txt、pdf等文件转为一行一行的doccano数据集输入格式
文章目录
- doccano 数据集导入
- 简介
- 代码实现
- 代码运行结果
- 代码公开
doccano 数据集导入
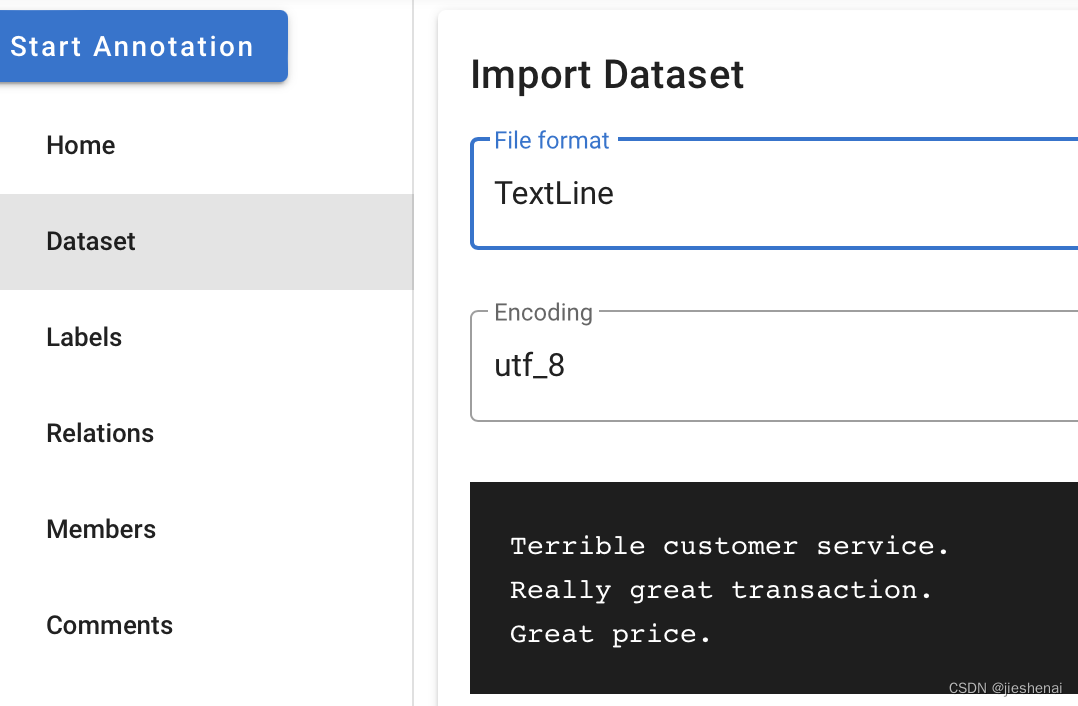
在Doccano 导入数据集时,使用TextLine的文件格式,导入的文件需要为一行一行文本的数据格式,每一行文本在导入Doccano后就是一条数据。
简介
主要工作说明:把pdf转成txt文件,在txt文件中,根据句号把文本分隔成一行一行文本,从而实现把pdf转换成doccano标注格式。
提供了两个文件转换功能:
- pdf转txt;
- txt转doccano的TextLine的文件格式;
下述是具体的函数说明:
trans_pdf_text: 实现把pdf转成txt文件,is_delete_page=True删除PDF的页码;
trans_folder_pdf2txt(prov, output_folder='pdf2txt'): 实现把prov文件夹下的所有pdf转成txt文件,存储到output_folder文件夹下;
cut_txt2sents(input_file, output_file, *args):
使用split('。')把文本切分成列表,args使用filters.py中的过滤函数进行过滤。
主要使用get_length_filter
代码实现
filters.py的代码如下:
def contains_digit_filters(sentence):"""判断句子中是否包含数字"""for char in sentence:if char.isdigit():return Truereturn Falsedef get_length_filter(bottom_len=8, top_len=1e3):"""文本长度过滤器,返回一个过滤器,用于筛选出文本长度在bottom_len与top_len之间的句子"""def _length_filter(text):if bottom_len <= len(text) <= top_len:return Truereturn Falsereturn _length_filterdef catalog_filter(text):"""过滤章节,识别到章节则返回False,删除掉:param text::return:"""text = text.strip()head = text[:5]if '第' == head[0]:if '章' in head or '节' in head or '篇' in head:return Falsereturn Truedef title_filter(text):if len(text) <= 45:if '国民经济和社会发展' in text and '五年规划' in text:return Falsereturn True
过滤器说明:
get_length_filter(bottom_len=8, top_len=1e3):
筛选长度在bottom_len与top_len之间的文本,bottom_len筛选掉长度太短的文本,top_len可筛选掉文本的目录。
下面是主要代码:
import os
import re
from filters import get_length_filter, title_filter"""
pdf -> txt
txt -> doccano
"""def delete_page_num(text):"""删除页码:param text::return:"""page_nums = [r'\n- \d+ -( *?)\n',r'\n— \d+ —( *?)+\n',r'\n\d+( *?)\n',r'\nI+( *?)\n',]patterns = [re.compile(pattern) for pattern in page_nums]for pattern in patterns:text = pattern.sub('', text)return textdef trans_pdf_text(input_file, output_file, is_delete_page=True):"""把pdf文件转为txt,删除页码,保存到output_file:param input_file::param output_file::param is_delete_page::return:"""import fitzpdf_file = fitz.open(input_file) # pdf_path是PDF文件的路径res = []for i in range(len(pdf_file)):page = pdf_file.load_page(i)res.append(page.get_text())text = ''.join(res)if is_delete_page:text = delete_page_num(text)with open(output_file, 'w') as f:f.write(text)def trans_folder_pdf2txt(prov, output_folder='pdf2txt'):"""把某目录下pdf文件转为txt,方便预览和手动修改:return:"""filenames = list(filter(lambda x: x.endswith('.pdf'),os.listdir(prov)))if not os.path.exists(p := os.path.join(output_folder, prov)):os.mkdir(p)for filename in filenames:filename = os.path.join(prov, filename)output_file = os.path.join(output_folder, filename.replace('.pdf', '.txt'))trans_pdf_text(filename,output_file)def cut_txt2sents(input_file, output_file, *args):"""这部分处理由pdf转的txt文件,再将txt文本按照句号。切分由于pdf转的txt文件,其文件内容很乱,需要进行一些处理* args: 过滤器针对句子的过滤器"""# 删除 delete_list = ['\xa0', '\t', '\u3000',' ', '', ' ', ' ', '','目\n录\n', '\n']if input_file.endswith('.txt'):with open(input_file, 'r', encoding='utf-8') as f:text = f.read()for char in delete_list:text = text.replace(char, '')text = text.replace(';', '。')text = text.replace(';', '。')## 本来按照\n切分最好,但是pdf转txt后,其中包含很多的\n,所以无法使用\n提前切分# texts = text.split('\n')# for text in texts:# data.extend(text.split('。'))data = text.split('。')# 过滤器for arg in args:data = filter(arg, data)with open(output_file, 'w') as f:f.write('\n'.join(data))def trans_folder_txt2doccano(input_folder, output_folder, *filter_funcs):"""把某目录下的txt文件转为doccano格式针对一整个文件夹内的文件,批量操作):return:"""filenames = list(filter(lambda x: x.endswith('.txt'),os.listdir(input_folder)))if not os.path.exists(output_folder):os.mkdir(output_folder)for filename in filenames:cut_txt2sents(os.path.join(input_folder, filename),os.path.join(output_folder, filename),*filter_funcs)trans_folder_txt2doccano(os.path.join(pdf_txt_folder, prov),os.path.join('doccano', prov),get_length_filter(8, 200),title_filter)trans_folder_txt2doccano(prov, f'doccano/{prov}',get_length_filter(8, 200))代码运行结果
原始文件夹介绍:
湖北省: 存放原始文件,里面有一些pdf文件和txt文件;
pdf2txt: 存放pdf转txt的结果,若希望修改可以手动修改;
doccano: 最终的doccano TextLine 输入格式的文件;

