【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
DiffSpeaker: 使用扩散Transformer进行语音驱动的3D面部动画
code:GitHub - theEricMa/DiffSpeaker: This is the official repository for DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
paper:https://arxiv.org/pdf/2402.05712.pdf
出处:香港理工大学,HKISI CAS,CASIA,2024.2
1. 介绍
语音驱动的3D面部动画,可以用扩散模型或Transformer架构实现。然而它们的简单组合并没有性能的提升。作者怀疑这是由于缺乏配对的音频-4D数据,这对于Transformer在扩散框架中充当去噪器非常重要。
为了解决这个问题,作者提出DiffSpeaker,一个基于Transformer的网络,设计了有偏条件注意模块,用作传统Transformer中自注意力/交叉注意力的替代。融入偏置,引导注意机制集中在相关任务特定和与扩散相关的条件上。还探讨了在扩散范式内精确的嘴唇同步和非语言面部表情之间的权衡。
总结:提出了一种将Transformer架构与基于扩散的框架集成的新方法,特点是一个带偏置的条件自注意/交叉注意机制,解决了用有限音频- 4d数据训练基于扩散的transformer的困难。能够并行生成面部动作,推理速度很快。

2. 背景
条件概率模型:学习语音和面部运动之间的概率映射,为语音驱动的3D面部动画提供了一种有效方法。目前的技术仍然倾向于在简短的片段中创建面部动画,严重依赖于GRU的顺序处理能力[Cho等人,2014]或卷积网络,导致在处理上下文方面表现差,不如Transformer。
Transformer架构整合到扩散框架的困难:需要在整个长度范围内对面部运动序列进行降噪,这对于数据密集型注意力机制来说要求很高。
语音驱动的3D面部动画,从音频语音输入中生成逼真的面部动作,需要同步捕捉语音的音调、节奏和动态。之前的工作遵循确定性映射的范式,即一个音频对应一个面部动作。比如:制定将语音(音素)与面部运动(视素)联系起来的人工规则,并使用系统测量音素对视素的影响。最近的研究认识到任务中固有的一对多关系,一个语音输入可以对应多个面部动作。CodeTalker 使用量化码本学习这种复杂的数据分布,显著提高了性能。
扩散模型的概率映射:FaceDiffuser 采用基于扩散的生成框架和GRU来单独处理音频段。扩散模型也被应用于头部姿势的并发生成[Park等人,2023;Sun等人,2023],对个人用户的定制[Thambiraja等人,2023],以及扩散蒸馏[Chen等人,2023a]等方法来加速生成过程。一些并行研究[Park and Cho, 2023;Aneja等,2023;Zhao等人,2024]专注于自定义数据集的混合形状级动画。
3. 方法
将语音驱动的三维面部动画作为一个条件生成问题,目标是通过从后验分布![]() 中采样,基于语音a1:T和第k个人的说话风格sk,生成面部运动x1:T,包含V个顶点的模板面网格上的一个顶点序列x i∈R T×V×3。ai∈RD是一个音频片段,只产生一帧运动。说话风格sk∈RK是一个one-hot嵌入,表示K个人物。n越大表示xn中的高斯噪声越多,xn为纯高斯噪声,x0为期望的面部运动。马尔可夫链依次将高噪声xn转换为低噪声版本,直到得到面部运动分布:
中采样,基于语音a1:T和第k个人的说话风格sk,生成面部运动x1:T,包含V个顶点的模板面网格上的一个顶点序列x i∈R T×V×3。ai∈RD是一个音频片段,只产生一帧运动。说话风格sk∈RK是一个one-hot嵌入,表示K个人物。n越大表示xn中的高斯噪声越多,xn为纯高斯噪声,x0为期望的面部运动。马尔可夫链依次将高噪声xn转换为低噪声版本,直到得到面部运动分布:

