PyTorch深度学习实战(39)——小样本学习
PyTorch深度学习实战(39)——小样本学习
- 0. 前言
- 1. 小样本学习简介
- 2. 孪生网络
- 2.1 模型分析
- 2.2 数据集分析
- 2.3 构建孪生网络
- 3. 原型网络
- 3. 关系网络
- 小结
- 系列链接
0. 前言
小样本学习 (Few-shot Learning) 旨在解决在训练集中只有很少样本的情况下进行分类和推理的问题。传统的机器学习方法通常要求大量的标记样本来训练模型,但在现实世界中,很多场景下我们只能获得非常有限的样本。在小样本学习中,我们希望通过利用已有的少量样本和先验知识来进行泛化,以便在面对新的、未见过的类别时能够做出准确的预测。这就要求模型能够从有限的训练样本中提取出有用的信息,并能够将这些信息应用到新类别的样本中去。在本节中,将介绍孪生、原型和关系网络的原理,并使用 PyTorch 实现孪生网络。
1. 小样本学习简介
小样本学习 (Few-shot Learning) 是一种用于在面对较少的数据时进行分类或识别任务的机器学习方法。传统机器学习算法需要大量数据来训练模型,并且可能会过拟合数据或无法泛化到新数据。而小样本学习则通过从较少的样本中学习如何分类或识别对象来解决这个问题。其基本思想是从已有的类别中提取出一些经验,进而利用这些经验去识别出一个新的类别。
假如我们只有 10 张关于猫的图像,并要求确定一张新图像是否属于猫类别,在人眼看来可以轻松地对此类任务进行分类,但深度学习算法通常需要成百上千的标记样本才能准确分类。
有多种元学习 (Meta-Learning) 算法能够解决小样本学习问题。在本节中,我们将了解用于解决小样本学习问题的孪生网络 (Siamese network)、原型网络 (prototypical network) 和关系网络 (relation network)。这三种算法都旨在学习比较两张图像,并根据它们的相似度得到一个分数。小样本分类过程中如下所示:

在以上数据集中,在训练时向网络模型展示了每个类别的几张图像,并要求模型根据这些训练图像预测新图像的类别。如果使用预训练模型来解决此类问题,鉴于可用数据量很少,此类模型可能很快就会过拟合。
我们可以通过多种指标、模型等方法解决这一问题,在本节中,将学习基于指标的架构,这类架构会提出了一个最优指标,例如欧几里得距离或余弦相似度,将相似的图像归为一组,并在新图像上进行预测。N-shot k-class 分类是指有 N 张图像用于训练网络,每个类别有 k 个样本。
2. 孪生网络
孪生网络 (Siamese network) 是一种常用于计算机视觉的神经网络,主要用于解决两个输入之间的相似度问题。该网络通常由两个共享权重的子网络组成,每个子网络都接收到一个不同的输入,然后提取其特征并将这些特征合并起来。
2.1 模型分析
接下来,我们介绍孪生网络的原理,并使用孪生网络识别只有少数几张训练图像的同一个人物的图像。孪生模型算法流程如下:
- 通过卷积网络传递图像
- 通过相同的神经网络传递另一张图像
- 计算两个图像的编码向量
- 计算两个编码向量之间的差异
- 通过
sigmoid激活传递差异向量得到相似性得分,表示两幅图像是否相似
孪生 (Siamese) 一词表示通过孪生网络 (Siamese network) (复制网络处理两张图像)传递两张图像,以获取每个图像的编码向量。此外,比较两个图像的编码向量以获取两个图像的相似度分数,如果相似度得分(或差异度得分)超过指定阈值,则认为这些图像属于同一个类别(同一人物)。
在本节中,我们将学习使用 PyTorch 实现孪生网络,以预测一个人物图像是否与训练数据库中的参考图像相匹配,模型构建策略如下:

- 获取数据集
- 创建数据,属于同一个人物的两张图像的差异度较小,而不同人物的图像之间的差异度较高
- 构建卷积神经网络 (
Convolutional Neural Networks,CNN) CNN模型的总损失值为对应于分类损失的损失值(如果图像属于同一个人物)和两幅图像之间的距离相加,在本节中,使用对比损失- 训练模型
2.2 数据集分析
为了构建孪生网络,使用人脸图像数据集。训练数据中包含 38 个文件夹(每个文件夹对应不同的人物),每个文件夹包含 10 张属于同一人物的图像样本。测试数据包括 3 张不同人物的 3 个文件夹,每个文件夹有 10 张图像。数据集下载地址:https://pan.baidu.com/s/111fWoBP-k9AAdWKw6kHeNA,提取码:udcr。
2.3 构建孪生网络
接下来,根据以上策略使用 PyTorch 实现孪生网络,预测图像对应类别,其中图像类别仅在训练数据中出现过少数几次。
(1) 导入相关库和数据集:
import torch
from torch import nn, optim
import cv2
from torch.utils.data import DataLoader, Dataset
from glob import glob
import random
import numpy as np
from matplotlib import pyplot as plt
import torch.nn.functional as F
device = 'cuda' if torch.cuda.is_available() else 'cpu'def parent(filename):return filename.split('/')[-2]def fname(filename):return filename.split('/')[-1]
(2) 定义数据集类 SiameseNetworkDataset。
__init__ 方法接受图像的件夹和要执行的图像转换 (transform) 作为输入:
class SiameseNetworkDataset(Dataset):def __init__(self, folder, transform=None, should_invert=True):self.folder = folderself.items = glob(f'{self.folder}/*/*')self.transform = transform
定义 __getitem__ 方法:
def __getitem__(self, ix):itemA = self.items[ix]person = fname(parent(itemA))same_person = random.randint(0, len(person))if same_person:itemB = random.choice(glob(f'{self.folder}/{person}/*'))else:while True:itemB = random.choice(self.items)if person != fname(parent(itemB)):breakimgA = cv2.imread(itemA, 0)imgB = cv2.imread(itemB, 0)if self.transform:imgA = self.transform(imgA)# .permute(2,0,1)imgB = self.transform(imgB)return imgA, imgB, np.array([1-same_person])
在以上代码中,获取并返回两张图像—— imgA 和 imgB,如果两张图像属于同一人物,则返回的第三个输出为 0,否则,返回 1。
定义 __len__ 方法:
def __len__(self):return len(self.items)
(3) 定义要执行的图像转换,并为训练、验证数据准备数据集和数据加载器:
from torchvision import transformstrn_tfms = transforms.Compose([transforms.ToPILImage(),transforms.RandomHorizontalFlip(),transforms.RandomAffine(5, (0.01,0.2),scale=(0.9,1.1)),transforms.Resize((100,100)),transforms.ToTensor(),transforms.Normalize((0.5), (0.5))
])val_tfms = transforms.Compose([transforms.ToPILImage(),transforms.Resize((100,100)),transforms.ToTensor(),transforms.Normalize((0.5), (0.5))
])trn_ds = SiameseNetworkDataset(folder="face-detection/data/faces/training/", transform=trn_tfms)
val_ds = SiameseNetworkDataset(folder="face-detection/data/faces/testing/", transform=val_tfms)trn_dl = DataLoader(trn_ds, shuffle=True, batch_size=64)
val_dl = DataLoader(val_ds, shuffle=False, batch_size=64)
(4) 定义神经网络架构。
定义卷积块 (convBlock):
def convBlock(ni, no):return nn.Sequential(nn.Dropout(0.2),nn.Conv2d(ni, no, kernel_size=3, padding=1, padding_mode='reflect'),nn.ReLU(inplace=True),nn.BatchNorm2d(no),)
定义孪生网络架构,接受输入并返回五维编码:
- 网络是由两个相同的卷积神经网络组成,这两个子网络共享权重
- 对于每个输入图像,都经过相同的卷积神经网络进行特征提取,并获得一个编码向量
- 两个编码向量通过距离计算层进行比较,获取它们之间的相似度得分
- 最后,将两个编码之间的差异度得分送入全连接层,输出一个五维编码向量