pdf_txt_folder = 'pdf2txt'
prov = '湖北省'
trans_folder_pdf2txt(prov, pdf_txt_folder)
上述代码实现把湖北省文件夹下的pdf文件转成txt文件,并保存到pdf2txt文件夹下,程序运行结果如下:

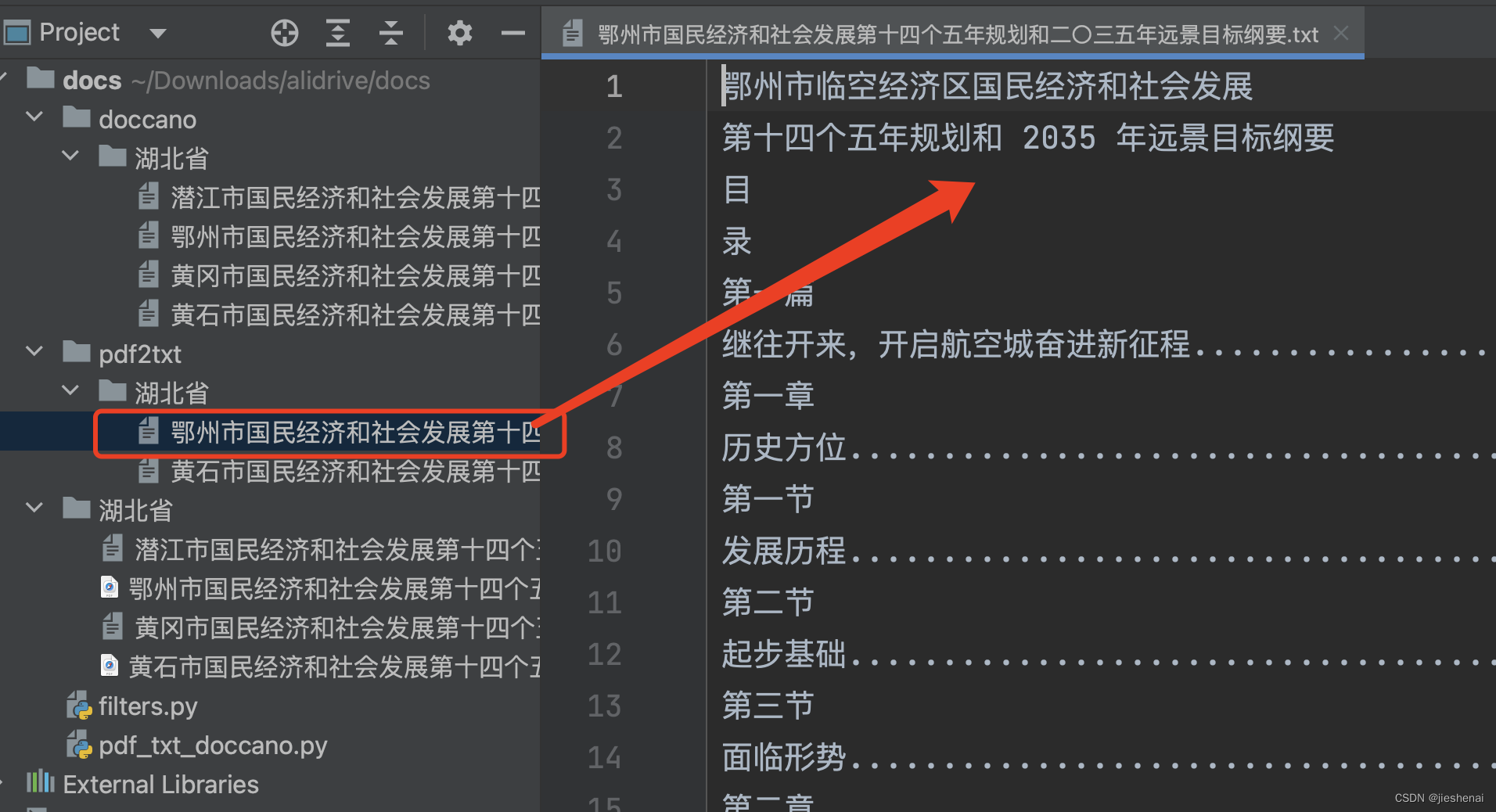
pdf2txt/湖北省/鄂州市国民经济和社会发展第十四个五年规划和二〇三五年远景目标纲要.txt:
在pdf转txt后的文件中,包含有目录信息。
下述代码实现把pdf2txt/湖北省和湖北省文件夹下的txt文件,转换为doccano输入格式,转换结果存储在doccano文件夹下
trans_folder_txt2doccano(os.path.join(pdf_txt_folder, prov),os.path.join('doccano', prov),get_length_filter(8, 200),title_filter