其中![]() 。目标是得到
。目标是得到![]() 。为了在a和sk的指导下,从p(xn)推断出低噪分布p (xn−1),取神经元网络G,表达式为:
。为了在a和sk的指导下,从p(xn)推断出低噪分布p (xn−1),取神经元网络G,表达式为:
![]()
G作为去噪器,根据音频a、说话风格sk和扩散步长n,从xn中恢复面部运动x0。然后使用x0来构造马尔可夫链下一步的分布p(xn−1)。即DDIM过程,构造了相对较短的马尔可夫链,实现高效生成。
3.1 Diffusion-based Transformer Architecture
接下来介绍如何将语音a、风格sk和扩散步骤n的条件合并到Transformer体系结构中:网络g采用编码器-解码器架构,如图2所示,条件分别由Ea、Es、En编码,并提供给解码器D,解码器D对输入进行去噪:
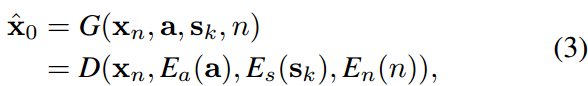
音频编码器ea = ea (a 1:T)∈RT×C是预训练的音频编码器,样式编码器es = es (sk)∈R1×C是线性投影层,步进编码器en = en (n)∈R1×C首先将标量n转换为频率编码,然后将其传递给线性层。重要的是,网络G并行处理所有帧步长t ={1,···,t},但在扩散步长n中发生变化。

图2:DiffSpeaker利用基于扩散的迭代去噪技术,从语音音频a 1:T和说话风格sk合成面部运动x 1:T。核心特征是带偏置的条件注意机制,该机制在自我/交叉注意中引入静态偏置,并采用编码和en来整合说话风格和扩散步骤信息。
Attention with Condition Tokens
将说话风格条件和扩散步骤融入自注意力和交叉注意力层中。传统的自注意机制使面部动作序列能够自我反映,而交叉注意机制整合了条件输入。假设面部运动输入xn是噪声输入的,为了准确处理运动,自注意力必须是扩散步长感知的,用n表示。由于步骤编码 en 和风格编码 es 都是一维嵌入,可以同时将它们引入作为条件标记到自注意力和交叉注意力层中。采用标准的Transformer架构,自注意力层(As)和交叉注意力层(Ac)的输出计算如下:

Qs、Ks、Vs∈R ×C表示自注意,Qc、Kc、Vc∈R T ×C表示交叉注意。方括号表示沿着序列维度进行连接。引入注意机制之前,风格编码e和步骤编码en被附加在键特征之后。
Static Attention Bias
为自注意和交叉注意机制引入了固定偏差,这些机制是专门为使用条件令牌而设计的。将包含条件令牌和静态偏差的注意操作称为有偏差条件注意。考虑长度为T的输入序列,计算第i个查询qi∈R1×C的注意分数,K对应Ks或Kc,注意得分计算如下:
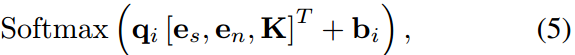
bi表示自注意或交叉注意机制的唯一偏差项。
Biased Conditional Cross-Attention.
交叉注意机制促进了面部动作序列与相关条件之间的交互,包括语音表征、风格编码和扩散步长编码。对于大小为T × (T + 2)的特征图,包括T个面部运动标记和2个附加条件标记,对于第i个查询,将bi(j)表示为第j个值的注意偏差,j的范围从1到T + 2。交叉注意偏差:
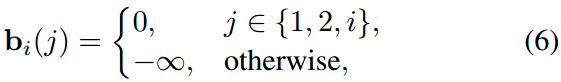
如图2所示,该设计的设置使特定帧的面部运动仅限于与其相应的语音表示以及es和en相关联。这一约束确保了音频信息的及时同步传递,同时还包含了有关扩散步骤和说话风格的信息。
Biased Conditional Self-Attention.在形状为T × (T + 2)的自注意映射中,偏差bi(j)表示为: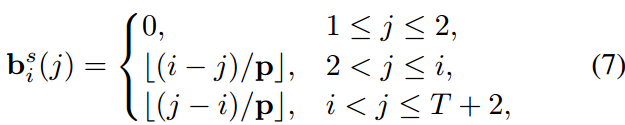
p表示与面部运动序列的帧速率相等的常数。如图2所示,对于最接近对角线的2p元素,这种一致的偏差为零,并随着与对角线的距离增加而减小。这种偏置通过将自我注意限制在一个集中的范围内,减轻了面部运动序列中噪声的破坏性影响。

3.2 Training Objective
训练如图2,包括预训练的音频编码器,目标是从任意扩散步骤n∈{1,···,n}中恢复原始信号。对于从数据集中采样的任意a, sk, x0,用以下损失来监督恢复的x = G(xn, a, sk, n):

