DataGrip 面试题及答案整理,最新面试题
DataGrip的数据库兼容性和多数据库支持如何实现?
DataGrip实现数据库兼容性和多数据库支持的方式包括:
1、广泛的数据库支持: DataGrip支持多种数据库,包括但不限于MySQL, PostgreSQL, SQL Server, Oracle, SQLite, 和MongoDB,实现对不同数据库的兼容。
2、统一的数据库访问接口: 提供统一的界面用于连接和管理不同的数据库,用户可以在同一工具中同时操作多个数据库。
3、数据库驱动: DataGrip通过使用各个数据库的官方驱动或第三方驱动来实现对特定数据库的支持。
4、自定义设置: 允许用户针对每个数据库连接进行详细的自定义设置,如连接参数、SSH隧道配置等。
如何使用DataGrip进行数据库重构,而不影响现有数据和结构?
使用DataGrip进行数据库重构而不影响现有数据和结构的策略包括:
1、安全检查: DataGrip提供重构前的安全检查,确保重构操作不会导致数据丢失或破坏数据完整性。
2、重构预览: 在执行重构操作之前,DataGrip会显示预览,让用户看到变更的具体内容,以做出明智的决策。
3、版本控制集成: 通过与版本控制系统的集成,DataGrip可以跟踪数据库结构变更,支持回滚到先前的状态以防出错。
4、逐步执行: 允许用户逐步执行重构过程,每步进行验证,确保每一步骤都不会对现有系统造成负面影响。
DataGrip中的智能代码补全功能是如何工作的?
DataGrip中的智能代码补全功能工作原理如下:
1、上下文分析: DataGrip会分析当前的编写上下文,包括SQL语句中的关键字、表名、列名等。
2、数据库模式信息: 利用已连接数据库的模式信息,提供表名、列名、函数等的自动补全建议。
3、学习用户习惯: DataGrip能够学习用户的编码习惯,优先显示常用的表名和字段。
4、语法和关键词支持: 根据SQL语言的语法和关键词提供智能补全,帮助用户快速编写SQL语句。
在DataGrip中如何有效管理大型数据库项目?
在DataGrip中有效管理大型数据库项目的方法包括:
1、项目分组: 将相关的数据库对象(如表、视图、存储过程等)组织到不同的项目分组中,以便管理和访问。
2、使用书签和颜色标记: 利用书签和颜色标记来标识重要的数据库对象和SQL脚本,快速访问和识别。
3、依赖性分析: 使用DataGrip的依赖性分析工具来理解不同数据库对象之间的关系和依赖,帮助进行更合理的更改和优化。
4、版本控制: 利用版本控制系统管理数据库变更,确保数据库项目的变更可追踪且可回滚。
DataGrip如何处理不同数据库方言的兼容性问题?
DataGrip处理不同数据库方言的兼容性问题通过以下方式:
1、方言识别和支持: DataGrip能够识别和支持多种数据库方言,为每种数据库提供专门的语法和功能支持。
2、智能代码补全: 针对不同的数据库方言,提供智能代码补全功能,帮助用户准确编写SQL语句。
3、语法高亮和检查: 根据所连接数据库的具体方言,提供语法高亮和错误检查功能,避免因方言差异导致的语法错误。
4、自定义方言支持: 允许用户自定义方言设置,以支持特定数据库的独特语法和功能。
DataGrip中的数据库版本控制如何工作,它提供哪些优势?
DataGrip中的数据库版本控制工作机制及其优势包括:
1、版本控制集成: DataGrip集成了Git, SVN等版本控制系统,可以直接从IDE内部管理数据库脚本和对象的版本。
2、变更跟踪: 自动跟踪数据库结构和内容的变更,确保每次更改都可以被记录和追溯。
3、团队协作: 支持多人协作开发,通过版本控制管理共享的数据库对象,避免冲突和数据不一致。
4、回滚和历史比较: 提供回滚到先前状态的能力,以及比较不同版本之间的差异,方便错误修正和版本对比。
DataGrip中的性能优化工具有哪些,它们如何帮助提升数据库性能?
DataGrip中的性能优化工具及其帮助提升数据库性能的方法包括:
1、查询执行计划分析: 提供SQL查询的执行计划分析工具,帮助识别查询中的性能瓶颈。
2、数据库监控: 集成数据库监控功能,可以实时观察数据库的运行状态和性能指标。
3、索引建议: 根据查询模式和数据使用情况,提出索引优化建议,改善查询效率。
4、代码优化: 通过分析SQL代码质量,给出优化建议,减少资源消耗和执行时间。
在DataGrip中如何使用事务管理,以确保数据库操作的一致性和完整性?
在DataGrip中使用事务管理以确保数据库操作的一致性和完整性的方法包括:
1、事务控制界面: DataGrip提供了直观的事务控制界面,允许用户手动开始、提交或回滚事务。
2、自动事务管理: 在执行SQL脚本时,DataGrip可以自动管理事务,确保操作在一个事务块中执行。
3、锁管理和监控: 提供数据库锁的管理和监控功能,帮助用户识别和解决死锁等并发问题。
4、事务隔离级别配置: 允许用户配置事务的隔离级别,以满足不同的数据一致性和并发控制需求。
DataGrip中如何处理大量数据的导入和导出?
在DataGrip中处理大量数据的导入和导出可以通过以下方法:
1、批量处理: DataGrip支持批量导入和导出数据,可处理大量数据而不会影响系统性能。
2、格式支持: 支持多种数据格式,如CSV, SQL, Excel等,提供灵活的数据导入导出选项。
3、后台执行: 大数据量的导入导出操作可以在后台执行,避免阻塞前台操作。
4、错误处理: 在数据导入导出过程中提供错误处理机制,确保数据的准确性和完整性。
DataGrip如何实现数据库安全性和权限管理?
