MySQL之表的记录操作
前言
存数据不是目的,目的是能够将存起来的数据取出来或者查出来,并且能够对数据进行增删改查操作,本文将详细介绍表中记录的增删改查操作。对记录的操作属于DML数据库操作语言,可以通过SQL实现对数据的操作,包括实现向表中插入数据(insert),对表中数据进行更新(update),删除表中数据(delete)以及查询数据(select)。
增 - insert
表准备
create table info ( id int primary key auto_increment, name varchar(6), age int, gender enum ( 'male', 'female' ) defaule 'male' );最标准的insert语句
-- INSERT INTO 表名(字段1, 字段2,...) VALUES (字段1对应的值, 字段2对应的值...);
mysql> insert into info(name, age, gender) values ('xu', 18, 'male');mysql> select * from info;
+----+------+------+--------+
| id | NAME | age | gender |
+----+------+------+--------+
| 1 | xu | 18 | male |
+----+------+------+--------+
1 row in set (0.00 sec)省事的写法,按照所有字段顺序进行插入数据
-- INSERT INTO 表名 VALUES (字段1对应的值, 字段2对应的值...);
mysql> insert into info values (2, 'lili', 20, 'female');
Query OK, 1 row affected (0.00 sec)mysql> select * from info;
+----+------+------+--------+
| id | NAME | age | gender |
+----+------+------+--------+
| 1 | xu | 18 | male |
| 2 | lili | 20 | female |
+----+------+------+--------+
2 rows in set (0.00 sec)针对性的录入数据
-- INSERT INTO 表名 (字段1, 字段2...) VALUES (字段1对应的值, 字段2对应的值...)
mysql> insert into info (name, age) values ('jack', 30);
Query OK, 1 row affected (0.00 sec)mysql> select * from info;
+----+------+------+--------+
| id | NAME | age | gender |
+----+------+------+--------+
| 1 | xu | 18 | male |
| 2 | lili | 20 | female |
| 3 | jack | 30 | male |
+----+------+------+--------+
3 rows in set (0.00 sec)同时录入多行数据
-- INSERT INTO 表名 (字段1, 字段2...) VALUES (字段1对应的值, 字段2对应的值...), (字段1对应的值, 字段2对应的值...)...;
mysql> insert into info (name, age) values ('python', 30),('java', 40),('go', 50);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from info;
+----+--------+------+--------+
| id | NAME | age | gender |
+----+--------+------+--------+
| 1 | xu | 18 | male |
| 2 | lili | 20 | female |
| 3 | jack | 30 | male |
| 4 | python | 30 | male |
| 5 | java | 40 | male |
| 6 | go | 50 | male |
+----+--------+------+--------+
6 rows in set (0.00 sec)删 - delete
删除操作一定要慎重慎重再慎重!!!!
-- 删除表中的所有数据,但是主键的自增不会停止
delete from 表名; -- 清空表数据并重置主键
truncate 表名; -- 删除表中某一条或几条数据:delete from 表名 where 条件; (where条件在介绍查询时会详细介绍)
mysql> delete from info where id=1;
Query OK, 1 row affected (0.00 sec)mysql> select * from info;
+----+--------+------+--------+
| id | NAME | age | gender |
+----+--------+------+--------+
| 2 | lili | 20 | female |
| 3 | jack | 30 | male |
| 4 | python | 30 | male |
| 5 | java | 40 | male |
| 6 | go | 50 | male |
+----+--------+------+--------+
5 rows in set (0.00 sec)mysql> delete from info where age=30;
Query OK, 2 rows affected (0.00 sec)mysql> select * from info;
+----+------+------+--------+
| id | NAME | age | gender |
+----+------+------+--------+
| 2 | lili | 20 | female |
| 5 | java | 40 | male |
| 6 | go | 50 | male |
+----+------+------+--------+
3 rows in set (0.00 sec)改 - update
对表中已经存在的记录进行修改。
-- update 表名 set 字段1=值1, 字段2=值2 where 条件;
-- 如果不加where条件会将表中所有记录都修改
mysql> update info set name='xxx', age=100;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0mysql> select * from info;
+----+------+------+--------+
| id | NAME | age | gender |
+----+------+------+--------+
| 2 | xxx | 100 | female |
| 5 | xxx | 100 | male |
| 6 | xxx | 100 | male |
+----+------+------+--------+
3 rows in set (0.00 sec)-- 如果不想修改全部的记录就需要使用where条件
mysql> update info set name='test', age=10 where id=2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select * from info;
+----+------+------+--------+
| id | NAME | age | gender |
+----+------+------+--------+
| 2 | test | 10 | female |
| 5 | xxx | 100 | male |
| 6 | xxx | 100 | male |
+----+------+------+--------+
3 rows in set (0.00 sec)
查 - select
