Spark on Yarn安装配置
目录
前言
初了解spark
Standalone模式
Yarn模式
前言
今天我们讲解Spark的安装配置,spark的部署分为两种,一种是Standalone模式,另一种就是on yarn 模式,我们这一节着重讲解on yarn 模式,因为符合生产活动,但也会提到Standalone模式
初了解spark
Spark是一个快速、通用、可扩展的集群计算引擎,它基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高伸缩性。Spark允许用户将其部署在大量廉价的硬件之上,形成集群。Spark诞生于2009年,最初由美国加州大学伯克利分校的AMP实验室开发,是一个基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
Spark的特点主要体现在以下几个方面:
Spark的主要组件包括SparkCore,它将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
总的来说,Spark作为一个强大而灵活的大数据处理工具,以处理各种类型的大数据任务和应用场景。
- 快速:Spark基于内存的运算速度比Hadoop的MapReduce快100倍,即使基于硬盘的运算也要快10倍以上。这得益于Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
- 通用:Spark的设计容纳了其它分布式系统拥有的功能,包括批处理(类似Hadoop)、迭代式计算(机器学习)、交互查询(类似Hive)和流处理(类似Storm)等,这降低了维护成本。
- 易用性:Spark提供了Python、Java、Scala、SQL的API和丰富的内置库,使其与其他的大数据工具整合得很好,包括Hadoop、Kafka等。此外,Spark还支持超过80种高级算法,使用户可以快速构建不同的应用。
Standalone模式
Standalone模式是Spark自带的资源调动引擎,构建一个由Master + Slave构成的Spark集群,Spark运行在集群中。
这个要和Hadoop中的Standalone区别开来。这里的Standalone是指只用Spark来搭建一个集群,不需要借助其他的框架。是相对于Yarn和Mesos来说的。
解压:
tar -zxvf spark-3.0.3-bin-hadoop3.2.tgz -C /opt/module/修改名字:
mv spark-3.0.3-bin-hadoop3.2/ spark-standalone配置集群节点:
mv slaves.template slaves
vim slaves
添加内容:
bigdata1
bigdata2
bigdata3修改spark-env.sh文件,添加bigdata1节点
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
添加内容:
SPARK_MASTER_HOST=bigdata1
SPARK_MASTER_PORT=7077向其他机器分发spark-standalone包
在其他机器创建spark-standalone目录。
scp -r /opt/module/spark-standalone/ bigdata2:/opt/module/spark-standalone/
scp -r /opt/module/spark-standalone/ bigdata3:/opt/module/spark-standalone/启动spark集群官方求PI案例
bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master spark://bigdata1:7077 \
> ./examples/jars/spark-examples_2.12-3.0.3.jar \
> 10结果:
Pi is roughly 3.1408591408591406
------------------------------ 命令 ---------------------------------------
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://bigdata1:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.0.3.jar \
10
Yarn模式
saprk客户端连接Yarn,不需要额外构建集群。
解压:
tar -zxvf spark-3.0.3-bin-hadoop3.2.tgz -C /opt/module/配置环境变量:
#SPARK_HOME
export SPARK_HOME=/opt/module/spark-3.0.3-yarn
export PATH=$PATH:$SPARK_HOME/bin修改配置文件:
修改hadoop配置文件/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml,添加如下内容:
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value>
</property>
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>分发配置文件:
scp -r /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml bigdata2:/opt/module/hadoop-3.1.3/etc/hadoop/
scp -r /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml bigdata3:/opt/module/hadoop-3.1.3/etc/hadoop/修改spark-env.sh
mv spark-env.sh.template spark-env.sh vim spark-env.sh内容:
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
重启Hadoop
start-all.sh
start-yarn.sh 求PI
spark-submit --master yarn --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-3.0.3.jar结果:
Pi is roughly 3.142211142211142
相关文章:

Spark on Yarn安装配置
目录 前言 初了解spark Standalone模式 Yarn模式 前言 今天我们讲解Spark的安装配置,spark的部署分为两种,一种是Standalone模式,另一种就是on yarn 模式,我们这一节着重讲解on yarn 模式,因为符合生产活动&#…...