DataGrip实现数据库安全性和权限管理的方式包括:
1、连接加密: 支持通过SSL/TLS加密数据库连接,保障数据传输的安全。
2、访问控制: 可以配置数据库的访问权限,控制用户对特定数据库对象的访问和操作。
3、密码管理: 集成密码管理工具,安全存储和管理数据库访问凭据。
4、角色和权限管理: 通过与数据库的集成,支持管理数据库的角色和权限设置,确保合理的权限分配和访问控制。
DataGrip中的SQL代码审查功能如何帮助提高代码质量?
DataGrip中的SQL代码审查功能帮助提高代码质量的方法包括:
1、语法检查: 自动进行SQL语法检查,及时发现并提示代码中的错误和不规范的用法。
2、代码风格指导: 提供代码格式化和风格指导功能,帮助统一代码风格,提高代码的可读性和维护性。
3、性能建议: 分析SQL代码的性能,给出优化建议,帮助提升查询效率和数据库性能。
4、最佳实践提示: 根据数据库开发的最佳实践,提供改进建议和警告,促进编写高质量的SQL代码。
在DataGrip中如何使用Git进行版本控制和协作开发?
在DataGrip中使用Git进行版本控制和协作开发的方法包括:
1、版本控制集成: DataGrip与Git等版本控制系统集成,可以直接从IDE管理SQL脚本和数据库对象的版本。
2、更改跟踪: 提供更改跟踪功能,帮助开发者了解代码变更的历史和影响。
3、分支管理: 支持Git分支管理,便于团队成员在不同的功能分支上进行协作开发。
4、合并和冲突解决: 提供合并工具和冲突解决支持,帮助开发者解决合并过程中的代码冲突。
DataGrip中的插件系统如何扩展其功能和灵活性?
DataGrip中的插件系统通过以下方式扩展其功能和灵活性:
1、插件市场: DataGrip通过JetBrains Plugin Repository提供多种插件,用户可以根据需要安装不同的插件来扩展功能。
2、定制开发: 允许开发者使用JetBrains平台的API开发自定义插件,满足特定的业务需求。
3、集成工具: 通过插件集成第三方工具和服务,如版本控制、数据可视化、代码分析工具等,增强开发和数据库管理能力。
4、用户体验优化: 插件可以用来改善用户界面和工作流程,提供更加个性化和优化的用户体验。
DataGrip中的调试功能是如何实现的,它有哪些特点?
DataGrip中的调试功能实现及其特点包括:
1、断点设置: 允许在SQL脚本或存储过程中设置断点,用于暂停执行并检查程序状态。
2、变量监控: 在调试过程中监控和查看变量的值,帮助理解程序逻辑和数据流。
3、步进执行: 支持逐行步进执行代码,允许开发者细致检查每个执行步骤和操作的结果。
4、调用堆栈分析: 提供调用堆栈信息,帮助分析程序执行的路径和上下文关系。
如何在DataGrip中优化SQL查询性能?
在DataGrip中优化SQL查询性能的方法包括:
1、执行计划分析: 使用DataGrip的执行计划分析工具,识别查询中的性能瓶颈和低效操作。
2、索引优化: 根据执行计划的建议,调整或添加索引来优化查询速度。
3、查询重写: 优化SQL语句结构,避免复杂的连接和子查询,使用更高效的查询逻辑。
4、资源管理: 调整数据库的资源分配和配置,如内存和CPU使用,以支持性能密集型查询。
DataGrip中的数据可视化功能如何帮助分析和理解数据?
DataGrip中的数据可视化功能帮助分析和理解数据的方式包括:
1、图表工具: 支持将查询结果转换为图表,如柱状图、线图、饼图等,帮助直观展示数据趋势和模式。
2、结果对比: 允许对不同时间点或条件下的查询结果进行视觉对比,便于识别数据变化和异常。
3、数据探索: 提供交互式的数据探索工具,允许用户通过点击和选择不同的数据点进行深入分析。
4、报告生成: 支持创建和导出数据报告,方便分享和展示数据分析结果。
DataGrip中的数据库模型设计工具有哪些功能?
DataGrip中的数据库模型设计工具功能包括:
1、实体关系图(ERD): 支持创建和编辑实体关系图(ERD),可视化地展示数据库结构和表之间的关系。
2、表结构设计: 允许设计和修改表结构,包括添加或修改字段、索引和约束。
3、反向工程: 支持从现有的数据库生成实体关系图,帮助理解和分析数据库结构。
4、模型同步: 可以将模型的更改同步到数据库中,或者将数据库的更改更新到模型中。
如何利用DataGrip提高数据库维护效率?
利用DataGrip提高数据库维护效率的方法包括:
1、自动化脚本执行: 使用DataGrip自动化执行常规维护脚本,如数据清理、备份和恢复操作。
2、定时任务管理: 设定定时任务来执行数据库维护工作,确保数据库的健康状态和性能优化。
3、性能监控: 利用DataGrip的性能监控工具,及时发现和解决性能问题。
4、数据库对象管理: 使用DataGrip统一管理数据库对象,如表、视图、存储过程等,提高管理效率和准确性。
DataGrip中的数据库迁移工具如何使用?它提供哪些功能?
DataGrip中的数据库迁移工具使用方法和功能包括:
1、迁移向导: 提供迁移向导,引导用户通过从源数据库到目标数据库的迁移过程。
2、结构比较: 支持比较不同数据库的结构,识别差异,并生成必要的迁移脚本。
3、数据迁移: 支持迁移数据库中的数据,包括完整迁移或选择性迁移特定的表和数据。
4、版本控制集成: 与版本控制系统集成,管理迁移过程中产生的变更和脚本。
如何在DataGrip中管理和优化数据库连接?