)trans_folder_txt2doccano(prov, f'doccano/{prov}',get_length_filter(8, 200)
)
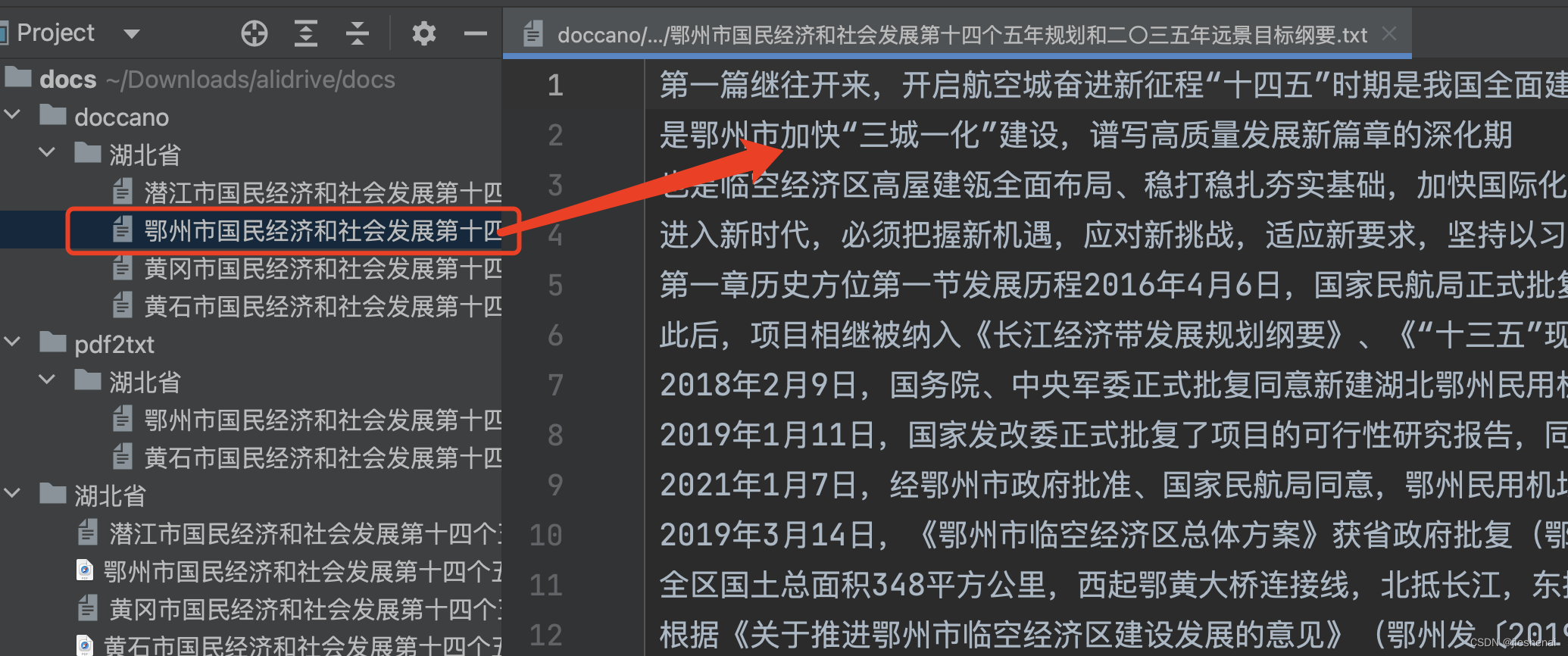
在txt转为doccano标注格式的过程中:
get_length_filter(8, 200):使用文件长度过滤器,只保留文本长度在8到200之间的文本;如下图所示,对比上图,利用长度过滤器删除掉了目录。
代码公开
- 链接: https://pan.baidu.com/s/1x_o70B9VJVg07VPxyMdubQ?pwd=ryku 提取码: ryku
在百度网盘中,包含了湖北省文件夹下的pdf和txt文件。 - https://github.com/JieShenAI/csdn/tree/main/24/03/pdf_txt_doccano
