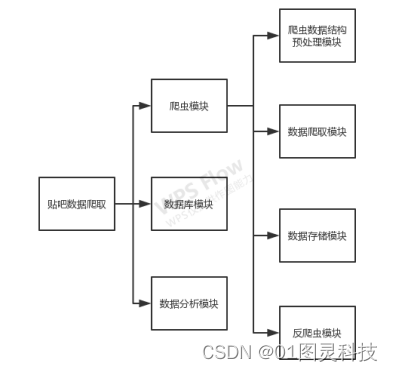
图3.3 系统模块设计
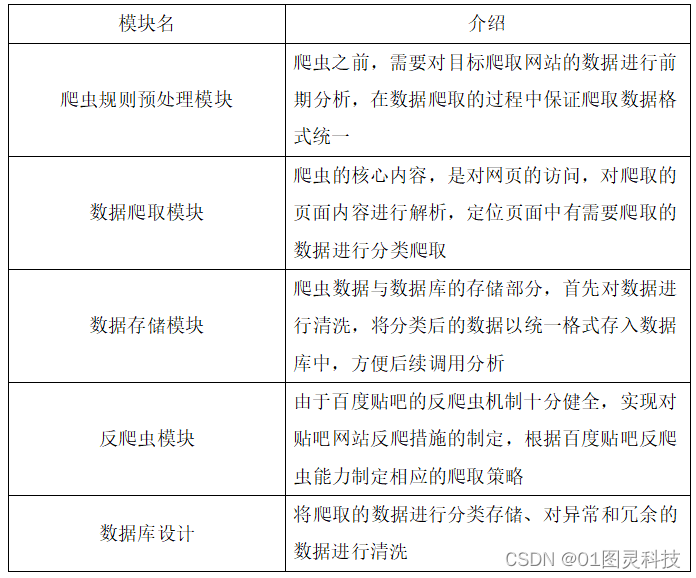
其中,爬虫模块涉及对网页的请求、对请求到页面的解析、对解析后网页内容中有价值资源的定位、与数据库的连接;数据库部分涉及对数据的存储;其细分的各个子模块的功能介绍如表3.2。
表3.2 子模块功能描述
四、系统实现
4.1爬虫模块
4.1.1 环境搭建与前期分析
Pycharm是一个开源的python编程软件,其中包含了大量第三方库使用时随时添加及其相互依赖的库,完成了多种环境的搭建,其中就包括scrapy的环境。完成对scrapy环境的安装。安装完成后,所有所需环境变量已自动配置好,所需的各种python库也已安装成功,可直接开始scrapy项目。所有使用到的第三方库如图4.1所示。
图4.1 PyCharm环境配置
创建scrapy项目需在命令行中进入准备开始项目的目录,运行如下命令:
scrapy startproject bishedemo;
创建项目后,文件结构如图4.2所示。
图4.2 scrapy文件结构
其中各个文件的简要介绍如表4.1。
表4.1 scrapy主要文件介绍

