Docker 安装 LogStash
关于LogStash
Logstash,作为Elastic Stack家族中的核心成员之一,是一个功能强大的开源数据收集引擎。它专长于从各种来源动态地获取、解析、转换和丰富数据,并将这些结构化或非结构化的数据高效地传输到诸如Elasticsearch等存储系统中进行集中分析和可视化展现。在本文中,我们将详细介绍如何借助Docker容器技术快速安装配置Logstash,以实现日志及各类事件数据的无缝集成与实时处理。

拉取镜像并拷贝配置
docker run -d --name logstash logstash:7.14.1# 拷贝数据
docker cp logstash:/usr/share/logstash/config ./config
docker cp logstash:/usr/share/logstash/data ./data
docker cp logstash:/usr/share/logstash/pipeline ./pipeline#文件夹赋权
chmod -R 777 ./config ./data ./pipeline
修改相应配置文件
修改config 下的 logstash.yml 文件,主要修改 es 的地址
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]
http.host:当设置为 “0.0.0.0” 时,意味着服务将在所有可用网络接口上监听HTTP请求,允许任何IP地址的客户端连接。xpack.monitoring.elasticsearch.hosts:指向Elasticsearch服务的URL->http://elasticsearch:9200,但这里没有使用具体的IP地址,而是用了一个名为elasticsearch的服务名或容器名。
elasticsearch:9200 就是通过内部DNS解析机制引用在同一网络命名空间下的Elasticsearch服务容器的9200端口,这意味着Logstash或相关组件收集的监控信息将被自动发送到关联的Elasticsearch容器进行存储和分析。
安全考虑
如果为了安全考虑给ElasticSearch设置了访问认证,则需要配置用户名与密码,需要新增2条认证配置:
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: "123456"
最终示例:
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: "123456"
修改config下的jvm.options
在Elasticsearch、Logstash或其他使用Java虚拟机(JVM)的应用程序中,jvm.options 文件是用来配置JVM运行时参数的重要文件。当你需要调整JVM相关的设置,比如堆内存大小、垃圾回收策略、线程数量等时,就需要修改这个文件。
# 增加JVM堆内存大小
-Xms512m
-Xmx512m
修改pipeline 下的 logstash.conf
input {tcp {mode => "server"host => "0.0.0.0"port => 5044codec => json_lines}
}output {elasticsearch {hosts => ["http://124.221.147.235:9200"]user => elasticpassword => 123456index => "logs-%{+YYYY.MM}"codec => "json"}stdout {codec => rubydebug}
}
input部分:
- 使用
TCP输入插件(tcp)创建一个服务器监听器,等待来自客户端的连接。mode => "server"指定为服务器模式,接受来自其他服务或应用的日志数据。host => "0.0.0.0"表示在所有网络接口上监听连接请求。port => 5044设置了监听端口为5044。codec => json_lines指定了编解码器类型,这意味着每个TCP消息应该包含一个或多条JSON格式的数据,每行一条JSON记录。
