《深入Linux内核架构》第2章 进程管理和调度 (3)
目录
2.5 调度器的实现
2.5.1 概观
2.5.2 数据结构
2.5.3 处理优先级
2.5.3.1 nice和prior
2.5.3.2 vruntime
2.5.3.3 weight权重
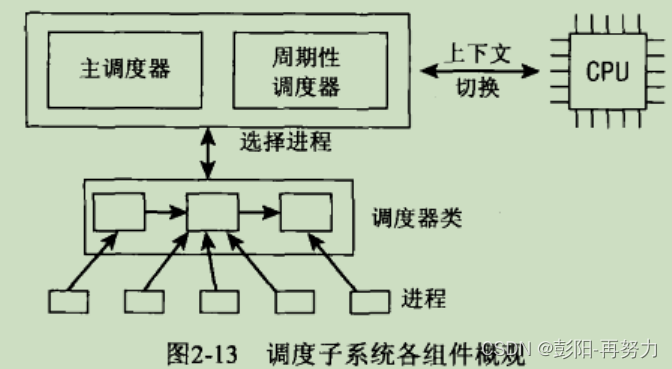
2.5.4 核心调度器
2.5 调度器的实现
调度器的任务:
1. 执行调度策略。
2. 执行上下文切换。
无论用户态抢占,还是内核态抢占,最终都调用schedule()函数,执行调度操作,实现进程切换。
调度分为:主动调用,周期调度
1. 主动调用:schedule()

