PyTorch学习笔记之基础函数篇(十五)
文章目录
- 数值比较运算
- 8.1 torch.equal()函数
- 8.2 torch.ge()函数
- 8.3 torch.gt()函数
- 8.4 torch.le()函数
- 8.5 torch.lt()函数
- 8.6 torch.ne()函数
- 8.7 torch.sort()函数
- 8.8 torch.topk()函数
数值比较运算
8.1 torch.equal()函数
torch.equal(tensor1, tensor2) -> bool
这个函数接受两个张量(tensor1 和 tensor2)作为参数,并返回一个布尔值(bool),表示这两个张量是否相等。
- tensor1 (Tensor): 第一个要比较的张量。
- tensor2 (Tensor): 第二个要比较的张量。
torch.equal 是 PyTorch 中的一个函数,用于比较两个张量(tensors)是否具有相同的形状和元素值。如果两个张量满足以下条件,则 torch.equal 返回 True:
- 两个张量具有相同的形状(shape)。
- 两个张量中的每个元素都相等。
这个函数在比较两个张量是否完全相同时非常有用。
示例:
import torch# 创建两个形状和值都相同的张量
tensor1 = torch.tensor([1.0, 2.0, 3.0])
tensor2 = torch.tensor([1.0, 2.0, 3.0])# 使用 torch.equal 检查它们是否相等
result = torch.equal(tensor1, tensor2)
print(result) # 输出: True# 创建两个形状相同但值不同的张量
tensor3 = torch.tensor([1.0, 2.0, 4.0])# 再次使用 torch.equal 检查
result = torch.equal(tensor1, tensor3)
print(result) # 输出: False
请注意,torch.equal 不仅比较张量的形状,还比较它们的元素值。这与 torch.eq 不同,后者仅比较两个张量中对应位置的元素值是否相等,并返回一个布尔值张量。
另外,如果两个张量都是稀疏的(即它们使用稀疏格式存储),则 torch.equal 还会比较它们的稀疏索引和值是否相同。
使用 torch.equal 时,请确保比较的张量在设备(CPU 或 GPU)和数据类型(如 float32、float64 等)上都是一致的,否则比较可能会失败或产生意外的结果。
8.2 torch.ge()函数
在PyTorch中,torch.ge() 函数用于逐元素地比较两个张量(tensors),并返回一个布尔值张量(boolean tensor),其中每个元素表示对应位置上的元素是否满足第一个张量中的元素大于或等于第二个张量中的元素。
函数签名如下:
torch.ge(input, other, *, out=None) -> Tensor
- input (Tensor): 要比较的第一个张量。
- other (Tensor or scalar): 要比较的第二个张量或标量。
- out (Tensor, optional): 输出张量。
如果 other 是一个标量,那么它会与 input 张量中的每个元素进行比较。如果 other 是一个张量,那么它必须具有与 input 相同的形状,以便进行逐元素的比较。
示例:
import torch# 创建两个张量
tensor1 = torch.tensor([1, 2, 3])
tensor2 = torch.tensor([1, 2, 4])# 使用 torch.ge 进行逐元素比较
result = torch.ge(tensor1, tensor2)print(result)
# 输出: tensor([ True, True, False])
# 因为 1 >= 1, 2 >= 2, 3 < 4# 使用标量进行比较
scalar = 2
result_scalar = torch.ge(tensor1, scalar)print(result_scalar)
# 输出: tensor([False, True, True])
# 因为 1 < 2, 2 >= 2, 3 >= 2
请注意,torch.ge() 返回的是一个布尔值张量,其形状与输入张量相同。如果比较操作涉及到不同类型的张量(例如,一个张量是浮点数类型,另一个是整数类型),则可能需要先将它们转换为相同的类型,以避免可能的类型不匹配错误。
此外,还可以使用张量的比较运算符 >= 来进行相同的操作,这在语法上可能更简洁:
result = tensor1 >= tensor2
这行代码与 torch.ge(tensor1, tensor2) 等效。
8.3 torch.gt()函数
torch.gt() 是 PyTorch 中的一个函数,用于逐元素地比较两个张量(tensors),并返回一个布尔值张量(boolean tensor),其中每个元素表示对应位置上的第一个张量中的元素是否大于第二个张量中的元素。
函数签名如下:
torch.gt(input, other, *, out=None) -> Tensor
- input (Tensor): 要比较的第一个张量。
- other (Tensor or scalar): 要比较的第二个张量或标量。
- out (Tensor, optional): 输出张量。
如果 other 是一个标量,那么它会与 input 张量中的每个元素进行比较。如果 other 是一个张量,那么它必须具有与 input 相同的形状,以便进行逐元素的比较。
示例:
import torch# 创建两个张量
