【译】矢量数据库 101 - 什么是矢量数据库?
原文地址:Vector Database 101 - What is a Vector Database?
1. 简介
大家好——欢迎回到 Milvus 教程。在上一教程中,我们快速浏览了每天产生的日益增长的数据量。然后,我们介绍了如何将这些数据分成结构化/半结构化数据和非结构化数据,它们之间的区别,以及现代机器学习如何通过嵌入来理解非结构化数据。最后,我们简要介绍了通过 ANN 搜索处理非结构化数据的方法。通过所有这些信息,我们现在可以清楚地看到,非结构化数据量的不断增加需要一种模式的转变和一种新的数据库管理系统——向量数据库。
2. 从宏观角度审视矢量数据库
猜猜现在著名的 ImageNet 数据集需要多少位馆长来标注。准备好答案了吗?25000人(这是个不小的数字)。通过图像、视频、文本、音频和其他形式的非结构化数据的内容而不是人为生成的标签或标记进行搜索,正是向量数据库要解决的问题。当与强大的机器学习模型相结合时,Milvus 等矢量数据库有能力彻底改变电子商务解决方案、推荐系统、计算机安全、制药和许多其他行业。
正如导言中提到的,矢量数据库是一种完全可管理的、不需要任何功能的解决方案,用于存储、索引和搜索海量非结构化数据集,并利用机器学习模型的 embeddings 功能。但是,让我们从用户的角度来思考一下。如果没有强大的可用性和良好的用户应用程序接口,技术又有什么用呢?与底层技术一样,多租户和可用性也是矢量数据库极其重要的属性。让我们列出一个成熟的矢量数据库应具备的所有功能(其中许多功能与结构化/半结构化数据数据库的功能重叠):
- 可扩展性和可调性: 当存储在矢量数据库中的非结构化数据元素数量增长到数亿或数十亿时,跨多个节点的水平扩展就变得至关重要。此外,不同的插入率、查询率和底层硬件可能会导致不同的应用需求,因此整体系统可调性成为矢量数据库必须具备的功能。Milvus 通过云原生架构实现了这一点,在负载平衡器后面维护多个服务和工作节点。内部对象存储和消息传递是通过其他云原生分布式工具实现的,因此可以在整个系统中轻松扩展。
- 多租户和数据隔离: 对于所有数据库系统来说,支持多用户是一项显而易见的功能。但是,为每个新用户创建一个新的矢量数据库可能会对每个人都不利。与这一概念平行的是数据隔离——对数据库中的一个数据集进行的任何插入、删除或查询对系统的其他部分都是不可见的,除非数据集所有者明确希望共享信息。Milvus 通过集合概念实现了这一点,我们将在今后的教程中深入探讨。
- 一套完整的应用程序接口: 坦率地说,没有全套 API 和 SDK 的数据库不是真正的数据库。Milvus 维护着 Python、Node、Go 和 Java SDK,用于与 Milvus 数据库通信并对其进行管理。
- 直观的用户界面/管理控制台: 用户界面有助于大大减少与矢量数据库相关的学习曲线。这些界面还能展示新的矢量数据库功能和工具,否则这些功能和工具将无法使用。Zilliz 为 Milvus 开源了一个高效、直观的基于网络的图形用户界面—— Attu。
我们在此总结一下:矢量数据库应具备以下功能: 1)可扩展性和可调性;2)多租户和数据隔离;3)一套完整的应用程序接口;4)直观的用户界面/管理控制台。在接下来的两节中,我们将分别通过比较矢量数据库与矢量搜索库和矢量搜索插件来跟进这一概念。
3. 矢量数据库与矢量搜索库
我在业界听到的一个常见误解是,矢量数据库只是 ANN 搜索算法的包装。这与事实大相径庭!矢量数据库的核心是针对非结构化数据的全面解决方案。正如我们在上一节已经看到的,这意味着当今结构化/半结构化数据的数据库管理系统所具有的用户友好功能“云计算性、多租户、可扩展性等”也应该成为成熟的矢量数据库的属性。当我们深入学习本教程时,所有这些特性都将变得清晰明了。
另一方面,FAISS、ScaNN 和 HNSW 等项目是轻量级 ANN 库,而非托管解决方案。这些库的目的是帮助构建向量索引——旨在显著加快多维向量近邻搜索速度的数据结构1。如果您的数据集较小且有限,那么这些库足以满足非结构化数据处理的需要,甚至对于在生产中运行的系统也是如此。然而,随着数据集规模的扩大和更多用户的加入,规模问题变得越来越难以解决。

