python爬虫基础实验:通过DBLP数据库获取数据挖掘顶会KDD在2023年的论文收录和相关作者信息
Task1

读取网站主页整个页面的 html 内容并解码为文本串(可使用urllib.request的相应方法),将其以UTF-8编码格式写入page.txt文件。
Code1
import urllib.requestwith urllib.request.urlopen('https://dblp.dagstuhl.de/db/conf/kdd/kdd2023.html') as response:html = response.read()html_text = html.decode()with open('page.txt','w',encoding='utf-8') as f:f.write(html_text)
Task2
打开page.txt文件,观察 Track 名称、论文标题等关键元素的组成规律。从这个文本串中提取各Track 的名称并输出(可利用字符串类型的split()和strip()方法)。
Code2
import rewith open('page.txt', 'r', encoding='utf-8') as f:content = f.read()# 使用正则表达式找到所有的 <h2 id="*"> 和 </h2> 之间的字符串
matches = re.findall(r'<h2 id=".*?">(.*?)</h2>', content)for match in matches:print(match)
Task3
可以看到, “Research Track Full Papers” 和 “Applied Data Track Full Papers” 中的论文占据了绝大多数,现欲提取这两个 Track 下的所有论文信息(包含作者列表authors、论文标题title、收录起始页startPage与终止页endPage),并按照以下格式存储到一个字典列表中,同时输出这两个 Track 各自包含的论文数量,然后把字典列表转化为 json 对象(可使用json包的相应方法),并以 2 字符缩进的方式写入kdd23.json文件中。
[{"track": "Research Track Full Papers","papers": [{"authors": ["Florian Adriaens","Honglian Wang","Aristides Gionis"],"title": "Minimizing Hitting Time between Disparate Groups with Shortcut Edges.","startPage": "1","endPage": "10"},...]}{"track": "Applied Data Track Full Papers","papers": [{"authors": ["Florian Adriaens","Honglian Wang","Aristides Gionis"],"title": "Minimizing Hitting Time between Disparate Groups with Shortcut Edges.","startPage": "1","endPage": "10"},...]}
]
Code3
import re
import jsonwith open('page.txt', 'r', encoding='utf-8') as f:content = f.read()# 定义一个列表来存储 Track 信息
tracks = []# 定义正则表达式
track_pattern = re.compile(r'<h2 id=".*?">(.*?)</h2>')
author_pattern = re.compile(r'<span itemprop="name" title=".*?">(.*?)</span>')
title_pattern = re.compile(r'<span class="title" itemprop="name">(.*?)</span>')
page_pattern = re.compile(r'<span itemprop="pagination">(.*?)-(.*?)</span>')# 找到 "Research Track Full Papers" 和 "Applied Data Science Track Full Papers" 的位置
start1 = content.find('Research Track Full Papers') - 50
start2 = content.find('Applied Data Track Full Papers') - 50
start3 = content.find('Hands On Tutorials') - 1
end = len(content)# 从整篇文本中划分出前两个Track中所有相邻"<cite"和"</cite>"之间的内容(即一篇文章的范围)
research_papers_content = re.split('<cite', content[start1:start2])[1:]
applied_papers_content = re.split('<cite', content[start2:start3])[1:]def extract_paper_info(papers_content):papers = []for paper_content in papers_content:paper_content = re.split('</cite>', paper_content)[0]papers.append(paper_content)return papersspit_research_content = extract_paper_info(research_papers_content)
spit_applied_content = extract_paper_info(applied_papers_content)# 提取每篇paper的author、title和startPage, endPage
def extract_paper_info(papers_content):papers = []for paper_content in papers_content:authors = author_pattern.findall(paper_content)titles = title_pattern.findall(paper_content)pages = page_pattern.search(paper_content)startPage, endPage = pages.groups()papers.extend([{'authors': authors, 'title': title , 'startPage': startPage , 'endPage': endPage} for title in titles])return papers# 提取 "Research Track Full Papers" 的论文信息
research_track = track_pattern.search(content[start1:start2]).group(1)
research_papers = extract_paper_info(spit_research_content)# 提取 "Applied Data Science Track Full Papers" 的论文信息
applied_track = track_pattern.search(content[start2:start3]).group(1)
#applied_papers = extract_paper_info(spit_applied_content)
applied_papers = extract_paper_info(spit_applied_content)
# 将论文信息存储到字典列表中
tracks.append({'track': research_track, 'papers': research_papers})
tracks.append({'track': applied_track, 'papers': applied_papers})# 将字典列表转换为 JSON 并写入文件
with open('kdd23.json', 'w', encoding='utf-8') as f:json.dump(tracks, f, indent=2)
Task4
基于之前爬取的页面文本,分别针对这两个 Track 前 10 篇论文的所有相关作者,爬取他们的以下信息:(1)该研究者的学术标识符orcID(有多个则全部爬取);(2)该研究者从 2020 年至今发表的所有论文信息(包含作者authors、标题title、收录信息publishInfo和年份year)。将最终结果转化为 json 对象,并以 2 字符缩进的方式写入researchers.json文件中,相应存储格式为:
[{"researcher": "Florian Adriaens","orcID": ["0000-0001-7820-6883"],"papers": [{"authors": ["Florian Adriaens","Honglian Wang","Aristides Gionis"],"title": "Minimizing Hitting Time between Disparate Groups with Shortcut Edges.","publishInfo": "KDD 2023: 1-10","year": 2023},...]},...
]
Code4
import re
import requests
import json
import time
import random# 打开并读取 "page.txt" 文件
with open('page.txt', 'r', encoding='utf-8') as f:content = f.read()# 定义正则表达式
author_link_pattern = re.compile(r'<span itemprop="author" itemscope itemtype="http://schema.org/Person"><a href="(.*?)" itemprop="url">')
orcID_pattern = re.compile(r'<img alt="" src="https://dblp.dagstuhl.de/img/orcid.dark.16x16.png" class="icon">(.{19})</a></li>')
researcher_pattern = re.compile(r'<head><meta charset="UTF-8"><title>dblp: (.*?)</title>')
year_pattern = re.compile(r'<span itemprop="datePublished">(.*?)</span>')# 找到 "Research Track Full Papers" 和 "Applied Data Track Full Papers" 的位置
start1 = content.find('Research Track Full Papers')
start2 = content.find('Applied Data Track Full Papers')
end = len(content)# 提取这两个部分的内容,并找到前 10 个 "persistent URL:" 之间的内容
research_papers_content = content[start1:start2].split('<cite')[1:11]
applied_papers_content = content[start2:end].split('<cite')[1:11]def extract_paper_info(papers_content):papers = []for paper_content in papers_content:paper_content = re.split('</cite>', paper_content)[0]papers.append(paper_content)return papersspit_research_content = extract_paper_info(research_papers_content)
spit_applied_content = extract_paper_info(applied_papers_content)def extract_paper_info2(paper_content):final_result = []# 使用正则表达式找到所有在 "<>" 之外的字符串outside_brackets = re.split(r'<[^>]*>', paper_content)# 遍历提取到的内容,删除含有'http'的字符串及其前面的字符串flag = -1for i in range(len(outside_brackets)):if 'http' in outside_brackets[i]:flag = ifor i in range(flag + 1 , len(outside_brackets)):if outside_brackets[i]:final_result.append(outside_brackets[i])return final_result# 定义一个列表来存储研究者信息
researchers = []# 访问每篇文章里所有作者的链接,获取作者的 orcID 和论文信息
for papers in [research_papers_content, applied_papers_content]:for paper in papers:author_links = author_link_pattern.findall(paper)for link in author_links:link_content = requests.get(link)response = link_content.text#爬虫时频繁请求服务器,可能会被网站认定为攻击行为并报错"ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接",故采取以下两个措施#使用完后关闭响应link_content.close() # 在各个请求之间添加随机延时等待time.sleep(random.randint(1, 3))researcher = researcher_pattern.search(response).group(1)orcID = orcID_pattern.findall(response)# 找到 "<li class="underline" title="jump to the 2020s">" 和 "<li class="underline" title="jump to the 2010s">" 之间的内容start = response.find('2020 – today')end = response.find('<header id="the2010s" class="hide-head h2">')# 提取这部分的内容,并找到所有 "</cite>" 之间的内容papers_content = response[start:end].split('</cite>')[0:-1]papers_dict = []for paper_content in papers_content:spit_content = extract_paper_info2(paper_content)year = int(year_pattern.search(paper_content).group(1))authors = []publishInfo = []for i in range(0 , len(spit_content) - 1):if spit_content[i] != ", " and (spit_content[i+1] == ", " or spit_content[i+1] == ":"):authors.append(spit_content[i])elif spit_content[i][-1] == '.':title = spit_content[i]for k in range(i+2 , len(spit_content)):publishInfo.append(spit_content[k])# 创建一个新的字典来存储每篇文章的信息paper_dict = {'authors': authors, 'title': title, 'publishInfo': ''.join(publishInfo), 'year': year}papers_dict.append(paper_dict)researchers.append({'researcher': researcher, 'orcID': orcID, 'papers': papers_dict})# 将字典列表转换为 JSON 并写入 "researchers.json" 文件
with open('researchers.json', 'w', encoding='utf-8') as f:json.dump(researchers, f, indent=2)
相关文章:
python爬虫基础实验:通过DBLP数据库获取数据挖掘顶会KDD在2023年的论文收录和相关作者信息
Task1 读取网站主页整个页面的 html 内容并解码为文本串(可使用urllib.request的相应方法),将其以UTF-8编码格式写入page.txt文件。 Code1 import urllib.requestwith urllib.request.urlopen(https://dblp.dagstuhl.de/db/conf/kdd/kdd202…...
简单记录一次帮维修手机经历(Vivo x9)
简介 手边有一台朋友亲戚之前坏掉的Vivo X9手机, 一直说要我帮忙修理一下, 我一直是拒绝的, 因为搞程序的不等于维修的(会电脑不等于维修电器),不知道这种思路如何根深蒂固的,不过好吧ÿ…...