4.1.2 系统爬取
用户通过系统输入任何一个合法贴吧名字,然后根据舆情预测规模大小和结合高校自身情况选择需要爬取贴吧网站的页数(每页的爬取时间在4秒钟左右)。

图4.3 数据爬取页面
获取页面信息,并用xpath解析内容,通过页面分析可知道每一个帖子都是一个li。循环遍历取出内容,并拼接帖子url,进入帖子详情页面通过html分析获得一楼文本。系统会自动翻页爬取贴吧的标题、作者、发布时间、链接、回复数量、帖子内容。将爬取到的数据存储到Mysql数据库的baidu库下。
系统通过解析数据库,从数据库读取bordered表中数据以表格的形式展示到系统的html页面上table class=“table table-bordered”>。如下图所示。
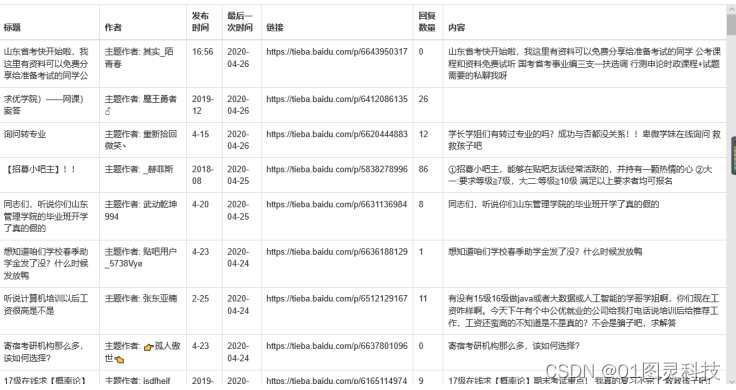
图4.4 数据可视化页面
用户可以根据数据的可视化完整的看到目标网站的所有帖子内容,根据标题、内容、回复数量直观的了解每一个话题的内容和关注程度。细致的掌握每一个话题的动向。
4.2数据分析模块
系统根据爬虫系统对贴吧网页的数据进行一定规模的爬取后,对目标数据进行重新审核检查和校验,将重复的数据信息进行删减,改正格式不正确,最终保证数据的独立性和统一性,完成系统可以将数据进行批处理的归一化。通过对初始脏数据的预处理,得到干净的、连续的、标准的可进行Python库可视化操作的数据。为系统进一步的模型建立提供准确性。通过使用duplicated()函数和pandas函数,集中进行检测是否存在数据重复,将重复的数据利用drop_duplicates()函数进行删除。
利用第三方Jieba库,导入自定义词典,获取停用词list,然后删除jieba空格、删除停止词后的分词,使用reverse降序排序字典,最后得到关键词以及关键词出现的次数,完成分词操作,对后面数据分析创造条件。
4.3数据可视化模块
4.3.1词云展示
Python语言中pyecharts库是一个开源的完成词云绘制的关键库。首先引入pandas库和numpy库对数据进行分析,通过pandas库中的read-csv进行文件的读取,再通过文件的具体类型进行sep参数的设置,利用字符串join方法,使列表转化为字符串。第二,引入collection库中的counter方法,返回词汇出现频率的统计。第三,使用sorted方法和lambda函数得到分词关键词,choices_number=50取出关键词出现频率排名在前50的关键词。最后,通过pyecharts库,设置wordcloud.add参数字体、颜色、大小、倾斜度,得到词云如下图所示。