Milvus 架构的高级概览。我知道这看起来很混乱,但别担心,我们会在下一个教程中深入介绍每个组件。
矢量数据库与矢量搜索库的抽象层完全不同——矢量数据库是完全成熟的服务,而 ANN 库则是要集成到你正在开发的应用程序中。从这个意义上说,ANN 库是建立在矢量数据库之上的众多组件之一,就像 Elasticsearch 建立在 Apache Lucene 之上一样。为了举例说明为什么这种抽象如此重要,让我们来看看在矢量数据库中插入一个新的非结构化数据元素。这在 Milvus 中非常简单:
from pymilvus import Collection
collection = Collection('book')
mr = collection.insert(data)
其实就这么简单——3 行代码。遗憾的是,对于像 FAISS 或 ScaNN 这样的库,如果不在某些检查点手动重新创建整个索引,就无法轻松做到这一点。即使可以,矢量搜索库仍然缺乏可扩展性和多租户性,而这正是矢量数据库最重要的两个特性。
4. 传统数据库的矢量搜索插件
既然我们已经确定了矢量搜索库和矢量数据库之间的区别,那么让我们来看看矢量数据库与矢量搜索插件有何不同。
越来越多的传统数据库和搜索系统(如 Clickhouse 和 Elasticsearch)都内置了矢量搜索插件。例如,Elasticsearch 8.0 就包含了矢量插入和 ANN 搜索功能,可以通过 restful API 调用。矢量搜索插件的问题应该一目了然——这些解决方案没有采用全栈方法来嵌入管理和矢量搜索。相反,这些插件的目的是在现有架构的基础上进行增强,从而使其具有局限性和未优化性。在传统数据库上开发非结构化数据应用程序,就好比在汽油动力汽车的车架上安装锂电池和电动马达,这不是一个好主意!
为了说明原因,让我们回到矢量数据库应实现的功能列表(来自第一部分)。矢量搜索插件缺少其中的两个功能——可调性和用户友好的 API/SDK。我将继续以 Elasticsearch 的 ANN 引擎为例;其他矢量搜索插件的操作也非常类似,因此我就不再过多赘述了。Elasticsearch 通过 dense_vector 数据字段类型支持矢量存储,并允许通过 _knn_search 端点进行查询:
PUT index
{"mappings": {"properties": {"image-vector": {"type": "dense_vector","dims": 128,"index": true,"similarity": "l2_norm"}}}
}PUT index/_doc
{"image-vector": [0.12, 1.34, ...]
}
GET index/_knn_search
{"knn": {"field": "image-vector","query_vector": [-0.5, 9.4, ...],"k": 10,"num_candidates": 100}
}
Elasticsearch 的 ANN 插件只支持一种索引算法: Hierarchical Navigable Small Worlds,又称 HNSW。除此之外,它只支持 L2/Euclidean 距离作为距离度量。这是一个不错的开端,但让我们把它与成熟的向量数据库 Milvus 进行比较。使用 pymilvus:
>>> field1 = FieldSchema(name='id', dtype=DataType.INT64, description='int64', is_primary=True)
>>> field2 = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='embedding', dim=128, is_primary=False)
>>> schema = CollectionSchema(fields=[field1, field2], description='hello world collection')
>>> collection = Collection(name='my_collection', data=None, schema=schema)
>>> index_params = {'index_type': 'IVF_FLAT','params': {'nlist': 1024},"metric_type": 'L2'}
>>> collection.create_index('embedding', index_params)
