YOLOv9改进策略:注意力机制 | SimAM(无参Attention),效果秒杀CBAM、SE
💡💡💡本文改进内容:SimAM是一种轻量级的自注意力机制,其网络结构与Transformer类似,但是在计算注意力权重时使用的是线性层而不是点积
yolov9-c-CoordAtt summary: 972 layers, 51024476 parameters, 51024444 gradients, 238.9 GFLOPs改进结构图如下:
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥50+ ,冲刺100+🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

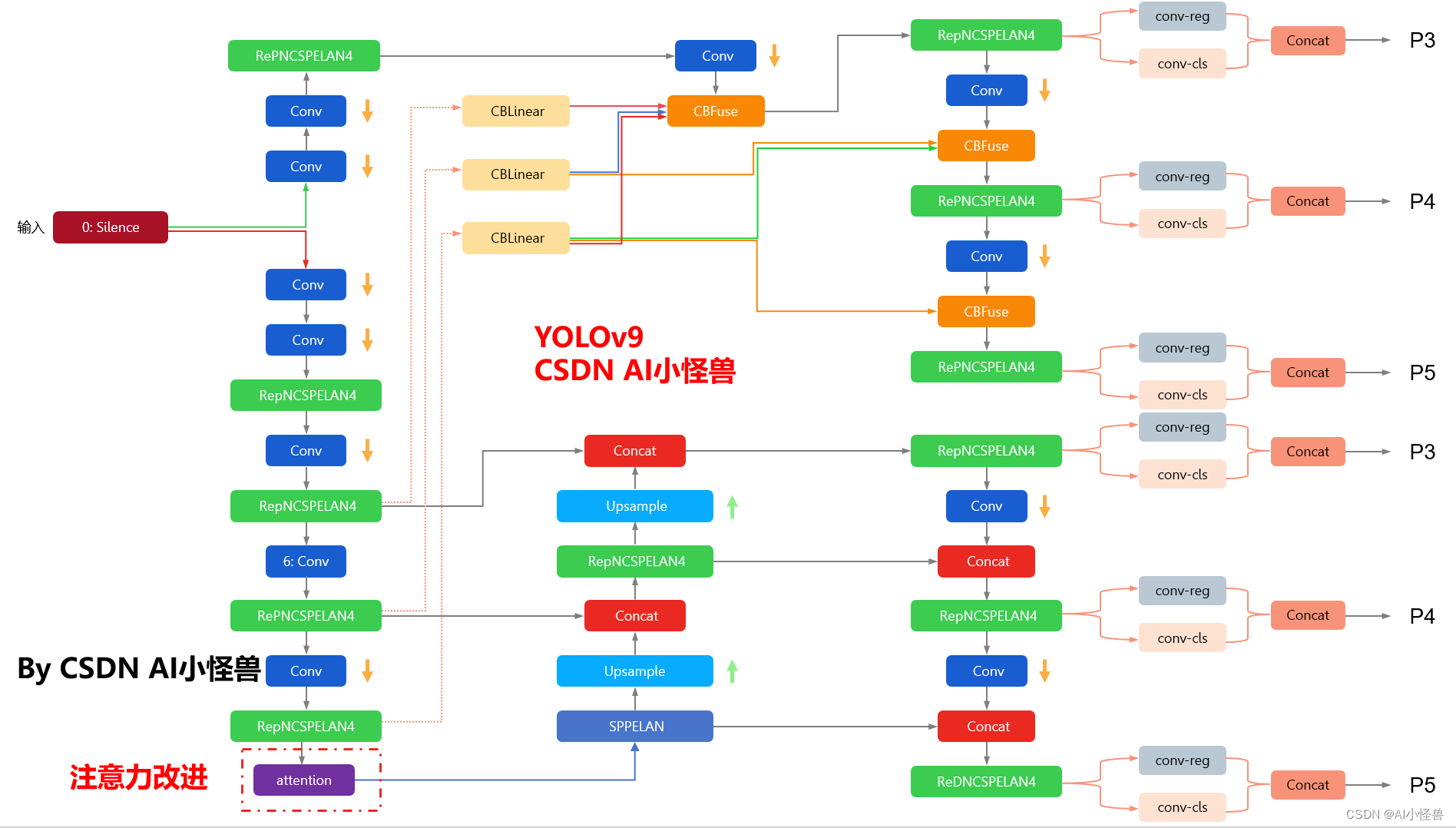
YOLOv9框架图
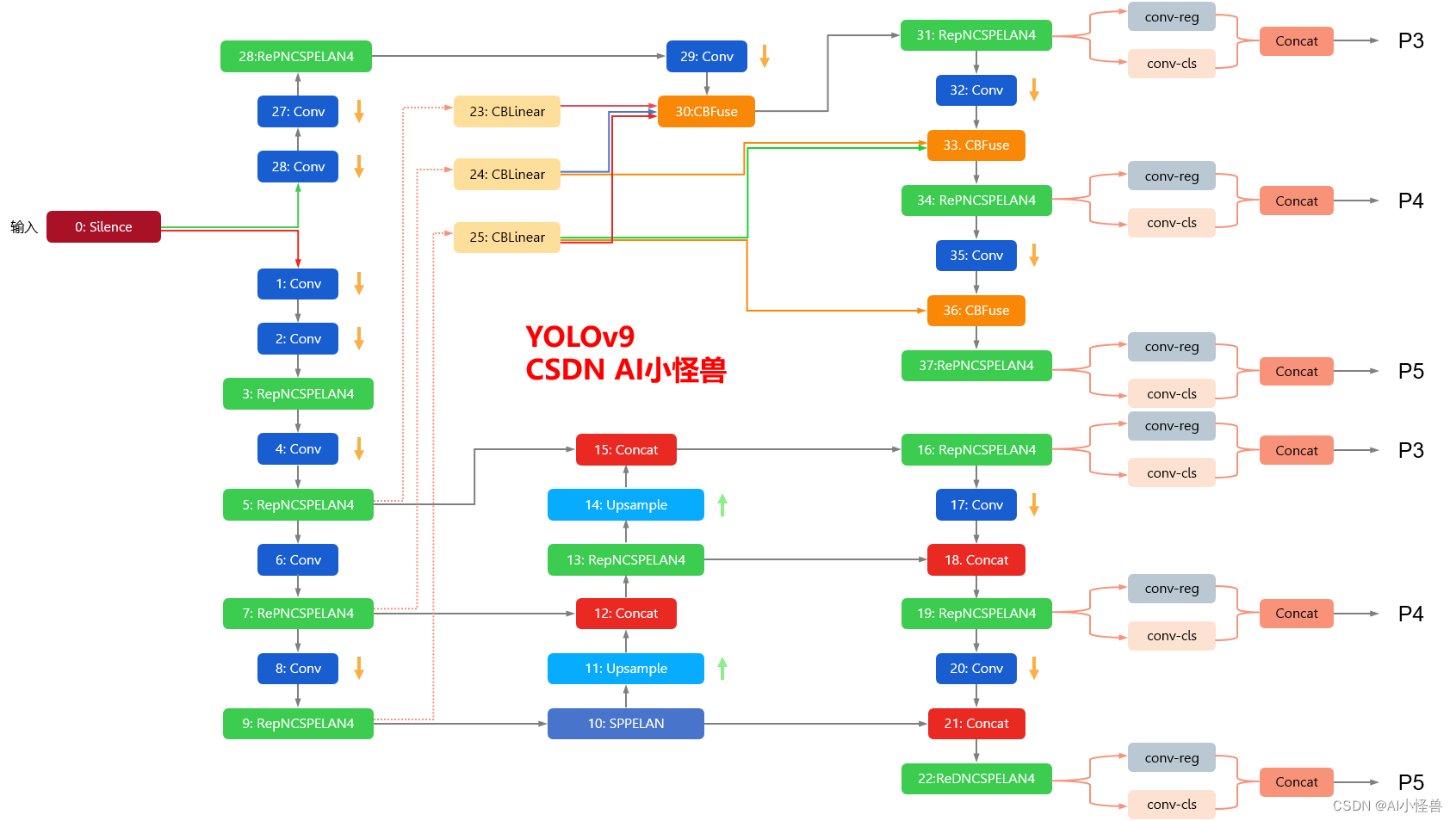
1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

