Spark杂谈
文章目录
- 什么是Spark
- 对比Hadoop
- Spark应用场景
- Spark数据处理流程
- 什么是RDD
- Spark架构相关进程
- 入门案例:统计单词数量
- Spark开启historyServer
什么是Spark
- Spark是一个用于大规模数据处理的统一计算引擎
- Spark一个重要的特性就是基于内存计算,从而它的速度可以达到MapReduce的几十倍甚至百倍
对比Hadoop
- Spark是一个综合性质的计算引擎,Hadoop既包含Mapreduce(计算)还包含HDFS(存储)和YARN(资源管理),两个框架定位不同,从综合能力来说Hadoop更胜一筹
- 计算模型:Spark任务可以包含多个计算操作,轻松实现复杂迭代计算,Hadoop中的mapreduce任务只包含Map和Reduce阶段,不够灵活
- 处理速度:Spark任务的数据是存放在内存里面的,而Hadoop中的MapReduce任务是基于磁盘的
在实际工作中Hadoop会作为一个提供分布式存储和分布式资源管理的一个角色存在,Spark会依赖于Hadoop去做计算。
Spark应用场景
- 低延时的海量数据计算需求
- 低延时的SQL交互查询需求
- 准实时计算需求
Spark数据处理流程

什么是RDD
- 通常通过Hadoop上的文件,即HDFS文件进行创建,也可以通过程序中的集合来创建
- 是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集
- 弹性:RDD数据在默认的情况下存放内存中,但是在内存资源不足时,Spark也会自动将RDD数据写入磁盘
- RDD在抽象上来说是一种元素数据的集合,它是被分区的,每个分区分布在集群中的不同节点上,从而RDD中的数据可以被并行操作
- 容错性:最重要的特性就是提供了容错性,可以自动从节点失败中恢复过来。比如某个节点的数据由于故障导致分区的数据丢了,RDD会自动通过数据来源重新计算数据
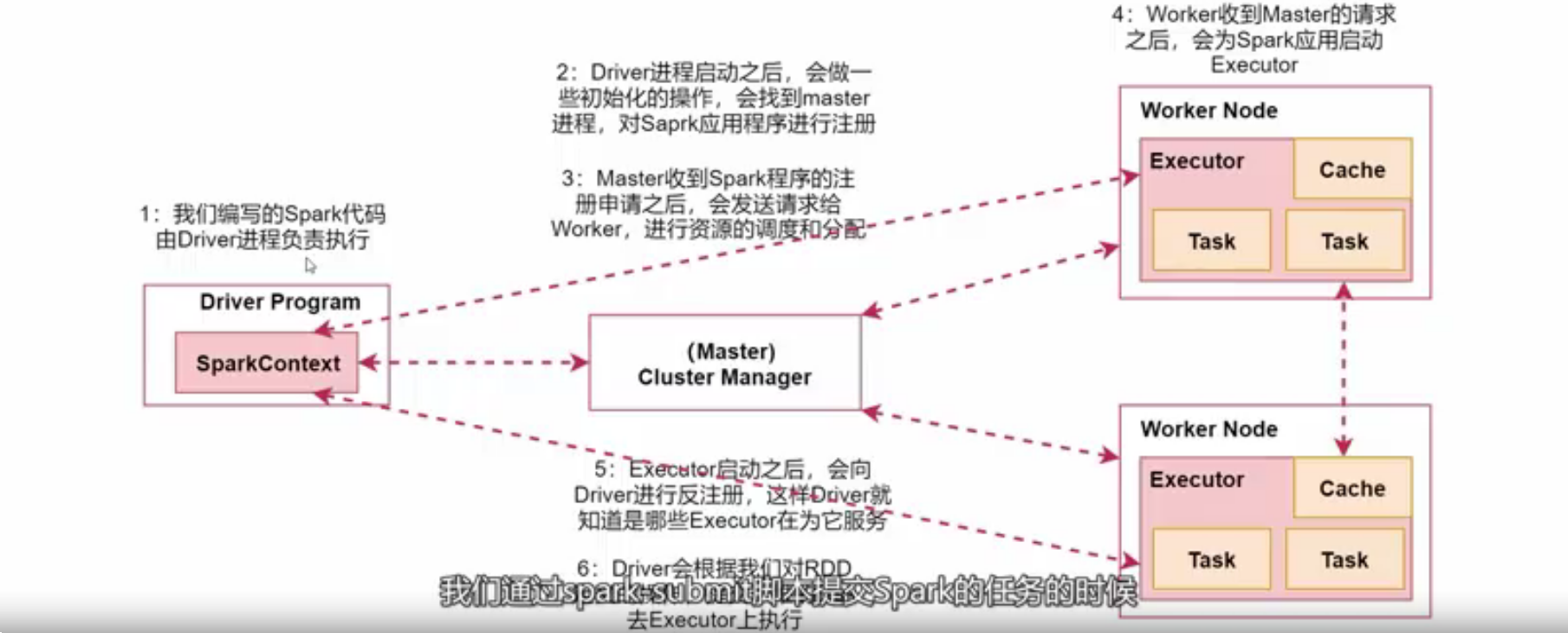
Spark架构相关进程
- Driver:我们编写的Spark程序由Driver进程负责执行
- Master:集群的主节点中启动的进程
- Worker:集群的从节点中启动的进程
- Executor:由Worker负责启动的进程,执行数据处理和数据计算
- Task:由Executor负责启动的线程,是真正干活的
入门案例:统计单词数量