output部分:
- 使用
Elasticsearch输出插件(elasticsearch)将处理后的日志事件发送到Elasticsearch集群。hosts => "127.0.0.1:9200"设置了Elasticsearch集群的地址与端口,这里指本地主机上的默认Elasticsearch实例。index => "%{[spring.application.name]}-%{+YYYY.MM.dd}"定义了索引名称模板。该模板会根据事件中的字段动态生成索引名,其中:%{[spring.application.name]}是从日志事件中提取的Spring Boot应用的名字作为索引前缀。%{+YYYY.MM.dd}是基于当前日期时间动态生成的索引后缀,每天都会创建一个新的索引以存储当天的日志数据。
这样配置后,Logstash将作为一个TCP日志收集服务器运行,并且能够接收JSON格式的日志数据,然后将其按照指定的规则写入到Elasticsearch集群中相应的索引里,便于后续进行搜索、分析和可视化展示。
启动容器并挂载
#注意先删除之前的容器
docker rm -f logstash# 启动容器并挂载
docker run --name logstash \
-p 5044:5044 \
-p 9600:9600 \
--privileged=true \
-e ES_JAVA_OPTS="-Duser.timezone=Asia/Shanghai" \
-v /mydata/logstash/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /mydata/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-d logstash:7.14.2
查看运行情况
docker logs -f logstash
SpringBoot 整合 ELK
引入Maven依赖
<!-- logstash -->
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId>version>7.1.1</version>
</dependency>
修改项目内的 logback.xml 文件 增加 logstash 配置
<springProperty scope="context" name="appName" source="spring.application.name"/><!--输出到logstash的appender--><appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><!--可以访问的logstash日志收集端口--><destination>127.0.0.1:5044</destination><encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"><customFields>{"spring.application.name":"${appName}"}</customFields></encoder></appender><root level="info"><appender-ref ref="logstash"/></root>
启动项目查看是否成功推送日志
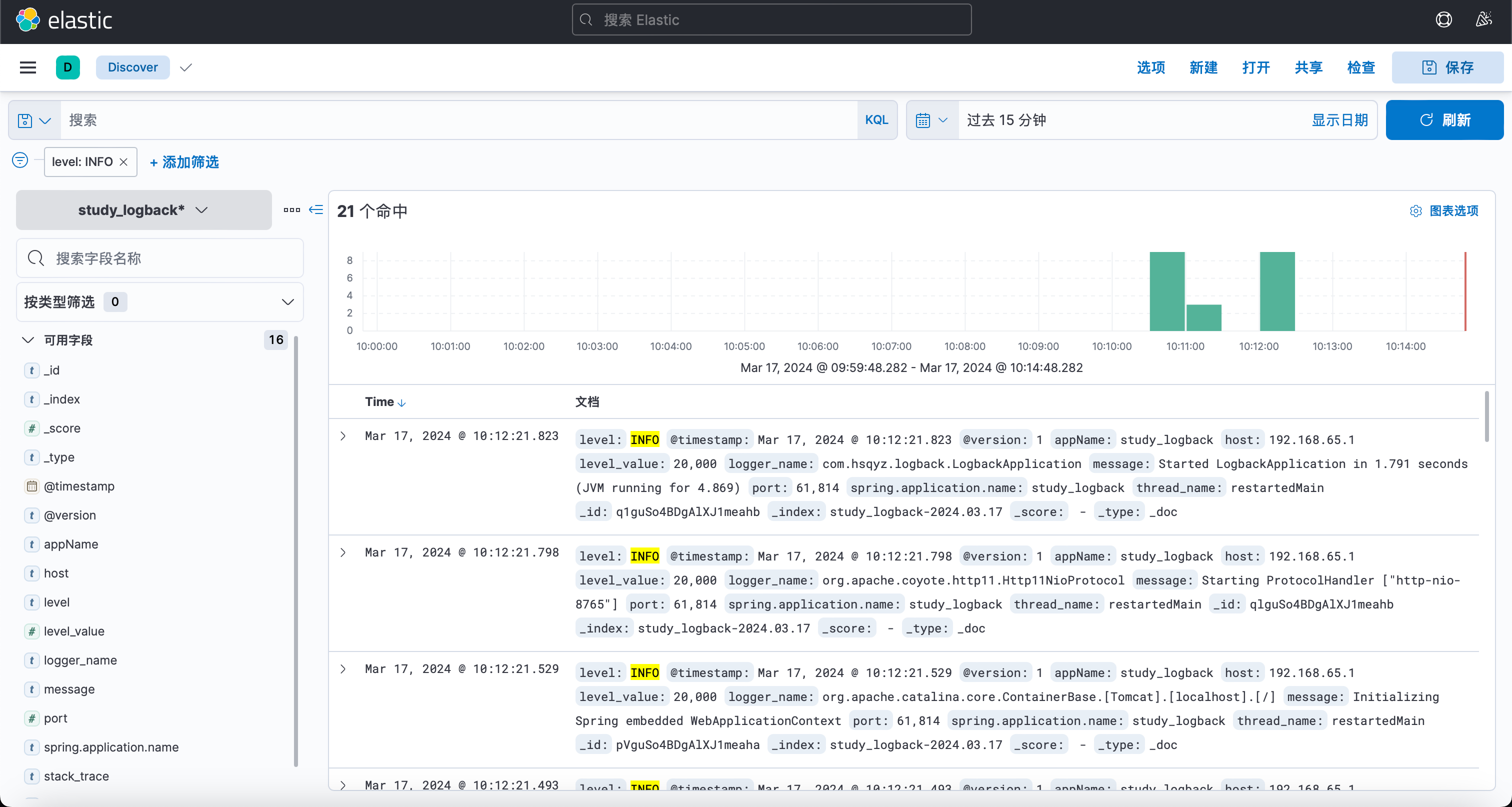
教程结束!
相关文章:
Docker 安装 LogStash
关于LogStash Logstash,作为Elastic Stack家族中的核心成员之一,是一个功能强大的开源数据收集引擎。它专长于从各种来源动态地获取、解析、转换和丰富数据,并将这些结构化或非结构化的数据高效地传输到诸如Elasticsearch等存储系统中进行集…...