tensor1 = torch.tensor([1, 2, 3])
tensor2 = torch.tensor([1, 2, 4])# 使用 torch.gt 进行逐元素比较
result = torch.gt(tensor1, tensor2)print(result)
# 输出: tensor([False, False, True])
# 因为 1 不大于 1, 2 不大于 2, 3 大于 4(这里的比较是错误的,应该是 3 < 4)# 修正比较操作
result_corrected = torch.gt(tensor1, 2)print(result_corrected)
# 输出: tensor([False, False, True])
# 因为 1 不大于 2, 2 不大于 2, 3 大于 2# 使用标量进行比较
scalar = 2
result_scalar = torch.gt(tensor1, scalar)print(result_scalar)
# 输出: tensor([False, False, True])
# 因为 1 不大于 2, 2 不大于 2, 3 大于 2
请注意,torch.gt() 返回的是一个布尔值张量,其形状与输入张量相同。在这个例子中,tensor1 和 tensor2 的比较结果是一个包含三个元素的布尔值张量,表示 tensor1 中每个元素是否大于 tensor2 中对应位置的元素。
另外,与 torch.ge() 类似,你也可以使用张量的比较运算符 > 来进行相同的操作:
result = tensor1 > tensor2
这行代码与 torch.gt(tensor1, tensor2) 等效。
8.4 torch.le()函数
在PyTorch中,torch.le() 函数用于逐元素地比较两个张量(tensors),并返回一个布尔值张量(boolean tensor),其中每个元素表示对应位置上的第一个张量中的元素是否小于或等于第二个张量中的元素。
函数签名如下:
torch.le(input, other, *, out=None) -> Tensor
- input (Tensor): 要比较的第一个张量。
- other (Tensor or scalar): 要比较的第二个张量或标量。
- out (Tensor, optional): 输出张量。
如果 other 是一个标量,那么它会与 input 张量中的每个元素进行比较。如果 other 是一个张量,那么它必须具有与 input 相同的形状,以便进行逐元素的比较。
示例:
import torch# 创建两个张量
tensor1 = torch.tensor([1, 2, 3])
tensor2 = torch.tensor([1, 2, 4])# 使用 torch.le 进行逐元素比较
result = torch.le(tensor1, tensor2)print(result)
# 输出: tensor([ True, True, True])
# 因为 1 <= 1, 2 <= 2, 3 <= 4# 使用标量进行比较
scalar = 2
result_scalar = torch.le(tensor1, scalar)print(result_scalar)
# 输出: tensor([ True, True, False])
# 因为 1 <= 2, 2 <= 2, 3 > 2
在这个例子中,torch.le(tensor1, tensor2) 返回一个布尔值张量,其中每个元素对应于 tensor1 和 tensor2 中相应位置的元素比较结果。同样,torch.le(tensor1, scalar) 将 tensor1 中的每个元素与标量 scalar 进行比较。
与 torch.ge() 类似,你也可以使用张量的比较运算符 <= 来进行相同的操作:
result = tensor1 <= tensor2
这行代码与 torch.le(tensor1, tensor2) 等效。
8.5 torch.lt()函数
在PyTorch中,torch.lt() 函数用于逐元素地比较两个张量(tensors),并返回一个布尔值张量(boolean tensor),其中每个元素表示对应位置上的第一个张量中的元素是否小于第二个张量中的元素。
函数签名如下:
torch.lt(input, other, *, out=None) -> Tensor
- input (Tensor): 要比较的第一个张量。
- other (Tensor or scalar): 要比较的第二个张量或标量。
- out (Tensor, optional): 输出张量。
如果 other 是一个标量,那么它会与 input 张量中的每个元素进行比较。如果 other 是一个张量,那么它必须具有与 input 相同的形状,以便进行逐元素的比较。
示例:
import torch# 创建两个张量
tensor1 = torch.tensor([1, 2, 3])
tensor2 = torch.tensor([1, 2, 4])# 使用 torch.lt 进行逐元素比较
result = torch.lt(tensor1, tensor2)print(result)
# 输出: tensor([False, False, True])
# 因为 1 不小于 1, 2 不小于 2, 3 小于 4# 使用标量进行比较
scalar = 2
result_scalar = torch.lt(tensor1, scalar)print(result_scalar)
