A Workload‑Adaptive Streaming Partitioner for Distributed Graph Stores(2021)
用于分布式图存储的工作负载自适应流分区器
对象:动态流式大图
划分方式:混合割
方法:增量重划分
考虑了图查询算法,基于动态工作负载
考虑了双动态:工作负载动态;图拓扑结构动态
缺点:分配新顶点时不做过多处理(不考虑初始化分的均衡),仅通过散列的方式分配节点,仅对变化后的图分区进行顶点重分配,需要维护所有节点中的活动顶点,对每个活动顶点进行计算,才能确定需要重新分配的顶点。
摘要:
流式图划分方法最近引起了人们的关注,因为它们能够利用有限的资源扩展到非常大的图。然而,许多此类方法没有考虑工作负载和图特征。这可能会增加节点间通信和计算负载不平衡,从而降低查询性能。此外,现有的工作负载感知方法不能始终如一地提供良好的性能,因为它们没有考虑图形应用程序中不断出现的动态工作负载。我们通过提出一种名为 WASP 的新颖的工作负载自适应流分区器来解决这些问题,旨在实现低延迟和高吞吐量的在线图查询。由于每个工作负载通常包含频繁的查询模式,因此 WASP 利用现有工作负载来分别捕获频繁访问和遍历的活动顶点和边。该信息用于启发式地提高分区的质量,方法是避免活动顶点集中在与其访问频率成比例的几个分区中,或者通过降低与其遍历频率成比例的活动边的切割概率。为了评估 WASP 对图形存储的影响并展示该方法如何轻松地插入到系统顶部,我们在基于分布式图形的 RDF 存储中利用它。我们对三个合成和真实图形数据集以及相应的静态和动态查询工作负载进行的实验表明,WASP 针对最先进的图形分区器实现了更好的查询性能,特别是在动态查询工作负载中。
引言
现实世界的图表(例如社交网络和网络图表)通常很大、不断变化并且同时被许多客户查询。因此,单个数据库服务器不再能够提供用于管理此类图的计算资源,以及为其客户端应用程序提供优质服务[13]。传统的解决方案是采用服务器垂直扩展和全复制的方式,成本高昂甚至无法实现。这导致分布式图存储的成本效益设计依赖于大型廉价商品服务器集群上的水平分区或分片以及图数据的并行处理。
现有的图划分策略大多是针对静态图设计的。当它们用于顶点和边不断变化的动态图(例如语义网和社交网络)时,需要在一批变化后对图进行重量级重新分区,这在大图中可能需要几个小时[41, 48 ,54]。因此,一些图存储(例如 OrientDB、Titan 和 Microsoft Trinity [43])使用朴素的分区方法,例如基于随机哈希的分区,其中每个顶点及其关联边都被分配给哈希桶中的服务器 [11 ]。然而,这些方法可能会导致昂贵的分区间遍历(通信开销大),从而极大地影响查询的性能。因此,一些图存储(例如 Neo4j [53]、HypergraphDB [24] 和 DEX [31])避免了图数据集的分区。
由于查询工作负载和图拓扑的不断变化,实际图中的分区质量可能会下降。自适应图分区器可以通过利用流方法[35]以及所获得的分区对上述变化的增量适应来处理这个问题。这通常会导致在线监视现有查询工作负载和图拓扑的变化,然后是分区之间某些顶点的可能移动(会产生系统开销)。这种调整可能会给系统带来开销,并可能降低在线查询的效率和吞吐量。因此,自适应策略在时间和内存需求方面应该是“轻量级的”。到目前为止,已经有一些关于工作负载驱动的分区策略的研究工作,以实现在线低延迟图查询[12,5,13-17,21,33,37,56]。然而,仍然存在一些重大缺陷。
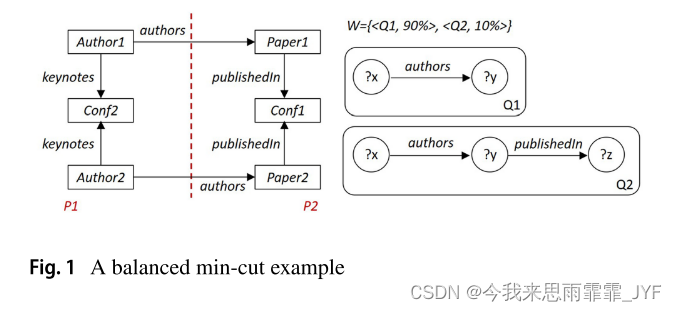
- 1、现有的策略大多与工作负载无关(例如,[10, 22]),因为它们假定遍历边或访问顶点的概率相同,而这并不总是适用于不同的查询工作负载。换句话说,他们没有考虑频繁的查询模式和图元素访问的局部性,这可能会降低系统性能。例如,图 1 描述了一个简单的属性图和查询工作负载。运行以顶点为中心的分区器后,我们得到最佳分区{P1,P2}。但是,这对于工作负载来说并不是最佳的。由于最前沿的“?x authors?y”,每个查询可能需要昂贵的分区间遍历。
- 2、现有的策略大多与图拓扑无关,因为它们不区分高度和低度顶点,这可能导致负载不平衡。在混合切割模型中,对低度顶点采用以顶点为中心的划分,而高度顶点的入射边则通过以边为中心的划分进行划分。只有两个图分析引擎 [9, 29] 利用混合切割模型。然而,还没有工作负载驱动的分区策略利用该模型。
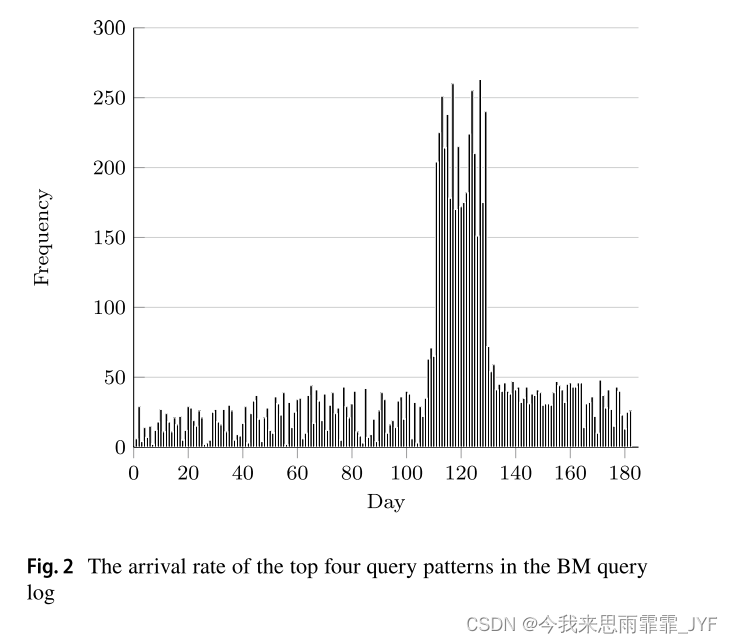
- 3、许多现有的工作负载感知策略无法适应查询模式频率波动的动态工作负载。例如,WARP [21]、Partout [17] 和 Peng 等人。方法[37]利用给定的查询日志来提取频繁的查询模式,从而对关联的三元组模式进行分区以增加访问局部性。然而,此类策略有两个缺点:(1) 随着时间的推移,频繁查询模式的流行程度可能会发生变化。据此,我们对大英博物馆(BM)查询日志进行了一些研究[40]。它的时间跨度为2014年4月12日至2014年10月16日,记录了超过120万条查询请求。前四种频繁查询模式的每日到达率如图 2 所示。我们将四种模式的频率添加在一起,因为它们遵循相似的到达趋势。正如我们所看到的,尽管在 2014 年 8 月 4 日到 2014 年 8 月 22 日的短时间内很频繁(每天超过 150 次),但这些模式在大多数时间都不常见。因此,基于具有临时峰值的频繁查询模式的分区计划大多数时候会导致查询效率低下。(2)随着时间的推移,现有的频繁查询模式可能会过时。换句话说,未来的查询很少能被过去的查询日志所反映。