只有代码,不包括pdf和txt文件;
相关文章:
txt、pdf等文件转为一行一行的doccano数据集输入格式
文章目录 doccano 数据集导入简介代码实现代码运行结果代码公开 doccano 数据集导入 在Doccano 导入数据集时,使用TextLine的文件格式,导入的文件需要为一行一行文本的数据格式,每一行文本在导入Doccano后就是一条数据。 简介 主要工作说明…...
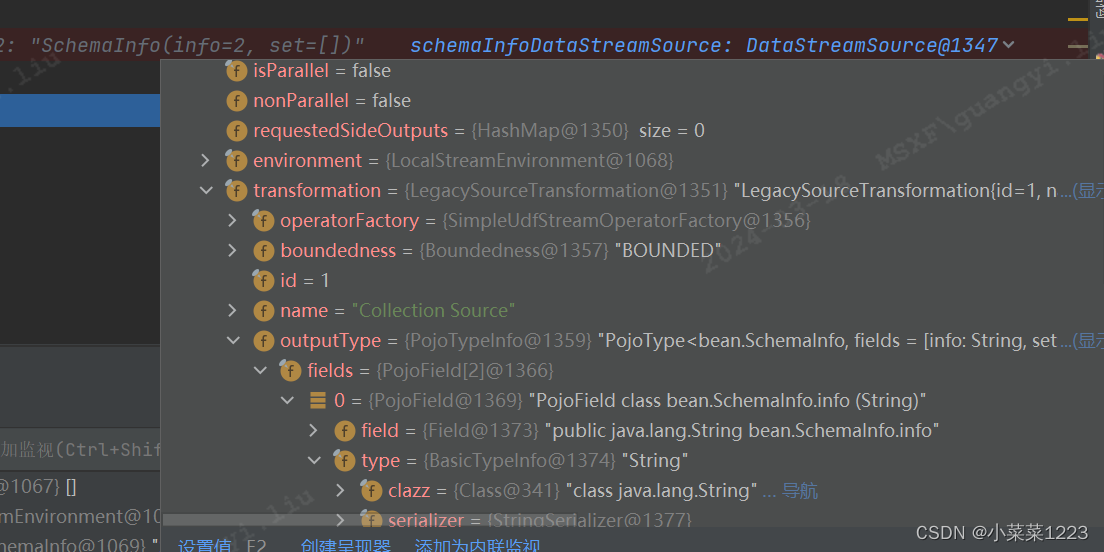
java Flink(四十二)Flink的序列化以及TypeInformation介绍(源码分析)
Flink的TypeInformation以及序列化 TypeInformation主要作用是为了在 Flink系统内有效地对数据结构类型进行管理,能够在分布式计算过程中对数据的类型进行管理和推断。同时基于对数据的类型信息管理,Flink内部对数据存储也进行了相应的性能优化。 Flin…...