在DataGrip中管理和优化数据库连接的方法包括:
1、连接池管理: 配置和管理连接池,优化数据库连接的创建和复用,提高性能。
2、连接参数设置: 调整连接参数,如超时设置、自动重连等,以适应不同的网络条件和数据库性能需求。
3、多数据库实例管理: 支持同时管理多个数据库实例的连接,便于跨数据库操作和维护。
4、资源监控: 监控数据库连接的资源使用情况,如CPU、内存和网络使用,及时调整以防止过载。
DataGrip中如何实现跨数据库查询和分析?
在DataGrip中实现跨数据库查询和分析的方法包括:
1、数据库连接配置: 配置并连接到需要进行跨数据库查询的多个数据库实例。
2、联合查询设置: 使用SQL语句中的联合查询功能,编写能够跨不同数据库访问数据的查询语句。
3、数据比较和同步: 利用DataGrip提供的数据比较工具,进行跨数据库的数据比较和同步分析。
4、虚拟数据源创建: 创建虚拟数据源,将不同数据库的数据集成到一个虚拟环境中,以便进行统一查询和分析。
DataGrip的用户界面自定义功能有哪些,如何提升用户体验?
DataGrip的用户界面自定义功能及其提升用户体验的方法包括:
1、主题和外观设置: 用户可以根据个人偏好选择和自定义IDE的主题和外观,包括颜色方案、字体大小和界面布局。
2、工具窗口管理: 用户可以自定义工具窗口的布局和显示方式,根据工作流程优化界面布局。
3、快捷键配置: 提供快捷键自定义功能,用户可以根据自己的习惯设置快捷键,提高操作效率。
4、编辑器选项定制: 支持定制编辑器的行为和属性,如代码补全、格式化规则和语法高亮等,以适应用户的编码习惯。
DataGrip中的代码片段功能是什么?如何高效利用它?
DataGrip中的代码片段功能及其高效利用方法包括:
1、代码片段定义: 代码片段是一段可重复使用的代码模板,用户可以定义常用的SQL语句或代码结构为代码片段,以便快速插入。
2、快速插入: 通过设定的快捷键或片段名称,快速将预定义的代码片段插入到编辑器中。
3、参数化配置: 代码片段支持参数化,用户可以在插入片段时填入特定的参数值,实现代码的动态生成。
4、代码库建设: 建立个人或团队的代码片段库,收集和分享常用的代码模板,提高编写效率。
DataGrip中如何利用外部工具和集成提高开发效率?
在DataGrip中利用外部工具和集成提高开发效率的方法包括:
1、外部工具集成: DataGrip允许集成外部工具,如版本控制系统、文件比较工具等,可以直接从IDE访问这些工具。
2、数据库工具集成: 支持与各种数据库管理和监控工具集成,提供一站式的数据库开发和维护环境。
3、自动化任务: 利用DataGrip的任务调度器,自动执行常规的数据库任务,如备份、数据导入导出等。
4、插件扩展: 利用DataGrip的插件生态系统,安装额外的插件来扩展IDE的功能,满足特定的开发需求。
在DataGrip中如何处理数据仓库的特殊需求?
在DataGrip中处理数据仓库的特殊需求,可以通过以下方式:
1、大数据集支持: DataGrip针对大数据集进行优化,确保对大型数据仓库的查询和管理操作效率高且响应快。
2、多维数据分析: 支持与数据仓库中的多维数据集进行交互,允许用户执行复杂的分析查询。
3、性能优化工具: 提供查询优化和分析工具,帮助用户优化数据仓库中的SQL查询,以提高执行效率。
4、数据可视化: 利用DataGrip的数据可视化工具,帮助用户更好地理解和分析数据仓库中的数据。
DataGrip中的数据比较和同步工具如何使用?
DataGrip中的数据比较和同步工具使用方法包括:
1、数据比较: 用户可以选择两个数据库或表进行比较,DataGrip会显示两者之间的差异,包括数据行的不同。
2、同步脚本生成: 在比较数据后,DataGrip可以自动生成同步脚本,帮助用户将一个数据库的数据更新到另一个数据库,实现数据同步。
3、配置比较选项: 允许用户配置比较过程中的详细选项,如比较哪些列、忽略哪些差异等。
4、执行同步: 用户可以直接在DataGrip中执行生成的同步脚本,完成数据的同步操作。
如何在DataGrip中使用版本控制系统来管理数据库变更?
在DataGrip中使用版本控制系统管理数据库变更的方法包括:
1、版本控制集成: DataGrip支持与Git等版本控制系统集成,允许用户从IDE内管理数据库脚本和对象的版本。
2、变更跟踪: 对数据库对象进行更改时,这些变更可以被版本控制系统跟踪,确保每次修改都有记录。
3、分支管理: 利用版本控制的分支管理功能,可以在不同的分支上进行数据库设计和修改,有助于测试新的数据库变更而不影响主分支。
4、合并和冲突解决: 在将数据库变更合并到主分支前,可以通过版本控制工具解决任何冲突,确保数据库结构的一致性。
DataGrip中的备份和恢复功能如何操作?它们提供哪些特点?
DataGrip中的备份和恢复功能操作及特点包括:
1、备份操作: DataGrip提供工具或插件支持数据库的备份操作,可以直接从界面选择需要备份的数据库对象,并执行备份操作。
2、恢复操作: 在需要时,用户可以通过DataGrip访问备份文件,并执行恢复操作,将数据还原到特定的状态。
3、自动化支持: 支持配置自动化的备份任务,定期执行数据库的备份,确保数据的安全性。
4、灵活性和可配置性: 用户可以配置备份的详细选项,如备份的范围、时间和方式,以及恢复时的特定要求和参数。
DataGrip中如何优化远程数据库的连接和查询性能?