图4.5 词云展示
为了使高校舆情信息的及时发现处理。词云是高校舆情管理人员发现学生动态异常、掌握学生近期关注话题最直接的方式。词云通过词汇的形式展示学生近期最佳关注的话题,词汇区分颜色大小位置,将出现次数最多的词汇放到图形的中心并且增加字号,系统管理人员可以第一时间发现高校内的热点话题,如果话题内容为负面词汇,高校可以第一时间掌控信息,扭转舆情的爆发。
4.3.2热点话题词频
通过引入jieba库中的anasyle方法,收集数据中每个关键词汇以及每个关键词出现的频率。对词频前20名的词汇出现频率以柱状图的形式展示出来,可以使得高校舆情管理人员掌握学生对热点话题的关注人数,了解舆情的规模大小。关键词频率可视化如下图。
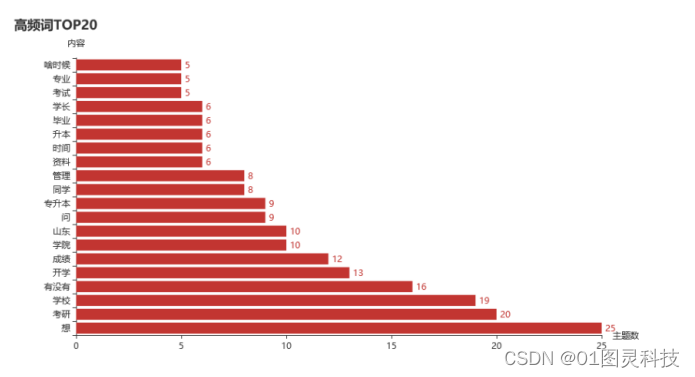
图4.6 高频词统计
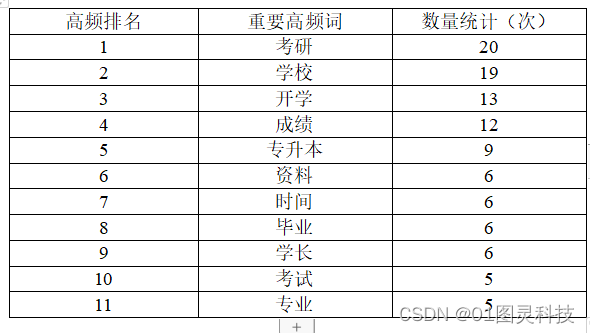
通过后台对高频词的分析,表4.2对有效、重要的高频词进行了统计,可以明显的看出关键词考研出现的频率最高,说明考研是山东管理学院最受关注的话题,足以说明学习氛围的浓郁。其次,开学、成绩、专升本、资料等关键词出现频率也都排名在前列并且差距不大,这些关键词都为正面话题。当某一种关键词的出现频率远高于其他关键词或者有负面关键词出现时,则会有舆情爆发的风险,管理人员应随时关注,及时作出相应的决策。
表4.2 重要高频词次数统计
通过词云与热点主题词汇出现的频率,使得高校舆情管理人员掌握学生对热点话题的关注人数,了解舆情的规模大小。针对不同程度,不同情感的舆情,高校可以及时作出相应的决策。
4.3.3贴吧评论数量区间
通过统计贴吧不同楼层范围内的回复数量,将20层设为分界点。统计数据中20层以上的楼层如果占比越大,说明此时间段内可能会出现热点话题讨论高潮,意味着将会有舆情的发生,所以用户根据实时监控楼层回复数量的占比,可以有效的预测舆情的发生,词云和排名前20的关键词分析出舆情的主题,从而高校舆情管理人员及时的做出决策,避免负面舆情的发展。贴吧评论数量区间扇形图和柱状图如下所示。