class SiameseNetwork(nn.Module):def __init__(self):super(SiameseNetwork, self).__init__()self.features = nn.Sequential(convBlock(1,4),convBlock(4,8),convBlock(8,8),nn.Flatten(),nn.Linear(8*100*100, 500), nn.ReLU(inplace=True),nn.Linear(500, 500), nn.ReLU(inplace=True),nn.Linear(500, 5))def forward(self, input1, input2):output1 = self.features(input1)output2 = self.features(input2)return output1, output2
(5) 定义 ContrastiveLoss 类:
class ContrastiveLoss(torch.nn.Module):def __init__(self, margin=2.0):super(ContrastiveLoss, self).__init__()self.margin = margin
代码中的 margin 类似于 SVM 中的边距,我们希望属于两个不同类别的数据点之间的 margin 值尽可能高。
定义前向传播方法 forward:
def forward(self, output1, output2, label):euclidean_distance = F.pairwise_distance(output1, output2, keepdim = True)loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))acc = ((euclidean_distance > 0.6) == label).float().mean()return loss_contrastive, acc
在以上代码中,获取两个不同图像的编码向量,output1 和 output2 并计算它们的欧氏距离 eucledian_distance。然后,计算对比损失 loss_contrastive,该损失函数将惩罚同一标签下图像之间欧氏距离过大的情况,并且对于不同标签下图像之间欧氏距离过小的情况也进行了惩罚,同时还需要加上了自定义的 self.margin 值。也就是说,对于同一标签下的两个图像,如果它们之间的欧氏距离超过一定阈值,则会受到惩罚;对于不同标签下的两个图像,如果它们之间的欧氏距离小于一定阈值,则同样会受到惩罚。
(6) 定义在批数据上进行训练和验证模型的函数:
def train_batch(model, data, optimizer, criterion):imgsA, imgsB, labels = [t.to(device) for t in data]optimizer.zero_grad()codesA, codesB = model(imgsA, imgsB)loss, acc = criterion(codesA, codesB, labels)loss.backward()optimizer.step()return loss.item(), acc.item()@torch.no_grad()
def validate_batch(model, data, criterion):imgsA, imgsB, labels = [t.to(device) for t in data]codesA, codesB = model(imgsA, imgsB)loss, acc = criterion(codesA, codesB, labels)return loss.item(), acc.item()
(7) 定义模型、损失函数和优化器:
model = SiameseNetwork().to(device)
criterion = ContrastiveLoss()
optimizer = optim.Adam(model.parameters(),lr = 0.001)
(8) 训练模型:
n_epochs = 200
trn_loss_epochs = []
val_loss_epochs = []
trn_acc_epochs = []
val_acc_epochs = []
for epoch in range(n_epochs):N = len(trn_dl)trn_loss = []val_loss = []trn_acc = []val_acc = []for i, data in enumerate(trn_dl):loss, acc = train_batch(model, data, optimizer, criterion)pos = (epoch + (i+1)/N)trn_loss.append(loss)trn_acc.append(acc)trn_loss_epochs.append(np.average(trn_loss))trn_acc_epochs.append(np.average(trn_acc))N = len(val_dl)for i, data in enumerate(val_dl):loss, acc = validate_batch(model, data, criterion)pos = (epoch + (i+1)/N)val_loss.append(loss)val_acc.append(acc)val_loss_epochs.append(np.average(val_loss))val_acc_epochs.append(np.average(val_acc))if epoch==10:optimizer = optim.Adam(model.parameters(), lr=0.0005)
绘制训练、验证期间的损失和准确率随时间的变化情况:
epochs = np.arange(n_epochs)+1
plt.subplot(121)
plt.plot(epochs, trn_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r-', label='validation loss')
plt.title('Variation in training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.grid('off')
plt.legend()
plt.subplot(122)
plt.plot(epochs, trn_acc_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_acc_epochs, 'r-', label='validation loss')
plt.title('Variation in training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.grid('off')
plt.legend()
plt.show()