还使用速度损失来解决抖动,并平滑运动:

总体损失为两者和:
![]()
λ1 = λ2 = 1。
4. 实验
4.1 Datasets and Implementations
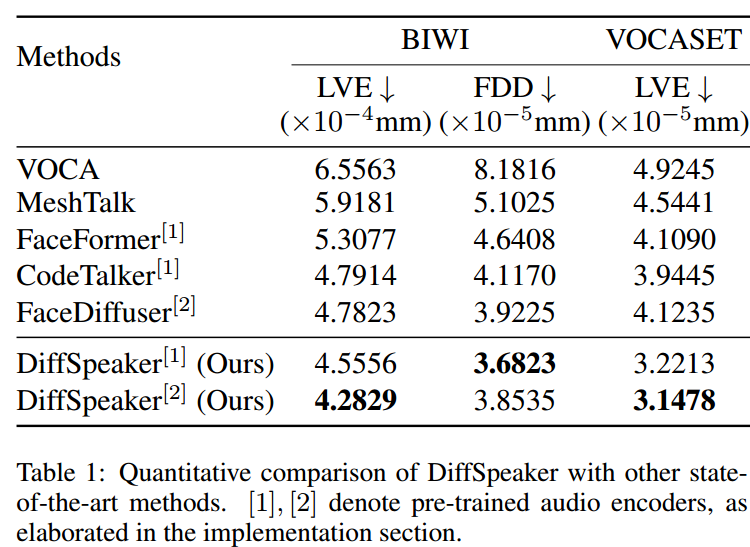
两个开源3D面部数据集BIWI和VOCASET进行训练和测试。这两个数据集都有4D面部扫描以及短句的录音。
BIWI数据集包含14名受试者(8名女性和6名男性)所说的40个句子的音频。每个主题将每个句子说两次——一次充满感情,一次中立。每句话记录的平均时间为4.67秒。记录以每秒25帧的速度捕获,每个3D面部扫描帧有23370个顶点。
VOCASET数据集包含从12个受试者中捕获的480对音频和3D面部运动序列。面部运动序列以每秒60帧的速度记录,长度约为4秒。VOCASET中的3D人脸网格注册到FLAME拓扑,每个网格有5023个顶点。
4.2 Implementation Detail
网络体系结构
Transformer模型,包括512维的隐藏层,1024维的前馈网络,4个头的多头注意和一个Transformer块。Transformer中的自注意/交叉注意用残差连接。对于BIWI数据集的实验[Fanelli et al ., 2010],它提供了更复杂的数据,通过将隐藏状态维数增强到1024,前馈网络维数增强到2048,模型进行了缩放,其他配置与VOCASET中概述的配置保持一致。
训练
用PyTorch框架和Nvidia V100 gpu开发。在VOCASET数据集上训练,批处理大小32,并在单个V100 GPU上运行训练大约24小时。BIWI数据集训练分布在8个V100 GPU上,每个GPU处理32个批处理大小,总训练时间为12小时。采用AdamW优化算法,学习率0.0001。

