kafka相关配置介绍
kafka默认配置
每个kafka broker中配置文件server.properties默认必须配置的属性如下:
broker.id=0
num.network.threads=2
num.io.threads=8
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=2
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=60000
log.cleaner.enable=false
zookeeper.connect=localhost:2181
zookeeper.connection.timeout.ms=1000000
配置文件中参数说明
#**Server Basics**
#broker的主机IP地址,一般不设置
host.name=
#broker服务端口,生产者和消费者再此端口建立连接
port =端口
#broker在集群中的唯一标识,正数
broker.id=1
#后台任务处理的线程数
background.threads=4
#请求队列最大数量
queued.max.requests=500
#**Socket Server Settings**
#处理消息的最大线程数,一般情况下数量为cpu核数
num.network.threads=3
#处理磁盘IO的线程数,数值为cpu核数2倍
num.io.threads=8
#发送缓冲区
socket.send.buffer.bytes=1000*1024
#接收缓冲区
socket.receive.buffer.bytes=1000*1024
#请求的最大数值
socket.request.max.bytes=104857600
#**Log Basics**
#kafka数据的存放位置,多个用逗号分隔;
log.dirs=/kafka/logs
#每个数据目录的线程数,用于启动时的日志恢复和关闭时的刷新
num.recovery.threads.per.data.dir=1
#**Log Retention Policy**
#是否开启清理
log.cleaner.enable=false
#清理运行的线程数
log.cleaner.threads = 2
#清理时每秒处理的字节数
log.cleaner.io.max.bytes.per.second=None
#segment即使没有达到log.segment.bytes设置的大小,也会强制新建一个segment
log.roll.hours =24*7
#数据文件保留多长时间
log.retention.minutes=3000
或者
log.retention.hours=50
#清理策略:delete或者compact
log.cleanup.policy = delete
#topic每个分区的最大文件大小,-1没有大小限制
log.retention.bytes=-1
#消息体的最大字节,小于socket.request.max.bytes
message.max.bytes=5242880
#自动创建topic时的默认副本的个数
default.replication.factor=3
#为每个分区设置获取的消息的字节数
replica.fetch.max.bytes=104857600
#topic的分区是以segment文件存储的,这个控制每个segment的大小
log.segment.bytes=1073741824
#文件大小检查的周期时间
log.retention.check.interval.ms=300000
#清理时候用到的IO缓存大小,一般不需要修改
log.cleaner.io.buffer.size=512*1024
#清理中hash表的扩大因子,一般不需要修改
log.cleaner.io.buffer.load.factor =0.9
#检查是否触发清理
log.cleaner.backoff.ms =15000
#清理频率,越大意味着更高效的清理,但浪费空间
log.cleaner.min.cleanable.ratio=0.5
#压缩信息保留的最长时间,也是客户端消费消息的最长时间
log.cleaner.delete.retention.ms =24*60*60*1000
#segment索引文件大小
log.index.size.max.bytes =10*1024*1024
#fetch操作,需要空间来扫描offset值,值越大扫描速度越快,但浪费空间
log.index.interval.bytes =4096
#partiton缓存,每当消息记录数达到1000时flush一次数据到磁盘
log.flush.interval.messages=1000
#检查数据是否要写入到硬盘的时间间隔
log.flush.scheduler.interval.ms =3000
#如果消息量始终没有达到阀值,但是离上一次磁盘同步的时间间隔达到阀值,也将触发表示每间隔1000毫秒flush一次数据到磁盘
log.flush.interval.ms=1000
#文件在索引中清除后保留的时间一般不需要去修改
log.delete.delay.ms =60000
#控制上次flush到硬盘的时间点,以便于数据恢复一般不需要去修改
log.flush.offset.checkpoint.interval.ms =60000
#**Internal Topic Settings**
#是否允许自动创建topic,若是false,就需要通过命令创建topic
auto.create.topics.enable =true
#每个topic的分区个数
num.partitions=3
#topic的offset的备份数,建议3、4个
offsets.topic.replication.factor=3
#事物备份数,建议3、4个
transaction.state.log.replication.factor=3
#事务重写备份数,建议3、4个
transaction.state.log.min.isr=3
#**Zookeeper**
#zookeeper集群的地址
zookeeper.connect=IP1:端口,IP2:端口,IP3:端口...
#zookeeper的连接超时时间
zookeeper.connection.timeout.ms =6000
#zookeeper的心跳间隔,不易过大
zookeeper.session.timeout.ms=6000
#zookeeper集群中leader和follower之间的同步时间
zookeeper.sync.time.ms =2000
#**Group Coordinator Settings**
#/*在进行第一次重新平衡之前,group协调员将等待更多消费者加入group的时间,
#延迟时间越长意味着重新平衡的可能性越小,但是等待处理开始的时间增加*/
