CMU 10-414/714: Deep Learning Systems --hw3
实现功能
- 在
ndarray.py文件中完成一些python array操作- 我们实现的NDArray底层存储就是一个一维向量,只不过会有一些额外的属性(如shape、strides)来表明这个flat array在维度上的分布。底层运算(如加法、矩阵乘法)都是用C++写的,以便达到理论上的最高速度。但像转置、broadcasting、矩阵求子阵等操作都可以在python框架里通过简单的调整array的属性(如strides)来实现
- 实现的python array功能:这四个功能都不需要重新分配内存,而是在原array的基础上修改shape/strides/etc来实现一些变形(除了第四个__getitem__(),它并不修改array的形状)
- reshape(new_shape):调用as_strided(new_shape, strides),再调用make(new_shape, strides, device=self.device, handle=self._handle)。(其中as_strided会额外检查一下shape的长度是否等于strides的长度,strides的数值是通过self.compact_strides(new_shape)算出来的)
- permute(new_axes):调换array的维度顺序。按照new_axes的顺序调换self.strides以及self.shape得到new_shape和new_strides,最后再调用self.as_strided"(new_shape, new_strides)
- broadcast_to():对于原shape中为1的维度,将其步幅设为0,然后调用as_strided(new_shape, new_strides),然后as_strided调用make(new_shape, new_strides, device=self.device, handle=self._handle)。即重新make,修改其中的shape和stride,但内存位置不变(即handle不变)。至于这里将stride部分设为0,猜测更底层有代码处理这里,但我目前还没找到
- __getitem__(idxs):这是一个非常好的理解我们所实现的NDArray的例子,前面也说了,底层的array存储就是一个一维向量,是通过shape、stride、offset这些属性来指示该向量的维度的。本例就是在原array的基础上求子矩阵,且不改变其内存位置,就是通过一系列计算得到新的new_offset、new_shape、new_stride,就可以将原本的大矩阵重新解释成一个小矩阵。图示如下

