【算法】雪花算法生成分布式 ID

![]() 个人中心:SueWakeup
个人中心:SueWakeup
![]() 系列专栏:学习Java框架
系列专栏:学习Java框架
![]() 个性签名:人生乏味啊,我欲令之光怪陆离
个性签名:人生乏味啊,我欲令之光怪陆离


目录
1. 什么是分布式 ID
2. 分布式 ID 基本要求
3. 数据库主键自增
4. UUID
5. Snowflake 雪花算法
5.1 开源的雪花算法
注:手机端浏览本文章可能会出现 “目录”无法有效展示的情况,请谅解,点击侧栏目录进行跳转
1. 什么是分布式 ID
在理解分布式 ID 之前请先阅读:【概念】神马是分布式?
分布式 ID 是指在分布式系统中,数据库的自增 ID 不能满足需求,需要在不同的节点之间通过一个唯一 ID 来进行标识。
个人理解:在分布式微服务项目中,多个线程同时对一张表新增数据,且这张表的主键 ID 存在唯一性
2. 分布式 ID 基本要求
| 基本要求 | 描述 |
|---|---|
| 全局唯一 | 在整个分布式系统中全局唯一,不能出现重复 ID |
| 高性能高可用 | 分布式 ID 的生成速度要快,生成分布式 ID 的服务要保证可用性无限接近于 100% |
| 趋势递增 | 在 MySQL InnoDB 引擎中使用的是聚焦索引,由于多数 RDBMS 使用 B-tree 的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能 |
| 单调递增 | 保证下一个 ID 一定大于上一个 ID |
| 具体的业务含义 | 生成的 ID 拥有具体的业务含义,可以让定位问题以及开发更透明化 |
| 独立部署 | 在分布式系统单独有一个发号器服务,专门用来生成分布式 ID,生成的 ID 的服务和业务相关的服务解耦,但会带来服务之间网络调用消耗增加 |
| 信息安全 | ID 中不能包含敏感信息,如果 ID 是连续的,恶意用户的扒取工作就非常容易做,订单号就更危险了,竞争对手可以获取到我们一天的订单信息,所以一些应用场景下,ID 需要呈现无规则状态 |
3. 数据库主键自增
通过关系型数据库的主键自增的方式,产生唯一的 ID
| 优点 | 缺点 |
|---|---|
|
|
解决方案:
在分布式系统中多部署几台及其,每台机器设置不同的初始值,且步长和机器数相等
如:两台机器,设置步长 step 为 2, TicketServer1 的初始值为 1(1,3,5,7,9...)、TicketServer2 的初始值为 2(2,4,6,8,10...)
4. UUID
Universally Unique Identifier(通用唯一标识符)的缩写
UUID 包含 32 个 16 进制数字(8-4-4-4-12)
生成规则:包括 MAC 地址、时间戳、命名空间(Namespace)、随机或伪随机数、时序等元素,基于这些规则生成的 UUID 不会重复
UUID.randomUUID();| 优点 | 缺点 |