# 输出: tensor([ True, False, False])
# 因为 1 小于 2, 2 不小于 2, 3 不小于 2
在这个例子中,torch.lt(tensor1, tensor2) 返回一个布尔值张量,表示 tensor1 中每个元素是否小于 tensor2 中对应位置的元素。同样地,torch.lt(tensor1, scalar) 将 tensor1 中的每个元素与标量 scalar 进行比较。
你也可以使用张量的比较运算符 < 来执行相同的操作:
result = tensor1 < tensor2
这行代码与 torch.lt(tensor1, tensor2) 等效。
8.6 torch.ne()函数
torch.ne() 是 PyTorch 中的一个函数,用于逐元素地比较两个张量(tensors),并返回一个布尔值张量(boolean tensor),其中每个元素表示对应位置上的第一个张量中的元素是否不等于第二个张量中的元素。
函数签名如下:
torch.ne(input, other, *, out=None) -> Tensor
- input (Tensor): 要比较的第一个张量。
- other (Tensor or scalar): 要比较的第二个张量或标量。
- out (Tensor, optional): 输出张量。
如果 other 是一个标量,那么它会与 input 张量中的每个元素进行比较。如果 other 是一个张量,那么它必须具有与 input 相同的形状,以便进行逐元素的比较。
示例:
import torch# 创建两个张量
tensor1 = torch.tensor([1, 2, 3])
tensor2 = torch.tensor([1, 2, 4])# 使用 torch.ne 进行逐元素比较
result = torch.ne(tensor1, tensor2)print(result)
# 输出: tensor([False, False, True])
# 因为 1 等于 1, 2 等于 2, 3 不等于 4# 使用标量进行比较
scalar = 2
result_scalar = torch.ne(tensor1, scalar)print(result_scalar)
# 输出: tensor([ True, True, False])
# 因为 1 不等于 2, 2 不等于 2, 3 不等于 2
在这个例子中,torch.ne(tensor1, tensor2) 返回一个布尔值张量,其中每个元素对应于 tensor1 和 tensor2 中相应位置的元素比较结果。同样,torch.ne(tensor1, scalar) 将 tensor1 中的每个元素与标量 scalar 进行比较。
与 torch.ne() 类似,你也可以使用张量的比较运算符 != 来进行相同的操作:
result = tensor1 != tensor2
这行代码与 torch.ne(tensor1, tensor2) 等效。
8.7 torch.sort()函数
torch.sort() 是 PyTorch 中的一个函数,用于对张量(tensor)进行排序。它返回排序后的张量以及原始张量中元素的索引。
函数签名如下:
torch.sort(input, dim=None, descending=False, out=None) -> (Tensor, Tensor)
- input (Tensor): 要排序的张量。
- dim (int, optional): 沿着哪个维度进行排序。默认为 None,表示对整个张量进行排序。
- descending (bool, optional): 是否按降序排序。默认为 False,即按升序排序。
- out (tuple[Tensor, Tensor], optional): 可选的输出张量元组,用于存放排序结果和索引。
torch.sort() 返回一个元组,其中包含两个张量:
- 排序后的张量(Tensor):沿着指定维度对输入张量进行排序后的结果。
- 索引张量(Tensor):原始张量中元素的索引,按照排序后的顺序排列。
示例:
import torch# 创建一个张量
x = torch.tensor([3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5])# 对张量进行排序
sorted_tensor, sorted_indices = torch.sort(x)print("Sorted tensor:", sorted_tensor)
# 输出: Sorted tensor: tensor([1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9])print("Sorted indices:", sorted_indices)
# 输出: Sorted indices: tensor([1, 3, 7, 0, 10, 2, 4, 8, 9, 5, 6])# 如果想按降序排序
sorted_tensor_desc, sorted_indices_desc = torch.sort(x, descending=True)print("Sorted tensor (descending):", sorted_tensor_desc)
# 输出: Sorted tensor (descending): tensor([9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1])print("Sorted indices (descending):", sorted_indices_desc)
# 输出: Sorted indices (descending): tensor([6, 5, 8, 9, 4, 2, 0, 10, 7, 3, 1])
在这个例子中,torch.sort(x) 返回了排序后的张量 sorted_tensor 和原始张量中元素的索引 sorted_indices。如果指定 descending=True,则会按降序排序。