优化远程数据库的连接和查询性能在DataGrip中的方法包括:
1、持久化连接: 配置DataGrip以保持与远程数据库的持久化连接,减少因频繁建立连接导致的延迟。
2、资源配置: 调整远程数据库服务器的资源配置,如内存和处理器优先级,以提高处理查询的能力。
3、网络优化: 确保网络配置优化,如使用高速网络连接,减少网络延迟。
4、查询优化: 在DataGrip中优化SQL查询,使用高效的查询语句和索引,减少数据传输量和查询时间。
DataGrip如何支持数据分析师的工作流程?
DataGrip支持数据分析师工作流程的方式包括:
1、数据查询和探索: 提供强大的SQL编辑器和查询工具,帮助数据分析师执行复杂的数据查询和探索分析。
2、数据可视化: 通过集成的数据可视化工具,将查询结果以图表或报表的形式展现,帮助分析和理解数据。
3、历史记录和比较: 保存查询历史,允许比较不同时间点或条件下的数据变化。
4、数据导出: 支持将查询结果导出到不同的格式,如CSV、Excel等,方便数据分析师进一步处理和分析数据。
在DataGrip中实现自动化测试和验证的策略有哪些?
在DataGrip中实现自动化测试和验证的策略包括:
1、使用SQL脚本: 编写SQL脚本进行数据库的自动化测试和验证,检查数据的完整性和准确性。
2、集成测试框架: 利用外部测试框架与DataGrip集成,执行数据库层面的自动化测试。
3、定期执行测试: 配置DataGrip或相关工具定期执行测试脚本,确保数据库的持续稳定和性能。
4、结果监控: 通过DataGrip的监控工具跟踪测试执行的结果,及时发现和解决问题。
DataGrip中的命令行工具如何使用,它提供了哪些功能?
DataGrip中的命令行工具使用及其功能包括:
1、数据库操作: 通过命令行工具,可以执行数据库的连接、查询、更新等操作,实现脚本化管理。
2、自动化任务: 支持使用命令行工具来自动化常见的数据库维护任务,如备份、恢复、数据导入导出等。
3、集成开发环境: 命令行工具可以与DataGrip的IDE集成,提供无缝的开发体验。
4、扩展脚本能力: 允许开发者编写和执行自定义脚本,通过命令行工具扩展DataGrip的功能和自动化复杂的工作流程。
DataGrip如何支持大数据环境下的数据库管理?
在DataGrip中支持大数据环境下的数据库管理的方法包括:
1、大数据适配: DataGrip支持连接到大数据技术栈中的数据库,如Apache Hive、Google BigQuery等,提供适配这些环境的工具和功能。
2、高效的数据处理: 针对大数据环境优化查询和数据处理操作,确保即使在大规模数据集上也能高效执行。
3、资源监控: 提供资源监控工具,帮助管理大数据环境中的数据库资源使用情况,如CPU、内存和存储使用。
4、性能优化: 提供分析和优化工具,帮助优化大数据查询,减少执行时间和资源消耗。
DataGrip中如何利用脚本自动化常见数据库任务?
在DataGrip中利用脚本自动化常见数据库任务的方法包括:
1、任务脚本化: 使用SQL或其他脚本语言编写常见的数据库维护和管理任务,如数据备份、清理和更新操作。
2、定时执行: 利用DataGrip或外部工具安排脚本在特定时间自动执行,实现任务的自动化。
3、集成执行结果: 将脚本执行的结果集成到DataGrip的用户界面,方便监控和审查任务执行情况。
4、错误处理和通知: 在脚本中包含错误处理逻辑,并设置通知机制,确保在任务执行出错时能及时发现和响应。
DataGrip中的Schema比较工具如何使用,它提供哪些功能?
DataGrip中的Schema比较工具使用方法及其功能包括:
1、选择比较对象: 允许用户选择两个数据库或两个数据库版本进行比较,识别Schema的差异。
2、差异显示: 显示两个Schema之间的差异,包括表、视图、存储过程等数据库对象的不同。
3、生成同步脚本: 基于差异结果生成同步脚本,帮助用户快速同步或更新数据库Schema。
4、自定义比较设置: 允许用户自定义比较的参数和选项,如排除特定的对象或属性。
如何在DataGrip中配置和使用SSH隧道以增强数据库连接的安全性?
在DataGrip中配置和使用SSH隧道的方法包括:
1、配置SSH连接: 在数据库连接设置中配置SSH隧道,包括SSH服务器地址、端口、用户名和认证方法。
2、建立安全通道: 通过SSH隧道建立加密的网络连接,确保数据库连接和数据传输的安全性。
3、透明访问数据库: 对于DataGrip用户来说,通过SSH隧道连接的数据库操作与直接连接无异,用户体验一致。
4、管理SSH密钥: 安全管理SSH密钥和凭证,确保只有授权用户可以建立SSH隧道。
DataGrip中的版本控制集成提供了哪些功能,如何支持数据库开发流程?
DataGrip中的版本控制集成提供的功能及其对数据库开发流程的支持包括:
1、代码变更跟踪: 能够跟踪和记录数据库对象和SQL脚本的更改,确保每次修改都可以审计和回溯。
2、分支管理: 支持使用版本控制的分支管理功能,允许在不同的分支上独立进行数据库开发和测试。
3、合并和冲突解决: 提供合并工具和冲突解决支持,帮助开发人员管理不同分支间的代码合并和冲突。
4、历史比较和回滚: 允许查看历史版本和变更记录,必要时可以回滚到之前的版本。
DataGrip如何支持多用户协作和并发控制?
