阿里云-零基础入门NLP【基于机器学习的文本分类】
文章目录
- 学习过程
- 赛题理解
- 学习目标
- 赛题数据
- 数据标签
- 评测指标
- 解题思路
- TF-IDF介绍
- TF-IDF + 机器学习分类器
- TF-IDF + LinearSVC
- TF-IDF + LGBMClassifier
学习过程
20年当时自身功底是比较零基础(会写些基础的Python[三个科学计算包]数据分析),一开始看这块其实挺懵的,不会就去问百度或其他人,当时遇见困难挺害怕的,但22后面开始力扣题【目前已刷好几轮,博客没写力扣文章之前,力扣排名靠前已刷有5遍左右,排名靠后刷3次左右,代码功底也在一步一步提升】不断地刷、遇见代码不懂的代码,也开始去打印print去理解,到后面问其他人的问题越来越少,个人自主学习、自主解决能力也得到了进一步增强。
赛题理解
- 赛题名称:零基础入门NLP之新闻文本分类
- 赛题目标:通过这道赛题可以引导大家走入自然语言处理的世界,带大家接触NLP的预处理、模型构建和模型训练等知识点。
- 赛题任务:赛题以自然语言处理为背景,要求选手对新闻文本进行分类,这是一个典型的字符识别问题。
学习目标
- 理解赛题背景与赛题数据
- 完成赛题报名和数据下载,理解赛题的解题思路
赛题数据
赛题以匿名处理后的新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。
赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。为了预防选手人工标注测试集的情况,我们将比赛数据的文本按照字符级别进行了匿名处理。
数据标签
处理后的赛题训练数据如下:

在数据集中标签的对应的关系如下:{‘科技’: 0, ‘股票’: 1, ‘体育’: 2, ‘娱乐’: 3, ‘时政’: 4, ‘社会’: 5, ‘教育’: 6, ‘财经’: 7, ‘家居’: 8, ‘游戏’: 9, ‘房产’: 10, ‘时尚’: 11, ‘彩票’: 12, ‘星座’: 13}
评测指标
评价标准为类别f1_score的均值,选手提交结果与实际测试集的类别进行对比,结果越大越好。
解题思路
赛题思路分析:赛题本质是一个文本分类问题,需要根据每句的字符进行分类。但赛题给出的数据是匿名化的,不能直接使用中文分词等操作,这个是赛题的难点。
因此本次赛题的难点是需要对匿名字符进行建模,进而完成文本分类的过程。由于文本数据是一种典型的非结构化数据,因此可能涉及到特征提取和分类模型两个部分。为了减低参赛难度,我们提供了一些解题思路供大家参考:
思路1:TF-IDF + 机器学习分类器
直接使用TF-IDF对文本提取特征,并使用分类器进行分类。在分类器的选择上,可以使用SVM、LR、或者XGBoost。
思路2:FastText
FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建出分类器。
思路3:WordVec + 深度学习分类器
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。深度学习分类的网络结构可以选择TextCNN、TextRNN或者BiLSTM。
思路4:Bert词向量
Bert是高配款的词向量,具有强大的建模学习能力。
这里使用思路1(TF-IDF + 机器学习分类器) 及 思路4(Bert词向量)
TF-IDF介绍
TF-IDF 分数由两部分组成:第一部分是词语频率(Term Frequency),第二部分是逆文档频率(Inverse Document Frequency)。其中计算语料库中文档总数除以含有该词语的文档数量,然后再取对数就是逆文档频率。
TF(t)= 该词语在当前文档出现的次数 / 当前文档中词语的总数
IDF(t)= log_e(文档总数 / 出现该词语的文档总数)
TF-IDF + 机器学习分类器
TF-IDF + LinearSVC
# TF-IDF + LinearSVC
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC
from sklearn.metrics import f1_score, confusion_matrix, recall_score, precision_scoreprint("开始读取数据")
train_df = pd.read_csv('train_set.csv', sep='\t')
test_df = pd.read_csv('test_a.csv', sep='\t')
print("结束读取数据")print("开始tfidf")
tfidf = TfidfVectorizer(sublinear_tf=True,strip_accents='unicode',analyzer='word',token_pattern=r'\w{1,}',stop_words='english',ngram_range=(1,3),max_features=10000)tfidf.fit(pd.concat([train_df['text'], test_df['text']]))
train_word_features = tfidf.transform(train_df['text'])
test_word_features = tfidf.transform(test_df['text'])X_train = train_word_features
y_train = train_df['label']
X_test = test_word_features
print("结束tfidf")print("开始TF-IDF + LinearSVC")
# https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html#sklearn.model_selection.KFold
KF = KFold(n_splits=10, random_state=7)
clf = LinearSVC()
test_pred = np.zeros((X_test.shape[0], 1), int) # 存储测试集预测结果 行数:len(X_test) ,列数:1列
for KF_index, (train_index,valid_index) in enumerate(KF.split(X_train)):print('第', KF_index+1, '折交叉验证开始...')# 训练集划分x_train_, x_valid_ = X_train[train_index], X_train[valid_index]y_train_, y_valid_ = y_train[train_index], y_train[valid_index]# 模型构建clf.fit(x_train_, y_train_)# 模型预测val_pred = clf.predict(x_valid_)print("LinearSVC准确率为:",f1_score(y_valid_, val_pred, average='macro'))# 保存测试集预测结果test_pred = np.column_stack((test_pred, clf.predict(X_test))) # 将矩阵按列合并
# 取测试集中预测数量最多的数
preds = []
for i, test_list in enumerate(test_pred):preds.append(np.argmax(np.bincount(test_list)))
preds = np.array(preds)result = pd.DataFrame(preds, columns=['label'])
result.to_csv("TFIDF_LinearSVC_submission_0304.csv", encoding='gbk', index=False)
print("结束TF-IDF + LinearSVC")
score:0.9410
TF-IDF + LGBMClassifier
# https://github.com/Goldgaruda/Tianchi-NLP-News-Text-Classification-Rank-5-solution/blob/main/tfidf/cv.py
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import f1_score
from lightgbm import LGBMClassifierprint("开始读取数据")
train_df = pd.read_csv('train_set.csv', sep='\t')
test_df = pd.read_csv('test_a.csv', sep='\t')
print("结束读取数据")print("开始tfidf")
tfidf = TfidfVectorizer(sublinear_tf=True,strip_accents='unicode',analyzer='word',token_pattern=r'\w{1,}',stop_words='english',ngram_range=(1,3),max_features=10000)print('train_df.head():', train_df.head())tfidf.fit(np.concatenate((train_df['text'].iloc[:].values,test_df['text'].iloc[:].values),axis=0))
train_word_features = tfidf.transform(train_df['text'].iloc[:].values)
test_word_features = tfidf.transform(test_df['text'].iloc[:].values)X_train = train_word_features
y_train = train_df['label']
X_test = test_word_features
print("开始tfidf")print("开始TF-IDF + LGBMClassifier")
KF = KFold(n_splits=5, random_state=7)
clf = LGBMClassifier(n_jobs=-1, feature_fraction=0.7, bagging_fraction=0.4, lambda_l1=0.001, lambda_l2=0.01, n_estimators=600)# 存储测试集预测结果 行数:len(X_test) ,列数:1列
test_pred = np.zeros((X_test.shape[0], 1), int)for KF_index, (train_index,valid_index) in enumerate(KF.split(X_train)):print('第', KF_index+1, '折交叉验证开始...')# 训练集划分x_train_, x_valid_ = X_train[train_index], X_train[valid_index]y_train_, y_valid_ = y_train[train_index], y_train[valid_index]# 模型构建clf.fit(x_train_, y_train_)# 模型预测val_pred = clf.predict(x_valid_)print("LGBMClassifier准确率为:",f1_score(y_valid_, val_pred, average='macro'))# 保存测试集预测结果test_pred = np.column_stack((test_pred, clf.predict(X_test))) # 将矩阵按列合并# 取测试集中预测数量最多的数
preds = []
for i, test_list in enumerate(test_pred):preds.append(np.argmax(np.bincount(test_list)))
preds = np.array(preds)result = pd.DataFrame(preds, columns=['label'])
result.to_csv("TFIDF_LGBMClassifier_submission_0304.csv", encoding='gbk', index=False)
print("结束TF-IDF + LGBMClassifier")
score:0.9509
比赛源自:阿里云天池大赛 - 零基础入门NLP - 新闻文本分类
相关文章:
阿里云-零基础入门NLP【基于机器学习的文本分类】
文章目录 学习过程赛题理解学习目标赛题数据数据标签评测指标解题思路TF-IDF介绍TF-IDF 机器学习分类器TF-IDF LinearSVCTF-IDF LGBMClassifier 学习过程 20年当时自身功底是比较零基础(会写些基础的Python[三个科学计算包]数据分析),一开始看这块其实挺懵的&am…...
蓝桥杯模块综合——高质量讲解AT24C02,BS18B20,BS1302,AD/DA(PCF8591),超声波模块
AT24C02——就是一个存储的东西,可以给他写东西,掉电不丢失。 void EEPROM_Write(unsigned char * EEPROM_String,unsigned char addr , unsigned char num) {IIC_Start();IIC_SendByte(0xA0);IIC_WaitAck();IIC_SendByte(addr);IIC_WaitAck();while(nu…...