表与表之间有时是有关系的,尤其是在同一个项目中的表,因此查询数据就分为单表查询和多表查询。这里师门使用MySQL官方提供的MySQL示例进行介绍查询操作,打开压缩包之后是world.sql文件,如何将这个文件导入到MySQL中呢,可以通过下面的语法:
-- source .sql文件的路径
mysql> source C:\Users\12801\Desktop\world.sqlmysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| book_manage |
| mysql |
| performance_schema |
| stu |
| test |
| world |
+--------------------+
7 rows in set (0.00 sec)单表查询
查询语句的标准用法是需要select配合其他子句进行查询,因为在实际项目开发中并不是每次都需要查询所有的数据,而是需要一些过滤条件进行过滤,查询出需要的数据,并且在实际开发中不推荐查询所有数据,因为如果一张表中数据太多的话,内存可能会不够用哦~会导致电脑卡死...
首先和select配合使用的子句有以下几个select /from/where/group by/having/order by/limit,上面这些子句的书写顺序也是默认的SQL书写顺序。
from子句
是从哪张表中查询数据。
-- select 列名 from 表名;-- 全表扫描,查询country表中的所有数据,不建议这样操作,数据过多可能导致电脑卡死
mysql>select * from country; -- 只查询表中部分列的所有值,查询country表中的code、name列的所有值
mysql> select code, name from country;where子句
where子句就需要和过滤条件配合使用,过滤条件包括= > < <= >= != and or not like in (between and),以下述例子进行说明:
-- 查询中国所有城市信息
select * from city where countrycode='CHN';-- 中国人口大于1000000的城市信息
select * from city countrycode='CHN' and population>5000000; -- 查询省的名字前面带guang开头的,注意:like语句时,%不能放在前面,因为不走索引(索引会在后续文章中介绍,这里就简单理解索引就是书的目录)
select * from city where district like 'guang%';-- 查询中国和美国所有城市信息
select * from city where countrycode in ('CHN' ,'USA');-- 查询世界上人口数量大于100w小于200w的城市信息
select * from city where population >1000000 and population <2000000;-- 查询世界上人口数量大于100w小于200w的城市信息
select * from city where population between 1000000 and 2000000;group by子句
group by是分组查询,根据情况是否需要where过滤条件,group by一般需要配合聚合函数使用,group by大致逻辑是取出分组和聚合函数参数的数据,根据分组依据进行排序,排序后对分组依据进行去重,由于MySQL数据库中不允许一行数据与多行数据对应(only_full_group_by严格模式),因此需要使用聚合函数将多个数据整合为与分组依据对应的一个数据。
聚合函数有max() min() sum() avg()---平均数 count()---计数 group_concat()---列转行等。
-- 统计世界上每个国家的总人口数
select countrycode ,sum(population) from city group by countrycode;-- 统计中国每个省的人口数
select district,sum(Population) from city where countrycode='chn' group by district;-- 统计中国每个省的名字,人数,城市个数,城市名字(由于严格模式,一行数据不能对应多行数据,需要使用group_concat聚合函数进行列转行操作)。
select district, sum(population), count(id), group_concat(name) from world.city where countrycode='chn' group by district;having子句
having子句与where子句功能差不多,只不过having是对分组后的数据进行筛选。
-- 统计中国每个省的总人口数,只打印总人口数小于100
select district,sum(Population) from city where countrycode='chn'group by district having sum(Population) < 1000000 ;order by
按照指定顺序输出结果,默认是从小到大,desc是从大到小。
-- 统计中国每个省的总人口数,只打印总人口数小于100,从大到小排列。
select district,sum(Population) from city where countrycode='chn'
group by district having sum(Population) < 1000000 order by sum(population) desc;limit
将结果分页显示,通常配合order by使用
-- LIMIT N, M; -- 跳过N行,显示M行
-- LIMIT M OFFSET N; -- 跳过N行,显示M行
select district,sum(Population) from city where countrycode='chn'group by district having sum(Population) < 1000000 order by sum(population) desc limit 5 6; -- 统计中国每个省的总人口数,只打印总人口数小于100,从大到小排列,只显示前6~11条。多表查询
需要的数据来自于多张表,单表无法满足,实际上是将多张表有关联的数据合并成一张新表,在新表中做where group by等子句等操作。
多表连接查询类型大概有三种类型,分别是笛卡尔乘积、内连接和外连接。
笛卡尔乘积join
是将多张表的数据合并成大表,不推荐使用。
select * from teacher join course; 内连接inner join
应用最广泛,取两张表有关联部分的数据,A表 inner join B表 on A.xx=B.xx;
-- teacher表和course表,查询teacher表中tno等于course表中的tno的数据
select * from teacher (inner) join course on(where) teacher.tno=course.tno;外连接left join/right join
left join左表所有的数据都展示,右表只展示与左表有关联的数据,没有对应项的用null标识;right join右表所有的数据都展示,左表只展示与右表有关联的数据,没有对应项的用null标识。
作用就是强制驱动表,将小表(查询得到的结果更少的结果集)作为驱动表降低next loop(循环)次数。
select city.name, cpuntry.name, city.population from city left join country on city.countrycode=country.code and city.poplation<100;驱动表的原理
join...on...的实现原理:拿到其中一张表作为驱动表,使用关联条件(on的条件)去和另一张表(内层循环)比对,如果符合就将这两张表的数据进行拼接。当两张表的行数差异较大时,将小表(查询得到的结果更少的结果集)作为驱动表,可以优化查询降低next loop的次数,对于内连接来说,无法控制驱动表是谁,完全由优化器决定,如果需要人为干预驱动表,可以通过外连接实现。
left join中驱动表就是左表,类似于双层for循环的外层循环,强制将左表作为驱动表.
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!