# scala 代码
object WordCountScala {def main(args: Array[String]): Unit = {val conf = new SparkConf();conf.setAppName("wordCount").setMaster("local")val context = new SparkContext(conf);val linesRDD = context.textFile("D:\\hadoop\\logs\\hello.txt");var wordsRDD = linesRDD.flatMap(line => line.split(" "))val pairRDD = wordsRDD.map(word => (word, 1))val wordCountRDD = pairRDD.reduceByKey(_ + _)wordCountRDD.foreach(wordCount => println(wordCount._1 + "---" + wordCount._2))context.stop()}
}public class WordCountJava {public static void main(String[] args) {SparkConf sparkConf = new SparkConf();sparkConf.setAppName("worldCount").setMaster("local");JavaSparkContext javaSparkContext = new JavaSparkContext();JavaRDD<String> stringJavaRDD = javaSparkContext.textFile("D:\\hadoop\\logs\\hello.txt");// 数据切割,把一行数据拆分为一个个的单词// 第一个是输入数据类型,第二个是输出数据类型JavaRDD<String> wordRDD = stringJavaRDD.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String line) throws Exception {return Arrays.asList(line.split(" ")).iterator();}});// 迭代word,装换成(word,1)这种形式// 第一个是输入参数,第二个是输出第一个参数类型,第三个是输出第二个参数类型JavaPairRDD<String, Integer> pairRDD = wordRDD.mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String