Neo4j 批量导入数据 从官方文档学习LOAD CSV 命令 小白可食用版
学习LOAD CSV🚀
在使用Neo4j进行大量数据导入的时候,发现如果用代码自动一行一行的导入效率过低,因此明白了为什么需要用到批量导入功能,在Neo4j中允许批量导入CSV文件格式,刚开始从网上的中看了各种半残的博客或者视频,拼拼凑凑也实现了功能,然后想写个博客记录一下,一想直接把代码沾上来讲的也不是很全面,就打算按照官方文档的思路讲一下,然后给中间补充一些文档中往往会省略的实践细节,故有了这篇博客,在对官方文档的翻译中加入自己对技术的理解会比机翻或者要求严格的文档更好理解一些。本文只介绍前几个常用的节点和关系的批量导入不然内容太多了,后面不常用的就先不介绍了。
阅读本文需要对Neo4j的基础知识有一些了解,如果还没有学习,可以阅读本文章的前置文章。
Neo4j 新手教程 环境安装 基础增删改查 python链接 常用操作 纯新手向
文章目录
- 学习LOAD CSV🚀
- 1.LOAD CSV 简介
- 2. Import CSV data into Neo4j 把CSV导入Neo4j 极简版(重要)
- 3.Import compressed CSV files 导入压缩的csv文件
- 4.Import data from relational databases 导入关联数据(重要)
- 结束
首先给出Neo4j的官方文档的地址:
https://neo4j.com/docs/cypher-manual/current/clauses/load-csv/
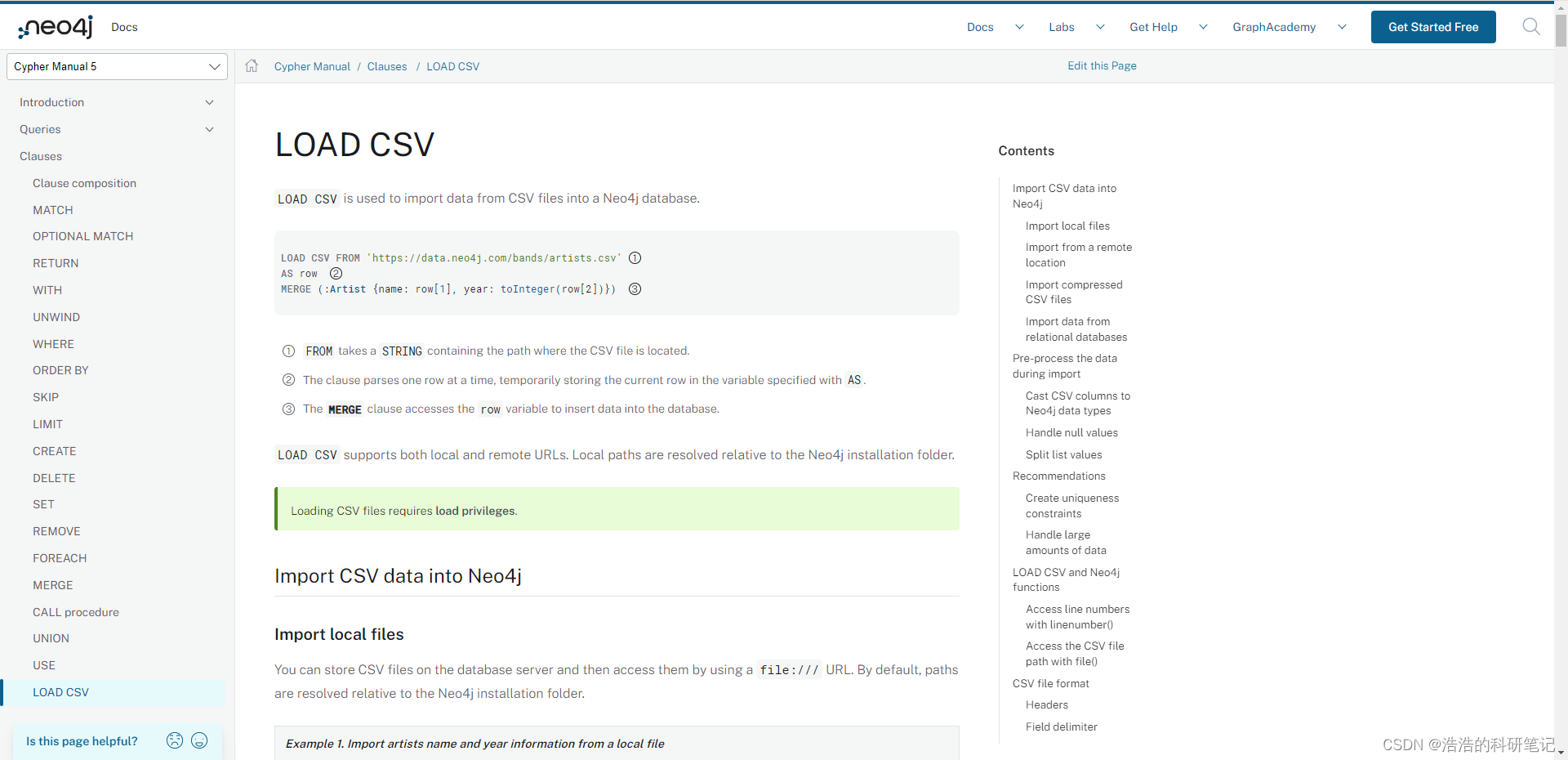
1.LOAD CSV 简介

LOAD CSV 是用来将CSV文件导入到Neo4j数据集当中的。
LOAD CSV FROM 'https://data.neo4j.com/bands/artists.csv'
AS row
MERGE (:Artist {name: row[1], year: toInteger(row[2])})
FROM后面接一个文件所在路径的字符串- 命令是一行一行处理文件的,每次处理的时候,用AS将这一行的数据临时存储在一个变量里(在这个例子中这个变量是row)
- 用MERGE访问row变量然后存入到数据集中
LOAD CSV 支持本地和远程的URL,本地路径关联在Neo4j的数据库的文件夹中。
URL Uniform Resource Locator
雅称:统一资源定位符
俗称:文件路径(新手可以直接这吗理解,虽然严格意义不准确)
2. Import CSV data into Neo4j 把CSV导入Neo4j 极简版(重要)
可以将CSV文件保存在本地数据集的文件夹import下面,然后使用一个file:///前缀名字。下面是官方给的一个例子,接下来我们具体实际操作一下