|---|---|
|
|
5. Snowflake 雪花算法
Snowflake 产生的 ID 由 64位 二进制数字组成,被拆分成 4 个部分:
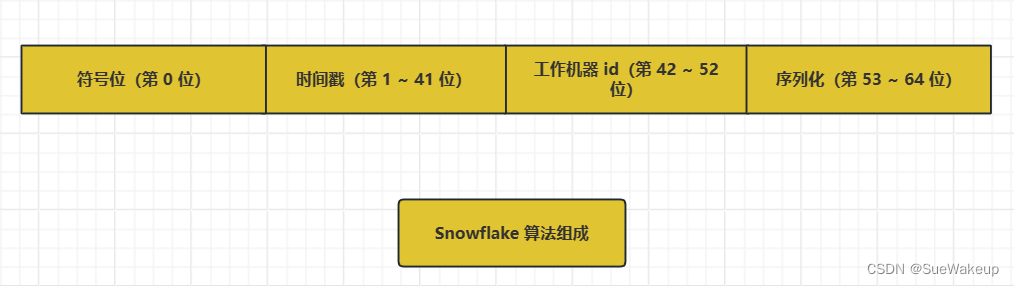
- 符号位:标识正负,始终为0
- 时间戳:单位 ms(毫秒),可以支持 2^41 毫秒(约 69 年)
- 工作时间 ID:一般前 5 位表示机房 ID,后 5 位表示机器ID,用于区分不同集群/机房的节点,10 位的长度,可以表示 1024 个不同节点。
- 序列号:序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数,也就是说单台机器每毫秒最多可以生成 4096 个唯一ID,最大支持 400W 左右的并发量。
5.1 开源的雪花算法
public class SnowFlake {// 机房(数据中心)IDprivate long datacenterId;// 机器 IDprivate long workerId;// 同一时间的序列号private long sequence;// 开始时间戳private long twepoch = 1634393012000L; // 时间起点,这里设置为"2021-10-17 00:00:00"// 机房ID所占的位数:5个 bitprivate long datacenterIdBits = 5L;// 机器ID所占的位数:5个 bitprivate long workerIdBits = 5L;// 最大机器ID:5 bit 最多只能有31个数字,就是说机器id最多只能是32以内// 最大:11111(2进制) --> 31(10进制)private long maxWorkerId = -1L ^ (-1L << workerIdBits); // 最大机器ID值// 最大数据中心ID:5 bit 最多只能有31个数字,就是说数据中心id最多只能是32以内private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); // 最大数据中心ID值// 同一毫秒内的序列号位数:12 bitprivate long sequenceBits = 12L;// workerId左移位数:12private long workerIdShift = sequenceBits;// datacenterId左移位数:12+5private long datacenterIdShift = sequenceBits + workerIdBits;// timestamp左移位数:12+5+5private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;// 序列号掩码:4095 (0b111111111111=0xfff=4095)private long sequenceMask = -1L ^ (-1L << sequenceBits);// 上次时间戳private long lastTimestamp = -1L;// 构造函数,传入workerId和datacenterIdpublic SnowFlake(long workerId, long datacenterId) {this(workerId, datacenterId, 0);}// 构造函数,传入workerId、datacenterId和sequencepublic SnowFlake(long workerId, long datacenterId, long sequence) {// 参数校验if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}// 输出信息System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);// 初始化参数this.workerId = workerId;this.datacenterId = datacenterId;this.sequence = sequence;}// 生成下一个IDpublic synchronized long nextId() {// 获取当前时间戳long timestamp = timeGen();// 检查时间回拨if (timestamp < lastTimestamp) {System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",lastTimestamp - timestamp));}if (lastTimestamp == timestamp) {// 同一毫秒内的序列号自增sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {// 如果同一毫秒内的序列号超出范围,等待下一毫秒timestamp = tilNextMillis(lastTimestamp);}} else {// 不同毫秒内,序列号重置为0sequence = 0;}// 更新上次时间戳lastTimestamp = timestamp;// 生成IDreturn ((timestamp - twepoch) << timestampLeftShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) |sequence;}// 等待下一毫秒private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}// 获取当前时间戳private long timeGen() {return System.currentTimeMillis();}// 主函数,测试生成IDpublic static void main(String[] args) {SnowFlake