2. SimAM:无参Attention

论文: http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
SimAM(Simple Attention Mechanism)是一种轻量级的自注意力机制,其网络结构与Transformer类似,但是在计算注意力权重时使用的是线性层而不是点积。其网络结构如下:
输入序列 -> Embedding层 -> Dropout层 -> 多层SimAM层 -> 全连接层 -> Softmax层 -> 输出结果
其中,SimAM层由以下几个部分组成:
-
多头注意力层:输入序列经过多个线性映射后,分成多个头,每个头计算注意力权重。
-
残差连接层:将多头注意力层的输出与输入序列相加,保证信息不会丢失。
-
前向传递层:对残差连接层的输出进行线性变换和激活函数处理,再与残差连接层的输出相加。
-
归一化层:对前向传递层的输出进行层归一化处理,加速训练并提高模型性能。
通过多层SimAM层的堆叠,模型可以学习到输入序列中的长程依赖关系,并生成对应的输出序列。

在不增加原始网络参数的情况下,为特征图推断三维注意力权重
1、提出优化能量函数以发掘每个神经元的重要性
2、针对能量函数推导出一种快速解析解,不超过10行代码即可实现。

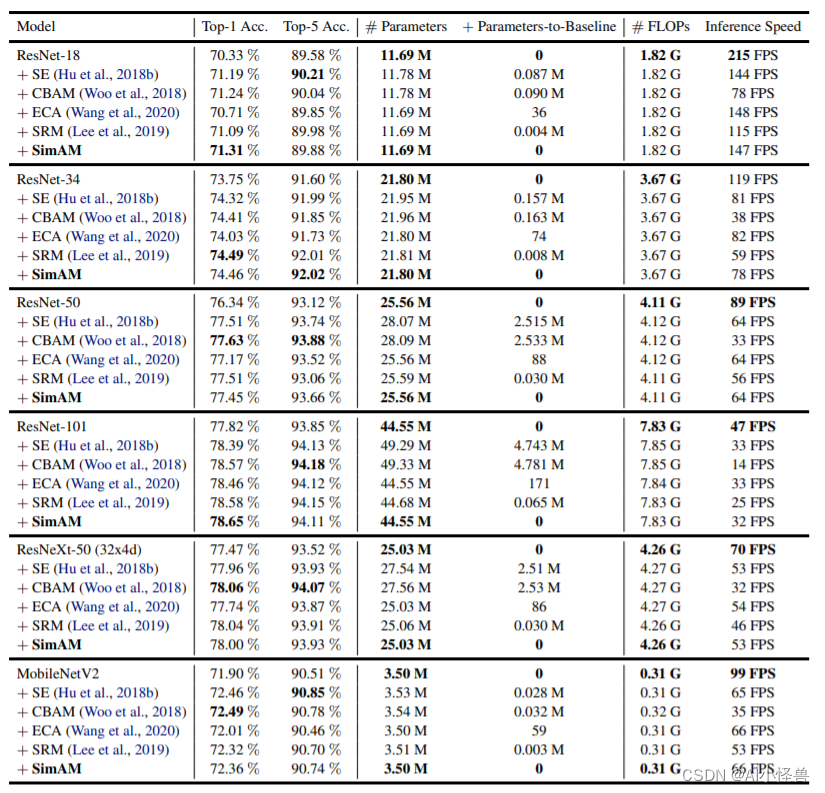
表格给出了ImageNet数据集上不同注意力机制的性能对比,从中可以看到:
- 所有注意力模块均可以提升基线模型的性能;
- 所提SimAM在ResNet18与ResNet101基线上取得了最佳性能提升;
- 对于ResNet34、ResNet50、ResNeXt50、MobileNetV2,所提SimAM仍可取得与其他注意力相当性能;
- 值得一提的是,所提SimAM并不会引入额外的参数;
- 在推理速度方面,所提SimAM与SE、ECA相当,优于CBAM、SRM。
1.1 加入yolov8 modules.py中
3.SimAM加入到YOLOv9
3.1新建py文件,路径为models/attention/attention.py
###################### SimAM #### start by AI&CV ###############################
import torch
from torch import nn
from torch.nn import init
import torch.nn.functional as Fclass SimAM(torch.nn.Module):def __init__(self,c1, e_lambda=1e-4):super(SimAM, self).__init__()self.activaton = nn.Sigmoid()self.e_lambda = e_lambdadef __repr__(self):s = self.__class__.__name__ + '('s += ('lambda=%f)' % self.e_lambda)return s@staticmethoddef get_module_name():return "simam"def forward(self, x):b, c, h, w = x.size()n = w * h - 1x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5return x * self.activaton(y)
###################### SimAM #### end by AI&CV ###############################3.2修改yolo.py
1)首先进行引用
from models.attention.attention import *2)修改def parse_model(d, ch): # model_dict, input_channels(3)
在源码基础上加入SimAM
elif m is nn.BatchNorm2d:args = [ch[f]]###attention #####elif m in {EMA_attention,CoordAtt,SimAM}:c2 = ch[f]args = [c2, *args]###attention #####3.3 yolov9-c-SimAM.yaml