2. 周期调度:时钟中断调用
一个进程一直while(1)不睡眠地执行任务,就是通过时钟中断,来调度其他进程的。
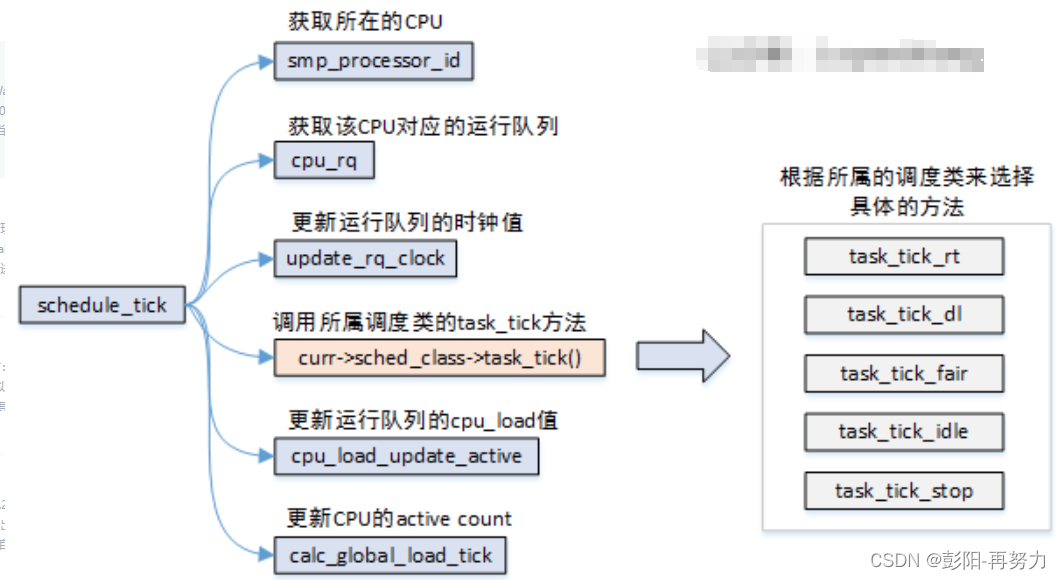
2.5.1 概观
CFS:完全公平调度器,调度器的一种。
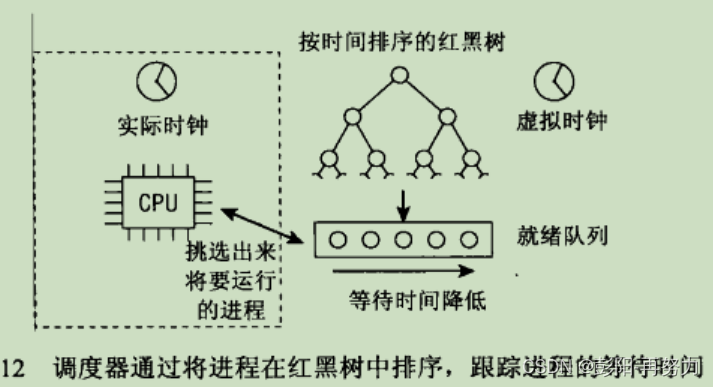
红黑树上不是task_struct,而是task_struct中的se成员,即调度实体。
调试:
#cat /proc/sched_debug 内容很多
2.5.2 数据结构
每个进程只能属于一个调度器。
常用调度器:
CFS:完全公平调度器,用于普通进程。
实时调度器:用于实时进程。
每种调度器通常都要实现:
主调度器:scheduler
周期调度器:scheduler tick
struct task_struct {int prio; //调度器最终参考值,通常等于normal_prio(除非临时提高优先级RT_mutex)int normal_prio; // CFS通过static_prio计算,RT通过rt_priority计算int static_prio; //用于普通进程,范围100-139unsigned int rt_priority; //用于实时进程,范围0-99struct sched_class *sched_class; //所属调度器类struct sched_entity se; //调度实体,不是指针unsigned int policy; //SCHED_NORMAL/SCHED_IDLE /SCHED_BATCH /SCHED_RR/SCHED_FIFOcpumask_t cpus_allowed; 该进程可在哪些CPU上运行}
static_prio:用于普通进程,系统启动时分配,可通过nice命令修改,否则一直不变。调度器类有:
CFS:
完全公平调度器。
struct sched_class fair_sched_class 普通进程使用
RT:
实时调度器
struct sched_class rt_sched_class 实时进程使用
STOP:
struct sched_class stop_sched_class
IDLE:
struct sched_class idle_sched_class
每种调度器类有各自策略policy:
CFS:
SCHED_NORMAL:默认策略。
SCHED_IDLE:CPU空闲时才允许进程,优先级较低。如后台任务
SCHED_BATCH:批处理任务。
RT:
SCHED_RR:基于时间片轮询。
SCHED_FIFO:任务一直运行,直到它自己主动放弃CPU。
struct sched_class { //每种调度器都要实现下列函数指针const struct sched_class *next;void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);void (*yield_task) (struct rq *rq);void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);struct task_struct * (*pick_next_task) (struct rq *rq,struct task_struct *prev);void (*put_prev_task) (struct rq *rq, struct task_struct *p);int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);void (*migrate_task_rq)(struct task_struct *p, int next_cpu);void (*set_cpus_allowed)(struct task_struct *p, const struct cpumask *newmask);void (*rq_online)(struct rq *rq);void (*rq_offline)(struct rq *rq);void (*set_curr_task) (struct rq *rq);void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);};enqueue_task:将进程加入到就绪队列中。
dequeue_task:从就绪队列中删除进程。
yield_task:主动放弃CPU,如CFS中会把调度实体放在红黑树最右端。
pick_next_task:根据调度策略从就绪队列中选择下一个要执行的任务。
check_preempt_curr:检查当前运行的进程是否应该被抢占,以便让更高优先级的进程运行。
select_task_rq:多核系统中,为进程选择合适CPU。
set_curr_task:更新当前正运行进程的调度信息。如修改调度策略,更新统计信息。
task_tick:系统周期性时钟中断时调用。用于更新进程的运行时间和统计信息。
struct rq { //运行队列,即就绪队列,每个CPU都有一个。unsigned long nr_running; //该CPU就绪的进程总数,包括cfs,RT就绪队列中进程unsigned long cpu_load[5]; //数组,1 分钟、5 分钟、15 分钟等5个平均负载数据。struct load_weight load; //该CPU可运行进程的权重总和,用于多处理器负载均衡。struct cfs_rq cfs; //cfs就绪队列struct rt_rq rt; //rt就绪队列struct task_struct *curr; //该CPU正运行的进程u64 clock;int cpu; //该就绪队列所属CPU}idle、stop调度类的就绪队列管理方式不同,所以struct rq中没有idle,stop的子就绪队列。
每个CPU都有自身就绪队列,定义方法:
DECLARE_PER_CPU(struct rq, runqueues);
一个进程在同一时刻只能在一个CPU的struct rq中。
如何知道一个进程运行在哪个CPU?
task_struct -> stack得到thread_info,thread_info存储当前运行的CPU
struct thread_info {__u32 cpu;}相关API:
返回指定CPU的就绪队列:
struct rq *rq = cpu_rq(cpu);
返回当前CPU的就绪队列:
struct rq *rq = this_rq();
#define this_rq() (&__get_cpu_var(runqueues))
返回当前进程所在CPU的就绪队列:
task_rq(p)
返回当前CPU正运行的进程:
cpu_curr(cpu)
调度实体:
struct sched_entity { //调度实体,调度系统中代表一个进程,被task_struct包含struct load_weight load; 负载权重struct rb_node run_node; 用于把调度实体连接到CFS就绪队列的红黑树unsigned int on_rq; 该调度实体是否在就绪队列上u64 exec_start; 当前实体上次被调度执行的时间u64 sum_exec_runtime; 当前实体总的执行时间,update_curr函数会周期更新u64 vruntime; 虚拟运行时间,用于在红黑树中排队,决定调度先后顺序u64 prev_sum_exec_runtime;//sum_exec_runtime - prev_sum_exec_runtime就是进程本次在CPU上执行的时间。struct cfs_rq *cfs_rq; 当前调度实体属于的cfs_rqu64 nr_migrations; 迁移次数。多核中,可能因为负载均衡而迁移到其它CPU上。};通过se的struct rb_node run_node成员,把进程挂在红黑树上,被调度器从树的左边往右依次调度。
struct task_struct {struct sched_entity se;}CFS调度类的yield_task_fair,enqueue_entity,entity_tick函数指针都会调用update_curr函数
update_curr函数:
用于计算和更新vruntime。
2.5.3 处理优先级
2.5.3.1 nice和prior
nice命令:
作用:更改普通进程的优先级(对应static_prior),不能用于实时进程。
nice值范围:-20到19。
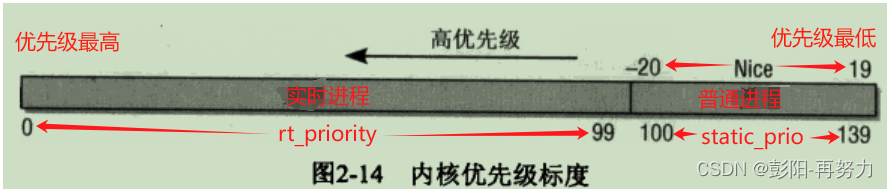
优先级范围:
0-139:0的优先级最高。
0-99:实时进程的优先级。
100-139:普通进程的优先级
static_prio = nice值+120
默认nice值为0,默认static_prio=120