worker = new SnowFlake(1, 1);for (int i = 0; i < 100; i++) {System.out.println(worker.nextId());}System.out.println();worker = new SnowFlake(1, 2);for (int i = 0; i < 100; i++) {System.out.println(worker.nextId());}}}测试用例
SnowFlake flake1 = new SnowFlake(1, 12);SnowFlake flake2 = new SnowFlake(1, 12);Thread t1 = new Thread(){@Overridepublic void run() {for(int i=0;i<10;i++){System.out.println("t1-"+flake1.nextId());}}};Thread t2 =new Thread(){@Overridepublic void run(){for(int i=0;i<10;i++){System.out.println("t2-"+flake2.nextId());}}};t1.start();t2.start();try {t1.join();t2.join();} catch (InterruptedException e) {e.printStackTrace();}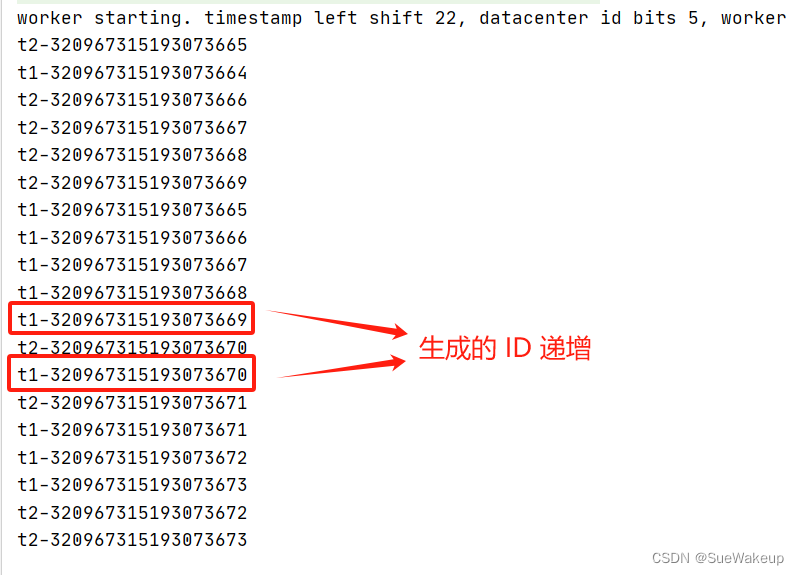
相关文章:
【算法】雪花算法生成分布式 ID
SueWakeup 个人中心:SueWakeup 系列专栏:学习Java框架 个性签名:人生乏味啊,我欲令之光怪陆离 本文封面由 凯楠📷 友情赞助播出! 目录 1. 什么是分布式 ID 2. 分布式 ID 基本要求 3. 数据库主键自增 4. UUID 5. S…...
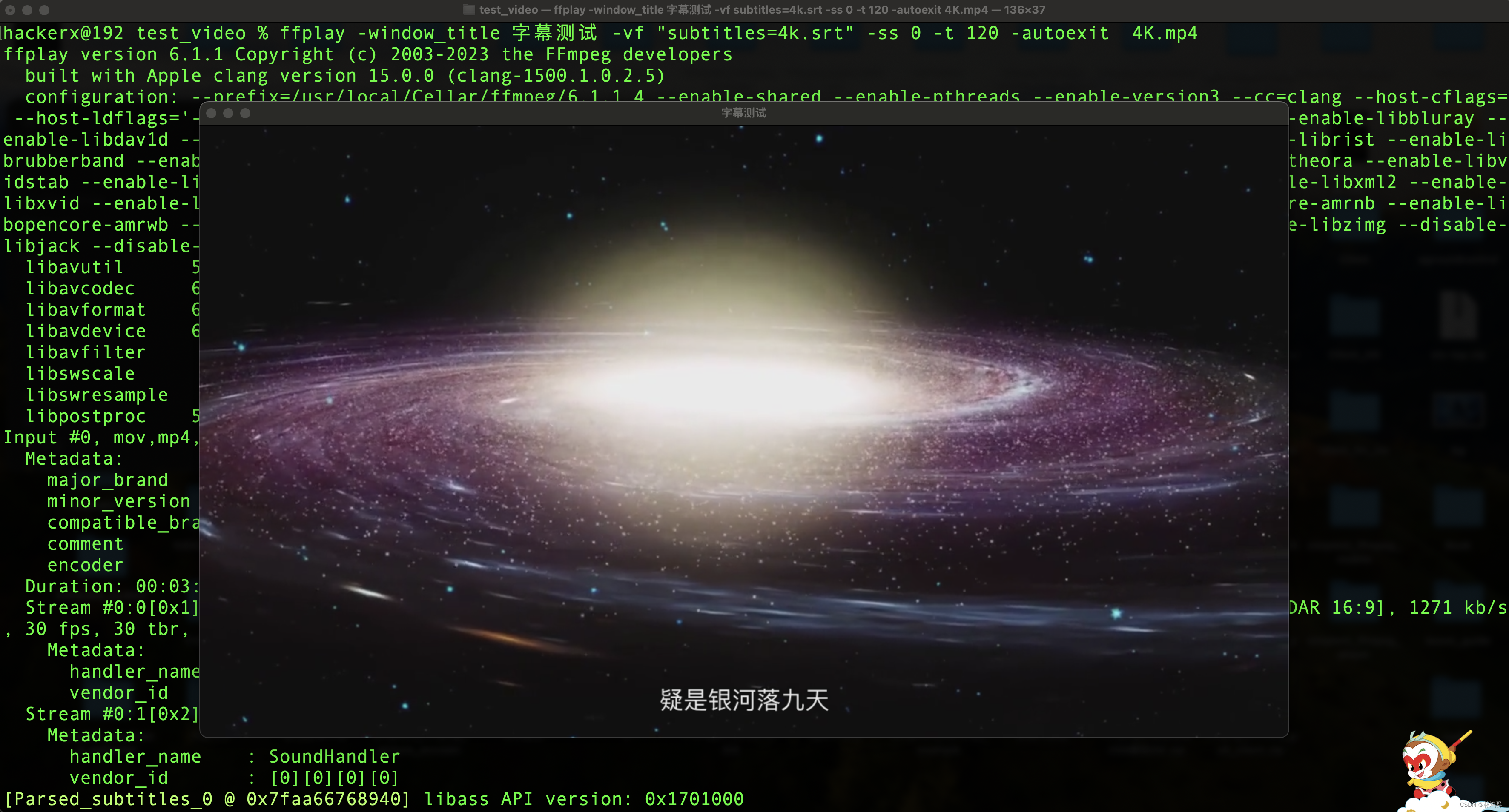
FFplay使用滤镜添加字幕到现有视频显示
1.创建字幕文件4k.srt 4k.srt内容: 1 00:00:01.000 --> 00:00:30.000 日照香炉生紫烟2 00:00:31.000 --> 00:00:60.000 遥看瀑布挂前川3 00:01:01.000 --> 00:01:30.000 飞流直下三千尺4 00:01:31.000 --> 00:02:00.000 疑是银河落九天2.通过使用滤镜显示字幕在视…...
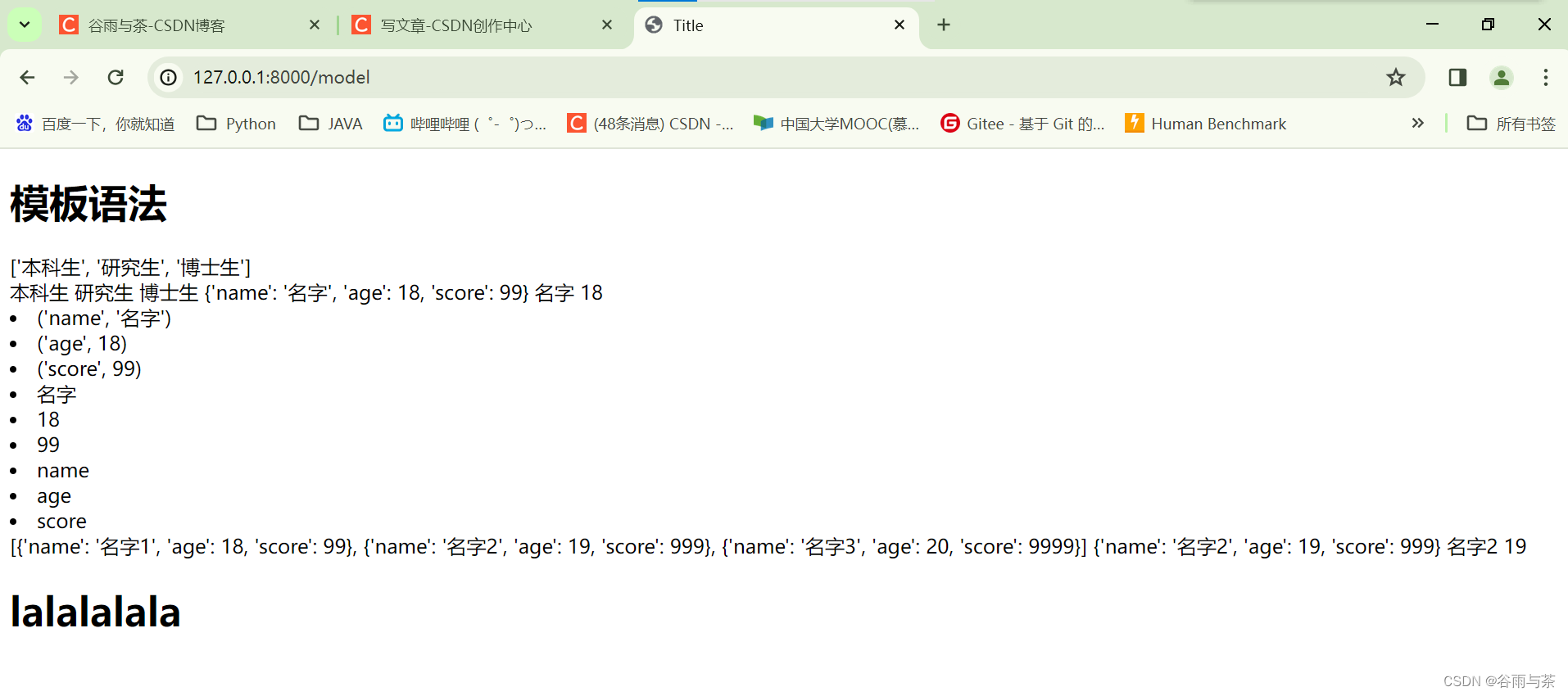
【Python + Django】Django模板语法 + 请求和响应
前言: 现在现在,我们要开始将变量的值展现在页面上面啦! 要是只会显示静态页面,我们的页面也太难看和死板了, 并且数据库的数据也没法展现在页面上。 但是呢,模板语法学习之后就可以啦!&…...