ap聚类是什么
AP聚类(Affinity Propagation clustering)是一种聚类算法,它基于数据点之间的相似度进行聚类。AP聚类算法无需预先指定簇的数量,而是根据数据点之间的相似性动态地确定簇的个数和分配情况。 AP聚类的核心思想是通过迭代计算数据点…...
C数据类型(C语言)---变量的类型决定了什么?
目录 数据类型(Data Type) 变量的类型决定了什么? (1)不同类型数据占用的内存大小不同 如何计算变量或类型占内存的大小 (2)不同数据类型的表数范围不同 (3)不同类型…...

axios、axios二次封装、api解耦
import axios from axios// 环境的切换切换测试与生产环境 if (process.env.NODE_ENV development) { axios.defaults.baseURL /api; } else if (process.env.NODE_ENV debug) { axios.defaults.baseURL ; } else if (process.env.NODE_ENV production) { axios.…...

HTML 特殊元素:展示PDF、展示JSON 数据
<pre> 标签 (preformatted text) <pre> 标签用来表示预格式化的文本内容 在页面数据展示时,后端返回了一段未经处理的JSON 数据,将这段数据在页面正常展示,让可读性更高。 {/"project": {/ "title": "…...

算法·动态规划Dynamic Programming
很多人听到动态规划或者什么dp数组了,或者是做到一道关于动态规划的题目时,就会有一种他很难且不好解决的恐惧心理,但是如果我们从基础的题目开始深入挖掘动规思想,在后边遇到动态规划的难题时就迎难而解了。 其实不然ÿ…...

鸿蒙Harmony应用开发—ArkTS-转场动画(共享元素转场)
当路由进行切换时,可以通过设置组件的 sharedTransition 属性将该元素标记为共享元素并设置对应的共享元素转场动效。 说明: 从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 属性 名称参数参数描述…...

【C语言】循环语句(语句使用建议)
文章目录 **while循环****while循环的实践****补充:if语句与while语句区别****for循环(使用频率最高)****for循环的实践****while循环和for循环的对比****Do-while循环****break和continue语句****循环的嵌套****goto语句(不常用)****循环语句的效率(来自于高质量的C/C编程书籍…...

Spring Data访问Elasticsearch----响应式Reactive存储库
Spring Data访问Elasticsearch----响应式Reactive存储库 一、用法二、配置 Reactive Elasticsearch存储库支持建立在存储库中解释的核心存储库支持之上,利用由 Reactive REST客户端执行的 Reactive Elasticsearch Operations提供的操作。 Spring Data Elasticsear…...

堆排序(c语言)
文章目录 前言一.什么是堆二.向下调整算法三.堆排序的创建总结 前言 堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于&#x…...