前端跨平台开发框架:简化多端开发的利器
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...
cesium.js加载模型后,重新设置旋转角度属性值
// 加载模型var position Cesium.Cartesian3.fromDegrees(longitude, latitude, height);// 计算矩阵var rollAngleDegrees 15; // 设置翻滚角度var rollAngleRadians Cesium.Math.toRadians(rollAngleDegrees); // 将角度转换为弧度var orientation Cesium.Transforms.eas…...
②免费AI软件开发工具测评:通义灵码 VS 码上飞
前言 我又双叒叕来测评了!上次给大家带来的是iFlyCode和CodeFlying两款产品的测评,受到了大家的一致好评~ 今天咱就继续来聊聊,这次我们选的的对象是通义灵码和码上飞,从名字上也能看到出来这两款产品一定是跟软件开发有关系的&…...
幻兽帕鲁游戏搭建(docker)
系列文章目录 第一章: 幻兽帕陆游戏搭建 文章目录 系列文章目录前言一、镜像安装1.创建游戏目录2.拉取镜像3.下载配置文件4.启动游戏 二、自定义配置总结 前言 这段时间一直在写论文还有找工作,也没学啥新技术,所以博客也很长时间没写了&am…...
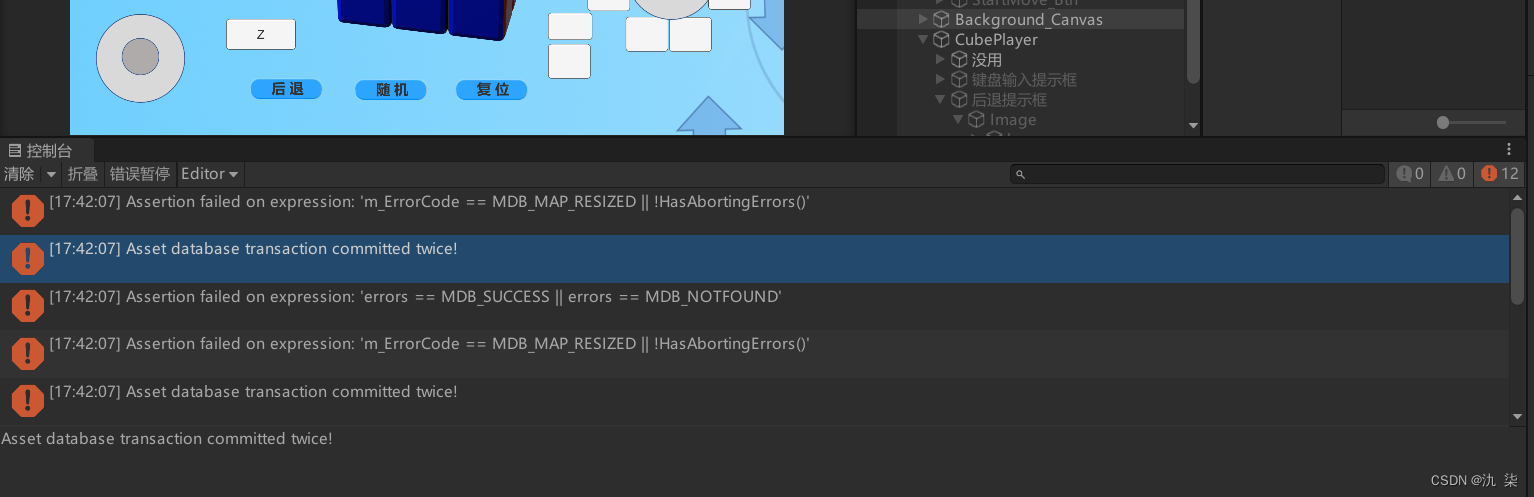
unity报错出现Asset database transaction committed twice!
错误描述: 运行时报错 Assertion failed on expression: ‘m_ErrorCode MDB_MAP_RESIZED || !HasAbortingErrors()’Asset database transaction committed twice!Assertion failed on expression: ‘errors MDB_SUCCESS || errors MDB_NOTFOUND’ 解决办法&…...