group.initial.rebalance.delay.ms=3000
生产者配置介绍
**bootstrap.servers**- 指定生产者客户端连接kafka集群所需的broker地址列表,格式为host1:port1,host2:port2,可以设置一个或多个。这里并非需要所有的broker地址,因为生产者会从给定的broker里寻找其它的broker。**key.serializer和value.serializer**- broker接收消息必须以字节数组byte[]形式存在,KafkaProducer<K,V>和ProducerRecord<K,V>中的泛型就是key和value的类型。key.serializer和value.serializer分别用来指定key和value序列化操作的序列化器,无默认值。类的全限定名。retry.backoff.ms- 用来设定两次重试之间的时间间隔,默认值100。**partitioner.class**- 显示配置使用哪个分区器。**interceptor.classes**- 指定自定义拦截器,多个传List集合。**compression.type**- 指定消息的压缩方式,默认值为"none",可以配置为"gzip",“snappy”和“lz4”。**connections.max.idle.ms**- 用来指定多久之后关闭闲置的连接,默认值540000(ms),即9min**receive.buffer.bytes**- 用来设置socket接收缓冲区的大小,默认值为32768(B),即32KB,如果设置为-1,则使用操作系统的默认值。**enable.idempotence**- 是否开启幂等性功能,默认值false**max.in.flight.requests.per.connection**- 限制每个连接,也就是客户端与Node之间的连接最多缓存请求数,默认值5**transactional.id**- 设置事物id,必须唯一,默认值nullacks:指定了必须有多少个分区副本收到消息,生产者才会认为消息写入是成功的。默认为**acks=1**-
acks=0如果设置为 0,则 Producer 不会等待服务器的反馈。该消息会被立刻添加到 socket buffer 中并认为已经发送完成。在这种情况下,服务器是否收到请求是没法保证的,并且参数**retries**也不会生效(因为客户端无法获得失败信息)。每个记录返回的 offset 总是被设置为-1。 -
acks=1如果设置为 1,表示只要集群的leader分区副本接收到了消息,就会向生产者发送一个成功响应的ack,此时生产者接收到ack之后就可以认为该消息是写入成功的。leader 节点会将记录写入本地日志,并且在所有 follower 节点反馈之前就先确认成功。在这种情况下,如果 leader 节点在接收记录之后,并且在 follower 节点复制数据完成之前产生错误,则这条记录会丢失。 -
acks=all如果设置为 all,这就意味着 leader 节点会等待**所有同步中的副本(ISR)**确认之后再确认这条记录是否发送完成。只要至少有一个同步副本存在,记录就不会丢失。这种方式是对请求传递的最有效保证。acks=-1 与 acks=all 是等效的。注意:
这里是所有的isr内副本,min.insync.replicas只是一个最低限制,即同步副本少于该配置值,则会抛异常,如果ISR中的副本数小于min.insync.replicas,消息只能读,不能写入。
-
buffer.memory:用来设置 Producer 缓冲区大小。compression.type:Producer 生成数据时可使用的压缩类型。默认值是 none(即不压缩)。可配置的压缩类型包括:none、gzip、snappy、lz4或zstd。压缩是针对批处理的所有数据,所以批处理的效果也会影响压缩比(更多的批处理意味着更好的压缩)。retries:用来设置发送失败的重试次数。batch.size:用来设置一个批次可占用的内存大小。linger.ms:用来设置 Producer 在发送批次前的等待时间。client.id:Kafka 服务器用它来识别消息源,可以是任意字符串。max.in.flight.requests.per.connection:用来设置Producer在单个连接上能够发送的未响应请求的个数。设置此值是1表示kafka broker在响应请求之前client不能再向同一个broker发送请求。默认值为5。如果设置1,可以避免生产者发送消息乱序,虽然吞吐量降低了,但是安全性得到了提升,要权衡业务场景配置。(比如生产者发送两条顺序消息1,2,都是异步发送,同步发送性能低,如果2成功,1因为网络问题重试发送成功,1就到2后面,乱序了)。timeout.ms:用来设置 Broker 等待同步副本返回消息确认的时间,与acks的配置相匹配。request.timeout.ms:Producer 在发送数据时等待服务器返回响应的时间。max.block.ms:该配置控制KafkaProducer.send()和**KafkaProducer.partitionsFor()** 允许被阻塞的时长。这些方法可能因为缓冲区满了或者元数据不可用而被阻塞。用户提供的序列化程序或分区程序的阻塞将不会被计算到这个超时。max.request.size:请求的最大字节数。receieve.buffer.bytes:TCP 接收缓冲区的大小。send.buffer.bytes- 用来设置socket发送缓冲区的大小,默认值为131072(B),即128KB,如果设置为-1,则使用操作系统默认值。request.timeout.ms- 配置Producer等待请求响应的最长时间,默认值为30000(ms),请求超时之后可以进行重试。注意这个参数需要比broker端参数replica.lag.time.max.ms的值要大,这样可以减少因客户端重试而引起的消息重复的概率。**buffer.memory**- 生产者客户端RecordAccumulator缓存大小,默认值为33554432B,即32M。**metadata.max.age.ms**- 当客户端超过这个时间间隔时就会更新元数据信息默认值300000,即5分钟。元数据指集群中有哪些主题,主题有哪些分区,每个分区leader副本在哪个节点上,follower副本在哪个节点上,哪些副本在AR,ISR等集合中,集群中有哪些节点等等。**max.request.size**- 用来限制生产者客户端能发送的消息的最大值,默认值为1048576B,即1MB。这个参数涉及到其它参数的联动,比如broker端的message.max.bytes参数。对kafka没有足够把控的时候不要更改此参数。producer.type:该参数指定了在后台线程中消息的发送方式是同步的还是异步的,默认是sync的方式,即producer.type=sync。