struct task_struct {int static_prio; //静态优先级,普通进程,范围100-139,对应nice值-20 到19unsigned int rt_priority; //实时进程的优先级,范围0-99int normal_prio; // CFS通过static_prio计算,RT通过rt_priority计算int prio;}task_struct->static_prio:
静态优先级,即普通进程的优先级。
值范围:100-139,默认值为120。
计算:static_prio = NICE_TO_PRIO(nice); //即static_prio = nice+120
修改:可通过nice命令或sched_setscheduler函数修改。
task_struct->rt_priority:
实时优先级,即实时进程的优先级。
值范围:0-99
task_struct->normal_prio:
普通优先级。
普通进程:normal_prio = static_prio
实时进程:normal_prio = 99 - rt_priority
task_struct->prio:
动态优先级。调度器最终使用。
计算:通常直接等于normal_prio。
特殊情况:
优先级反转:低优先级进程A使用RT_mutex上锁后,高优先级进程B等待该锁,此时A进程临时拥有B进程的高优先级,可让A尽早执行,尽早释放锁。此时prio就不等于normal_prio。
总结如下图:
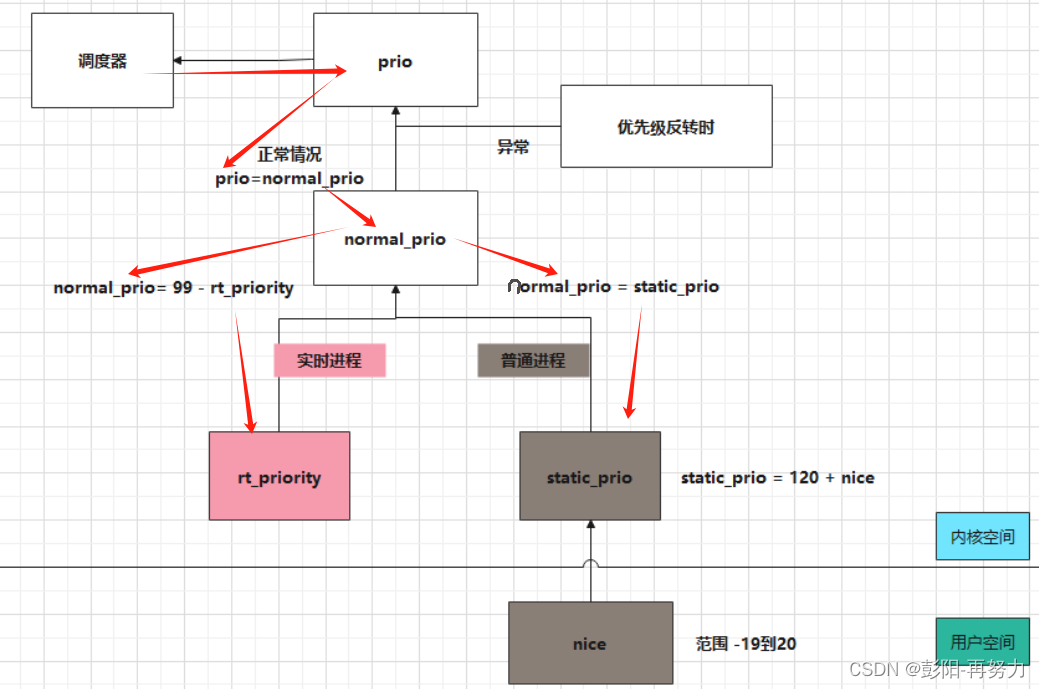
修改普通进程的nice,可影响运行时间比例。
应用层nice -> prio - > weight -> 最终得到进程可运行时间比例。
2.5.3.2 vruntime
struct sched_entity {u64 vruntime;}普通进程的CFS调度器使用,而实时进程不用vruntime。
vruntime:表示进程虚拟运行时间。
进程的vruntime值作用:
决定了在CFS红黑树中的位置,树的最左端节点的vruntime最小。
CFS调度器选择红黑树最左进程调度。
为什么叫虚拟运行时间?
根据nice把实际运行时间放大缩小。
计算方法:vruntime += delta_exec * NICE_0_LOAD / weight
delta_exec: 最近一次实际执行时间。
NICE_0_LOAD:固定值。nice值为0对应的权重值
weight:当前进程的nice值对应的权重值。
下节讲如何查找nice对应权重weight。
sum_exec_runtime更新:
curr->se.sum_exec_runtime += delta_exec;
撤销CPU时,prev_exec_runtime = sum_exec_runtime
sum_exec_runtime不清0,一直递增。
CFS起初为进程分配相同的vruntime,子进程会继承父进程的vruntime。
当一个进程进入内核空间执行系统调用或发生中断时,自动将处理器的状态信息(包括通用寄存器、程序计数器PC、栈指针SP等)保存到当前进程的内核栈中的pt_regs结构体中。
因为寄存器不一样,所以不同CPU架构定义的struct pt_regs不一样。
x86架构:
struct pt_regs {unsigned long ebx;unsigned long ecx;unsigned long edx;unsigned long esi;unsigned long edi;unsigned long ebp;unsigned long eax;unsigned long xds;unsigned long xes;unsigned long orig_eax;unsigned long eip;unsigned long xcs;unsigned long eflags;unsigned long esp; 栈指针unsigned long xss;};ARM架构:
struct pt_regs {long uregs[18];};#define ARM_cpsr uregs[16]#define ARM_pc uregs[15]#define ARM_lr uregs[14]#define ARM_sp uregs[13]#define ARM_ip uregs[12]#define ARM_fp uregs[11]#define ARM_r10 uregs[10]#define ARM_r9 uregs[9]#define ARM_r8 uregs[8]#define ARM_r7 uregs[7]#define ARM_r6 uregs[6]#define ARM_r5 uregs[5]#define ARM_r4 uregs[4]#define ARM_r3 uregs[3]#define ARM_r2 uregs[2]#define ARM_r1 uregs[1]#define ARM_r0 uregs[0]#define ARM_ORIG_r0 uregs[17]2.5.3.3 weight权重
实时进程的权重比普通进程更高。
struct sched_entity { //被task_struct包含struct load_weight load;}struct load_weight {unsigned long weight; 权重,用来确定进程运行时间比例unsigned long inv_weight; 权重倒数,方便做除法计算};根据进程prio值计算weight和inv_weight:
void set_load_weight(struct task_struct *p){int prio = p->static_prio - MAX_RT_PRIO; //MAX_RT_PRIO=100struct load_weight *load = &p->se.load;load->weight = prio_to_weight[prio]; 数组load->inv_weight = prio_to_wmult[prio]; 数组}通过prio_to_weight数组把prio转换为weight,而weight最终影响CPU运行时间比例。
static const int prio_to_weight[40] = { //将nice值转化为prio后,作为数组index。/* -20 */ 88761, 71755, 56483, 46273, 36291,/* -15 */ 29154, 23254, 18705, 14949, 11916,/* -10 */ 9548, 7620, 6100, 4904, 3906,/* -5 */ 3121, 2501, 1991, 1586, 1277,/* 0 */ 1024, 820, 655, 526, 423,/* 5 */ 335, 272, 215, 172, 137,/* 10 */ 110, 87, 70, 56, 45,/* 15 */ 36, 29, 23, 18, 15,}; 数组nice/prio差1,se的weight相差大约1.25倍,即CPU时间比例相差1.25倍。进程加入CPU就绪队列时,把该进程权重加入CPU就绪队列总权重中。
进程从CPU就绪队列移除时,就从CPU就绪队列总权重减去该进程权重。
const struct sched_class fair_sched_class = {.enqueue_task = enqueue_task_fair,.dequeue_task = dequeue_task_fair,}enqueue_task_fair-> enqueue_entity -> update_load_add(&cfs_rq->load, se->load.weight);CPU进程总权重用于多CPU间负载均衡。
参数:/proc/sys/kernel/sched_latency_ns
即调度延迟,或调度周期,就绪队列的所有进程在该周期内至少有运行一次。
单位:纳秒。
默认值:24000000,24毫秒
举例:调度延迟是24毫秒,如果有4个进程,则每个进程可执行6毫秒。
参数:/proc/sys/kernel/sched_min_granulariry_ns
即调度最小粒度,每次调度后进程至少执行的时间。
单位:纳秒。
默认值:3000000,3毫秒
参数:/proc/sys/kernel/sched_nr_latency
含义:一个调度延迟周期内可处理的最大进程数。
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
计算一个进程se在本轮调度周期应分得的真实运行时间。
计算公式:
进程的时间片= (调度周期 ×(进程se权重 / CFS运行队列中进程权重总和))
__sched_period函数:
作用:获取调度周期值,即sysctl_sched_latency = /proc/sys/kernel/sched_latency_ns
nice prior weight总结图:

2.5.4 核心调度器
核心调度器分为:
周期性调度器:scheduler_tick
主调度器:scheduler
周期性调度器:scheduler_tick
时钟周期性调度器,根据HZ自动调用。如果为了省电,可关闭该调度器。
任务:
1 更新调度器clock。
2. 更新当前runqueue的clock。用于辅助计算进程上次调度运行时长
3. 执行不同调度类中的task_tick回调函数。
curr->sched_class->task_tick(rq, curr);
周期任务有:
CFS会更新进程vruntime
如果进程已执行足够时间或更高优先级的进程需运行时,当前进程应立即让出CPU,此时可给该进程thread_info中flag设置TIF_NEED_RESCHED标志位。
4. 更新该就绪队列的CPU load。
注意:周期性调度器scheduler_tick不会去主动调度其他进程,而是为当前进程设置TIF_NEED_RESCHED标志位,tick时钟中断返回时检测到设置了该标志位,则调度其他进程。
__sched前缀修饰的变量或函数:
存储在对应elf文件中.sched.text段,当coredump时可忽略.sched.text相关调用。
主调度器:scheduler
1. preempt_disable( );
关闭内核抢占
2. pick_next_task:
选择下一个进程
3. context_switch:
进程上下文切换,包含:
switch_mm : 加载新地址空间,更新页表,刷出TLB(若是内核线程,无需刷出TLB)
switch_to: 从进程thread_info中保存的信息,恢复CPU寄存器,内核栈等。
进程的寄存器内容,进入内核态时保存在它的内核栈中。
内核抢占:
即是否让出CPU,让别的进程执行。
如何判断需要抢占?
检查进程thread_info的flags成员是否设置TIF_NEED_RESCHED,若设置,则让出CPU。
scheduler和scheduler_tick函数都会根据需要设置TIF_NEED_RESCHED标志。并在下一个抢占点到来时检查该标志,调度其他进程,完成抢占操作。
抢占点:
中断处理程序的返回到内核态,如时钟中断。
系统调用结束返回用户空间。
不允许抢占:响应慢,吞吐高。
允许抢占:响应快,吞吐低。
浪费部分CPU在进程切换,所以导致吞吐低。
ARM中:
struct thread_info {unsigned long flags;int preempt_count;}flags的TIF_NEED_RESCHED标志:
是否让出CPU,让其他进程抢占。
preempt_count:一个计数器。
大于 0 时:即当前进程在临界区或执行关键操作,禁止其他更高优先级的任务抢占当前线程。
等于0:表示允许抢占。
举例:
spin_lock函数将preempt_count+1
spin_unlock函数preempt_count-1
一个进程用spin_lock上锁后,不允许其他进程无法抢占当前进程。
每次内核前函数检查preempt_count值。
惰性FPU:如果没有使用扩充寄存器(如浮点寄存器),不会保存和恢复。
举例:A进程使用了浮点寄存器,切换到B进程,但B进程未使用,不替换寄存器值,节省恢复寄存器时间。
相关文章:
《深入Linux内核架构》第2章 进程管理和调度 (3)
目录 2.5 调度器的实现 2.5.1 概观 2.5.2 数据结构 2.5.3 处理优先级 2.5.3.1 nice和prior 2.5.3.2 vruntime 2.5.3.3 weight权重 2.5.4 核心调度器 2.5 调度器的实现 调度器的任务: 1. 执行调度策略。 2. 执行上下文切换。 无论用户态抢占,还是…...

鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Refresh)
可以进行页面下拉操作并显示刷新动效的容器组件。 说明: 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 支持单个子组件。 从API version 11开始,Refresh子组件会跟随手势下拉而下移…...

数据资产管理解决方案:构建高效、安全的数据生态体系
在数字化时代,数据已成为企业最重要的资产之一。然而,如何有效管理和利用这些数据资产,却是许多企业面临的难题。本文将详细介绍数据资产管理解决方案,帮助企业构建高效、安全的数据生态体系。 一、引言 在信息化浪潮的推动下&a…...

Visual Studio 2013 - 调试模式下查看监视窗口
Visual Studio 2013 - 调试模式下查看监视窗口 1. 监视窗口References 1. 监视窗口 Ctrl Alt W,1-4:监视窗口 (数字键不能使用小键盘) or 调试 -> 窗口 -> 监视 -> 监视 1-4 调试状态下使用: 在窗口中点击空白行,…...
CTF 题型 SSRF攻击例题总结
CTF 题型 SSRF攻击&例题总结 文章目录 CTF 题型 SSRF攻击&例题总结Server-side Request Forgery 服务端请求伪造SSRF的利用面1 任意文件读取 前提是知道要读取的文件名2 探测内网资源3 使用gopher协议扩展攻击面Gopher协议 (注意是70端口)python…...

【Swing】Java Swing实现省市区选择编辑器
【Swing】Java Swing实现省市区选择编辑器 1.需求描述2.需求实现3.效果展示 系统:Win10 JDK:1.8.0_351 IDEA:2022.3.3 1.需求描述 在公司的一个 Swing 的项目上需要实现一个选择省市区的编辑器,这还是第一次做这种编辑器…...
spring suite搭建springboot操作
一、前言 有时候久了没开新项目了,重新开发一个新项目,搭建springboot的过程都有点淡忘了,所有温故知新。 二、搭建步骤 从0开始搭建springboot 1.创建work空间。步骤FileNewJava Working Set。 2.选择Java Working Set。 3.自…...

mysql重构
力扣题目链接 列转行 SELECT product_id, store1 store, store1 price FROM products WHERE store1 IS NOT NULL UNION SELECT product_id, store2 store, store2 price FROM products WHERE store2 IS NOT NULL UNION SELECT product_id, store3 store, store3 price FROM p…...