首先是保存这个csv文件,首先我们直接来一个简单的txt直接过去,之后再做用excel转的,直接新建一个txt然后粘进去。
1,ABBA,1992
2,Roxette,1986
3,Europe,1979
4,The Cardigans,1992
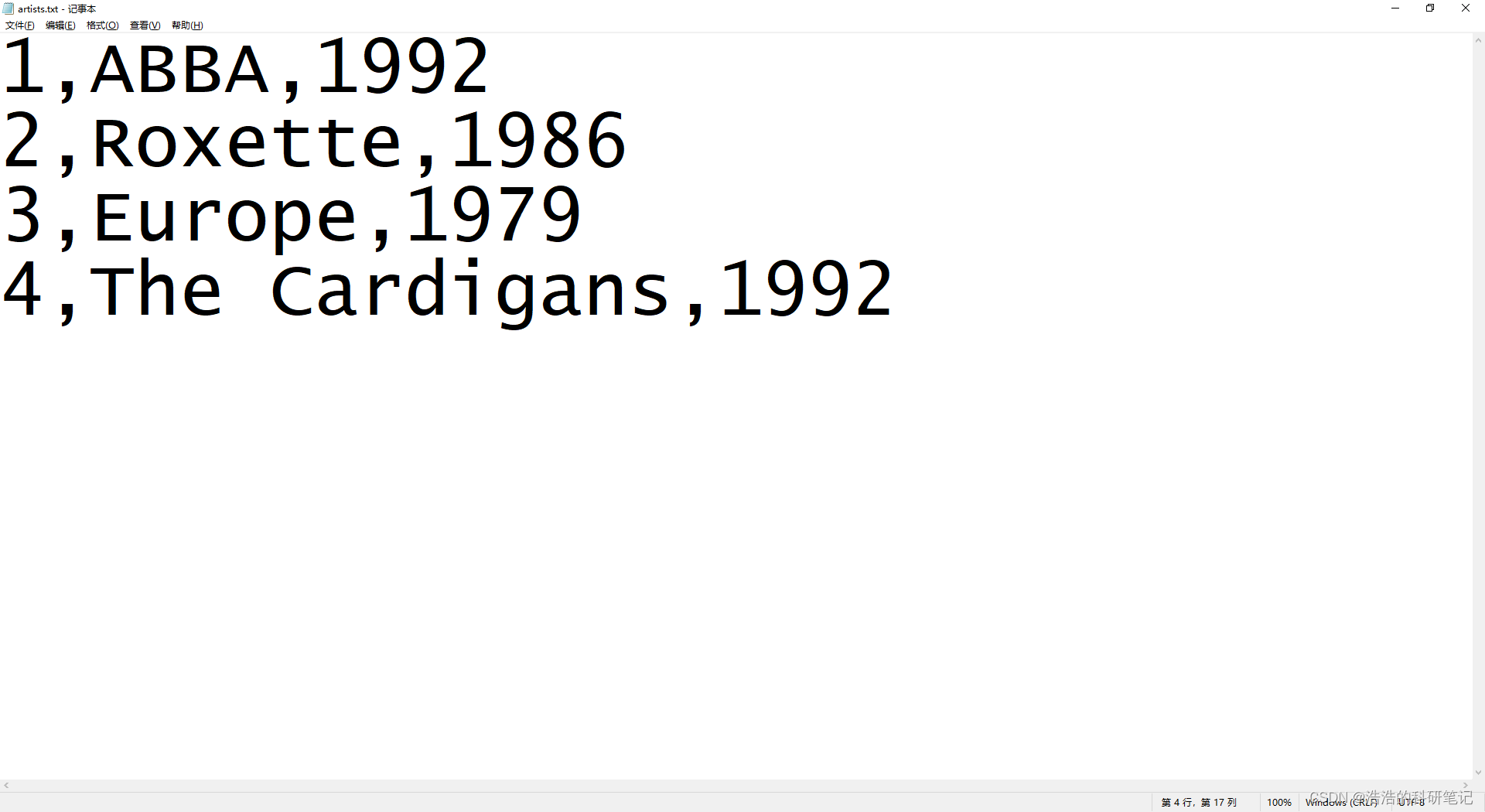
然后点右上角的文件选择另存为,然后进入到Neo4j的import文件夹的目录下
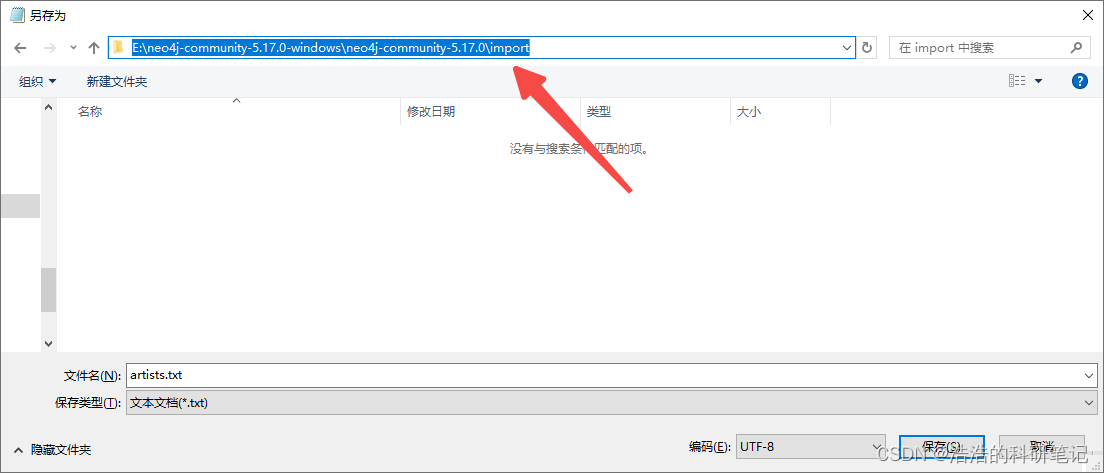
之后把文件后缀的txt直接改为csv,然后确认一下文件编码为UTF-8
然后打开该目录你会看到一个csv文件
用excel打开看一眼,嗯!