Debezium日常分享系列之:Debezium 2.5.3.Final发布
Debezium日常分享系列之:Debezium 2.5.3.Final发布 一、重大改变1.SQL Server 二、改进和变化1.Debezium 服务器的 TRACE 级别日志记录2.Informix 将 LSN 附加到事务标识符3.PostgreSQL 改进 三、Debezium技术总结 一、重大改变 1.SQL Server 首次部署连接器时&am…...
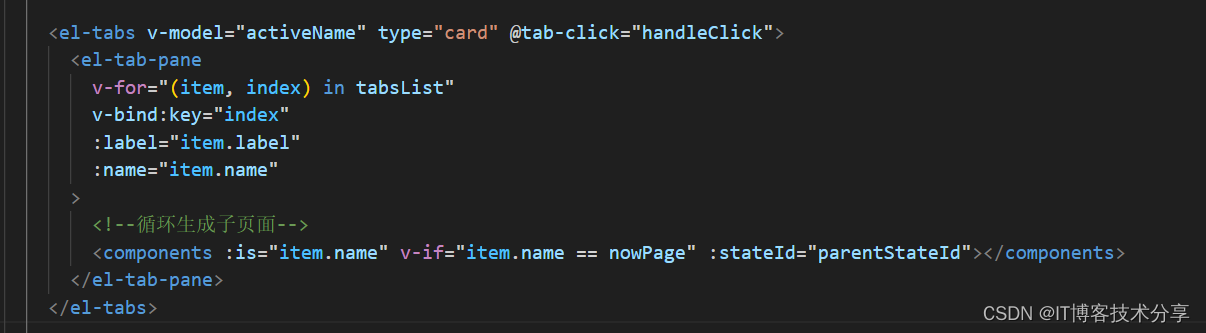
elment-ui el-tabs组件 每次点击后 created方法都会执行2次
先看错误的 日志打印: 错误的代码如下: 正确的日志打印: 正确的代码如下: 前言: 在element-ui的tabs组件中,我们发现每次切换页面,所有的子组件都会重新渲染一次。当子页面需要发送数据请求并且子页面过多时,这样会过多的占用网络资源。这里我们可以使用 v-if 来进行…...

sheng的学习笔记-AI-Network in Network(NIN)和1*1卷积
目录:sheng的学习笔记-AI目录-CSDN博客 简介 Network In Network 是发表于 2014 年 ICLR 的一篇 paper。当前被引了 3298 次。这篇文章采用较少参数就取得了 Alexnet 的效果,Alexnet 参数大小为 230M,而 Network In Network 仅为 29M&#x…...
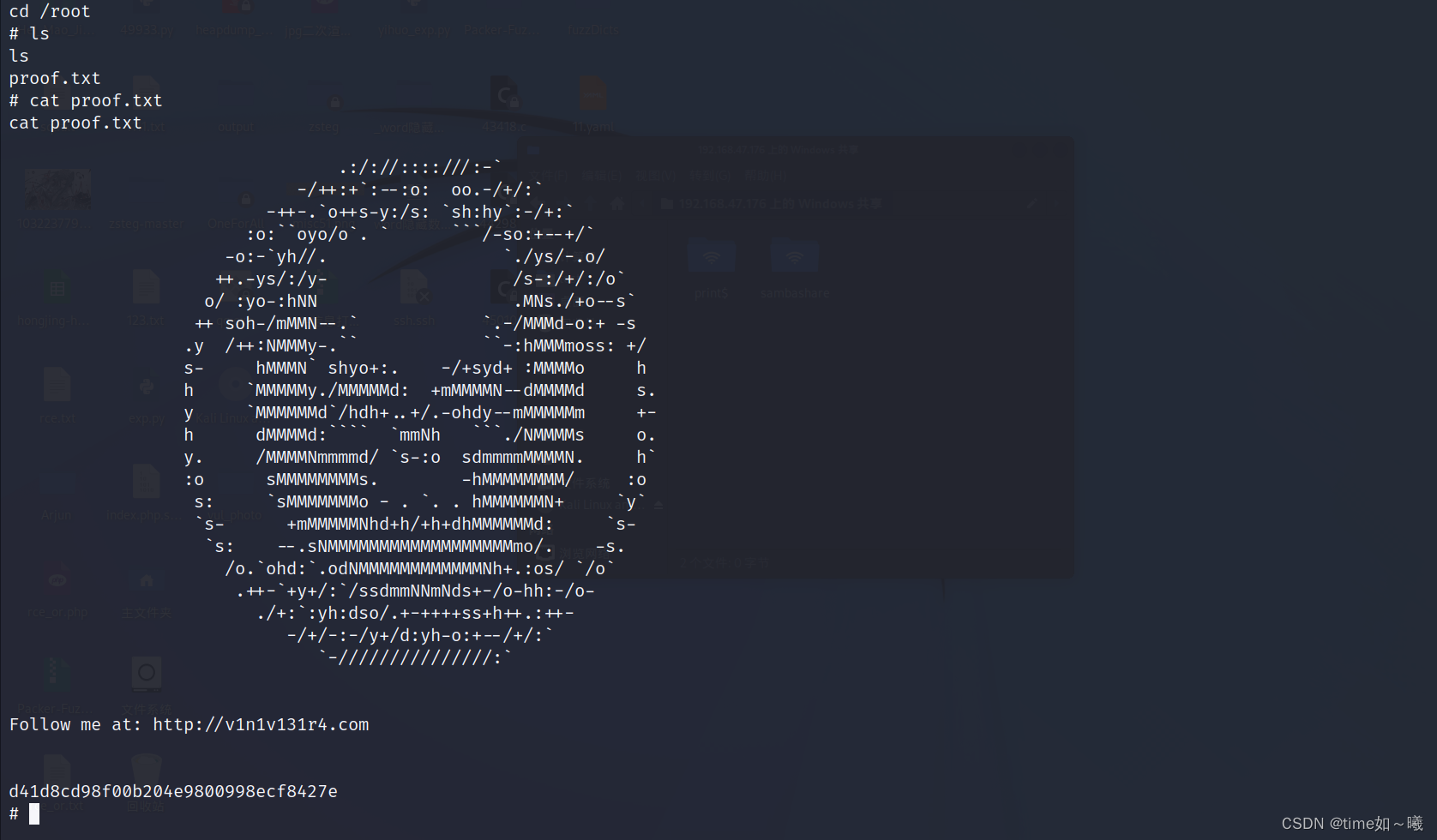
【靶机测试--PHOTOGRAPHER: 1【php提权】】
前期准备 靶机下载地址: https://vulnhub.com/entry/photographer-1%2C519/ 信息收集 nmap 扫描同网段 ┌──(root㉿kali)-[/home/test/桌面] └─# nmap -sP 192.168.47.0/24 --min-rate 3333 Starting Nmap 7.92 ( https://nmap.org ) at 2024-03-19 07:37 …...