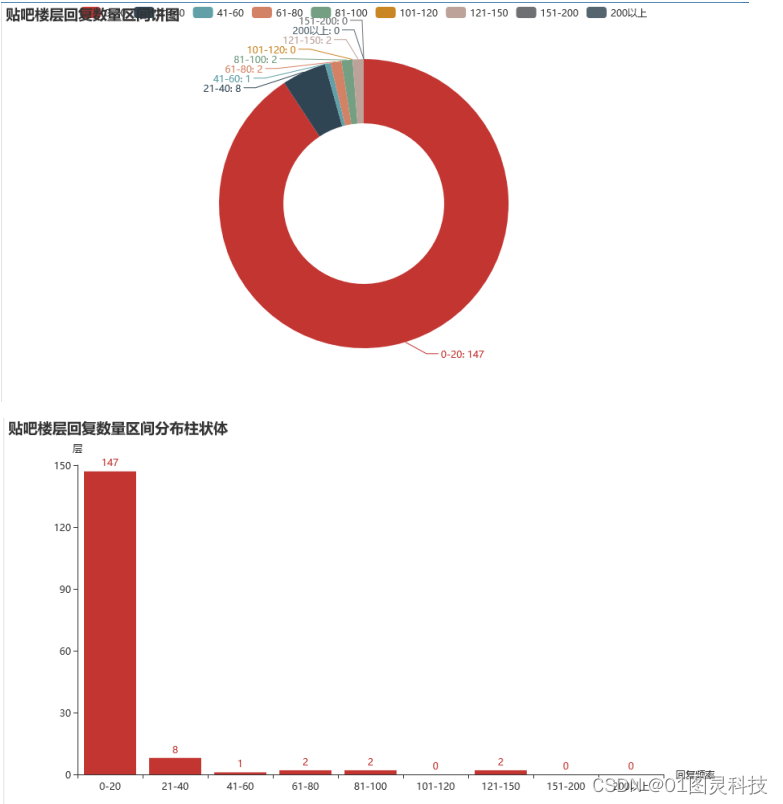
图4.7 楼层回复数量统计
五、 总结
本文通过使用python语言按照前期开题报告要求实现了一个高校舆情监测与分析系统,功能基本完善,对高校贴吧的监测具有一定的效果。随着大数据时代的前进,高校学生作为新时代下的接班人,对网络的依赖性与迷茫性很高,此系统将高校学生在网络中的言行举止记录下来,关注他们在生活中的另一种状态,使得高校在一定程度上帮助学生调整心态,避免舆情的大面积爆发,具有一定的实现意义。
在本系统的设计开发中,我学习使用了scrapy框架对网页进行数据的爬取,将爬取的工作量降到最低。Python中的第三方库是完成此系统的关键,通过开源的第三方库,Jieba库实现了对数据的分词,pandas库和numpy库对数据进行分析,pyecharts库是一个开源的完成词云绘制的关键库。对第三方库的综合利用,发现数据分析技术已经逐渐渗透到我们的工作生活当中,使得我们摆脱传统的手工统计工作,以最高的效率得到我们想要的统计结果。
但是本系统还有很大的优化空间,现在数据分析操作较为简单,距离市面上的高级舆情监测与分析系统仍具有很大差距,在今后的学习中还需继续完善此系统,以便我们更加深入的挖掘的研究。
相关文章:
计算机毕业设计-基于大数据技术下的高校舆情监测与分析
收藏和点赞,您的关注是我创作的动力 文章目录 概要 一、研究背景与意义1.1背景与意义1.2 研究内容 二、舆情监测与分析的关键技术2.1 robot协议对本设计的影响2.2 爬虫2.2.1 工作原理2.2.2 工作流程2.2.3 抓取策略2.3 scrapy架构2.3.1 scrapy:开源爬虫架…...