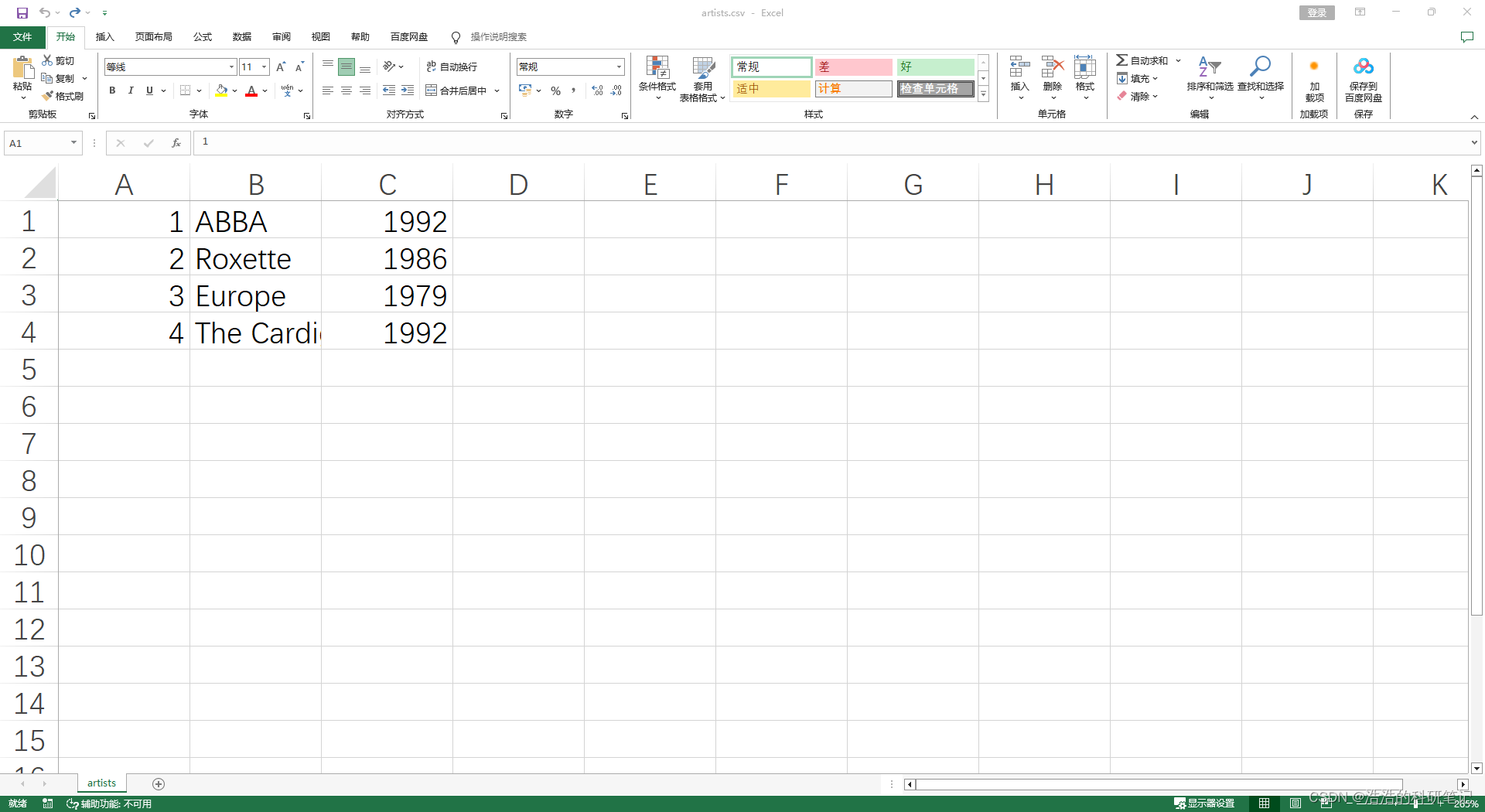
然后打开Neo4j的控制台。在上方的命令框输入命令
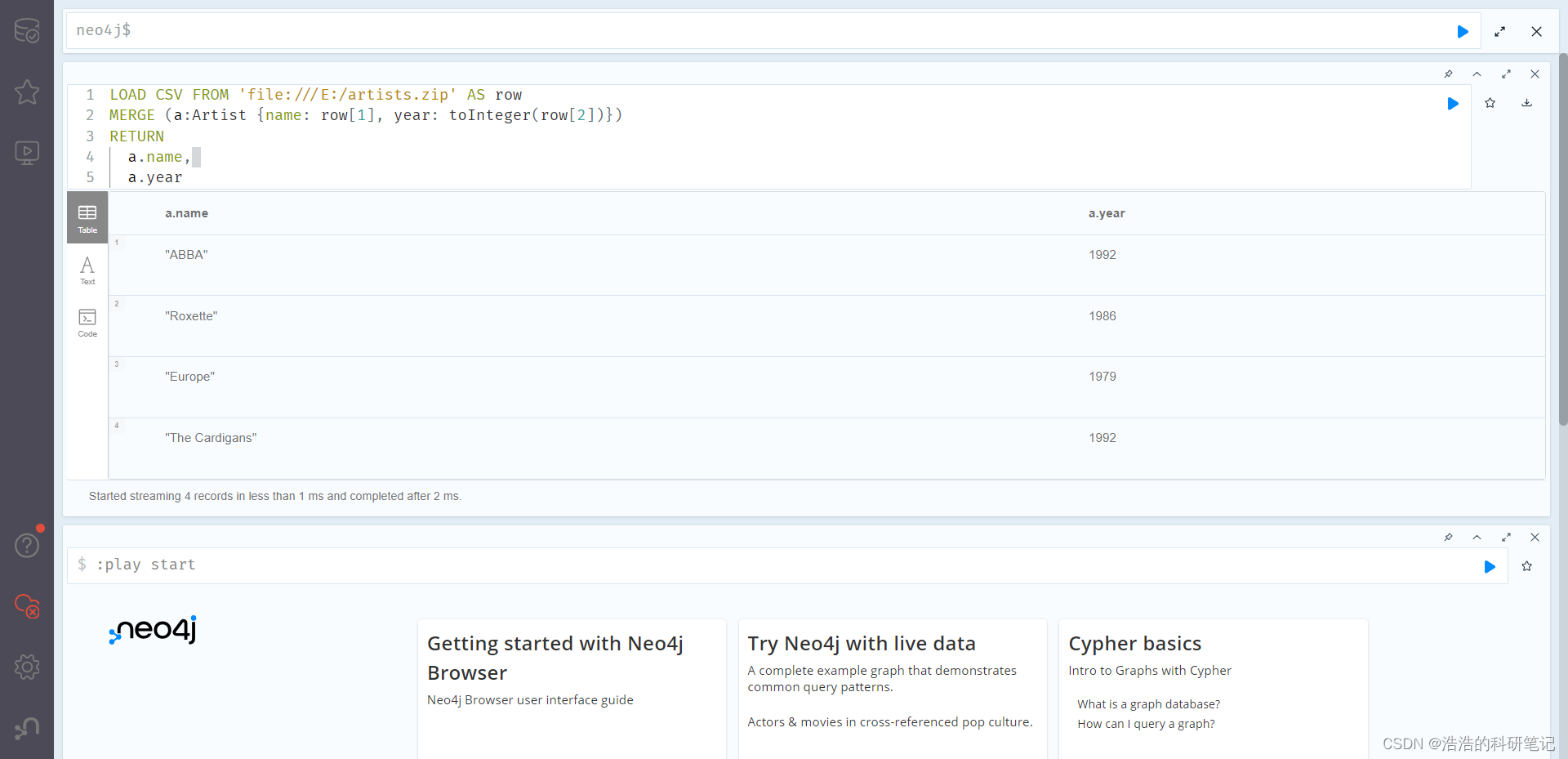
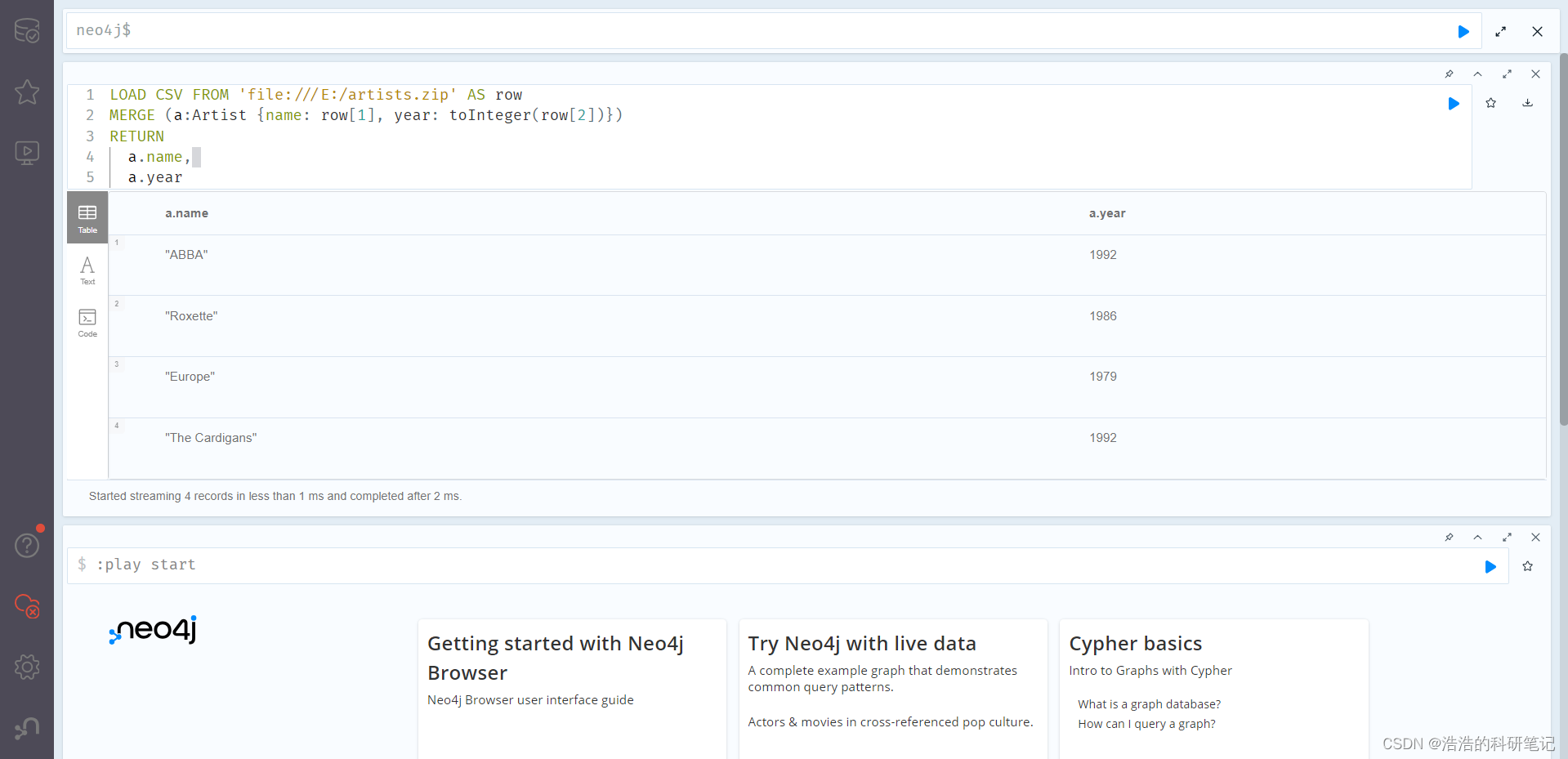
LOAD CSV FROM 'file:///artists.csv' AS row
MERGE (a:Artist {name: row[1], year: toInteger(row[2])})
RETURNa.name,a.year
如果不知道如何打开请移步愚作:Neo4j 新手教程 环境安装 基础增删改查 python链接 常用操作 纯新手向