社科赛斯考研:二十二载岁月铸辉煌,穿越周期的生命力之源
在考研培训行业的浩瀚海洋中,社科赛斯考研犹如一艘稳健的巨轮,历经二十二载风礼,依然破浪前行。在考研市场竞争白热化与学生对于考研机构要求越来越高的双重影响下,社科赛斯考研却以一种分蘖成长的姿态,扎根、壮大&…...

【视频图像取证篇】模糊图像增强技术之锐化类滤波场景应用小结
【视频图像取证篇】模糊图像增强技术之锐化类滤波场景应用小结 模糊图像增强技术之锐化类滤波场景应用小结—【蘇小沐】 (一)锐化类滤波器 模糊消除类滤波器(Remove blur / Unsharpness)。 通用去模糊滤波器:针对大…...
win10 禁止谷歌浏览器自动更新(操作贼简单)
禁止谷歌浏览器自动更新 (1)修改 "C:\Windows\System32\drivers\etc\hosts 文件,在最后增加 127.0.0.1 update.googleapis.com(2)保存后,winr 快捷键,输入cmd ,打开命令行 &am…...

LeetCode每日一题【24. 两两交换链表中的节点】
思路:先创建虚拟头结点,再用双指针,两两交换 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr…...
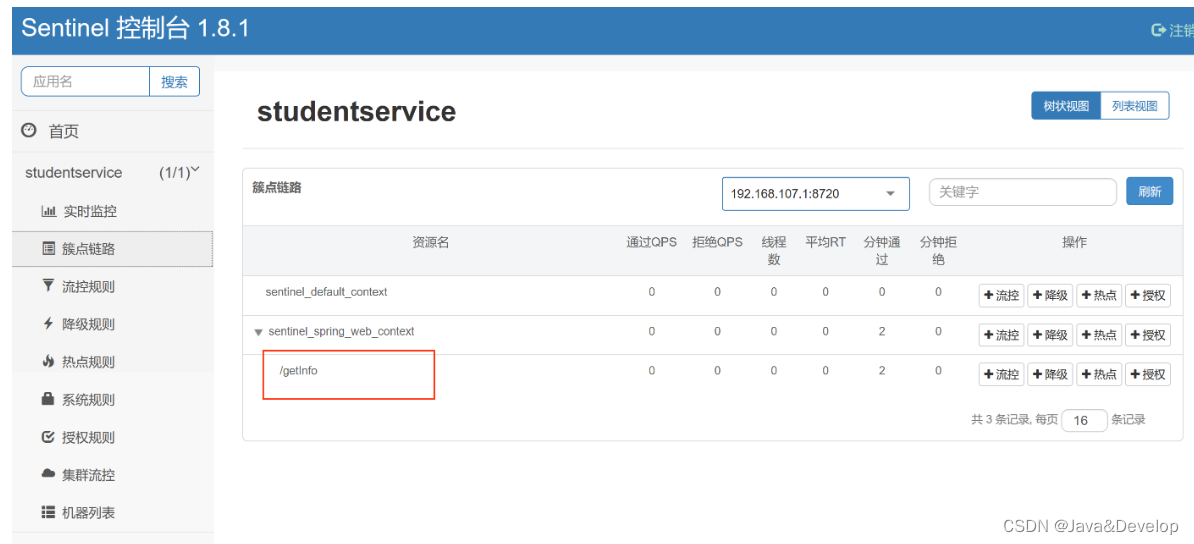
jeecg启动Sentinel 一直是空白页面 解决办法用 外部 Sentinel SpringCloud之Sentinel概述和安装及简单整合
jeecg启动Sentinel 一直是空白页面 解决办法用 外部 Sentinel SpringCloud之Sentinel概述和安装及简单整合 文章目录 jeecg启动Sentinel 一直是空白页面 解决办法用 外部 Sentinel SpringCloud之Sentinel概述和安装及简单整合 Sentinel概述基本介绍 Sentinel安装下载地址: http…...

易基因:人类大脑的单细胞DNA甲基化和3D基因组结构|Science
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 高通通量表观基因组分析技术可用于阐明大脑中细胞复杂性的基因调控程序。5-甲基胞嘧啶 (5mCs)是哺乳动物基因组中最常见的修饰碱基,大多数5mCs发生在胞嘧啶-鸟嘌呤二核苷酸&a…...

Nginx中设置反向代理
在Nginx中设置反向代理,你需要使用proxy_pass指令。以下是一个简单的配置示例,它将Nginx配置为反向代理,将进入的流量转发到在本地运行的Web服务器上。 nginx http { server { listen 80; location / {proxy_pass http://localhost:8080;pro…...
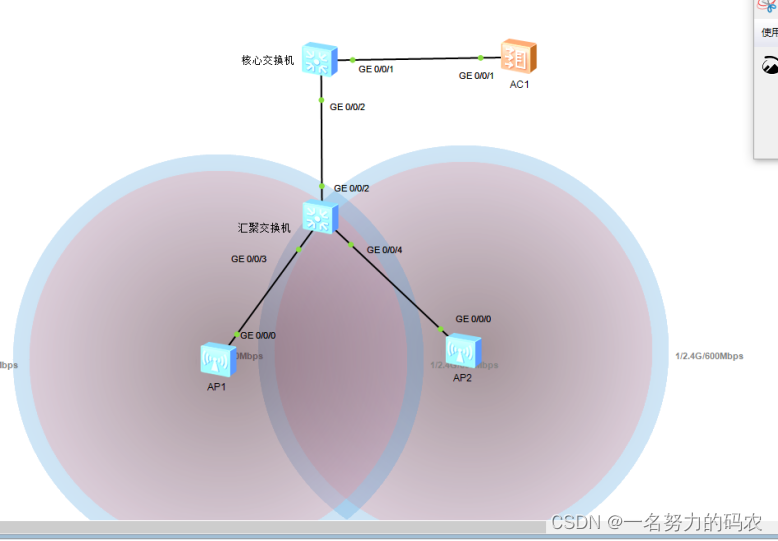
无线局域网——wlan
目录 一.wlan的含义和发展 二.wlan技术带来的挑战 1.企业办公场景多样 2.位置速度的要求 3.安全的要求 4.规范的挑战 三.家庭和企业不同的部署需求 1.胖AP模式组网 2.AC瘦AP模式组网 3.组网模式的不同 四.三层隧道转发实验 1.拓扑 2.AP上线 核心交换机vlan 编辑…...
ASP.NET 服务器控件
目录 一、使用的软件 1、下载 2、新建文件(写一个简单的web网页) 二、相关知识点 1、Web窗体网页的组件 (1)可视化组件 (2)用户接口逻辑 2、Web Form网页的代码模型 (1)单文件…...