Selenium笔记
Selenium笔记 Selenium笔记 Selenium笔记element not interactable页面刷新 element not interactable "element not interactable"是Selenium在执行与网页元素交互操作(如点击、输入等)时抛出的一个常见错误。这个错误意味着虽然找到了对应的…...
ChatGPT :确定性AI源自于确定性数据
ChatGPT 幻觉 大模型实际应用落地过程中,会遇到幻觉(Hallucination)问题。对于语言模型而言,当生成的文本语法正确流畅,但不遵循原文(Faithfulness),或不符合事实(Factua…...
linux驱动开发面试题
1.linux中内核空间及用户空间的区别? 记住“22”,两级分段两级权限。 例如是32位的机器,从内存空间看:顶层1G是内核的,底3G是应用的;从权限看:内核是0级特权,应用是3级特权。 2.用…...

【AI】Ubuntu系统深度学习框架的神经网络图绘制
一、Graphviz 在Ubuntu上安装Graphviz,可以使用命令行工具apt进行安装。 安装Graphviz的步骤相对简单。打开终端,输入以下命令更新软件包列表:sudo apt update。之后,使用命令sudo apt install graphviz来安装Graphviz软件包。为…...
:2024.03.05-2024.03.10—(2))
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.05-2024.03.10—(2)
论文目录~ 1.Debiasing Large Visual Language Models2.Harnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering3.Towards a Psychology of Machines: Large Language Models Predict Human Memory4.Can we obtain significant succ…...

AI解答——DNS、DHCP、SNMP、TFTP、IKE、RIP协议
使用豆包帮助我解答计算机网络通讯问题—— 1、DHCP 服务器是什么? DHCP 服务器可是网络世界中的“慷慨房东”哦🤣 它的全称是 Dynamic Host Configuration Protocol(动态主机配置协议)服务器。 DHCP 服务器的主要任务是为网络中的…...

【TypeScript系列】声明合并
声明合并 介绍 TypeScript中有些独特的概念可以在类型层面上描述JavaScript对象的模型。 这其中尤其独特的一个例子是“声明合并”的概念。 理解了这个概念,将有助于操作现有的JavaScript代码。 同时,也会有助于理解更多高级抽象的概念。 对本文件来讲,“声明合并”是指编…...
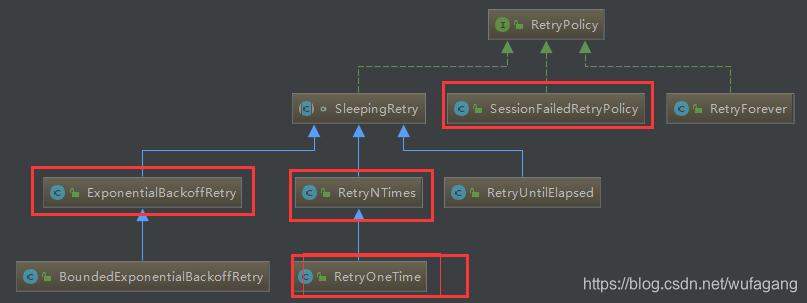
zookeeper基础学习之六: zookeeper java客户端curator
简介 Curator是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等。Patrixck Hunt(Zookeeper)以一句“Guava is to Java…...
表查询)
MySQL数据库操作学习(2)表查询
文章目录 一、表查询1.表字段的操作①查看表结构②字段的增加③字段长度/数据类型的修改④字段名的修改⑤删除字符段⑥清空表数据⑦修改表名⑧删除表 2、表数据查询3、where 字段4、聚合函数 一、表查询 1.表字段的操作 ①查看表结构 desc 表名; # 查看表中的字段类型&#…...
Java学习
目录 treeSet StringBuilder treeSet TreeSet 是 Java 中实现了 Set 接口的一种集合类,它使用红黑树数据结构来存储元素,放到TreeSet集合中的元素: 无序不可重复,但是可以按照元素的大小顺序自动排序。 TreeSet一般会和Iterator迭代器一起使…...