word) throws Exception {return new Tuple2<>(word, 1);}});// 根据key进行分组聚合JavaPairRDD<String, Integer> wordCountRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer v1, Integer v2) throws Exception {return v1 + v2;}});// 输出控制台wordCountRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {@Overridepublic void call(Tuple2<String, Integer> tuple2) throws Exception {System.out.println(tuple2._1 + "=:=" + tuple2._2);}});javaSparkContext.stop();}}Spark开启historyServer
[root@hadoop04 conf]# vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop01:9000/tmp/logs/root/logs"[root@hadoop04 conf]# vim spark-defaults.conf
spark.eventLof.enable=true
spark.eventLog.compress=true
spark.eventLog.dir=hdfs://hadoop01:9000/tmp/logs/root/logs
spark.history.fs.logDirectory=hdfs://hadoop01:9000/tmp/logs/root/logs# 启动
[root@hadoop04 conf]# sbin/start-history-server.sh # 访问
http://hadoop04:18080/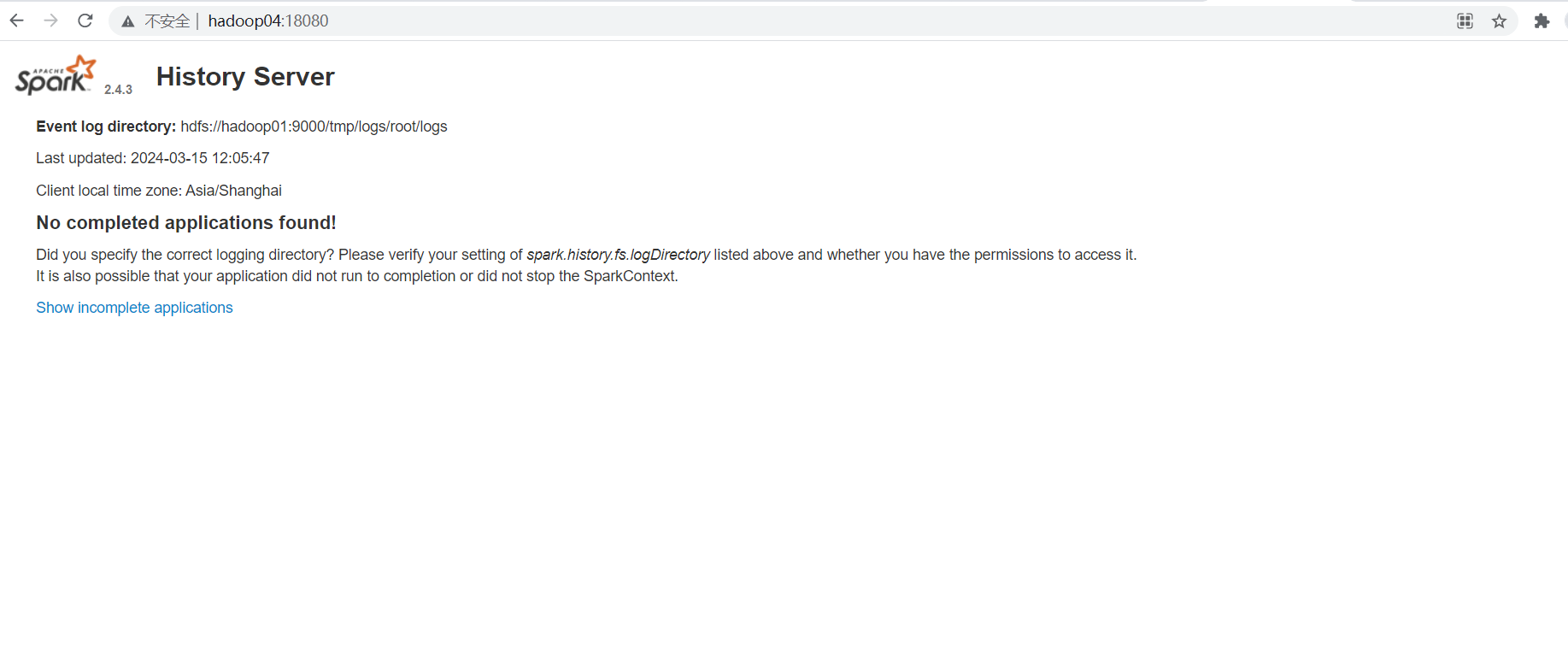
相关文章:
Spark杂谈
文章目录 什么是Spark对比HadoopSpark应用场景Spark数据处理流程什么是RDDSpark架构相关进程入门案例:统计单词数量Spark开启historyServer 什么是Spark Spark是一个用于大规模数据处理的统一计算引擎Spark一个重要的特性就是基于内存计算,从而它的速度…...