相关文章:
MySQL之表的记录操作
前言 存数据不是目的,目的是能够将存起来的数据取出来或者查出来,并且能够对数据进行增删改查操作,本文将详细介绍表中记录的增删改查操作。对记录的操作属于DML数据库操作语言,可以通过SQL实现对数据的操作,包括实现…...

一种动态联动的实现方法
安防领域中的联动规则 有安防领域相关的开发经历的人知道,IPCamera可以配置使能“侦测”功能,并且指定仅针对图像传感器的某个区载进行侦测。除了基本的“移动侦测"外,侦测的功能点还有细化的类别,如人员侦测、车辆侦测、烟…...
kotlin中使用ViewBinding绑定控件
kotlin中使用ViewBinding绑定控件 什么是ViewBinding? View Binding是Android Studio 3.6推出的新特性,主要用于减少findViewById的冗余代码,但内部实现还是通过使用findViewById。通过ViewBinding,可以更轻松地编写可与视图交互…...

知识积累(五):Transformer 家族的学习笔记
文章目录 1. RNN1.1 缺点 2. Transformer2.1 组成2.2 Encoder2.2.1 Input Embedding(嵌入层)2.2.2 位置编码2.2.3 多头注意力2.2.4 Add & Norm 2.3 Decoder2.3.1 概览2.3.2 Masked multi-head attention 2.4 Transformer 模型的训练和推理2.4.1 训练…...

[Java、Android面试]_13_map、set和list的区别
本人今年参加了很多面试,也有幸拿到了一些大厂的offer,整理了众多面试资料,后续还会分享众多面试资料。 整理成了面试系列,由于时间有限,每天整理一点,后续会陆续分享出来,感兴趣的朋友可关注收…...

Linux进程管理:(六)SMP负载均衡
文章说明: Linux内核版本:5.0 架构:ARM64 参考资料及图片来源:《奔跑吧Linux内核》 Linux 5.0内核源码注释仓库地址: zhangzihengya/LinuxSourceCode_v5.0_study (github.com) 1. 前置知识 1.1 CPU管理位图 内核…...