如果设置成异步的模式,即producer.type=async,但是这样会增加丢失数据的风险。如果需要确保消息的可靠性,必须要将producer.type设置为sync。queue.buffering.max.ms默认值:5000。启用异步模式时,producer缓存消息的时间。比如我们设置成1000时,它会缓存1s的数据再一次发送出去,这样可以极大的增加broker吞吐量,但也会造成时效性的降低。queue.buffering.max.messages默认值:10000。启用异步模式时,producer缓存队列里最大缓存的消息数量,如果超过这个值,producer就会阻塞或者丢掉消息。queue.enqueue.timeout.ms默认值:-1。当达到上面参数时producer会阻塞等待的时间。如果设置为0,buffer队列满时producer不会阻塞,消息直接被丢掉;若设置为-1,producer会被阻塞,不会丢消息。batch.num.messages默认值:200。启用异步模式时,一个batch缓存的消息数量。达到这个数值时,producer才会发送消息。(每次批量发送的数量)
消费者配置介绍
bootstrap.servers- Broker 集群地址,格式:ip1:port,ip2:port…,不需要设定全部的集群地址,设置两个或者两个以上即可。group.id- 消费者隶属的消费者组名称,如果为空会报异常,一般而言,这个参数要有一定的业务意义。fetch.min.bytes- 消费者获取记录的最小字节数。Kafka 会等到有足够的数据时才返回消息给消费者,以降低负载。**fetch.max.bytes**- 单次获取数据的最大消息数。fetch.max.wait.ms- Kafka 需要等待足够的数据才返回给消费者,如果一直没有足够的数据,消费者就会迟迟收不到消息。所以需要指定 Broker 的等待延迟,一旦超时,直接返回数据给消费者。max.partition.fetch.bytes- 指定了服务器从每个分区返回给消费者的最大字节数。默认为 1 MB。session.timeout.ms- 指定了消费者的心跳超时时间。如果消费者没有在有效时间内发送心跳给群组协调器,协调器会视消费者已经消亡,从而触发分区再均衡。默认为 3 秒。enable.auto.commit- 指定了是否自动提交消息偏移量,默认开启。- **
partition.assignment.strategy**消费者的分区分配策略。Range- 表示会将主题的若干个连续的分区分配给消费者。RoundRobin- 表示会将主题的所有分区按照轮询方式分配给消费者。
client.id- 客户端标识。max.poll.records- 一次性拉取的条数,这个参数用来配置 Consumer 在一次拉取请求中拉取的最大消息数,默认值为500(条)。如果消息的大小都比较小,则可以适当调大这个参数值来提升一定的消费速度。max.poll.interval.ms-receive.buffer.bytes- 用于设置 Socket 接收消息缓冲区(SO_RECBUF)的大小,默认值为 64KB。如果设置为-1,则使用操作系统的默认值。send.buffer.bytes- 用于设置 Socket 发送消息缓冲区(SO_SNDBUF)的大小,默认值为 128KB。与 receive.buffer.bytes 参数一样,如果设置为-1,则使用操作系统的默认值。connections.max.idle.ms- 这个参数用来指定在多久之后关闭闲置的连接,默认值是540000(ms),即9分钟。exclude.internal.topics- Kafka 中有两个内部的主题:__consumer_offsets和__transaction_state。exclude.internal.topics 用来指定 Kafka 中的内部主题是否可以向消费者公开,默认值为 true。如果设置为 true,那么只能使用 subscribe(Collection)的方式而不能使用 subscribe(Pattern)的方式来订阅内部主题,设置为 false 则没有这个限制。receive.buffer.bytes- 这个参数用来设置 Socket 接收消息缓冲区(SO_RECBUF)的大小,默认值为65536(B),即64KB。如果设置为-1,则使用操作系统的默认值。如果 Consumer 与 Kafka 处于不同的机房,则可以适当调大这个参数值。**send.buffer.bytes**- 这个参数用来设置Socket发送消息缓冲区(SO_SNDBUF)的大小,默认值为131072(B),即128KB。与receive.buffer.bytes参数一样,如果设置为-1,则使用操作系统的默认值**request.timeout.ms**- 这个参数用来配置 Consumer 等待请求响应的最长时间,默认值为30000(ms)。**metadata.max.age.ms**- 这个参数用来配置元数据的过期时间,默认值为300000(ms),即5分钟。如果元数据在此参数所限定的时间范围内没有进行更新,则会被强制更新,即使没有任何分区变化或有新的 broker 加入**reconnect.backoff.ms**- 这个参数用来配置尝试重新连接指定主机之前的等待时间(也称为退避时间),避免频繁地连接主机,默认值为50(ms)。这种机制适用于消费者向 broker 发送的所有请求。**auto.offset.reset**- 在 Kafka 中,每当消费者组内的消费者查找不到所记录的消费位移或发生位移越界时,就会根据消费者客户端参数 auto.offset.reset 的配置来决定从何处开始进行消费,这个参数的默认值为 “latest” 。**earliest**:当各分区下存在已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,从头开始消费。**latest**:当各分区下存在已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费该分区下新产生的数据。none:topic 各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的offset,则抛出异常。
interceptor.class- 用来配置消费者客户端的拦截器
--------------------------------------欢迎叨扰此地址---------------------------------------
本文作者:Java技术债务
原文链接:https://cuizb.top/myblog/article/1677833372
版权声明: 本博客所有文章除特别声明外,均采用 CC BY 3.0 CN协议进行许可。转载请署名作者且注明文章出处。
相关文章:

kafka相关配置介绍
kafka默认配置 每个kafka broker中配置文件server.properties默认必须配置的属性如下: broker.id0 num.network.threads2 num.io.threads8 socket.send.buffer.bytes1048576 socket.receive.buffer.bytes1048576 socket.request.max.bytes104857600 log.dirs/tmp/…...
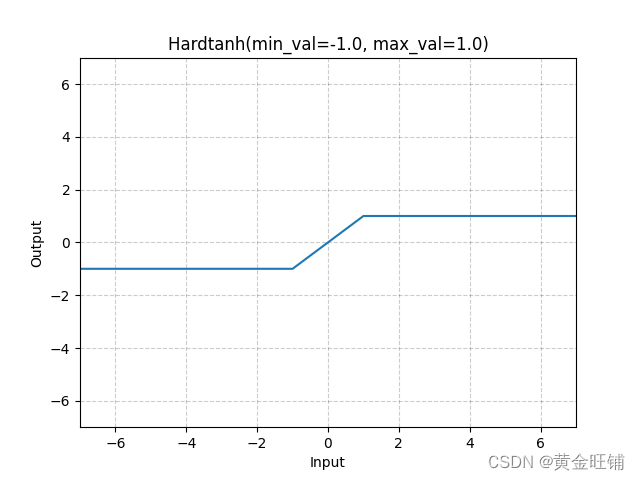
【PyTorch】教程:torch.nn.Hardtanh
torch.nn.Hardtanh 原型 CLASS torch.nn.Hardtanh(min_val- 1.0, max_val1.0, inplaceFalse, min_valueNone, max_valueNone) 参数 min_val ([float]) – 线性区域的最小值,默认为 -1max_val ([float]) – 线性区域的最大值,默认为 1inplace ([bool]) …...