大数据面试总结 四
1、当hadoop集群中某一个节点挂了,内部数据流程是如何进行的? 每一个datanode都会定期向namenode发送heardbeat消息,当一段时间namenode没有接收到某一个datanode的消息,此时namenode就会将该datanode标记为死亡,并不…...

Spring Boot: 使用MongoOperations操作mongodb
一、添加依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4…...

PyTorch 深度学习(GPT 重译)(六)
十四、端到端结节分析,以及接下来的步骤 本章内容包括 连接分割和分类模型 为新任务微调网络 将直方图和其他指标类型添加到 TensorBoard 从过拟合到泛化 在过去的几章中,我们已经构建了许多对我们的项目至关重要的系统。我们开始加载数据…...

MyBatis3源码深度解析(十七)MyBatis缓存(一)一级缓存和二级缓存的实现原理
文章目录 前言第六章 MyBatis缓存6.1 MyBatis缓存实现类6.2 MyBatis一级缓存实现原理6.2.1 一级缓存在查询时的使用6.2.2 一级缓存在更新时的清空 6.3 MyBatis二级缓存的实现原理6.3.1 实现的二级缓存的Executor类型6.3.2 二级缓存在查询时使用6.3.3 二级缓存在更新时清空 前言…...

Go --- Go语言垃圾处理
概念 垃圾回收(GC-Garbage Collection)暂停程序业务逻辑SWT(stop the world)程序根节点:程序中被直接或间接引用的对象集合,能通过他们找出所有可以被访问到的对象,所以Go程序的根节点通常包括…...

力扣每日一题30:串联所有单词的子串
题目描述 给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。 s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。 例如,如果 words ["ab","cd","ef"], 那么 &q…...

vim | vim的快捷命令行
快捷进入shell界面 -> :nnoremap <F8> :sh<CR> -> 绑定到了F8 :nnoremap <F8> :sh<CR> 快捷执行 -> :nnoremap <F5> :wa<CR>:!g % -o a.out && ./a.out<CR> -> 绑定到了F5 :nnoremap <F5> :wa<CR>…...

项目管理平台-01-BugClose 入门介绍
拓展阅读 Devops-01-devops 是什么? Devops-02-Jpom 简而轻的低侵入式在线构建、自动部署、日常运维、项目监控软件 代码质量管理 SonarQube-01-入门介绍 项目管理平台-01-jira 入门介绍 缺陷跟踪管理系统,为针对缺陷管理、任务追踪和项目管理的商业…...
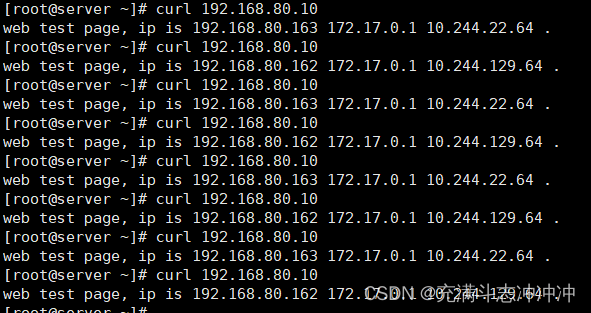
web集群-lvs-DR模式基本配置
目录 环境: 一、配置RS 1、安装常见软件 2、配置web服务 3、添加vip 4、arp抑制 二、配置LVS 1、添加vip 2、安装配置工具 3、配置DR 三、测试 四、脚本方式配置 1、LVS-DR 2、LVS-RS 环境: master lvs 192.168.80.161 no…...