Linux用户、用户组
用户管理命令: 首先要先知道两个配置文件:/etc/group 用户组配置文件/etc/passwd 保存了所有用户的用于读取的必要信息**/etc/shadow **是 Linux 系统中用于存储用户密码信息的文件。这个文件也被称为“影子文件”,因为它包含了 /etc/passwd…...
操作系统系列学习——信号量的代码实现
文章目录 前言信号量的代码实现 前言 一个本硕双非的小菜鸡,备战24年秋招,计划学习操作系统并完成6.0S81,加油! 本文总结自B站【哈工大】操作系统 李治军(全32讲) 老师课程讲的非常好,感谢 【哈…...

【Python操作基础】——变量操作
🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972 个人介绍: 研一|统计学|干货分享 擅长Python、Matlab、R等主流编程软件 累计十余项国家级比赛奖项,参与研究经费10w、40w级横向 文…...
讲解-案例(附C代码))
滑模控制算法(SMC)讲解-案例(附C代码)
目录 一、滑模控制算法的基本原理 1)滑模面(Sliding Surface)的设计 2)达到条件(Reaching Condition)...
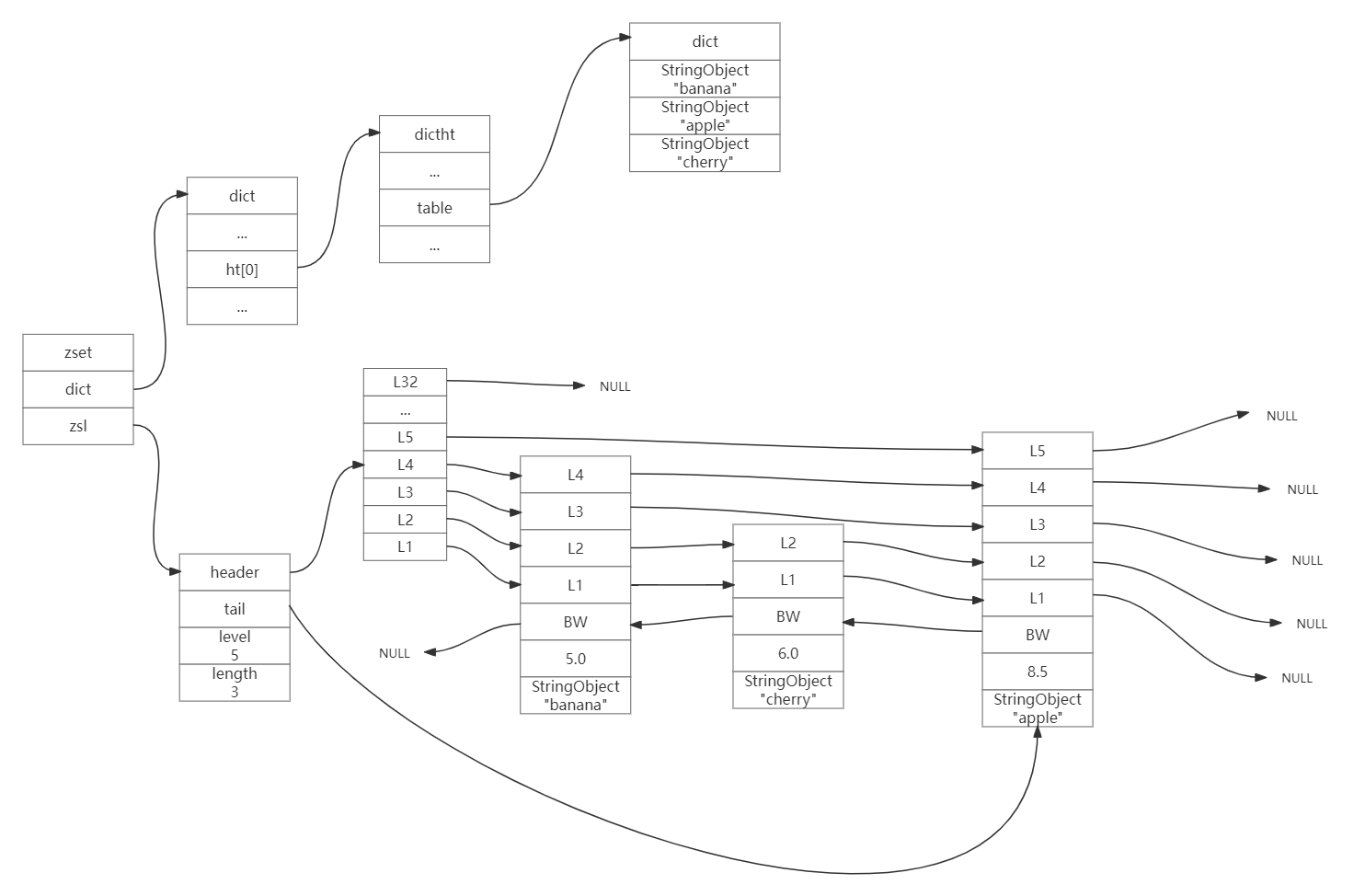
Redis数据结构对象之集合对象和有序集合对象
集合对象 集合对象的编码可以是intset或者hashtable. 概述 intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面。 另一方面,hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个…...