【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例
【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程…...

私域流量运营的关键要素和基本步骤
解锁增长的四大关键: 关键要素一:精准营销 精准营销是私域流量运营的核心所在。通过精细化运营和个性化服务,企业可以将普通用户转化为忠实粉丝,提高用户的粘性和转化率。采用数据驱动的精准营销策略,深度挖掘用户需求…...

k8s部署hadoop
(作者:陈玓玏) 配置和模板参考helm仓库:https://artifacthub.io/packages/helm/apache-hadoop-helm/hadoop 先通过以下命令生成yaml文件: helm template hadoop pfisterer-hadoop/hadoop > hadoop.yaml用kube…...
卡住)
deepspeed分布式训练在pytorch 扩展(PyTorch extensions)卡住
错误展示: Using /root/.cache/torch_extensions/py310_cu121 as PyTorch extensions root... Using /root/.cache/torch_extensions/py310_cu121 as PyTorch extensions root... 错误表现: 出现在多卡训练过程的pytorch 扩展,deepspee…...

Rust 的 HashMap
在 Rust 中,HashMap 是一个从键(key)映射到值(value)的数据结构。它允许你以 O(1) 的平均时间复杂度存储、检索和删除键值对。HashMap 实现了 std::collections::HashMap 结构体,通常通过 use std::collect…...
exporter方式监控达梦数据库
蓝鲸监控 随着国产化和信创的深入,开始普遍使用国产化数据库–如达梦数据库,蓝鲸平台默认没有对其进行监控,但是平台了提供监控告警的能力。比如脚本采集,脚本的是一种灵活和快速的监控采集方式,不同层的监控对象都可…...
供应链安全之被忽略的软件质量管理平台安全
背景 随着我国信息化进程加速,网络安全问题更加凸显。关键信息基础设施和企业单位在满足等保合规的基础上,如何提升网络安全防御能力,降低安全事件发生概率?默安玄甲实验室针对SonarQube供应链安全事件进行分析,强调供…...

python入门(二)
python的安装很方便,我们这里就不再进行讲解,大家可以自己去搜索视频。下面分享一下Python的入门知识点。 执行命令的方式 在安装好python后,有两种方式可以执行命令: 命令行程序文件,后缀名为.py 对于命令行&…...

Mysql,MongoDB,Redis的横纵向对比
一,什么是Mysql Mysql是一款安全,可以跨平台,高效率的数据库系统,运行速度高,安全性能高,支持面向对象,安全性高,并且成本比较低,支持各种开发语言,数据库的存储容量大,有许多的内置函数。 二,什么是MongoDB MongoDB是基于分布式文件存储的数据库,是一个介于关…...

css3 实现html样式蛇形布局
文章目录 1. 实现效果2. 实现代码 1. 实现效果 2. 实现代码 <template><div class"body"><div class"title">CSS3实现蛇形布局</div><div class"list"><div class"item" v-for"(item, index) …...
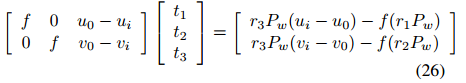
基于消失点的相机自标定
基于消失点的相机自标定 附赠最强自动驾驶学习资料:直达链接 相机是通过透视投影变换来将3D场景转换为2D图像。在射影变换中,平行线相交于一点称之为消失点。本文详细介绍了两种利用消失点特性的标定方法。目的是为根据实际应用和初始条件选择合适的标…...

Python:filter过滤器
filter() 是 Python 中的一个内置函数,用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该函数接收两个参数,一个是函数,一个是序列,序列的每个元素作为参数传递给函数进行判定&…...

Python函数学习
Python函数学习 1.函数定义 在函数定义阶段只检查函数的语法问题 2.实参形参 总结: (1)位置参数就是经常用的按照位置顺序给出实参的值; (2)关键字实参形式:key123;放在…...

IDEA中的Project工程、Module模块的概念及创建导入
1、IDEA中的层级关系: project(工程) - module(模块) - package(包) - class(类)/接口具体的: 一个project中可以创建多个module一个module中可以创建多个package一个package中可以创建多个class/接口2、Project和Module的概念: 在 IntelliJ …...

如何快速下载并剪辑B站视频
1、B站手机端右上角缓存视频; 2、在手机文件管理助手中找到android/data/80找到两个文件,video.m4s和audio.m4s,将它们发送到电脑,系统会默认保存在你的个人文件夹里,C:\users\用户名 3、下载ffmepg https://blog.cs…...
智慧矿山新趋势:大数据解决方案一览
1. 背景 随着信息技术的快速发展和矿山管理需求的日益迫切,智慧矿山作为一种创新的矿山管理方式应运而生。智慧矿山借助先进的信息技术,实现对矿山生产、管理、安全等各方面的智能化、高效化、协同化,是矿山行业转型升级的必然趋势。 欢迎关…...
Ubuntu使用Docker部署Nginx容器并结合内网穿透实现公网访问本地服务
目录 ⛳️推荐 1. 安装Docker 2. 使用Docker拉取Nginx镜像 3. 创建并启动Nginx容器 4. 本地连接测试 5. 公网远程访问本地Nginx 5.1 内网穿透工具安装 5.2 创建远程连接公网地址 5.3 使用固定公网地址远程访问 ⛳️推荐 前些天发现了一个巨牛的人工智能学习网站&#…...
面试笔记——Redis(使用场景、面临问题、缓存穿透)
Redis的使用场景 Redis(Remote Dictionary Server)是一个内存数据结构存储系统,它以快速、高效的特性闻名,并且它支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合等。它主要用于以下场景: 缓…...