去除项目git的控制 端口号的关闭
以下操作都是在windows下。只是记录一下。 find . -name “.git” | xargs rm -rf 查看所有分支 git branch -a 查看当前分支 git branch -a 切换分支 git chenkout develop docker 查看容器的ip docker inspect -f ‘{{.Name}} - {{range .NetworkSettings.Networks}}{{.IP…...
交叉注意力融合时域、频域特征的FFT + CNN -BiLSTM-CrossAttention电能质量扰动识别模型
往期精彩内容: 电能质量扰动信号数据介绍与分类-Python实现-CSDN博客 Python电能质量扰动信号分类(一)基于LSTM模型的一维信号分类-CSDN博客 Python电能质量扰动信号分类(二)基于CNN模型的一维信号分类-CSDN博客 Python电能质量扰动信号分类(三)基于Transformer…...

简单的Charles抓包教程
安装Charles 安装地址:https://www.charlesproxy.com/download/ 开关本机抓包 一般我们在抓取手机端内容时需要将Proxy菜单栏下的Windows Proxy取消勾选,禁止charles抓取本机上的请求信息。 注:开启电脑端抓包后,会为电脑添加局…...
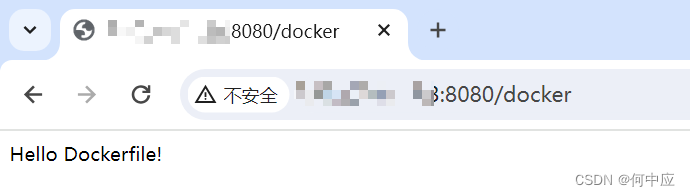
如何构建Docker自定义镜像
说明:平常我们使用Docker运行各种容器,极大地方便了我们对开发应用的使用,如MySQL、Redis,以及各种中间件,使用时只要拉镜像,运行容器即可。本文介绍如何创建一个Demo,自定义构建一个镜像。 开…...
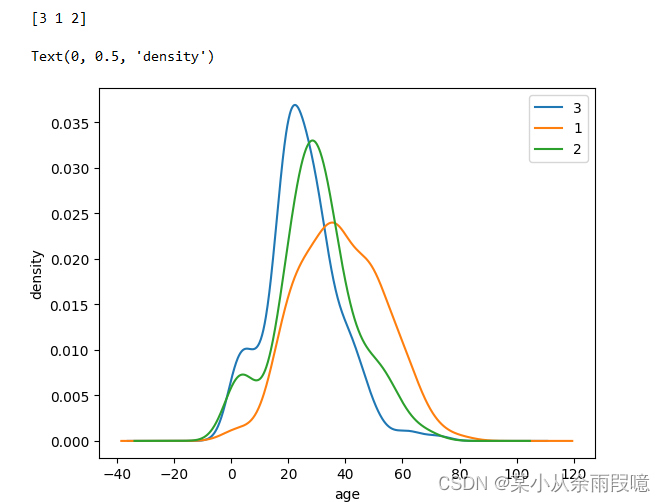
一起学数据分析_2
写在前面:代码运行环境为jupyter,如果结果显示不出来的地方就加一个print()函数。 一、数据基本处理 缺失值处理: import numpy as np import pandas as pd#加载数据train.csv df pd.read_csv(train_chinese.csv) df.head()# 查看数据基本…...

