Google云计算原理与应用(四)
目录
- 七、海量数据的交互式分析工具Dremel
- (一)产生背景
- (二)数据模型
- (三)嵌套式的列存储
- (四)查询语言与执行
- (五)性能分析
- (六)小结
- 八、内存大数据分析系统PowerDrill
- (一)产生背景与设计目标
- (二)基本数据结构
- (三)性能优化
- (四)性能分析与对比
- 九、Google应用程序引擎
- (一)Google App Engine简介
- (二)应用程序环境
- (三)Google App Engine服务
七、海量数据的交互式分析工具Dremel

(一)产生背景


Google 的团队结合其自身的实际需求,借鉴搜索引擎和并行数据库的一些技术,开发出了实时的交互式查询系统 Dremel。
Dremel支持的典型应用:
- Web 文档的分析
- Android 市场的应用安装数据的跟踪
- Google 产品的错误报告
- Google 图书的光学字符识别
- 欺诈信息的分析
- Google 地图的调试
- Bigtable 实例上的 tablet 迁移
- Google 分布式构建系统的测试结果分析
- 磁盘 I/O 信息的统计
- Google 数据中心上运行任务的资源监控
- Google 代码库的符号和依赖关系分析
(二)数据模型
两方面的技术支撑:
一方面:统一的存储平台
实现高效的数据存储,Dremel使用的底层数据存储平台是GFS。
另一方面:统一的数据存储格式
存储的数据才可以被不同的平台所使用。
面向记录和面向列的存储:
Google 的 Dremel 是第一个在嵌套数据模型基础上实现列存储的系统。

- 好处一:处理时只需要使用涉及的列数据
- 好处二:列存储更利于数据的压缩
嵌套模型的形式化定义:
τ = d o m ∣ ⟨ A 1 : τ [ ∗ ∣ ? ] , … , A n : τ [ ∗ ∣ ? ] ⟩ τ=dom|⟨A_{1}:τ[*|?],…,A_{n}:τ[*|?]⟩ τ=dom∣⟨A1:τ[∗∣?],…,An:τ[∗∣?]⟩
原子类型(Atomic Type): 原子类型允许的取值类型包括整型、浮点型、字符串等。
记录类型(Record Type): 记录类型则可以包含多个域。记录型数据包括三种类型:必须的(Required)、可重复的(Repeated)以及可选的(Optional)。
嵌套结构的模式和实例:

文档的模式(Schema)定义,利用该数据模型,可以使用 Java 语言,也可以使用 C++ 语言来处理数据,甚至可以用 Java 编写的 MapReduce 程序直接处理 C++ 语言产生的数据集。这种跨平台的优良特性正是 Google 所需要的。
(三)嵌套式的列存储
1、数据结构的无损表示
如下图示,带有重复深度和定义深度的r1与r2的列存储。

重复深度主要关注的是可重复类型,而定义深度同时关注可重复类型和可选类型(optional)。每一列最终会被存储为块(Block)的集合,每个块包含重复深度和定义深度且包含字段值。
2、高效的数据编码
Dremel 利用图中算法创建一个树状结构,树的节点为字段的 writer,它的结构与模式中的字段层级匹配。核心的想法是只在字段 writer 有自己的数据时执行更新,非绝对必要时不尝试往下传递父节点状态。子节点 writer 继承父节点的深度值。当任意值被添加时,子 writer 将深度值同步到父节点。
下图是计算重复和定义深度的基础算法。