LeetCode每日一题——删除有序数组中的重复项
删除有序数组中的重复项OJ链接:26. 删除有序数组中的重复项 - 力扣(LeetCode) 题目: 思路: 题目要求每个数只能出现一次,然后返回新数组的长度。仔细一看,其实与我们之前的移除元素那道题十分…...
元宇宙VR数字化艺术展降低办展成本
元宇宙AI时代已经来临,越来越多人期待在元宇宙数字空间搭建一个属于自己的虚拟展厅,元宇宙虚拟展厅搭建平台是VR公司深圳华锐视点为企业研发的可编辑工具,那么元宇宙虚拟展厅搭建平台有哪些新突破? 元宇宙虚拟展厅搭建平台采用了先进的web3D…...
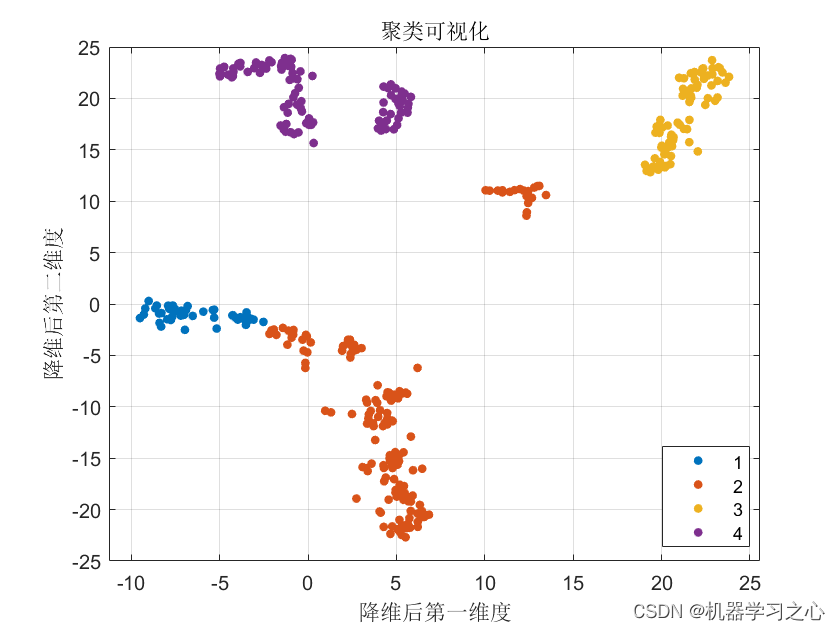
聚类分析 | Matlab实现基于PCA+DBO+K-means的数据聚类可视化