而这里也天然解释了什么是紧凑型(compact)矩阵和非紧凑型矩阵:上述原矩阵就是紧凑型的,切片后形成的蓝底矩阵就是非紧凑型的。
而这也带出了下一个问题:如何选择原矩阵的一个子矩阵进行修改内容。因为本课程中几乎所有setitem操作都会先调用.compact(),而这会导致从原矩阵中copy子矩阵到一个新的内存空间,这显然不是__setitem__()所期望的,因此要大动干戈。
- 【CPU】compact和setitem
其实这里的实现主要就是根据这个原理:out[cnt++] = in[strides[0]*i + strides[1]*j + strides[2]*k];(这里是按三维矩阵算的,下面的代码通过while循环可以扩展到其他维度)- Compact:就是将原来的非紧凑型矩阵a变成紧凑型矩阵out,具体是根据输入的shape、strides、offset(以a为主体确定的),将a中的子矩阵提出来,将各位置的值赋给另一个矩阵out。下面的mode是INDEX_IN,即调用
_strided_index_setter(&a, out, shape, strides, offset, INDEX_IN);// 从后往前每一个维度,都根据该维度的步长、offset以及循环次数来确定本次要copy矩阵a的哪一个元素 // 其实就是根据strides、offset来确定一维下的index void _strided_index_setter(const AlignedArray* a, AlignedArray* out, std::vector<uint32_t> shape,std::vector<uint32_t> strides, size_t offset, strided_index_mode mode, int val=-1) {int depth = shape.size();std::vector<uint32_t> loop(depth, 0);int cnt = 0;while (true) {// inner loopint index = offset;for (int i = 0; i < depth; i++) {index += strides[i] * loop[i];}switch (mode) {case INDEX_OUT: out->ptr[index] = a->ptr[cnt++]; break;case INDEX_IN: out->ptr[cnt++] = a->ptr[index]; break;case SET_VAL: out->ptr[index] = val; break;}// incrementloop[depth - 1]++;// carryint idx = depth - 1;while (loop[idx] == shape[idx]) {if (idx == 0) {// overflowreturn;}loop[idx--] = 0;loop[idx]++;}} } - EwiseSetitem(a, out, shape, strides, offset):这里a是紧凑型矩阵,out是一个非紧凑行矩阵,需要将a的各元素的值赋给out的指定位置上(根据shape、strides、offset确定)。只需要复用上面的代码,将mode改为INDEX_OUT,即调用
_strided_index_setter(&a, out, shape, strides, offset, INDEX_OUT); - ScalarSetitem(size, val, out, shape, strides, offset):out是一个非紧凑型子矩阵,根据shape、strides、offset在out的对应位置将值写为val,即调用
_strided_index_setter(nullptr, out, shape, strides, offset, SET_VAL, val);
- Compact:就是将原来的非紧凑型矩阵a变成紧凑型矩阵out,具体是根据输入的shape、strides、offset(以a为主体确定的),将a中的子矩阵提出来,将各位置的值赋给另一个矩阵out。下面的mode是INDEX_IN,即调用
- 【CPU】Elementwise和scalar操作
这个就非常简单了,根据矩阵的size属性遍历其每个元素即可 - 【CPU】Reductions
这个也很简单,条件是矩阵的底层存储都是一维、行优先的。这类里有两个函数:ReduceSum和ReduceMax,其参数都是原矩阵a、输出矩阵out、reduce_size,其中a.size = out.size * reduce_size。看代码就懂了- ReduceMax:
void ReduceMax(const AlignedArray& a, AlignedArray* out, size_t reduce_size) {for (int i = 0; i < out->size; i++) {scalar_t max = a.ptr[i * reduce_size];for (int j = 0; j < reduce_size; j++) {max = std::max(max, a.ptr[i * reduce_size + j]);}out->ptr[i] = max;} } - ReduceSum:
void ReduceSum(const AlignedArray& a, AlignedArray* out, size_t reduce_size) {for (int i = 0; i < out->size; i++) {scalar_t sum = 0;for (int j = 0; j < reduce_size; j++) {sum += a.ptr[i * reduce_size + j];}out->ptr[i] = sum;} }
- ReduceMax:
- 【CPU】矩阵乘
- 朴素矩阵乘
Matmul:void Matmul(const AlignedArray& a, const AlignedArray& b, AlignedArray* out, uint32_t m, uint32_t n,uint32_t p) {for (int i = 0; i < m; i++) {for (int j = 0; j < p; j++) {out->ptr[i * p + j] = 0;for (int k = 0; k < n; k++) {out->ptr[i * p + j] += a.ptr[i * n + k] * b.ptr[k * p + j];}}} } MatmulTiled和AlignedDot:前者负责根据分片大小计算目前参与运算的是a、b、out的哪些元素(哪部分block);后者根据前者传进来的block进行计算(a分片与b分片进行矩阵乘法得到out分片void MatmulTiled(const AlignedArray& a, const AlignedArray& b, AlignedArray* out, uint32_t m,uint32_t n, uint32_t p) {for (int i = 0; i < m * p; i++) out->ptr[i] = 0;for (int i = 0; i < m / TILE; i++) {for (int j = 0; j < p / TILE; j++) {for (int k = 0; k < n / TILE; k++) {AlignedDot(&a.ptr[i * n * TILE + k * TILE * TILE], &b.ptr[k * p * TILE + j * TILE * TILE], &out->ptr[i * p * TILE + j * TILE * TILE]);}}} }
过程原理图:inline void AlignedDot(const float* __restrict__ a,const float* __restrict__ b,float* __restrict__ out) {a = (const float*)__builtin_assume_aligned(a, TILE * ELEM_SIZE);b = (const float*)__builtin_assume_aligned(b, TILE * ELEM_SIZE);out = (float*)__builtin_assume_aligned(out, TILE * ELEM_SIZE);for (int i = 0; i < TILE; i++) {for (int j = 0; j < TILE; j++) {for (int k = 0; k < TILE; k++) {out[i * TILE + j] += a[i * TILE + k] * b[k * TILE + j];}}} }