计算机专业学生的成长之路:超越课堂的自我提升策略
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
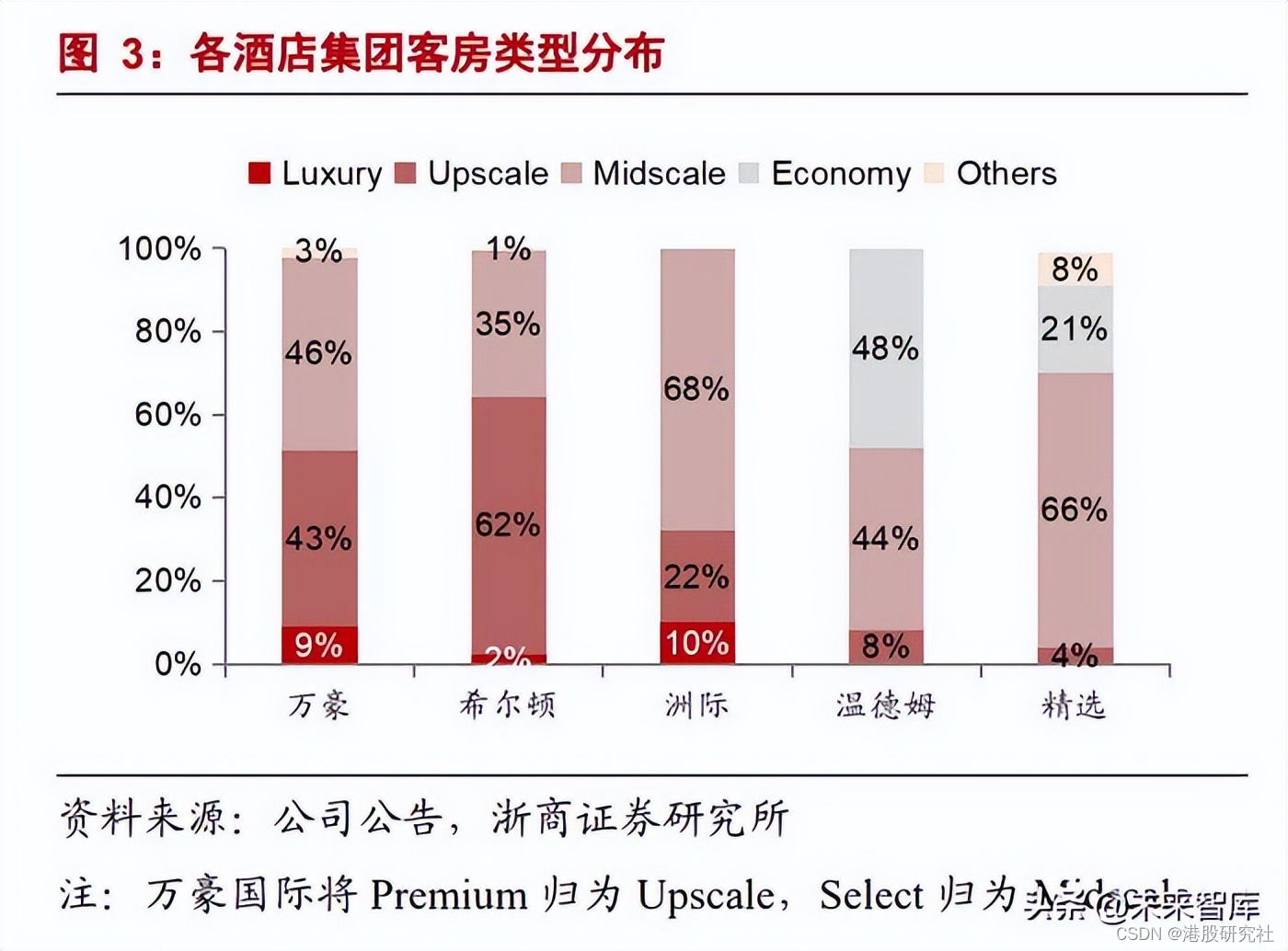
财报解读:“高端化”告一段落,华住开始“全球化”?
2023年旅游业快速复苏,全球酒店业直接受益,总体运营指标大放异彩,多数酒店企业都实现了营收上的明显增长,身为国内龙头的华住也不例外。 3月20日晚,华住集团发布2023年四季度及全年财报。整体实现扭亏为盈,…...