C#八皇后算法:回溯法 vs 列优先法 vs 行优先法 vs 对角线优先法
目录 1.八皇后算法(Eight Queens Puzzle) 2.常见的八皇后算法解决方案 (1)列优先法(Column-First Method): (2)行优先法(Row-First Method)&a…...

springboot整合swagger,postman,接口规范
一、postman介绍 1.1概述 工具下载 Postman(发送 http 请求的工具) 官网(下载速度比较慢):Download Postman | Get Started for Free 网盘下载:百度网盘 请输入提取码 1.2Http 请求格式 请求地址请求方法状…...

029—pandas 遍历行非向量化修改数据
前言 在 pandas 中,向量化计算是指利用 pandas 对象的内置方法和函数,将操作应用到整个数据结构的每个元素,从而在单个操作中完成大量的计算。 但在一些需求中,我们无法使用向量化计算,就需要迭代操作,本例…...

相机安装位置固定后开始调试设备供电公司推荐使用方法
摄像头安装位置固定后开始调试 设备供电:无电源设备需要连接12V/2A电源并连接到摄像机的DC端口,而有电源的摄像机可以直接连接到220V电源。 连接设备:如果是有线连接,请使用网线将设备连接到电脑(建议直接连接&#…...

AI视频批量混剪系统|罐头鱼AI视频矩阵获客
AI视频批量混剪系统助您轻松管理和编辑视频素材 如今,视频营销已成为企业推广的重要方式。为了满足用户对视频管理、发布和编辑的需求,《罐头鱼AI视频批量混剪系统》应运而生。这款智能化系统集成了多种功能,助您轻松管理和发布精彩视频内容…...

线程池学习-了解,自定义线程池
什么是线程池,这个池字是什么 线程池,主要利用池化思想,线程池,字符串常量池等 为什么要有一个线程池? 正常线程的创建:1,手动创建一个线程 2.给该线程分配任务,线程执行任务 3…...

CentOS7.9 安装SIPp3.6
epel里面的SIPp版本比较旧,先不要epel yum remove -y epel-release okay有很多CentOS软件,可以这样安装: 编辑 /etc/yum.repos.d/okay.repo,内容为: [okay] nameExtra OKay Packages for Enterprise Linux - $basearc…...
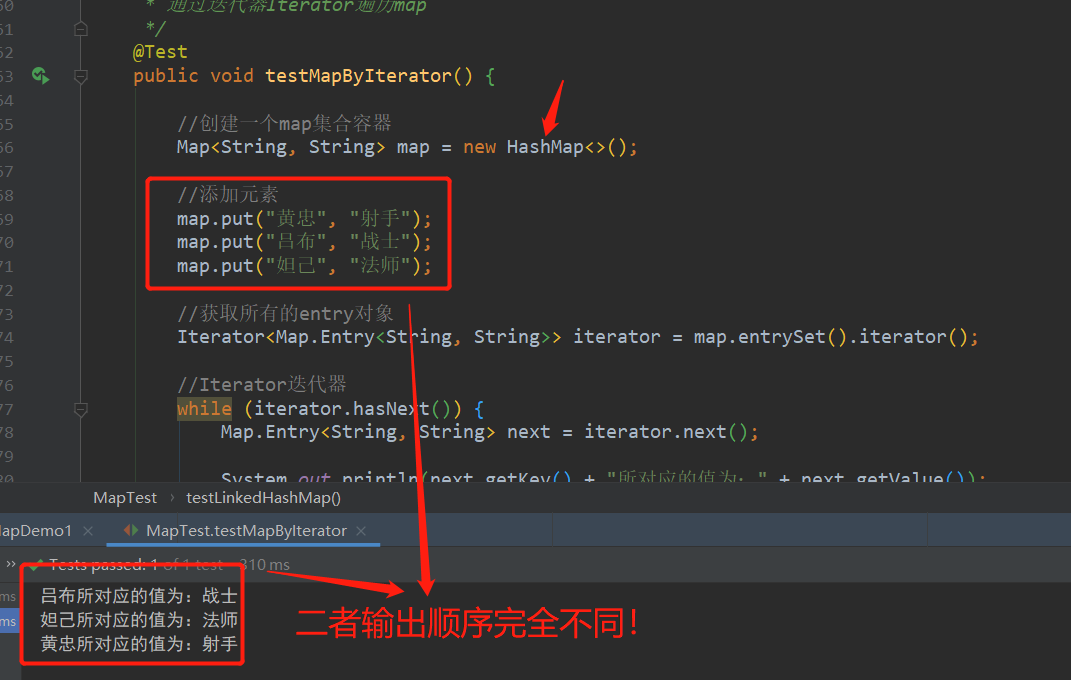
Java零基础入门-LinkedHashMap集合
一、本期教学目标 学习LinkedHashMap集合的概念及特点。学习LinkedHashMap存储结构。学习LinkedHashMap集合常用方法及示例代码演示。 二、正文 1、概述 我们学习了map接口之HashMap集合,今天我们要来学习map接口的另一个实现类-LinkedHashMap,不知道…...