(9) 在新图像上测试模型,模型未见过这些新图像。在测试时,随机获取一张测试图像,并将其与测试数据中的其他图像进行比较:
from torchvision.utils import make_grid
model.eval()
val_dl = DataLoader(val_ds,num_workers=6,batch_size=1,shuffle=True)
dataiter = iter(val_dl)
x0, _, _ = next(dataiter)for i in range(2):_, x1, label2 = next(dataiter)concatenated = torch.cat((x0*0.5+0.5, x1*0.5+0.5),0)# torch.unsqueeze(torch.cat((x0*0.5+0.5, x1*0.5+0.5),0), dim=0)output1,output2 = model(x0.cuda(),x1.cuda())euclidean_distance = F.pairwise_distance(output1, output2)output = 'Same Face' if euclidean_distance.item() < 0.6 else 'Different'plt.subplot(121)plt.imshow((x0*0.5+0.5).squeeze(0).permute(1,2,0).numpy(), cmap='gray')plt.subplot(122)plt.imshow((x1*0.5+0.5).squeeze(0).permute(1,2,0).numpy(), cmap='gray')plt.suptitle('Dissimilarity: {:.2f}\n{}'.format(euclidean_distance.item(), output))plt.show()


从上图中可以看出,即使每一类别只有少数几张图像,也可以识别图像中的人物。为了提高模型性能,训练模型或测试模型前可以从完整图像中裁剪人物面部图像。
了解了孪生网络的原理后,继续学习其他基于指标的网络模型,包括原型和关系网络。
3. 原型网络
原型网络 (Prototypical Networks) 是一种元学习算法,旨在解决在小样本场景下进行分类的问题。该算法的核心思想是将图像表示为嵌入空间中的点,并计算每个类别的“原型”作为该类别所有图像的平均嵌入。在测试时,将测试图像的嵌入与每个类别的原型进行比较,并选择最接近的原型所对应的类别作为预测结果。原型网络已经在许多小样本分类任务上取得了很好的效果。
可以将原型理解为类别中的代表。假如,有 5 种类别,且每个类别包含 10 张图像。原型网络通过计算属于同一类别的每张图像嵌入的平均值,为每个类别提供一个代表性的嵌入(原型)。
考虑以下实际场景:假设数据集中有 5 个不同类别的图像,其中每个类别包含 10 张图像。此外,在训练中为每个类别提供 5 张图像,并在其他 5 张图像上测试网络的准确率。使用每个类别的一张图像和随机选择的测试图像作为查询来构建网络,我们的任务是识别与查询图像(测试图像)具有最高相似性的已知图像(训练图像)。
对于人脸识别任务而言,原型网络的工作原理如下:
- 随机选择
N个不同的人物进行训练 - 选择与每个人物对应的
k个样本作为用于训练的数据点,即支持集 - 选择每个人物对应的
q个样本作为要测试的数据点,即查询集

- 选择 Nc 个类别,支持集中有 N s 张图像,查询集中有 N q 张图像:
- 通过卷积神经网络 (
Convolutional Neural Networks,CNN)网络时,获取支持集(训练图像)和查询集(测试图像)中每个数据点的嵌入向量,CNN可以确定训练图像中与测试图像最相似的图像索引,将训练图像集合视为支持集 (support set),测试图像集合视为查询集 (query set)。通过获取每个数据点的嵌入向量,可以计算它们之间的相似度得分 - 训练网络后,计算与支持集(训练图像)嵌入向量对应的原型:
- 原型是属于同一类别的所有图像的平均嵌入向量:

在以上示例图像中,有三个类别,每个圆圈代表属于该类别的图像嵌入向量。每个星形(原型)是同一类别的所有图像(圆圈)的平均嵌入向量:
- 计算查询嵌入向量和原型嵌入向量之间的欧几里得距离:
- 如果有
5个查询图像和10个类别,将得到50个欧几里得距离 - 在以上所获得的欧几里德距离之上执行
softmax,以识别对应于不同支持集类别的概率 - 训练模型,以最小化将查询图像分配给正确类别的损失值。此外,在遍历数据集时,每次迭代时随机选择一组新的人物(即数据集中的子集)
- 如果有
在迭代结束时,模型将根据支持集图像和查询图像,学习识别查询图像所属的类别。
3. 关系网络
关系网络 (relation network) 算法的核心思想是通过学习如何计算不同图像之间的相似度来实现快速分类。该算法从一对图像中提取特征,并将这些特征输入到一个神经网络中,该网络可以计算两个图像之间的关系得分。在测试时,将测试图像与训练集中所有图像计算关系得分,并使用这些得分进行分类。
关系网络与孪生网络非常相似,但关系网络所优化的指标不是嵌入向量之间的 L1 距离,而是关系分数,关系网络的工作原理如下图所示:

在上图中,左边的图像是五个类别的支持集,底部的小狗图片是查询图像:
- 通过嵌入模块 (
embedding module) 传递支持和查询图像,该模块用于获取输入图像的嵌入向量 - 将支持图像的特征图与查询图像的特征图连接起来
- 通过
CNN模块传递连接的特征以预测关系分数 - 具有最高关系分数的类别是查询图像的预测类别
根据关系网络原理,将查询图像与支持集中的图像进行比较,以确定具有最高相似度的对象类别,从而为查询图像确定所属的类别。
小结
少样本学习在许多领域都具有重要的应用价值。例如,在计算机视觉领域,少样本学习可以用于人脸识别、目标检测和图像分类等任务;在自然语言处理领域,少样本学习可以用于文本分类、命名实体识别和机器翻译等任务。本节中,我们了解了孪生网络,通过学习了两个图像之间的距离函数来识别相似人物的图像;最后,我们了解了原型网络和关系网络,以及如何将它们用于执行小样本图像分类。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——从零开始实现SSD目标检测
PyTorch深度学习实战(24)——使用U-Net架构进行图像分割
PyTorch深度学习实战(25)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(26)——多对象实例分割
PyTorch深度学习实战(27)——自编码器(Autoencoder)
PyTorch深度学习实战(28)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(29)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(30)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(31)——神经风格迁移
PyTorch深度学习实战(32)——Deepfakes
PyTorch深度学习实战(33)——生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(34)——DCGAN详解与实现
PyTorch深度学习实战(35)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(36)——Pix2Pix详解与实现
PyTorch深度学习实战(37)——CycleGAN详解与实现
PyTorch深度学习实战(38)——StyleGAN详解与实现
相关文章:
PyTorch深度学习实战(39)——小样本学习
PyTorch深度学习实战(39)——小样本学习 0. 前言1. 小样本学习简介2. 孪生网络2.1 模型分析2.2 数据集分析2.3 构建孪生网络 3. 原型网络3. 关系网络小结系列链接 0. 前言 小样本学习 (Few-shot Learning) 旨在解决在训练集中只有很少样本的情况下进行分…...

论文阅读——Vision Transformer with Deformable Attention
Vision Transformer with Deformable Attention 多头自注意力公式化为: 第l层transformer模块公式化为: 在Transformer模型中简单地实现DCN是一个non-trivial的问题。在DCN中,特征图上的每个元素都单独学习其偏移,其中HWC特征图上…...

AJAX概念和axios使用、URL、请求方法和数据提交、HTTP协议、接口、form-serialize插件
AJAX概念和axios使用 AJAX概念 AJAX就是使用XMLHttpRequest对象与服务器通信,它可以使用JSON、XML、HTML和text文本等格式发送和接收数据,AJAX最吸引人的就是它的异步特性,也就是说它可以在不重新刷新页面的情况下与服务器通信,…...

【R语言基础操作】
🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972 个人介绍: 研一|统计学|干货分享 擅长Python、Matlab、R等主流编程软件 累计十余项国家级比赛奖项,参与研究经费10w、40w级横向 文…...
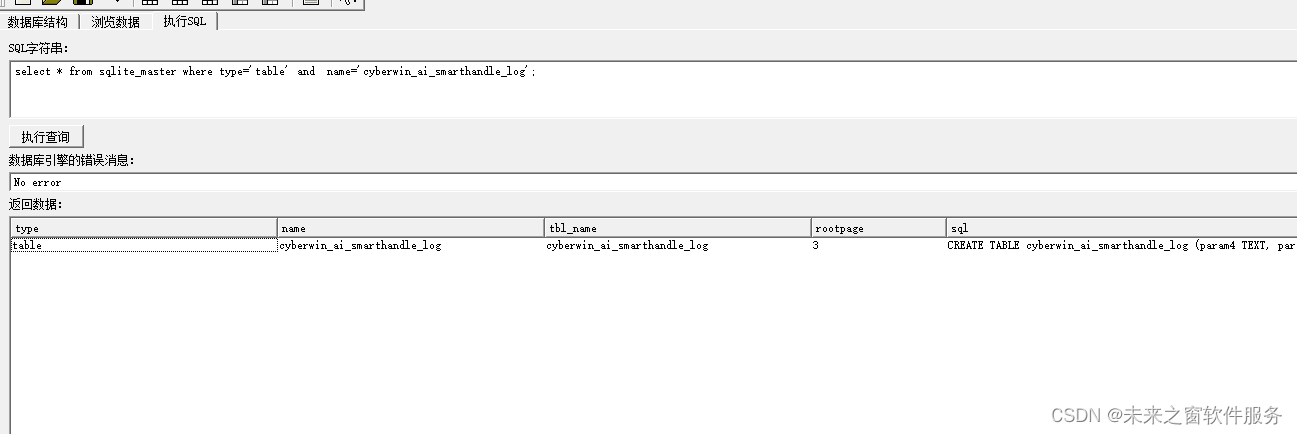
sqlite 常见命令 表结构
在 SQLite 中,将表结构保存为 SQL 具有一定的便捷性和重要性,原因如下 便捷性: 备份和恢复:将表结构保存为 SQL 可以方便地进行备份。如果需要还原或迁移数据库,只需执行保存的 SQL 脚本,就可以重新创建表…...