Wifi环境下Unity开发iOS应用启动后HTTPS请求未弹出是否允许无线数据使用数据的弹窗
情况说明 笔者项目在首次启动,登录界面点击登录按钮会先HTTPS请求创建帐号,但是在WIFI网络下,请求后一直提示网络连接失败。但是切换到流量包后,则会弹出"无线数据"使用数据的弹窗,选择允许后则可顺利进入。…...
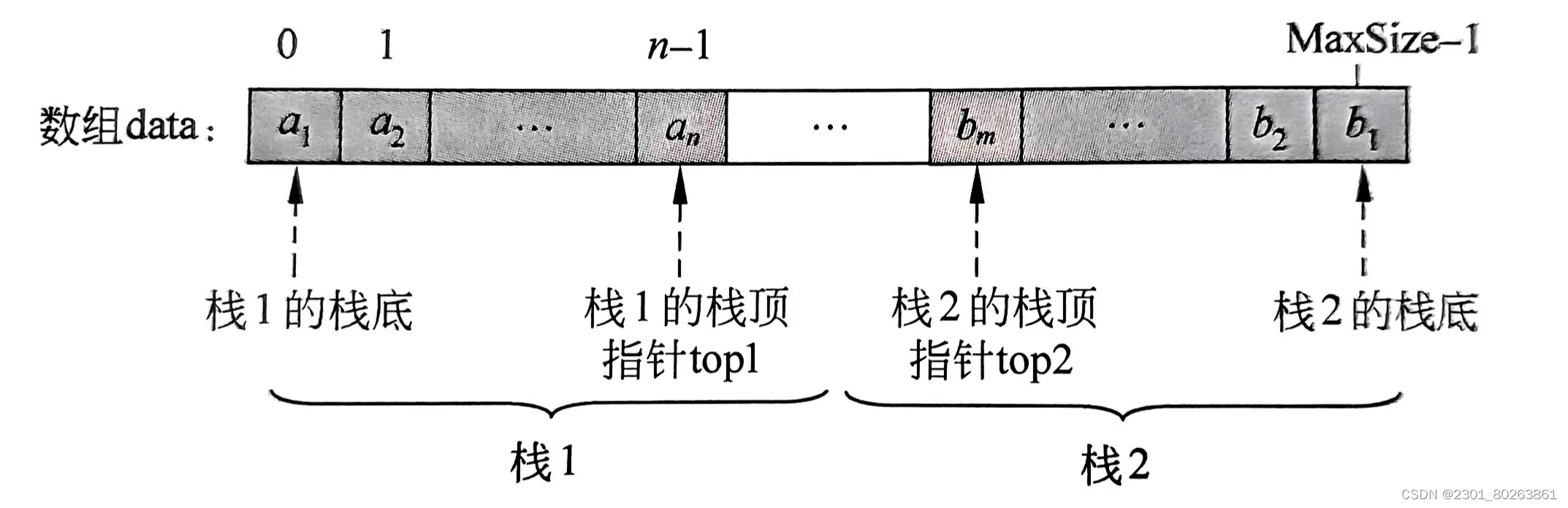
数据结构的概念大合集03(栈)
概念大合集03 1、栈1.1 栈的定义和特点1.2 栈的基础操作1.3 栈的顺序存储1.3.1 顺序栈1.3.2 栈空,栈满,进栈,出栈的基本思想1.3.3 共享栈1.3.3.1 共享栈的4要素 1.4 栈的链式存储1.4.1 链栈的实现1.4.2 链栈的4个要素 1、栈 1.1 栈的定义和特…...
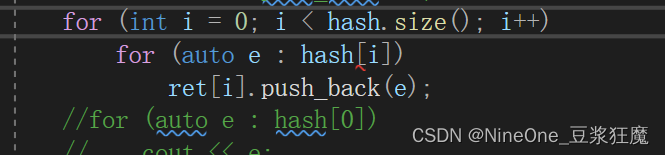
C++ 哈希表
目录 两数之和 面试题 01.02. 判定是否互为字符重排 存在重复元素 存在重复元素 II 字母异位词分组 两数之和 1. 两数之和 思路1:两层for循环 思路2:逐步添加哈希表 思路3:一次填完哈希表 如果一次填完,那么相同元素的值&…...
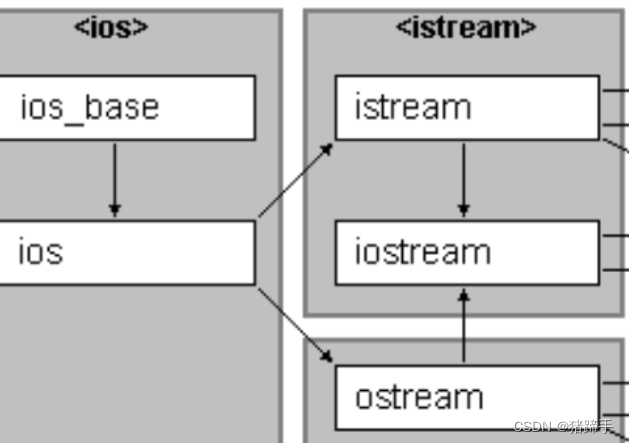
C++之继承详解
一.继承基础知识 继承定义: 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保 持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象 程序设…...