请解释Redis是什么?它有哪些主要应用场景?Redis支持哪些数据类型?并描述每种数据类型的特性和使用场景。
请解释Redis是什么?它有哪些主要应用场景? Redis是一款内存高速缓存NoSQL数据库,使用C语言编写,它支持丰富的数据类型,如String、list、set、zset、hash等,并且这些数据类型都直接支持数据的原子性操作&…...
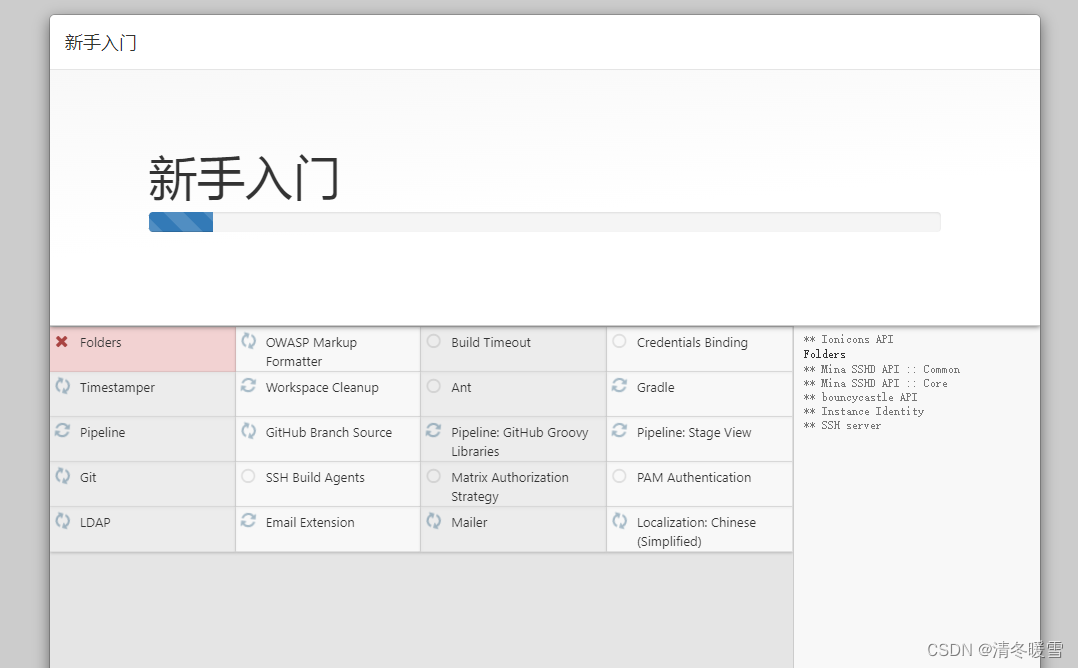
在centos8中部署Tomcat和Jenkins
参考链接1:tomcat安装和部署jenkins_jenkins和tomcat-CSDN博客 参考链接2:--配置开机启动tomcat文件 x超详细:Centos8安装Tomcat并配置开机自动启动_centos设置tomcat开机自启-CSDN博客文章浏览阅读4.4k次,点赞4次&…...