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []], # conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# avg-conv down[-1, 1, ADown, [256]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# avg-conv down[-1, 1, ADown, [512]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# avg-conv down[-1, 1, ADown, [512]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9[-1, 1, SimAM, [512]], # 10]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 11# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)# avg-conv-down merge[-1, 1, ADown, [256]],[[-1, 14], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)# avg-conv-down merge[-1, 1, ADown, [512]],[[-1, 11], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)# multi-level reversible auxiliary branch# routing[5, 1, CBLinear, [[256]]], # 24[7, 1, CBLinear, [[256, 512]]], # 25[9, 1, CBLinear, [[256, 512, 512]]], # 26# conv down[0, 1, Conv, [64, 3, 2]], # 27-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 28-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29# avg-conv down fuse[-1, 1, ADown, [256]], # 30-P3/8[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32# avg-conv down fuse[-1, 1, ADown, [512]], # 33-P4/16[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35# avg-conv down fuse[-1, 1, ADown, [512]], # 36-P5/32[[26, -1], 1, CBFuse, [[2]]], # 37# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38# detection head# detect[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]相关文章:
YOLOv9改进策略:注意力机制 | SimAM(无参Attention),效果秒杀CBAM、SE
💡💡💡本文改进内容:SimAM是一种轻量级的自注意力机制,其网络结构与Transformer类似,但是在计算注意力权重时使用的是线性层而不是点积 yolov9-c-CoordAtt summary: 972 layers, 51024476 parameters, 510…...
宝塔 安装对外服务Tomcat和JDK
一、安装Tomcat\JDK 切记1:如果选择下载节点失败,请到软件商城安装 。 切记2:提醒安装Nginx或Apache ,先点安装,进入再打叉关闭。因为Tomcat服务足够为我们搭建JavaWeb网站服务了。 切记3:Nginx占用80端口…...

rust最新版本安装-提高下载速度
1)拉取依赖包将安装脚本输出到本地rust.sh脚本中 curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs > rust.sh 2)更新rust.sh脚本内容、修改源 # 编辑rust.sh vi rust.sh # 将RUSTUP_UPDATE_ROOT的值替换为: RUSTUP_UPDATE_ROOT&q…...