聚类分析 | Matlab实现基于PCADBOK-means的数据聚类可视化 目录 聚类分析 | Matlab实现基于PCADBOK-means的数据聚类可视化效果一览基本介绍程序设计参考资料 效果一览 基本介绍 PCA(主成分分析)、DBO(蜣螂优化算法)和K-means聚类…...
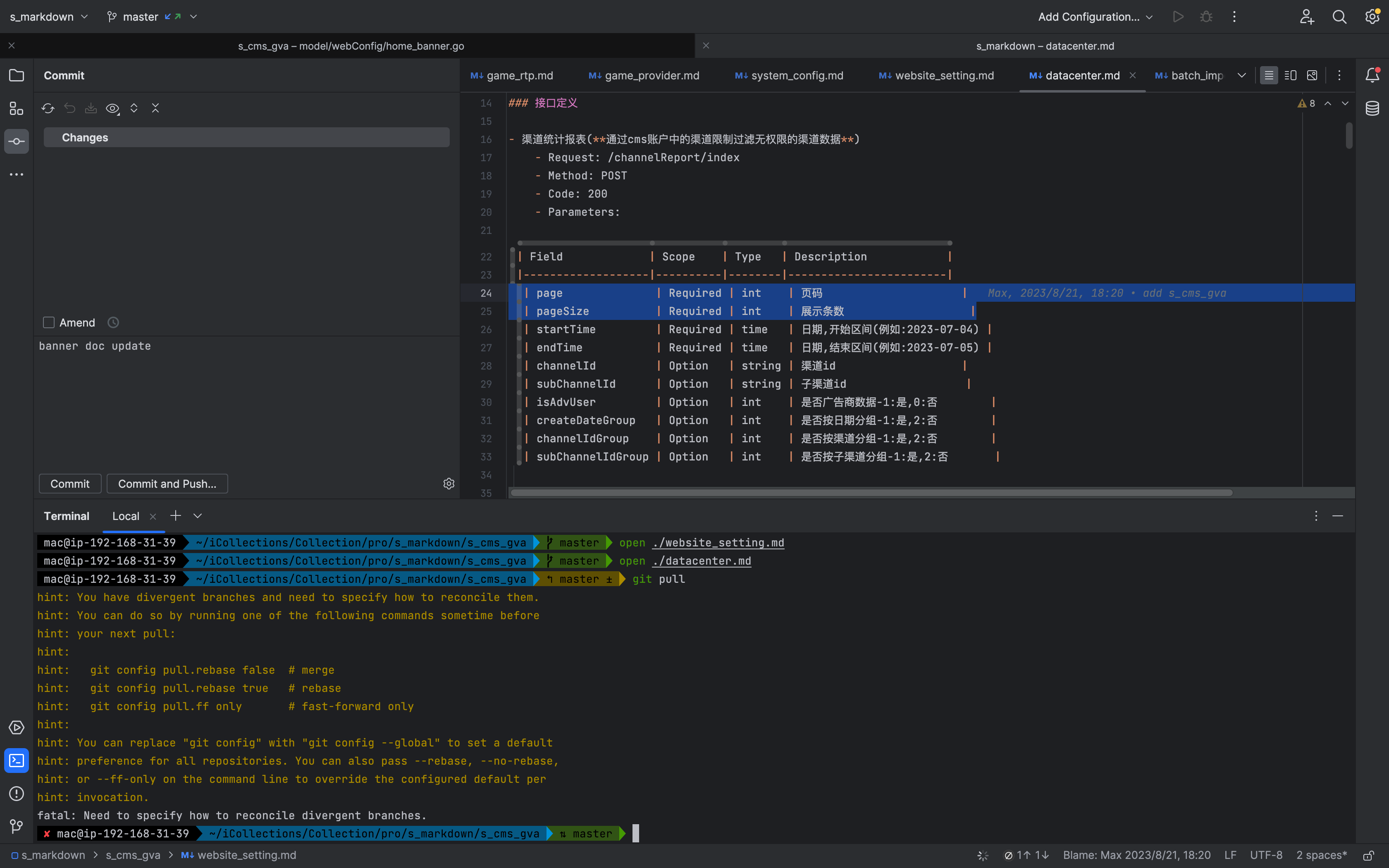
使用 git 先提交后拉取的时候远程分支不允许问题
问题场景 修改本地代码使用 git 先提交后拉取的时候远程分支不允许的问题 修改本地代码时,远程分支存在其他新提交先执行了 git commit -m xxx update然后再执行 git pull 拉取远程分支代码,出现如下提示 hint: You have divergent branches and need…...