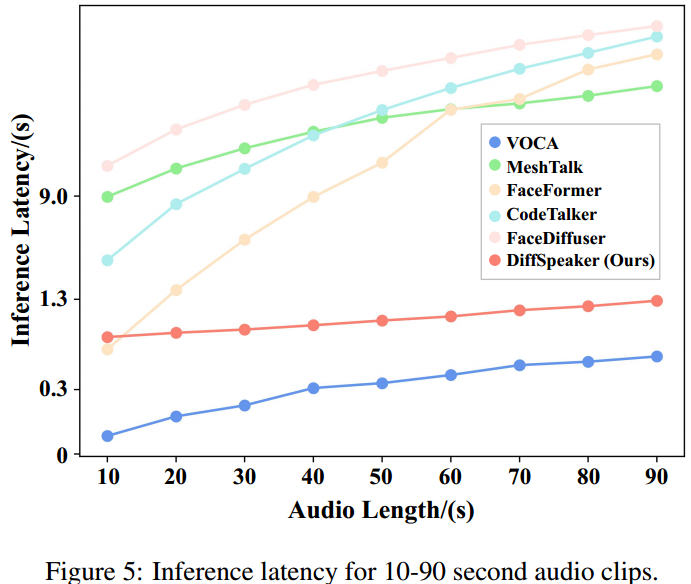
尽管人们普遍认为基于扩散的方法速度较慢,但我们的语音驱动3D面部动画方法证明了比大多数现有替代方法更快的推理速度。在3090 GPU上测量了不同长度的音频的延迟,图5中的结果显示,我们的方法在10秒以上的音频上优于除VOCA之外的所有其他方法。
由于使用了固定的去噪迭代,无论音频长度如何,这种速度优势在较长的音频剪辑中更明显。与并行处理所有音频窗口的VOCA不同,其他方法依赖于顺序地关注前面的片段以进行后续预测,从而导致扩展音频的迭代增加。
相关文章:
【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
DiffSpeaker: 使用扩散Transformer进行语音驱动的3D面部动画 code:GitHub - theEricMa/DiffSpeaker: This is the official repository for DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer paper:https://arxiv.org/pdf/…...
NVM使用教程
文章目录 ⭐️写在前面的话⭐️1、卸载已经安装的node2、卸载nvm3、安装nvm4、配置路径以及下载源5、使用nvm下载node6、nvm常用命令7、全局安装npm、cnpm8、使用淘宝镜像cnpm9、配置全局的node仓库🚀 先看后赞,养成习惯!🚀&#…...

mysql 学习
本文来自于《sql必知必会》 所需要的文件教程连接 本站其他的小伙伴 第一课 了解sql 数据库基础 什么是数据库 数据库(database) 保存有组织的数据的容器(通常是一个文 件或一组文件)。 表 表(table)…...
Jenkins 一个进程存在多个实例问题排查
Jenkins 一个进程存在多个实例问题排查 最近Jenkins升级到2.440.1版本后,使用tomcat服务部署,发现每次定时任务总会有3-4个请求到我的机器人上,导致出现奇奇怪怪的问题。 问题发现 机器人运行异常,总有好几个同时请求的服务。…...

mysql数据类型和常用函数
目录 1.整型 1.1参数signed和unsigned 1.2参数zerofill 1.3参数auto_increment 2.数字类型 2.1floor()向下取整 2.2随机函数rand() 2.3重复函数repeat() 3.字符串类型 3.1length()查看字节长度,char_length()查看字符长度 3.2字符集 3.2.1查看默认字符…...

Elastic 线下 Meetup 将于 2024 年 3 月 30 号在武汉举办
2024 Elastic Meetup 武汉站活动,由 Elastic、腾讯、新智锦绣联合举办,现诚邀广大技术爱好者及开发者参加。 活动时间 2024年3月30日 13:30-18:00 活动地点 中国武汉 武汉市江夏区腾讯大道1号腾讯武汉研发中心一楼多功能厅 13:30-14:00 入场 活动流程…...
中的体现)
线性代数在卷积神经网络(CNN)中的体现
案例:深度学习中的卷积神经网络(CNN) 在图像识别领域,卷积神经网络(Convolutional Neural Networks, CNN)是一个广泛应用深度学习模型,它在人脸识别、物体识别、医学图像分析等方面取得…...

服务器根据用途划分有哪几种?
随着企业需求的不同,服务器的类型也变得多种多样了,有根据机箱结构来划分的服务器类型,如机架式服务器、刀片式服务器和塔式服务器等,也有按照应用层次来划分的服务器类型,如入门级服务器和工作组服务器等。 那根据用途…...