DataGrip支持多用户协作和并发控制的方式包括:
1、连接管理: 允许多个用户使用不同的配置独立连接到同一数据库,支持团队成员的并发工作。
2、事务隔离: 支持数据库的事务隔离级别,确保并发操作时数据的一致性和隔离性。
3、版本控制集成: 利用版本控制系统管理数据库对象和脚本的更改,协助团队成员协作和解决代码合并冲突。
4、权限和角色管理: 结合数据库的权限和角色管理,确保团队成员根据权限进行操作,避免数据和结构的不当更改。
在DataGrip中如何自定义和扩展SQL编码功能?
在DataGrip中自定义和扩展SQL编码功能的方法包括:
1、用户代码片段: 允许用户创建和管理自定义的SQL代码片段,快速插入常用的SQL模式和语句。
2、外部插件: 利用DataGrip的插件生态系统安装和使用第三方插件,扩展SQL编码的功能。
3、编辑器配置: 自定义SQL编辑器的行为和外观,如代码补全、格式化样式和语法高亮。
4、脚本执行选项: 配置SQL脚本的执行选项,如事务控制、执行计划分析和性能优化。
DataGrip如何处理大型复杂查询的优化和分析?
DataGrip处理大型复杂查询的优化和分析的方法包括:
1、执行计划分析: 使用DataGrip的执行计划工具分析复杂查询的执行过程,识别性能瓶颈和优化点。
2、资源监控: 监控查询执行时的资源使用情况,如CPU、内存和I/O使用,帮助判断性能瓶颈。
3、查询重写建议: 提供查询优化建议,帮助重新编写或调整查询语句,提高查询效率。
4、索引优化: 分析查询使用的索引,并提出创建或调整索引的建议,以改善查询性能。
DataGrip如何实现数据库的异地备份和恢复?
在DataGrip中实现数据库的异地备份和恢复的方法包括:
1、远程连接配置: 配置DataGrip以连接到远程数据库服务器,确保可以访问异地备份的数据库。
2、备份工具集成: 使用DataGrip集成的备份工具或兼容的第三方工具来执行异地备份操作。
3、定时备份计划: 设置定时任务,自动执行数据库的异地备份,确保数据的定期保存。
4、恢复流程测试: 定期测试数据恢复流程,确保异地备份的数据可以被成功恢复。
DataGrip中的多维数据查询和处理有哪些特点?
DataGrip中的多维数据查询和处理的特点包括:
1、复杂查询支持: 支持编写和执行多维数据查询,如使用SQL的联接、子查询和窗口函数处理复杂的数据关系。
2、数据可视化: 提供强大的数据可视化工具,帮助用户理解多维数据的结构和关系。
3、性能优化: 针对多维数据查询提供优化建议和工具,如索引建议和查询调整,以提高查询效率。
4、分析和报告: 支持多维数据分析和报告生成,方便用户对数据进行深入分析和展示。
如何在DataGrip中配置和管理大规模分布式数据库系统?
在DataGrip中配置和管理大规模分布式数据库系统的方法包括:
1、集群配置支持: 支持配置和管理分布式数据库集群,如Apache Cassandra或MongoDB等,提供集群状态监控和管理功能。
2、分片和复制管理: 提供对数据库分片和复制的管理支持,帮助用户优化分布式数据库的性能和可靠性。
3、负载均衡监控: 监控分布式数据库系统的负载情况,确保负载均衡,提高系统稳定性和响应速度。
4、故障恢复和备份策略: 配置故障恢复计划和备份策略,确保分布式数据库系统的数据安全和高可用性。
DataGrip如何处理和优化大数据环境中的SQL查询?
在DataGrip中处理和优化大数据环境中的SQL查询的方法包括:
1、性能分析工具: 利用DataGrip的查询分析工具,识别和优化大数据环境中的低效SQL查询。
2、执行计划优化: 分析SQL查询的执行计划,找出并优化长时间运行的查询部分,如调整索引或改写查询语句。
3、资源管理: 配置和优化大数据平台的资源使用,如调整内存和计算资源,以提高查询性能。
4、批处理和异步执行: 对于大规模数据处理,采用批处理和异步执行策略,减少即时查询负载,提高系统整体性能。
DataGrip如何支持云数据库服务,如AWS RDS或Azure SQL Database?
DataGrip支持云数据库服务的方式包括:
1、直接连接支持: DataGrip可以直接连接到云数据库服务,如AWS RDS或Azure SQL Database,提供与本地数据库相同的管理功能。
2、云特定功能: 支持云数据库的特定功能和配置,例如自动备份、缩放和性能监控。
3、安全连接: 提供通过SSL/TLS等加密方法安全连接到云数据库的能力,确保数据传输的安全性。
4、集成云服务管理: 可以通过DataGrip集成云服务提供的管理和监控工具,进行数据库的综合管理。
在DataGrip中如何实现高效的数据库代码审计和复审?
在DataGrip中实现高效的数据库代码审计和复审可以通过以下方法:
1、版本控制集成: 利用DataGrip与版本控制系统的集成,跟踪数据库代码的变更历史,便于审计和复审。
2、代码审查工具: 使用DataGrip的代码审查功能,对数据库更改进行评审,确保遵循最佳实践和标准。
3、注释和文档: 鼓励在数据库代码中添加详细的注释和文档,以便于理解和审计代码的目的和逻辑。
4、更改日志记录: 维护数据库更改的日志记录,包括更改内容、时间和责任人,支持审计过程。
DataGrip中的异构数据库迁移工具如何使用,它们有哪些功能?