这里有一个疑问,a、b虽然每次通过MatmulTiled计算的分片的起始位置是正确的,但是如何保证连续的Tile*Tile分块元素就是如图所示那样的呢。按理说a、b的底层存储应该是连续的行优先,那(按照tile=2算)a[2]、a[3]、b[2]、b[3]应该是按行走下去而不是取下一行啊。待解答…
- 朴素矩阵乘
- 【CUDA】compact和setitem
- compact:
图示如下:__device__ size_t index_transform(size_t index, CudaVec shape, CudaVec strides, size_t offset) {size_t idxs[MAX_VEC_SIZE];size_t cur_size, pre_size = 1;// 将给定的线性索引映射回多维数组的索引,即计算index值在各维度上对应是第几个// 思路就是从后往前遍历shape,cur_size表示当前处理的维度由几个元素构成// index%cur_size/pre_size就表示在当前维度的第几个分量// index%cur_size表示是当前维度(只看当前维)的第几个元素,再/pre_size就表示是当前维度的第几块for (int i = shape.size - 1; i >= 0; i--) {cur_size = pre_size * shape.data[i]; idxs[i] = index % cur_size / pre_size;pre_size = cur_size;}// 根据上述算好的多维数组索引,计算在原非紧凑型矩阵中的线性索引size_t comp_idx = offset;for (int i = 0; i < shape.size; i++) comp_idx += idxs[i] * strides.data[i];return comp_idx; }__global__ void CompactKernel(const scalar_t* a, scalar_t* out, size_t size, CudaVec shape,CudaVec strides, size_t offset) {size_t gid = blockIdx.x * blockDim.x + threadIdx.x;/// BEGIN YOUR SOLUTIONif (gid < size)out[gid] = a[index_transform(gid, shape, strides, offset)];/// END YOUR SOLUTION }void Compact(const CudaArray& a, CudaArray* out, std::vector<uint32_t> shape,std::vector<uint32_t> strides, size_t offset) {CudaDims dim = CudaOneDim(out->size);CompactKernel<<<dim.grid, dim.block>>>(a.ptr, out->ptr, out->size, VecToCuda(shape),VecToCuda(strides), offset); }