8.8 torch.topk()函数
torch.topk() 是 PyTorch 中的一个函数,用于返回张量中每个指定维度上的前 k 个最大值(或最小值)及其索引。这个函数非常有用,特别是在你需要获取张量中的顶部元素或进行排序相关的操作时。
函数签名如下:
torch.topk(input, k, dim=None, largest=True, sorted=True, *, out=None) -> (Tensor, Tensor)
- input (Tensor): 输入张量。
- k (int): 要返回的最大(或最小)值的数量。
- dim (int, optional): 在哪个维度上进行操作。默认是第一个维度(dim=0)。
- largest (bool, optional): 是否返回最大的 k 个值。如果是 True,则返回最大的 k 个值;如果是 False,则返回最小的 k 个值。默认为 True。
- sorted (bool, optional): 是否对结果进行排序。如果为 True,则返回的 k 个值会按照降序(对于 largest=True)或升序(对于 largest=False)排列。默认为 True。
- out (tuple[Tensor, Tensor], optional): 可选的输出张量元组,用于存放结果和索引。
torch.topk() 返回一个元组,其中包含两个张量:
第一个张量包含每个指定维度上的前 k 个最大值(或最小值)。
第二个张量包含这些最大值(或最小值)在原始张量中的索引。
示例:
import torch# 创建一个张量
x = torch.tensor([[ 3, 2, 1],[ 2, 3, 1],[ 1, 2, 3]])# 获取每个行的前 2 个最大值及其索引
values, indices = torch.topk(x, k=2, dim=1, largest=True, sorted=True)print("Top 2 values:", values)
# 输出: Top 2 values: tensor([[3, 2],
# [3, 2],
# [3, 2]])print("Indices of top 2 values:", indices)
# 输出: Indices of top 2 values: tensor([[0, 1],
# [1, 0],
# [2, 1]])# 获取每个列的最小值及其索引
values, indices = torch.topk(x, k=1, dim=0, largest=False, sorted=True)print("Smallest value in each column:", values)
# 输出: Smallest value in each column: tensor([[1, 1, 1]])print("Indices of smallest values in each column:", indices)
# 输出: Indices of smallest values in each column: tensor([[2, 2, 2]])
在这个例子中,我们首先使用 torch.topk() 获取了每个行(dim=1)的前两个最大值(largest=True)及其索引。然后,我们改变了维度和条件,获取了每个列(dim=0)的最小值(largest=False)及其索引。
相关文章:
)
PyTorch学习笔记之基础函数篇(十五)
文章目录 数值比较运算8.1 torch.equal()函数8.2 torch.ge()函数8.3 torch.gt()函数8.4 torch.le()函数8.5 torch.lt()函数8.6 torch.ne()函数8.7 torch.sort()函数8.8 torch.topk()函数 数值比较运算 8.1 torch.equal()函数 torch.equal(tensor1, tensor2) -> bool这个函…...
Latex插入pdf图片,去除空白部分
目录 参考链接: 流程: 参考链接: 科研锦囊之Latex-如何插入图片、表格、参考文献 http://t.csdnimg.cn/vpSJ3 流程: Latex的图片插入支持PDF文件,这里笔者建议都使用PDF文件进行图片的插入,因为PDF作…...
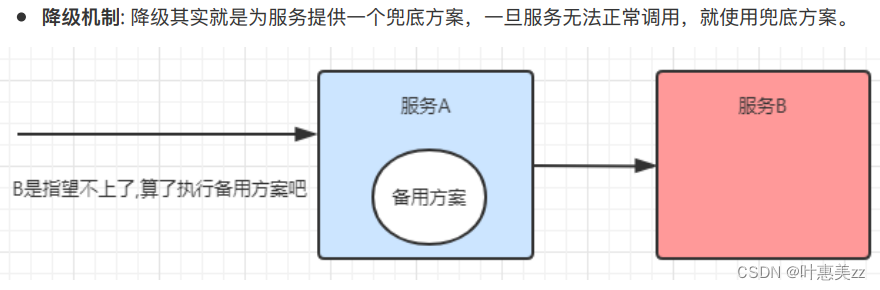
微服务:高并发带来的问题的容错方案
1.相关脚本(陈天狼) 启动nacos客户端: startup.cmd -m standalone 启动sentinel控制台: # 直接使⽤jar命令启动项⽬(控制台本身是⼀个SpringBoot项⽬) java -Dserver.port8080 -Dcsp.sentinel.dashboard.serverlocalhost:808…...
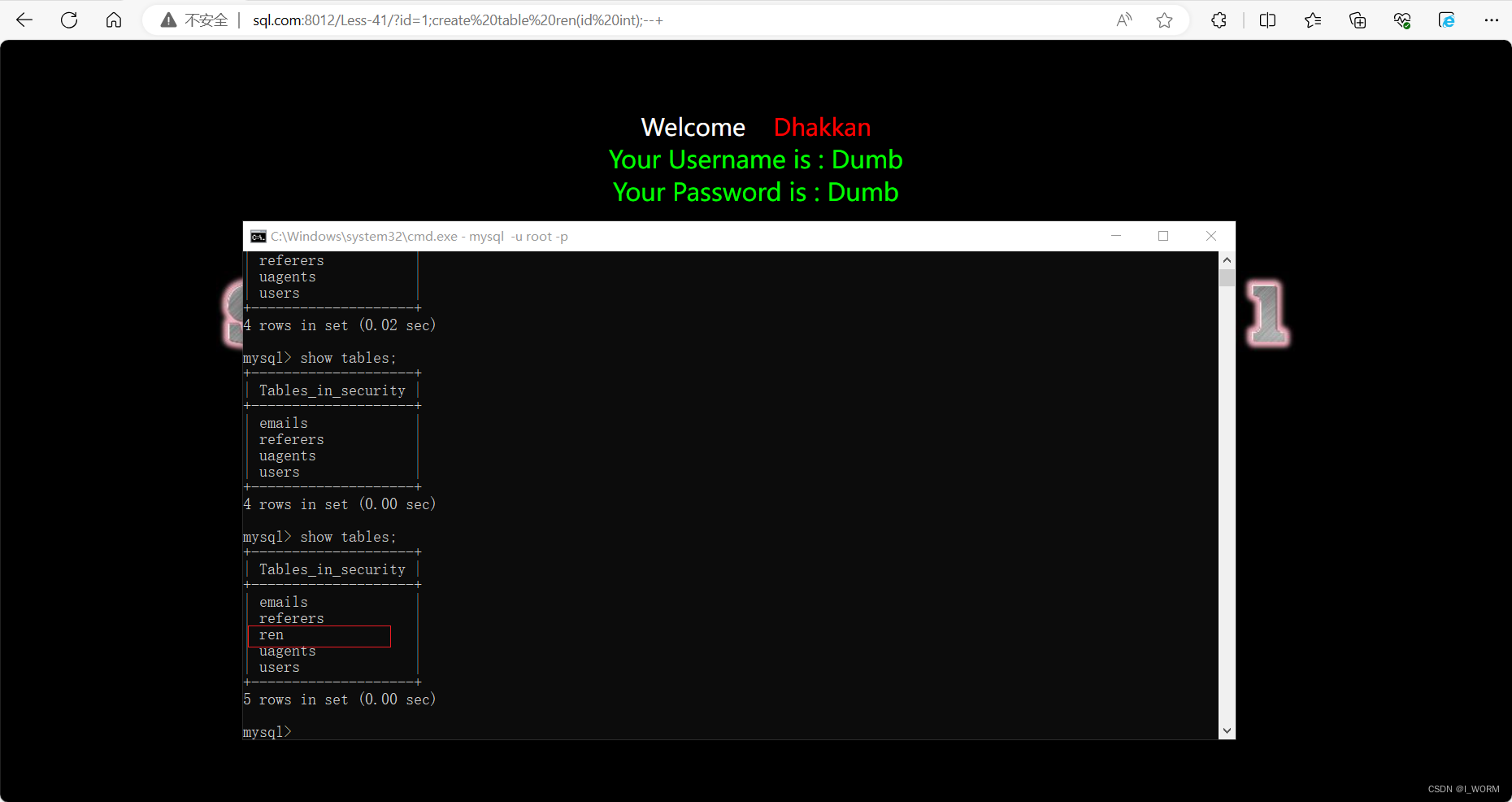
sqllab第35-45关通关笔记
35关知识点: 宽字节注入数值型注入错误注入 payload:id1andextractvalue(1,concat(0x7e,database(),0x7e))0--联合注入 payload:id0unionselect1,database(),version()-- 36关知识点: 字符型注入宽字节注入错误注入 payload:id1%df%27andextractvalue(…...