DataGrip中的异构数据库迁移工具使用方法及其功能包括:
1、数据转换和映射: 支持不同数据库系统间的数据类型转换和映射,确保数据迁移过程中信息的准确性。
2、迁移向导: 提供交互式的迁移向导,指导用户完成从一个数据库系统到另一个系统的迁移过程。
3、自动生成迁移脚本: 根据源数据库和目标数据库的结构差异,自动生成迁移脚本,简化迁移过程。
4、数据完整性检查: 在迁移过程中进行数据完整性检查,确保迁移后的数据与原数据一致。
如何在DataGrip中定制和优化数据报告工具?
在DataGrip中定制和优化数据报告工具的方法包括:
1、报告模板定制: 允许用户根据需要定制数据报告的模板,包括报告结构、样式和内容。
2、动态数据集成: 支持将动态查询结果集成到数据报告中,确保报告内容的实时性和准确性。
3、自动化报告生成: 配置自动化任务,定期生成和更新数据报告,减少手动操作的需求。
4、可视化元素优化: 利用DataGrip的数据可视化工具优化报告中的图表和图形,使报告更加直观易懂。
DataGrip中的数据加工和清洗功能有哪些,它们如何使用?
DataGrip中的数据加工和清洗功能及使用方法包括:
1、查询编辑器: 使用DataGrip的查询编辑器编写SQL脚本进行数据筛选、转换和清洗,实现数据的预处理。
2、数据转换工具: 利用内置的数据转换工具,如格式转换、数据类型变更等,对数据进行加工。
3、重复数据处理: 提供查找和处理重复数据的功能,帮助清洗数据集,确保数据的唯一性和准确性。
4、数据质量检查: 使用DataGrip进行数据质量检查,识别并修正数据中的错误和不一致性。
DataGrip中如何实现敏捷的数据库迭代开发?
在DataGrip中实现敏捷的数据库迭代开发的方法包括:
1、版本控制集成: 利用DataGrip与版本控制系统的集成,管理数据库模式和数据变更,支持敏捷的迭代开发流程。
2、快速原型设计: 使用DataGrip的模式编辑器快速设计和调整数据库模式,支持迭代中的快速原型构建。
3、持续集成支持: 通过集成持续集成(CI)工具,自动执行数据库的构建、测试和部署,保证迭代过程中的质量和效率。
4、团队协作功能: 利用DataGrip的协作功能,如共享数据库连接、脚本和查询结果,促进团队成员之间的沟通和协作。
DataGrip中的数据库文档生成工具如何使用,它提供了哪些功能?
DataGrip中的数据库文档生成工具的使用及其功能包括:
1、自动文档生成: 可以自动从数据库模式生成文档,包括表结构、关系、索引、约束等详细信息。
2、自定义文档内容: 允许用户选择包含在文档中的数据库对象和细节级别,定制化文档内容。
3、导出和分享: 支持将生成的数据库文档导出为多种格式,如HTML、PDF等,方便分享和查阅。
4、文档更新和维护: 提供工具和功能支持文档的定期更新和维护,确保文档内容与数据库实际状态同步。
在DataGrip中如何优化复杂的SQL查询和报告生成?
在DataGrip中优化复杂的SQL查询和报告生成的方法包括:
1、查询性能分析: 利用DataGrip的查询分析工具,识别复杂查询中的性能瓶颈,进行优化。
2、索引和查询计划调整: 基于性能分析结果,调整索引使用和查询计划,改善查询效率。
3、批量处理和异步执行: 对于报告生成等需要长时间运行的查询,采用批量处理和异步执行策略,减少对系统资源的占用。
4、报告模板优化: 定制和优化报告模板,确保报告生成过程高效且结果清晰易读。
相关文章:
DataGrip 面试题及答案整理,最新面试题
DataGrip的数据库兼容性和多数据库支持如何实现? DataGrip实现数据库兼容性和多数据库支持的方式包括: 1、广泛的数据库支持: DataGrip支持多种数据库,包括但不限于MySQL, PostgreSQL, SQL Server, Oracle, SQLite, 和MongoDB&a…...
)
2、设计模式之单例模式详解(Singleton)
单例模式详解 一、什么是单例模式 单例模式是Java中最简单的设计模式之一。这种类型的设计模式属于创建者模式,它提供了一种访问对象的最佳方式。 这种设计模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个…...
【django framework】ModelSerializer+GenericAPIView,如何在提交前修改某些字段值
【django framework】ModelSerializerGenericAPIView,如何在提交前修改某些字段值 我们经常会遇到下面这种情况: 序列化器用的是ModelSerializer,写视图的时候继承的是generics.CreateAPIView。现在我想在正式提交到数据库(perform_create)之…...

2024年【P气瓶充装】模拟考试及P气瓶充装证考试
题库来源:安全生产模拟考试一点通公众号小程序 P气瓶充装模拟考试是安全生产模拟考试一点通生成的,P气瓶充装证模拟考试题库是根据P气瓶充装最新版教材汇编出P气瓶充装仿真模拟考试。2024年【P气瓶充装】模拟考试及P气瓶充装证考试 1、【多选题】《中华…...

<JavaEE> 数据链路层 -- 以太网协议、MTU限制、ARP协议
目录 以太网协议 什么是以太网? 以太网的帧格式 什么是MAC地址? MAC地址和IP地址的对比? MTU(最大传输单元)限制 什么是MTU限制? MTU对IP协议有什么影响? MTU对UDP协议有什么影响&…...

认识Testbench仿真激励
一、认识Testbench Bench有平台之意,所以Testbench就是测试平台的意思。 任何一个被测模块,都有输入和输出,此模块是否合格的判断依据,就是在满足输入要求的情况下,能否得到符合预期的输出。我们把被测模块称作UUT&…...