数据清洗与预处理:打造高质量数据分析基础
随着数据的快速增长,数据分析已经成为企业和组织的核心业务。然而,原始数据往往包含各种杂质和异常,这就需要我们进行数据清洗和预处理,以确保分析结果的准确性和可靠性。 1. 数据清洗的重要性: 数据清洗是指对原始数据进行检查、修正和完善,以消除错误、不一致性和噪声…...
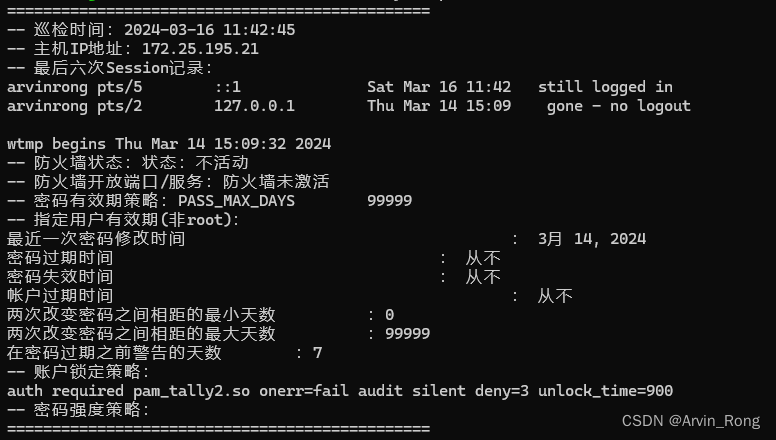
Linux服务器(Debian系)包含UOS安全相关巡检shell脚本
#!/bin/bash# Define output file current_date$(date "%Y%m%d") # Gets the current date in YYYYMMDD format output_file"server_security_inspection_report_${current_date}.txt"# Empty the file initially echo > $output_file# 获取巡检时间 (…...

BS4网络提取selenium.chrome.WebDriver类的方法及属性
BS4网络提取selenium.chrome.WebDriver类的方法及属性 chrome.webdriver: selenium.webdriver.chrome.webdriver — Selenium 4.18.1 documentation class selenium.webdriver.chrome.webdriver.WebDriver 是 Selenium 中用于操作 Chrome 浏览器的 WebDriver 类。WebDriver 类…...

Prompt Engineering(提示工程)
Prompt 工程简介 在近年来,大模型(Large Model)如GPT、BERT等在自然语言处理领域取得了巨大的成功。这些模型通过海量数据的训练,具备了强大的语言理解和生成能力。然而,要想充分发挥这些大模型的潜力,仅仅…...

移远通信亮相AWE 2024,以科技力量推动智能家居产业加速发展
科技的飞速发展,为我们的生活带来了诸多便利,从传统的家电产品到智能化的家居设备,我们的居家生活正朝着更智能、更便捷的方向变革。 3月14日,中国家电及消费电子博览会(Appliance&electronics World Expo…...

Java中上传数据的安全性探讨与实践
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 引言 一. 文件上传的风险 二. 使用合适的框架和库 1. Spr…...

Leetcode 17. 电话号码的字母组合
心路历程: 之前看过这道题的解法但是忘了。一开始想多重循环遍历,发现不知道写几个for循环,于是想到递归;发现递归需要记录选择的路径而不是返回节点值,想到了回溯。 回溯的解题模板:维护两个变量…...

蓝桥杯单片机快速开发笔记——独立键盘
一、原理分析 二、思维导图 三、示例框架 #include "reg52.h" sbit S7 P3^0; sbit S6 P3^1; sbit S5 P3^2; sbit S4 P3^3; void ScanKeys(){if(S7 0){Delay(500);if(S7 0){while(S7 0);}}if(S6 0){Delay(500);if(S6 0){while(S6 0)…...
Swift 面试题及答案整理,最新面试题
Swift 中如何实现单例模式? 在Swift中,单例模式的实现通常采用静态属性和私有初始化方法来确保一个类仅有一个实例。具体做法是:定义一个静态属性来存储这个单例实例,然后将类的初始化方法设为私有,以阻止外部通过构造…...

微信小程序上传图片c# asp.net mvc端接收案例
在微信小程序上传图片到服务器,并在ASP.NET MVC后端接收这个图片,可以通过以下步骤实现: 1. 微信小程序端 首先,在微信小程序前端,使用 wx.chooseImage API 选择图片,然后使用 wx.uploadFile API 将图片上…...