按下Ctrl+Enter或者右上侧的蓝色小三角运行命令,运行结果如下,导入成功。

如果不想保存到数据库文件的import文件夹下,直接换成本地路径直接导入,例如直接把文件复制到E盘,然后把路径直接换成E:/artists.csv结果是不行。

为了解决这个问题需要求改Neo4j数据库的配置文件,首先在数据库的conf文件下下找到neo4j.conf文件然后用记事本打开。

找到这个serve.directories.import=import给它前面加一个#号注释掉

注释之后变成这样

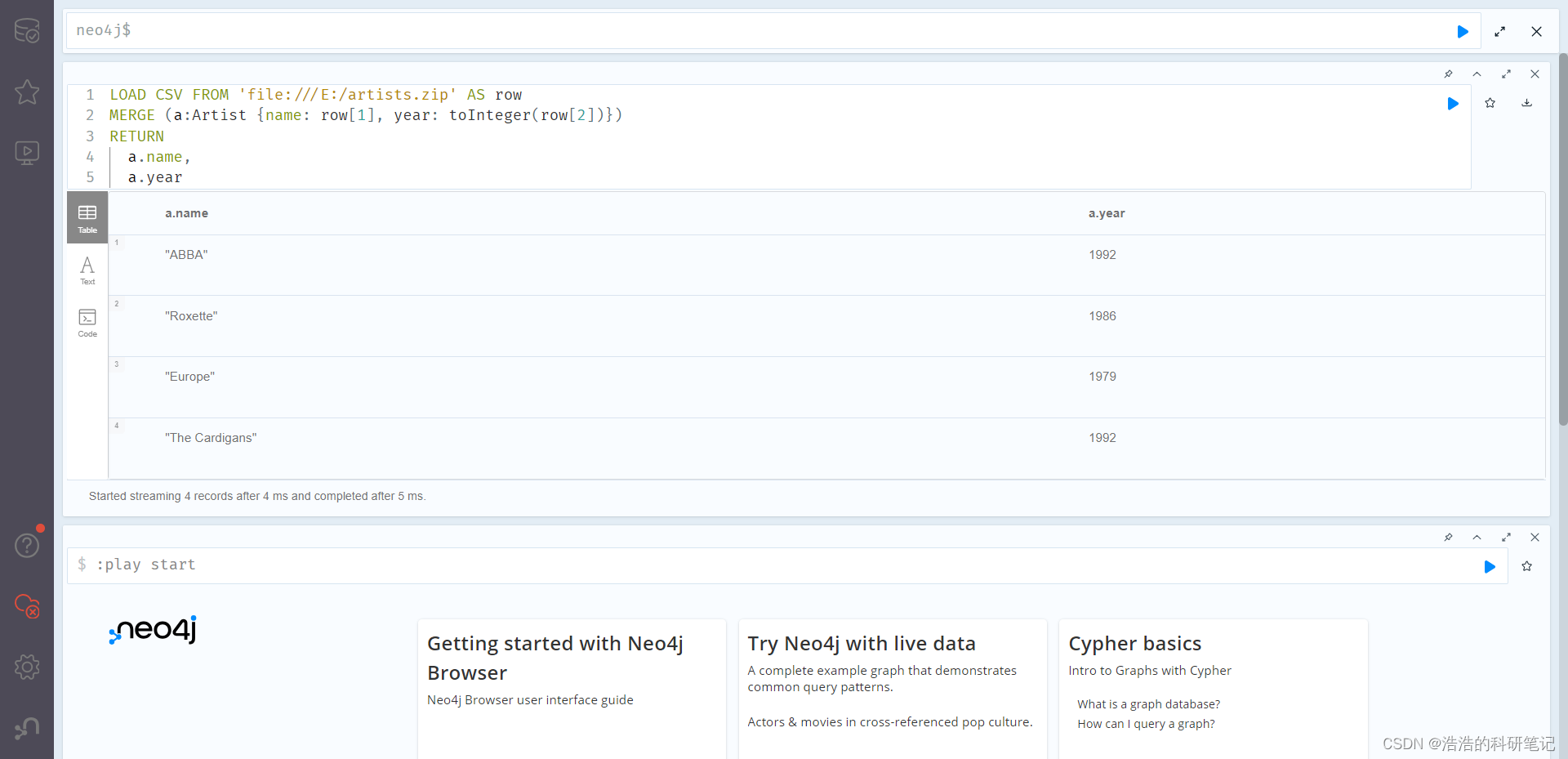
然后Ctrl+S保存一下,或者关闭的时候点一下也行,然后把E:/artists.csv改成'file:///E:/artists.csv'然后再运行,成功!
file:///必须加,不加报错- 在配置文件中注释了
server.directories.import=import之后,把路径设置回file:///artists.csv,也依旧可以从Import文件下下导入文件
LOAD CSV FROM 'file:///E:/artists.csv' AS row
MERGE (a:Artist {name: row[1], year: toInteger(row[2])})
RETURNa.name,a.year

3.Import compressed CSV files 导入压缩的csv文件
LOAD CSV也可以上传压缩成ZIP的CSV文件,不管套了几个文件,最后这个ZIP文件里只能有一个CSV文件,文档里写的太官方,我这里尝试重新描述一下,然后再给它分几种情况测一测,挖一挖它这个功能。