Jenkins流水线将制品发布到Nexus存储库
1、安装jenkins(建议别用docker安装,坑太多) docker run -d -p 8089:8080 -p 10241:50000 -v /var/jenkins_workspace:/var/jenkins_home -v /etc/localtime:/etc/localtime --name my_jenkins --userroot jenkins/jenkins:2.449 坑1 打开x…...
信息学奥赛一本通之MAC端VSCode C++环境配置
前提 安装 Visual Studio CodeVSCode 中安装 C/C扩展确保 Clang 已经安装(在终端中输入命令:clang --version 来确认是否安装)未安装,在命令行执行xcode-select --install 命令,会自行安装,安装文件有点大…...
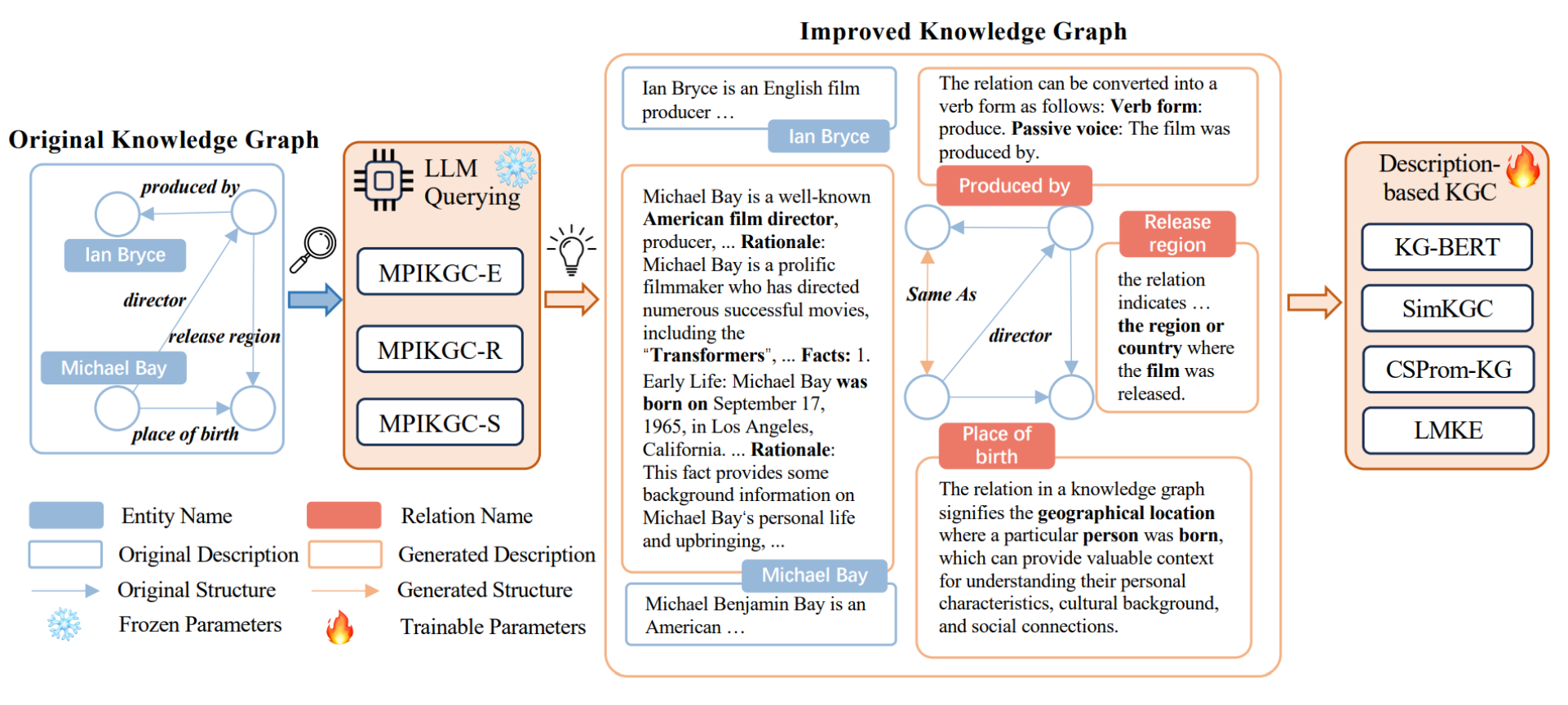
MPIKGC:大语言模型改进知识图谱补全
MPIKGC:大语言模型改进知识图谱补全 提出背景MPIKGC框架 论文:https://arxiv.org/pdf/2403.01972.pdf 代码:https://github.com/quqxui/MPIKGC 提出背景 知识图谱就像一个大数据库,里面有很多关于不同事物的信息,这…...
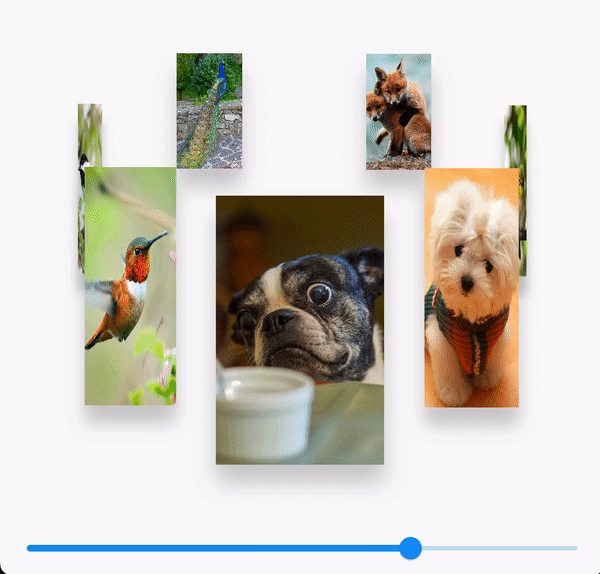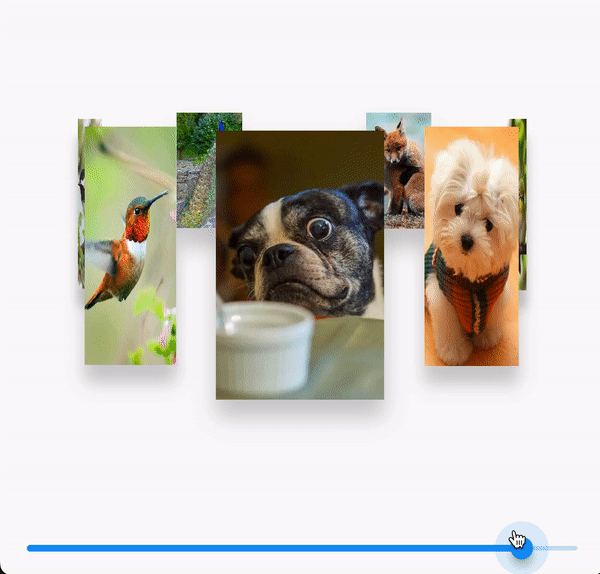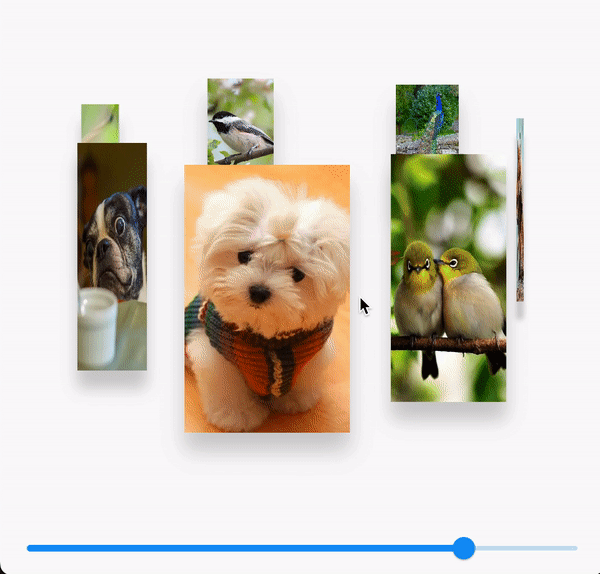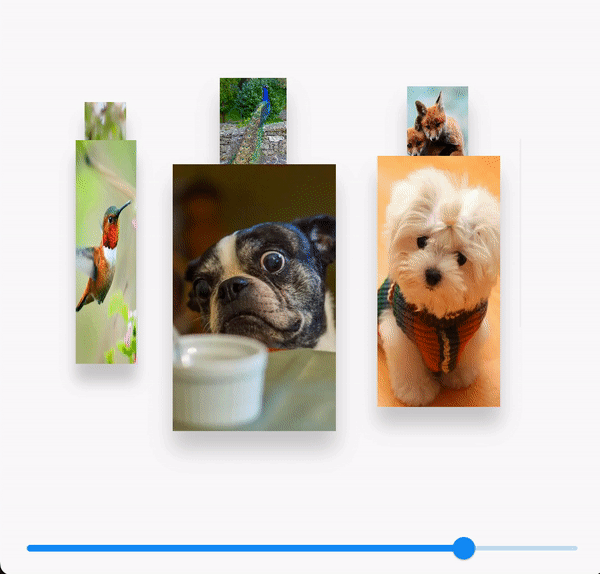
Flutter-自定义图片3D画廊
效果 需求 3D画廊效果 设计内容 StackGestureDetectorTransformPositioned数学三角函数 代码实现 具体代码大概300行 import dart:math;import package:flutter/material.dart; import package:flutter_xy/widgets/xy_app_bar.dart;import ../../r.dart;class ImageSwitc…...
python中如何解析Html
在最近需要的需求中,需要 python 获取网页内容,并从html中获取到想要的内容。这里记录一下两个比较常用的python库对html的解析。 1. BeautifulSoup 它是一个非常流行的python脚本库,用于解析HTML和XML文档。如果你对 java 很熟悉ÿ…...
)
Hystrix的原理及应用:构建微服务容错体系的利器(一)
本系列文章简介: 本系列文章旨在深入剖析Hystrix的原理及应用,帮助大家理解其如何在微服务容错体系中发挥关键作用。我们将从Hystrix的核心原理出发,探讨其隔离、熔断、降级等机制的实现原理;接着,我们将结合实际应用场…...