3、数据重组
Dremel 数据重组方法的核心思想是为每个字段创建一个有限状态机(FSM),读取字段值和重复深度,然后顺序地将值添加到输出结果上。

| 当前FSM | 写入值 | 下一个重复深度值 | 动作 |
|---|---|---|---|
| DocId(开始) | 10 | 0 | 跳转至Links.Backward |
| Links.Backward | NULL | 0 | 跳转至Links.Forward |
| Links.Forward | 20 | 1 | 停留在Links.Forward |
| Links.Forward | 40 | 1 | 停留在Links.Forward |
| Links.Forward | 60 | 0 | 跳转至Name.Language.Code |
| Name.Language.Code | en-us | 2 | 跳转至Name.Language.Country |
| Name.Language.Country | us | 2 | 跳转至Name.Language.Code |
| Name.Language.Code | en | 1 | 跳转至Name.Language.Country |
| Name.Language.Country | NULL | 1 | 跳转至Name.Url |
| Name.Url | http://A | 1 | 跳转至Name.Language.Code |
| Name.Language.Code | NULL | 1 | 跳转至Name.Language.Country |
| Name.Language.Country | NULL | 1 | 跳转至Name.Url |
| Name.Url | http://B | 1 | 跳转至Name.Language.Code |
| Name.Language.Code | en-gb | 0 | 跳转至Name.Language.Country |
| Name.Language.Country | gb | 0 | 跳转至Name.Url |
| Name.Url | NULL | 0 | 结束 |
如果具体的查询中不是涉及所有列,而是仅涉及很少的列的话,上述数据重组的过程会更加便利,下图中仅仅涉及 DocId 和 Name.Language.Country 的有限状态机。

核心的思想如下:
设置t为当前字段读取器的当前值f所返回的下一个重复深度。在模式树中,找到它在深度 t 的祖先,然后选择该祖先节点的第一个叶子字段 n。由此得到一个 FSM 状态变化 (f,t)->n。

(四)查询语言与执行
Dremel 的 SQL 查询输入的是一个或多个嵌套结构的表以及相应的模式,而输出的结果是一个嵌套结构的表以及相应的模式。

Dremel 的类 SQL 语言支持嵌套子查询、记录内聚合、top-k、joins、自定义函数等操作类型。
Dremel 利用多层级服务树(multi-level service tree)的概念来执行查询操作。
- 根服务器:接受客户端发出的请求,读取相应的元数据,将请求转发至中间服务器。
- 中间服务器:负责查询中间结果的聚集。
- 叶子服务器:负责执行数据来源。

Dremel 中的数据都是分布式存储的,因此每一层查询涉及的数据实际都被水平划分后存储在多个服务器上。Dremel 是一个多用户系统,因此同一时刻往往会有多个用户进行查询。查询分发器有一个很重要参数,它表示在返回结果之前一定要扫描百分之多少的 tablet。
(五)性能分析
由于 Dremel 并不开源,我们只能通过 Google 论文中的分析大致了解其性能。Google 的实验数据集规模如下图:

MR 从面向记录转换到列状存储后性能提升了一个数量级(从小时到分钟),而使用 Dremel 则又提升了一个数量级(从分钟到秒)。

(六)小结
- Dremel 和 MapReduce 并不是互相替代,而是相互补充的技术。在不同的应用场景下各有其用武之地。
- Drill 的设计目标就是复制一个开源的 Dremel,但是从目前来看,该项目无论是进展还是影响力都达不到 Hadoop 的高度。
- 希望未来能出现一个真正有影响力的开源系统实现 Dremel 的主要功能并被广泛采用。
八、内存大数据分析系统PowerDrill
(一)产生背景与设计目标
两个假设结论:
(1)绝大多数的查询是类似和一致的;
(2)存储系统中的表只有一小部分是经常被使用的,绝大部分的表使用频率不高。
考虑两方面的内容:
(1)如何尽可能在查询中略去不需要的数据分块;
(2)如何尽可能地减少数据在内存中的占用,占用越少意味着越多的数据可以被 加载进内存中处理。
PowerDrill整个系统实际分为三个部分:
(1)Web UI
(2)一个抽象层
(3)列式存储
(二)基本数据结构
下图阐述了 PowerDrill 采用的数据结构,简单来说就是一个双层数据字典结构。