57、服务攻防——应用协议RsyncSSHRDP漏洞批扫口令猜解
文章目录 口令猜解——Hydra-FTP&RDP&SSH配置不当——未授权访问—Rsync文件备份协议漏洞——应用软件-FTP&Proftpd搭建 口令猜解——Hydra-FTP&RDP&SSH FTP:文本传输协议,端口21;RDP:windows上远程终端协议…...

java:Druid工具类解析sql获取表名
java:Druid工具类解析sql获取表名 1 前言 alibaba的druid连接池除了sql执行的功能外,还有sql语法解析的工具提供,参考依赖如下: <dependency><groupId>com.alibaba</groupId><artifactId>druid</ar…...

MySQL--深入理解MVCC机制原理
什么是MVCC? MVCC全称 Multi-Version Concurrency Control,即多版本并发控制,维持一个数据的多个版本,主要是为了提升数据库的并发访问性能,用更高性能的方式去处理数据库读写冲突问题,实现无锁并发。 什…...

数据挖掘简介与应用领域概述
数据挖掘,作为信息技术领域中的重要分支之一,旨在从大量数据中发现潜在的模式、关联和趋势,以提取有用的信息和知识。在信息爆炸时代,大量数据的积累成为了常态,数据挖掘技术的出现填补了人们处理这些数据的空白&#…...
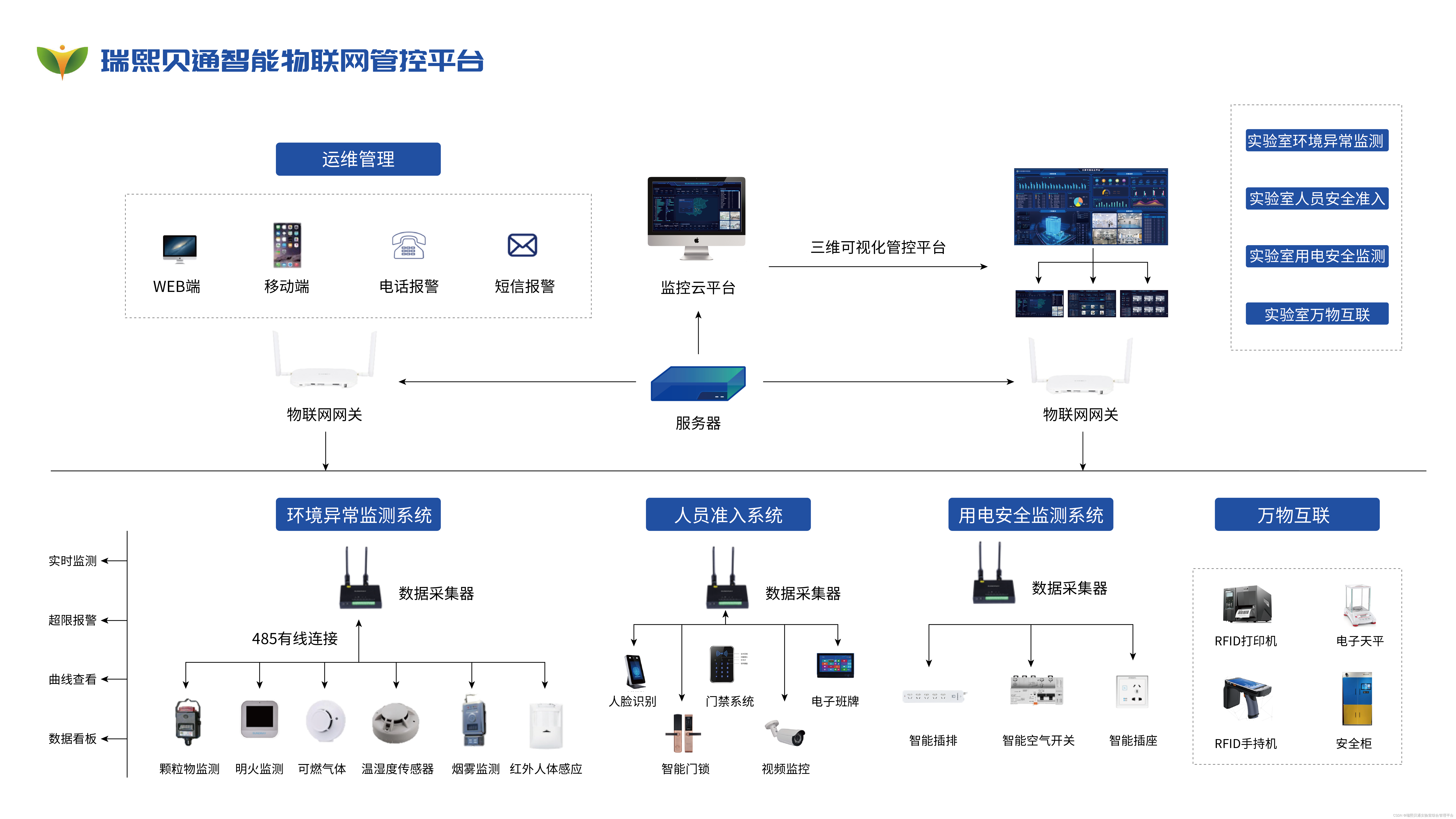
瑞熙贝通打造智慧校园实验室安全综合管理平台
一、建设思路 瑞熙贝通实验室安全综合管理平台是基于以实验室安全,用现代化管理思想与人工智能、大数据、互联网技术、物联网技术、云计算技术、人体感应技术、语音技术、生物识别技术、手机APP、自动化仪器分析技术有机结合,通过建立以实验室为中心的管…...