电机学(笔记一)
磁极对数p: 直流电机的磁极对数是指电机定子的磁极对数,也等于电机电刷的对数。它与电机的转速和扭矩有直接关系。一般来说,极对数越多,电机转速越低,扭矩越大,适用于低速、高扭矩的场合;相反&…...
)
Origin绘图进阶:如何在现有图形上叠加散点图与等高线(附完整操作步骤)
Origin高级绘图技巧:散点图与等高线的完美叠加实战指南 科研数据可视化中,单一图表往往难以全面展示复杂数据关系。当您需要在同一坐标系中同时呈现离散数据点与连续趋势时,散点图与等高线的组合堪称黄金搭档。这种混合图表特别适合展现发动机…...

百考通:AI全流程智能化赋能期刊论文写作,让学术创作更高效
在学术研究领域,期刊论文的撰写是成果输出的关键环节,却也让众多科研工作者与学生倍感压力:选题迷茫、逻辑梳理困难、格式规范复杂、内容提炼耗时,严重拖慢了学术成果的发表节奏。百考通(https://www.baikaotongai.com…...

终极指南:Muzic数据增强技术PDAugment如何通过音高和时长调整提升模型性能
终极指南:Muzic数据增强技术PDAugment如何通过音高和时长调整提升模型性能 【免费下载链接】muzic 这是一个微软研究院开发的音乐生成AI项目。适合对音乐、音频处理以及AI应用感兴趣的开发者、学生和研究者。特点是使用深度学习技术生成音乐,具有较高的创…...

测试报告编写核心技巧:让结果一目了然的专业模板指南
测试报告的价值重构在软件质量保障体系中,测试报告不仅是项目交付的最终凭证,更是驱动质量改进的战略工具。优秀的测试报告需实现三重价值:决策支持:为上线评审提供数据化依据问题追踪:形成缺陷治理的闭环链路效能度量…...

UI-TARS-desktop效果实测:内置Qwen3-4B模型响应速度有多快
UI-TARS-desktop效果实测:内置Qwen3-4B模型响应速度有多快 在当今AI应用日益普及的背景下,响应速度已成为衡量模型实用性的关键指标。本文将带您实测UI-TARS-desktop内置的Qwen3-4B-Instruct-2507模型在实际使用中的响应表现,通过多场景测试…...

玩转西门子S7-1200气力输送仿真系统
气力输送系统管道气力输送系统 (21)采用西门子S7-1200博图WinCC画面组态,博图V16及以上版本都可以仿真运行,无需硬件。 系统带有手动/自动模式,运行数据动态实时显示,带压力实时曲线显示&#x…...

3步告别音乐APP的广告轰炸,这款开源工具让你回归纯粹聆听
3步告别音乐APP的广告轰炸,这款开源工具让你回归纯粹聆听 【免费下载链接】tonzhon-music 铜钟 (Tonzhon.com): 免费听歌; 没有直播, 社交, 广告, 干扰; 简洁纯粹, 资源丰富, 体验独特!(密码重置功能已回归) 项目地址: https://gitcode.com/GitHub_Tre…...

如何高效定制Steam界面:实用美化插件开发指南
如何高效定制Steam界面:实用美化插件开发指南 【免费下载链接】millennium-steam-patcher Apply themes/customize Steam after the 2023-04-27 Chromium UI update https://discord.gg/MXMWEQKgJF 项目地址: https://gitcode.com/gh_mirrors/mi/millennium-steam…...

终极fabio配置验证指南:避免生产环境错误的10个实用技巧
终极fabio配置验证指南:避免生产环境错误的10个实用技巧 【免费下载链接】fabio Consul Load-Balancing made simple 项目地址: https://gitcode.com/gh_mirrors/fa/fabio fabio是一个快速、现代的零配置负载均衡HTTP(S)和TCP路由器,专为Consul管…...
)
STL---stack/queue/deque/priority_queue详解(从使用到底层)
前言string,vector,list等容器,都在我的C专栏里有收录,重复的接口相似的使用我就不再过多介绍了,大家可以去我的C专栏里看string那篇文章,基本的使用写的比较详细。本文的重点在于讲解底层。stack和queue的…...