神垕古镇景区5A级十年都没有实现的三大主因
钧 瓷 内 参 第40期(总第371期) 2023年3月5日 神垕古镇景区5A级十年都没有实现的三大主因 这是2013年,禹州市市政府第一次提出创建5A级景区到今年三月份整整十年啊! 目前神垕古镇景区是4A级景区,5A级一直进行中&a…...

react函数组件常用的几个钩子函数useState、useEffect、useRef、useCallback
react框架react框架包括包括两大类:类组件函数组件。类组件构成:constructor自定义方法。调用方法通过this.方法名()。constructor(superstate)构造器里面必有super字段。render()方法里面写页面布局。函数组件构成:各种钩子函数return()方法…...

4N60-ASEMI高压MOS管4N60
编辑-Z 4N60在TO-220封装里的静态漏极源导通电阻(RDS(ON))为2.5Ω,是一款N沟道高压MOS管。4N60的最大脉冲正向电流ISM为16A,零栅极电压漏极电流(IDSS)为1uA,其工作时耐温度范围为-55~150摄氏度。4N60功耗(…...
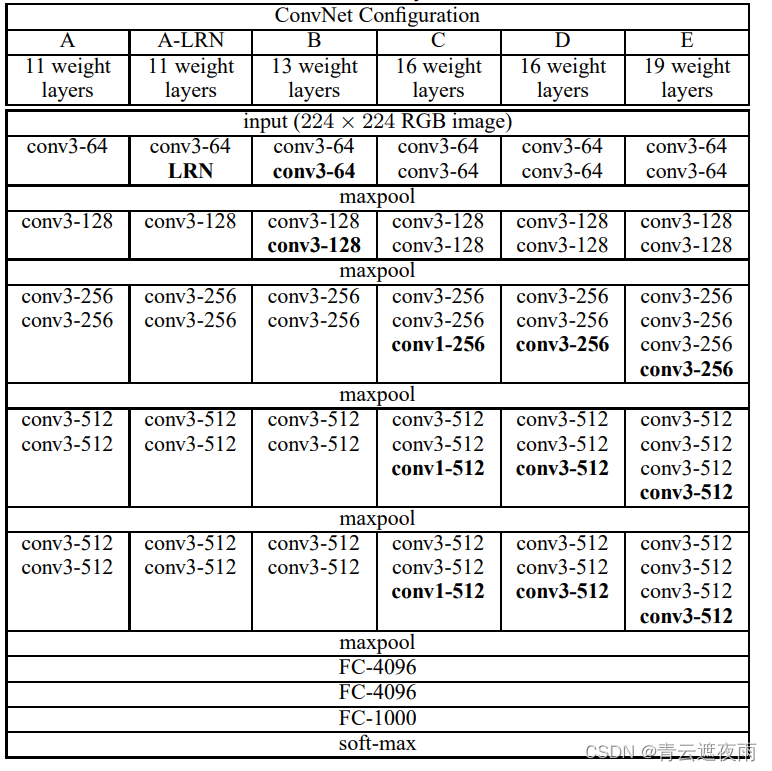
现代神经网络(VGG),并用VGG16进行实战CIFAR10分类
专栏:神经网络复现目录 本章介绍的是现代神经网络的结构和复现,包括深度卷积神经网络(AlexNet),VGG,NiN,GoogleNet,残差网络(ResNet),稠密连接网络…...
)
Java代码弱点与修复之——Dereference null return value(间接引用空返回值)
弱点描述 Dereference null return value,间接引用空返回值。是Coverity Scan静态代码分析工具中的一个警告,表示代码中有对可能为空(null)的方法或函数返回值进行间接引用(Dereference)操作。 该类型的漏洞可能会导致 NullPointerException 异常,并且会导致程序崩溃或…...