好现在import文件下直接右键CSV压缩一层得到一个zip压缩包

然后再Neo4j控制台导入OK成功
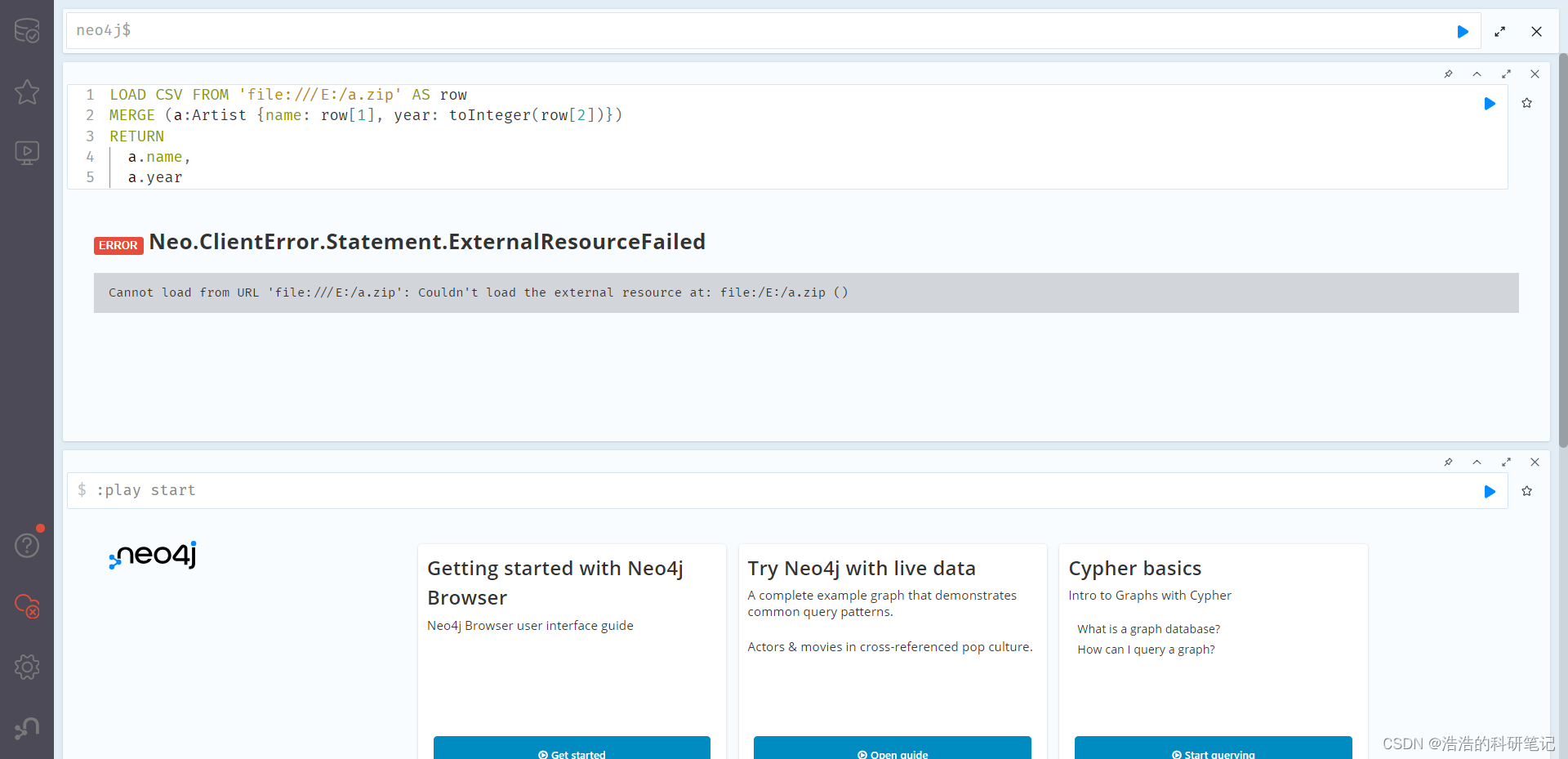
LOAD CSV FROM 'file:///artists.zip' AS row
MERGE (a:Artist {name: row[1], year: toInteger(row[2])})
RETURNa.name,a.year
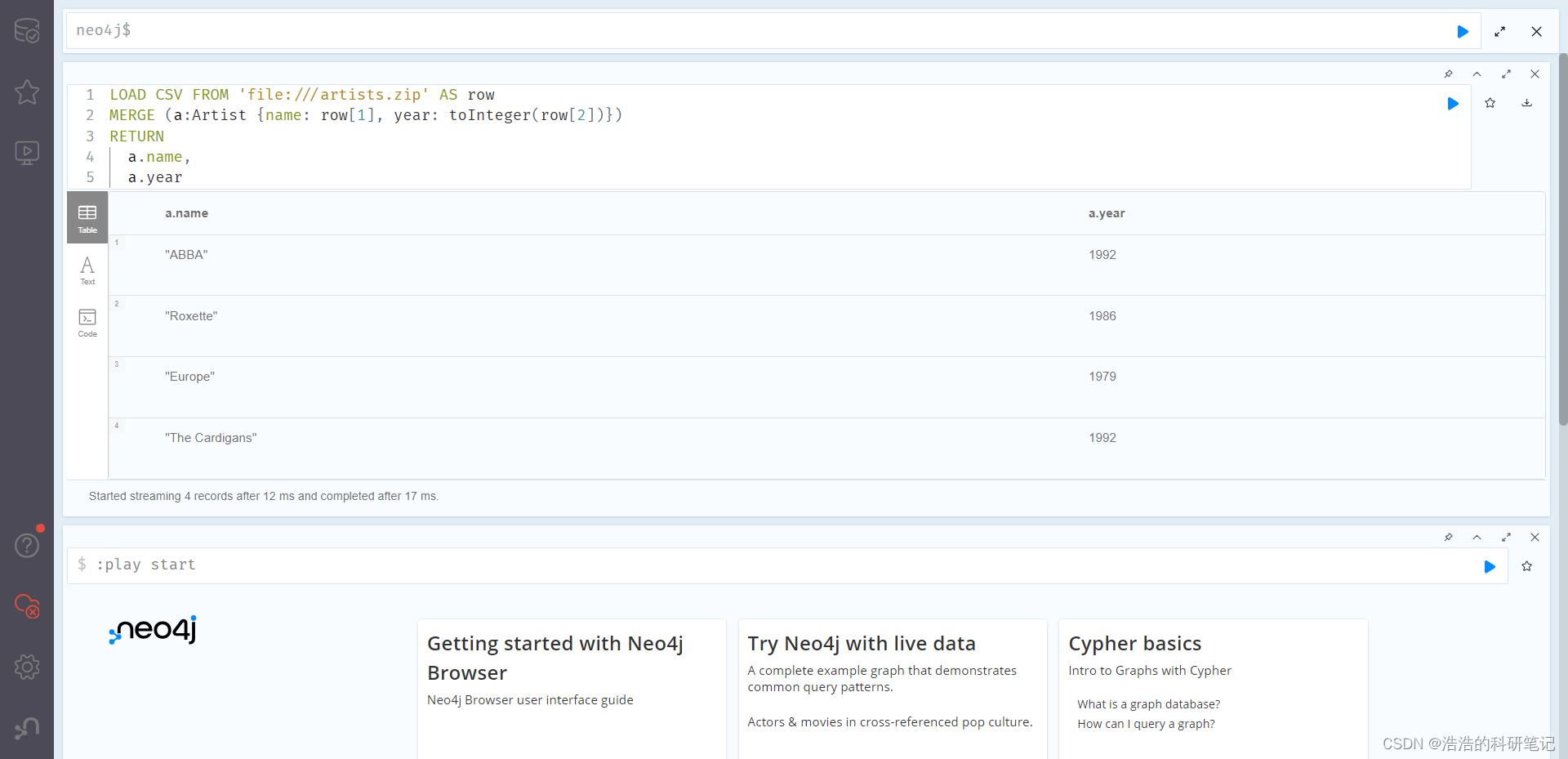
然后将压缩文件从import目录移动到E盘,然后运行OK
LOAD CSV FROM 'file:///E:/artists.zip' AS row
MERGE (a:Artist {name: row[1], year: toInteger(row[2])})
RETURNa.name,a.year
然后开始套娃
首先套了两层文件
然后将套娃文件打包成zip

然后运行ok可行

接下来套娃的时候把套娃的文件夹名字修改一下,先修改一下套娃中间文件夹的名字,给它改成a再打包再运行

OK可行

然后把套娃最外层的文件夹的名字改了,改成和CSV文件的名字不一致,然后打包成zip


这个不可行
然后把最外层的文件夹名字改成和CSV一致,然后在artist.csv在路径下加一些奇奇怪怪的文件,然后再打包成zip然后运行

可行
然后在路径下加个其他的csv文件,然后再打包成csv然后运行
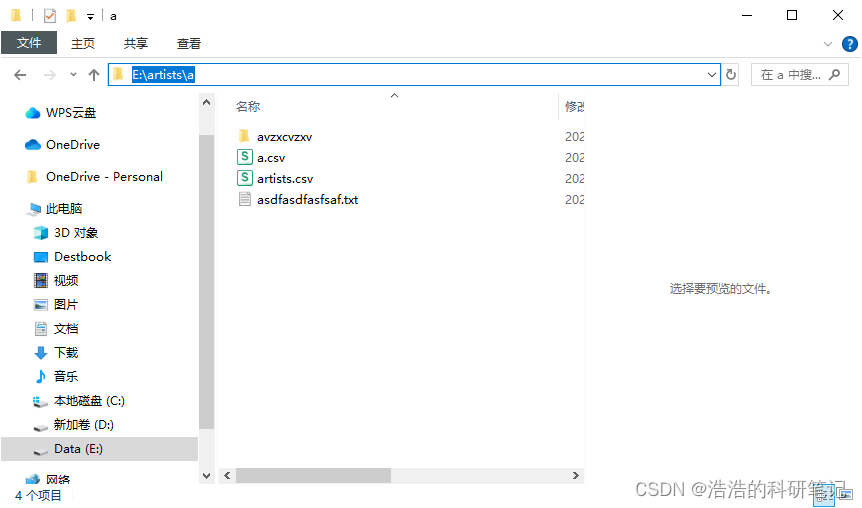 OK可行
OK可行
结论:和文档中的描述基本一致,就说最外层文件夹的名字得和要导入的csv文件一致,最外层文件夹名字是哪个就读哪个CSV
桀桀桀!感受到中国算法工程师的执着了吗Neo4j的官方人员(笑)。
4.Import data from relational databases 导入关联数据(重要)
在官方文档中给了这样一个例子,一个数据和其作者的数据集,那这里不但包含着作者和书籍的节点node,还包含着A作者写了B书的一个关系relationship