不要百花齐放
javascript中数组的遍历有如下方法: 1、for (var i 0; i < arr.length; i) 2、for(var item of arr) 3、for(var item in arr) 4、arr.forEach 5、arr.map 6、arr.filter 7、arr.find 8、arr.findIndex 9、arr.indexOf arr.lastIndexOf 10、arr.every…...
使用Java JDBC连接数据库
在Java应用程序中,与数据库交互是一个常见的任务。Java数据库连接(JDBC)是一种用于在Java应用程序和数据库之间建立连接并执行SQL查询的标准API。通过JDBC,您可以轻松地执行各种数据库操作,如插入、更新、删除和查询数…...
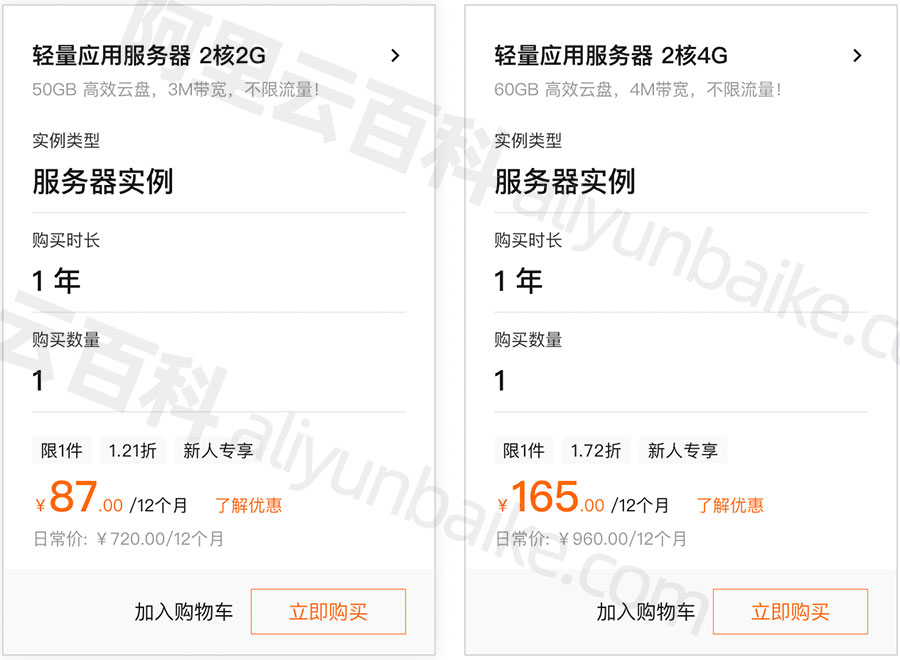
阿里云2核4G4M轻量应用服务器价格165元一年
阿里云优惠活动,2核4G4M轻量应用服务器价格165元一年,4Mbps带宽下载速度峰值可达512KB/秒,系统盘是60GB高效云盘,不限制月流量,2核2G3M带宽轻量服务器一年87元12个月,在阿里云CLUB中心查看 aliyun.club 当前…...
的原理)
连续纯合片段(runs of homozygosity, ROH)的原理
连续纯合片段(Runs of Homozygosity, ROH)的原理及其结果查看方式包含以下几个方面: 原理 定义和识别: ROH是指基因组中由相同祖先遗传下来的连续纯合等位基因组成的片段。它们可以通过比较个体基因组上的等位基因序列来识别。当…...
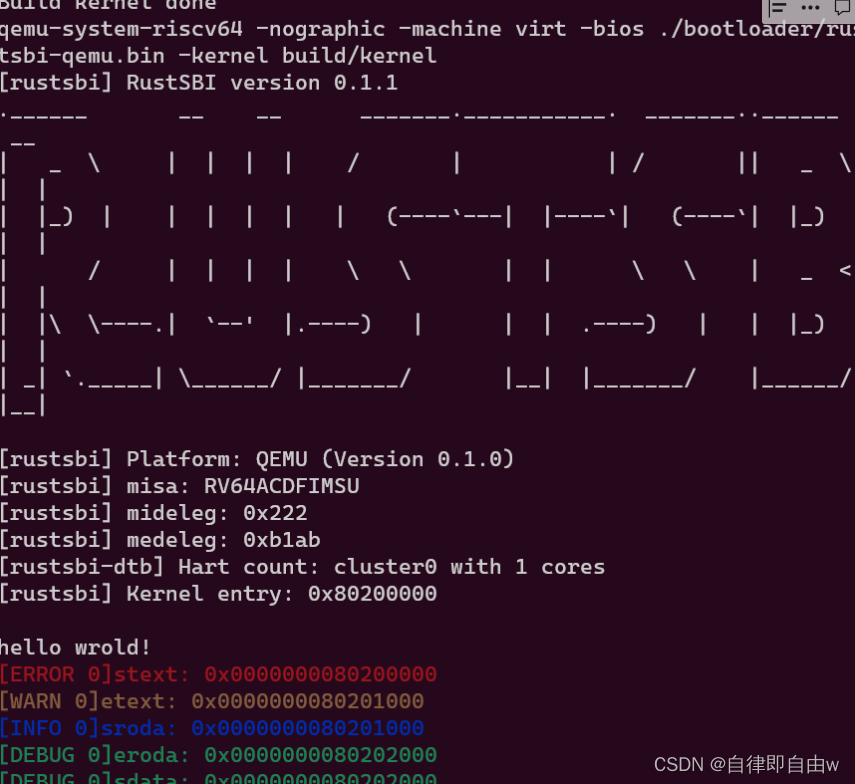
UCORE 清华大学os实验 lab0 环境配置
打卡 lab 0 : 环境配置 : 首先在ubt 上的环境,可以用虚拟机或者直接在windows 上面配置 然后需要很多工具 如 qemu gdb cmake git 就是中间犯了错误,误以为下载的安装包,一直解压不掉,结果用gpt 检查 结…...
linux 安装常用软件
文件传输工具 sudo yum install –y lrzsz vim编辑器 sudo yum install -y vimDNS 查询 sudo yum install bind-utils用法可以参考文章 《掌握 DNS 查询技巧,dig 命令基本用法》 net-tools包 yum install net-tools -y简单用法: # 查看端口占用情况…...