【冲刺蓝桥杯的最后30天】day3
大家好😃,我是想要慢慢变得优秀的向阳🌞同学👨💻,断更了整整一年,又开始恢复CSDN更新,从今天开始更新备战蓝桥30天系列,一共30天,如果对你有帮助或者正在备…...

光伏发电嵌入式ARM工控机
随着智慧电力技术的不断发展和普及,越来越多的电力设备和系统需要采用先进的控制和监测技术来实现自动化管理和优化运行。其中,嵌入式 ARM 控制器技术在智慧电力领域中得到了广泛应用。同时,导轨安装也是该技术的重要应用场景之一。 导轨安装…...

推荐 7 个 Vue.js 插件,也许你的项目用的上(五)
当我们可以通过使用库轻松实现相同的结果时,为什么还要编写自定义功能?开发人员最好的朋友和救星就是这些第三方库。我相信一个好的项目会利用一些可用的最佳库。Vue.js 是创建用户界面的最佳 JavaScript 框架之一。这篇文章是关于 Vue.js 的优秀库系列的…...

1.1基于知识图谱的项目实战:优酷搜索泛查询意图优化
NLU的技术实现主要分为在线识别和离线数据挖掘两块。 1.在线识别 NLU的在线识别技术栈如下图所示,共由下述2个部分组成: 第一个部分是Slot Filling(成分分析),负责对query进行实体识别和槽位抽取;第二部分Inention Detection(意图识别),根据提取的槽位进行意图的判定(目…...
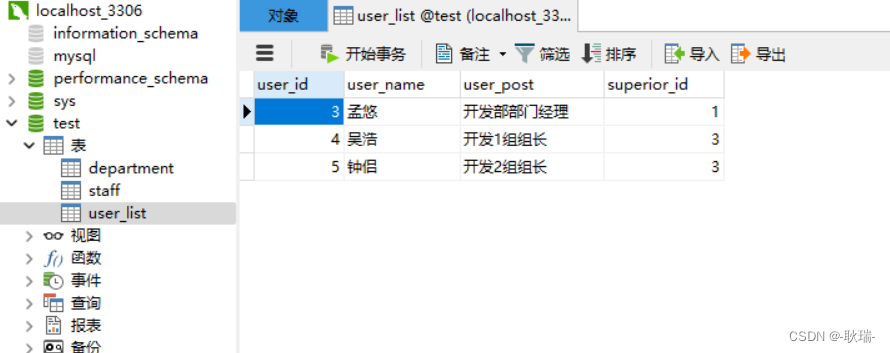
[java Spring JdbcTemplate配合mysql实现数据批量删除
之前的文章 java Spring JdbcTemplate配合mysql实现数据批量添加和文章java Spring JdbcTemplate配合mysql实现数据批量修改 先后讲解了 mysql数据库的批量添加和批量删除操作 会了这两个操作之后 批量删除就不要太简单 我们看到数据库 这里 我们用的是mysql工具 这里 我们有…...
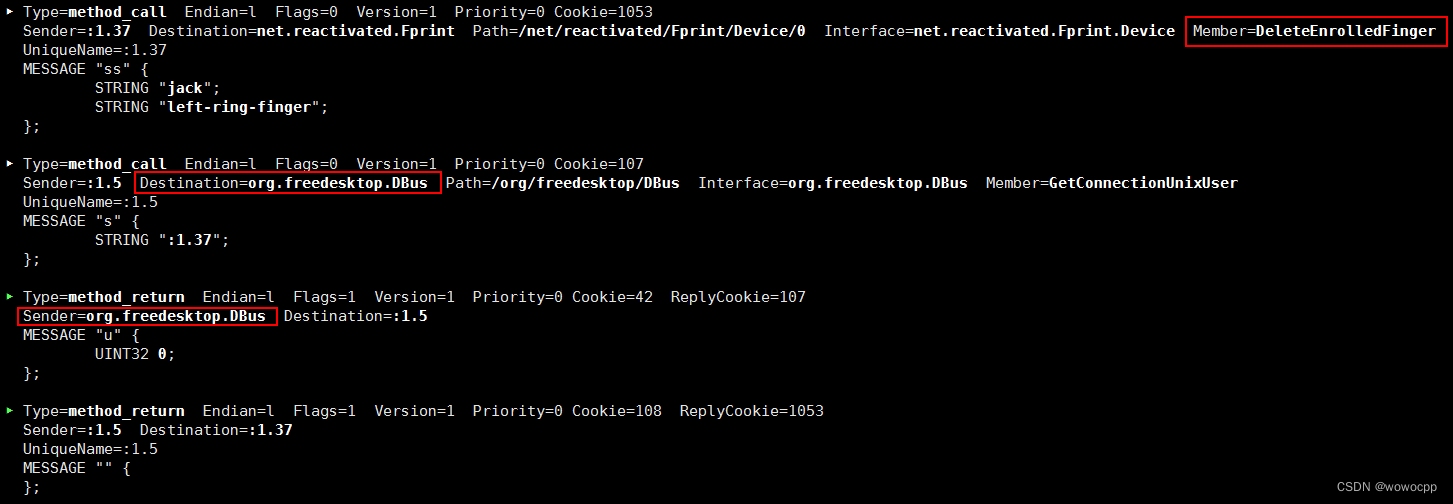
uos 20 统信 fprintd 记录
uos 20 统信 fprintd 记录 sudo busctl deepin-authenticate.service /usr/lib/systemd/system/deepin-authenticate.service [Unit] DescriptionDeepin Authentication[Service] Typedbus BusNamecom.deepin.daemon.Authenticate ExecStart/usr/lib/deepin-authenticate/d…...