- EWiseSetitem:
__global__ void EwiseSetitemKernel(const scalar_t* a, scalar_t* out, size_t size, CudaVec shape,CudaVec strides, size_t offset) {size_t gid = blockIdx.x * blockDim.x + threadIdx.x;if (gid < size)out[index_transform(gid, shape, strides, offset)] = a[gid]; }void EwiseSetitem(const CudaArray& a, CudaArray* out, std::vector<uint32_t> shape,std::vector<uint32_t> strides, size_t offset) {/// BEGIN YOUR SOLUTIONCudaDims dim = CudaOneDim(out->size);EwiseSetitemKernel<<<dim.grid, dim.block>>>(a.ptr, out->ptr, a.size, VecToCuda(shape),VecToCuda(strides), offset);/// END YOUR SOLUTION } - ScalarSetitem:
__global__ void ScalarSetitemKernel(size_t size, scalar_t val, scalar_t* out, CudaVec shape, CudaVec strides, size_t offset) {size_t gid = blockIdx.x * blockDim.x + threadIdx.x;if (gid < size)out[index_transform(gid, shape, strides, offset)] = val; }void ScalarSetitem(size_t size, scalar_t val, CudaArray* out, std::vector<uint32_t> shape,std::vector<uint32_t> strides, size_t offset) {/// BEGIN YOUR SOLUTIONCudaDims dim = CudaOneDim(out->size);ScalarSetitemKernel<<<dim.grid, dim.block>>>(size, val, out->ptr, VecToCuda(shape),VecToCuda(strides), offset);/// END YOUR SOLUTION }- 其实总结一下,CPU版的将紧凑小矩阵的index转换成非紧凑大矩阵的index,是在一个loop中实现的,并在loop中找到index后就完成了copy工作;对于GPU版来说,是将copy工作分配给各个线程,因此若要让每个线程都能正确copy,还需要每个线程根据自己分配到的紧凑小矩阵的index,计算得到非紧凑大矩阵的index。即每个线程完成CPU版中一个loop的操作(但不需要后续的检查)。
- compact:
- 【CUDA】Elementwise和scalar操作
和CPU版本的一样,也很简单。且这part非常能体现CUDA的并行、高效特性。举个例子:__global__ void EwiseMulKernel(const scalar_t* a, const scalar_t* b, scalar_t* out, size_t size){size_t gid = blockInx.x * blockDim.x + threadIdx.x;if (gid<size){out[gid] = a[gid] * b[gid];} } void EwiseMul(const CudaArray &a, const CudaArray &b, CudaArray* out){CudaDims dim = CudaOneDim(out->size);EwiseMulKernel<<<dim.grid, dim.block>>>(a.ptr, b.ptr, out->ptr, out->size); } - 【CUDA】Reductions
- ReduceMax
__global__ void ReduceMaxKernel(const scalar_t* a, scalar_t* out, size_t reduce_size, size_t size){size_t gid = blockIdx.x * blockDim.x + threadIdx.x;if (gid<size){size_t offset = gid * reduce_size;scalar_t reduce_max = a[offset];for (int i=1; i<reduce_size; i++){reduce_max = max(reduce_max, a[offset+i]);}out[gid] = reduce_max;} }void ReduceMax(const CudaArray& a, CudaArray* out, size_t reduce_size) {CudaDims dim = CudaOneDim(out->size);ReduceMaxKernel<<<dim.grid, dim.block>>>(a.ptr, out->ptr, reduce_size, out->size); } - ReduceSum
- ReduceMax
- 【CUDA】矩阵乘
使用朴素矩阵乘即可,一个线程负责out矩阵的一个元素
线程分布如下:__global__ void MatmulKernel(const scalar_t* a, const scalar_t* b, scalar_t* out, uint32_t M,uint32_t N, uint32_t P) {size_t i = blockIdx.x * blockDim.x + threadIdx.x; size_t j = blockIdx.y * blockDim.y + threadIdx.y;if (i < M && j < P) {out[i * P + j] = 0;for (int k = 0; k < N; k++) {out[i * P + j] += a[i * N + k] * b[k * P + j];}} } void Matmul(const CudaArray& a, const CudaArray& b, CudaArray* out, uint32_t M, uint32_t N,uint32_t P) {dim3 grid(BASE_THREAD_NUM, BASE_THREAD_NUM, 1);dim3 block((M + BASE_THREAD_NUM - 1) / BASE_THREAD_NUM, (P + BASE_THREAD_NUM - 1) / BASE_THREAD_NUM, 1);MatmulKernel<<<grid, block>>>(a.ptr, b.ptr, out->ptr, M, N, P); }