基于深度学习的车辆检测技术
基于深度学习的车辆检测技术是现代智能交通系统的重要组成部分,它利用计算机视觉和机器学习算法,特别是深度学习模型,来识别和定位图像或视频中的车辆。这项技术广泛应用于自动驾驶、交通监控、违章抓拍等多个领域。 深度学习车辆检测技术的…...

MyBatis 之三:配置文件详解和 Mapper 接口方式
配置文件 MyBatis 的配置文件是 XML 格式的,它定义了 MyBatis 运行时的核心行为和设置。默认的配置文件名称为 mybatis-config.xml,该文件用于配置数据库连接、事务管理器、数据源、类型别名、映射器(mapper 文件)以及其他全局属性…...

【PyTorch】基础学习:一文详细介绍 torch.load() 的用法和应用
【PyTorch】基础学习:一文详细介绍 torch.load() 的用法和应用 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程ὄ…...

事务、并发、锁机制的实现
配置全局事务 DATABASES {default: {ENGINE: django.db.backends.mysql,NAME: mydb,USER:root,PASSWORD:pass,HOST:127.0.0.1,PORT:3306,ATOMIC_REQUESTS: True, # 全局开启事务,绑定的是http请求响应整个过程# (non_atomic_requests可局部实现不让事务控制)} } …...

PC-DARTS: PARTIAL CHANNEL CONNECTIONS FOR MEMORY-EFFICIENT ARCHITECTURE SEARCH
PC-DARTS:用于内存高效架构搜索的部分通道连接 论文链接:https://arxiv.org/abs/1907.05737 项目链接:https://github.com/yuhuixu1993/PC-DARTS ABSTRACT 可微分体系结构搜索(DARTS)在寻找有效的网络体系结构方面提供了一种快速的解决方案…...
git的下载与安装
下载 首先,打开您的浏览器,并输入Git的官方网站地址 点击图标进行下载 下载页面会列出不同操作系统和平台的Git安装包。根据您的操作系统(Windows、macOS、Linux等)和位数(32位或64位),选择适…...

windows文档格式转换的实用工具
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

四级缓存实现
CommandLineRunner接口的run方法 什么是多级缓存? 多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Server端的压力,提升服务性能。 一级缓存:1.CDN:内容分发网络 二级缓存:2.NGINX+Lua脚本+OpenResty服务器 负载均衡反向代理【静态和转发】 三级缓存:J…...

程序员如何规划职业赛道?
在快速发展的信息技术时代,程序员作为数字世界的构建者,面临着前所未有的职业选择和发展机会。选择合适的职业赛道,不仅关乎个人职业发展的高度和速度,更影响着个人职业生涯的满意度和幸福感。本文将从自我评估与兴趣探索、市场需…...

蓝桥杯day3刷题日记--P9240 冶炼金属
P9240 [蓝桥杯 2023 省 B] 冶炼金属 经典二分,先在第一组中找到最小值,在利用最小值限制范围寻找最大值 #include <iostream> #include <algorithm> using namespace std; int n,kk; int m[10001],num[10001]; int maxs,mins;bool check1…...

Mybatis-xml映射文件与动态SQL
xml映射文件 动态SQL <where><if test"name!null">name like concat(%,#{name},%)</if><if test"username!null">and username#{username}</if></where> <!-- collection:遍历的集合--> <!-- …...
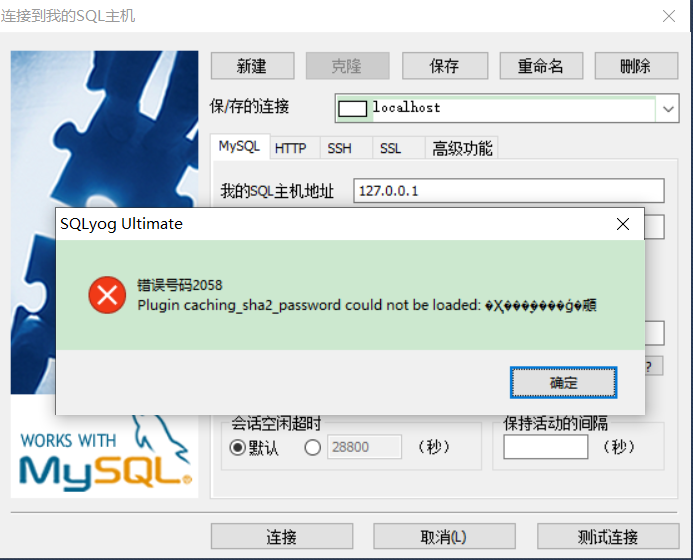
MySQL_数据库图形化界面软件_00000_00001
目录 NavicatSQLyogDBeaverMySQL Workbench可能出现的问题 Navicat 官网地址: 英文:https://www.navicat.com 中文:https://www.navicat.com.cn SQLyog 官网地址: 英文:https://webyog.com DBeaver 官网地址&…...
——FEC逻辑分析(6))
流媒体学习之路(WebRTC)——FEC逻辑分析(6)
流媒体学习之路(WebRTC)——FEC逻辑分析(6) —— 我正在的github给大家开发一个用于做实验的项目 —— github.com/qw225967/Bifrost目标:可以让大家熟悉各类Qos能力、带宽估计能力,提供每个环节关键参数调节接口并实现一个json全…...