机器学习模型—K means
文章目录 机器学习模型—K means聚类的目标k 均值原理k 均值 的实现手动实现Python 实现K 的确定 手肘法总结机器学习模型—K means K-Means 聚类是一种无监督机器学习算法,它将未标记的数据集分为不同的簇。本文旨在探讨 k 均值聚类的基本原理和工作原理以及实现。 无监督机…...

QT UI设计
在QT中添加VTK 在main函数中初始化 //VTK的初始化语句 #ifndef INITIAL_OPENGL #define INITIAL_OPENGL #include <vtkAutoInit.h> VTK_MODULE_INIT(vtkRenderingOpenGL); VTK_MODULE_INIT(vtkInteractionStyle); VTK_MODULE_INIT(vtkRenderingVolumeOpenGL); VTK_MODU…...
)
前端小白的学习之路(CSS3 一)
提示:CSS3 是 Cascading Style Sheets(层叠样式表)的第三个主要版本,引入了许多新的特性和增强功能,用于设计和布局网页。本章记录CSS3新增选择器,盒子模型。 目录 一、C3新增选择器 1) 属性选择器 1.[c…...
春暖花开,一起来看看2024年品牌春分海报吧!
春分(Vernal equinox)已至,春花烂漫、燕子归来、百草回芽。 今天我们要分享的是2024年品牌发布的春分节气海报合集,快来随我们一起感受这昂扬、蓬勃的春意吧! (1)泸州老窖 (2)BD…...
golang面试题总结
零、go与其他语言 0、什么是面向对象 在了解 Go 语言是不是面向对象(简称:OOP) 之前,我们必须先知道 OOP 是啥,得先给他 “下定义” 根据 Wikipedia 的定义,我们梳理出 OOP 的几个基本认知: …...
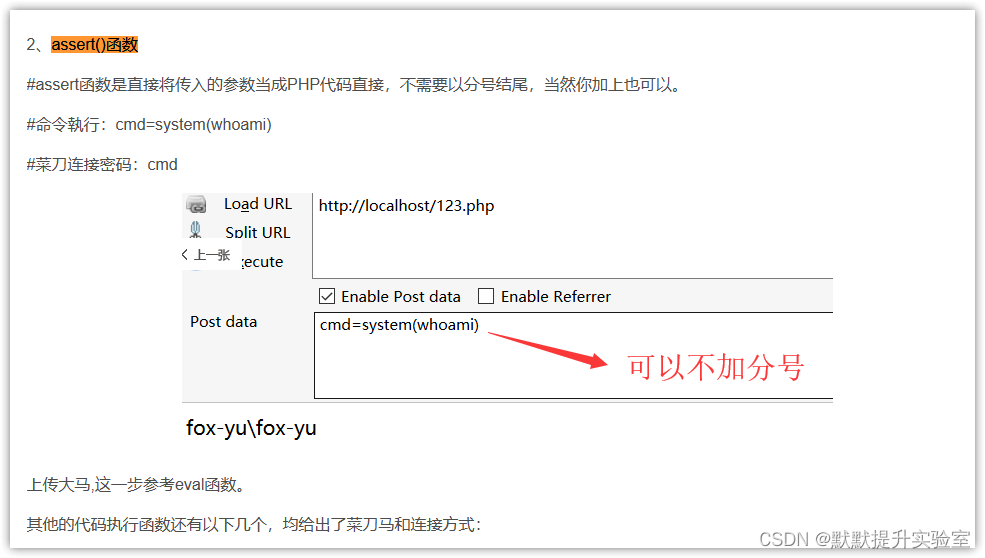
BUGKU-WEB shell
题目描述 题目截图如下: 描述: $poc "a#s#s#e#r#t";$poc_1 explode("#", $poc);$poc_2 $poc_1[0].$poc_1[1].$poc_1[2].$poc_1[3].$poc_1[4].$poc_1[5];$poc_2($_GET[s])进入场景看看:是一个空白的界面 解题思路 …...