C#装箱和拆箱
一,装箱 装箱是指将值类型转化为引用类型。 代码如下: 装箱的内部过程 当值类型需要被装箱为引用类型时,CLR(Common Language Runtime)会为值类型分配内存,在堆上创建一个新的对象。值类型的数据会被复…...
企业用大模型如何更具「效价比」?百度智能云发布5款大模型新品
服务8万企业用户,累计帮助用户精调1.3万个大模型,帮助用户开发出16万个大模型应用,自2023年12月以来百度智能云千帆大模型平台API日调用量环比增长97%...从一年前国内大模型平台的“开路先锋”到如今的大模型“超级工厂”,百度智能…...
linux 外部GPIO Watchdog驱动适配
前言 文章描述, 利用外部gpio看门狗芯片驱动芯片的复位功能。 芯片:RK3568 平台: Linux ubuntu.lan 4.19.232 #27 SMP Sat Sep 23 13:43:49 CST 2023 aarch64 aarch64 aarch64 GNU/Linux 硬件接线图示 看门狗芯片采用GPIO喂狗,W…...

活动回顾 | 走进华为向深问路,交流数智办公新体验
3月20日下午,“企业数智办公之走进华为”交流活动在华为上海研究所成功举办。此次活动由上海恒驰信息系统有限公司主办,华为云计算技术有限公司和上海利唐信息科技有限公司协办,旨在通过对企业数字差旅和HR数智化解决方案的交流,探…...
【Java】Oracle发布Java22最新版本
甲骨文(ORACLE)已经于2023年3月19日正式发布了最新版本的JDK,版本号:22 根据官方声明,Java 22 (Oracle JDK 22) 在性能、稳定性和安全性方面进行了数千种改进,包括对Java 语言、其API 和性能,以…...

Vue reactive函数的使用
let searchForm reactive({}); let data reactive({ isAdmin: true, isshowAccount: true }); reactive 是什么? reactive 是 Vue 3 Composition API 中的一个函数,用于创建一个包含响应式数据的对象。在 Vue 2.x 中,我们通常使用 data 选项…...

unity自动引用生成
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using UnityEditor; using UnityEngine; using UnityEngine.UI;/// <summary> /// 模板脚本生成 /// </summary> public class ScriptCreater : EditorW…...

【Linux系统】线程互斥与同步
目录 一.几个概念 二.线程互斥 1.定义并初始化锁 2.加锁 3.解锁 4.销毁锁 三.互斥锁的本质 1.xchg的原子性 2.加锁的过程 3.解锁的过程 四.可重入VS线程安全 五.死锁 1.死锁的概念 2.具体实例 3.死锁产生的四个必要条件 4.解决或避免死锁 六.线程同步 七.…...

Simulink中Repeating Sequence锯齿波显示恒为0解决方案
锯齿波设置如图1时,其示波器显示恒为0(如图2)。图1图2于是新建模型,只添加Repeating Sequence模块,采用原始设置发现可以正常输出锯齿波,于是调整时间参数,发现当时间设置为≥[0 0.06]时可以正常…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...

Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间
Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对C盘爆红的警告束手无…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...

Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能
Windows 11终极优化指南:Win11Debloat一键清理系统提升51%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...
功能才是宝藏)
Unity Cinemachine相机系统深度使用:除了自动跟随,它的边界限制(Confiner)功能才是宝藏
Unity Cinemachine Confiner:解锁专业级镜头边界控制的实战指南在游戏开发中,镜头控制往往是被低估的艺术。许多开发者对Cinemachine的印象停留在"智能跟随相机"层面,却不知道它的Confiner功能能够彻底改变游戏镜头的专业度。想象一…...

023、深度可分离卷积:MobileNet背后的计算优化
深度可分离卷积:MobileNet背后的计算优化 一个让我加了两天班的bug 去年调试一块基于Cortex-M7的AI推理引擎,跑MobileNetV1时发现推理速度比理论计算慢了整整一个数量级。当时我盯着逻辑分析仪上的波形,CPU在卷积层卡了将近300ms——这不对劲,理论计算应该只要30ms。 排…...