win10企业版LTSC可以识别鼠标,无法识别移动硬盘问题
1. USB控制器重置:在设备管理器中,展开"通用串行总线控制器"。右键点击每个USB控制器,选择"卸载设备"。完成后,重新启动计算机。操作系统将自动重新安装USB控制器驱动程序。这可能有助于解决与USB控制器相关的…...

[经验分享]OpenCV显示上一次调用的图片的处理方法
最近在研究OpenCV时发现,重复调用cv::imshow("frame", frame)时,会显示出上一次的图片。 网上搜索了方法,有以下3种因素可能导致: 1. 图像变量未正确更新:可能在更新 frame 变量之前就已经调用了 imshow。…...

NFS性能优化参考 —— 筑梦之路
CentOS 7 NFS服务优化的配置参考—— 筑梦之路_nfs 读取优化-CSDN博客 核心原则是减少客户端与服务端的交互次数,因此我们在访问文件的时候应该尽量保持文件的打开状态,避免重复打开关闭文件,这样NFS全路径的逐级检查。这种方法对NFSv4以后的…...

Vue3学习日记 Day4 —— pnpm,Eslint
注:此课程需要有Git的基础才能学习 一、pnpm包管理工具 1、使用原因 1.1、速度快,远胜过yarn和npm 1.2、节省磁盘空间 2、使用方式 2.1、安装方式 npm install -g pnpm 2.2、创建项目 pnpm create vue 二、Eslint配置代码风格 1、环境同步 1、禁用Pret…...
二叉树遍历(牛客网)
描述 编一个程序,读入用户输入的一串先序遍历字符串,根据此字符串建立一个二叉树(以指针方式存储)。 例如如下的先序遍历字符串: ABC##DE#G##F### 其中“#”表示的是空格,空格字符代表空树。建立起此二叉树…...
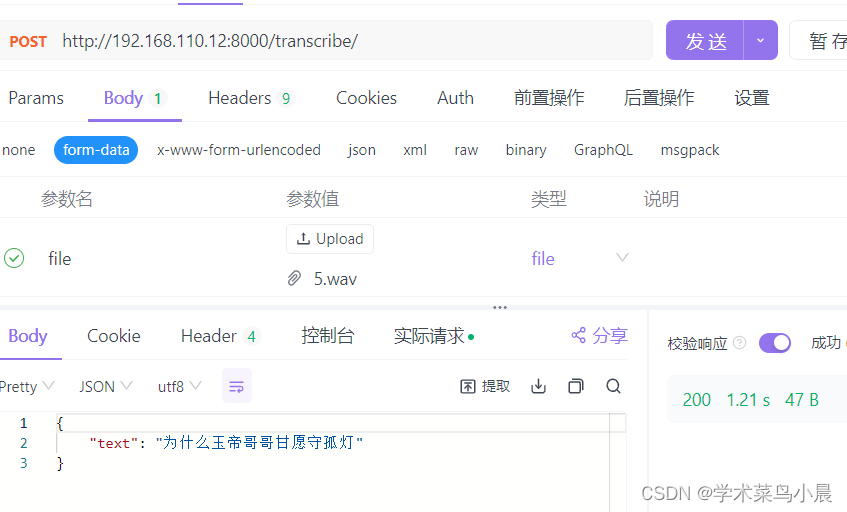
语音识别:whisper部署服务器(远程访问,语音实时识别文字)
Whisper是OpenAI于2022年发布的一个开源深度学习模型,专门用于语音识别任务。它能够将音频转换成文字,支持多种语言的识别,包括但不限于英语、中文、西班牙语等。Whisper模型的特点是它在多种不同的音频条件下(如不同的背景噪声水…...