补充知识
一、CUDA相关代码
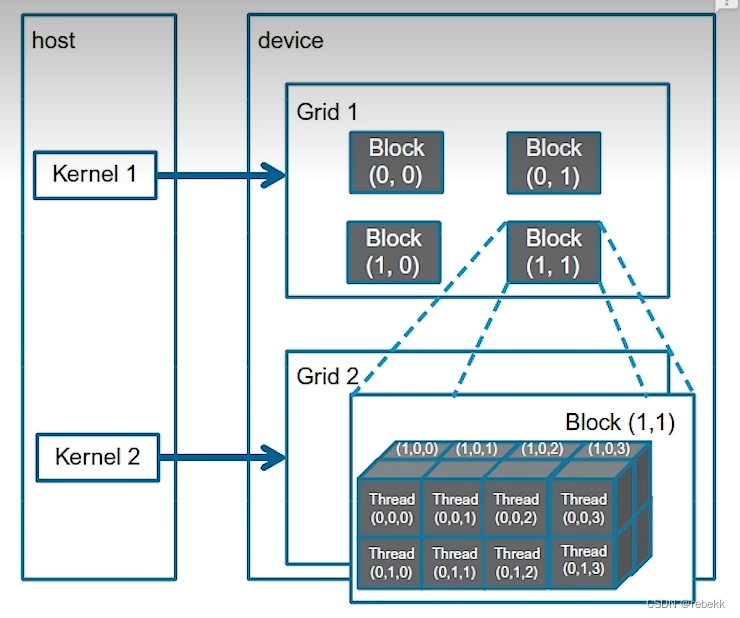
如上图的结构,首先定义Cuda的维度:
struct CudaDims {dim3 block, grid;
};
根据数据数量来判定需要多少个block、多少个thread(都是一个维度下的)
CudaDims CudaOneDim(size_t size) {/*** Utility function to get cuda dimensions for 1D call*/CudaDims dim;size_t num_blocks = (size + BASE_THREAD_NUM - 1) / BASE_THREAD_NUM;dim.block = dim3(BASE_THREAD_NUM, 1, 1); // 一个block里的线程dim.grid = dim3(num_blocks, 1, 1); // 一个grid里的blockreturn dim;
}
相关文章:
CMU 10-414/714: Deep Learning Systems --hw3
实现功能 在ndarray.py文件中完成一些python array操作 我们实现的NDArray底层存储就是一个一维向量,只不过会有一些额外的属性(如shape、strides)来表明这个flat array在维度上的分布。底层运算(如加法、矩阵乘法)都…...
)
前端小白的学习之路(lessscss)
提示:less,sass&scss 目录 一、less 1.变量 2.嵌套规则 3.混合 4.针对属性值进行操作的函数 5.循环 6.拓展语法 二、scss&sass 1.sass 2.scss 一、less 是一个开源的、基于 CSS 的预处理器,它使得编写和维护 CSS 更加简单和高效。通…...
)
算法体系-15 第十五节:贪心算法(下)
一 、贪心算法的解题套路实战 贪心的算法和排序和堆有关 1.1 描述 一些项目要占用一个会议室宣讲,会议室不能同时容纳两个项目的宣讲。 给你每一个项目开始的时间和结束的时间 你来安排宣讲的日程,要求会议室进行的宣讲的场次最多。 返回最多的宣讲场次…...

2.10 模型评估的方法有哪些?优缺点
2.10 模型评估的方法有哪些?优缺点? 场景描述 在机器学习中,我们通常把样本分为训练集和测试集,训练集用于训练模型,测试集用于评估模型。在样本划分和模型验证的过程中,存在着不同的抽样方法和验证方法。…...

Linux centos7安装nginx-1.24.0并且实现自启动
1.安装之前的操作 ps -ef|grep nginx 查看是否有运行 如果有就杀掉 kill -9 pid find / -name nginx 查看nginx文件 rm -rf file /usr/local/nginx* 通通删掉删掉 yum remove nginx 限载一下服务 1.2.下载安装包 地址 nginx: download 2.减压文件 tar…...
)
001-Windows下PyTorch极简开发环境配置(上)
本节介绍Windows系统下配置一套基于Pytorch框架的极简深度学习开发环境。 目录 0.1 缘起 0.1 缘起 其实大概在2016就开始接触深度学习的相关知识,但一直到2018年左右,还停留在门外汉的状态太,原因很简单,感觉学习的门槛过高。…...
分布式Raft原理详解,从不同角色视角分析相关状态
分布式Raft原理详解,从不同角色视角分析相关状态 1. CAP定理2.Raft 要解决的问题3. Raft的核心逻辑3.1. Raft的核心逻辑2.1. 复制状态机2.2. 任期 Term2.3. 任期的意义:逻辑时钟2.4 选举定时器 3. Leader选举逻辑4. 从节点视角查看Leader选举4.1. Follow…...