linux 命令笔记:gpustat
1 命令介绍 gpustat是一个基于Python的命令行工具,它提供了一种快速、简洁的方式来查看GPU的状态和使用情况它是nvidia-smi工具的一个封装,旨在以更友好和易于阅读的格式显示GPU信息。gpustat不仅显示基本的GPU状态(如温度、GPU利用率和内存…...
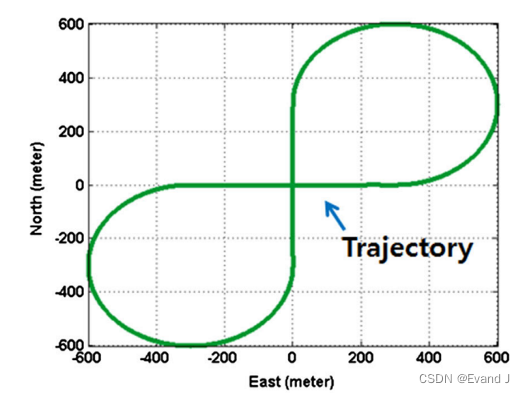
【阅读笔记】Adaptive GPS/INS integration for relative navigation
Lee J Y, Kim H S, Choi K H, et al. Adaptive GPS/INS integration for relative navigation[J]. Gps Solutions, 2016, 20: 63-75. 用于相对导航的自适应GPS/INS集成 名词翻译 formation flying:编队飞行 摘要翻译 在编队飞行、防撞、协同定位和事故监测等许多…...
Java版直播商城免 费 搭 建:电商、小程序、三级分销及免 费 搭 建,平台规划与营销策略全掌握
随着互联网的快速发展,越来越多的企业开始注重数字化转型,以提升自身的竞争力和运营效率。在这个背景下,鸿鹄云商SAAS云产品应运而生,为企业提供了一种简单、高效、安全的数字化解决方案。 鸿鹄云商SAAS云产品是一种基于云计算的软…...

经典Bug永流传---每周一“虫”(四十五)
如果有人错过机会,多半不是机会没来,而是因为机会过来时,没有一伸手抓住它。 大写W惹的祸 前提: A账号已登录 步骤: 打开某商品链接,然后在商品的评论区任意一条评论,点击回复,回…...
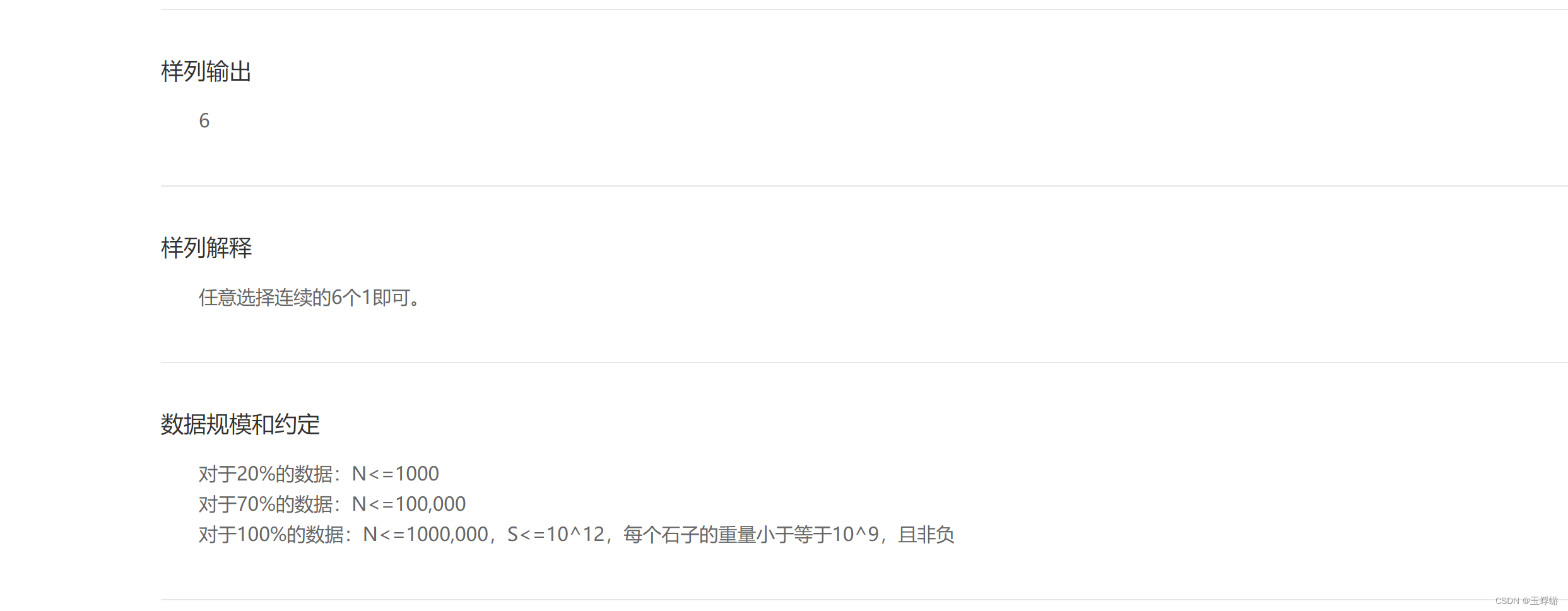
蓝桥杯-礼物-二分查找
题目 思路 --刚开始想到暴力尝试的方法,但是N太大了,第一个测试点都超时。题目中说前k个石头的和还有后k个石头的和要小于s,在这里要能想到开一个数组来求前n个石头的总重,然后求前k个的直接将sum[i]-sum[i-k-1]就行了࿰…...