LRC转SRT
最近看到一首很好的英文MTV原版,没又字幕,自己找字幕,只找到LRC,ffmpeg不支持LRC,网上在线转了SRT。 Subtitle Converter | Free tool | GoTranscript 然后用 ffmpeg 加字幕 ffmpeg -i LoveMeLikeYouDo.mp4 -vf sub…...

基于BLE模块的低功耗无线遥控器设计与实现
1. 项目概述:基于BLE模块的无线遥控器设计与实现几年前,我在捣鼓智能家居时,一直想找一个低功耗、响应快、又能自己完全掌控的无线遥控方案。市面上的成品要么协议封闭,要么功耗感人,要么延迟高得让人着急。后来&#…...
)
Midjourney辉光效果失效诊断手册(含12个隐性触发条件与4类GPU显存陷阱)
更多请点击: https://codechina.net 第一章:Midjourney辉光效果失效诊断手册(含12个隐性触发条件与4类GPU显存陷阱) 辉光效果(Glow Effect)在 Midjourney v6 的 --style raw 模式下常被用于强化主体边缘光…...

让B站缓存视频重获自由:一个简单实用的格式转换工具
让B站缓存视频重获自由:一个简单实用的格式转换工具 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还记得那个周末的下午吗…...

抖音批量下载工具:高效获取用户主页全作品的专业解决方案
抖音批量下载工具:高效获取用户主页全作品的专业解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

Arm Cortex-M的FP和MVE
Floating-point Support目前Arm architecture支持的floating-point extension版本是FPv5。FPv5提供了以下功能:单精度算术运算;可选的双精度算术运算;整数、双精度、单精度、和半精度格式之间的转换;用于浮点处理的寄存器…...
)
别再手动触发ADC了!用STM32CubeMX配置定时器触发+DMA搬运,实现精准采样(附F1/F4差异说明)
STM32CubeMX定时器触发ADCDMA全自动采样实战指南 在嵌入式数据采集系统中,ADC采样的精准度和效率直接影响整个系统的性能表现。传统的手动触发方式不仅占用CPU资源,还难以保证采样间隔的一致性。本文将深入解析如何利用STM32CubeMX配置定时器触发ADC配合…...

尤斯伯恩书籍购买指南:多语言版本可选,不同地区购买方式大揭秘!
按年龄浏览书籍 如果禁用了 cookies,商店将无法正常工作。您的浏览器似乎禁用了 JavaScript。为了在我们的网站上获得最佳体验,请确保在浏览器中启用 JavaScript。跳转到内容,英语 - 英镑 £,选择语言:英语、法语、…...

Qwen-Agent:企业级AI智能体框架的架构深度解析与实战指南
Qwen-Agent:企业级AI智能体框架的架构深度解析与实战指南 【免费下载链接】Qwen-Agent Agent framework and applications built upon Qwen>3.0, featuring Function Calling, MCP, Code Interpreter, RAG, Chrome extension, etc. 项目地址: https://gitcode.…...

Claude Code 接入 DeepSeek
安装 Claude Code DeepSeek 文档: 使用如下命令安装 Claude Code: npm install -g anthropic-ai/claude-code安装完成后,可以输入下面的命令检查是否安装成功。 claude --version购买 DeepSeek API 创建 Api Key 点击如下链接创建 DeepSeek API Ke…...

告别卡顿:用微PE给旧电脑无损重装Win11,顺便教你用分区工具合理分配C盘空间
旧电脑焕新指南:用微PE无损重装Win11与智能分区实战 当你的旧电脑开始频繁卡顿、开机时间超过两分钟,甚至打开浏览器都要等待十几秒时,先别急着换新机。很多情况下,这只是系统长期使用积累的"垃圾"和不当分区导致的性能…...