>>> search_param = {'data': vector,'anns_field': 'embedding','param': {'metric_type': 'L2', 'params': {'nprobe': 16}},'limit': 10,'expr': 'id_field > 0'}
>>> results = collection.search(**search_param)
虽然 Elasticsearch 和 Milvus 都有创建索引、插入嵌入向量和执行近邻搜索的方法,但从这些示例中可以明显看出,Milvus 拥有更直观的向量搜索 API(更好的面向用户的 API)和更广泛的向量索引 + 距离度量支持(更好的可调性)。Milvus 还计划在未来支持更多向量索引,并允许通过类似 SQL 的语句进行查询,从而进一步提高可调性和可用性。
我们刚刚介绍了很多内容。这部分内容确实相当长,所以对于那些略读过这部分内容的人来说,我在这里简要地说一下:Milvus 比矢量搜索插件更好,因为 Milvus 从一开始就是作为矢量数据库构建的,因此具有更丰富的功能和更适合非结构化数据的架构。
5. 技术挑战
在本教程的前面部分,我列出了矢量数据库应实现的理想功能,然后将矢量数据库与矢量搜索库和矢量搜索插件进行了比较。现在,让我们简要回顾一下与现代矢量数据库相关的一些高层次技术挑战。在今后的教程中,我们将概述 Milvus 如何应对这些挑战,以及与其他开源矢量数据库相比,这些技术决策如何提高了 Milvus 的性能。
想象一架飞机。飞机本身包含许多相互连接的机械、电气和嵌入式系统,所有这些系统协调工作,为我们提供平稳、愉悦的飞行体验。同样,矢量数据库也由许多不断发展的软件组件组成。粗略地说,这些组件可分为存储、索引和服务。虽然这三个部分紧密结合在一起2,但像 Snowflake 这样的公司已经向更广泛的存储行业表明,“无共享(shared nothing)”数据库架构可以说优于传统的“共享存储(shared storage)”云数据库模式。因此,与矢量数据库相关的第一个技术挑战是设计一个灵活、可扩展的数据模型。
很好,我们有了数据模型。下一步是什么?既然数据已经存储在矢量数据库中,那么下一个重要组成部分就是能够搜索这些数据,即查询和索引。机器学习和多层神经网络的计算繁重特性使得 GPU、NPU/TPU、FPGA 和其他通用计算硬件蓬勃发展。矢量索引和查询也是计算密集型的,在加速器上运行时可达到最高速度和效率。计算资源的多样性带来了第二个主要技术挑战,即开发异构计算架构。
有了数据模型和架构,最后一步就是确保您的应用程序能从数据库中读取数据——这与第一节中提到的应用程序接口和用户界面要点密切相关。虽然新的数据库类别需要新的架构,以便以最小的成本获得最高的性能,但大多数矢量数据库用户仍然习惯于传统的 CRUD 操作(如 SQL 中的 INSERT、SELECT、UPDATE 和 DELETE)。因此,最后的主要挑战是开发一套 API 和图形用户界面,充分利用现有的用户界面惯例,同时保持与底层架构的兼容性。
请注意,这三个部分中的每个部分都与一个主要技术挑战相对应。尽管如此,矢量数据库并不存在放之四海而皆准的架构。最好的矢量数据库将通过专注于提供第一节中提到的功能来应对所有这些技术挑战。
6. 总结
在本教程中,我们快速浏览了矢量数据库。具体来说,我们了解了:1)成熟的矢量数据库具有哪些功能;2)矢量数据库与矢量搜索库有何不同;3)矢量数据库与传统数据库或搜索系统中的矢量搜索插件有何不同;以及 4)构建矢量数据库所面临的主要挑战。
本教程无意深入探讨矢量数据库,也无意展示如何在应用程序中使用矢量数据库。相反,我们的目标是提供一个矢量数据库概览。这才是你旅程的真正开始!
在下一篇教程中,我们将介绍世界上最流行的开源矢量数据库 Milvus:
- 我们将简要介绍 Milvus 的历史,包括最重要的问题——名称的由来!
- 我们将介绍 Milvus 1.0 与 Milvus 2.0 的不同之处,以及 Milvus 的未来发展方向。
- 我们将讨论 Milvus 与谷歌顶点人工智能匹配引擎等其他矢量数据库的区别。
- 我们还将简要介绍一些常见的矢量数据库应用。
下期教程再见。
我们将在接下来的教程中更详细地介绍矢量索引,敬请期待。 ↩︎
例如,更新存储组件除了会影响向量索引的构建方式外,还会影响面向用户的服务如何实现读取、写入和删除。 ↩︎
相关文章:
【译】矢量数据库 101 - 什么是矢量数据库?
原文地址:Vector Database 101 - What is a Vector Database? 1. 简介 大家好——欢迎回到 Milvus 教程。在上一教程中,我们快速浏览了每天产生的日益增长的数据量。然后,我们介绍了如何将这些数据分成结构化/半结构化数据和非结构化数据&…...