- 全局字典表:存储全局id和搜索关键字的对应关系
- 3个块的数据:块字典记录的是块 id(chunk-id)和全局 id 的映射关系;块元素记录的是块中存储数据的块 id(注意不是全局id)。
(三)性能优化
1、数据分块
(1)背景
传统的索引对于 PowerDrill 的查询场景作用不是很大,因此一个很自然的考虑就是对数据进行分块,过滤查询中不需要的数据块来减少数据量。
(2)方法
常见的分区方法有范围分区、散列分区等。PowerDrill 实际采用的是一种组合范围分区方法。
(3)步骤
领域专家确定若干个划分的域 → 利用这几个域对数据进行划分 → 每个块的行数达到阈值时就停止划分。
(4)局限
PowerDrill 采用的数据分块方法简单实用,但是由于域的确定需要领域专家,因此这种方法在实际使用中还有一定的局限性。
2、数据编码的优化
- 对于不同的块,如果我们可以确定块中不同值的数量,那么就可以根据这个数量值来选择可变的比特位来记录块 id。
- 统计一组数中不同值的个数有一个专有名词,称为 “基数估计”。
- 对于小规模的数据集,可以比较容易地统计出精确的基数。但是在大数据的环境下,精确的基数统计非常耗时,因此能保证一定精度的基数估计就可以满足实际的需求。
- 基数估计的方法很多,大多利用了散列函数的一些特性,Google 内部使用的是一种称为 Hyperloglog 的基数估计方法的变种。
3、全局字典优化
优化中主要利用两个特性:
(1)全局字典是有序的
(2)排序后的数据常常有共同的前缀
实际使用中为了进一步减少查询中需要加载到内存的全局字典,对全局字典又进行了分块。对每个全局字典块还会维护一个布隆过滤器(bloom filter)来快速确定某个值是否在字典中。
4、压缩算法
Google 曾经对一些主流的压缩算法做过简单的测试,如下图:

- 不管压缩算法的解压速度多快,总会消耗一定的物理资源与时间。对此PowerDrill采用了一种冷热数据分别对待的策略。
- 在冷热数据切换策略中,比较常用的是LRU算法。PowerDrill开发团队采用了启发式的缓存策略来代替原始的LRU算法。
5、行的重排
数据压缩的算法有很多,比较常用的一种称为游程编码(Run-Length Encoding,RLE),又称行程长度编码,其好处是压缩和解压缩都非常快。
数据重排的过程等效于著名的 TSP(旅行商)问题。两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。PowerDrill 在实际生产环境中对数据分块时选定的那几个域按照字典序进行排序来得到重排的结果。

(四)性能分析与对比
我们比较关注的两组数据:
(1)在查询过程中,平均92.41%的数据被略去,5.02%的数据会直接被缓存命中,一般仅须扫描2.66%的数据即可得到查询结果。
(2)超过70%的查询是不需要从磁盘访问任何数据的,这些查询的平均访问延迟大约是25,96.5%的查询需要访问的磁盘量不超过1GB。

性能分析与对比:

PowerDrill与Dremel的对比:
| PowerDrill | Dremel | |
|---|---|---|
| 设计目标 | 处理非常大量的数据集 | 分析少量的核心数据集 |
| 设计理念 | 处理的数据来自外存 | 处理的数据尽可能地存于内存 |
| 未进行数据分区,分析时要扫描所有需要的列 | 使用了组合范围分区,分析时可以跳过很多不需要的分区 | |
| 数据通常不需要加载,增加数据很方便 | 数据需要加载,增加数据相对不便 |
九、Google应用程序引擎
(一)Google App Engine简介
什么是 Google App Engine:
Google App Engine是一个由 Python 应用服务器群、Bigtable 数据库及 GFS 数据存储服务组成的平台,它能为开发者提供一体化的可自动升级的在线应用服务。

- Google App Engine 可以让开发人员在 Google 的基础架构上运行网络应用程序。
- 在 Google App Engine 中,用户可以使用 appspot.com 域上的免费域名为应用程序提供服务,也可以使用 Google 企业应用套件从自己的域为它提供服务。
- 可以免费使用 Google App Engine。注册一个免费账户即可开发和发布应用程序,而且不需要承担任何费用和责任。
Google App Engine的整体架构:

- 应用管理节点 :主要负责应用的启停和计费。
- 前端和静态文件 :负责将请求转发给应用服务器并进行负载均衡和静态文件的传输。
- 应用服务器 :能同时运行多个应用的运行时(Runtime)。
- 服务器群 :提供了一些服务,主要有Memcache、Images、URLfetch、E-mail和Data Store等。
(二)应用程序环境
应用程序环境的特性:
(1)动态网络服务功能。能够完全支持常用的网络技术。
(2)具有持久存储的空间。在这个空间里平台可以支持一些基本操作,如查询、分类和事务的操作。
(3)具有自主平衡网络和系统的负载、自动进行扩展的功能。
(4)可以对用户的身份进行验证,并且支持使用 Google 账户发送邮件。
(5)有一个功能完整的本地开发环境,可以在自身的计算机上模拟 Google App Engine 环境。
(6)支持在指定时间或定期触发事件的计划任务。
沙盒的限制:
(1)用户的应用程序只能通过 Google App Engine 提供的网址抓取 API 和电子邮件服务 API 来访问互联网中其他的计算机,其他计算机如请求与该应用程序相连接,只能在标准接口上通过 HTTP 或 HTTPS 进行。
(2)应用程序无法对 Google App Engine 的文件系统进行写入操作,只能读取应用程序代码上的文件,并且该应用程序必须使用 Google App Engine 的 Data Store 数据库来存储应用程序运行期间持续存在的数据。
(3)应用程序只有在响应网络请求时才运行,并且这个响应时间必须极短,在几秒之内必须完成。与此同时,请求处理的程序不能在自己的响应发送后产生子进程或执行代码。
(三)Google App Engine服务

相关文章:
Google云计算原理与应用(四)
目录 七、海量数据的交互式分析工具Dremel(一)产生背景(二)数据模型(三)嵌套式的列存储(四)查询语言与执行(五)性能分析(六)小结 八、…...