openstack调整虚拟机CPU 内存 磁盘 --来自gpt
在OpenStack中调整虚拟机(即实例)的CPU、内存(RAM)和磁盘大小通常涉及到以下几个步骤:首先,确定你要修改的实例名称或ID;其次,根据需要调整的资源类型,使用相应的命令进行…...
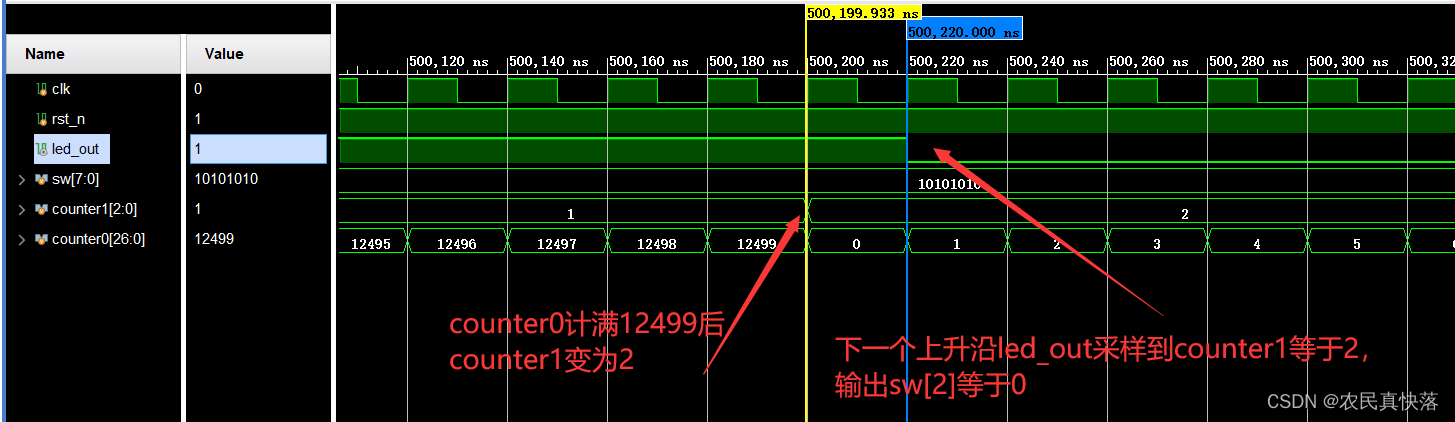
【IC设计】Verilog线性序列机点灯案例(三)(小梅哥课程)
声明:案例和代码来自小梅哥课程,本人仅对知识点做做笔记,如有学习需要请支持官方正版。 文章目录 该系列目录设计目标设计思路RTL及Testbench代码RTL代码Testbench代码 仿真结果上板视频 该系列目录 Verilog线性序列机点灯案例(一)ÿ…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...