Python Web开发记录 Day12:Django part6 用户登录
名人说:东边日出西边雨,道是无晴却有晴。——刘禹锡《竹枝词》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 1、登录界面2、用户名密码校验3、cookie与session配置①cookie与session②配置4、登录验证5、注销登录6、图片验证码①Pillow库②图片验证码的…...
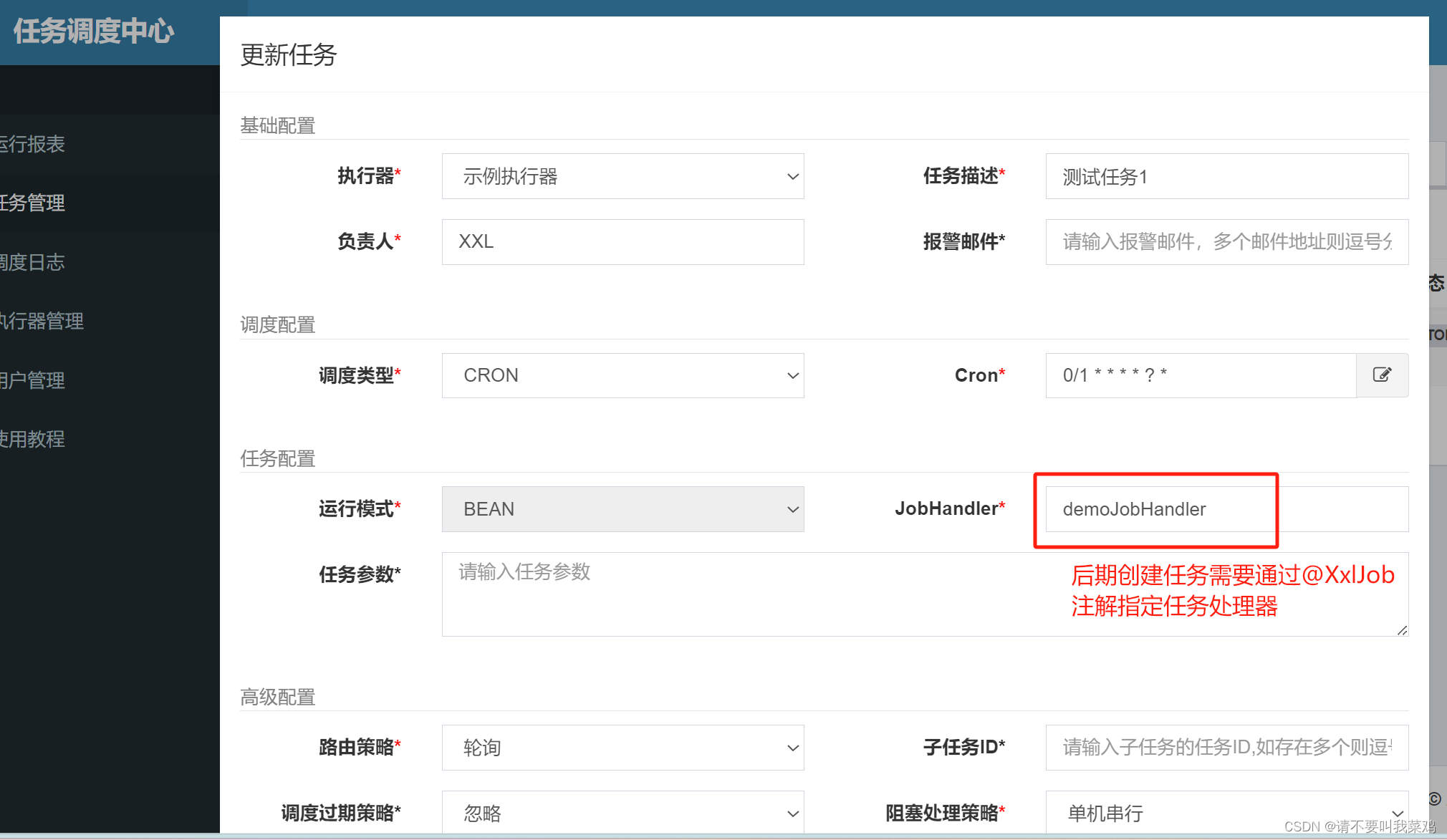
SpringTask实现的任务调度与XXL-job实现的分布式任务调度【XXL-Job工作原理】
目录 任务调度 分布式任务调度 分布式任务调度存在的问题以及解决方案 使用SpringTask实现单体服务的任务调度 XXL-job分布式任务调度系统工作原理 XXL-job系统组成 XXL-job工作原理 使用XXL-job实现分布式任务调度 配置调度中心XXL-job 登录调度中心创建执行器和任务 …...