设计原则、工厂、单例模式
什么是设计模式 简单来说,设计模式就是很多程序员经过相当长的一段时间的代码实践、踩坑所总结出来的一套解决方案,这个解决方案能让我们少写一些屎山代码,能让我们写出来的代码写出来更加优雅,更加可靠。所以设计模式的好处是显而…...

笔记:Mysql 主从搭建
主库 创建用户并授权 create user slave identified with mysql_native_password by 123456 GRANT REPLICATION SLAVE ON *.* to slave%; FLUSH PRIVILEGES;主库配置文件 /etc/my.cnf #日志路径及文件名,目录要是mysql有权限写入 log-bin/var/lib/mysql/binlog …...

HTTP Error 400. The request hostname is invalid.
异常信息 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN""http://www.w3.org/TR/html4/strict.dtd"> <HTML><HEAD><TITLE>Bad Request</TITLE> <META HTTP-EQUIV"Content-Type" Content"text/html;…...
)
mysql日志( Redo Log 、Undo Log、Bin Log)
InnoDB是一个带有ACID事务支持的存储引擎,其中redo log和undo log是其实现原子性、一致性、隔离性和持久性(ACID)的重要机制。 Redo Log(重做日志) Redo log主要用于实现事务的持久性。它记录了后续可以用来恢复数据…...

HarmonyOS如何创建及调用三方库
介绍 本篇主要向开发者展示了在Stage模型中,如何调用已经上架到三方库中心的社区库和项目内创建的本地库。效果图如下: 相关概念 Navigation:一般作为Page页面的根容器,通过属性设置来展示页面的标题、工具栏、菜单。Tabs&#…...

我手写的轮子开源了
我手写的轮子开源了 文章目录 1.gitee坐标和地址1.1.gitee坐标1.2.gitee地址 2.github坐标和地址2.1.github坐标2.2.github地址 3.总结 1.gitee坐标和地址 1.1.gitee坐标 <dependency><groupId>io.gitee.bigbigfeifei</groupId><artifactId>es-sprin…...
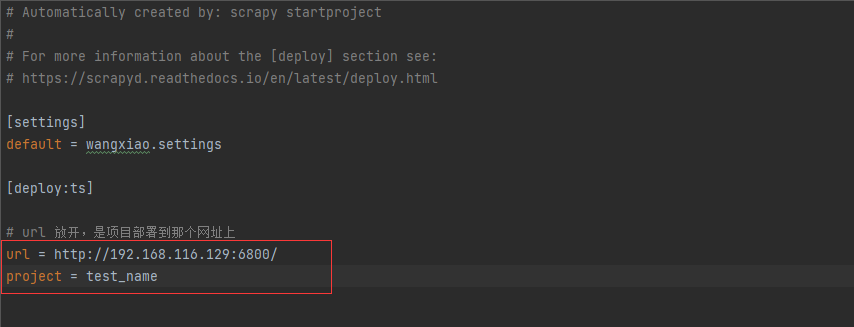
第十九章 linux部署scrapyd
文章目录 1. linux部署python环境1. 部署python源文件环境2. 下载python3. 解压安装包4. 安装5. 配置环境变量6. 检查是否安装成功7. 准备python使用的包8. 安装scrapyd9. 配置scrapyd10. 开放6800端口 2. 部署gerapy1. 本机下载包2. 初始化3. 进入gerapy同步数据库4. 创建用户…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...
)
Windows10下V-REP教育版安装保姆级教程(附百度网盘资源与避坑点)
Windows10系统V-REP教育版完整安装指南:从下载到实战避坑在机器人仿真和自动化控制领域,V-REP(现更名为CoppeliaSim)作为一款功能强大的跨平台机器人仿真软件,已经成为众多工科学生和研究人员的首选工具。特别是其教育…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...