WPF使用LiveCharts画图时,横坐标转换成时间
一、背景 使用LiveCharts画图时,横坐标通常为数值类型,要转换成时间等自定义类型,需要用到Formatter进行类型转换。 示例使用MVVM模式编写 二、View代码 关键是设置LabelFormatter属性 <lvc:CartesianChart Series"{Binding Series…...
Qt客户端开发的技术难点
在Qt客户端开发中,可能会遇到一些技术难点,这些难点可能与UI设计、性能优化、跨平台兼容性等方面有关。以下是一些可能的技术难点,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作…...

杰理AD155儿童玩具语音集成电路
一、杰理AD155集成电路是由杰理科技设计、开发和销售的一款产品,AD15系列 SoC 芯片支持以下特性: 工作电压:2.0V-5.5V主频可达120MHz的32bitCPU,片上集成20K字节SRAM,8K字节ICache支持最多2路解码同时运行,支持F1A/A/…...
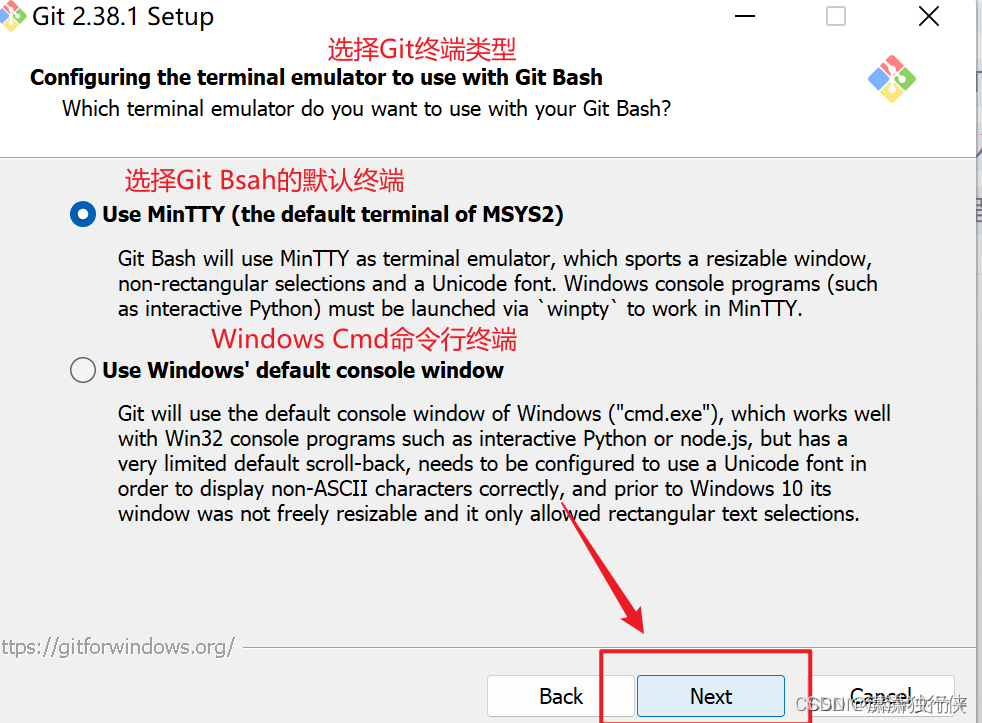
git bash 命令行反应慢、卡顿(定位出根本原因)
参考该博主: https://blog.csdn.net/weixin_50212044/article/details/131575987?utm_mediumdistribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-131575987-blog-130024908.235v43pc_blog_bottom_relevance_base4&spm1001.210…...
)
Android 启动service(Kotlin)
一、使用startForegroundService()或startService()启用service **Activity //启动service val intent: Intent Intent(ServiceActivitythis,MyService::class.java) //Build.VERSION_CODES.O 26 // Android8以后,不允许后台启动Service i…...
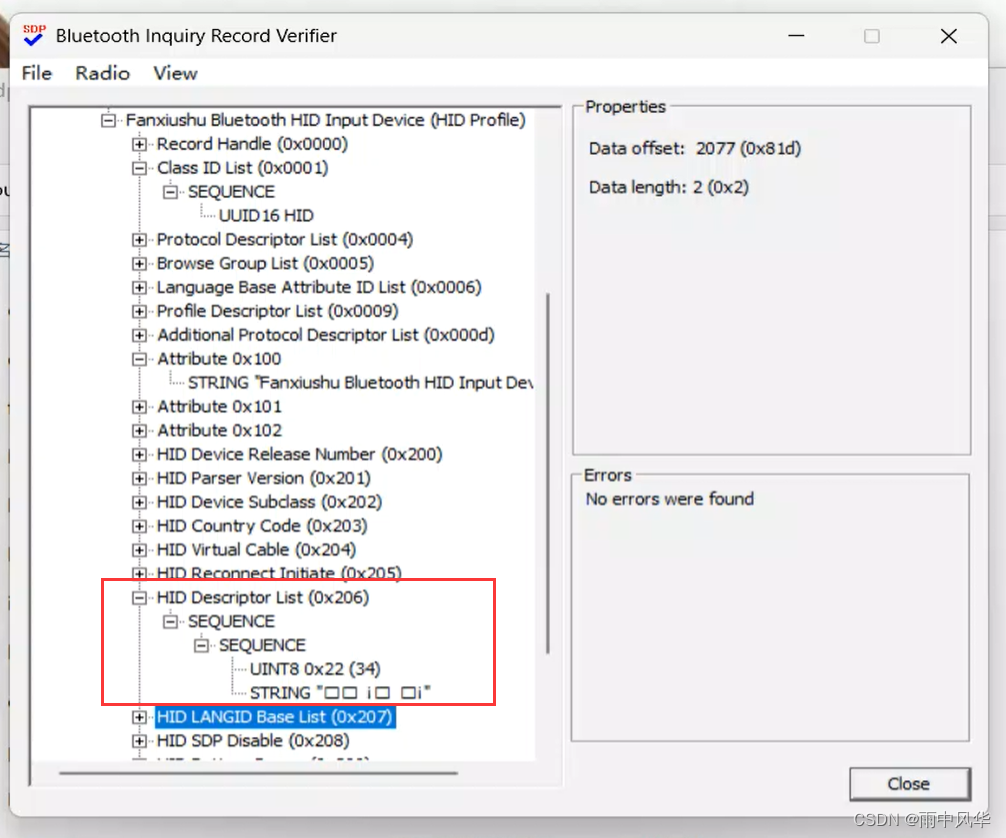
Windows蓝牙驱动开发之模拟HID设备(一)(把Windows电脑模拟成蓝牙鼠标和蓝牙键盘等设备)
by fanxiushu 2024-03-14 转载或引用请注明原作者 把Windows电脑模拟成蓝牙鼠标和蓝牙键盘,简单的说,就是把笨重的PC电脑当成鼠标键盘来使用。 这应该是一个挺小众的应用,但有时感觉也应该算比较好玩吧, 毕竟实现一种一般人都感觉…...