为了解决上述问题,我们提出了一种工作负载自适应流图分区器,名为 WASP,它也是拓扑感知的。WASP是自适应工作负载的,它根据现有查询工作负载中频繁遍历的活动边和频繁探索的活动顶点,逐步调整分区(最初通过图顶点的随机散列获得)。从这个意义上说,我们的分区器将活动顶点分布在与访问频率成比例的分区之间。这将导致现有计算负载的平衡,从而增加吞吐量。另一方面,它降低了活动边的切割概率,与它们的遍历频率成正比。因此,属于同一查询的活动顶点可能被并置到同一分区中,这反过来又减少了查询响应时间。WASP通过跟踪活动权重来监视活动边和顶点,活动权重越大意味着活动越多。为了适应现有的工作负载,减少旧的活动边和顶点的影响,WASP利用了一组活动边日志,每个日志存储在一个计算节点中。通过将(现有工作负载的)新的活动边插入边缘日志,(以前工作负载的)旧的活动边逐渐从日志中删除。这种移除将旧的活动边及其相关的旧活动顶点变为被动点,在调整图分区时不再考虑被动点。WASP具有拓扑感知能力,利用混合切割模型,将对高度顶点的探索分布在多个节点上,从而提高了吞吐量。我们的贡献总结如下。 - 我们提出了一个专用的成本模型来根据频繁的查询模式和图拓扑来管理顶点重新分配。该模型决定应该移动哪个顶点以及移动到哪里,以便最大化重新分配增益。同时,保留每个计算节点上的负载平衡。
- 我们提出增量轻量级元数据管理,其中数据结构主要是权重计数器。因此,诸如计算托管在不同节点上的活动顶点的兴趣度之类的耗时计算被权重的连续更新所取代。我们利用 Redis [7] 以键值对的形式快速内存存储和访问每个节点中的各种权重。
- 我们使用现实世界和合成图数据集进行广泛的评估。结果表明,在动态工作负载方面,我们的方法比最先进的图存储要快得多,并且增加了访问图的高度顶点的并行性。
背景
平衡 k 路图分区将图划分为 k 个不相交且平衡的分区,并最小化切割大小。这是一个众所周知的 NP 难问题,其中计算负载平衡(为了最大化并行性)和数据访问局部性(为了最小化节点间通信)是两个相互冲突的问题 [18]。这导致了许多图数据集的启发式划分方法,这些方法可以分为两个正交类别:以顶点为中心/以边为中心和离线/在线。
以顶点为中心的分区器将每个源顶点及其关联边分配到同一分区中,这反过来又增加了局部性。然而,相应的目标顶点可能被分配给不同的分区,这导致切割它们之间的边切割。这些分区器旨在跨节点执行顶点的平衡分配,以及最小化边切割的数量。尽管以顶点为中心的分区器促进了局部性,但它们可能会严重影响幂律图的计算负载平衡。换句话说,通过将高度顶点的所有边分组在一起,节点的子集会过载。另一方面,以边为中心的方法倾向于将与特定顶点相关的边分配到不同的分区中。但是,边的顶点会在与边位置相同的节点中复制。这些分区器旨在跨节点执行边的平衡分配,并最大限度地减少副本数量。尽管以边为中心的分区器缓解了高度顶点的计算负载不平衡,但它们通常由于较差的局部性而导致更高的通信和同步成本[19]。
离线或非流式分区器,例如 METIS [25],需要访问整个图数据集,以便在分区之前执行预处理。然而,由于大量使用内存和高计算成本,它们对于非常大的图的扩展性很差,这反过来又影响了在线(非分析)查询处理的性能。这种分区方法后来通过并行化技术得到了改进,例如 ParMETIS [26]。这些并行策略仍然需要全局视图,从而降低了它们的可扩展性。
由于针对大型图扩展离线方法很困难,因此引入了在线或流式方法,随着新的更改流入系统,这些方法会不断更新分区。更准确地说,它们根据输入图的局部知识(例如流元素的当前属性和先前的信息)一次对传入的顶点(对于以顶点为中心的分区)或边(对于以边为中心的分区)进行分区的。这些流方法是一次性的,因为在将顶点或边分配给分区后,不会执行重新分配。由于这些方法的在线性质,轻量级启发式方法(例如 Fennel [49])用于决定在何处分配传入元素。然而,由于图元素被分配一次,图的新流元素可能会恶化其先前的分区。因此,流方法有多种扩展 [34, 50],其中图在几次传递或迭代中被划分。但是分区的质量仍然依赖于流元素的顺序,因为可能没有足够的输入图的局部知识。
相关工作
近年来,为了支持大规模动态图的低延迟查询执行,提出了几种在线分区策略。他们的目标是提高离线图分析的性能,如[27,30,39,42,51,52,55,12,13],或在线图查询的性能,如[10,13 - 17,21,22,32,33,37,38,56],其工作负载驱动的性能与我们在本研究中的工作更相关。由于我们只回顾了图分区方法的一个方面,感兴趣的读者可以参考最近关于图分区的调查[6,20,35]。
Hermes[33]是一种工作负载驱动的分区方法,其中每个顶点知道其在每个分区中的邻居数量、每个分区的权重和分区的总权重。节点是基于其承载顶点的权重来平衡的,其中顶点的权重表示对它的查询频率。当顶点的权重改变时触发顶点重新分配。将顶点从源分区重新分配到目标分区的增益是它在目标分区中的邻居比源分区中的邻居多多少。Peng等人[36,37]提出了一种工作负载驱动的分区方法,该方法从具有代表性的查询工作负载中挖掘频繁的查询模式。然后,它将相同频繁模式的匹配放到相同的片段中,以改善整个工作负载。
WARP[21]是一种工作负载驱动的复制方法,根据其主题,RDF三元组最初使用METIS进行分区。然后,它使用一个代表性的查询工作负载,使用n-hop保证方法[23]在集群中复制频繁访问的三元组。给定一个用户查询,WARP确定其中心顶点和半径。如果查询在n跳保证范围内,则WARP将查询发送到所有服务器,这些服务器并行计算查询。否则,查询将被分解为子查询,并为这些子查询创建分布式查询计算计划。子查询由所有服务器并行计算,并将结果发送到合并它们的主服务器。Partout[17]也是由工作负载驱动的,它从具有代表性的查询工作负载中提取频繁的查询模式,并使用它们将数据划分为片段。
Loom[15]是一种流分区策略,它假定给定图形模式及其相对频率的查询工作负载。在工作负载期间,它发现边缘遍历的常见模式。然后将子图模式匹配查询与这些常见模式进行比较,并尝试通过将每个匹配分配到单个分区来减少频繁遍历的子图的分区间遍历。Taper [16] 将任何给定的初始分区作为起点,并通过估计给定路径查询工作负载的遍历概率来迭代增强它。然后使用它们跨分区交换选定的顶点,并减少分区间遍历的概率。