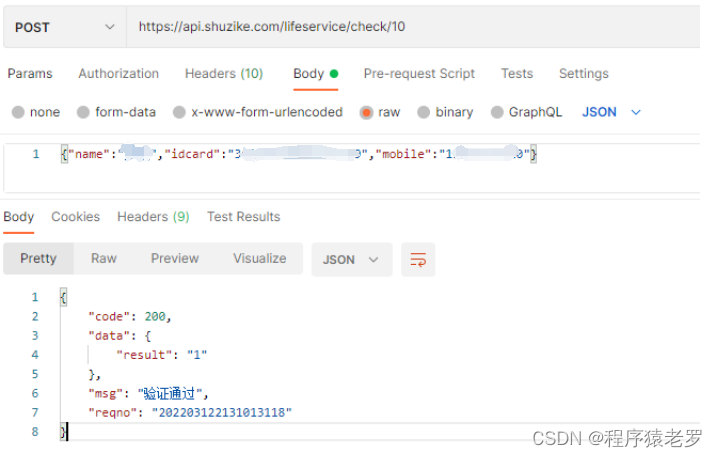
Postman请求API接口测试步骤和说明
Postman请求API接口测试步骤 本文测试的接口是国内数智客(www.shuzike.com)的API接口手机三要素验证,验证个人的姓名,身份证号码,手机号码是否一致。 1、设置接口的Headers参数。 Content-Type:applicati…...

这是二叉搜索树吗?
一棵二叉搜索树可被递归地定义为具有下列性质的二叉树:对于任一结点, 其左子树中所有结点的键值小于该结点的键值;其右子树中所有结点的键值大于等于该结点的键值;其左右子树都是二叉搜索树。 所谓二叉搜索树的“镜像”…...

5.82 BCC工具之tcpdrop.py解读
一,工具简介 tcpdrop工具打印被内核丢弃的 TCP 数据包或段的详细信息,包括导致丢弃的内核堆栈跟踪。 当网络出现拥堵、资源不足或其他原因导致数据包被内核丢弃时,tcpdrop可以帮助开发者和网络管理员识别并定位问题。 该工具通过钩住内核中处理TCP数据包的相关函数,捕获…...

JavaScript 基础知识
一、初识 JavaScript 1、JS 初体验 JS 有3种书写位置,分别为行内、内部和外部。 示例: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"wid…...

【判断是否为回文数】
法一:用字符串形式判断(依次对比前面和后面的数是否相等) #include<stdio.h> #include<string.h> int main() {char st[100];scanf("%s",st);int flag1,nstrlen(st);for(int i0,jn-1;i<n,j>0;i,j--){if(st[i]!…...
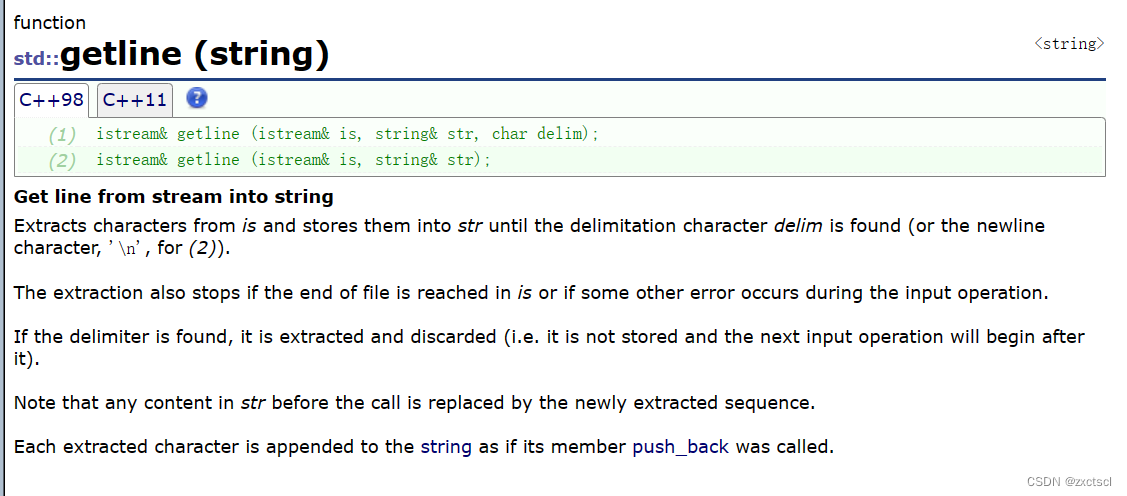
【C++】string进一步介绍
个人主页 : zxctscl 如有转载请先通知 文章目录 1. 前言2. 迭代器2.1 反向迭代器2.2 const对象迭代器 3. Capacity3.1 size和length3.2 max_size3.3 capacity3.4 clear3.5 shrink_to_fit (了解即可)3.6 reserve3.7 resize 4. Element access4…...

思科设备下面主机访问公网经常时好时坏延迟大丢包不稳定
环境: 思科防火墙ASA5555 Cisco Adaptive Security Appliance Software Version 9.4(2)6 Device Manager Version 7.5(2)153 内外为DMZ区域 思科交换机(C3560E-UNIVERSALK9-M), Version 12.2(55)SE5 主机 centos 7 问题描述: 思科设备下面主机访问公网经常时好时坏不稳定…...

nuxtjs 如何通过ecosystem.config.js配置pm2?
在 Nuxt.js 项目中,您可以通过 ecosystem.config.js 文件来配置 PM2,以便使用 PM2 来管理 Nuxt.js 应用的进程。ecosystem.config.js 是一个特殊的配置文件,它允许您定义应用的各种属性,如脚本路径、环境变量、日志设置等。 下面…...