【java】图书管理系统
有了前几篇文章关于封装、继承、多态、接口等的介绍,想必各位读者对java面向对象的思想有了一定的认识。接下来这篇文章就让我们趁热打铁,利用所学知识做一个小项目图书管理系统吧 目录 一、图书类 1、book类 2、bookList类 二、功能实现 1、IOpera…...

C#实现约瑟夫环算法
目录 1.约瑟夫环定义 2.约瑟夫环算法实现需要注意的地方 3.通过一个例子来演示这个过程 4.三人的约瑟夫环示例 4.十二人的约瑟夫环示例 1.约瑟夫环定义 约瑟夫环即设有n个人坐成一个圈,从某个人开始报数,数到m的人出列,接着从出列的下一…...
游戏服务端配置“热更”及“秒启动”终极方案(golang/ygluu/卢益贵)
游戏服务端配置“热更”及“秒启动”终极方案 ygluu 卢益贵 关键词:游戏微服务架构、游戏服务端热更、模块化解耦、golang 目录 一、前言 二、异步线程加载/重载方案 三、配置表碎片化方案 四、指针间接引用 五、重载通知 六、示例代码 七、相关连接 一、…...

鸿蒙开发的入门
鸿蒙开发的入门 注册并实名认证华为开发者账户 华为官网 注册 有账户可以直接登录 并进行实名认证 下载并安装开发工具 鸿蒙开发使用的语言 java js c/c 仓颉 手机app java 硬件 c/c 应用开发工具的下载地址 Windows(64-bit) 下载地址 程序的运行过程 解析config.j…...

为什么要减少Http的请求以及如何减少Http请求
为什么要减少Http的请求 减少 HTTP 请求的数量是优化网页性能的一个重要策略,原因有以下几点: 1.延迟:每个 HTTP 请求都会有一定的网络延迟。即使数据量很小,请求和响应的往返时间也可能相当长,特别是在网络条件不好…...

Linux性能测试工具整理
性能测试工具:Unixbench lmbench stream iozone fio netperf spec2000 spec2006 一、unixbench unixbench主要是用于系统基础性能测试,unixbench也包含一些非常简单的2D和3D图形测试 UnixBench一个基于系统的基准测试工具,不单纯是CPU 内存 …...

前端路由history路由和hash路由的区别?原理?
前端路由是指在单页应用程序(SPA)中通过改变 URL 路径来实现页面切换和导航的机制。在前端开发中,有两种主要的前端路由实现方式:基于 History API 的路由(history-based routing)和基于哈希(Ha…...