接下来老操作,直接复制到txt文件然后给它转存成UTF-8编码的csv,文件名字是books,要是忘了咋操作或者跳读到这的话,翻回到上面的这里。
Import CSV data into Neo4j 把CSV导入Neo4j 极简版
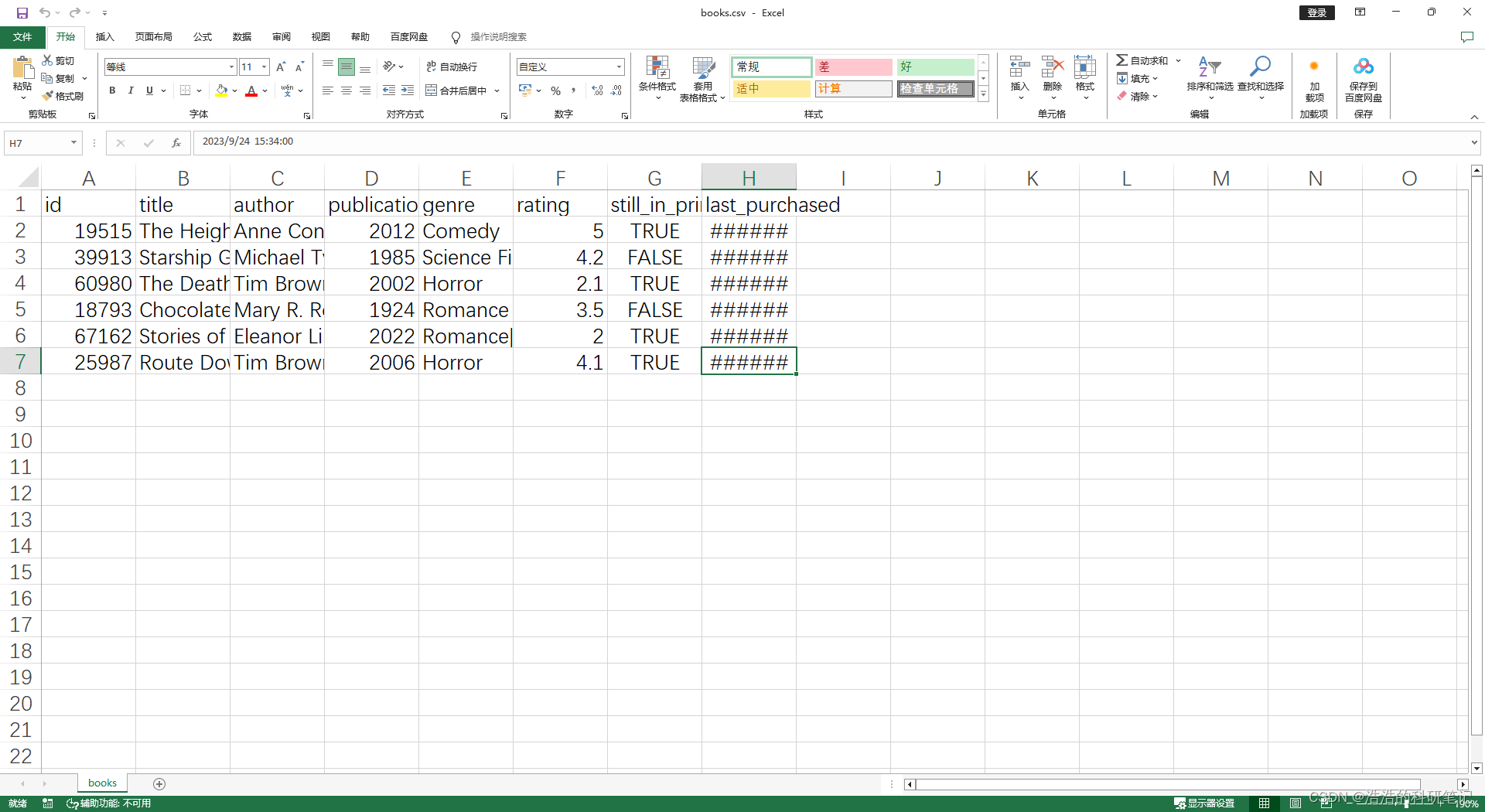
id,title,author,publication_year,genre,rating,still_in_print,last_purchased
19515,The Heights,Anne Conrad,2012,Comedy,5,true,2023/4/12 8:17:00
39913,Starship Ghost,Michael Tyler,1985,Science Fiction|Horror,4.2,false,2022/01/16 17:15:56
60980,The Death Proxy,Tim Brown,2002,Horror,2.1,true,2023/11/26 8:34:26
18793,Chocolate Timeline,Mary R. Robb,1924,Romance,3.5,false,2022/9/17 14:23:45
67162,Stories of Three,Eleanor Link,2022,Romance|Comedy,2,true,2023/03/12 16:01:23
25987,Route Down Below,Tim Brown,2006,Horror,4.1,true,2023/09/24 15:34:18