Faust勒索病毒:了解最新变种[nicetomeetyou@onionmail.org].faust,以及如何保护您的数据
导言: 在一个快节奏的数字世界中,我们经常忽视数据安全的重要性。然而,最新的勒索病毒——[nicetomeetyouonionmail.org].faust、[support2022cock.li].faust、[tsai.shenmailfence.com].faust 、[Encrypteddmailfence.com].faust、[Deciphe…...
EI Scopus检索 | 第二届大数据、物联网与云计算国际会议(ICBICC 2024) |
会议简介 Brief Introduction 2024年第二届大数据、物联网与云计算国际会议(ICBICC 2024) 会议时间:2024年12月29日-2025年1月1日 召开地点:中国西双版纳 大会官网:ICBICC 2024-2024 International Conference on Big data, IoT, and Cloud C…...
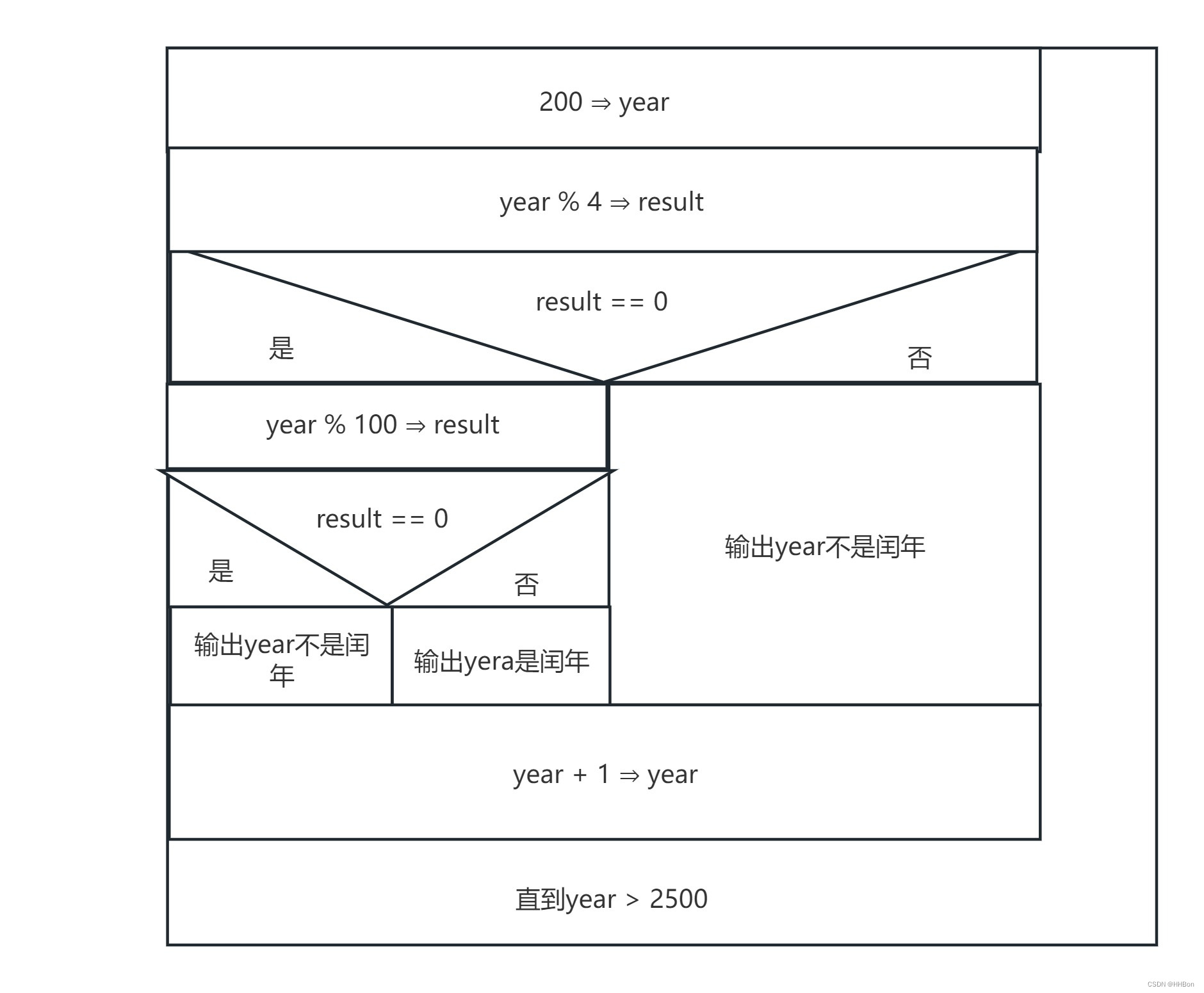
判断闰年(C语言)
一、运行结果; 二、源代码; # define _CRT_SECURE_NO_WARNINGS # include <stdio.h>int main() {//初始化变量值;int year 2000;//执行循环判断;while (year < 2010){//执行流程;//判断能否整除4࿱…...
2024全国水科技大会【协办单位】凌志环保股份有限公司
凌志环保股份有限公司成立于1998年5月,集团共有20余家经营主体组成,凌志环保作为村镇污水处理领域的领军企业、农村污水处理“家电化”的开创者,深耕水治理行业25年,2022年被工信部认定为国家级专精特新“小巨人”企业。公司的核心…...