表 1 总结了支持在线图形查询的最先进的工作负载驱动分区策略。Loom、Partout、WARP 和 Peng 等方法基于了解先验查询工作负载。此外,Taper 假定现有路径查询工作负载中模式的给定频率。通过利用这些先验知识,可以突出显示未来查询共同针对的数据集部分。然而,实际上不仅提前掌握这些知识可能很困难,而且这种策略也不能(适当地)适应变化。这将导致分区的质量下降,因为在没有重新分区的情况下,工作负载会不断变化。Hermes考虑了均匀的边缘遍历频率,尽管现实世界图的边缘权重不均匀。另一方面,WARP广泛利用图顶点的复制来改善其访问的局部性。然而,维护副本意味着额外的元数据管理,这反过来又增加了系统开销。更改工作负载也会使副本变得无用,从而增加存储开销。相反,WASP可以采用任何给定的初始分区,且无需预先假定工作负载。此外,它通过不使用复制来避免额外的存储开销。WASP还利用超割模型来缓解高度顶点的负载不平衡并提高并行性。
WASP框架
在本节中,我们将更详细地描述 WASP 的设计。
数据和查询模型
在本文中,数据由属性图模型表示,因为它已经被广泛接受,并在许多图数据库系统中使用,如Neo4j和Titan。定义如下:

直观地说,G是一个有向、有标记和有属性的多重图,其中每个顶点代表一个实体,并具有一个标签或类型以及与该实体相关的一组属性(可能为空),每个边表示实体之间的二元关系,并具有一个标签和一些属性。
在线图查询可以分为两大类,即路径查询和模式匹配查询[11]。因此,我们假设查询工作负载W ={<Q1, f1>, <Q2, f2>,…,<Qn, fn>}作为一组路径查询或模式匹配查询[2,3]及其频率,由基于探索的查询处理器处理[44,57]。模式匹配查询Q遵循与属性图相同的结构,但不允许其顶点VQ,边EQ,标签LQ和属性值ValQ只包含常量,它也允许变量。路径查询确定连接属性图的两个顶点的路径是否存在,可以将其视为模式匹配查询的子集。
工作负载特征
由于查询工作负载通常是动态的(通过更改关联查询的频率),因此图分区的质量可能会随着时间的推移而降低。因此,WASP 根据以下定义将工作负载特征编码为顶点和边权重。
给定一个属性图 G,对于每条方向边 <u, v>∈EG,其中 u 和 v 在 VG 中,分别驻留在节点 N 和 M 上,有一个遍历权值 𝜔(<u, v>) 表示遍历该边所传递的数据量。
更详细地说,在处理查询 Q 的过程中,从源顶点 u 到目标顶点 v 的遍历将 Q 和 u 从 N 发送到 M,其中 Q 的处理继续,然后接收 u 所需的探索结果。该权重从默认最小值 0 开始,表示其对应的被动边尚未被遍历。通过在现有查询工作负载期间遍历一条边,边的权重逐渐增加,同时减少切边的概率。给定一个属性图 G,对于每个顶点 v ∈ VG ,其中 v 托管在节点 N 上,有一个活动权重 𝜔(v),它等于 v 的关联边的总权重。
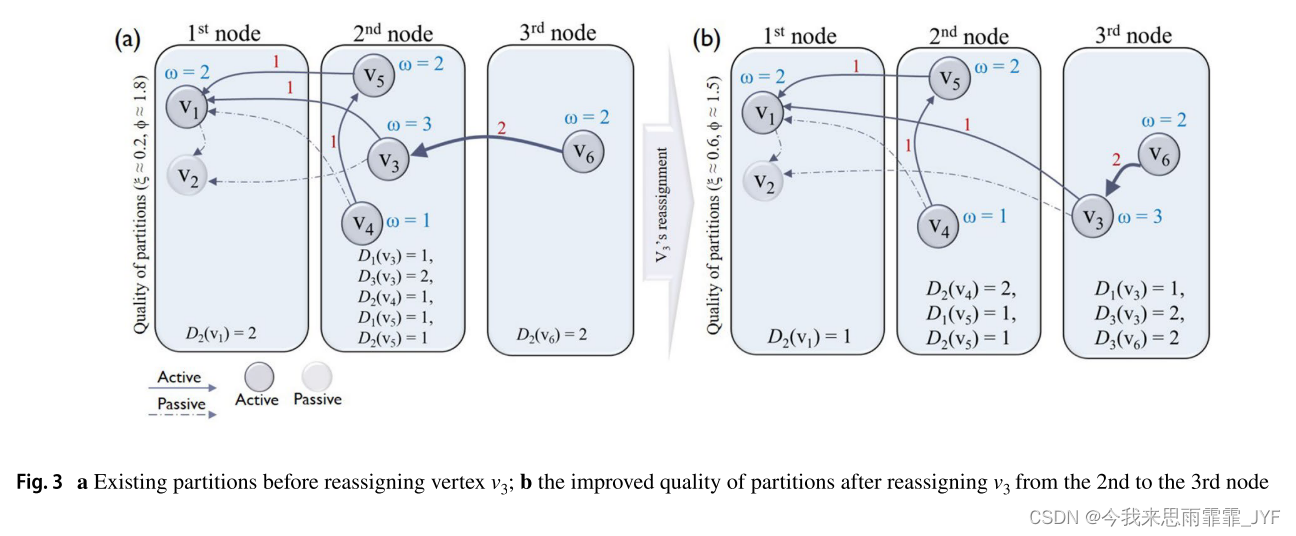
更详细地说,由于任何向 v 或从 v 的遍历都需要探索它的邻域,𝜔(v)表示通过访问相应的局部索引对节点 N 施加的计算负载(参见第4.4节)。因此,通过在现有查询工作负载期间访问活动顶点,其活动权重将大于0。作为说明,图3a显示了样本属性图的顶点/边权重。在该图中,越粗的边在图形上表示遍历频率越高的边。
顶点重新分配
Fennel流启发式[49]用于大规模图的在线一次分区,其中新添加的顶点被分配(仅一次)给具有最多邻居的现有分区;与此同时,应该对较大的分区进行惩罚,以防止其相对于托管顶点的数量变得过大。该启发式如Eq. 1所示,其中v表示待分配的顶点,N(v)表示v的邻居集合,Vi表示第i个节点上承载的顶点集合,n表示节点数, α \alpha α和 β \beta β为参数。
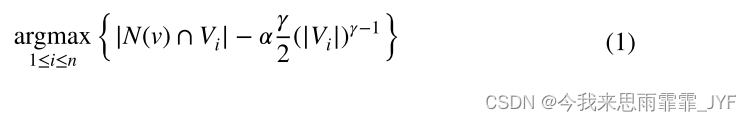
这种一次通过的流启发式算法类似于图的动态分区,其新流的顶点/边被增量地添加到现有分区中[45,49]。然而,一次分区在四个方面无法适应工作负载:(1)一个已分配的顶点永远不会被重新分配;(2)不考虑去除顶点/边;(3)考虑边遍历的均匀频率,(4)分区可能无法根据其承载顶点的总活动权进行平衡。这些缺点促使我们使用自适应工作负载的选择性重分配,这种重分配会不断地重新访问活动顶点,并在适当的时候重新分配它们。这就需要在计算节点的主内存中维护一些基于工作负载的元数据。这种信息量是无法与给定图形数据集的巨大信息量相比的。更详细地说,根据现有的工作负载,假设v∈Si,其中Si是托管在第i个节点上的活动顶点集。以下元数据需要在第i个节点的主存中维护:
- 在每个节点上托管的 v 的兴趣度,其中每个度从默认最小值0初始化。更详细地说,v对第j个节点的兴趣度(j∈[1…]n])称为Dj(v),它表示v与第j个节点上驻留的顶点之间的关联边的总权重。在查询遍历期间,Dj(v)通过从v向第j个节点上的顶点发送请求来递增,反之亦然。因此,𝜔(v)可以简单地通过v对所有节点的兴趣度求和来计算。请注意,默认值为零的度数不会存储在内存中。它们在图3中也没有显示。
- 第i个节点的活度权值,称为𝜔(Si)。它表示承载在该节点上的所有活动顶点的聚合活动权重。
- 托管在第 i 个节点上的边缘日志,称为 l l li。日志存储与第 i 个节点上的活动顶点相关的所有活动边和相应的权重。更详细地说,在现有工作负载期间,最近遍历的边事件与托管在第 i 个节点上的活动顶点有关,被插入到 l l li 的顶部。因此,不再遍历的边e(即属于以前的工作负载)逐渐移到日志的底部,并最终移出日志。这就把e变成了一条被动边,它的权值被设为0,这反过来又改变了e端点的局部性程度。更准确地说,假设e的权值是w,它的端点是u驻留在第j个节点上,v驻留在第i个节点上,那么w要从Di(u)和Dj(v)中减去。w也从𝜔(Si)和𝜔(Sj)中减去。
- 每个边日志都有一个可配置的大小Δ,它是为所有节点统一设置的,因为它们的日志包含几乎相同数量的活动边。这是因为在查询时通过以边为中心的高度顶点分区减轻了负载倾斜(参见4.3.3节)。当Δ太小时,每个日志存储现有工作负载中遍历的活动边的子集。这意味着会移出一些属于工作负载的频繁遍历的边,并错误地使它们成为被动的。另一方面,当Δ太大时,每个日志存储以前工作负载期间遍历的活动边,而不是现有的边。在这两种情况下,由于不精确的顶点重分配,分区的质量可能会受到影响。Δ的选择和影响将在5.4节中讨论。
如上所述,出于两个原因,我们的框架使用简单的散列分区方案对节点间的顶点进行初始分区。首先,在为分区分配新顶点时不涉及复杂的逻辑。其次,对于给定的顶点,我们可以简单地查找它的原始托管节点。因此,承载新到达顶点的初始节点可以通过对顶点ID的散列简单地找到。但是,重新分配顶点需要使用查找表来查找它的新托管节点。这个表可以通过一组查找变量以分布式方式实现。更准确地说,每个重新分配的顶点 v 都有一个查找变量作为元数据存储在 v 的初始节点中。注意,只要 v 驻留在初始节点上,就不需要这个查找变量。
我们的选择性重新分配启发式算法如Eq. 2所示。
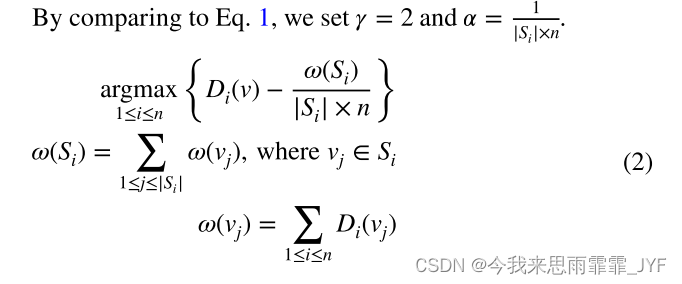
这种重新分配以顶点 v 作为输入,计算集群中每个节点的分数,并确定得分最高的节点作为 v 的潜在目标节点。为了保证对节点的活动权值进行均衡的划分,有一个惩罚函数 ω ( S i ) ∣ S i ∣ × n \frac{{\omega ({S_i})}}{{\left| {{S_i}} \right| \times n}} ∣Si∣×nω(Si),其中每个节点的活动权值越高,其得分就越低。
为防止源节点欠载,要求为:{𝜔( S s {{S_s}} Ss)−𝜔(v)}≥(2−Φ)×Ω,其中Ω表示所有节点的平均聚合活动权值。另外,参数Φ∈[1,2]表示分区的最大负载不平衡程度。例如,Φ= 1表示要求所有节点具有相同的活动权重总和。如果源节点负载不足,则不允许顶点 v 被移动。另一方面,在潜在目标节点(假设是第t个节点)上检查条件:{𝜔( S t {{S_t}} St)+𝜔(v)}≤Φ×Ω,以防止超载。如果节点过载,则在下一个得分最高的节点上检查条件;不过载则选择第 t 个节点作为目标节点。
假设分区的质量由一对质量因素决定:(1)分区内遍历的概率(衡量局部性)( ξ \xi ξ)和(2)表明现有分区不平衡程度的负载不平衡因子( ϕ \phi ϕ)。这些因素定义如下:

选择性重分配改进 ξ \xi ξ,因为边的权重越高,切割它的概率越低。换句话说,通过增加边的权重,可以增加其端点分配在同一节点上的兴趣。 ξ \xi ξ 的值越高意味着在现有查询工作负载期间跨分区遍历的概率越小。
图 3 说明了选择性重新分配的一个例子,假设有三个节点, Φ= 1.6 ,并且选择顶点 v3 进行重新分配。
顶点重新分配数据维护
重新分配顶点 v 会导致将其拓扑数据从作为源的第 i 个节点移动到作为目标的第 j 个节点。此类数据包括 v 与其他顶点的关系以及 v 的属性。它还需要维护相关的元数据,如下所示:(1)将所有与v相关的活动边(及其权值)从 l l li中移除并插入到 l l lj中;(2)将 v 对所有节点的兴趣度移动到目标节点;(3)对于每个与u和v相关的活动边e, u对源节点和目标节点的兴趣度发生变化。更准确地说,将𝜔(e)从Di(u)中减去,再加上Dj(u),(4)改变源节点和目标节点的总活动权值。更准确地说,将w从𝜔(Si)中减去并添加到𝜔(Sj)中,并且(5)将v在其初始节点中的查找变量更新为指向目标节点。
在重分配过程中,源节点的查询处理器不回答v上的任何请求,以防止它们访问不一致的数据。因此,在查询处理器中维护请求队列,从而使v上的所有请求排队。通过完成重新赋值,v的查找变量指向目标节点。因此,v上的请求将从队列中释放并重定向到目标节点。
顶点重新分配时间
重新分配顶点的时机对于在分区质量和上述数据/元数据维护开销之间取得平衡至关重要。回想一下,通过改变一个顶点的活动权值,它对不同节点的兴趣程度可能会改变。反过来,这会触发检查重新分配顶点的可能性。另一方面,通过增加顶点的活动权值,对不同节点的兴趣程度的新探索的影响可以忽略不计。因此,在一次重新分配后,只有在进行了类似数量的新探索后,我们才会检查另一次重新分配的可能性。更详细地说,假设重新分配阈值 k,则在 {k, 2 × k, 4 × k, …, 2i× k, …} 次探索后触发顶点重新分配。这显着减少了顶点的重新分配次数。例如,如果k等于10,对于活动权重为10,240的顶点,最大重新分配次数仅为10。目前,我们使用固定的重新分配阈值。重新分配阈值的选择和影响将在5.3节中讨论。
高度顶点
高度活跃的顶点可能会显著降低在线查询的效率和吞吐量。更准确地说,它们的大邻居可能会在它们的托管节点上产生显著的处理开销,以及在它们的事件边上产生大量的网络流量。作为说明,图4a描绘了一个高度活跃的顶点u,驻留在节点N1上,其邻居分散在N1到N3之间。另外,假设在模式匹配查询Q中有一个图遍历,输入图中的顶点t、u和v1到v100,000是查询中顶点t、u和V的实例。因此,从源顶点u到目标顶点v1到v100,000的遍历需要收集和处理大量的结果,这些结果被发送回N1。此外,从驻留在节点N2上的源顶点t到目标顶点u的遍历会导致从N1到N2发送回大量收集到的结果。
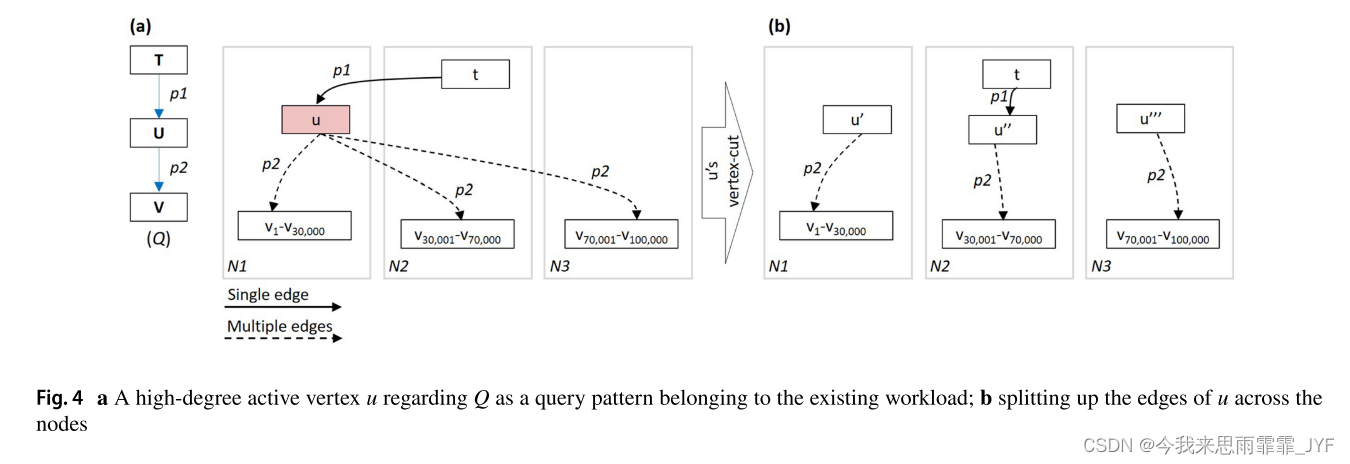
WASP通过指定和分割高度顶点缓解了这些问题。因此,对于每个顶点u,当u的度(进出边的度)超过一个可配置的分割阈值时,它被认为是一个高度顶点,这反过来导致u的边被划分,从而顶点u与其邻居并置。更详细地说,出边u→v与其目标顶点v并置,入边u←v与其源顶点v并置。因此,由于u的邻居是通过哈希随机分布的,所以u的边是均匀分布的。这将统一地将查询处理开销分配给托管其拆分的所有节点。如图4b所示,顶点u被分成三个顶点u '、u '和u ',分别驻留在N1、N2和N3上。因此,从作为源顶点的t遍历到作为目标邻居的u的分叉,将导致在所有节点之间划分流量负载。分割阈值的选择和影响将在5.5节中讨论。
实验评价
在本节中,我们将在广泛的实验中评估WASP,以全面测试其针对不同静态和动态查询工作负载的适应性和性能。
硬件/软件设置我们已经在C/ c++中实现了WASP。更详细地说,MPICH-3.1.4库和ZeroMQ10套接字用于跨节点通信。WASP部署在一个有10个同质节点以点对点方式连接的集群上,每个节点有48GB RAM, 16个2.4GHz的四核cpu, 160GB SATA HDD,运行Debian Linux 6.0.6。
数据集和查询工作负载 我们使用三个合成数据集和真实数据集(见表2)以及对这些数据集的六个查询工作负载进行了实验。WatDiv[1]和LUBM[47]是两个合成属性图基准,我们创建了两个数据集,每个数据集包含超过10亿个边。我们使用它们的查询模板生成器分别生成20个和14个基本模板或模式。然后我们为每个模板实例化1K个查询。因此,我们为WatDiv创建了两个工作负载,即WatDiv- sw和WatDiv- dw,每个工作负载总共包含20K个查询。前者通过在没有波动频率的情况下对所有模式的查询进行洗牌来模拟静态工作负载。后者通过连续执行相同模式的查询来模拟动态工作负载。类似地,我们为LUBM创建LUBM- sw和LUBM- dw工作负载,每个工作负载总共包含14K查询。
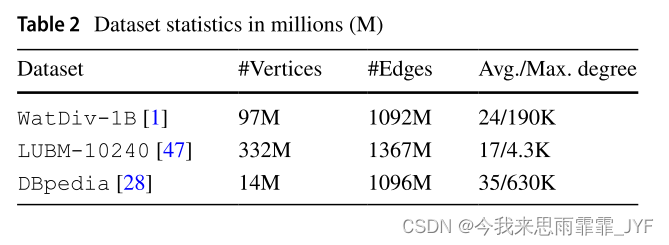