command failed: npm install --loglevel error --legacy-peer-deps
在使用vue create xxx创建vue3项目的时候报错。 解决方法,之前使用的https://registry.npm.taobao.org 证书过期更换镜像地址即可 操作如下: 1.cd ~2.执行rm .npmrc3. sudo npm install -g cnpm --registryhttp://registry.npmmirror.com…...
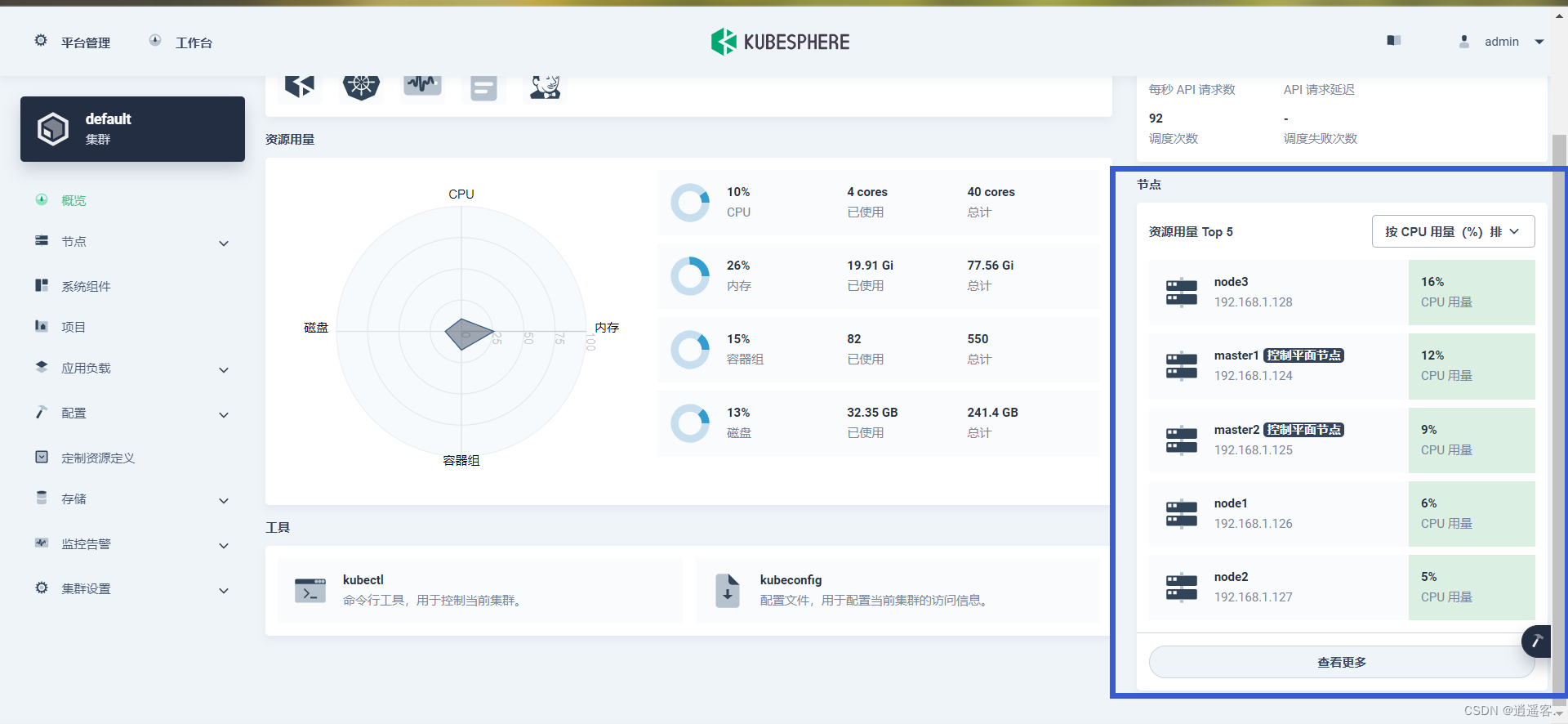
KubeSphere集群安装-nfs分布式文件共享-对接Harbor-对接阿里云镜像仓库-遇到踩坑记录
KubeSphere安装和使用集群版 官网:https://www.kubesphere.io/zh/ 使用 KubeKey 内置 HAproxy 创建高可用集群:https://www.kubesphere.io/zh/docs/v3.3/installing-on-linux/high-availability-configurations/internal-ha-configuration/ 特别注意 安装前注意必须把当前使…...