vue移动端h5,文本溢出显示省略号,且展示‘更多’按钮
问题: 元素宽度100%,宽度会随着浏览器缩放而变化。元素内文本超过4行时显示省略号,同时展示‘更多’按钮,点击更多按钮展示全部文本。如下图所示 超出四行显示省略号(…)的代码 .content{overflow:hidden;text-overflow: elli…...

php宝塔搭建部署实战兰空图床程序网站PHP源码
大家好啊,我是测评君,欢迎来到web测评。 本期给大家带来一套Lsky Pro兰空图床程序网站PHP的源码。感兴趣的朋友可以自行下载学习。 技术架构 PHP8.0 nginx mysql5.7 JS CSS HTMLcnetos7以上 宝塔面板 文字搭建教程 下载源码,宝塔添加…...
如何开展测试?)
软件测试面试:拿到一个产品(版本)如何开展测试?
产品提测后,如何开展测试? 我们都了解软件测试的执行流程,......提测-冒烟测试-详细测试-提交缺陷报告-回归测试,但软件测试并不总是线性过程,它甚至可能是螺旋结构,不断地试错,不断地迭代&…...

【Opencv项目实战】图像的像素值反转
文章目录一、项目思路二、算法详解2.1、获取图像信息2.2、新建模板2.3、图像通道顺序三、项目实战:彩图的像素值反转(方法一)四、项目实战:彩图的像素值反转(方法二)五、项目实战:彩图转换为灰图…...