面试常问:为什么 Vite 速度比 Webpack 快
前言 最近作者在学习 webpack 相关的知识,之前一直对这个问题不是特别了解,甚至讲不出个123....,这个问题在面试中也是常见的,作者在学习的过程当中总结了以下几点,在这里分享给大家看一下,当然最重要的是…...
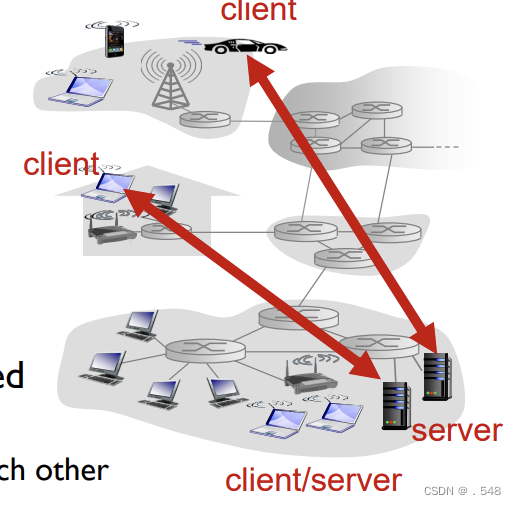
principles of network applications网络应用原理
Creating a network app write programs that: ▪ run on (different) end systems ▪ communicate over network ▪ e.g., web server software communicates with browser software application transport network data link physical application transport network data li…...
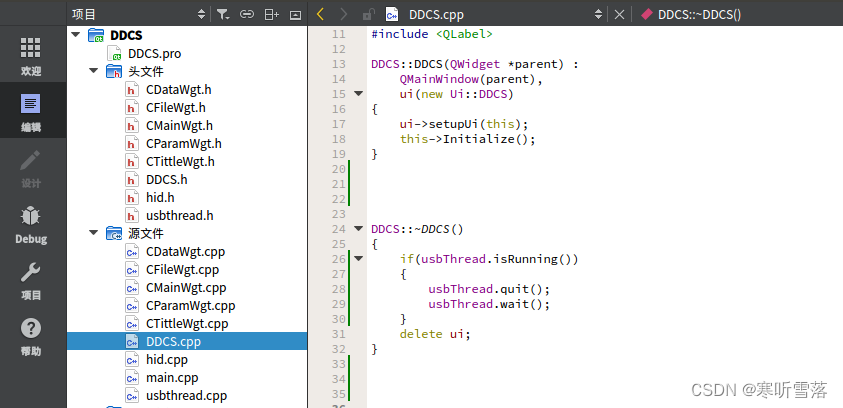
QT增加线程函数步骤流程
在使用线程的时候,不仅要关注线程开启的时机,同时还要关注线程安全退出,这样才能保证程序的健壮性,如果线程开启的较多,且开启关闭比较频繁,建议使用线程池来处理。开启线程有三种方式:第一种C的…...
)
Python基础----字符串(持续更新中)
字符串的介绍 定义:是python中常用的数据类型之一,可以使用单引号、双引号、三引号来进行创建 字符串的标识类型:str 字符串的特性 字符串属于不可变数据类型,不能直接修改字符串的本身 数字、元组也属于不可变数据类型 字符串…...
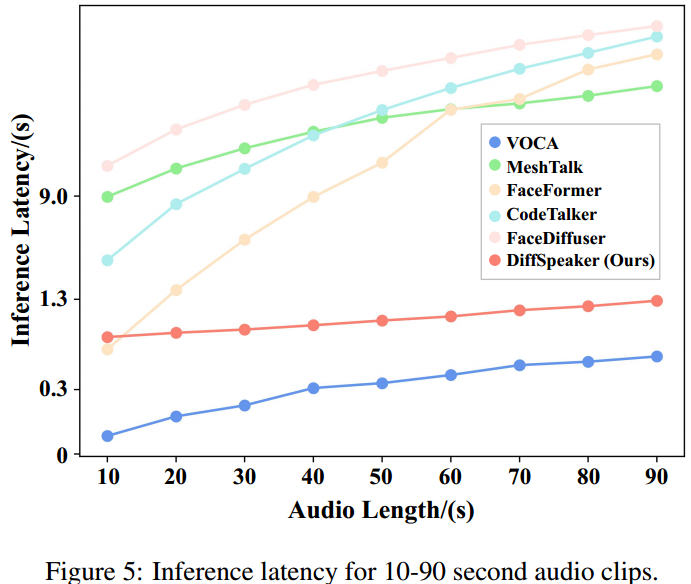
【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
DiffSpeaker: 使用扩散Transformer进行语音驱动的3D面部动画 code:GitHub - theEricMa/DiffSpeaker: This is the official repository for DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer paper:https://arxiv.org/pdf/…...
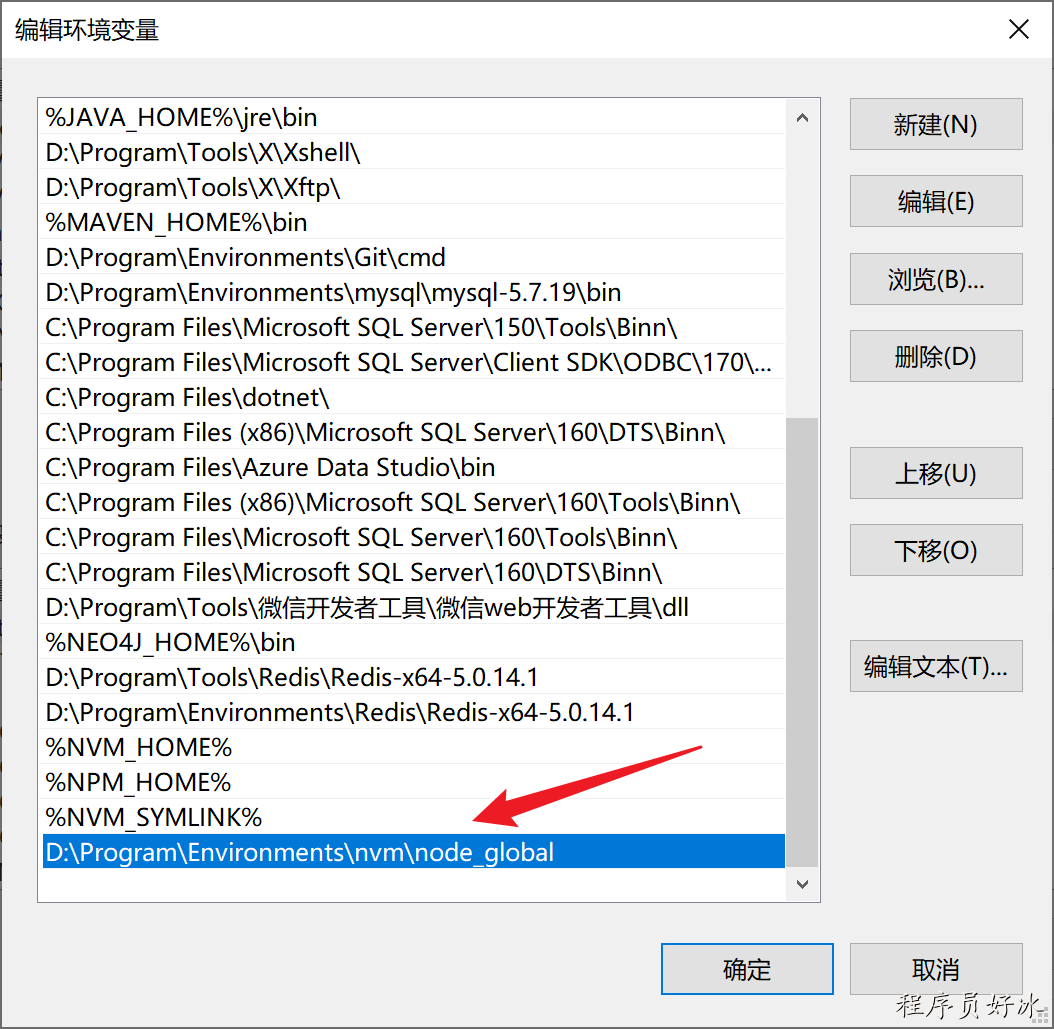
NVM使用教程
文章目录 ⭐️写在前面的话⭐️1、卸载已经安装的node2、卸载nvm3、安装nvm4、配置路径以及下载源5、使用nvm下载node6、nvm常用命令7、全局安装npm、cnpm8、使用淘宝镜像cnpm9、配置全局的node仓库🚀 先看后赞,养成习惯!🚀&#…...