由于WatDiv和LUBM都是合成的,我们也使用DBpedia[28]作为通过众包从Wikipedia中提取的真实属性图数据集。我们从DBpedia查询日志[40]中提取了44个查询模板,从2014年4月12日到2014年10月16日,记录了超过170万个查询请求。我们之所以使用这个日志,是因为它也被其他最先进的图分区器所使用,这反过来又会产生公平的比较。我们删除了有解析错误或运行时错误的查询,最后仍然有120万个查询。和前面一样,我们创建了两个工作负载,即DBpediaSW和DBpedia-DW,每个工作负载总共包含44K个查询。请注意,DBpedia查询日志中的大多数查询只包含一个或几个三重模式,因此DBpedia的模板比其他数据集简单得多。
关于表1,我们比较了WASP和Hermes[33],后者是唯一没有查询工作负载先验知识的策略。我们还将Peng等人的方法[36]作为基于了解先验查询工作负载的策略的代表进行了比较。它已经显示出对WARP[21]和Partout[17]具有更快的查询响应时间。
分区质量
我们首先研究了三个分区器在六个静态和动态工作负载下实现的分区间遍历(IPT)比率。在图6a中,x轴显示了10个单元的WatDiv-SW查询流,每个单元包含2K个查询。y轴表示通过执行每个单元的查询获得的IPT比率。从图中可以看出,Hermes和WASP通过顶点重分配策略逐步提高了数据访问局部性,IPT比率逐渐降低。但是由于Hermes没有考虑活动边的权值,所以相应的递减率比WASP要低。另一方面,尽管WASP和Hermes最初通过简单的散列策略对图数据集进行分区,但Peng等人的方法[36]在假设对WatDiv-SW工作负载有先验知识的情况下对整个图数据集进行分区。因此,该图显示了一个几乎稳定的小于0.1的IPT比率,因为Peng等人的方法已经将每个频繁模式的匹配分配到相同的分区。
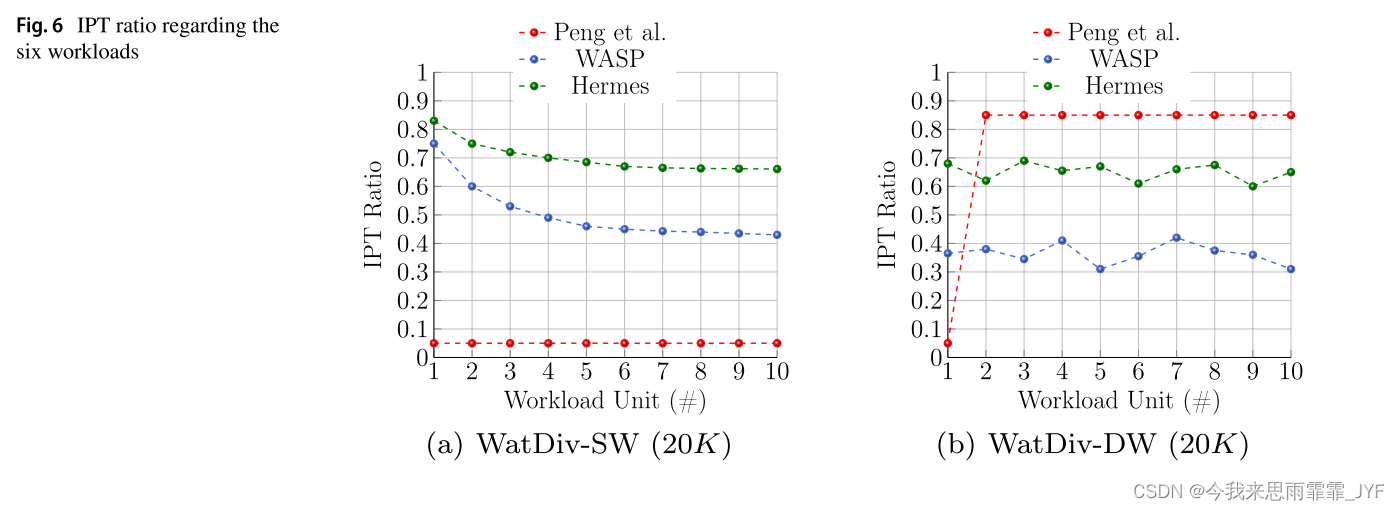
相反,对于如图6b所示的WatDiv-DW查询流,Peng等方法的IPT比率非常高(大于0.8)。更详细地说,它基于第一个工作负载单元中的频繁查询模式对图数据集进行分区,假设对该单元有先验知识。然而,现有的频繁查询模式在随后的单元中会发生变化,这将导致IPT比率的严重增加,因为Peng等人的方法不是工作负载自适应的。另一方面,WASP和Hermes使自己适应了WatDiv-DW查询流。在工作负荷期间,WASP中的IPT比率大约在0.3到0.4之间波动。然而,Hermes的比率上限在0.6到0.7之间,因为它考虑了均匀的边遍历频率,尽管在现实场景中不均匀。类似的推理可以用来证明从LUBM和DBpedia数据集获得的结果。类似的推理可以用来证明从LUBM和DBpedia数据集获得的结果。如图6c所示,在执行LUBM-SW查询流之后,WASP获得了比WatDiv-SW更好的IPT比率(接近0.27),而WatDiv-SW的IPT比率(接近0.43),如图6a所示。这是由于LUBM中存在比WatDiv更复杂的长路径查询。更详细地说,更复杂的查询导致更多的边遍历,这导致WASP识别热(hot)边并配置其端点顶点。另一方面,如图6e所示,与图6a, c相比,WASP和Hermes的行为更接近。这是因为DBpedia中存在简单的短路径查询。
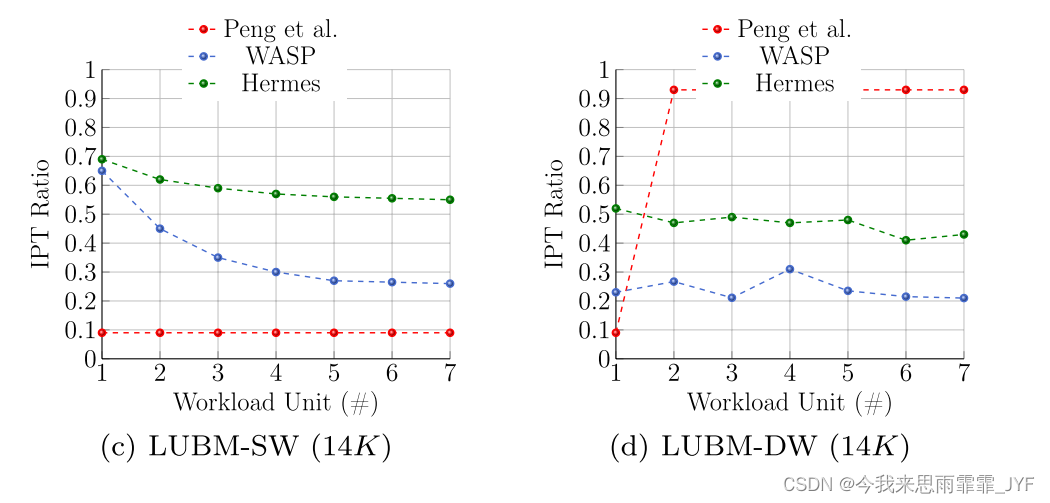
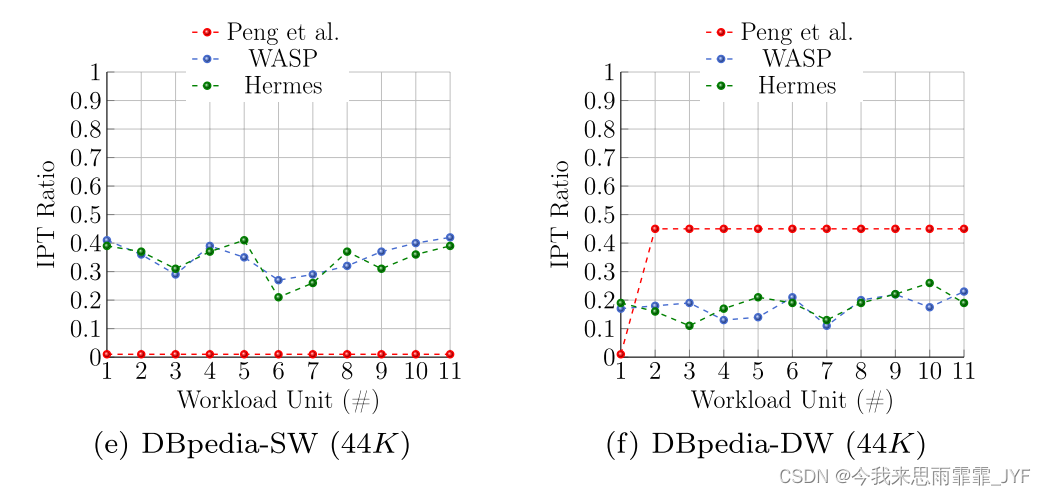
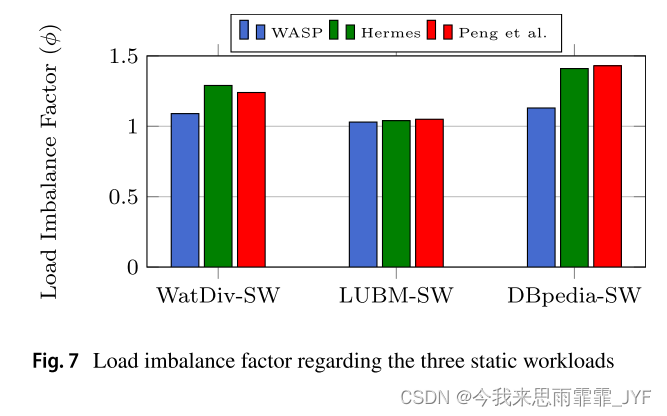
请注意,IPT 比率的提高并不一定会导致查询性能的提高,除非存在均衡的负载分布[35]。因此,我们研究三个分区器实现的“计算”负载平衡。在这方面,尽管Hermes和Peng等人的方法利用现有的工作负载来实现均衡的负载分布,但它们在WatDiv和DBpedia中表现不佳,因为非常高度顶点的所有边都被分组在一起。这将导致一部分机器在计算上被高度活跃的顶点过载。另一方面,WASP拆分这些顶点(见4.3.3节)。因此,图7显示了分区策略在三种静态工作负载上实现的负载不平衡系数( ϕ \phi ϕ)。如图所示,在所有工作负载中,WASP都比其他负载实现了更好的负载不平衡。
结论及未来工作
为了在分布式图存储中实现低延迟和高吞吐量的在线查询,我们提出了一种新的**自适应工作负载(顶点重分配)和拓扑感知(混合割)**流分区器WASP。由于每个查询工作负载通常包含流行的或类似的查询,因此WASP捕获在现有查询工作负载中经常访问和遍历的活动顶点和边。利用这些信息,通过避免活动顶点集中在与其访问频率成比例的几个分区中,或者通过减少与它们的遍历频率成比例的活动边的切割概率,可以提高分区的质量。我们的实验表明,WASP显著减少了查询工作负载期间的分区间遍历次数。它能够处理不断变化的查询工作负载和图拓扑,同时保持分区的质量。未来,我们计划通过基于工作负载的复制来提高静态工作负载中查询的性能,其中顶点的复制方案(即顶点的副本数量以及这些副本分配到的分区)将根据顶点的读/写频率动态变化。
相关文章:
A Workload‑Adaptive Streaming Partitioner for Distributed Graph Stores(2021)
用于分布式图存储的工作负载自适应流分区器 对象:动态流式大图 划分方式:混合割 方法:增量重划分 考虑了图查询算法,基于动态工作负载 考虑了双动态:工作负载动态;图拓扑结构动态 缺点:分配新顶…...

鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Search)
搜索框组件,适用于浏览器的搜索内容输入框等应用场景。 说明: 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 无 接口 Search(options?: { value?: string, placeholder?: Reso…...

GPIO八种工作模式实践总结
到目前为止我还是没搞懂,GPIO口输入输出模式下,PULLUP、PULLDOWN以及NOPULL之间的区别,从实践角度讲,也就是我亲自测试来看,能划分的区别有以下几点: GPIO_INPUT 在输入模式下使用HAL_GPIO_WritePin不能改变…...
ElementUI两个小坑
1.form表单绑定的是一个对象,表单里的一个输入项是对象的一个属性之一,修改输入项,表单没刷新的问题, <el-form :model"formData" :rules"rules" ref"editForm" class"demo-ruleForm"…...

前端基础——HTML傻瓜式入门(2)
该文章Github地址:https://github.com/AntonyCheng/html-notes 在此介绍一下作者开源的SpringBoot项目初始化模板(Github仓库地址:https://github.com/AntonyCheng/spring-boot-init-template & CSDN文章地址:https://blog.c…...
操作系统(AndroidIOS)图像绘图的基本原理
屏幕显示图像的过程 我们知道,屏幕是由一个个物理显示单元组成,每一个单元我们可以称之为一个物理像素点,而每一个像素点可以发出多种颜色。 而图像,就是在不同的物理像素点上显示不同的颜色构成的。 像素点的颜色 像素的颜色是…...
测试用例的设计(2)
目录 1.前言 2.正交排列(正交表) 2.1什么是正交表 2.2正交表的例子 2.3正交表的两个重要性质 3.如何构造一个正交表 3.1下载工具 3.1构造前提 4.场景设计法 5.错误猜测法 1.前言 我们在前面的文章里讲了测试用例的几种设计方法,分别是等价类发,把测试例子划分成不同的类…...

HTML与CSS
前言 Java 程序员一提起前端知识,心情那是五味杂陈,百感交集。 说不学它吧,说不定进公司以后,就会被抓壮丁去时不时写点前端代码说学它吧,HTML、CSS、JavaScript 哪个不得下大功夫才能精通?学一点够不够用…...
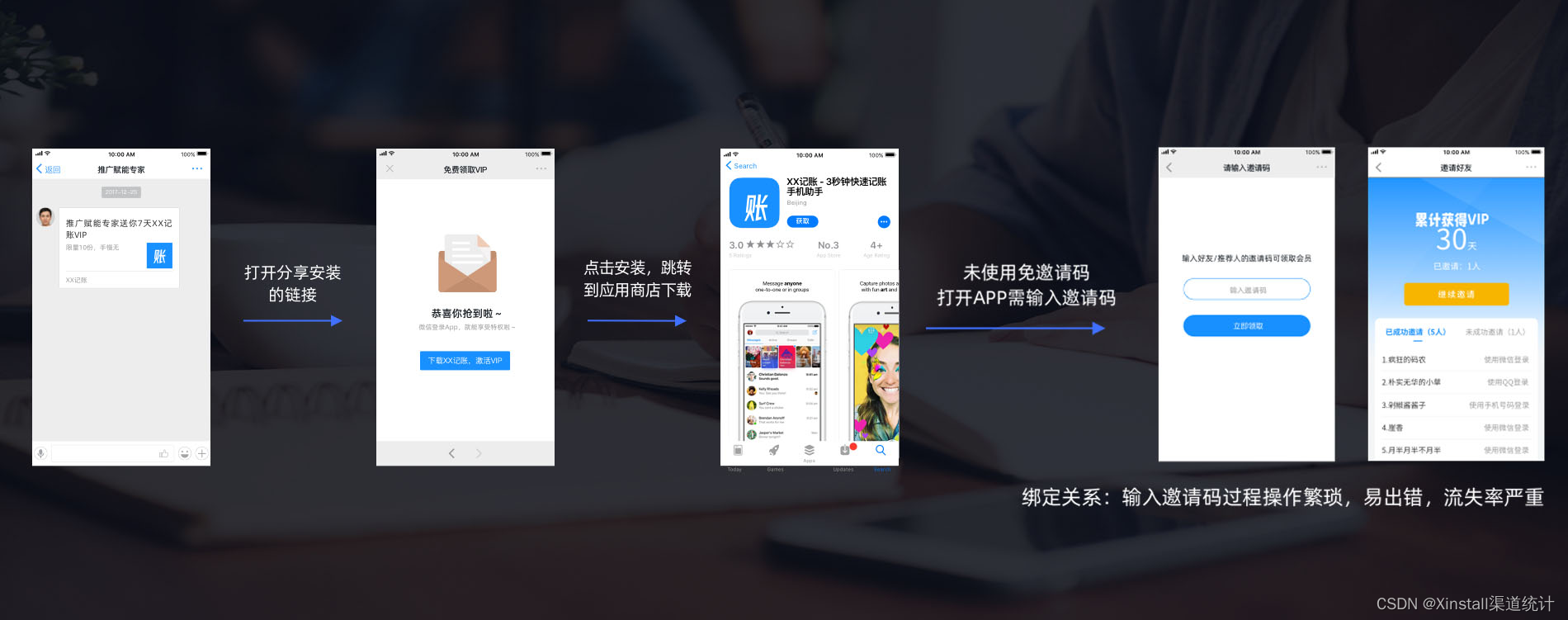
App推广不再难!Xinstall神器助你快速获客,提升用户留存
在如今的移动互联网时代,App推广已经成为了各大应用商家争夺用户的重要手段。然而,面对竞争激烈的市场环境,如何快速提升推广效率,先人一步获得用户呢?这就需要我们借助专业的App全渠道统计服务商——Xinstall的力量。…...

MySQL建表以及excel内容导入
最近自学MySQL的使用,需要将整理好的excel数据导入数据库中,记录一下数据导入流程。 --建立数据库 create table SP_sjk ( --增加列 id NUMBER(20), mc VARCHAR2(300) ) /*表空间储存参数配置。一个数据库从逻辑上来说是由一个或多个表空间所组成&#…...

让el-input与其他组件能够显示在同一行
让el-input与其他组件能够显示在同一行 说明:由于el-input标签使用会默认占满一行,所以在某些需要多个展示一行的时候不适用,因此需要能够跟其他组件显示在同一行。 效果: 1、el-input标签内使用css属性inline 111<el-inp…...
)
学完Efficient c++ (44-45)
条款 44:将与参数无关的代码抽离模板 模板可以节省时间和避免代码重复,编译器会为填入的每个不同模板参数具现化出一份对应的代码,但长此以外,可能会造成代码膨胀(code bloat),生成浮夸的二进制…...
鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:ColumnSplit)
将子组件纵向布局,并在每个子组件之间插入一根横向的分割线。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 可以包含子组件。 ColumnSplit通过分割线限制子组件的高度。初始…...
jenkins部署go应用 基于docker-compose
丢弃旧的的构建 github 拉取代码 指定go的编译版本 安装插件 拉取代码是排除指定的配置文件 比如 conf/config.yaml 文件 填写配置文件内容 比如测试环境一些主机信息 等 可以配置里面 构建的时候选择此文件替换开发提交的配置文件。。。。 编写docker-compose 文件 docker…...