AcWing 727. 菱形——像拼图一样做题
题目描述] 分析: 利用程序根据输入的整数,画出由字符*构成的该整数阶的实心菱形。给出一个示例: n 7 n7 n7。 * * * * * * * * * * * * * * * * * * * * * * * * * 我们将采取拆解问题,通过四个部分的…...

深入理解生成型大型语言模型:自监督预训练、细调与对齐过程及其应用
分析概述 本文主要介绍了生成型大型语言模型(LLM)的预训练过程,特别是通过下一个令牌(token)预测的自监督学习方法,以及后续的细调(finetuning)和对齐(alignment&#x…...
个人简历主页搭建系列-03:Hexo+Github Pages 介绍,框架配置
今天的更新内容主要是了解为什么选择这个网站搭建方案,以及一些前置软件的安装。 Why Hexo? 首先我们了解一下几种简单的网站框架搭建方案,看看对于搭建简历网站的需求哪个更合适。 在 BuiltWith(网站技术分析工具)上我们可以…...

【堆、位运算、数学】算法例题
目录 十九、堆 121. 数组中的第K个最大元素 ② 122. IPO ③ 123. 查找和最小的K对数字 ② 124. 数据流的中位数 ③ 二十、位运算 125. 二进制求和 ① 126. 颠倒二进制位 ① 127. 位1的个数 ① 128. 只出现一次的数字 ① 129. 只出现一次的数字 II ② 130. 数字范围…...
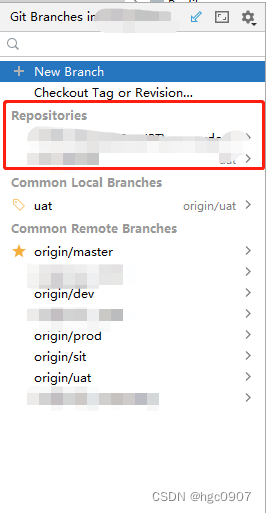
IDEA 多个git仓库项目放一个窗口
1、多个项目先通过新建module或者CtrlAltShiftS 添加module引入 2、重点是右下角有时候git 分支视图只有一个module的Repositories。这时候需要去设置把多个git仓库添加到同一个窗口才能方便提交代码。 3、如果Directory Mappings已经有相关项目配置,但是灰色的&…...
)
全球变暖(蓝桥杯,acwing每日一题)
题目描述: 你有一张某海域 NN 像素的照片,”.”表示海洋、”#”表示陆地,如下所示: ....... .##.... .##.... ....##. ..####. ...###. .......其中”上下左右”四个方向上连在一起的一片陆地组成一座岛屿,例如上图就…...

多数据源 - dynamic-datasource | 集成 Quartz 及 ShardingJDBC
文章目录 集成 Quartz引入 quartz-starter配置数据源参数创建任务配置 Quartz 实际使用的数据源方式一: 自定义 SchedulerFactoryBeanCustomizer方式二: 使用@QuartzDataSource来指明quartz数据源集成 ShardingJDBC项目引入 shardingsphere 依赖分别配置shardingjdbc和多数据…...

四连杆机构运动学仿真 | 【Matlab源码+理论公式文本】| 曲柄滑块 | 曲柄摇杆 | 机械连杆
【程序简介】💻🔍 本程序通过matlab实现了四连杆机构的运动学仿真编程,动态展现了四连杆机构的运动动画,同时给出了角位移、角速度和角加速度的时程曲线,除了程序本身,还提供了机构运动学公式推导文档&…...

Lightroom Classic 2024 for mac 中文激活:强大的图像后期处理软件
对于追求极致画面效果的摄影师来说,Lightroom Classic 2024无疑是Mac平台上的一款必备软件。它凭借其强大的功能和出色的性能,赢得了众多摄影师的青睐。 软件下载:Lightroom Classic 2024 for mac 中文激活版下载 在Lightroom Classic 2024中…...