Swagger生成接口在线文档
OpenAPI规范(OpenAPI Specification 简称OAS)是Linux基金会的一个项目,试图通过定义一种用来描述API格式或API定义的语言,来规范RESTful服务开发过程,目前版本是V3.0,并且已经发布并开源在github上。&#…...
)
104.第十九章 MySQL数据库 -- MySQL主从复制、 级联复制和双主复制(十四)
6.1.2 实现主从复制配置 参考官网 https://dev.mysql.com/doc/refman/8.0/en/replication-configuration.html https://dev.mysql.com/doc/refman/5.7/en/replication-configuration.html https://dev.mysql.com/doc/refman/5.5/en/replication-configuration.html https://m…...
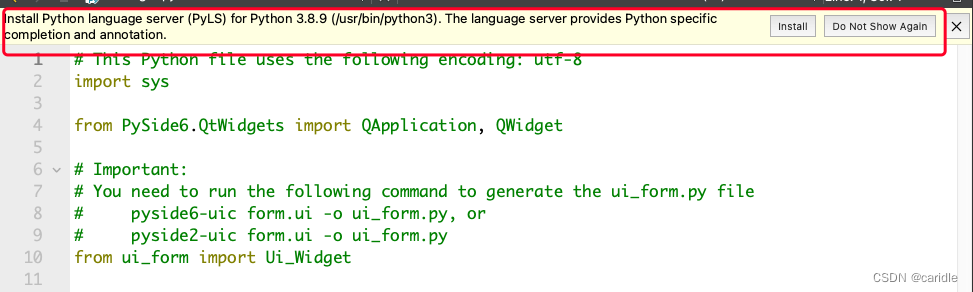
第一次使用Python for Qt中的问题
在创建带有form的python for qt的时候,使用的库是pySide6,而不是pyqt。 因此,需要安装pyside6。 Running "/usr/bin/python3 -m pip install PySide6 --user" to install PySide6. ERROR: Could not find a version that satisfi…...

基于Circuit Playground Express与3D打印的机械心脏制作指南
1. 项目概述:一个会“呼吸”的机械心脏如果你对创客、STEAM教育或者互动艺术装置感兴趣,那么亲手制作一个能模拟真实心跳、并且心率可以手动调节的解剖心脏模型,绝对是一个能让你成就感爆棚的项目。这不仅仅是一个静态的展示品,它…...

嵌入式开发中的模拟信号处理:ADC、DAC与PWM核心原理与CircuitPython实战
1. 项目概述:从数字世界到物理世界的桥梁在嵌入式开发的世界里,我们写的代码最终是要和物理世界打交道的。物理世界是连续的、模拟的——光线强弱、温度高低、声音大小,这些都不是简单的“开”或“关”,而是平滑变化的连续量。而我…...

企业内部分享Taotoken在代码审查与生成场景下的应用实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内部分享Taotoken在代码审查与生成场景下的应用实践 在软件开发团队中,代码审查与代码生成是提升代码质量、保障项…...
问题排查)
Win10 任务管理器点击“详细信息”崩溃 + U盘 PPTX 无法删除/复制(0x800700EA)问题排查
一、问题现象 最近遇到一个比较奇怪的问题: Win10 系统 任务管理器只能以“小窗口模式”打开 点击“详细信息”后直接崩溃 事件查看器报错: 错误应用程序名称: taskmgr.exe 版本: 10.0.19041.6280同时还伴随另一个问题: U盘中的 .pptx …...

JAVA练习:单一职责原则重构
问题背景原始Login类同时承担界面展示、登录校验、数据库连接、用户查询、程序入口多重职责,功能高度耦合,违反单一职责原则(一个类只负责一类功能),修改某部分功能易影响其他模块。重构思路按职责拆分,分为…...

碧蓝航线Alas自动化脚本:10分钟解放双手的智能游戏助手
碧蓝航线Alas自动化脚本:10分钟解放双手的智能游戏助手 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为每…...

TimerBlox:基于电流基准的硬件定时新方案,替代555与MCU
1. 项目概述:重新认识定时电路的设计范式在嵌入式系统、电源管理、电机控制乃至各类信号发生器的设计中,定时功能几乎无处不在。无论是生成一个精确的PWM波去调节LED亮度,还是产生一个可调的时钟信号驱动VCO,亦或是需要一个精准的…...

如何用免费开源工具彻底解决Dell G15散热问题:3步终极控制方案
如何用免费开源工具彻底解决Dell G15散热问题:3步终极控制方案 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否正在为Dell G15游戏本的散热问…...

tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南
tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南 【免费下载链接】tcpdive A TCP performance profiling tool. 项目地址: https://gitcode.com/gh_mirrors/tc/tcpdive tcpdive作为一款专业的TCP性能分析工具,在生产环境中的性能表现至关重要…...

Next.js静态站点图片优化实战:next-image-export-optimizer配置指南
1. 项目概述:为什么我们需要一个“静态图片优化器”?如果你和我一样,经常用 Next.js 做项目,那你肯定对next/image组件又爱又恨。爱的是它开箱即用的图片懒加载、自动格式转换和响应式适配,恨的是它在构建和部署时带来…...