大数据的实时计算和离线计算你理解吗?
不管是实时计算还是离线计算,都有着同样的业务目标,那就是根据业务要求把数据源计算处理成业务需要的直接可用的数据结果。 如果把数据源比作是水龙头里的水,把数据计算比作是生产纯净水的过程;那么实时计算就是用一根水管接在水龙…...

OS Package Manager
Windows Package Manager winget chocolatey Mac homebrew Linux apt-get apt snap yum 使用wget和curl拉取相关工具的shell脚本执行安装...
【滑动窗口、矩阵】算法例题
目录 三、滑动窗口 30. 长度最小的子数组 ② 31. 无重复字符的最长子串 ② 32. 串联所有单词的子串 ③ 33. 最小覆盖子串 ③ 四、矩阵 34. 有效的数独 ② 35. 螺旋矩阵 ② 36. 旋转图像 ② 37. 矩阵置零 ② 38. 生命游戏 ② 三、滑动窗口 30. 长度最小的子数组 ② 给…...
【事务】开发用到的事务,TransactionDefinition实例详解,事务的传播机制
【事务】开发中用到的事务,TransactionDefinition实例详解 一、TransactionDefinition 介绍1、隔离级别(Isolation Level):2、传播行为(Propagation Behavior):3、超时设置(Timeout …...

Linux信号处理
Linux信号处理 什么是linux信号 本质是一种通知机制,用户 or 操作系统通过发送一定的信号,通知进程,某些事情已经发生,你可以在后续进行处理。 信号产生是随机的,进程可能正在忙自己的事情,所以…...

nuclei使用方法
nuclei使用方法 查看帮助 nuclei -h 列出所有模板 nuclei -tl 查找某种cms的相关漏洞模板,wordpress为例 nuclei -tl -tc "contains(name,wordpress)"便会列出内容里含有wordpress关键字的漏洞检测模板 使用与某cms相关的所有漏洞模板进行扫描&#…...
【并查集专题】【蓝桥杯备考训练】:网络分析、奶酪、合并集合、连通块中点的数量、格子游戏【已更新完成】
目录 1、网络分析(第十一届蓝桥杯省赛第一场C A组/B组) 2、奶酪(NOIP2017提高组) 3、合并集合(模板) 4、连通块中点的数量(模板) 5、格子游戏(《信息学奥赛一本通》…...
数据结构(三)复杂度的深层次剖析
之前发布了数据结构(一),很多同学反响不够清晰,那今天就发一篇对复杂度专题的博客,希望对大家理解复杂度提供一些帮助。 时间复杂度 我们先来一个理解一个复杂度,二分查找的复杂度(之前写过二…...
JavaWeb -- HTTP -- WEB服务器TOMCAT
一.HTTP介绍: HTTP(Hyper Text Protocol) 实际上是一种超文本传输的协议,规定了浏览器跟服务器之间的一些数据传输的规则 例如B/S 对于浏览器的请求,以及相应服务器的响应,都必须依靠这种协议,规范,才能够彼此之间相互 理解 HTTP的协议特点: 1.基于TCP协议: 面向连接 更加安全…...