基于深度学习的面部情绪识别算法仿真与分析
声明:以下内容均属于本人本科论文内容,禁止盗用,否则将追究相关责任 基于深度学习的面部情绪识别算法仿真与分析 摘要结果分析1、本次设计通过网络爬虫技术获取了七种面部情绪图片:吃惊、恐惧、厌恶、高兴、伤心、愤怒、自然各若…...
)
C语言经典面试题目(十六)
1、什么是C语言中的指针常量和指针变量?它们有什么区别? 在C语言中,指针常量和指针变量是指针的两种不同类型。它们的区别在于指针的指向和指针本身是否可以被修改。 指针常量:指针指向的内存地址不可变,但指针本身的…...
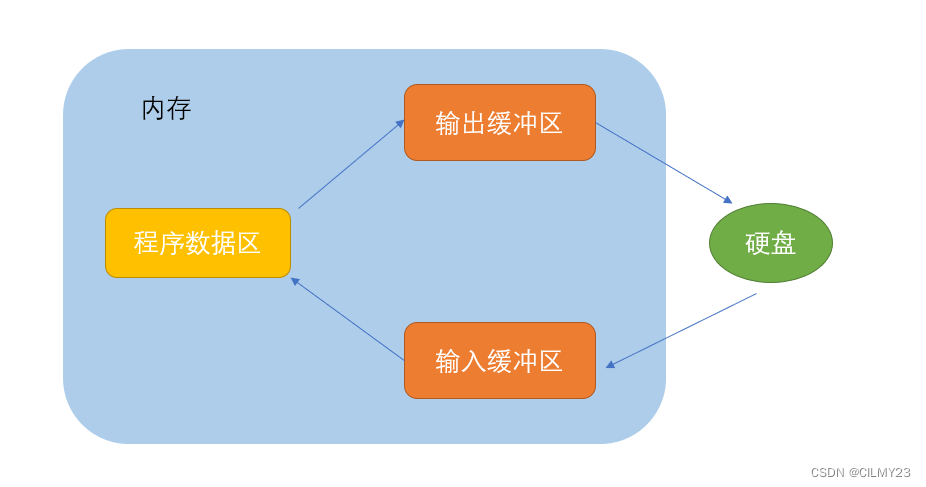
【C语言】文件操作揭秘:C语言中文件的顺序读写、随机读写、判断文件结束和文件缓冲区详细解析【图文详解】
欢迎来CILMY23的博客喔,本篇为【C语言】文件操作揭秘:C语言中文件的顺序读写、随机读写、判断文件结束和文件缓冲区详细解析【图文详解】,感谢观看,支持的可以给个一键三连,点赞关注收藏。 前言 欢迎来到本篇博客&…...

JAVA八股文面经问题整理第6弹
文章目录 目录 文章目录 提问问题 问题1 问题2 问题3 问题4 问题5 问题6 问题7 问题8 问题9 问题10 问题11 问题12 写在最后 提问问题 介绍一下Linux常⽤命令,例如:Vim快捷键,常⽤查看Log的命令,路径相关&#x…...

pytest相关面试题
pytest是什么?它有什么优点? pytest是一个非常流行的Python测试框架,它具有简洁、易用、高校等优点。他可以帮助测试人员方便地编写和运行测试用例,并且提供了丰富的插件和扩展,支持各种测试需求介绍下pytest常用的库 …...

Keras库搭建神经网络
Keras并非简单的神经网络库,而是一个基于Theano的强大的深度学习库,利用它不仅仅可以搭建普通的神经网络,还可以搭建各种深度学习模型,如自编码器、循环神经网络、递归神经网络、卷积神经网络等。 安装代码: pip ins…...

适配器模式与桥接模式-灵活应对变化的两种设计策略大比拼
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》 💪🏻 制定明确可量化的目标,坚持默默的做事。 🚀 转载自:设计模式深度解析:适配器模式与桥接模式-灵活应对变…...

Elasticsearch8搭建及Springboot中集成使用
1.搭建 1.1.下载地址 Elasticsearch:https://www.elastic.co/cn/downloads/elasticsearch Kibana:https://www.elastic.co/cn/downloads/kibana 1.2.具体过程 下载安装包:访问上述链接,下载适合你操作系统的Elasticsearch和Ki…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理
淘宝淘金币自动化脚本终极指南:如何每天节省25分钟实现智能任务管理 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taoji…...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...