ok好的看一下,然后右侧的这个时间是缩略了,展开就能看见了不用害怕。
// Create `Book` nodes 导入节点
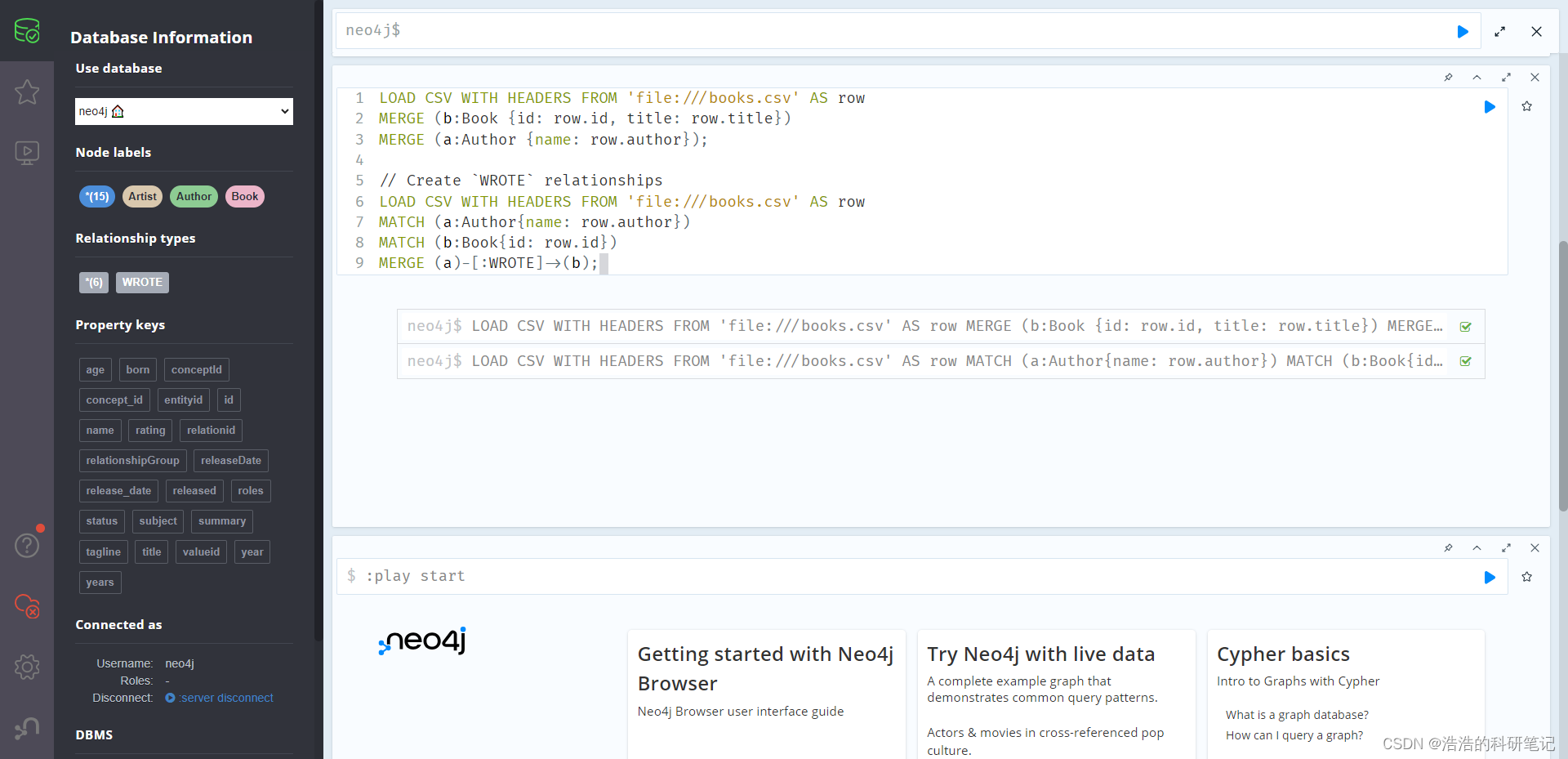
LOAD CSV WITH HEADERS FROM 'file:///books.csv' AS row
MERGE (b:Book {id: row.id, title: row.title})
MERGE (a:Author {name: row.author});// Create `WROTE` relationships 导入关系
LOAD CSV WITH HEADERS FROM 'file:///books.csv' AS row
MATCH (a:Author{name: row.author})
MATCH (b:Book{id: row.id})
MERGE (a)-[:WROTE]->(b);
这段代码使用了Cypher查询语言来处理两个主要任务:
首先,它从一个CSV文件中导入数据来创建Book和Author节点;
其次,它基于相同的CSV文件创建这些Book和Author节点之间的WROTE关系。下面是对这两个过程的详细解释:
第一部分:创建Book和Author节点
LOAD CSV WITH HEADERS FROM 'file:///books.csv' AS row
MERGE (b:Book {id: row.id, title: row.title})
MERGE (a:Author {name: row.author});
LOAD CSV WITH HEADERS FROM 'file:///books.csv' AS row这条命令告诉Neo4j从给定的路径file:///books.csv'加载一个CSV文件,该文件具有标题行(即每列的第一行包含列名)。AS row表示每一行数据都会被赋予变量名row,之后可以通过这个变量访问行中的数据。MERGE (b:Book {id: row.id, title: row.title}):MERGE命令用于创建一个新的Book节点,或者如果具有相同id和title属性的节点已经存在,则匹配(不重复创建)该节点。这里,row.id和row.title是从CSV文件中读取的每一行的对应列数据。MERGE (a:Author {name: row.author}):类似地,这条命令用于创建或匹配一个Author节点,其name属性由当前行的author列提供。
第二部分:创建WROTE关系
LOAD CSV WITH HEADERS FROM 'file:///books.csv' AS row
MATCH (a:Author{name: row.author})
MATCH (b:Book{id: row.id})
MERGE (a)-[:WROTE]->(b);
- 加载数据部分一样
MATCH (a:Author{name: row.author})和MATCH (b:Book{id: row.id}):这两个MATCH命令分别用于查找当前行中提到的Author和Book节点。它们通过比较name和id属性与文件中的相应列来定位节点。MERGE (a)-[:WROTE]->(b):最后,MERGE命令用来创建一个新的WROTE关系,从找到的Author节点指向Book节点。如果这样的关系已经存在,则不会创建重复的关系。
然后运行上诉代码这里我把URL改成本地了,而文档中用的是网络URL,这里还是先了解怎么在本地导入节点和关系网络导入暂时不需要
然后点一下这个WROTE,ok完美
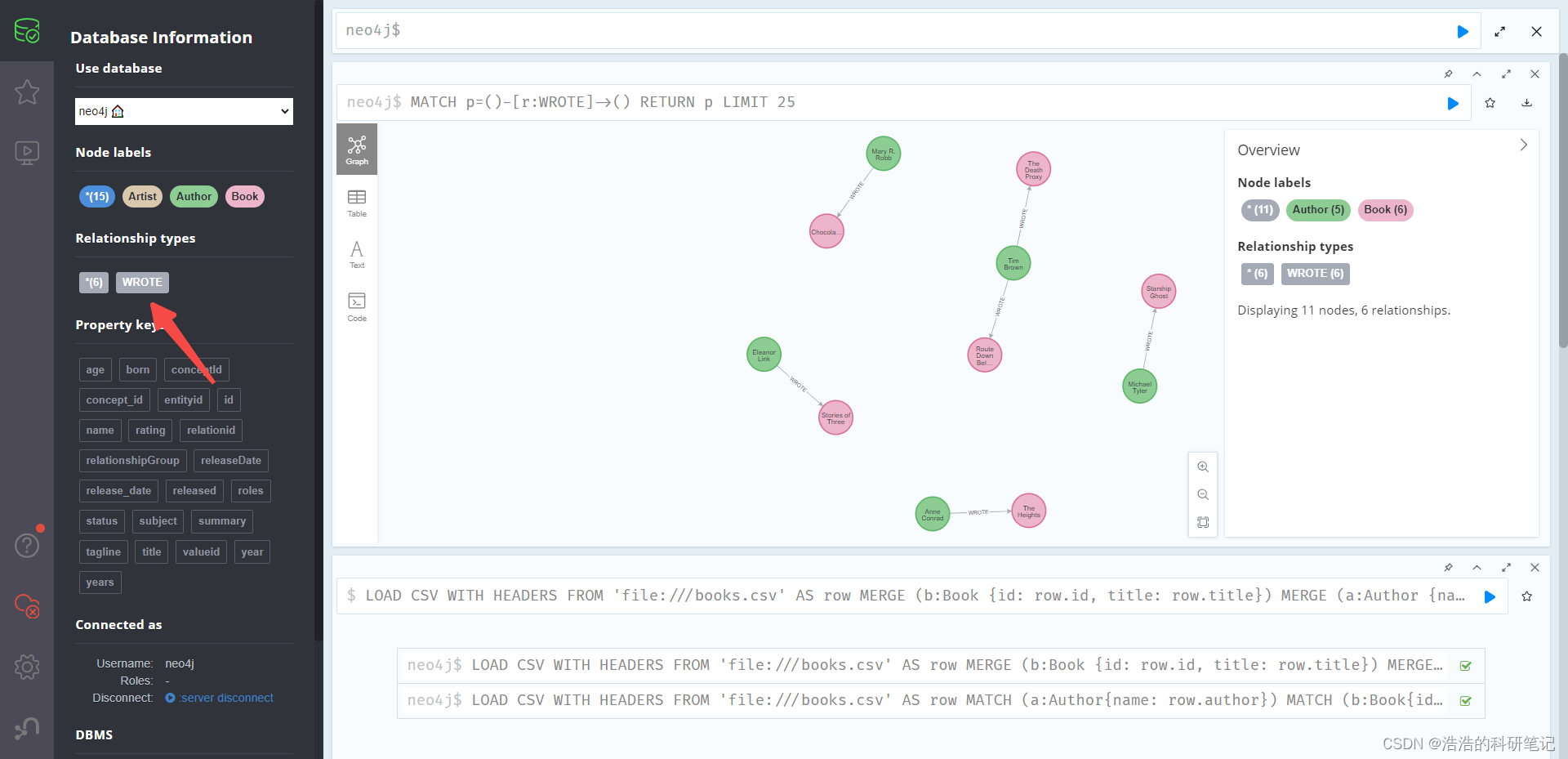
结束
然后文档的后面还有一些增加属性以及处理数据例如去除Null值等诸如此类的工作,不是重点暂时就先不介绍了。然后有个小麻烦的地方,在导入不同类别的数据的时候需要分批导入,类别参数不能直接用CSV中的导入值,我自己有个数据集有50类关系,我手动输入了50次命令,我简单了解了一下之后应该可以用Foreach命令解决,这个问题会纳入到后续的更新规划当中。
相关文章:
Neo4j 批量导入数据 从官方文档学习LOAD CSV 命令 小白可食用版
学习LOAD CSV🚀 在使用Neo4j进行大量数据导入的时候,发现如果用代码自动一行一行的导入效率过低,因此明白了为什么需要用到批量导入功能,在Neo4j中允许批量导入CSV文件格式,刚开始从网上的中看了各种半残的博客或者视频…...
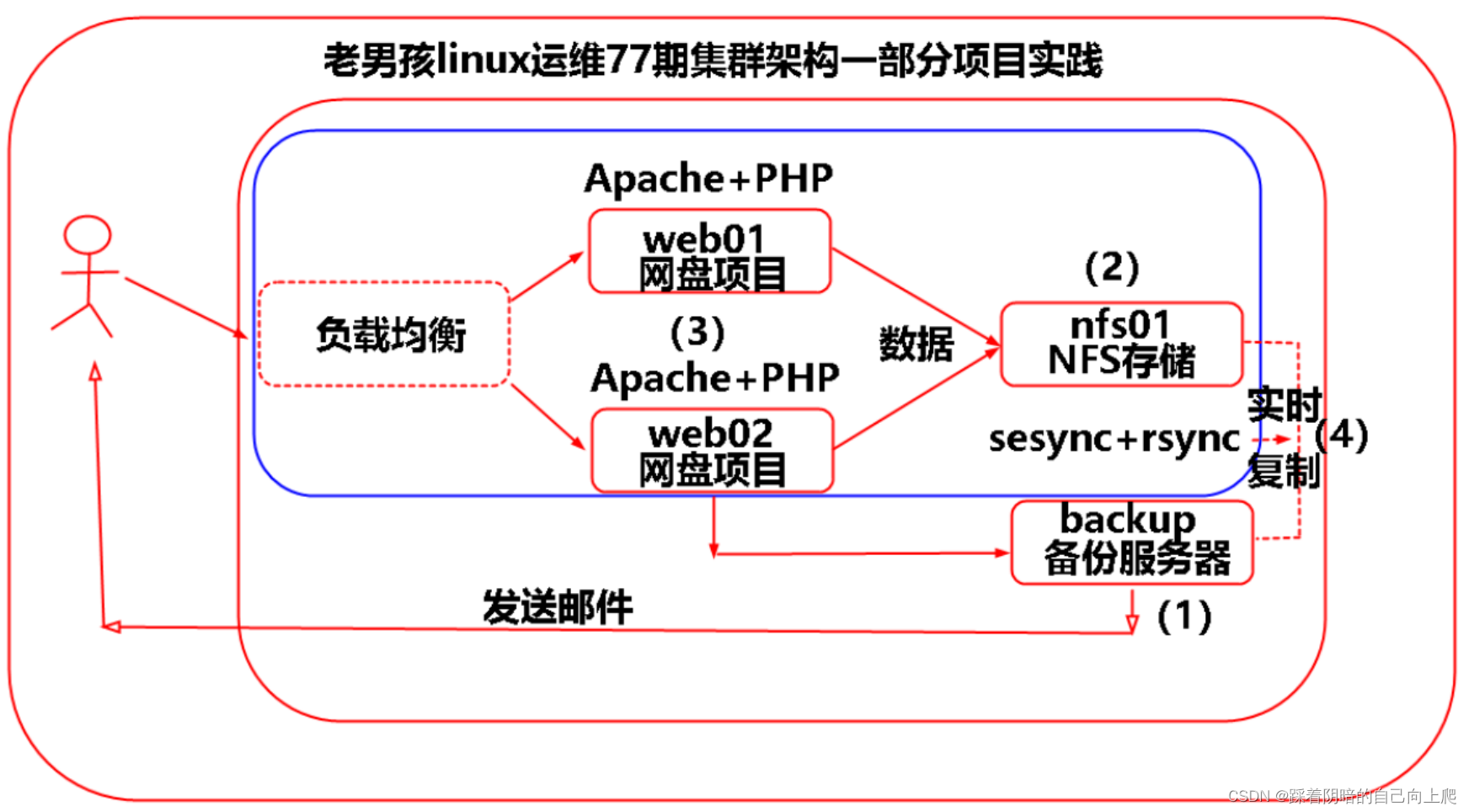
Day43-2-企业级实时复制intofy介绍及实践
Day43-2-企业级实时复制intofy介绍及实践 1. 企业级备份方案介绍1.1 利用定时方式,实现周期备份重要数据信息。1.2 实时数据备份方案1.3 实时复制环境准备1.4 实时复制软件介绍1.5 实时复制inotify机制介绍1.6 项目部署实施1.6.1 部署环境准备1.6.2 检查Linux系统支…...