[数据集][目标检测]麻雀检测数据集VOC+YOLO格式1157张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1157 标注数量(xml文件个数):1157 标注数量(txt文件个数):1157 标注…...
嵌入式学习第二十九天!(数据结构的概念、单向链表)
数据结构: 1. 定义: 一组用来保存一种或者多种特定关系的数据的集合(组织和存储数据) 1. 程序设计: 将现实中大量而复杂的问题以特定的数据类型和特定的数据结构存储在内存中,并在此基础上实现某个特定的功…...
【ZooKeeper】2、安装
本文基于 Apache ZooKeeper Release 3.7.0 版本书写 作于 2022年3月6日 14:22:11 转载请声明 下载zookeeper安装包 wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz解压 tar -zxvf apache-zookeeper-3.7.0-b…...

通过Pytest 多数据库连接实例了解Python工厂模式与单例模式的区别
1. 前言 在做自动化测试时,有些特殊项目需要连接不同的数据库进行造数或者断言。自动化框架中,一般使用Pytest yaml 数据驱动的居多,如果一个项目中有上百条数据库相关测试用例,在数据库测试时,如果设计不合理的连接模…...

超拟人语音合成上线,打造有温度的交互新体验
语言使得人类可以构建共同想象的现实,即共同的信念,从而进行大规模团结合作,这是认知革命赋予人类力量的核心。在《人类简史》中,语言被描述成为人类进化的关键力量,而语音的能力是推动语言逐渐进化的火花。 人工智能…...

word 及PPT 中修改公式字体
主要参考: 1.word修改公式默认字体并打出漂亮公式_word 公式 字体-CSDN博客 2.word 使用数学公式字体 在2中 提供的 链接下载字体,或者可以在这里直接下载,下载链接: https://www.lanzoub.com/iNt3g1rs3w0h 密码:a52p 然后按…...
将数据转换成xml格式的文档并下载
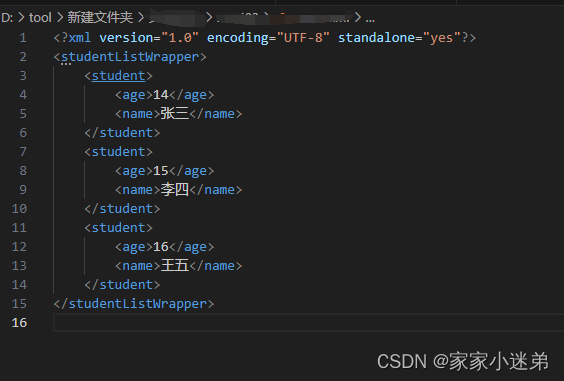
现在有一个实体类对象的集合,需要将它们转换为xml文档,xml文档就是标签集合的嵌套,例如一个学生类,有姓名、年龄等,需要转换成一下效果: <student><age>14</age><name>张三</na…...

深入理解与实践AB测试:从理论到实战案例解析
一、引言 在互联网产品优化和运营策略制定中,AB测试(也称为分组测试或随机化对照实验)是一种科学且严谨的方法。它通过将用户群体随机分配至不同的实验组(通常是A组和B组),对比不同版本的产品或策略对关键…...

flask之请求钩子
请求钩子是通过装饰器的形式实现,Flask支持如下四种请求钩子: 1、before_first_request: 在第一次请求处理之前先被执行 2、before_request: 在每次请求前执行 3、after_request: 在每次请求处理之后被执行 接受一个参数:视图函数的响应在…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

因果推断与机器学习融合:量化分析社会运动中镇压与抗议的动态关系
1. 项目概述:当数据科学遇见社会运动如果你研究过社会运动,尤其是那些看似突然爆发、席卷全国的抗议浪潮,你可能会被一个核心问题困扰:国家机器的镇压,究竟是浇灭火焰的冷水,还是火上浇油的催化剂ÿ…...