Unity 创建快捷方式开机自动启动
Unity 创建快捷方式自动启动 🌭食用方法 🌭食用方法 先导入插件包👈,再 把导入的ZYF_AutoRunApp.cs 挂到物体上即可。 using System; using System.Collections; using System.Collections.Generic; using System.IO; using Uni…...
)
什么是docker(docker客户端、镜像、容器、仓库)
一、docker Docker 是一个开源的容器化平台,它可以让开发者打包应用程序及其依赖项成为一个轻量级、可移植的容器,然后在任何环境中运行。Docker 容器将应用程序及其依赖项打包到一个标准化单元中,包括代码、运行时环境、系统工具、系统库等…...

[Python人工智能] 四十三.命名实体识别 (4)利用bert4keras构建Bert+BiLSTM-CRF实体识别模型
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前文讲解如何实现中文命名实体识别研究,构建BiGRU-CRF模型实现。这篇文章将继续以中文语料为主,介绍融合Bert的实体识别研究,使用bert4keras和kears包来构建Bert+BiLSTM-CRF模型。然而,该代码最终结…...

Android Framework开发之Linux +Vim命令
一、linux常用命令 在Android源码开发中,Linux命令的运用是至关重要的。这些命令不仅帮助开发者有效管理文件、目录和系统资源,还能在源码编译、调试和排错过程中发挥关键作用。以下是对Android源码开发中常用Linux命令的更详细介绍: 当然可…...

MySQL 索引的10 个核心要点
文章目录 🍉1. 索引底层采用什么数据结构?为什么不用hash🍉2. B树与B树区别?为何用B树?🍉3. 自增主键理解?🍉4. 为什么自增主键不连续🍉5. Innodb为什么推荐用自增ID&…...
MaixSense-A010 接入 ROS
MaixSense 是什么 MaixSense 系列产品搭载 TOF 深度摄像头,目前有 MaixSense-A010 和 MaixSense-A075V 两款产品。 MS-A010 是一款由 BL702 炬佑 100x100 TOF 模组所组成的极致性价比的 TOF 3D 传感器模组,最大支持 100x100 的分辨率和 8 位精度&…...
使用WordPress在US Domain Center上建立招聘网站的详细教程
第一部分:介绍招聘网站 招聘网站是指用于发布招聘信息、吸引求职者、进行简历筛选和管理招聘流程的网站。在WordPress中,您可以轻松地创建一个功能齐全的招聘网站,以便企业能够方便地管理招聘流程,并为求职者提供信息和应聘渠道。…...
C++:类和对象(上篇)
目录: 一:面向对象和过程的介绍 二:类的引入 三:类的定义 四:类的访问限定符以及封装 五:类的作用域 六:类的实例化 七:类对象大小的计算 八:类成员函数的this指…...

氧化铝电容的工艺结构原理及选型参数总结
🏡《总目录》 目录 1,概述2,工作原理3,结构特点4,工艺流程4.1,材料准备4.2,氧化处理4.3,薄膜处理4.4,电极制作4.5,封装4.6,测试与筛选5,选型参数5.1,电容量(Capacitance)...
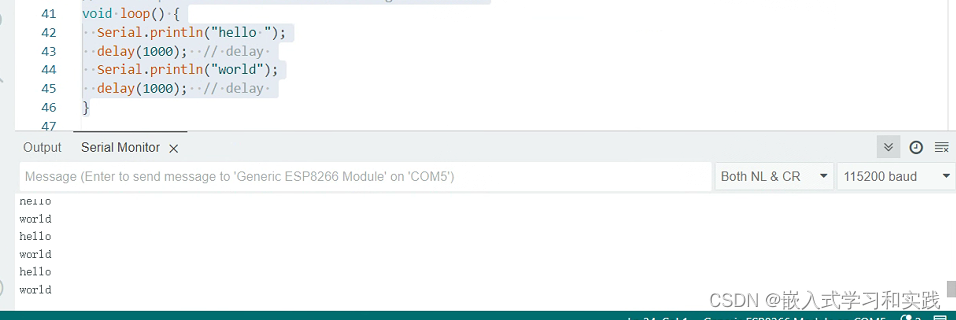
野火ESP8266模块开发-基于Arduino IDE
一、野火ESP8266模块介绍 ESP8266 拥有高性能无线 SOC,给移动平台设计师带来福音,它以最低成本提供最大实用性,为 WiFi 功能嵌入其他系统提供无限可能。ESP8266 是一个完整且自成体系的 WiFi 网络解决方案,能够独立运行࿰…...