终极Buefy缓存策略指南:提升Vue.js应用性能的完整方案
终极Buefy缓存策略指南:提升Vue.js应用性能的完整方案 【免费下载链接】buefy Lightweight UI components for Vue.js based on Bulma 项目地址: https://gitcode.com/gh_mirrors/bu/buefy Buefy作为基于Bulma的轻量级Vue.js UI组件库,以其简洁的…...

如何快速掌握PyWavelets:10个实用小波变换技巧
如何快速掌握PyWavelets:10个实用小波变换技巧 【免费下载链接】pywt PyWavelets - Wavelet Transforms in Python 项目地址: https://gitcode.com/gh_mirrors/py/pywt PyWavelets是一个强大的Python库,专门用于实现小波变换,为信号处…...

【CKF与RTS,MATLAB例程】二维非线性目标跟踪,观测为距离+角度,滤波使用容积卡尔曼滤波,附加RTS平滑,获得高精度定位。附代码下载链接
通过模拟二维平面下目标的运动模型与传感器的距离/方位/俯仰观测,利用容积卡尔曼滤波(CKF)进行前向状态估计,并结合RTS算法进行后向平滑优化,最终对比可视化三者的轨迹与定位精度 原创代码,包运行成功。请勿…...

从 0 到 1 构建销售 AI Agent Harness Engineering:线索生成、客户画像与转化预测实战
从0到1落地销售AI Agent Harness Engineering体系:线索生成、客户画像与转化预测全栈实战 关键词 销售AI Agent、Harness Engineering、线索智能生成、动态客户画像、转化预测、LLM编排、销售流程自动化 摘要 当前国内企业销售团队普遍面临「30%时间浪费在无效线索挖掘、客…...

软件规模-功能点分析法
功能点分析法是在20世纪70年代中期由IBM委托 Allan Albrecht 工程师和他的同事为解决代码行度量法所产生的问题和局限性而研究发布,发表于1979年,随后被国际功能点用户协会继承。该方法基于应用软件的外部,内部特性以及软件性能进行一系列间接…...

从“面包重量”到“用户停留时长”:产品经理/运营必懂的CDF与PDF实战解读
从“面包重量”到“用户停留时长”:产品经理/运营必懂的CDF与PDF实战解读 想象你走进一家面包店,发现每个面包的重量都有些微差异——有的重152克,有的148克,几乎没有恰好150克的。这种连续变量的特性,恰恰是理解用户行…...

使用Jmeter对接口进行压力测试
今天第一次使用Jmeter对系统进行了压力测试,测试了一下纯数据库方案以及添加了缓存的方案,结果惊人。只使用MySQL处理请求在设置并发量为每秒1000次的时候,可以看到MySQL的处理速度已经很慢了,平均响应时间达到了5235ms使用Caffei…...

SQL分组统计时如何处理文本类型聚合_GROUP_CONCAT的用法
GROUP_CONCAT返回NULL或空字符串主因是默认忽略NULL值,全NULL则结果为NULL;结果截断因默认长度1024;需用IFNULL预处理、调大group_concat_max_len、显式ORDER BY和SEPARATOR,并依场景选JSON_ARRAYAGG。GROUP_CONCAT 为什么返回 NU…...

1.3大白菜重装Windows 10
前置条件:启动盘制作完成,插入U盘,BIOS选择U盘启动1.选择“启动Win10 X64 PE”2.等待一会3.等待一会4.双击桌面“大白菜一键装机”5.目标盘选择C盘,选择映像文件6.选择上传到U盘的要安装的Windows版本镜像,点击“执行”…...

C语言宏定义续行符踩坑实录:手把手教你解决‘backslash and newline separated by space’警告
C语言宏定义续行符的隐秘陷阱:从警告解析到工程级解决方案 第一次在CLion里看到backslash and newline separated by space这个警告时,我盯着那个无辜的反斜杠看了足足三分钟。作为一个刚接触C语言宏编程的开发者,这个看似简单的格式问题背后…...