AI检测率太高论文过不了?这4个降AI率平台2026年别再错过了
随着AI技术在学术领域的广泛应用,论文中的AI痕迹越来越容易被检测系统识别。如何有效降低AIGC率、去除AI痕迹,已成为众多学者和学生关注的焦点。依托权威检测平台数据、高校实测结果及用户真实反馈,本文将深入解析当前最值得尝试的降AI率工具…...

Unity编辑器Play模式状态保存与还原原理详解
1. 这个插件不是“自动存档”,而是 Unity 编辑器生命周期里的状态锚点你有没有在 Unity 编辑器里调试一个带复杂初始化逻辑的 MonoBehaviour,刚把 Inspector 里十几个字段调到理想值、挂好引用、连好事件,一按 Play,对象瞬间变空—…...

重新理解AI:从工具到可协作的助手
动手的事在减少,动脑的事在增加。从AI正式出场算起,不过短短三年多时间,许多事都在喧嚣中悄悄变化。翻看2023年的对话,无非就是和AI说句话,让它写写工作报告,分析具体的业务或数据,心底里还是把…...

【Android】Hypic 醒图国际版 最新版-免登录
【Android】Hypic 醒图国际版 最新版-解锁永久会员-免登录 链接:https://pan.xunlei.com/s/VOtJaC8K4sK_rrqnINu3HULdA1?pwddfdj# Hypic醒图国际版是一款功能强大的照片编辑应用程序,专为满足专业摄影师和业余爱好者的多样化需求而设计。...

Node.js后端服务如何集成多模型能力并管理API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js后端服务如何集成多模型能力并管理API成本 1. 场景与需求 在Node.js后端服务中集成AI对话功能,开发者通常面临…...

在Taotoken模型广场根据任务需求挑选合适模型的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务需求挑选合适模型的实践 1. 模型广场:你的模型选型起点 当你开始一个新项目,或…...

告别抢票焦虑:大麦网自动抢票系统终极使用指南
告别抢票焦虑:大麦网自动抢票系统终极使用指南 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 还在为抢不到心仪演出门票而烦恼吗&#…...

Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的应用 当企业将大模型能力集成到业务流程中时,除了关注模型…...
)
别再死记硬背了!用Python+MATLAB/Simulink,5步搞定自动控制原理的时域分析(附代码)
从理论到代码:用PythonMATLAB玩转自动控制时域分析 为什么我们需要用代码实现控制理论? 翻开任何一本自动控制原理教材,满眼都是微分方程、传递函数和响应曲线。传统学习方法强调手工计算和记忆公式,但现代工程师更需要的是将抽象…...

工业视觉光源颜色选型全攻略|白/红/蓝/绿光适用场景、原理与避坑细则
摘要:在工业AI视觉缺陷检测项目落地中,绝大多数工程师过度聚焦相机参数、镜头焦距、模型调参优化,却忽略了光源颜色选型这一核心前置条件。工业检测有一条公认铁律:成像决定上限,模型只负责兜底。相同工件、相同光源结…...