2024年AI辅助研发趋势深度解析:科技革新与效率提升的双重奏
随着人工智能技术的迅猛发展,AI辅助研发正逐渐成为科技界和工业界的热门话题。特别是在2024年,这一趋势将更加明显,AI辅助研发将在各个领域展现出强大的潜力和应用价值。 首先,AI辅助研发将进一步提升研发效率。传统的研发模式往…...

bash: mysqldump: command not found
问题:在linux上执行mysql备份的时候,出现此异常 mysqldump命令找不到 解决: 1、找到mysql目录(找到mysql可执行命令目录) which mysql 有图可知,mysql安装在: /usr1/local/java/mysql 2、my…...

hcie数通和云计算选哪个好?
1. 基础知识与技能要求 数通技术是网络技术的核心,它涉及到网络协议、路由交换、网络安全等多个方面。如果你是一名网络工程师或开发者,想要在数通领域有所建树,你需要具备扎实的基础知识和丰富的实战经验。 云计算则更注重于虚拟化、存储、网…...
浅易理解:非极大抑制NMS
什么是非极大抑制NMS 非极大值抑制(Non-Maximum Suppression,简称NMS)是一种在计算机视觉和图像处理领域中广泛使用的后处理技术,特别是在目标检测任务中。它的主要目的是解决目标检测过程中出现的重复检测问题,即对于…...

C语言如何进⾏字符数组的复制?
一、问题 有两个字符数组a和b,a的值是“Good Bye” ,b的值是 “Bye Bye”,现在要把b 复制到a中,使a变成“Bye Bye”,应该怎么做? 二、解答 在字符串操作中,字符串复制是⽐较常⽤的操作之⼀。在…...

Linux 中搭建 主从dns域名解析服务器
CSDN 成就一亿技术人! 作者主页:点击! Linux专栏:点击! CSDN 成就一亿技术人! ————前言———— 主从(Master-Slave)DNS架构是一种用于提高DNS系统可靠性和性能的配置方式。…...

CSS3病毒病原体图形特效
CSS3病毒病原体图形特效,源码由HTMLCSSJS组成,双击html文件可以本地运行效果,也可以上传到服务器里面 下载地址 CSS3病毒病原体图形特效代码...
Tomcat Web 开发项目构建教程
1下载Tomcat安装包,下载链接:Apache Tomcat - Welcome!,我电脑环境为JDK8,所以下载Tomcat9.0 2、下载完压缩包后,解压到指定位置 3.在intelij中新建一个项目 4.选中创建的项目,双击shift,输入add frame...然…...
 gauss的使用)
Elasticsearch(9) gauss的使用
elasticsearch version: 7.10.1 在Elasticsearch中,gauss作为衰减函数(decay function)被用于function_score查询中,用于实现基于地理位置或其他数值字段的衰减权重评分。gauss衰减函数模拟了高斯分布,即距…...

php前端和java后端数据调用流程
php前端和java后端数据调用流程 前端 1、新建php页面title.php <title>标题</title> <td width"30%" class"form-key">标题内容</td> <td width"70%"><input type"text" class"form-control…...
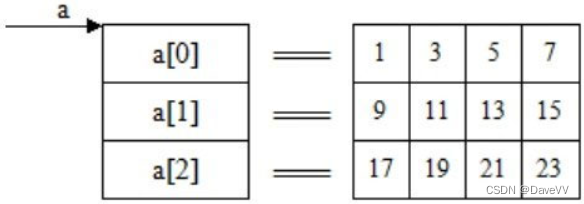
C语言从入门到熟悉------第四阶段
指针 地址和指针的概念 要明白什么是指针,必须先要弄清楚数据在内存中是如何存储的,又是如何被读取的。如果在程序中定义了一个变量,在对程序进行编译时,系统就会为这个变量分配内存单元。编译系统根据程序中定义的变量类型分配…...
【目标检测-数据集准备】DIOR转为yolo训练所需格式
【目标检测】DIOR遥感影像数据集,转为yolo系列模型训练所需格式。 标签文件位于Annotations下,格式为xml,yolo系列模型训练所需格式为txt,格式为 class_id x_center,y_center,w,h其中,train,textÿ…...

Nacos为什么对于临时实例采用心跳检测,非临时实例采用主动询问?Nacos同时作为配置中心和注册中心有什么坏处?为什么Nacos可以抗住那么高的注册?
Nacos为什么对于临时实例采用心跳检测,非临时实例采用主动询问? Nacos 对于临时实例采用心跳检测,而对于非临时实例采用主动询问,这两种不同的健康检查机制是为了满足不同场景下的服务发现需求。具体分析如下: 临时实例的心跳检测…...

【NLP】如何实现快速加载gensim word2vec的预训练的词向量模型
1 问题 通过以下代码,实现加载word2vec词向量,每次加载都是几分钟,效率特别低。 from gensim.models import Word2Vec,KeyedVectors# 读取中文词向量模型(需要提前下载对应的词向量模型文件) word2vec_model KeyedV…...
前端实例:页面布局1(后端数据实现)
效果图 注:这里用到后端语言php(页面是.php文件),提取纯html也可以用 inemployee_index.php <?php include(includes/session.inc); $Title _(内部员工首页); $ViewTopic 内部员工首页; $BookMark 内部员工首页; include(includes/…...
【调参】如何为神经网络选择最合适的学习率lr-LRFinder-for-Keras
【调参】如何为神经网络选择最合适的学习率lr-LRFinder-for-Keras_学习率选择-CSDN博客文章浏览阅读9.2k次,点赞6次,收藏55次。keras 版本的LRFinder,借鉴 fast.ai Deep Learning course。前言学习率lr在神经网络中是最难调的全局参数&#x…...
)
【设计模式】Java 设计模式之享元模式(Flyweight)
享元模式(Flyweight)的深入分析 一、概述 享元模式是一种结构型设计模式,它提供了一种有效的方式来减少在大量对象中产生的内存开销。通过共享尽可能多的对象,享元模式可以使程序更高效地使用内存。享元模式常用于那些创建对象实…...
异次元发卡源码系统/荔枝发卡V3.0二次元风格发卡网全开源源码
– 支付系统,已经接入易支付及Z支付免签接口。 – 云更新,如果系统升级新版本,你无需进行繁琐操作,只需要在你的店铺后台就可以无缝完成升级。 – 商品销售,支持商品配图、会员价、游客价、邮件通知、卡密预选&#…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

【DeepSeek架构评审功能深度解密】:20年架构师亲授3大避坑指南与5步落地 checklist
更多请点击: https://kaifayun.com 第一章:DeepSeek架构评审功能全景概览 DeepSeek架构评审功能是一套面向大模型系统设计与工程落地的自动化分析框架,聚焦于模型结构合理性、计算图优化潜力、内存访问模式、算子兼容性及部署约束等多维度评…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...