GitHub与Git命令使用笔记
GitHub与Git命令使用笔记 文章目录 GitHub与Git命令使用笔记上传本地的新项目到github1. 创建新的GitHub仓库2. 初始化本地项目目录3. 将本地仓库关联到GitHub4. 推送本地代码到GitHub上传本地项目到GitHub时发生冲突 将默认分支名称从master改为maingit 把远程项目拉到本地&am…...
二叉树的层次遍历经典问题-算法通关村
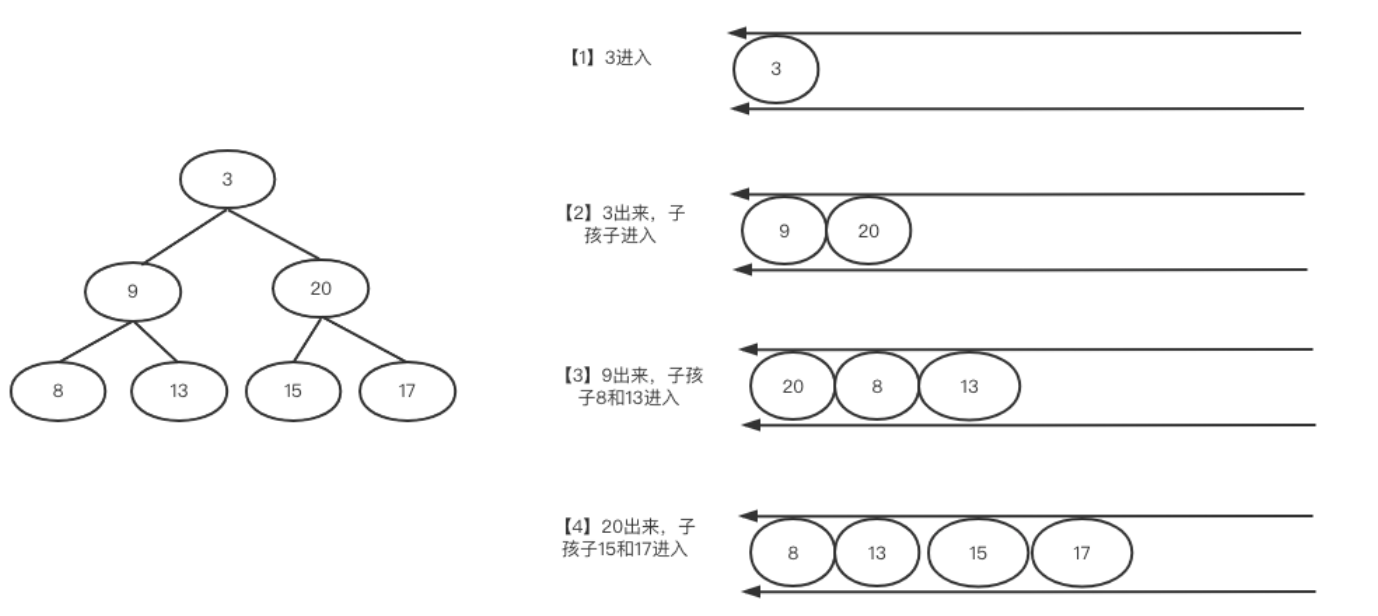
二叉树的层次遍历经典问题-算法通关村 1 层次遍历简介 广度优先在面试里出现的频率非常高,整体属于简单题。广度优先又叫层次遍历,基本过程如下: 层次遍历就是从根节点开始,先访问根节点下面一层全部元素,再访问之后…...

SQLiteC/C++接口详细介绍sqlite3_stmt类(十二)
返回:SQLite—系列文章目录 上一篇:SQLiteC/C接口详细介绍sqlite3_stmt类(十一) 下一篇: SQLiteC/C接口详细介绍sqlite3_stmt类(十三) 48、sqlite3_stmt_isexplain sqlite3_stmt_is…...

大模型时代如何做安全?
现在应该没人怀疑AI时代的到来了吧,在HUB上每天100的新的预训练模型产生,不夸张的说的,现在稍微有点计算机基础的人都可以训练自己的模型了。 说远了,还是说说那些不争气的安全厂商吧。为啥只说安全厂商?因为国内还是…...

四旋翼变形控制:RL与MPC在混合动力学中的对比
1. 四旋翼变形控制的技术挑战与解决方案四旋翼变形控制(Quadrotor Morpho-Transition)是当前机器人领域最具挑战性的前沿技术之一。这项技术使机器人能够在空中完成形态变换,实现从飞行模式到地面模式的平滑切换。想象一下,一架四…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

告别鼠标点击,微博图片批量下载的轻松方案
告别鼠标点击,微博图片批量下载的轻松方案 【免费下载链接】weiboPicDownloader Download weibo images without logging-in 项目地址: https://gitcode.com/gh_mirrors/we/weiboPicDownloader 还记得那个周末的下午吗?你喜欢的博主发布了九宫格美…...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...