LlamaParse: 高效的PDF文件RAG解析工具
LlamaParse: 高效的PDF文件RAG解析工具 通过Thomas Reid的深入探索,LlamaParse成为了目前我所见最优秀的RAG实现用PDF解析器。基于AI的技术,尤其在处理像SEC Q10这样的复杂文件时表现出色,这些文件通常包含文本、数字及其组合构成的表格&…...

platform设备注册驱动模块的测试
一. 简介 上一篇文章编写了 platform设备注册代码,文章地址如下: 无设备树platform驱动实验:platform设备注册代码实现-CSDN博客 本文继续无设备树platform驱动实验,本文对编译好的 设备注册程序进行测试,测试所实…...

鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:ListItemGroup)
该组件用来展示列表item分组,宽度默认充满List组件,必须配合List组件来使用。 说明: 该组件从API Version 9开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。该组件的父组件只能是List。 使用说明 当List…...

Docker:常用命令
文章目录 docker作用常用指令 docker 作用 Docker 是一种容器化平台,可以让开发者打包应用程序及其依赖项,并以容器的形式进行发布、交付和运行。 Docker 的一些主要作用: 应用程序隔离:Docker 使用容器技术,将应用程…...

如何搭建“Docker Registry私有仓库,在CentOS7”?
1、下载镜像Docker Registry docker pull registry:2.7.1 2、运行私有库Registry docker run -d -p 5000:5000 -v ${PWD}/registry:/var/lib/registry --restartalways --name registry registry:2.7.1 3、拉取镜像 docker pull busybox 4、打标签,修改IP&#x…...