[Qt学习笔记]Qt实现自定义控件SwitchButton开关按钮
1、功能介绍 在项目UI中使用较多的打开/关闭的开关按钮,一般都是找图片去做效果,比如说如下的图像来表征打开或关闭。 如果想要控件有打开/关闭的动画效果或比较好的视觉效果,这里就可以使用自定义控件,使用Painter来绘制控件。软…...
)
大模型服务化落地卡点突破:基于CUDA 13 Stream Ordered Memory Allocator的动态batching算子框架(含GitHub Star≥1.2k的开源实现)
更多请点击: https://intelliparadigm.com 第一章:大模型服务化落地的工程瓶颈与CUDA 13时代新范式 随着千亿参数模型常态化部署,传统推理服务架构在显存带宽、内核调度粒度和多卡协同效率上遭遇系统性瓶颈。CUDA 13 引入的 Unified Memory …...

终极指南:30秒在iOS 14.0-16.6.1上安装TrollStore的完整教程
终极指南:30秒在iOS 14.0-16.6.1上安装TrollStore的完整教程 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS 14.0至16.6.1设备…...

基于Gemini AI的视频会议智能分析与结构化提取
1. 项目概述:从视频会议中提取结构化洞察的智能工作流作为一名长期从事AI和MLOps实践的工程师,我经常需要处理大量视频会议记录。每次会议结束后,那些关键决策、待办事项和技术细节就像沙滩上的字迹,随着时间流逝逐渐模糊。传统的…...

BetterNCM Installer深度评测:为什么这是最好的网易云插件解决方案
BetterNCM Installer深度评测:为什么这是最好的网易云插件解决方案 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer BetterNCM Installer是一款专为网易云音乐PC客户端打造的…...

Vue+ElementUI:构建企业级后台管理系统的终极解决方案
VueElementUI:构建企业级后台管理系统的终极解决方案 【免费下载链接】vue-backend 简单的后台管理框架 项目地址: https://gitcode.com/gh_mirrors/vu/vue-backend 在数字化转型浪潮中,企业面临后台管理系统开发效率低下、权限管理复杂、用户体验…...

MQCloud消息追踪与审计:如何实现全链路消息监控与追溯
MQCloud消息追踪与审计:如何实现全链路消息监控与追溯 【免费下载链接】mqcloud RocketMQ企业级一站式服务平台 项目地址: https://gitcode.com/gh_mirrors/mq/mqcloud 在分布式系统架构中,消息中间件扮演着至关重要的角色,而消息的可…...

【Docker 27低代码集成权威指南】:20年DevOps专家亲授容器化低代码平台落地的5大避坑法则
第一章:Docker 27低代码平台容器集成全景认知 Docker 27 是一款面向企业级低代码开发场景深度优化的容器化运行时环境,其核心能力在于将可视化建模、组件编排与容器生命周期管理无缝融合。它并非 Docker CE 或 EE 的简单版本迭代,而是基于 Mo…...

LinkSwift网盘直链下载助手:一键解锁八大平台高速下载通道
LinkSwift网盘直链下载助手:一键解锁八大平台高速下载通道 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...

Redis通用命令 easy learning
大家好,这篇文章带来的是有关Redis的相关内容讲解,希望各位能够有所收获~ 1.set 给指定的键(Key)设置一个值(Value),覆盖已存在的旧值。 set key value 类似哈希表一样设置key和value的映射 …...

华硕笔记本终极控制方案:G-Helper 3分钟快速上手指南
华硕笔记本终极控制方案:G-Helper 3分钟快速上手指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Sca…...