OpenMP使用教程:入门到精通
在并行编程的领域中,OpenMP无疑是一个强大而又便捷的工具,它让程序员能够以最少的努力实现程序的并行化。本文将详细介绍OpenMP的基本概念、环境配置、核心指令以及实际代码示例,旨在帮助读者从入门到精通OpenMP的使用。 什么是OpenMP&#…...

实战应用:基于快马构建高保真抖音模块,为技术方案选型与竞品分析提供实例
最近在研究抖音最新版本的技术实现方案,发现用InsCode(快马)平台可以快速搭建一个高保真的功能模拟应用。这个实战项目不仅能帮助理解抖音的核心模块设计,还能为技术选型提供直观参考。下面分享下我的实现思路和关键要点: 智能推荐流实现 通过…...

从“能用”到“精准”:Halcon相机内参标定后的参数验证与实战应用指南
从“能用”到“精准”:Halcon相机内参标定后的参数验证与实战应用指南 当你完成Halcon相机内参标定,生成了那个看似完美的参数文件时,真正的挑战才刚刚开始。很多开发者会陷入"标定完成即大功告成"的误区,却不知未经验证…...

Sony-PMCA-RE技术解析与实战指南:解锁Sony相机潜能的开源工具
Sony-PMCA-RE技术解析与实战指南:解锁Sony相机潜能的开源工具 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 一、价值定位:重新定义相机控制边界 1.1 开源…...

零基础5分钟上手:Wan2.2-T2V-A5B文本生成视频保姆级教程
零基础5分钟上手:Wan2.2-T2V-A5B文本生成视频保姆级教程 1. 为什么选择Wan2.2-T2V-A5B 如果你正在寻找一个快速、轻量级的文本生成视频工具,Wan2.2-T2V-A5B绝对值得考虑。这个50亿参数的模型专为快速内容创作优化,能在普通显卡上实现秒级出…...

终极Mac风扇控制指南:3步掌握smcFanControl让Intel Mac运行更凉爽
终极Mac风扇控制指南:3步掌握smcFanControl让Intel Mac运行更凉爽 【免费下载链接】smcFanControl Control the fans of every Intel Mac to make it run cooler 项目地址: https://gitcode.com/gh_mirrors/smc/smcFanControl 当你的Intel Mac在高负载下工作…...
)
告别联网烦恼:uv离线安装科学计算包的3种实战姿势(NumPy/TensorFlow实测)
数据科学家必备:三种高效离线安装Python科学计算包的终极方案 实验室的服务器突然断网了,而你的TensorFlow模型训练正进行到关键时刻——这种场景对数据科学家来说简直是噩梦。别担心,离线安装Python包并非无解难题。本文将带你掌握三种经过实…...

Qwen3-VL-8B在软件测试中的应用:自动生成测试用例与缺陷报告截图分析
Qwen3-VL-8B在软件测试中的应用:自动生成测试用例与缺陷报告截图分析 最近和几个做软件测试的朋友聊天,大家普遍都在吐槽一件事:写测试用例和缺陷报告太费时间了。尤其是现在敏捷开发节奏快,版本迭代频繁,测试人员不仅…...

XUnity.AutoTranslator:如何为Unity游戏构建智能翻译解决方案?
XUnity.AutoTranslator:如何为Unity游戏构建智能翻译解决方案? 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 在全球化游戏市场中,语言障碍成为玩家体验的最大障碍之一…...

WordPress开发工具链配置:IDE集成与CI/CD自动化
WordPress开发工具链配置:IDE集成与CI/CD自动化 【免费下载链接】WordPress-Coding-Standards PHP_CodeSniffer rules (sniffs) to enforce WordPress coding conventions 项目地址: https://gitcode.com/gh_mirrors/wo/WordPress-Coding-Standards WordPres…...

SiameseUIE Vue前端开发:交互式信息抽取平台构建
SiameseUIE Vue前端开发:交互式信息抽取平台构建 如果你用过一些信息抽取工具,可能会遇到这样的体验:要么是命令行黑框框,要么是简陋的网页界面,输入一段文本,返回一堆看不懂的JSON数据。整个过程冷冰冰的…...