DBA面试题:MySQL缓存池LRU算法做了哪些改进?
下图是MySQL(MySQL5.7版本)体系架构图 MySQL的InnoDb Buffer Pool 缓冲池是主内存中的一个区域,用来缓存InnoDB在访问表和索引时的数据。对于频繁使用的数据可以直接从内存中访问,从而加快处理速度。如果一台服务器专用作MySQL数据…...
idea+vim+pycharm的块选择快捷键
平时开发的时候,有的时候我们想用矩形框住代码,或者想在某列上插入相同字符 例如下图所示,我想在22-24行的前面插入0000 1. Idea的快捷键:option 鼠标 2. Pycharm的快捷键:shift option 鼠标 2. Vim 块选择 v/V/c…...
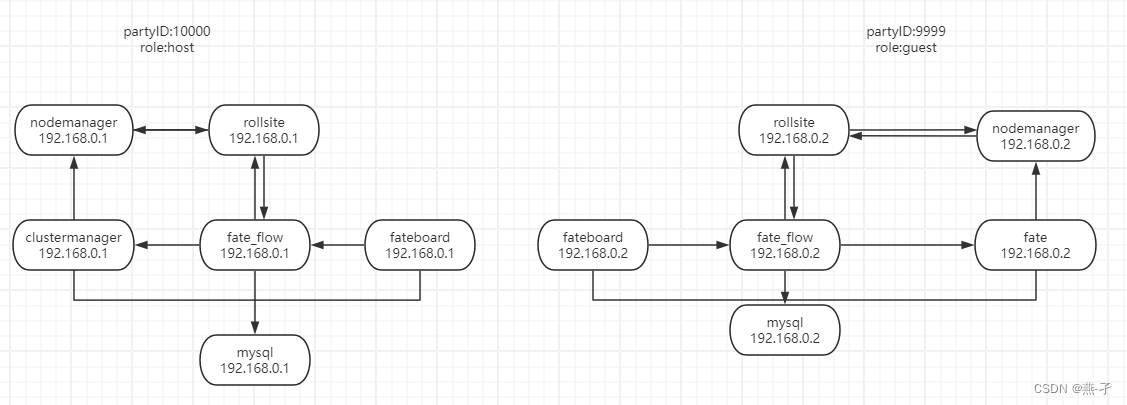
ansible 部署FATE集群单边场景
官方文档: https://github.com/FederatedAI/AnsibleFATE/blob/main/docs/ansible_deploy_FATE_manual.md https://github.com/FederatedAI/AnsibleFATE/blob/main/docs/ansible_deploy_two_sides.md gitee详细文档: docs/ansible_deploy_one_side.md…...

融入Facebook的世界:探索数字化社交的魅力
融入Facebook的世界,是一场数字化社交的奇妙之旅。在这个广袤的虚拟社交空间中,人们可以尽情展现自己、分享生活,与全球朋友、家人和同事保持紧密联系,共同探索社交互动的乐趣与魅力。让我们深入了解这个世界的魅力所在࿱…...
stm32-定时器输出比较PWM
目录 一、输出比较简介 二、PWM简介 三、输出比较模式实现 1.输出比较框图(以通用定时器为例) 2.PWM基本结构 四、固件库实现 1.程序1:PWM呼吸灯 2.程序2:PWM驱动直流电机 3.程序3:控制舵机 一、输出比较简介 死区生成和互补输出一般…...

Redis对过期key的删除策略
假设设置了一批 key 只能存活 1 个小时,那么 1 小时后,redis 是怎么对这批 key 进行删除的? 定期删除 惰性删除 定期删除: redis是默认每隔100ms就随机抽取一些设置了过期时间的key,检查是否过期,如果过期就删除。…...

http的body格式
body数据都通常放在 HTTP 请求的 body 部分。 在 HTTP 请求中,Content-Type 头用于指示 body 中的数据格式。例如,对于 x-www-form-urlencoded 格式的数据,通常会设置 Content-Type: application/x-www-form-urlencoded,而对于 fo…...

Java Web开发从0到1
文章目录 总纲第1章 Java Web应用开发概述1.1 程序开发体系结构1.1.1 C/S体系结构介绍1.1.2 B/S体系结构介绍1.1.3 两种体系结构的比较1.2 Web应用程序的工作原理1.3 Web应用技术1.3.1 客服端应用技术1.3.2 服务端应用技术1.4 Java Web应用的开发环境变量1.5 Tomcat的安装与配置…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

如何快速无损转换B站m4s视频:完整工具使用指南
如何快速无损转换B站m4s视频:完整工具使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他设备…...