mysql 学习
本文来自于《sql必知必会》 所需要的文件教程连接 本站其他的小伙伴 第一课 了解sql 数据库基础 什么是数据库 数据库(database) 保存有组织的数据的容器(通常是一个文 件或一组文件)。 表 表(table)…...
Jenkins 一个进程存在多个实例问题排查
Jenkins 一个进程存在多个实例问题排查 最近Jenkins升级到2.440.1版本后,使用tomcat服务部署,发现每次定时任务总会有3-4个请求到我的机器人上,导致出现奇奇怪怪的问题。 问题发现 机器人运行异常,总有好几个同时请求的服务。…...

mysql数据类型和常用函数
目录 1.整型 1.1参数signed和unsigned 1.2参数zerofill 1.3参数auto_increment 2.数字类型 2.1floor()向下取整 2.2随机函数rand() 2.3重复函数repeat() 3.字符串类型 3.1length()查看字节长度,char_length()查看字符长度 3.2字符集 3.2.1查看默认字符…...

Elastic 线下 Meetup 将于 2024 年 3 月 30 号在武汉举办
2024 Elastic Meetup 武汉站活动,由 Elastic、腾讯、新智锦绣联合举办,现诚邀广大技术爱好者及开发者参加。 活动时间 2024年3月30日 13:30-18:00 活动地点 中国武汉 武汉市江夏区腾讯大道1号腾讯武汉研发中心一楼多功能厅 13:30-14:00 入场 活动流程…...
中的体现)
线性代数在卷积神经网络(CNN)中的体现
案例:深度学习中的卷积神经网络(CNN) 在图像识别领域,卷积神经网络(Convolutional Neural Networks, CNN)是一个广泛应用深度学习模型,它在人脸识别、物体识别、医学图像分析等方面取得…...