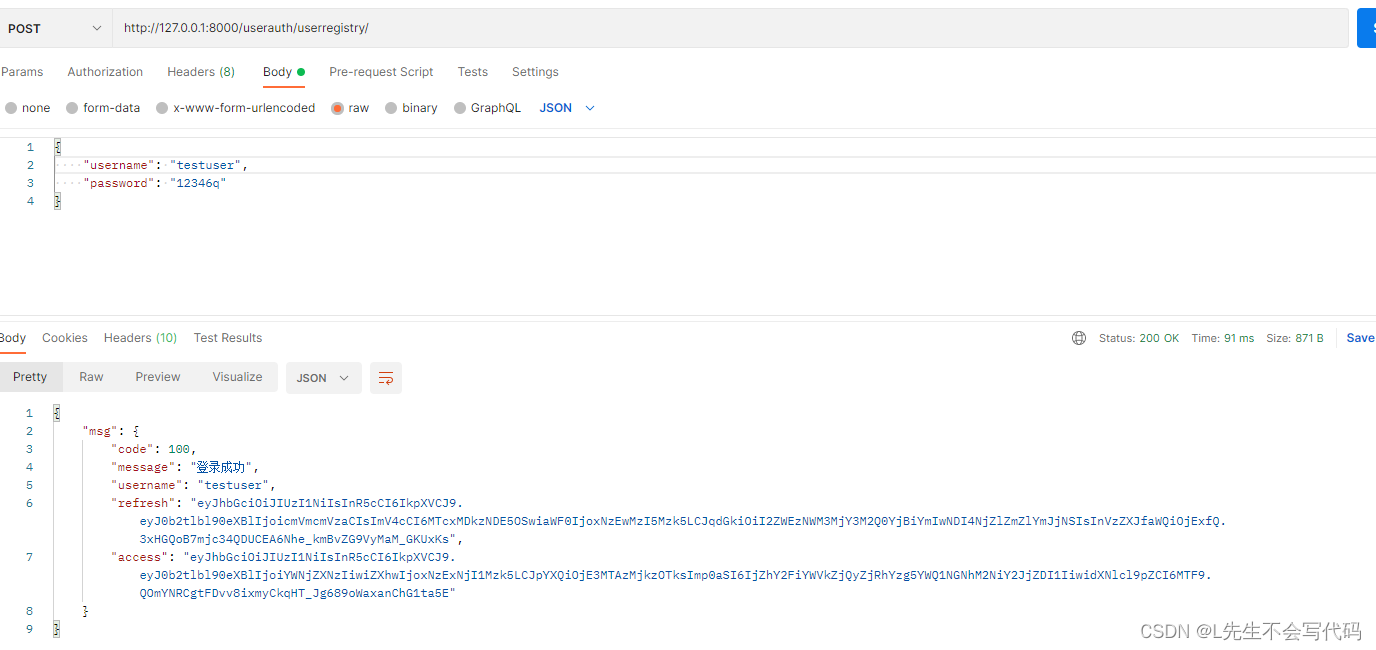
个人博客系列-后端项目-用户注册功能(7)
介绍 用户注册API的主要流程:1.前端用户提交用户名,密码 2. 序列化器校验用户名,密码是否合法。3.存入数据库。4.签发token 创建序列化器 from rest_framework import serializers from rest_framework_simplejwt.serializers import Toke…...
vue项目因内存溢出启动报错
前端能正常启动,但只要一改动就报错启动出错。 解决办法: 安装依赖 npm install cross-env increase-memory-limit 然后再做两件事:在node 在package.json 里的 script 里进行配置 LIMIT是你想分配的内存大小,这里的8192单位…...

UI 学习 二 可访问性 模式
教程:Accessibility – Material Design 3 一 颜色对比 颜色和对比度可以用来帮助用户看到和理解应用程序的内容,与正确的元素交互,并理解操作。 颜色可以帮助传达情绪、语气和关键信息。可以选择主色、辅助色和强调色来支持可用性。元素之…...
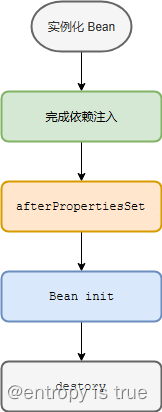
Spring学习
Maven 的配置文件是一个强约定的XML格式文件,它的文件名一定是pom.xml。 1、POM (Project Object Model) 一个 Java 项目所有的配置都放置在 POM 文件中,大概有如下的行为: 定义项目的类型、名字管理依赖关系定制插件的 1.maven坐标 <…...

鸿蒙开发-UI-动画-组件内转场动画
鸿蒙开发-UI-组件3 鸿蒙开发-UI-气泡/菜单 鸿蒙开发-UI-页面路由 鸿蒙开发-UI-组件导航-Navigation 鸿蒙开发-UI-组件导航-Tabs 鸿蒙开发-UI-图形-图片 鸿蒙开发-UI-图形-绘制几何图形 鸿蒙开发-UI-图形-绘制自定义图形 鸿蒙开发-UI-图形-页面内动画 文章目录 前言 一、基本概…...

Leet code 179 最大数
解题思路 贪心算法 贪心算法就是走一步看一步 每一步都取当前位置的最优解 这题我们该如何贪呢? 我们先把int数组转换为string数组 以示例2为例 3 30 34 5 9 排序哪个在前哪个在后? 3 30 (330)> 30 3 (30…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

PrivacyGuard实战:基于实证差分隐私的机器学习模型隐私审计框架
1. 项目概述与核心价值在过去的几年里,我亲眼见证了机器学习模型从实验室走向银行、医疗、社交网络等各个敏感领域的全过程。模型性能的每一次飞跃都令人兴奋,但随之而来的隐私泄露事件也一次次为我们敲响警钟。一个在医疗数据上训练出的诊断模型&#x…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...