【晴问算法】入门篇—贪心算法—整数配对
题目描述 有两个正整数集合S、T,其中S中有n个正整数,T中有m个正整数。定义一次配对操作为:从两个集合中各取出一个数a和b,满足a∈S、b∈T、a≤b,配对的数不能再放回集合。问最多可以进行多少次这样的配对操作。 输入描…...
)
九种背包问题(C++)
0-1背包,背包大小target,占用容积vec[i][0],可以带来的利益是vec[i][1] 一件物品只能取一次,先遍历物品然后遍历背包更新不同容积下最大的利益 int func(vector<vector<int>>&vec,int target){vector<int>dp(target1,…...
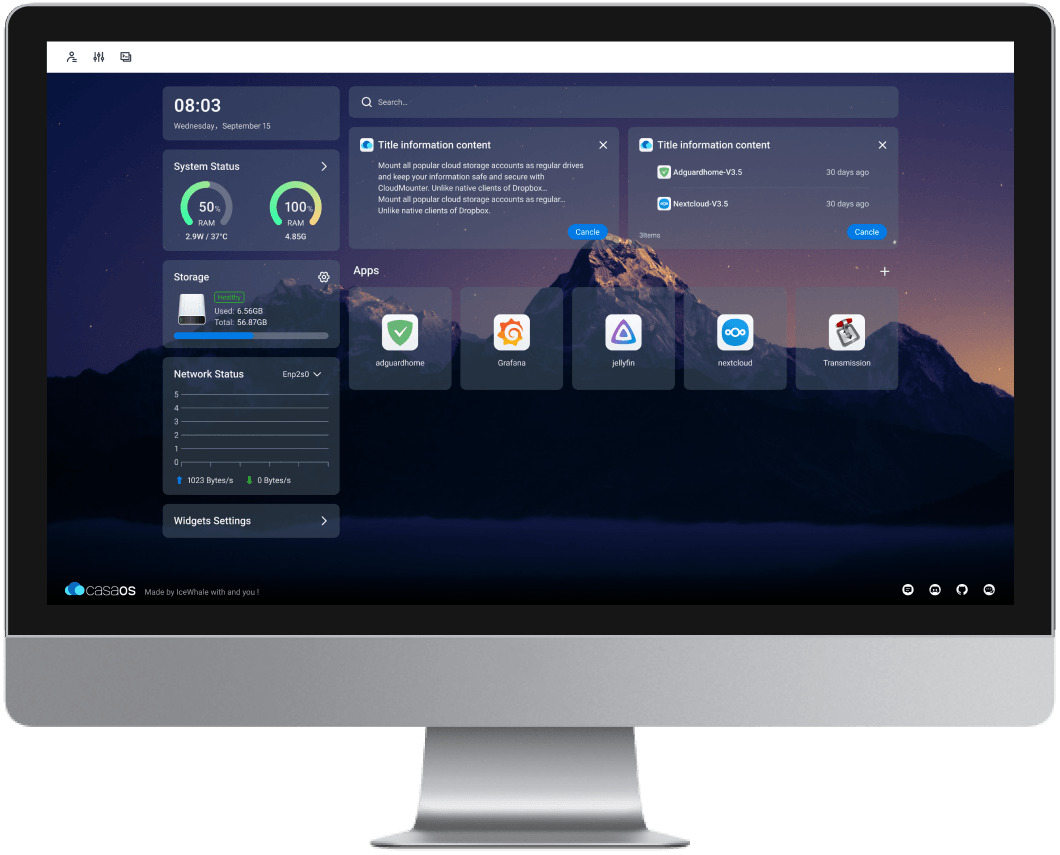
008:安装Docker
安装Docker 如果不太熟悉Linux命令,不想学习Linux命令,可以直接看文末NAS面板章节,通过面板,像使用Window一样操作NAS。 一、安装 Docker 1.安装 Docker wget -qO- https://get.docker.com/ | sh2.启动 Docker 服务 sudo sys…...
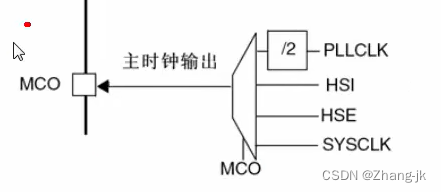
STM32第九节(中级篇):RCC(第一节)——时钟树讲解
目录 前言 STM32第九节(中级篇):RCC——时钟树讲解 时钟树主系统时钟讲解 HSE时钟 HSI时钟 锁相环时钟 系统时钟 SW位控制 HCLK时钟 PCLKI时钟 PCLK2时钟 RTC时钟 MCO时钟输出 6.2.7时钟安全系统(CSS) 小结 前言 从…...
Web核心,HTTP,tomcat,Servlet
1,JavaWeb技术栈 B/S架构:Browser/Server,浏览器/服务器架构模式,它的特点是,客户端只需要浏览器,应用程序的逻辑和数据都存储在服务器端。浏览器只需要请求服务器,获取Web资源,服务器把Web资源…...

空间(Space)概念:元素、集合、空间和数学对象
摘要: 在数学中,一个空间(Space)是一种特殊类型的数学对象。它通常是一个集合,但不仅仅是一个普通的集合,而是具有某种附加的结构和定义在其上的运算规则。这些额外的结构使得空间能够反映现实世界中的几何…...

从NLP到RAG:AI标书生成系统的技术架构与落地路径深度剖析
引言2026年2月,国家发改委等八部门联合印发《关于加快招标投标领域人工智能推广应用的实施意见》,明确到2026年底招标文件检测、智能辅助评标、围串标识别等重点场景在部分省市实现全覆盖。同一时期,《招标投标法》修订草案经国务院常务会议原…...

BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能
BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否觉得网易云音乐PC版功能有限,界面单调?…...

WarcraftHelper:让经典魔兽争霸3完美适配现代电脑的终极解决方案
WarcraftHelper:让经典魔兽争霸3完美适配现代电脑的终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代操…...

OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS
OpenCore Legacy Patcher完整指南:让老旧Mac焕发新生,运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台被苹…...

服务器数据下载安全:实时加密与动态访问控制实战
1. 这不是又一个“加个密码”的方案,而是服务器数据流动的实时安检闸机IP-guard安全网关——这个名字在企业IT运维圈里,常被误读为“桌面端U盘管控工具”或“员工上网行为审计系统”。但真正用过它来守服务器的人,会立刻意识到:它…...

英雄联盟回放播放难题终极解决方案:ROFLPlayer完整使用指南
英雄联盟回放播放难题终极解决方案:ROFLPlayer完整使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟旧…...

Python多智能体建模终极指南:用Mesa轻松构建复杂系统仿真
Python多智能体建模终极指南:用Mesa轻松构建复杂系统仿真 【免费下载链接】mesa Mesa is an open-source Python library for agent-based modeling, ideal for simulating complex systems and exploring emergent behaviors. 项目地址: https://gitcode.com/gh_…...

为什么选择Mesa框架?Python智能体建模的终极指南与实战秘籍
为什么选择Mesa框架?Python智能体建模的终极指南与实战秘籍 【免费下载链接】mesa Mesa is an open-source Python library for agent-based modeling, ideal for simulating complex systems and exploring emergent behaviors. 项目地址: https://gitcode.com/g…...

8大网盘文件直链一键获取:LinkSwift让你的下载速度突破限速瓶颈
8大网盘文件直链一键获取:LinkSwift让你的下载速度突破限速瓶颈 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...

eqMac终极指南:macOS系统级音频均衡器免费使用教程
eqMac终极指南:macOS系统级音频均衡器免费使用教程 【免费下载链接】eqMac macOS System-wide Audio Equalizer & Volume Mixer 🎧 项目地址: https://gitcode.com/gh_mirrors/eq/eqMac 你是否曾经觉得Mac电脑的音质不够理想?想要…...