服务器根据用途划分有哪几种?
随着企业需求的不同,服务器的类型也变得多种多样了,有根据机箱结构来划分的服务器类型,如机架式服务器、刀片式服务器和塔式服务器等,也有按照应用层次来划分的服务器类型,如入门级服务器和工作组服务器等。 那根据用途…...

linux 命令笔记:gpustat
1 命令介绍 gpustat是一个基于Python的命令行工具,它提供了一种快速、简洁的方式来查看GPU的状态和使用情况它是nvidia-smi工具的一个封装,旨在以更友好和易于阅读的格式显示GPU信息。gpustat不仅显示基本的GPU状态(如温度、GPU利用率和内存…...
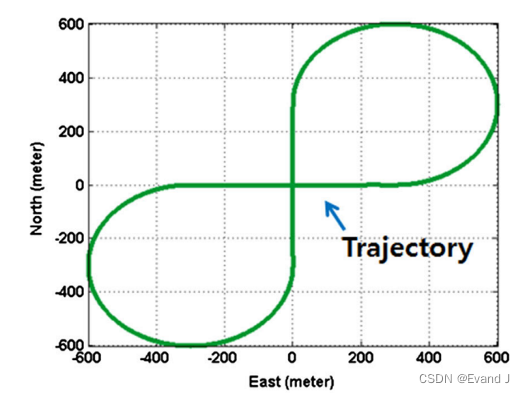
【阅读笔记】Adaptive GPS/INS integration for relative navigation
Lee J Y, Kim H S, Choi K H, et al. Adaptive GPS/INS integration for relative navigation[J]. Gps Solutions, 2016, 20: 63-75. 用于相对导航的自适应GPS/INS集成 名词翻译 formation flying:编队飞行 摘要翻译 在编队飞行、防撞、协同定位和事故监测等许多…...
Java版直播商城免 费 搭 建:电商、小程序、三级分销及免 费 搭 建,平台规划与营销策略全掌握
随着互联网的快速发展,越来越多的企业开始注重数字化转型,以提升自身的竞争力和运营效率。在这个背景下,鸿鹄云商SAAS云产品应运而生,为企业提供了一种简单、高效、安全的数字化解决方案。 鸿鹄云商SAAS云产品是一种基于云计算的软…...

经典Bug永流传---每周一“虫”(四十五)
如果有人错过机会,多半不是机会没来,而是因为机会过来时,没有一伸手抓住它。 大写W惹的祸 前提: A账号已登录 步骤: 打开某商品链接,然后在商品的评论区任意一条评论,点击回复,回…...
蓝桥杯-礼物-二分查找
题目 思路 --刚开始想到暴力尝试的方法,但是N太大了,第一个测试点都超时。题目中说前k个石头的和还有后k个石头的和要小于s,在这里要能想到开一个数组来求前n个石头的总重,然后求前k个的直接将sum[i]-sum[i-k-1]就行了࿰…...

设计原则、工厂、单例模式
什么是设计模式 简单来说,设计模式就是很多程序员经过相当长的一段时间的代码实践、踩坑所总结出来的一套解决方案,这个解决方案能让我们少写一些屎山代码,能让我们写出来的代码写出来更加优雅,更加可靠。所以设计模式的好处是显而…...

笔记:Mysql 主从搭建
主库 创建用户并授权 create user slave identified with mysql_native_password by 123456 GRANT REPLICATION SLAVE ON *.* to slave%; FLUSH PRIVILEGES;主库配置文件 /etc/my.cnf #日志路径及文件名,目录要是mysql有权限写入 log-bin/var/lib/mysql/binlog …...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能
BetterNCM安装器终极指南:5分钟解锁网易云音乐无限潜能 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 你是否觉得网易云音乐PC版功能有限,界面单调?…...