Unity Timeline激活与动画控制实战:5分钟精准调度
1. 这不是“Timeline入门”,而是你真正能用上的控制逻辑很多人第一次点开Unity Timeline面板时,第一反应是:“这不就是个时间轴剪辑工具吗?跟AE差不多?”——然后转身就去写Update里硬编码的if-else开关,或…...
)
CentOS服务器上VNC连接总出问题?这份保姆级排错手册(含端口混乱、服务重启、密码修改)
CentOS服务器VNC连接全流程排错指南:从端口混乱到服务恢复当你正埋头调试一个关键的仿真任务,突然VNC连接断开,所有工作界面瞬间消失——这种场景对使用CentOS服务器的工程师和科研人员来说绝不陌生。VNC作为远程桌面的生命线,一旦…...
torchvision transforms 报错怎么办?教你一招避坑
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 torchvision.transforms报错大揭秘:一招解决90%的坑目录torchvision.transforms报错大揭秘:一招解决90%的…...
基MSM型日盲紫外光电探测器仿真研究)
基于Silvaco的β-氧化镓(β-Ga₂O₃)基MSM型日盲紫外光电探测器仿真研究
基于Silvaco的β-氧化镓(β-Ga₂O₃)基MSM型日盲紫外光电探测器仿真研究 摘要 日盲紫外光电探测技术在导弹预警、火灾监测、紫外通信等军用和民用领域具有重要的应用价值。β-氧化镓(β-Ga₂O₃)作为一种超宽禁带半导体材料,因其禁带宽度约为4.8-4.9 eV(对应吸收截止边约25…...

QrazyBox终极指南:专业二维码修复工具拯救你的损坏二维码
QrazyBox终极指南:专业二维码修复工具拯救你的损坏二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾因打印模糊、水渍污染或屏幕划痕导致的重要二维码无法扫描而焦急…...

市场有效的透明化矿场安全防护系统
在矿场作业中,安全问题一直是重中之重。近年来,矿场事故时有发生,给生命和财产带来了巨大损失。据统计,过去十年间,全球矿场事故造成的直接经济损失高达数千亿美元,伤亡人数更是数以万计。因此,…...

ALMA评审系统:基于分层规则与LDA的专家精准匹配工程实践
1. 项目概述:当评审专家遇上“千人千面”的提案在科研项目管理,尤其是大型天文观测设施如ALMA(阿塔卡马大型毫米/亚毫米波阵列)的提案评审中,一个核心的工程难题是如何把一份探讨“原行星盘尘埃动力学”的提案…...

初次在Taotoken模型广场切换不同模型进行文本生成的体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次在Taotoken模型广场切换不同模型进行文本生成的体验 作为一名开发者,初次接触大模型聚合平台时,最关心…...

通过Taotoken用量看板与账单追溯功能实现团队成本精细化管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板与账单追溯功能实现团队成本精细化管理 对于技术团队的管理者而言,在引入大模型能力支持业务创新…...

[Android] VideoCook Glitch视频效果 v3.014.9 高级版
【Android】VideoCook Glitch视频效果 v3.014.9 高级版 链接:https://pan.xunlei.com/s/VOtMpY5BigBVra7bQlA73BLxA1?pwdb65a# VideoCook Glitch视频效果 是一款非常强大的安卓视频编辑工具,它为用户提供了丰富多样的视觉特效、滤镜以及音频编辑功能&am…...