程序员下班以后做什么副业合适?
我就是一个最普通的网络安全工程师,出道快10年了,不出意外地遭遇到瓶颈期,但是凭技术在各大平台挖漏洞副业,硬是妥妥扛过来了。 因为对于程序员来讲,这是个试错成本很低、事半功倍的选择。编程技能是一种强大生产力&a…...

TouchGal Next:基于现代Web技术栈的Galgame社区架构解析
TouchGal Next:基于现代Web技术栈的Galgame社区架构解析 【免费下载链接】kun-touchgal-next TouchGAL是立足于分享快乐的一站式Galgame文化社区, 为Gal爱好者提供一片净土! 项目地址: https://gitcode.com/gh_mirrors/ku/kun-touchgal-next TouchGal Next作…...

2025届最火的六大AI科研神器实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 跟随人工智能技术以迅猛之势发展,AI工具已然深度介入到毕业论文写作的整个流程之…...

ModTheSpire终极教程:5步轻松掌握Slay The Spire模组加载器
ModTheSpire终极教程:5步轻松掌握Slay The Spire模组加载器 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire ModTheSpire是专为《杀戮尖塔》(Slay The Spire&…...

UML和面向对象
UML(统一建模语言,Unified Modeling Language)和面向对象(Object-Orientation)是软件工程中紧密相连的两个概念。面向对象是一种程序设计思想,而 UML 是一种可视化建模语言,用于表达面向对象分析(OOA)与设计(OOD)的成果。两者结合,使复杂系统的分析、设计、沟通和文…...
)
别再折腾CUDA了!Win10/Win11下用Anaconda一键搞定PyTorch环境(含CUDA 10.2 + cuDNN)
告别CUDA安装噩梦:Anaconda一站式部署PyTorch开发环境 在深度学习领域,PyTorch已成为众多研究者和开发者的首选框架。然而对于初学者而言,配置PyTorch开发环境往往成为第一道门槛——CUDA版本冲突、cuDNN兼容性问题、系统路径配置错误...这些…...
)
别再死记硬背了!用Python+GPT-4打造你的个性化英语学习伴侣(附完整代码)
用PythonGPT-4构建智能英语学习系统的全栈实践 当传统英语学习遇到代码和AI,会发生什么化学反应?我曾用三个月时间将《新概念英语》纸质书改造成能自动批改作业、智能对话的AI学习系统,学员的完课率提升了47%。这套系统核心由三个模块组成&am…...

游戏开发者必看:TGA文件在OpenGL/Unity/Unreal引擎中的正确打开与使用姿势
游戏开发者必看:TGA文件在OpenGL/Unity/Unreal引擎中的正确打开与使用姿势 在游戏开发的世界里,纹理贴图就像建筑师的砖瓦,而TGA格式则是其中一块被低估的金砖。不同于普通图像编辑者只需要"打开"和"查看"TGA文件&#x…...

小白程序员必看!收藏这份AI大模型学习进阶指南,轻松入行!
本文针对AI大趋势下,大学生如何快速进入AI领域的问题,提出解决方案。文章从专业背景出发,将学生分为技术背景和非技术背景两类,并分别给出适合的AI岗位选择,如算法工程师、AI产品经理等。随后,针对技术岗和…...

OpenClaw 微信通道搭建方法 三种部署模式详细讲解
一、方案背景与核心价值 在微信私域运营与自动化客服场景中,OpenClaw 可以打通微信客户端与后端服务的通信链路,降低接入门槛,支持本地、云端等多种环境部署,兼顾数据安全与连接稳定性。本文围绕部署细节与故障排查逻辑展开&…...

AUTOSAR SPI通信避坑指南:从逻辑分析仪波形反推EB/IB配置与数据顺序问题
AUTOSAR SPI通信调试实战:从波形异常到配置优化的逆向工程 当逻辑分析仪上那些跳动的波形与预期不符时,作为嵌入式工程师的你一定经历过那种抓耳挠腮的焦虑时刻。SPI作为嵌入式系统中使用最广泛的同步串行通信协议之一,在AUTOSAR架构下的配置…...