开源IT自动化运维工具Ansible解析
Ansible 是一款开源的 IT 自动化工具,用于简化应用程序部署、配置管理、持续集成、基础设施即代码(Infrastructure as Code, IaC)和服务编排。它由 Michael DeHaan 创建,并在2012年首次发布,到2015年被红帽公司&#x…...
【C++】仿函数优先级队列反向迭代器
目录 一、优先级队列 1、priority_queue 的介绍 2、priority_queue 的使用 3、 priority_queue 的模拟实现 1)priority_queue()/priority_queue(first, last) 2)push(x) 3)pop() 4&#…...
UE4_调试工具_绘制调试球体
学习笔记,仅供参考! 效果: 步骤: 睁开眼睛就是该变量在此蓝图的实例上可公开编辑。 勾选效果:...
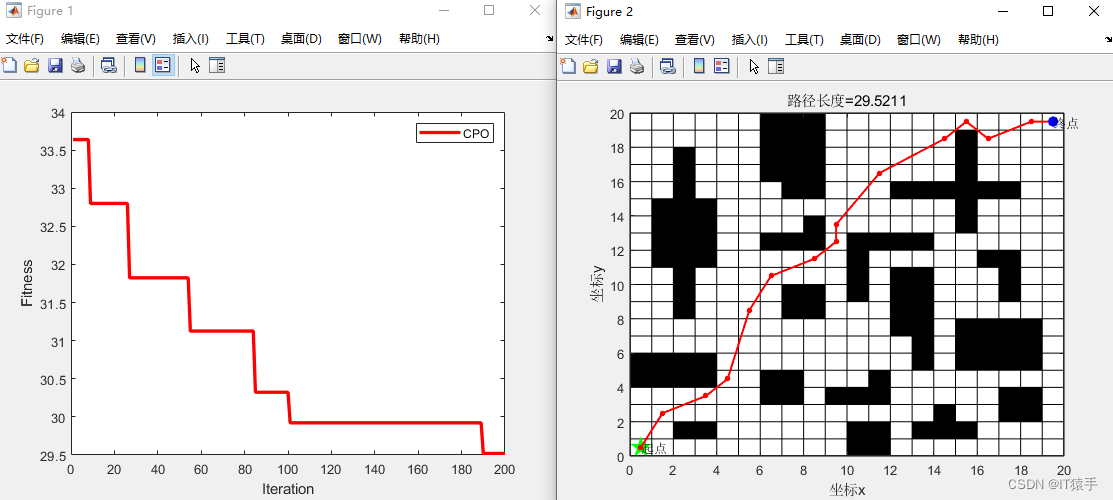
机器人路径规划:基于冠豪猪优化算法(Crested Porcupine Optimizer,CPO)的机器人路径规划(提供MATLAB代码)
一、机器人路径规划介绍 移动机器人(Mobile robot,MR)的路径规划是 移动机器人研究的重要分支之,是对其进行控制的基础。根据环境信息的已知程度不同,路径规划分为基于环境信息已知的全局路径规划和基于环境信息未知或…...

探索.NET中的定时器:选择最适合你的应用场景
概述:.NET提供多种定时器,如 System.Windows.Forms.Timer适用于UI,System.Web.UI.Timer用于Web,System.Diagnostics.Timer用于性能监控,System.Threading.Timer和System.Timers.Timer用于一般定时任务。在.NET 6及以上…...

5467: 【搜索】流浪奶牛
题目描述 吃不到饭的奶牛Bessie一气之下决定离开农场,前往阿尔费茨山脉脚底下的农场(听说那儿的草极其美味)投靠她的亲戚Jimmy。但是前往目的地的山路崎岖,Bessie又没有吃饭,她需要尽量保存体力,以最轻松的…...

spring boot整合elasticsearch实现查询功能
第一步、添加依赖(注意版本对应关系)根据spring boot版本选择合适的版本 <dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.6.2</version></dependenc…...

白嫖阿里云程序员日历
https://developer.aliyun.com/topic/lingma/activities/202403?taskCode14508&recordId44f3187f7950776f494eec668a62c65f#/?utm_contentm_fission_1 「通义灵码 体验 AI 编码,开 AI 盲盒」 打开链接直接领就行了...
ubuntu20.04搭建rtmp视频服务
1.安装软件 sudo apt-get install ffmpeg sudo apt-get install nginx sudo apt-get install libnginx-mod-rtmp 2.nginx配置 修改/etc/nginx/nginx.conf文件,在末尾添加: rtmp {server {listen 1935;application live {live on;}} } 3.视频测试 本…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

不止于绘图:用GMT 6.4的`grdtrack`和`project`命令玩转地形剖面分析与可视化
不止于绘图:用GMT 6.4的grdtrack和project命令玩转地形剖面分析与可视化 当我们谈论地理空间分析时,很多人首先想到的是绘制精美的地图。但GMT(Generic Mapping Tools)的真正魅力在于它强大的地理计算能力。本文将带你超越基础绘图…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...